
Relatively Robust Multicriteria Decisions
Abstract
For a general multicriteria decision problem with linear scalarization and unknown weights, we propose relatively robust decisions, which are Pareto-efficient and at the same time maximize a performance index. The latter measures the worst-case ratio, attained by the weighted objective relative to its maximum value, with respect to all possible weights. The main results include a simple boundary representation of the performance index as the minimum of criterion-specific performance ratios, and a computationally simple method of determining a relatively robust decision up to any prespecified performance tolerance by maximizing an -augmented performance index. The proposed method relies merely on the continuity of all criterion functions and the compactness of the set of feasible decisions which may be nonconvex. This imposes no restrictions at all for any finite action set. A notable feature of our method is that it endogenously yields the tradeoffs between all criteria, including a performance guarantee relative to decisions justified by any other weighting. A number of structural results, examples, and applications are provided, as well as generalizations to allow for limited weight ambiguity, criterion ambiguity, and generalized aggregation of criteria based on an axiomatic foundation.
This paper was accepted by Peng Sun, optimization and decision analytics.
1. Introduction
In real-world decision making, evaluating alternatives often involves multiple, sometimes conflicting criteria. Whether considering investment portfolios under Environmental, Social, and Governance (ESG) parameters, selecting products based on bundles of attributes, or valuing companies for both profitability and sustainability, decision makers must navigate tradeoffs between competing objectives. Similarly, lifecycle environmental impact assessments—such as comparing vehicles with electric, combustion, or hybrid engines—require reconciling diverse metrics like emissions, cost, and resource consumption. These complex but often inevitable comparisons highlight the critical need for robust multicriteria optimization frameworks.
Multicriteria optimization involves identifying solutions that balance conflicting objectives in a manner consistent with the decision maker’s priorities. Traditional approaches often rely on scalarization techniques, where multiple criteria are combined into a single weighted objective function using weighted sums. However, these methods depend heavily on the precise specification of weights, which are rarely known a priori and can be difficult to justify. This uncertainty complicates the search for decisions that are both Pareto-efficient and robust to variations in tradeoff preferences. To address these challenges, we specialize the concept of relatively robust decisions by Weber (2023) so as to refer to decisions that achieve Pareto-efficiency among all relevant criteria while also maximizing a performance index designed to account for the ambiguity in weights. Specifically, the performance index measures the worst-case (WC) ratio attained by the weighted objective relative to its maximum value over all possible weight configurations. By focusing on worst-case performance, this framework provides guarantees of robustness and tradeoff transparency, which are particularly valuable in high-stakes or uncertain decision contexts.
1.1. Practical Examples
The approach developed here can be used for virtually all multicriteria decision problems, such as the following three example applications.1
ESG Investing: Investors face the challenge of balancing financial returns with social and environmental impact. For example, a fund manager might evaluate portfolios based on criteria such as profitability, carbon footprint, and diversity inclusion. Weighting these criteria is inherently subjective, and the optimal portfolio might vary widely depending on the chosen weights. The relatively robust optimization framework proposed here enables the identification of investment strategies that remain robust across different weight configurations, offering a performance guarantee regardless of the specific preferences.2
Lifecycle Assessment of Vehicles: Consider evaluating the environmental impact of electric, combustion, and hybrid cars. Criteria might include greenhouse gas emissions, energy efficiency, and resource use (see, e.g., Hawkins et al. 2012). A relatively robust decision could pinpoint vehicle types or designs that perform well across a broad range of plausible weightings, resulting in a balanced and defensible choice.
Product Evaluation and Design: Companies frequently design products to optimize attributes such as cost, durability, and aesthetic appeal. For example, in designing a smartphone, decision makers must weigh the importance of battery life, screen quality, and price.3 Relatively robust multicriteria optimization helps determine design specifications that ensure competitive performance across various market segments with diverse preferences, valuing the availability of different attributes with different weights.
For the application of our method, one only needs that there exists a default action, that is, a baseline alternative that performs adequately across all criteria (which can always be achieved by reindexing evaluation scales), together with the technical assumption that criteria are continuous in actions, and that the finite-dimensional action set is closed and bounded (i.e., compact).
1.2. Literature
1.2.1. Origins of Multicriteria Decision Making.
The idea of multicriteria optimization in Economics can be traced back to the distribution of resources among different individuals, leading to a set of undominated solutions such as the “contract curve” proposed by Edgeworth (1881, p. 21) for a simple exchange economy, and more generally a set of efficient outcomes as implied by Pareto (1894; 1897, sections 721–723),4 which cannot be improved upon for one agent without making another agent worse off. The latter avoids a direct interpersonal comparison of individuals’ utilities (or “ophelimities” in Pareto’s terminology); see also Harsanyi (1955) as well as Keeney and Raiffa (1993, chapter 10) who explore group utility functions. The drawback of such an agnostic approach to optimality with multiple criteria is that the set of Pareto-optimal allocations, because of its typically large cardinality, offers only imperfect guidance about which solution should actually be implemented. For example, in the two-agent exchange economy, the contract curve usually includes allocations that attribute all resources to any single individual, which almost completely undermines the notion of multicriteria optimization.
In Operations Research, “goal programming” refers to the notion of minimizing the weighted deviation from criterion-specific targets (Charnes and Cooper 1961). The technique was first employed in the context of executive compensation based on different “factors” (i.e., criteria) using linear programming techniques (Charnes et al. 1955). This basic approach is usually applied to a “utopian” (or “ideal”) target point, which corresponds to the (generically infeasible) vector of individually maximized criteria. Depending on the distance measure (e.g., a weighted Chebyshev distance; see, e.g., Steuer 1986, chapter 14),5 the corresponding solutions trade off among criteria according to the specified weights, and they are naturally Pareto-efficient.6 Instead of minimizing the distance to the ideal point (in the outcome space), it is also possible to maximize the distance to a (generically infeasible) “nadir” point, which contains the minimum value of each individual criterion on the Pareto-efficient set.7 In this approach, known as “compromise programming” (Zeleny 1974), the appropriate choice of the weights for the different criteria remains the critical point, and in our view, very little satisfying progress has been made in the assignment of weights without imposing subjectivity, which arguably amounts to picking a solution from the Pareto-efficient set. For instance, based on an exogenous ranking of the criterion importance, it is possible to apply an ordered weighted average (Yager 1988) which in turn can be related to compromise programming (Zarghami and Szidarovszky 2010, Wang and Fu 2020).8 Besides being subjective from the start by requiring the imposition of a preference order on criteria, this method does not provide any nontrivial performance guarantee relative to other choices of weights and/or importance rankings that might be plausible for other decision makers.9
1.2.2. Relative Robustness.
By contrast, we approach the selection of weights from the standpoint of relative robustness (Weber 2023), involving only comparisons between feasible points, thus avoiding fictitious targets such as the aforementioned utopian and nadir points. Rather than minimizing a fixed distance metric with specific weights, the proposed method evaluates performance in terms of the worst-case tradeoffs among criteria, ensuring a solution that remains defensible regardless of the exact weighting chosen ultimately. The underlying robustness measure, equivalent to relative regret, has been used in computer science to evaluate the relative performance of algorithms (Sleator and Tarjan 1985, Ben-David and Borodin 1994), for the scenario-based evaluation of operational decisions (Kouvelis and Yu 1997), in price discrimination (Han and Weber 2023), robust optimization (Weber 2024), and fair resource allocation (Goel et al. 2009). The idea of absolute regret (AR) is due to Savage (1951), based on the maximin robustness approach by Wald (1945) in his general treatment of sequential decision problems. The main issue with absolute regret is that it is inherently sensitive to the scale of the reference point. This sensitivity may make it impossible to derive reasonable performance guarantees, such as ensuring positive profits in a monopoly pricing problem with unknown demand (Weber 2025), because a zero-profit reference point is intrinsically small-scale. A relative robustness approach, we argue, yields more acceptable results, particularly in the context of multicriteria optimization, where changing the units of any given criterion would usually affect solutions that are based on absolute performance measures.
1.2.3. Connection to Distributionally Robust Optimization.
Because one can reinterpret a (normalized) weight vector as a probability distribution, our approach is naturally related to distributionally robust optimization (DRO), where the true probability distribution governing uncertain parameters is unknown but assumed to lie within a known ambiguity set. Important early contributions include Delage and Ye (2010), who studied DRO with moment-based sets, and Ben-Tal et al. (2013), who developed tractable reformulations for DRO with Wasserstein ambiguity sets. More recently, Blanchet and Murthy (2019) and Mohajerin Esfahani and Kuhn (2018) developed general formulations based on Wasserstein balls, offering strong out-of-sample guarantees. Whereas DRO typically focuses on expectations or risk measures over stochastic uncertainty, our approach generalizes worst-case robustness to a multicriteria setting without requiring a probabilistic model. This positions our proposed framework as a deterministic analogue to DRO, where ambiguity arises from unknown relative preferences and state-dependent criteria rather than unknown probability distributions.
1.2.4. Relative Evaluations.
The proposed approach to robust multicriteria decisions is entirely relative, in the sense that the question underlying all of our developments is “How well am I doing relative to how well I could be doing?” Indeed, the idea that the size of an object can be judged only relative to other objects goes back at least to the Taoist writings of Zhuang Zhou in the fourth century BC.10 In Economics, Cournot (1838) was among the first to note that there is no absolute value (“Il n’y a pas de valeurs absolues,” p. 22) and that inference from a social system can be likened to the observation of astronomical objects and their relative positions to each other (pp. 15–16), concluding by analogy that the concept of value is fundamentally relative (“Il y en a en ce sense que des valeurs relatives,” p. 18). In fact, human perception is inherently relative, as demonstrated by Weber (1846) and his student Fechner (1860) in extensive experiments which showed that across different senses (e.g., hearing, touch, and vision) the minimum perceptible difference is proportional to the current level of the stimulus, giving rise to the Weber-Fechner law of psychophysics. Similarly, in an economic context, it is often relative reference points such as one’s current wealth level (Kahneman and Tversky 1979) or the outcomes experienced by others (Loewenstein et al. 1989) that tend to determine human behavior. For example, when pondering whether to purchase a product from a cheaper store within walking distance, humans base decisions less on absolute gains than on the prospective relative savings in expenditure (Kahneman and Tversky 1984).
Beyond the aforementioned congruence with human perception, there are other practical arguments for relative evaluations. First, there is the insensitivity to scale, common to all relative measures such as internal rate of return (IRR), demand elasticity, profit margin, or relative regret, which allows for a direct comparison across different sizes. For example, with IRR one can readily benchmark projects of different financial magnitudes against outside investment options (of comparable risk), whereas the equivalent absolute indicator of net present value (NPV) remains silent about the required absolute investment (see, e.g., Weber 2014).11 Second, normalization facilitates fairness and equity. When stakeholders have differing capacities or baselines, a relative comparison may help to ensure fairness (Goel et al. 2009). Third, relative evaluation criteria allow for comparability across contexts. For example, demand elasticity (as introduced by Marshall 1890, p. 162) is a unit-free relative measure that allows one to compare the changes of demand relative to price changes across widely differing goods, irrespective of the underlying unity of measurement (e.g., units of cars versus units of electric power). This last point is especially salient for multicriteria decision making, as the units (and inherent scale) for different criteria generally differ, so that a robustness criterion (and robust decision) should remain unaffected if the values of a given criterion are all multiplied by 10, for example. The relatively robust framework developed here uses a relative worst-case performance perspective. This methodology not only identifies solutions with reliable tradeoff characteristics, but also provides a transparent representation of the tradeoffs themselves. These tradeoffs are reflected in a robust weight vector consistent with a robust solution.
