
Iterative Rule Extension for Logic Analysis of Data: An MILP-Based Heuristic to Derive Interpretable Binary Classifiers from Large Data Sets
Abstract
Data-driven decision making is rapidly gaining popularity, fueled by the ever-increasing amounts of available data and encouraged by the development of models that can identify nonlinear input–output relationships. Simultaneously, the need for interpretable prediction and classification methods is increasing as this improves both our trust in these models and the amount of information we can abstract from data. An important aspect of this interpretability is to obtain insight in the sensitivity–specificity trade-off constituted by multiple plausible input–output relationships. These are often shown in a receiver operating characteristic curve. These developments combined lead to the need for a method that can identify complex yet interpretable input–output relationships from large data, that is, data containing large numbers of samples and features. Boolean phrases in disjunctive normal form (DNF) are highly suitable for explaining nonlinear input–output relationships in a comprehensible way. Mixed integer linear programming can be used to obtain these Boolean phrases from binary data though its computational complexity prohibits the analysis of large data sets. This work presents IRELAND, an algorithm that allows for abstracting Boolean phrases in DNF from data with up to 10,000 samples and features. The results show that, for large data sets, IRELAND outperforms the current state of the art in terms of prediction accuracy. Additionally, by construction, IRELAND allows for an efficient computation of the sensitivity–specificity trade-off curve, allowing for further understanding of the underlying input–output relationship.
History: Accepted by Andrea Lodi, Area Editor for Design & Analysis of Algorithms–Discrete.
Funding: This work was supported by the Netherlands Organization for Scientific Research (Nederlandse Organisatie voor Wetenschappelijk Onderzoek) [Grant VI.VENI.192.043].
Supplemental Material: The online supplement is available at https://doi.org/10.1287/ijoc.2021.0284.
1. Introduction
Over the past decade, the field of machine learning and artificial intelligence (AI) has seen major developments alongside a tremendous increase in popularity among academics, industry, and the general public. Supervised machine learning models, which are among the most frequently used approaches in AI, aim to learn the relationship between input features and an output feature or class label. Examples are training a model to “read” handwritten digits from images, recommending a new video for streaming-service customers based on their viewing history or predicting the effectiveness of drugs for cancer patients based on their tumor’s genetic characteristics. The development of supervised learning models was mainly focused on improving prediction or classification accuracy, and many of the developed methods are, to various degrees, black box methods: whereas they yield high prediction accuracy, the input–output relationship that the models identify and on which they base their predictions is difficult to comprehend or even invisible to humans.
The interpretability of machine learning methods is essential for their acceptance for several reasons (Doshi-Velez and Kim 2017, Molnar 2020). First, when decisions that impact people’s lives are made, users need to understand why a model makes certain predictions in order to trust them. This particularly holds for medical applications. Second, for several applications, the relationship between input data and predictions is more important than the predictions themselves. For example, when developing medication, one needs to understand the biological processes that cause a disease and should be targeted by the drug. Analyzing bioinformatics data with machine learning models that do not only provide predictions of drug response, but also give insight into the underlying input data–prediction relationship can play an important role. Third, the General Data Protection Regulation of the European Union requires that a data subject has the right to explanation when decisions affecting them are made using automated models (Parliament of the European Union 2016). These motivations have led to an increased interest in developing interpretable machine learning models (Molnar 2020 and references therein).
In the case of predicting a binary class from binary input data, the focus of this work, Boolean phrases are very well-suited for prediction, providing an interpretable and comprehensible input–output relationship (Lakkaraju et al. 2016). This work focuses on identifying a Boolean phrase in disjunctive normal form (DNF), which is an OR combination of AND clauses. For example, the following is a Boolean statement in DNF: “if AND OR AND AND OR , then sample n is predicted to be in class 1; else it is predicted to be in class 0,” where denotes the input matrix for a data set with N samples and J features. This data format is motivated by applications in medical genetics, in which combinations of genetic variants lead to disease or drug resistance. Individuals either do or do not have the considered genetic characteristics, represented in the matrix X, and they do or do not have a certain personal trait, represented by the binary class. Note that categorical and continuous input data can be transformed into binary data (Boros et al. 1997).
Identifying Boolean phrases in DNF for classification from binary data has been an active research topic in learning theory, especially since Valiant (1984) posed the question whether DNF rules were efficiently learnable from data. The work in this field has focused on developing solution algorithms and providing the corresponding complexity bounds for the noiseless setting (Bshouty 1996, Tarui and Tsukiji 1999, Klivans and Servedio 2004). No efficient algorithm was found, and recently, Daniely and Shalev-Shwartz (2016) showed that learning DNF rules from data is hard.
Integer programming has been shown to be a suitable method for identifying Boolean phrases in DNF from binary data (Hammer and Bonates 2006, Hauser et al. 2010, Chang et al. 2012, Malioutov and Varshney 2013, Wang and Rudin 2015, Knijnenburg et al. 2016, Dash et al. 2018). The approach was previously termed the logical analysis of data. Whereas existing approaches work well for data sets of limited size, novel solution algorithms to solve large instances are needed: with the current rapid increase in data collection efforts and skills, data sets containing millions of features for thousands of samples are now available for analysis. The number of binary decision variables included in the integer program quickly increases with the numbers of samples, features, and AND clauses included. As a result, the integer program cannot be applied to these large data sets. Dash et al. (2018) have taken the first step in overcoming this issue: they develop a column-generation approach in which, in each iteration, a new AND clause is generated, forming a new column in the overall problem. In order to do so, whereas others minimize the misclassification error, Dash et al. (2018) need to minimize the Hamming loss defined as the number of false negatives plus the number of AND clauses satisfied by each of the controls, summed over the controls. Here, controls (cases) are defined as negatively (positively) labeled samples. Whereas Dash et al. (2018) resolve the issue of the increase in the number of binary decision variables with the number of AND clauses, the effect of the number of samples and features on the complexity partially remains as the subproblem is large for a large number of samples and features.
