
Tightening the Difference-of-Convex Formulation for the Piecewise Linear Approximation in General Dimensions
Abstract
This paper addresses the problem of tightening the mixed-integer linear programming (MILP) formulation for continuous piecewise linear (CPWL) approximations of data sets in arbitrary dimensions. The MILP formulation leverages the difference-of-convex (DC) representation of CPWL functions. We introduce the concept of well-behaved CPWL interpolations and demonstrate that any CPWL interpolation of a data set has a well-behaved version. This result is critical to tighten the MILP problem. We present six different strategies to tighten the problem, which include fixing the values of some variables, introducing additional constraints, identifying small big-M parameter values, and applying tighter variable bounds. These methods leverage key aspects of the DC representation and the inherent structure of well-behaved CPWL interpolations. Experimental results demonstrate that specific combinations of these tightening strategies lead to significant improvement in solution times, especially for tightening strategies that consider well-behaved CPWL solutions.
Funding: Financial support from the Department of Energy Office of Energy Efficiency and Renewable Energy [Contract DE-AC02-06CH11357] is gratefully acknowledged.
Supplemental Material: The electronic companion is available at https://doi.org/10.1287/ijoo.2025.0074.
1. Introduction
A continuous piecewise linear (CPWL) function is a continuous function defined on a compact set which can be partitioned into a finite set of affine domains within which the function is affine. CPWL functions are a fundamental tool in mathematics, engineering, and data science. This is due to their ability to approximate any continuous nonlinear function defined on a compact set to an arbitrary level of precision using a finite number of linear pieces (Huang 2020). CPWL functions are also an essential tool when fitting a data set for which the analytical expression of the nonlinear relationship is unknown (Rebennack and Krasko 2020). In optimization models, using CPWL functions to represent complex nonlinear relationships enables the use of mature mixed-integer linear programming (MILP) solvers, which are often significantly faster than nonlinear solvers (Vielma et al. 2010, Vielma 2015).
Not only can CPWL functions be represented in MILP models, but the optimal CPWL fitting problem itself can also be expressed as a MILP problem (Toriello and Vielma 2012). The objective function may vary depending on the application. For instance, given a fixed number of affine functions, one may wish to determine the CPWL approximation that minimizes an approximation error metric—for example, the maximum or average error (Rebennack and Krasko 2020). Alternatively, one may wish to identify the CPWL approximation with the minimal number of affine pieces (Kong and Maravelias 2020).
MILP formulations for the CPWL fitting problem have been extensively investigated for univariate functions and one-dimensional data sets. Frenzen et al. (2010) studied optimal partitioning of the range of the univariate function to be approximated and provided a quantitative result regarding how the number of segments depends on the function and the approximation error. Rebennack and Krasko (2020) developed a finitely convergent method to generate CPWL approximations for one-dimensional data sets or continuous univariate functions identifying the minimal number of breakpoints required to meet an acceptable approximation error. Similarly, Kong and Maravelias (2020) introduced a novel method of enforcing continuity at breakpoints through a set of linear constraints. The two formulations are compared in detail in Warwicker and Rebennack (2022), and it is shown that the formulation from Rebennack and Krasko (2020) is generally faster in practice. The work from Warwicker and Rebennack (2023) extends the work from Warwicker and Rebennack (2022) and uses a Benders decomposition approach to improve the solution time of the MILP problem. Ploussard (2024) introduces a tightening method that significantly shortens the MILP solution time of the CPWL fitting problem when hierarchically minimizing the number of linear pieces and approximation error. More recently, Warwicker and Rebennack (2025) presented an efficient approach for approximating continuous univariate functions with a CPWL function by embedding a linear-time algorithm into an adaptive discretization framework.
For bivariate functions and two-dimensional data sets, most existing methods constrain the affine domains of the CPWL approximation to be simplices. For example, D’Ambrosio et al. (2010) partition the CPWL function domain into rectangles that are later split into triangles along predefined diagonals. Toriello and Vielma (2012) use a similar method but select a set of splitting diagonals that minimize the approximation error. Rebennack and Kallrath (2015) use a different triangulation strategy that iteratively partitions the triangles covering the approximation domain into smaller ones until a target approximation error is reached. Duguet and Ngueveu (2022) propose a similar iterative refinement, but without imposing the affine domains to be simplices. Bärmann et al. (2023) introduce an approximation algorithm for the optimal piecewise linear interpolation of the continuous bivariate function xy over rectangular domains.
The literature addressing the optimal CPWL fitting problem for data sets of higher dimensions is significantly more limited (Misener and Floudas 2010, Rebennack and Kallrath 2015). Besides, most of the existing methods essentially extend the simplex-based partitioning strategy used for two dimensions, which result in computational challenges due to the exponential growth of the number of possible simplex-based partitions as the data dimension increases (Hughes and Anderson 1996). Kazda and Li (2021) introduced the first MILP formulation able to identify the optimal CPWL approximation of data sets of any dimension for a given maximum approximation error. They achieve this by leveraging the difference-of-convex (DC) representation of CPWL functions (Kripfganz and Schulze 1987), which allows for the affine domains partitioning the CPWL function to be implicitly defined by the difference of the pointwise maxima of two sets of affine functions. The strength of the DC representation lies in its ability to describe any CPWL function with affine domains of arbitrary shape. However, the computational cost of the MILP problem rapidly increases with the dimension of the data set, the number of data points, and the number of affine functions.
Deep learning techniques offer an alternative way to identify CPWL approximations (Huang 2020). In fact, the function represented by a neural network (NN) using ReLU activation function is a CPWL function, and the NN loss function represents the CPWL approximation error (DeVore et al. 2021). To the best of our knowledge, the only existing methods to identify CPWL approximations of data sets in multiple dimensions without explicitly specifying the partitioning of affine domains are the ReLU NN approach and the DC MILP approach introduced by Kazda and Li (2021). Training an NN to identify a good CPWL approximation is significantly faster than solving an MILP problem, contributing to NN growing popularity in recent years. However, the MILP approach provides three key advantages over the ReLU NN approach:
The NN approach uses a gradient-based method that identifies local optima, whereas the MILP approach is guaranteed to yield the CPWL function with the smallest approximation error.
