
Cost Patterns of Multiple Chronic Conditions: A Novel Modeling Approach Using a Condition Hierarchy
Abstract
Healthcare cost predictions are widely used throughout the healthcare system. However, predicting these costs is complex because of both uncertainty and the complex interactions of multiple chronic diseases: chronic disease treatment decisions related to one condition are impacted by the presence of the other conditions. We propose a novel modeling approach inspired by backward elimination, designed to minimize information loss. Our approach is based on a cost hierarchy: the cost of each condition is modeled as a function of the number of other, more expensive chronic conditions the individual member has. Using this approach, we estimate the additive cost of chronic diseases and study their cost patterns. Using large-scale claims data collected from 2007 to 2012, we identify members that suffer from one or more chronic conditions and estimate their total 2012 healthcare expenditures. We apply regression analysis and clustering to characterize the cost patterns of 69 chronic conditions. We observe that the estimated cost of some conditions (for example, organic brain problem) decreases as the member’s number of more expensive chronic conditions increases. Other conditions, such as obesity and paralysis, demonstrate the opposite pattern; their contribution to the overall cost increases as the member’s number of other more serious chronic conditions increases. The modeling framework allows us to account for the complex interactions of multimorbidity and healthcare costs and, therefore, offers a deeper and more nuanced understanding of the cost burden of chronic conditions, which can be utilized by practitioners and policy makers to plan, design better intervention, and identify subpopulations that require additional resources. More broadly, our hierarchical model approach captures complex interactions and can be applied to improve decision making when the enumeration of all possible factor combinations is not possible, for example, in financial risk scoring and pay structure design.
History: Rema Padman served as senior editor for this article.
Data Ethics & Reproducibility Note: This study is based on proprietary deidentified insurance claims data, so it is not possible to share the original data. To assist in reproducibility, the complete output of the model and statistics related to the cost and prevalence of the conditions studied as well as the diagnosis codes used are included in the online supplement. The modeling approach in this study utilizes healthcare costs as a proxy for severity, which can cause racial disparities. We discuss this in more detail in the Discussion section. The research plan for this study was approved by the institutional review board at the University of Maryland College Park on April 28, 2020. The code capsule is available on Code Ocean at https://doi.org/10.24433/CO.6703019.v1 and https://doi.org/10.24433/CO.1745085.v1 and in the e-companion to this article (available at https://doi.org/10.1287/ijds.2022.0010).
1. Introduction
Healthcare cost predictions and estimations are widely used throughout the healthcare system. For example, health systems extensively use predictive models to identify patients with complex needs for additional support in navigating the healthcare system. Healthcare cost predictions are further used for public health support (Taloba et al. 2022) and insurance business planning. They are also the foundation for personalized insurance plan recommendations (Morid et al. 2017). Developing models that accurately estimate and/or predict healthcare costs and identifying factors linked to increased costs can be crucial for both cost reduction and the improvement of patients’ health through targeted interventions (Bates et al. 2014).
Chronic conditions contribute significantly to individuals’ healthcare costs, which make up 90% of the $4.1 trillion in annual U.S. healthcare spending (Centers for Disease Control and Prevention 2020). More than half of the U.S. adult population is estimated to have at least one chronic condition with one in four adults having multiple (two or more) chronic conditions (Ward et al. 2014). The healthcare utilization patterns of those with chronic conditions are characterized by more frequent outpatient and emergency department visits (Rezaee and Pollock 2015, Powell et al. 2018), and the resulting and often high cost burden of chronic disease is well documented (Glynn et al. 2011, Bähler et al. 2015, Skinner et al. 2016, Centers for Disease Control and Prevention 2020). In addition to higher costs, chronic conditions are linked to worse health outcomes and to the prevalence of other chronic conditions (Sambamoorthi et al. 2015, Han and Han 2016, Guy et al. 2017, Admon et al. 2018). It is, therefore, critical to develop a better understanding of how different chronic conditions contribute to healthcare cost estimates.
The impact of chronic conditions on healthcare costs, utilization, and outcomes is well-documented with numerous studies reporting on the association between chronic conditions and increased healthcare costs. The majority of the literature focuses on one or a few conditions at a time, highlighting the fact that, because they harm patients’ health and increase their healthcare utilization, chronic conditions lead to higher healthcare costs. A few studies take a more systematic approach, most often studying a handful of chronic conditions, their combinations, and the resulting healthcare costs. In summary, the literature finds a general trend of increasing costs with additional disease burden.
The approach that is used to study more than a single combination of chronic conditions is typically to either estimate the cost contribution of each chronic condition as fixed or exhaustively enumerate all combinations and estimate the cost of each. There are a number of limitations to these approaches. The literature shows that, for most combinations of two chronic conditions, a superadditive effect is observed, meaning that the sum of the cost of having each condition separately is lower than the cost of having both conditions. However, the alternative approach of estimating the cost of all combinations does not scale. When studying a large set of 69 chronic conditions, the number of possible combinations grows exponentially: considering all combinations of two, three, or four of any of the 69 chronic conditions results in more than 900,000 combinations. We, therefore, need an alternative flexible modeling approach that can account for the complexities of chronic conditions and their associated and interacting costs and also remain scalable. In this paper, therefore, we introduce a novel modeling approach that aims to address these challenges by modeling the cost of chronic conditions as a function of each condition’s place in a cost hierarchy. This modeling framework may have applicability beyond chronic conditions, such as skill “pricing” for salary explanation: given specific skills listed in a job description and using the order in which they appear in the list of requirements, we could estimate how much each skill contributes to the salary.
1.1. Problem Setup
As highlighted, the cost of treating any chronic condition is affected by the presence of other chronic conditions. Our model approach aims to highlight how each condition contributes to the member’s overall cost as a function of the other, more costly conditions. We, therefore, introduce a condition cost hierarchy that is scalable to multiple chronic conditions. In other words, we utilize cost as a surrogate for condition severity and model the cost of any chronic condition as a function of whether the condition is the most expensive condition the member has, the second most expensive, and so on. This formulation enables us to study whether the cost of each condition increases or decreases with disease burden. It, thus, facilitates an understanding of the additive cost pattern of each chronic condition and, therefore, an improved overall understanding of chronic cost patterns.
To support this analysis, we order the conditions in decreasing order of average annual cost for members who have that chronic condition and no others (we explain the condition cost ranking in more detail in Section 3.2). We then define the cost-order of chronic diseases for each member and create indicator variables xjl, which take a value of one if condition j is the lth costliest condition for the member. For example, a condition ranked as a member’s third most expensive condition is that member’s third cost-ordered condition.
Our goal is then to regress members’ overall healthcare costs on these indicator variables, and the resulting regression coefficients can then be interpreted as the cost pattern for each condition. To limit the scale of the model, we further define the parameter Lj, which acts as a cost-order threshold for each condition, limiting the cost level of the model. Specifically, we do not attempt to estimate the cost contribution of a condition j beyond Lj. There are both statistical and medical justifications for this modeling choice. Typically, there is a limited number of members who have condition j high in the cost order; this is because, thankfully, most members only have a handful of chronic conditions. Second, typically the most serious chronic conditions are the most aggressively treated, so other, less critical conditions may be managed less aggressively, and therefore, the cost contribution of a condition may level off. More formally,
We can then formulate an estimation problem using linear regression, in which the dependent variable (y) is the member’s annual healthcare cost and N is the number of chronic conditions:
We then use both regression and clustering to summarize the cost characteristics of the different chronic conditions.
1.1.1. Illustrative Example.
As an illustrative example, consider a scenario in which there are six chronic conditions (e.g., hypertension, asthma, cancer, etc.) A, B, C, D, E, and F, named in decreasing order of cost, and we seek to understand the cost characteristics of these conditions.
To run the regression model we define, we translate each member’s conditions into binary indicator variables. Consider a member diagnosed with conditions B, E, and F. Based on the cost rank of these conditions, condition B has the cost order 1, E has the cost order 2, and F has the cost order 3. Using these definitions, the variables and equal one for the member, and all other binary indicators would be zero.
Assume that, in our population, very few members have more than four conditions. It is, therefore, statistically challenging to estimate the cost contribution of a condition when it is the fifth or sixth most costly condition. We then limit the cost level of the model to four. Thus, we aim to characterize the cost behavior of our conditions up to the fourth order, and as a result, represents the cost contribution of condition j if it is ranked fourth or higher for a member. Equation (2) is the regression formulation for this example.