This work presents a solution algorithm that allows for solving the mixed integer linear program (MILP) for data sets with a large number of samples and features. The algorithm is termed the iterative rule extension for logical analysis of data (IRELAND) and breaks up the MILP into smaller problems. Similar to Malioutov and Varshney (2013) and Dash et al. (2018), the algorithm uses a subproblem to generate a set of promising AND clauses. From this set, the master problem selects those AND clauses that, when combined through OR statements, yield the best accuracy. With a large number of samples, the subproblem, in itself, remains computationally heavy. Therefore, this work proposes two model adaptations. First, IRELAND uses an alternative formulation of the subproblem constraints that leads to lower computation time because of a reduction in the number of constraints without changing the feasible region. Second, each subproblem considers only a subset of the samples, containing all controls and only those cases that have not been classified as cases in the previous solution. As such, the subproblem focuses on adding an AND clause that, when added to the Boolean phrase of the previous solution, increases the number of true positives, limiting the increase in the number of false positives.
Besides achieving maximum accuracy, users of classification models are often interested in the trade-off between sensitivity and specificity. This work shows that, by construction, IRELAND allows for easy computation of the sensitivity–specificity trade-off curve. When directly optimizing the original MILP, one can only obtain information on this trade-off by solving an MILP in which the objective function is to maximize sensitivity, placing a constraint on specificity or vice versa. Varying the lower bound on specificity (or sensitivity) provides the trade-off curve between sensitivity and specificity. This means that a computationally heavy MILP needs to be solved several times. IRELAND, on the other hand, naturally accommodates the analysis of the sensitivity–specificity trade-off as it generates a large pool of promising AND clauses. The master problem, which is now maximizing sensitivity, constraining the specificity, can then be solved several times for various lower bounds on specificity, selecting combinations of AND clauses that provide different trade-offs between sensitivity and specificity.
This paper contains four contributions. First, several formulations of the MILP are compared based on runtime and objective value for small synthetic data sets. Second, an algorithm is introduced, called IRELAND, that allows for solving problems for the logical analysis of data for data sets with up to 10,000 samples and features. Third, rules of thumb are provided for which data sets IRELAND gives the best performance and for which data sets the original MILP or the model proposed by Dash et al. (2018) perform best. Fourth, IRELAND enables the efficient construction of the sensitivity–specificity trade-off curve, a useful feature in many real-world applications. All code is available on Github,1 and data sets can be requested from the author.
2. Methods
The MILP that abstracts Boolean phrases from data can be formulated in several ways. In Section 2.1, the formulations are provided and compared. As all MILP formulations are limited in the amount of the data that they can process, Section 2.2 presents the proposed algorithm IRELAND. An extension to generating the sensitivity–specificity trade-off curve is presented in Section 2.3.
2.1. Mixed Integer Linear Programming Formulation
Let denote the set of samples and the set of features. Let denote the feature matrix in which Xnj = 1 if sample n has characteristic j and 0 otherwise. Let denote the class vector, where yn = 1 if sample n is a case and yn = 0 if sample n is a control. Based on X and y, the model identifies Boolean phrases in DNF that predict a sample’s class from input information . The decision variables represent the predicted class for each sample.
The MILP aims to find a Boolean phrase in DNF that yields the best balanced prediction accuracy:
Alternatively, one could minimize the Hamming loss (Lakkaraju et al. 2016, Dash et al. 2018), which is defined as the number of incorrectly classified cases plus the number of AND clauses that each control satisfies. Let for be an auxiliary decision variable that denotes whether sample n satisfies AND clause k, that is,
The Hamming loss can then be computed as
The AND clauses and OR combinations of AND clauses are modeled by separate constraints. OR rules can be represented by two different sets of constraints. The following set of constraints ensures that, for given n, if and only if (Knijnenburg et al. 2016):
Together with an objective function that minimizes (maximizes) for (), these constraints yield the correct values for . Constraints (1) are equivalent to
Although the feasible regions described by constraint sets (1) and (2) are identical, their relaxations, in which the integrality constraint on is replaced by , are not: for the relaxation, the feasible region defined by Constraints (2) is a subset of the feasible region described by Constraints (1); see Online Supplement A.
AND clauses can be represented in two different ways as well. Let for denote the vector of decision variables indicating whether feature j is included in the kth AND clause. The following set of constraints enforces tnk = 1 if and only if there exists no j such that skj = 1 and Xnj = 0 (Knijnenburg et al. 2016):
Note that these constraints hold because tnk is minimized for and maximized for . The following alternative set of inequalities yields the same feasible region:
For , Constraints (3) are equivalent to (4). However, when the integrality constraints are relaxed to tnk, , the polyhedron defined by (4) is a subset of the polyhedron defined by Equations (3); see Online Supplement A.
Eight different MILPs can be formulated to abstract Boolean phrases in DNF from data by combining one of the objective functions with one of the formulations for the OR rules and one of the formulations for AND clauses as defined. Note that, when the objective is to minimize the Hamming loss, the decision variables for are redundant as are Constraints (1b) and (2b). Because Constraints (1a) and (2a) are identical, only six formulations remain; see Table 1 for an overview. The models in this manuscript use an additional constraint that bounds the number of features in an AND clause by M:
|

Table 1. Six MILP Formulations That Abstract Boolean Phrases in DNF from Binary Data
| Model | Objective | Constraints | Number of constraints | Continuous variables | Binary variables | |
|---|---|---|---|---|---|---|
| OR | AND | |||||
| Accuracy | (1) | (3) | ||||
| skj | ||||||
| Accuracy | (1) | (4) | tnk | skj | ||
| Accuracy | (2) | (3) | ||||
| skj | ||||||
| Accuracy | (2) | (4) | skj | |||
| Hamming loss | (1a) | (3) | ||||
| skj | ||||||
| Hamming loss | (1a) | (4) | tnk | skj | ||
Notes. N0 denotes the number of controls, N1 the number of cases, and . K denotes the number of AND clauses included in the model and J the number of features.
