
Agent-Based Data Curation Practices: Customer Responses to Human versus Algorithmic Data Requesters in Established Business-to-Business Relationships
Abstract
With the increasing value generated by data curation and the rise of artificial intelligence (AI) agents that converse and act like human agents, vendor companies in established business-to-business (B2B) relationships increasingly delegate data curation tasks to algorithmic data requesters (ADRs) rather than human data requesters (HDRs). Firms employ these data requesters to email existing customers either to collect new information for improved services (data enrichment) or to update outdated information to maintain existing ones (data reconciliation). Despite the growing use of agents in data curation, little is known about how customers respond to these practices—particularly how their responses vary by requester type (HDR versus ADR) and by the nature of the data work practice (enrichment versus reconciliation). Drawing on the effort-accuracy framework and gain-loss message framing, we investigate customer agreement with email-based data requests from HDRs (versus ADRs) in data enrichment (versus data reconciliation) in a multimethod approach. Evidence from a randomized field experiment with a leading European pharmaceutical company followed by an online experiment reveals that customers have a reduced inclination to agree (versus disagree) with a data request from an HDR (versus ADR) in data enrichment because of their preference for minimizing effort in interactions with the data requester. However, for data reconciliation, customers prefer an HDR (versus ADR) because they have lower concerns about errors that could arise in these interactions. A post hoc analysis reveals that although the findings on customer agreement are supported for data enrichment (i.e., the customer completion rate is higher for ADRs versus HDRs), we find only marginal support for data reconciliation (i.e., the customer completion rate is only marginally higher for HDRs versus ADRs). Qualitative responses from a follow-up online survey and interviews with customers of the pharmaceutical company corroborate and complement the main quantitative findings. Overall, this research expands our understanding of continued customer engagement in data curation practices and has implications for vendor companies seeking to deploy ADRs instead of HDRs in data work and established B2B relationships.
History: Jeffrey Parsons, Senior Editor; David Xu, Associate Editor.
Funding: This work was supported by the Deutsche Forschungsgemeinschaft [Grant 522190413].
Supplemental Material: The online appendix is available at https://doi.org/10.1287/isre.2023.0478.
1. Introduction
As data curation moves to the forefront of customer value creation (e.g., Alaimo and Kallinikos 2022, Parmiggiani et al. 2024) and with the rise of artificial intelligence (AI) agents that converse and act as human agents (e.g., Adam et al. 2025, Wessel et al. 2025), vendor companies increasingly delegate data curation tasks to algorithmic data requesters (ADRs) instead of human data requesters (HDRs) (e.g., Xu et al. 2024). These data requesters enact agent-based data curation practices, which we define as routines that differ depending on the type of agent—either human (i.e., HDRs) or algorithm-based (i.e., ADRs)—who interacts with customers to identify and request data, elicit agreement and contributions, verify and enrich records, and maintain customer data for long-term use, to enhance data quality (e.g., accuracy, completeness) and value creation (e.g., Chua et al. 2022, Aaltonen and Stelmaszak 2024, Xu et al. 2024). These practices form part of data work, typically studied as skillful efforts to make data in organizations relevant and useful (e.g., Pine and Bossen 2020, Parmiggiani et al. 2024). Positive customer responses to data requests initiated in these practices enable vendors to use the provided data and deliver better customized services that strengthen existing business relationships, engage customers, and drive sales (e.g., Liebman et al. 2019, Sia et al. 2024). At the same time, customers benefit significantly from the data provision, resulting in improved outcomes, such as enhanced interaction experiences, streamlined processes, collaborative planning, more accurate forecasting, timely replenishment, and targeted promotions (e.g., Palmatier et al. 2008, Rai et al. 2012). Vendors that excel at eliciting positive customer responses to agent-based data curation practices tend to have more satisfied customers and higher revenue than their market counterparts (e.g., Forrester 2024, IBM 2024). However, more than half of companies currently fail to elicit such positive customer responses, resulting in missing or outdated customer data and consequently, suboptimal customer value creation (e.g., Validity 2024, Salesforce 2025). As improving customer responses to agent-based data curation practices benefits both vendors and customers, the phenomenon requires more theoretical and practical attention. Accordingly, the objective of this paper is to investigate customer responses to the emerging phenomenon of agent-based data curation practices.
Notably, customer responses to agent-based data curation practices should not be seen as a one-time event. Instead, data curation practices unfold across the entire data life cycle, evolving alongside the business relationship—from initial data collection at the outset to ongoing data curation that supports retention and deeper engagement with customized services (e.g., Maass et al. 2018, Mikalef et al. 2020). Ongoing data curation transforms customer data into a dynamic asset that enhances profile accuracy and depth—directly fueling customer retention and business growth. For instance, Netflix’s continuously enriched viewing data powers a recommender system responsible for roughly 80% of streamed hours and saves over $1 billion annually through reduced churn (Gomez-Uribe and Hunt 2015). Similar patterns hold across industries; Gartner (2025) reports that poor data quality costs firms at least $12.9 million per year, whereas companies excelling in data-enabled personalization—built on well-curated data—earn about 40% more revenue from these initiatives than competitors (McKinsey & Company 2021).
Although building trust is pivotal for customer agreement to data requests in the early stages of a business relationship, customers in later stages rely more on the established rapport and place less emphasis on trust formation (Hanelt et al. 2025). Instead, they evaluate the specifics of the data request itself when deciding whether to agree with the data request: that is, indicating consent for further data exchanges (e.g., Liu and Goodhue 2012). These assessments are often associated with the information processing of effort and accuracy attributes linked to a decision (e.g., Payne et al. 1993). This is particularly important for long-lasting and high-stakes relationships, such as in business-to-business (B2B) settings, where data requesters in later-stage interactions draw upon past encounters between vendor companies and customer firms to facilitate decision making (e.g., Blois 1999, Alsaad et al. 2017). Vendor-customer relationships evolve, and each stage brings different expectations. If vendors fail to align their data requests with customers’ specific needs in later stages of the relationship, it can lead to frustration, disrupt data collection efforts, and hinder the delivery of customized services. Treating all data requests and related data curation practices the same, regardless of the stage and context of the relationship (i.e., later-stage B2B interactions), thus risks overlooking important nuances and can stall the data curation critical to value creation.
In established B2B relationships, two agent-based data curation practices are particularly important (see Figure 1 for details), which typically occur independently of one another to avoid overwhelming customers during communication (e.g., Maass et al. 2018, Mikalef et al. 2020). The first practice is data enrichment, which entails data requests for new data collection to provide new or better services as vendors aim to deliver more and better offerings (e.g., Scherer et al. 2015, Leonelli and Tempini 2020, Parmiggiani et al. 2024). In the field, data requesters spell out what new data they need and why, collect them from customers via data requests, and then, verify and attach them to existing records to build a richer profile that supports new or improved services. The second practice, called data reconciliation, comprises data requests about keeping the already acquired data up to date to maintain the existing services as even the best customized services cannot operate successfully without current data (e.g., Ballou 1985, Ballou and Tayi 1989, Gitelman 2013). In practice, data requesters use quality checks and flag missing or conflicting fields, request customers to confirm or fix those items, and update the primary record with a clear log of changes to restore accuracy and integrity. Vendors can only create data-driven value when they know what their customers need; if needs are not yet identified, this calls for data enrichment, and if needs have changed since the last interaction, it requires data reconciliation. Without such practices and related customer data, vendor companies miss out on the potential value generated for their customers through customized services and also risk cluttering their customers’ email inboxes with ineffective content (e.g., Malthouse and Li 2017, Gartner 2019). At the same time, customers miss out on tailored offerings and spend more time and effort to find the products and services they need.

Once the responsibility of HDRs, these data curation practices are now increasingly enacted by ADRs,1 reflecting the broader shift toward “automation everywhere” in practice (e.g., Salesforce 2022) and particularly, the rise of AI agents that can act as human agents (e.g., Adam et al. 2025, Wessel et al. 2025). To preserve customers’ autonomy, ADRs typically disclose their algorithmic identity (e.g., using an algorithmic name) at the outset of customer interactions, making themselves distinguishable from HDRs (e.g., Adam et al. 2023, Gnewuch et al. 2024). As such, the type of agent (i.e., HDR or ADR), based on which data curation practices are enacted (e.g., Xu et al. 2024), has become a key element in related customer responses. For instance, ADRs offer benefits, such as reduced costs, faster response times, and greater availability (e.g., Puntoni et al. 2021, Schanke et al. 2021). As a result, organizations worldwide are embracing ADRs to interact with customers (e.g., Gartner 2022, Statista 2023). However, customers often question the accuracy and contextual understanding of ADRs (e.g., Castelo et al. 2019, Longoni and Cian 2022), particularly for complex tasks, where they continue to prefer human interaction (e.g., Longoni et al. 2019, Dietvorst and Bharti 2020). It thus remains an open question whether customers favor ADRs or HDRs in different data curation practices.
Despite the rising prevalence of agent-based data curation practices in the field, limited research has explored customer responses to these practices. Indeed, evidence for ADRs’ presumed superiority in data curation is thin in the literature, highlighting the need for rigorous comparisons between ADRs and HDRs in established B2B relationships. Meanwhile, the rapid diffusion of agent-based data curation practices offers natural and contemporary settings for uncovering fresh, revelatory insights for both research and practice. Thus, it is crucial to enhance our understanding of how and why human (versus algorithm-based) data requesters are preferred for data curation practices in established B2B relationships. Drawing on our literature review on algorithm aversion (e.g., Jussupow et al. 2024), as illustrated in Online Appendix A, we particularly highlight three salient opportunities.
First, prior research has focused predominantly on data requests during the initial stages of business relationships, especially in business-to-consumer (B2C) settings—when trust is still forming and the goal is to acquire data for initial service customization (e.g., Li and Karahanna 2015, Diederich et al. 2022). B2C settings are typically characterized by efficiency and scalability, providing fast and convenient support to a large number of customers with relatively simple interactions between the business and its customers, which both parties usually recognize as short term in nature. Thus, these interactions often resemble one-shot games with little interest in fostering and continuing a long-term relationship, paving the way for potential hazardous behaviors, such as defection and exploitation (e.g., Ba and Pavlou 2002, McKnight et al. 2002). For example, previous research has investigated whether customers provide data to algorithmic agents of different human-like designs (e.g., Schanke et al. 2021, Adam and Benlian 2024) and to human versus algorithmic agents (e.g., Xu et al. 2014, Castelo et al. 2019, Luo et al. 2019), particularly in early relationships and/or e-commerce settings, often finding that HDRs elicit higher agreement because of greater perceived trustworthiness. Yet, data requests are also essential later in the data life cycle, particularly in B2B settings—when trust has already been established and customers can focus more directly on the attributes of the data request and the requester (e.g., Liu and Goodhue 2012). B2B settings are noteworthy because they include strategic and repeated interactions that occur over multiple periods between the same parties, fostering cooperation guided by a more relational approach as both customers and vendors recognize that short-term gains from opportunism are less attractive than the benefits of sustained cooperation (e.g., Goo et al. 2009, Klein and Rai 2009). Over time, mutual expectations and reputational considerations in B2B settings can create a stable foundation of trust embedded in the ongoing interactions. Vendors thus usually aim to provide a seamless, knowledgeable experience for a smaller number of customers, to whom they provide more attention and assistance, leveraging prior knowledge, expert advice, product documentation, and technical specifications. Relatedly, professional data requesters for data curation are primarily applied in the B2B settings as data curation is especially relevant in long-term customer-vendor relationships. Surprisingly, little attention has been paid to these established, later-stage business interactions, particularly in B2B settings. This is critical because the use of HDRs versus ADR could differ significantly between B2B and B2C settings because of the nature of interactions and transactions, the complexity of the issues, and the value of the relationship between vendors and customers. To emphasize, data work practices are not enacted in isolation but in use contexts (i.e., “situated practices”), which are a key consideration for successful data curation (e.g., Jones 2019). Understanding whether ADRs (versus HDRs) are more or less effective in mature B2B relationships has thus significant theoretical and design-related implications for agent-based data curation practices as it challenges the prevailing assumptions of a consistent human advantage for customer responses (e.g., Jussupow et al. 2024) and that all data requesters are human (e.g., Aaltonen and Stelmaszak 2024, Parmiggiani et al. 2024). Moreover, it informs the design and application of AI agents in human-AI interactions (e.g., Adam et al. 2025, Wessel et al. 2025).
Second, prior research has begun to explore the mechanisms by which agent types influence data-related outcomes, primarily in the early stages of business relationships—such as when customers share data for an initial product recommendation (e.g., Castelo et al. 2019). Given the critical role of trust in these initial interactions, the literature has largely focused on trust-related constructs, including trusting beliefs, social presence, and uncertainty (e.g., Qiu and Benbasat 2009, Xu et al. 2020). Some studies also investigated factors related to the data requesters’ competencies and limitations (e.g., Castelo et al. 2019, Luo et al. 2019) and the complexity of tasks (e.g., Xu et al. 2014), but much of this research focused on early interactions with customers and yielded inconsistent findings. Existing research has yet to unpack how the specific mechanisms of effort and accuracy shape customer responses to data requests depending on agent type, particularly in mature business relationships. Indeed, in established B2B relationships, vendors have already demonstrated their trustworthiness. As such, customers no longer base their judgments on trust and rather, focus on the effort required to interact with the data requester and their confidence that safeguards will prevent data errors. This shift in priorities suggests that customer willingness to agree with data requests may vary between ADRs and HDRs depending on whether efficiency or accuracy is more salient to them. Clarifying these explanatory mechanisms in established B2B relationships can enrich the literature and prevent firms from defaulting to HDRs under the assumption of greater accuracy when customers may in fact favor the lower effort offered by ADRs.
Third, prior research has primarily examined data provision in scenarios where customers faced only potential gains, such as receiving personalized product recommendations in exchange for disclosing their preferences (e.g., Qiu and Benbasat 2009, Castelo et al. 2019). However, data requests may also occur in perceived loss situations: for instance, when refusing a data request might jeopardize access to an existing service. In such cases, customers’ loss-framed message perceptions can influence their preference for different data requester types (HDRs versus ADRs). Because most studies overlook loss-framed messages, we lack a nuanced understanding of how data provision decisions vary depending on the perceived stakes. The notion of gain-loss framing may help explain customers’ differing perceptions of data curation practices, including data enrichment (i.e., receiving new services) and data reconciliation (i.e., not losing existing services). Addressing this gap is thus critical to understanding why customers respond differently to the same type of data requester across data curation practices.
