
Quality Control for Crowd Workers and for Language Models: A Framework for Free-Text Response Evaluation with No Ground Truth
Abstract
In recent years, the field of natural language processing has made remarkable progress with the emergence of large language models (LLMs). In particular, the ability of LLMs to provide fact-based, free-text responses to user queries has the potential to revolutionize domains such as online search and the use of informative chatbots. However, extensive validation is required so that the response accuracy of question-answering LLMs can be confidently trusted. This paper introduces a framework to address this challenge: automated quality evaluation based on textual responses (AQER). The AQER framework focuses on two primary tasks: evaluating the quality of individual workers based on their free-text responses given that no ground-truth data are available and assessing the quality of LLM responses given a set of worker-generated responses. AQER is advantageously intuitive, easy to implement, and flexible to accommodate different components. To evaluate AQER’s effectiveness, we conducted empirical evaluations using semi-synthetic and real-world question-and-answer data sets as well as stress testing through numerical simulations. We also provide analytical motivation and show method convergence and boundary conditions using the probably approximately correct learning framework. The results demonstrate AQER’s robustness in evaluating LLMs and workers, and its superiority over baseline approaches. These findings establish AQER as a benchmark for future research in this field.
History: Olivia Liu Sheng, Senior Editor; Dokyun (DK) Lee, Associate Editor.
Funding: T. Geva and I. Yahav acknowledge research grants from the Jeremy Coller Foundation and the Henry Crown Institute for Business Research.
Supplemental Material: The online appendix is available at https://doi.org/10.1287/isre.2023.0426.
1. Introduction
The field of natural language processing has recently made significant progress with the emergence of large language models (LLMs). Within a few years, such models have gained immense popularity in both academic research and practice (Hadi et al. 2023). One promising application of LLMs is question answering. The capacity to interpret users’ questions across diverse contexts and to reply with appropriate fact-based responses, formulated in natural text, has the potential to transform various fields, including online search and usage of informative chatbots (Dam et al. 2024, Zhou and Li 2025).
However, before new question-answering LLMs are put into practice, extensive validation is required to measure the correctness of their free-text responses (Chang et al. 2024). In this study, our objective is to provide a practical, easy-to-implement, scalable, and well-supported method for this purpose. To this end, we introduce an unsupervised framework called Automated Quality Evaluation based on textual Responses (AQER); this framework assesses the quality of workers tasked with generating free-text responses, and it evaluates LLMs on the basis of these responses. AQER operates in settings in which multiple workers provide short textual responses to fact-based1 questions, in which each question has a single correct answer (which may be expressed in more than one way) and no ground truth is provided or readily available. The framework builds upon the probably approximately correct (PAC) learning theory (Valiant 1984) and specifically upon PAC learning from noisy crowd-based data (Awasthi et al. 2017; Heinecke and Reyzin 2019; Zeng and Shen 2022, 2023).
In developing the AQER framework, we sought to address two primary goals. The first goal is, in a given area of interest, to evaluate workers’ quality based on the correctness of their responses. This capability is paramount for improving response quality for evaluating LLMs. For example, it can be used to preselect high-quality crowd workers who provide accurate responses or for incentivizing high-quality workers to elicit more accurate responses. The second goal is to evaluate the quality of LLM responses to fact-based questions given a set of worker-generated responses for comparison. Such a capability can facilitate the evaluation of new language models as well as repeated evaluation of existing LLM architectures given different setup parameters, configurations, and prompting strategies toward improving model performance; it can also be used to compare the question-answering capabilities of different LLMs and to select the LLM of choice in a given domain.
To address these goals, we designed the AQER framework to comprise two effective, advantageously intuitive, and simple-to-implement steps: (i) initialization by framing the evaluation of workers’ response quality as a voting problem and (ii) extending the voting using an iterative algorithm. Notably, as we elaborate in what follows, AQER is modular, meaning that each step is realized using independent components for which the user can select implementations corresponding to the user’s own preferences or needs.
We evaluated the effectiveness of the AQER framework through multiple procedures. First, to empirically assess the framework’s ability to evaluate worker quality, we used a semi-synthetic data set derived from a publicly available computer science (CS) question-and-answer (Q&A) data set (Mohler et al. 2011). Second, we evaluated the framework’s performance by compiling two additional Q&A data sets using online work platforms. Third, we subjected the framework to stress testing in challenging settings through numerical simulations. Fourth, we assessed the framework’s effectiveness in scoring LLMs’ question-answering performance given multiple worker-generated responses to the same questions. Additionally, we show that the main findings can be replicated when implementing AQER using different implementations of its various components (e.g., alternative text representations or initialization methods). The results show that AQER displays robust performance, regularly surpassing benchmark approaches or, at minimum, matching the best performing baseline. Moreover, AQER is robust to the selection of the textual representation scheme, and it maintains strong performance even under challenging conditions (e.g., a high percentage of low-quality workers).
The main contribution of this work is the development of a novel framework for addressing our research goals. The framework produces state-of-the-art (SOTA) results and consists of simple-to-implement, effective, and intuitively understandable procedures. The framework is also modular, and its components can be implemented using different methods. Unlike related methods in this domain that only provide empirical results, our work also computes worst and average case scenarios, and we derive AQER’s boundary conditions analytically, building on PAC learning theory.
A secondary contribution of our work is in formalizing the problems of evaluating the quality of crowd workers based on their free-text responses to fact-based questions without access to ground truth data and evaluating the correctness of LLM responses given an unverified reference set of worker-generated responses. Additionally, our work contributes by providing insights, through extensive evaluations and ablation studies, regarding the capabilities and operating conditions of the AQER framework. We further provide an extensive discussion of other real-world applications of our framework (see Section 7.3). Finally, our work contributes to the design science research literature within information systems (Hevner et al. 2004, Abbasi et al. 2024) by developing a computational design artifact that addresses a previously underexplored problem formulation.
2. Problem Formulation
We consider a setting in which multiple workers (e.g., online crowd workers or a set of experts) provide textual responses to the same set of questions in a given domain of interest. The responses to the questions are fact-based, and each question has a single correct answer (though the answer may be phrased in more than one way). Formally, we consider a set of individual workers. Each worker provides short textual responses, in natural language, to the same set of n questions . Worker textual response for question is denoted by . In accordance with prior research on evaluating text-based responses (Burrows et al. 2015), we require that the questions and responses meet the following additional criteria: (i) the response length ranges from a short phrase (possibly even one word) to a single paragraph and (ii) responses are evaluated solely based on the correctness of their textual content in addressing the focal questions (e.g., responses are not assessed according to writing style or formatting). We further impose the requirement that the solution must be domain-agnostic and cannot rely on any domain-specific properties; moreover, it should not necessitate prior knowledge of workers’ capabilities.
Given these conditions, our first goal is to automatically assign a score, , to each worker according to the average correctness of the worker’s responses. We operationalize the correctness of a focal worker’s response as the level of similarity between the response and the (unobserved) correct response for the corresponding question.
Our second goal is to use the set of worker-generated responses and the workers’ scores to automatically score the correctness of an LLM’s response to question , denoted by for each question in .
3. Related Work
In addressing the problems outlined above, we draw upon and contribute to several streams of literature that were separately developed. In what follows, we relate to each stream. The main differences between our paper and closely related studies from other streams of work are also summarized in Table J.1 in Online Appendix J.
3.1. PAC Learning Theory
The PAC learning framework, introduced by Valiant (1984) and popularized by Kearns and Vazirani (1994), provides a theoretical foundation for understanding when a learning algorithm can, with high probability, produce a hypothesis whose error is below a specified threshold. Formally, given an instance space , a concept class of Boolean functions mapping to , and a distribution over , a learning algorithm receives training examples drawn independently from . For any accuracy and confidence in , the algorithm must, with probability at least , output a hypothesis such that the probability (over ) that differs from is not greater than , using a number of examples and computation time that are polynomial in , , and the problem size. Traditionally, PAC learning is applied in supervised settings with binary or finite discrete spaces, in which labels are provided by a single oracle, laying the groundwork for rigorous sample complexity bounds and generalization guarantees.
Over time, PAC learning has evolved to address practical challenges, such as noise, computational efficiency, and structural complexity. Agnostic PAC learning extends the classic framework by allowing for noisy data and misspecified models with recent refinements improving learning guarantees in these settings (Hanneke et al. 2024, Karchmer 2024). Parameterized PAC learning introduces complexity-theoretic insights to analyze structured concept classes (Brand et al. 2023), whereas bagging is shown to achieve optimal PAC bounds for binary classification (Larsen 2023). Advances in online and distribution-free learning continue to refine generalization bounds under minimal assumptions (Mohri et al. 2012). Collectively, these developments enhance PAC learning’s applicability to real-world data constraints.
The PAC framework is extended to address learning from crowdsourced labels, in which annotators may be noisy, unreliable, or even adversarial. Awasthi et al. (2017) introduce a PAC learning model for crowdsourced data, demonstrating that efficient aggregation methods can denoise training labels and achieve PAC guarantees under reasonable assumptions about annotator quality. Heinecke and Reyzin (2019) further explore this setting by incorporating classification noise models, proposing an algorithm that combines majority voting, bandit-based exploration, and noisy PAC learning to reduce labeling effort, maintaining accuracy. Zeng and Shen (2022) expand the framework to pairwise comparisons, showing that relative judgments can provide more reliable learning guarantees than absolute labels. More recently, Zeng and Shen (2023) propose a semiverified PAC learning model, leveraging a trusted oracle to enhance robustness against adversarial annotators, minimizing labeling costs. Collectively, these works provide performance guarantees in the presence of noise and inform practical strategies for crowdsourcing when the diversity in annotator quality is a central challenge.
Inspired by PAC learning and its extensions to noisy and crowdsourced settings, our work extends the PAC learning framework to handle the aggregation of noisy textual data from the crowd. In particular, by introducing an aggregation strategy for continuous noisy embedding outputs, we enhance traditional PAC analysis to deal with the challenges of learning from heterogeneous, unstructured textual answers.
3.2. Automatic Evaluation of Workers’ Performance Without Ground Truth
Another relevant stream addresses automatic evaluation of (typically crowd) workers’ performance in the absence of ground-truth information. Motivated by work quality issues in general and in particular with crowd workers (Kittur et al. 2013), most works in this stream focus on evaluating workers (also known as labelers or raters) according to their decision accuracy, which an algorithm determines by inferring the correct label for each instance (e.g., Dawid and Skene 1979, Kumar and Lease 2011, Dalvi et al. 2013, Rodrigues et al. 2013, Wang et al. 2017). Examples of studies in this vein include the work of Whitehill et al. (2009), who propose an expectation maximization (EM)–based algorithm to assess labelers’ binary decisions and the quality of their labels.2 In the medical domain, Warfield et al. (2004) consider raters’ binary decisions regarding image-voxel classification to determine image segmentation and to assess workers’ quality. Other studies in this stream propose methods for efficiently selecting instances for repeated labeling (Wauthier and Jordan 2011, Ipeirotis et al. 2014), minimizing the number of annotated instances (Karger et al. 2014, Branson et al. 2017), or inducing more accurate models (Raykar et al. 2010). These works consider a popular setting in which multiple workers repeat the same decisions multiple times (a practice also known as repeated labeling). Other works in this stream of literature consider evaluating workers in settings in which each label is provided by a single worker (Geva and Saar-Tsechansky 2016, 2021; Geva et al. 2019; Dong et al. 2024), filtering out low-quality labels in the case of single-labeled instances (Dekel and Shamir 2009), and evaluating labeling accuracy in settings in which both single-labeled instances and multiple-labeled instances are available (Khetan et al. 2017, Tanno et al. 2019). Yet a common characteristic of these works is that they assess workers’ decisions when workers’ output is binary, numerical, or multicategorical (Yin et al. 2021).3 Our framework, in contrast, is designed to evaluate workers’ and LLMs’ correctness according to their textual responses.
