
Learning Payoffs While Routing in Skill-Based Queues
Abstract
Motivated by applications in service systems, we consider queueing systems where each customer must be handled by a server with the right skill set. We focus on optimizing the routing of customers to servers in order to maximize the total payoff of customer-server matches. In addition, customer-server-dependent payoff parameters are assumed to be unknown a priori. We construct a machine learning algorithm that adaptively learns the payoff parameters while maximizing the total payoff and prove that it achieves polylogarithmic regret. Moreover, we show that the algorithm is asymptotically optimal up to logarithmic terms by deriving a regret lower bound. The algorithm leverages the basic feasible solutions of a static linear program as the action space. The regret analysis overcomes the complex interplay between queueing and learning by analyzing the convergence of the queue length process to its stationary behavior. We also demonstrate the performance of the algorithm numerically and have included an experiment with time-varying parameters highlighting the potential of the algorithm in nonstatic environments.
Funding: This work is part of Valuable AI, a research collaboration between the Eindhoven University of Technology and the Koninklijke KPN N.V. Parts of this research have been funded by the IMPULS program of the Eindhoven Artificial Intelligence Systems Institute, and by Holland High Tech through the Top Consortium for Knowledge and Innovation program High Tech Systems and Materials, via the public–private partnership allowance scheme.
Supplemental Material: The online appendix is available at https://doi.org/10.1287/stsy.2024.0095.
1. Introduction
Service systems such as contact centers, computer networks, and manufacturing systems are widely used in practice (Koole and Mandelbaum 2002, Harchol-Balter 2013, Chen et al. 2020). Achieving the highest possible quality of service in such systems is consequently of general importance. However, actually doing so is typically quite challenging because of complex interactions within the system between, for example, customers and servers. Moreover, service provisioning is an intrinsically uncertain process.
In this paper, we develop a machine learning algorithm that can attain the highest possible performance in one such service system. Specifically, we focus on a finite skill-based queueing system with customer-server-dependent random payoffs. One such system is illustrated in Figure 1. We consider different customers to have different needs and different servers to be better at helping certain types of customers over others. In fact, some servers might even be unable to help some types of customers. We model these aspects by assuming that there are compatibility relations between customers and servers and by assuming that whenever a customer is served by a server, a random payoff is generated that depends on the specific customer-server pairing. Because the different servers are shared between the different customer types, and because they are limited in their number, the highest possible average reward can only be achieved by optimizing how one matches customers to servers.
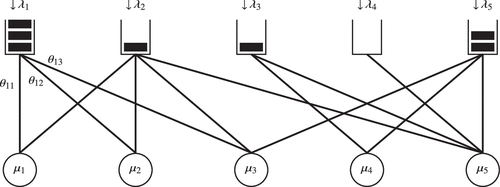
Note. Here, the denote arrival rates, the denote service rates, and the indicate the average payoff generated upon service completion of a type-i customer at server j.
Within queueing literature, a canonical tool for doing server allocation is routing policies. Routing policies decide which customer is served by which server, and at what time. However, routing policies typically do not take into account (i) compatibility relations or (ii) payoffs generated by different customer-server pairs. Furthermore, they usually do not consider (iii) uncertainty in and/or a lack of knowledge of model parameters (such as the average payoffs ).
Our machine learning algorithm, Algorithm 1 in Section 4, does take into account aspects (i)–(iii). Letting refer to the number of departures of type-i customers at server j up to time t, and to the set of compatibility lines, Algorithm 1 maximizes the long-term expected reward rate
Algorithm 1 does so while (a) honoring the queueing dynamics and compatibility relations; (b) guaranteeing the stability of all queues; (c) being able to hone in on the true system parameters when either misspecified or unknown a priori; and (d) dealing with the exploration-exploitation dilemma efficiently. These aspects (a)–(d) will be discussed in more detail in Section 1.4 below but may be summarized in one sentence as follows: we establish in Theorem 2 that Algorithm 1 achieves a polylogarithmic regret and in Theorem 1 that this is (asymptotically), up to logarithmic terms, the best possible within a certain class of stable policies.
The nature of the optimization problem that we study required us to combine techniques from different fields to develop Algorithm 1 and prove Theorems 1 and 2. Firstly, we were inspired by techniques for Multiarmed Bandit (MAB) problems from machine learning for the learning aspect. Secondly, in the regret analysis of Algorithm 1, we had to rely on queueing theory to establish the typical behavior of the queue length process under the dynamic routing policy. Finally, a key idea was to leverage combinatorial optimization to come up with “good” actions for Algorithm 1.
Let us briefly discuss these three facets in more detail:
We first discuss how queueing dynamics complicate decision making and how MAB techniques can be adapted to cope.
Contrary to the classical MAB setting (Lai and Robbins 1985), we have to deal with queueing dynamics and stability constraints that complicate the problem. Specifically, both the decision moments and the set of available routing decisions are subject to the underlying random queueing dynamics: we can only route a customer if there are a compatible customer and server available. Moreover, simply routing each customer to the server with the highest payoff might not result in a stable system in the long run.
To overcome this, we define episodes and only make a decision on the routing strategy at the start of each episode. The estimated reward of the chosen action is updated after each episode based on observed payoff samples. This way, similar to the MAB setting, the algorithm learns the average reward of each action adaptively. To face the exploration-exploitation trade-off efficiently, we use Upper Confidence Bounds (UCBs) for the payoff parameters (Auer et al. 2002).
We next describe how queueing theory is used to analyze Algorithm 1.
Each episode, Algorithm 1 chooses an action that determines a fixed routing policy for the duration of that episode. This means that the queue length process will show different behavior in each episode. Worse yet, at the moment that the routing policy changes, the queueing system will likely be far from its new equilibrium behavior. It then takes some time to adjust to the new environment. Still, in order to prove convergence results of Algorithm 1, we must show that sufficient payoff samples of all the different lines are collected. To this end, we utilize known results of the stationary behavior and analyze the typical time of convergence of the queue length process to stationarity.
Lastly, we explain how combinatorial optimization allows one to identify “good” actions.
The optimal routing problem inherently poses combinatorial challenges. In particular, the optimal routing problem can be considered as a stochastic variant of the optimal transport problem (Bertsimas and Tsitsiklis 1997) with a finite set of possible solutions. We formulate an optimal transport linear program (LP) and exploit its structural properties in the construction of our algorithm: First, we characterize the basic feasible solutions of the LP in terms of routing rates. We then consider the different sets of routing rates as candidate routing policies in an MAB setting. In the analysis, we exploit the dual of the LP to decompose the regret.
1.1. Main Contributions
Our main contributions can be summarized as follows:
1.1.1. Regret Lower Bound.
We present an asymptotic regret lower bound for a class of routing policies satisfying certain stability constraints in Theorem 1. The stability constraints ensure that the queue backlog does not grow infinitely large. In particular, we prove that any policy of this class must suffer regret to learn the payoff parameters.
In an MAB setting, a regret lower bound is often described in terms of a suboptimality gap for each suboptimal action. The gap measures the instant loss in reward by choosing this action over the optimal action (Lai and Robbins 1985, Burnetas and Katehakis 1996, Auer et al. 2002). A straightforward implementation of this approach proves to be difficult because in our model, some suboptimal routing decision might be necessary to maintain stability. Therefore, it is not trivial to identify the optimal action at each decision moment, nor to quantify the suboptimality gaps.
Our solution to this problem is as follows: we split the lines into an “optimal” and “suboptimal” set, based on the optimal solution of the optimal transport LP, and consequently quantify the suboptimality gaps using the dual. Burnetas and Kanavetas (2012) and Burnetas et al. (2017) use a similar method to obtain a regret lower bound in an MAB setting with cost constraints, although their work is limited to programs with only two equality constraints. The proof of Theorem 1 also uses a change-of-measure argument, a technique that is frequently used in the MAB setting (Lai and Robbins 1985; Burnetas and Katehakis 1996, 1997; Lattimore and Szepesvári 2020).
1.1.2. Adaptive Learning and Routing Algorithm.
We present a machine learning algorithm that utilizes the basic feasible solutions of the optimal transport LP as actions in Algorithm 1—a method that, to the best of our knowledge, has not been explored before in this setting. We consider the related optimal transport LP, where the objective function (that includes the payoff parameter ) is unknown. However, by the properties of the LP, the set of basic feasible solutions is finite, and the optimal solution is attained at one of these solutions (Bertsimas and Tsitsiklis 1997). Hence, we identify the set of basic feasible solutions as actions. Each solution uniquely defines a set of routing rates. Moreover, the objective function is approximated using UCB indices of the payoff parameters.
The learning is schematically depicted in Figure 2 and works as follows. At the start of each episode, the algorithm chooses the action with maximal (estimated) reward. During the episode, customers are routed according to the rates of the chosen action. In particular, customers are assigned a label corresponding to one of the compatible servers upon arrival (illustrated by colors in Figure 2). Each server serves customers with matching label in First-Come-First-Served (FCFS) order, and service completions generate payoffs. If, at the start of an episode, the chosen action differs from the action of the previous episode, the algorithm assigns new labels for all queueing customers sampled according to the routing rates of the new action.