Contrary to the MILP approach, the NN approach does not allow for the explicit enforcement of a target maximum approximation error.
Because of the complex relationship between the structure (width and depth) of an NN and the number of affine pieces of the CPWL functions they can model, it is difficult for NNs to identify good CPWL approximations with a manageable number of affine pieces (Chen et al. 2023). Conversely, the MILP approach allows the user to identify CPWL functions with a predefined, or minimal, number of linear pieces. This is a critical feature when these CPWL functions are subsequently embedded in MILP formulations to model nonlinear relationships, where the number of binary variables required to model CPWL functions typically increases with the number of affine pieces that compose them, making the MILP problem harder to solve. In other words, although an NN can quickly identify a good-quality CPWL approximation of a nonlinear relationship, the resulting approximation may render the MILP formulation in which it is embedded computationally intractable.
To address the high computational cost of solving the MILP problem, authors Kazda and Li (2024) introduce an iterative linear programming (LP) approach that identifies a valid CPWL approximation given a target maximum error. However, the identified CPWL solution is not necessarily optimal. A priori, identifying the global optimum of the CPWL fitting problem can only be achieved by solving an MILP problem. Therefore, it is critical to improve the MILP formulation of the CPWL fitting problem to reduce its computational cost. The method described in Ploussard (2024) achieves a tightening of the MILP problem that significantly improves the solution time, but the method only applies to one-dimensional data sets. This raises the need to develop MILP tightening methods that can be extended to data sets of any dimensions.
This paper aims to address this research gap. To achieve this, we introduce a critical class of CPWL interpolations called “well-behaved” and demonstrate that any CPWL interpolation has a well-behaved version. This important result is then leveraged to identify six tightening strategies that can be combined to significantly reduce the solution time of the MILP CPWL fitting problem.
The five main contributions of this paper are the following. First, we formalize the concept of well-behaved CPWL interpolations, a class of CPWL interpolations in which each affine piece interpolates a number of points greater than the dimension of the interpolated data set. Second, we demonstrate that any CPWL interpolation of a data set has a well-behaved version, which serves as a key theoretical foundation for our tightening method. Third, we leverage this result to introduce six tightening strategies for the MILP formulation of the CPWL fitting problem. Fourth, we analyze the theoretical impact of each tightening strategy together with the time complexity of the preprocessing step involved. Fifth, we assess the practical impact of multiple combinations of the tightening strategies. The proposed tightening strategies enable the identification of an optimal CPWL approximation in a relatively low computation time (i.e., up to 20 times faster than the existing literature).
The remainder of the article is organized as follows: Section 2 introduces the theoretical background of the CPWL-fitting problem. Section 3 describes the proposed MILP formulation. Section 4 formalizes the concept of well-behaved CPWL fitting and demonstrates the fact that any CPWL interpolation or approximation of a data set has a well-behaved version. Section 5 introduces the six tightening strategies of the MILP formulation. Section 6 introduces the case studies and assesses the performances of several combinations of tightening strategies. Section 7 presents the conclusions.
2. Background
Let be a set of N points of . We assume that the points are in general position in —that is, no subset of points is contained within a single hyperplane (Edelsbrunner et al. 1986). Let be the projection defined as . Let be the projection of S by . Let be the convex hull of .
We say that is a CPWL function when f is continuous and there is a set of P affine functions such that the are convex polytopes, , and . The are called the affine pieces of f, and the are called the affine domains of f.
Note that, contrary to the more common definition of CPWL functions from Geißler et al. (2012), we do not assume that the form a partition of D. The intersection of two affine domains is not required to have an empty interior. In addition, an affine domain can be empty, and two affine domains can be equal as long as the corresponding affine pieces are equal. This implies that the set of affine functions representing the CPWL function is not unique. However, apart from this, Definition 1 describes exactly the same mathematical object as the CPWL functions defined in the literature. The flexibility of our definition enables us to compare CPWL functions to one another, which will be useful in the following section.
Let be a CPWL function. f can be expressed as the difference of two convex CPWL functions and . Specifically, there is a set of affine functions and affine functions such that:
are called the affine pieces of , and are called the affine domains of . In addition, is a partition of D.
The proof of Proposition 1 is provided in Kripfganz and Schulze (1987). The above formulation is called the DC representation of f. Note that the DC representation of a CPWL function is not unique.
Let be a CPWL function. Let be a DC representation of f. The affine domains of and are convex polytopes. In addition, any affine domain of f is the intersection of an affine domain of and . In other words, for any affine domain of f, there is an affine domain and of and such that , and .
The proof of Proposition 2 is given in Kripfganz and Schulze (1987) and stems from the DC representation of f.
We say that is an interpolation of, or interpolates, S when (Davis 1975).
We say that is an ε-approximation of, or ε-approximates, S when there exists such that and f interpolates the set . In other words, f is an ε-approximation of S if .
Let and be two ε-approximations of S. We say that f and g are equivalent with respect to S when .
3. MILP Formulation
We aim to identify the optimal CPWL fitting of a set of points S. More specifically, we aim to identify the CPWL ε-approximation of S that minimizes an objective Q subject to a given error tolerance . For example, Q can be the maximum fitting error, the average fitting error, or the number of affine pieces.
The following MILP formulation is largely based on the formulation presented in Kazda and Li (2021), where , , , , , and are continuous variables; are binary variables; and are big-M parameters.
Equation (1) represents the objective function to be minimized. As long as Q is a linear expression, Equations (1)–(10) formulate an MILP problem. For the rest of the paper, we will refer to this MILP problem as . Equation (2) is the DC representation of the CPWL function, where , , and represent the value at of the functions f, , and . Equations (3) and (4) formulate the representation of each convex function as the maximum of a set of affine functions , where and are the linear coefficients and bias terms of each affine piece . The binary variable is equal to one when the point belongs to the domain , and the big-M parameter ensures that when . Note that the big-M parameter in Equation (4) must be large enough so that it does not constrain the term when . In Equation (5), we will identify a tight value for . and are the numbers of affine pieces of and , respectively. Equation (5) ensures that each point belongs to at least one affine domain of and one affine domain of . Note that, contrary to the literature (e.g., Kazda and Li 2021), we use an inequality constraint instead of an equality constraint. By doing so, we allow the points to belong to multiple affine domains. This can occur if, for example, some affine pieces are identical or if some points are at the border between two or more affine domains. This inequality is also critical to ensure that some well-behaved CPWL solutions are feasible in , which is a property that will be discussed in the next section. Equation (6) defines the approximation error at each point as the distance between and the value of the CPWL function at . Equation (7) ensures that this distance is never greater than the specified error tolerance . Finally, Equations (8)–(10) define the domain of the continuous and binary variables.