1.3. Outline
The remainder of this paper is organized as follows: Section 2 discusses the multicriteria optimization problem and associated comparative statics, together with the performance index for a robust evaluation of different decisions. Section 3 introduces pseudo-robustness and Pareto-efficiency, which together characterize relatively robust decisions. Here we also provide a computational approach for determining a relatively robust decision up to any given performance tolerance, and we allow for the possibility of close-to-arbitrary restrictions in the set of admissible weights, for example, based on a priori knowledge about physical constraints or a given priority ranking of criteria. In addition, there are extensions to criterion ambiguity and general aggregation of criteria, followed by a practical guide for how to apply the method. Section 4 focuses on discrete applications where our framework relies on virtually no assumptions, so the approach can be entirely data-driven. Section 5 concludes.
2. Basic Framework
Let be a nonempty, compact action set, for a given integer . Consider a decision maker who faces the multicriteria optimization problem of having to select an action (or decision, or point) so as to “simultaneously maximize” the continuous functions , for , each of which is referred to as a criterion, where is a given integer.
(i) The continuity of each criterion ensures that small perturbations in the action yield correspondingly small changes in the objective value. Notably, this assumption is trivially satisfied at any isolated point of .12 In particular, this means that there is no imposed regularity requirement when the action set is finite. (ii) The requirement that each be nonnegative is without loss of generality: any real-valued (continuous) criterion can be translated as , where denotes the minimum value of .13
2.1. Decision Problem
To evaluate goal achievement for any decision , the decision maker considers a scalarization of his multicriteria optimization problem by means of a weighted objective,
The weighted objective is homogeneous of degree one, that is, for all and , it is , whereas the set of ex post optimal decisions is homogeneous of degree zero, in the sense that , for all and . It is therefore possible to extend the definition of in Equation (1) and the definition of in Equation (2) to a domain containing any nonzero weight vector , because a unique normalized weight , with , is always available:14
Limited ambiguity, that is, allowing for weights in a (nonempty, compact) subset of , is discussed in Section 3.7. Criterion ambiguity is treated in Section 3.8, and Section 3.9 investigates the use of general multicriteria objectives. All three generalizations can be treated, after suitable adjustment, within the basic framework.
To keep matters nontrivial, we assume that there exists a (feasible) default decision () such that the decision maker’s weighted objective is positive, that is,
The nontriviality condition (N) ensures that the ex post optimal objective (or value function) is positive:
The sign-definiteness of the ex post optimal objective is critical for its role as a reference, against which the goal achievement of any feasible decision can be compared.
The nontriviality condition (N) can be satisfied without affecting , that is, without changing any set of ex post optimal decisions. It is sufficient to consider the translated criterion instead of , for all , using a suitable shift , in which case , because is strictly positive (as it is bounded from below by ).
2.2. Comparative Statics
What happens to the criteria at the optimum when shifting weight from one criterion to another? At the optimum, one would naturally expect that a criterion which receives relatively more weight than before cannot decrease, whereas a criterion that receives relatively less weight cannot increase. The following result formalizes this intuition for a weight shift from one criterion to another.
Let , where and denote the i-th and j-th Euclidean unit vectors, respectively. Consider such that for some and some with . Then for any it is and .
A transfer from the j-th criterion weight to the i-th criterion weight augments the optimal value of criterion i and lowers the optimal value of criterion j (at least weakly). Criteria other than i and j, whose weights remain constant but whose values are affected when decisions change, may go either way as a result of the weight shift. Similarly, the value function could go up or down, depending primarily on the difference between and at the optimum.
The conclusion of Proposition 1 can be applied multiple times. In particular, it can also be used for shifts in nonnormalized weights ; see Remark 2. Thus, increasing is equivalent to (at most) successive weight transfers in the normalized weight from the components of to , resulting in an increase of the j-th criterion at the optimum.
For small shifts of weight from criterion j to criterion i, the value of the ex post optimal objective goes up (resp., down) when the corresponding score difference, , is positive (resp., negative), at the selection .
The following result states that for a simple nonnormalized increase of the i-th weight, the value function goes up, as long as the i-th criterion is always positive at an optimum.
Let be nonnormalized weights, such that , for a given and a given . Provided that , for any , it is .15
2.3. Performance Index
The decision maker may a priori have no knowledge about which weight should be used to compute the weighted objective in Equation (1).16 To deal with this ambiguity, the decision maker evaluates any feasible decision with respect to any given weight by the performance ratio,17
By the nontriviality condition (N), it is , for all . Thus, all maximized individual criteria are strictly positive. The next result provides an important representation of the performance index, in terms of relative goal achievement of a decision, relative to the various maximized individual criteria.
The performance index is equal to
The representation in Equation (6) expresses the performance index as the minimum of the criterion-specific performance ratios . Hence, to compute as the minimum of over all weights , it is sufficient to restrict attention to the Euclidean unit vectors , as , for all . This simplification arises because is quasiconcave for fixed , implying that its minimum over is attained at a vertex. This highlights a “perfect complementarity” among the criterion-specific performance ratios in the determination of the performance index.
The idea of perfect complementarity, discussed by Cournot (1838) and Edgeworth (1897), describes elements contributing to a common goal in fixed proportions. This is equivalent to evaluating the criterion (i.e., the performance index) using the Leontief production function,18 that is, taking the minimum among the inputs , resulting in , for all , as in Proposition 2.
Let be a compact action set with , where is an integer. Consider a decision problem with criteria (containing an egalitarian and a utilitarian evaluation),
Here is a compact interval, with , and the best average coordinate (subject to all coordinates being at least of size t),
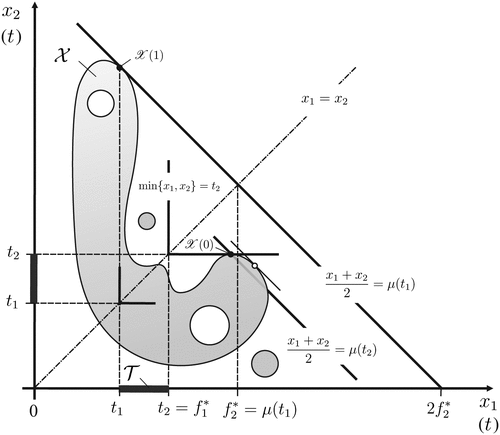
Here the criterion-specific performance ratios are and .
3. Robust Multicriteria Decision Making
3.1. Pseudo-Robustness
We refer to a decision which maximizes the performance index as pseudo-robust. The corresponding (compact, nonempty) set of pseudo-robust decisions,19
Optimizing the performance index determined in Example 1, using the same two-stage maximization procedure, yields the optimal performance index,
Here, the first term in the minimand increases continuously in t, whereas the second is (weakly) decreasing and may be discontinuous; see Figure 2. As a result, at the optimal value the two terms are about to cross, resulting in a “balancedness condition,”
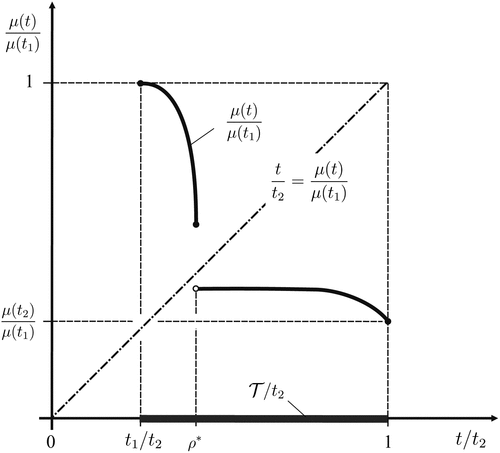
Note. and .
so that , as shown in Figure 2. Because for any it is , one obtains . This implies that the optimal performance index,
3.2. Efficiency
When is not a singleton, the decision maker may have good reason to prefer one pseudo-robust decision over another, based on “efficiency” (or a lack thereof). Specifically, given two feasible actions , we say that decision is more efficient than decision with respect to the vector of criteria , if and only if strictly improves on at least one criterion while weakly improving on all other criteria (over their values achieved at ). The corresponding preference relation on is defined by20
It is easy to see that a pseudo-robust decision is not necessarily efficient, in the sense that it may be possible to find a different decision which strictly improves on at least one criterion-specific performance ratio while maintaining the optimal performance index achieved by .
Following up on our analysis in Example 1 and Example 2, consider the (nonconvex, compact) action set , for some integer . Because , for all , where and , the optimality condition yields . Hence, the optimal performance index attains its maximum possible value, . This makes sense, because it is feasible (in ) to attain simultaneously the highest possible minimum coordinate and the highest possible average coordinate, regardless of the weights assigned to the two objectives. Note also that the set of pseudo-robust actions,
Note. The set of Pareto-optimal decisions is .
It is well known that for any weight vector with strictly positive components (ensuring all criteria are considered) an ex post optimal decision must also be efficient (see, e.g., Ehrgott 2010, proposition 3.9, p. 71). That is, for any , the corresponding optimal decision set satisfies .
3.3. Robust Decision Set
Requiring efficiency in addition to pseudo-robustness is important, because, by avoiding unnecessary shortfalls, it can only improve the weighted objective in Equation (1)—at least weakly. A decision is called robust if it is pseudo-robust and efficient. Thus, our goal becomes to examine the properties of the robust decision set,
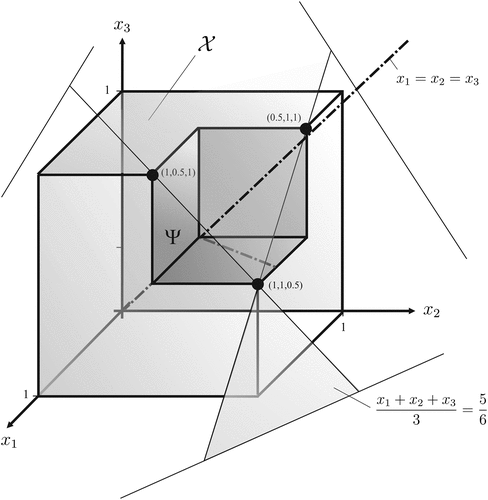
Following up on our analysis in Example 1 and Example 2, consider the (convex, compact) action set , which is equal to the unit ball in the standard Euclidean distance, where the dimension of the underlying space is given by some integer . By direct computation, for all , and . As in Example 3, the balancedness condition (8) yields , and thus an optimal performance index of . The set of pseudo-robust actions,
In Example 3, we examined a problem where (so ), whereas in Example 4, for the same multicriteria decision problem with a different action set, it was (so ). Neither of these two extremes might apply, in which case , as illustrated next.