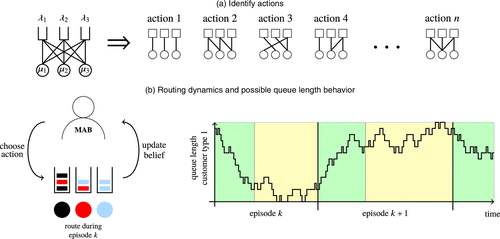
For each line, we maintain a UCB index of its payoff parameter. At the end of the episode, the payoff samples are used to update the UCB indices. The reward of an action is then computed as the sum over all lines of the UCB index weighted by the routing rate of the action. We assume Bernoulli payoffs for simplicity.
1.1.3. Regret Upper Bound.
We show that the asymptotic regret of our policy is for any in Theorem 2. This regret is only slightly worse than the regret of the benchmark UCB policy (Auer et al. 2002) in the classical MAB setting, even though our learning problem is more challenging. The regret analysis relies on concentration inequalities that bound the probability that the empirical average of payoff samples deviates far from its mean. However, it differs from the standard MAB techniques because the number of routing decisions and therefore the number of samples is subject to queueing dynamics. We deal with this issue by splitting each episode into a transient and a stationary phase and analyzing the convergence time of the queue length process to its stationary measure. We let the episodes grow in length such that the probability that the queue length process does not reach stationarity decreases sufficiently fast.
1.1.4. Numerical Experiments.
Lastly, we analyze Algorithm 1 and its performance in several numerical experiments. We find that in our experiments, the average reward of Algorithm 1 converges quickly to the optimal reward and chooses the optimal action most of the time, even in a larger system with many different actions. The algorithm outperforms a benchmark greedy policy that myopically optimizes the instantaneous payoff without considering long-term effects. Even though the theoretical analysis of Algorithm 1 is for a static setting, we test its robustness against the change of a parameter value and find that the algorithm adapts adequately. This highlights the potential applicability of our algorithm beyond static environments.
1.2. Related Literature
The majority of literature on optimal routing in skill-based queues does not account for customer-server-dependent payoffs and focuses on waiting time minimization (Koole and Mandelbaum 2002; Gurvich and Whitt 2010; Adan and Weiss 2012, 2014; Visschers et al. 2012; Krishnasamy et al. 2018; Choudhury et al. 2021; Lee and Vojnovic 2021; Zhong et al. 2022; Yang et al. 2023). In this scenario, the (or in case of abandonments) routing policy that prioritizes customer types based on a ranking depending on the holding costs, is known to be asymptotically optimal (Zhong et al. 2022). Therefore, an intuitive approach for an adaptive learning policy is to route according to a variant of the policy where the unknown parameters are replaced by empirical estimators. In our case, however, the objective in (1) is difficult to evaluate in full generality, because the departure process depends on the availability of servers and the state of the queues, which are random and fairly intractable. Even for simple routing policies like FCFS Assign-the-Longest-Idle-Server (ALIS), the expected number of type-i departures at server j is, to the best of our knowledge, unknown for finite time. Only a select few convergence results are known for specific queueing systems (Adan and Weiss 2012, 2014).
On top of the classical exploration-exploitation trade-off, learning in queueing systems requires one to deal with limited capacity and the interplay between queueing and learning (queueing degrades learning and vice versa). Some works decouple learning and queueing by splitting the time horizon into distinct exploration and exploitation phases (Johari et al. 2021, Zhong et al. 2022, Jia et al. 2024), whereas others directly implement a reinforcement learning algorithm (Liu et al. 2019, Choudhury et al. 2021) or apply Bayesian inference (Bimpikis and Markakis 2019, Shah et al. 2020). Our Algorithm 1, however, is an integrated learning and routing policy.
The focus in our work lies on online payoff maximization in skill-based queues. Payoff maximization problems with unknown utility functions are well studied in literature (Tan and Srikant 2012, Agarwal et al. 2013, Agrawal et al. 2014, Yu et al. 2017, Tan et al. 2020, Vera and Banerjee 2021). In the setting of queueing systems, there exists a variety of algorithms based on different approaches. For example, Sun et al. (2023), Hsu et al. (2022), and Kim and Vojnovic (2021) propose utility guided algorithms based on a static LP. This method is an extension of the Lyapunov drift plus penalty reward, where the Lyapunov drift assures stability and the penalty is used for payoff maximization. Sun et al. (2023) obtain moment bounds for the maximal queue length in the system and an instance independent regret upper bound of order . However, the algorithm suffers a linear loss in reward due to stability constraints. In our work, we instead split the regret into a queueing and a learning component.
Other algorithms for online payoff maximization in queueing systems are considered by Liu et al. (2020) and Steiger et al. (2022), who use Lyapunov drift analysis. A different method is used by Fu and Modiano (2022), who present a routing algorithm that combines the Join-the-Shortest-Queue (JSQ) routing scheme with a confidence ball learning algorithm (introduced by Dani et al. 2008) in the setting of optimization under bandit feedback. It is shown that, given a fixed horizon, the threshold parameter K in the JSQ-K algorithm can be tuned in such a way that polylogarithmic regret can be attained, but no guarantees are provided on the convergence of the routing rates to their optimal values. In our work, we consider an asymptotic result, and, therefore, our algorithm does not require the knowledge of the time horizon.
Lastly, primal-dual methods can be applied that make routing decisions based on estimates of the dual variables. Such methods are especially useful when there is uncertainty in the feasible region of the primal problem, making it impractical to solve directly. For example, Tan and Srikant (2012) present an algorithm in which current queue lengths serve as proxies for the dual variables in a setting with unknown arrival rates. Similarly, Wei et al. (2023) introduce an algorithm for two-sided matching with unknown arrival rates where a notion of customer shortage is used to ensure convergence to the optimal matching rates. In contrast, our method does not rely on estimating the feasible region. Instead, we exploit the structure of the known feasible region to learn the optimal routing rates.
The analysis of our learning algorithm relies on establishing convergence properties of an episodic queue length process to a stationary probability measure. Similar convergence properties have been used in Jia et al. (2024), and Besbes and Zeevi (2015). We let the episodes grow in duration so that convergence is achieved with increasing probability. Sanders et al. (2016), Comte et al. (2023), Jiang and Walrand (2010), and Liu et al. (2019) use similar concepts in different settings of optimal control in queueing networks.
The methodology of our learning algorithm bears most resemblance with the achievable region approach in Bertsimas (1995) and Dacre et al. (1999), where the goal is to solve an optimization problem with an unknown utility function using the feasible region spanned by a set of constraints. Bertsimas (1995) and Dacre et al. (1999) consider the optimal routing problem in a static setting with known parameters, whereas our policy integrates learning and optimization in an online fashion.
1.3. Outline
The remainder of this work is organized as follows. In Section 2, we discuss the model, optimal routing problem, and regret formulation. Next, in Section 3, we study the regret of routing policies and present an asymptotic regret lower bound for a class of routing policies. In Section 4, we present the adaptive learning algorithm and show that its asymptotic regret is of polylogarithmic order. Lastly, in Section 5, we present a numerical implementation of the algorithm.
2. Model Description
In this section, we describe the queueing system and routing policies in more detail. We analyze a related deterministic optimal transport LP and discuss its properties. Lastly, we present a definition of regret of a routing policy, which is based on the optimal transport LP.
2.1. Arrival and Service Process
We consider a continuous-time queueing system with a fixed set of customer types , servers , and a set of lines connecting compatible customer types and servers . Here, . Let denote the number of compatible lines. We assume that the bipartite graph of customer types, servers, and lines is connected. To exclude trivial cases, we assume that . We denote the set of servers that are compatible with customer type i by , and, similarly, we denote the set of customer types that are compatible with server j by —that is,
An example of such a queueing network is given in Figure 3.
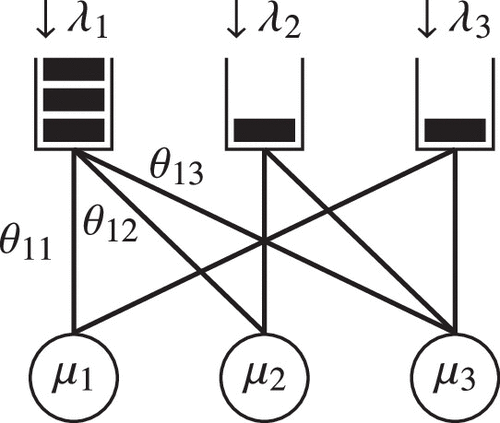
Note. Here, for example, and .
For , type-i customers are assumed to arrive according to a Poisson process with rate . They wait in queue i until they are allocated to a compatible (and idle) server. We assume that there are no customers in the system at time . For , service times of customers at server j are assumed exponentially distributed with rate . We also assume that service times are independent between servers and across customers. Note that the service time distribution only depends on the server and not the customer type. For convenience, we write and similarly . For stability, we assume that for any subset of customer types ,
Here, denotes the set of servers that are compatible with any of the customer types . By Adan and Weiss (2014, theorem 2.1), there exists a routing policy such that the joint queue length process under that policy is ergodic.