Note that some optimization solvers like Gurobi (Gurobi Optimization LLC 2024a) make it possible to formulate Equation (4) without using a big-M parameter. Instead, Equation (4) can be replaced by the indicator constraint below (Gurobi Optimization LLC 2024b):
We note the alternative MILP formulation using the indicator constraint, which is composed of Equations (1)–(3) and (5)–(11).
The objective can be set to minimize different error metrics. Formulating the objective with Equation (12) minimizes the average fitting error ( norm), the discrete analogue of minimizing the area between two functions. Alternatively, using Equation (13) minimizes the maximum fitting error ( norm), which provides a strict pointwise guarantee on the approximation quality.
Other objective functions may include the number of affine pieces of , , or f, as well as a combination of error metric and number of affine pieces. These alternative objective functions can be found in Electronic Companion Section EC.1.
4. Well-Behaved CPWL Interpolations
This section introduces a new class of CPWL interpolations called “well-behaved” CPWL interpolations. Loosely speaking, well-behaved CPWL interpolations are composed of affine pieces whose gradients are not excessively steep. This class of CPWL interpolations aligns with the intuitive representation of what the CPWL interpolation of a data set should look like, and they have desirable properties when modeled in . This section formalizes the definition of a well-behaved CPWL interpolation and defines what constitutes a well-behaved version of a CPWL interpolation. We then demonstrate that any CPWL interpolation has a well-behaved version. This result is critical to the tightening procedure introduced in Section 5.
Let be a set of points of , where the are in general position. There exists a unique linear interpolation of S. In other words, S can be interpolated by a unique affine function.
Proposition 3 is a fundamental result from linear algebra (Boyd and Vandenberghe 2004). The system of linear equations , with variables and , is exactly determined and has a unique solution due to the general position of the . If the number of points is less than , the system is underdetermined, and there is an infinite number of possible linear interpolations. If the number of points is greater than , because the are in general position, the system becomes overdetermined, and there exists either one or no linear interpolation.
Let be a CPWL interpolation of S, with . We say that an affine piece of f is underdetermined, exactly determined, or overdetermined with respect to S if it interpolates less than, exactly, or more than points of S, respectively.
We say that is a well-behaved CPWL interpolation of S when f is a CPWL interpolation of S and each affine piece of f is exactly determined or overdetermined—that is, each affine piece interpolates at least points of S. Additionally, let be an -approximation of S and . We say that f is a well-behaved CPWL -approximation of S when f is a well-behaved CPWL interpolation of .
Let f and g be two CPWL interpolations of S composed of the set of affine pieces {} and {}, respectively. We say that g is a well-behaved version of the CPWL interpolation f with respect to S if g is a well-behaved CPWL interpolation of S and . Additionally, let f and g be two CPWL -approximations of S and . We say that g is a well-behaved version of the CPWL -approximation f with respect to S if g is a well-behaved version of the CPWL interpolation f with respect to .
If g is a well-behaved version of the CPWL -approximation f with respect to S, then the -approximations f and g are equivalent according to Definition 4.
In other words, a well-behaved version of a CPWL interpolation f of S is a transformation of f where each affine piece has been adjusted, or “tilted,” to interpolate at least points of S, including the points it was originally interpolating (before being tilted). An illustration for is provided in Figure 1. In the following sections, we show that well-behaved CPWL interpolations have interesting properties that can be used to tighten the MILP formulation. To the best of the authors’ knowledge, this is the first time this class of CPWL interpolations is introduced. We prove below that for any CPWL interpolation, a well-behaved version always exists.
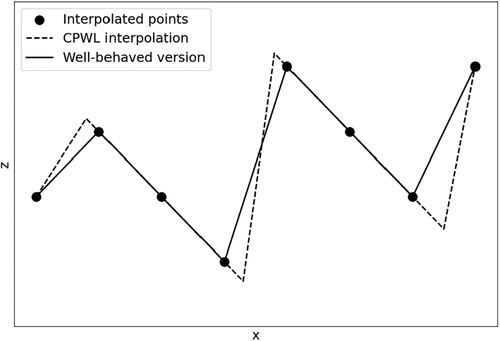
Note. Both CPWL functions interpolate the points and are composed of five affine pieces, but the affine pieces of the well-behaved interpolation have been tilted to interpolate at least two points per piece.
If f is well-behaved, then f is a well-behaved version of itself.
Let S be a set of N points in , with . Let be a CPWL interpolation of S. Let be one of the affine pieces of f, and let be a neighboring affine piece of —that is, an affine piece of f sharing a common domain boundary with . Let be the affine extension of to the domain D. Then,
Let . According to Proposition 2, a shared domain boundary between and is either a shared domain boundary between two affine pieces of or between two pieces of .
Case 1: The shared domain boundary is between two affine pieces of . Then, using Proposition 2, we can write and . Because , we therefore have . Thus .
Case 2: The shared domain boundary is between two affine pieces of . We can write and . Because , we therefore have . Thus, .
Let and . Assume that rows of are linearly independent and the polyhedron is nonempty. Then, there exists a point such that for rows of .
Proposition 4 is a well-established fact from LP theory, as described in Bertsimas and Tsitsiklis (1997). The constraints “” are also known as the active constraints of the solution . The point lies on the boundary of U, and, if , is a vertex of U.
Let S be a set of N points in , with . Let be a CPWL interpolation of S that is not well-behaved—that is, at least one of the affine pieces of f is underdetermined. Let represent an underdetermined affine piece of f that interpolates n points of S (). Let be the J neighboring pieces of —that is, the affine pieces that share a domain boundary with . Let . Assume there is a total of points in S whose projections lie in (interpolated by the J neighboring pieces but not by ). Then, there exists an alternative CPWL interpolation of S in which is adjusted to interpolate points of S without impacting the points interpolated by the neighboring pieces. In other words, we can construct a new CPWL interpolation of S defined over and represented by a set of affine functions , such that: (1) The functions and are equal on their shared domain—that is, ; (2) the points that are interpolated by and are the same—that is, ; and (3) the function interpolates points of S, which include the n points interpolated by —that is, and .
