
Spatial Branch-and-Bound for Nonconvex Separable Piecewise Linear Optimization
Abstract
Nonconvex separable piecewise linear functions (PLFs) frequently appear in applications and to approximate nonlinearitites. The standard practice to formulate nonconvex PLFs is from the perspective of discrete optimization using special ordered sets and mixed-integer linear programs (MILPs). In contrast, we take the viewpoint of global continuous optimization and present a spatial branch-and-bound algorithm for optimizing a separable discontinuous PLF over a closed convex set. It offers slim and sparse linear programming relaxations, sharpness throughout the search tree, and an increased flexibility in branching decisions. The main feature of our algorithm is the generation of convex underestimators at the root node of the search tree and their quick and efficient updates at each node after branching. Convergence to the global optimum is achieved when the PLFs are lower semicontinuous. A Python implementation of our algorithm is tested on knapsack and network flow problems for both continuous and discontinuous PLFs. Our algorithm is compared with four logarithmic MILP formulations solved by Gurobi’s MILP solver as well as Gurobi’s PLF solver. We also compare our method against mixed-integer nonlinear program formulations solved by Gurobi. The numerical experiments indicate significant performance gains up to two orders of magnitude for medium- to large-sized PLFs. Finally, we also give an upper bound on the additive error from PLF approximations of nonconvex separable optimization.
History: Accepted by Andrea Lodi, Area Editor for Design & Analysis of Algorithms–Discrete.
Funding: The research of S. Rebennack is supported by the Deutsche Forschungsgemeinschaft [Grant 445857709].
Supplemental Material: The software that supports the findings of this study is available within the paper and its Supplemental Information (https://pubsonline.informs.org/doi/suppl/10.1287/ijoc.2024.0755) as well as from the IJOC GitHub software repository (https://github.com/INFORMSJoC/2024.0755). The complete IJOC Software and Data Repository is available at https://informsjoc.github.io/.
1. Introduction
1.1. Literature Review
A piecewise linear function (PLF) is a multivariate function whose domain can be partitioned into pieces such that the function is affine in each piece. Such a nonsmooth function arises naturally in some optimization problems or more commonly, as an approximation of a nonlinear, nonconvex function (Geisler et al. 2012, Dey and Gupte 2015, Nagarajan et al. 2019, Burlacu et al. 2020, Beach et al. 2022, Bärmann et al. 2023, Warwicker and Rebennack 2024). When a PLF is convex and is either minimized or appears in a constraint, it can be modeled as a linear program (LP). In general, a PLF is NP-hard to optimize (Keha et al. 2006) even for separable PLFs, which can be written as a sum of univariate PLFs each of which is in a different coordinate. Separable PLFs appear naturally in a wide variety of problems in various fields dealing with economies of scale, such as logistics, management, finance, or engineering (Markowitz and Manne 1957, Dantzig 1960, Beale and Forrest 1976). Univariate PLFs also arise as approximations to one-dimensional nonconvex functions in a global optimization problem (Leyffer et al. 2008, Natali and Pinto 2009, Rebennack and Kallrath 2015, Grimstad and Knudsen 2020, Posypkin et al. 2020, Sundar et al. 2022). In fact, a separable concave function minimization can be approximated to an arbitrary precision by a single separable PLF problem (Magnanti and Stratila 2004).
The common way to approach problems with nonconvex PLFs is by developing exact formulations based on either mixed-integer linear programs (MILPs) or special ordered sets of type 2 (SOS2). In both approaches, the problem is reformulated by using a number of additional variables, some of which are binary, and constraints for each breakpoint of the PLF. This reformulation is then solved with an MILP solver. Classical MILP and SOS2 modeling approaches (see surveys in Vielma et al. 2010 and Rebennack 2016) initially focused on continuous separable PLFs but were later extended by Vielma et al. (2010) to the nonseparable case. It is known that their LPs provide the same relaxation strength (Sherali 2001, Croxton et al. 2003, Keha et al. 2004). However, they have the drawback of using as many binary variables as the number of segments of a PLF. This was remedied by Vielma and Nemhauser (2011) and Huchette and Vielma (2023), who produced MILPs that require only a logarithmic number of binary variables, thereby allowing for greater scalability of such models. Other research has focused on specialized valid inequalities for the SOS2-based models of separable PLFs (Keha et al. 2006, Vielma et al. 2008, de Farias et al. 2013, Zhao and de Farias 2013). Extensions of MILP models to lower semicontinuous (l.s.c.) PLFs have been studied (Vielma et al. 2008, 2010). For general discontinuous PLFs, one cannot expect an MILP formulation with bounded integer variables (Meyer 1976, theorem 2.1), but the SOS2 branching scheme has been adapted (de Farias et al. 2008). Many of these modeling and algorithmic advances have been implemented in state-of-the-art MILP solvers and leveraged to build stronger polyhedral relaxations of nonconvex functions (Rebennack 2016, Kim et al. 2024, Lyu et al. 2025).
Because a PLF is a nonconvex function, the problem of optimizing a PLF can be viewed through the lens of global optimization. A commonly used algorithmic framework for global optimization is spatial branch-and-bound (sBB). The use of an sBB for optimizing a separable function (sum of univariate functions, not necessarily PLF) was first done by Falk and Soland (1969). This was improved upon by Horst (1986) and Tuy and Horst (1988) to general nonconvex functions; since then, sBB algorithms for global optimization have matured immensely (cf. Locatelli and Schoen 2013, Tuy 2016), and there are many sophisticated implementations in global solvers for optimizing smooth functions. However, this global optimization approach has so far not been undertaken for PLF optimization, and state-of-the-art global solvers are unable to take PLFs directly as input without first being modeled using integer variables as mentioned above. Another drawback of existing methods is that they do not always scale well with the number of segments in the PLF. We adopt the global optimization approach, and our experiments show that the sBB approach has better scalability properties than the MILP or SOS2 models.
1.2. Our Contributions
We study the global optimization of a separable nonconvex PLF over a closed convex set. Contrary to the standard combinatorial approach of using an MILP or special ordered sets formulation to model the PLF, we take the nonlinear approach to solving such problems. We do not reformulate the PLF with integer variables, but instead, we generate convex underestimators for it and refine them to develop an sBB algorithm. A key ingredient of our algorithm is how the underestimator is generated even when the PLF is discontinuous and how it is efficiently and quickly updated at a child node using the information from the parent node and without having to generate it from scratch. Our contribution of adding a new method to the literature complements the MILP and SOS2 approaches by offering the following advantages: (i) slim and sparse LP relaxations, (ii) sharpness throughout the search tree, and (iii) more freedom in branching decisions. Through extensive computational experiments, we demonstrate that even a rudimentary Python implementation of the sBB can provide speedups of two orders of magnitude over modern logarithmic models solved by Gurobi if the number of segments is sufficiently large and that these speedups tend to grow with every segment added to the PLFs.
The existing approaches for PLF optimization use integer branch-and-bound (B&B), where branching takes place on integer (mostly binary) variables in a binary search tree and bounding is through LP relaxations (enhanced with cutting planes). Our sBB also uses LP relaxations (albeit of a different kind) for bounding but branches on continuous variables only (hence, the term spatial). Hence, finite convergence to the global optimum is not obvious with our approach and in fact, is not possible for all branching rules. We provide a rule that branches only at the breakpoints and enables the sBB to converge finitely. The classical largest-error branching rule is known to converge asymptotically for a continuous separable objective, and we present an independent and self-contained proof using Lipschitz continuity of PLFs. For general objective functions that are either lower semicontinuous or such that their values at infeasible points are no lower than the global minimum, the longest-edge branching rule has been shown to achieve asymptotic convergence, and this also carries over to our PLF optimization problem. The lack of finite convergence for any branching rule could be perceived as a drawback of sBB versus integer B&B, which always terminates finitely for bounded integer variables. However, our experiments show that this convergence issue arises only when the number of segments in a PLF is small, and the sBB generally terminates quicker for larger instances.
To the best of our knowledge, the various sBB-based state-of-the-art global solvers cannot handle PLFs directly unless they are explicitly input to the solver formulated as MILPs. Thus, we see our work as a first step in the direction of creating an sBB solver that can optimize a separable PLF without creating integer variables. We begin in Section 2 by describing the problem input and basics of sBB from the literature. Section 3 introduces the basic concepts of our sBB algorithm and relates it to the MILP and SOS2 approaches. Section 4 studies various convexification properties of a univariate PLF that underpin our algorithm. The sBB algorithm, with all of its elements, is described and analyzed for convergence in Section 5. Computational testing is done in Section 6, where comparisons are also drawn with logarithmic-sized MILP models, Gurobi’s PLF solver, and Gurobi’s global solver. Section 7 derives a bound on the number of segments necessary in a good PLF approximation of separable Hölder-continuous functions. Lastly, conclusions and some future directions are mentioned in Section 8.
1.3. Importance of Scalable Algorithms
Because our experiments show the sBB to have better computational performance than MILP or SOS2 models as the number of segments in the PLF increases, we briefly discuss here the importance of a method with such good scalability properties.
PLFs are commonly employed to linearize nonlinear terms and thereby, create a tractable approximation to a nonconvex optimization problem. PLF approximations can be constructed either as relaxations (outer approximations) or through discretizations (inner approximations). When the nonconvexities are present in the constraints, the PLF approximation resulting from discretization may not necessarily produce an inner approximation of the feasible region but can nonetheless be used to obtain some approximate solution. Small segments in the PLF give fine approximations of the problem, which may translate into sharp primal or dual bounds. Thus, a key question when building PLF approximations is to determine how many pieces each PLF should have if the approximation error, defined as the largest distance between the function value and the approximate value, is to be no more than some given error bound. We mention some results for a continuous univariate function over a closed interval because that is the focus of this paper, but we note that some error-bounding analysis has also been done for higher-dimensional functions (Dey and Gupte 2015, Adams et al. 2019, Duguet and Ngueveu 2022, Bärmann et al. 2023).
The errors in the PLF relaxation of a univariate function are an elementary calculation because this relaxation is constructed by first partitioning the interval into alternate regions of convexity and concavity for the function and then, drawing tangents at different points in the convex regions and drawing secants in the concave regions. The analysis is nontrivial for the case of the PLF approximation, which is constructed by choosing some breakpoints in the interval (either equidistant or not) and connecting them at their function values. For this discretization, Frenzen et al. (2010, theorems 1 and 2) gave an asymptotic answer by showing that for thrice-continuously differentiable functions, the number of breakpoints to achieve an error of is roughly as , where the constant c depends on the second-order derivative of the function. Another related question is to consider optimization of a separable function and determine the number of breakpoints necessary to construct a PLF approximation whose optimal value is no worse than a given tolerance away from the true optimum. Such bounds on the number of segments have been derived using first- and second-order derivatives when the function is convex or concave (Thakur 1978, Kontogiorgis 2000, Magnanti and Stratila 2004). When the objective function is nonseparable, it is possible to construct separable PLF underestimators and use their error bounds to obtain a globally convergent algorithm (Feijoo and Meyer 1988).
There are computationally intensive MILP-based methods for computing best-fit PLFs (Toriello and Vielma 2012, Ngueveu 2019, Kong and Maravelias 2020, Rebennack and Krasko 2020, Warwicker and Rebennack 2022) as well as efficient algorithms (Warwicker and Rebennack 2024). Even if logarithmically many binary variables are used, the number of continuous variables generally scales linearly with the number of pieces in each function. Therefore, in order to obtain tight approximations of nonlinear functions, large-sized MILPs have to be solved, and branch-cut algorithms do not always converge very quickly on these. Recognizing this obstacle, some recent studies (Nagarajan et al. 2019, Burlacu et al. 2020, Gupte et al. 2022) have looked at algorithms that adapt the location of the breakpoints in the PLF approximation so that large-sized mixed-integer formulations do not have to be created a priori; but, their results are far from conclusive, and there is still scope for devising new methods with better scalability.