In Equation (2), we observe that not all chronic conditions have the same number of variables. The most costly condition only has a single regression coefficient (as it is always the most costly condition that a member has). Thus, there exists an upper threshold Lj, the maximum order associated with each condition j, which differs from one condition to the next.
The regression coefficients () translate to the cost behavior of each condition. They highlight how the cost contribution of each condition changes depending on how many more costly conditions a member has. This can be estimated based on because all variables xjl are binary, so the interpretation of each coefficient shows the corresponding cost contribution. If the relationship between the cost (y) and the binary variables (xjl) is linear, then the coefficients of the model () reflect the actual cost contribution in dollars of each cost order. However, if the model has a log link function, we need additional steps to translate the regression coefficients into a cost contribution in dollars. For example, for a member who has condition j in cost order l, if , then the member’s predicted annual cost is times higher than an otherwise similar member who does not have condition j in order l. Thus, if, for example, in our population, the average predicted annual cost of members with condition j in order l is , the contribution in dollars of disease j in cost order l is (because ). In Figure 1, we show what the resulting cost patterns could look like with the figure depicting both superadditive and subadditive patterns. Superadditive cost behavior can have multiple causes; for instance, some conditions are more difficult to manage or more aggressively managed in the presence of other chronic conditions, or some conditions may exacerbate others. Subadditive cost patterns may indicate that one condition is not aggressively managed in the presence of others.

Notes. The cost pattern of condition E is superadditive, whereas the cost pattern of condition F is subadditive. (a) Condition E. (b) Condition F.
The paper proceeds as follows. First, we review the relevant literature in Section 2 and present our case study in Section 3 before formally introducing our modeling approach in Section 4. We then apply our modeling approach to a case study using real-world data in Section 5. In Section 6, we conclude the paper with a discussion of key insights, limitations, possible extensions, and future directions.
The analysis was conducted in R version 3.5.3, utilizing the packages MASS, sqldf, Rmisc, rsq, and ggplot2, and in Python version 3.9.13, utilizing tslearn, dtaidistance, networkx, and matplotlib. The research plan for the study was reviewed and approved by the institutional review board at the University of Maryland College Park.
2. Literature Review
A large body of literature focuses on the impact of chronic conditions on healthcare costs, utilization, and outcomes. However, with few exceptions, these studies focus on one condition at a time. For example, diabetic patients are found to be at higher risk of depression, and the combination of diabetes and depression is linked to increased total healthcare costs (Egede et al. 2002). Cancer survivors are more likely to get (multiple) chronic conditions (e.g., heart disease, stroke) and have higher medical costs for those chronic conditions than people without a history of cancer (Guy et al. 2017). Depression is another well-studied condition; it is linked to higher nonmental health costs in patients with chronic conditions, whereas at the same time, chronic conditions are more prevalent in people with depression (Welch et al. 2009). For additional examples, we point the reader to Sambamoorthi et al. (2015) and references therein.
A number of papers do take a broader view, linking the number of chronic conditions (e.g., Wolff et al. 2002, Schneider et al. 2009) or clusters of conditions (Hajat et al. 2021) with resulting healthcare costs. However, within the vast chronic condition cost literature, only a handful of papers study the cost of combinations of specific chronic conditions. For instance, the cost of concurrent arthritis, diabetes mellitus, heart disease, and hypertension is studied by Meraya et al. (2015). The study concludes that, perhaps unsurprisingly, adults with all four chronic conditions have the highest cost. In the cases in which only two or three conditions are present, combinations including arthritis, diabetes mellitus, and/or heart disease lead to the highest overall costs. Combinations of two and three chronic conditions are studied in Majumdar et al. (2019) and ordered based on prevalence and cost. In particular, the authors focus on 69 chronic conditions and generate all possible combinations of two or three conditions and the member’s gender and age group. This allows them to investigate the burden of combinations of conditions in the population studied, compare the results with the national numbers, and identify the population subsets that might cause most concern. The cost of 10 common chronic conditions and all combinations of two of the conditions is studied by Cortaredona and Ventelou (2017), who observe a superadditive effect for most combinations of two conditions, meaning that the sum of the cost of having each condition separately is lower than the cost of having both conditions. However, some combinations show the opposite effect. For example, the combination of cancer and stroke leads to lower costs than the sum of the costs of the individual conditions. A notable exception to the standard approach of calculating or estimating average costs of conditions is Eckardt et al. (2017), who use a finite mixture of generalized linear models to relate costs to the number of chronic conditions. The resulting model separates the patients into four groups, which each have different relationships between the mean cost and the number of chronic conditions. Based on the prevalence of the conditions in each group, the authors draw conclusions about the specific conditions and the changes in cost when multiple chronic conditions are present. However, this approach does not allow one to study the specific cost pattern of each condition as the number of other conditions that are present changes.
The modeling approaches of the papers summarized are limited by the fact that the number of possible combinations grows exponentially with the number of chronic diseases addressed. Further, when each combination is studied independently, combinations of less common conditions are hard to study. The modeling approaches also do not capture well the different elements that influence the cost of chronic conditions, namely, the number, severity, and interactions of other chronic conditions present. This is a crucial omission as comorbidity may affect the severity of other conditions, the course of treatment for those conditions, and health outcomes. More specifically, the aggressive treatments associated with each chronic disease (and, therefore, potentially the associated costs) may be affected by the number of other, more serious diseases that are present. This paper aims to fill this gap.
2.1. Healthcare Cost Estimation and Predictions
Healthcare expenditures tend to be positively skewed because there is a small number of patients with very high costs generating a long tail on the right side of the distribution. Traditionally, a transformation of the dependent variable (i.e., healthcare cost) is used to address the distributional skewness when using ordinary least squares (OLS) regression to predict or explain healthcare cost. In the healthcare expenditure literature, the logarithmic transformation is most commonly used (Raval and Sambamoorthi 2012, Bähler et al. 2015, Meraya et al. 2015), in part because of the interpretability of the resulting regression coefficient. Other transformations include a square root transformation of healthcare expenditures (Veazie et al. 2003).
More recently, generalized linear models (GLMs) have been increasingly used to model healthcare costs because they address some of the limitations of OLS. GLMs are a generalization of the OLS, and they allow the dependent variable to follow a distribution that is not necessarily the normal distribution and allow the model to have a nonlinear relationship with the dependent variable (controlled by a link function). The gamma distribution with a log link function is the most commonly used GLM approach to model healthcare costs (Malehi et al. 2015, Han and Han 2016, Cortaredona and Ventelou 2017, Eckardt et al. 2017, Vohra et al. 2017) because the distribution of healthcare costs is skewed with nonnegative values. Other approaches found in the literature include inverse Gaussian distribution (Moran et al. 2007) and a Poisson distribution (Barber and Thompson 2004).
Independent of the regression modeling of healthcare costs, a series of papers use machine learning techniques for cost prediction. These techniques include the application of regression (Zhao et al. 2005), regularized regression with both the least absolute shrinkage and selection operator and ridge (Duncan et al. 2016, Morid et al. 2017), classification trees, clustering (Bertsimas et al. 2008), random forest (Sushmita et al. 2015), and deep learning (Drewe-Boss et al. 2022). Each of these approaches has a trade-off in terms of predictive accuracy and explainability. In contrast to the machine learning literature, we aim to get a better understanding of the cost behavior of chronic conditions in the presence of other chronic conditions. This is, in many cases, difficult to achieve with machine learning approaches. Thus, we utilize a regression approach in combination with clustering to provide us with interpretable results highlighting chronic cost patterns. With our approach, we get specific coefficients associated with each chronic condition, which we can then translate to cost impact.