Let and be the linear coefficients and bias terms of —that is, . Let denote the n points of S whose projections on lie in and denote the m points of S whose projections on lie in . Let denote the smallest integer such that . According to Lemma 1, . Because and , this can be expressed as: . In other words, is a point of the polyhedron U defined by:
U is not empty because . Therefore, according to Proposition 4, there exists a solution with active constraints. Note that the constraints “” are already active, which means that there must be additional active constraints of type “.” We define as the affine function defined by . We define the domain of as the domain delimited by the J boundaries . We define as the J affine pieces for which the domains were updated according to the J boundaries of . The set of affine functions constitutes a valid CPWL interpolation of S over , with interpolating points of S, including the original n points interpolated by . The points of S interpolated by are the same as the points interpolated by , .
Let S be a set of N points in , where . Any CPWL interpolation of S has a well-behaved version.
Let be a CPWL interpolation of S. If every affine piece of f interpolates at least points, f is already well-behaved. Otherwise, we construct a well-behaved version iteratively. The procedure begins by identifying an underdetermined piece, , with a neighboring domain containing at least one point not interpolated by ; the existence of such a piece is proven in Section EC.2 of the electronic companion. Using Lemma 2, we then adjust to interpolate this additional point without affecting its neighbors. Repeating this process guarantees termination, as each step incorporates a new point from the finite set S. The final CPWL interpolation is, by construction, a well-behaved version of f. Note that this constructive procedure serves as a theoretical proof of existence of the well-behaved version; a computational implementation is not required for the scope of this work. The process is illustrated in Figure 2.
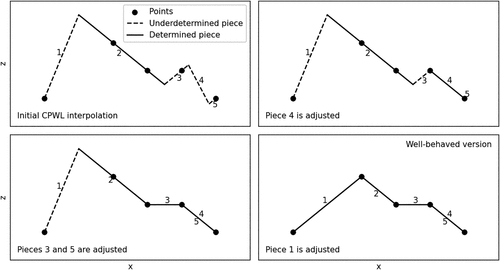
Notes. At the beginning of the process, piece 5 could not be selected because its neighboring piece (piece 4) does not interpolate any point. At the end of the process, pieces 4 and 5 have identical domain, which is allowed by our definition of CPWL functions.
Any CPWL -approximation of S has a well-behaved version.
The proof of Corollary 1 directly follows from Theorem 1 and Definition 7.
Note that the procedure of tilting the affine pieces of f to construct a well-behaved version may result in two or more underdetermined pieces merging together. In other words, initially distinct pieces may end up interpolating the same subset of points and having the same expression and affine domain after converting f to a well-behaved interpolation. In this case, the well-behaved version is still a valid CPWL function owing to the flexibility of Definition 1.
A well-behaved version of a CPWL interpolation is not necessarily unique. That is, a CPWL interpolation may have several well-behaved versions. This stems from the fact that the point with active constraints in Proposition 4 is not necessarily unique.
An important application of this theorem is that we can significantly reduce the set of CPWL functions to be considered in without impacting the feasibility of the problem. Specifically, if a CPWL -approximation f of S exists, a well-behaved version g of f also exists. The two CPWL solutions f and g have the same number of affine pieces and are equivalent with respect to S—that is, . Therefore, we can eliminate CPWL solutions that are not well-behaved from the feasible region of because they are redundant solutions and may have excessively steep gradients due to their underdetermined affine pieces. In the next section, we will see how this theorem allows us to derive valid tight bounds and constraints for the MILP problem.
Herein, we will refer to the set of CPWL -approximations of S as . The subset of that can be represented using affine pieces for , respectively, is denoted . The set of well-behaved CPWL -approximations of S will be denoted as , and when represented by affine pieces. Note that . Additionally, note that the feasible region of the MILP problem is given by .
5. Tightening the MILP Formulation
This section introduces six strategies to tighten and enhance the formulation of . First, we demonstrate that we can fix one of the affine pieces of without affecting the set of CPWL solutions. Next, we impose an ordering on the affine pieces of and that does not affect the set of CPWL solutions. We can also impose that each affine piece of and contains at least points, which serves as a valid tightening of the set of feasible well-behaved CPWL solutions. Alternatively, we may require that each affine piece of f contains at least points, which requires the use of additional variables. Finally, we identify tight values for the big-M parameters and establish tight bounds for the linear variables.
Additional strategies that leverage the convexity of the functions and and of their affine domains are included in the electronic companion, Section EC.3. However, contrary to the six strategies presented here, their impact on the feasible region is unclear, and they do not seem to have a significant impact on the solution time.
Herein, it is assumed that .
5.1. Fixing One Affine Piece
Let be a set of functions. We have .
Lemma 3 follows directly from the translation invariance of the max function—that is, .
The following equation constitutes a valid tightening constraint of :
To prove this, we must demonstrate that any CPWL function f can be expressed as the difference of two convex CPWL functions , with . According to Proposition 1, there is a set of affine functions such that f can be expressed as . Let . The function is affine because it is the difference of two affine functions. Moreover, . According to Lemma 3, we have . Therefore, we can rewrite f as .
Note that Equation (14) affects not only the set of possible values for , but also for all . Also note that the fixed values of zero for are chosen arbitrarily; any value could be imposed and serve as a valid tightening constraint for the problem. Imposing Equation (14) effectively reduces the dimensionality of the search space by . Formally, Equation (14) does not introduce any additional linear constraints; instead, it introduces tight bounds on linear variables.
5.2. Sorting the Affine Pieces
Let denote the linear coefficients of the affine piece .
The following equation constitutes a valid tightening constraint of :
The problem exhibits symmetries with respect to the group of variables and , respectively. This means that permuting the affine pieces of , or , does not affect the solution of the problem. Therefore, we can arbitrarily sort the affine pieces of and based on the ascending order of the values and , respectively.