Some of the decision variables can be relaxed from binary to the interval without altering the optimal solution. Each of the six models has a different subset of decision variables that can be relaxed; see Online Supplement B for further details. An overview of the models considered in this work, their constraints and objective, the number of constraints, and the number of binary and continuous decision variables is given in Table 1. Note that can be simplified to reduce the total number of decision variables and constraints by combining Constraints (4b) and (2b) into one:
This makes the decision variables tnk for obsolete.
2.2. IRELAND: A Solution Algorithm
The complexity of the MILP is due to its large number of binary decision variables (Table 1). As can be seen from Online Supplement B for , an increase in the number of samples N, the number of features J, and the number of included AND clauses K all lead to an increase in solution time. To overcome the computational burden arising from large data, this work presents the solution algorithm IRELAND. The idea behind IRELAND is to break up the problem into subproblems that contain only a subset of the decision variables, mostly limiting N and K. The subproblems together generate a large pool of AND clauses with various levels of sensitivity and specificity in preparation for generating the trade-off curve.
The algorithm is summarized in Figure 1. IRELAND consists of two components: the initialization in which an initial pool of AND clauses is generated (left part of Figure 1) and the subroutine that iteratively generates AND clauses (right part of Figure 1). IRELAND uses three MILPs, namely, a subproblem for the initialization and subroutine, a master problem for the subroutine and an overall master problem. Each of the MILPs uses Constraints (1) and (3); see Section 3.2 for a motivation of this choice. Details of the initialization, the subroutine, and the three MILPs are given as follows.
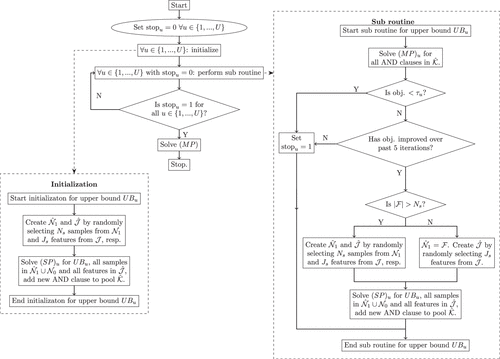
Notes. The set is an a priori chosen set of upper bounds on the number of false positives. and are the sets of controls and cases, respectively; is the set of false negatives; Ns is an a priori chosen size for the subset ; and Js is an a priori chosen size for the subset . denotes the pool of AND clauses that is generated iteratively. are objective function values for ,…, that are sufficient for the algorithm to stop.
2.2.1. The Subproblem.
Both the initialization and the subroutine make use of the subproblem. Every time the subproblem is solved, an AND clause is generated and added to the pool . The subproblem generates a single AND clause by maximizing the number of true positives, restricting the number of false positives to be at most UBu, with U the number of upper bounds considered:
2.2.2. The Initialization.
In the initialization phase, is solved for all upper bounds in the predefined set . Even though the subproblem only solves for a single AND clause, it still takes a large amount of time when N is large. Therefore, a random subset of size Ns is selected. Each upper bound UBu contributes one AND clause to the initial pool .
2.2.3. The Subroutine Master Problem.
In every call of the subroutine, a slight modification of the master problem is solved. For a given upper bound UBu, the subroutine master problem chooses those AND clauses from the pool that maximize the number of true positives, limiting the number of false positives to be at most UBu:
Here, is as before, and qk is a binary decision variable that indicates whether AND clause k is included in the final Boolean phrase in DNF. The parameter znk is equal to one when sample n satisfies AND clause and zero otherwise. Note that, as the AND clauses are predefined, this is a parameter, not a decision variable. The maximum number of AND clauses included in the final Boolean statement is limited to at most a predetermined number K to control the complexity of the statement.
2.2.4. The Subroutine.
In each iteration, the same subroutine is executed for a predefined set of upper bounds on Constraint (8). The subroutine begins by solving using all the AND clauses that were generated so far, denoted by . If the objective value of is at most τu, where τu is the predefined desired objective value of , the subroutine for UBu ends. If the objective value of is above τu, the subproblem is solved. As before, solving the subproblem for all is computationally challenging. Therefore, the subproblem is solved only for a subset of the samples. First, the set of false negatives corresponding to the solution to , denoted as , is computed. These false negatives are the class 1 samples for which no AND clause exists yet or for which no AND clause exists that, in combination with the other available AND clauses, yields a good solution to . If , a random subset of is selected. If the set is set equal to ; (SP) is then solved for all samples in . This ensures that a new AND clause is created that has the potential to increase the number of true positives when added to the most recently created Boolean phrase. Also, the number of features influences the computation time required for solving the subproblem. Therefore, following Dash et al. (2018), IRELAND allows for selecting a random subset of features to be included in the subproblem. The new AND clauses resulting from the subroutine are added to .
2.2.5. The Master Problem.
Once an objective value below τu is reached for all subroutine master problems , the master problem can be solved using the obtained pool of AND clauses . The master problem selects those AND clauses that constitute the best Boolean phrase in DNF in terms of classification accuracy. Let be a pool of AND clauses. The master problem is formulated as follows:
Here, w, , znk and qk are as before.
2.2.6. IRELAND.
Solving the subroutine for various upper bounds on the number of false positives gives AND clauses that represent various trade-offs between sensitivity and specificity. This allows IRELAND to select those AND clauses from the pool that together yield the best balanced accuracy. Note that this approach is highly parallelizable: the subroutine is carried out for U upper bounds; hence, the algorithm can solve up to U optimization problems in parallel depending on the number of available threads.
2.3. Generating the Sensitivity–Specificity Trade-off Curve
IRELAND creates a pool of AND clauses with various sets of true and false positives and negatives, from which the master problem selects those that together yield the best balanced accuracy. This pool can be used to efficiently generate the sensitivity–specificity trade-off curve by solving a slight adaptation of the master problem. Two adaptations are used: maximizes sensitivity, placing a lower bound on the specificity, whereas maximizes the specificity, placing a lower bound on the sensitivity. By varying the lower bounds, the sensitivity–specificity trade-off curve can be obtained. As and only solve which AND clauses from the pool are used without generating new AND clauses, generating the trade-off curve can be done within a limited amount of time.