Against this backdrop, our paper aims to address the following research question. How and why do customers agree (versus disagree) differentially to data requests from HDRs (versus ADRs) when engaged in data enrichment (versus data reconciliation) in established B2B relationships? To answer this question, we conducted a multimethod investigation, including a randomized field experiment with a leading European pharmaceutical company and a subsequent randomized online experiment (e.g., Mingers 2003, Fink 2022). The quantitative findings revealed consistent and contrasting patterns in customer agreement with data requests depending on both the type of data requester and the data curation practice. For data enrichment, customers are less inclined to agree (versus disagree) with data requests from HDRs than from ADRs because of their preference for minimizing effort in interactions with the data requester. Conversely, customers are more likely to accommodate HDRs than ADRs for data reconciliation because they are less concerned about data errors that could arise in these interactions. Further analysis regarding customer completion—that is, the proportion of customers who successfully completed the entire process of agreeing to and fulfilling a data request—shows significant support for the contrasting effects of data requesters in data enrichment (i.e., the customer completion rate is higher for ADRs versus HDRs) and only marginal support in data reconciliation (i.e., the customer completion rate is only insignificantly higher for HDRs versus ADRs). Supplementary qualitative insights from a follow-up online survey and interviews further provide support for the main premises and findings of our quantitative research.
This paper contributes to research by conceptualizing agent-based data curation practices and empirically showing how seemingly minor differences in data requester types (i.e., HDR versus ADR) and data curation practices (i.e., data enrichment versus data reconciliation) can have different effects on customer responses to data requests in established B2B relationships. This paper makes three key contributions to the literature on algorithm aversion (e.g., Jussupow et al. 2024) at the intersection with data work practices (e.g., Aaltonen and Stelmaszak 2024, Alaimo and Kallinikos 2024, Parmiggiani et al. 2024). First, departing from prior studies centered on the early phases of B2C relationships (e.g., Castelo et al. 2019, Schanke et al. 2021, Adam and Benlian 2024), our research brings to light a critical yet previously underexplored insight; in later stages of B2B relationships, the relative effectiveness of ADRs and HDRs is highly practice dependent. This is because the differences inherent in established B2B relationship settings from B2C or early B2B relationship contexts engender different levels of fit between ADR features and data curation practices. This highlights a more differentiated and dynamic view of data curation practices, advancing our understanding of the effectiveness of HDRs versus ADRs and acknowledging that ADRs—and no longer HDRs as an implicit default—can effectively take over data work. Second, we contribute to the literature by revealing effort expectancy and error concerns as core mechanisms—rooted in effort-accuracy trade-offs—that explain differential customer agreement with data requests from ADRs versus HDRs in ongoing B2B relationships. This complements earlier research focused on initial trust formation and relational cues (e.g., Qiu and Benbasat 2009, Castelo et al. 2019, Xu et al. 2020). Third, we contribute to the literature by showing that customer responses to data requests vary significantly depending on whether the practice suggests gains (i.e., data enrichment) or losses (i.e., data reconciliation). By comparing these distinct message framings, which are inherent to data curation practices, our paper expands on prior work that has largely emphasized gain-oriented scenarios (e.g., Qiu and Benbasat 2009, Castelo et al. 2019) and underscores the critical role of perceptual framing in data-sharing decisions. In summary, our findings emphasize the relevance of customer responses to agent-based data curation practices for the deployment of ADRs (versus HDRs) and offer practical insights into when ADRs—and when ADRs do not—outperform HDRs in established B2B relationships.
2. Theoretical Background
In the following subsections, we first conceptualize agent-based data curation practices. Subsequently, we synthesize the literature on customer responses to data requests from human versus algorithmic agents and explain how our research on customer agreement with data requests in established B2B relationships departs from it. Lastly, we draw on the effort-accuracy framework from information processing theory and gain-loss message framing from prospect theory as a theoretical lens to explain how and why customers agree with data requests across distinct agent-based data curation practices.
2.1. Conceptualizing Agent-Based Data Curation Practices
As data science, analytics, and other data-intensive technologies permeate organizations (e.g., Berente et al. 2021, Lebovitz et al. 2021, Wessel et al. 2025), scholars highlight the often-invisible data work done by humans that renders data actionable and valuable. Far from routine chores, this work demands expertise, coordination, and resources (e.g., Pine and Bossen 2020, Parmiggiani et al. 2022). It spans the full data life cycle—creating, collecting, managing, curating, analyzing, and communicating—and those who perform it are data workers (e.g., Chua et al. 2022, Aaltonen and Stelmaszak 2024). Growing research emphasizes its variety, complexity, and importance, introducing ideas, such as data stretching (Almklov et al. 2014), transfiguration work (Cunha and Carugati 2018), data-centric knowing (Mikalsen and Monteiro 2021), and configuration work (Aaltonen and Stelmaszak 2024), to describe how professionals make data work.
Data curation practices in this regard comprise activities conducted by data requesters (i.e., data workers who interact with data providers to ask for data) aimed at improving data quality (e.g., accuracy, completeness) by identifying, enriching, and maintaining data for long-term use and preservation (e.g., Aaltonen and Stelmaszak 2024, Parmiggiani et al. 2024). These practices exhibit a certain regularity, and thus, they are recurring, goal-directed patterns or routines rather than one-off actions (e.g., Schatzki et al. 2001). Moreover, they occur in use contexts (i.e., “situated practices”), which require an adequate understanding of the data curation setting (e.g., Jones 2019). For the purpose of increasing data quality and related value for vendors as well as customers, primary data curation practices involve data requesters contacting customers by eliciting customer agreement to data requests via emails and other channels across various points in the data life cycle (e.g., Chua et al. 2022, Günther et al. 2022). In the early stage of a business relationship, no customer data are directly available to the vendor, so the main task of a data requester is to reach out to customers and persuade them to provide a first round of data for the offering of an initial customized service. In the later stages, when trust has been established, vendors aim to either maintain existing customized services or introduce additional ones that necessitate data requesters to collect new or updated data beyond what was initially provided by customers, which is the focus of this paper.
For data curation purposes in these later relationship stages, data requesters build on the established relationship and deploy two typical practices, which are distinct requests to prevent overwhelming customers during interactions. The first practice is data enrichment: that is, engaging customers to acquire fresh data for providing new or better services. Data enrichment is extensional by nature and relates to opening up possibilities and enabling new value creation. It expands existing data sets in databases by adding attributes, increasing granularity, or integrating new sources (e.g., Leonelli and Tempini 2020, Parmiggiani et al. 2024). In practice, data requesters in data enrichment specify the needed new data attributes and their purpose, collect them from customers via data requests, and then, validate and link them to existing records to expand granularity and unlock new data value. The second practice is data reconciliation: that is, engaging customers to update existing data to maintain and thus, not lose existing services. Data reconciliation is a corrective and stabilizing process that aims to close gaps in existing data in databases, preserving the reliability and factual accuracy of the data and restoring order in case of errors. It identifies and resolves inconsistencies to ensure data integrity (e.g., Ballou 1985, Ballou and Tayi 1989, Gitelman 2013). In practice, data requesters in data reconciliation detect gaps and inconsistencies in existing data using quality rules and record matching, reach out to customers via data requests to ask them to confirm or correct data fields, and update the master record with an auditable trail to restore accuracy and integrity.
In each data curation practice, customers can respond by agreeing with the respective data request: that is, indicating their consent and approval for data exchanges. If customers agree, they may subsequently submit the required data immediately or at a scheduled time. These data are then used to populate or update cells in the vendor’s database, laying the foundation for customized services in the future. Figure 1 illustrates the typical data request process for agent-based data curation practices with respect to data enrichment and reconciliation.
As data curation practices are increasingly conducted by different types of agents—particularly HDRs versus ADRs—a theoretical shift is required that puts the (algorithmic) agent more to the fore in these practices (e.g., Xu et al. 2024), thereby giving rise to the emergent phenomenon of agent-based data curation practices. In this vein, the same data curation practice may lead to different customer responses depending on which data requester enacts the data work practice—a human or an algorithm. To further address customer responses to agent-based data curation practices, we next present the existing literature on customer agreement with data requests from different data requesters.
2.2. Customer Agreement with Data Requests from Different Data Requesters
Previous research has primarily examined customer agreement with data requests from ADRs at the beginning of business relationships, particularly in B2C settings, to provide initial data—mostly preferences for products and services—to ADRs for the first time (c.f., Li and Karahanna 2015, Diederich et al. 2022). Early research mainly focused on the design features of ADRs without comparisons with HDRs, such as the presentation of recommendations (e.g., Tam and Ho 2005, Komiak and Benbasat 2006) and human-like features (e.g., Qiu and Benbasat 2009). Because of the increasing prominence of ADRs and their replacement of HDRs in customer interactions (e.g., Luo et al. 2021, Schanke et al. 2021), research has started to compare ADRs with HDRs (e.g., Burton et al. 2020, Castelo et al. 2023) and their effects on customer agreement with data requests and related outcomes, such as perceived decision quality (Xu et al. 2017), interest indications (Adam et al. 2023), and sales (Luo et al. 2019). Overall, studies mainly found that HDRs were more effective in eliciting data provision in initial business interactions, often because of customers’ priorities of trust and related variables (e.g., Qiu and Benbasat 2009, Xu et al. 2020, Adam and Benlian 2024).
Although extant studies have started to examine customer agreement with data requests from HDRs versus ADRs, limited attention has been paid to these dynamics in data requests beyond initial business interactions. Customers in established B2B relationships are less concerned about intentional exploitation by the vendor and are more concerned about the effort and accuracy required to fulfill the data request, which affects their agreement with the data request (e.g., Dwyer et al. 1987, Doney and Cannon 1997). Moreover, ADRs increasingly emerge in technology-mediated communication channels because of their advanced conversational capabilities, which often make them indistinguishable from HDRs while at the same time, offering efficiency improvements for both vendors and customers (e.g., Luo et al. 2019, Gnewuch et al. 2024). Yet, evidence is lacking regarding with whom—ADRs or HDRs—customers prefer to interact for data curation in established B2B relationships. Prior research in contexts unrelated to data curation indicates that customers tend to favor algorithms over humans, particularly in situations that are effortful, highly instrumental, and end result oriented (e.g., Puntoni et al. 2021). Concurrently, customers prefer humans over algorithms in highly consequential and uncertain cases, which require accurate decisions with minimal errors (e.g., Longoni et al. 2019, Dietvorst and Bharti 2020). Such divergent findings suggest that further research is necessary to provide empirical evidence and better understand how, why, and when customers agree with data requests from HDRs versus ADRs beyond early-stage B2C relationships.
Data enrichment and reconciliation play crucial roles as data curation practices in established relationships (e.g., Wixom and Watson 2001, Parmiggiani et al. 2022), encompassing data quality assurance and error identification (e.g., Klein et al. 1997, Lebovitz et al. 2021). Hence, customers may prioritize different attributes in the data requester because of the diverse purposes and implications inherent in data curation practices. Against this backdrop, it is of scholarly interest to study how and why the effects of ADRs versus HDRs on customer agreement with data requests differ in data curation and whether they persist or change across practices, representing different customer responses to agent-based data curation practices. These insights may shed light on how customers respond in established B2B relationships and thus, in broader terms, can also enhance our understanding of the human versus algorithmic agent phenomenon (e.g., Jussupow et al. 2024). Specifically, the findings can help determine whether customers’ algorithm aversion to data requesters is limited to first-time interactions or whether it persists in later stages. In the following section, we elaborate on information processing theory, the related effort-accuracy framework, and gain-loss message framing from prospect theory to understand the mechanisms through which customers process and evaluate characteristics of the data request and requester: that is, how, why, and when they may prefer ADRs or HDRs in the later stages of the B2B relationship.
2.3. Information Processing, Effort-Accuracy Trade-offs, and Gain-Loss Framings
Information processing theory was proposed by Simon (1955, 1978) and Newell and Simon (1972) to examine the mental processes involved in decision making for solving problems. This theory suggests that humans have limited cognitive capacity, act as cognitive misers, and thus, do not process all of the available information needed to make fully rational decisions. Instead, people seek and employ what they need to produce a satisfactory result, a result that is not necessarily optimal but good enough—one that satisfices (e.g., Simon 1955). Therefore, they prioritize the available information for deeper processing and use attention to identify the relevant pieces for a specific situation (e.g., Hann et al. 2007). Thus, information processing involves trade-offs as humans can only deeply engage with selected information while prioritizing it from among the available information for problem-solving.
Payne (1980, p. 95) referred to information processing theory in his seminal work and claimed that it has the “greatest potential for helping us achieve a better understanding of the psychology of decisions.” Payne et al. (1993) built on the theory and proposed the effort-accuracy framework, which provides a more detailed account of information processing. They suggest that decision making hinges on a cost-benefit analysis in which the effort needed to achieve an outcome and the accuracy of that outcome are considered. Effort attributes, such as the number of filtering steps to derive a product recommendation, signal effort and thus, indicate how demanding achieving the outcome is. In contrast, accuracy attributes, such as the fit of a product recommendation with a customer’s preferences, signal an outcome’s quality and error proneness. Similar to information processing theory, the effort-accuracy framework and its theoretical propositions have been used extensively to examine decision making with organizational data, such as in the use of decision aids for data analytics (e.g., Gerhart et al. 2022), for the adaptation of existing database queries (e.g., Allen and Parsons 2010), and for decision making on websites for B2C and B2B settings (e.g., Song et al. 2007).
Previous IS studies have built on the effort-accuracy framework to investigate decisions related to customer agreement with data requests from algorithmic recommendation agents because of their promise of reducing effort and increasing accuracy when searching for a product on the internet (c.f., Xiao and Benbasat 2007, Li and Karahanna 2015). These studies investigated, for instance, (1) customers’ use of recommendation systems in general (Todd and Benbasat 1992); (2) design features of algorithmic agents, such as decision strategies and explanation facilities (Wang and Benbasat 2009), preference elicitation methods (Lee and Benbasat 2011), and trade-off transparency (Xu et al. 2014); and (3) customer characteristics, such as age (Ghasemaghaei et al. 2019). The findings suggest that customers use the systems’ attributes and that they fit the tasks at hand to shape their expectations of effort and accuracy when making a decision. However, no prior study has yet considered an algorithm’s role in contrast to its human counterpart in data curation practices. Similar to the question of whether customers rely on a system or only on themselves for finding suitable products (Todd and Benbasat 1992), it is theoretically intriguing to investigate whether customers demonstrate divergent agreement with data requests from ADRs or HDRs to attain better customized services. Specifically, findings from this investigation can complement the human versus algorithmic agent literature (e.g., Jussupow et al. 2024) by shedding light on customers’ evaluations of effort and accuracy in established business relationships, which are explanatory mechanisms for customers’ main decisions regarding agreement with data requests for data enrichment and reconciliation.
At the core of the effort-accuracy framework lies the notion that decision making is not a one-calculus-fits-all-situations approach. Instead, decision makers consciously weigh the trade-offs between effort and accuracy, employing distinct information processing strategies to optimize one of these variables. Accordingly, customers’ selected decision strategies depend on their priorities in the respective decision context (e.g., Todd and Benbasat 1992, Benbasat and Todd 1996). However, customers do not haphazardly navigate the trade-offs between effort and accuracy. Rather than maintaining rigid priorities, individuals respond adaptively to contexts, leading them toward allocating their attention to effort or accuracy attributes accordingly. This adaptability fosters more nuanced cost-benefit evaluations, enabling the avoidance of trade-offs altogether by focusing solely on either effort or accuracy while disregarding other factors (e.g., Johnson and Payne 1985, Payne et al. 1988).