It is important to note that, after sorting the affine pieces of and , the procedure outlined in the proof of Theorem 2 can be applied to impose Equation (14) with no impact on the CPWL solution. Thus, Equations (14) and (15) are compatible and can be applied simultaneously with no impact on the CPWL solution. The number of possible arrangements for affine pieces is , which implies that implementing Equation (15) reduces the feasible region by a factor of its original extent. Additionally, applying Equation (15) introduces constraints to the MILP problem.
5.3. Imposing Points per Affine Domain of
Adding the following equation to reduces the feasible region to a superset of . In other words, some non-well-behaved solutions may be eliminated from the new feasible region, but all well-behaved solutions are preserved.
Let be a well-behaved CPWL solution. Let be one of the affine domains of . According to Proposition 1, and . Therefore, there exists a k such that . According to Proposition 2, is an affine domain of f. According to Definition 6, . Furthermore, implies . Therefore, we have . Similarly, for an affine domain of , we obtain . In other words, each affine domain of and contains at least points.
Note that the inequality from Equation (5), which allows each point to belong to more than one affine domain of or , is critical for utilizing Equation (16). If we were instead imposing a single affine domain per point, as in the formulation from Kazda and Li (2021), Equation (16) would become too restrictive. In fact, the combined requirement of having only one affine domain per point and at least points per affine domain would imply that , making the MILP problem infeasible if that condition was not satisfied. Using Equation (16) eliminates some non-well-behaved CPWL solutions from the feasible region. However, all well-behaved solutions are preserved. Owing to Theorem 1, it is proven that this does not impact the quality of the feasible CPWL solutions, as any CPWL -approximation of S has a well-behaved version. Implementing Equation (16) adds constraints to the MILP problem.
5.4. Imposing Points per Affine Domain of f
Alternatively, we can impose a set of constraints that further reduces the feasible region to the set of well-behaved CPWL solutions. This approach requires the introduction of two additional sets of variables, and . In the following equations, the indices , , , unless otherwise specified.
Adding the following equations to reduces the feasible region to :
Equations (17)–(19) and (22) define as an indicator variable which is equal to one if and zero otherwise—that is, . Equations (20) and (23) define as an indicator variable which is equal to one if contains at least one point—that is, . Finally, Equation (21) formulates the condition that if one point is in , then must contain at least points—that is, . Formally, and should be defined as binary variables. However, the tight constraints from Equations (17)–(21) involving the binary variables ensure that and can only take values in .
Equations (17)–(23) involve the use of additional variables, variable bounds, and additional constraints. These constraints restrict the feasible space to be . Note that the indicator variable is necessary in Equation (21) because the intersection of an affine domain of and may be empty.
Equation (16) is implied by Equations (17)–(23), meaning that the latter dominate the former. In other words, imposing points per affine domain of f implies, and is more restrictive than, imposing points per affine domain of .
5.5. Tightening the Big-M Parameters
In order to identify tight big-M values, we first need to define several sets. Let A denote the set of all affine functions . Let denote the set of all subsets of S composed of points. Let . We define the set . We define the set ε-approximates and interpolates . We also note and . For convenience, let . Finally, given a CPWL solution , we define .
The set contains at most affine functions.
First, we have . Additionally, . Therefore, .
Let , . Let . Then, we have:
Because f is well-behaved, is an affine piece of f that -approximates a subset . Therefore, . As a result, . What remains to be proven is that the extrema of on can be found on . Note that is equal to the optimal objective value of the LP optimization problem :
Similarly, is equal to the optimal objective value of . In addition, corresponds to the feasible region of and , whereas corresponds to the vertices—that is, extreme points—of , where the optimal solution is located. Consequently, . Similarly, .
Let , , , . Then,
We prove the case , the case being symmetric. Let , . By convexity of D, there exists a line segment L connecting to that is contained in D. L crosses T affine domains of f, each of which is the intersection of an affine domain of and . Let be such that L crosses the nonempty domains in ascending order of m when traversing from to . An example is depicted in Figure 3 for . We have and . Without loss of generality, we assume that at each step m, the line segment L transitions to either a new affine domain of or a new affine domain of , but not both. In other words, . Because the intersection of L with an affine domain is convex, and are sets of consecutive numbers—that is, without gaps. Consequently, and can change value at most and times, respectively. That is, . Thus, we have:
Similarly, the lower bound of is proven by flipping the inequality in in and .
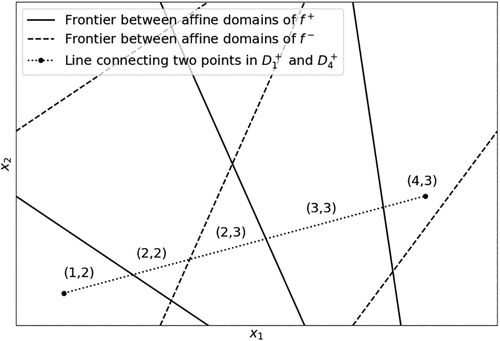
Notes. Here, both and have four affine domains, and the line connects a point in to a point in . The line crosses five pairs of affine domains in and : . We have .
Assuming we only consider well-behaved CPWL solutions, the following value is a tight value for the parameter in Equation (4):
Let , , . Let k be such that —that is, . Owing to Lemma 5, we have:
Herein, it is assumed that the value of the parameter from Equation (4) is the one described in Theorem 6. Note that the big-M values defined in Equation (24) are only valid when considering the solution space of well-behaved CPWL solutions. This implies that using these values may eliminate some CPWL solutions that are not well-behaved from the feasible region, although not necessarily all of them.
5.6. Bounding the Variables
We define the following parameters:
Let . Let . Then, we have:
The partial derivatives of an affine function are equal to its linear coefficients, and its value in corresponds to its bias term. In particular, and . Because , we have and . Similar to Lemma 5, we can show that the extrema of and on can be found on . Let . , , , are the optimal objective values of the following LP optimization problem, with , , , , respectively.
Therefore, the extrema of and on can be found on the vertices . It follows that the extrema on can be found on .
Let , . Then,
This is demonstrated by using the same sum decomposition as in Lemma 5 but for , instead of . The result follows from applying Lemma 6 to identify a similar inequality as and .