Initially, and are solved for a lower bound equal to zero on the specificity and the sensitivity, respectively, to obtain the extreme points on the trade-off curve. Then, in every iteration, the algorithm searches for two neighboring points on the trade-off curve for which the sensitivities or specificities differ by more than a predetermined threshold. When two neighboring points with a difference in sensitivity (specificity) larger than the threshold are found, () is solved with a lower bound on the sensitivity (specificity) that is equal to the average sensitivity (specificity) of the two identified solutions on the trade-off curve. This procedure is repeated until there are no gaps larger than the threshold that can still be improved upon.
3. Experiments and Results
Section 3.1 explains how test data were generated or obtained. In Section 3.2, the six MILP formulations from Table 1 are compared based on solution time. Section 3.3 discusses the hyperparameter optimization for IRELAND. The performances of the original MILP and IRELAND are compared based on objective value and runtime for data sets of various sizes without and with noise in Sections 3.4 and 3.5, respectively. In Section 3.6, the performance of IRELAND is compared with the Boolean rule column generation (BRCG) model proposed by Dash et al. (2018), which is considered the current state of the art. The performance of BRCG and IRELAND on the DNF and PEPS collections of the 1000 Genomes Project data are assessed in Section 3.7. The Boolean rules obtained by IRELAND are illustrated through three examples in Section 3.8. Results for generating the sensitivity–specificity trade-off curve are presented in Section 3.9.
3.1. Data Sets
Synthetic data sets were generated for various N, J, and K. Details on how these data sets were generated can be found in Online Supplement D. Two collections of data sets were generated. The first is the no noise collection, and it contains 126 data sets with no noise introduced. This means that the optimal Boolean phrase in DNF yields a classification error and Hamming loss of zero. Additionally, 144 data sets with noise were generated in the same way as the noiseless data sets except that a predetermined fraction of the labels is inverted, meaning that, if the sample was a case, it becomes a control and vice versa. The error rates used were 1%, 2.5%, and 5%.
IRELAND was also tested on genomics data, the motivation for developing IRELAND. Genome data were obtained from Bayat et al. (2020) who use genome data from the 1000 Genomes Project Consortium (2015). As this data set contains too many (genetic) features, the data were preprocessed to contain 9,633 features; see Online Supplement D.2 for details. No real-world class labels are publicly accessible; hence, they were generated in two ways. For the first collection of data sets, referred to as the DNF collection, class labels were generated in the same way as for the synthetic data sets; hence, the true underlying input–output data relationship is a Boolean phrase in DNF. The data sets in the second collection, referred to as the PEPS collection, contain binary class labels generated and made available by Bayat et al. (2020).
3.2. The Formulation of Constraints for AND Clauses Largely Affects Solution Time of the Original Linear Programming (LP) Models
The six model formulations summarized in Table 1 were tested on the no noise data sets, and the results were compared based on solution times. All models were solved using the Gurobi 9.0.2 optimizer (Gurobi Optimization, Inc., Houston, TX) interfaced with Python version 3.7.7 on a computer with an Intel i7-9700 processor. Gurobi used four threads and was stopped after 300 seconds. Note that a problem that is solved to optimality within 300 seconds finds the optimal objective value of zero.
The results are presented in Figure 2 for the models with all decision variables binary (Figure 2(a)) as well as their LP relaxation in which only those decision variables are relaxed that do not alter the optimal solution (Figure 2(b)). The results show that the formulations that contain AND Constraints (3) largely outperform the formulations that contain Constraints (4). This result was unexpected as Constraints (4) yield a tighter relaxation. Although the reason for the better performance of Constraints (3) over Constraints (4) cannot be pinpointed with certainty, a possible cause might be the larger number of constraints in Constraints (4), a feature that is known to cause longer computation times for Gurobi. The choice of OR constraints and objective function does not significantly influence the solution times. Additionally, a two-sided t-test was conducted to test the null hypothesis that the solution time of the formulation with all decision variables binary is equal to the solution time of that same formulation with some of the decision variables relaxed. From the results, it can be concluded that there is no statistically significant difference in solution times between models with all decision variables binary and some relaxed decision variables () except for (p = 0.0074), for which the relaxation is slightly slower (on average, 3.1 seconds). In the remainder of this work, we use .
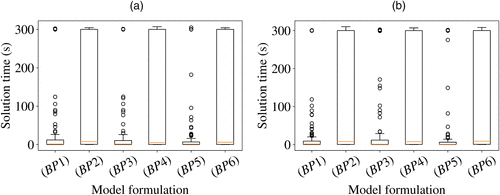
Notes. The models were tested on the data sets in the no noise collection, in which the optimal accuracy is known to be zero. The runtimes are limited to 300 s. (a) All decision variables are binary. (b) Decision variables are relaxed whenever this does not alter the solution.
3.3. Hyperparameter Selection for IRELAND
3.3.1 Data Sets Without Noise.
The no noise data sets were run for UB = 0 only on a computer with an Intel i7-9700 processor using four threads. Because a single value of UB is used, no parallelization is employed. Each model (sub or master problem) solved by Gurobi uses up to four threads. IRELAND was tested on 26 noiseless data sets for , and 500 and for a time limit on the subproblem of 60, 120, and 300 seconds. Online Figures 2 and 3 in Online Supplement E show that all combinations of Ns and the time limit lead to near perfect classification accuracy except when n = 10,000 and J = 10,000. In that case Ns = 500 and time limit = 300 s give the best results in terms of objective value and runtime; hence, these settings were used for all data sets.