Upon the service completion of a type-i customer at server j, a random payoff is obtained, sampled from a payoff distribution with support and unknown and finite mean . Note that although all lines share the same payoff distribution, the mean payoff differs per line. We denote the vector of unknown mean payoffs as . As quantification of the difference between the payoff distribution for two lines and , we use the Kullback-Leibler (KL) divergence, given by
We assume that the payoff distribution is such that
2.2. Routing Policies
A routing policy determines which customer is served by which server at what time. We denote the probability measure and expectation with respect to routing policy and payoff vector by and , respectively. Moreover, we denote the total number of service completions—that is, departures—of type-i customers at server j up to time by .
We consider a class of routing policies that satisfy for and for any payoff vector the following conditions:
Constraint (7) is a notion of stability: we require that the difference between the expected number of arrivals and departures—that is, the expected queue length—of any customer type does not diverge. Note that the set of policies satisfying (7) is nonempty by Assumption (4). Constraint (8) requires that the expected utilization of server j is at most . If , (8) prevents critically loaded servers.
We consider the reward of a policy with respect to payoff vector up to time as the total average payoff—that is,
As discussed previously, (9) can be difficult to compute in full generality. Instead, we consider a static version of the optimal control problem which is discussed next.
2.3. Optimal Transport LP
For a payoff vector and , let
The objective of is to maximize the average payoff per time unit. Each optimization variable can be interpreted as the long-term rate of type-i customers that are routed to server j per time unit. Constraint (10b) requires that all customers are routed to some server, and Constraint (10c) states that the capacity of each server must not be exceeded. Here, is a fixed amount of slack at each server. The feasibility of depends on the value of , which will be discussed later. can be regarded as a variant of the assignment problem initially presented in Shapley and Shubik (1971), where the resources are divisible. Similar LP formulations of the static planning problem in the context of reward maximization in queueing models are used in Hsu et al. (2022), Fu and Modiano (2021, 2022), Tan and Srikant (2012), Tan et al. (2020), and Vera and Banerjee (2021).
We briefly discuss some fundamental properties of LPs. Consider an LP in standard form: s.t. , with . For with , we denote by the matrix formed by the columns . We call B a basis if is invertible (or, equivalently, has full rank); see Bertsimas and Tsitsiklis (1997). In this case, the vector obtained by setting for and for , is a basic solution. A basis (or equivalently a basic solution) is feasible if and nondegenerate if for all . Lastly, recall that if an LP has an optimal solution, then it has an optimal basic feasible solution (Bertsimas and Tsitsiklis 1997, theorem 2.7).
In the remainder of this work, we assume nondegeneracy—that is, we assume that all basic feasible solutions of and its dual are nondegenerate. We note that this assumption implies that each basic feasible solution of the primal (dual) implies a unique basic feasible solution of the dual (primal) (see, e.g., Bertsimas and Tsitsiklis 1997, exercise 4.12)).
2.3.1. Basic Feasible Solutions.
We will now characterize the basic feasible solutions of in (10). Because has a finite number of linear inequality constraints, the set of basic feasible solutions is finite (Bertsimas and Tsitsiklis 1997, corollary 2.1).
It is a known result that a basic feasible solution of induces a spanning forest on the bipartite graph (Fu and Modiano 2022, proposition 2). We extend the result of Fu and Modiano (2022) by providing the explicit form of any basis (see Lemma 1 below) and any basic solution (see Lemma 2 below). The proofs are presented in Online Appendix C.1 and Online Appendix C.2, respectively.
The introduction of Lemmas 1 and 2 requires some more notation. For and we denote by the subgraph of induced by and . We say that is a spanning forest of if (i) it is a union of trees—that is, it contains no cycles; (ii) each is contained in ; and (iii) each tree of contains a unique root node . In such a tree, parent and child nodes of servers are customer types and vice versa. We denote the subtree rooted in v, including v itself, by . We let denote the set of customer types contained in the subtree rooted in v—that is, . Similarly, . An example is shown in Figure 4.
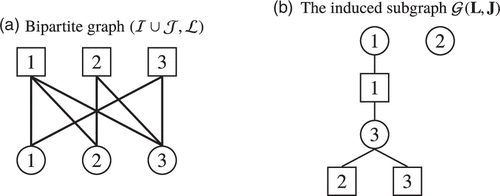
Note. is then a spanning forest of consisting of two trees.
We are now in a position to state Lemmas 1 and 2:
Let , , and . is a basis of if and only if is a spanning forest of .
Let , , and . If is a basis of , then its corresponding basic solution satisfies
2.3.2. Feasibility.
Note that by (4), is feasible—that is, there exists at least one basic feasible solution. The feasibility region of in (10) depends on : the larger , the smaller the feasible region. Lemma 3 characterizes the range of such that the has the same set of feasible bases as . The lemma is proven in Online Appendix C.3.
Let with and be a nondegenerate feasible basis of . If
2.4. Regret Formulation
We use the value of in (10) as the oracle reward to define the regret of a learning policy. Let satisfy (12), be a payoff vector, and be the optimal basic feasible solution of in (10). We define the (expected) regret of a routing policy at time as
Lemma 4 states that the asymptotic regret is nonnegative and is proven in Online Appendix C.4.
3. Regret Lower Bound
We provide an asymptotic lower bound for the regret for routing policies satisfying Constraints (7) and (8) in Theorem 1. To this end, we first provide a regret decomposition in Lemma 5.
3.1. Regret Decomposition
Let satisfy (12), be a payoff vector, and be the unique optimal solution of in (10). We define the set of optimal lines as the lines with nonzero load in the optimal solution and the set of suboptimal lines as its complement:
The dual problem (Bertsimas and Tsitsiklis 1997) of is given by
By strong duality, we have that is feasible because is feasible. Moreover, and , are an optimal primal-dual pair if and only if they satisfy the complementary slackness conditions (Bertsimas and Tsitsiklis 1997, theorem 4.5), which are given by
We note that the optimal solutions of and are unique due to the nondegeneracy assumption. Moreover, the nondegeneracy assumption implies strict complementarity (see, e.g., in Bertsimas and Tsitsiklis 1997, exercises 4.12 and 4.20c).
For a line , we define
Lemma 5 presents a regret decomposition based on the line classification. The proof can be found in Online Appendix C.5.
Let , be the optimal solution of in (16). Let satisfy (7) and (8). Then, the regret in (13) can be expressed as
In Decomposition (20), term I represents the loss in reward due to customers being routed over suboptimal lines. The other two summations represent regret accumulated by deviating from the oracle routing rates. In particular, II measures regret from not utilizing the allowed capacity from servers, and III measures regret accumulated from customers that are still waiting in the queue or are in service at time t, because we do not obtain any payoff until a customer finishes service. Note that because , the queue length can actually contribute to negative regret, because it might be beneficial to let customers wait until a high payoff server is available.
3.2. Regret Lower Bound
Before we can state the asymptotic regret lower bound, we need to introduce some further notation. Let . We define element-wise by
In particular, represents a payoff vector that is (almost) equal to except for index . For , we define
Lemma 6 states that any suboptimal line could become optimal by changing its payoff value. It is proven in Online Appendix C.6.
For any , we have .
Theorem 1 provides an asymptotic regret lower bound and is proven in Online Appendix A.
Let satisfy (12) and let satisfy (7) and (8). Moreover, we assume that is consistent—that is, that for any deterministic payoff vector ,
Then, for any ,
The lower bound in (25) is a summation over all suboptimal lines of the suboptimality gap divided by the infimum KL distance as defined in (23). This means that a suboptimal line that is nearly optimal, in the sense that its suboptimality gap is small, leads to a large contribution to the regret, because it is difficult for a policy to distinguish between optimal and nearly optimal lines. Note that the lower bound is not redundant, as strict positivity is guaranteed.
Assumption (24) is a notion of consistency which is a common assumption in regret analysis in MAB literature (Lattimore and Szepesvári 2020), as it excludes policies that are specialized on a subset of problem instances. Intuitively speaking, it states that optimal lines are sufficiently explored. In particular, (24) requires that the number of departures of optimal lines eventually grows larger than logarithmic with probability one. In classical bandit literature, an assumption on the concentration of the expectation of the number of optimal decisions is often sufficient, because there is exactly one decision at each time step. In our case, however, the number of departures is random even for stationary policies. It remains an open question whether a similar regret lower bound can be proven for a class of policies satisfying a weaker constraint such as for any and , in combination with Assumptions (7) and (8).
Theorem 1 states that the regret is , which is the same order as the lower bound for classical MABs (Lai and Robbins 1985, theorem 2). The proof of Theorem 1 in Online Appendix A is structured in a similar way as those presented in Lai and Robbins (1985), Burnetas and Katehakis (1996, 1997), and Lattimore and Szepesvári (2020) and uses a change-of-measure argument. Because payoffs are random samples, each line is associated with a level of uncertainty that decreases with the number of obtained samples, which in our case corresponds to departures. In order to prove the theorem, we construct a second, “confusing” system which has the same parameters as the original model with the exception of the average payoff for some line , which we set to a high value such that line is an optimal line in the second model. We then prove that a consistent policy needs samples of payoffs of line in order to distinguish between the two models.