For well-behaved CPWL solutions, the following equations represent valid upper and lower bounds of the linear variables:
The bounds from Equation (29) derive from Equations (6) and (7). Equation (30) is based on Equation (14), using . In addition, . Thus, according to Lemma 5, . Equation (31) derives from Equations (29) and (30) combined with . Using Equation (14) and Lemma 7, , leading to Equation (32). Equation (33) arises from Equation (15): . Next, combining Equation (32), Lemma 6, and k such that , we deduce: and , leading to Equation (34). Equation (35) stems from Equations (33) and (34). Further, applying Equation (14) and Lemma 7, we deduce , resulting in Equation (36). Finally, Equation (37) stems from Equation (36), Lemma 6, and k such that .
Note that the bounding values from Equations (30)–(37) are only valid when considering the solution space of well-behaved CPWL solutions. This implies that using these bounding values may eliminate some CPWL solutions that are not well-behaved from the feasible region, although not necessarily all of them. In addition, Equations (32)–(37) apply owing to Equations (14) and (15). This implies that using these values may eliminate some DC representations of the CPWL solutions but not the CPWL solutions themselves.
The time complexity for calculating the bounds and big-M parameters is .
The proof of Proposition 6 is based upon the number of elements in and the time complexity of inverting a matrix in . A more detailed proof is provided in Section EC.4 of the electronic companion.
Table 1 gives a summary of the tightening strategies, together with their impact on the feasible region and the preprocessing involved.
|

Table 1. Summary of Tightening Strategies
| Eq. | Description | # of new constraints or variable boundsa | # of new variables | Impact on search region | Preprocessing | Time complexity |
|---|---|---|---|---|---|---|
| (14) | Fix one affine piece | 0 a | 0 | Eliminate dimensions | None | |
| (15) | Sort the affine pieces | 0 | Reduce the feasible region by a factor of | None | ||
| (16)b | Impose points per affine piece of | 0 | Eliminate some non-well-behaved CPWL solutions | None | ||
| (17)–(23)b | Impose points per affine piece of f | a | Eliminate all non-well-behaved CPWL solutions | None | ||
| (24) | Tighten the big-M parameters | 0 | 0 | Eliminate some non-well-behaved CPWL solutions | Compute all , evaluate g in N points, compute extrema for each point | |
| (29)–(37) | Bound the variables | 0 a | 0 | Bound the search space in all variable dimensions | For all , evaluate the extrema of the coefficients of g |
aIn the number of additional constraints, indicates the number of additional variable bounds.
bThe two sets of equations are alternative to one another, the first set being dominated by the second set but involving less constraints and variables than the second set.
Note that applying all equations presented in Section 5 is a valid tightening of the MILP problem to the feasible region of the well-behaved CPWL solutions. As a result, applying any subset of equations from Section 5 is also a valid tightening. For example, although the variable bounds from Section 5.6 derive from fixing and sorting the affine pieces of and , applying the variable bounds without sorting or fixing any affine piece is still a valid tightening of the MILP problem. As a matter of fact, any combination of the tightening strategies described here is a valid tightening. This fact is leveraged in Section 6 to identify effective combinations of tightening strategies.
6. Computational Experiments
This section illustrates the computational performances of the tightening strategies. In Section 6.1, the data sets used to assess the efficiency of the tightening strategies are described. In Section 6.2, different combinations of the tightening strategies are evaluated to identify the ones that have the most impact on the solution time. In addition, the computational performance of the tightening procedure is assessed.
The algorithms are implemented in Python (3.12.7), and the MILP problems are solved with the Gurobi solver (12.0.0). The code used for the computational experiments can be found at Ploussard (2025). Models are run on an Intel 2.3-GHz machine with 16 cores and 32 GB of RAM. For all MILP problems, the relative optimality gap (MIPGap) is set to . In addition, the primal feasibility tolerance (FeasibilityTol) and integer feasibility tolerance (IntFeasTol) are both set to their minimum value of to mitigate numerical errors.
The objective function used for all MILP problems is the maximum error—that is, Equation (13).
6.1. Description of the Data Sets
To assess the efficiency of the proposed method, six data sets are used. The data sets are summarized in Table 2. Four of the data sets are derived from mathematical functions, and two data sets are based on real-world data. Data sets based on mathematical functions are generated by randomly selecting a certain number of points in a given domain of . The first four data sets from Table 2 are two-dimensional and are illustrated by the dots in Figure 4. The last two data sets are three-dimensional (Figure 5). The third data set represents the water-to-power conversion factor (z) at the Crystal hydropower plant based on the forebay elevation () and the average daily water release () from the years 2014–2024 (Bureau of Reclamation 2024). The fourth data set represents the discharge temperature of a gas compressor (z) based on the volumetric flow rate () and rotation speed () (Marfatia and Li 2022). Data sets were rescaled in all dimensions to prevent numerical issues during the MILP solving process.
|
Table 2. Data Sets Used for Numerical Experiments
| Data set | Number of data points | Dimension d |
|---|---|---|
| , | 121 | 2 |
| , | 64 | 2 |
| Crystal power plant, Bureau of Reclamation (2024) | 116 | 2 |
| Gas compressor, Marfatia and Li (2022) | 102 | 2 |
| , | 64 | 3 |
| , | 64 | 3 |
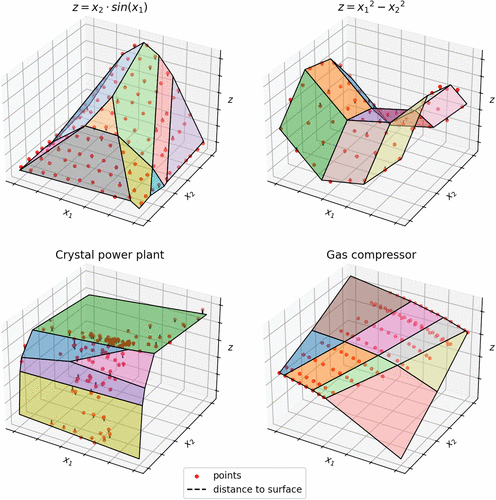
Note. Each polygonal face represents an affine piece of the CPWL function f.
Note. Each polyhedron represents the domain of an affine piece of f.
6.2. Evaluating Different Combinations of Tightening Strategies
There are several ways to apply the tightening strategies to the MILP problem:
The first affine piece of may or may not be set to zero (Equation (14)).