One contextual factor that influences the information processing of customers in making choices is the reference point and related gain-loss framings (e.g., Luce et al. 1997, 1999), which are central concepts used in prospect theory (Tversky and Kahneman 1991). Extensive research on reference points has consistently demonstrated that individuals possess a psychological inclination toward assigning different significance to the negative consequences of a loss compared with the positive outcomes of an equivalent gain. Consequently, individuals exhibit a decision-making bias, wherein they strive to minimize losses rather than maximize gains. Studies have used the concept of loss aversion to explain why loss-framed and related emotion-laden situations influence customers to perceive trade-offs more negatively and shape their overall decisions in favor of accuracy gains over effort savings (e.g., Payne 1982, Luce et al. 1999, Lee and Benbasat 2011). IS studies mainly examine early-stage, gain-framed customer interactions with ADRs, such as when sharing data to receive new product recommendations. Consequently, we know far less about late-stage, loss-framed interactions, such as when customers agree with data requests to maintain rather than lose an existing service (c.f., Li and Karahanna 2015).
The role of the reference points and related gain-loss framings is critical to our research on existing services and the two data curation practices. Although customers benefit from improved services by agreeing with data requests in the practice of data enrichment, those engaged in data reconciliation may lose their services if they choose not to agree with the data request. The underlying fear stems from the utilization of outdated data, which can potentially deteriorate the quality of services in the future. Thus, a customer’s agreement to a data request is significantly influenced by the perceptual message frame of the data request (i.e., potential gain or loss), the vendor company’s established business relationship with the customer firm, and the customized services already offered (i.e., reference point). Customer agreement with data requests can thus depend on the specific data curation practice as their prioritization of effort and accuracy attributes is affected by the perceived consequences of gaining additional services (i.e., data enrichment) or losing existing services (i.e., data reconciliation). Because of variations in the effort and accuracy attributes associated with ADRs and HDRs, customer agreement may differ within different agent-based data curation practices in established B2B relationships depending on how well the requester’s characteristics align with the specific context. Overall, we posit that customer agreement with data requests will depend on both the type of agent (i.e., HDR or ADR) and the kind of data curation practice (i.e., data enrichment or data reconciliation) because of different customers’ effort-accuracy trade-offs.
3. Hypotheses Development
Based on the aforementioned theoretical background, we develop our research model to hypothesize customer responses to agent-based data curation practices. Drawing on the broader information processing theory, we hypothesize the effects of HDRs relative to ADRs, focusing on the comparative effects of the data requesters. Moreover, we build on the effort-accuracy model and gain-loss message framings to unpack and include the explanatory mechanisms underlying customers’ information processing. Specifically, we develop mediation hypotheses that shed light on customers’ cognitive cost-benefit calculus. As such, we highlight the important role of effort expectancy, which represents customers’ beliefs about the level of effort required in shaping customer agreement with data requests in data enrichment. Additionally, we examine the significant impact of error concerns, which encompass customers’ considerations of processing accuracy, on customer agreement with data requests during data reconciliation. Figure 2 depicts the research model.
Note. H, hypothesis.
3.1. The Effects of Data Requester Type in Data Enrichment
During data enrichment, a customer is typically approached by a data requester to obtain new data, enabling the provision of customized services that cater to individual preferences and offer additional products and services (e.g., upselling and cross-selling). This approach involves setting up a customer profile beyond simple sales transactions. In this situation, the customer already has an interaction history with the vendor company and thus, an established B2B relationship. In an established relationship, customers no longer question the requester’s intentions or integrity; instead, they focus on evaluating the value of the requested data for improving services—essentially asking themselves if “sharing these additional data is worth the better service.” The customer, considering the consequences of data enrichment within the established B2B relationship, will likely view the data request as a potential gain as the provided data can enhance existing services. Consequently, the customer will use the vendor’s already established customized services as a reference point and identify the data request as an opportunity to benefit beyond the status quo. Moreover, a gain in services may not be particularly critical for receiving existing services, and the customer’s relationship with the vendor may not be in jeopardy if he or she disagrees with the data request. As such, the customer will likely seek and process information that aligns with the associations of this gain situation (e.g., Simon 1955, Newell and Simon 1972, Lee and Benbasat 2011).
We argue that a customer in an established B2B relationship is less likely to agree with a data request from an HDR (versus ADR) when engaged in data enrichment given the potential gain of more specific services and the priority of low effort. The literature on automation and the future of work (e.g., Jain et al. 2021, Chen et al. 2022) indicate the operational benefits of ADRs over HDRs, which allow for vast efficiency gains and improved convenience for customers. As such, gains in today’s increasingly digitalized customer services are particularly associated with the introduction and use of an algorithmic (versus human) workforce (e.g., Gnewuch et al. 2024, Adam et al. 2025). Specifically, in an established B2B relationship where customers have already used vendor services, they are likely to associate new algorithms, such as ADRs, with improvements in service, particularly with respect to efficiency in data enrichment, reflecting a suitable fit between the tasks and the technology. This argument aligns well with previous research showing that users prefer algorithms over humans performing tasks that are analytical, objective, and automatable, particularly those related to the use of data (e.g., Castelo et al. 2019, Logg et al. 2019). Hence, we propose that a customer in an established B2B relationship perceives agreement with a data request for data enrichment from an ADR as more closely associated with these potential gains at low incremental effort from technological progress than with those from an HDR. Consequently, a customer is more likely to exhibit lower agreement toward an HDR than toward an ADR. Thus, we hypothesize the following.
(
Next, we focus on the likely mechanism linking customer information processing and a related agreement with a data request from an ADR versus an HDR when engaged in data enrichment. We argue that customers involved in data enrichment find themselves in an advantageous position as they can gain access to enhanced services that surpass existing customized offerings. However, these additional services are not critical for accessing and receiving existing offerings. Accordingly, we postulate that a customer in an established B2B relationship prefers effortless over accurate interactions because providing additional data is not critical to receiving current services and is solely related to potential benefits in the form of additional services. In contrast to the early stages of a relationship, when the customer must evaluate whether the interaction is free of malicious intent and safe, the customer in an established relationship can focus on aspects directly related to the data request and the data requester. Because this data request aims to enhance services, customers primarily seek to minimize the effort needed to realize the potential gains. They may, therefore, wonder: “Will engaging with the data requester require extra effort?” To answer this question, the customer searches and evaluates the presented data request based on attributes related to effort (e.g., ease of use, goal achievement) rather than accuracy (e.g., quality of data acquisition and related services). Consequently, the customer tends to adopt an information trade-off strategy that favors conserving cognitive resources by minimizing effort rather than maximizing accuracy. This strategy centers on prioritizing effort-related characteristics that signify attaining the desired outcome with minimal exertion. Hence, when customers observe signals related to effectiveness and seamless progress toward their objectives of data movement from them to the data requester, they are more inclined to anticipate reduced effort. This anticipation, in turn, significantly boosts their willingness to agree with data requests for data enrichment, which are cognitively demanding and time-consuming tasks. Consequently, we expect that effort expectancy, a customer’s belief that the interaction with a data requester is effortful (Venkatesh et al. 2003), explains why a customer in an established B2B relationship is more (or less) likely to agree with a data request for data enrichment.
Indeed, researchers emphasize that ADRs executing operational tasks are less constrained by human limitations, such as response delays, sick days, occupational frustration, exhaustion, or inattentiveness (e.g., Huang and Rust 2018, Schanke et al. 2021). ADRs are more flexible and easier to use for operational routines, focus better on customers’ organizational demands, and require less communication for data curation, suggesting a good fit between the data curation practice and requester related to data curation. In contrast to HDRs, who may not be available during nighttime, break times, or less busy times, ADRs are always available. Moreover, ADRs can react spontaneously to the customer’s preferences (e.g., when a different appointment was canceled at short notice) and can easily answer routine questions for data enrichment by allowing customers to interrupt the ADR and skip unanswerable questions, which would be considered rather impolite with an HDR. As such, ADRs excel at addressing customer queries promptly, whereas HDRs are bound by a fixed schedule, resulting in limitations for direct interactions (e.g., response times) and engagement (e.g., constrained time resources for interactions). In addition, using an ADR instead of an HDR reduces the likelihood of missed interactions and the subsequent need to reschedule. As a result, customers find it less demanding to agree with a data request from an ADR than from an HDR and to realize the potential gain from engaging in data enrichment.
These arguments are in line with previous research that demonstrated that individual decision makers consider the assessment of effort to be more readily available and observable than accuracy and hence, often choose effort saving over increased accuracy when facing an uncritical and gain-framed decision (e.g., Payne et al. 1993, Fasolo et al. 2005). Similarly, customers opted to save effort over increasing accuracy when using recommendation agents for purchasing new products (e.g., Benbasat and Todd 1996, Luce et al. 1997). Moreover, IS research has demonstrated that effort expectancy is one of the strongest predictors of users’ acceptance of technologies, particularly in utilitarian contexts (e.g., Venkatesh et al. 2003, Cenfetelli et al. 2008). Relatedly, customers are more likely to accept product recommendations in utilitarian-focused decisions the more that the recommendation agent can assess and provide utilitarian value (e.g., Longoni and Cian 2022, Adam et al. 2023). In this regard, data studies point toward the importance of “data friction,” which is the cost of time, energy, and human attention at the interface between data surfaces, such as when data are transferred between agents (e.g., Edwards et al. 2011, Edwards 2013). Thus, the more a data requester evokes effort expectancy, the less likely it is that a customer will agree with a data request in a gain situation, such as data enrichment. Given that humans are considered more effortful than algorithmic agents (e.g., Castelo et al. 2019, Logg et al. 2019), we expect the key mechanism that explains customer agreement with data requests from HDRs over ADRs when engaged in data enrichment to be effort expectancy. Thus, a customer should be less likely to agree with a data request from an HDR than from an ADR because of higher levels of effort expectancy. Hence, we hypothesize the following.
(
3.2. The Effects of Data Requester Type in Data Reconciliation
During data reconciliation, customers are typically confronted with the choice of reviewing and potentially updating existing data. This decision is crucial because it enables them to continue receiving tailored services while avoiding irrelevant communication and offers. Vendors requesting agreement with data requests during data reconciliation may implicitly indicate to customers that the existing data are ineffective and unsuitable for providing appropriate services. Given this loss-related request in data reconciliation, a customer in an established business relationship likely wonders: “Can I address the required data update sufficiently when I agree with the data request from this data requester?” We contend that the inclination to agree during data reconciliation is rooted in the cognitive prioritization of information that supports the best solutions for consequential, disadvantage-related decisions. Specifically, a customer engaged in data reconciliation seeks reassurance signals indicating high familiarity and low failure proneness to avoid misunderstandings and incorrect or mishandled data insertion. These indicators influence the customer’s decision to secure or discontinue existing customized services. Accordingly, we anticipate a different prioritization of information when engaged in data reconciliation than in data enrichment (e.g., Simon 1955, Newell and Simon 1972, Lee and Benbasat 2011).
We posit that a customer in an established B2B relationship is more inclined to agree with a data request from an HDR than from an ADR when engaged in data reconciliation. This inclination can be attributed to customers’ heightened awareness of potential data losses or errors, prompting them to prioritize information on familiarity and safety when evaluating the data requester. The existing captured data ensure the seamless delivery of existing services. As such, ignoring updates of these data could potentially jeopardize customers’ processes and interrupt the receipt of existing services; so, more is at stake in data reconciliation than in data enrichment. We thus expect a customer in an established relationship to be more likely to perceive the desired information related to safety and familiarity in an HDR (versus an ADR). In this regard, we argue that the type of data requester plays a significant role. Customers often perceive ADRs as limited to standardized and repetitive processes, unable to handle complex and nonroutine data inputs, and thus, are poorly suited for data reconciliation practice. Unlike ADRs, HDRs are seen as being familiar with human demands and capable of accommodating nuanced and complex needs (e.g., Leung et al. 2018, Castelo et al. 2019). Thus, customers are likely to prefer HDRs as data requesters, particularly for their ability to understand customer data and handle nonroutine queries effectively. This customer association with HDRs mitigates perceived data insecurities and preempts expectations of future data-related challenges, making customers more likely to agree with a data request from an HDR rather than from an ADR.
These arguments align with previous research demonstrating that customers prioritize humans over algorithmic agents in consequential and stressful situations (e.g., Longoni et al. 2019, Dietvorst and Bharti 2020). Extensive empirical evidence demonstrates that algorithmic processes perform worse than human decision making when handling intricate customer data that rely on contextual understanding. Customers often express legitimate concerns over the perceived erosion of judgment that accompanies automation (c.f., Smith et al. 1996). A famous case at American Express illustrates this. An algorithmic data process failed to identify suspicious data (e.g., all zeros as the social security number and “God” as the employer) and issued a Gold Card to the wife of a man who had been dead for 14 years, a mistake that a human would have easily avoided (Smith 1994). Given the above arguments, we propose that a customer is more likely to reconcile data with an HDR (versus an ADR).
(
We now examine the plausible mechanism linking customer agreement to a data request from an ADR versus an HDR during data reconciliation. We posit that customers in an established B2B relationship will likely prioritize accuracy over efficiency when making their agreement decisions regarding data reconciliation. This preference stems from their apprehension regarding potential inaccuracies in future service provisions. Accordingly, we anticipate a reversal of the hierarchy of effort-accuracy priorities when engaged in data reconciliation (versus data enrichment). When a customer encounters signs that inspire confidence and indications of data quality, they enable informed judgments, heightening the propensity to agree (versus disagree) with data requests during data reconciliation. Thus, we posit that error concerns encompassing a customer’s anxieties about the effectiveness of safeguards against intentional or unintentional errors in customer data (Smith et al. 1996) will play a pivotal role in elucidating the underlying factors driving customer agreement when engaged in data reconciliation. As such, a customer may ask: “Will the engagement with the data requester produce error-free results?”
Given that potential data errors are the key reason for data reconciliation, we believe that a customer’s foremost concern in an established relationship is ensuring accuracy, particularly against accidental errors, as customers are unlikely to expect a deliberate error in the established business relationship. We contend that the type of data requester plays a crucial role in eliciting concerns about data accuracy. A customer may believe that a specific type of requester does not prioritize error-minimization measures, leading to diminished agreement with requests from a requester who exhibits insufficient attributes to reduce data errors. Accordingly, a customer’s perception of accuracy, particularly regarding error concerns, may be significantly diminished when interacting with an HDR who is considered more personal and understanding. At the same time, it may become more pronounced when dealing with an ADR, which is often considered more standardized and process rigid (e.g., Castelo et al. 2019, Longoni et al. 2019). As a result, customers will feel more secure when they recognize the presence of an HDR, leading to increased cooperation and agreement with data requests during data reconciliation. In contrast, customers may have reservations about the reliability of an ADR, leading them to question the accuracy that they seek and a lack of alignment between the technology features and the nature of the practice. This may be particularly significant because the more challenging, nonroutine, and semantically intensive needs of customers are likely to be handled better by HDRs than by ADRs.