Recall that Theorem 1 assumes that the payoff distribution is discrete (see the end of Section 2.1). We note that the proof can be adapted to include payoff distributions defined by a probability density function : in this case, the KL divergence in (5) changes to
Similarly, the Radon-Nikodym (RN) derivative in the proof of Theorem 1 in Online Appendix A changes to , and Equations (69), (72), and (73) change accordingly. Extension of our result to general probability measures requires careful construction of the RN derivative. This can be done in line with the discussion following Lattimore and Szepesvári (2020, proposition 4.8).
4. Adaptive Queue Routing Policy
In this section, we introduce a routing algorithm called Adaptive UCB Queue Routing Algorithm (UCB QR) and show that its asymptotic regret is close to the lower bound in Theorem 1. Specifically, Theorem 2 proves that its regret is polylogarithmic as time grows large.
4.1. Description of the Algorithm
We consider a fixed network structure , and satisfying (12). We assume that the payoff distribution of line is Bernoulli distributed with parameter .
We consider the basic feasible solutions of in (10) as the different actions in an MAB setting. Because the set of basic feasible solutions of is finite (see Section 2.3.1), the set of actions is finite and will be denoted by . Concretely, each action is associated with a basic feasible solution of . We call the action corresponding to the optimal basic feasible solution the optimal action, which is unique by the nondegeneracy assumption.
For , we denote the set of lines with positive load by —that is,
The long-term average reward of action a will be denoted by
The UCB QR algorithm is given in Algorithm 1.
(
1: Initialize , for all initialize , , and and for all initialize .
2: for each episode of length do
3: Choose action , with ties broken arbitrarily.
4: if then
5: Reallocate customers to virtual queues: for each waiting type-i customer, assign it to the virtual queue of server j with probability .
6: For each , order the customers in virtual queue j by their arrival time.
7: end if
8: for time do
9: Serve customers according to Algorithm 2: .
10: end for
11: For each line , observe payoff samples .
12: For each line , update
(30)(31)(32)13: Update the UCB index of action ,
(33)14: end for
(
1: for each arrival of a type-i customer do
2: Assign customer to the virtual queue of server j with probability .
3: If the server is idle, start service.
4: end for
5: for each service completion at server j do
6: Obtain a payoff , where i is the departing customer’s type.
7: If the virtual queue of server j is nonempty, start service of the customer at the head of the queue.
8: end for
The learning algorithm works as follows. We maintain UCB indices for the average payoffs of lines and use these to compute UCB indices for each action . At the start of each episode, we choose the action with the highest UCB index. During the episode, we route customers according to the rates using the FCFS Random-Routing (FCFS RR) scheme in Algorithm 2. We use virtual queues to implement the FCFS RR scheme. For each departure of a type-i customer at server j, we obtain a payoff sample from a Bernoulli distribution with parameter . At the end of each episode, we use the obtained payoff samples to update the UCB indices. Note that customers may be reallocated to a different virtual queue when a change in action occurs at episode transitions. Episode k has a predetermined length that may depend on k.
For each line , we keep track of , the total number of departures of type-i customers at server j up to episode number . Similarly, we keep track of the empirical mean of type- payoffs and a UCB estimator . The counters and empirical means are both initialized at zero, whereas the UCB estimator is initialized at infinity as an incentive for the algorithm to obtain at least one sample from each line. The number of type- departures in episode k, , in line 11 is random due to the queueing dynamics.
We note that Algorithm 2 may lead to higher queueing delays when compared with other throughput optimal routing rules such as Serve-the-Longest-Queue. However, for the regret analysis, we require a routing rule for which the empirical routing rates converge to the target rates as . To the best of our knowledge, not many such rules exist in literature, because routing rates and even stability conditions are generally difficult to determine for arbitrary routing rules for skill-based queues (Adan and Weiss 2012, Weiss 2021).
4.2. Small Example
We illustrate how the algorithm works on a small example. We consider the queueing system illustrated on the left in Figure 5 with . It can be verified that (12) is satisfied. in (10) has six nondegenerate basic feasible solutions which we label as actions in Figure 5.
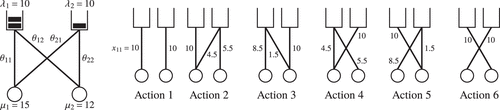
Note. For each action, the routing rates are illustrated next to the corresponding lines.
The routing of customers using the virtual queues is shown in Figure 6.
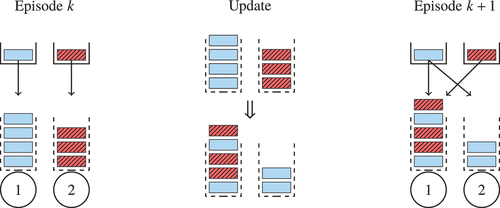
Notes. Arriving customers are placed in virtual queues, depicted by dashed lines, according to the routing rates associated with the action. In particular, in episode k, type-i customers are routed to virtual queue i (left), whereas in episode , a type-1 customer is routed to virtual queue 1 with probability (w.p.) 0.45 and to virtual queue 2 w.p. 0.55 (right). Just before episode starts (middle), waiting customers are redistributed over the virtual queues according to the routing rates of the new action.
4.3. Regret Upper Bound
Theorem 2 analyzes the regret of Algorithm 1.
We denote the minimal positive rate on a line across any action as . Moreover, denotes the total arrival rate of customers at server j under action a and
Let satisfy (12), let , and let satisfy
Let and the episode lengths , , satisfy
Lastly, let be a payoff vector. Then, Algorithm 1 satisfies (24). Moreover, the regret of Algorithm 1 satisfies
The regret upper bound in Theorem 2 provides a theoretical guarantee on the performance of Algorithm 1. It shows that the regret scales with rate at most as the time horizon t grows large. Note that this matches the regret lower bound in Theorem 1 up to logarithmic terms. From the right side of (37), we observe that the upper bound increases with the cardinality of the action set , this will be discussed in Section 4.5.2. Moreover, the regret for each suboptimal action is upper bounded by the instantaneous regret of suboptimal lines in the set (recall (15)) multiplied by the maximal expected departure rate at server j, which is by construction. For a suboptimal line , the instantaneous regret is expressed by the suboptimality gap in (19). The last term in (37) is related to the queueing regret: it represents the regret obtained at the start of optimal episodes when the queue length process is not necessarily close to its stationary behavior. We outline the proof of Theorem 2 in Section 4.4. The full proof is given in Online Appendix B.
4.3.1. Episode Length.
In order to analyze the regret of the algorithm, we provide lower bounds on the number of departures for each line. The analysis is challenging because the routing scheme changes at the start of each episode; hence, the starting state of the queueing system is not necessarily close to its stationary behavior, as illustrated in Figure 7. This motivates the introduction of a warmup time in the construction of the episode length in (36). The warmup time is followed by a period of fixed length.
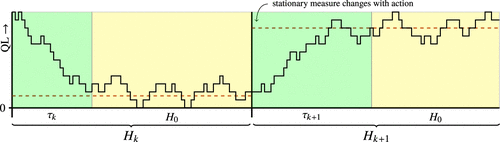
Notes. Episode k consists of a warmup time followed by a period of fixed length . Every episode, the algorithm can choose a different action with its own stationary measure.
In the analysis of the algorithm, we provide a lower bound on the probability of convergence of the queue length process to its stationary behavior within the warmup time. Constraint (35) guarantees that this bound is sharp enough. The warmup time is increasing in k, so that this probability converges to one at the right speed in terms of the episode number k.
4.4. Proof Outline
We sketch the proof of Theorem 2, highlighting the key contributions. The proof can be split into four steps. We briefly explain these steps, followed by a more in-depth elaboration per step. Without loss of generality, we label the first action as the unique optimal action—that is, .
Step 1. Analyzing the number of departures in FCFS RR. For the proof of Theorem 2, we need to show that Algorithm 1 learns the payoff parameters sufficiently fast. Because payoff samples are collected upon departures, we need to prove a lower bound on the number of departures in the queueing system. We do so via an intermediate step: we consider the scenario where the system is initially empty at the start of an episode, which represents a “worst-case” scenario. Next, we show that this worst-case queue length process reaches stationarity within warmup time with sufficiently high probability (Lemma 7).