The affine pieces of and may or may not be sorted (Equation (15)).
We can impose points either for each affine piece of and (Equation (16)), for each affine piece of f (Equations (17)–(21)), or for no affine piece.
For the big-M parameters, we can either use an indicator constraint (Equation (11)), a reasonably large (“default”) big-M value, or the tight big-M values (Equation (24)).
The variables may or may not be bounded (Equations (29)–(37)).
In total, there are up to 72 combinations of tightening strategies. Because of this large number, only 11 combinations were selected. The selected combinations, referred to as “C1” to “C11,” are described in Table 3. The “default” big-M value is set equal to the rounded-up maximum value of —for example, 700 if the maximum value is 632.8. For each data set, the 11 combinations of tightening strategies are applied to the MILP problem before solving it, and the solution time is measured for each combination. The same number and of candidate affine pieces and the same upper bound for the maximum error are used across all combinations. The time limit to solve the MILP problem is set to 7,200 seconds. Numerical results are summarized in Table 4.
|
Table 3. Combinations of Tightening Strategies Assessed
| Combination | Fix one affine piece | Sort the affine pieces | Impose points per affine piece | Big-M parameters | Bounded variables |
|---|---|---|---|---|---|
| C1 | Indicator | ||||
| C2 | Default | ||||
| C3 | Tight | ||||
| C4 | ✓ | Tight | |||
| C5 | ✓ | ✓ | Tight | ||
| C6 | ✓ | ✓ | Tight | ✓ | |
| C7 | ✓ | ✓ | of and | Tight | ✓ |
| C8 | ✓ | ✓ | of f | Tight | ✓ |
| C9 | of and | Tight | ✓ | ||
| C10 | of f | Tight | ✓ | ||
| C11 | ✓ | of and | Tight | ✓ |
Note. A blank cell indicates that the tightening strategy does not apply to the combination.
|
Table 4. Summary of Computation Times for Each Data Set and Combination
| Data set | Computation time (s) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Preprocessing | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | |||
| 2, 6 | 0.2 | 9 | 7,200a | 7,200a | 7,200a | 7,200a | 7,200a | 7,200a | 7,200a | 7,200a | 1,877 | 7,200a | 2,554 | |
| 3, 3 | 0.1 | 1 | 7,200a | 576.7 | 112.8 | 116.9 | 507.8 | 382.2 | 406.4 | 2,752 | 98.3 | 516.6 | 200.2 | |
| Crystal power plant | 1, 5 | 0.2 | 8 | 197.6 | 8.7 | 9.9 | 8.6 | 72.0 | 42.0 | 32.3 | 31.5 | 11.4 | 9.7 | 20.8 |
| Gas compressor | 2, 4 | 0.2 | 5 | 7,200a | 7,200a | 1,584 | 2,090 | 847.4 | 1,356 | 944.9 | 7,200a | 457.2 | 3,720 | 303.2 |
| 8, 1 | 0.1 | 37 | 7,200a | 3,402 | 1,441 | 111.0 | 7,200a | 7,200a | 7,200a | 7,200a | 531.1 | 478.3 | 159.5 | |
| 2, 4 | 0.1 | 38 | 7,200a | 2,740 | 460.3 | 558.3 | 2,496 | 1,968 | 974.2 | 7,200a | 698.1 | 4,390 | 438.1 | |
Notes. Summary of computation times for each data set, including the computation time of the preprocessing step and the MILP solving time of each combination of tightening strategies. Bold numbers indicate the two shortest solving times for each data set across all combinations.
aIndicates that the time limit was reached before meeting the target optimality gap.
For each data set, the optimal objective value of the MILP problem is identical across all combinations. However, solution times noticeably vary across combinations. Results show that there is a clear benefit of using tight big-M parameter values (C3) as opposed to using a default big-M parameter value (C2) or an indicator constraint (C1). Fixing the first affine piece of (C4) without imposing points per affine piece does not seem to have a significant additional benefit, except for the case “.” Although it reduces the feasible region, sorting the affine pieces of and has a negative impact on the solution time (C5–C8). This might be due to the fact that these additional constraints increase the solution time of the relaxed LP problem in each node of the MILP search tree without improving the tree search itself—that is, without constraining the binary variables. Because of its negative impact, the strategy of sorting the affine pieces is discarded from the rest of the combinations. Imposing points per affine piece of and and bounding the variables (C9 and C11) has a clear positive impact on the solution time. This positive effect can be explained by the reduction in the feasible region of the binary variables using few additional constraints (). Although this feasible region is further reduced when imposing points per affine piece of f (C10), this constraint has a negative impact on the solution time. This might be due to the larger number of additional variables and constraints required to model the affine pieces of f. The only difference between combinations C9 and C11 is whether the first affine piece of is being fixed. Numerical results show that adding this strategy may either improve or worsen the solution time, depending on the data set—that is, there is not a clear systematic benefit in applying this strategy. When comparing the best solution time of C9 and C11 to the solution time of C2, the reduction factor in solving time ranges from 4 to 23, except for the Crystal power plant case. For the worst solution time, the reduction factor ranges from 3 to 16. Overall, the following combination consistently performs among the best ones: imposing points for each affine piece of and (Equation (16)), tightening the big-M parameters (Equation (24)), fixing the first affine piece of (Equation (14)), and bounding all variables (Equations (29)–(37)).
The computation time of the preprocessing step, used to calculate the big-M parameters and variable bounds, is also included in Table 4. The computation time of this step is negligible for two-dimensional data sets. However, the computation time becomes significant for three-dimensional data sets. This is due to the fact that the time complexity of the preprocessing steps increases exponentially with the dimension of the data set (Table 1). Yet, the combined execution time of preprocessing and solving the tightened MILP problem is still shorter than the time required to solve the nontightened MILP problem, demonstrating the efficiency of the tightening approach in reducing overall computational effort.
