A Combined Simulation-Optimization Approach for Robust Timetabling on Main Railway Lines
Abstract
Performance aspects such as travel time, punctuality, and robustness are conflicting goals of utmost importance for railway transports. To successfully plan railway traffic, it is therefore important to strike a balance between planned travel times and expected delays. In railway operations research, a lot of attention has been given to construct models and methods to generate robust timetables—that is, timetables with the potential to withstand design errors, incorrect data, and minor everyday disturbances. Despite this, the current state of practice in railway planning is to construct timetables manually, possibly with support of microsimulation for robustness evaluation. This paper aims to narrow the gap between the state-of-the-art optimization-based research approaches and the current state of practice to construct timetables by combining simulation and optimization. The paper proposes a combined simulation-optimization approach for double-track lines, which generalizes previous work to allow full flexibility in the order of trains by including a new and more generic model to predict delays. By utilizing delay data from simulation, the approach can make socioeconomically optimal modifications of a given timetable by minimizing predicted disutility—the weighted sum of scheduled travel time and total predicted delay. In a large simulation experiment on the heavily congested Swedish Western Main Line, it is demonstrated that compared with a real-life, manually constructed timetable, large reductions of delays as well as improvements in punctuality could be obtained for a small cost of marginally longer travel times. The cost of scheduled in-vehicle travel time and mean delay was reduced by 5% on average, representing a large improvement for a highly utilized railway line. Furthermore, a separate scaling experiment indicates that the approach can also be suitable for larger problems.
Funding: This research was funded by Trafikverket [Grants TRV 2016/5090 and TRV 2020/72690].
1. Introduction
Two important properties of a railway transportation service are short travel times and high reliability. In particular, service reliability has a central role when assessing the quality of a railway service, and it is commonly considered to have a high impact on traveler’s satisfaction and thus, also the general attractiveness of the transport mode. Because reliability is important when evaluating the quality of a railway service, it is important to include the perspective of reliability in the planning of the timetable.
In previous research, where the earliest examples date back to the early 1970s, much effort has been concentrated on developing methods and models for designing and improving timetables, with many different perspectives. To improve reliability, robust timetabling has been extensively researched, resulting in several state-of-the-art optimization-based approaches. Despite this, none of these approaches seem to have been applied, and only two examples of successful applications of optimization in timetabling seem to exist: in the Berlin subway (Liebchen 2008) and in the Dutch railway (Kroon et al. 2009). Instead, the state of practice in railway planning is still based on manual timetabling with limited computational support, possibly in combination with microsimulation for performance evaluation.
A problem with this manual process, as noticed in the Swedish railways (Palmqvist, Olsson, and Winslott Hiselius 2018) but likely a common problem for the railway industry in general, is that timetable planners are too busy with constructing the timetable and resolving conflicts to also ensure a sufficient level of robustness. To narrow the substantial gap between research and practice in robust railway timetabling, this paper is intended to address how robustness in a given timetable can be improved semiautomatically using a combination of simulation and optimization. This approach is intended for application in the annual timetabling process to improve the robustness of the proposed timetable on important corridors of the network before it is established. In comparison with the rich research body of solely optimization-based approaches for railway timetabling, this type of approach seems to have received little attention.
In previous research, Högdahl, Bohlin, and Fröidh (2019) proposed a combined simulation-optimization approach to minimize the weighted sum of scheduled travel time and expected delay, in which the weighting was done considering the socioeconomic valuation of reducing mean delay relative to reducing scheduled travel time. In other words, they addressed the conflict between short travel times and high reliability that is important for the transport mode’s attractiveness. An essential part of their contribution involved the expected delay of the optimal timetable being predicted using a combined simulation-optimization approach, in which (1) the delays of a given original timetable were estimated using simulation and (2) delays in the optimized timetable were minimized via a surrogate model that was included in the timetable optimization problem to predict these delays. However, a shortcoming with their approach is that the delay prediction model computes delays by including the knock-on effect from preceding trains in each single realization of the original timetable. For this reason, the model is tractable only if the train order is fixed, which is a significant obstacle to its practical use, as minor train order adjustments are often necessary. Furthermore, because of the formulation of the delay prediction model, the entry time (which is the time a train enters the network) for each train also had to be fixed.
Considering these restrictions, this paper aims to describe a generalized approach that allows full flexibility in the order of trains; to evaluate the effects of the new approach on robustness, travel times, delays, and punctuality; and to evaluate its scalability for large-scale problems. The new and significantly extended approach is made possible by a new and more generic model to predict traffic delays that considers both delay recovery and knock-on delays from preceding trains. Consequently, this new approach can be used to compute the most suitable train order based on a given timetable and delay data from simulation. The approach in this paper was implemented with a commercial microsimulation software. However, because it only uses macroscopic data from the simulator, it is expected that the approach can, with minor adjustment to its data exchange interface, be adapted relatively easily for use with most industry railway simulators that are currently in use.
1.1. State of Practice in European Railway Timetabling
In most European countries, the railway market is deregulated to comply with the European Union railway directives. For this reason, the railway industry in each country is vertically separated into an infrastructure manager, which owns and manages the railway infrastructure, and one or several railway undertakings, which are responsible for train services. Ait Ali and Eliasson (2022) have recently reviewed how capacity is allocated in 11 European countries. They found that the capacity allocation process is fairly similar in these countries and involves the following actors: one or several railway undertakings that request capacity for train paths; a capacity allocator (usually the infrastructure manager) that coordinates the capacity allocation process and establishes the annual timetable; and a railway regulator that oversees that the capacity allocation complies with regulations and that capacity is allocated in a nondiscriminatory way.
Because the capacity allocation process in each country is similar, the Swedish process is used as an example. Figure 1 shows an overview of the involved steps. The process starts when the capacity allocator publishes the network statement, which defines how to apply for train paths and the constraints that apply to each section in the network. Based on the network statement and the estimated travel demand, railway undertakings construct requests for train paths. In Sweden, timetables are currently constructed in Trainplan (https://www.signaturerail.com), but this will soon be replaced by TPS (https://www.hacon.de) (Palmqvist, Olsson, and Winslott Hiselius 2018). In their marketing material, neither Trainplan nor TPS seem to support timetable optimization.
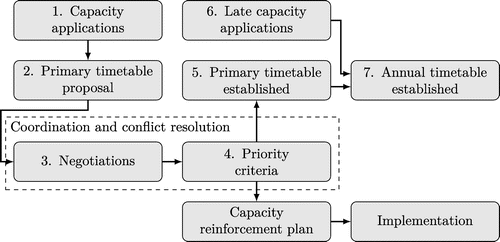
Note. Based on Trafikverket (2021b)
The railway undertakings submit applications that should be included in the primary timetable in mid-April. Applications submitted after this date can be added after the primary timetable has been finalized. Adding requests for maintenance work, the capacity allocator then constructs a proposal for the next annual timetable using Trainplan. The timetable proposal is sent in the beginning of July to each railway undertaking for review. When applications conflict, the capacity allocator coordinates negotiation between the railway undertakings involved for resolution. The conflicts that cannot be resolved by the railway undertakings are resolved by the capacity allocator following predefined prioritization criteria. In this case, the concerned sections are also declared congested, which initiates an investigation into how to improve capacity.
When all conflicts have been resolved, the capacity allocator evaluates the timetable on a few lines of the Swedish network using the microsimulation software Railsys (https://www.rmcon.de/railsys-en/), ensuring that it is conflict free and sometimes, assessing compliance with newly updated construction rules. At this stage, during the second half of September, the capacity allocator establishes a primary timetable. If late applications exist at this stage, they are added to the timetable if it is possible and in the order they were submitted to the capacity allocator. Finally, once late applications have been handled, the capacity allocator establishes the new timetable in mid-November, which is put in operation in mid-December.
In the context of the current capacity allocation process, the intended application for the approach in this paper is to make adjustments before the primary timetable is finalized and before the annual timetable is established (when late requests have been added to the primary timetable). The approach could therefore be part of steps 5 and 7 in Figure 1.
1.2. Contributions
This paper makes the following scientific contributions.
A new and generalized delay prediction model, which can be used to predict delays based on adjustments in a given timetable and delay data from simulation, is proposed (Section 3.3).
The considered optimization problem, which utilizes simulation output to improve a given timetable, is defined and formulated as a mixed integer linear program (Section 3.4). A simulation-optimization approach, combining estimated delays from a state of practice simulation software with the optimization problem to make optimal adjustments to a given timetable, is introduced (Section 3.5). In comparison with previous work, the proposed approach (a) can manage full flexibility in the order of trains, (b) is formulated to enable being solved using a general purpose mixed integer linear programming (MILP) solver, and (c) is implemented with a state of practice simulation tool.
A thorough simulation study based on the busiest railway line in Sweden was used to analyze and compare several variants of the approach with each other and the original timetable (Section 4). Compared with the original timetable, at the cost of marginally longer travel times, significant reductions in delays as well as punctuality improvements were observed (Section 5.2). The total disutility (i.e., the weighted sum of scheduled in-vehicle travel time and mean delay) was reduced by 5% on average, a substantial improvement for a highly congested railway line. Finally, a scaling experiment considering planning flexibility and the number of trains showed that variants of the approach appear to be feasible for large-scale problems (Section 5.3).
1.3. Paper Outline
This paper is divided into six sections, including this introduction. The next section presents related work in railway timetabling and is mainly focused on approaches that combine simulation and optimization for robust railway timetabling. The third section constitutes the main technical content of the paper and presents the delay prediction model, the timetabling model in which it is applied, and the combined simulation-optimization approach. After this, Section 4 describes the evaluation scenario and the simulation and optimization model setup. Section 5 describes the results of the simulation experiments. Finally, the last section presents the conclusions and possible future work.
2. Related Work
Railway timetabling has been an active field in the operations research community for several decades. A central topic in railway timetabling is the timetabling problem, which is the problem with deciding the optimal arrival and departure times to and from each station in a railway network for a given set of trains. To address the timetabling problem, several models have been proposed in the literature: for example, Szpigel (1973), Serafini and Ukovich (1989), Jovanovic and Harker (1991), Higgins, Kozan, and Ferreira (1996), Brännlund et al. (1998), Caprara, Fischetti, and Toth (2002), and Lamorgese, Mannino, and Natvig (2017). Surveys have also been conducted by Cacchiani and Toth (2012), Harrod (2012), and Caimi, Kroon, and Liebchen (2017). A common characteristic between the models described in Szpigel (1973), Serafini and Ukovich (1989), Jovanovic and Harker (1991), and Higgins, Kozan, and Ferreira (1996) is that they are all macroscopic event-based models, in which arrivals and departures to and from stations are events that are each associated with a scheduled time, which should be decided. This type of model has been widely used in the literature (see, for instance, Herrigel et al. 2018, Polinder et al. 2019, or Yan, Bešinović, and Goverde 2019 for recent examples), and the timetabling model used in this paper belongs to this class.
An important topic in railway timetabling is designing timetables that are applicable in practice. For this reason, it is important that generated timetables are robust to model and data inaccuracies as well as to random disturbances that occur in everyday operation. The concept of timetable robustness varies between definitions provided by several authors. Andersson, Peterson, and Törnquist Krasemann (2013, p. 96), for instance, define a robust timetable as “a timetable that can recover from small delays and keep the delays from spreading over the network,” whereas Goverde and Hansen (2013, p. 304) defined robustness as “the ability of a timetable to withstand design errors, parameter variations, and changing operational conditions.” Others have considered timetable robustness in relation to reliability for passengers. For instance, Dewilde et al. (2014, p. 279) defined a robust railway system as one that “minimizes the total weighted real travel time of the passengers, in case of frequently occurring, small disturbances,” whereas Schöbel and Kratz (2009, p. 121) defined robustness as the “largest possible delay such that all transfers are maintained under some given strategy.”
An intuitive way to address this robustness issue could be to enforce the necessary robustness by applying techniques from stochastic programming or robust optimization, which are standard methodologies used to deal with uncertainties in operations research. However, stochastic programming is considered to yield too complicated models to be solvable for real-life applications (Fischetti and Monaci 2009, Liebchen et al. 2009), whereas robust optimization is considered to yield solutions that are too conservative to be accepted in real-life applications (Fischetti and Monaci 2009, Liebchen et al. 2009, Caimi, Kroon, and Liebchen 2017). These methodologies have therefore been thought to be unsuitable for robust railway timetabling. Instead, many approaches developed specifically for robust railway timetabling have been proposed in the literature.
Kroon et al. (2008) applied a two-stage stochastic programming approach to minimize delays in a cyclic timetable. Fischetti, Salvagnin, and Zanette (2009) defined the concept of light robustness, which they described as a framework in which robustness is maximized and objective deterioration is bounded, and applied it to improve a nonperiodic timetable. They observed that it achieved similar performance as a stochastic programming model but in shorter time. Later, Cacchiani, Caprara, and Fischetti (2012) proposed a Lagrangian heuristic approach, which was observed to yield a solution with performance similar to light robustness but in shorter time.