3.3.2. Data Sets with Noise.
Experiments for the data sets with noise were run on a computer with Intel Xeon Platinum 8268 2.9 GHz processors using 24 threads. IRELAND was tested on 30 data sets with noise for parameters —where Js = J refers to no feature subsampling—and time limit . The resulting objective values obtained with the full training data are shown in Figure 3, split per N and J. All runtimes are within six hours as shown in Online Figure 4 in Online Supplement E. The most important conclusion is that feature subsampling does not improve performance except when . Giving the subproblem a sufficient amount of time is key to IRELAND’s performance, for which the size of the data set determines how much time is sufficient. Choosing a smaller Ns can speed up the process if J is large and N sufficiently small (J = 10,000, n = 1,000 or n = 5,000). Note that, for , the classification accuracies are no higher than 0.724. This is why additional experiments with increased Js were run, which did not lead to further improvement (Figure 2). In the experiments conducted in this work, the choice of hyperparameters depends on N and J. For , we used Ns = 500, Js = J, and a time limit of 300 s. When n = 10,000 and , and the time limit is 600 s. For all other data sets Ns = 500, Js = J, and the time limit is 600 s.

Notes. Various values for Ns and the time limit of the subproblem are tested: —where Js = J refers to no feature subsampling—and time limit . Note that for data sets in which J = 1,000, subsampling 1,000 features is identical to no feature subsampling; hence, these runs are omitted.
3.4. Performance of vs. IRELAND on Data Without Noise
and IRELAND were both used to solve the classification problem of the 128 instances in the data collection without noise for a maximum runtime of four hours. Performances were compared based on objective values as well as runtimes as shown in Figure 4. Each dot represents a data set for which the normalized objective function values, that is, the objective function values divided by the number of samples (Figure 4(a)) and runtimes (Figure 4(b)) obtained with are shown on the horizontal axis and those for IRELAND on the vertical axis. A diagonal line is included to indicate equal objective function values and runtimes for the two solution methods. Note that, for these data sets, a solution with an objective value equal to zero exists as they do not contain any noise.
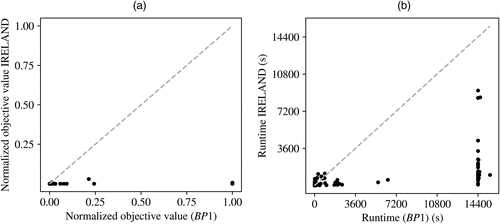
Notes. Each dot represents a data set, for which the normalized objective value and the runtime of are shown on the horizontal axis and the normalized objective value and runtime of IRELAND are shown on the vertical axis. The dashed line indicates equal performance between the methods.
Figure 4(a) shows that, for the majority of data sets, both and IRELAND find a near optimal solution. finds the optimal solution for 90 data sets, and IRELAND finds the optimal solution for 119 data sets. For all data sets for which IRELAND did not find the optimal solution, the obtained objective function value was the same as or lower than the objective function value obtained with . For 10 data sets, ran out of memory; hence, an objective value of one and the maximum runtime of 14,400 seconds (four hours) were assigned to these data sets. For these data sets, IRELAND did find solutions with a normalized objective function value between 0.0 and 0.045.
The results in Figure 4(b) show that, for the data sets for which has runtimes below approximately 90 seconds, IRELAND cannot improve upon this. For those data sets in which finds an optimal solution within four hours, IRELAND finishes within 20 minutes. The data sets that could not be solved by because of memory issues or a time limit of four hours were all solved by IRELAND. In most cases, IRELAND finished within an hour; only for two data sets it needed 1 hour 15 minutes and 2 hours 30 minutes, respectively.
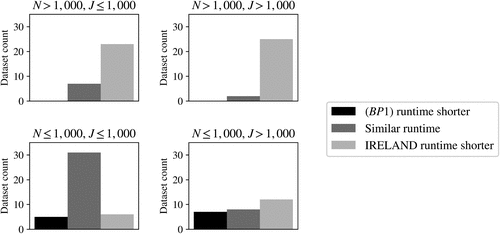
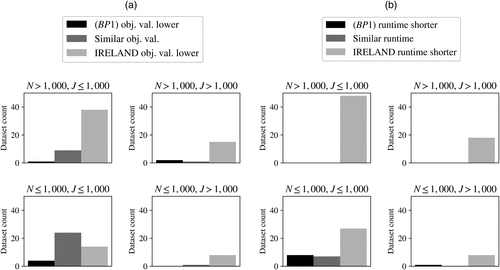
In order to see for which data sets it is best to use and for which to use IRELAND, Figure 5 shows the number of data sets for which has a lower runtime than IRELAND, the number of data sets for which IRELAND has a lower runtime than , and the number of data sets for which the difference in runtime is less than 30 seconds, split by number of samples N, of features J, and of AND clauses K. For has lower runtimes for most data sets, whereas for IRELAND has a clear advantage over . Figure 5 shows that, when J is large, there are data sets for which outperforms IRELAND. However, this is only the case when N is at most 1,000; see Figure 6. K seems to be a weak indicator of which method performs best.
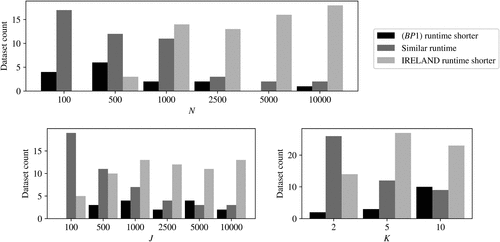
Note. The results corresponding to a single value for N, J, or K are averaged over all combinations of the other two parameters.
Note. The results are aggregated over all values of K.
3.5. Performance vs. IRELAND on Data with Noise
The data sets with noise were run on a computer with 24 threads. The sub and master problems were solved for six values of UB in parallel, , allowing Gurobi to use four threads for each optimization. The corresponding τu were set to .
Figure 7 shows a comparison between and IRELAND in terms of objective value (a) and runtime (b) for noisy data sets. Figure 7(b) shows that, for 74 out of the 118 data sets, required more than four hours of runtime. For another 25 data sets, no solution was found at all as the system ran out of memory; hence, these data sets were assigned an objective value of 1.0 and a runtime of four hours. For those data sets in which did find a solution within the set time limit, Figure 7 shows that, for most data sets IRELAND outperformed .