3.3. Automatic Short Answer Grading
A third stream of literature related to our work is automatic short answer grading (ASAG), which focuses on evaluating the correctness of textual responses in educational settings. Several survey papers provide comprehensive coverage of this field (Burrows et al. 2015, Roy et al. 2015, Galhardi and Brancher 2018, Bonthu et al. 2021, Haller et al. 2022). It is possible to distinguish between various ASAG studies according to the methods they use to represent the text of the responses being evaluated; such text-representation methods include rule-based approaches (e.g., Leacock and Chodorow 2003), information extraction (e.g., Jordan 2012), knowledge representation–based methods (e.g., Mohler et al. 2011), and word embeddings (e.g., Saha et al. 2018).
An important characteristic of the vast majority of works in the field of ASAG is that they require ground-truth information. ASAG studies relying on ground truth can be classified into two groups, according to the types of ground-truth inputs that they require: The first group comprises studies requiring as input one or more exemplary (i.e., correct or ground truth) answers to each question (e.g., Alfonseca and Pérez 2004, Gütl 2008, Mohler and Mihalcea 2009, Mohler et al. 2011, Dzikovska et al. 2012, Gomaa and Fahmy 2012, Sultan et al. 2016). The second group comprises studies requiring multiple, manually graded, ground truth–scored responses (e.g., Klein et al. 2011, Heilman and Madnani 2015, Ramachandran et al. 2015, Zesch et al. 2015, Horbach and Pinkal 2018, Singh et al. 2018, Sung et al. 2019,4 Steimel and Riordan 2020, Xia et al., 2021). As both types of ASAG methods rely on ground truth, they require the evaluator (the person seeking to evaluate the workers or their responses) to have prior knowledge of the correct response for each question and to invest efforts either in manually grading responses or having a domain expert specify exemplary answers for each question. Thus, ASAG approaches do not scale well to large numbers of questions. They are also unsuitable for settings in which workers are experts hired to provide responses to questions for which the evaluator does not possess the required knowledge or for settings in which workers are tasked, on an ongoing basis, with answering large numbers of new questions requiring knowledge of very recent events or state-of-the-art information in a given domain. In contrast, our AQER framework does not require ground-truth data and is designed to handle large volumes of questions and evaluate response quality on an ongoing basis.
To our knowledge, the work of Roy et al. (2016) is the sole ASAG study addressing question-level textual response assessment without ground-truth data. The study utilizes a scoring mechanism based on multiple, customized textual sequences generated from each response. This method is computationally costly and lacks detailed implementation clarity.5 Unlike the method developed by Roy et al. (2016), our AQER framework is built around a general voting mechanism independent of textual representation and can accommodate various standard textual methods such as word embeddings, bag of words (BOW), or entailment-based scoring. This compatibility simplifies implementation and can leverage advances in textual representations. Additionally, unlike the Roy et al. (2016) approach, which assesses each response individually, our framework holistically evaluates worker-level capabilities, improving performance through an iterative reweighted voting strategy. Importantly, our work also considers the LLM evaluation problem, which is not considered by Roy et al. (2016) or, more broadly, by ASAG research. Our work also differs from the Roy et al. (2016) method by providing analytical motivation and deriving boundary conditions. We use an adaptation of the algorithm by Roy et al. (2016) as a baseline for comparison against our framework.
3.4. Complex Label Aggregation
A recent, small stream of works focuses on a related problem of complex label aggregation, assuming the correct label is unknown (e.g., Li and Fukumoto 2019, Braylan and Lease 2020, Li 2020, Chai et al. 2022). Studies in that stream consider a setting in which multiple reference texts are provided, from which the best reference text should be selected. Examples include cases in which the reference texts could be either multiple possible translations for a given sentence (all of which may be generally correct, but some translations could be better than others), multiple responses for a given question, or multiple text summarizations. Other studies in that stream consider a rather different setting in which correct reference answers must be provided (Zhu et al. 2022) or only sought to develop metrics for annotator agreement (Braylan et al. 2022).
Whereas the objectives of these abovementioned works are different from our own, a few of the methodologies they develop share some similarities with our approach. Specifically, Li and Fukumoto (2019) and Li (2020) use an iterative approach to combine answers, taking their quality into consideration. Braylan and Lease (2020) use a hierarchical Bayesian probabilistic model with a multidimensional likelihood function to find the coordinates of a correct response given a set of distances between existing responses. Chai et al. (2022), who mention producing the latest SOTA approach compared with prior work on complex label aggregation, propose a gradient descent–based approach to iteratively aggregate responses. The Chai et al. (2022) paper uses a dual representation, including both text embedding and mutual GLEU scores.
In addition to addressing a different problem, our work differs from these studies in providing formal assumptions, analytical motivation, evaluation of the boundary conditions, and a modular framework. We use the Chai et al. (2022) approach (the current SOTA) as a baseline for comparison as well as the work of Li and Fukumoto (2019), which also uses an iterative unsupervised procedure.
3.5. Q&A Data Sets and Evaluation of LLM Question-Answering Capabilities
Our work also contributes to the emerging literature that focuses on collecting Q&A data sets for the purpose of training and evaluating automated question-answering models (e.g., Berant et al. 2013, Bajaj et al. 2016, Nguyen et al. 2016, Kočiský et al. 2018, Rajpurkar et al. 2018, Kwiatkowski et al. 2019, d’Hoffschmidt et al. 2020, Möller et al. 2021, Abedissa et al. 2023). Some of these works (e.g., Rajpurkar et al. 2016, Kwiatkowski et al. 2019) focus on extraction tasks in which crowd workers are provided with texts that contain (or are expected to contain) a response to a given question. The workers are asked to mark, within the texts provided, a span of text containing the relevant response as well as to report, in their own words, the correct response based on the marked-down text.6 In these studies, workers’ responses are effectively limited to a single source of information within the text and do not incorporate workers’ own knowledge and expertise. Additionally, in formulating their responses, workers could not use their powers of reasoning to combine multiple sources of information (e.g., different paragraphs in the text or different pages) to derive a correct response (Nguyen et al. 2016). Other works avoid this limitation (e.g., Berant et al. 2013, Bajaj et al. 2016, Nguyen et al. 2016, Kočiský et al. 2018), relying on methods in which workers generate free-text (or otherwise textual) responses by relying on their own knowledge or by reasoning across information sources.7
Notably, many studies in the domain of Q&A generation have not devoted much attention to assessing the quality of the workers involved or developing methods for comparing language model responses to (multiple) crowd responses. In fact, some of these works suffice with a single response per question (Joshi et al. 2017), whereas other studies use multiple responses with rudimentary evaluation techniques, many of which were originally designed to address different problems altogether. For example, in Kwiatkowski et al. (2019), the authors propose assessing the internal quality of their data set and identifying the correct response on the basis of the most frequently marked span of text. However, this approach is much less applicable for responses that are provided in free text (e.g., in the common scenario in which relevant text pages containing an answer are not known in advance or when it is necessary to infer the correct response from multiple sources), for which the likelihood of obtaining identical responses from multiple individuals is much lower.
Other studies (Bajaj et al. 2016, Nguyen et al. 2016, Kočiský et al. 2018) use standard machine translation evaluation-based performance measures such as Bilingual Evaluation Understudy (BLEU) scores (Papineni et al. 2002) to assess the correctness of model responses given that more than one free-text response is provided by the crowd.8 BLEU scores, which rely on matching exact words between focal and reference answers, were originally designed to assess machine translations in settings in which multiple, correct reference translations are provided. As such, they do not deal with the potential inaccuracies in crowd-based data and inherently, incorrectly assume that correct responses are available. Yet, in reality, correct (ground truth) information is often difficult or costly to obtain (Geva and Saar‐Tsechansky 2021). In particular, these measures provide high scores when the machine’s response matches even a single reference answer. In a context such as ours, in which answers provided by the crowd are not guaranteed to be correct,9 an accidental match between an LLM-generated answer and a single worker’s response does not necessarily indicate that the LLM’s response is correct.
A recent enhancement to the BLEU score is the Bidirectional Encoder Representations from Transformers score (BERTScore) (Zhang et al. 2019), which also evaluates how a focal answer matches a set of reference answers. BERTScore uses a more sophisticated scoring mechanism based on text embedding; nevertheless, it shares the BLEU score’s limiting assumption that all answers are equally correct. Another alternative metric, F1 for text matching, is recently implemented by Liang et al. (2023) to evaluate a model’s question-answering accuracy. Similarly to the original BLEU score, the F1 score used by Liang et al. (2023) compares an answer to (assumed correct) reference answers, using actual words rather than text embedding.
Recent works use LLMs to evaluate LLMs’ question-answering capabilities as either a metric or a part of the LLM development process. One approach uses internal consistency of multiple responses by a focal LLM to a given question, generating different responses using various techniques, such as variations in prompts and benefiting from the inherent randomness of LLM responses. This approach is typically used to select the best response but not as an independent LLM evaluation framework (Wang et al. 2022, Chen et al. 2023). Another approach is LLM-as-a-judge, in which a judge LLM is used to score the responses obtained from a focal LLM (e.g., Lin et al. 2022, Chiang and Lee 2023, Wang et al. 2023b, Zheng et al. 2023). Whereas this approach is simple to implement, it is likely to be inapplicable to LLMs that are being trained or evaluated in a proprietary domain in which the judge does not have previous knowledge—a setting accommodated by our AQER framework.
Our work differs from prior work on Q&A data sets and LLM evaluation and contributes to these streams in several important aspects. First, we offer a new approach to address LLM evaluation given no ground-truth information. Second, unlike prior works, we analytically motivate our approach and derive its boundary conditions. Third, none of these prior studies aims to assess the quality of the workers generating reference responses or to benefit from a holistic evaluation of workers’ capabilities; instead, they consider each response separately, independently of the worker who generated it. Lastly, whereas our approach is explicitly developed to evaluate workers and LLMs, most prior studies use readily available metrics or mechanisms. Yet, in our empirical evaluation, we use the F1 score and BLEU1 and BLEU4 machine translation measures as baseline approaches to compare against our proposed approach. We also evaluate the use of BERTScore (Zhang et al. 2019) and the LLM-as-a-judge approach as baselines.
Finally, we note that our problem settings differ from an industry practice in which companies showcase the capabilities of their LLMs by having the models take well-known exams such as the U.S. Medical Licensing Examination or the Bar Exam.10 Many of these exams involve multiple-choice questions that do not measure the ability of the LLM to correctly answer in free text or essay grading that does not evaluate the correctness of the response. Other exams require human-based grading and are, thus, not scalable for continuous development of the model or for hyperparameter optimization—only for showcasing its performance once finalized. Furthermore, importantly, these exams reflect isolated knowledge domains and are inapplicable for evaluation of LLM performance across other or new domains of interest. The number of questions in these exams is also considerably smaller than in Q&A data sets, which can comprise tens of thousands of questions.