Liebchen et al. (2009) defined the concept of recoverable robustness, in which a solution is recoverable robust if it can be recovered in finite time for a set of delay scenarios by a recovery algorithm. In Liebchen et al. (2010), they proposed the concept of delay-resistant timetables, in which the expected delay is added to the nominal objective. The expected delay depends on the delay management policy for which they propose a formula considering a strict no-wait delay management policy.
Another robustness measure has been proposed by Andersson, Peterson, and Törnquist Krasemann (2013). They defined the concept of robustness in critical points, in which some scheduling situations (e.g., overtakes) were pointed out as sensitive to small delays. Later, in Andersson, Peterson, and Törnquist Krasemann (2015), the robustness measure was applied in a timetabling model to redistribute the margins in a timetable to obtain a predefined robustness level at critical points.
Because efficiency and robustness are conflicting objectives in timetable planning, bicriteria methods to find Pareto-optimal solutions have also been proposed by some authors. Schöbel and Kratz (2009), for instance, proposed three robustness measures, which all focus on robustness for passengers and derived necessary conditions for the Pareto-optimal solutions. Another example was also described in Schlechte and Borndörfer (2010), who considered a robustness measure based on allocated buffer time between trains.
Ferreira and Higgins (1996) proposed an analytical model to quantify the risk of delay, which was implemented in a timetabling model to minimize trip time and risk of delay on a single-track railway line. Later, the delay model was extended by Higgins and Kozan (1998) to allow for application to urban networks. A similar perspective (to explicitly minimize delays) has also been adopted by Sels et al. (2016). They derived an analytical model to compute the expected passenger travel time, proposed a linear approximation of it, and implemented it with an event-based timetabling model to generate a robust timetable.
2.1. Simulation-Optimization Approaches for Robust Railway Timetabling
Simulation of railway operation often plays an important role when evaluating and comparing a limited set of timetables. In the research community, simulation has also been widely used to evaluate the impact of optimization methods for timetabling (e.g., as in Kroon et al. 2008, Fischetti, Salvagnin, and Zanette 2009, Cacchiani, Caprara, and Fischetti 2012, Sels et al. 2016, and Solinen, Nicholson, and Peterson 2017). However, despite the extensive use of both simulation and optimization in the literature, the combined use of simulation and optimization to construct timetables seems to have received little attention. This may be partially because of simulations tending to be time consuming and also requiring detailed data for modeling, particularly valid for highly detailed microsimulation models. However, simulation also has the benefit of allowing detailed modeling for track layout and can be implemented with sophisticated dispatching strategies, which are essential to actual operations. In the literature review, the following approaches combining simulation and optimization for robust railway timetabling have been found: Bešinović et al. (2016), Burggraeve and Vansteenwegen (2017), Högdahl, Bohlin, and Fröidh (2017, 2019), Lee et al. (2017), Chow and Pavlides (2018), and Högdahl (2019b).
Bešinović et al. (2016) described an iterative micro-macro approach to generate timetables that are microscopically feasible, stable, and robust. Their approach is based on alternating between a macroscopic module and a microscopic module. The macroscopic module solves an integer progamming timetabling problem using a heuristic algorithm that includes Monte Carlo simulation to evaluate the robustness of each candidate solution. The microscopic module evaluates whether the macroscopic timetable is microscopically feasible. If the macroscopic timetable is not microscopically feasible, the results are used to relax or to tighten the formulation of the macroscopic timetabling problem, which is solved again until a solution is found that is both macro- and microscopically feasible.
Burggraeve and Vansteenwegen (2017) described an approach for a related problem, which is routing and timetabling in complex station areas (where a station area “consists of a number of stations close to each other” (Burggraeve and Vansteenwegen, 2017, p. 172)). Instead of only considering the timetabling phase of the planning process, they also assign station routes to each train. The approach is based on four main components: (1) assign station routes, (2) schedule a timetable that satisfies the routing plan, (3) evaluate the robustness of the solution with simulation, and (4) assign supplements and buffer times for the next iteration according to a set of rules.
Högdahl, Bohlin, and Fröidh (2017) presented a simulation-optimization approach based on alternating between simulating a given timetable and optimizing the weighted sum of scheduled travel time and expected delay, in which the expected delay was computed using a model based on the observed delays from the simulation of the original timetable and the difference in scheduled arrival times compared with the original timetable. Because of the formulation of the model, the sequence of the trains was required to be fixed. The approach was only partially evaluated (by a single iteration of the approach).
Lee et al. (2017) presented a timetable improvement heuristic to adjust margins in a given feasible timetable to improve its robustness. The core of their approach was to alternate between solving a timetabling problem (to allocate margins) and simulating the resulting timetable. The timetabling problem was formulated as an linear progamming problem with the objective to minimize a weighted sum of scheduled time supplement that exceeds a certain threshold and the deviation from targeted supplements and buffer times. The simulation module was used to evaluate the latest timetable, and the simulation result was used to update target values in the objective function of the timetabling problem. Unless the termination criterion was satisfied, the approach proceeded by solving the timetabling problem again. Because their timetabling problem was formulated as a linear program, the approach was restricted to a fixed train order.
Chow and Pavlides (2018) described a multiobjective approach to mainline timetabling, in which travel times, waiting times, crowding, and punctuality were minimized. To solve that problem, they proposed a simulation-optimization algorithm, which was based on a genetic algorithm to find the best sequence of the trains paired with Dijkstra’s algorithm to construct a schedule for each train. Monte Carlo simulation of the current candidate timetable was utilized to evaluate the objective function, which was done in each iteration of their approach
Högdahl, Bohlin, and Fröidh (2019) extended the earlier paper by Högdahl, Bohlin, and Fröidh (2017), which described an iterative simulation-optimization approach based on essentially two steps to adjust a given original timetable. In comparison with Högdahl, Bohlin, and Fröidh (2017), a simplified single-operation approach was proposed. The original timetable was simulated in the first step to generate estimates of delays, and in the second step, the original timetable was modified by solving a timetabling problem by minimizing the weighted sum of scheduled travel time and expected delay. The paper used the model to compute the expected delay that was proposed in Högdahl, Bohlin, and Fröidh (2017). To calibrate the model parameters to compute the expected delay, an additional calibration problem was also included in the approach, which was solved using a random search method.
Finally, Högdahl (2019b), which this paper is an extension of, has also described a simulation-optimization approach to improve a given timetable. They described early work to extend the approach in Högdahl, Bohlin, and Fröidh (2019) and proposed an approach with a delay prediction model that made it possible to allow a flexible train order. The approach was partially evaluated in a small simulation experiment, limited to 35 trains on a short section of the Swedish Southern Main Line. The present paper differs from the paper by Högdahl (2019b) as follows. The delay prediction model has been further developed by providing additional justifications and by simplifying the model; a procedure to calibrate the parameters of the delay prediction model has been described; several new experiments have been added, which were conducted on larger problem instances; and the analyses of the results have been greatly extended. The added experiments and extended analyses enabled new conclusions in the present paper compared with Högdahl (2019b).
Table 1 provides a brief overview of differences and commonalities with respect to some qualitative aspects between the described approaches and this paper. As can be seen, most of the previous approaches are aimed at timetabling of individual lines, which is also the case in this paper. It can also be seen that the approaches by Högdahl, Bohlin, and Fröidh (2017; 2019), Lee et al. (2017), and Högdahl (2019b) require an original timetable as input to the approach. These approaches can therefore be categorized as designed to improve a given timetable, which is also the aim with the approach in this paper. Among these approaches, it is also seen that only the paper by Högdahl (2019b), which the present paper is an extension of, is able to handle a flexible train order. It is therefore concluded that earlier approaches to improve a given timetable cannot handle a flexible order of trains, which limits their ability to improve the given timetable.
|

Table 1. A Comparison Between Simulation-Optimization Approaches for Robust Railway Timetabling
| Authors | Scope | Original timetable needed | Flexible train order | Solution approach | Model granularity |
|---|---|---|---|---|---|
| Bešinović et al. (2016) | Network | No | Yes | Heuristic | Micro-macro |
| Burggraeve and Vansteenwegen (2017) | Station area | No | Yes | Heuristic | Micro |
| Chow and Pavlides (2018) | Line | No | Yes | GA | Micro |
| Högdahl (2019b) | Line | Yes | Yes | MILP | Macro |
| Högdahl, Bohlin, and Fröidh (2017, 2019) | Line | Yes | No | MILP | Macro |
| Lee et al. (2017) | Line | Yes | No | Heuristic | Micro |
| This paper | Line | Yes | Yes | MILP | Macro |
Note. GA, genetic algorithm; MILP, mixed integer linear progamming.
A commonality between the approaches proposed by Bešinović et al. (2016), Burggraeve and Vansteenwegen (2017), and Lee et al. (2017) is that they iteratively generate a sequence of candidate timetables by alternating between solving an optimization problem and simulating the resulting timetable. They each formulate separate optimization problems, but similarly, they use the simulation result in each iteration to update parameters in the optimization problem for the next iteration using a set of heuristic rules (which naturally also differ in each approach). As indicated in Table 1, these approaches can therefore be categorized as heuristic approaches. In addition, the approach proposed by Chow and Pavlides (2018) is based on metaheuristics.
In contrast, the methods by Högdahl (2019b) and Högdahl, Bohlin, and Fröidh (2019) are single-operation methods based on exact optimization, in which the aim is to compute the impact of the modifications compared with the given timetable rather than bounding or guiding the optimization problem by iteratively updating the parameters or constraints to the problem. Because of the formulation of the model in Högdahl, Bohlin, and Fröidh (2017, 2019), it was necessary to restrict their approach to cases where the train order was fixed. For the general case where train order can vary, the only approach based on exact optimization that to the best of our knowledge seems to exist is the approach by Högdahl (2019b). However, Högdahl (2019b) is part of the same research leading to the present paper and can therefore be viewed as an earlier version.
This therefore leads to the conclusion that the following two gaps in the literature are identified, which this paper aims to address: (1) none of the approaches attempting to improve a given timetable can handle flexible train order, and (2) among the approaches based on exact optimization, no approach can handle a flexible train order.
3. Timetable Adjustments for Travel Time and Delay Minimization
Railway traffic operation is usually planned by sequentially solving a series of planning problems. These problems (illustrated in Figure 2) can be categorized as (1) line planning to define train lines and their operating frequencies and stopping patterns, (2) timetabling to construct a detailed timetable based on the line plan, (3) crew and rolling-stock scheduling to operate the timetable, (4) ad hoc timetabling where the timetable can be modified before operation to insert additional trains and similar, and (5) operational dispatching used to resolve conflicts that arise during operation.

This paper deals with the following problem that mainly occurs in the timetabling phase when a timetable has been constructed but not established, although it can also be applied in the ad hoc timetabling phase. If the preliminary timetable would be evaluated using simulation, how could the simulation results be used to modify it? How would these modifications impact the robustness of the timetable, and which modifications would optimize it? By solving this problem, optimal modifications could be applied to the preliminary timetable, which is expected to give a more reliable operation and hence, benefit customers and society.
3.1. Terminology
The aim with the approach in this paper is to adjust a given timetable to optimize its robustness. The given timetable will be referred to as the original timetable, and the resulting timetable from the approach will be referred to as the modified timetable.
An important concept here is delays. In this paper, the term delay means the nonnegative difference between the observed time for a particular event and its scheduled time. If the observed time occurs before the scheduled time, then the train is early, which is treated as the delay is zero. To include early observations, the term deviation is used instead, where deviation is the difference between an event’s observed time and its scheduled time. Delay increments caused by external factors (e.g., signaling errors, track or vehicle failures, weather conditions) are called primary delays. Delay increments caused by other trains are not primary delays; instead, they are called knock-on delays.
3.1.1. Timetable Disutility and Robustness.
The term robustness is a core concept relating to mitigating the consequences of delays. The robustness of a timetable can be described as its potential to withstand design errors (e.g., too short headways or running times), incorrect data (e.g., assuming incorrect train types or running times), and minor disturbances that cause primary delays that occur during everyday operation. This is essentially the definition of robustness presented in Goverde and Hansen (2013). It has the benefit of being intuitively close to the dictionary definition of robustness. However, it has a major weakness by failing to provide a criterion for when a timetable should be considered robust or not, leaving it a vague definition. Dewilde et al. (2014, p. 279) defined robustness alternatively as follows: “A railway system that is robust minimizes the total weighted real travel time of the passengers, in case of frequently occurring, small disturbances.” The present paper uses a similar definition as Dewilde et al. (2014), namely that a robust timetable minimizes total disutility when traffic is operated in normal conditions. In this definition, the term total disutility corresponds to the total weighted real travel time of the passengers in Dewilde et al. (2014), which measures the disutility passengers and freight customers experience because of, for instance, in-vehicle travel time, transfer time, waiting time, expected delay, and similar delays.