Mixing and matching features from Example 3 and Example 4, let us consider the (nonconvex, compact) action set in the Euclidean plane. The corresponding set of Pareto-optimal actions is given by the intersection of the unit circle with both the action set and the positive quadrant , so . Meanwhile, the set of pseudo-robust actions is . Thus, by Equation (11) it is , which in this setting means .
The existence of robust actions is ensured by the next result, together with the fact that the robust decision set must be closed and bounded (i.e., compact).
The robust decision set is nonempty and compact.
The proof of Lemma 2 starts by noting that the set of efficient actions is compact because it must be bounded (by the boundedness of the encompassing action set ) and closed (by the continuity of the criteria). One can then construct a sequence of pseudo-robust actions in the (nonempty) compact set which might be inefficient (or else holds true immediately). But each inefficient pseudo-robust action suggests the existence of a more efficient action, which incidentally must also be pseudo-robust. Given that is compact, the Bolzano-Weierstrass theorem (Berge 1963, p. 67) then guarantees the existence of a converging subsequence of pseudo-robust actions, with a limit that must be a feasible decision which is both pseudo-robust and efficient, so . Compactness of the robust decision set then follows, as it has to be both closed and bounded.
The optimal performance index ρ* is such that and .
The preceding result (re)states the fact that the decision maker can restrict attention to efficient actions when maximizing the performance index, meaning that there always exists an efficient action which attains the optimal performance index ; this action is by definition robust. Conversely, any robust action necessarily achieves a performance index of , which is quite straightforward in light of both Lemma 2 and the definition of the robust decision set in Equation (11).
3.4. Robust Decisions: Computation
How can one determine a (relatively) robust decision? By Lemma 3 we can limit attention to maximizing the performance index over all efficient decisions in our search for robust decisions. Thus, to be guaranteed an efficient decision which is also approximately pseudo-robust, by virtue of Proposition 2 we introduce the -augmented performance index,
The (nonempty, compact) outcome space,
Using ideas from Example 1, maximization of this weighted objective yields
In addition, one can easily verify that
Proposition 1 implies that any selection must be decreasing in , and similarly, must be increasing in , at least weakly. The latter also follows directly from the monotonicity of , because must be nonincreasing in t.
Let . (i) . (ii) . (iii) If and , then there exists such that , for all .
Part (i) of the preceding result notes that without -augmentation (i.e., for ) the weighted objective specializes to the performance index (via Proposition 2), the maximization of which produces the set of pseudo-robust decisions, as in Equation (7). Part (ii) stipulates that whenever the -augmentation is nontrivial (i.e., for ), maximization yields efficient actions. Finally, part (iii) means that if a decision maximizes the -augmented performance index in Equation (12), for some nontrivial , without being pseudo-robust, then any pseudo-robust decision would strictly improve upon in terms of any -augmented performance index, as long as (smaller than ) lies in a sufficiently small right-neighborhood of the origin.
We are now able to establish a cornerstone property for the practice of robust multicriteria optimization, in the sense that a robust decision (i.e., an element of ) can be obtained as a lower limit of the set of -robust actions, for .21 In Section 3.5, we then show that can be chosen so as to guarantee an approximation of the optimal performance up to any desired precision.
Let . Then and .
The following example shows that it is possible that . In other words, some points in the robust decision set might not be reached using the proposed approximation procedure.
Consider a (nonconvex, compact) action set as shown in Figure 4(a), specified by
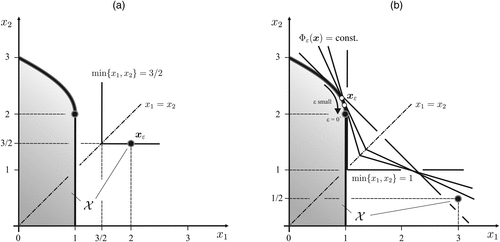
Notes. (a) Action set in Example 6 with . (b) Action set in Example 7 with .
There are criteria that simply measure the coordinate achievement, so , for all . The set of efficient actions is
At this point, let us consider the -augmented performance index in Equation (12). By Lemma 4 we have , and for the maximizer of is efficient, so
The fact that is an isolated point (cf. Endnote 12) is not important, because one could easily connect it to by adding points to the action set that are always suboptimal.23
3.5. Approximation Error of -Robust Decisions
Maximizing the -augmented performance index in Equation (12) enables us to approximate a robust decision to an arbitrary prespecified precision, as a function of . The quality of any approximate decision in Equation (11) is gauged by its approximation error,
The following result guarantees continuity, as well as first- and second-order monotonicity of the optimal -augmented performance index.
is continuous, increasing, and convex in .
The proof of the first-order monotonicity uses the fact that (for all ), together with natural properties of an optimal solution to Equation (13) in order to establish that in Equation (16) must increase in (at least weakly). That the optimal -augmented performance index also exhibits a second-order monotonicity means that tightening the approximation parameter further and further leads to progressively slower decreases of toward (as ). The convexity of the optimal -augmented performance index also implies its smoothness (almost everywhere), as pointed out next.
By the Rademacher theorem (Villani 2008, theorem 10.8, p. 222), the convexity of in , which implies Lipschitz continuity, guarantees that the optimal -augmented performance index is differentiable almost everywhere (a.e.) on [0, 1]. The Alexandrov theorem (Villani 2008, theorem 14.25, p. 402) goes even further by establishing its second-order differentiability a.e., in the sense of having a Taylor expansion with a smaller-than-quadratic local error at almost every point . By the envelope theorem (see, e.g., Mas-Colell et al. 1995, theorem M.L.1, pp. 965–966), at points of differentiability one therefore obtains:
In other words, the gradient of the optimal -augmented performance index is (a.e.) equal to the difference between the average performance ratio () and the minimum performance ratio () attained by the approximately robust decision .
The maximized weighted objective in Equation (16) is a convex combination of and ; the latter both exhibit “natural” comparative statics as implied by the reweighting result in Proposition 1.
(i) is decreasing in . (ii) , for all . (iii) . (iv) is increasing in . (v) , for all .
Parts (i) and (iv) of Lemma 6 assert that decreasing the augmentation parameter can only decrease the average criterion-specific performance ratio and at the same time increase the performance index , where both are achieved at a given -robust selection . Meanwhile, by parts (ii) and (v) the optimal performance ratio is bracketed by these two values, in the sense that , for all . Finally, parts (i) and (iii) establish the monotone convergence of to , as .
The following result provides a performance guarantee for any -approximation of our robust multicriteria decision problem, alluded to at the outset of our discussion.
Fix any . If , then .
A special case of the preceding result is that for any the approximation error cannot exceed . In other words, any -robust decision , for , attains a performance index , where is the optimal performance index. The following example applies this result in an already familiar context.
Somewhat similar to Example 6, we consider the (nonconvex, compact) action set
Thus, to guarantee that the approximation error in Equation (15) cannot exceed , it is by Proposition 4 enough to find an action that maximizes the -augmented performance index in Equation (12) for some . Incidentally, for , we find , so that the realized approximation error of (with respect to ) is actually much smaller than the prespecified 5% approximation-error bound.
It is also possible to derive a priori performance estimates without knowledge of the optimal performance index () just by solving the -approximation problem in Equation (13) for some admissible . Indeed, Lemma 6 (ii) and Lemma 5 together imply that
For any , let us now consider the midpoint estimator,
The latter means that effectively approximates , for .
, for all .
Because , a somewhat simpler (though generally less precise) approximation inequality than the one given in the preceding Lemma 7 is , for all .
For a robust decision let ; in addition, let be the utopian point in the outcome space. Because by construction , for all , it is
3.6. Robust Weights
3.6.1. General Case.
An interesting and useful byproduct of a robust decision is its associated robust (normalized) weight,
When the action set is convex, then the chosen robust action naturally also maximizes the robustly weighted criterion, that is, . One can think of the robust weight as an endogenous belief that can be used to evaluate the expected criterion achievement. It defines the tradeoffs compatible with the robust decision, where the latter was found while remaining agnostic over all possible weights (in ).
3.6.2. Balanced Case.
In the case where , for all (cf. Remark 11), we have
In the balanced case, the robust weight can therefore be determined based on the maximized individual criteria alone. If all maximized individual criteria are equal, the robust weight becomes uniform. Indeed, , for all , implies that , so .25
In Example 1, we determined the value function , so that by Equations (19′) and (20′) in this balanced case (as established in Example 2):
Generically, it is , even when the decision set is convex. To see this, let and consider the convex domain, , where the constants are such that . Then , so that . Meanwhile, , for , and
Therefore, , where
Note also,
That is, the robust weight puts more than twice as much emphasis on the Rawlsian (or egalitarian) objective as on the utilitarian objective. One can conclude that in general there is no “robustness equivalence principle,” in the sense that substituting the robust parameter into the original scalarization (via maximization of the corresponding weighted objective) might not lead to a robust decision.26
Consider the robust allocation of two resources to agents. The total amount of each resource has been normalized to one. Allocations are determined as decisions , under which agent 1 obtains of resource 1 and of resource 2, whereas agent 2 obtains of resource 1 and of resource 2. Agent 1’s utility is , and agent 2’s utility is , where are given scalars. Figure 5 provides an illustration in the corresponding Edgeworth box (see, e.g., Pareto 1906, p. 187). Because a robust allocation is necessarily Pareto-optimal, both agents’ marginal rates of substitution for the two goods must be equal, so if and only if
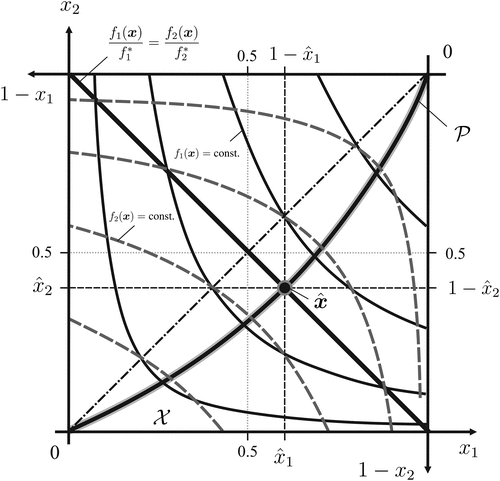
Note. For two agents with utility functions ( and ) specified in Example 9 (for ), the unique robust allocation satisfies Pareto-efficiency in Equation (22) and the balancedness condition in Equation (23), under full ambiguity.
In addition, a robust allocation must maximize the performance ratio, and one can verify that this requires the boundary performance ratios to be equal (i.e., a balancedness condition), so
3.7. Limited Ambiguity
Consider the (nonempty, compact) subset which may reflect the decision maker’s a priori knowledge about the relevant weights for the problem at hand, and let
Let be a (nonempty, compact) subset of . Then (i) (a) is nonempty and compact, and (b) . (ii) If is open (in ), then is open (in ). (iii) If and , then is nonempty and compact. (iv) If is convex, then is convex. (v) If is a straight line segment, then is a straight line segment (or a point). (vi) . (vii) If for some , then . (viii) If for some , then .