2. Preliminaries
2.1. Problem Input
We consider the separable nonconvex piecewise linear optimization problem given by
Each PLF is input with its breakpoints in for some integer , and these are indexed by the set . The breakpoints include the two endpoints and and the points where either changes its slope or is discontinuous. Denote the x values of the breakpoints by
The function values at the breakpoints are . Because we allow discontinuities at the breakpoints, we also need to know the left and right limits at each breakpoint to characterize . The left limit is denoted by , and the right limit is denoted by . For the left (respectively, right) endpoint, we set the left (respectively, right) limit to the function value. Thus, for every , we have as input the tuple
Using this input, a univariate PLF can be defined over , for any , as
If is continuous at a breakpoint (i.e., ), we write , knowing that the left and right limits coincide with the function value.
2.2. Background on sBB
The spatial branch-and-bound is similar to the integer branch-and-bound, but it has some major differences. In sBB, lower bounds are computed by a convex relaxation (convexification), which is obtained after replacing every nonconvex function by a convex underestimator over its bounded function domain. The strength of relaxations is important for convergence of the algorithm, and a fast numerical performance depends on the speed and efficiency with which the relaxations are generated and updated throughout the branching tree. Second, branching takes place on continuous variables, which leads to a partition of the feasible region in hyperrectangles. Third, after branching has occurred and any bound tightening has been performed on the variables, the underestimator is updated and refined to obtain a stronger relaxation than what is implied by the original relaxation with new variable bounds on it. Convergence in limit to the global optimum can then be obtained under mild conditions and assumption of lower semicontinuity of the functions because branching results into smaller hyperrectangles, which allow for tighter underestimators that force the gap between the function and its underestimator to converge to zero. The reader is referred to Locatelli and Schoen (2013, chapter 5.4) for a more detailed description of the general convergence theory of sBB algorithms. It is known that for optimizing any nonconvex function over a closed convex set, an sBB algorithm converges in finitely many iterations for any optimality tolerance if the following two properties are satisfied:
exhaustiveness of branching (which means that any nested infinite subsequence of hyperrectangles used for branching converges to a point) and
exactness in the limit for the underestimators (which means that their gap to the function value at any point goes to zero as the branching hyperrectangles shrink to a point).
With , only convergence in the limit is guaranteed if besides the above two properties, the sBB also selects nodes infinitely often using the best bound rule. Some of the branching rules can also lead to finite convergence with if there is some special structure on the optimal solutions, such as an extreme point property (Shectman and Sahinidis 1998, Al-Khayyal and Sherali 2000).
3. Overview of Our sBB
3.1. Main Ideas
There are two main components to our sBB—convex relaxations using underestimators to obtain lower bounds and branching rules to guarantee convergence to global optimum. We do not employ any heuristics, and so, upper bounds are calculated in the standard way of evaluating the value of F at a solution to a node relaxation in the sBB search tree. One could possibly obtain stronger upper bounds by employing derivative-free optimization algorithms to minimize F using the node relaxation solution as a starting point, but exploring this idea is out of scope for this paper. Our branching rules are adopted from the literature and explained later in Section 5.2. In the remainder of this section, we outline our convex relaxation.
The convex envelope of a function over a compact convex set is defined as the point-wise supremum of all of the convex underestimators of that function over the set. Minimizing the function over the set is equivalent to minimizing its convex envelope. However, this envelope is generally intractable to compute, and the same is also true for nonconvex PLFs. The difficulty generally arises from the presence of the set , which could be nontrivial and complicated, and so, the standard approach in global optimization is to generate convex underestimators of the objective function over the hyperrectangle H instead of over . Because H is the Cartesian product of one-dimensional convex compact intervals and F is a separable function, the envelope of F over H is a sum of univariate envelopes. Using cvx to denote the convex envelope operator, we can write . Each is a PLF, but because is allowed to be discontinuous, this PLF may not be l.s.c. For computational tractability, we need the underestimators to be l.s.c. so that they have a polyhedral representation; otherwise, the corresponding feasible set of the relaxation will not be a closed set, which creates numerical difficulties in solving this relaxation. Hence, we carry out one additional step for the underestimators. For each i, we take the envelope of an l.s.c. function underestimating . The resulting function is not only convex and l.s.c. but in fact, convex and continuous because of convex functions being u.s.c. over polytopes. Let us denote this underestimator for each i by . Summing these yields a convex continuous PLF underestimator on F,
This yields a convex relaxation for Problem (1) whose value we denote by :
Because each is a convex continuous PLF, its epigraph is a polyhedron, and so, is equal to the point-wise maximum of finitely many affine functions. Thus, there is a finite set and coefficients for such that
Our construction of is such that with , where we recall from (2a) that indexes the breakpoints of . Hence, the coefficients for each can be obtained in terms of the values of at these breakpoints. Therefore, our convex relaxation of problem is as follows:
A salient feature of this work is the efficient computation of the underestimator , and this is presented in Algorithm 4.1. However, this only represents the root-node relaxation. In the search tree of sBB, H is successively partitioned into a sequence of hyperrectangles , and so, the relaxation (4) has to be constantly updated and solved again over . In order to make our algorithm competitive and efficient, for any , we do not compute the lower bound by computing from scratch using the breakpoints of , although this is certainly an option. Instead, we update the underestimator that was computed for the parent node of the node corresponding to by exploiting structural properties of PLFs. Let us elaborate on this point. If is the hyperrectangle for the parent node of the node for and was the branching variable used to create from , then our underestimators at the two nodes differ only in the coordinate so that
Thus, if the underestimator over is stored in memory, then the underestimator for requires update only in one coordinate . This is simply because of separability of the functions. The crucial thing, however, is whether needs to be computed from scratch using the breakpoints of and employing Algorithm 4.1 for univariate PLFs. This is not necessary because of a property of PLFs that only a subset of the breakpoints of is different than those of as we show in Section 4.2. This allows for (on average) a quick and fast update to the underestimator of over (assuming that it is stored in memory), although in the worst case, it is possible that all the breakpoints have to be updated. Hence, we calculate by starting with the relaxation (4) for and modifying some of the linear constraints in (4b) as needed for and . If is a polyhedron, we can then employ the dual-simplex method to compute starting from , which is generally significantly faster than using the primal simplex for .
The sBB algorithm developed here can be modified to accommodate separable PLFs in constraints using similar arguments as the classical results by Soland (1971). Yet, for ease of exposition, we restrict our attention in this paper to PLFs in the objective only. Similarly, it is possible to integrate the methods developed here in general-purpose (spatial) branch-and-bound-based solvers and solve a broader class of mixed-integer nonlinear problems.
3.2. Relation to MILP and SOS2 Approaches
It is well known that all of the MILP models for PLFs share the sharpness property when the functions are l.s.c.; their LP relaxations (when is a polyhedron) give the same lower bound as convexifying each function over its interval domain, which is equivalent to our relaxation (4). However, upon branching, most relaxations lose this guarantee of providing the same bound as (4). In fact, only the incremental and SOS2 models share this property called hereditary sharpness (Huchette and Vielma 2023). This property is very desirable because it leads to balanced search trees (Yıldız and Vielma 2013). Indeed, experiments indicate that the incremental and SOS2 models perform very well on PLFs with a small number of segments and are only outperformed by the logarithmic model with growing numbers of segments (cf. Rebennack 2016, Huchette and Vielma 2023). These considerations have been summarized by Huchette and Vielma (2023, p. 1839) with the remark that “the high performance of the [logarithmic] formulation is due to its strength and small size and in spite of its poor branching behavior.” The addition of some valid inequalities and cutting planes to the MILP model would strengthen the LP relaxation, but the fact remains that a desirable method for solving problems with PLFs should combine both hereditary sharpness and a small-scale formulation.
This gave the motivation to our sBB approach. By updating our convex underestimator over every subset , we manually achieve relaxations of the strength (4) at every node of the branch-and-bound tree. Moreover, the LP relaxations are particularly small. In contrast to SOS2 and MILP formulations, the size of the relaxation (4) does not grow with the number of segments of but with the number of segments of its envelope. To illustrate this, let be the number of segments of and be the number of segments of . If each is continuous, the logarithmic MILP model adds continuous variables, binary variables, and constraints (cf. Vielma et al. 2010). In contrast, the sBB relaxation (4) adds n continuous variables, zero integers, and constraints. Because typically, we have far fewer variables. For the constraints, is no more than , although it can be more than . Hence, if the PLFs are such that their envelopes have few segments, then our relaxations will be smaller in size while being of the same strength as the conventional models. An extreme case of this is when each is concave where our relaxations will add n constraints, which can be much smaller than the number of constraints in MILP and SOS2 because of being arbitrary.
Furthermore, the sBB offers the advantage of a sparser constraint matrix. Rebennack (2016) pointed out that formulations like the logarithmic model result in a dense constraint matrix. On the other hand, the sBB relaxation (4) is, in particular, sparse; each added inequality has exactly two nonzeros. Indeed, LPs with convex PLFs can be solved very efficiently by exploiting its structure (Fourer 1985, Gorissen 2022). Finally, spatial branching offers a higher degree of flexibility in branching decisions compared with integer or SOS2 branching. Both integer and spatial branching choose a branching variable . However, although spatial branching can branch at any point in the interval , integer branching in MILP and SOS2 models can be mapped to specific points in each interval. Therefore, spatial branching can mimic integer and SOS2 branching, but the converse is not true.
4. Convexifying Univariate PLFs
It was outlined in Section 3.1 that the key ingredient of this work is generation and efficient updates of convex continuous underestimators of univariate PLFs. Therefore, in this section, we focus on a univariate (possibly discontinuous) PLF , where we omit the subscript i for ease of notation and better readability. The results derived here will be utilized in the sBB algorithm in the next section by applying them to the PLFs in Problem (1).
Let f have breakpoints in I for some integer , and these are indexed by the set , with the x values of the breakpoints being given by the set , where . The function values at the breakpoints are for . The left and right limits at each breakpoint are and , respectively. For the left (respectively, right) endpoint, we set the left (respectively, right) limit to the function value. Thus, f is completely defined by the following finite collection of tuples as input:
Note the following obvious fact.
Any finite set of points in corresponds to a continuous univariate PLF obtained by doing linear interpolation between consecutive (taken w.r.t. x coordinates) points.
4.1. PLF Underestimator
We construct a tight convex and continuous PLF underestimator for f. To describe this, define the following PLF over I:
is an l.s.c. PLF underestimator of f over I.
It is clear that for all . It is continuous at because f is a PLF. At any breakpoint , we have
But, this l.s.c. underestimator need not be convex. Hence, we convexify it to obtain the function
is a convex and continuous PLF underestimator of f whose breakpoints are given by the set
where for all . Furthermore, we have
We use the following technical results to establish the above claims on .
(
A continuous univariate PLF is convex if and only if the slopes of its linear pieces form an increasing sequence when arranged from left to right.
In the following condition from planar geometry, we say that three points form a convex (respectively, concave) triangle when the point in between lies below (respectively, above) the segment joining the other two points.
The continuous PLF formed by joining a finite set of points in is a convex function if and only if every triplet of points forms a convex triangle. Consequently, if the PLF is nonconvex, then a point is not a breakpoint if and only if it forms a concave triangle with two other points, one to its left and one to its right.