According to Carrion and Levinson (2012), the value of travel time (VOT) and the value of travel time reliability (VOR) are the most important factors for travel behavior in travel demand studies. The former (VOT) represents the monetary values travelers or consumers place on reducing their travel time, whereas the latter (VOR) represents the monetary values placed on reducing the uncertainty of their travel time (Carrion and Levinson 2012). As the work in this paper is concerned mainly with the adjustment of existing timetables, a utility model most closely related to the mean lateness model is used. Essentially, the total disutility of a timetable can accordingly be approximated by the weighted sum of total scheduled (in-vehicle) travel time and total mean delay as follows:
The quotient is the so-called “lateness multiplier” giving the trade-off between destination mean lateness and scheduled travel time. Using this measure, the cost of delays is, in other words, weighted relatively to the cost of in-vehicle travel time, and the scheduled (in-vehicle) travel time and mean delay with each train can be weighted with respect to the passenger or freight volumes. In previous studies, this measure has been proposed by Warg and Bohlin (2016) as a measure to assess the socioeconomic benefit of railway timetables, and a very similar measure is (or was) used for reliability analyses in the British railway (Batley and Ibáñez 2012). In addition, this measure was also used by Högdahl, Bohlin, and Fröidh (2017, 2019) and Högdahl (2019b). Following the definition of Dewilde et al. (2014), this measure was also used by Sels et al. (2016) and Burggraeve and Vansteenwegen (2017). For this reason, this measure of robustness is considered an established measure in robust railway timetabling.
3.2. The Timetabling Model
A common way in railway operations research is to describe a timetable as a set of individual train paths composed of an ordered sequence of arrival and departure events, where each event is associated with a scheduled time. This has been the basis in the widely used periodic event scheduling problem model (Serafini and Ukovich 1989) as well as in related models used for nonperiodic timetabling. This paper proposes a new model to predict delays in a modified timetable based on its deviation from a given original timetable and the mean deviation and delay of each event sampled by simulating the original timetable. To keep a close connection to the aforementioned timetabling models, train paths are therefore modeled as sequences of arrival and departure events, which are illustrated by nodes in the time-distance graph in Figure 3.

Note. Each train path consists of an ordered sequence of arrival and departure events, which are marked with red nodes.
In our approach, intended for double-track lines, it is assumed that each track is only traversed by trains in one specific direction. The events are denoted by i, and a train consists of an ordered sequence of alternating departure and arrival events. Each event i is associated with a unique train. Thus, when referring to events i and i + 1, it is assumed that these are two consecutive events of the same train. The time points for these events are dictated by various operational constraints for minimum travel times, time supplements, minimum dwell times, and headway separation times. Using the notation as described in Table 2, these constraints are formulated as follows.
|
Table 2. A List of Variables and Parameters Used in This Paper
| Notation | Type | Description |
|---|---|---|
| ti | Var | Scheduled time of event i |
| si | Var | Scheduled time supplement between events i and i + 1 |
| xij | Var | A binary variable indicating the sequence of events i and j in two different trains; |
| pi | Var | A binary variable that is 1 if event i is a scheduled stop |
| Var | Predicted delay for event i | |
| Var | Predicted nonrecovered delay at event i | |
| Var | Predicted knock-on delay for event i | |
| di | Param | Minimum dwell time if a stop is scheduled between events i and i + 1 |
| ri | Param | Minimum running time between events i and i + 1 |
| Δij | Param | Minimum headway between events i and j to ensure safe and smooth operation |
| Li | Param | Lower boundary of ti |
| Ui | Param | Upper boundary of ti |
| M | Param | Parameter for linearization of conditional constraints and relations, etc. |
| λij | Param | Weight of the trip between events i and j |
| Param | Scheduled time of event i with the original timetable | |
| Param | Allocated time supplement between events i and i + 1 with the original timetable | |
| Param | A binary parameter that is 1 if event i was a scheduled stop with the original timetable and 0 otherwise | |
| Param | Observed mean deviation for event i with the original timetable | |
| β | Param | A sensitivity parameter that determines how changes in the allocated time supplements affect the predicted nonrecovered delay |
| τ | Param | The average delay increment for the predicted knock-on delays |
| W | Param | Planning-window width, which defines the width of the interval that each event must be scheduled within |
| Tmin | Param | The time of the earliest event with the original timetable |
| Tmax | Param | The time of the latest event with the original timetable |
Notes. Param, parameter; Var, variable.
The time of a departure from a station is determined by the train’s previous arrival ti (or an earliest arrival time for the origin of the train), and if it stops, the predetermined minimum dwell time di and the variable time supplement si at the station, in which the last two determine the actual dwell time of the train at the station. Provided that the minimum dwell time is nonzero (e.g., 30 seconds), a decision has to be made whether to schedule a stop at the station, which is indicated by the binary variable pi that is one if and only if a stop is scheduled. To model this, the following constraints apply for any arrival event i:
Similarly, the time of an arrival is determined by the time of the train’s previous departure ti, the minimum running time ri, and the variable time supplement si, in which the last two determine the actual running time of the train on the line. In other words, for any departure event i, the following constraint is imposed:
Next, we consider headway separation of trains to ensure safe and smooth operation of the timetable. In essence, for any station, two trains arriving or departing in or from the same direction must be separated by a minimum headway time. In this paper, the minimum headway time is considered as a requirement imposed by the infrastructure manager. These values may be based on, for example, simulation or experience, and possibly, they may also include small margins. Formally, two events i and j for different trains, which denote arrivals from the same direction to (or departures in the same direction from) the same station, are separated by a minimum headway as follows:
Finally, faster trains are allowed to overtake slower trains at stations if sidetracks can be reached from the main track without crossing the main track for traffic in the opposite direction. This means that overtakes are not allowed between stations and inside stations without such capacity. In these circumstances, the following condition applies for events of the same type, at the same station and for trains heading in the same direction. The order of events i and j must be equal to the order of the subsequent events i + 1 and j + 1: that is,
3.3. A Train Order-Independent Delay Prediction Model
The core of the new method is the new train order-independent delay prediction model for double-track lines. To compute the predicted delay of an event with the modified timetable, it is assumed that each track is used only in one direction and that trains in different directions do not cross each other. By also assuming that traffic is operated under normal conditions, it can be assumed that the trains are operated according to the planned sequence in the timetable. Under these conditions, the delay of any event will be determined by either the delay that is not recovered since the previous departure (or arrival) or by the preceding train. This is illustrated in Figure 4, in which the delay of departure event i of train h depends on the nonrecovered delay from the arrival event i – 1 of train h and the knock-on delay from the departure event j of train k.
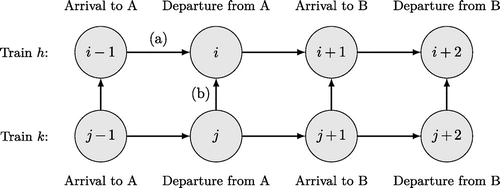
Note. The predicted delay of event i is assumed to depend on (a) nonrecovered delay carried over from the preceding event i−1 of the same trains and (b) knock-on delay from event j of the same type (arrival or departure) as event i from a different but immediately preceding train.
Furthermore, if the delay is still not recovered from the previous departure (or arrival) and is larger than the delay that may be propagated from the preceding train, then the delay from the preceding train will not contribute to the delay. For the opposite situation, the opposite holds. This implies that the predicted delay because of the two preceding events can be modeled using a function. By following the notation as described in Table 2, the predicted delay for an event i in the modified timetable is therefore computed as
3.3.1. Predicted Nonrecovered Delay.
The predicted nonrecovered delay is the delay component that propagates the delay from one event to the following event for the same train and acts as the source for delay increments in the delay prediction model. Its main purpose is to connect the predicted delays with the modified timetable, the simulated delays with the original timetable, and the allocation of time supplements. For this reason, it also models how the delay recovery depends on the allocated time supplements.
The predicted nonrecovered delay is computed based on the following assumptions: (1) the delay at event i is the sum of the delay at the previous event i – 1 and the expected delay development between these events, and (2) by increasing or reducing the scheduled time supplement, the delay at i is reduced or increased linearly.
Based on these assumptions, the following model is proposed for computing the predicted nonrecovered delay at arrival events and departure events following scheduled stops:
In Equation (13), which is also illustrated in Figure 5, the first term is simply the predicted delay at the previous event, the second term is the expected delay development between events i – 1 and i estimated by simulating the original timetable, and the third term is the difference in time supplement compared with the original timetable between events i – 1 and i. Because the expected delay development is computed based on observations with the original timetable, it may contain knock-on delays. However, this is not anticipated to be a problem because the model is intended for limited modifications of the original timetable.
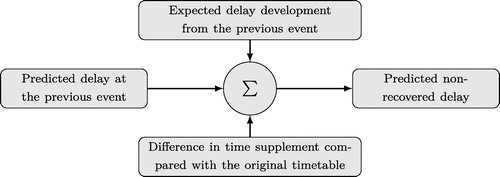
As can be seen, the difference in time supplement in Equation (13) is multiplied by the parameter β—meaning that if the time supplement is increased by a unit of time, then the predicted nonrecovered delay is reduced by β. This is because the possibility to recover delays depends on several factors that are not modeled. Examples of such factors are the driving behavior of the individual train drivers, the exact location of the delays, and if delays occur once or repeatedly to mention a few.
To illustrate this, consider the following two examples: (1) if a train is delayed at event i – 1 and does not become further delayed after that, then it can use the full time supplement to reduce the delay before event i and (2) If the train instead follows its schedule and get delayed precisely before event i, it cannot reduce the delay at all—independent of the size of the time supplement. For this reason, the impact of increasing the time supplement depends on the particular situation.
Because delays are not modeled in detail, this leads to an uncertainty on how much delays can be reduced by increasing the time supplement. It is therefore assumed that on average for all events the predicted nonrecovered delay is reduced by the increase in time supplement multiplied by some unknown factor β. Many more parameters could of course be used to make it possible to get a better fit: for example, one βi for each event. However, for the sake of model simplicity as well as practical tractability, it is proposed to choose a single parameter that is applied globally for all events. In Section 4.4.3, it is described how the value of β is decided in this paper.
The formula in Equation (13) is used for arrival events and departure events following after scheduled stops. In this paper, it is assumed that the arrival and the departure events at the same station occur at the same location—meaning that if a train is scheduled to pass a station, then the departure time equals the arrival time and the two events can essentially be considered as a single event. For the departure events where the train with the modified timetable is scheduled not to stop (which it may have done in the original timetable), the following model is therefore proposed:
Finally, the predicted nonrecovered delay in Equations (13) and (14) is not applicable for entry events because they are the first event of each train. In this paper, it is assumed that entry delays are independent of the planned timetable. For this reason, the predicted nonrecovered delay is not defined for entry events. Instead, the predicted delay for entry events is set to equal the mean delay observed with the original timetable.
3.3.2. Predicted Knock-On Delay.
The predicted knock-on delay is the delay component that can propagate a predicted delay from one train to its following train if they are not scheduled with a sufficiently large headway. It is computed based on the following assumptions: (1) the traffic is operated in the scheduled sequence, (2) the predicted earliest time of event i—preceded by event j—is the predicted time of event j plus a delay increment, and (3) the predicted knock-on delay is reduced by scheduling event i at a later time or reducing the predicted delay of event j.
Based on these assumptions, the following model to compute the predicted knock-on delay is proposed:
As can be seen, the delay increment is assumed to be a single parameter for all events. This is because the real delay increment depends on factors not modeled explicitly (e.g., the signaling system, the location where the follower first catches up with the leader, the station routes of the involved trains, etc.). For this reason, the delay increment is considered as random, and to handle this uncertainty, it is assumed that it on average is equal to τ. Naturally, the model can be extended with more than a single parameter to possibly get a better fit between model predictions and outcome. However, for the sake of model simplicity and practical tractability, it is in this paper—as with the predicted nonrecovered delay—described by a single parameter. In Section 4.4.3, it is described how the model parameters β and τ are decided in this paper.
3.3.3. The Complete Delay Prediction Model.
Finally, as a summary, the complete delay prediction model is—for nonentry events—formulated as follows:
Because the delay prediction model contains (nonlinear) functions and conditional expressions, the delay prediction model must be linearized before it can be included in a mixed integer linear programming formulation. Linearization can easily be conducted using binary variables and big-M constraints; this is a standard procedure for mixed integer linear programming as presented in, for example, Chen, Batson, and Dang (2010) and therefore, is not discussed further.
3.4. Applying the Delay Prediction Model to Nonperiodic Timetabling
The train timetabling problem is the problem of finding the timetable that optimizes utility for a given set of trains and satisfies a set of operational constraints. As noted earlier, a common approach to solve this problem is to formulate it as an event-based problem, where such events are either an arrival or a departure for a specific train at a specific station; then, the problem is to decide the optimal order for all trains and the optimal time for each event.
