
March 3, 2026 in Member Insights
AI That Actually Ships
A product operating model for moving from prototype to production
SHARE: PRINT ARTICLE: https://doi.org/10.1287/orms.2026.01.13
https://doi.org/10.1287/orms.2026.01.13
Most artificial intelligence (AI) fails in translation – not from model to metrics but from demo to daily use. Here’s a practical playbook that leaders can use to move AI from prototype to pilot to production with clear gates, simple metrics and accountable ownership.
The Uncomfortable Truth
The most common AI artifact in large organizations is a demo. Teams prove something is possible, executives applaud and then … nothing changes on Monday.
The pressure has never been higher. Generative AI hype has put AI on every board agenda; shadow tools are proliferating faster than governance can track; and executives are demanding return on investment from experiments. Without a deliberate operating model, most organizations will continue producing impressive demos that never touch a real workflow.
Why do so many efforts stall?
- There is no explicit business pain point or owner.
- “Success” is not defined in measurable terms.
- Data is messy or restricted.
- Compliance and security arrive at the end.
- No human is accountable after launch.
The cure isn’t a bigger model. It’s a better operating model.
A Three-Stage Path with Hard Exits
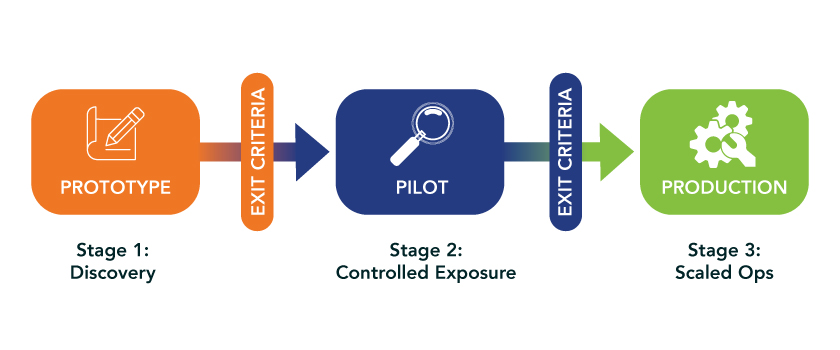
Every AI initiative should live in one of three states: Prototype → Pilot → Production – with nothing in between. Each stage has a purpose and explicit exit criteria (see Figure 1).
- Prototype (discovery): Build the smallest working version to prove a signal. Define what “good” looks like before building. If the signal is weak, kill it fast.
- Pilot (controlled exposure): Put the prototype in a narrow, real workflow with real users. Measure real usage and surface real risk. Integrate just enough to learn.
- Production (scaled ops): Harden data access, privacy and lineage. Name an owner. Rehearse rollback. Monitor cost, drift and behavior.
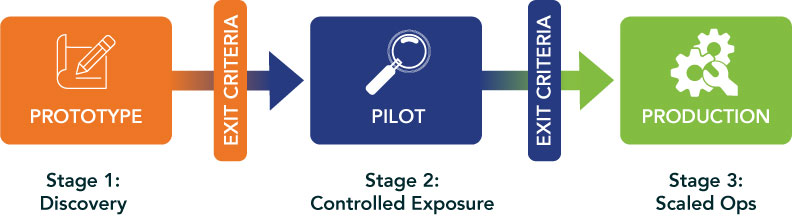
Figure 1: Every AI initiative lives in one of three states with explicit exit criteria between each. No initiative graduates without evidence.
Stage language creates shared expectations across product, engineering, compliance and operations. Everyone knows what “good enough to graduate” means.
The AI Product Manager’s Real Job
An excellent AI product manager (PM) is not “the prompt person.” The AI PM is the system architect for value, feasibility, trust, adoption and safety:
- Value – Why build this? Name the painful workflow and the metric to move (time saved, risk reduced, revenue protected).
- Feasibility – Can we ship it here? Do we have the data and access? Choose the correct pattern for the problem: prompting, retrieval-augmented generation (RAG), fine-tuning or agent with tools – not “just use GPT.”
- Trust – Will people believe it? Fit the user experience (UX) to the job (inline assist, sidebar copilot, background automation). Constrain answers to an approved, source-of-truth context.
- Adoption – Will it stick? Make the first value less than 30 seconds. Start with one hungry team; expand by evidence, not enthusiasm.
- Safety/quality – Can we defend it? Run live evaluations for hallucinations, bias and policy violations. Provide a human escalation path when confidence is low. Adhere to this rule: no evaluations, no launches.
Mini-example: Instead of “AI tutor,” ship “advisor copilot that answers the 40 most repetitive questions from approved policy text, auto-links sources and escalates everything else to a human.”
The Promotion Gate: Progress Must Be Earned
Moving from prototype to pilot or pilot to production requires passing a simple, auditable gate:
- Quantified value with real users (not opinions)
- Usage evidence (engagement, task completion, deflection)
- An approved data path (privacy, security, access control)
- A named owner post-launch
- Monitoring and rollback defined and rehearsed
- Policy and risk review cleared; unmitigated high-risk use cases stop here
Graduation isn’t a vibes-based decision – it’s a checklist you can audit.
What “In Production” Actually Means
Deployment is not successful; stability is. Production AI is continuously observed across three layers:
- Technical health: uptime, latency, error rate
- Behavioral quality: accuracy/relevance, hallucination, human-escalation rates, safety/bias boundaries
- Business value: cost to run versus outcome delivered
If health, quality and value aren’t on dashboards with named owners, then it isn’t production – it’s an unmanaged experiment wearing production clothes (see Figure 2).

Figure 2: Production AI is monitored across three layers. If all three aren’t on dashboards with named
owners, it’s not production; it’s an unmanaged experiment.