Necessity is obvious from the definition of convexity. Sufficiency can be argued by contraposition. Suppose that the PLF is not convex. We will use Lemma 4.3. Therefore, nonconvexity means that there exists some breakpoint such that the slope to the left of is greater than the slope to the right (equality of slopes is impossible because of being a breakpoint). This implies that there is a nonconvex (concave) triangle with as its apex. In particular, letting for some , we have , which after rearranging, becomes , leading to a nonconvex triangle formed by the points indexed by . □
Because is the convex envelope of the PLF , it is obviously a convex PLF over I. Lemma 4.1 implies that this PLF is an underestimator of f. The convex envelope of an l.s.c. function is l.s.c. convex, is continuous over the interior of its domain, and can only be discontinuous on the boundary. Combining this fact with Lemma 4.2, where we use I being a polyhedron in , gives us that is a convex and continuous underestimator.
The breakpoints of must be breakpoints of and hence, of f. The convex continuous PLF is formed by joining its finitely many breakpoints. From Lemma 4.4, the characterization of the breakpoints of the underestimator follows immediately. The breakpoints of a PLF form what is more generally called the generating set in the global optimization literature for general nonconvex functions, and it is known that the envelope of an l.s.c. function equals the function value at points in its generating set. Hence, the underestimator equals at its breakpoints. □
Another convex underestimator to f is the convex envelope of f denoted by . This equals at its breakpoints in , whereas at the endpoints , we may have inequality and so, can only say that for . It is also not hard to see that and have the same set of breakpoints. Therefore,
Thus, the only difference between and is in their values at the endpoints, where the latter will be u.s.c. because of Lemma 4.2 but may not be l.s.c.
We now build upon the characterization of breakpoints in Proposition 4.1 to derive an efficient algorithm for computing given f as an input through its breakpoints.
Algorithm 4.1 produces after iterations.
Each application of the while loop is repeatedly checking the necessary and sufficient conditions for the slopes from Lemma 4.4. Furthermore, because of the updates done to the lists where the last element is removed, at any stage the last two elements in the lists yield a lower bound on the slope required to make the kth point a breakpoint. This implies that the while loop executes only a constant number of times for each k, and so, the entire algorithm runs in iterations. The points in the lists that it outputs indeed represent the breakpoints of because they were obtained by checking the conditions in Lemma 4.4 and so, correspond to the characterization in Proposition 4.1. □
(
Data: Lists and of PLF
Result: Lists and defining the tuples of .
Compute for
Initialize and
for to K do
while and do
Remove the last element of and .
end
Update and
end
return and
The worst-case running time of for our algorithm cannot be improved further because a convex f would take K iterations because of every breakpoint of f also being a breakpoint of its envelope. However, it may be possible to improve the average running time by considering one of the many different algorithms in the literature; cf. Cormen et al. (2009, chapter 33.3) for generating the convex hull of a finite set of points in (note that this convex hull is composed of the convex envelope, the concave envelope, and at most, two vertical segments). For example, the classical Graham’s scan algorithm begins with a reference point having the smallest y coordinate, calculates the polar angles of the other points w.r.t. the reference point (equivalent to slopes of the line segments joining the two points), and then, applies Lemma 4.4 to discard points that will not be breakpoints of the envelope (Graham 1972). Our algorithm starts with the leftmost breakpoint as the reference point and compares slopes w.r.t. the previous candidate breakpoint. Although there are conceptual similarities with Graham’s scan, it is not clear (and probably not true) that the two algorithms are in a bijection.
4.2. Updating Envelope over Subintervals
The branching procedure of sBB algorithms requires constant updating/recomputing of the underestimator over a subinterval
Of course, Algorithm 4.1 can be used to compute , but this would scan the breakpoints from scratch, which can be computationally expensive when there are many segments, and we show that this is not necessary. Yet, using Algorithm 4.1 to calculate requires rescanning all breakpoints of f in . Especially for PLFs with many segments, this can be an expensive computation. However, this is usually not necessary because we show that equals over some part of in th middle and needs to be updated only over the end pieces. In particular, the envelope does not change between the leftmost and rightmost breakpoints in , which can lead to substantial savings in computation if the subinterval is large w.r.t. I. To describe our result, let us denote
Note that if and do not exist, then the updated envelope is trivial. Henceforth, assume that they exist and partition into three intervals:
Assume and exist. The underestimator over can be described as follows:
The function on the right side of the equality is obtained by gluing together three different convex functions. Hence, we need to argue convexity of this glued function. But, this follows rather immediately from the necessary and sufficient conditions in Lemmas 4.3 and 4.4. Because the breakpoints of in were not breakpoints of , they form a concave triangle with the breakpoints in , and so, after convexifying over , the slopes of the resulting linear segments can be no more than the slopes of the segments in . Similar arguments hold for . □
4.3. An Illustrative Example
The PLF in Figure 1 has five segments (so, ) with the breakpoints . Note that f is discontinuous at but otherwise, continuous. The tuples corresponding to the breakpoints are , , , , , and .
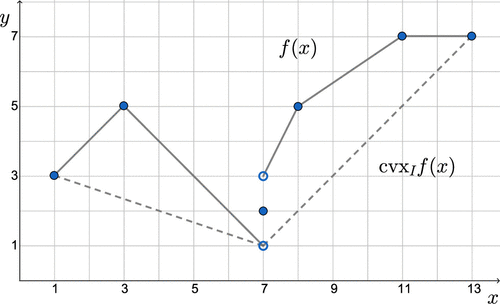
Applying Algorithm 4.1 to this function over receives as input the lists and and outputs the lists and . They define the continuous PLF formed by the tuples , , and , which equals depicted in Figure 1 if Algorithm 4.1 is invoked to compute over , and the input lists are and . Realize that because the discontinuity at is at the edge of , and hence, because .
Let and . is given by , , and . Hence, . Consequently, , , and . is given by , , , and . Hence, is formed by and , and is formed by and . Finally, is given by , , and .
This example illustrates that Proposition 4.3 does not always lead to a reduction in the number of breakpoints to be scanned. However, if f is highly nonconvex with many segments, the savings can be enormous. Therefore, Proposition 4.3 is particularly useful for PLFs that accurately approximate a highly nonlinear function.
5. Spatial Branch-and-Bound Algorithm
Our main ideas for an sBB algorithm to solve the PLF optimization Problem (1) were sketched in Section 3.1. The algorithm is presented formally in Algorithm 5.1. The bounding operation is specified next, the branching schemes are in Section 5.2, and convergence is discussed in Section 5.3.
The following notation is used to describe our algorithm. Iteration number is k. For each k, is the partition element; and are the optimal solution and the optimal value of relaxation , respectively; and are the global upper and lower bounds, respectively, to ; and is the incumbent solution. denotes the list of unfathomed subproblems at any stage of the algorithm. The user-defined absolute termination gap is .
5.1. Node Relaxations
Each node of the search tree corresponds to a hyperrectangle and the subproblem
Our lower bound on this nonconvex problem is denoted by , which is obtained by solving the following convex relaxation:
Because is polyhedral as per the results of the previous section, using the epigraph modeling trick as in (4) leads to a tractable convex formulation for the node relaxation subproblem. It will be useful to separate a single coordinate from the above sum so that we can write
In our context, the coordinate j will correspond to the branching variable that was used to create this node subproblem from its parent node in the sBB tree. In particular, if this node was created from its parent node by branching on , then using in (8d) gives us
Note that when using Proposition 4.3 to update the underestimator over a child node, the breakpoints of must be stored for each partition element . It is common for sBB/B&B methods to store LP relaxation data in order to solve the child-node relaxation in a few iterations using the dual simplex rather than from scratch. However, if memory is scarce, Algorithm 4.1 can be called at each child node to compute from scratch, and no additional data need to be stored.
(
Root node: Compute as per (8c) using Algorithm 4.1 for for all i
Solve to obtain and
if is infeasible then return is infeasible
else Set , , , , and
while do
Node selection: Find an . Mark it as parent node, and set and
Branching: Partition into using a branching rule from Section 5.2. Let denote the branching variable
Bounding: for do
Compute as per (8e) with and and using Proposition 4.3 to update the envelope in the coordinate
Solve relaxation to obtain and
if is infeasible then remove from
end
Update: Set . Examine whether the previous global upper bound can be improved,
Update the incumbent accordingly.
Add child nodes to list:
Pruning: Fathom subproblems by bound dominance as .
end
5.2. Branching Rules
Consider partition element with the optimal solution to its relaxation . We give three different rules for the branching step of Algorithm 5.1 to partition into and . The first follows the common concept to branch on the variable , which causes the largest violation (i.e., contributes most to the convexification gap). It was first proposed by Falk and Soland (1969), and variations of it can be found, for instance, in the solver BARON (Tawarmalani and Sahinidis 2004). It is similar to the integer branching rule, where the variable with the largest fractional part is chosen. The second branching rule follows the simple concept of branching at the midpoint of the longest edge and was used, for instance, in the solver BB (Adjiman et al. 1998).
5.2.1. Largest-Error Branching Rule.
Select the index that contributes most to the convexification gap at :
5.2.2. Longest-Edge Branching Rule.
Select the index with the longest edge by
5.2.3. Breakpoint Branching Rule.
Select the index by the largest-error rule (9a) applied only to breakpoints (i.e., select a breakpoint with the largest error). Partition at this breakpoint:
Preliminary computational experiments conducted on our test problems indicated a superiority of the largest-error branching rule. This computational superiority is also intuitive as this rule provides the maximum tightness at the former solution for both child nodes, allowing for a visible increase in the lower bound and a balanced search tree. The other two branching rules do not possess these desirable computational properties, but they do have theoretical superiority because they allow for stronger convergence results as we explore in the next sections. We also note that integer branching applied to MILP-PLF models leads to unbalanced trees (cf. Yıldız and Vielma 2013).
5.3. Convergence Guarantees
Falk and Soland (1969, theorem 2) established asymptotic convergence of the largest-error branching rule when F is any continuous separable function. They also gave an example showing that for this rule, continuity of the functions is necessary for convergence. Under the weaker assumption of F being l.s.c., Falk and Soland (1969, theorem 1) established convergence under a stronger branching rule that creates more than two nodes at each step and thus, does not lead to binary search trees. Their results directly apply to our PLF optimization problem because we also consider a separable objective. Furthermore, as mentioned in Section 2.2 and described in Locatelli and Schoen (2013, chapter 5), finite convergence can also be obtained for general nonconvex optimization with . However, we give some independent and self-contained proofs in this section. First, we show that the breakpoint rule yields finite convergence even with .
When each is l.s.c., Algorithm 5.1 using the breakpoint branching rule converges finitely for any .
The l.s.c. condition implies that at a breakpoint , and so, our underestimator is exact at each breakpoint as per Proposition 4.1. Hence, a breakpoint is chosen at most once for branching because once it is branched upon, the underestimator will have zero error at this point throughout the subtree from this node. Because there are finitely many breakpoints, the claim follows because every feasible leaf node of the sBB tree will yield an exact representation of some restriction of the original Problem (1), and the union of all of these leaves will be Problem (1). □
The largest-error rule is finitely convergent when and has asymptotic convergence when . We give an independent proof of the second result by exploiting Lipschitz continuity of PLFs, which makes our arguments different than those of Falk and Soland (1969) for general separable functions.
When each is continuous, Algorithm 5.1 using the largest-error branching rule converges in the limit for .
By construction, for every k, and the sequence is decreasing, whereas is increasing. Hence, if the sBB algorithm terminates at iteration p, we have , and thus, the infimum is found with -precision.
If the sBB algorithm does not terminate after a finite number of iterations, the sequence of partition elements is infinite. Thus, there must be at least one infinite nested subsequence of denoted by
We have to show the consistent bounding property (i.e., there exists an infinite nested subsequence of , for which ). By boundedness of the sequences, we can extract subsequences such that with
the sequence of optimal solutions of relaxation converges to a limit point and
only one index gets branched on infinitely often.