Using the notation as described in Tables 2 and 3 and the basic equations expressed in Section 3.2, an event-based model for the nonperiodic timetabling problem can be formulated as follows:
|
Table 3. A List of Sets Used in This Paper
| Set | Description |
|---|---|
| E | The set of all events |
| EA | The set of all arrival events |
| ED | The set of all departure events |
| ET | The set of all terminal events, in which the terminal events are the last event of each train; |
| EH | The set of pairwise events (i, j) that must be separated with a minimum headway, where i and j are events of different trains ordered such that i < j |
| ES | The set of pairwise events (i, j) that must be scheduled in the same order as the subsequent pair , where i and j are events of different trains ordered such that i < j |
| J | The set of all possible trips (i.e., all pairs of departure and arrival events i and j, respectively, such that i and j are events with the same train and where i precedes j), which is defined as , in which Eh and T denote the events of train h and the set of all trains, respectively |
| Ni | The set of events of the same type (either departure or arrival events for trains in the same direction as the train with event i) and at the same station as event i |
3.4.1. Objective Function.
The objective function for the timetabling problem is the predicted disutility computed as the weighted sum of total scheduled travel time and total predicted delay (corresponding to total disutility as defined in Section 3.1.1), which is formulated as follows:
A commonality for Equations (21) and (22) is the binary variable pi, which is used to obtain flexibility in determining the events counted in the objective function (which occur only if a stop is scheduled). This follows from the assumption that the scheduled travel time and the delay at intermediate stations without a scheduled stop do not affect any customer and should therefore not be included. A practical consequence of this is that stops will not be scheduled unless they are necessary to obtain a feasible timetable or required for some other reason (for example, staff, freight, or passenger exchange). Because of the binary variable, which multiplies the travel time and the predicted delay, both equations become nonlinear and must be linearized before they can be implemented in an MILP formulation. This can be achieved using binary variables and big-M constraints; this is a standard procedure, and it is therefore not discussed further.
3.5. The Combined Simulation-Optimization Approach
The optimization problem, as formulated by Equations (19a)–(22), can be used in a combined simulation-optimization approach to improve a given timetable. As described in the introduction, the given timetable can be a draft timetable in a late stage of the annual timetabling process. At that stage, it can be assumed that the given timetable is feasible and conflict free, although slight deviations can be accepted as long as it can be simulated. Because the approach is applied on a given timetable, it can be assumed that the modified timetable cannot be allowed to deviate too much from it. Before starting, lower and upper bounds for the time of each event should therefore be defined.
The approach is illustrated in Figure 6 and consists of the following steps. First, the original timetable, as given, is simulated. Based on the simulation data, the mean deviation of each event (the mean delay of each entry event) is computed. Second, the optimization problem is solved using the original timetable and the mean deviation of each event (mean delay for entry events) as input data. The outcome of solving the optimization problem is the modified timetable. Third, the modified timetable is simulated. In the final step, the total disutility of the original and modified timetables is compared to verify that the original timetable has been improved.
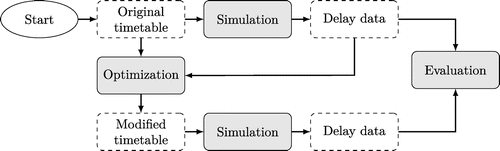
A possible extension would be to iterate the approach by taking the modified timetable and the simulated delays of the modified timetable as input to the optimization problem. Discussions with potential users of the approach have, however, revealed the importance of control over deviations from the original timetable and of predictability of results and execution times, all of which can more easily be controlled with a single-step approach.
4. Simulation Experiment
The approach was implemented in Python and evaluated in a set of simulation experiments. This section describes the evaluation scenario as well as the simulation and the optimization model setup. The overall evaluation methodology is outlined in Figure 7. As can be seen, the experiment was started with an original timetable, described in Section 4.1. This timetable was then simulated and optimized by applying several variants of the approach, described in Section 4.2. Finally, the outcome was evaluated by simulating the modified timetables and analyzing the delay data as described in Section 5.

All experiments, except the scalability experiment in Section 5.3.2, have been conducted on a regular laptop equipped with 32 GB RAM and a processor with four physical cores running at 2.7 GHz. The scalability experiment in Section 5.3.2 was conducted on a workstation equipped with 256 GB RAM and dual processors with a total of 48 physical cores running at 3.0 GHz.
4.1. Evaluation Scenario
The experiment was conducted on the double-track section of the Swedish Western Main Line, Sweden’s busiest railway connecting the two largest cities, Stockholm and Gothenburg, and passing Hallsberg, an important hub in the Swedish railway network that includes the largest freight yard in Scandinavia. The Western Main Line is a 455-km-long electrified double-track line, except for four-track sections close to Stockholm and Gothenburg, with maximum speed of 200 km/h. The traffic is highly heterogeneous as it is shared by long-distance passenger trains, regional trains, and local and commuter trains as well as freight trains. Furthermore, the line is partially shared with traffic that runs on the Southern Main Line toward Malmö, the third largest city in Sweden, and to Copenhagen in Denmark and with international traffic to Norway. Consequently, the line is one of the most heavily used lines in Sweden. It is widely argued that the line has a large capacity shortage and that increases in traffic are not possible without major quality deterioration for existing traffic. The selected section in the experiments covers 383 km and consists of 53 stations, including tracks for overtakes.
The experiments were conducted on a double-track line where traffic in each direction is scheduled on separate tracks and overtakes usually are planned to avoid crossing routes with opposite direction traffic. Because of this, it is considered a fair assumption to only study traffic in one direction. This has the benefit that the simulation times can be substantially reduced compared with simultaneously simulating the traffic in both directions. Therefore, only traffic in the southbound direction was included in the simulation experiments. The original timetable for the line section was derived from the Swedish national timetable of 2015. Among the southbound trains, all trains that operate on any part of the chosen section (except the trains that traffic only branch lines) between 05:00 and 12:00 on September 23 were included. The choice of excluding trains that only traffic the branch lines was assumed to be of minor importance because branch line traffic generally has lower priority compared with main line traffic.
In comparison with the national timetable, the original timetable was modified so that it is macroscopically feasible and conflict free. This means that with the original timetable, all trains were scheduled with feasible running times and between any pair of trains the headway was at least four or five minutes depending on the section. In this process, four trains had to be excluded. The excluded trains were considered to have lower priority than the trains that were kept. In total, the original timetable therefore consisted of 87 trains. A microscopic simulation of the timetable without disturbances resulted in no registered delays and no rerouting decisions.
4.2. Alternative Variants of the Approach
In previous research, the train order and the entry time (the time a train enters the network) of each train had been fixed. To evaluate the effect of lifting these restrictions, the following variations of the new approach were evaluated.
Flexible train order + flexible entry time. Optimizes the timetable using the delay prediction model proposed in this paper. Both the train order and the entry time for each train are flexible.
Fixed train order + fixed entry time. Optimizes the timetable using the delay prediction model proposed in this paper. Both the train order and the entry time for each train are fixed.
Fixed train order + flexible entry time. Optimizes the timetable using the delay prediction model proposed in this paper. The train order is fixed, whereas the entry time for each train is flexible.
Flexible train order + fixed entry time. Optimizes the timetable using the delay prediction model proposed in this paper. The train order is flexible, whereas the entry time for each train is fixed.
To provide a comparison with alternative model formulations, including past work, the following alternatives were also evaluated.
Naïve model. Optimizes the timetable only on scheduled travel time with a naïve delay prediction model, in which the predicted delay of each event is assumed to be equal to the mean delay obtained by simulating the original timetable. Both the train order and the entry time for each train are flexible.
Old model. Optimizes the timetable using the delay prediction model in Högdahl, Bohlin, and Fröidh (2019). This variant requires that both the train order and the entry time for each train are fixed as in the original timetable.
Simplified model. Optimizes the timetable using a simplified variant of the delay prediction model proposed in this paper, in which knock-on delays are not considered. Both the train order and the entry time for each train are flexible.
It would have been interesting to include additional approaches in the evaluation. However, it is generally complicated to implement approaches described by others, and it would likely require adaptations to make fair comparisons. For the scope of this paper, it was therefore justified to limit the evaluation to only consider these alternatives.
The variants of the approach were implemented by varying the delay prediction model and by adding constraints to the timetabling problem to control the train order and fix the entry time for each train. In addition, all variants were evaluated the same way using the same track section with the same original timetable and the same simulation model. Each modified timetable was simulated with perturbed timetables that were randomly generated independent of each other.
4.3. Simulation Model Setup
The simulations were carried out using Railsys version 9.8.25 (https://www.rmcon.de/railsys-en/), which is a commercial software to plan and simulate railway operations. Railsys uses a highly detailed infrastructure model, which includes physical objects (e.g., signaling equipment, switches, and crossings) and virtual objects (e.g., station borders, timing points, and stopping locations). Further, the network is divided into block sections, where the blocks are separated by signals. The timetable contains detailed information for each train, such as the scheduled arrival/departure times; the planned routes through stations, including the passing and stopping points; and planned train configuration. By combining infrastructure data, timetable information, and train dynamics, Railsys automatically calculates running times.
Before simulating a timetable, a set of perturbed timetables is generated and used as input to Railsys, as illustrated in Figure 8. The perturbed timetables contain randomly generated primary delays, which are entry delays, running time extensions, or dwell time delays. The output of the simulation is a set of traffic realizations, which can be interpreted as different traffic days; this set is used to compute statistics such as mean delays and punctuality. In this study, both the original and modified timetables were simulated using 200 perturbed timetables each. This is in the upper range of the recommended number of replications found in Radtke and Hauptmann (2004).

Source. Reproduced from Högdahl (2019a).
4.3.1. Delay Scenario.
To generate the perturbed timetables, it was assumed that traffic is operated under normal conditions without major incidents, such as train or infrastructure failures, that would heavily impact the traffic and distort the results. To facilitate this, all primary delays were restricted to less than 10 minutes. The delay distributions in the experiments were a combination of uniform entry delays between zero to six minutes, empirical dwell times delays (a de facto standard in Sweden originating in Nelldal et al. 2008), and negative exponentially distributed running time extensions that on average yielded running time extensions of approximately 15% of the minimum running times. Between 2017 and 2019, the end-station punctuality between Stockholm and Gothenburg was between 69.5% and 95.6% for different train categories (Trafikverket 2021a), whereas the simulated end-station punctuality with these distributions and a similar partitioning of the trains was between 79.0% and 98.6%. The numbers are not directly comparable as some factors differ (for example, the timetable, exact set of trains, and the time period), but they still give an indication of the overall suitability of the chosen delay scenario from a practical perspective.
4.3.2. Dispatching.
If the operation deviates from the schedule, operative dispatching decisions may be required. In Railsys, a heuristic dispatching algorithm is used with the aims to give priority to higher-prioritized trains, avoid deadlocks at single-track lines, and select alternative tracks (i.e., routes through stations) if a planned track for a train is already occupied. The dispatcher can apply several actions to resolve conflicts (e.g., overtakes, dwell extensions, replatforming), which are selected using the heuristic algorithm that considers lateness and train priority between the involved trains. In the experiment, the default settings for the dispatching algorithm were used. The configurations on train priorities and use of alternative tracks are described.
A basic dispatching principle in the Swedish railway is that on-time trains should be prioritized before delayed trains in order to prevent delay propagation. This behavior can be simulated in Railsys by assigning dynamic priority values, setting lower priority for trains delayed above a certain threshold. In the experiments, it was assumed that individual trains are prioritized according to their category from commuter trains to fast passenger trains, other passenger trains, and freight trains. To prevent overly strict down prioritization of late trains, the threshold for lowering the priority of delayed trains was set to six minutes for all train categories.
In addition to the priority rules, the use of alternative tracks also has an important role in the dispatching. A train can be routed to an alternative track if, for instance, its planned track is occupied or to allow an unscheduled overtake. According to Solinen, Nicholson, and Peterson (2017), sidetracks are rarely used if the main track for traffic in the opposite direction must be crossed. For this reason and because only the southbound traffic was considered in the evaluation, the alternative tracks for the dispatching were configured so routing to a sidetrack is only allowed if it can be reached without crossing the main track for northbound traffic, as illustrated in Figure 9. This principle was applied at all stations except in Hallsberg, an important hub in the middle of the line. The exception in Hallsberg was because it is one of the largest stations on the line—with a total of seven parallel tracks. For this reason, it seemed too restrictive not allowing the dispatching algorithm to use the capacity at that station.
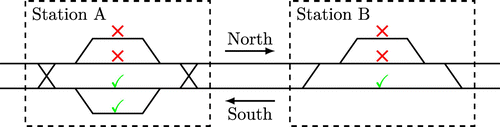
Note. For trains in the southbound direction, the tracks marked with a green check mark can be used by the dispatcher as alternative tracks to reroute a train in case its planned track is occupied or to allow an overtake.
4.3.3. Driving Behavior.
In Railsys, it is assumed that train drivers reduce the speed if they become early, accelerate to the maximum allowed speed if they are late, and otherwise, drive according to the scheduled speed profile. In other words, they try to follow the schedule as well as possible.
The Swedish Western Main Line is equipped with an automatic train control (ATC) signaling system, which supervises train movements and interferes if a train is operated at an unsafe speed; this can occur if a train runs above the permitted speed or if a driver does not react in time after a signal or reduction of the permitted speed. One feature with the Swedish ATC system is that it is possible to drive slightly faster than the permitted speed (9 km/h according to Rosberg and Thorslund 2020) without interference from the system, which can be used to recover delays.