As many chronic conditions are rare, we have a limited number of observations of rare conditions in high cost order, so we build on variable selection approaches to eliminate nonsignificant regression coefficients. More generally, there are a number of variable selection methods that exist to help decide which variables to include in a regression model. This includes the best subset method, which builds all possible combinations of models based on the available variables and chooses the best model based on some statistical measure. However, the best subset method is computationally demanding, and stepwise regression methods offer a less expensive alternative. These include forward selection, in which variables are added one by one to an initially empty model; backward elimination, in which variables are excluded one by one from a model initially containing all variables; and stepwise regression, which is a modification of forward selection that allows variables to be removed in a future iteration of the algorithm (Montgomery et al. 2021). Regularization is another common approach to variable selection that aims to maximize out-of-sample prediction accuracy. The loss function of the regularization methods includes a penalty on the magnitude of the regression coefficients and, as a result, biases regression coefficients toward zero (Heinze et al. 2018). Regularization approaches are, therefore, not well-suited for our purposes as our goal is to estimate and understand cost patterns of chronic conditions. Whereas our modeling approach builds on backward elimination, we extend the approach to what we call “backward aggregation.” Specifically, in order to ensure that our estimates are mostly statistically significant, we adjust the standard backward elimination algorithm, merging variables when they are not statistically significant (refer to Section 4 for details). This allows us to retain the information unlike the standard variable selection discussed earlier, and the resulting variables for each condition have consecutive orders.
The modeling approach we develop for this paper is a novel one that adapts variable selection approaches to respect a variable hierarchy and limits information loss when variables are excluded. This allows us to study a larger set of chronic conditions than previously considered in the literature. We aim to provide insight into how costs of chronic conditions are affected by other, more expensive conditions, and in so doing, we contribute to the larger body of literature examining the healthcare costs of patients with multimorbidity. This work, therefore, opens a new direction in the use of large data to support more nuanced modeling of healthcare costs, and it provides insight into the complex interactions between chronic diseases.
3. Case Study: Chronic Conditions
This case study is based on claims data provided by two large insurance companies in the Rochester area of New York State. The data set is a repository of fully deidentified, Health Insurance Portability and Accountability Act–compliant data containing several years of historical claims records for adult patients 18 or older. The repository is administered by the Finger Lakes Health Systems Agency and comprises data from commercial accounts, Medicare Advantage and Medicaid Managed Care accounts, and account data for which the two insurers serve as third-party administrators. It contains more than 300 million claims records related to outpatient, inpatient, and pharmacy services. The data extends from 2007 through 2013.
We note that the cost of each service is averaged across all providers to protect proprietary pricing information. Each cost can be separated into (1) group costs, which are the total costs attributed to hospital resources utilized during a member’s inpatient stays (such as room charges), and (2) claim costs, which are the total costs attributed to physician services provided by medical staff in either outpatient or inpatient (e.g., services delivered by an anesthesiologist not employed by the hospital) settings. In this study, we combine the group and claim costs as well as the pharmaceutical claim costs to calculate each member’s total healthcare cost. We use each member’s total healthcare costs in 2012 as the outcome variable. Note that the cost is not limited to the expenses related to the chronic conditions under study but is simply the total annual healthcare cost for the member.
3.1. Chronic Condition Identification
A number of approaches and definitions have been used to determine which conditions are considered chronic (Sambamoorthi et al. 2015, Bernell and Howard 2016). With our goal of building a comprehensive picture of chronic cost burden, we adapt the algorithm provided in Magnan (2015), which summarizes diagnosis codes for 69 chronic conditions. This algorithm has been used to identify chronic conditions in a number of recent studies (Vickery et al. 2018, Waddle et al. 2019, Aizpuru et al. 2020, Harrington et al. 2020). For certain clinical conditions, we augmented the algorithm with additional codes (see the online supplement for details) in order to improve the sensitivity of the algorithm.
Table 1 includes the chronic conditions considered in this study and the corresponding abbreviations used in figures and tables throughout the paper (the number of members diagnosed with each condition can be found in the online supplement). Because this study focuses on explaining the overall healthcare costs, a member is considered to have a chronic condition if the member had at least one claim with a corresponding diagnosis code in 2012 and a second claim with a diagnosis code (for the same condition) within at least three months (in 2012 or earlier). This ensures the exclusion of short-term chronic conditions or potentially erroneous coding of claims associated with diagnostic testing. Sensitivity analysis of the inclusion criteria is provided in the online supplement. Note that all diagnosis codes (not only primary ones) are considered as secondary (or other) diagnosis codes are considered as confirmation of a chronic condition.
|

Table 1. The Chronic Conditions Studied and Their Corresponding Abbreviations
| Abbreviation | Chronic condition description | Abbreviation | Chronic condition description |
|---|---|---|---|
| Allergy | Allergy, ENT, and other upper respiratory disorders | kidney | Kidney and vesicoureteral disorders (excluding renal failure) |
| anemia | Anemia and other noncancer hematologic disorders | liver | Chronic liver disease (excluding chronic hepatitis) |
| aneurysm | Aneurysm | lupus | Lupus |
| anxiety | Anxiety disorders | malegu | Male GU excluding benign prostatic hyperplasia |
| asthma | Asthma, COPD, other chronic lung disease | malig | Malignant neoplasm |
| athero | Coronary atherosclerosis | malnutr | Malnutrition (not obesity), disorders of metabolism |
| back | Back problems | menop | Menopause and perimenopause |
| behavio | Behavior disorders | mi | Acute myocardial infarction |
| benign | Benign neoplasm | migrain | Migraines |
| bipol | Bipolar disorder | miscmh | Miscellaneous mental health |
| bph | Benign prostatic hypertrophy | ms | Multiple sclerosis |
| breast | Breast noncancer | obesity | Obesity |
| cerebro | Cerebrovascular disease | osteo | Osteoarthritis |
| chf | Congestive heart failure | othendo | Other endocrine |
| chroninf | Chronic infectious and parasitic diseases | othmsk | Other musculoskeletal including osteoporosis |
| cnspns | Other central and peripheral nervous system disorders | panc | Chronic pancreatitis |
| conc | Congenital heart disease | para | Paralysis |
| congen | Noncardiac congenital disorder | parkin | Parkinson’s disease |
| cystic | Cystic fibrosis | periph | Peripheral atherosclerosis |
| dem | Organic brain problem | persnal | Personality disorder |
| dental | Dental and mouth disorders | pulmhrt | Pulmonary heart disease |
| depress | Depression and depressive disorders | renal | Chronic renal failure |
| dm | Diabetes mellitus | rheum | Rheumatoid arthritis |
| dysrhy | Conduction disorder or cardiac dysrhythmia | schiz | Schizophrenia and psychotic disorders |
| epilepsy | Epilepsy | sickle | Sickle cell anemia |
| esoph | Esophageal disorder and GI ulcers | skin | Chronic skin ulcer |
| eye | Degenerative eye problem | sleep | Sleep disorders |
| femalegu | Female infertility and GU anatomic disorders | sti | Sexually transmitted infections |
| gi | Diverticulosis, diverticulitis, enterocolitis, intestinal malabsorption | strctht | Cardiomyopathy and structural heart disease |
| gout | Gout or other crystal arthropathy | subst | Substance use disorders |
| hep | Chronic hepatitis | tb | Tuberculosis |
| hiv | Human immunodeficiency virus | thrombemb | Thrombosis and embolism |
| htn | Hypertension | valve | Heart valve disorder |
| hyprlip | Hyperlipidemia | vasc | Nonthrombotic, nonathlerosclerotic vascular disease |
| immun | Immunity disorder |
We identify 409,238 members with at least one chronic condition in 2012. The average age of members with at least one chronic condition was 55.7, 58% were female, and in 2012, about 28% of all members were enrolled in Medicare and 8% in Medicaid. The average number of chronic conditions was 3.76 (with a standard deviation of 2.79).
3.1.1. Chronic Condition Combinations.
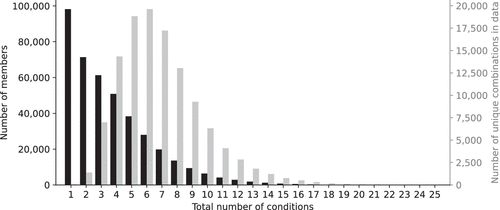
In total, there are 119,054 unique combinations of conditions in our data. There are 98,220 members with a single chronic condition and 311,018 members with multiple conditions, ranging from 2 to 25 conditions. Figure 2 shows a histogram of the number of chronic conditions our members have (left axis) as well as the number of unique combinations (right axis). We observe that members are rarely diagnosed with a high number of chronic conditions. Nevertheless, the count of unique combinations of members with a fixed number of chronic diseases increases with the number of conditions, up to seven conditions per member, even if the corresponding number of members drops considerably. Then, the number of combinations gradually decreases with thousands of unique combinations for up to 15 conditions per member. This high number of combinations underlines the importance of modeling the cost burden as a function of the number of other diseases as it allows us to capture the impact of rare disease combinations in an aggregated manner.