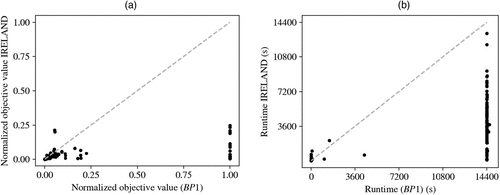
Notes. Each dot represents a data set, for which the normalized objective value and the runtime of are shown on the horizontal axis and the normalized objective value and runtime of IRELAND are shown on the vertical axis. The dashed line indicates equal performance between the methods.
Figures 8 and 9 show histograms of the number of data sets for which IRELAND outperformed outperformed IRELAND, or performance was similar in terms of objective and runtime, respectively, separated by number of samples N, of features J, and of AND clauses K. Similar to the noiseless setting, the histograms show that, for , IRELAND often but not always outperforms in terms of objective values and runtimes, whereas for , the main purpose of this work, IRELAND always outperforms . Figures 8–10 show that IRELAND outperforms when either N or J is large.
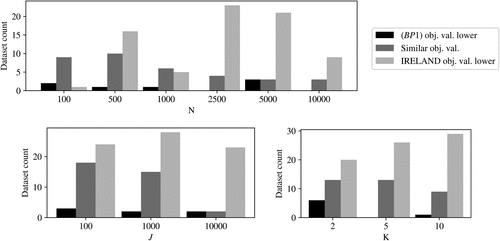
Note. The results corresponding to a single value for N, J, or K are averaged over all combinations of the other two parameters.
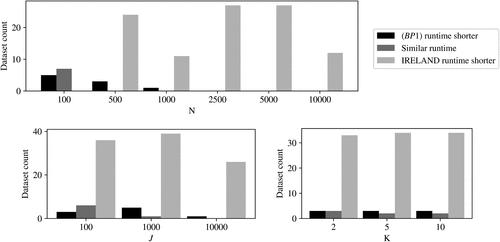
Note. The results corresponding to a single value for N, J, or K are averaged over all combinations of the other two parameters.
Note. The results are aggregated over all values of K.
3.6. Comparing IRELAND and BRCG
Recently, Dash et al. (2018) implemented a column-generation approach to the problem of generating Boolean phrases in DNF from binary data. The authors show that their method, referred to as BRCG, outperforms various state-of-the art approaches. Therefore, in this section, the performance of IRELAND is compared with BRCG. Because the implementation of BRCG that is provided on Github and Anaconda uses beam search rather than an MILP solver to solve the subproblem, the available implementation of BRCG does not allow for a comparison between the algorithms of IRELAND and BRCG. Therefore, BRCG was reimplemented in Python, and the master and subproblems were optimized using the Gurobi 9.0.2 optimizer. Dash et al. (2018) use Constraints (4) in their subproblem. Online Figure 5 in Online Supplement F shows that, also, for BRCG, Constraints (3) outperform Constraints (4); hence, in the BRCG implementation, Constraints (4) were replaced by (3) to allow for a fair comparison.
Figures 11 and 12 compare the performances of BRCG and IRELAND for data sets with and without noise, respectively. For data sets without noise, BRCG outperforms IRELAND in terms of runtime for most data sets with similar or better objective values (Figure 11). When noise is introduced, we need to distinguish three groups of data sets based on N and J (Figure 12). When either or , BRCG outperforms IRELAND in terms of both objective value and runtime. For the second group, when J = 5,000 and n = 5,000 or n = 10,000, whereas IRELAND requires much more time than BRCG, it obtains better objective values. For the third group, when J = 10,000 and n = 5,000 or n = 10,000, BRCG is faster for many instances though IRELAND yields much better objective values. Online Figure 6 in Online Supplement G summarizes these results: IRELAND yields an improved objective value for nearly all data sets, and the absolute gain in objective value can go up to 0.24. For nearly all data sets, IRELAND does require more computational time than BRCG, and the ratio between IRELAND’s and BRCG’s runtime decreases as the data set size increases with IRELAND requiring only twice as much time as BRCG for the largest data sets. Results on test data—that is, data that was not included in the optimization process—show that IRELAND is less prone to overfitting than BRCG; see Online Figure 7 in Online Supplement H.
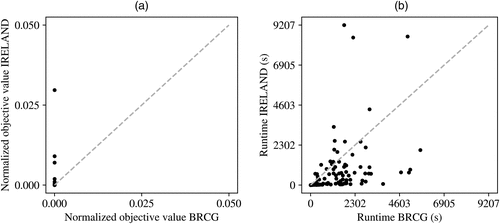
Notes. Each dot represents a data set, for which the normalized objective value and the runtime of BRCG are shown on the horizontal axis and the normalized objective value and runtime of IRELAND are shown on the vertical axis. The dashed line indicates equal performance between the methods.
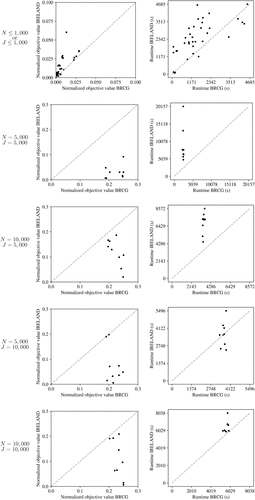
3.7. Testing on Genomics Data
IRELAND and BRCG were tested on genome data from the 1000 Genomes Project Consortium. The results obtained for DNF class labels are shown in Figure 13, (a) and (b). The results obtained with PEPS class labels are shown in Figure 13, (c) and (d). The pattern observed with fully synthetic data are similar for the 1000 Genomes Project data: whereas IRELAND requires more time than BRCG, it achieves better objective values. For the PEPS phenotypes, the subproblem was unable to find a solution; hence, it always gave an AND clause that none of the samples satisfied, predicting all samples as a control. In all of the PEPS data sets, about 25% of the samples is a case; hence, the objective value is 0.25 for all data sets. For both the Boolean rule-based class labels and the class labels from Bayat et al. (2020), results on test data show that IRELAND is less prone to overfitting that BRCG; see Online Figure 7, (b) and (c) in Online Supplement H.