3.6. Additional Related Research
In addition to the main streams of literature discussed above, we acknowledge other distantly related streams. One stream—a substream of the web retrieval literature—focuses on question-related search queries with a specific interest in determining the credibility of the retrieved web pages and whether they contain misinformation (e.g., Clarke et al. 2020, 2022). Importantly, the approaches developed in that stream of research are inapplicable to the problems we address because either, similarly to ASAG methodologies, they use ground truth or labeled texts (e.g., Pradeep et al. 2021, Fernández-Pichel et al. 2022) or they rely on external information that is unavailable in our problem setting. Examples of such external information include external links (e.g., Fernández-Pichel et al. 2020), page rank information (e.g., Lima et al. 2021), website certification (e.g., Abualsaud et al. 2021), or domain-specific dictionaries (e.g., Bondarenko et al. 2019).
Another related stream focuses on automated essay scoring (e.g., see survey by Ramesh and Sanampudi 2022). However, whereas essay scoring primarily focuses on assessing the quality and style of writing (e.g., whether the text is convincing, has internal logic, or is grammatically correct), our goal is to score workers/LLMs based on the correctness of their responses to fact-related questions. Our problem setting also differs from works on automated fact checking (e.g., Guo et al. 2022) as our approach does not require available, external, sources of information with ground truth. Additionally, importantly, we note that a response may include correct facts but not answer the question. In this case, fact checking is inapplicable for addressing our problem settings. Similarly, our work differs from works on text summarization (e.g., Widyassari et al. 2022) as we do not aim to summarize texts but also to ascertain whether a response correctly answers a given question.
Our work also has relevance to automated, fact-based, question-answering research (see Zhang et al. 2023 for an extensive survey of this domain). However, unlike prior works in this domain, which developed question-answering mechanisms, our work focuses on the development of an evaluation mechanism.
Finally, we note that our work differs from prior works using multiple-choice trap questions to detect low-quality workers (e.g., Wang et al. 2023). First, our worker evaluation may be done automatically at no extra cost when collecting responses for LLM evaluation (that is, our approach does not involve the use of questions whose sole purpose is to identify low-quality workers). Second, given that we aim to evaluate the human workers as part of the process of evaluating an LLM’s textual responses (e.g., for prescreening or incentivizing workers), it is essential that we evaluate human workers based on the same type of question. Specifically, answering multiple-choice questions provides information on certain thinking skills, such as recognition of a correct response, that differ from the skills (e.g., information synthesis) required to provide textual responses (Polat 2020).
4. The AQER Framework
In Sections 4.1–4.4, we discuss the AQER framework’s handling of worker response evaluation. The framework is unsupervised and comprises two main components. The first component is voting-based initialization, in which workers’ responses to a focal question are aggregated via a voting mechanism to create a proxy for the (unobserved) correct answer to the question, referred to as a synthetic exemplary answer (SEA). In Section 4.1, we elaborate on an implementation of this voting mechanism based on cosine similarity (in Online Appendix B.1, we describe alternative implementations). We build on PAC learning theory to provide analytical motivation for the use of this mechanism, specify its underlying assumptions in a stylized setting, and analyze the boundaries of the error (between the SEA and the actual correct response). The second component of our framework relies on an iterative reweighting procedure that benefits from holistic assessment of each worker’s quality and continuously adjusts the voting weight of each worker to fine-tune the SEA (Section 4.2). In Section 4.3, we discuss the implementation considerations, the specific implementation of each step of the AQER framework, and additional implementation options. Section 4.4 provides a practical discussion of the method’s operating conditions, for example, when the PAC-learning-theory assumptions are not met.
Finally, in Section 4.5, we address our remaining research goal, namely, using AQER to assess LLM performance on the basis of a set of worker-generated responses. We show that this can be easily achieved given the previously obtained SEA. For convenience, the main notations are summarized in Table 1.
|

Table 1. Summary of Main Notations
| Notation | Description |
|---|---|
| Set of individual workers | |
| Set of questions | |
| Worker textual response for question | |
| Response represented by a vector | |
| The true answer to question represented by a vector | |
| The vector representing the synthetic exemplary answer for question | |
| The true score for response | |
| The true score of worker | |
| The score provided by the AQER framework for response | |
| The score provided by the AQER framework for worker | |
| Worker ’s voting weight | |
| Large language model response to question |
4.1. Primary Component of the AQER Framework—Initial Generation of SEAs Using a Multidimensional Voting Scheme
We use the vector to represent . This vector can be generated using various popular textual representation schemes, such as text embedding or even BOW. We then compute for each question a synthetic exemplary answer () via an element-wise multidimensional voting function of the responses: . For example, if is a numeric vector representation of (e.g., embedding), function could be the average vote function.11 Thus, a straightforward implementation of AQER would be to score each worker by measuring the average similarity (e.g., cosine similarity) between the worker’s responses and the SEAs: . Whereas AQER can use different similarity mechanisms (see also Section 4.3), in the discussion that follows, we focus on the cosine similarity between embedding vectors. This focus is in line with various well-known and influential works that use cosine similarity between embedding vectors as a measure of semantic and contextual similarity between texts (e.g., Cer et al. 2018, Reimers and Gurevych 2019, Gao et al. 2021).
4.1.1. Analysis of the Multidimensional Voting Scheme Using the PAC Learning Framework.
In this section, we provide analytical motivation for using as a proxy for the correct response to question , represented by an embedding vector (denoted as ). Without loss of generality, we assume that is normalized and that it is a unit vector.
Recall that our work deals with crowdsourced textual responses to questions. For a given question , each worker provides a textual response , which is represented by a vector, denoted as . Each worker has the worker’s own value of latent quality, quantified by , which is modeled here as the average cosine similarity between the worker’s responses and the correct responses across all questions. The synthetic exemplary answer for question , denoted as , is computed as the average of all vectors (i.e., the average response embedding across all M workers).
In classic PAC learning, the ground-truth label for each instance is typically a binary vector (i.e., an element of {0,1}) (Valiant 1984). In our setting, however, the ground truth for each question is a high-dimensional embedding (the correct response vector ). This high-dimensional label space complicates direct analysis.
We now formalize our setting in PAC learning terms.
Let be the instance space (in our case, the set of questions ).
Let be a distribution over , which is assumed to be independent and identically distributed (iid).
Let be the concept class, in which each concept is a mapping from a question to its correct response: , where is the correct embedding for question .
As the correct embedding () is unknown, AQER receives the multiple crowdsourced response representations ().
Our hypothesis is then constructed by aggregating the workers’ responses; that is, for each question .
Because directly comparing high-dimensional vectors is challenging, we evaluate the quality of by computing the cosine similarity between and the correct embedding . This reduction is inspired by techniques from Zeng and Shen (2022), who extract essential similarity information from high-dimensional data via pairwise comparisons.
Specifically, let denote the cosine similarity between worker ’s response for and (recall that the latent quality of worker is ). We define the per-question average cosine similarity as .
Finally, we compute the error for , denoted , which is defined as . Under a common noise model, we express each worker’s embedding as having a component along and an orthogonal noise component. That is, we assume that , where is a unit vector orthogonal to . Then, the aggregated embedding becomes
Under an assumption of independency among workers’ errors, we can assume that the noise terms (the components) average out as increases. Equation (1), thus, becomes
Given that is a unit vector, we can further reduce Equation (2) to
Thus, the effective cosine similarity between and is given by
And becomes
4.1.2. Boundary Analysis of ): Worst and Average Cases.
Assume that the expected average cosine similarity between workers’ responses and the true answer for question is .
Because each worker’s cosine similarity lies in 12, we can apply Hoeffding’s (1963) inequality with the bound for variables in an interval of length one. Specifically, we have
By setting the right-hand side , we get and ensure that, with probability at least , . Thus, with probability at least , the error is bounded by
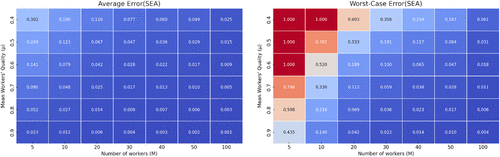
Figure 1 provides numerical computations of the average value of and of the upper bound on (i.e., the worst case error) as a function of workers’ mean quality () and the number of workers () for .
4.2. Full AQER Framework—Iterative Reweighting
The discussion above focuses on why a multidimensional voting scheme is useful for evaluating the quality of workers’ textual outputs given the problem conditions we have defined. Yet the multidimensional voting scheme considers each question separately and does not utilize holistic information about each worker’s inherent capabilities, which are demonstrated across multiple different questions. To make use of this additional, potentially important, information, we use an iterative process to recompute (previously initialized by multidimensional voting) based on the quality of workers’ responses. Specifically, we define a weight, for each worker, which is a function of workers’ scores as computed in the multidimensional voting component of the AQER framework. We then iteratively compute as a weighted average of the responses and update the estimated scores (and weights) of the workers given the new similarities between their responses and the corresponding, adjusted, . This procedure ensures that workers who are deemed by the framework as having demonstrated higher quality across multiple questions have a greater impact on the voting outcomes.
The iterative procedure we propose is motivated by the EM algorithm. We build on the general EM design described by Dawid and Skene (1979) as it aims to numerically estimate unknown parameters of interest given latent properties. In the context of AQER, our goal is to estimate the true answers for all questions given the set of observed workers’ responses over all questions, denoted . The likelihood function of interest is, thus,
The corresponding maximization likelihood estimate of the unknown true answers is then determined by maximizing the marginal likelihood of the observed responses (Bishop 2006):
Because the distribution of follows a latent, nonparametric distribution (Lee et al. 2021), it is infeasible to analytically compute the at each EM iteration. Following Lee et al. (2021), we, thus, use a heuristic approach in which is iteratively estimated as the weighted vote of all workers’ responses to that question, in which weights are proportional to the workers’ scores. Our entire framework is outlined in Algorithm 1. In Online Appendix B.3, we provide mathematical proof that the framework converges. Specific implementation details are discussed below.13
(
Input:
Initialization:
# (t is the iteration number)
Iterate:
Step 1: Compute the latent workers’ scores (and weights) based on the estimated correct response
Step 2: Estimate the correct response
Stopping criteria:
If stop.
Output:
4.3. Implementation
An important aspect of the AQER framework is that it is intentionally general and modular to accommodate multiple implementation possibilities, each of which may be advantageous in different domains. At the same time, when implementing the AQER framework—and in line with many machine-learning studies—we make practical improvements and simplifications and incorporate operationalizations of abstract concepts included in the framework. Below, we discuss the implementation possibilities and considerations and describe our specific implementations for the different steps in Algorithm 1.
4.3.1. Input Data.
In this step, each response is represented by a vector that can be operationalized in many ways, including BOW representation, term frequency–inverse document frequency, or word embeddings (e.g., Devlin et al. 2018). To ensure that our evaluation focuses on the value of the AQER framework rather than on complex textual representations, in our implementation, we intentionally use embeddings from a standard pretrained language model. Specifically, we use a robustly optimized BERT pretraining approach (RoBERTa)–semantic textual similarity benchmark large model for paraphrase detection (Liu et al. 2019).14 In Online Appendix G, we provide an ablation study that demonstrates the utility of using such a transformer-based embedding rather than the simpler BOW. For robustness, we also tested additional implementations using other LLM embeddings such as masked and permuted pretraining for language understanding (MPNet)15 and generative pretrained transformer 3 (GPT3),16 reaching similar findings. Naturally, it may be possible within the AQER framework to further improve performance by using more sophisticated or customized representation methods.
4.3.2. Initialization.
As discussed in Section 4.1, in our main implementation, is initialized by considering the average vote function for the SEA calculation. values are initialized with equal weights (. However, both and values may be initialized using other mechanisms. In Online Appendix B.1, we discuss how they may be initialized using a textual entailment-based classifier (Lewis et al. 2019).