This rationale aligns with previous research on individual decision making that highlights the importance of reducing error proneness as the focal aspect of accuracy when customers expect the potential for errors (c.f., effort-error trade-offs) (e.g., Payne 1982). Previous studies have pointed toward customers reacting more acutely in loss situations, indicating that they value effort saving less in comparison with reaching a more accurate and error-free outcome, even to the degree that effort expenditure is no longer a significant variable in the mental cost-benefit calculus (e.g., Luce et al. 1997, Lee and Benbasat 2011). Recent research has consistently highlighted the positive relationship between a recommender’s perceived accuracy and customer acceptance of recommendations (e.g., Castelo et al. 2019, Longoni and Cian 2022). Therefore, if a data requester raises concerns about errors, indicating a lack of effective error-handling measures, a customer is less likely to agree with a data request during data reconciliation. As such, a customer is more likely to agree with a data request when engaged in data reconciliation by an HDR than by an ADR because of the lower error concerns associated with the HDR.
(
4. Study 1: Randomized Field Experiments
4.1. Purpose and Methods
We employed a multimethod approach (e.g., Mingers 2003, Fink 2022) and leveraged the complementary properties of a randomized field experiment and a subsequent randomized online experiment to test our hypotheses. The first study addressed the direct effect hypotheses (i.e., Hypotheses 1a and 2a). It was based on a customer agreement with data requests via email communication from a real company, enabling high ecological validity and generalizability.
4.2. Company Background and Context
We collaborated with the vendor company DataRequesterCo2 to conduct the randomized field experiment. DataRequesterCo is a leading European pharmaceutical company with more than €5 billion in annual sales. It sells various pharmaceutical products, including machines, supplies, and services for laboratory applications, to customer firms in the pharmaceutical and related technological sectors. Sales representatives from DataRequesterCo typically interact with professionals from customer firms to inform them about service offerings that can help them accomplish their tasks. Thus, these professionals need to decide whether their “own” organizational data should be entered into or disclosed to DataRequesterCo to receive offerings. The purchased products are often highly customer specific (e.g., chemicals used, daily volume needs, monitoring requirements, necessary certifications). Relatedly, DataRequesterCo’s customized services can provide important information that can help these professionals with their business tasks (e.g., valuable updates for offerings, alternative products, proactive communication, automatic reminders as well as maintenance schedules, and reduced time spent searching for suitable products), so they are generally open to elevating these services via data enrichment.
It is important to note that machine and supply usage and customer contacts change over time; hence, DataRequesterCo often encounters outdated customer data. It thus requires data reconciliation to keep providing customized services (e.g., material availability, end of production of certain products) that customers value. Without these services, customers need to retrieve the required information individually from DataRequesterCo’s website or other sources (e.g., DataRequesterCo’s staff, competitors’ websites). As the requested data can help improve customized services specific to customers, it is in their interest to provide these data. As such, if customers provide the data following a data request, it can help the vendor improve the services so that the provision is relevant to the customers. Online Appendix E.1 provides sample questions regarding the requested data.
DataRequesterCo granted us access to its customers who had acquired a machine between 2000 and 2022. Customers typically modify their operations after using this machine for awhile, requiring additional or different supplies (e.g., chemicals) and services (e.g., repair and maintenance) and presenting further sales opportunities. These sales usually reach up to €30,000 for a single transaction, excluding other potential sales, such as cross-selling and after sales. However, the required supplies and services rely on open standards and can easily be provided by competitors, hence not representing guaranteed sales for DataRequesterCo. Therefore, correct and timely services are crucial to avoid missing out on sales opportunities. Furthermore, customer data provided during the initial purchase are usually not documented in detail because of operational inconsistencies and a lack of standards and guidelines on the vendor’s side. Thus, customer profiles may or may not exist depending on whether the service representatives have set up such profiles, even for customers with long relationships with the vendor. Customers are usually unaware of what is documented in DataRequesterCo’s data management system, so they consider both data enrichment and reconciliation requests realistic and appropriate. Moreover, data requests from customers during data curation resemble established B2B encounters and the potential to gain both new data and update existing data because (1) a period has elapsed since the sale of the original machine to the customer, usually without any major data exchanges in between; (2) customers’ machine usage and needs change over time, making their data outdated yet crucial for customized services and further sales; and (3) there are substantial fluctuations, particularly on the data requesters’ side (e.g., job rotation, promotion, turnover), making it likely that the data requesters and customers have had no direct touchpoint before, necessitating fresh contact and the request for data curation.
During recent automation processes, DataRequesterCo decided to use both ADRs and HDRs to request customer data via email. Collaborating with DataRequesterCo, we designed and executed a randomized field experiment unbeknownst to the customers. DataRequesterCo’s customers made real-life data decisions with considerable implications for themselves and DataRequesterCo. Given this setting, the study’s findings are not influenced by reporting biases or demand effects commonly associated with survey and laboratory research.
4.3. Experimental Design
We randomly assigned customers to one of four experimental conditions in a between-subjects design. Each customer received one email from one of two data requesters (i.e., an ADR or HDR) to respond to a data request in one data curation practice (i.e., data enrichment or data reconciliation). In the baseline data requester condition, ADR, the data requester represented an algorithmic identity, whereas in the HDR condition, the data requester represented a human identity. Customers were aware that the vendor’s representatives would occasionally approach them, but they were unaware of what data the vendor company had collected and whether a profile with their data existed. This ambiguity provided an opportunity for us to use the situation for both data enrichment and reconciliation. As such, the data requester could refer to the same data from a data enrichment or reconciliation perspective, ensuring the comparability and validity of the effects regarding data requesters and data curation practices. The data enrichment manipulation included a data request to provide new additional customer data to the data requester for customized services by explicitly setting up a customer profile. In contrast, the data reconciliation condition had a data request to review existing customer data and potentially update it with the data requester for customized services within an established profile. Besides these differences, the data requesters presented identical emails (e.g., introduction, presentation) and saliently indicated the data request type and their identity several times (i.e., in the address, farewell message, and signature). Similarly, it was equally effortful to agree to or reject a data request with both types (i.e., clicking a button). Online Appendix B presents examples of the emails sent. We ran a pretest with 407 participants to ascertain that customers could identify the respective data requester type and data curation practice as intended. Online Appendix C provides details on the manipulation checks.
The authors have a long-lasting partnership with DataRequesterCo. The planning, preparation, and execution of the field experiment took approximately one and a half years, starting in 2022 and concluding in 2023, with subsequent interactions extending into 2025 to better understand the emerging insights (e.g., Van de Ven 2007). Before the field experiment, we conducted one workshop with DataRequesterCo’s data requesters, specialists, and customers, ensuring that we correctly interpreted the setting (e.g., established customer-vendor relationship, customer perceptions of benefits from existing services and data at DataRequesterCo) and that our experimental design (e.g., the email design and content) was realistic and adequate. Additionally, we conducted one pilot study to test the technical functionality and effectiveness of our experimental design. We ensured that the procedure and sent emails included content representative of the regular data requests. The requested data were important for service provision but did not indicate any data related to a customer’s personal preferences that could potentially intimidate the customer. To rule out any confounding effects because of previous interactions between data requesters and customers, we ascertained that no type of data requester had previous touchpoints (e.g., emails, calls) with the contacted customers. We also ensured that effects were free of time-related confounds by ascertaining that those emails went out at 10 a.m. during the customers’ usual working hours. Lastly, we conducted the experiment in February and March 2023, a period when DataRequesterCo did not expect any seasonal fluctuations (e.g., common vacation periods, budget constraints) that could influence the experiment.
4.4. Experimental Procedure and Sample Description
The experimental procedure comprised the following steps, allowing us to directly examine how different data requester types influenced customer agreement. (1) DataRequesterCo sent each customer an email from an ADR or HDR. In this email, the data requester requested that the customer agree or disagree with a data request specific to the data curation practice. (2) Each customer could respond to the email directly or by clicking one of two implemented buttons within the email. (3) After answering and clicking the respective link, customers were forwarded to DataRequesterCo’s customer interaction center, a modern form of call center that provides various forms of interaction (e.g., contact form, phone, video calling, webchat), which can happen ad hoc or as preparation for future interactions (e.g., scheduling an appointment). To keep the conditions simple and similar as well as to avoid potential biases in the chosen kinds of interactions, we did not provide details on the kinds of interactions in the email to the customers. This approach of not explicitly mentioning the form of interaction is also the practice used by DataRequesterCo as the customer interaction center provides various interaction options, which are also usually known to the customers. (4) Customers who disagreed with the data request were thanked for their answer (i.e., “refused setup/update”) and bid farewell on the website of the customer interaction center. Customers who agreed with the data request received access to an interface in the customer interaction center for data enrichment or data reconciliation, which the data requester prepared and with which they could interact right away or within two weeks to realize the data request once they agreed by clicking the link. (5) Customers were thanked for their engagement and forwarded to DataRequesterCo’s main website.
We applied stratified random sampling to a pool of DataRequesterCo’s customers from different geographic regions and sectors in Germany, ensuring that each condition had approximately the same number of customers and similar characteristics regarding gender, education, and years since the initial purchase. Of a total of 1,315 emails sent, 250 (19.0%) customers responded to the emails and thus, were considered for our analyses.3 Of these 250, 173 (69.2%) agreed with the data request, and 77 (30.8%) disagreed. We provide additional information on the descriptive statistics in Online Appendix D.
4.5. Analyses and Results
4.5.1. Model-Free Results.
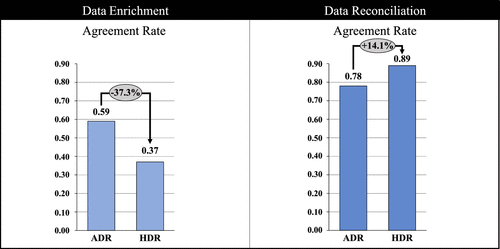
As an initial analysis, we first report model-free results based on the mean comparisons between data requesters and the data curation practices. Consistent with previous research on data requests (e.g., Perez et al. 2023), we calculated a (Customer) Agreement Rate for each data request condition, which is the ratio of the number of customers who explicitly agreed with the data request to the total number of customers who explicitly responded (i.e., agreed or disagreed). We calculated the Agreement Rate for each data curation practice as follows:
Figure 3 shows the Agreement Rate across the two data requester types and data curation practices. For data enrichment, HDR had a significantly lower Agreement Rate than ADR, which was 37.3% lower when comparing HDR with ADR (MHDR = 0.37 versus MADR = 0.59, F = 4.80, p < 0.05). Thus, we find initial support for Hypothesis 1a. Regarding data reconciliation, HDR had a significantly higher Agreement Rate than ADR. Specifically, the Agreement Rate was 14.1% higher when comparing HDR with ADR (MHDR = 0.89 versus MADR = 0.78, F = 3.43, p < 0.1). Thus, we also find initial support for Hypothesis 2a.
4.5.2. Main Effects.
Next, we focus on our dependent variable, Customer Agreement Likelihood, which indicates how likely customers are to respond (i.e., agree versus disagree) to a data request. We employed logistic regression to assess the identified effects of data requester types on the (Customer) Agreement Likelihood after accounting for other covariates (i.e., gender, education, years since initial purchase). The Agreement Likelihood is a function of the randomized conditions as described below:
Ui denotes whether customer i decided to agree (versus disagree) with the data request in the respective data curation practice. The key variables are the data requester types (i.e., HDR and ADR), with ADR as the comparison baseline. Table 1 presents the results of the logistic regression to examine the effects of HDR (versus ADR) for Agreement Likelihood in data enrichment and data reconciliation.
|

Table 1. Customer Agreement Likelihoods (Study 1)
| Variables | Data enrichment | Data reconciliation |
|---|---|---|
| HDR (vs. ADR) | −0.94** (0.42) | 0.92* (0.48) |
| Control variables | ||
| Gendera | −0.26 (0.42) | 0.31 (0.47) |
| Educationb | −0.04 (0.69) | −0.38 (0.80) |
| Years Since Sale | −0.07* (0.04) | −0.02 (0.04) |
| Intercept | −1.01** (0.38) | 1.19*** (0.51) |
| N | 100 | 150 |
| −2 log likelihood | 129.89 | 127.38 |
| Nagelkerke R2 | 0.11 | 0.05 |
Notes. Standard errors are in parentheses. ADR is the baseline.
a0 = female; 1 = male.
b0 = non-PhD; 1 = PhD.
*p < 0.1; **p < 0.05; ***p < 0.01.
Our results corroborated the model-free results. For data enrichment, customers had a significantly lower Agreement Likelihood when encountering an HDR relative to an ADR. Relative to encountering an ADR, customers were 61% less likely to indicate fulfilling the data request when engaged in data enrichment and encountering an HDR (βHDR = −0.94, Exp(βHDR) = 0.39, p < 0.05). These results support Hypothesis 1a. For data reconciliation, the analyses reveal that customers had a significantly higher Agreement Likelihood when encountering an HDR relative to an ADR. As such, customers were 150% more likely to agree with the data request when encountering an HDR (βHDR = 0.92, Exp(βHDR) = 2.50, p < 0.1). These results support Hypothesis 2a. We also checked for potential nonresponse bias. Our analyses and interpretations do not indicate any concerns regarding the main findings (see Online Appendix D).
4.5.3. Post Hoc Analysis: Customer Completion Rate.
In the main analyses, we investigated customer agreement with data requests. In the post hoc analysis, we also checked customer completion—whether customers successfully completed the entire process of agreeing to and fulfilling a data request (i.e., they added or updated data) relative to the total number of customers who responded to the data request. This metric reflects the effectiveness and efficiency of the data request in securing customer participation and compliance during data curation above and beyond whether responding customers agreed or disagreed with the request (i.e., Customer Agreement). Online Appendices E.2 and E.3 provide details of the calculations.
Of the 250 customers who responded, 173 (69.2%) agreed with the data request, but only 148 (59.2%) completed the data request, representing 85.6% of the customers who agreed. All customers who started the interaction to fulfill the data request also completed it fully. Figure 4 shows the Completion Rate across the two data requester types and data curation practices. For data enrichment, there was a significant difference between HDR and ADR regarding the Completion Rate in that the Completion Rate was 54.2% lower when comparing HDR with ADR (MHDR = 0.22 versus MADR = 0.48, F = 7.67, p < 0.01). Regarding data reconciliation, there was no significant difference regarding the Completion Rate (MHDR = 0.78 versus MADR = 0.74, F = 0.41, p > 0.1).