Because we are only interested in the limit behavior, we can, therefore, focus exclusively on the index . First, note that and thus, also are Lipschitz continuous with constant for all iterations q. Now, let us define function over . Note that is Lipschitz with constant . By the largest-error branching rule, namely (9b), we obtain and thus, . Consequently,
Because is continuous and , we obtain that , and hence,
Because , we have that , and therefore,
Finally, there is a so that for all , the branching index is selected by (9a). Hence, we get that
Statement (i) follows then as a consequence of the definition of , , and by
For statement (ii), realize that has only finitely many breakpoints. Hence, after a finite iteration, holds that is affine over , and thus, . By similar arguments, like in (12a) and (12b), it follows then that , and hence, is finite.
Now that consistent bounding has been established, convergence can be concluded by standard arguments from the literature (cf. Tuy and Horst 1988, theorem 2.3) (i.e., and every accumulation point of solves ). Remember that is a subsequence of , and thus, and for all . By the monotony of the sequences and , convergence follows then directly by . □
Wechsung and Barton (2014) imposed the requirement of strongly consistent on the branching scheme to obtain asymptotic convergence for general l.s.c. functions with the longest-edge branching rule. Their underestimators applied to PLFs are possibly no stronger than ours; so, their convergence result might carry over to our sBB for l.s.c. PLFs, but a rigorous exploration of this is left for future research.
6. Computational Experiments
6.1. Design of Experiments
We compare the computational performance of the sBB algorithm with MILP approaches from the literature as well as the state-of-the-art solver Gurobi. In Section 6.2, we consider continuous PLFs in network flow problems with concave PLFs (Section 6.2.1) and knapsack problems with both nonconcave and concave PLFs (Section 6.2.2). Discontinuous l.s.c. PLFs are tested for a network flow problem with fixed charges in Section 6.3. Further, we test our sBB algorithm against the global solver Gurobi in Section 6.4. We conclude with a general discussion of our numerical results in Section 6.5.
Let us begin by outlining the design of our experiments. Algorithm 5.1 was implemented in Python version 3.11.9. The largest-error branching rule is chosen because in our initial testing, it seemed to do better than the other rules described in Section 5.2. Nodes were selected using the best-bound rule. The LPs on the nodes are solved with Gurobi. The MILP models are generated in Julia version 1.10 using the package PiecewiseLinearOpt developed by Huchette and Vielma (2023) and are solved by Gurobi. We use Gurobi version 11.0.3 with standard settings. All tests were carried out on a workstation with 4.70 GHz and 128 GB RAM running Windows 11 Enterprise. For termination, we used a relative optimality gap of and a time limit of 30 minutes. All times given are wall-clock times. The code of the sBB implementation and the MILP generation as well as the instance generator are available at GitHub (Hübner et al. 2025).
We compare our sBB algorithm (sBB) against the PLF solver inside Gurobi (GRB) and four state-of-the-art logarithmic-sized MILP models available in the package PiecewiseLinearOpt. In particular, these are the logarithmic (Log) and disaggregated logarithmic (DLog) (Vielma et al. 2010) as well as the recently introduced binary zigzag (ZZB) and general integer zigzag (ZZI) models (Huchette and Vielma 2023). In contrast to these four logarithmically sized MILP formulations, to our knowledge, Gurobi’s PLF solver is built on a linear-sized MILP model.
Similar to findings in the literature (cf. Vielma et al. 2010), first experiments indicated that linear-sized MILP models are not competitive to logarithmic-sized models when nonconvex PLFs with 50 or more segments are involved. Therefore, we restrict our comparisons to the four logarithmic-sized MILP models above available in the literature.
6.2. Continuous PLFs
6.2.1. Network Flow Problem with Concave Cost.
Network flow problems with nonconvex PLFs occur in many applications ranging from telecommunications to logistics (Croxton et al. 2007). They can be defined as follows:
An instance of the network flow problem is created similar to Keha et al. (2006), Vielma et al. (2010), and Huchette and Vielma (2023) as follows. First, declare each node a demand, supply, or transshipment node with equal probability . The transshipment nodes have , whereas the demand and supply nodes have . To obtain a balanced problem, the final node n has . The breakpoints , of the concave PLFs are determined as follows. Set and ; generate points , ; and order them. Subsequently, generate K slopes by , , and order them in decreasing order to obtain a concave PLF. Finally, set , and compute the y coordinates of the breakpoints by , .
We perform our computational test on network flow problems with nodes. For each K, 50 random network flow instances are generated and solved. The statistics of the solve times are given in Table 1. We display the median, the arithmetic mean, and the standard deviation as well as the number of instances that cannot be solved by a method within the time limit (fail) and the number of instances in which each method was the fastest (win).
|

Table 1. Solve Times (Seconds) for Network Flow Problems with Continuous Concave PLFs
| Method | Med. | Avg. | Std. | Win | Fail |
|---|---|---|---|---|---|
| Panel A: 10 segments | |||||
| ZZI | 0.26 | 0.28 | 0.12 | 20 | 0 |
| Log | 0.26 | 0.34 | 0.50 | 12 | 0 |
| DLog | 0.33 | 0.32 | 0.14 | 9 | 0 |
| ZZB | 0.39 | 0.41 | 0.22 | 4 | 0 |
| GRB | 0.40 | 0.36 | 0.14 | 5 | 0 |
| sBB | 4.55 | 8.96 | 14.65 | 0 | 0 |
| Panel B: 100 segments | |||||
| ZZI | 1.82 | 2.11 | 1.06 | 24 | 0 |
| ZZB | 1.95 | 2.30 | 1.15 | 15 | 0 |
| Log | 2.36 | 2.68 | 1.19 | 5 | 0 |
| DLog | 3.90 | 4.67 | 2.20 | 0 | 0 |
| sBB | 4.11 | 6.17 | 7.08 | 6 | 0 |
| GRB | 9.38 | 9.65 | 3.95 | 0 | 0 |
| Panel C: 500 segments | |||||
| sBB | 8.2 | 11.1 | 11.2 | 39 | 0 |
| Log | 15.1 | 17.2 | 8.0 | 6 | 0 |
| ZZI | 15.5 | 18.0 | 9.0 | 4 | 0 |
| ZZB | 15.8 | 19.4 | 11.9 | 1 | 0 |
| DLog | 23.6 | 27.6 | 14.6 | 0 | 0 |
| GRB | 90.0 | 114.6 | 94.8 | 0 | 0 |
| Panel D: 1,000 segments | |||||
| sBB | 5.8 | 10.9 | 14.6 | 50 | 0 |
| Log | 45.7 | 49.5 | 18.2 | 0 | 0 |
| DLog | 46.5 | 57.4 | 32.4 | 0 | 0 |
| ZZI | 48.4 | 48.9 | 21.1 | 0 | 0 |
| ZZB | 61.6 | 61.2 | 23.9 | 0 | 0 |
| GRB | 270.6 | 363.4 | 241.9 | 0 | 0 |
| Panel E: 5,000 segments | |||||
| sBB | 7.2 | 11.0 | 11.0 | 50 | 0 |
| Log | 330 | 331 | 132 | 0 | 0 |
| ZZI | 333 | 329 | 152 | 0 | 0 |
| DLog | 379 | 405 | 200 | 0 | 0 |
| ZZB | 515 | 518 | 198 | 0 | 0 |
| GRB | 1,800 | 1,800 | 0 | 0 | 50 |
| Panel F: 10,000 segments | |||||
| sBB | 8 | 12 | 15 | 50 | 0 |
| Log | 729 | 763 | 294 | 0 | 0 |
| DLog | 940 | 876 | 374 | 0 | 1 |
| ZZI | 976 | 924 | 299 | 0 | 1 |
| ZZB | 1,419 | 1,368 | 410 | 0 | 9 |
| GRB | 1,800 | 1,800 | 0 | 0 | 50 |
Notes. sBB is the proposed method in this paper. Avg., arithmetic mean; Fail, number of instances that cannot be solved by a method within the time limit; Med., median; Std., standard deviation; Win, number of instances in which each method was the fastest. The methods are sorted according to the bold numbers.
6.2.2. Knapsack Problem with Approximated Nonlinearities.
As discussed in Section 1, PLFs are often used to approximate difficult nonlinear expressions in optimization problems. To test the sBB and MILP methods in this context, we consider the following nonlinear continuous knapsack problem:
Each is a nonconvex continuous PLF randomly generated by approximating a smooth nonconvex function from Table 2. The functions therein are mostly taken from Casado et al. (2003).
|
Table 2. Nonconvex Univariate Functions
| No. | Function | Domain |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | [0.1, 10] | |
| 6 | [0.1, 10] | |
| 7 | ||
| 8 | ||
| 9 | ||
| 10 | ||
| 11 | ||
| 12 | ||
| 13 | [0, 5] | |
| 14 | ||
| 15 | ||
| 16 | ||
| 17 | ||
| 18 | ||
| 19 | ||
| 20 | [0.1, 10] |
6.2.2.1. Nonconvex, Nonconcave Knapsack Problems.
A random instance of the knapsack problem is then generated as follows. First, n functions with bounds and are arbitrarily drawn from Table 2. Second, points are generated and ordered. The first and last breakpoints are set to and , respectively. Each is then approximated by a PLF with K segments given by the breakpoints . The demand parameter d is then as well randomly determined by , in which and . We perform our computational test on knapsack problems of dimension . For each K, 50 random knapsack instances are generated and solved. The statistics of the solve times are given in Table 3.
|
Table 3. Solve Times (Seconds) for Nonconcave Knapsack Problems
| Method | Med. | Avg. | Std. | Win | Fail |
|---|---|---|---|---|---|
| Panel A: 10 segments | |||||
| GRB | 0.03 | 0.04 | 0.02 | 36 | 0 |
| Log | 0.04 | 0.12 | 0.50 | 7 | 0 |
| ZZI | 0.05 | 0.05 | 0.02 | 6 | 0 |
| DLog | 0.05 | 0.06 | 0.04 | 1 | 0 |
| ZZB | 0.06 | 0.07 | 0.03 | 0 | 0 |
| sBB | 0.15 | 0.24 | 0.27 | 0 | 0 |
| Panel B: 100 segments | |||||
| Log | 0.50 | 0.53 | 0.23 | 44 | 0 |
| ZZI | 0.72 | 0.77 | 0.40 | 5 | 0 |
| DLog | 0.82 | 1.08 | 1.15 | 0 | 0 |
| ZZB | 0.82 | 0.87 | 0.47 | 1 | 0 |
| sBB | 1.05 | 1.75 | 2.33 | 0 | 0 |
| GRB | 1.05 | 1.19 | 0.66 | 0 | 0 |
| Panel C: 500 segments | |||||
| Log | 2.5 | 3.0 | 1.7 | 41 | 0 |
| sBB | 4.0 | 9.8 | 23.1 | 4 | 0 |
| ZZI | 4.2 | 5.3 | 4.5 | 3 | 0 |
| ZZB | 5.0 | 6.3 | 7.4 | 1 | 0 |
| DLog | 5.9 | 9.2 | 11.0 | 1 | 0 |
| GRB | 24.8 | 486.9 | 786.5 | 0 | 13 |
| Panel D: 1,000 segments | |||||
| sBB | 7.0 | 18.3 | 33.8 | 13 | 0 |
| Log | 7.6 | 8.5 | 7.2 | 34 | 0 |
| DLog | 15.9 | 22.9 | 23.6 | 2 | 0 |
| ZZI | 18.1 | 18.1 | 12.1 | 1 | 0 |
| ZZB | 19.7 | 20.1 | 14.2 | 0 | 0 |
| GRB | 1,800 | 962.6 | 880.6 | 0 | 26 |
| Panel E: 5,000 segments | |||||
| sBB | 58.8 | 100.0 | 98.5 | 25 | 0 |
| Log | 71.8 | 103.1 | 86.5 | 24 | 0 |
| DLog | 149.4 | 331.3 | 380.9 | 0 | 1 |
| ZZI | 188.9 | 213.3 | 131.9 | 1 | 0 |
| ZZB | 197.8 | 240.7 | 202.2 | 0 | 0 |
| GRB | 1,800 | 1,800 | 0 | 0 | 50 |
| Panel F: 10,000 segments | |||||
| sBB | 111 | 229 | 359 | 31 | 2 |
| Log | 208 | 470 | 550 | 17 | 5 |
| DLog | 327 | 549 | 543 | 2 | 5 |
| ZZB | 462 | 649 | 521 | 0 | 6 |
| ZZI | 487 | 611 | 484 | 0 | 4 |
| GRB | 1,800 | 1,800 | 0 | 0 | 50 |
Notes. sBB is the proposed method in this paper. Avg., arithmetic mean; Fail, number of instances that cannot be solved by a method within the time limit; Med., median; Std., standard deviation; Win, number of instances in which each method was the fastest. The methods are sorted according to the bold numbers.
