
Volatility During the COVID-19 Pandemic
Abstract
We examine the impact of COVID-19 on market volatility in an equilibrium framework. The model combines beliefs-dependent preferences for economic dynamics and a stochastic Susceptible-Exposed-Infectious-Recovered-Deceased (SEIRD) model with unpredictable birth/vaccine events and mitigating policies for disease propagation. The estimated model explains the realized trajectories of the S&P 500 volatility and number of new cases and identifies the source and composition of the volatility spike while providing a good match for 25 unconditional moments of economic series. Beliefs dependence, in conjunction with real effects due to the short-term decline of the effective workforce early in the pandemic, is critical for this comprehensive explanation of short- and long-run properties. A model comparison study is performed. Out-of-sample volatility prediction exercises document that the good in-sample model fit for volatility and cases is not due to over-parametrization. The effects of alternative mitigation policies such as changes in contamination rate, shelter-in-place duration, and shelter-in-place compliance rate are examined. They document the tradeoff in number of cases and stock volatility during the pandemic, and the dominant role of unemployment news volatility.
This paper was accepted by Lukas Schmid, finance.
Supplemental Material: The data files are available at https://doi.org/10.1287/mnsc.2024.04352.
1. Introduction
The COVID-19 outbreak challenges economic theory on several grounds. It is characterized by a small decline in the aggregate consumption growth rate followed by a quick reversal. It features a short recession followed by a quick return to normal economic growth conditions. It displays episodes of large and fluctuating volatility in the financial market. This paper seeks to explain the magnitudes and patterns of these short-run empirical regularities in an integrated epidemic-economy model consistent with moment properties of long-run economic time series.
The outbreak took markets across the world by surprise. Although data from China showed clear and early evidence of rapid propagation and associated economic damage, markets initially failed to react, discounting the possibility of contagion across regions and continents. The rapid decrease in the U.S. market, for instance, began on February 20, several months after the epidemic started to rage in China. The S&P500 reached its trough on March 23, about 30% below average levels during the first two months of 2020. The index took nearly five months to recover its February 20 level. In parallel, the VIX, a measure of market volatility, went from 15.56 on February 20 to a peak of 82.69 on March 16. It then progressively decreased to 24.52 on June 5, before bouncing back to 40.79 on June 11. Another spike occurred on September 3 following a short-lived downward adjustment. For an extended period thereafter, it has evolved in the 15–40 range. Markets in other countries have experienced similar volatility patterns although at different dates and over different periods. Subsequent data pertaining to the United States led the National Bureau of Economic Research (NBER) to identify the period from February to April 2020 as a recession.
The goal of this paper is to explain volatility phenomena that have characterized U.S. markets. A key question is whether the empirical evidence associated with COVID-19 is consistent with the predictions of a “finely tuned” asset pricing model. By finely tuned, we mean an equilibrium asset pricing model based on fundamentals that explains the long-run behavior of financial markets, that is, outside epidemic states. Given such a model, questions pertaining to the origins of economic fluctuations can be addressed. Are volatility bursts the result of certain policy decisions or of natural disease propagation mechanisms? Do they reflect behavioral responses of economic agents? Are they tied to events unrelated to COVID-19? Answers to these questions may help to provide perspective on the scope and effectiveness of policy making.
For these purposes, we use the model with beliefs-dependent risk aversion (BDRA) in Berrada et al. (2018) as a starting point. This choice is motivated by the overall performance, static, and dynamic of the model. On the static front, it provides a good match for 25 moment conditions, for example, unconditional estimates of the equity premium, log price-dividend ratio (PDR), stock market volatility, and correlations between log PDR and growth rate of consumption. On the dynamic front, it has attractive properties, for example, spikes in model-implied recession probabilities coincide with NBER recession periods, model volatility tracks realized volatility, and the equity premium displays countercyclical behavior.