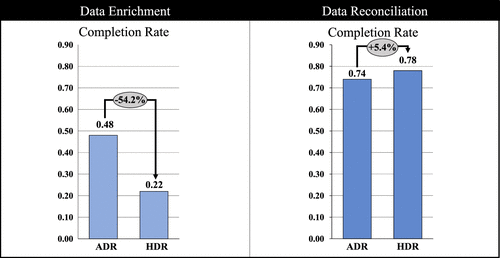
We subsequently conducted regression analyses to assess the identified effects of data requester types on Completion Rates for both practices after accounting for other covariates. Table 2 shows the findings. For data enrichment, the binary regression analysis consistently corroborated the model-free results. Customers had a significantly lower Completion Likelihood when encountering an HDR relative to an ADR. Relative to encountering an ADR, customers were 71% significantly less likely to fulfill the data request when encountering an HDR (βHDR = −1.24, Exp(βHDR) = 0.29, p < 0.01). For data reconciliation, customers were not significantly more likely to fulfill the data request when encountering an HDR (βHDR = 0.29, Exp(βHDR) = 1.34, p > 0.1).
|
Table 2. Completion Likelihoods (Study 1)
| Variables | Data enrichment | Data reconciliation |
|---|---|---|
| HDR (vs. ADR) | −1.24*** (0.45) | 0.29 (0.40) |
| Control variables | ||
| Gendera | 0.34 (0.45) | 0.32 (0.40) |
| Educationb | −0.50 (0.75) | 0.13 (0.61) |
| Years Since Sale | −0.03 (0.04) | 0.01 (0.04) |
| Intercept | −0.60 (0.48) | 0.76* (0.44) |
| N | 100 | 150 |
| −2 log likelihood | 119.05 | 164.13 |
| Nagelkerke R2 | 0.12 | 0.01 |
Notes. Standard errors are in parentheses. ADR is the baseline.
a0 = female; 1 = male.
b0 = non-PhD; 1 = PhD.
*p < 0.1; **p < 0.05; ***p < 0.01.
In sum, although the main findings of the field experiment allow us to conclude that the data requester type significantly affected customer agreement as hypothesized, the effects of the data requester types and data curation practices are mixed and do not necessarily translate into customer completion.
4.5.4. Additional Qualitative Insights Related to the Completion Rate.
To gain additional insight into the customer completion findings, we asked DataRequesterCo to track potential responses to the email outreach. Moreover, we requested that DataRequesterCo reach out to some customers who did not fulfill the data request on time and ask for their rationale. Through these responses and interviews with willing customers, we learned that customers who encountered the HDR indicated their intent but that they planned to return and fulfill the data request later when they had more time to act with the HDR. For instance, one customer wrote an email as a reaction to the HDR’s outreach with the content: “Just a short note: I have clicked on the suggested button in the email to do the data task. I will get back to you once I have sufficient time to interact with you.” However, they did not return to complete it within the experiment’s time frame. In line with this statement, other customers also seemed to fulfill the data request more immediately with the ADR and planned to engage more thoroughly with the HDR. However, their daily work environments had constraints (e.g., a lack of time and cognitive resources, distractions, and tasks with higher priorities) that did not push them to fulfill the data request in time. For example, one customer said, “I still have it on my to-do list, but haven’t found the time yet to get back to you.” Similarly, another customer, after being contacted regarding completion, stated: “Thanks for getting back to me. I completely forgot about the task. I will do it right away with you.” Thus, customers fulfilled the data request less with HDRs, even if they initially had a higher agreement rate in terms of numbers. Postponed completion supports the assumption that although HDRs are preferred by customers engaged in data reconciliation regarding agreement, customer actions are not immediate and context agnostic. Instead, features of the data curation setting—here, specifically, the postponement of the fulfillment of the data request—can crucially affect the completion of data requests when engaged in data curation and thus, the realized effectiveness of different data requester types. We discuss the findings in more detail in the discussion in Section 7.
5. Study 2: Randomized Online Experiment
5.1. Purpose and Methods
The randomized field experiment in Study 1 afforded high ecological validity because of its real-life setting, in which we investigated customer agreement with data requests from different data requesters and data curation practices within established B2B relationships. However, the study was constrained in terms of internal validity as customers processed our emails as part of their day-to-day business operations, and we were unable to assess the underlying mechanisms that explain the direct effects of data requester types on customer agreement. Moreover, our analyses focused on responding customers who explicitly agreed or disagreed with the data request, leaving out customers who did not respond because of unclear reasons for nonresponding. We aimed to address these limitations in Study 2 by supplementing the high external validity of the first study with a controlled, randomized online experiment to achieve high internal validity. Further, we aimed to investigate the key explanatory mechanisms underlying the direct effects of data requester types in each of the two data curation practices.
We designed Study 2 analogously to Study 1 regarding the experimental procedures, the design of the outgoing emails with the data requests, and the manipulations of the data requester types and data curation practices. Study 2 mainly differs from Study 1 in some aspects of the experimental procedures, the sample, and the measured variables (i.e., dependent variable, mediators, controls, and attention checks). The following subsections detail these differences.
5.2. Experimental Procedures
Following established guidelines for experimental designs (e.g., Aguinis and Bradley 2014, Maruping et al. 2025), we used a scenario to simulate realistic decision making for our randomized online experiment. To set the research setting briefly without unintentionally priming participants, we instructed them to imagine that they had an established business relationship with a well-known vendor company with which they had already interacted and provided data in the past. With this information in mind, the participants would then see an email from this company. We randomly assigned participants to one of four conditions, which differed in terms of the data requester type and data curation practice, and were identical to the four conditions in Study 1.
To collect sample data comparable with Study 1, we contacted a European market research firm and recruited participants who worked in B2B sales settings (i.e., relationship management, buying products and services). Similar to the timing in Study 1, we released the experiment links at approximately 10 a.m. In the experiment, participants underwent an experimental procedure similar to that of Study 1. However, all participants had to decide whether to agree or disagree with the data request, so “not responding” was not an option. Making the agreement decision mandatory also allowed us to capture the decisions and perceptions of those who would not necessarily have responded to the email, such as was the case in the field experiment, thus increasing the robustness of our findings from Study 1. The experiment duration was not affected by the choice to agree or disagree. After the participants had indicated their responses, we instructed them to complete a questionnaire that included measures for our mediators, controls, and attention checks. We did not ask participants to fill in data request-related questions in a customer interaction center as the presentation and provision of fake data associated with the conversion were considered somewhat artificial in an online experiment and would have created rather misleading effects and insights (e.g., Fink 2022).
5.3. Dependent Variable, Mediators, Controls, and Sample Description
Similar to Study 1, we also calculated the Agreement Rate for Study 2. We also accounted for and measured sample characteristics and controls (i.e., Age, Gender, Education, and Knowledge About Algorithmic Agents) to check for the robustness of our findings. Additionally, we used and adapted established scales to measure Effort Expectancy (Venkatesh et al. 2003) and Error Concerns (Smith et al. 1996) to conduct mediation analyses as well as Privacy Concerns (Dinev and Hart 2006) to rule out alternative explanations. We mainly used seven-point Likert-type scales ranging from strongly disagree (one) to strongly agree (seven). Finally, we included two attention checks.
From a total of 400 participants who were assigned to one of the four conditions, we removed 76 participants (19.0%) who failed at least one of our attention checks to increase the validity of our results, a rate and procedure comparable with other scenario-based online experiments (e.g., Aguinis and Bradley 2014). Our final sample comprised 324 participants for the subsequent analyses. Online Appendix F provides descriptive statistics, the measurement items, the constructs’ psychometric properties, and the results of a confirmatory factor analysis demonstrating our constructs’ convergent and discriminant validity.
5.4. Results
5.4.1. Model-Free Results.
We first report model-free results based on mean comparisons between the data requester types across the data curation practices (see Figure 5). Results for data enrichment show that HDR had a significantly lower Agreement Rate than ADR; the Agreement Rate was 19.5% lower when comparing HDR with ADR (MHDR = 0.66 versus MADR = 0.82, F = 5.11, p < 0.05). In contrast, for data reconciliation, HDR had a 19.4% higher Agreement Rate than ADR (MHDR = 0.86 versus MADR = 0.72, F = 5.17, p < 0.05). Thus, in line with Study 1, we find initial support for Hypotheses 1a and 2a.
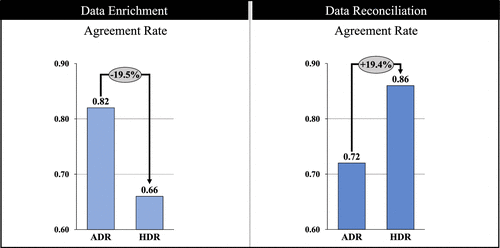
5.4.2. Main Effects.
We next conducted a logistic regression similar to that in Study 1 to ensure that covariates (i.e., Age, Gender, Education, and Knowledge About Algorithmic Agents) do not drive the model-free findings of the effects of data requester types. Table 3 presents the details of the results.
|
Table 3. Customer Agreement Likelihoods (Study 2)
| Variables | Data enrichment | Data reconciliation |
|---|---|---|
| HDR (vs. ADR) | −0.81** (0.39) | 0.89** (0.41) |
| Control variables | ||
| Age | −0.01 (0.45) | 0.01 (0.40) |
| Gendera | 0.04 (0.37) | −0.18 (0.61) |
| Educationb | −0.18 (0.19) | −0.18 (0.18) |
| Knowledge | 0.01 (0.15) | −0.24* (0.04) |
| Intercept | 0.38 (1.26) | 0.00 (1.35) |
| N | 154 | 170 |
| −2 log likelihood | 167.40 | 166.51 |
| Nagelkerke R2 | 0.07 | 0.08 |
Notes. Standard errors are in parentheses. ADR is the baseline.
a0 = female; 1 = male.
b0 = non-PhD; 1 = PhD.
*p < 0.1; **p < 0.05.
The regression analyses corroborated the model-free results. Specifically, customers were more than 56% less likely to agree with the data request when encountering an HDR in contrast to encountering an ADR during data enrichment (βHDR = −0.81, Exp(βHDR) = 0.44, p < 0.05) and 143% more likely when encountering an HDR during data reconciliation (βHDR = 0.89, Exp(βHDR) = 2.43, p < 0.05). Thus, the results further support Hypotheses 1a and 2a.
5.4.3. Mediation Analyses.
We hypothesized that customers in established B2B relationships face different priorities in different data curation practices, which drive their effort-accuracy trade-offs and responses. Whereas customers tend to focus on effort attributes to assess the effort required when engaged in data enrichment, they care more about error attributes to address their concerns about errors when engaged in data reconciliation.
To test our mediation hypotheses, we performed mediation analyses using the bootstrapping mediation technique with 10,000 samples and 95% confidence intervals (CIs). For this approach, we used PROCESS, a widely used tool in social and business research, to estimate direct and indirect effects in single-mediator and multiple-mediator models through observed variable ordinary least squares and logistic regression path analysis modeling (Hayes 2022, model 4). We used ADR as the baseline. We first entered HDR as the independent variable and Agreement Likelihood as the dependent variable along with the control variables, which are similar to our models in Table 3. We then added Effort Expectancy and Error Concerns as mediators. Results reveal that in the practice of data enrichment, the direct effect of HDR on Agreement Likelihood is significantly mediated via Effort Expectancy (indirect effect = −0.73, 95% CI = [−1.64, −0.22]), whereas Error Concerns does not significantly mediate the direct effect (indirect effect = 0.08, 95% CI = [−0.15, 0.43]). In contrast, for data reconciliation, we find that the direct effect of HDR on Agreement Likelihood is significantly mediated via Error Concerns (indirect effect = 0.62, 95% CI = [0.15, 1.54]) but not via Effort Expectancy (indirect effect = −0.31, 95% CI = [−1.14, 0.21]). Overall, these results support our mediation hypotheses (Hypotheses 1b and 2b), demonstrating diverging indirect effects of HDR (versus ADR) on Agreement Likelihood via Effort Expectancy and Error Concerns depending on the data curation practice. Moreover, the significant direct effects of data requester types in the base models became insignificant in the mediation models, signifying that the analyses did not omit any crucial mediators (e.g., Zhao et al. 2010).
As supplementary analyses, we ran the same mediation analyses, including Privacy Concerns as an additional covariate for both the mediators and dependent variable, with qualitatively similar results. This indicates that our findings are robust, even when accounting for Privacy Concerns in the mediation models, helping to extend the generalizability of our findings.
6. Supplementary Qualitative Insights from the Follow-up Survey and Interviews with Customers
To gain a more nuanced understanding of our findings from the quantitative studies, we gathered qualitative follow-up insights. Two primary purposes guided us. First, with a focus on later-stage B2B relationships, we wanted to understand the importance of data sharing and key assumptions that shape it. Second, we sought richer insights into why—and under what conditions—different data requesters influence customer agreement to data requests. After careful deliberations, we decided to employ open-ended questions based on findings from our experiments to both corroborate the quantitative results and better round out our understanding of the emerging phenomenon of agent-based data curation practices (e.g., Venkatesh et al. 2013, 2016).
To do so, we requested and received permission to email DataRequesterCo’s customers directly for follow-up questions on their interactions with DataRequesterCo. We emailed the same 1,315 customers from our experiment in Study 1, inviting them to participate in a follow-up online survey of approximately 30 minutes, which included open-ended questions. We chose this interaction form as our initial follow-up method as recommended by representatives of DataRequesterCo. The online survey provided the freedom and autonomy to complete at the customer’s convenience. At the end of the survey, we asked if respondents would like to participate in a face-to-face 45-minute interview via Zoom. To incentivize participation, we provided a €50 Amazon voucher for completing the survey and an additional €50 Amazon voucher for participating in the interview. Moreover, we promised anonymity when presenting the findings (e.g., Podsakoff et al. 2024).
In total, 37 participated in the online survey, of whom 5 also participated in the face-to-face interviews. This effort resulted in more than 100 pages of new transcribed information. Table G.1 in Online Appendix G presents the open-ended questions from the survey and the interview guide along with the semistructured questions used in the interviews. We analyzed the resulting qualitative data based on a structural, thematic coding approach, which refers to assigning labels to segments of data based on specific topics or themes that reflect the structure of the research or interview questions (e.g., Braun and Clarke 2021, Saldaña 2021). We focused on questions that explored the nature of B2B relationships as they related to the respondents and the differences and similarities between ADRs and HDRs. For the former, we examined field assumptions related to customer expectations in their established B2B relationships, which included (1) perceived value of data provision to data requesters, (2) perceived adverse consequences when the vendor does not have accurate and up-to-date data, (3) differences between early- and late-stage B2B relationships and relationship dynamics, and (4) reasons for missing task completion. We also investigated customer perceptions of differences in interaction with customer agent types, particularly regarding (1) effort expectancies; (2) error concerns; and as a new category through discussions, (3) sales inclinations.4 We applied inductive coding to generate complementary insights regarding our field assumptions, whereas we used deductive coding to deepen our understanding of customers’ perceived differences in data requester types based on existing results from Study 1 and Study 2 (e.g., Saldaña 2021). The coding was carried out independently by two of the authors, and any differing responses were recorded. After completing the initial structural coding, we convened regular meetings to compare codes and resolve any disagreements until reaching a shared decision on the final coding scheme. Table G.2 in Online Appendix G presents the coding scheme along with the qualitative results and illustrative quotes. Next, we present the main inferences from our qualitative research in relation to the findings from the quantitative experimental studies.