Part (i) of Lemma 8 notes that (a) the radial projection of onto can be obtained by simply intersecting the conical closure of with , and (b) one can limit attention to the boundary (ignoring interior points of ). Although a continuous function generally does not map open sets to open sets (e.g., a constant function would not), part (ii) guarantees that does exactly that, provided the “interiority” of a point in is assessed in and then, after its projection, in the lower-dimensional . Part (iii) ensures that weight ambiguity in any (nonempty) subset of leads to a compact domain for a robust decision according to Proposition 5 below. Part (iv) establishes that convex sets are projected to convex sets.28 Following (v) and (vi), the radial projection leaves straight-line geometries intact, thus, for example, converting (bounded) polyhedra in to polytopes in . Finally, parts (vii) and (viii) note that the radial projection of a union of sets is the union of the corresponding single-set projections, but the same does generally not apply to an intersection.29
Assume the (nonnormalized) weights considered reasonable by the decision maker are such that each of its components , for , is known to lie in some interval, resulting in a rectangular ambiguity set,
Note. With and , a radial projection onto yields , as described in Example 10.
Under limited ambiguity, a coordinate-wise decomposition is no longer available. However, because is quasiconcave, for any given , as established in the proof of Proposition 2, the upper contour sets of the performance ratio in the space of weights are necessarily convex. This in turn allows restricting attention, for the representation of the performance index, to the extreme points of the convex hull of the ambiguity set, which yields a representation much in the same spirit as before.
The -conditioned performance index in Equation (24) is such that
Although choosing (cf. Lemma 8 (i) (b)) is always possible, it is usually advantageous to opt for the smallest possible extremal base , so it consists only of the “extreme points” of , where the latter cannot be represented as convex combinations of other points in (see, e.g., Rockafellar 1970, section 18, p. 162).30 If is finite or a (finite) polytope, then the smallest extremal base of extreme points of is also finite.31 Because any bounded convex set can be approximated by a finite polytope (Bronstein 2008), a finite extremal base can be used to represent the convex hull of the given ambiguity set (or its radial projection onto ) up to any desired precision. That may be nonconvex is not important because the level sets of the performance ratio are convex, so that the minima of on are attained on the boundary of its convexification, .
Consider the robust allocation of resources to agents as in Example 9, given the box-shaped ambiguity set as in Example 11, with its radial projection specified by Equation (25),
For a pseudo-robust decision (in ), balancedness must hold, so that, by substituting from Example 9,
Meanwhile, a feasible allocation decision is Pareto-optimal (in ) if and only if it satisfies Equation (22), as before. When the box-shaped ambiguity set becomes smaller, the elements of the extremal base become more similar and coincide in the limit (i.e., as ). Figure 7 shows the robust allocation on the contract curve between the Pareto-optimal allocations that maximize the weighted objective for . Under full ambiguity (i.e., for ), it is ; see Example 9.
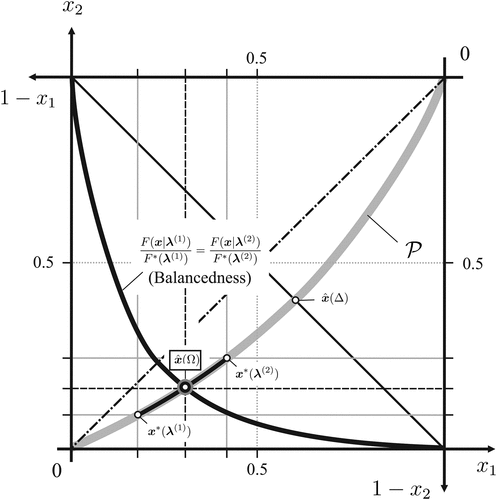
Note. Under limited ambiguity as in Example 10, the robust allocation satisfies Pareto-efficiency in Equation (22) and balancedness in Equation (26); it differs from the allocation under full ambiguity, which maximizes on .
In some applications, the weights are naturally ranked by importance (see, e.g., Wang and Fu 2020). The ordered set of weights, , has a radial projection onto of the form , where , for all . Combining this importance-ranking with a box-shaped ambiguity set as in Example 10, with , where , for all , leads to
This extremal base (of cardinality n) suits practical applications where a decision maker disposes of plausible ranges for the weights to be placed on the criteria, together with a ranking of their importance (cf. Section 4.3.2).
(i) Limiting ambiguity can only increase robustness performance. That is, if are nonempty and compact and satisfy , then , which follows directly from the definition of the -conditioned performance index in Equation (24). (ii) In the absence of ambiguity, the optimal robustness performance has to be maximal. That is, if , then .
3.8. Criterion Ambiguity
Given a (nonempty, compact) action set as in Section 2, we now allow for ambiguity in each of the criteria, given by the continuous functions , for , which map to real numbers, where is a feasible action and is an ex ante unknown state in the (nonempty, compact) state space , and where are given integers. The unknown state represents the decision maker’s uncertainty about the exact value that each of his objectives may attain under a chosen action .
(i) Continuity of the criteria in the state implies that a small perturbation in the state can have only a small impact on the decision maker’s objective. This continuity is automatically satisfied when the state space is finite.32 (ii) The unknown state may introduce dependencies between the different . Indeed, even if (for ) and criteria are such that , for all , then the different criteria’s ambiguity may still be linked via common constraints in .33 But if in addition the state space is a Cartesian product, so , and , for all , then the decoupling of ambiguity across the different criteria is complete, in the sense that observing the part of the state that determines one criterion does not reduce ambiguity for any other criterion.
To assess goal achievement of an action in a given state, the decision maker considers a scalarization of his multicriteria optimization problem by means of a weighted objective,
The modified nontriviality condition (N′) ensures that the ex post optimal objective is always positive, so
The modified nontriviality condition (N′) can always be satisfied, without altering the set of ex post optimal decisions, by using a (positive, translated) criterion , for some ; see also Remark 4.
Given a (nonempty, compact) ambiguity set , the decision maker’s robustness objective, as in Section 3.7, is to maximize the -conditioned performance index,
The following result recasts the robustness objective into a by-now-familiar representation.
Let be an extremal base of . Then
Based on Proposition 6, if the (smallest) extremal base is finite, we can reduce the general multicriteria decision problem to our basic framework in Section 2, with full weight ambiguity and no criterion ambiguity.
Assume that there exists a (finite, smallest) integer so that and , and let , for all . Then
where , for all , represents in Equation (27).
(i) In the case of full ambiguity, it is , so that and , with , for all . (ii) Consider now a multicriteria decision problem under full ambiguity, with criteria of the form , for all , where the state is only known to lie in the (nonempty, compact) set (with to avoid trivialities), and where the functions are continuous. Let and ; furthermore, set
(i) The minimization over the state space in Example 13 reflects a robust, precautionary stance: the decision maker evaluates actions under the most adverse plausible realization of the state with respect to the achievable performance ratio, consistent with a notion of relative worst-case robustness. (ii) The treatment of criterion ambiguity in this section also bears a conceptual resemblance to models of DRO, where decisions are evaluated against worst-case distributions within a specified ambiguity set. In our framework, the uncertainty is not over probability distributions but over states , with performance assessed under the worst-case realization of both the state and the weights. This can be viewed as a nonprobabilistic analogue of DRO, where the ambiguity set over the weights plays a role similar to ambiguity sets over distributions in DRO models. In particular, the two-layer minimization in Equation (27)—over weights and states—mirrors the inner DRO minimization over distributions, highlighting a parallel structure between worst-case evaluation across distributional and multicriteria settings.
3.9. General Multicriteria Objectives
In certain practical applications, it may seem appealing to consider alternatives to the arithmetic mean in Equation (1), such as a harmonic or geometric mean, with suitable weights. One could even think of using a (weighted) power mean which would accommodate each of the earlier options as a special case; see Example 14 below, which illustrates aggregation ambiguity. Rather than commit to a particular functional form for aggregating multiple criteria, however, we propose a general class of multicriteria objectives that adhere to a set of reasonable axioms. These axioms reduce (in the case of uniform weights) to those known to characterize the quasiarithmetic mean. A key finding, notably, is that maximizing this general weighted objective is entirely equivalent to maximizing the arithmetic mean objective in Equation (1), provided the criteria are suitably transformed.
Let denote a (continuous) multicriteria objective, where is a (nonempty) domain such that , with the vector of criteria , and where is the unit simplex; see Section 2.1. For any decision and weight , the multicriteria objective produces an overall score , which the decision maker would like to maximize by choosing an appropriate decision—in the presence of (possibly limited) ambiguity about (and possibly also about ) as discussed in Section 3.7 (and Section 3.8). To guide the form of a sufficiently flexible and interpretable objective, we posit five axioms (Axioms 1–5), which nest those proposed by Kolmogorov (1930) in his seminal work “On the notion of mean.”
(
(
(
(
(
The significance of these five basic requirements is as follows: Monotonicity (Axiom 1) means that as long as the weight component is positive, increasing the value of criterion must also increase the weighted objective, whereas for the weighted objective becomes insensitive to criterion i; symmetry (Axiom 2) requires that the weighted objective is invariant with respect to any joint permutation of indices belonging to criteria and their associated weights; reflexivity (Axiom 3) imposes score-consistency in the sense that if all criterion scores are identical, then that should also be the value of the weighted objective, no matter what (normalized) weights are applied; in a similar vein, associativity (Axiom 4) postulates that replacing a group of inputs with their internal weighted average leaves the overall aggregation unchanged; finally, in order to guarantee that the weights provide a homotopic relation between all criteria in isolation, the weighted objective is a coordinate filter (Axiom 5) if it yields the i-th component of when putting all weight on the i-th coordinate (i.e., for ).
Based on Kolmogorov’s result,36 we define the general h-mean,
The general h-mean in Equation (29) satisfies Axioms 1–5.
The following example illustrates the flexibility afforded by the general h-mean.
Consider two well-known averages.
Let . For any weight and power parameter , define the power mean:
which corresponds to Equation (29) with for , and for . This recovers the harmonic (), geometric (), and arithmetic () means, among others. In the limit, the power mean approaches the minimum (for ) or maximum (for ) of all with positive weights. Importantly, is increasing in p (see, e.g., Hardy et al. 1934, theorem 16, p. 26) and uniquely satisfies homogeneity: for all (see, e.g., Hardy et al. 1934, theorem 84, p. 68).37For , the general h-mean in Equation (29) becomes a weighted mean in the log-semiring, related to the LogSumExp (LSE) function, because , for all , where , for all . Such a formulation carries fruit in probabilistic modeling and neural networks, where LSE and softmax appear naturally because of their smoothness properties.38
3.9.1. Reduction to Basic Framework.
Crucially, the general h-mean in Equation (29) reduces to our standard weighted objective in Equation (1) under a transformation of the criteria, by setting , so that
If the kernel h is increasing (resp., decreasing), then maximizing is equivalent to maximizing (resp., minimizing) . Thus, our earlier results carry over directly—with minor adjustments in the decreasing case, as detailed in Section 3.9.2.
