
August 14, 2019 in Supply Chain Management
How machine learning can heal a supply chain
SHARE: PRINT ARTICLE: https://doi.org/10.1287/LYTX.2019.05.07
https://doi.org/10.1287/LYTX.2019.05.07

Unless you’ve been Rip Van Winkle, asleep in a hollow for 20 years, you’ve witnessed a big increase in the buzz around artificial intelligence and machine learning (AI/ML). In Washington Irving’s famous folktale, Van Winkle fell asleep as a subject of English King George III but woke up post-independence, with portraits of a new George on the walls, America’s first president. When he visits the town tavern and is asked questions about his politics, he is laughed at for giving yesterday’s answers. Keeping up with what feels like the ever-increasing speed of change can be daunting, so you may feel sympathy for Van Winkle trying to play catch up.
So what is AI/ML? Gartner’s definition is that “AI applies advanced analysis and logic-based techniques, including machine learning, to interpret events, support and automate decisions, and take actions” [1]. My focus in this article will be on machine learning, which are the techniques I’ve seen most widely adopted in industry today. By Gartner’s definition, machine learning spans the categories of predictive and prescriptive analytics, yet most have only started with descriptive analytics, which might report that 27 percent of your orders are late. But as my friend, longtime analytics leader and former UPS executive Jack Levis is fond of saying, “Insight that doesn’t lead to a better decision is trivia.”
To make an impact, we need to know why the orders are late and what to do about it. These kinds of insights only happen by moving up the maturity curve to deploy predictive and prescriptive analytics. As Jeff Camm has written, predictive analytics can help us understand what is likely to happen (through a statistical forecast or predictive model from regression or machine learning techniques). Prescriptive analytics go a step further and advise a course of action, typically using mathematical optimization, heuristics or other rule-based systems.
Rip Van Winkle could be forgiven for being confused on the topic of machine learning, because while it seems to have quickly risen to the top of the hype heap, it is not new at all. The concepts behind machine learning date back to World War II and the code-breaking work of English mathematician Alan Turing. And the origins of the deep learning method date to the perceptron, a precursor of neural networks first named by Frank Rosenblatt in 1958. While work continued on these methods, they fell in and out of favor due to repeated conceptual or computational roadblocks, spawning the term “AI winter” to describe the troughs of interest. But in recent years, advances in computer processors and storage capacity have unleashed these methods anew, with no sign of winter in sight. Use of machine learning is abundant, across many industries and application areas.
Supply Chain Management
Supply chain management is just one of these areas. Imagine a Van Winkle who is an attentive demand planner who fell asleep 20 years ago as ERP systems gained widespread adoption in the midst of Y2K preparations. In 1999, U.S. imports from China were $82 billion and Amazon.com was only two years old; when our Van Winkle woke up at the end of last year, Chinese imports reached $540 billion and Amazon has completely transformed the retail industry and consumer expectations of availability, cost and fulfillment. The trends shaping supply chain today are global trade and tariffs, automation and labor shortages, the digital supply chain, rising consumer expectations of speed, and yes, machine learning.
Machine learning opportunities in supply chain are abundant – improving forecast accuracy, inspection of physical assets, improved modeling for new product introductions, predictive asset maintenance, and great visibility across the collaborative supply chain network are a few. In fact, Deloitte has proclaimed that the days of “cognitive planning” are upon us, where computing advances, the maturation of machine learning, and the data available in connecting systems enable this step. They have christened it “synchronized planning,” a world in which data can constantly flow throughout the supply chain and allow organizations to far more accurately match production of supply to demand than ever before.
At my own company, Kinaxis, we use a related term, concurrent planning, to illustrate the importance of being able to plan, monitor and respond to changes across the supply chain in a single, harmonious environment. Based on the foundation of data in our in-memory database, we launched our own machine learning journey.
Our focus is to increase the efficiency of the supply chain for our customers, and when analysis of data from a major customer revealed that 53 percent of their lead times were wrong as designed, we started there.
Why Lead Times Matter
If Van Winkle’s assumptions are too optimistic, he will plan on supplies arriving sooner than they actually do. Waiting for their arrival will lead to delayed production and inability to deliver orders to customers on time. It will also lead to a build-up of inventory of parts that did arrive on time but cannot yet be used, since the remaining necessary parts are still missing.
What if Van Winkle opts for careful pessimism instead? In this case, if lead times are shorter than planned, some parts will arrive early and will build up inventory and storage costs while other required parts are still in transit. Companies will lock in plans too early, in order to reduce inventory overhead, limiting their agility when things change, as they inevitably do. And if demand turns out to be slower than expected, parts will still accrue in inventory, unused due to obsolete needs. Our young Van Winkle, before falling asleep, would recognize the dilemma of the poor choices before him and his inability to choose smartly and respond quickly.
If lead times used in plans are more accurate, companies are likely to be able to deliver customer orders on time and minimize inventory. If the overall variability in lead times can be smoothed, then buffer stocks necessary to ensure production can be lower. Van Winkle sees the value, but how does he increase the accuracy of the lead times? He doesn’t have the time to analyze what could easily be a 100K+ combination of parts and suppliers.
Fortunately, with a large amount of historical data (a requirement for machine learning models), predicting lead times is a problem well-suited to this approach. Our models predict what lead times will actually be, and we also analyze the data to identify similar patterns in the form of groups of clusters, which represent opportunities to efficiently do root cause analysis. For example, there might be a pattern with specific suppliers, or perhaps with certain types of parts.