Five Levers to Scale (It’s a System, Not a Hero)
Stop hunting for the unicorn engineer and build the machine:
- People: AI PM, data engineering, machine learning (ML) engineering, platform/infra, risk/compliance and operations to clear lanes and escalation paths
- Process: Scrappy in discovery, disciplined in delivery (change control, approvals, lineage)
- Data: Source of truth, retention and access governed; always answers “where did this answer come from?”
- Technology: Infrastructure that supports iteration and scale; avoids fragile one-offs
- Production ops: Monitoring, alerting, retraining cadence and incident playbooks – the launch is the beginning
You don’t productionize a model; you productionize the system around it (see Figure 3).
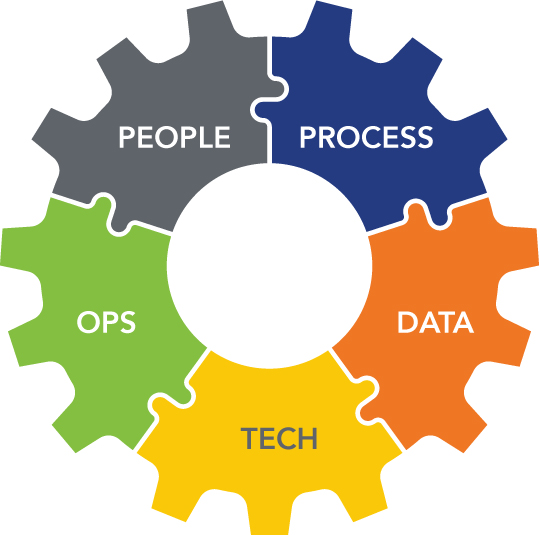
Figure 3: Scaling AI requires five interlocking levers. You don’t productionize a model; you productionize the system around it.
Three Pragmatic Use Cases (with Simple Numbers)
These patterns ship reliably across education, customer service and back-office operations. They’re specific enough to copy and general enough to adapt.
- Support the copilot with human escalation:
- Pain: Frontline teams drowning in repeat questions
- Pattern: A policy-grounded copilot answers first-line questions; uncertain cases escalate with a transcript and suggested following actions
- Metrics: First-contact resolution, median handle time, user satisfaction and percentage escalated
- Target: A 20%-40% deflection with <5% unsafe responses (auto-flagged), human-in-the-loop for the rest
- One-liner: Narrow domain + approved content + clear escalation path = durable wins.
- Look for early-warning retention signals:
- Pain: Outreach too late
- Pattern: A supervised model flags at-risk users, the copilot drafts personalized outreach from customer relationship management notes and activity, and staff approve/send
- Metrics: Precision/recall on risk, time-to-outreach and conversion to “stayed engaged”
- Target: A 10%-15% lift in proactive outreach within 48 hours of the risk signal; staff keep authorship and accountability
- One-liner: Predict, then assist the human – don’t auto-decide.
- Document intake and routing with an audit trail:
- Pain: Manual extraction, validation and routing slowing the back office
- Pattern: AI extracts fields, checks policy, classifies and routes with confidence scores; low-confidence and exceptions go to humans
- Metrics: Cycle time, percentage auto-approved, exception rate by reason and audit completeness
- Target: A 30%-50% cycle-time reduction while lifting audit completeness to ~100% via structured logs
- One-liner: Automate the boring; preserve the judgment.
These patterns work but only if you avoid the organizational pitfalls that quietly erode AI investments over time.
Anti-patterns That Quietly Create AI Debt
- Shadow AI: This includes unsanctioned tools with sensitive data. Fix with an internal AI register and clear “what not to paste” guidance.
- One-person stacks: Only one engineer can deploy or fix it. Fix with shared infra, handoffs and documentation.
- “Metrics later”: You’ll never cleanly retrofit measurement. Establish success metrics at the outset.
- Compliance at the end: This is a rework tax. Fix by embedding legal/risk at the stage definition.
AI debt is primarily organizational, rather than technical, incurred when ownership, policy and measurement are afterthoughts.
Responsible AI, Translated for Operators
Responsible AI shouldn’t be a philosophy; it should be controls that anyone can run:
- Owner: Every AI system has a named human responsible for performance, compliance and escalation from day 1.
- Risk control: Impact is reviewed before rollout; high-risk uses trigger deeper review (ethics, legal, compliance). Human override and a tested shutdown path exist.
- Transparency: An operator can document what the AI does, the data it uses and whom it affects; disclose AI involvement in consequential decisions; and maintain an internal register of systems.
“No policy, no production” isn’t red tape – it’s how you earn the right to scale.
Here’s an executive playbook you can steal for Monday:
- Start with a painful workflow, not a shiny model. If no one is begging for help, don’t build it.
- Define success before you sprint. Agree on the single number that proves impact.
- Stand up the cross-functional team early. Embed the product, data/ML, platform, compliance and ops – don’t “throw it over the wall.”
- Enforce the promotion gate. Do not advance without value evidence, policy sign-off, monitoring and a named owner.
- Treat post-launch as stewardship. Implement dashboards, evaluations, retraining, rollback and cost control. Make “still valuable six months later” the brag.
Closing Thought
Enterprises don’t need more prototypes; they need more production-grade AI that teams trust and leaders will fund again. When you make the operating model explicit through three stages (promotion gates, three-layer monitoring and a policy with a named owner), the conversation changes. AI stops being theater. It becomes infrastructure.
And when it does, something actually changes on Monday.
Ram Kumar Nimmakayala is a Principal Product Manager – AI & Data Strategy at Western Governors University, one of the largest online universities in the U.S. He leads AI products that support over 190,000 learners and is a frequent invited speaker and panelist on pragmatic, responsible AI for large enterprises.