6.1. Qualitative Insights on Differences in Relationship Stages and Dynamics
A key aspect emphasized in this paper is that the nature of interactions between vendors and customers is dependent on whether the relationship between them is new or well established, and furthermore, this difference impacts the use of ADRs and HDRs in different data curation practices. Our qualitative analysis suggests strongly that customers distinguish between early- and late-stage B2B relationships and relationship dynamics, particularly in terms of trust and concerns related to exploitation. As a result, the nature of data exchanged between them may differ based on the stage of the relationship as is evident from the following quote from a respondent.
At the beginning, there isn’t always trust right away. Of course, we also disclose data or ideas about what we do here. We’ve also done this with other companies in the past. For example, we do organ cultures on pig eyes here. We used to be the only ones doing this. In the meantime, it has become a little more established, but we have also seen that this idea has suddenly been taken further. Perhaps not intentionally on the part of the representatives, but it has also taught us that perhaps you don’t always reveal everything at the beginning and don’t give away your price expectations straight away, for example. That’s no longer the case at DataRequesterCo, when you say, okay, we’ve known each other for five, six, seven years now and, above all, if it’s often the same person or the successor has been introduced, then I don’t worry as much in the conversation as I would if it was someone completely new.
Similarly, customers in established B2B relationships are less concerned about intentional exploitation by the vendor, which is a significant concern in early stages of a business relationship. This is aptly captured by a quote by one of the respondents.
Yes, my attitude to providing and using information might change if I were to interact with DataRequesterCo for the first time. Currently, my relationship with DataRequesterCo is based on 10 years of working together, characterized by mutual trust. I know that interactions are in good faith, and I don’t have to worry about rogue behavior, exploitation, or intentional misleading. With a new provider, however, I would initially be more cautious and approach the provision of information with a healthy dose of skepticism. Only through positive experiences and clear, trustworthy communication would this attitude relax, and a basis of trust similar to DataRequesterCo’s would develop.
The comments above demonstrate that the dynamics of interactions between vendors and customers evolve over time, with the focus shifting from establishing trust to more functional aspects. Customers in established B2B relationships are thus more concerned about aspects other than trust when required to fulfill the data request (e.g., effort and errors), which affects their agreement with the data request and differentiated preference for ADRs and HDRs in different situations. We posit that customers in new B2B relationships, in contrast, may mandate HDRs in all situations until the trust has been established with the vendor.
6.2. Customer Expectations for Data Provision in B2B Relationships
Given our interest in customer expectations of data provision in established B2B relationships, we scoped for insights that align with our field assumptions. Through inductive coding, we discovered compelling evidence that customers perceive significant benefits from providing data to data requesters and believe that adverse consequences will result from the vendor not having accurate and up-to-date data. Lastly, we uncovered substantial backing for forgetting to complete data requests, which is a common phenomenon that occurs more frequently in less urgent interactions. Online Appendix G provides more details and quotes regarding the supplementary findings from the investigation of our field assumptions.
6.3. Boundary Conditions for Deploying Human vs. Algorithmic Data Requesters
We also sought qualitative insights into why and when different kinds of data requesters influence customer agreement to data requests in their established B2B relationship, corroborating important boundary conditions on when to deploy them: specifically, whether customers perceive similarities and differences between HDRs and ADRs. Grounded in the definitions of and prior research on the respective variables, we employed a deductive coding approach to test two primary types of customer perceptions related to effort expectancies and error concerns. Online Appendix G provides the coding schemes and more example quotes as well as information on further customer perception related to sales inclinations that emerged from the analysis.
6.3.1. Effort Expectancy.
The quantitative findings indicated that customers exhibit reduced agreement rates when engaged in data enrichment when faced with an HDR (versus ADR), primarily because of higher levels of effort expectancy associated with the HDR. Accordingly, we asked customers what they think about interacting with a human versus an algorithm for data tasks in their established B2B relationship. Emphasizing the fact that effort expectancy is much lower with an ADR and that an ADR is more efficient, one of our respondents said:
Similarly, another respondent said:“It [an algorithm] can probably process everything much, much faster, significantly faster than a human. In terms of speed, I don’t think a machine can be beaten. That’s what I would say, yes, in favor of the machine.”
A third respondent stated:“An AI-powered assistant would be ideal for providing information quickly, as it usually offers faster processing speed and shorter response times. In addition, the AI could be available around the clock and solve simple requests efficiently.”
Together, these comments provide strong support to our quantitative findings, showing that customers value ADRs (versus HDRs) regarding effort expectancies in situations in which interactions are standardized and simple, which are more pertinent to data enrichment where data interactions are expected to follow established schemes. These insights enrich our understanding of the effects of deploying ADRs (versus HDRs) in data enrichment and propose that ADRs (as opposed to HDRs) likely fare better in this condition.“Yes, I think it makes a difference whether the information request comes from a human customer support or an automated agent (e.g., AI-based like ChatGPT).”
6.3.2. Error Concerns.
Our findings from the experiments indicated that customers are more likely to agree with a data request from an HDR than an ADR when engaged in data reconciliation, which is driven by lower error concerns associated with an HDR. Therefore, we sought customers’ opinions on whether they prefer interactions with a human or an algorithm for data tasks given the context of their ongoing B2B relationship. Emphasizing the fact that HDRs may be preferred in complex requirement situations and when error concerns are primary, one of our respondents said:
Similarly, another respondent stated,“[F]or complex requests or final sales conversations, a human agent would be better suited as it could understand my needs better and take individual nuances into account.”
This seems to be particularly relevant in data reconciliation situations as a customer stated:“If they are general inquiries, they can also come from AI. For specific technical questions, it must be a customer support employee, as well as for sales inquiries. If it is now a matter of calling up stock levels and preparing direct quotations with existing discounts etc., this can also be done by AI. Purchases of new systems, on the other hand, are made by people.”
In summary, these qualitative insights reinforce our quantitative findings, demonstrating that customers place greater value on HDRs (versus ADRs) in situations marked by pronounced error concerns—particularly in data reconciliation where data are implicitly marked as flawed and risks of losing a service can occur. These findings enhance our understanding of the effects of deploying ADRs (versus HDRs) in data reconciliation and enable us to propose HDRs that seem to perform better under this condition.“What I fear and have already experienced to some extent when using automated agents is that flexibility and personality fall by the wayside. I prefer to have human support [in these situations].”
7. Discussion
7.1. Key Findings
In an era where demand for data value continues to surge, vendors increasingly need to curate and effectively manage data throughout their life cycles, offering customers enhanced interaction experiences, time savings, and improved performance. The rise and promises of automation technologies and specifically, AI agents cause vendors to increasingly substitute HDRs with ADRs for data curation practices, whereas existing research in early stages of B2C relationships mainly considers HDRs superior to ADRs (e.g., Castelo et al. 2019, Luo et al. 2019). As building trust in established B2B relationships is not a focal point, it is plausible to assume that ADRs outperform HDRs in these later stages because of their efficiency. Existing research is unclear whether this assumed superiority of ADRs for data curation is grounded in reality, highlighting the need to explore the roles of ADRs versus HDRs in established B2B relationships. Against this background, we sought to investigate customer responses to the emerging phenomenon of agent-based data curation practices and specifically, how and why customers agree differentially to data requests from HDRs (versus ADRs) when engaged in data enrichment (versus data reconciliation) in established B2B relationships.
7.1.1. Key Findings of the Main Studies.
The findings of two experimental studies support the assertion that ADRs (versus HDRs) have differential effects on customer agreement across data curation practices. Specifically, we find consistent support that customers are about 61% (Study 1) and 56% (Study 2) less likely to agree (versus disagree) with data requests in data enrichment from an HDR (versus ADR) primarily because of higher levels of effort expectancy associated with the HDR, whereas they are about 150% (Study 1) and 143% (Study 2) more likely to agree with data requests in data reconciliation from an HDR (versus ADR), which is driven by lower error concerns with an HDR. Overall, these findings shed significant light on customer agreement regarding data requests from HDRs as opposed to ADRs in established B2B relationships.
7.1.2. Post Hoc Findings on Data Completion.
The post hoc analysis of Study 1 reveals a more nuanced picture of how data requester types affect customer completion rates across different data curation practices. For data enrichment, the evidence is clear. ADRs are markedly more effective than HDRs as reflected in significantly higher customer completion rates. For data reconciliation, however, the pattern is less clear; although customers initially expressed stronger preferences for HDRs, this translated only into a marginally higher completion rate. Our additional interviews suggest that customers often deferred HDR requests, anticipating more time-intensive interactions while perceiving ADRs as quicker to engage with. However, many of those who postponed never returned, potentially exposing an intention-behavior gap (e.g., Sheeran and Webb 2016). Overall, these findings suggest that the relative effectiveness of ADRs and HDRs is shaped by contextual framing and real-world constraints (e.g., Venkatesh 2025), underscoring the need for further investigation.
7.1.3. Supplementary Qualitative Insights.
The qualitative insights from a follow-up online survey and interviews reinforced our field assumptions and supported the key findings from the quantitative experiments. Notably, they reveal that customers tend to prefer ADRs over HDRs in practices involving effort expectancies, whereas HDRs are favored when data error prevention is paramount. These supplementary insights emphasize the importance of distinguishing and strategically deploying different types of data requesters (HDR versus ADR) for data curation practices within established B2B relationships.
7.2. Contributions to Research
The rise of AI agents is frequently portrayed as enabling vendors to delegate data curation wholesale to ADRs, reducing or even eliminating the role of HDRs (e.g., Adam et al. 2025, Wessel et al. 2025). However, this narrative assumes a straightforward substitution and neglects the possibility—well documented in studies of human and human-like agents—that algorithms can provoke unfavorable customer reactions rather than universal acceptance (e.g., Castelo et al. 2019, Schanke et al. 2021). Our research advances the understanding of how customers respond to agent-based data curation practices in established B2B relationships. We show that preferences for ADRs versus HDRs are not uniform but hinge on the cognitive trade-off that customers make between effort and accuracy in specific data curation practices, such as data enrichment (gain oriented, efficiency driven) and reconciliation (loss oriented, accuracy driven). By conceptualizing agent-based data curation practices and empirically demonstrating how seemingly minor variations in data requester type (HDR versus ADR) and data curation practice (data enrichment versus reconciliation) shape customer responses, we extend research on algorithm aversion (e.g., Jussupow et al. 2024) and connect it to emerging debates on data work (e.g., Aaltonen and Stelmaszak 2024, Alaimo and Kallinikos 2024, Parmiggiani et al. 2024) in three important ways. Table 4 synthesizes the assumptions underlying earlier work, illustrates how our paper revises and extends them, and clarifies the novel insights that we bring to the scholarly conversation.
|
Table 4. Summary of Challenged Assumptions and Contributions
| Currently held assumptions | Adapted assumption | Contribution of this research |
|---|---|---|
| Prior research largely assumes that in early-stage B2C interactions marked by one-off exchanges, little continuity, and higher risk of opportunism, HDRs are more effective than ADRs (e.g., Castelo et al. 2019, Luo et al. 2019). | We extend the focus to later-stage B2B relationships, where repeated exchanges and collaborative routines create different conditions for decision making. In these settings, HDRs are not necessarily favored over ADRs. | We demonstrate that algorithm aversion extends beyond initial B2C encounters but does not hold uniformly in long-term B2B contexts. This finding challenges the notion of a universal “human advantage” and highlights that both HDRs and ADRs have legitimate roles in different relational contexts. |
| Existing studies on algorithm aversion focus on initial B2C interactions, where customer agreement is explained mainly through trust dynamics, with HDRs seen as more trustworthy than ADRs (e.g., Qiu and Benbasat 2009, Xu et al. 2020). | Our findings suggest that in long-term B2B relationships, trust recedes into the background. Customers instead rely on cognitive evaluations of effort and accuracy, viewing HDRs as perceived to be stronger in accuracy and ADRs as stronger in efficiency. | We show that the effort-accuracy trade-off accounts for divergent response patterns; customers prefer ADRs in data enrichment (low effort, gain frame) but HDRs in data reconciliation (high accuracy, loss frame). This extends the literature by revealing mechanisms that matter in ongoing B2B settings—beyond the early trust-centric explanations dominant in B2C studies. |
| Prior research largely portrays data requests as gain-framed initiation events at the start of relationships (e.g.,Qiu and Benbasat 2009, Castelo et al. 2019). | Rather than being uniform events, data requests are situated practices whose reception depends on both the relational context and whether they are understood as gain or loss oriented. | We demonstrate that customer preferences are context and motivation specific rather than inherent to an agent. ADRs are favored in data enrichment (gains/efficiency), whereas HDRs are preferred in data reconciliation (losses/accuracy), thereby offering a practice-sensitive account of data-sharing decisions in established B2B relationships. |
First, we advance prior research by revealing a previously overlooked divergence in customer agreement with data requests issued by HDRs versus ADRs in established B2B relationships. Whereas existing studies have predominantly shown HDRs to be more trusted and persuasive in early, unfamiliar B2C interactions (e.g., Xu et al. 2014, Castelo et al. 2019, Schanke et al. 2021, Adam and Benlian 2024), our findings present a more differentiated view. As B2B interactions move beyond initial contact into stages of relationship maintenance, customer preferences shift; ADRs are favored for data enrichment (gain framed, efficiency oriented), whereas HDRs are preferred for data reconciliation (loss framed, accuracy oriented). Thus, B2B settings create distinct conditions for HDRs versus ADRs, demonstrating that customers’ preferences are context and motivation specific rather than inherent to agent type. These insights challenge the prevailing assumption of a uniform human advantage (e.g., Jussupow et al. 2024) and contest the view that data work practices are carried out only by humans (e.g., Aaltonen and Stelmaszak 2024, Parmiggiani et al. 2024). By recasting data curation as agent-based practices, we offer a practice-sensitive account of customer responses and inform design-oriented research that moves beyond substitutionist narratives of AI in human-AI interactions (e.g., Adam et al. 2025, Wessel et al. 2025).