4.3.3. Iterative Procedure.
Step 1: In this step, the AQER framework first calculates the similarity measure between the vector representing each worker’s response and the vector for question . Whereas AQER is general and supports the use of various similarity or distance measures (e.g., cosine similarity, Euclidian distance), in our main implementation, we use the popular cosine similarity measure. Nevertheless, for robustness, in Online Appendix B.2, we repeat the analysis using negative Euclidean distance. After calculating the similarity measures, for each worker , the framework calculates the corresponding . The score is calculated as a function of the worker’s average over n questions. In other words, , where f is a normalization function across all workers’ average scores. We implement f using the min-max normalization.
Step 2: In this step, the AQER framework creates , the vector representing the SEA for each question , using a weighted average voting scheme.
4.3.4. Stopping Criteria.
The iterative steps are repeated until convergence. We set a convergence threshold of 10−6 for the root mean squared error difference between the vectors of workers’ weights from two consecutive iterations. We also set the maximal number of iterations to 100 (though this number was not reached in our experiments). The AQER framework naturally supports the use of other convergence threshold metrics and cutoff values.
4.4. A Practical Discussion of the Method’s Expected Operating Conditions
We analyze the boundaries of the SEA’s error under the PAC learning–based assumptions outlined in Section 4.1.1, and we prove mathematically that, under these assumptions, AQER’s iterative process converges (see Online Appendix B.3). However, this analysis does not reveal how well the framework handles scenarios that do not fulfill these assumptions. An example of such a scenario is the case in which workers’ responses are not independently distributed, for example, the majority of workers provide the same or very similar incorrect responses for a specific question. This scenario might arise when a question is too difficult and the majority of responders reply, “I don’t know.” Yet AQER is designed to overcome such challenges as it does not rely on a simple voting estimate; rather, the iterative reweighting procedure is intended to provide resiliency to such cases. As illustrated in Figure 2, AQER can converge to an SEA that represents the correct response or is very close to a correct response even in cases in which most of the lower quality workers (in terms of their inherent ability to answer questions correctly) provide the same incorrect response and only a few higher quality workers provide an accurate response. The correct SEA is achieved because higher voting weights are assigned to higher quality workers, meaning that their votes count more than those of lower quality workers.
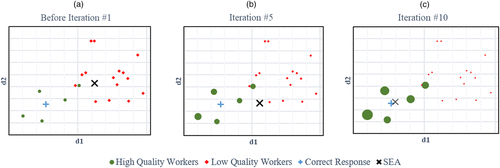
Notes. This figure illustrates the convergence of the SEA to the correct response for question in the case in which the majority of the responses are incorrect and correlated and were obtained from lower-quality workers. For clarity of presentation, the figure shows a simplified setting in which each response is represented using two-dimensional vectors (the dimensions are denoted by d1 and d2). In the figure, each oval-shaped (diamond-shaped) point represents a response from a high- (low-) quality worker. Point size represents the weight of the worker’s voting (larger point size corresponds to higher voting weight). The “+” sign represents the correct response, and the “X” sign represents the calculated SEA. We observe that, in panel (a)—before the first EM iteration—all workers’ voting weights are the same, and the SEA calculation places the SEA far away from the correct response and in proximity to the majority of incorrect responses. In panel (b)—after five iterations—the weights for the high- (low-) quality workers increase (decrease), and the SEA is now closer to the correct response. Finally, in panel (c)—after 10 iterations—the weights for the high- (low-) quality workers further increase (decrease), and the SEA converges to the correct response (the “X” sign overlaps with the “+” sign). It is important to note that, whereas this figure shows convergence for a specific question , workers’ weights are calculated iteratively based on their responses to the full set of questions.
Naturally, the method’s capacity to successfully handle such a condition depends on several factors, such as the fraction of questions in which the majority provides the same incorrect response as well as the number of incorrect responses for each focal question. We discuss these ideas further in Section 6.1.3 and in Online Appendix F, in which we numerically simulate more challenging conditions compared with those of our studies involving real-world data sets (and in which AQER was successful). In Section 6.1, we also present empirical studies that demonstrate the robustness of the AQER framework’s ability to evaluate workers under various conditions.
4.5. Assessing LLM Responses
Sections 4.1–4.4 focus on our first research goal and detail how the AQER framework can be used to assess workers’ response quality by determining the value of : the vector representing a synthetic exemplary answer for each question We now proceed to explain how AQER uses the previously obtained in a straightforward and intuitive way to address our second research goal, namely, using the calculated SEA values to evaluate LLM performance.
Specifically, to score the quality of an LLM’s responses to the set of questions , AQER first applies the same textual representation procedure used when representing the workers’ responses (e.g., a RoBERTa-based embedding) for representing each LLM response (. The resulting representation of an LLM response to a specific question is denoted as . AQER then scores the responses according to the similarity between and for each question . In the applications described below, we consider cosine similarity and RoBERTa-based embedding to represent the textual responses. Nevertheless, other measures and representation techniques can also be used.
5. Empirical Evaluation Setup
To evaluate our framework, we conducted several different types of empirical evaluations, using (i) semi-synthetic data, (ii) two purposely compiled data sets, and (iii) numerical simulations.
5.1. Semi-synthetic Data–Based Simulation
First, we conducted simulations using semi-synthetic data based on a popular, publicly available data set of questions and (graded) answers taken from a computer science course (Mohler et al. 2011). The data set contains 87 questions that students answered as part of various homework assignments and exams. Given the complex and technical nature of the questions, this data set is useful as a proxy for evaluating the work of professional crowd workers. In this data set, each question was answered by 24–30 individuals. The responses were scored (0–5) by two course instructors; for each response, we calculated the “true” score as the average score across the instructors, similarly to Mohler et al. (2011). Importantly, in this data set, the answers are not attributed to specific individuals. Thus, we simulated 20 individual workers or pseudo-responders, characterized by different predefined quality levels, and assigned responses to each pseudo-responder. The simulation is rooted in the assumption that different workers have distinct levels of inherent quality. This assumption is pivotal in many related works (e.g., Dawid and Skene 1979, Whitehill et al. 2009, Ipeirotis et al. 2014). Additionally, the simulation is intended to enable repeated evaluation, generating variability in workers’ responses and correctness levels. The procedure is described in Table 2.
|
Table 2. Semi-synthetic Data Generation Procedure
| Step | Procedure |
|---|---|
| Step 1 | We set G = {1…g} quality groups, sorted by quality. Each group is assigned x pseudo-responders. In this simulation, quality group 1 has the top-quality responders. Quality group g has the lowest quality responders. |
| Step 2 | For each question, we sort the responses according to their scores in descending order and then sequentially assign the responses to the G quality groups according to their score (e.g., the first x top scored responses are assigned to group 1, the next x responses with somewhat lower scores are assigned to group 2, and so on). |
| Step 3 | For each question, each response that is assigned to a given quality group u ∈ 1…g is randomly assigned to a pseudo-responder Wi who is a member of that quality group and has not yet been assigned a response for the question. |
| NOTES | For consistency, we used the (g × x =) 20 highest quality responders in all simulations. Specifically, we simulated the following settings: five quality groups with four responders in each group and 10 quality groups with two responders in each group. We obtained similar results and findings using both simulation settings. For brevity, we report the results using the latter setting. All simulations were repeated 25 times. In Online Appendix N, we explore other variants of these simulations, reaching similar findings. |
5.2. Purposely Compiled Data Sets
For this evaluation, we composed two relevant Q&A data sets. Each data set consists of 600 responses provided by 40 workers in response to 15 different questions. The workers were recruited from an online work platform (Prolific.com) and were asked to read two short texts (200–300 words) extracted from Wikipedia articles in different domains; the texts in the first data set addressed science and technology17 and sports events,18 and the texts in the second data set addressed history19 and movies.20 Each text was taken from the first few paragraphs of its corresponding Wikipedia article. The responders were asked to read the texts carefully, and after reading each text, the responders were presented with several questions. The responders were told to answer according to the text they had read, but to make the task more challenging, we did not allow the responders to return to the corresponding text. Each worker responded to 15 questions in total. Within each data set, all workers responded to the same set of (15) questions, but the two texts were presented in random order. After each text was presented, the questions corresponding to that text were also presented in random order. Mutually exclusive sets of workers were recruited to work on each data set. Two expert human evaluators, who were both involved in the composition of the questions, then manually graded workers’ responses; for each response, we used the average score across the two evaluators21 as a measure of the true score. Naturally, these scores were carefully concealed from the AQER framework, whose goal was to reconstruct them. In Online Appendix A, we provide extensive details and statistics on the questions, the (human-based) grading scores, and their analysis. Notably, for multiple questions in both data sets, the overall correctness scores (as determined by the human evaluators) were low, rendering the algorithmic evaluation task particularly challenging. Specifically, for 40% of the questions in the science/technology and sports data set and for 20% of the questions in the movies and history data set, workers’ responses achieved, on average, (evaluator-generated) correctness scores of 50% or lower. (See Online Appendix A for details.)
5.3. Numerical Simulation
The purposely compiled data sets and the semisynthetic data enabled us to test AQER under realistic settings. Such settings are likely to be compatible with the standard assumptions of PAC learning theory (e.g., Awasthi et al. 2017), under which our framework is proven to converge (see Online Appendix B.3). Yet the problem space of text-based Q&A evaluation is vast and complex, and some scenarios may violate PAC learning theory’s standard assumptions. Accordingly, we built an additional, numerical simulation procedure that provided a substantial level of control and, thus, enabled us to stress test our framework and evaluate its robustness under especially challenging conditions. Specifically, we evaluated the impact of introducing bias into workers’ responses, increasing the correlation between workers’ responses, increasing variance of the responses, and reducing the number of workers. Detailed descriptions of the numerical simulation procedure and its results are provided in Online Appendix F.
5.4. Baseline Approaches
We compare AQER’s performance to the performance of multiple baseline approaches taken from distinct streams of research discussed in Section 3. As discussed, most prior related works did not aim to address our specific problem settings. Therefore, we also compare AQER to methods used in studies dealing with related problems, and we slightly adapted these to our problem settings.
We use the following baseline approaches: (i) the approach developed by Roy et al. (2016), which is, to our knowledge, the only ASAG paper handling a closely related problem of evaluating textual responses without ground-truth data in the context of education (see Section 3.3); (ii) adapted versions of the approaches by Li and Fukumoto (2019) and Chai et al. (2022), whose studies deal with a related, but not similar, problem of complex label aggregation (Section 3.4); and (iii) baselines inspired by various studies that have compiled Q&A data sets (e.g., Nguyen et al. 2016, Bajaj et al. 2018, Kočiský et al. 2018) (Section 3.5). These studies do not develop methods to assess worker quality or score LLM responses. Instead, they employ machine translation measures (e.g., BLEU scores) in an ad hoc manner for internal consistency verification (see Section 3). Following these works, we construct baselines using the popular BLEU1 score and BLEU4 score machine translation metrics (Papineni et al. 2002);22 (iv) BERTScore (Zhang et al. 2019), discussed in Section 3.5; (v) the F1 text similarity metric (see, e.g., Liang et al. 2023) (Section 3.5); and (vi) the LLM-as-a-judge approach (e.g., Chiang et al. 2023) (Section 3.5).23 Note that the LLM-as-a-judge approach may have an inherent (unfair) advantage when serving as a baseline for the CS semisynthetic data set (Section 5.1). The CS data set is available online, and its questions are linked to the correct responses. Consequently, both the questions and the corresponding correct responses may have been jointly included in the data available for the LLM model used as a judge. Whereas this approach may unfairly benefit from data leakage, it is nonetheless useful to report as a baseline. We note that we also considered the frequent response approach used by Kwiatkowski et al. (2019). This approach was highly uncompetitive, however, and led to degenerate results in various cases (e.g., when each worker provided a different answer to a given question). Thus, we do not report its performance in the results. The details of our implementations and adaptations of the baseline approaches are discussed in Online Appendix H.
