
May 21, 2026 in AI Energy Challenge
AI’s Energy Challenge
Optimizing Data Centers in an Age of Power Constraints
SHARE: PRINT ARTICLE: https://doi.org/10.1287/LYTX.2026.02.04
https://doi.org/10.1287/LYTX.2026.02.04

Have you ever wondered what limits the growth of AI?
In the past, the answer seemed straightforward: hardware and GPUs. Larger models needed faster chips, more GPUs, and increasingly powerful compute capacity. Much of the industry’s attention focused on semiconductor supply chains and getting more powerful GPUs deployed faster to meet the growing need of AI.
Over the past couple of years, semiconductor manufacturers ramped up GPU production, cloud infrastructure providers accelerated datacenter construction, and AI companies built faster models to meet the surge in demand.
Today, however, a new constraint has emerged: energy global data center energy consumption is projected to grow rapidly and double within the next five years. (See Figure 1)
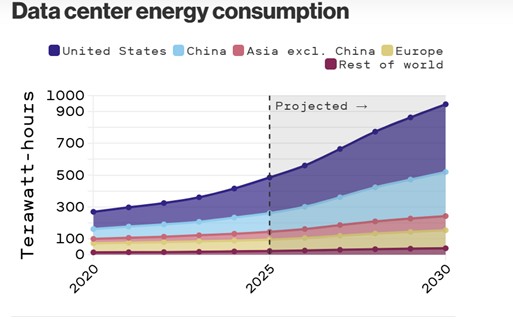
In many regions, new data center projects are waiting not for hardware deliveries, but for power availability and grid interconnection approvals, which are increasingly delayed by concerns from local communities over higher utility bills and water consumption. During the past year, opposition from local communities and government officials blocked $18B of data center projects. In other places, energy price volatility and corporate renewable energy commitments are affecting how fast data centers can be built. The constraint is no longer simply chips; it is megawatts, cooling systems, and the reliability of the power grid.
In early 2026, major technology companies announced a pledge to help finance new electricity generation to support the rapidly growing power demands of data centers. This might offset costs, but it could prove insufficient to accelerate data center projects, as energy infrastructure takes time to build.
As energy analyst Jon Gordon noted in a recent discussion with Reuters, “The real problem is the inability to get generation online fast enough to meet the data center demand. ‘Hyperscalers’ paying for the generation doesn’t get it online any faster.” These developments open a fascinating and complex domain of optimization problems that are becoming central to conversations among infrastructure planners, utility operators, and cloud providers. It would mean the future of AI would depend more on optimizing existing available energy than it does on advances in GPUs or computing hardware.
A Dual Transformation: Physical Infrastructure and Power Systems
Scaling AI is increasingly becoming a joint challenge of computing infrastructure and energy systems.
AI workloads – both large-scale training workloads and inference systems – now require sustained levels of power draw that were uncommon just a few years ago. As a result, data centers supporting these workloads can require hundreds of megawatts of power capacity, shifting infrastructure bottlenecks away from semiconductor availability and toward power readiness.
At the same time, the power systems that support these workloads are undergoing their own transformation. Utilities are integrating renewable generation and modernizing transmission networks. These two developments evolved largely independently, but now scaling AI increasingly depends on the joint evolution of physical infrastructure and energy systems.
In practice, this convergence is already visible in the planning timelines for new data centers. While data centers can be built in two years, it might be much longer before it can draw power from the grid as interconnection queues for large energy consumers can stretch years into the future.
This reintroduces something that operations researchers understand well: the physical system ultimately constrains the digital system. The modern AI ecosystem is often described as a stack of interdependent layers, from application layer to model layer, and down to physical infrastructure and energy systems. (See Figure 2)
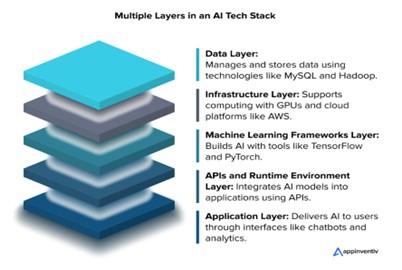
Source: https://appinventiv.com/blog/choosing-the-right-ai-tech-stack/
While most innovations in AI focus on the upper layers of this stack (e.g., models and frameworks), the physical infrastructure and energy systems below it increasingly determine how quickly AI systems can scale. Consequently, infrastructure planning for AI is no longer a simple cost minimization problem, but a multi-objective planning challenge.
From Cost Minimization to Multi-Objective Planning
Historically, data center location decisions were dominated by cost considerations. Companies sought regions with inexpensive electricity, favorable tax policies, and reliable connectivity.
Those factors remain important, but they are no longer sufficient.
Today’s infrastructure planners must consider a broader set of trade-offs, including:
- Workload flexibility based on location and time
- Carbon emissions and environmental sustainability impact
- Latency and proximity to users
- Water usage for cooling systems
- Long-term regulatory exposure
A region with inexpensive electricity may also rely heavily on fossil fuel generation. A power grid relies significantly on renewable energy may reduce emissions, but it may also introduce variability in power availability. Liquid cooling technologies can improve efficiency, but they can also increase water consumption, depending on local climate conditions. These trade-offs resemble classic multi-objective optimization problems. There is rarely a single optimal solution. Instead, decision-makers operate along Pareto frontiers, balancing competing objectives based on business priorities, regulatory requirements, and long-term risk considerations.
Workload Flexibility as a Strategic Lever
One underutilized lever in addressing energy constraints is workload flexibility.