However, driving above the permitted speed cannot be done in Railsys. To compensate for this, Railsys was instead configured so that 100% of running and dwell time supplements can be used when a train is delayed. Furthermore, Railsys was configured so trains immediately enter the delay-recovery mode if they become more than zero seconds delayed and remain in that mode until the delay is completely recovered. In other words, this means that the trains are accelerated up to maximum permitted speed if they become delayed and follow this speed profile until the delay is zero again.
4.4. Optimization Model Setup
The optimization problem was solved with Gurobi 8.1.0 (https://www.gurobi.com), except in the scalability experiment in Section 5.3.2, in which a later version (Gurobi 9.1.2) was used to capture possible solver improvements. In all experiments, Gurobi was used with its default settings. The solver was configured to terminate if either a 24-hour time limit was reached or the relative gap between the lower and upper bounds for the objective function becomes less than 0.01%. The solver terminated in all experiments within one hour (except in the scalability experiment).
4.4.1. Timetabling Restrictions and Degrees of Freedom.
The original timetable is assumed to be the product of at least one but very often several annual planning processes involving the infrastructure manager, node managers, and railway undertakings. It therefore embodies a significant amount of information on passenger demand and exchange, plans (and thus, operational costs) for rolling-stock usage, and driver and crew assignments. For this reason, the original timetable is the desired timetable, and the modified timetable cannot be allowed to deviate from it too much. Therefore, the set of feasible solutions to the timetabling problem needs to be restricted. These timetabling restrictions and the degrees of freedom are described in this section and summarized in Table 4.
|
Table 4. The Degrees of Freedom for Optimizing Passenger and Freight Trains in the Simulation Experiments
| Degree of freedom | Passenger trains | Freight trains |
|---|---|---|
| The scheduled time of each event | Must be within minutes from the scheduled time in the original timetable; different values on W have been evaluated | Same as for the passenger trains |
| The scheduled running times | Must be larger than the minimum running time | Same as for the passenger trains |
| The scheduled dwell times | Must be larger than the predetermined minimum dwell time in the original timetable | Can be chosen freely |
| Overtakes | Can be modified; however, new overtakes are only allowed at stations if a feasible sidetrack exists, and in addition, if the overtaken train is a passenger train, then it must already be scheduled to stop at the overtake station (because new stops have not been allowed) | Can be modified; new overtakes of freight trains are allowed at any stations that have a feasible sidetrack |
| Are additional stops allowed to be scheduled? | No | Yes, at intermediate stations |
| Are scheduled stops allowed to be removed? | No | Yes, at intermediate stations |
Because the original timetable was the desired timetable, the primary assumption was to preserve trains in their original setting (which means that if a train was scheduled in the morning, it should remain in the morning with the modified timetable). To enforce this, the following boundaries were used in the timetabling problem.
Each event must be scheduled within minutes from the original time. For this reason, the lower and upper bounds for each event i were and , respectively, where is the original scheduled time of event i. Because the parameter W defines the width of a symmetrical interval that each event must be scheduled within, W will be referred to as the planning-window width further in this paper. In the experiments, different values of W were used ranging from 0 to 60 minutes. As a logical consequence of limiting the feasible times of each event, this also limits the possibility for events to change order. For this reason, this implies that all sequence variables xij become fixed parameters for events originally scheduled with a time difference greater than W minus the minimum headway.
Because the selected original timetable in the experiments only covered part of a whole day, it was also important that the entire modified timetable was scheduled within its original time frame—which also prevents increasing the capacity utilization. To enforce this, the following boundaries were also used in the timetabling problem. Each event must be scheduled later than the earliest event and earlier than the latest event in the original timetable. This means that for all events, the lower and upper bounds on the scheduled time ti were and , respectively, where Tmin and Tmax are used to denote the time of the earliest and latest events, respectively, with the original timetable. These boundaries also include the boundaries described in the previous paragraph.
The minimum headway between train pairs was set according to the official timetabling guidelines, as described in Trafikverket (2014). This means that the minimum headway between trains was four or five minutes depending on the track section.
The conditions for passenger and freight traffic often differ significantly; therefore, stop management and (implicitly) overtakes were handled differently for passenger and freight trains. In this paper, the assumptions for passenger trains were that (1) the stops in the original timetable had to be preserved (as they expressed demand fulfillment), (2) the originally scheduled dwell time was the minimum allowed dwell time at a stop to facilitate passenger exchange, and (3) new stops were not allowed to be scheduled as this allowed passenger trains to run relatively uninterrupted. The assumptions for freight trains were that (1) stops at the first and last stations had to be preserved (because these stops were scheduled for handling cargo, changing drivers, etc.), (2) intermediate stops had been scheduled for technical timetable reasons (meaning they were scheduled to allow overtakes or acted as time supplements), and (3) intermediate stops could be scheduled when needed. For this reason, stops for freight trains could be added or skipped at intermediate stations.
4.4.2. Objective Function Parameters.
The objective function was defined as the weighted sum of scheduled travel time and predicted delay. The cost of experiencing delays is commonly perceived as higher or worse than the planned travel time. For this reason, it is natural to assume that the predicted delay should be associated with a higher cost in the objective function. According to Warg and Bohlin (2016), the delay cost factor used for cost-benefit analysis in the transport sector varies between different countries. Further, in a selection of mainly European countries, they found that the delay cost factor varied between 2.0 and 3.7. In Sweden, the recommended delay cost factor used by the Swedish Transport Administration is 3.5 (Trafikverket 2020), which means that reducing the mean delay is valued 3.5 times higher than reducing the planned (in-vehicle) travel time. Because the evaluation in this paper was conducted in a Swedish context, the delay cost factor used in the objective function, α, was set to the recommended value of 3.5. Additionally, this value was also used as the value of the quotient VOR/VOT in the total disutility, as defined in Section 3.1.1.
The two components of the objective function (i.e., the total scheduled travel time and the total predicted delay) both were defined with weighting parameters to express that not all events were equal in importance. For instance, these parameters could be chosen proportionally to the number of passengers or the freight value. However, the necessary data for such parameter values are often considered commercially sensitive, and in this evaluation, this was not available. Instead, it was assumed that only events associated with a scheduled stop were important for passengers and railway undertakings and that they were valued equally. Furthermore, the travel time to a station with a scheduled stop was considered from the first station only, which means that trips between intermediate stations not were considered. To enforce this, the weighting parameters λij therefore were set to one for all arrival events j, with i being the entry event for the same train and otherwise zero. To limit the scheduled dwell time at the last station for each train, the weighting parameters were also set to one for the trip to the last departure event for each train.
Finally, because the evaluation not was conducted on a complete network, trains could exit the simulation area without a scheduled stop. In this case, because only events associated with sheduled stops were included in the objective function, the scheduled arrival and departure times at the last station could become arbitrary (within the defined boundaries of each event). To avoid this, the arrival and departure event at the last station for each trains were therefore included in the objective function, independently of the value of pi.
4.4.3. The Delay Prediction Model Parameters.
The delay prediction model contains the following two parameters whose values must be selected: (1) the sensitivity parameter β, which determines how much the predicted nonrecovered delay decreases or increases when the time supplement is increased or decreased, and (2) the average delay increment τ used to compute the predicted knock-on delay. The two parameters β and τ were further described in Sections 3.3.1 and 3.3.2, respectively.
In this paper, the values of these parameters were selected using a stochastic search procedure, in which a set of modified timetables was generated by solving the timetabling problem with randomly chosen values of β and τ. To validate the predicted delays with these modified timetables, each modified timetable was simulated for 16 replications. Based on the simulation outcome, the root mean square error (RMSE) for the predicted delay of each modified timetable was computed as follows:
The stochastic search procedure described was implemented in Python 2.7.12 and executed for 100 iterations on a regular laptop (i.e., the same as was described in the introduction to Section 4). Based on this, the parameter values and resulted in the smallest RMSE and were therefore chosen for the experiments.
5. Results
This section presents the results from the experiments divided in three parts. In the first part, the delay prediction model was validated to assure that it was reasonably accurate. In the second part of this section, several variants of the approach were compared, and the effects on total disutility, total scheduled travel time, total mean delay, and punctuality were evaluated. Finally, in the third part, the scalability of the approach was evaluated.
5.1. Validation of the Delay Prediction Model
The overall purpose with the delay prediction model is to provide the means to combine the microscopic simulation results and the optimization model. Nonetheless, evaluating the accuracy of the prediction model may provide insights useful to further develop the approach, and with this in mind, an experiment was conducted to validate that the prediction model provides reasonable accuracy.
The delay prediction model was validated by generating a modified timetable, as described in Figure 6, with the assumption that any event could deviate ±15 minutes from its originally planned time and within the feasible timetabling frame (as described in Section 4.4.1). The modified timetable was then simulated with 200 replications, and the predicted delay of each event was compared with the corresponding actual delay in each replication.
One observation, or sample, is the outcome of a single event in a single simulation cycle. The total number of trains was 87, and each train consisted of between 8 and 106 events, each of which was observed 200 times. In total, 636,004 observations were generated this way. Among these observations, 15.4% occurred before the scheduled time. The predicted delay was defined in Equation (12) as nonnegative, and consequently, these early observations were counted as zero delays.
The metrics used to validate the model, chosen for ease in interpretation and providing insight into both precision and accuracy, were the distribution of the real and absolute prediction errors, the mean error, the median error, and the mean absolute prediction error. In addition, to provide a normalized result, the mean absolute percentage error (MAPE) for the predicted travel time to each event from the entry event of the corresponding train was also computed.
5.1.1. Analysis of Prediction Errors.
Figure 10 shows the distribution of the prediction error in absolute and real terms. The left panel shows the distribution and cumulative distribution function (CDF) of the absolute prediction error for all observations, in which is the predicted delay of event i and δir is the actual delay at event i for a single realization r. From the figure, it can be noted that 50% of the observations had an absolute prediction error less than or equal to 46 seconds, that 75% of the observations had an absolute prediction error less than or equal to 111 seconds, and that 90% of the observations had an absolute prediction error less than or equal to 195 seconds. In comparison, the mean scheduled travel time to each event from the entry event with the same train was 3,566 seconds. The absolute prediction error can therefore be considered relatively small in comparison with the mean scheduled travel time.
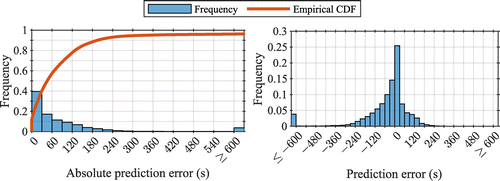
The right panel in Figure 10 shows the distribution of the real prediction error . As also indicated by the left panel, most observations were centered around the predicted value. However, from the right panel, it can also be seen that the distribution was skewed to the left, which means that the delay model tended to underestimate delays. This was due to that the predicted delay was zero in many events, which occured as a consequence of the linear delay prediction model if sufficiently large time supplements and buffer times were allocated.
Because the predicted delay only depends on two preceding events, it cannot fully capture the effect of train prioritization. Because on-time trains are prioritized over delayed trains in the simulations, unfavorable circumstances can lead to late trains developing larger delays over long distances, as on the Swedish Western Main Line. Further, a delayed train can also be placed on a sidetrack for long periods if several following trains with higher priority pass by with relatively short headways, which can occur on highly utilized lines such as the Swedish Western Main Line. The effect of this on the prediction model can be observed in Figure 10, in which the tail with an absolute prediction error larger than 600 seconds included 3.8% of all observations. For the tail, the mean prediction error was –1,690 seconds (i.e., the observed delays were much larger than the predicted delays).
A summary of the error analysis is shown in Table 5. As can be seen, the mean error was not zero, which was a consequence of the tail that was observed in Figure 10 and the linear relationship between the allocated supplements in the modified timetable and the predicted delays. Because the tail does not affect the median errors, they were also substantially smaller than the mean errors. For each train class, the mean absolute error ranged from 55 to 194 seconds, where commuter trains and fast passenger trains represented the low and high ends.
|
Table 5. Summary of Error Measures by Train Class
| Train class | No. of trains | No. of samples | ME (seconds) | MdnE (seconds) | MAE (seconds) | MAPE (%) |
|---|---|---|---|---|---|---|
| Freight trains | 9 | 48,954 | −124.0 | −17 | 166.4 | 5.8 |
| Fast passenger trains | 21 | 291,336 | −143.2 | −4 | 193.6 | 4.9 |
| Commuter trains | 17 | 83,978 | −47.6 | −29 | 54.8 | 10.3 |
| Other passenger trains | 40 | 211,736 | −32.7 | −3 | 64.1 | 5.9 |
| All trains | 87 | 636,004 | −92.3 | −9 | 130.1 | 6.0 |
Note. MAE, mean absolute error; MAPE, mean absolute percentage error; MdnE, median error; ME, mean error.