6. Results
6.1. Worker Evaluation
First, we assessed the performance of the AQER framework versus that of the baseline approaches for evaluating workers’ quality. Evaluating workers’ quality is valuable for identifying and selecting a set of high-quality workers from a larger pool of online workers available for question-answering tasks. Therefore, for this study, in each data set, we utilized the responses from all the available workers. The results of our evaluations for the semi-synthetic data set and for the purposely compiled data sets are presented in Table 3, which shows the Pearson correlation between the average score of each worker as determined by each approach and the score determined by the expert human evaluators. As observed, the AQER-based worker evaluation showed robust performance, regularly surpassing benchmark approaches or, at minimum, matching the best performing baseline across evaluation data sets. These results demonstrate the usefulness of AQER in identifying and selecting high-quality workers.
|
Table 3. Worker Evaluation—AQER Performance vs. Baseline Approaches
| Method\data set | Science & sports | History & movies | Computer science |
|---|---|---|---|
| BERTScore | 0.620 | 0.44 | 0.895 |
| BLEU1 score | 0.692 | 0.645 | 0.87 |
| BLEU4 score | 0.680 | 0.548 | 0.864 |
| Chai et al. (2022) | 0.121 | −0.012 | 0.055 |
| F1 score | 0.759 | 0.634 | 0.893 |
| Li and Fukumoto (2019) | 0.901 | 0.791 | 0.927 |
| LLM as a judge | 0.888 | 0.793 | 0.960 |
| Roy et al. (2016) | 0.85 | 0.779 | 0.924 |
| AQER (ours) | 0.950*** | 0.915*** | 0.964 |
Notes. This table presents the Pearson correlation coefficients between each worker’s average response grade as determined by human expert evaluators and the worker’s score as calculated using our AQER framework and various baseline approaches. The reported results for the semisynthetic computer science data set represent the average of 25 simulation repetitions. The best result for each task is presented in bold font. Significance of the difference between the AQER framework and the best-performing baseline is computed using BCA bootstrap p-values for the mean difference in correlation values.
***p < 0.01; **p < 0.05; *p < 0.1.
We also note that the baseline approach derived from Chai et al. (2022), which is the SOTA in the complex label aggregation literature (see Section 3.3), produced weak results in our problem settings. It is possible that the weak results were because of the different type of empirical focus of their work, which was applied for human translation aggregation. In the case of the CS semisynthetic data set, the LLM-as-a-judge baseline achieved results that were not far behind those of our AQER method. This strong performance by the LLM-as-a-judge approach may be because of the well-documented capabilities of LLMs in coding and computer science–related tasks, or it may have benefited from a potential data leakage issue previously discussed (Section 5.4). It is also noteworthy that the dedicated machine translation–based metrics, BLEU1 and BLEU4, and the more recent BERTScore displayed relatively weak performance on the two Wikipedia data sets (science and sports, history and movies), which included large numbers of workers. This weak performance may have resulted from the fact that, as noted in previous sections, these metrics assume that all answers are equally correct and, thus, provide a very high score in any event of a match between a focal answer (in our context, an answer provided by a focal worker) and a reference answer (in our context, an answer provided by at least one other worker) even if the answer is incorrect. And, given a large number of workers (40 workers were used in the purposely compiled data sets), the likelihood of two workers making the same error may be substantial. Finally, we note that, for robustness, in Online Appendix D, we repeat the comparison across methods using another performance measure: the Spearman rank correlation coefficient. Using this measure as well, AQER is the method of choice, either significantly outperforming all baselines or otherwise providing equivalent results to the best baseline approach.
6.1.1. The Individual Impact of the Multidimensional Voting and Iterative Reweighting Components.
In Online Appendix C, we report an ablation study designed to evaluate how each of AQER’s two main components impacts its performance: the multidimensional voting and the iterative reweighting procedures. In that study, we compare the performance of a full implementation of the AQER framework against the performance of a simplified implementation in which the reweighting procedure was turned off, leaving the framework with only the multidimensional voting-based initialization mechanism. As observed in Table C.1 in Online Appendix C, our multidimensional voting component obtains very good performance even without using the iterative reweighting procedure. Nevertheless, activating the iterative reweighting procedure provides a statistically significant performance improvement of 1%–2%. These results indicate that the multidimensional voting concept is the more impactful component of our approach (it is also a prerequisite for applying the second component); yet, when accuracy is paramount, it is recommended to apply both components to obtain the best performance. Furthermore, as detailed in Section 6.1.3, the iterative reweighting component also provides significant robustness when task conditions become more challenging.
6.1.2. The Impact of Textual Representation, Similarity Metric, and Initialization.
As discussed, AQER is modular and may accommodate different textual representations and similarity metrics. In Online Appendix B.2, we evaluate the robustness of AQER’s results when AQER is implemented using different word embeddings, including MPNet and GPT3 (using its application programming interface (API)), and when using a different, Euclidian distance–based similarity measure. We also evaluate the impact of the original equal weight initialization before the iterative procedure adds random noise to the initial weight. The results show that the different variants of AQER display robust performance—regularly surpassing benchmark approaches or, at minimum, producing comparable results to the best performing baseline. Moreover, we observe that AQER with random weight initialization converges to almost exactly the same results (three digits after the decimal point) as the standard AQER implementation, providing an indication of the robustness of the convergence of the iterative procedure.
As noted in Section 4.1, AQER may be implemented with different voting functions ; in our standard implementation, we use average voting, but alternatives may be useful for different text representations (e.g., majority voting for text represented in a binary format as in BOW). In Online Appendix G, we compare the performance of implementing AQER using average voting with RoBERTa-based embedding (our standard implementation) to the performance of implementing AQER with majority voting and a corresponding simple BOW representation. The results indicate that, although a simple BOW representation with majority voting is useful for worker evaluation and provides meaningful scores, using more recent approaches, such as RoBERTa-based embedding, for representing the text, in combination with average voting, provides substantially better results.
6.1.3. Numerical Simulation.
The results elaborated above, obtained using both semisynthetic and purposely compiled data sets, show that AQER performs well in assessing workers’ quality in various realistic settings. In Online Appendix F, we describe in detail a numerical simulation that we used to stress test our approach under especially challenging conditions, including conditions that relax the standard PAC learning theory assumptions reported in Section 4.1.1: these include relaxing the assumptions that workers are iid and that the number of responses is large. The results show that AQER’s performance is robust to certain levels of violation of the method’s assumptions. However, as the conditions become more and more challenging, AQER may ultimately fail.
6.1.4. The Impact of the Number of Questions.
In another robustness test, described in detail in Online Appendix E, we used our semisynthetic data set from a computer science course to evaluate how the number of questions impacts AQER’s performance. Briefly, we gradually (randomly) reduced the number of questions and then applied the AQER method and measured the Pearson correlation between the algorithm-based scores and the human evaluator–based scores. As shown in Figure E.1 in Online Appendix E, correlation values were substantial and positive even when the number of questions was much smaller than the number of questions in the complete data set (87). For example, when supplied with 30 questions, AQER obtained a mean Pearson correlation above 0.91, and when the number of questions was reduced to only 10, AQER obtained a mean Pearson correlation of 0.787 (with a p-value lower than 0.05 in 49 out of 50 simulation repetitions).
6.1.5. Additional Semisynthetic Simulation.
Our semisynthetic simulation procedure (Section 5.1) provides a useful means of repeatedly generating workers of prespecified quality given a challenging set of real-world questions and human-generated answers. Recall that this procedure entails assignment of responses of certain quality levels to (randomly selected) workers in corresponding quality groups. Nevertheless, as in any simulation, this process relies on specific assumptions. In Online Appendix N, we provide a robustness analysis in which we modify the simulation procedure to accommodate additional randomization so that low-quality workers might occasionally provide high-quality answers and vice versa. The results are consistent with our main finding that AQER produces superior results to the baseline approaches.
6.2. Evaluating Language Models
Our next step was to evaluate the performance of AQER and of the baseline approaches when implemented for the assessment of LLM responses. We considered four LLMs: OpenAI’s GPT 3.0, and ChatGPT version 3.5, OpenChat (7B), and Lamini (1.5B).24 First, we used each LLM to answer all the questions from our three data sets (specifically, the questions used in the semisynthetic and purposely generated Q&A data sets) and generated a combined set of responses for each LLM. Next, two human expert evaluators graded all the LLMs’ responses using a procedure similar to the worker-response grading procedure described in Section 5.2 and Online Appendix A.25 We then applied AQER and the baseline approaches—utilizing the worker-generated responses—to grade each LLM’s responses. We emphasize that, as elaborated in Section 4, the LLM’s responses were not included in the generation of the SEAs; rather, only worker responses were used for this purpose, and AQER graded the LLM’s responses in comparison with these SEAs. Finally, we computed the Pearson correlations between the resulting evaluations and the expert-based evaluations.
In applying AQER and the baselines to score each LLM’s responses, we began with the premise that large-scale tasks (such as evaluating many responses by LLMs) are typically designed to minimize the numbers of workers used, owing to cost considerations. Thus, and in order to observe the cost-benefit of using different numbers of workers, we repeated the evaluation beginning with a small number of workers (M = 5) and then gradually increased the number of workers recruited to answer each question (considering also M = 10, 15). For each value of M, we repeated the evaluation 25 times. In each repetition, we randomly sampled the responses of M individual workers from the entire set of workers in each data set; we then applied AQER and the baselines to score the LLM responses.
Figure 3 shows, for each LLM, the mean Pearson correlation between the real (expert evaluator–generated) grades assigned to the LLM’s responses and the grades assigned by each of the various algorithms (i.e., AQER and baselines) along with 95% confidence intervals. As observed, the AQER method consistently significantly outperformed the baselines across all settings and is the method of choice for evaluating language models’ responses.
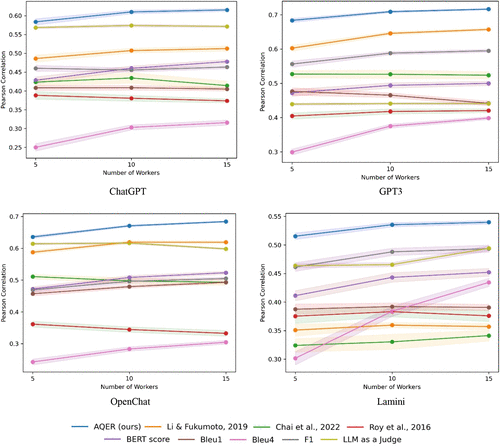
Notes. The figure shows the mean Pearson correlation between human evaluator grades and the grades assigned by AQER and by each baseline approach for each of the responses generated by the language models. The figure also shows 95% confidence intervals (lightly shaded areas). Results are reported for LLM responses to all the questions from the three data sets (combined) and are presented when AQER and the baselines are implemented using responses from 5, 10, or 15 randomly selected workers from each data set. For each number of workers selected, the results are based on 25 repetitions of a random sampling of workers.