Consider Example 13 (ii) for the “diagonal” state space , where the constants are such that . By Example 14 (i), this represents a situation in which the decision maker is uncertain about the appropriate aggregation method, except that a (homogeneous) power mean should be used, for some . The result in Example 13 (ii) suggests as robust choice the largest available option: the power mean .
(i) As Example 15 suggests, the insights about criterion ambiguity in Section 3.8 may sometimes be combined with the general representation of multicriteria objectives in Section 3.9 to handle aggregation ambiguity, that is, uncertainty over which aggregation rule or kernel should be used. (ii) For the general h-mean in Equation (29), we define with . However, in general, with , so our optimization focuses on directly. (iii) For the practically very important power mean in Example 14 (i) and Example 15 (as long as ), the robust optimization of is equivalent to the robust optimization of , because and both feature multiplicative separability.
3.9.2. Special Case: Minimization Under Decreasing Kernel.
For a decreasing kernel, transforms larger into smaller , so that the objective reflects a smaller-is-better interpretation (akin to optimizing a loss function). Assuming , by Axiom 3 it is . Because in most practical applications (e.g., for logarithmic or inverse transformations in multiobjective loss minimization) it is , we obtain , so that on the compact action set it is , for all , as is necessarily finite. Hence, we can consider the adjusted performance ratio,
The set of Pareto-optimal actions needs to be based on the original vector of criteria , so that
3.10. Applying the Method
“What do I do? What do I get? How do I adapt it to my case?”—We now address these practitioner questions by outlining the method’s core, the interpretation of its results, and important extensions for customization, as a navigation device for approaching the multicriteria decision problem introduced in Section 2.1 and its generalizations.
(Core) To determine an approximately robust decision (at any prespecified precision ) with respect to n criteria, one needs to solve just optimization problems: one to maximize the -augmented performance index in Equations (12) and (13) and n to compute the normalization constants in Equation (5) for the criterion-specific performance ratios in Equation (6). The associated normalized robust weight , which encapsulates the tradeoffs between the criteria embedded in both the action set and the shape of the criterion functions (independent of any scaling), is then obtained (approximately) from Equations (19) and (20) by setting .
(Interpretation) The performance index , with given in Equation (6), guarantees a minimum percentage that the robust solution achieves of the optimal weighted objective in Equation (1), for any weight in . This means that the performance of is guaranteed to be no worse than times the best achievable performance under any possible weight vector, ensuring robustness to unknown or contested preferences. In this manner, the weight-induced subjectivity in multicriteria optimization can be removed. The robust weight rationalizes the robust decision as an optimum of the weighted objective in Equation (1) for . The vector can be interpreted as the revealed weight structure that best justifies the robust solution, based on the problem’s internal tradeoffs.
(Customization) The method accommodates several practically important extensions:
– Partial weight information: Prior knowledge or constraints on weights can be imposed by requiring weight vectors (not necessarily normalized) to belong to a suitable subset (cf. Section 3.7).
– State-dependent criteria: Uncertain or context-dependent criteria can be captured by worst-case performance ratios, effectively reducing the problem to the core framework (cf. Section 3.8).
– Generalized aggregation: Rather than relying on the arithmetic mean in Equation (1), one may adopt alternative scalarization functions consistent with an axiomatic foundation (cf. Section 3.9).
Overall, the relatively robust methodology provides a computationally tractable and conceptually transparent toolkit for balancing multiple, possibly ambiguous objectives in diverse real-world settings (cf. Section 4.3).
4. Discrete Applications
4.1. Finite Action Set
4.1.1. Relative Robustness Criterion.
Consider a finite set of alternatives , evaluated according to n positive criteria . Each alternative receives a score , for all . If we set , then the performance index for the j-th option becomes
By Proposition 3, a robust decision can be found by computing the lower limit, as follows:
This robust decision achieves the optimal performance index,
As discussed in Section 3, simply maximizing the performance index yields pseudo-robust solutions, which are generically inefficient; see, for instance, Example 6. We now compare the proposed approach with several alternative robustness criteria.
4.1.2. Alternative Robustness Criteria.
The following three robustness criteria, defined in the present context of discrete action sets, are frequently used in the literature for dealing with parameter ambiguity.
The Laplace criterion corresponds to a weighted objective in Equation (1) with a uniform weight, , leading to the “Laplace solution,”
(34)The worst-case criterion is defined as the minimum payoff across the admissible weights, which yields a so-called “maximin solution,”
(35)The absolute-regret criterion evaluates absolute regret, that is, the maximum difference ex post between what is and the best that could have been, resulting in the “(minimax) absolute-regret solution,”
(36)
4.1.3. Comparison.
The following example, which features a finite action set, illustrates the proposed robust solution in Equation (32) against decisions recommended by alternative robustness criteria, notably the Laplace criterion in Equation (34), the WC (or maximin) solution in Equation (35), and the solution minimizing the (maximum) AR in Equation (36).
Consider a discrete-choice situation for options, for which the scores across criteria are recorded in Table 1. In the context of relative robustness, options 2 and 5 are tied for the highest performance index in Equation (31) and are thus both pseudo-robust, so . At the same time, option 5 Pareto-dominates option 2 (with ), so that is the unique robust choice. This solution can also be obtained directly from Equation (32), written in the form
|

Table 1. Discrete Decision Options in Example 16, Evaluated with Different Robustness Criteria
| Option (j) | Criteria | Performance ratios/index | Alternative evaluations | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Laplace | WC | AR | ||||||||
| 1 | 24 | 20 | 16 | 1 | 10/11 | 4/15 | 4/15 | 20 | 16 | 44 |
| 2 | 7 | 6 | 32 | 7/24 | 3/11 | 8/15 | 3/11 | 15 | 6 | 28 |
| 3 | 1 | 2 | 60 | 1/24 | 1/11 | 1 | 1/24 | 21 | 1 | 23 |
| 4 | 22 | 22 | 16 | 11/12 | 1 | 4/15 | 4/15 | 20 | 16 | 44 |
| 5 | 12 | 6 | 36 | 1/2 | 3/11 | 3/5 | 3/11 | 18 | 6 | 24 |
Note. Values in bold indicate optimality for the corresponding robustness criterion.
where , for all and all . Indeed, because , for sufficiently small the -augmented performance index is
Meanwhile, it is
Therefore, , for all sufficiently small , so , and one finds as the unique robust option. Regarding alternative robustness evaluation, both the Laplace criterion in Equation (34) and the absolute-regret criterion in Equation (36) produce the solution with very poor performance in at least one criterion. In fact, changing the payoff from one to zero would produce even a zero performance index and zero worst-case performance guarantee for that same decision (still optimal under these criteria),39 which may be rather difficult to justify in any real-world scenario. Finally, maximizing the worst-criterion performance in Equation (35) leads to indifference between options 1 and 4, at a suboptimal performance index and largest absolute regret. By contrast, the proposed robust solution provides (by construction) the best performance index and a reasonable compromise solution in terms of the other criteria. It guarantees a strictly positive performance across all criteria. From Equations (19) and (20) we find that the corresponding (normalized) robust weight vector is
Consistent with Equation (21), it is such that
|
Table 2. Discrete Decision Options in Example 16, Evaluated after Robust Reweighting
| Option (j) | Criteria | Performance ratios/index | Alternative evaluations | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Laplace | WC | AR | ||||||||
| 1 | 7.2 | 12 | 1.6 | 1 | 10/11 | 4/15 | 4/15 | 20.8 | 1.6 | 4.4 |
| 2 | 2.1 | 3.6 | 3.2 | 7/24 | 3/11 | 8/15 | 3/11 | 8.9 | 2.1 | 9.6 |
| 3 | 0.3 | 1.2 | 6 | 1/24 | 1/11 | 1 | 1/24 | 7.5 | 0.3 | 12 |
| 4 | 6.6 | 13.2 | 1.6 | 11/12 | 1 | 4/15 | 4/15 | 21.4 | 1.6 | 4.4 |
| 5 | 3.6 | 3.6 | 3.6 | 1/2 | 3/11 | 3/5 | 3/11 | 10.8 | 3.6 | 9.6 |
Note. Values in bold indicate optimality for the corresponding robustness criterion.
4.2. Data-Driven Approach
Consider any (nonempty, compact) action set for some integer , as in Section 2. Assume further that the decision maker does not know the functional form of the multicriterion , but is still able to observe its value for different decisions over the course of experiments, where . Indeed, given the realized score set and the realized action set , the average criterion scores are40
In other words, captures the worst-case relative performance of action across all observed criteria, and identifies a robust decision, which is efficient and has the best-possible worst-case performance. Note that instead of going through the motions of actually taking the limit, it is sufficient to maximize the -augmented performance index, that is, the maximand in Equation (37), for a sufficiently small . This approximates the optimal robustness performance, captured by the optimal performance index , arbitrarily closely by virtue of the -performance guarantee provided in Proposition 4. Finally, as in Equations (19) and (20), the (data-driven) robust weight is
Based on the observed data, this vector provides a robust estimate of the tradeoffs between the different criteria from the vantage point of relative robustness.
Consider the joint evaluation of human performance on a certain task (such as giving a university lecture) by K evaluators who score J individuals in N different performance dimensions (or criteria) on a Likert scale (from one to seven),41 so , , and . Figure 8 shows a spider plot comparing different individuals. Assuming that all evaluators scored all the individuals using a seven-point Likert scale, the realized score set has elements , for all , whereas the realized action set is equal to . Individual 3, although never achieving a highest criterion-specific average score, exhibits the best data-driven performance index (). Because in a noisy observation environment ties in the performance index are fairly unlikely, the set of pseudo-robust alternatives tends to be a singleton, thus also resulting in a singleton set of robust options (e.g., ). This example illustrates how the data-driven approach identifies robust performance through balanced tradeoffs rather than peak performance in any one dimension, thus favoring individual 3, whose weakest dimension is relatively strong.
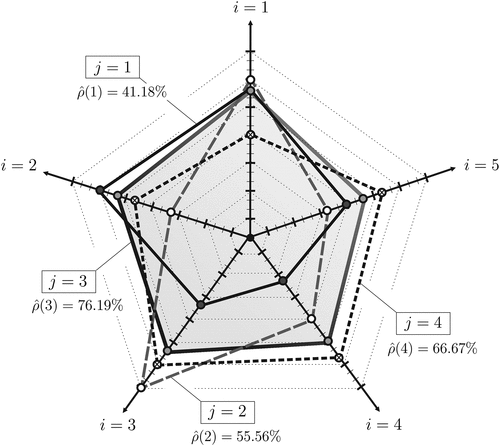
Note. All options are Pareto-efficient (i.e., ); only option 3 is also pseudo-robust (i.e., ), so .