In addition, we are interested in the impact of more segments on the approximation quality. Thereby, a knapsack problem is generated like described above, and each function is approximated by a PLF , which has equidistantly distributed breakpoints. Then, the piecewise linear optimization problem is solved with solution . The real objective value of the nonlinear problem given this point is . Table 4 shows the relative improvement in the real objective value if the approximation is refined (i.e., the value , where means the next K value in Table 4 (e.g., and )).
|
Table 4. Relative Improvement in Real Objective Value over Previous Numbers of Segments K
| K | Min. | Med. | Avg. | Max. | Std. |
|---|---|---|---|---|---|
| 20 | −486.67% | 25.87% | 39.00% | 347.59% | 100.62% |
| 50 | −3.37% | 5.32% | 7.78% | 37.73% | 7.81% |
| 100 | −0.87% | 1.33% | 1.84% | 9.77% | 1.82% |
| 500 | 0.072‰ | 5.974‰ | 7.646‰ | 21.176‰ | 5.246‰ |
| 1,000 | −0.197‰ | 0.205‰ | 0.302‰ | 2.060‰ | 0.415‰ |
| 5,000 | 0.011‰ | 0.107‰ | 0.168‰ | 0.839‰ | 0.173‰ |
| 10,000 | −0.001‰ | 0.003‰ | 0.004‰ | 0.027‰ | 0.005‰ |
Notes. For , the improvement in real objective value is measured relative to the value of . Min., the minimum; Med., median; Avg., arithmetic mean; Max., the maximum; Std., standard deviation. The methods are sorted according to the bold numbers.
6.2.2.2. Concave Knapsack Problems.
To evaluate the impact of nonconcavity on the solution methods, we also solve instances of knapsack problems where the PLFs are concave. Results are presented in Table 5. The knapsack problems are generated as before. To obtain a concave PLF, the slopes of the segments are computed and sorted in decreasing order. Subsequently, the y value of each breakpoint is recomputed by using the new slopes and x coordinate of the breakpoints. Table 5 shows that problems with concave PLFs are in general harder to solve for every method than problems with nonconcave PLFs. Indeed, nonconcave PLFs have at least one more convex segment than concave PLFs, which allows for tighter lower bounds.
|
Table 5. Solve Times (Seconds) for Concave Knapsack Problems
| Method | Med. | Avg. | Std. | Win | Fail |
|---|---|---|---|---|---|
| Panel A: 10 segments | |||||
| Log | 0.04 | 0.05 | 0.02 | 26 | 0 |
| GRB | 0.04 | 0.06 | 0.03 | 15 | 0 |
| DLog | 0.05 | 0.06 | 0.02 | 1 | 0 |
| ZZI | 0.05 | 0.06 | 0.02 | 8 | 0 |
| ZZB | 0.05 | 0.06 | 0.03 | 0 | 0 |
| sBB | 0.12 | 0.19 | 0.19 | 0 | 0 |
| Panel B: 100 segments | |||||
| Log | 0.70 | 0.73 | 0.33 | 27 | 0 |
| ZZI | 1.00 | 1.06 | 0.71 | 3 | 0 |
| DLog | 1.07 | 1.05 | 0.48 | 1 | 0 |
| sBB | 1.12 | 2.42 | 4.56 | 19 | 0 |
| ZZB | 1.12 | 1.11 | 0.58 | 0 | 0 |
| GRB | 3.19 | 3.35 | 1.70 | 0 | 0 |
| Panel C: 500 segments | |||||
| sBB | 2.3 | 33.4 | 83.3 | 32 | 0 |
| Log | 5.0 | 8.4 | 10.6 | 16 | 0 |
| ZZI | 8.6 | 19.9 | 33.3 | 0 | 0 |
| ZZB | 8.8 | 20.1 | 30.5 | 0 | 0 |
| DLog | 10.6 | 25.0 | 57.6 | 2 | 0 |
| GRB | 164.4 | 621.8 | 743.0 | 0 | 13 |
| Panel D: 1,000 segments | |||||
| sBB | 2.6 | 95.2 | 309.9 | 37 | 1 |
| Log | 10.8 | 28.3 | 41.4 | 12 | 0 |
| DLog | 21.7 | 74.0 | 253.2 | 1 | 1 |
| ZZI | 31.8 | 102.9 | 275.5 | 0 | 1 |
| ZZB | 36.0 | 109.3 | 279.4 | 0 | 1 |
| GRB | 1,800 | 1,220 | 731.9 | 0 | 29 |
| Panel E: 5,000 segments | |||||
| sBB | 22.4 | 390.3 | 658.5 | 40 | 8 |
| Log | 97.2 | 584.1 | 735.2 | 2 | 10 |
| DLog | 147.1 | 719.7 | 782.6 | 0 | 16 |
| ZZB | 580.5 | 948.6 | 741.0 | 0 | 19 |
| ZZI | 714.2 | 948.6 | 681.2 | 0 | 17 |
| GRB | 1,800 | 1,800 | 0.0 | 0 | 50 |
| Panel F: 10,000 segments | |||||
| sBB | 9 | 300 | 604 | 45 | 5 |
| Log | 215 | 666 | 697 | 0 | 12 |
| DLog | 401 | 786 | 700 | 0 | 14 |
| ZZB | 1,518 | 1,269 | 574 | 0 | 24 |
| ZZI | 1,571 | 1,288 | 593 | 0 | 24 |
| GRB | 1,800 | 1,800 | 0 | 0 | 50 |
Notes. sBB is the proposed method in this paper. Avg., arithmetic mean; Fail, number of instances that cannot be solved by a method within the time limit; Med., median; Std., standard deviation; Win, number of instances in which each method was the fastest. The methods are sorted according to the bold numbers.
6.2.3. Details on Computational Experiments.
This section dives deeper into our numerical results. Means and medians are point estimators that do not necessarily provide a complete picture of the algorithms’ performance on the randomly generated data set, and means can be distorted by heavy outliers. Therefore, in addition to the statistics provided in the preceding tables, we further investigate the behavior of the different models and algorithms by plotting the performance profiles of their solution times. We also investigate the amount of time that the sBB spends on its different operations.
6.2.3.1. Performance Profiles.
Each model/algorithm gets one profile curve, which is interpreted as its approximate cumulative distribution function. This implies that the curves in panel (a) of Figure 2 and panel (a) of Figure 3 have stochastic dominance over other curves and hence, correspond to the best method. The horizontal axes in Figures 2 and 3 are relative running times obtained by dividing by the shortest running time. The vertical intercepts in Figures 2 and 3 give the number of instances for which each method solved the fastest (the win column in the associated tables).
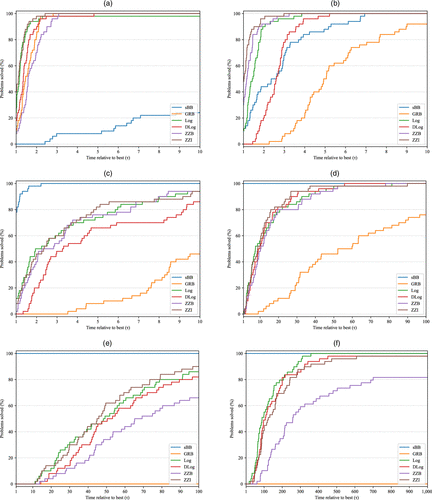
Notes. (a) Ten segments. (b) One hundred segments. (c) Five hundred segments. (d) One thousand segments. (e) Five thousand segments. (f) Ten thousand segments.
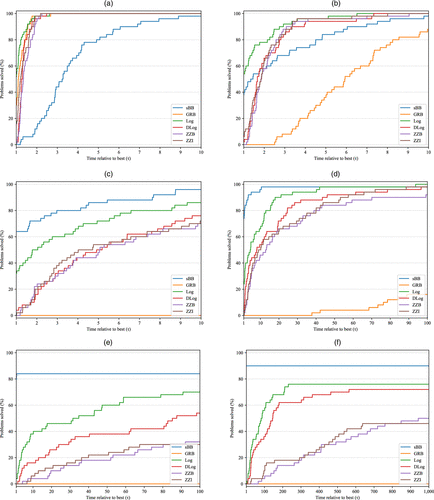
Notes. (a) Ten segments. (b) One hundred segments. (c) Five hundred segments. (d) One thousand segments. (e) Five thousand segments. (f) Ten thousand segments.
Figures 2 and 3 give these profiles, respectively, for the network flow problems and knapsack problems with concave PLFs. In the former, the sBB profiles are consistent with Table 1 and give superior performance for 500 segments and beyond. The profiles for the concave knapsacks reveal that for up to 1,000 segments, the actual performance of sBB is much better than the high values for average times in Table 5. At 100 segments, sBB is quickest on the same number of instances as Log and dominates DLog and the two zigzag models, whereas beyond 500 segments, the dominance of sBB keeps growing steadily. Similar behavior is observed for the nonconcave PLFs, and so, their profiles are omitted. This underscores the point that the average numbers in Table 5 are a bit distorted and do not provide complete information on performance of the algorithms.
6.2.3.2. Timing Statistics for the sBB.
Here, we take a look at some details of the operation of the sBB implementation. Table 6 indicates that solving LPs takes only a small share of the sBBs solution time, although it is by far the most complicated operation in a branch-and-bound algorithm. Instead, operations like building the model and repeatedly adding constraints over the Python-Gurobi interface, evaluating PLFs, and generating the envelope take a high share. This is another indicator that an integration into a fully developed solver, such as Gurobi or BARON, would result in considerable speedups.
|
Table 6. Average Proportion of Run Time That Is Allotted to the Various Suboperations of the sBB Algorithm When Solving Knapsack Problems
| Operation | Nonconcave, % | Concave, % | ||
|---|---|---|---|---|
| Gurobi interface | 68 | 76 | 33 | 10 |
| Solving LPs | 2 | 15 | 2 | 1 |
| Envelope generation | 0 | 1 | 0 | 35 |
| PLF evaluations | 28 | 1 | 62 | 49 |
| Other operations | 2 | 8 | 3 | 4 |
In addition, Table 6 indicates that the generation of the convex envelope takes more time if the PLF is concave. The reason for that is the while loop of Algorithm 4.1, which is always entered because every point results in a concave turn. However, if it is a priori known that the PLF is concave, then one could modify the algorithm to make it simply output the first and last breakpoints of the PLF without entering any loop.
6.3. Discontinuous l.s.c. PLF
In many real-world applications in logistics, supply chains, and telecommunications, the network flow problem involves fixed charges (Rebennack et al. 2009). Those are fixed costs that are incurred as soon as a flow is strictly positive (). They can represent real-world setup costs, like opening shipping lanes or starting equipment. However, they turn the continuous concave piecewise linear cost function of Section 6.2.1 into a discontinuous but lower semicontinuous PLF.