6.3. Additional Evaluations
6.3.1. Additional Prompting Strategy.
In general, AQER may be used to evaluate the accuracy of LLM responses also given different fine-tuning alternatives and different prompting strategies. In Online Appendix L, we report the performance of AQER compared with the baseline approaches under an alternative prompting strategy. As observed in Figure L.1 in Online Appendix L, AQER continued to obtain superior performance.
6.3.2. Best Response Selection.
The goal of some of the baseline approaches (e.g., Li and Fukumoto 2019, Chai et al. 2022) was to select the best response for each question rather than evaluate LLMs. Although best response selection is not one of AQER’s main goals, in Online Appendix I, we evaluate how AQER (with a straightforward modification) performs for the task of best response selection. As shown in Figure I.1 in Online Appendix I, AQER either obtains superior performance to the baseline approaches or obtains equivalent performance to the top-performing baseline for each task.
7. Discussion
7.1. Summary
In this work, we present AQER: an unsupervised framework for automatically evaluating workers and language models according to the correctness of their free-text responses in the absence of ground-truth information. The framework is inexpensive, simple to implement, and scalable to large sets of questions or to situations requiring repeated application (such as reevaluation of a given LLM with different parameters and configurations). The AQER framework is based on two main ideas: The first is the use of a multidimensional voting scheme to initialize the SEA for each question. We show the usefulness of such a voting scheme empirically and analytically, building on the PAC learning framework. An important advantageous property of the multidimensional voting concept is that it is intuitive and easy to implement. The second component of the AQER framework is the iterative reweighting procedure, which holistically considers workers’ overall performance instead of focusing solely on responses to isolated questions. Thus, workers’ inherent capabilities can be iteratively assessed and used to improve their voting weights and ultimately produce better SEAs for different questions. We empirically show the additive contribution of this component to the performance of the AQER framework (see the ablation study in Section 6.1.1 and Online Appendix C).
We carried out an extensive empirical evaluation of the AQER framework using three complementary procedures: (i) using semi-synthetic data that included questions and scored responses from a computer science course, which we used in simulation experiments; (ii) using two purposely compiled data sets of scored responses attributed to individual workers; (iii) using numerically simulated data that were intended to generate more challenging conditions compared with those in the real-world data sets mentioned above. Notably, AQER is highly modular, and we, therefore, implement it and evaluate its performance, using several textual embedding schemes: RoBERTa, MPNet, and GPT 3.0-based embedding (see Online Appendix B.2). We also tested it when implemented using a Euclidean similarity/distance measure instead of cosine similarity (Online Appendix B.2) and when it is initialized using a different, textual entailment–based initialization (Online Appendices B.1, B.2). Our empirical evaluations show that AQER significantly outperformed all tested baseline approaches in evaluating workers’ question-answering performance and, crucially, in evaluating LLMs’ accuracy.
An ablation study (Online Appendix G) tested the sensitivity of the framework to the text representation used and shows that even a simple text representation (BOW) is sufficient to produce meaningful positive correlations between AQER’s assessments and those of human evaluators. Yet the use of a more advanced textual representation scheme (such as the RoBERTa-based embeddings) is advantageous and provides improved results. Another study (see Section 6.1.4 and Online Appendix E) evaluates the extent to which AQER’s performance in accurately grading workers is sensitive to the number of questions in the data set. We find that AQER obtains good performance even when it is provided with a relatively small number of questions. Together, these results suggest that AQER has the potential to provide practical value as an inexpensive, scalable solution for evaluating workers and language models on the basis of their textual responses.
7.2. Limitations and Future Work
The extensive evaluations elaborated throughout this paper lend confidence in AQER’s performance in evaluating workers and LLM responses. Nevertheless, as is the case for most data science methods, there are possible conditions under which AQER may not work. We note, however, that the development of new methods, even if they do not operate under all possible conditions, contributes to scientific progress and provides a basis for future improvements. We aimed to provide an understanding of the conditions that are required for our method to operate successfully. First, in our discussion of the analytical motivation for our framework (Section 4.1.1), we present the assumptions underlying our multidimensional voting–based initialization (the first part of the AQER framework). Conditions that violate these assumptions may cause the AQER framework to be unsuccessful. Such conditions might include, for example, a large percentage of workers who intentionally or unintentionally provide the same incorrect response (e.g., responding “I don’t know”). In our numerical simulation study (Online Appendix F), we empirically evaluate the AQER framework under various challenging conditions, including conditions in which, for a substantial portion of the questions, a large percentage of workers provide biased responses or correlated answers. The results of this study suggest that, whereas AQER is robust, in extreme circumstances, such as when a large percentage of the responses are biased or correlated, the system fails to grade workers correctly. Developing automated methods to safeguard against or detect conditions detrimental to our method is an interesting avenue of future research.
As specified in the problem formulation, AQER is designed to operate in settings in which there is a correct answer for each question. However, an interesting avenue of future research is to enhance AQER’s capabilities to handle questions to which there may be more than one correct response.
As discussed in Section 4.3, AQER is highly modular, and each step of the framework (Algorithm 1) can accommodate multiple implementation options. In this work, we intentionally use simple implementations based on standard textual representations and standard similarity and weighting schemes to measure the raw capabilities of the basic framework rather than the capabilities of optimized implementation procedures. Developing and testing various sophisticated implementations is an interesting avenue for future research. Such implementations may include using alternative similarity/distance measures rather than those considered herein or different weighting schemes. Future research might also explore various preprocessing techniques, such as spelling correction algorithms. Moreover, given that advanced embedding-based textual representations produced results that were superior to those obtained with simple, BOW-based representations (see Online Appendix G), it would be of particular interest to test increasingly sophisticated text-based representations.
This work built on standard assumptions in PAC learning theory to provide analytical motivation to support the AQER method. However, future work may be able to motivate and support AQER using other assumptions and frameworks. These include ensemble learning, boosting, and wisdom of the crowd (Hastie et al. 2009).
Finally, in this work, we develop a single framework that addresses two main goals: evaluating worker quality and evaluating LLM performance. Our framework addresses both goals by deriving the SEA. However, in principle, each goal may be addressed using distinct mechanisms. We hope that our work can encourage other studies in this domain to develop such mechanisms.
7.3. Business and Managerial Applications of AQER
The AQER framework has many possible business and managerial applications. First, AQER can benefit companies that develop LLMs or chatbots and that wish to evaluate their methods’ question-answering capabilities across different domains, conduct repeated evaluations over multiple successive versions, or evaluate possible external knowledge augmentation strategies (e.g., retrieval augmented generation). The capacity to measure LLMs’ question-answering performance is critical to evaluating and, consequently, improving, these models’ utility in various tasks. Given the vast market potential and scope of LLMs (and of generative AI in general),26 such improvements could have immeasurable economic and societal impact.
Second, AQER could assist firms in managing crowd workers recruited for question-answering tasks; this usage would be common, for example, among developers of LLMs, who recruit crowd workers for various text-generation tasks that are used to improve modeling (Ziegler et al. 2019). AQER could enable informed management of such crowd workers, including preselecting knowledgeable workers in specific fields of interest and incentivizing workers to display high accuracy in their responses. These capabilities could also benefit companies that rely on crowd workers’ responses to fine-tune LLMs or to test prompting strategies.
Other applications of our approach are more relevant to downstream users. For example, AQER could enable companies that seek to implement LLM-driven chatbots (e.g., customer service chatbots that interact with customers and answer free-text questions) to assess multiple alternative commercial chatbots or open-source solutions as well as to assess the quality of version updates so as to select the best alternative for their usage domain. Furthermore, evaluating the quality of a specific LLM or chatbot version can be done repeatedly for different fine-tuning and prompt engineering strategies. Notably, in these cases, implementation of AQER could contribute to improvements in concrete outcomes, such as revenue or customer satisfaction. Measuring these improvements would enable the downstream users to gauge the value of using AQER.
Finally, an important benefit of our approach is that it allows the evaluation of LLMs (and human workers) in distinct domains. In other words, whereas a certain LLM vendor may show that its approach is generally successful, our approach allows both LLM developers and downstream companies purchasing/using LLM solutions to evaluate the LLM responses in any domain of interest, such as the domain in which the downstream company operates. Importantly, AQER does not rely on worker reputation transfer across domains as, in many cases, reputation transfer is inapplicable (e.g., an expert in history could have no expertise in computer science). Instead, AQER offers an intuitive and easy-to-implement approach that can be seamlessly applied for worker evaluation in each new domain of interest. It is also effective because it can reuse the same workers’ responses for both worker evaluation and LLM evaluation. Online Appendix M graphically illustrates this process flow (see scenario 4) as well as other process flows for various potential use cases of AQER.
7.4. Additional Problems That AQER Can Address
In addition to evaluating the question-answering performance of language models and of crowd workers in the absence of ground truth, the AQER framework can potentially be useful for addressing other related problems. Evaluation of AQER’s capacity to address these problems goes beyond the scope of the current paper; nevertheless, we highlight several intriguing challenges as potential avenues for follow-up research:
The AQER framework can be used to evaluate responses from multiple LLMs without human-generated responses.27 Specifically, for each question , instead of comparing an LLM’s response to the responses of crowd workers, the framework can compare responses from different LLMs to one another. In this setting, human workers’ responses from our original problem formulation are replaced by language models’ responses , keeping the rest of the approach unchanged. This application of AQER can be used, for example, to determine the most accurate language model in a given domain. However, it is important to note that substituting (human) worker Wj’s responses with LLM responses may degrade the fulfillment of the assumption of independent responses by different workers (or language models)—particularly if the language models are trained on the same data or if one model builds upon another model’s design (e.g., a newer version of the same algorithm). Thus, a thorough empirical evaluation is necessary to demonstrate the usefulness of AQER in this context.
Similarly, AQER can be used to jointly evaluate LLMs and humans. In such a setting, both humans and multiple LLMs provide responses to each focal question. This application can also be useful to determine whether LLMs outperform or underperform human workers in a given domain and can be useful for determining whether it is advantageous to use chatbots to provide correct factual responses in a particular context.
One of the motivations of our current work was to evaluate crowd workers for the purpose of LLM evaluation. However, AQER can be applied in organizational settings for worker evaluation, testing, and pre-hiring screening tasks. The framework may be especially beneficial if these evaluation tasks are carried out routinely and at a large scale.
In sum, in this research, we demonstrate AQER’s capabilities in assessing workers’ quality as well as the quality of LLMs on the basis of their textual responses. We hope that our work will serve as a catalyst for further investigation into such quality assessment methods, opening up new possibilities and applications in this field.
The authors are grateful for the excellent comments and suggestions from the senior editor, associate editor, and three reviewers. The first three authors contributed equally and are listed in reverse alphabetical order.
1 In accordance with the Oxford English Dictionary’s definition of “fact” as “a thing that is known or proved to be true,” we refer to “fact-based questions” as questions for which the (single) correct answer is based on objective truth.
2 Our work also uses an EM-like procedure; however, it differs from the works of Whitehill et al. (2009) and Dawid and Skene (1979) as well as other studies that rely on their approach in several important aspects: (i) our goal is to evaluate textual responses and not single-dimensional labels, (ii) our method requires adjustment of the EM algorithm and specific heuristics to handle the inherent complexities of dealing with multidimensional textual data (in contrast to single-dimensional labels), and (iii) our work is supported by an analytical motivation based on PAC learning.