4.3. Real-World Applications
Relatively robust multicriteria optimization provides a flexible and transparent framework for decision-making under uncertainty. As developed in Sections 2 and 3, it is especially well suited for complex problems where the relative importance of multiple criteria is ambiguous or hard to justify. The method systematically balances competing objectives using only minimal assumptions on the decision maker’s preferences, and delivers solutions that are both Pareto-efficient and robust (cf. Proposition 3). We illustrate its practical relevance in three diverse contexts: the energy trilemma, quality-adjusted life year (QALY)-based health evaluations, and corporate resource allocation. In each case, the relatively robust methodology facilitates structured tradeoff management and data-informed robustness, whether operating in an abstract policy space or on a finite empirical action set (cf. Sections 4.1 and 4.2).
4.3.1. Energy Trilemma: Balancing Energy Security, Equity, and Sustainability.
The World Energy Council’s Energy Trilemma framework evaluates nations on three key dimensions, namely “energy security” (i.e., the reliability and resilience of energy supply), “energy equity” (i.e., the accessibility and affordability of energy for all citizens), and “environmental sustainability” (i.e., the reduction of greenhouse gas emissions and environmental impact). Nations face challenges in improving one dimension without compromising others (World Energy Council 2024).42 For instance, increasing energy equity by subsidizing fossil fuels may undermine sustainability, while prioritizing environmental sustainability through renewable energy investment might initially reduce energy security or equity. An optimal strategy depends on the relative importance attributed to each of the three criteria. In this setting, a relatively robust approach can
Identify Robust Policies: By modeling each nation’s energy policies and outcomes as feasible decisions, the method identifies those policies that achieve strong tradeoffs across all three dimensions. For example, a relatively robust policy might balance investment in renewable energy, grid modernization, and subsidies for low-income households, ensuring consistent performance regardless of variations of the relative importance across dimensions, which might still be importance-ranked (cf. Section 3.7).
Quantify Tradeoffs: The approach provides a clear representation of tradeoffs, such as how much equity might need to be sacrificed for a given improvement in sustainability under different weighting scenarios.
“Robustify” Strategic Goals: Policymakers can develop long-term strategies that are resilient to evolving societal priorities, such as shifts toward greater emphasis on the precautionary principle (cf. Section 3.9).
4.3.2. QALY Impact of Diseases: Evaluating Quality-Adjusted Life Years.
QALYs measure the impact of diseases and medical treatments by combining longevity and quality of life into a single index (Pliskin 1974, Pliskin and Beck 1976, Miyamoto et al. 1998).43 The impact of different impairments—such as mobility loss, chronic pain, or cognitive decline—depends on how these are weighted relative to each other in calculating overall health outcomes. Subject to restrictions on weights (e.g., a priority ranking; cf. Example 12) and with a flexible aggregation of criteria (cf. Section 3.9) the method can
Handle Uncertain Weightings: When precise utility-weightings for different impairments are unavailable (as one would generally assume), the method identifies health interventions or treatment plans that remain effective across a wide range of subjective assessments. For example, it might suggest treatments that optimize outcomes for both pain relief and mobility restoration, ensuring robust quality-of-life improvements.
Optimize Resource Allocation: Health authorities can use the method to prioritize interventions that deliver the highest QALY improvements per dollar spent, even when the relative importance of various health dimensions (e.g., physical versus mental health) is uncertain.44
Support Evidence-Based Policy: The method provides a performance guarantee for proposed policies, demonstrating their effectiveness regardless of the relative emphasis placed on specific impairments.
4.3.3. Resource Allocation in Companies: Balancing Risk, Resources, and Rival Assets.
In organizations, resource allocation involves deciding how to distribute limited resources—financial, human, or physical—across competing projects. Each project is evaluated based on multiple criteria, such as “risk of noncompletion” (i.e., the probability that a project fails because of delays or unforeseen issues), “use of human resources” (i.e., the availability and workload of skilled personnel required for the project), and “use of rival assets” (i.e., the occupation of assets that cannot be used by multiple projects simultaneously, for example, specialized machinery). Applying the framework of relatively robust decision making allows organizations to45
Identify Balanced Portfolios: By modeling projects and their criteria as feasible decisions , with performance criteria , the method selects a portfolio of projects that balances competing objectives, ensuring efficient resource use even when preferences over criteria are unclear.
Manage Tradeoffs: By aggregating criterion-specific performance ratios into a performance index , the method reveals, for example, how prioritizing low-risk projects impacts resource utilization and asset deployment, informing decisions about a robust balance between risk and resource efficiency.
Adapt to Uncertainty: As organizational priorities shift (e.g., toward innovation or risk aversion), the method ensures that allocation strategies can remain robust across changing criteria (cf. Section 3.8) and weight configurations for the criteria, and possibly across different aggregation methods (cf. Section 3.9).
In settings with discrete project sets and empirical observations, a data-driven approach can be applied (cf. Section 4.2).
5. Conclusion
Multicriteria optimization aims to resolve conflicts between competing objectives by finding Pareto-efficient decisions for which improving one criterion necessarily degrades at least one other. Although Pareto-efficiency sets a minimum standard of nonwastefulness, practical decision making often requires selecting a single compromise solution from the available Pareto frontier. Scalarization, such as assigning weights to criteria, is a common method for operationalizing this selection, but it assumes knowledge of the weights, which may not be available or easily justifiable, and it may also exclude Pareto-efficient solutions when the action set is nonconvex.
Here, we seek to mitigate the dependence on precise weight specifications by introducing a performance index that evaluates the worst-case weighted performance of a decision relative to its maximum potential. A Pareto-efficient decision that maximizes this index is viewed as relatively robust, balancing competing criteria in a way that offers resilience to weight uncertainty. A critical feature of the method is its computational simplicity, relying only on the compactness of the feasible set and the continuity of criterion functions to guarantee the existence and basic regularity of the solutions. This ensures broad applicability, even for complex, nonconvex problems. Criterion ambiguity and more general aggregation methods can be accommodated. In the case of finite sets, this method is completely general and can be operationalized through a data-driven approach under virtually no assumptions.
Appendix. Proofs
The proof proceeds by analyzing what happens when either one of the two inequalities is violated, and subsequently when both are violated. This yields three cases, each of which leads to a contradiction.
Case 1: If and , then
which is a contradiction.Case 2: If and , then
which is a contradiction.Case 3: If and , then
But because , this implies
Hence, and , as claimed. □
Fix and , and let . Then
We first show that, for any given decision, the performance ratio is quasiconcave in the weight. To that end, fix any feasible action , and define
Because and , the definition of the weighted objective in Equation (1) implies
Therefore, as long as , the fact that , together with Equations (A.4) and (A.5), implies that Equation (A.3) holds. As an immediate consequence, it is , which in turn means that is convex for all and all , as claimed.
The convexity of the upper contour sets implies that is quasiconcave in (see, e.g., Arrow and Enthoven 1961, p. 780). Hence, the minimum of the performance ratio over all weights in is attained on the boundary:
The same quasiconcavity argument applies to any face of , so the minimum must also lie on the boundary of each face. Repeating this argument recursively over edges and vertices, we conclude that the minimum is attained in the set of the n vertices of . Thus, we obtain a form of “perfect complementarity,”
For any , Proposition 2 provides for a representation of the performance index, which can be rewritten in the form , where . The set of pseudo-robust decisions in Equation (7) is nonempty by the extreme-value theorem (Rudin 1976, theorem 4.16, p. 89), and it is compact by the maximum theorem (Berge 1963, p. 116). These two theorems also guarantee that the correspondence is upper semicontinuous and nonempty-valued. Consider now , which by Equations (9) and (10) can be written as
By Lemma 2, the robust decision set is nonempty and compact. Hence, by the extreme-value theorem there exists , and Equation (7) yields , as well as , establishing the claim. □
(i) The claim follows by combining Equations (7) and (12). (ii) Fix , and—following the outcome-based logic discussed in Remark 9—consider a selection
We now show that is efficient (with respect to the coordinates of points in ).47 Suppose it is not; then there exists a feasible which achieves a strictly greater payoff, a contradiction, which in turn establishes the claimed efficiency of . Moreover, it is clear that , so that
As a result, , for all , as claimed. (iii) Let , and consider any . If , then
On the other hand, implies that . Let be the total coordinate-wise difference in performance. Then for any ,
This establishes the claim in part (iii), for any and . For , the claim follows from part (i). □
We first note that is upper semicontinuous in , and set . The proof proceeds in two steps. We first show that and then .
Step 1: . By upper semicontinuity of we have that (see, e.g., Aubin and Frankowska 1990, p. 41), taking into account that is compact; cf. Endnote 19 for Section 3.1. Because , for all , we further obtain . Assume that there is a point , which means that , for some selection , where . Because , there exists such that . That is, for some , and . If we denote by the average performance over all criteria, then implies that . By the continuity of on , it is therefore . Hence, there exists a such that for all . Thus, for any given :
Step 2: . Consider a monotone sequence with , for all , and such that . Using the same selection as in Step 1, the sequence is a sequence of points contained in the compact set , so that by the Bolzano-Weierstrass theorem (Berge 1963, p. 67) there exists a convergent subsequence (with limit in ). That is, there exists , such that , and by the definition of we therefore obtain that and thus, , as stated in the result.
This concludes the proof. □
Continuity of the optimal -augmented performance index over follows from the maximum theorem (Berge 1963, p. 116), given the continuity of in both arguments and the compactness of . To establish monotonicity, fix with . By optimality of for and feasibility of at , we obtain
Subtracting , we find
(i)/(iv) The function conforms to Equation (1) as a weighted objective comprising the two criteria and . By Proposition 1, increasing , which shifts weight from the first criterion to the second, can only decrease the optimal value of the first and increase that of the second. Thus, is decreasing and is increasing in , as claimed. (ii) Because , we have that . Hence, by part (i) we have that , for all . (iii) Because is bounded above by and nonincreasing in , the sequence converges as by the monotone convergence theorem (see, e.g., Rudin 1976, theorem 3.14, p. 55). Moreover, because is the least upper bound, the limit of as must equal . (v) This result follows from the monotonicity of established in Lemma 5. Because is nondecreasing in , and , by parts (i) and (ii), it must be that for all ; otherwise, the convex combination would decrease, contradicting monotonicity. □
By Equations (15) and (16), along with Lemma 5, we have
Thus, given a desired approximation-error bound , for any , it is
Because, by Lemma 6 (iv), the function is decreasing, a simpler implication follows by choosing :
This establishes the claimed approximation guarantee. □
Fix any . By Equation (16), the difference between the upper and lower bounds in Equation (17) is given by
The midpoint estimator defined in Equation (18) is the arithmetic average of these bounds:
By construction, this implies
Therefore, approximates to within , as claimed. □
Let be a nonempty compact set, which is not reduced to the origin.
(a) Because is nonempty, its radial projection is nonempty as well. Moreover, is continuous on the compact set , so is compact (Apostol 1974, theorem 4.25, p. 82). We now show that . For the inclusion , take any . Then there exists such that , i.e., . Because , it follows that for any , we have , and in particular, for . Hence . Conversely, suppose . Then there exists such that . Applying the radial projection yields , because . Therefore, , proving . Together, we obtain . (b) Because , we trivially have . To prove the reverse inclusion, let . Then for some , with . Because is compact and , the ray intersects in a bounded interval of positive length. That is, there exist real numbers , with , such that . Hence, , so , completing the proof that .