To test the sBB algorithm under this discontinuous setting, we generate the network flow problem as described in Section 6.2.1 but add to every cost function a fixed-charge jump at given by a random uniformly distributed number between 10 and 50. We compare the sBB with the largest-error branching rule against the built-in PLF solver of Gurobi, which can also handle discontinuous l.s.c. PLFs. The logarithmic formulations either do not support discontinuous PLFs or are not implemented in the package PiecewiseLinearOpt (Huchette and Vielma 2023). The results are displayed for 50 random instances in Table 7.
|
Table 7. Solve Times (Seconds) for Network Flow Problems with Fixed Charges (Discontinuous PLFs)
| Method | Med. | Avg. | Std. | Win | Fail |
|---|---|---|---|---|---|
| Panel A: 10 segments | |||||
| GRB | 0.76 | 0.78 | 0.41 | 50 | 0 |
| sBB | 18.52 | 59.92 | 98.25 | 0 | 0 |
| Panel B: 100 segments | |||||
| GRB | 16.63 | 17.18 | 8.86 | 34 | 0 |
| sBB | 24.29 | 71.05 | 111 | 16 | 0 |
| Panel C: 500 segments | |||||
| sBB | 17.2 | 84.5 | 159.5 | 46 | 0 |
| GRB | 90.0 | 147.6 | 183.4 | 4 | 0 |
| Panel D: 1,000 segments | |||||
| sBB | 22.0 | 61.6 | 96.3 | 50 | 0 |
| GRB | 291.2 | 599.9 | 629 | 0 | 5 |
| Panel E: 5,000 segments | |||||
| sBB | 25.8 | 110.8 | 232.8 | 50 | 0 |
| GRB | 1,800 | 1,800 | 0 | 0 | 50 |
| Panel F: 10,000 segments | |||||
| sBB | 33 | 92 | 134 | 50 | 0 |
| GRB | 1,800 | 1,800 | 0 | 0 | 50 |
Notes. sBB is the proposed method in this paper. Avg., arithmetic mean; Fail, number of instances that cannot be solved by a method within the time limit; Med., median; Std., standard deviation; Win, number of instances in which each method was the fastest. The methods are sorted according to the bold numbers.
Note that the sBB with the largest-error branching rule has no asymptotic convergence guarantee in general. Falk and Soland (1969) present an example that showcases a corner case where the sBB never converges. However, in our experiments, the sBB with the largest-error branching rule always converged. In Section 5.3, we pointed out that the breakpoint branching rule could achieve finite convergence even for discontinuous PLFs. However, we did not fully implement the breakpoint branching rule as early experiments indicated poor performance. This poor performance is caused by the failure to provide good improvements in the lower bounds after branching. The breakpoint branching rule does not necessarily branch in the surrounding of the solution of the parent node—in contrast to the largest-error rule—and thus, cannot guarantee a tighter convex envelope around the parent’s solution after branching. Consequently, the parent’s optimal point might also be the optimal point of the child node, and no improvement in the lower bound is gained. This branching behavior is similar to that of integer PLF branching rules and leads to imbalanced search trees (Yıldız and Vielma 2013). This sharply contrasts the largest-error branching rule, which branches directly at the parent’s solution, thus guaranteeing an increase in lower bounds and a balanced search tree. The following example illustrates this.
Consider the problem
It is easy to verify that the optimal solution of the above problem is (0,2) with an optimal value of one. Given the convex envelopes of both PLFs, the root-node solution would be (0,1). The breakpoint branching rule would then branch at the breakpoint (1,10) of . The convex envelopes of and would thus not be tightened around (0,1). Point (0,1) would still be a solution for the left child node, leading to no improvement of the lower bound and an imbalanced search tree. This contrasts the largest-error branching rule, which would branch at (0,1), tightening the convex envelope of at (0,1) and ensuring that the solution is found in the next iteration.
By adding breakpoints to function , it would not be difficult to extend the above example so that the break-point branching rule would continue to branch on the unimportant variable for any number in . The break-point branching rule would not be able to detect that finding the optimal solution would require a single branching on variable .
We believe that when designing convergent and computationally efficient branching rules for discontinuous PLFs, the idea of branching around the previous solution should be the guiding star as only that guarantees balanced search trees, which are essential for efficient B&B algorithms. However, the design of tailored branching rules for discontinuous PLFs, which have both theoretical convergence guarantees and are computationally efficient, is out of the scope of this work and is left for future research.
6.4. Comparison with Global MINLP Solvers
As mentioned before, to motivate this work, PLFs can be used to approximate nonlinear functions within mixed-integer nonlinear program (MINLP) problems to yield MILP problems (Füllner and Rebennack 2022). Therefore, we want to compare our proposed sBB with a global solver on some nonconvex nonlinear optimization problems. However, the results of this comparison need to be interpreted carefully as global solvers guarantee global optimality of the computed solutions—if they converge and the assumptions of the underlying algorithms are met—whereas our tested sBB method uses a static a priori approximation of the problem with 10,000 segments. Nevertheless, such a comparison can give insights into the scalability of our sBB versus the global solver tested.
The most well-known global solvers are ANTIGONE, BARON, SCIP, and LindoGLOBAL. These are all based on an sBB algorithm that computes the lower bound by disaggregating functions into elementary functions, such as , a polynomial, or a bilinear function . To compute lower bounds, those elementary functions are replaced by a known convex underestimator. For more details on global solvers, we refer to Burer and Letchford (2012). Since its recent release of version 11, Gurobi also provides a global solver. This global solver is also based on an sBB using disaggregation into elementary functions. See the documentation on the website of Gurobi (Gurobi Optimization 2024) for more details.
Global solvers disaggregate more complex functions, such as those in Table 2, into a cascade of supported univariate functions (Burer and Letchford 2012). Solvers such as ANTIGONE, BARON, SCIP, and LindoGLOBAL do this behind the scenes. However, in the current version of Gurobi, the user needs to disaggregate this manually (Gurobi Optimization 2024). Either way, the disaggregation may result in weaker lower bounds compared with a direct treatment, like our sBB is capable of. The following example illustrates the disaggregation and the resulting lower bounds:
Consider the function over the interval [1, e]. By definition, this function equals and is convex. However, by the process of disaggregation, a variable y is introduced, and f is rewritten as
The concave function is then underestimated over the interval by its convex envelope given by the linear function
Finally, the convex underestimator of over the interval [1, e] is given by
The largest distance to the function —the convex envelope of —to this underestimator is approximately at and amounts to ≈0.35. Consequently, in the worst case, the convex underestimator resulting from disaggregation is around 17% smaller than the convex envelope. □
In the following, we compare Gurobi’s global solver (G-sBB) regarding computation time and root-node lower bounds with a static piecewise linear approximation using 10,000 equidistant segments. We solve this piecewise linear approximation with our sBB algorithm. We do not test the other PLF formulations as extensive comparisons for 10,000 segments were already provided in Tables 1, 3, and 5. As the other mentioned global solvers are also based on sBB and disaggregation, we treat Gurobi as a representative for this algorithm class and do not test the other solvers.
Therefore, consider the knapsack problem from Section 6.2.2 with the approximated functions from Table 2 again. Next to the PLF approximation of these nonlinear functions, we hand them over to a global MINLP solver that treats them directly within the algorithm. For those experiments, we construct knapsack problems as described in Section 6.2.2 but only consider functions 2, 9, 11, 12, 13, 14, 15, and 20 of Table 2 as we encountered numerical issues in Gurobi with the other functions. We believe that this is because of the relative novelty of Gurobi’s solver and the difficult concatenation of elementary functions (exp, log, etc.) within the functions in Table 2. This causes problems with disaggregation.
Table 8 provides results for different numbers of variables, each for 50 random instances. Table 9 presents descriptive statistics of the lower bound obtained at the root node of our sBB and the lower bound at the root node of Gurobi’s sBB method and presents the difference between them. Table 9 explains why Gurobi’s sBB solver is not competitive for this knapsack problem. It can be seen that the root-node bound of Gurobi is always considerably lower than that of the sBB. Whereas our sBB computes the convex envelope of the PLF (and thus, approximately a convex envelope of the original non-PLF function), this cannot be said about Gurobi’s sBB solver, which employs disaggregation. Consequently, the underestimator is less tight and results in weaker lower bounds. This, in turn, leads to longer run times as it takes longer to close the gap between upper and lower bounds.
|
Table 8. Solve Times (Seconds) for Knapsack Problems with Gurobi’s MINLP Global Solver
| Method | Med. | Avg. | Std. | Win | Fail |
|---|---|---|---|---|---|
| Panel A: 10 variables | |||||
| G-sBB | 5.15 | 147.77 | 397.56 | 28 | 2 |
| sBB | 9.20 | 9.47 | 2.05 | 22 | 0 |
| Panel B: 11 variables | |||||
| sBB | 10.54 | 10.60 | 2.32 | 27 | 0 |
| G-sBB | 17.16 | 312.19 | 584.67 | 23 | 5 |
| Panel C: 12 variables | |||||
| sBB | 12.44 | 13.05 | 3.50 | 34 | 0 |
| G-sBB | 55.65 | 450.99 | 698.20 | 16 | 8 |
| Panel D: 13 variables | |||||
| sBB | 14.07 | 13.99 | 2.50 | 37 | 0 |
| G-sBB | 243.29 | 781.63 | 834.28 | 13 | 18 |
| Panel E: 14 variables | |||||
| sBB | 14.64 | 15.32 | 3.74 | 46 | 0 |
| G-sBB | 579.94 | 914.11 | 804.96 | 4 | 20 |
| Panel F: 15 variables | |||||
| sBB | 16.33 | 16.76 | 3.73 | 45 | 0 |
| G-sBB | 1,800 | 1,236 | 794.76 | 5 | 32 |
| Panel G: 20 variables | |||||
| sBB | 22.53 | 23.65 | 7.82 | 49 | 0 |
| G-sBB | 1,800 | 1,665 | 441.88 | 1 | 45 |
| Panel H: 30 variables | |||||
| sBB | 36.15 | 40.40 | 16.15 | 50 | 0 |
| G-sBB | 1,800 | 1,800 | 0.59 | 0 | 50 |
Notes. sBB is the proposed method in this paper. Avg., arithmetic mean; Fail, number of instances that cannot be solved by a method within the time limit; Med., median; Std., standard deviation; Win, number of instances in which each method was the fastest. The methods are sorted according to the bold numbers.
|
Table 9. Distribution of Root-Node Lower Bounds of Our sBB and Gurobi’s sBB and the Differences Between Them
| Method | Min. | Med. | Avg. | Max. | Std. |
|---|---|---|---|---|---|
| Panel A: 10 variables | |||||
| sBB | −149 | −92 | −94 | −31 | 32 |
| G-sBB | −13,083 | −3,586 | −3,813 | −147 | 3,239 |
| Diff | 39 | 3,496 | 3,718 | 13,039 | 3,255 |
| Panel B: 11 variables | |||||
| sBB | −155 | −87 | −83 | 5 | 37 |
| G-sBB | −9,803 | −3,624 | −4,267 | −84 | 2,672 |
| Diff | 68 | 3,557 | 4,184 | 9,744 | 2,679 |
| Panel C: 12 variables | |||||
| sBB | −160 | −90 | −91 | 5 | 40 |
| G-sBB | −16,081 | −6,535 | −5,871 | −205 | 3,563 |
| Diff | 61 | 6,398 | 5,780 | 16,039 | 3,573 |
| Panel D: 13 variables | |||||
| sBB | −166 | −84 | −87 | 8 | 42 |
| G-sBB | −13,137 | −5,275 | −5,409 | −198 | 3,374 |
| Diff | 119 | 5,182 | 5,322 | 13,060 | 3,388 |
| Panel E: 14 variables | |||||
| sBB | −175 | −117 | −104 | −15 | 40 |
| G-sBB | −13,184 | −4,156 | −6,260 | −557 | 3,337 |
| Diff | 422 | 4,044 | 6,157 | 13,073 | 3,351 |
| Panel F: 15 variables | |||||
| sBB | −236 | −104 | −114 | −36 | 47 |
| G-sBB | −13,455 | −6,962 | −7,252 | −331 | 3,571 |
| Diff | 250 | 6,859 | 7,139 | 13,370 | 3,584 |
| Panel G: 20 variables | |||||
| sBB | −257 | −167 | −165 | 44 | 55.37 |
| G-sBB | −16,562 | −7,450 | −8,190 | −532 | 3,981 |
| Diff | 347 | 7,331 | 8,025 | 16,516 | 3,998 |
| Panel H: 30 variables | |||||
| sBB | −379 | −263 | −252 | −51 | 89 |
| G-sBB | −28,956 | −13,225 | −13,215 | −4,169 | 5,360 |
| Diff | 384 | 12,981 | 12,963 | 28,792 | 5,390 |
Notes. sBB is the proposed method in this paper. Avg., arithmetic mean; Diff, difference; Med., median; Std., standard deviation. The methods are sorted according to the bold numbers.