A drawback with mean error, median error, and mean absolute error is that they do not relate the errors to the scale of the data. To overcome this, MAPE is often used as an error measure. However, because the observed delays often were zero and depend on their scheduled times (meaning that the error has no meaningful zero), MAPE is not an appropriate measure for the prediction error of the delay according to Hyndman and Koehler (2006). Therefore, the MAPE was computed with respect to the predicted travel time to each event from the entry event with the same train using the following formula for the absolute percentage error eir of event i for a realization r:
5.1.2. The Relation Between Traveled Distance and Prediction Error.
A possible concern when considering delay propagation in a network is that the prediction error may propagate and grow as trains travel through the network. Figure 11 shows the distribution of the prediction error for all 87 trains as a function of the event sequence number. The figure is divided in two panels, in which the left panel shows the distribution of all prediction errors and the right panel zoom in on errors between –7 and 3 minutes so that the mean, the median, and the 25th to 75th percentiles of the errors can be seen.
The right panel shows that the median of the prediction error did not deviate substantially from zero, and the width of the 25th to 75th percentiles remained relatively stable as the event number increased.
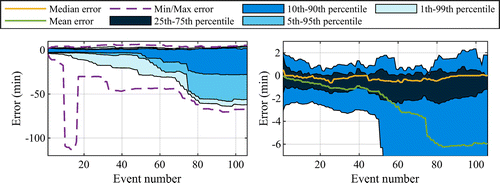
Note. The left panel shows the complete set of all observations, whereas the right panel focuses on errors between −7 and 3 minutes.
The left panel in Figure 11 shows increasing variability and risk of observing very large prediction errors as the event number increased, which is the reason the mean error was seen to deviate from zero. These large prediction errors correspond to the tail data that were observed in Figure 10. The largest prediction error was –113 minutes, which was observed for a freight train that entered the network 5 minutes late. Because of this, Railsys’ dispatching routine let the freight train wait on a sidetrack (near its last station) for almost two hours until it was allowed to proceed. The reason for this was that it could not proceed earlier without obstructing other trains. Although an extreme event in this case, it is consistent with established practice and illustrates the shortcoming of the dispatching strategy to prioritize on-time trains.
In conclusion, the analysis of Figure 11 shows that with increased traveled distance, the variability of the prediction errors increased, as could be expected. However, most commonly, the impact on the errors was small because the median error remained close to zero and the width of the 25th to 75th percentiles was relatively stable.
5.2. Evaluating the Impact of the Approach
The main purpose of this paper was to narrow the gap between research and practice by combining simulation and optimization to improve a given timetable. To demonstrate the approach’s usefulness (that it can be used in railway planning to improve a given timetable) and to evaluate how planning flexibility impacts the performance of the approach, a simulation experiment was conducted.
To investigate how planning flexibility affects the approach and how it compares to alternative formulations, each variant of the approach (as described in Section 4.2) was used to generate a set of modified timetables. These timetables were generated with planning-window width W ranging from 0 to 60 minutes in 2-minute steps, in which the planning-window width defines the width of the interval each event must be scheduled within. Table 6 lists the included variants of the approach, their corresponding abbreviations, the number of replications, the number of excluded replications, and the number of samples included in the analysis. As described in Section 4.3, each timetable was simulated with 200 replications. However, because each variant returned the original timetable when the planning-window width was zero minutes, the result of these simulations was instead reported as results for the original timetable. Therefore, each variant was simulated for 6,000 replications, whereas the original timetable was simulated for 1,400 replications.
|
Table 6. Summary of Conducted, Excluded, and Used Replications in the Evaluation for Each Variant of the Approach
| Alternative | Abbreviation | Replications | Excluded replications | Samples |
|---|---|---|---|---|
| Flexible train order + flexible entry time | Flex-flex | 6,000 | 2 | 5,998 |
| Flexible train order + fixed entry time | Flex-fix | 6,000 | 4 | 5,996 |
| Fixed train order + flexible entry time | Fix-flex | 6,000 | 3 | 5,997 |
| Fixed train order + fixed entry time | Fix-fix | 6,000 | 0 | 6,000 |
| Simplified model | Simplified | 6,000 | 0 | 6,000 |
| Old model | Old | 6,000 | 4 | 5,996 |
| Naïve model | Naïve | 6,000 | 5 | 5,995 |
| Original timetable | Original | 1,400 | 0 | 1,400 |
Note. The rightmost column shows how many replications for each variant of the approach that were included in the analysis.
As can be seen in Table 6, a few replications were excluded. These replications were excluded because trains were left in the system when the simulation ended, which was because of one of two reasons: (1) a single train was not registered by Railsys when arriving at its last station, and (2) a single train never departed from its entry station. The underlying causes for these events are unknown. However, with a more recent version of Railsys, they did not occur. For this reason, it was considered a bug with Railsys. These replications could have been simulated again with a different perturbed timetable. However, as only a few replications were excluded with no practical impact on the results, they instead were reported as excluded.
As performance measures, total disutility (corresponding to total predicted disutility used as an objective function in the optimization problem), total scheduled travel time, total mean delay, and punctuality were analyzed.
5.2.1. Comparing the Impact on Total Disutility.
To evaluate whether the approach can improve the robustness of the given timetable, the impact on total disutility was measured (using the robustness measure described in Section 3.1.1). Total disutility was computed as the objective function—predicted disutility—defined by Equation (20) but with the actual delay of each event instead of the predicted delay. As in the predicted disutility, early observations were included as observations with zero delay.
The evaluation was conducted by comparing the total disutility of each variant and using statistical tests for differences. The results are reported in Figure 12 and Tables 7 and 8. In Figures 12–16, moving mean values as a function of the planning-window width are reported for each variant. The moving mean value for planning-window width n was computed by considering the five symmetrically closest planning windows (i.e., ), except near the endpoints where the included planning windows were truncated.
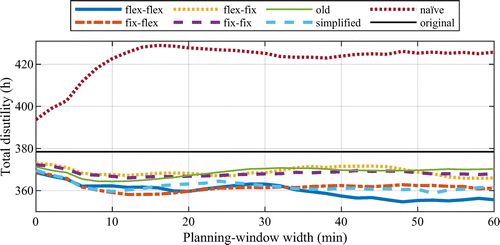
Notes. The lines represent moving mean values of the total disutility for each variant of the approach, where the robustness in a point n was computed as the mean of the five closest planning windows (truncated near the endpoints). As a reference, the total disutility with the original timetable is included as the black solid line.
|
Table 7. Pairwise Mann-Whitney U Test Comparisons
| Alternative A | Alternative B | Effect size (%) | p-value | Reject h0 |
|---|---|---|---|---|
| Flex-flex | Fix-flex | 57.3 | 0 | True |
| Flex-flex | Flex-fix | 83.9 | 0 | True |
| Flex-flex | Fix-fix | 82.2 | 0 | True |
| Flex-flex | Old | 81.2 | 0 | True |
| Flex-flex | Naïve | 100.0 | 0 | True |
| Flex-flex | Simplified | 58.5 | 0 | True |
| Fix-flex | Flex-fix | 79.4 | 0 | True |
| Fix-flex | Fix-fix | 77.3 | 0 | True |
| Fix-flex | Old | 76.5 | 0 | True |
| Fix-flex | Naïve | 100.0 | 0 | True |
| Fix-flex | Simplified | 51.7 | 0.001 | False |
| Flex-fix | Fix-fix | 46.0 | 0 | True |
| Flex-fix | Old | 48.1 | 0.0002 | True |
| Flex-fix | Naïve | 99.9 | 0 | True |
| Flex-fix | Simplified | 23.5 | 0 | True |
| Fix-fix | Old | 51.6 | 0.0024 | False |
| Fix-fix | Naïve | 99.9 | 0 | True |
| Fix-fix | Simplified | 25.9 | 0 | True |
| Old | Naïve | 99.9 | 0 | True |
| Old | Simplified | 26.2 | 0 | True |
| Naïve | Simplified | 0.0 | 0 | True |
Notes. Bonferroni correction was applied to assure an experimental-wise significance value of 0.01; for this reason, the significance value in each test was approximately 0.0005. The effect size column shows the probability that a random sample in A is better than a random sample in B.
|
Table 8. A Summary of Aggregated Performance Measures
| Variant | Total disutility | Total scheduled travel time | Total mean delay | Punctuality | ||||
|---|---|---|---|---|---|---|---|---|
| Hours | % | Hours | % | Hours | % | % | p.p. | |
| Flex-flex | 359.4 | −5.0 | 324.9 | 6.5 | 9.9 | −52.8 | 96.2 | 9.3 |
| Fix-flex | 361.2 | −4.5 | 328.5 | 7.7 | 9.3 | −55.4 | 96.5 | 9.5 |
| Flex-fix | 368.7 | −2.6 | 325.9 | 6.8 | 12.2 | −41.6 | 93.8 | 6.8 |
| Fix-fix | 368.0 | −2.8 | 329.8 | 8.1 | 10.9 | −48.0 | 95.5 | 8.5 |
| Old | 368.5 | −2.6 | 322.9 | 5.8 | 13.0 | −37.8 | 93.3 | 6.3 |
| Naïve | 423.5 | 11.9 | 275.8 | −9.6 | 42.2 | 101.6 | 49.2 | −37.8 |
| Simplified | 361.6 | −4.4 | 324.8 | 6.4 | 10.5 | −49.7 | 95.8 | 8.8 |
| Original timetable | 378.4 | 0.0 | 305.2 | 0.0 | 20.9 | 0.0 | 87.0 | 0.0 |
Notes. For each variant, except the bottom row, all performance measures were computed as the mean for all planning window widths between 2 and 60 minutes. The performance with the original timetable is included as a reference. For each performance measure, the left column shows absolute values, whereas the right column shows percentage differences compared with the original timetable.
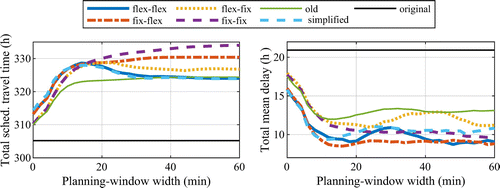
Notes. The lines represent moving mean values for each variant of the approach, where the value in a point n has been computed as the mean of the five closest planning windows (truncated near the endpoints). As a reference, the value with the original timetable is included as the black solid lines.
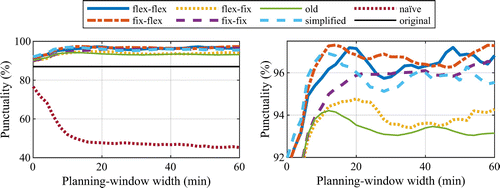
Notes. The lines represent moving mean values for each variant of the approach, where the value in a point n has been computed as the mean of the five closest planning windows (truncated near the endpoints). As a reference, the punctuality with the original timetable is included using a black solid line.
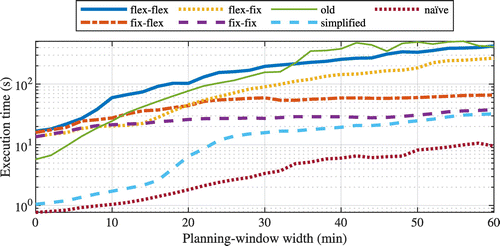
Notes. The lines represent moving mean values for each variant of the approach, where the value in a point n has been computed as the mean of the five closest planning windows (truncated near the endpoints). Note that the y axis is in logarithmic scale.
As can be seen in Figure 12, the variants flex-flex (i.e., the new approach with full flexibility), fix-flex (i.e., the new approach with fixed train order and flexible entry times), and simplified (i.e., the variant with a simplified delay prediction model) yielded the lowest values for total disutility, which means they were more robust than the other variants. For planning-window widths up to approximately 30 minutes, all three performed similarly, whereas for wider planning windows, it can be seen that the flex-flex variant resulted in lower total disutility than the two others. This means that when planning flexibility was sufficiently large, the flex-flex variant found train orders that yielded better timetables than were possible with the original train order that the fix-flex variant was bound to. Further, because the flex-flex variant yielded lower total disutility than the simplified variant for wide planning windows, this indicates that robustness was improved by considering the effect of knock-on delays when computing predicted delays.
Figure 12 also shows that the two variants implemented with a fixed train order and fixed entry time for each train, the fix-fix variant (i.e., the new approach) and the old variant (i.e., the variant that used the delay prediction model as proposed by Högdahl, Bohlin, and Fröidh 2019), seemed to perform very similar. Because they performed similarly, this indicates that the formulation of the delay prediction model proposed in this paper in itself did not result in a substantial difference in total disutility compared with the model by Högdahl, Bohlin, and Fröidh (2019). Instead, the main benefit with the new delay prediction model was that it allowed lifting the restriction on train order and entry times. This led to the new approach with full flexibility (i.e., the flex-flex variant) and the new approach with fixed order of trains and flexible entry times (i.e., the fix-flex variant) yielded timetables with better robustness than the old variant. Somewhat surprisingly, the new approach with flexible train order and fixed entry times (i.e., the flex-fix variant) also yielded results similar to the old variant. This indicates that fixed entry times were more restrictive than fixed train order in this experiment.
Finally, Figure 12 also shows that the naïve variant, which had a naïve delay prediction model, had worse robustness than all other variants because it had substantially higher mean values on total disutility for all planning-window widths. This was because when the optimization problem was solved, the predicted delay of each event was constant, whereby only scheduled travel times were minimized. For this reason, the timetables that were generated with the naïve variant had very low robustness, making them sensitive to disturbances.
