
February 4, 2019 in Last Word
Sampling bias, surveys and undocumented immigrants
SHARE: PRINT ARTICLE: https://doi.org/10.1287/orms.2019.01.07
https://doi.org/10.1287/orms.2019.01.07

Sampling bias pervades nearly all survey-based studies, as it remains nearly impossible to obtain true probability samples from populations of interest. Sometimes it is possible to make reasonable adjustments when the shortcomings of observed data are understood. Take the problem of missing data. If such responses are truly “missing at random,” then it becomes possible to construct defensible imputation methods to account for nonresponse. For example, among participants in the 2017 American Community Survey (the most recent year for which data are available) [1], only 1.7 percent of observations identifying the age of respondents are missing. For such missing data, it is not a stretch to impute an age conditional on the values of other reported survey items, and indeed this is common practice in the best-known surveys employed by the federal government.
While quite sophisticated methods based on resampling-based multiple imputation techniques are sometimes employed, more often missing values are imputed via “hot deck” allocation, which in essence matches each missing record with a record that is similar in its other answers, and then assumes the missing value should also match. While there is no guarantee that such a seemingly ad hoc approach will get the right answer in any given application, overall the distribution of imputed responses will turn out to be reasonably accurate, again providing that the missing data are truly missing at random.
Of course, sometimes data are not missing at random. Returning to the 2017 American Community Survey, it turns out that 9.3 percent of survey participants did not provide a response indicating their place of birth. While one can again turn to the hot deck to impute responses to this question, there is a potential problem that amounts to pouring cold water on the hot deck. Persons who are illegally in the country have a strong incentive to avoid answering this question. Contrary to the assumptions underlying hot deck or other imputation methods, such persons are not missing at random: they are missing on purpose.
Survey-based methods for estimating the number of undocumented immigrants in the United States rely upon the answers to this place-of-birth question, for such methods subtract the estimated total number of foreign born who are legally in the country (as ascertained from government records such as citizenship documents, work permits, student visas etc.) from the total estimated number of foreign born individuals in the country (and this latter estimate comes from the surveys). Making matters worse, the discussion above has focused on survey participants. It turns out that in 2017, upwards of 5 percent of those targeted for the American Community Survey were not questioned at all, either because those intended for questioning refused to participate, were not at home or otherwise absent when the survey came calling, or some other reason. Missing at random? You decide.
There are different sampling biases, however, that derive from simple, physical constraints. An interesting example involves a study called the Mexican Migration Project (MMP), which regularly surveys people living in Mexico who have spent time in the United States without authorization. A question of interest to demographers and those who care about unauthorized immigration is: How long do undocumented immigrants spend in the United States? To try and answer this question empirically, a group of researchers decided to consult the MMP data. These data provide observations of respondents’ estimated “sojourn times” in the United States, the distribution of which can then be studied and used to produce estimates of, for example, the mean time unauthorized immigrants spend in the U.S., or sojourn-time-dependent emigration rates.
Of course, there is a not-so-subtle problem with this approach. For a formerly undocumented immigrant to be included in the sample described above requires that the immigrant in question returned to Mexico in time for the survey! Equally obvious is that data from undocumented immigrants still residing in the United States at the time of the survey cannot be collected. That such truncation leads to a biased sample is obvious, but perhaps the extent of the bias is not. Here’s a simple example to help fix ideas.
Imagine a scenario in which on average, a constant number of new undocumented immigrants cross into the United States each year. Once in the United States, assume that immigrants remain for exponentially distributed lengths of time with an average of 10 years before returning. Now imagine an MMP-style survey being administered at various points in time, and that all undocumented immigrants who had visited the United States and returned are available for sampling. Ignoring the sorts of nonresponse biases discussed earlier in conjunction with the American Community Survey, what would the truncated data report regarding the average duration of time spent in the United States? Recall that the true average is 10 years, but administering such a survey at 10, 20 or even 30 years after the start of the migration would yield apparent mean sojourn times of 2.8, 4.8 and 6.1 years. A plot showing the average duration of stay one would deduce from such a survey versus the time the survey is administered from the start of the migration is shown in Figure 1. The actual picture is even more complicated due to changes in both border crossing attempts and border enforcement over time (so the constant annual influx of unauthorized immigrants does not hold).
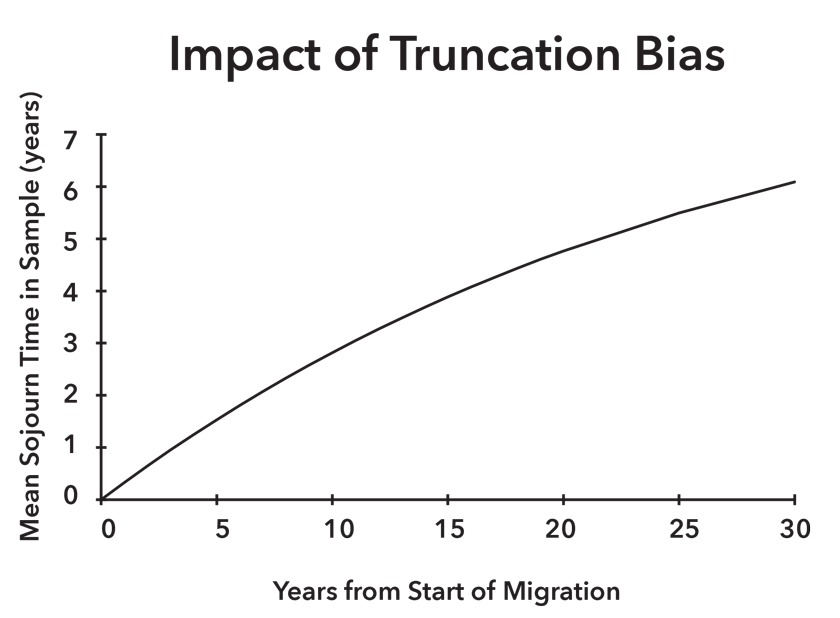
Whether due to nonrandom nonresponse, the “physics” of survey administration or other myriad reasons that can cause survey data to go awry, it is important to be aware of potential biases when trying to make sense of surveys. Indeed, understanding survey bias can buy us the means to figure out what survey data are really trying to tell us.
Reference
Editor’s note: A 2018 study by Kaplan and co-authors Jonathan Feinstein and Mohammad M. Fazel-Zarandi suggests that the number of undocumented immigrants in the United States is nearly twice as many as experts previously thought. The study, which estimates the number of such immigrants at 22.1 million instead of 11.3 million, garnered worldwide attention from major media outlets including the Los Angeles Times, Boston Globe, Fox News, Bloomberg News and Daily Mail.
The study, which provides an estimated range of undocumented immigrants between 16 million and 29 million with 22.1 million as the mean, is based on demographic modeling with data from 1990 to 2016. The authors were quick to point out, as Kaplan did in an appearance on “Fox and Friends,” that their research does not indicate that the number of undocumented immigrants in the U.S. is suddenly exploding. To the contrary, the research shows that the greatest growth of undocumented immigrants occurred in the 1990s through the mid-2000s, that it was vastly undercounted at the time, and that the number has remained relatively stable over the past decade.
To view a video of the “Fox and Friends” segment, click here.
Edward H. Kaplan, a past president of INFORMS, is the William N. and Marie A. Beach Professor of Management Sciences at the Yale School of Management, professor of Public Health at the Yale School of Public Health and professor of Engineering in the Yale School of Engineering and Applied Science.