Not all AI workloads require immediate execution. For example, training new AI models – such as improving a chatbot’s accuracy or updating recommendation systems used by streaming services – can be scheduled for when electricity is cheaper. Similarly, simulation runs that are used to test new models or large batch tasks (including generating product recommendations) can be scheduled overnight. When paired with real-time information about energy prices or renewable generation availability, such AI workloads can potentially be shifted across both time and geography.
This raises an intriguing question: Should AI clusters operate at constant utilization, or should they flex in response to power grid conditions? For example, training workloads could be scheduled to coincide with periods of high renewable generation, such as midday solar output or nighttime wind production. Similarly, geographically distributed data centers could shift non-latency-sensitive tasks to regions where electricity is temporarily abundant or inexpensive. Data centers dedicated to training workloads are being built in remote locations, including Indiana, Iowa, and Wyoming, as illustrated in a recent analysis by McKinsey & Company. (See Figure 3)
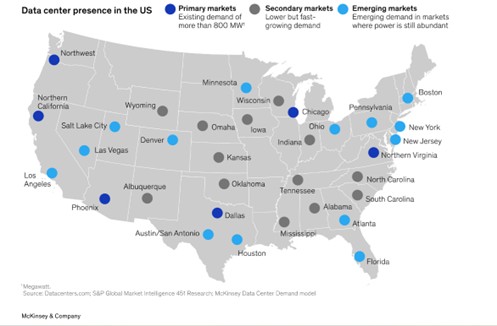
Figure 3: Data center energy markets in US
Implementing this approach introduces its own modeling challenges. Workload scheduling must account for queueing dynamics, network latency, data movement costs, and reliability requirements. The system must also integrate signals from energy markets and grid conditions. These challenges are precisely the types of resource allocation problems we are equipped to address.
Cooling Is Not Just an Engineering Problem
While much of the public discussion regarding AI infrastructure focuses on GPUs and networking equipment, cooling architecture increasingly plays a central role in both efficiency and sustainability.
Modern AI clusters generate enormous amounts of heat. Removing that heat efficiently is essential not only for performance, but also for energy consumption and environmental impact.
Air cooling, liquid cooling, and hybrid designs each carry trade-offs in capital cost, energy efficiency, and water usage. Climate conditions and regional water availability further complicate these decisions.
Metrics such as Power Usage Effectiveness (PUE) have traditionally been used to measure data center efficiency. While useful, PUE alone does not capture the full picture. Water Usage Effectiveness (WUE) and lifecycle environmental impact must also be considered.
A cooling strategy that performs well in a temperate climate with abundant water resources may be unsuitable for a water-stressed region. Conversely, colder climates may reduce cooling costs but increase latency relative to major user populations.
Once again, the challenge resembles a multi-variable optimization problem rather than solely an engineering decision.
Environmental Sustainability as an Optimization Variable
Perhaps the most significant shift is that sustainability is no longer treated as a reporting metric after infrastructure decisions have already been made. Instead, it is becoming an explicit planning and optimization variable.
Investors, regulators, and customers increasingly expect transparency around energy sourcing and carbon emissions. Data center operators must therefore consider not only the operational cost of computing infrastructure, but also its environmental emissions impact and regulatory risk.
Some organizations are beginning to integrate carbon intensity directly into scheduling decisions to meet corporate sustainability goals. In such systems, compute tasks may be dispatched based not only on latency or capacity constraints, but also on the marginal emissions associated with electricity generation at a particular location and time.
This approach reflects a broader transformation in infrastructure planning. Energy availability, environmental impact, and operational efficiency are no longer separate considerations; they are interconnected variables in a single optimization problem.
A New Class of Infrastructure Decisions for AI at Scale
The rapid expansion of AI is driving a convergence between computing infrastructure and energy systems. Historically, these domains evolved largely independently. Data center planners optimized computing performance, while utilities managed electricity supply. Today, the scale of AI infrastructure is bringing these systems into closer alignment, reshaping how infrastructure decisions are made at scale.
As AI clusters grow larger and more energy-intensive, decisions about where and when to deploy computing capacity increasingly resemble classical operations research problems involving constrained resources, uncertain demand, and competing objectives.
The central question is no longer how fast we can scale AI systems. It is how intelligently we can scale them, given the constraints of energy infrastructure. The future of artificial intelligence will undoubtedly continue to depend on advances in algorithms and hardware. But equally important will be the optimization of the physical systems that power those technologies.
In the age of large-scale AI, megawatts may become just as important as GPUs.
References
Bhardwaj, C., 2024, “Choosing the right AI tech stack: A complete guide,” Appinventiv.
Cownhart, C., 2025, “These four charts sum up the state of AI and energy,” MIT Technology Review.
International Energy Agency, 2025, “Sources of global electricity generation for data centres, Base Case, 2020–2035,” IEA.
Numata, Y., Gorin, A., Speelman, L, et. al., 2025, “Fast, flexible solutions for data centers,” Rocky Mountain Institute.
Renshaw, J., Kearney, L., 2026, “Tech giants sign energy pledge at White House ahead of midterms,” Reuters.
Srivathsan, B., Sorel, M., Sachdeva, P., et. al., 2024, “AI power: Expanding data center capacity to meet growing demand,” McKinsey & Company.
Sandeep Prakash is a Senior Program Manager at Microsoft specializing in AI infrastructure planning, large-scale system optimization, and data center capacity strategies. His work focuses on the intersection of AI workloads, energy infrastructure, and operational decision making in hyperscale cloud environments.