Solving the ‘Skills’ Issue
According to a McKinsey survey, 42 percent of organizations who have started an AI journey say skills are a top barrier to expansion. The demand for machine learning talent is at an all-time high, and LinkedIn named AI the second most in-demand technical skill for 2019. In the war for machine learning talent, the FANG (Facebook, Amazon, Netflix and Google) companies command top talent, leaving less for the rest. In response, vendors are embedding models into their solutions so that “pure” data scientists with Ph.D.-level credentials are not required.
At Kinaxis, we address this skills issue with an approach called AutoML, an emerging term for a level of modeling automation that does not require users to be able to build a machine learning pipeline. Van Winkle doesn’t have to go back to school to get a Ph.D. in artificial intelligence, because the machine learning that drives this automated modeling is invisible to him. He doesn’t need to understand the fancy math under the covers. His job is to know his business and understand what variations in lead times he can tolerate. Based on tolerance factors he sets, we can configure processing rules for what actions to take based on lead time deviations, as well as business metrics he sets.
The time series forecasting models driving our automated machine learning use historical lead time data to predict what actual lead times will be in the future. These predictions are then compared to the designed lead times. Based on the tolerances Van Winkle defined, the processing rules will kick in to improve his decisions with machine learning. These changes will lead to results that are more realistic than the stale assumptions he used before he fell asleep. Van Winkle will be able to focus on those decisions that matter the most and let the math automatically handle those that do not, thus saving him time.
Self-Healing Supply Chain
When the deviations from those expected are so minor that they are not worth the time to analyze and determine a response but are deemed worthy of a change to the original plan, the models automatically accepts them, thereby “self-healing” the deviation (which is why we call it the Self-Healing Supply ChainTM). Built-in buffers may be sufficient to absorb the deviation. In other cases, the change the models recommend may have a significant enough impact that it is flagged for a manual review by Van Winkle, whose job is to ensure that following the model’s recommendation will actually have the positive effect intended. We provide visualizations of potential impacts on KPIs so he can make the best decision. In a third category of cases, the deviation is so minor that no change in lead times is needed, so the processing rules simply ignore the change. The effort to make the change would be greater than the impact on the supply chain.
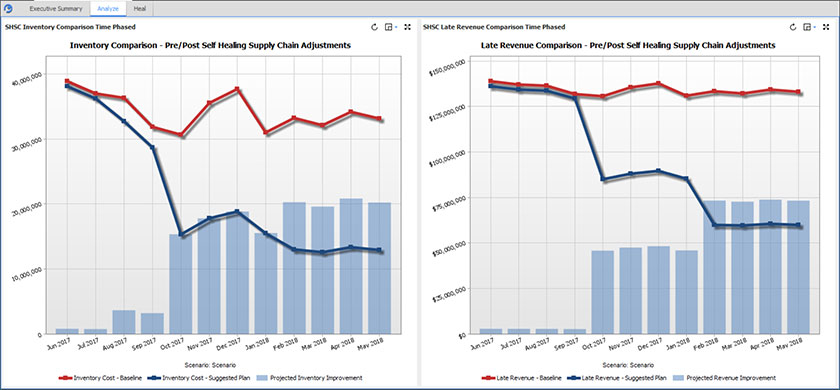
Sample results from the Kinaxis Self-Healing Supply ChainTM.
Finally, the models will look for trends and patterns that may not be obvious to Van Winkle but might be worthy of his action, for example a consistently late supplier or problematic part. With time freed up from the machine learning models, he can focus on these areas of concern. Since any items not flagged for his review are changed automatically, the gap between planning and execution is shortened. The additional benefit of our concurrent planning architecture is that the changes made to these lead times are cascaded across all the links in the chain right away, so that all the functions across the supply chain immediately see the impact on their role.
Approaches like AutoML are having a democratizing effect in supply chain and other areas, allowing the power of machine learning to be readily accessible for a much wider range of people and applications. This greater access fuels more interest, which in turn spurs more investment, so I am bullish on the prospects for continued growth, with no fear of a return to an AI winter.
Reference
- Gartner Glossary, Artificial Intelligence (AI), https://www.gartner.com/it-glossary/artificial-intelligence/.
A Look Under the Machine Learning Covers
Kinaxis has taken a similar approach to yield times and has more work underway to improve the quality of planning by applying machine learning to other areas. One of the top benefits of machine learning models is their increased accuracy, and while there is often a tradeoff in interpretability, we are also working on methods to provide the user greater insight into why the models recommend certain actions. In other words, making the so-called machine learning black box at least a little less opaque.
One challenge is sorting those who say they do machine learning from those who actually embed complex algorithms in their applications. At Kinaxis we have patents pending on our work and improve our modeling approaches with every release (thereby changing the methods used). Typically, we apply an ensemble approach, but some of the techniques we use include regression analysis, boosting meta-algorithms, traditional forecasting techniques, dimensionality reduction and vector quantization.
This article appears in INFORMS Analytics Collections Vol. 16: Advances in Integrating AI & O.R.
Visit this collection for free access to more articles showcasing the depth and breadth of research and applications at the intersection of AI and operations research.
Polly Mitchell-Guthrie is the VP of Industry Outreach and Thought Leadership at Kinaxis, the leader in empowering people to make confident supply chain decisions. Previously she served in roles as director of Analytical Consulting Services within Enterprise Analytics and Data Sciences at the University of North Carolina Health Care System, senior manager of the Advanced Analytics Customer Liaison Group in SAS’ Research and Development Division, and Director of the SAS Global Academic Program. Mitchell-Guthrie has an MBA from the Kenan-Flagler Business School of the University of North Carolina at Chapel Hill, where she also received her BA in political science as a Morehead Scholar. Within INFORMS, she has served as the chair and vice chair of the Analytics Certification Board and secretary of the Analytics Society. She is a member of INFORMS’ 2019 Strategic Planning Committee, as well as its Industry Engagement and Outreach Committee.