Notes. Performance is evaluated in terms of normalized objective function value ((a) and (c)) and runtime ((b) and (d)) in seconds. Each dot represents a data set, for which the normalized objective value and the runtime of BRCG are shown on the horizontal axis and the normalized objective value and runtime of IRELAND are shown on the vertical axis. The dashed line indicates equal performance between the methods.
3.8. Illustration of Model Outcomes
Online Supplement I shows the Boolean rules in DNF obtained by IRELAND for three data sets compared with the true Boolean rules that underly the data. The first two data sets come from the noise data collection, and the third data set comes from the genomics collection. For all three data sets, IRELAND finds those AND clauses that yield a significant number of true positives. When an AND clause yields a low number of positives, it is difficult for IRELAND to retrieve it, which is particularly visible for the genomics data set on which IRELAND returns only one AND clause. For Inst1003, three out of five clauses are retrieved exactly (Table 4 in Online Supplement I). One of the two AND clauses identified by IRELAND for this data set has a Pearson correlation of 0.46 with one of the true underlying AND clauses; the other clauses are uncorrelated (Online Figure 8 in Online Supplement I).
3.9. The Sensitivity–Specificity Trade-off Curve
As IRELAND generates a pool of AND clauses on the fly, one can readily use these to generate the trade-off curve between sensitivity and specificity. Trade-off curves were generated for the synthetic data set collection with noise. Examples of these trade-off curves are shown in Figure 14(a), and runtimes are provided in Figure 14(b).
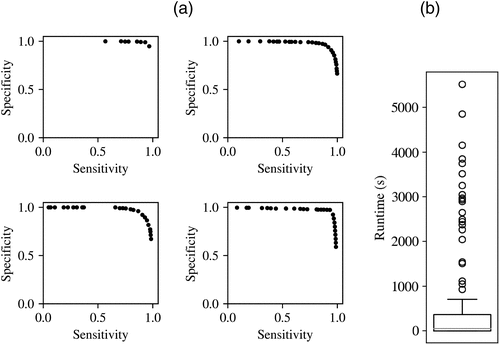
Notes. (a) Examples of sensitivity–specificity trade-off curves for four data sets. (b) Boxplot of the runtimes for generating the sensitivity–specificity trade-off curve.
4. Discussion
For large data sets, the primary focus of this work, IRELAND was able to outperform , the original MILP, in terms of both normalized objective function value and runtime. Whereas could not be solved for several instances because of memory issues, IRELAND was able to find a solution for each data set within four hours. For the data sets for which could not finish within four hours, IRELAND was able to do so and found solutions with an improved normalized objective function value. The column-generation approach developed by Dash et al. (2018), called BRCG, outperforms IRELAND for data sets without noise. For noisy data sets, BRCG largely outperforms IRELAND in terms of runtimes, whereas IRELAND yields a significant improvement in objective value that can be as large as 0.24. IRELAND also outperforms BRCG in terms of the objective value obtained on the test data set.
BRCG obtains a trivial normalized objective value for all PEPS phenotypes in the genomics data set. This is due to BRCG’s subproblem being unable to find a suitable AND clause. As a result, BRCG does not select any AND clauses and classifies all samples as a control. The case/control ratio in all PEPS data sets is roughly the same; hence, the same objective value is obtained for all data sets. IRELAND does find Boolean rules in DNF that yield a reasonable normalized objective value in one up to nearly five hours. The normalized objective value obtained on the test data are only slightly above the normalized objective value obtained on the training data.
IRELAND often generalizes better than BRCG. One explanation for this could be sought in the complexity of the Boolean rules in DNF identified by the two methods, reflected by the number of clauses and the number of features that are included in a rule. IRELAND generally uses more but smaller AND clauses than BRCG; see Online Figure 9 in Online Supplement J. Another explanation may be found in the sampling nature of IRELAND: the algorithm generates new clauses based on a subset of the samples and selects those clauses that work best for all samples. This approach is comparable to cross-validation.
N and J both are good indicators to decide whether to use IRELAND instead of . For data sets without noise, IRELAND always found a solution with an objective function value that was at least as good as the solution found by and often much better. IRELAND obtains improved runtimes when the data set contains more than 1,000 samples for data sets without noise and for or J > 1,000 for data sets with noise. When choosing whether to use IRELAND or BRCG, N and J together provide a good indicator. BRCG outperforms IRELAND when either or , and IRELAND outperforms BRCG otherwise.
IRELAND is similar to a column-generation approach in the sense that it consists of a master problem that finds the optimal Boolean phrase in DNF from a given set of AND clauses and a subproblem that iteratively generates AND clauses that are likely to improve the objective function of the master problem. Directly using column generation has the drawback of a large subproblem when the data set contains a large number of samples N and features J. This was previously observed by Dash et al. (2018), who include a random subset of the samples and features in the subproblem whenever the data set is large. IRELAND includes a subset of the samples that is chosen such that all controls are included in order to avoid generating an AND clause that yields a high number of false positives, which would not be used by the master problem. As for the cases, if the random subset of samples includes many cases that were already predicted as cases by the master problem, the newly generated AND clause would have little added value to the set of already existing AND clauses. IRELAND, therefore, only selects (a subset of) the false negatives, that is, the cases that were not predicted as cases by the master problem in the previous iteration. This is similar to a column-generation approach though without the need to compute shadow prices: one can easily show that, in column generation, the shadow prices of Constraints (1a) are zero when for .
Experiments with selecting random subsets of features show that, in many settings, this leads to worse objective values and runtimes. Only when the data set is too large to handle for the subproblem, that is, when , feature sampling can be helpful. The limited benefit obtained from feature sampling is likely because of the randomness in the feature selection, which hampers the probability that the subset contains a good set of features. IRELAND could be further improved by designing a clever way of selecting promising features. This is left for future research.