Step 2. Bounding the probability of choosing a suboptimal action. We note that Algorithm 1 chooses a suboptimal action in row 3 only if the UCB index of the suboptimal action in (33) is at least as high as the UCB index of the optimal action. Broadly speaking, this can happen if (A) the index of the suboptimal action overestimates its true mean; or (B) the index of the optimal action underestimates its true mean. Compared with the classical MAB analysis in Lattimore and Szepesvári (2020), event (A) is more complicated to analyze in our model, because the number of payoff samples we obtain within one episode is stochastic rather than deterministic as in the classical MAB setting. We show that event (A) is unlikely by showing that on the one hand, overestimation based on “sufficient” samples is unlikely, and on the other hand, it is unlikely to obtain “insufficient” samples. Here, the term sufficient is carefully constructed, as discussed below. Event (B) is unlikely by construction of the UCB estimators. We bound the probability of event (A) in Lemmas 8 and 9 and event (B) in Lemma 10.
Step 3. Bounding the number of suboptimal episodes. We use the bounds from Step 2 to bound the number of episodes where Algorithm 1 chooses a suboptimal action in Lemma 11.
Step 4. Bounding the regret of Algorithm 1. Finally, we prove Theorem 2 in Online Appendix B using the Regret Decomposition (20). Term I is the main contributing factor because it measures the regret accumulated by using suboptimal lines. We bound this term using Lemma 11. Term II is bounded by analyzing the queue length behavior in episodes where the algorithm chooses the optimal action. Lastly, we bound term III using the properties of FCFS RR and the constraints in .
Let us next describe Steps 1–4 in more detail.
4.4.1. Step 1. Analyzing the Number of Departures in FCFS RR.
We consider the queue length process , of the virtual queue of server during episode , where denotes the action chosen by Algorithm 1 in row 3. Within an episode, Algorithm 1 routes customers according to the fixed FCFS RR policy in Algorithm 2. Because arrival processes are independent across customer types, we have by the Poisson splitting and merging properties (Çinlar and Agnew 1968) that the arrival process of is a Poisson process with rate . This implies that behaves as an queueing system independently from other servers. Recall that is a basic feasible solution of in (10), so by Constraint (10c), we have . Therefore, , and hence, is positive recurrent (Cohen 1982), and its stationary distribution is given by
For each server, we associate two new queue length processes and where the initial value is sampled from the stationary measure and . We couple the processes , , and in the sense that the sampled arrival times and service completions (if possible) are the same for all processes, as illustrated in Figure 8.
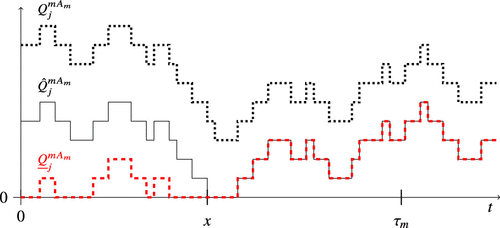
Notes. Customer arrivals lead to a unit increase and service completions to a unit decrease (unless the queue is empty). At hitting time x, the processes and collide and evolve identically afterward.
Note that if and collide, then the departure process of is stationary afterward. Lemma 7 provides a bound on the hitting time of and . The proof relies on hitting time analysis of an queueing system. Lemma 7 extends the result of Jia et al. (2024, proposition 4), in the sense that we provide a sharper bound by exploiting the known formula for the moment generating function of hitting times in an system. We also provide exact values for the constants in our result, which are not provided in Jia et al. (2024).
Let and let satisfy with
For any , where is defined as in (36), we have
The proof of Lemma 7 is in Online Appendix C.7.
4.4.2. Step 2. Bounding the Probability of Choosing a Suboptimal Action.
4.4.2.1. Bound on Event (A).
Note that the confidence bound in (33) decreases with the number of obtained samples (departures). This means that overestimation of the true mean is likely when the number of samples is small, but becomes less likely as the number of obtained samples increases. We split the analysis into two parts. First, Lemma 8 bounds the probability that Algorithm 1 has not obtained sufficient samples after episodes. Here, we quantify sufficient by in (43) below.
To provide the lemma, we introduce some notation. Let
We define for , , and the quantities
We are interested in the event that the number of type- departures under action a after episodes is at least —that is,
Let and . Then, .
The proof of Lemma 8 in Online Appendix C.8 relies on Lemma 7. We use that the number of departures is at least as high as the number of departures in a coupled system that starts from the empty state at the start of the episode (the worst-case scenario). We then apply Lemma 7 to show that the worst-case process reaches stationarity with high probability. Next, we use Poisson merging and splitting properties (see, e.g., Çinlar and Agnew 1968) and Burke’s Theorem (Cohen 1982, II.2.4 theorem 2.1) to obtain that the stationary departure process of the policy in Algorithm 2 is a Poisson process with rate . Lastly, we use a Poisson tail bound (see Lemma C.3 in the Online Appendix) to obtain a lower bound on the number of departures of the stationary process.
For the second part of event (A), Lemma 9 shows that the probability of overestimating the true reward is small if the number of obtained samples (departures) is sufficiently large. The proof in Online Appendix C.9 relies on Hoeffding’s inequality (Hoeffding 1963, theorem 2).
Let , , and , then for in (29),
The value in (43) is constructed precisely such that Lemma 8 and Lemma 9 hold simultaneously. The intuition behind this value is as follows: if we have observed episodes with action a, then for approximately of those episodes, the number of departures can be bounded from below by the number of departures of the stationary process, which is Poisson distributed. From these episodes, we lose approximately episodes where the Poisson tail bound fails (see Lemma C.3 in the Online Appendix). Hence, we collect payoff samples (departures) at a rate of approximately , as reflected in the definition of .
4.4.2.2. Bound on Event (B).
For event (B), recall that the true mean of action is as defined in (28). By construction, the UCB index in (33) includes a confidence bound (exploration bonus) which implies that the probability of event (B) is small. This is made precise in Lemma 10, which is proven in Online Appendix C.9. We let denote the -norm.
Let , , , and . Then,
4.4.3. Step 3. Bounding the Number of Suboptimal Episodes.
We define as the number of episodes where Algorithm 1 chooses action in Row 3 up to and including episode number k—that is,
From Lemma 11, it follows that the expected number of suboptimal episodes grows asymptotically with rate at most with the number of episodes k. The proof of Lemma 11 is given in Online Appendix C.11 and relies on Lemma 8, 9, and 10.
Let . For any suboptimal action we have
4.4.4. Step 4. Bounding the Regret of Algorithm 1.
We bound the terms in the Regret Decomposition (20) individually. For term I, we use that suboptimal lines are only used in suboptimal episodes by construction. Hence, for , the expected number of type- departures can be upper bounded by the maximal departure rate of server , which is by construction, multiplied by the total number of suboptimal episodes. This, we bound using Lemma 11.
For term II, we show that the queue length process in consecutive optimal episodes converges sufficiently fast to its stationary behavior. Specifically, we use the bound in Lemma 7: if and the queue length processes reaches stationarity within the warmup period of episode k, then the process is stationary at the start of episode , because the stationary measure does not change in this case.
Lastly, for term III, we use the fact that satisfies (10c) to show that the virtual queues of all servers are positive recurrent under the policy. In view of (10b), this implies that the queue of any customer type is positive recurrent as well. This means that the expected queue lengths remain finite, and hence, the contribution of term III to the regret vanishes on a logarithmic scale.
4.5. Discussion
4.5.1. Avoiding Carryover Effect Between Episodes.
The reallocation in rows 5 and 6 avoids a delay in observations when a new episode starts: if the chosen action in episode k differs from the action that was chosen in the previous episode , we reallocate all waiting customers to the virtual queues according to new rates of the action chosen in episode k. After the new reallocation, we order the customers in each virtual queue in order of their arrival times, so that the service order within the virtual queue is FCFS. This reallocation improves the learning efficiency because there is no “carryover” effect between episodes, unlike other learning algorithms in literature (Fu and Modiano 2022, Jia et al. 2024).
4.5.2. Transfer Learning.
The rewards of the actions are related by the common unknown payoff parameter via (28). Algorithm 1 utilizes transfer learning in the sense that knowledge about the payoff parameter is shared between actions: specifically, the UCB index of a reward is computed using the UCB indices of the lines. This effect also becomes evident in the numerical analysis in Section 5.1.
Our regret bound in Theorem 2 is pessimistic: in analyzing the convergence of the UCB index in (33), we only account for departures that are obtained in episodes where action a was chosen. However, we possibly observe type- departures as well in episodes where another action with was chosen. This insight can be used in future work to improve the bound in Lemma 8 and, in turn, improve the regret bound in Theorem 2. In particular, it might be possible to replace the cardinality of the action set in (37) by the number of lines L, which is typically smaller. Such analysis methods are often used in the setting of linear bandits (Lattimore and Szepesvári 2020).
4.5.3. Parameter Values.
To implement UCB QR, we need to set , and . These parameters determine the episode length via (36). Smaller values of , and lead to shorter episodes, thereby increasing the learning rate. Indeed, the asymptotic regret bound in (37) is increasing in and .
Theorem 2 requires that satisfies (35) and satisfies (36). We briefly discuss how to deal with these constraints in practice. Because (35) involves a maximum taken over all actions, it can be tedious to compute when the action set is large. However, we can provide an upper bound on (35) to ease evaluation. We show in Online Appendix C.12 that
To set according to (36), we need to determine . We show in Online Appendix C.12 that in case and are integer valued, we have . In that case,
4.5.4. Dependency on the Value of .
We note that the required lower bound on in (35) can be large when the slack parameter is small. In particular, if for some action a and server j, then the lower bound in (35) is . This is in line with (47). In this case, the regret of Algorithm 1 is which diverges when .