3 Evaluating textual responses also cannot be framed as a multiple-choice question. Multiple-choice questions have a limited set of responses, including correct and incorrect alternatives, whereas textual responses can have an almost infinite number of alternatives. Moreover, constructing multiple-choice questions requires a priori knowledge of the correct response or a small set of alternatives that includes the correct response. In contrast, evaluating textual responses does not require this prior knowledge. This is particularly useful when nonexperts hire expert crowd workers to evaluate LLM responses in a specialized domain.
4 Sung et al. (2019) uses graded responses and also uses exemplary answers.
5 The paper by Roy et al. (2016) is not clear on several implementation issues, including maximal sequence length and the use of specific stop lists and stemming algorithms.
6 For example, Kwiatkowski et al. (2019) create a set of questions based on users’ internet search queries. Crowd workers were presented with related Wikipedia pages and were asked to mark the relevant text span and provide a short textual answer extracted from the marked span.
7 In some cases, the responses were specifically restricted to entities, dates, or numbers.
8 Kočiský et al. (2018) collect only two crowd workers’ answers per question. They use a machine translation measure to assess the quality of the first response per question by comparing it to the second response.
9 Some related works that use reference answers considered to be truthful are, in fact, also based on answers from the crowd (e.g., Rajpurkar et al. 2016, Kwiatkowski et al. 2019).
10 See, for instance, https://www.businessinsider.com/list-here-are-the-exams-chatgpt-has-passed-so-far-2023-1.
11 Alternatively, if is a binary representation (such as in BOW), then function can be a majority vote function.
12 The observed lower bound (0) for cosine similarity in BERT-based sentence embeddings can be explained by the use of max pooling (as in Reimers and Gurevych 2019). Max pooling tends to select the largest (often positive) activation in each dimension, pushing embeddings into a similar region of the vector space and thereby reducing the angular separation between them.
13 AQER’s code is available on GitHub: https://github.com/TAUCollerLab/AQER.
14 The model is available at https://huggingface.co/sentence-transformers/stsb-roberta-large.
15 The model is available at https://huggingface.co/sentence-transformers/all-MPNet-base-v2 (results are presented in Online Appendix B.2).
16 We used text-embedding-3-large as described in https://platform.openai.com/docs/guides/embeddings/what-are-embeddings (results are presented in Online Appendix B.2).
20 See https://en.wikipedia.org/wiki/The_Wonderful_World_of_the_Brothers_Grimm.
21 The responses were evaluated by two of the authors.
22 Following related works, we calculate the BLEU score for each focal answer by considering all other answers as (correct) reference answers.
23 We used OpenAI’s ChatGPT-4o-mini as the judge model to score the responses. As discussed in Online Appendix H, we also evaluated the larger ChatGPT-4o model on a small evaluation set and saw negligible difference in performance for our task. Thus, given the multiple repeated evaluations used in this study, we used ChatGPT-4o-mini as it is significantly less costly.
24 These LLMs were selected because they are LLMs developed in recent years, were popular when released, have an API, and are generally known as capable models. Yet it is important to note that the goal here is to measure how well AQER and the baselines evaluate LLMs rather than have the LLM obtain best results. Therefore, in the context of this task, the actual performance of the LLMs is less important.
25 Two of the authors who constructed the Wikipedia text–based question data sets graded the responses to these questions. Two of the authors with computer science degrees graded the responses to the questions corresponding to the computer science data set.
27 Recall that, although AQER was used to evaluate LLMs, as detailed in previous sections, AQER determines the SEA according to human-based responses.
References
- (2024) Pathways for design research on artificial intelligence. Inform. Systems Res. 35(2):441–459.Link, Google Scholar
- (2023) AmQA: Amharic question answering dataset. Preprint, submitted March 6, https://arxiv.org/abs/2303.03290.Google Scholar
- (2021) UWaterlooMDS at the TREC 2021 health misinformation track. 30th Text REtrieval Conf. Proc. (National Institute of Standards and Technology, Gaithersburg, MD).Google Scholar
- Alfonseca E, Pérez D (2004) Automatic assessment of open ended questions with a BLEU-inspired algorithm and shallow NLP. Vicedo JL, Martínez-Barco P, Muńoz R, Saiz Noeda M, eds. Advances in Natural Language Processing. EsTAL 2004, Lecture Notes in Computer Science, vol. 3230 (Springer, Berlin, Heidelberg).Google Scholar
- (2017) Efficient PAC learning from the crowd. Proc. 2017 Conf. Learn. Theory, vol. 65 (PMLR, New York), 127–150.Google Scholar
- (2016) MS MARCO: A human generated machine reading comprehension dataset. Preprint, submitted November 28, https://arxiv.org/abs/1611.09268.Google Scholar
- (2013) Semantic parsing on freebase from question-answer pairs. Proc. 2013 Conf. Empirical Methods Natural Language Processing (Association for Computational Linguistics, Stroudsburg, PA), 1533–1544.Google Scholar
- (2006) Pattern Recognition and Machine Learning (Springer, New York).Google Scholar
- (2019) Webis at TREC 2019: Decision Track. TREC 2019 Proc. (National Institute of Standards and Technology, Gaithersburg, MD).Google Scholar
- (2021) Automated short answer grading using deep learning: A survey. Internat. Cross-Domain Conf. Machine Learn. Knowledge Extraction (Springer, Berlin, Heidelberg), 61–78.Google Scholar
- (2023) A parameterized theory of PAC learning. Proc. AAAI Conf. Artificial Intelligence, vol. 37 (AAAI Press, Palo Alto, CA), 6834–6841.Google Scholar
- (2017) Lean crowdsourcing: Combining humans and machines in an online system. Proc. IEEE Conf. Comput. Vision Pattern Recognition (IEEE, Piscataway, NJ), 7474–7483.Google Scholar
- (2020) Modeling and aggregation of complex annotations via annotation distances. Proc. Web Conf. (Association for Computing Machinery, New York), 1807–1818.Google Scholar
- (2022) Measuring annotator agreement generally across complex structured, multi-object, and free-text annotation tasks. Proc. ACM Web Conf. (Association for Computing Machinery, New York), 1720–1730.Google Scholar
- (2015) The eras and trends of automatic short answer grading. Internat. J. Artificial Intelligence Ed. 25(1):60–117.Crossref, Google Scholar
- , Constant N, et al. (2018) Universal sentence encoder. Preprint, submitted March 29, https://arxiv.org/abs/1803.11175.Google Scholar
- (2022) An error consistency based approach to answer aggregation in open-ended crowdsourcing. Inform. Sci. 608:1029–1044.Crossref, Google Scholar
- (2024) A survey on evaluation of large language models. ACM Trans. Intelligent Systems Tech. 15(3):1–45.Crossref, Google Scholar
- (2023) Universal self-consistency for large language model generation. Preprint, submitted November 29, https://arxiv.org/abs/2311.17311.Google Scholar
- (2023) Can large language models be an alternative to human evaluations? Preprint, submitted May 3, https://arxiv.org/abs/2305.01937.Google Scholar
- Clarke CLA, Maistro M, Smucker MD (2022) Overview of the TREC 2021 health misinformation track. Proc. Thirtieth Text Retrieval Conf. (TREC 2021), Special Publication 500-335 (National Institute of Standards and Technology (NIST), Washington, DC).Google Scholar
- (2020) Overview of the TREC 2020 health misinformation track. TREC 2020 Proc.Google Scholar
- (2013) Aggregating crowdsourced binary ratings. Proc. 22nd Internat. Conf. World Wide Web, 285–294.Google Scholar
- (2024) A Complete Survey on LLM-based AI Chatbots. Preprint, submitted June 17, https://arxiv.org/abs/2406.16937.Google Scholar
- (1979) Maximum likelihood estimation of observer error‐rates using the EM algorithm. J. Roy. Statist. Soc. Ser. C Appl. Statist. 28(1):20–28.Google Scholar
- (2009) Vox populi: Collecting high-quality labels from a crowd. 22nd Annual Conf. Learn. Theory (COLT) Proc.Google Scholar
- (2018) BERT: Pre-training of deep bidirectional transformers for language understanding. Preprint, submitted October 11, https://arxiv.org/abs/1810.04805.Google Scholar
- (2020) FQuAD: French question answering dataset. Preprint, submitted February 14, https://arxiv.org/abs/2002.06071.Google Scholar
- (2024) A machine learning framework for assessing experts’ decision quality. Management Sci. 71(7):5696–5721.Link, Google Scholar
- (2012) Towards effective tutorial feedback for explanation questions: A dataset and baselines. Proc. 2012 Conf. North Amer. Chapter Assoc. Comput. Linguistics Human Language Tech. (ACL, Stroudsburg, PA), 200–210.Google Scholar
- (2022) A multistage retrieval system for health-related misinformation detection. Engrg. Appl. Artificial Intelligence 115:105211.Crossref, Google Scholar
- (2020) CiTIUS at the TREC 2020 health misinformation track. TREC 2020 Proc.Google Scholar
- (2018) Machine learning approach for automatic short answer grading: A systematic review. Ibero-Amer. Conf. Artificial Intelligence (Springer, Cham, Switzerland), 380–391.Google Scholar
- (2021) SimCSE: Simple contrastive learning of sentence embeddings. Preprint, submitted April 18, https://arxiv.org/abs/2104.08821.Google Scholar
- (2016) Who’s a good decision maker? Data-driven expert worker ranking under unobservable quality. Proc. 37th Internat. Conf. Inform. Systems (Association for Information Systems, Atlanta).Google Scholar
- (2021) Who is a better decision maker? Data‐driven expert ranking under unobserved quality. Production Oper. Management 30(1):127–144.Crossref, Google Scholar
- (2019) More for less: Adaptive labeling payments in online labor markets. Data Mining Knowledge Discovery 33(6):1625–1673.Crossref, Google Scholar
- (2012) Short answer grading using string similarity and corpus-based similarity. Internat. J. Advanced Comput. Sci. Appl. 3(11).Google Scholar
- (2022) A survey on automated fact-checking. Trans. Assoc. Comput. Linguistics. 10:178–206.Crossref, Google Scholar
- (2008) Moving towards a fully automatic knowledge assessment tool. Internat. J. Emerging Tech. Learn. 3(1).Google Scholar
- , Shah M (2025) Large language models: A comprehensive survey of its applications, challenges, limitations, and future prospects. Preprint, submitted February 10, http://dx.doi.org/10.36227/techrxiv.23589741.v8.Google Scholar
- (2022) Survey on automated short answer grading with deep learning: From word embeddings to transformers. Preprint, submitted March 11, https://arxiv.org/abs/2204.03503.Google Scholar
- (2024) Revisiting agnostic PAC learning. Proc. 65th IEEE Annual Sympos. Foundations Comput. Sci., 1968–1982.Google Scholar
- (2009) The Elements of Statistical Learning: Data Mining, Inference, and Prediction (Springer, New York).Crossref, Google Scholar
- (2015) The impact of training data on automated short answer scoring performance. Proc. 10th Workshop Innovative Use NLP Building Ed. Appl. (ACL, Stroudsburg, PA), 81–85.Google Scholar