Because the mean values reported in Figure 12 only represent a comparison of point estimates, a statistical analysis was also performed. The statistical analysis used nonparametric tests because it cannot be assumed that the samples were generated from normal distributions (because each sample of the total disutility is computed as a sum of dependent and nonnormal stochastic variables).
The first null hypothesis was that the samples generated by the different variants of the approach came from the same population. This hypothesis was rejected by the Kruskal–Wallis test (Kruskal and Wallis 1952) with p-value of zero (because of the large sample size). Because this indicated that the samples were generated from significantly different distributions, the variants were then compared pairwise.
To make the pairwise comparisons, the Mann–Whitney U test was used with the null hypothesis that samples of the two groups were generated from the same distribution. To mitigate the risk of falsely rejecting the null hypothesis (i.e., a type 1 error) because of multiple comparisons, the Bonferroni correction method was used. For this reason, the significance level of each individual test was approximately 0.0005, which yielded an experimental-wise significance level of 0.01. The outcome from these pairwise comparisons is reported in Table 7, which for each comparison, shows the effect size (which is the probability that a random sample in the first group was better than a random sample in the second group), the p-value, and the conclusion whether the null hypothesis was rejected or not.
As can be seen, the null hypothesis was rejected for each comparison with the flex-flex variant, which indicates a significant difference (with p-value of zero because of large sample sizes) between this variant and the other variants. Furthermore, the effect size column shows that the flex-flex variant yielded a lower total disutility than the fix-flex variant and the simplified variant with probabilities of 57% and 59%, respectively, and with more than 80% for the other variants. It can therefore be concluded that the new approach with full flexibility resulted in timetables with significantly better robustness than the other variants. Additionally, it is noted that the difference between the simplified variant and the flex-flex variant was moderate because the effect size was 59%. It is therefore concluded that the impact of modeling knock-on delays in the delay prediction model was moderately positive.
Finally, compared with the original timetable, the flex-flex variant reduced the total disutility by 5% computed as the mean over all planning-window widths, which can be seen in Table 8. This is a statistically significant improvement (the Mann–Whitney U test yielded a p-value of zero and an effect size of 96%), which for a highly utilized line such as the Swedish Western Main Line, is considered to be a substantial improvement. Furthermore, as indicated in Table 8, the simplified variant yielded almost as large of improvements on total disutility as the proposed approach with full flexibility.
5.2.2. Comparing the Impact on Scheduled Travel Time and Total Delays.
Because delay reduction was valued higher than reducing the scheduled travel times, a possible concern with the approach can be that the observed benefit comes with an unacceptable cost in terms of substantial travel time extensions, which can potentially reduce the demand and hence, reduce the welfare benefit. Figure 13 shows the two components of total disutility, namely total scheduled travel time (as given in Equation (21)) and total mean delay (as given in Equation (22) but using the actual delay of each event in each replication instead of the predicted values) for all variants except the naïve variant, which performed much worse than the other variants. Aggregated results are also reported in Table 8. Note that the values for total mean delay have not been multiplied by the delay cost factor α (which was 3.5 in the experiments) in Figure 13 and Table 8.
As Figure 13 shows, the extensions of the total scheduled travel time were larger in real numbers than the reductions in total mean delay. However, because reducing delays was valued 3.5 times higher than reducing the scheduled travel times, the combined effect led to reduced total disutility. In percentages, the total scheduled travel times were extended less than 10% with all variants, whereas the reductions in total mean delay were about 50%. For the approach proposed in this paper, it can be seen in Table 8 that aggregated over all planning-window widths, the variant with full flexibility (i.e., the flex-flex variant) reduced the total mean delay by 53% at a marginal cost of extending the total scheduled travel time by 7%. It can therefore be concluded that the improvement in total disutility was caused by a substantial reduction of delays at the price of marginally longer travel times. Given that the robustness measure can be given an economic interpretation (Batley and Ibáñez 2012, Carrion and Levinson 2012, Warg and Bohlin 2016), it can be concluded that this seems to yield an economic benefit for society.
5.2.3. Comparing the Impact on Punctuality.
Because punctuality is one of the most important quality indicators for a railway service and because the impact on punctuality is nontrivial to estimate based on the reported delay reductions, the punctuality of each variant of the approach is reported in Figure 14 and Table 8. The punctuality was measured at the last station for each train and was computed as the percentage of trains that arrived at most five minutes after the scheduled arrival time (in which both the scheduled and actual arrival times were rounded down to full minutes), which according to Palmqvist, Olsson, and Hiselius (2017), corresponds to the punctuality measure used in the Swedish railway.
Figure 14 shows that all variants except the naïve variant substantially improved punctuality. As with the total mean delay, a rapid improvement in punctuality, which reached a relatively stable level for planning-window widths larger than approximately 10 minutes, was observed for all variants except the naïve variant. For the approach proposed in this paper with full flexibility (i.e., the flex-flex variant), it was observed (see Table 8) that the mean punctuality over all planning-window widths was 96%, which is a substantial improvement over the punctuality of 87% that was observed with the original timetable.
5.3. Scalability
For most nontrivial optimization problems, a direct practical concern is how the execution time of the approach is impacted by a change in the problem parameters. Therefore, in this section, the scalability of the approach was evaluated by considering the sensitivity with respect to two key parameters: the width of the planning window and the number of trains in the planning problem. The planning-window width is important because wide planning windows lead to timetabling problems in which more sequencing decisions must be solved, leading to a harder problem. For the same reason, it is simultaneously expected that larger problem instances, in terms of the number of trains, lead to a harder timetabling problem.
5.3.1. Sensitivity to the Planning-Window Width.
To study the sensitivity of execution times when the planning-window width increases, the execution time to solve the optimization problem for each variant is reported in Figure 15. As with Figures 12–14, it shows execution times as moving mean values. Because the difference in optimization times is in the orders of magnitude, the y axis is in logarithmic scale.
As can be seen in Figure 15, the execution times increased for all variants when the planning-window width increased. The largest execution times were observed for the new approach with full flexibility (the flex-flex variant) and the variant based on the approach from Högdahl, Bohlin, and Fröidh (2019) (the old variant). Among the variants of the approach with the delay prediction model proposed in this paper, the fix-fix variant is comparable with the old variant because for both variants, the train order and the entry times were fixed. As can be seen, the optimization times for the old variant increased much faster than with the fix-fix variant. For planning-window widths above 30 minutes, observed execution times for the old variant were on the order of 10 times larger than for the fix-fix variant. For this reason, it is concluded that the new formulation of the delay prediction model as proposed in this paper yielded a problem that was less sensitive to the planning-window width than with the model from Högdahl, Bohlin, and Fröidh (2019).
Finally, it was also observed that the optimization times for the simplified variant, which used a simplified delay prediction model, were relatively small. This is because the knock-on delays, which depend on the integer variables of the problem, were not considered in this variant. Because the simplified variant was also one of the variants that yielded the largest reductions in terms of total disutility, it is seems that the simplified variant may be suitable for applications that demand short execution times.
5.3.2. Sensitivity to the Number of Trains.
To evaluate how execution time increases as the number of trains increases, an experiment with an increasing number of trains was conducted. The scenarios in this experiment were generated by repeating the original timetable k times for , resulting in scenarios with 87, 174, 348, 696, and 1,392 trains. Because the original timetable was repeated, the generated timetables contained some unutilized areas (shown in Figure 16, in which the original timetable was repeated eight times). Although a simplification, it is still considered that the experiment provides an indication of the applicability of the approach to larger scenarios.
Because of the size and the expected computational times of the largest instances, the experiment was limited to the flex-flex variant (i.e., the proposed approach with full flexibility) and the simplified variant (i.e., the variant with the simplified delay prediction model). Both variants were applied with narrow and wide planning-window widths. The narrow planning-window width was 6 minutes, whereas the wide planning-window width was 60 minutes. In a real implementation, it is expected that the narrow planning window would be tolerated for most trains, whereas the wide window width was included to capture the possible interaction effect between increased planning flexibility and increased instance size.
Because of the size of the scenarios, the experiment was conducted on a different system than the previous experiments. This was a workstation equipped with 256 GB RAM and dual processors with a total of 48 physical cores running at 3.0 GHz. Furthermore, the approach was implemented in Python 3 with Gurobi 9.1.2 (https://www.gurobi.com) as a solver. The simulations were conducted in parallel with 25 instances, whereas the optimization problem was solved using only a single thread (to prevent an out of memory exception for the two largest instances). The experiment was repeated five times, and the time limit to solve the optimization problem to an optimality gap less than 0.01% was set to 24 hours.
In Table 9, the means and standard deviations of the total execution time, the optimization time, and the optimality gap are reported. The total execution time is the wall-clock time in hours to execute the full approach, whereas the optimization time is the wall-clock time in hours to solve the optimization problem. The optimality gap is reported as the percentage difference between the lower bound and the best solution.
|
Table 9. Mean and Standard Deviation of the Total Execution Time, the Optimization Time, and the Optimality Gap
| Scenario | Total (hours) | Optimization (hours) | Gap (%) | |||
|---|---|---|---|---|---|---|
| Width and no. of trains | Flex-flex | Simplified | Flex-flex | Simplified | Flex-flex | Simplified |
| Window width: 6 minutes | ||||||
| 87 | 0.2 ± 0.0 | 0.1 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 |
| 174 | 0.3 ± 0.0 | 0.2 ± 0.0 | 0.1 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 |
| 348 | 0.8 ± 0.0 | 0.5 ± 0.0 | 0.3 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 |
| 696 | 3.0 ± 0.2 | 1.1 ± 0.0 | 1.9 ± 0.2 | 0.0 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 |
| 1,392 | 15.9 ± 0.9 | 3.0 ± 0.1 | 12.7 ± 0.9 | 0.1 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 |
| Window width: 60 minutes | ||||||
| 87 | 0.3 ± 0.0 | 0.2 ± 0.0 | 0.1 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 |
| 174 | 0.9 ± 0.1 | 0.3 ± 0.0 | 0.7 ± 0.1 | 0.0 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 |
| 348 | 5.5 ± 0.4 | 0.6 ± 0.0 | 5.0 ± 0.4 | 0.1 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 |
| 696 | 24.4 ± 1.6a | 1.4 ± 0.1 | 23.3 ± 1.6a | 0.3 ± 0.1 | 0.2 ± 0.3 | 0.0 ± 0.0 |
| 1,392 | N/A | 4.3 ± 0.4 | N/A | 1.3 ± 0.3 | N/A | 0.0 ± 0.0 |
Note. N/A indicates that the problem could not be solved within the time limit.
aIn four of five replications of the experiment, an optimal solution was not found. For these replications, the optimization time was counted as 24 hours.
As can be seen in Table 9, the total execution time with the flex-flex variant increased much faster than with the simplified variant when the number of trains increased, which was because of the fast growth in optimization time for the flex-flex variant. This, in turn, was expected because the flex-flex variant considered knock-on delays with a flexible train order, whereas the simplified variant did not consider knock-on delays at all, which made the optimization problem solved in the flex-flex variant much harder than in the simplified variant.
The simplified variant found an optimal solution in each scenario within the time limit, whereas the flex-flex variant struggled in the scenario with the wide planning window. In the scenario with the wide planning window and 696 trains, the flex-flex variant reached the time limit in four of five replications. The optimality gaps in these replications were 0.63%, 0.06%, 0.06%, and 0.05%, which led to a mean optimality gap of 0.2% for all five replications. Because the optimality gaps in these cases were small, the optimization time in these cases was counted as 24 hours. In the scenario with the wide planning window and 1,392 trains, the flex-flex variant only found a feasible solution (with optimality gap of 4.1%) in one of five replications. Because the gap was relatively large for the only found solution and because no solution was found in the other replications, the total execution time and the optimization time are not reported for this scenario.
The intended application for the approach is in tactical timetabling, which currently is conducted in a process that takes several months. Because of this, it is expected that execution times up to 24–48 hours are feasible (because it can be left running over a weekend). This experiment therefore indicates that the method can be applied to large-scale instances if the planning-window width is limited, whereas it may be applied to medium to large instances if the flexibility for individual events is large. Because the approach is intended for modifications in a late stage of the capacity allocation process, large modifications are not expected to be tolerated by the railway undertakings. It is therefore concluded that within its intended use case, the approach seems to be applicable for large-scale problems.
Finally, an interesting result was also that the simplified variant of the proposed approach substantially decreased the execution time. Given that the simplified variant yielded almost as large of robustness improvements as the proposed approach, the simplified variant is likely a suitable alternative for very large instances. Furthermore, it could also be a suitable variant if the approach is extended to full networks.