Let . Because , it follows that . Because is a smooth manifold and the intersection of an open set with it is open (in the relative topology), we obtain that is open in ,48 and thus . This proves that the radial projection maps interior points of to interior points of . It follows that if is open in , then is open in .
Let be nonempty. Then is nonempty. Its closure is compact because is contained in the compact set . Using continuity of and part (i) (b) we have that
Hence, the boundary of equals the boundary of the projection of the boundary of .
Suppose is convex. If were not convex, then there would exist and such that . Let , and . Then for any ,
In particular, define
Then
by convexity of . Hence, , contradicting our assumption. Therefore, must be convex.We now show that the image of a straight line segment is a straight line segment in , with the possibility of a degenerate case when the straight line segment is projected to a single point in . Indeed,
where , andThe latter function is continuously differentiable, with
which implies that is strictly increasing on [0, 1]. Thus, provided that , the radial projection of a straight line is a bijection, which also preserves the orientation of any straight path between two different points in , as long as they do not map to the same point in (for ).Consider first the case where is a bounded polyhedron (i.e., a polytope; see, e.g., Nemhauser and Wolsey 1999, definition 2.2, p. 86). By part (i) (b) it is . By part (iv), the set is convex. Part (v) then guarantees that the straight lines between any two vertices of remain straight lines in their radial projection onto , which implies it is enough to project the vertices of and then take the convex hull. Because the vertices are included in , we therefore obtain that as claimed. If the bounded convex set is not a polytope, then it can be approximated arbitrarily closely by a polytope (see, e.g., Bronstein 2008), so that the claim—omitting some of the convergence-specific details—follows in the limit.
Let such that . Then , which implies the claim by part (i) (a) (cf. Endnote 48): .
Let such that . Then, by part (i) (a) we have . If for some , then , as claimed. □
Recall that the ambiguity set is compact, nonempty, and not reduced to the origin. For any feasible decision , the -conditioned performance index corresponds to its worst-case relative performance. Using the radial projection of and invoking Lemma 8 (i), we obtain:49
As shown in the proof of Proposition 2, the performance ratio is quasiconcave in for fixed . Because is compact, the minimum is attained on the boundary , which equals by Lemma 8 (i) (b). Moreover, the quasiconcavity of implies that all upper contour sets are convex, so the minimum is also attained on the boundary of the convex hull . Thus, if there exists an extremal base such that , then the minimum is attained on the compact set , as claimed. □
Fix any , and consider the state-contingent -conditioned performance index,
By Equation (27), the performance index is the minimum of the state-contingent -conditioned performance index in Equation (A.7) over all , that is,
Thus, reversing the order of minimization in Equation (A.8) yields Equation (27), as claimed. □
Let be the (smallest) extremal base of (or, equivalently, of ), which is finite by hypothesis, with . Then Equation (27) becomes
Fix (with ), , and . Then for any : If , then
This implies Axiom 1.50 Consider now the case where . Then for , Axiom 2 holds trivially. For , it is
With this, one obtains
1 Practical examples for multicriteria decision making are legion; see, for example, the collections of case studies by Berbel et al. (2018) in agriculture, Masri et al. (2018) in financial decision making, and Ravindran (2016) for supply chain management, to name just a few.
2 Extant ESG metrics differ widely. In their approach to “quantifying the impact of impact investing,” Lo and Zhang (2024) remain agnostic about the impact factors to be used, taking them as given and thus keeping at bay the difficulties of attributing weights to different ESG criteria and of dealing with this model uncertainty.
3 Lancaster (1966) already noted that a product can be viewed as a bundle of its attributes, with consumer valuations often empirically assessed using conjoint analysis (see, e.g., Green and Srinivasan 1990).
4 Example 9 in Section 3.6 discusses robust allocation in a two-agent exchange economy using the proposed framework.
5 This is notwithstanding the “norm equivalence” in a finite-dimensional Euclidean space, in the sense that any norm can be bracketed by any other norm , so for suitable scalars .
6 For the computation of Pareto sets, see Kung et al. (1975), Gabow et al. (1984), and Bentley et al. (1993).
7 See Yamamoto (2002) for details about maximizing a function on a Pareto-efficient set in a polyhedral setting.
8 A lexicographic evaluation of criteria based on perceived importance may justify an “elimination by aspects” (Tversky 1972), or more nuanced partial elimination heuristics using “attribute filters” (Kimya 2018).
9 Numerous ad hoc methods for determining weights exist, for example, in reliability engineering based on standards (Jiang and Chen 2020).
10 In his “Discussion on Making Things Equal,” Zhuang Zhou points out that “[t]here is nothing in the world bigger than the tip of an autumn hair, and Mount T’ai is tiny” (Watson 1968, p. 44), where Mount Tai is the highest point in the Shandong province of China.
11 For example, getting $100 in a month, in addition to repayment of the invested principal, would be attractive if obtained by investing a principal of $1 today, but not if it required investing a principal of $10 million today.
12 A point is said to be isolated if there exists an open set such that .
13 By the extreme-value theorem (Rudin 1976, theorem 4.16, p. 89), the minimum of a continuous function on a compact set exists and is finite.
14 It is .
15 More precisely, as shown in the proof of Lemma 1, we have .
16 This “complete ignorance” (or full ambiguity) is relaxed in Section 3.7 where we allow the decision maker to face limited ambiguity.
17 Because , the function is well defined.
18 Leontief (1941) employed this aggregation in fixed proportions as a simplification for his analysis of a larger economy.
19 By the extreme-value theorem, is nonempty, and by the maximum theorem, it is compact.
20 Given two vectors , where and , the standard vector inequalities are defined as follows: (i) ; (ii) ; (iii) . Here, , with .
21 The relevant lower (set) limit is given by (see, e.g., Aubin and Frankowska 1990, definition 1.4.6, p. 41). Given a sequence with , this lower limit contains the accumulation points of any sequence with elements , for all .
22 Note that: , for all .
23 The larger (path-connected, compact) action set leaves results unchanged.
24 It is if and only if .
25 Normalizing the maximum criteria to the same score (e.g., ) is natural in many applications.
26 The term “robustness equivalence principle” is analogous to the well-known “certainty equivalence principle,” for example, in linear-quadratic optimal control problems (Bertsekas 1995, p. 23), where it is optimal (i.e., maximizing the expected value of a quadratic objective functional) to replace uncertain parameters by their means.
27 For , Equations (22) and (23) imply the unique robust allocation , achieving .
28 The converse of part (iv) does not hold. That is, if is nonconvex, then may still be convex.
29 The analysis in Example 10 yields an extreme counterexample for , with , , and . Indeed, for one obtains , so , whereas is merely a singleton.
30 The underlying justification is Minkowski’s theorem, which states that any compact convex set is equal to the convex hull of its extreme points; see, for example, Rockafellar (1970, corollary 18.5.1, p. 167) or Schneider (2014, corollary 1.4.5, p. 17).
31 In general, the smallest may not be finite (e.g., if is a unit ball, then the smallest has a continuum of elements).
32 For analogous comments about the assumed continuity of the criteria in the action, see Remark 1 (i) in Section 2.
33 For example, in the case where for , observing implies (and vice versa).
34 For any , we define .
35 It is , with the radial projection , from onto ; see Section 3.8.
36 Kolmogorov (1930) showed that if Axioms 1–4 are satisfied for (cf. Endnote 34), then there exists a (continuous) strictly monotonic function , defined on a suitable domain , such that
Nagumo (1930) obtained a similar result, and the preceding “quasiarithmetic mean” is therefore also known as the “Kolmogorov-Nagumo mean.”
37 Homogeneity is not required by Axioms 1–5, because relatively robust decisions (cf. Proposition 2) are invariant under rescaling.
38 The gradient of LSE is the softmax function (Boltzmann 1871; Gibbs 1902, chapter XIV), widely used in machine learning (Bridle 1990).
39 The purpose of restricting all criteria to strictly positive values was merely to skip checking the nontriviality condition (N) in Section 2.1 which is satisfied here (e.g., ). Hence, setting poses no problem.
40 Under some mild additional assumptions (which we omit), the law of large numbers would guarantee convergence of the average scores to the true criterion-function values, at least when the number of available score observations for each realized action (i.e., each element of ) goes to infinity, assuming that decisions can be properly recognized, as may naturally be the case on a sufficiently discrete underlying action set .
41 Nathan and Lord (1983) propose “knowledge,” “delivery,” “relevance,” “interpersonal,” and “organization” as criteria for the quality of a university lecturer; see also DeNisi and Murphy (2017) for a survey.
42 This is not the only “energy trilemma”; Tilman et al. (2009) discuss a food-energy-environment trilemma in the context of biofuels.
43 Klarman et al. (1968) recognized the need for quality-of-life considerations in cost-effective treatment options (for chronic renal disease).
44 Cutler and Richardson (1997), Buxton (2005), and Newhouse (2021) discuss QALY for assessing cost-effectiveness in healthcare.
45 Baker and Freeland (1975) provide an overview of early scoring models. Stewart (1991) proposes a multicriteria decision support system for project selection using essentially equal weights for different objectives (akin to the Laplacian approach; cf. Section 4.1). Finally, Hall et al. (2015) suggest a project evaluation with an “underperformance riskiness index” relying on (typically unavailable) past statistical data.
46 Indeed, because , for all , Equation (A.2) implies that .
47 Efficiency in the outcome set corresponds directly to efficiency in the action set (cf. Section 3.2), because the latter is evaluated via a criterion vector that produces points in the outcome set.
48 The representation was given in part (i) for a compact set , but it also applies to any subset of .
49 By part (a) of Lemma 8 (i), is nonempty and compact, so the minimum with respect to must be attained by the extreme-value theorem.
50 When h is increasing, the argument of cannot become smaller by dropping the term . Conversely, when h is decreasing, the argument of weakly decreases, so the value of that inverse cannot go down.