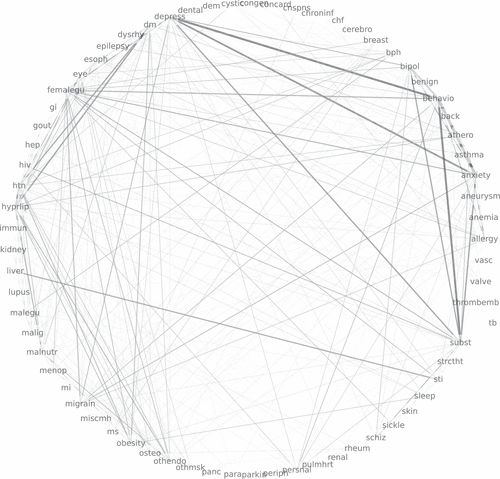
To gain insights into common combinations of chronic conditions, we create a bipartite network projection of our data (for details refer to Zinoviev 2018). The edges in Figure 3 connect the different chronic conditions, and the edge weights reflect the number of members who have both conditions. Some edges are not visible in the figure because it is uncommon for a member to be diagnosed with both conditions. The only condition that has no edges is tuberculosis (TB). The edge with the highest weight is that connecting hypertension and hyperlipidemia (125,429 members are diagnosed with both conditions). We also observe numerous other edges linking hypertension and hyperlipidemia with other conditions. Excluding hypertension and hyperlipidemia from the network reveals strong connections between (1) a number of mental health conditions and (2) allergy/ear, nose, and throat (ENT)/other upper respiratory disorders and asthma/COPD/other chronic lung disease (refer to the online supplement for additional details).

Noting the abundance of connections in Figure 3, we identify conditions that have a high relative frequency of occurring in combination with other conditions (in contrast to simply having a high prevalence in our population) by normalizing the edge weights of each condition by the number of members with the condition. This calculation highlights five chronic conditions with the highest number of connections relative to their prevalence. They are (in decreasing order): hyperlipidemia, diabetes mellitus, hypertension, degenerative eye problems (including glaucoma), and coronary atherosclerosis. Hyperlipidemia, diabetes mellitus, and hypertension are the most prevalent chronic conditions in the United States. Degenerative eye problems and coronary atherosclerosis are associated with older age, and older members have a higher chronic disease burden. The five chronic conditions with the fewest connections are noncancerous breast conditions, HIV, sickle cell anemia, cystic fibrosis, and TB.
Figure 3 highlights common conditions. One of our key goals is to understand which combinations of conditions occur more frequently than expected irrespective of their underlying prevalence. To do so, we calculate the expected number of members with each combination, assuming that the chronic conditions are independent of each other (e.g., the probability of having diabetes is not influenced by whether you have hypertension).1 We then compare the expected counts with the realized counts from our data and build a new network in which each edge represents the relative percentage increase in the expected counts compared with the actual counts. This network is summarized in Figure 4.
The pairs of conditions with the largest percentage increase, ranging from 39% to 115%, include the co-occurrence of pairs of anxiety disorders, behavior disorders, depression, substance abuse, and bipolar disorder. The graph also highlights the connections between common chronic conditions, such as diabetes mellitus and hypertension, between chronic liver disease and sexually transmitted infections, and between female infertility and genitourinary (GU) anatomic disorders (conditions affecting women) and depression, anxiety, and migraines. A full list of the top 20 pairs is provided in the online supplement.
3.2. Chronic Conditions Cost Hierarchy
We rank the chronic conditions in decreasing order of their cost. Table 2 includes the 10 conditions with the highest and the 10 conditions with the lowest average cost as well as the 10 most common conditions in our population (a complete version of this table can be found in the online supplement). The complete names of those conditions can be found in Table 1. Table 2 further includes the average annual cost (and standard deviation) of the members in our data who have been diagnosed with each specified chronic condition and no others as well as the average cost (and standard deviation) of all members with each condition. From the table, we observe a large range in the average cost across the different chronic conditions.
|
Table 2. Condition Costs and Cost Ranks
| Chronic condition | Order | Average cost (and standard deviation) members with only this condition | Average cost (and standard deviation) all members with condition | ||
|---|---|---|---|---|---|
| Highest average cost | |||||
| cystic | 1 | 18,245 | (15,919) | 32,056 | (24,196) |
| hiv | 2 | 17,094 | (10,167) | 24,392 | (17,381) |
| thrombemb | 3 | 16,177 | (24,393) | 27,853 | (34,436) |
| ms | 4 | 15,599 | (15,205) | 23,994 | (21,190) |
| hep | 5 | 12,423 | (29,036) | 21,076 | (36,295) |
| mi | 6 | 12,136 | (16,907) | 30,792 | (33,213) |
| benign | 7 | 8,473 | (16,587) | 12,453 | (14,776) |
| renal | 8 | 7,481 | (17,098) | 23,470 | (31,909) |
| panc | 9 | 7,323 | (6,346) | 19,722 | (21,869) |
| rheum | 10 | 7,309 | (9,896) | 13,766 | (17,321) |
| Most common | |||||
| osteo | 23 | 3,626 | (5,881) | 12,327 | (16,707) |
| dm | 33 | 3,180 | (4,426) | 11,252 | (17,601) |
| othendo | 39 | 2,822 | (5,139) | 9,320 | (15,281) |
| asthma | 42 | 2,742 | (3,930) | 12,526 | (18,963) |
| esoph | 43 | 2,738 | (3,491) | 10,660 | (15,808) |
| depress | 46 | 2,420 | (3,056) | 9,570 | (15,115) |
| anxiety | 53 | 2,157 | (2,897) | 8,921 | (14,358) |
| allergy | 55 | 2,068 | (2,914) | 7,962 | (12,341) |
| malnutr | 56 | 2,044 | (3,660) | 9,867 | (17,186) |
| eye | 57 | 2,011 | (3,316) | 9,602 | (14,456) |
| Lowest average cost | |||||
| chf | 60 | 1,958 | (2,544) | 25,987 | (29,871) |
| menop | 61 | 1,952 | (2,132) | 7,379 | (10,708) |
| aneurysm | 62 | 1,948 | (2,093) | 15,961 | (21,645) |
| htn | 63 | 1,925 | (3,774) | 9,070 | (14,753) |
| periph | 64 | 1,900 | (2,646) | 20,442 | (26,943) |
| bph | 65 | 1,892 | (2,891) | 10,001 | (15,045) |
| hyprlip | 66 | 1,669 | (2,605) | 8,351 | (13,736) |
| gout | 67 | 1,387 | (2,116) | 13,641 | (21,916) |
| tb | 68 | 1,058 | (0) | 1,058 | (0) |
| dental | 69 | 706 | (479) | 14,033 | (16,699) |
4. Methodological Approach
In this section, we describe our backward aggregation algorithm and justify our model selection before describing how we summarize the cost patterns.
4.1. Backward Aggregation Approach
As previously discussed, we introduce a cost hierarchy to model whether healthcare cost is a function of disease burden. To support this analysis, we order the conditions in decreasing order of cost. The cost for each condition is the average annual cost across all members with each chronic condition and no other chronic conditions. In order to estimate the effect that each chronic condition has on healthcare cost as a function of its cost order (or rank) for each member, we formulate the problem using linear regression. Recall our earlier definition of xjl as a binary indicator variable that equals one if condition j is the lth costliest condition for a member and Lj as the highest cost rank for condition j, limiting the cost level of the model. The dependent variable (y) is the member’s annual healthcare cost, and the model we specify earlier is
Setting the threshold parameter Lj = 1 for all j results in a model that simply regresses the total healthcare cost on each condition (i.e., xjl would be a binary indicator for the presence of each chronic condition under study). Increasing Lj allows for more detailed analysis. However, there are practical limitations to how large Lj can be even with a large data set. For example, if Lj = 10 for all j, we would attempt to estimate the cost of each chronic condition when it is the member’s most costly condition, second most costly condition, and so on, all the way to the 10th most costly condition. As most members only have a limited number of chronic conditions, for high values of l, there are very few (if any) observations for most conditions. In addition, it is important to note that, for rare conditions, there may not be a large enough population to estimate its impact when it is the lth most costly condition from which a member suffers. For example, there are only eight people in our data set who have dental and mouth disorders as their fifth most expensive condition, and when the corresponding variable is included in the regression, it leads to a coefficient that is not statistically significant.