A binary classification problem is biobjective by nature: there is a trade-off between the number of true versus false positives. Using the ε-constraint method, IRELAND efficiently generates the sensitivity–specificity trade-off curve from the previously generated pool of AND clauses. Using IRELAND, it is not necessary to solve multiple large MILPs that generate the trade-off curve through either the ε-constraint method or the weighted sum method. The trade-off between sensitivity and specificity can be very valuable in practical applications as it allows the user to choose the level of sensitivity or specificity that is most suitable for the application. Note that this trade-off curve is an estimation because (1) IRELAND is a heuristic, (2) the generated trade-off curve depends on the available AND clauses, and (3) the upper bounds chosen for solving the subproblems highly impact the granularity of the pool of AND clauses.
The parameters UB and τ, that is, the upper bound on the number of false positives and the aspired number of true positives obtained by the subroutine, influence the sensitivity–specificity trade-off of the generated AND clauses and, hence, the final sensitivity–specificity trade-off curve. A dense grid for UB and τ improves the quality of the trade-off curve but leads to lengthier computations as more subproblems need to be solved, many of which are likely redundant. This is partially resolved by using the number of iterations without improvement as a stopping criterion. In IRELAND’s current form, the choice of UB and τ is dependent on the user’s wishes as well as the estimation of the error present in the data. Using τu speeds up IRELAND as it can prevent the subroutine from going through several iterations without improving on the subroutine’s master problem. The user may, however, find it difficult or undesirable to choose a value for τ. In this case, one could choose a very tight value for τ, which results in the subroutine using the magnitude of improvement between two iterations as its only stopping criterion. IRELAND could be improved by implementing a funneling or learning strategy to find the right values for UB and τ as the algorithm progresses. This is left for future work.
Whereas IRELAND in its current form is designed for binary classification problems, one can readily extend the framework to the multiclass case by introducing decision variables , which is equal to one if sample n is assigned to class c and zero otherwise. As each class has its own Boolean phrase, the decision variables t and s need to be extended with the class dimension c as well, leading to an increase in the number of decision variables by a factor equal to the number of classes. IRELAND can handle this increase in model size very well: the set of subproblems that needs to be solved in each iteration can simply be extended by defining subproblems for each of the classes separately. In this way IRELAND allows for parallelization with regard to classes.
IRELAND can handle large data sets of up to 10,000 samples and 10,000 features. Currently, data set sizes are growing rapidly, and in many fields, the number of samples and features may grow into the millions. Therefore, though IRELAND is a major step forward, further improvements are needed to keep up with the steady growth of data sets.
In order to improve generalization, one is often interested in Boolean phrases that are as simple as possible, that is, with a minimum number of AND clauses and a minimum number of features per clause. Currently IRELAND uses an upper bound on the number of clauses and the number of features per clause. It could be interesting for the user to see the trade-off between rule complexity and classification accuracy. IRELAND can be extended to accommodate for this by generating a pool of AND clauses that do not only vary regarding the number of false positives but also vary in the number of included features. The master problem can then be solved for various bounds on the complexity of the final Boolean phrase, yielding the desired trade-off curve. This extension is left for future work.
5. Conclusion
IRELAND is an algorithm that can efficiently generate Boolean phrases in disjunctive normal form from data sets with a large number of samples and features. Making use of parallel computation, it generates a large pool of AND clauses representing various trade-offs between the number of true and false positives. From this pool, IRELAND can then efficiently generate the sensitivity–specificity trade-off curve without the need for solving a large number of computationally heavy mixed integer programs.
References
1000 Genomes Project Consortium (2015) A global reference for human genetic variation. Nature 526(7571):68–74.Crossref, Google Scholar- (2020) Variantspark: Cloud-based machine learning for association study of complex phenotype and large-scale genomic data. GigaScience Database 9(8):giaa077.Google Scholar
- (1997) Logical analysis of numerical data. Math. Programming 79(1):163–190.Crossref, Google Scholar
- (1996) A subexponential exact learning algorithm for DNF using equivalence queries. Inform. Processing Lett. 59(1):37–39.Crossref, Google Scholar
- (2012) An integer optimization approach to associative classification. Adv. Neural Inform. Processing Systems, 269–277.Google Scholar
- (2016) Complexity theoretic limitations on learning DNF’s. Conf. Learn. Theory, 815–830.Google Scholar
- (2018) Boolean decision rules via column generation. Adv. Neural Inform. Processing Systems, 4655–4665.Google Scholar
- (2017) Toward a rigorous science of interpretable machine learning. Preprint, submitted February 28, https://arxiv.org/abs/1702.08608.Google Scholar
- (2006) Logical analysis of data-an overview: From combinatorial optimization to medical applications. Ann. Oper. Res. 148(1):203–225.Crossref, Google Scholar
- (2010) Disjunctions of conjunctions, cognitive simplicity, and consideration sets. J. Marketing Res. 47(3):485–496.Crossref, Google Scholar
- (2004) Learning DNF in time 2O(n1/3). J. Comput. System Sci. 68(2):303–318.Crossref, Google Scholar
- (2016) Logic models to predict continuous outputs based on binary inputs with an application to personalized cancer therapy. Sci. Rep. 6(1):36812.Crossref, Google Scholar
- (2016) Interpretable decision sets: A joint framework for description and prediction. Proc. 22nd ACM SIGKDD Internat. Conf. Knowledge Discovery Data Mining (ACM, New York), 1675–1684.Google Scholar
- (2013) Exact rule learning via Boolean compressed sensing. Internat. Conf. Machine Learn. (PMLR, New York), 765–773.Google Scholar
- (2020) Interpretable machine learning, First edition (Leanpub, Victoria, Canada).Google Scholar
Parliament of the European Union (2016) Article 22 of the EU GDPR. Accessed March 21, 2021, https://www.privacy-regulation.eu/en/article-22-automated-individual-decision-making-including-profiling-GDPR.htm.Google Scholar- (1999) Learning DNF by approximating inclusion-exclusion formulae. Proc. 14th Annual IEEE Conf. Comput. Complexity (IEEE, Piscataway, NJ), 215–220.Google Scholar
- (1984) A theory of the learnable. Comm. ACM 27(11):1134–1142.Crossref, Google Scholar
- (2015) Learning optimized OR’s of AND’s. Preprint, submitted November 6, https://arxiv.org/abs/1511.02210.Google Scholar