- (2019) Crowdsourced PAC learning under classification noise. Proc. Seventh AAAI Conf. Human Comput. Crowdsourcing (AAAI, Palo Alto, CA), 41–49.Google Scholar
- (2004) Design science in information systems research. MIS Quart. 28(1):75–105.Crossref, Google Scholar
- (1963) Probability inequalities for sums of bounded random variables. J. Amer. Statist. Assoc. 58(301):13–30.Crossref, Google Scholar
- (2018) Semi-supervised clustering for short answer scoring. Proc. 11th Internat. Conf. Language Resources Evaluation (ACL, Stroudsburg, PA).Google Scholar
- (2014) Repeated labeling using multiple noisy labelers. Data Mining Knowledge Discovery 28(2):402–441.Crossref, Google Scholar
- (2012)
Short-answer e-assessment questions: Five years on . Whitelock D, Wills G, Warburton B, eds. Proc. 15th Internat. Comput. Assisted Assessment Conf. (Southampton).Google Scholar - (2017) TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. Preprint, submitted May 9, https://arxiv.org/abs/1705.03551.Google Scholar
- (2024) Agnostic membership query learning with nontrivial savings: New results and techniques. Proc. 35th Internat. Conf. Algorithmic Learn. Theory. Proc. Machine Learn. Res., vol. 237 (PMLR, New York), 654–682.Google Scholar
- Karger DR, Oh S, Shah D (2014) Budget-optimal task allocation for reliable crowdsourcing systems. Oper. Res. 62(1):1–24.Google Scholar
- (1994) An Introduction to Computational Learning Theory (MIT Press, Cambridge, MA).Crossref, Google Scholar
- (2017) Learning from noisy singly-labeled data. Preprint, submitted December 13, https://arxiv.org/abs/1712.04577.Google Scholar
- (2011) Automated assessment of short free-text responses in computer science using latent semantic analysis. Proc. 16th Annual Joint Conf. Innovation Tech. Comput. Sci. Ed. (ACM, New York), 158–162.Google Scholar
- Kittur A, Nickerson JV, Bernstein M, Gerber E, Shaw A, Zimmerman J, Lease M, Horton J (2013) The future of crowd work. Proc. 2013 Conf. Comput. Supported Cooperative Work (Association for Computing Machinery, New York), 1301–1318.Google Scholar
- (2018) The narrative QA reading comprehension challenge. Trans. Assoc. Comput. Linguistics 6:317–328.Crossref, Google Scholar
- (2011) Modeling annotator accuracies for supervised learning. Proc. Workshop Crowdsourcing Search Data Mining Fourth ACM Internat Conf Web Search Data Mining (ACM, New York), 19–22.Google Scholar
- (2019) Natural questions: A benchmark for question answering research. Trans. Assoc. Comput. Linguistics 7:452–466.Google Scholar
- (2023) Bagging is an optimal PAC learner. Proc. 36th Annual Conf. Learn. Theory Proc. Machine Learn. Res., vol. 195 (PMLR, New York), 1–20.Google Scholar
- (2003) C-rater: Automated scoring of short-answer questions. Comput. Humanities 37(4):389–405.Crossref, Google Scholar
- (2021) Learning to perturb word embeddings for out-of-distribution QA. Preprint, submitted May 6, https://arxiv.org/abs/2105.02692.Google Scholar
- (2019) Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. Preprint, submitted October 29, https://arxiv.org/1910.13461.Google Scholar
- (2020) Crowdsourced text sequence aggregation based on hybrid reliability and representation. Proc. 43rd Internat. ACM SIGIR Conf. Res. Development Inform. Retrieval (Association for Computing Machinery, New York), 1761–1764.Google Scholar
- (2019) A dataset of crowdsourced word sequences: Collections and answer aggregation for ground truth creation. Proc. First Workshop Aggregating Analysing Crowdsourced Annotations NLP (Association for Computational Linguistics, Stroudsburg, PA), 24–28.Google Scholar
- (2023) Holistic evaluation of language models. Preprint, submitted November 16, 2022, https://arxiv.org/2211.09110.Google Scholar
- (2021) University of Copenhagen participation in TREC Health Misinformation track 2020. Preprint, submitted March 3, https://arxiv.org/2103.02462.Google Scholar
- (2022) Truthfulqa: Measuring how models mimic human falsehoods. Preprint, submitted September 8, 2021, https://arxiv.org/2109.07958.Google Scholar
- (2019) RoBERTa: A robustly optimized BERT pretraining approach. Preprint, submitted July 26, https://arxiv.org/1907.11692.Google Scholar
- (2009) Text-to-text semantic similarity for automatic short answer grading. Proc. 12th Conf. Eur. Chapter ACL (ACL, Stroudsburg, PA), 567–575.Google Scholar
- (2011) Learning to grade short answer questions using semantic similarity measures and dependency graph alignments. Proc. 49th Annual Meeting Assoc. Comput. Linguistics Human Language Tech. (ACL, Stroudsburg, PA), 752–762.Google Scholar
- (2012) Foundations of Machine Learning (MIT Press, Cambridge, MA).Google Scholar
- (2021) GermanQuAD and GermanDPR: Improving non-English question answering and passage retrieval. Preprint, submitted April 26, https://arxiv.org/2104.12741.Google Scholar
- (2016) MS MARCO: A human generated machine reading comprehension dataset. Workshop Adv. Neural Inform. Processing Systems (CEUR-WS.org).Google Scholar
- (2002) BLEU: A method for automatic evaluation of machine translation. Proc. 40th Annual Meeting Assoc. Comput. Linguistics (Association for Computational Linguistics, Stroudsburg, PA), 311–318.Google Scholar
- (2020) Analysis of multiple-choice versus open-ended questions in language tests according to different cognitive domain levels. Novitas-ROYAL 14(2):76–96.Google Scholar
- (2021) Vera: Prediction techniques for reducing harmful misinformation in consumer health search. Proc. 44th Internat. ACM SIGIR Conf. Res. Development Inform. Retrieval (ACM, New York), 2066–2070.Google Scholar
- (2018) Know what you don’t know: Unanswerable questions for SQuAD. Preprint, submitted June 11, https://arxiv.org/1806.03822.Google Scholar
- (2016) Squad: 100,000+ questions for machine comprehension of text. Proc. 2016 Conf. Empirical Methods Natural Language Processing (Association for Computational Linguistics, Stroudsburg, PA), 2383–2392.Google Scholar
- (2015) Identifying patterns for short answer scoring using graph-based lexico-semantic text matching. Proc. 10th Workshop Innovative Use NLP Building Ed. Appl. (ACL, Stroudsburg, PA), 97–106.Google Scholar
- (2022) An automated essay scoring systems: A systematic literature review. Artificial Intelligence Rev. 55(3):2495–2527.Crossref, Google Scholar
- (2010) Learning from crowds. J. Machine Learn. Res. 11(43):1297–1322.Google Scholar
- (2019) Sentence-BERT: Sentence embeddings using Siamese BERT-networks. Preprint, submitted August 27, https://arxiv.org/1908.10084.Google Scholar
- (2013) Learning from multiple annotators: Distinguishing good from random labelers. Pattern Recognition Lett. 34(12):1428–1436.Crossref, Google Scholar
- (2015) A perspective on computer assisted assessment techniques for short free-text answers. Internat. Comput. Assisted Assessment Conf. (Springer, Cham, Switzerland), 96–109.Google Scholar
- (2016) Wisdom of students: A consistent automatic short answer grading technique. Proc. 13th Internat. Conf. Natural Language Processing (ACL, Stroudsburg, PA), 178–187.Google Scholar
- (2018) Sentence level or token level features for automatic short answer grading? Use both. Internat. Conf. Artificial Intelligence Ed. (Springer, Cham, Switzerland), 503–517.Google Scholar
- (2018) Descriptive answer evaluation. Internat. Res. J. Engrg. Tech. 5(5):2709–2712.Google Scholar
- (2020) Towards instance-based content scoring with pre-trained transformer models. Proc. 34th AAAI Conf. Artificial Intelligence (AAAI, Palo Alto, CA).Google Scholar
- (2016) Fast and easy short answer grading with high accuracy. Proc. 2016 Conf. North Amer. Chapter Assoc. Comput. Linguistics Human Language Tech. (ACL, Stroudsburg, PA), 1070–1075.Google Scholar
- (2019) Improving short answer grading using transformer-based pre-training. Internat. Conf. Artificial Intelligence Ed. (Springer, Cham, Switzerland), 469–481.Google Scholar
- (2019) Learning from noisy labels by regularized estimation of annotator confusion. Proc. IEEE Conf. Comput. Vision Pattern Recognition (IEEE, Piscataway, NJ), 11244–11253.Google Scholar
- (1984) A theory of the learnable. Comm. ACM 27(11):1134–1142.Crossref, Google Scholar
- (2023a) Perspectives of patients with chronic diseases on future acceptance of AI–based home care systems: Cross-sectional web-based survey study. JMIR Human Factors 10(1):e49788.Crossref, Google Scholar
- (2017) Cost-effective quality assurance in crowd labeling. Inform. Systems Res. 28(1):137–158.Link, Google Scholar
- (2022) Self-consistency improves chain of thought reasoning in language models. Preprint, submitted March 21, https://arxiv.org/2203.11171.Google Scholar
- (2023b) Large language models are not fair evaluators. Preprint, submitted May 29, https://arxiv.org/2305.17926.Google Scholar
- (2004) Simultaneous truth and performance level estimation (STAPLE): An algorithm for the validation of image segmentation. IEEE Trans. Medical Imaging 23(7):903–921.Crossref, Google Scholar
- (2011) Bayesian bias mitigation for crowdsourcing. Adv. Neural Inform. Processing Systems, vol. 24 (Curran Associates Inc., Red Hook, NY), 1800–1808.Google Scholar
- (2009) Whose vote should count more: Optimal integration of labels from labelers of unknown expertise. Adv. Neural Inform. Processing Systems, vol. 22 (Curran Associates Inc., Red Hook, NY).Google Scholar
- (2022) Review of automatic text summarization techniques & methods. J. King Saud Univ. Comput. Inform. Sci. 34(4):1029–1046.Crossref, Google Scholar
- (2021)
Attention-based bidirectional long short-term memory neural network for short answer scoring . Guan M, Na Z, eds. Internat. Conf. Machine Learn. Intelligent Comm. (Springer, Cham, Switzerland), 104–112.Crossref, Google Scholar - (2021) Learning from crowdsourced multi-labeling: A variational Bayesian approach. Inform. Systems Res. 32(3):752–773.Abstract, Google Scholar
- (2022) Efficient PAC learning from the crowd with pairwise comparisons. Proc. Internat. Conf. Machine Learn. (PMLR, New York), 25973–25993.Google Scholar
- (2023) Semi-verified PAC learning from the crowd. Proc. 26th Internat. Conf. Artificial Intelligence. Statist. (PMLR, New York), 2068–2086.Google Scholar
- (2015) Reducing annotation efforts in supervised short answer scoring. Proc. 10th Workshop Innovative Use NLP Building Ed. Appl. (ACL, Stroudsburg, PA), 124–132.Google Scholar
- (2019) BERTscore: Evaluating text generation with BERT. Preprint, submitted April 21, https://arxiv.org/1904.09675.Google Scholar
- (2023) A survey on complex factual question answering. AI Open 4:1–12.Crossref, Google Scholar
- (2023) Judging LLM-as-a-judge with MT-bench and chatbot arena. Adv. Neural Inform. Processing Systems, vol. 36 (Curran Associates Inc., Red Hook, NY), 46595–46623.Google Scholar
- (2025) Understanding user switch of information seeking: From search engines to generative AI. J. Librarianship Inform. Sci. Forthcoming.Google Scholar
- (2022) Answer quality aware aggregation for extractive QA crowdsourcing. Findings Assoc. Comput. Linguistics (Association for Computational Linguistics, Stroudsburg, PA), 6147–6159.Google Scholar
- (2019) Fine-tuning language models from human preferences. Preprint, submitted September 18, https://arxiv.org/1909.08593.Google Scholar