Second, we deepen the understanding of the mechanisms driving customer responses to agent-based data curation practices, particularly customer agreement with different data requesters in established B2B relationships. Prior research has focused on how human versus algorithmic agents influence customer responses in early relationship stages in B2C contexts, focusing on trust-related explanations (e.g., Qiu and Benbasat 2009, Xu et al. 2020, Hanelt et al. 2025) and on algorithms’ competencies and limitations (e.g., Castelo et al. 2019, Luo et al. 2019). Yet, little is known about what exactly motivates customers to agree with data requests in ongoing B2B data curation practices. Our findings indicate that customers perceive ADRs as requiring less effort but offering lower accuracy compared with HDRs. Specifically, the results from two experimental studies and supplementary qualitative insights indicate that customers prefer HDRs less in data enrichment, where efficiency and potential gains are emphasized, but more in data reconciliation, where accuracy and loss avoidance dominate. These perceptions help explain heterogeneous customer response patterns across requester types. In sum, this research demonstrates that insights from early-stage B2C studies cannot be directly translated to later-stage B2B relationships, where data enrichment and reconciliation involve different trade-offs between efficiency and accuracy and where these contextual dynamics shape the suitability of ADRs versus HDRs. By doing so, we expand the conceptual foundations for understanding the reasons for customer responses in long-term data-sharing relationships.
Third, we advance the literature by offering a more nuanced account of how distinct data curation practices, which are embedded particularly in B2B data infrastructures and framed as potential gains and losses, shape customers’ responses to data requests. Although prior research has predominantly examined data requests at the initiation of relationships, where customers presume gain-oriented interactions with no accumulated service experience (e.g., Qiu and Benbasat 2009, Castelo et al. 2019), our paper reveals that customers’ preferences shift depending on the message framing characteristic of the specific data curation practice. In gain-oriented practices, such as data enrichment, customers rather value ADRs for their lower effort. This is because data enrichment is an extensional process that opens up possibilities and enables new value creation by adding data attributes and increasing granularity. Conversely, in loss-oriented practices, such as data reconciliation, HDRs are preferred because of lower error concerns. This is because data reconciliation is a corrective and stabilizing process aimed at closing gaps and restoring order by identifying and resolving data inconsistencies to ensure data integrity. By showing that customers read the data curation practice and adapt their preferences accordingly, we highlight the practice-dependent effectiveness of different agent types. In doing so, our paper offers a more cognitive and performative account of algorithm aversion (e.g., Jussupow et al. 2024) and data work (e.g., Aaltonen and Stelmaszak 2024, Alaimo and Kallinikos 2024, Parmiggiani et al. 2024), showing how the perceptual framing of data work practices—customers’ interpretation of data requests as potential gains or losses—serves as a key lens through which the value and risk of data requests are mentally constructed. These findings underscore that data curation practices are not uniform and are not governed solely by technical affordances of the surrounding infrastructure but that they are profoundly shaped by customers’ psychological representations and by the type of agent enacting them.
7.3. Practical Implications
Our findings offer valuable practical insights, particularly for vendors in established B2B relationships that are considering deploying ADRs (versus HDRs) for data curation. Specifically, the findings on how, why, and when the effects of data requester types persist or change are essential because without proper forethought, vendor companies may assume that customers will consistently appreciate ADRs or HDRs in data curation, which is misleading. Our field experiment findings are particularly useful because we studied customers who made consequential decisions for data curation.
Our findings suggest that ADRs and HDRs should not be treated as interchangeable in data curation but deployed selectively based on the nature of the data curation practice. Customers tend to favor ADRs for data enrichment activities (e.g., adding new client attributes) because they perceive them as efficient and requiring less effort. By contrast, in data reconciliation tasks (e.g., correcting existing records), customers prioritize accuracy and accountability, making HDRs more effective. For vendors, this means that the impact of ADRs on customer agreement is highly context dependent, shaped by the trade-off between perceived effort and error risk. To maximize acceptance, vendors should match requester type to task demands and reinforce the relevant attribute through communication—for example, highlighting efficiency and low effort in data enrichment requests and highlighting accuracy and reliability in data reconciliation requests.
Our findings hold relevance beyond the studied context and can inform B2B settings where ADRs are becoming part of the broader AI-driven service landscape, such as pharmaceuticals, automotive, or healthcare—domains in which customer data provision is routine yet tolerance for mistakes is low. For instance, an insurance provider introducing a new coverage option may find that long-standing clients are more willing to respond to ADR-initiated data requests as these are perceived as reducing effort and streamlining the process. By contrast, when updating or reconciling an existing policy, where accountability is paramount and errors carry significant risks, requests delivered by human representatives may be more readily accepted. These insights can guide organizations in tailoring their data requester strategies to align with the specific stakes and framing of different data curation practices.
7.4. Limitations and Directions for Future Research
Our paper has limitations that provide fertile ground for future research. First, we conducted our research in an established B2B relationship with high transaction volumes and complex products. We believe that the core patterns of the findings—differential customer agreement with data requests from data requesters across different data curation practices in established B2B relationships—can be generalized to other B2B situations where professional workers respond as representatives of a company while communicating with the vendors of the company. These situations could arise, for example, during design collaborations, collaborative planning, joint order fulfilment, financial settlement, and the postpurchase phase. Future research should examine the boundary conditions of our findings across different settings, particularly keeping the role of the relationship in focus. More research is also required to test the generalizability of our findings in other domains affected by the rise of AI agents (e.g., finance, healthcare) and in other cultural and geographic contexts. Similarly, although our research focused on data curation practices via email, an established medium with high relevance and broad applicability, we encourage future researchers to examine agent-based data curation practices via alternative technology-mediated channels (e.g., chats, phones, or smart speakers). Future research is also warranted to explore other data-setting specificities, such as data request initiation (e.g., vendor initiated versus customer initiated) and data requester design (e.g., text- versus voice-based communication). In this vein, the amount, quality, and sensitivity of data in customers’ profiles can differ, so future studies can consider such pre-existing data and customers’ awareness of such data to assess whether and how it influences customer responses. Our research specifically focused on established B2B relationships, in which trust has already been formed. It might be interesting to conduct contrasting studies on customer responses at every stage in the relationship—including at the beginning of the relationship (i.e., initial data elicitation) and the end of the relationship (i.e., data reduction or deletion)—and compare with what relative degree customers prioritize effort (i.e., effort expectancies) over accuracy (i.e., errors concerns) and relatedly, ADRs over HDRs.
Second, future research could investigate how to shape the effort- and accuracy-related attributes of the data requester to affect customer agreement, such as emphasizing effort-related cues (e.g., fast data processing and response times) to evoke better effort expectancies during data enrichment or accuracy-related cues (e.g., data input control mechanisms) to decrease customers’ error concerns during data reconciliation. Research could also explore pairing HDRs with ADRs. In this way, one may explore whether hybrid data requester teams are superior to mutually exclusive single requesters. Intuitively, data requester teams may lead customers to expect more effort as they need to handle two data requesters. However, such teams may also lower error concerns as ADRs may augment HDRs to increase accuracy and vice versa. As such, similar to providing customized services at the right time, in the right place, and in several other “right” circumstances, the right data requester types and combinations should also be deployed under the proper data curation practices.
Finally, we do not examine the different capabilities of AI agents in our paper. Particularly in the B2B context, vendors are typically careful to roll out technologies to customers only after rigorous testing to avoid downsides. However, we acknowledge that AI capabilities can impact B2B relationship dynamics in later stages. Future research can explicitly examine such capabilities to assess their effects. In this vein, we also see a great opportunity for more studies on data work that consider differences in how human and AI agents handle organizational data, which has so far been considered mainly the domain of humans. Relatedly, it may not only be the presentation to customers that will make a difference for data curation but also, whether and how human versus AI agents distinctly enact the work practices, expanding our “agent-based” notion. Complementary to this, AI agents may also be introduced by customers as their new interface to the vendor, allowing vendor AI agents to communicate with customer AI agents, which then convey the results to the respective human parties. This can transform the effort-accuracy trade-off dynamics as well as requiring a revised understanding of customer responses to human-AI interactions and related agent-based data curation practices when more than two agents are involved, such as in emerging customer-AI-AI-vendor constellations (e.g., Jussupow et al. 2024, Adam et al. 2025).
7.5. Conclusion
The emergence of agent-based data work practices opens new frontiers at the customer interface while also raising critical questions about how customers respond to different data requesters that enact distinct practices. Recognizing the growing importance of customers’ ongoing collaboration for data curation, our paper takes important steps toward unpacking the conditions under which ADRs versus HDRs are more effective in data curation practices in lasting B2B relationships. We reveal that these customer responses are shaped not only by agentic features but also, by how the data requester cognitively frames the interaction: as a potential gain (e.g., data enrichment) or a potential loss (e.g., data reconciliation). These practice-specific framings fundamentally shape how the value of data services is perceived and in turn, influence whether ADRs or HDRs are preferred. In doing so, our findings advance a cognitive and performative view of data practices, emphasizing that data interactions are mediated by customers’ mental models. These insights highlight the need to treat data not as inherently meaningful artifacts but as psychologically constructed representations whose legitimacy depends on situational interpretation. We encourage future research to investigate how agent-based data work practices shape customer responses and in turn, condition processes of data value creation, consent, and control.
The authors thank the senior editor, the associate editor, and anonymous reviewers for a highly constructive and developmental review process. The authors also highly appreciate the feedback on earlier versions of the manuscript in workshops, especially at LMU Munich, and from friendly reviewers, particularly Marta Stelmaszak. Moreover, the authors gratefully acknowledge the funding support by the German Research Foundation (DFG).
1 In line with previous information systems (IS) research on algorithmic agents (e.g., Nunamaker et al. 2011, Li and Karahanna 2015), we use the term data requester to refer to a human or algorithm-based agent who aims to request, gather, and process data.
2 We use pseudonyms for the names of the vendor company because they and their data requesters as well as customers wished to remain anonymous.
3 We base our analyses on those clients who explicitly responded (i.e., agreed or disagreed) to the data request and not on the entire range of clients that the data requesters contacted. This is because of the more explicit articulation of their decision regarding agreement or disagreement and thus, the more reliable interpretation of clients’ responses. For example, the reasons for clients not responding included client email addresses no longer being legitimate (e.g., new email address or switching position within or across firms), clients being on vacation and not reading their emails, and clients being overwhelmed with their email inbox and prioritizing other emails over that from DataRequesterCo. As such, considering and analyzing only client responses as a baseline (i.e., explicitly agreeing versus disagreeing with the data request) provide a more reliable interpretation of the findings than taking all sent-out emails as a baseline.
4 We thank a reviewer for bringing up this potential alternative explanation for our results in the review process, which required further investigation to increase the robustness of our findings.
References
- (2024) The performative production of trace data in knowledge work. Inform. Systems Res. 35(3):1448–1462.Link, Google Scholar
- (2024) From web forms to chatbots: The roles of consistency and reciprocity for user information disclosure. Inform. Systems J. 34(4):1175–1216.Crossref, Google Scholar
- (2023) Human versus automated sales agents: How and why customer responses shift across sales stages. Inform. Systems Res. 34(3):1148–1168.Link, Google Scholar
- (2025) Generating tomorrow’s me: How collaborating with generative AI changes humans. Bus. Inform. Systems Engrg. 67:583–594.Crossref, Google Scholar
- (2014) Best practice recommendations for designing and implementing experimental vignette methodology studies. Organ. Res. Methods 17(4):351–371.Crossref, Google Scholar
- (2022) Organizations decentered: Data objects, technology and knowledge. Organ. Sci. 33(1):19–37.Link, Google Scholar
- (2024) Data Rules: Reinventing the Market Economy (MIT Press, Cambridge, MA).Crossref, Google Scholar
- (2010) Is query reuse potentially harmful? Anchoring and adjustment in adapting existing database queries. Inform. Systems Res. 21(1):56–77.Link, Google Scholar
- (2014) Situated with infrastructures: Interactivity and entanglement in sensor data interpretation. J. Assoc. Inform. Systems 15(5):2.Google Scholar
- (2017) The moderating role of trust in business to business electronic commerce (B2B EC) adoption. Comput. Human Behav. 68:157–169.Crossref, Google Scholar
- (2002) Evidence of the effect of trust building technology in electronic markets: Price premiums and buyer behavior. MIS Quart. 26(3):243–268.Crossref, Google Scholar
- (1985) Reconciliation process for data management in distributed environments. MIS Quart. 9(2):97–108.Crossref, Google Scholar
- (1989) Methodology for allocating resources for data quality enhancement. Comm. ACM 32(3):320–329.Crossref, Google Scholar
- (1996) The effects of decision support and task contingencies on model formulation: A cognitive perspective. Decision Support Systems 17(4):241–252.Crossref, Google Scholar
- (2021) Managing artificial intelligence. MIS Quart. 45(3):1433–1450.Crossref, Google Scholar
- (1999) Trust in business to business relationships: An evaluation of its status. J. Management Stud. 36(2):197–215.Crossref, Google Scholar