Additionally, the costliest conditions also have a limit to the value that Lj can take. For example, in our data, cystic fibrosis is ranked as the most expensive condition. For cystic fibrosis, Lj = 1 because a member has cystic fibrosis as the number one condition or not. Similarly, for conditions ranked second, third, and fourth, the maximum value that Lj can take is 2, 3, and 4, respectively.
Furthermore, because the population consists only of members who have at least one chronic condition, each member has exactly one chronic condition ranked as first (which leads to linearly dependent variables). Thus, we set the condition with the lowest average cost as the baseline first condition. This means that there is no variable corresponding to having the condition with the lowest average cost as the most expensive for a member; instead, the intercept of the regression model give information about this cost.
Based on these considerations, Lj is set for each condition through an iterative process in order to ensure the statistical significance of the regression coefficients. We set Lmax as the maximum value any Lj can take, and we first set for all conditions with two exceptions. First, for the conditions that are ordered as the most expensive conditions, we set their Lj equal to their place in the cost hierarchy. Second, for rare conditions, we observe their maximum position in the hierarchy. For example, in our data, chronic infectious and parasitic diseases appear anywhere from the most to the fourth most expensive condition. Thus, for this condition, Lj is set to 4.
Given these considerations and the fact that we have very few observations for some conditions, we seek a method that excludes nonsignificant variables, simultaneously minimizing information loss. We, therefore, apply a variant of backward elimination that, at each step for each condition, only considers removing the highest cost-order variable. If, based on it not being statistically significant, a variable is removed, we update the next highest cost-order variable for the corresponding condition to capture the cost of members with the condition at the next highest cost rank and above, therefore maximizing the information about the cost behavior of each condition. We retain information contained in the variable that is not statistically significant because we merge it with the variable of the previous cost order instead of simply excluding it from the model. Additionally, this approach produces a model consisting of variables with consecutive cost orders for each condition. This is important as it enables a better interpretation of the coefficients because our goal is to analyze the cost behavior of each condition.
More specifically, after selecting Lmax and setting the initial Lj for all conditions j, we systematically remove variables that are not statistically significant as detailed in Algorithm 1. We start by fitting the fully specified model. From the initial model, we study the regression coefficients of all conditions with and focus on (the coefficients corresponding to each condition when it is the Lmax most expensive condition (or higher) for the member). If is not statistically significant, we update and update the data accordingly (i.e., ). In other words, we merge the information included in variables and into an updated variable , which indicates whether condition j is ranked or higher for each member.
We then refit the model based on the updated data, and in the next iteration, we focus on the statistical significance of for those conditions that have . We continue this iterative process until we have considered all conditions with Lj = 2.
(Backward Aggregation: Reducing the Variable Set Based on Statistical Significance, Minimizing Information Loss)
Data: Initial set of variables .
Result: Reduced set of variables .
Initiation:
Lj equals Lmax (with exceptions discussed in the main text);
Estimate a linear regression model based on x1 and obtain initial set of coefficients ;
Updates: for do
;
;
for each chronic condition j do
if ()
AND ( is not statistically significant at the 5% level) then
;
remove from xn;
set ;
end
end
Estimate a linear regression model based on the updated xn and obtain set of coefficients ;
end
4.2. Model Fitting
Algorithm 1 can be used with any linear regression approach. For our case study, we use a GLM instead of OLS as GLMs offer additional flexibility and are found to effectively model healthcare cost data (Blough et al. 1999). Specifically, there are two ways in which the flexibility of GLMs is particularly helpful for fitting healthcare costs.
First, GLMs are a generalization of OLS that allow the relationship between the dependent and independent variables to be related via link function and allows the variability to be a function of the outcome, therefore addressing heteroscedasticity. For example, to address skewed healthcare costs, we can use a log link function instead of using a log-transformation of the dependent variable as we would in an OLS modeling approach. The advantage of the link function is that we model the relationship between the logarithm of the mean and the independent variables (i.e., ), which means that we can easily transform the regression coefficients to real dollars by taking the exponent of the resulting fitted values. In contrast, in OLS, with log-transformation, we model the relationship of the mean of the logarithm to the independent variables (i.e., ), making the transformation back more complicated. One way to address this issue is by using a smearing estimate (Duan 1983), which allows for an accurate prediction in real dollars (Basu and Rathouz 2005, Moran et al. 2007). An additional benefit of using a log link function, which is not applicable in our case, is that it can handle zero costs, whereas in the log-transformation version the log of zero is undefined.
Second, GLM models are especially suited for handling heteroscedasticity because they do not assume a constant variance. Depending on the distribution family used in the model, the variance is modeled as a function of the mean. In healthcare expenditure data, heteroscedasticity can be an issue because higher expected costs also tend to have higher variance (Deb and Norton 2018).
In order to fit a GLM model, a modeler needs to decide on the link function and the distribution family. To do this, we use the Box–Cox parameter (Box and Cox 1964), which indicates the type of transformation that should be used on the dependent variable (cost) in order for it to become (nearly) normally distributed. For example, a Box–Cox parameter close to −1.0 corresponds to a reciprocal transformation; close to −0.5 corresponds to a reciprocal of the square root; close to 0.0 a logarithmic transformation; close to 0.5 a square root transformation; and if the parameter is close to 1.0, no transformation is needed (Lee 2020). Next, to determine the distribution family, a modified Park (1966) test is applied in order to estimate the relationship of the mean to the variance. If the value of the test is close to 0.0, a Gaussian distribution is appropriate; if it is close to 1.0, a Poisson is appropriate; if it is close to 2.0, a gamma distribution is appropriate; and if it is close to 3.0, an inverse-Gaussian distribution may make sense (Jones et al. 2013, Deb and Norton 2018).
We model the healthcare costs with gamma regression with a log link (justified by the results presented in Section 5) in order to address the skewed data, handle the heteroscedasticity, and more accurately retransform the resulting coefficients to real dollars as we discuss next.
4.3. Model Interpretation
Because we use a model with a log link, the resulting coefficients are in a logarithmic scale as is the case in an OLS model with a logarithmic transformation of the dependent variable. The regression coefficients βjl in our regression model can be interpreted as the percentage change in the expected annual healthcare cost of the individual member when a specific chronic condition is the lth most expensive condition when (and if l = Lj, the interpretation is the percentage change when the condition is at least the Lj most expensive condition). Because the underlying costs of someone with no other chronic conditions are quite different than they are for someone with, say, four other conditions, then the same percentage increase can correspond to very different cost impacts. Thus, we cannot study the cost patterns of the various chronic conditions based only on the resulting regression coefficients. In order to compare the cost impact across positions in the cost hierarchy for the same condition, we transform the coefficients to reflect the change in actual dollars. For this translation, we use the average fitted annual cost corresponding to individuals who have a specific condition in a specific order as our estimate.
More specifically, the dollar contribution of each condition in each order is estimated as ,2 where βjl is the coefficient corresponding to condition j appearing in order l and is the average fitted cost of members having condition j in order l. We discuss how we summarize these patterns in the next section.
4.4. Characterizing Cost Patterns
We summarize the results of the regression model from two different angles. First, we fit a simple linear regression model to each condition to capture whether the cost is (on average) increasing or decreasing as a function of the number of other more expensive conditions the member has. Specifically, for each condition j, we use the cost contribution (cjl) of the regression coefficients as the dependent variable and the corresponding order as the independent variable:
Second, we apply time series k-means clustering3 to group together conditions with similar cost characteristics, using the elbow method in order to decide on the number of clusters (Teoh and Rong 2022). The features used in the clustering are the estimated cost contributions derived from the regression coefficients for each condition. We view the cost contributions of each chronic condition as a time series, using the cost order as the time dimension. We scale the features such that the resulting scaled cost contributions of each condition have zero mean and unit variance. This allows us to compare the chronic conditions based only on their cost patterns and not their cost magnitude. To measure similarity between the different chronic conditions, we use dynamic time warping, an algorithm commonly used to compare time series because it can account for time shifts in the shapes of time series (Petitjean et al. 2011). This enables us to cluster together chronic conditions with different numbers of cost coefficients. Thus, chronic conditions that follow a similar cost pattern are clustered together even if one of them consists of fewer coefficients.