References
- Apostol TM (1974) Mathematical Analysis, 2nd ed. (Addison-Wesley, Reading, MA).Google Scholar
- (1961) Quasi-concave programming. Econometrica 29(4):779–800.Crossref, Google Scholar
- (1990) Set-Valued Analysis (Birkhäuser, Boston).Google Scholar
- (1975) Recent advances in R&D benefit measurement and project selection methods. Management Sci. 21(10):1164–1175.Link, Google Scholar
- (1994) A new measure for the study of on-line algorithms. Algorithmica 11(1):73–91.Crossref, Google Scholar
- (2013) Robust solutions of optimization problems affected by uncertain probabilities. Management Sci. 59(2):341–357.Link, Google Scholar
- (1993) Fast linear expected-time algorithms for computing maxima and convex hulls. Algorithmica 9(2):168–183.Crossref, Google Scholar
- Berbel J, Bournaris T, Manos B, Matsatsinis N, Viaggi D, eds. (2018) Multicriteria Analysis in Agriculture: Current Trends and Recent Applications (Springer, New York).Crossref, Google Scholar
- (1963) Topological Spaces (Oliver and Boyd, Edinburgh, UK).Google Scholar
- (1995) Dynamic Programming and Optimal Control, vol. 1 (Athena Scientific, Belmont, MA).Google Scholar
- (2019) Quantifying distributional model risk via optimal transport. Math. Oper. Res. 44(2):565–600.Link, Google Scholar
- (1871) Über das Wärmegleichgewicht zwischen mehratomigen Gasmolekülen. Sitzungsberichte der Mathematisch-Naturwissenschaftlichen Classe der Kaiserlichen Akademie der Wissenschaften, Wien 63(3):397–418.Google Scholar
- (1990)
Probabilistic interpretation of feedforward classification network outputs, with relationships to statistical pattern recognition . Fogelman Soulié F, Hérault J, eds. Neurocomputing: Algorithms, Architectures and Applications, NATO ASI Series, vol. 68 (Springer, New York), 227–236.Crossref, Google Scholar - Bronstein EM (2008) Approximation of convex sets by polytopes. J. Math. Sci. 153(6):727–762. [Translation of Russian original, which appeared in Sovremennaya Matematika / Fundamental’nye Napravleniya (Contemporary Mathematics / Fundamental Directions), Vol. 22, Geometry, 2007.]Google Scholar
- (2005) How much are health-care systems prepared to pay to produce QALY? Eur. J. Health Econom. 6(4):285–287.Crossref, Google Scholar
- (1961) Management Models and Industrial Applications of Linear Programming, vol. 1 (Wiley, New York).Google Scholar
- (1955) Optimal estimation of executive compensation by linear programming. Management Sci. 1(2):138–151.Link, Google Scholar
- (1838) Recherches sur les Principes Mathématiques de la Théorie des Richesses (Hachette, Paris).Google Scholar
- (1997) Measuring the health of the U.S. population. Brookings Papers Econom. Activity Microeconom. 28(1997):217–282.Crossref, Google Scholar
- (2010) Distributionally robust optimization under moment uncertainty with application to data-driven problems. Oper. Res. 58(3):595–612.Link, Google Scholar
- (2017) Performance appraisal and performance management: 100 years of progress? J. Appl. Psych. 102(3):421–433.Crossref, Google Scholar
- (1881) Mathematical Psychics (C. Kegan Paul, London).Google Scholar
- (1897) La teoria pura del monopolio. Giornale degli Economisti 15(Anno 8):13–31.Google Scholar
- (2010) Multicriteria Optimization, 2nd ed. (Springer, Berlin).Google Scholar
- (1860) Elemente der Psychophysik (Part II) (Breitkopf & Härtel, Leipzig, Germany).Google Scholar
- (1984) Scaling and related techniques for geometry problems. Proc. 16th Annual ACM Sympos. Theory Comput. (Association for Computing Machinery, New York), 135–143.Google Scholar
- (1902) Elementary Principles in Statistical Mechanics (General Publishing, Toronto).Google Scholar
- (2009) Fair welfare maximization. Econom. Theory 41(3):465–494.Crossref, Google Scholar
- (1990) Conjoint analysis in marketing: New developments with implications for research and practice. J. Marketing 54(4):3–19.Crossref, Google Scholar
- (2015) Managing underperformance risk in project portfolio selection. Oper. Res. 63(3):660–675.Link, Google Scholar
- (2023) Price discrimination with robust beliefs. Eur. J. Oper. Res. 306(2):795–809.Crossref, Google Scholar
- (1934) Inequalities (Cambridge University Press, Cambridge, UK).Google Scholar
- (1955) Cardinal welfare, individualistic ethics, and interpersonal comparisons of utility. J. Political Econom. 63(4):309–321.Crossref, Google Scholar
- (2012) Environmental impacts of hybrid and electric vehicles: A review. Internat. J. Life Cycle Assessment 17(8):997–1014.Crossref, Google Scholar
- (2020) A standard-based approach for multi-criteria performance evaluation of engineered systems. Reliability Engrg. System Safety 202(107001):1–12Crossref, Google Scholar
- (1979) Prospect theory: An analysis of decision under risk. Econometrica 47(2):263–291.Crossref, Google Scholar
- (1984) Choices, values, and frames. Amer. Psychologist 39(4):341–350.Crossref, Google Scholar
- (1993) Decisions with Multiple Objectives (Cambridge University Press, Cambridge, UK).Crossref, Google Scholar
- (2018) Choice, consideration sets, and attribute filters. Amer. Econom. J. Microeconom. 10(4):223–247.Crossref, Google Scholar
- (1968) Cost effectiveness analysis applied to the treatment of chronic renal disease. Medical Care 6(1):48–54.Crossref, Google Scholar
- (1930) Sur la notion de la moyenne. Atti della Accademia Nazionale dei Lincei, Classe di Scienze Fisiche, Matematiche e Naturali Rendiconti 12(9):388–391.Google Scholar
- (1997) Robust Discrete Optimization and Its Applications (Springer, New York).Crossref, Google Scholar
- (1975) On finding the maxima of a set of vectors. J. ACM 22(4):469–476.Crossref, Google Scholar
- (1966) A new approach to consumer theory. J. Political Econom. 74(2):132–157.Crossref, Google Scholar
- (1941) The Structure of American Economy 1919–1929: An Empirical Application of Equilibrium Analysis (Harvard University Press, Cambridge, MA).Google Scholar
- (2024) Quantifying the impact of impact investing. Management Sci. 70(10):7161–7186.Link, Google Scholar
- (1989) Social utility and decision making in interpersonal contexts. J. Personality Soc. Psych. 57(3):426–441.Crossref, Google Scholar
- (1890) Principles of Economics (Macmillan, London).Google Scholar
- (1995) Microeconomic Theory (Oxford University Press, Oxford, UK).Google Scholar
- Masri H, Pérez-Gladish B, Zopounidis C, eds. (2018) Financial Decision Aid Using Multiple Criteria: Recent Models and Applications (Springer, New York).Crossref, Google Scholar
- (1998) The zero-condition: A simplifying assumption in QALY measurement and multiattribute utility. Management Sci. 44(6):839–849.Link, Google Scholar
- (2018) Data-driven distributionally robust optimization using the Wasserstein metric: Performance guarantees and tractable reformulations. Math. Programming 171(1–2):115–166.Crossref, Google Scholar
- (1930) Über eine Klasse der Mittelwerte. Japanese J. Math. 7:71–79.Crossref, Google Scholar
- Nathan BR, Lord RG (1983) Cognitive categorization and dimensional schemata: A process approach to the study of halo in performance ratings. J. Appl. Psychol. 68(1):102–114.Google Scholar
- (1999) Integer and Combinatorial Optimization (Wiley Interscience, New York).Google Scholar
- (2021) An ounce of prevention. J. Econom. Perspect. 35(2):101–118.Crossref, Google Scholar
- (1894) Il massimo di utilità dato dalla libera concorrenza. Giornale degli Economisti 9(2):48–66.Google Scholar
- (1897) Cours d’Économie Politique, vol. 2 (F. Rouge, Lausanne, Switzerland).Google Scholar
- (1906) Manuale di Economia Politica (Società Editrice Libraria, Milan).Google Scholar
- (1974) The management of patients with end-stage renal failure: A decision-theoretic approach. Doctoral thesis, Harvard University, Boston.Google Scholar
- (1976) A health index for patient selection: A value function approach with application to chronic renal failure patients. Management Sci. 22(9):1009–1021.Link, Google Scholar
- Ravindran AR, ed. (2016) Multiple Criteria Decision Making in Supply Chain Management (CRC Press, New York).Crossref, Google Scholar
- (1970) Convex Analysis (Princeton University Press, Princeton, NJ).Crossref, Google Scholar
- (1976) Principles of Mathematical Analysis, 3rd ed. (McGraw-Hill, New York).Google Scholar
- (1951) The theory of statistical decision. J. Amer. Statist. Assoc. 46(253):55–67.Crossref, Google Scholar
- (2014) Convex Bodies: The Brunn-Minkowski Theory, 2nd ed. (Cambridge University Press, Cambridge, UK).Google Scholar
- (1985) Amortized efficiency of list update and paging rules. Comm. ACM 28(2):202–208.Crossref, Google Scholar
- (1986) Multiple Criteria Optimization: Theory, Computation, and Application (Wiley, New York).Google Scholar
- (1991) A multi-criteria decision support system for R&D project selection. J. Oper. Res. Soc. 42(1):17–26.Google Scholar
- (2009) Beneficial biofuels: The food, energy, and environment trilemma. Science 325(5938):270–271.Crossref, Google Scholar
- (1972) Elimination by aspects: A theory of choice. Psych. Rev. 79(4):281–299.Crossref, Google Scholar
- (2008) Optimal Transport: Old and New, Grundlehren der Mathematischen Wissenschaften, vol. 338 (Springer, Berlin).Google Scholar
- (1945) Statistical decision functions which minimize the maximum risk. Ann. Math. 46(2):265–280.Crossref, Google Scholar
- (2020) Constructing composite indicators with individual judgements and best-worst method. Soc. Indicators Res. 149(1):1–14.Crossref, Google Scholar
- (1968) The Complete Works of Chuang Tzu (Columbia University Press, New York).Google Scholar
- (1846)
Der Tastsinn und das Gemeingefühl . Wagner R, ed. Handwörterbuch der Physiologie mit Rücksicht auf die physiologische Pathologie, vol. 3, section 2 (Vieweg, Braunschweig, Germany), 481–588.Google Scholar - (2014) On the (non-)equivalence of IRR and NPV. J. Math. Econom. 52:25–39.Crossref, Google Scholar
- (2023) Relatively robust decisions. Theory Decision 94(1):35–62.Crossref, Google Scholar
- (2024) Optimal depth of discharge for electric batteries with robust capacity-shrinkage estimator. Proc. 2024 4th Internat. Conf. Smart Grid Renewable Energy (SGRE) (IEEE, New York), 1–5.Google Scholar
- (2025) Monopoly pricing with unknown demand. Scandinavian J. Econom. 127(1):235–285.Crossref, Google Scholar
World Energy Council (2024) World Energy Trilemma 2024: Evolving with resilience and justice. Technical report, World Energy Council, London.Google Scholar- (1988) On ordered weighted averaging aggregation operators in multi-criteria decision making. IEEE Trans. Systems Man Cybernetics 18(1):183–190.Crossref, Google Scholar
- (2002) Optimization over the efficient set: Overview. J. Global Optim. 22(1–4):285–317.Crossref, Google Scholar
- (2010) On the relation between compromise programming and ordered weighted averaging operator. Inform. Sci. 180(11):2239–2248.Crossref, Google Scholar
- (1974) A concept of compromise solutions and the method of the displaced ideal. Comput. Oper. Res. 1(3):479–496.Crossref, Google Scholar