In this paper we only consider policies satisfying (8). For fixed , Condition (8) excludes some stable policies. Indeed, one can construct a stable policy by replacing with in (8). Hence, if is reduced, we allow for a larger class of stable policies. At the same time, the regret of Algorithm 1 increases as decreases. So there always exists a stable policy with an arbitrarily smaller regret when compared with Algorithm 1.
If one aims to relax Condition (8) to the set of all stable policies, then a more suitable benchmark for the regret would be instead of . The regret of Algorithm 1 would then also include a linear term because the difference between and is . That is, in that case, . Optimizing over all possible values of yields , where the notation omits polylogarithmic factors in T.
There thus exists a trade-off in choosing the value of in practice. A smaller increases the optimal value of , but also increases the regret of Algorithm 1. More precisely, the reward obtained by Algorithm 1 in T time is proportional to . The value should be chosen carefully to maximize this reward.
We require the Lower Bound (35) in the mixing time analysis of an M/M/1 queue (see Lemma 7). Lower Bound (35) is constructed in such a way to bound a term in the proof of Lemma 7 (see (167) in the Online Appendix). However, this bound is quite loose. More careful analysis of the individual terms may give a lower value than (35). We show in Section 5.3 that Algorithm 1 still performs well in finite time, even when is chosen smaller than the lower bound in (35).
Another method to improve the scaling of the regret would be to use another routing rule. An alternative to Algorithm 2 that mixes the process faster may be beneficial. We leave this for future work.
4.5.5. Number of Actions.
The number of actions grows exponentially with the number of queues I, servers J, and lines L in the queueing system. Concretely, the number of bases of in (10) is ; hence, the number of basic feasible solutions grows exponentially with the system’s complexity.
Although the cardinality of the action set appears in the Regret Upper Bound (37), this does not necessarily pose a problem in practical implementation of the algorithm. With slight modification, we can avoid the need to keep track of all basic feasible solutions of the LP and evaluate their estimators at the start of each episode (Algorithm 1, row 3). Rather, we can solve in (10) directly and take its maximizer as the action for the next episode. Modern numerical solvers can efficiently solve LPs using, for example, the simplex method or interior-point methods (Bertsimas and Tsitsiklis 1997). If the LP solver correctly finds the optimal solution, the performance of the algorithm is not affected because the optimal basic feasible solution of is the same as the action with maximal value.
In case the number of customer types, servers, and lines of the queueing system are so large that the LP cannot be solved sufficiently fast, column generation (Desrosiers and Lübbecke 2005), or a branch-and-bound technique like Bender’s decomposition (García-Muñoz et al. 2023), can be used to solve the LP efficiently.
5. Numerical Results
In this section, we analyze the properties of Algorithm 1 (UCB QR) numerically. In Section 5.1, we consider a small skill-based queueing system. For this system, we analyze the regret of the UCB QR algorithm and compare its long-term average payoff rate with several benchmark routing policies. In Section 5.2, we analyze the robustness of the learning policy against changes in the true payoff parameter. In Section 5.3, we consider a larger queueing system and compare the performance of UCB QR against benchmark policies in several scenarios.
We consider four different benchmark policies which are described as follows.
Oracle: This is almost the same as the UCB QR algorithm, but with row 3 replaced by . Note that this policy relies on the true payoff parameter . This policy represents the optimal upper bound for the long-term reward rate of any stabilizing policy.
FCFS ALIS: If there are nonempty compatible queues at a service completion, assign the customer with maximal waiting time. If there are compatible servers idle upon a customer arrival, assign it to the server with maximal idle time. This policy is widely used in practice because both customers and servers experience a sense of fairness (Adan and Weiss 2014).
Greedy: If there are nonempty compatible queues at a service completion of server j, assign the first-in-line customer from queue . If there are compatible servers idle upon a type-i customer arrival, assign it to server . This policy myopically optimizes the instantaneous payoff without considering long-term effects or stability constraints.
Random: If there are nonempty compatible queues at a service completion, choose one of these queues uniformly at random and assign the first-in-line customer. If there are compatible servers idle at a customer arrival, assign it to one of these servers uniformly at random. This policy serves as a most naive baseline by making completely uninformed decisions.
Empirical : Lastly, we consider a variation of the classical rule (Smith 1956), which is known to be optimal for holding cost minimization in a multicustomer single-server setting and has been well-studied in multicustomer multiserver settings (Xia et al. 2022, Long et al. 2024) and even in adaptive learning settings (Krishnasamy et al. 2018). Instead of holding costs, we balance the empirical average payoff with service speed . Concretely, if there are nonempty compatible queues at a service completion of server j, assign the first-in-line customer from queue . If there are compatible servers idle upon a type-i customer arrival, assign it to server .
5.1. Small Example
We consider the queueing system and action set as shown in Figure 5. The optimality of the actions depends on the payoff vector as illustrated in Figure 9.
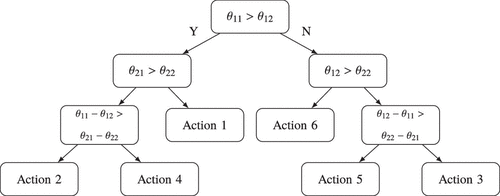
We set the true payoff vector as . This implies that action 2 is optimal and that the optimal long-term payoff rate is approximately 5.4. Moreover, line 12 is suboptimal because it has zero load in the optimal solution. The suboptimality gap of line 12 (recall (19)) is . The suboptimality gaps for each action in (29) are given by
Recall that the UCB QR algorithm requires configuration parameters , and which define the episode length according to (36). We set , , and . These parameters satisfy (35) and (36). All of our numerical results are based on 50 independent replications, and all plots show 95% confidence areas, although these intervals are too small to be visible in Figure 10.
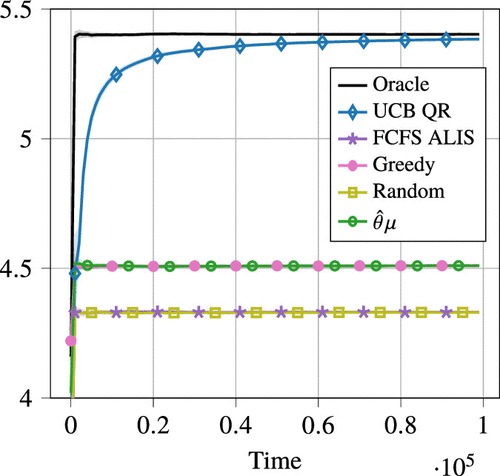
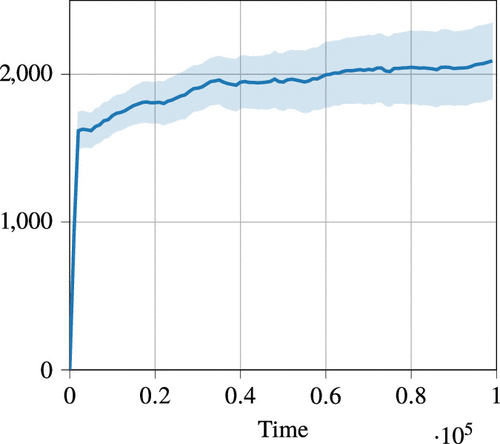
We observe in Figure 10 that, as expected, the payoff rate of the UCB QR algorithm converges to the optimal payoff rate of the Oracle policy. The accumulated regret grows slowly over time, as shown in Figure 11. In the initial period up to approximately time 2,000, the UCB QR algorithm has not yet collected sufficient samples to distinguish the actions. Therefore, it chooses actions uniformly at random, which corresponds to the first few episodes in Figure 12. In turn, the regret accumulation is high because actions with large suboptimality gaps are chosen. After the initial period, we observe in Figure 12 that the algorithm primarily struggles to differentiate the optimal action 2 and action 4. This leads to a sharp decrease in regret accumulation, because action 4 has a small suboptimality gap.
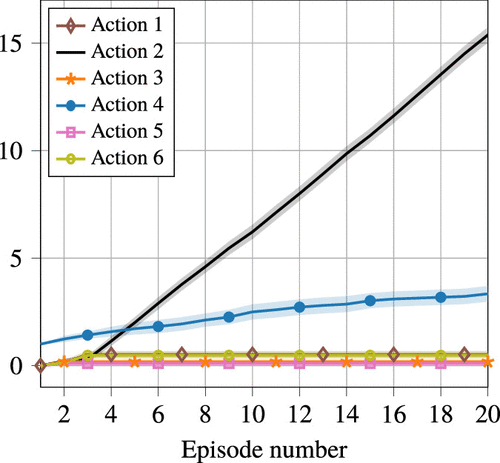
Moreover, we observe in Figure 12 that actions are hardly ever chosen by the UCB QR algorithm. As opposed to a classical MAB, the rewards of the actions are related by the common unknown payoff parameter . Therefore, it suffices to only sample a subset of actions, as long as we observe sufficient payoff samples from all lines. By only using actions 2 and 4, the algorithm infers sufficient information about all four payoff parameters. In particular, in accordance with Algorithm 1, row 12, the indices , , and are updated after episodes with action 2, whereas , , and are updated after episodes with action 4. We note that our regret analysis in Section 4 does not exploit this feature of transfer learning in the construction of the regret upper bound. This remains an interesting direction for future research.