5. Case Study: Results
5.1. Model Estimation
Following the approach discussed in Section 4.2, we find that the Box–Cox parameter equals −0.02, which supports the use of a log link in our GLM, whereas the modified Park test result is 1.78, which supports the use of the gamma distribution. Thus, we fit our data using gamma regression with a log link. In order to examine the robustness of our results, we reconduct our analysis using a logarithmic transformation on cost and an OLS model, which is a common data science approach. The results of this analysis and a comparison with the outcome of GLM are included in the online supplement.
We also must set a value for the parameter Lmax. To strike a balance between setting a large enough value of Lmax to observe potential cost patterns and retaining sufficient sample sizes, we select Lmax = 5. The regression model (included in the online supplement) has an R2 of 42.5%.4
Several conditions have fewer than Lmax regression coefficients. In particular, four of the conditions have fewer than five coefficients because they were ranked as one of the four most expensive conditions (cystic fibrosis, HIV, thrombosis and embolism, and multiple sclerosis (MS)), and 13 have fewer than five coefficients because of their limited sample size (benign neoplasm, chronic infectious and parasitic diseases, dental and mouth disorders, gastrointestinal (GI) problems, chronic hepatitis, malignant neoplasm, acute myocardial infarction, chronic pancreatitis, Parkinson’s disease, chronic renal failure, rheumatoid arthritis, sickle cell anemia, and TB). Additionally, 60 variables were removed because of linear dependency or, after applying Algorithm 1, lack of statistical significance.
5.1.1. Examples of Cost Patterns.
Figure 5 provides examples of different cost patterns resulting from the regression model. Figure 5(a) (coronary atherosclerosis) shows that, when this condition goes from most expensive to second most expensive, it yields a large increase in cost contribution. However, after that, the contribution remains relatively stable, and there is even a small decrease when the condition goes from second most expensive to third, fourth, or fifth (or higher) most expensive. In contrast, Figure 5(b) (obesity) shows a relatively stable increase in cost as the number of more expensive conditions increases. Figure 5, (c) and (d), highlights conditions with . In Figure 5(c), we see a clear decrease in the cost contribution of pulmonary heart disease when it appears third or higher. Finally, chronic renal failure in Figure 5(d) is estimated to have a large increase in cost if the member has at least one additional, more expensive chronic condition. Altogether, Figure 5 clearly shows that the cost characteristics of some conditions can change considerably as the number of other, more expensive chronic conditions increases.
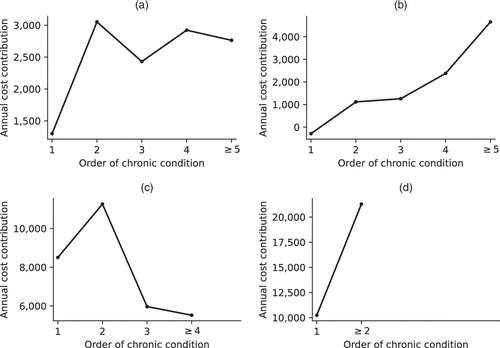
Notes. (a) Coronary atherosclerosis. (b) Obesity. (c) Pulmonary heart disease. (d) Chronic renal failure.
5.2. Pattern Summary Based on Slopes
Figure 6 summarizes the resulting slopes for all conditions for which Lj is at least 2 (the minimum requirement to be able to estimate a slope). From the figure, we can understand the condition’s cost behavior based on the direction and magnitude of its estimated slope. We note that most conditions have a positive slope, meaning that the higher the number of other, more expensive chronic conditions, the higher the estimated contribution to the member’s annual healthcare costs. For example, chronic renal failure, paralysis, anemia and other noncancer hematologic disorders, and sickle cell anemia are conditions with a high positive slope. This means that, as the number of more expensive concurrent conditions increases, the cost contribution of those conditions to the member’s total healthcare costs increases significantly. The only conditions that have a negative slope are Parkinson’s disease, pulmonary heart disease, and rheumatoid arthritis.
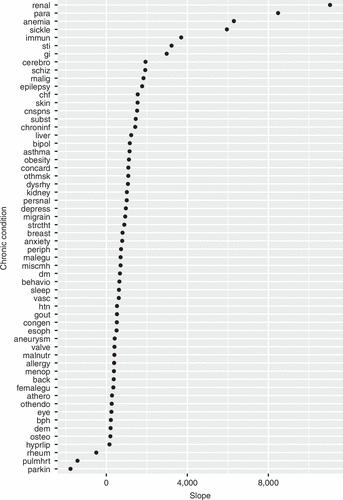
Note. Conditions corresponding to only one coefficient in the regression are excluded.
5.3. Pattern Summary Based on Clustering
We apply clustering to group the chronic conditions together based on their cost characteristics. We exclude from the analysis conditions that only correspond to one or two coefficients. In total, 18 of the 69 conditions are excluded. The analysis results in two clusters with 30 and 21 conditions. Figure 7 shows the clusters resulting from the k-means algorithm. We can see the cost patterns of all conditions included in each cluster as well as the centroid of each cluster, which summarizes the cluster’s pattern. The conditions of each cluster are listed in Table 3.

|
Table 3. Resulting Clusters Using Two Centers in the k-Means Clustering Algorithm
| Cluster | Conditions in cluster |
|---|---|
| 1 | Aneurysm—Anxiety disorders—Asthma, COPD, other chronic lung disease—Behavior disorders—Bipolar disorder—Breast noncancer—Cardiomyopathy and structural heart disease—Conduction disorder or cardiac dysrhythmia—Congenital heart disease—Congestive heart failure—Depression and depressive disorders—Diabetes mellitus—Diverticulosis, diverticulitis, enterocolitis, intestinal malabsorption—Epilepsy—Esophageal disorder and GI ulcers—Gout or other crystal arthropathy—Hypertension—Immunity disorder—Kidney and vesicoureteral disorders (excluding renal failure)—Malnutrition (not obesity/overweight), disorders of metabolism—Miscellaneous mental health—Obesity—Other central and peripheral nervous system disorders—Other MSK including osteoporosis—Paralysis—Peripheral atherosclerosis—Personality disorder—Sleep disorders—STI—Substance-use disorders |
| 2 | Allergy, ENT and other upper respiratory disorders—Anemia and other noncancer hematologic disorders—Back problems—Benign prostatic hypertrophy—Chronic liver disease (excluding chronic hepatitis)—Chronic skin ulcer—Coronary atherosclerosis—Degenerative eye problem (glauc/eye)—Female infertility and GU anatomic disorders—Heart valve disorder—Hyperlipidemia—Malignant neoplasm—Menopause and perimenopause—Migraines—Noncardiac congenital disorder—Nonthrombotic, nonatherosclerotic vascular disease—Organic brain problem (dementia)—Osteoarthritis—Other endocrine—Pulmonary heart disease—Schizophrenia and psychotic disorders |
The results indicate that conditions can be divided into two main groups. Conditions in the first group do not show a clear increase in cost contribution as the number of more expensive conditions that are present increases. In particular, in most cases, the cost increases when the condition goes from the most expensive to the second most expensive for the member, and then, the cost either remains constant or decreases on average. In contrast, conditions in the second group demonstrate a relatively stable and significant increase in cost as the number of more expensive conditions increases.
The clustering analysis highlights our observation that different chronic conditions have different cost patterns. A constant increase in cost may reflect additional treatment complexity that becomes necessary in the presence of other, more complex conditions; alternatively, it may reflect the increased cost of treating other conditions when the focal condition is a comorbidity. In these cases, the complexity becomes more distinct as the number of more expensive conditions that a member has increases. When a condition’s cost contribution decreases, this may mean that the treatment focus has shifted to the member’s other, more serious conditions; however, further study is required to determine the factors contributing to this dynamic.
Finally, because k-means is not the only clustering algorithm, we perform extensive empirical evaluations to study the robustness of these results with respect to the clustering algorithm. Specifically, we implement k-medoids and hierarchical agglomerative clustering algorithms. In the case of k-medoids, the resulting clusters agree with k-means for more than 92% of the clustered conditions, and in hierarchical agglomerative clustering, the resulting clusters agree with k-means for more than 94% of the conditions. For most cases in which the clustering algorithms do not agree on the appropriate cluster for a given condition, the cost contribution of the condition does not follow a clear pattern, which places it on the border between the two clusters. The overall cost patterns hold in all three clustering algorithms that we consider. The resulting clusters and a more detailed comparison can be found in the online supplement.