7. Conclusions
In this paper, we formalize the concept of well-behaved CPWL interpolations, a class of CPWL interpolations in which each affine piece interpolates a number of points greater than the dimension of the interpolated data set. Next, we demonstrate that any CPWL interpolation has a well-behaved version. Then, we introduce several tightening strategies aimed at improving the solution time of the MILP formulation of the CPWL-fitting problem for data sets in general dimensions. Some of the tightening strategies leverage the fact that any CPWL interpolation has a well-behaved version. In addition, we analyze each tightening strategy in terms of additional constraints, additional variables, impact on the feasible region, and time complexity of the preprocessing step. Then, we identify the combinations of tightening strategies that have the most impact on the solution time of the MILP problem. Experimental results show that the tightening procedure significantly reduces the solution time of the MILP problem in most cases. However, the solution time reduction factor can vary significantly, depending on the size and dimension of the data set, with values ranging from 3 to 23 across five of the six case studies. In addition, the computation time of the preprocessing step rapidly increases with the dimension of the data set, making the tightening procedure computationally challenging for high-dimensional data sets (). This issue can be partially addressed using parallelization, as the preprocessing step is inherently suited for parallel processing.
The theoretical work presented here applies to data points in general position (no subset of points is contained within a single hyperplane). There is a need to address the special case where the points are not in general position—for example, if the points are located on a lattice. Research work should also focus on improving the time complexity of the preprocessing algorithms for high dimensions. In addition, future research should aim to conduct a comprehensive comparison between the MILP and NN approaches with respect to computation time, number of affine pieces, and approximation error.
This work was authored for the Department of Energy (DOE) Office of Energy Efficiency and Renewable Energy by Argonne National Laboratory, operated by UChicago Argonne LLC under contract number DE-AC02-06CH11357. This study was supported by the HydroWIRES Initiative of DOE’s Water Power Technologies Office.
References
- (2023) An approximation algorithm for optimal piecewise linear interpolations of bounded variable products. J. Optim. Theory Appl. 199(2):569–599.Google Scholar
- (1997) Introduction to Linear Optimization (Athena Scientific, Nashua, NH).Google Scholar
- (2004) Convex Optimization (Cambridge University Press, Cambridge, UK).Google Scholar
Bureau of Reclamation (2024) HDB data service. Accessed April 3, 2025, https://www.usbr.gov/lc/region/g4000/riverops/_HdbWebQuery.html.Google Scholar- (2023) Improved bounds on neural complexity for representing piecewise linear functions. Preprint, submitted January 16, https://arxiv.org/abs/2210.07236.Google Scholar
- (2010) Piecewise linear approximation of functions of two variables in MILP models. Oper. Res. Let. 38(1):39–46.Google Scholar
- (1975) Interpolation and Approximation (Courier Corporation, North Chelmsford, MA).Google Scholar
- (2021) Neural network approximation. Acta Numer. 30:327–444.Google Scholar
- (2022)
Piecewise linearization of bivariate nonlinear functions: Minimizing the number of pieces under a bounded approximation error . Ljubić I, Barahona F, Dey SS, Mahjoub AR, eds. Combinatorial Optimization (Springer International Publishing, Cham, Switzerland), 117–129.Google Scholar - (1986) Constructing arrangements of lines and hyperplanes with applications. SIAM J. Comput. 15(2):341–363.Google Scholar
- (2010) On the number of segments needed in a piecewise linear approximation. J. Comput. Appl. Math. 234(2):437–446.Google Scholar
- (2012)
Using piecewise linear functions for solving MINLPs . Lee J, Leyffer S, eds. Mixed Integer Nonlinear Programming (Springer, New York), 287–314.Google Scholar Gurobi Optimization LLC (2024a) Gurobi Optimizer reference manual. Accessed April 3, 2025, https://www.gurobi.com.Google ScholarGurobi Optimization LLC (2024b) Model.addGenConstrIndicator(). Accessed April 3, 2025, https://www.gurobi.com/documentation/current/refman/py_model_agc_indicator.html.Google Scholar- (2020) ReLU networks are universal approximators via piecewise linear or constant functions. Neural Comput. 32(11):2249–2278.Google Scholar
- (1996) Simplexity of the cube. Discrete Math. 158(1):99–150.Google Scholar
- (2021) Nonconvex multivariate piecewise-linear fitting using the difference-of-convex representation. Comput. Chemical Engrg. 150:107310.Google Scholar
- (2024) A linear programming approach to difference-of-convex piecewise linear approximation. Eur. J. Oper. Res. 312(2):493–511.Google Scholar
- (2020) On the derivation of continuous piecewise linear approximating functions. INFORMS J. Comput. 32(3):531–546.Link, Google Scholar
- (1987) Piecewise affine functions as a difference of two convex functions. Optimization 18(1):23–29.Google Scholar
- (2022) Data-driven natural gas compressor models for gas transport network optimization. Digital Chem. Engrg. 3:100030.Google Scholar
- (2010) Piecewise-linear approximations of multidimensional functions. J. Optim. Theory Appl. 145(1):120–147.Google Scholar
- (2024) Piecewise linear approximation with minimum number of linear segments and minimum error: A fast approach to tighten and warm start the hierarchical mixed integer formulation. Eur. J. Oper. Res. 315(1):50–62.Google Scholar
- (2025) Continuous piecewise linear fitting: Code repository. Accessed April 3, 2025, https://github.com/quentinplsrd/cpwl-nd-optimization.Google Scholar
- (2015) Continuous piecewise linear delta-approximations for bivariate and multivariate functions. J. Optim. Theory Appl. 167(1):102–117.Google Scholar
- (2020) Piecewise linear function fitting via mixed-integer linear programming. INFORMS J. Comput. 32(2):507–530.Link, Google Scholar
- (2012) Fitting piecewise linear continuous functions. Eur. J. Oper. Res. 219(1):86–95.Google Scholar
- (2015) Mixed integer linear programming formulation techniques. SIAM Rev. 57(1):3–57.Google Scholar
- (2010) Mixed-integer models for nonseparable piecewise-linear optimization: Unifying framework and extensions. Oper. Res. 58(2):303–315.Link, Google Scholar
- (2022) A comparison of two mixed-integer linear programs for piecewise linear function fitting. INFORMS J. Comput. 34(2):1042–1047.Link, Google Scholar
- (2023) Generating optimal robust continuous piecewise linear regression with outliers through combinatorial Benders decomposition. IISE Trans. 55(8):755–767.Google Scholar
- (2025) Efficient continuous piecewise linear regression for linearising univariate non-linear functions. IISE Trans. 57(3):231–245.Google Scholar