The FCFS ALIS, Greedy, Random, and policies maintain a consistent gap to the optimal payoff of the Oracle policy. The value of this gap depends on the true payoff parameter . Because the total load in the system is far from critical, the long-term routing rates under the FCFS ALIS policy are close to those of the Random policy. This leads to minor difference in total payoff rate with respect to the Random policy, as shown in Figure 10. In particular, the FCFS ALIS policy is indistinguishable from the Random policy in terms of reward. The Greedy policy obtains a slightly higher reward, making a greedy decision whenever possible. The empirical policy performs similarly to the Greedy policy in terms of payoff accumulation. We observe that the empirical estimators concentrate quickly because the policy shows stable behavior early on in Figure 10, without fluctuations in the average payoff rate. However, even provided with accurate parameter estimates, this policy does not achieve the optimal payoff rate, similar to the Oracle policy.
To summarize, we have shown for a small queueing system that the payoff rate of the UCB QR algorithm converges to the optimal rate and that it chooses the optimal action most of the time. Thereby, it outperforms our benchmark policies that (a) are agnostic to the payoff parameters or (b) rely on the payoff parameters but make suboptimal routing decisions.
5.2. Changing Parameters
Although our theoretical analysis of the UCB QR algorithm in Section 4 is for a static environment, we analyze its robustness against changes in the payoff parameter . Learning in nonstatic settings is an important challenge for practical applications where underlying system parameters may evolve over time due to changes in, for example, demand patterns, staffing, or external disruptions. Detection and adaptation to such changing conditions are crucial for maintaining high performance over time. Although a formal analysis of such scenarios is beyond the scope of this paper, we perform an initial exploration of learning in nonstatic settings in this section. Our numerical results suggest that UCB QR can correctly identify changes in the true system parameters.
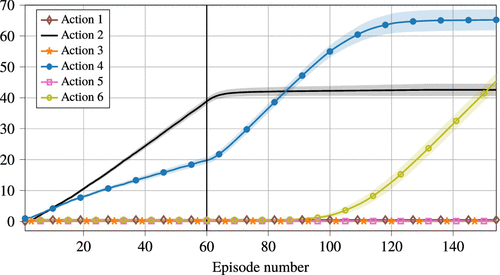
In this experiment, we use the same payoff vector as in Section 5.1 initially. At one-third of the total runtime, we update the payoff parameter of line 12 to . As a consequence, the optimal action under the new payoff parameter is action 6. We set and . Our numerical results are based on 100 independent replications.
Observe in Figure 13 that upon the parameter change (at episode number 60, depicted by a vertical line), the UCB QR algorithm at first prefers action 4. This makes sense because action 4 is closest to the initially optimal action 2, while it also includes line 12 which is an optimal line under the updated parameter . From approximately episode number 100 onward, the learning algorithm switches more to the optimal action 6. Hence, we see that the UCB QR algorithm suffers from a switchover period, but eventually changes to the optimal action. The convergence after the parameter change is slower than the initial convergence. We see this effect because the empirical estimators take into account the complete history. Therefore, after the parameter update, learning is hindered by samples obtained before the update. We expect that robustness against changing parameter values can be improved by decreasing the episode length or altering the empirical estimators in (31) by decreasing the weight of observations from the past. This remains open for future work.
5.3. Complex Queueing System
We consider the queueing system illustrated in Figure 14. This system is inspired by the operation of the call center of a real-world telecommunications company. We let such that (12) is satisfied. The number of basic feasible solutions of in (10)—that is, the number of actions—is 88. The lower bound in (35) is 165,088. However, because a large slows down learning, we set . We set and . Our numerical results are based on 100 independent replications.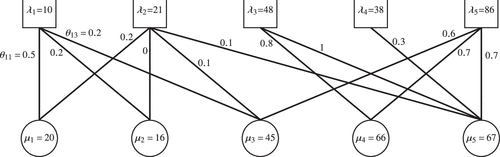
Note. The parameter values are shown in the figure.
We note that the average runtime of one simulation for the UCB QR algorithm was approximately 90 seconds. This was comparable to the runtimes of the benchmark policies, which ranged from approximately 100 to 150 seconds.
We consider three different scenarios with different levels of difficulty for adaptive learning:
Initial parameters: The first scenario is the system with initial parameters as shown in Figure 14.
Minimal payoff discrepancy: In this scenario, all but one payoff parameters are equal. In particular, for all except for . The learning policy must identify this minimal payoff gap.
Balanced arrival rates: In the third scenario, the arrival rates are equal for all customers, namely, for all . This value is chosen so that the total load of the system is high, namely, approximately 0.98.
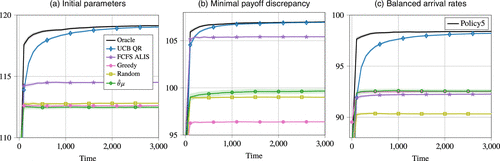
We compare the UCB QR algorithm with the other benchmark policies as described above. The average number of customers in the system is provided in Table 1, and the payoff rate is illustrated in Figure 15.
|

Table 1. Mean () and Standard Deviation () of the Number of Customers in the System over the Entire Simulation Time for All Policies and Scenarios
| Policy | Scenario | |||||
|---|---|---|---|---|---|---|
| Initial parameters | Min. payoff discrepancy | Balanced arrival rates | ||||
| Oracle | 329 | 106 | 269 | 80 | 277 | 90 |
| UCB QR | 315 | 101 | 147 | 31 | 248 | 71 |
| FCFS ALIS | 9 | 0.3 | 12 | 0.8 | 12 | 0.8 |
| Greedy | 14,069 | 142 | 17,372 | 148 | 14,193 | 207 |
| Random | 8,491 | 138 | 8,483 | 130 | 9,447 | 130 |
| 14,253 | 806 | 10,552 | 1,869 | 12,931 | 1,841 | |
Note. The legend is the same for all subplots.
Observe in Table 1 that the UCB QR and Oracle policies have a similar average number of customers in the system in all scenarios. The average queue lengths of the FCFS ALIS policy are much smaller than those of Oracle and the UCB QR algorithm. This is to be expected, because this policy inherently aims to decrease the queue length. However, the nonidling nature of this policy leads to a gap in payoff rate with respect to the Oracle policy, as can be seen in Figure 15. For the Greedy, Random, and policies, the average number of customers in the system is much higher than for the other policies. Despite the high average queue length, the average payoff of Greedy, Random, and in Figure 15 is comparable to that of FCFS ALIS. This is explained as follows: the policies obtain high reward by routing customer types with high average payoffs, whereas other customer types with overall lower average payoffs are not served at all. We find that for the initial parameters and minimal payoff discrepancy scenarios, especially the queue length of customer type 4 is large for these policies, because this customer type is only compatible with server 5, whereas the service capacity of server 5 is for a large part used by customer types 3 and 5. For this reason, the Greedy policy obtains an even lower average reward than the Random policy.
Observe also in Figure 15 that the convergence of the payoff rate of the UCB QR algorithm to the optimal payoff of the Oracle policy is faster than in the small queueing system considered in Section 5.1 (see Figure 10)—that is, the regret is smaller. This can be explained by the choice of (10 versus 364). A smaller value of implies that the episodes are shorter. Hence, per time interval, there are more decision moments where the policy can switch between actions, which speeds up learning.
The Greedy and policy obtain similar payoffs in the initial and balanced arrival rate scenario. In the minimal payoff discrepancy scenario, the policy obtains higher payoffs than the Greedy policy, only just outperforming the Random policy. Concentration of the estimators is sufficiently fast such that we do not see fluctuations in the average payoff rate of the policy.
Comparing the different scenarios, we find that in the minimal payoff discrepancy scenario, the UCB QR algorithm chooses suboptimal actions more frequently than in the other scenarios. However, because the suboptimality gaps of the suboptimal actions are small by construction, the average reward is still close to the optimal, as shown in Figure 15(b). Out of the three scenarios, the convergence is slowest in Figure 15(c). Our belief is that in this case, the algorithm needs approximately the same number of suboptimal episodes to learn the payoff parameters as in the initial scenario, whereas the suboptimality gaps are larger—that is, the cost of exploration is higher.
Lastly, we note that Algorithm 1, although it maintains system stability by construction, is not incentivized to minimize or balance the queue lengths or server loads. Possible extensions of the algorithm where customer waiting times, server loads, or fairness constraints are taken into account are interesting for future research. For example, in (10) can be altered to include either waiting time constraints or a penalty factor proportional to the average queue length in the objective function. This would result in a different action space for the algorithm.