6. Discussion
In this study, we propose a novel modeling framework that can account for the contribution of one factor that is dependent on other factors. In order to do this, we update the standard backward elimination approach to minimize information loss by accounting for the variable hierarchy. Our framework is developed in the context of healthcare cost prediction, in which it allows us to account for the complex interactions of multimorbidity and healthcare costs. However, it can potentially be applied in other prediction scenarios with complex interdependencies and insufficient data to support exhaustive numeration of all possible factor combinations. For example, our approach could be used in both genetic and financial risk scoring as well as explaining salary structures (in which the contribution of, say, managerial skills to employee pay may depend on the importance of those skills in the job description).
Motivated by the fact that treatment of one chronic disease and its overall impact on a person’s health is influenced by the presence of other chronic diseases, our approach goes beyond simply modeling the number of chronic diseases present. Using cost as a proxy for complexity, we are able to more fully account for the dynamics arising from multiple concurrent chronic conditions. When compared with approaches that study groups of members with the same set of chronic diseases, our approach scales well in terms of the number of conditions it can consider. Using this new modeling approach to healthcare cost estimation and prediction, we have studied the cost behavior of 69 chronic conditions, highlighting two main cost patterns.
The findings and the proposed methodology of this paper can help researchers and policymakers better estimate the effect of interventions on and generate accurate predictions of the healthcare costs of members with specific chronic conditions. Such predictions could also direct the focus of healthcare interventions. For example, if a member has a chronic condition that is observed to have a continuous increase in cost as the number of concurrent, more expensive conditions increases, then this person may be a good candidate for a prevention campaign or care management. Because the overall health risk for an individual increases along with the number of concurrent conditions, limiting the presence of such conditions yields multiple benefits at both the individual and population levels. Our observations of the patterns of specific diseases and combinations can also lead to hypothesis generation for future studies of the complex interactions between chronic conditions.
Furthermore, our results can help identify conditions that are linked to lower costs and, by extension, lower healthcare utilization in the presence of other, more expensive conditions. Our findings and approach could, thus, be used to improve healthcare equity: a decrease in the cost contribution of a particular condition may be clinically expected in the presence of other comorbidities, or it may signal possible systematic undertreatment. In the latter case, it points to a need to better understand and improve the treatment of specific subpopulations.
Our work here presents a number of important avenues for future research, some of which are based on our study’s limitations. For one, our study is based on a population in a specific geographical region and the corresponding healthcare costs during a calendar year. However, different states are found to have different prevalence of specific chronic conditions and different hospitalization rates (Raghupathi and Raghupathi 2018). Thus, although we expect many of the patterns we observe to be similar across geographical locations, our findings may not directly translate to other locations, and additional work is needed to establish generalizability. In addition, we were unable to acquire certain patient-level details, including socioeconomic characteristics, demographic data, and other background information that may affect both healthcare utilization and outcomes. Integrating such information is an important future research direction.
More broadly, there are other underlying factors that may affect cost patterns of chronic conditions. In addition to the aforementioned individual demographic characteristics, clinical or medical characteristics, such as the treatment protocol at the place of service, condition severity, or time since onset, may also influence cost patterns. Future research that studies the impact of these and other factors on costs and cost patterns may lead to a more detailed understanding of cost drivers and root causes and may help identify subpopulations of interest.
Furthermore, our model is built on specific chronic condition specifications. The diagnosis codes used are organized in predetermined groups based on the algorithm provided in Magnan (2015) with each group often consisting of multiple codes and sets of similar conditions. Whereas diagnoses belonging to the same chronic condition categories are to some extent similar, in some cases, we expect to find differences in their treatment costs. Future research should study the impact of other chronic condition definitions and potentially expand the identified cost patterns to more than 69 conditions. However, in order to achieve that level of analysis, a larger cohort is required to ensure that there are enough individuals with each condition.
In addition, to generate the independent variables used in our regression model, we ranked conditions based on their average costs and used this average cost as a surrogate for severity. However, this may not always be the most accurate approach, and it can also cause racial bias (Obermeyer et al. 2019). Specifically, Black patients tend to incur lower healthcare costs for several reasons, including limited access to care (Ohlson 2020), discrimination (Sacks 2018), and mistrust of the healthcare system (Alsan and Wanamaker 2018). This means that, when healthcare costs are used as a proxy for severity, Black patients are erroneously assumed to be in better health than they actually are, and they might not get selected for interventions that would improve their health, which leads to racial disparities. It is possible that, in our study, for conditions that disproportionately affect Black members, such disparity may affect our data and may artificially decrease the severity rank of these conditions. Therefore, future research should investigate other ways to rank the severity of chronic conditions.
Other future research paths involve extending our modeling approach, which can be done in multiple ways. For instance, in the current framework, we do not consider the correlations between the different chronic conditions. This is because, in our data, we only find indications of low correlation (with absolute values between 0.33 and 0.42) in three pairs of conditions and no indication of correlation among all other conditions. Yet, in other contexts, it may be important to examine the correlations and extend our modeling approach to account for multicollinearity when present.
Another extension of the modeling approach accounts for the average cost difference between a member’s various conditions in addition to each condition’s cost rank. This could give us more information about the cost contribution of each condition and how it is impacted by the cost difference from the immediately more expensive conditions at the member level. Initial results within this research direction indicate that about 73% of the original coefficients are statistically significant in this new model, whereas in the original approach (before applying Algorithm 1), 78% of those coefficients were statistically significant. Thus, we see only a small drop in the percentage of (original) variables that are statistically significant. A considerable but lower number (about 42%) of the new variables that capture average cost differences are statistically significant. Another interesting aspect of this research direction is that introducing new variables changes the coefficients of the original variables and the way that the model is interpreted.
Beyond the many direct extensions of our approach discussed, we believe this paper marks the first steps toward more detailed modeling of healthcare costs. With larger data, the level of the cost hierarchy can be extended, the medical characteristics of each disease (e.g., implications if not treated) incorporated, and the complex interactions between different diseases better understood. On the methodological side, we see significant potential for the applicability of the backward aggregation approach. This ranges from modeling complex systems and cases such as chronic healthcare costs to simpler tasks, such as categorical dummy combination (when it can replace direct elimination).
7. Conclusions
The methodology proposed here can potentially be utilized by both researchers and policymakers. It offers a deeper and more nuanced understanding of the cost burden of chronic conditions in the presence of other serious comorbidities, which may, in turn, lead to new studies that provide a basis for better and more targeted health interventions. From a broader modeling perspective, this paper introduces a new transparent hierarchical approach to model complex interactions, which is worthy of future exploration.
The authors acknowledge Research Computing at the Rochester Institute of Technology (2022) for providing computational resources and support that have contributed to the research results reported in this publication.
1 For example, assume that the prevalence of condition A is 10% and condition B is 20%. If the conditions are independent, we expect 2% of the population to have both conditions A and B.
2 Because, in our model, there is a logarithmic relationship between the dependent variable and the mean of the independent variables, condition j appearing in order l (i.e., xjl = 1) leads to a fitted annual cost that is times the fitted annual cost we would get if condition j did not appear in order l (i.e., xjl = 0). Because we are interested in the contribution of condition j appearing in order l (i.e., the difference in cost between having condition j in order l and not having this condition in order l), we have . Thus, gives us the proportion of the average fitted annual cost that is explained by a member having condition j appearing in order l.
3 There are numerous clustering algorithms that could be applied. We find k-means to work well for our data, but we also compare the results with k-medoids and hierarchical agglomerative clustering in order to examine whether (and to what extent) the resulting clusters change depending on the clustering algorithm.