6. Conclusions and Future Work
This paper considered the problem of constructing robust and efficient timetables by combining microsimulation and optimization to improve a given timetable. The main contribution of the paper is a new delay prediction model, which considers delay recovery and knock-on delays from preceding trains. The model can be used to predict remaining delays when a given timetable is modified based on delay data from simulation and can be included in event-based MILP timetabling problems to compute the optimal modifications to a given timetable. The intended application for this type of model is in the annual timetabling process to adjust a preliminary timetable based on an evaluation with simulation. The model was applied in a combined simulation-optimization approach that allows full flexibility in the order of trains. The evaluation was conducted in a simulation experiment on the most important Swedish railway line—the Western Main Line—considering three parts: (1) validating the proposed delay prediction model; (2) evaluating the impact of the proposed approach on total disutility, total scheduled travel time, total mean delay, and punctuality in relation to the level of planning flexibility; and (3) evaluating the sensitivity of execution time to deviations in important parameters for the problem instances—planning flexibility and number of trains.
The validation showed that, in simulation, the prediction errors were mostly small. For approximately 90% of all observations, the prediction error was less than approximately 3 minutes, and the mean absolute percentage error with respect to predicted travel time from the first event was only 6% for all trains. Further, the observed prediction errors remained relatively stable when the traveled distance increased (although increased variability also was observed). For this reason, it was concluded that the proposed delay prediction model is sufficiently good for its purpose: to guide the optimization problem when improving the given timetable.
The evaluation showed that the proposed approach with full flexibility yielded timetables with significantly lower total disutility than with several other variants of the approach and the original timetable. In particular, it yielded timetables that were significantly better than with a variant based on the formulation in Högdahl, Bohlin, and Fröidh (2019). This was because the new approach made it possible to lift the limitations in Högdahl, Bohlin, and Fröidh (2019), which were fixed order of trains and fixed entry times. For planning-window widths (determining how much any event can deviate from its original scheduled time) between 2 and 60 minutes, total disutility was on average reduced by 5%. Because the Western Main Line is highly utilized and large improvements on total mean delay and punctuality were observed, this is considered as a substantial improvement. Compared with the original timetable, punctuality was in the simulations improved from 87% to 96% on average. In contrast, the total scheduled travel time was on average only extended by 7%. Additionally, it was observed that a simplification of the delay prediction model, which did not model the impact of knock-on delays, yielded timetables with almost as low of total disutility as with the proposed model.
The last two experiments were conducted to evaluate the impact on execution times with respect to planning-window width as well as planning-window width and number of trains, respectively. These experiments showed that execution time was extended when both planning-window width and number of trains were increased, which was expected. In the first of the two experiments, it was shown that the variant based on Högdahl, Bohlin, and Fröidh (2019) was more sensitive to the planning-window width than the proposed approach. In the second experiment, it was observed that the proposed approach solved instances with 1,392 trains in 16 hours and 696 trains in 24 hours with narrow and wide planning-window widths, respectively. Because the intended use for the approach is within the annual timetabling process, which today takes several months, execution times were considered as feasible. Because of this, it was concluded that the approach within its intended use case—for late-stage improvements in the annual timetabling process—is applicable to large-scale instances, provided that the traffic in each direction can be separated. Interestingly, it was also observed that total execution times with the variant implemented with a simplified delay prediction model were much shorter than with the proposed approach (yielding an optimization problem that, even with the largest timetable, was solved in a few minutes with the narrow planning-window width). Because this simplified variant also yielded almost as large an improvement in total disutility, this variant may be a candidate for very large problem instances or if the approach is extended to network optimization.
In summary, the most important conclusions of this paper are that—in simulation—the approach significantly improved the robustness of the given timetable, which led to a considerable improvement in punctuality at a cost of marginally extended travel times, and that the approach within its intended use case seems to be feasible for large-scale problems. To further increase the applicability of the approach, future work should focus on extending the approach to single-track lines and networks. A related problem of interest, which an adapted approach can address, is to maximize punctuality directly. Finally, because the proposed approach has shown promising results, it would also be interesting to evaluate it on real traffic.
The authors express their gratitude to Pär Johansson (Trafikverket) for providing valuable input regarding the state of practice in today’s railway planning; Magnus Wahlborg (Trafikverket) for providing the necessary Railsys infrastructure models and timetable data; Oskar Fröidh (KTH Royal Institute of Technology) for valuable input during the preparation of the manuscript; and two anonymous reviewers whose insightful comments helped improving the paper. This paper is an extension of the conference paper by Högdahl (2019b) presented at the Eighth International Conference on Railway Operations Modelling and Analysis–RailNorrköping2019.
References
- (2022) European railway deregulation: An overview of market organization and capacity allocation. Transportmetrica A Transport Sci. 18(3):594–618.Crossref, Google Scholar
- (2013) Quantifying railway timetable robustness in critical points. J. Rail Transport Planning Management 3(3):95–110.Crossref, Google Scholar
- (2015) Reduced railway traffic delays using a MILP approach to increase robustness in critical points. J. Rail Transport Planning Management 5(3):110–127.Crossref, Google Scholar
- (2012) Randomness in preference orderings, outcomes and attribute tastes: An application to journey time risk. J. Choice Model. 5(3):157–175.Crossref, Google Scholar
- (2016) An integrated micro-macro approach to robust railway timetabling. Transportation Res. Part B Methodological 87:14–32.Crossref, Google Scholar
- (1998) Railway timetabling using Lagrangian relaxation. Transportation Sci. 32(4):358–369.Link, Google Scholar
- (2017) Optimization of supplements and buffer times in passenger robust timetabling. J. Rail Transport Planning Management 7(3):171–186.Crossref, Google Scholar
- (2012) Nominal and robust train timetabling problems. Eur. J. Oper. Res. 219(3):727–737.Crossref, Google Scholar
- (2012) A Lagrangian heuristic for robustness, with an application to train timetabling. Transportation Sci. 46(1):124–133.Link, Google Scholar
- (2017) Models for railway timetable optimization: Applicability and applications in practice. J. Rail Transport Planning Management 6(4):285–312.Crossref, Google Scholar
- (2002) Modeling and solving the train timetabling problem. Oper. Res. 50(5):851–861.Link, Google Scholar
- (2012) Value of travel time reliability: A review of current evidence. Transportation Res. Part A Policy Pract. 46(4):720–741.Crossref, Google Scholar
- (2010) Applied Integer Programming: Modeling and Solution (John Wiley & Sons, Hoboken, NJ).Google Scholar
- (2018) Cost functions and multi-objective timetabling of mixed train services. Transportation Res. Part A Policy Pract. 113:335–356.Crossref, Google Scholar
- (2014) Improving the robustness in railway station areas. Eur. J. Oper. Res. 235(1):276–286.Crossref, Google Scholar
- (1996) Modeling reliability of train arrival times. J. Transportation Engrg. 122(6):414–420.Crossref, Google Scholar
- (2009)
Light robustness . Ahuja RK, Möhring RH, Zaroliagis CD, eds. Robust and Online Large-Scale Optimization, Lecture Notes in Computer Science, vol. 5868 (Springer, Berlin), 61–84.Crossref, Google Scholar - (2009) Fast approaches to improve the robustness of a railway timetable. Transportation Sci. 43(3):321–335.Link, Google Scholar
- (2013) Performance indicators for railway timetables. 2013 IEEE Internat. Conf. Intelligent Rail Transportation Proc., 301–306. https://ieeexplore.ieee.org/xpl/conhome/6684703/proceeding.Google Scholar
- (2012) A tutorial on fundamental model structures for railway timetable optimization. Surveys Oper. Res. Management Sci. 17(2):85–96.Crossref, Google Scholar
- (2018) Periodic railway timetabling with sequential decomposition in the PESP model. J. Rail Transport Planning Management 8(3):167–183.Crossref, Google Scholar
- (1998) Modeling train delays in urban networks. Transportation Sci. 32(4):346–357.Link, Google Scholar
- (1996) Optimal scheduling of trains on a single line track. Transportation Res. Part B Methodological 30(2):147–161.Crossref, Google Scholar
- (2019a) A simulation-optimization approach for improved robustness of railway timetables. Licentiate thesis, Kungliga Tekniska högskolan, Stockholm.Google Scholar
- (2019b) Delay prediction with flexible train order in a MILP simulation-optimization approach for railway timetabling. Proc. 8th Internat. Conf. Railway Oper. Model. Anal. RailNorrköping.Google Scholar
- (2017) Combining optimization and simulation to improve railway timetable robustness. Proc. 7th Internat. Conf. Railway Oper. Model. Anal. RailLille.Google Scholar
- (2019) A combined simulation-optimization approach for minimizing travel time and delays in railway timetables. Transportation Res. Part B Methodological 126:192–212.Crossref, Google Scholar
- (2006) Another look at measures of forecast accuracy. Internat. J. Forecasting 22(4):679–688.Crossref, Google Scholar
- (1991) Tactical scheduling of rail operations. The SCAN I system. Transportation Sci. 25(1):46–64.Link, Google Scholar
- (2008) Stochastic improvement of cyclic railway timetables. Transportation Res. Part B Methodological 42(6):553–570.Crossref, Google Scholar
- (2009) The new Dutch timetable: The OR revolution. Interfaces 39(1):6–17.Link, Google Scholar
- (1952) Use of ranks in one-criterion variance analysis. J. Amer. Statist. Assoc. 47(260):583–621.Crossref, Google Scholar
- (2017) An exact micro-macro approach to cyclic and non-cyclic train timetabling. Omega 72:59–70.Crossref, Google Scholar
- (2017) Balance of efficiency and robustness in passenger railway timetables. Transportation Res. Part B Methodological 97:142–156.Crossref, Google Scholar
- (2008) The first optimized railway timetable in practice. Transportation Sci. 42(4):420–435.Link, Google Scholar
- (2009)
The concept of recoverable robustness, linear programming recovery, and railway applications . Ahuja RK, Möhring RH, Zaroliagis CD, eds. Robust and Online Large-Scale Optimization, Lecture Notes in Computer Science, vol. 5868 (Springer, Berlin), 1–27.Crossref, Google Scholar - (2010) Computing delay resistant railway timetables. Comput. Oper. Res. 37(5):857–868.Crossref, Google Scholar
- (2008)
Improved punctuality for X2000: Analyzed using simulation . Report, Kungliga Tekniska Högskolan, Stockholm.Google Scholar - (2017) Some influencing factors for passenger train punctuality in Sweden. Internat. J. Prognostics Health Management 8(3):1–13.Google Scholar
- (2018) The planners’ perspective on train timetable errors in Sweden. J Adv. Transportation 2018:58502819.Google Scholar
- (2019) An adjustable robust optimization approach for periodic timetabling. Transportation Res. Part B Methodological 128:50–68.Crossref, Google Scholar
- (2004)
Automated planning of timetables in large railway networks using a microscopic data basis and railway simulation techniques . Allan J, Brebbia CA, Hill RJ, Sciutto G, Sone S, eds. Computers in Railways IX (WIT Press, Southampton, United Kingdom), 615–625.Google Scholar - (2020) Simulated and real train driving in a lineside automatic train protection (ATP) system environment. J. Rail Transport Planning Management 16:1.Crossref, Google Scholar
- (2010)
Balancing efficiency and robustness: A bi-criteria optimization approach to railway track allocation . Ehrgott M, Naujoks B, Stewart TJ, Wallenius J, eds. Multiple Criteria Decision Making for Sustainable Energy and Transportation Systems, Lecture Notes in Economics and Mathematical Systems, vol. 634 (Springer, Berlin), 105–116.Crossref, Google Scholar - (2009)
A bicriteria approach for robust timetabling . Ahuja RK, Möhring RH, Zaroliagis CD, eds. Robust and Online Large-Scale Optimization, Lecture Notes in Computer Science, vol. 5868, (Springer, Berlin), 119–144.Crossref, Google Scholar - (2016) Reducing the passenger travel time in practice by the automated construction of a robust railway timetable. Transportation Res. Part B Methodological 84:124–156.Crossref, Google Scholar
- (1989) A mathematical model for periodic scheduling problems. SIAM J. Discrete Math. 2(4):550–581.Crossref, Google Scholar
- (2017) A microscopic evaluation of railway timetable robustness and critical points. J. Rail Transport Planning Management 7(4):207–223.Crossref, Google Scholar
- (1973) Optimal train scheduling on a single track railway. Ross M, ed. Oper. Res. ’72: Proc. Sixth IFORS Internat. Conf. Oper. Res. (North-Holland Publishing Company, Amsterdam), 343–352.Google Scholar
Trafikverket (2014) Guidelines for train density: Planning prerequisites: Train plan T15. Report, Trafikverket, Borlänge, Sweden.Google ScholarTrafikverket (2020) Method of analysis and socio-economic calculation values for the transport sector: ASEK 7.0. Report, Trafikverket, Borlänge, Sweden.Google ScholarTrafikverket (2021a) Analysis of designated deficiencies at the Swedish Western Main Line: Background for the revision of the National Plan 2018–2029. Report, Trafikverket, Borlänge, Sweden.Google ScholarTrafikverket (2021b) Network statement 2023. Report, Trafikverket, Borlänge, Sweden.Google Scholar- (2016) The use of railway simulation as an input to economic assessment of timetables. J. Rail Transport Planning Management 6(3):255–270.Crossref, Google Scholar
- (2019) Multi-objective periodic railway timetabling on dense heterogeneous railway corridors. Transportation Res. Part B Methodological 125:52–75.Crossref, Google Scholar