To summarize the findings of this section, we have shown that even in a complex queueing system with 88 different actions, the UCB QR algorithm converges quickly to the oracle reward, while maintaining reasonable queue lengths in different scenarios.
The authors thank Thomas van Vuren for his insightful comments and fruitful discussions. This work is part of Valuable AI, a research collaboration between the Eindhoven University of Technology and the Koninklijke KPN N.V.
References
- (2012) Exact FCFS matching rates for two infinite multitype sequences. Oper. Res. 60(2):475–489.Link, Google Scholar
- (2014) A skill-based parallel service system under FCFS-ALIS—Steady state, overloads, and abandonments. Stochastic Systems 4(1):250–299.Link, Google Scholar
- (2013) Stochastic convex optimization with bandit feedback. SIAM J. Optim. 23(1):213–240.Google Scholar
- (2014) A dynamic near-optimal algorithm for online linear programming. Oper. Res. 62(4):876–890.Link, Google Scholar
- (2002) Finite-time analysis of the multiarmed bandit problem. Machine Learn. 47(2–3):235–256.Google Scholar
- (1995) The achievable region method in the optimal control of queueing systems; formulations, bounds and policies. Queueing Systems 21(3–4):337–389.Google Scholar
- (1997) Introduction to Linear Optimization (Athena Scientific, Belmont, MA).Google Scholar
- (2015) On the (surprising) sufficiency of linear models for dynamic pricing with demand learning. Management Sci. 61(4):723–739.Link, Google Scholar
- (2019) Learning and hierarchies in service systems. Management Sci. 65(3):1268–1285.Link, Google Scholar
- (2012)
Adaptive policies for sequential sampling under incomplete information and a cost constraint . Daras N, ed. Applications of Mathematics and Informatics in Military Science, Springer Optimization and its Applications, vol. 71 (Springer, New York), 97–112. Google Scholar - (1996) Optimal adaptive policies for sequential allocation problems. Adv. Appl. Math. 17(2):122–142.Google Scholar
- (1997) Optimal adaptive policies for Markov Decision Processes. Math. Oper. Res. 22(1):222–255.Link, Google Scholar
- (2017) Asymptotically optimal multi-armed bandit policies under a cost constraint. Probab. Engrg. Infom. Sci. 31(3):284–310.Google Scholar
- (2020) A survey on skill-based routing with applications to service operations management. Queueing Systems 96(1–2):53–82.Google Scholar
- (2021) Job dispatching policies for queueing systems with unknown service rates. MobiHoc’21 Proc. Twenty-Second Internat. Sympos. Theory Algorithmic Foundations Protocol Design Mobile Networks Mobile Comput. (Association for Computing Machinery, New York), 181–190.Google Scholar
- (1968) On the superposition of point processes. J. Roy. Statist. Soc. Ser. B Methodological 30:576–581.Google Scholar
- (1982) The Single Server Queue. 2nd ed. (Elsevier, Amsterdam).Google Scholar
- (2023) Score-aware policy-gradient methods and performance guarantees using local Lyapunov conditions: Applications to product-form stochastic networks and queueing systems. Preprint, submitted December 5, https://arxiv.org/abs/2312.02804v1.Google Scholar
- (1999) The achievable region approach to the optimal control of stochastic systems. J. Roy. Statist. Soc. Ser. B Statist. Methodology 61(4):747–791.Google Scholar
- (2008) Stochastic linear optimization under bandit feedback. 21st Annual Conf. Learn. Theory COLT 2008 (Omnipress, Madison, WI), 355–366.Google Scholar
- (2005)
A primer in column generation . Desaulniers G, Desrosiers J, Solomon MM, eds. Column Generation (Springer, Boston), 1–32.Google Scholar - (2021) Learning-NUM: Network Utility Maximization with unknown utility functions and queueing delay. Proc. Internat. Sympos. Mobile Ad Hoc Networking Comput. MobiHoc (Association for Computing Machinery, New York), 21–30.Google Scholar
- (2022) Joint learning and control in stochastic queueing networks with unknown utilities. Proc. ACM Measurement Anal. Comput. Systems 6(3):58.Google Scholar
- (2023) A Benders decomposition approach for solving a two-stage local energy market problem under uncertainty. Appl. Energy 329:120226.Google Scholar
- (2010) Service-level differentiation in many-server service systems via queue-ratio routing. Oper. Res. 58(2):316–328.Link, Google Scholar
- (2013) Performance Modeling and Design of Computer Systems: Queueing Theory in Action (Cambridge University Press, Cambridge, UK).Google Scholar
- (1963) Probability inequalities for sums of bounded random variables. J. Amer. Statist. Assoc. 58(301):13–30.Google Scholar
- (2022) Integrated online learning and adaptive control in queueing systems with uncertain payoffs. Oper. Res. 70(2):1166–1181.Link, Google Scholar
- (2024) Online learning and pricing for service systems with reusable resources. Oper. Res. 72(3):1203–1241.Link, Google Scholar
- (2010) A distributed CSMA algorithm for throughput and utility maximization in wireless networks. IEEE/ACM Trans. Networking 18(3):960–972.Google Scholar
- (2021) Matching while learning. Oper. Res. 69(2):655–681.Link, Google Scholar
- (2021) Scheduling servers with stochastic bilinear rewards. Preprint, submitted December 13, https://arxiv.org/abs/2112.06362v1.Google Scholar
- (2002) Queueing models of call centers: An introduction. Ann. Oper. Res. 113(1–4):41–59.Google Scholar
- (2018) On learning the cμ rule in single and parallel server networks. 2018 56th Annual Allerton Conf. Commun. Control Comput. Allerton 2018 (IEEE, Piscataway, NJ), 153–154.Google Scholar
- (1985) Asymptotically efficient adaptive allocation rules. Adv. Appl. Math. 6(1):4–22.Google Scholar
- (2020) Bandit Algorithms (Cambridge University Press, Cambridge, UK).Google Scholar
- (2021) Scheduling jobs with stochastic holding costs. Adv. Neural Inform. Processing Systems 23:19375–19384.Google Scholar
- (2019) RL-QN: A reinforcement learning framework for optimal control of queueing systems. 2019 57th Annual Allerton Conf. Commun. Control Comput. Allerton 2019 (IEEE, Piscataway, NJ), 663–670.Google Scholar
- (2020) POND: Pessimistic–Optimistic oNline Dispatching. Preprint, submitted October 20, https://arxiv.org/abs/2010.09995v1.Google Scholar
- (2024) The generalized c/μ rule for queues with heterogeneous server pools. Oper. Res. 72(6):2488–2506.Link, Google Scholar
- (2016) Online network optimization using product-form Markov processes. IEEE Trans. Automatic Control 61(7):1838–1853.Google Scholar
- (2020) Adaptive matching for expert systems with uncertain task types. Oper. Res. 68(5):1403–1424.Link, Google Scholar
- (1971) The assignment game I: The core. Internat. J. Game Theory 1(1):111–130.Google Scholar
- (1956) Various optimizers for single‐stage production. Naval Res. Logist. Quart. 3:59–66.Google Scholar
- (2022) Learning from delayed semi-bandit feedback under strong fairness guarantees. IEEE INFOCOM 2022 IEEE Conf. Comput. Commun. (IEEE, Piscataway, NJ), 1379–1388.Google Scholar
- (2023) Congestion-aware matching and learning for service platforms. Preprint, submitted March 14, https://doi.org/10.2139/ssrn.5258944.Google Scholar
- (2012) Online advertisement, optimization and stochastic networks. IEEE Trans. Automatic Control 57(11):2854–2868.Google Scholar
- (2020) Mechanism design for online resource allocation: A unified approach. SIGMETRICS’20 Abstracts 2020 SIGMETRICS/Performance Joint Internat. Conf. Measurement Modeling Comput. Systems (Association for Computing Machinery, New York), 11–12.Google Scholar
- (2021) The Bayesian prophet: A low-regret framework for online decision making. Management Sci. 67(3):1368–1391.Link, Google Scholar
- (2012) A product form solution to a system with multi-type jobs and multi-type servers. Queueing Systems 70(3):269–298.Google Scholar
- (2023) Constant regret primal-dual policy for multi-way dynamic matching. Performance Evaluation Rev. 51(1):79–80.Google Scholar
- (2021) Scheduling and Control of Queueing Networks (Cambridge University Press, Cambridge, UK).Google Scholar
- (2022) A c/μ-rule for job assignment in heterogeneous group-server queues. Production Oper. Management 31(3):1191–1215.Google Scholar
- (2023) Learning while scheduling in multi-server systems with unknown statistics: MaxWeight with Discounted UCB. Proc. Machine Learn. Res. 206:4275–4312.Google Scholar
- (2017) Online convex optimization with stochastic constraints. Adv. Neural Inform. Processing Systems 30:1429–1439.Google Scholar
- (2022) Learning the scheduling policy in time-varying multiclass many server queues with abandonment. Preprint, submitted April 21, https://doi.org/10.2139/ssrn.4090021.Google Scholar