4 R2 for GLM (Nagelkerke 1991) is estimated using the rsq package in R.
References
- (2018) Obstetric outcomes and delivery-related healthcare utilization and costs among pregnant women with multiple chronic conditions. Preventing Chronic Disease 15:E21.Google Scholar
- (2020) Hospitalizations for heart failure: Epidemiology and health system burden based on data gathered in routine practice. Medicina Clínica Práctica 3(4–5):100140.Google Scholar
- (2018) Tuskegee and the health of black men. Quart. J. Econom. 133(1):407–455.Google Scholar
- (2015) Multimorbidity, healthcare utilization and costs in an elderly community-dwelling population: A claims data based observational study. BMC Health Services Res. 15(1):23.Google Scholar
- (2004) Multiple regression of cost data: Use of generalised linear models. J. Health Services Res. Policy 9(4):197–204.Google Scholar
- (2005) Estimating marginal and incremental effects on health outcomes using flexible link and variance function models. Biostatistics 6(1):93–109.Google Scholar
- (2014) Big data in healthcare: Using analytics to identify and manage high-risk and high-cost patients. Health Affairs 33(7):1123–1131.Google Scholar
- (2016) Use your words carefully: What is a chronic disease? Frontiers Public Health 4:159.Google Scholar
- (2008) Algorithmic prediction of health-care costs. Oper. Res. 56(6):1382–1392.Link, Google Scholar
- (1999) Modeling risk using generalized linear models. J. Health Econom. 18(2):153–171.Google Scholar
- (1964) An analysis of transformations. J. Roy. Statist. Soc. B 26(2):211–243.Google Scholar
Centers for Disease Control and Prevention (2020) National Center for Chronic Disease Prevention and Health Promotion. Health and economic costs of chronic diseases. Accessed February 5, 2020, https://www.cdc.gov/chronicdisease/about/costs/index.htm.Google Scholar- (2017) The extra cost of comorbidity: Multiple illnesses and the economic burden of non-communicable diseases. BMC Medicine 15(1):216.Google Scholar
- (2018) Modeling healthcare expenditures and use. Annual Rev. Public Health 39:489–505.Google Scholar
- (2022) Deep learning for prediction of population health costs. BMC Medical Informatics Decision Making 22(1):1–10.Google Scholar
- (1983) Smearing estimate: A nonparametric retransformation method. J. Amer. Statist. Assoc. 78(383):605–610.Google Scholar
- (2016) Testing alternative regression frameworks for predictive modeling of healthcare costs. North Amer. Actuarial J. 20(1):65–87.Google Scholar
- (2017) Analysis of healthcare costs in elderly patients with multiple chronic conditions using a finite mixture of generalized linear models. Health Econom. 26(5):582–599.Google Scholar
- (2002) Comorbid depression is associated with increased healthcare use and expenditures in individuals with diabetes. Diabetes Care 25(3):464–470.Google Scholar
- (2011) The prevalence of multimorbidity in primary care and its effect on healthcare utilization and cost. Family Practice 28(5):516–523.Google Scholar
- (2017) Economic burden of chronic conditions among survivors of cancer in the United States. J. Clinical Oncology 35(18):2053–2061.Google Scholar
- (2021) Clustering and healthcare costs with multiple chronic conditions in a US study. Frontiers Public Health 8:607528.Google Scholar
- (2016) Comorbid conditions are associated with healthcare utilization, medical charges and mortality of patients with rheumatoid arthritis. Clinical Rheumatology 35(6):1483–1492.Google Scholar
- (2020) Impact of multimorbidity subgroups on the healthcare use of early pediatric cancer survivors. Cancer 126(3):649–658.Google Scholar
- (2018) Variable selection—A review and recommendations for the practicing statistician. Biometrical J. 60(3):431–449.Google Scholar
- (2013) Applied Health Economics (Routledge, Abingdon, UK).Google Scholar
- (2020) Data transformation: A focus on the interpretation. Korean J. Anesthesiology 73(6):503–508.Google Scholar
- (2015) Algorithm for identifying patients with multiple chronic conditions (multimorbidity). University of Wisconsin–Madison department of family medicine, the University of California–Davis department of family and community medicine, and the UW Health Innovation Program. Accessed October 15, 2019, https://www.hipxchange.org/comorbidities.Google Scholar
- (2019) Multiple chronic conditions at a major urban health system: A retrospective cross-sectional analysis of frequencies, costs and comorbidity patterns. BMJ Open 9(10):e029340.Google Scholar
- (2015) Statistical models for the analysis of skewed healthcare cost data: A simulation study. Health Econom. Rev. 5(1):11.Google Scholar
- (2015) Chronic condition combinations and healthcare expenditures and out-of-pocket spending burden among adults, medical expenditure panel survey, 2009 and 2011. Preventing Chronic Disease 12:E12.Google Scholar
- (2021) Introduction to Linear Regression Analysis (John Wiley & Sons, New Jersey).Google Scholar
- (2007) New models for old questions: Generalized linear models for cost prediction. J. Evaluation Clinical Practice 13(3):381–389.Google Scholar
- (2017) Supervised learning methods for predicting healthcare costs: Systematic literature review and empirical evaluation. AMIA Annual Symp. Proc. 2017 (American Medical Informatics Association, Bethesda, MD).Google Scholar
- (1991) A note on a general definition of the coefficient of determination. Biometrika 78(3):691–692.Google Scholar
- (2019) Dissecting racial bias in an algorithm used to manage the health of populations. Science 366(6464):447–453.Google Scholar
- (2020) Effects of socioeconomic status and race on access to healthcare in the United States. Perspectives 12(1):2.Google Scholar
- (1966) Estimation with heteroscedastic error terms. Econometrica (Pre-1986) 34(4):888.Google Scholar
- (2011) A global averaging method for dynamic time warping, with applications to clustering. Pattern Recognition 44(3):678–693.Google Scholar
- (2018) National trends in hospital emergency department visits among those with and without multiple chronic conditions, 2007–2012. Hospital Topics 96(1):1–8.Google Scholar
- (2018) An empirical study of chronic diseases in the United States: A visual analytics approach to public health. Internat. J. Environ. Res. Public Health 15(3):431.Google Scholar
- (2012) Incremental healthcare expenditures associated with thyroid disorders among individuals with diabetes. J. Thyroid Res. 2012:418345.Google Scholar
- (2015) Prevalence and associated cost and utilization of multiple chronic conditions in the outpatient setting among adult members of an employer-based health plan. Population Health Management 18(6):421–428.Google Scholar
Rochester Institute of Technology (2022) Research computing services. Accessed February 15, 2023, https://www.rit.edu/researchcomputing.Google Scholar- (2018) Performing black womanhood: A qualitative study of stereotypes and the healthcare encounter. Critical Public Health 28(1):59–69.Google Scholar
- (2015) Multiple chronic conditions and healthcare costs among adults. Expert Rev. Pharmacoeconomics. Outcomes Res. 15(5):823–832.Google Scholar
- (2009) Prevalence of multiple chronic conditions in the United States’ Medicare population. Health Quality Life Outcomes 7(1):1–11.Google Scholar
- (2016) The effects of multiple chronic conditions on hospitalization costs and utilization for ambulatory care sensitive conditions in the United States: A nationally representative cross-sectional study. BMC Health Services Res. 16(1):77.Google Scholar
- (2015) Population cost prediction on public healthcare datasets. Proc. Fifth Internat. Conf. Digital Health, 87–94.Google Scholar
- (2022) Estimation and prediction of hospitalization and medical care costs using regression in machine learning. J. Healthcare Engrg. 2022:7969220.Google Scholar
- (2022) Artificial Intelligence with Python (Springer, Singapore).Google Scholar
- (2003) Improving risk adjustment for Medicare capitated reimbursement using nonlinear models. Medical Care 41(6):741–752.Google Scholar
- (2018) Integrated, accountable care for Medicaid expansion enrollees: A comparative evaluation of Hennepin Health. Medical Care Res. Rev. 77(1):46–59.Google Scholar
- (2017) Comorbidity prevalence, healthcare utilization, and expenditures of Medicaid enrolled adults with autism spectrum disorders. Autism 21(8):995–1009.Google Scholar
- (2019) Cost of acute and follow-up care in patients with pre-existing psychiatric diagnoses undergoing radiation therapy. Internat. J. Radiation Oncology Biol. Phys. 104(4):748–755.Google Scholar
- (2014) Peer reviewed: Multiple chronic conditions among US adults: A 2012 update. Preventing Chronic Disease 11:E62.Google Scholar
- (2009) Depression and costs of healthcare. Psychosomatics 50(4):392–401.Google Scholar
- (2002) Prevalence, expenditures, and complications of multiple chronic conditions in the elderly. Arch. Internal Medicine 162(20):2269–2276.Google Scholar
- (2005) Predicting pharmacy costs and other medical costs using diagnoses and drug claims. Medical Care 43(1):34–43.Google Scholar
- (2018) Complex Network Analysis in Python: Recognize-Construct-Visualize-Analyze-Interpret (Pragmatic Bookshelf, Raleigh, NC).Google Scholar