To obtain tight lower bounds of concatenated univariate functions, like in Table 2, global MINLP solvers could either (i) approximate them by a PLF, thus obtaining an approximation of the convex envelope, or (ii) use a method like that introduced in Gounaris and Floudas (2008) to directly compute the (possibly piecewise nonlinear) convex envelope of f.
6.5. Discussion
Because of the difference in implementation quality—a rudimentary sBB implementation in Python compared with a commercial branch-and-cut solver in a low-level language (such as C)—it is difficult to draw firm conclusions from these computational results. Nevertheless, we sketch a summary of our observations.
Tables 1 and 3 indicate a superior scalability of the sBB; each added segment leads to a relative improvement in the computation time of the sBB compared with logarithmic approaches. This is further illustrated in performance profiles given in Figures 2 and 3. This superior scalability can be attributed to the sBB’s slim and sparse LP relaxations, which may not always grow linearly with the number of segments (see Section 3.2). The value of a method with good scalability is illustrated in Table 4; significant improvements in solution quality are possible by refining the PLF, even if it already contains many segments. This is usually even more true for obtaining an appropriate optimality certificate.
As discussed in Section 3.2, the incremental and SOS2 models, which guarantee sharpness in the entire search tree, usually outperform logarithmic models for problems with few segments. Because the sBB also guarantees these sharpness properties, one might expect similar results for problems with smaller segments. One could even assume that this effect is enhanced because spatial branching can additionally lead to more balanced search trees by branching at the previous solution instead of at the breakpoints (see Section 5.2). However, the computational results do not support this claim. We believe that the poor performance of the sBB compared with logarithmic approaches on problems with few segments is because of the superior implementation of Gurobi’s branch-and-cut solver. When the sBB is integrated into a full-featured solver, such as Gurobi or BARON, the advantage of a balanced search tree may lead the sBB to outperform logarithmic models even on problems with few segments as the SOS2 model and the incremental model do. In fact, a closer look at the performance of the sBB implementation (cf. Table 6) reveals that up to 50% of the solution time is spent on the Python-Gurobi interface. This is significant time that could be saved by integrating our sBB algorithm into a full-featured solver.
The computational results for discontinuous l.s.c PLFs show that the discontinuity results in more difficult to solve instances (cf. Table 7 versus Tables 3 and 5). None of the 50 instances for 5,000 segments could be solved by Gurobi within the 1,800 seconds; it is the same for the 50 instances of 10,000 segments. The relative performance of our sBB to Gurobi’s PLF solver is similar to the continuous PFL instances in that our sBB is superior for 500 and more segments (cf. Tables 1, 3, and 5).
The comparisons with Gurobi as a global solver confirmed the good scalability of our sBB method (Table 8). Although the running time of our sBB method scales approximately linearly with the number of variables, the global solver scales approximately exponentially. Already with 11 variables, our sBB is clearly superior. Remarkable is the extremely low standard deviation of the running times of our sBB, which shows that the computational performance is very consistent among the 50 instances tested. The superior performance of our sBB can be explained by the better lower bounding (cf. Table 9).
7. Approximating Separable Functions
We mentioned earlier in Section 1.3 the need for computationally efficient scalable algorithms and the various error bounds that have been calculated in the literature to determine the number of breakpoints needed from a good PLF approximation. We present an error bound for the number of breakpoints required in a PLF approximation to achieve a desired error to the problem of optimizing a separable function. Our bound is different than existing results because we do not assume differentiability of the function that is being approximated. Instead, we work with Hölder continuous functions, which are defined as follows.
A function over a closed set is said to be (α, β)-Hölder continuous for some constants if
The function is Lipschitz continuous when , whereas for , the function must be constant over its domain. We assume .
For some closed convex set and hyperrectangle H, consider the nonconvex separable minimization problem
Let denote its optimal solution, which exists because is continuous and is compact. Suppose that for each , we construct a continuous PLF approximation with breakpoints that are indexed by the set . This PLF is constructed in the natural way by joining consecutive breakpoints so that the kth segment is obtained by joining the points and for . Summing these over creates the PLF , whose optimization yields a finite value and solution :
There is no immediate relation between and , but we can deduce two inequalities. First, the optimal solution of the PLF problem being feasible to implies that the optimum of the original problem can be upper bounded.
.
Second, if the approximate solution belongs to subintervals of concavity,1 then we can also lower bound the global optimum.
if for each , is concave over the subinterval containing .
This is because the stated assumption implies , and we know from the optimality of that . □
In general, is neither a lower bound nor an upper bound on . Our main result here is that to control the additive gap on , there is a formula for the number of breakpoints in the PLFs that depends on the continuity parameters and the width of interval bounds.
Let be given, and denote
Solving the PLF approximate problem by creating for each i at least segments such that the breakpoints are spaced at least -apart yields an approximate value that satisfies .
We argue this by establishing the approximation error for univariate functions and then, gluing together the individual pieces.
7.1. PLF Approximations of Univariate Functions
Suppose that we are given a univariate function that is -Hölder continuous on the interval , meaning that for all . For any finite integer and , let
For every , has a Lipschitz constant equal to .
Let us begin with the following general result, which may be known, but because we could not find a reference, a self-contained proof is given in the appendix for completeness. □
(
We derive another technicality.
for all .
By construction of , we have and , and so, the definition of slope gives us . The Hölder property leads to , which after noting , reduces to
Our assertion follows after combining the above two claims.
We will need one more technical result.
Let be a compact set and R be the radius of a ball with its center in X such that the ball encloses X. Let be L-Lipschitz over X and be (α, β)-Hölder continuous over X. Then, is -Hölder continuous over X.
For any , we have
Substituting this into the above inequality gives us
Now, let us derive our error bound for a univariate function. The error of a continuous PLF with respect to f is defined as the largest additive approximation gap over the domain. Thus, we have the error function given by
To state our lower bound for the number of breakpoints required to achieve a given error, let us introduce two parameters dependent on the minimum spacing parameter :
Given any , we have if
Because is a PLF that can be described as when for any i, the error function can be written as
Consider the function that appears in the error function. This is the difference of an (α, β)-Hölder continuous function and a linear function, which is Lipschitz continuous with constant . Applying Lemma 7.2 with for the interval I, we obtain to be Hölder continuous with parameters and . Using the definition of Hölder continuity for any leads to
When uniformly spaced breakpoints are to be considered only, the above proof can be modified at the step where we upper bound the maximum separation . In particular, we have in the uniform case, and the remaining proof carries through. Hence, we can bound as follows the error , where B is the unique set of K breakpoints that are uniformly spaced (note that is not needed as an input parameter in the uniform case).
uniformly spaced segments guarantee an additive error of at most .
7.2. Proof of Proposition 7.1
We have from Observation 7.1. For every i, we can apply Proposition 7.2 to control the approximation error to by selecting the number of segments to be large enough. Our claim follows after recognizing that the errors are additive and is a separable function.
8. Conclusion and Future Work
In this paper, a new perspective on piecewise linear optimization is taken. We adopt a global and nonlinear continuous approach instead of discrete optimization. The developed spatial branch-and-bound algorithm has small, sparse, and sharp LP relaxations throughout the search tree. Computational experiments have shown that even a rudimentary sBB implementation in Python can outperform state-of-the-art logarithmic models solved by Gurobi if the number of segments is sufficiently high. Nonetheless, we advocate a problem-specific approach when selecting a solution method for separable piecewise linear optimization problems. If the PLFs involved have many segments, the sBB could be the method of choice because of its slim and sparse LP relaxations. However, for PLFs with few segments, MILP models, such as the classical incremental model, might be faster because of their large formulation and thus, the better possibilities for cutting planes.
Discrete approaches in piecewise linear optimization have witnessed over 60 years of fruitful research, which led to the current state of the art. In contrast, this paper is an initial attempt toward an efficient method that is based on continuous optimization techniques and is globally convergent. We recognize that our implementation is rudimentary at this stage and can benefit from several enhancements and sophistications that would accelerate its performance. Therefore, there are still some open questions. Further research can focus on extensions to nonseparable cases, cutting planes, specialized branching rules, integration in a full branch-and-cut solver, or further development of sBB algorithms for discontinuous functions. We leave these for future research but outline some of these ideas in the next paragraphs.
The ideas of pseudocost, strong, and reliability branching from MILP (Achterberg et al. 2005) could be adopted here. Moreover, there have been many works (Benson 1990, Kesavan et al. 2004, D’Ambrosio et al. 2020) on strengthening the relaxations for separable nonconvex terms in a branch-and-cut algorithm, and it is conceivable that some of these ideas can be applied to separable PLFs to accelerate our sBB. This would be a counterpart to the valid inequalities and cutting planes that have been developed for MILP and SOS2 models.
Future work could also extend our work to non-l.s.c. PLFs. Although our sBB can generate polyhedral relaxations of any separable PLF, we currently do not have a branching rule that gives asymptotic convergence when the PLF is non-l.s.c. This does not seem to be an easy task because convergence issues for relaxations of discontinuous functions are well known and also, easy to see with simple examples (cf. Figure 1). Nonetheless, it may be worth tackling this problem at least for separable PLFs because the SOS2 branching rule has been generalized (de Farias et al. 2008), although only as a proof of concept and not something that has been implemented in MILP solvers. Moreover, one could explore machine learning techniques for branching decisions as was done recently for nonconvex polynomial optimization problems (Ghaddar et al. 2023).
Lastly, our approach could be extended to handle nonseparable PLFs. Although the Graham’s scan algorithm is limited to two dimensions and thus, only applicable to univariate or separable PLFs, other algorithms, such as Quickhull (Barber et al. 1996), can compute the convex hull in multiple dimensions. This makes them suitable for identifying the convex envelope of nonseparable PLFs.
Appendix. Proof of Claim 7.1
(
Let h be a continuous PLF on formed by breakpoints , where , , and . Denote the slope of the ith segment by . Take any distinct with and for some . The case is trivial because of linearity in each piece, so assume . We have
Switching the roles of x and and following similar steps give us
Recall that any four reals with and also satisfy . Using this fact with the above two inequalities gives us
Because x and are arbitrary in I, the correctness of the Lipschitz constant follows from above. This is also the best-possible constant because we can take x and to be between the breakpoints where the slope has the highest absolute value. □
1 Every continuous univariate function on an interval can be partitioned into subintervals such that over each subinterval, it is either convex or concave.