- (2021) Thematic Analysis: A Practical Guide (SAGE, Los Angeles).Google Scholar
- (2020) A systematic review of algorithm aversion in augmented decision making. J. Behav. Decision Making 33(2):220–239.Crossref, Google Scholar
- (2019) Task-dependent algorithm aversion. J. Marketing Res. 56(5):809–825.Crossref, Google Scholar
- (2023) Understanding and improving consumer reactions to service bots. J. Consumer Res. 50(4):848–863.Crossref, Google Scholar
- (2008) Addressing the what and how of online services: Positioning supporting-services functionality and service quality for business-to-consumer success. Inform. Systems Res. 19(2):161–181.Link, Google Scholar
- (2022) How does intelligent system knowledge empowerment yield payoffs? Uncovering the adaptation mechanisms and contingency role of work experience. Inform. Systems Res. 33(3):1042–1071.Link, Google Scholar
- (2022) MISQ research curation on data management. MIS Quart. (February 1), https://scholarsmine.mst.edu/cgi/viewcontent.cgi?article=1422&context=bio_inftec_facwork.Google Scholar
- (2018) Transfiguration work and the system of transfiguration. MIS Quart. 42(3):873–894.Crossref, Google Scholar
- (2022) On the design of and interaction with conversational agents: An organizing and assessing review of human-computer interaction research. J. Assoc. Inform. Systems 23(1):96–138.Google Scholar
- (2020) People reject algorithms in uncertain decision domains because they have diminishing sensitivity to forecasting error. Psych. Sci. 31(10):1302–1314.Crossref, Google Scholar
- (2006) An extended privacy calculus model for e-commerce transactions. Inform. Systems Res. 17(1):61–80.Link, Google Scholar
- (1997) An examination of the nature of trust in buyer–seller relationships. J. Marketing 61(2):35–51.Crossref, Google Scholar
- (1987) Developing buyer-seller relationships. J. Marketing 51(2):11–27.Crossref, Google Scholar
- (2013) A Vast Machine: Computer Models, Climate Data, and the Politics of Global Warming (MIT Press, Cambridge, MA).Google Scholar
- (2011) Science friction: Data, metadata, and collaboration. Soc. Stud. Sci. 41(5):667–690.Crossref, Google Scholar
- (2005)
The effect of site design and interattribute correlations on interactive web-based decisions . Haugtvedt CP, Machleit KA, Yalch RF, eds. Online Consumer Psychology: Understanding and Influencing Consumer Behavior in the Virtual World (Psychology Press, New York), 325–342.Google Scholar - (2022) Why and how online experiments can benefit information systems research. J. Assoc. Inform. Systems 23(6):1333–1346.Google Scholar
Forrester (2024) Forrester’s 2024 US customer experience index: Brands’ CX quality is at an all-time low. (June 17), https://www.forrester.com/press-newsroom/forrester-2024-us-customer-experience-index/.Google ScholarGartner (2019) Gartner predicts 80% of marketers will abandon personalization efforts by 2025. Retrieved April 10, https://www.gartner.com/en/newsroom/press-releases/2019-12-02-gartner-predicts-80--of-marketers-will-abandon-person#:~:text=Gartner%20Reveals%20Marketing%20Predictions%20to%20Guide%20Marketers%20Through%20Uncertain%20Times%20Ahead&text=By%202025%2C%2080%25%20of%20marketers,%2C%20according%20to%20Gartner%2C%20Inc.Google ScholarGartner (2022) Gartner predicts chatbots will become a primary customer service channel within five years. (July 27), https://www.gartner.com/en/newsroom/press-releases/2022-07-27-gartner-predicts-chatbots-will-become-a-primary-customer-service-channel-within-five-years.Google ScholarGartner (2025) Data quality: Why it matters and how to achieve it. Accessed October 1, 2025, https://www.gartner.com/en/data-analytics/topics/data-quality.Google Scholar- (2022) Effort minimization theory in the data analytics era. J. Comput. Inform. Systems 62(4):837–849.Crossref, Google Scholar
- (2019) Assessing the design choices for online recommendation agents for older adults: Older does not always mean simpler information technology. MIS Quart. 43(1):329–346.Crossref, Google Scholar
- (2013) Raw Data is an Oxymoron (MIT Press, Cambridge, MA).Crossref, Google Scholar
- (2024) More than a bot? The impact of disclosing human involvement on customer interactions with hybrid service agents. Inform. Systems Res. 35(3):936–955.Link, Google Scholar
- (2015) The Netflix recommender system: Algorithms, business value, and innovation. ACM Trans. Management Inform. Systems 6(4):13.Google Scholar
- (2009) The role of service level agreements in relational management of information technology outsourcing: An empirical study. MIS Quart. 33(1):119–145.Crossref, Google Scholar
- (2022) Resourcing with data: Unpacking the process of creating data-driven value propositions. J. Strategic Inform. Systems 31(4):101744.Crossref, Google Scholar
- (2025) Opening the network of trust: How domain experts in triadic relationships build trust in AI-based counterparts. MIS Quart., ePub ahead of print May 22, https://doi.org/10.25300/MISQ/2025/18041.Crossref, Google Scholar
- (2007) Overcoming online information privacy concerns: An information-processing theory approach. J. Management Inform. Systems 24(2):13–42.Crossref, Google Scholar
- (2022) Introduction to Mediation, Moderation, and Conditional Process Analysis: A Regression-Based Approach, 3rd ed. (Guilford Publications, New York).Google Scholar
- (2018) Artificial intelligence in service. J. Service Res. 21(2):155–172.Crossref, Google Scholar
IBM (2024) State of Salesforce 2024–2025. Accessed October 1, 2025, https://www.ibm.com/thought-leadership/institute-business-value/en-us/report/state-of-salesforce-2024.Google Scholar- (2021) Editorial for the special section on humans, algorithms, and augmented intelligence: The future of work, organizations, and society. Inform. Systems Res. 32(3):675–687.Link, Google Scholar
- (1985) Effort and accuracy in choice. Management Sci. 31(4):395–414.Link, Google Scholar
- (2019) What we talk about when we talk about (big) data. J. Strategic Inform. Systems 28(1):3–16.Crossref, Google Scholar
- (2024) An integrative perspective on algorithm aversion and appreciation in decision-making. MIS Quart. 48(4):1575–1590.Crossref, Google Scholar
- (2009) Interfirm strategic information flows in logistics supply chain relationships. MIS Quart. 33(4):735–762.Crossref, Google Scholar
- (1997) Can humans detect errors in data? Impact of base rates, incentives, and goals. MIS Quart. 21(2):169–194.Crossref, Google Scholar
- (2006) The effects of personalization and familiarity on trust and adoption of recommendation agents. MIS Quart. 30(4):941–960.Crossref, Google Scholar
- (2021) Is AI ground truth really “true?” The dangers of training and evaluating AI tools based on experts’ know-what. MIS Quart. 45(3):1501–1526.Crossref, Google Scholar
- (2011) Research note—The influence of trade-off difficulty caused by preference elicitation methods on user acceptance of recommendation agents across loss and gain conditions. Inform. Systems Res. 22(4):867–884.Link, Google Scholar
- (2020) Data Journeys in the Sciences (Springer Nature, Cham, Switzerland).Crossref, Google Scholar
- (2018) Man versus machine: Resisting automation in identity-based consumer behavior. J. Marketing Res. 55(6):818–831.Crossref, Google Scholar
- (2015) Online recommendation systems in a B2C e-commerce context: A review and future directions. J. Assoc. Inform. Systems 16(2):72–107.Google Scholar
- (2019) The right music at the right time: Adaptive personalized playlists based on sequence modeling. MIS Quart. 43(3):765–786.Crossref, Google Scholar
- (2012) Two worlds of trust for potential e-commerce users: Humans as cognitive misers. Inform. Systems Res. 23(4):1246–1262.Link, Google Scholar
- (2019) Algorithm appreciation: People prefer algorithmic to human judgment. Organ. Behav. Human Decision Processes 151:90–103.Crossref, Google Scholar
- (2022) Artificial intelligence in utilitarian vs. hedonic contexts: The “word-of-machine” effect. J. Marketing 86(1):91–108.Crossref, Google Scholar
- (2019) Resistance to medical artificial intelligence. J. Consumer Res. 46(4):629–650.Crossref, Google Scholar
- (1997) Choice processing in emotionally difficult decisions. J. Experiment. Psych. Learn. Memory Cognition 23(2):384–405.Crossref, Google Scholar
- (1999) Emotional trade-off difficulty and choice. J. Marketing Res. 36(2):143–159.Crossref, Google Scholar
- (2021) Artificial intelligence coaches for sales agents: Caveats and solutions. J. Marketing 85(2):14–32.Crossref, Google Scholar
- (2019) Frontiers: Machines vs. humans: The impact of artificial intelligence chatbot disclosure on customer purchases. Marketing Sci. 38(6):937–947.Abstract, Google Scholar
- (2018) Data-driven meets theory-driven research in the era of big data: Opportunities and challenges for information systems research. J. Assoc. Inform. Systems 19(12):1.Google Scholar
- (2017) Opportunities for and pitfalls of using big data in advertising research. J. Advertising 46(2):227–235.Crossref, Google Scholar
- (2025) Quantitative behavioral IS research—A look back and a look forward. MIS Quart. 49(1):iii–xviii.Crossref, Google Scholar
McKinsey & Company (2021) The value of getting personalization right—or wrong—is multiplying. Retrieved June 20, https://www.mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/the-value-of-getting-personalization-right-or-wrong-is-multiplying.Google Scholar- (2002) The impact of initial consumer trust on intentions to transact with a web site: A trust building model. J. Strategic Inform. Systems 11(3–4):297–323.Crossref, Google Scholar
- (2020) Big data and business analytics: A research agenda for realizing business value. Inform. Management 57(1):103237.Crossref, Google Scholar
- (2021) Acting with inherently uncertain data: Practices of data-centric knowing. J. Assoc. Inform. Systems 22(6):1715–1735.Google Scholar
- (2003) The paucity of multimethod research: A review of the information systems literature. Inform. Systems J. 13(3):233–249.Crossref, Google Scholar
- (1972) Human Problem Solving, vol. 104 (Prentice-Hall, Englewood Cliffs, NJ).Google Scholar
- (2011) Embodied conversational agent-based kiosk for automated interviewing. J. Management Inform. Systems 28(1):17–48. Crossref, Google Scholar
- (2008) Achieving relationship marketing effectiveness in business-to-business exchanges. J. Acad. Marketing Sci. 36:174–190.Crossref, Google Scholar
- (2024) Data curation as anticipatory generification in data infrastructure. Eur. J. Inform. Systems 33(5):748–767.Crossref, Google Scholar
- (2022) In the backrooms of data science. J. Assoc. Inform. Systems 23(1):139–164.Google Scholar
- (1980)
Information processing theory: Some concepts and methods applied to decision research . Wallsten TS, ed. Cognitive Processes in Choice and Decision Behavior (Routledge, London), 95–115.Google Scholar - (1982) Contingent decision behavior. Psych. Bull. 92(2):348–402.Crossref, Google Scholar
- (1988) Adaptive strategy selection in decision making. J. Experiment. Psych. Learn. Memory Cognition 14(3):534–552.Crossref, Google Scholar
- (1993) The Adaptive Decision Maker (Cambridge University Press, Cambridge, UK).Crossref, Google Scholar
- (2023) “No, thanks”: How do requests for feedback affect the consumption behavior of non-compliers? Marketing Lett. 34(1):83–97.Crossref, Google Scholar
- (2020) Good organizational reasons for better medical records: The data work of clinical documentation integrity specialists. Big Data Soc. 7(2):2053951720965616.Crossref, Google Scholar
- (2024) Common method bias: It’s bad, it’s complex, it’s widespread, and it’s not easy to fix. Annual Rev. Organ. Psych. Organ. Behav. 11(1):17–61.Crossref, Google Scholar
- (2021) Consumers and artificial intelligence: An experiential perspective. J. Marketing 85(1):131–151.Crossref, Google Scholar
- (2009) Evaluating anthropomorphic product recommendation agents: A social relationship perspective to designing information systems. J. Management Inform. Systems 25(4):145–182.Crossref, Google Scholar
- (2012) Interfirm IT capability profiles and communications for cocreating relational value: Evidence from the logistics industry. MIS Quart. 36(1):233–262.Crossref, Google Scholar
- (2021) The Coding Manual for Qualitative Researchers (SAGE, Los Angeles).Google Scholar
Salesforce (2022) Automation everywhere. Retrieved July 10, https://www.salesforce.com/news/stories/automation-success-now-bundle/.Google ScholarSalesforce (2025) State of data and analytics. Accessed October 1, 2025, https://www.salesforce.com/en-us/wp-content/uploads/sites/4/documents/research/state-of-data-analytics.pdf.Google Scholar- (2021) Estimating the impact of humanizing customer service chatbots. Inform. Systems Res. 32(3):736–751.Link, Google Scholar
- (2001) The Practice Turn in Contemporary Theory, vol. 44 (Routledge, London).Google Scholar
- (2015) The value of self-service: Long-term effects of technology-based self-service usage on customer retention. MIS Quart. 39(1):177–200.Crossref, Google Scholar
- (2016) The intention–behavior gap. Soc. Personality Psych. Compass 10(9):503–518.Crossref, Google Scholar
- (2024) Website localization strategies to promote global e-commerce: The moderating role of individualism and collectivism. MIS Quart. 48(1):31–66.Crossref, Google Scholar
- (1955) A behavioral model of rational choice. Quart. J. Econom. 69(1):99–118.Crossref, Google Scholar
- (1978)
Information-processing theory of human problem solving . Estes WK, ed. Handbook of Learning & Cognitive Processes: V. Human Information (Lawrence Erlbaum, Mahwah, NJ), 271–295.Google Scholar - (1994) Managing Privacy: Information Technology and Corporate America (UNC Press Books, Chapel Hill, NC).Google Scholar
- (1996) Information privacy: Measuring individuals’ concerns about organizational practices. MIS Quart. 20(2):167–196.Crossref, Google Scholar
- (2007) The effects of incorporating compensatory choice strategies in web-based consumer decision support systems. Decision Support Systems 43(2):359–374.Crossref, Google Scholar
Statista (2023) E-mail marketing worldwide—Statistics & facts. Retrieved April 10, https://www.statista.com/topics/1446/e-mail-marketing/#topicOverview.Google Scholar- (2005) Web personalization as a persuasion strategy: An elaboration likelihood model perspective. Inform. Systems Res. 16(3):271–291.Link, Google Scholar
- (1992) The use of information in decision making: An experimental investigation of the impact of computer-based decision aids. MIS Quart. 16(3):373–393.Crossref, Google Scholar
- (1991) Loss aversion in riskless choice: A reference-dependent model. Quart. J. Econom. 106(4):1039–1061.Crossref, Google Scholar
Validity (2024) The state of CRM data management in 2024. Accessed October 1, 2025, https://www.validity.com/resource-center/the-state-of-crm-data-management-in-2024/.Google Scholar- (2007) Engaged Scholarship: A Guide for Organizational and Social Research (Oxford University Press, Oxford, UK).Crossref, Google Scholar
- (2025) Leveraging context: Re-thinking research processes to make “contributions to theory”. Inform. Systems Res. 36(3):1871–1886.Link, Google Scholar
- (2013) Bridging the qualitative-quantitative divide: Guidelines for conducting mixed methods research in information systems. MIS Quart. 37(1):21–54.Crossref, Google Scholar
- (2016) Guidelines for conducting mixed-methods research: An extension and illustration. J. Assoc. Inform. Systems 17(7):2.Google Scholar
- (2003) User acceptance of information technology: Toward a unified view. MIS Quart. 27(3):425–478.Crossref, Google Scholar
- (2009) Interactive decision aids for consumer decision making in e-commerce: The influence of perceived strategy restrictiveness. MIS Quart. 33(2):293–320.Crossref, Google Scholar
- (2025) Generative AI and its transformative value for digital platforms. J. Management Inform. Systems 42(2):346–369.Crossref, Google Scholar
- (2001) An empirical investigation of the factors affecting data warehousing success. MIS Quart. 25(1):17–41.Crossref, Google Scholar
- (2007) E-commerce product recommendation agents: Use, characteristics, and impact. MIS Quart. 31(1):137–209.Crossref, Google Scholar
- (2014) The nature and consequences of trade-off transparency in the context of recommendation agents. MIS Quart. 38(2):379–406.Crossref, Google Scholar
- (2017) A two-stage model of generating product advice: Proposing and testing the complementarity principle. J. Management Inform. Systems 34(3):826–862.Crossref, Google Scholar
- (2020) The relative effect of the convergence of product recommendations from various online sources. J. Management Inform. Systems 37(3):788–819.Crossref, Google Scholar
- (2024) Time to reassess data value: The many faces of data in organizations. J. Strategic Inform. Systems 33(4):101863.Crossref, Google Scholar
- (2010) Reconsidering Baron and Kenny: Myths and truths about mediation analysis. J. Consumer Res. 37(2):197–206.Crossref, Google Scholar