References
- (2005) Branching rules revisited. Oper. Res. Lett. 33(1):42–54.Crossref, Google Scholar
- (2019) Error bounds for monomial convexification in polynomial optimization. Math. Programming 175(1–2):355–393.Crossref, Google Scholar
- (1998) A global optimization method, αBB, for general twice-differentiable constrained NLPs—I. Theoretical advances. Comput. Chemical Engrg. 22(9):1137–1158.Crossref, Google Scholar
- (2000) On finitely terminating branch-and-bound algorithms for some global optimization problems. SIAM J. Optim. 10(4):1049–1057.Crossref, Google Scholar
- (1996) The quickhull algorithm for convex hulls. ACM Trans. Math. Software 22(4):469–483.Crossref, Google Scholar
- (2023) On piecewise linear approximations of bilinear terms: Structural comparison of univariate and bivariate mixed-integer programming formulations. J. Global Optim. 85(4):789–819.Crossref, Google Scholar
- (2022) Compact mixed-integer programming formulations in quadratic optimization. J. Global Optim. 84(4):869–912.Crossref, Google Scholar
- (1976) Global optimization using special ordered sets. Math. Programming 10(1):52–69.Crossref, Google Scholar
- (1990) Separable concave minimization via partial outer approximation and branch and bound. Oper. Res. Lett. 9(6):389–394.Crossref, Google Scholar
- (2012) Non-convex mixed-integer nonlinear programming: A survey. Surveys Oper. Res. Management Sci. 17(2):97–106.Crossref, Google Scholar
- (2020) Solving mixed-integer nonlinear programmes using adaptively refined mixed-integer linear programmes. Optim. Methods Software 35(1):37–64.Crossref, Google Scholar
- (2003) New interval analysis support functions using gradient information in a global minimization algorithm. J. Global Optim. 25(4):345–362. Crossref, Google Scholar
- (2009) Introduction to Algorithms (MIT Press, Cambridge, MA).Google Scholar
- (2003) A comparison of mixed-integer programming models for nonconvex piecewise linear cost minimization problems. Management Sci. 49(9):1268–1273.Link, Google Scholar
- (2007) Variable disaggregation in network flow problems with piecewise linear costs. Oper. Res. 55(1):146–157.Link, Google Scholar
- (2020)
Handling separable non-convexities using disjunctive cuts . Baiou, M Gendron B, Gunluk O, Mahjoub A, eds. Combinatorial Optimization: ISCO 2020, Lecture Notes in Computer Science, vol. 12176 (Springer, Cham, Switzerland), 102–114.Crossref, Google Scholar - (1960) On the significance of solving linear programming problems with some integer variables. Econometrica 28(1):30–44.Crossref, Google Scholar
- (2008) A special ordered set approach for optimizing a discontinuous separable piecewise linear function. Oper. Res. Lett. 36(2):234–238.Crossref, Google Scholar
- (2013) Branch-and-cut for separable piecewise linear optimization and intersection with semi-continuous constraints. Math. Programming Comput. 5(1):75–112.Crossref, Google Scholar
- (2015) Analysis of MILP techniques for the pooling problem. Oper. Res. 63(2):412–427.Link, Google Scholar
- (2022)
Piecewise linearization of bivariate nonlinear functions: Minimizing the number of pieces under a bounded approximation error . Ljubíc I, Barahona F, Dey SS, Mahjoub AR, eds. Combinatorial Optimization: ISCO 2022, Lecture Notes in Computer Science, vol. 13526 (Springer, Cham, Switzerland), 117–129.Crossref, Google Scholar - (1969) An algorithm for separable nonconvex programming problems. Management Sci. 15(9):550–569.Link, Google Scholar
- (1988) Piecewise-linear approximation methods for nonseparable convex optimization. Management Sci. 34(3):411–419.Link, Google Scholar
- (1985) A simplex algorithm for piecewise-linear programming I: Derivation and proof. Math. Programming 33(2):204–233.Crossref, Google Scholar
- (2010) On the number of segments needed in a piecewise linear approximation. J. Comput. Appl. Math. 234(2):437–446.Crossref, Google Scholar
- (2022) Non-convex nested Benders decomposition. Math. Programming 196(1):987–1024.Crossref, Google Scholar
- (2012)
Using piecewise linear functions for solving MINLPs . Lee J, Leyffer S, eds. Mixed Integer Nonlinear Programming, IMA Volumes in Mathematics and Its Applications, vol. 154 (Springer, Cham, Switzerland), 287–314.Crossref, Google Scholar - (2023) Learning for spatial branching: An algorithm selection approach. INFORMS J. Comput. 35(5):1024–1043.Link, Google Scholar
- (2022) Interior point methods can exploit structure of convex piecewise linear functions with application in radiation therapy. SIAM J. Optim. 32(1):256–275.Crossref, Google Scholar
- (2008) Tight convex underestimators for C2-continuous functions: I. Univariate functions. J. Global Optim. 42(1):51–67.Crossref, Google Scholar
- (1972) An efficient algorithm for determining the convex hull of a finite planar set. Inform. Processing Lett. 1(4):132–133.Crossref, Google Scholar
- (2020) Mathematical programming formulations for piecewise polynomial functions. J. Global Optim. 77(3):455–486.Crossref, Google Scholar
- (2022)
An adaptive refinement algorithm for discretizations of nonconvex QCQP . Schulz C, Ucar B, eds. 20th International Symposium on Experimental Algorithms: SEA 2022, Leibniz International Proceedings in Informatics (LIPIcs), vol. 233 (Schloss Dagstuhl Publishing, Wadern, Germany), 24:1–24:14.Google Scholar Gurobi Optimization (2024) Documentation—General constraints. https://www.gurobi.com/documentation/current/refman/general_constraints.html.Google Scholar- (1986) A general class of branch-and-bound methods in global optimization with some new approaches for concave minimization. J. Optim. Theory Appl. 51(2):271–291.Crossref, Google Scholar
- (2025) Spatial branch and bound for nonconvex separable piecewise linear optimization. https://github.com/INFORMSJoC/2024.0755.Google Scholar
- (2023) Nonconvex piecewise linear functions: Advanced formulations and simple modeling tools. Oper. Res. 71(5):1835–1856.Link, Google Scholar
- (2004) Models for representing piecewise linear cost functions. Oper. Res. Lett. 32(1):44–48.Crossref, Google Scholar
- (2006) A branch-and-cut algorithm without binary variables for nonconvex piecewise linear optimization. Oper. Res. 54(5):847–858.Link, Google Scholar
- (2004) Outer approximation algorithms for separable nonconvex mixed-integer nonlinear programs. Math. Programming 100(3):517–535.Crossref, Google Scholar
- (2024) Piecewise polyhedral relaxations of multilinear optimization. SIAM J. Optim. 34(4):3167–3193.Google Scholar
- (2020) On the derivation of continuous piecewise linear approximating functions. INFORMS J. Comput. 32(3):531–546.Link, Google Scholar
- (2000) Practical piecewise-linear approximation for monotropic optimization. INFORMS J. Comput. 12(4):324–340.Link, Google Scholar
- (2008) Branch-and-refine for mixed-integer nonconvex global optimization. Working Paper No. ANL/MCS-P1547-0908, Mathematics and Computer Science Division, Argonne National Laboratory, Lemont, IL.Google Scholar
- (2013) Global Optimization: Theory, Algorithms, and Applications, MOS-SIAM Series on Optimization, vol. MO15 (SIAM, Philadelphia).Crossref, Google Scholar
- (2025) Building formulations for piecewise linear relaxations of nonlinear functions. Oper. Res., ePub ahead of print April 24, https://doi.org/10.1287/opre.2023.0187.Google Scholar
- (2004)
Separable concave optimization approximately equals piecewise linear optimization . Bienstock D, Nemhauser G, eds. Integer Programming and Combinatorial Optimization: IPCO 2004, Lecture Notes in Computer Science, vol. 3064 (Springer, Berlin), 234–243.Crossref, Google Scholar - (1957) On the solution of discrete programming problems. Econometrica 25(1):84–110.Crossref, Google Scholar
- (1976) Mixed integer minimization models for piecewise-linear functions of a single variable. Discrete Math. 16(2):163–171.Crossref, Google Scholar
- (2019) An adaptive, multivariate partitioning algorithm for global optimization of nonconvex programs. J. Global Optim. 74(4):639–675.Crossref, Google Scholar
- (2009) Piecewise polynomial interpolations and approximations of one-dimensional functions through mixed integer linear programming. Optim. Methods Software 24(4–5):783–803.Crossref, Google Scholar
- (2019) Piecewise linear bounding of univariate nonlinear functions and resulting mixed integer linear programming-based solution methods. Eur. J. Oper. Res. 275(3):1058–1071.Crossref, Google Scholar
- (2020) Piecewise linear bounding functions in univariate global optimization. Soft Comput. 24(23):17631–17647.Crossref, Google Scholar
- (2016) Computing tight bounds via piecewise linear functions through the example of circle cutting problems. Math. Methods Oper. Res. 84(1):3–57.Crossref, Google Scholar
- (2015) Continuous piecewise linear delta-approximations for univariate functions: Computing minimal breakpoint systems. J. Optim. Theory Appl. 167(2):617–643.Crossref, Google Scholar
- (2020) Piecewise linear function fitting via mixed-integer linear programming. INFORMS J. Comput. 32(2):507–530.Link, Google Scholar
- (2009) Bilinear modeling solution approach for fixed charge network flow problems. Optim. Lett. 3(3):347–355.Crossref, Google Scholar
- (1998) A finite algorithm for global minimization of separable concave programs. J. Global Optim. 12(1):1–36. Crossref, Google Scholar
- (2001) On mixed-integer zero-one representations for separable lower-semicontinuous piecewise-linear functions. Oper. Res. Lett. 28(4):155–160.Crossref, Google Scholar
- (1971) An algorithm for separable nonconvex programming problems II: Nonconvex constraints. Management Sci. 17(11):759–773.Link, Google Scholar
- (2022) Sequence of polyhedral relaxations for nonlinear univariate functions. Optim. Engrg. 23(2):877–894.Crossref, Google Scholar
- (2004) Global optimization of mixed-integer nonlinear programs: A theoretical and computational study. Math. Programming 99(3):563–591.Crossref, Google Scholar
- (1978) Error analysis for convex separable programs: The piecewise linear approximation and the bounds on the optimal objective value. SIAM J. Appl. Math. 34(4):704–714.Crossref, Google Scholar
- (2012) Fitting piecewise linear continuous functions. Eur. J. Oper. Res. 219(1):86–95.Crossref, Google Scholar
- (2016) Convex Analysis and Global Optimization, 2nd ed., Springer Optimization and Its Applications, vol. 110 (Springer, Cham, Switzerland).Crossref, Google Scholar
- (1988) Convergence and restart in branch-and-bound algorithms for global optimization. Application to concave minimization and D.C. Optimization problems. Math. Programming 41(1):161–183.Crossref, Google Scholar
- (2011) Modeling disjunctive constraints with a logarithmic number of binary variables and constraints. Math. Programming 128(1–2):49–72.Crossref, Google Scholar
- (2010) Mixed-integer models for nonseparable piecewise-linear optimization: Unifying framework and extensions. Oper. Res. 58(2):303–315.Link, Google Scholar
- (2008) Nonconvex, lower semicontinuous piecewise linear optimization. Discrete Optim. 5(2):467–488.Crossref, Google Scholar
- (2022) A comparison of two mixed-integer linear programs for piecewise linear function fitting. INFORMS J. Comput. 34(2):1042–1047.Link, Google Scholar
- (2024) Efficient continuous piecewise linear regression for linearising univariate non-linear functions. IISE Trans. 57(3):231–245.Crossref, Google Scholar
- (2014) Global optimization of bounded factorable functions with discontinuities. J. Global Optim. 58(1):1–30.Crossref, Google Scholar
- (2013) Incremental and encoding formulations for mixed integer programming. Oper. Res. Lett. 41(6):654–658.Crossref, Google Scholar
- (2013) The piecewise linear optimization polytope: New inequalities and intersection with semi-continuous constraints. Math. Programming 141(1–2):217–255.Crossref, Google Scholar