First, we extend the model to incorporate short-term dynamics associated with a pandemic. This extension accounts for the unpredictable nature of pandemic events and vaccine discoveries, mitigating governmental policies, and social distancing responses. Pandemic uncertainty is modeled through a nonrecurrent Markov chain with three possible regimes: no pandemic, pandemic, and vaccine. It is injected into the benchmark pandemic model employed: the Susceptible-Exposed-Infectious-Recovered-Deceased (SEIRD) model.1 Mitigating government policy takes the form of mandates to shelter-in-place (SIP) and terminations thereof (LIFT). Social distancing responses take the form of variations in the transmission rate of the disease at certain times including policy change dates. The combined model is called the BDRA-SSL model, that is, BDRA with SEIRD pandemic propagation and SIP-LIFT policy response. Of particular note is the fact that BDRA-SSL produces quasi–closed-form solutions for equilibrium quantities, including stock return volatility components, despite the unpredictability associated with the pandemic uncertainty and the complexities of policy and social responses. There are two difficulties hindering the derivation of fully explicit equilibrium formulas: the uncertainty pertaining to pandemic regimes and the parameters dependence on pandemic regimes within economic regimes. The first difficulty introduces an additional source of uncertainty in the model. The second precludes the computation of closed form solutions for prices using the method in Berrada et al. (2018) because coefficients are now functions of stochastic pandemic-regime variables. To overcome the first difficulty, we express the price as an average over perfect foresight prices, each conditional on a realization of the pair of jump times characterizing pandemic uncertainty. To overcome the second difficulty, we show that perfect foresight prices can be expressed as ratios of quadratic forms depending on matrices satisfying backward Ordinary Differential Equations (ODEs). The overall solution combining the two elements is (quasi) explicit up to backward matrix ODEs.
Second, we estimate the model using a two-stage procedure. In the first stage, the prepandemic stage, the economic model is estimated based on 25 moment conditions pertaining to asset returns, macro-fundamentals, and their comovements. Relative to prior literature relying on the BDRA model, the estimation uses an augmented data set from 1957 to 2019. In the second stage, the pandemic stage, the disease propagation parameters and the parameters governing its effects on consumption, dividend, and unemployment, in total 26 parameters, are estimated based on COVID-19 data and S&P500 volatility data. Estimation is carried out to minimize the mean squared distance between daily model implied and observed trajectories of the S&P500 volatility and the number of new COVID-19 cases. The data set used for that purpose goes from January 1, 2020, to August 7, 2020, comprising 220 days. Given this sample size, the second-stage procedure is equivalent to matching 440 conditional moment conditions with 26 parameters.
Third, we document the performance of the BDRA-SSL model. There are three aspects. We first show that the model performs well regarding the quantities that were targeted in the estimation. Model-implied variables and statistics are close to their empirical counterparts, both during the prepandemic period and the early stages of the outbreak. Prepandemic, the estimated model provides a good fit for 25 targeted moment conditions, confirming the results in Berrada et al. (2018) for the longer data set. Intrapandemic, it closely matches the targeted variables, namely the number of new cases and the values, hence patterns, of the S&P 500 volatility at 220 dates. Next, we document the reasons behind the model’s performance and in the process establish performance along a nontargeted dimension, that is, the ability to detect recessions. At the core is the behavior of the model-implied recession probability. It increases during the COVID-19 recession period declared by the NBER, but decreases immediately thereafter, thus explaining the ability to capture sharp variations in the data. Crucially, BDRA is a necessary ingredient for explaining the empirical patterns. Last, we use the decomposition of volatility into its constituents associated with consumption, dividend, and unemployment fluctuations to examine the sources of volatility during the outbreak. We show the spike in volatility recorded during the first wave of the pandemic is entirely captured by the unemployment component and hence has a purely informational origin because unemployment only serves to update regime probabilities.
Fourth, the paper compares performance across models. Alternatives examined are the nested specifications BDRA (without pandemic component), CRRA-SSL (constant relative risk aversion), BDRA-SSL-C (constrained version of BDRA-SSL), and the nonnested model BDRA-SIRD-SL (with SIRD pandemic propagation). It shows that standalone BDRA, without feedback effects from an epidemic component, is unable to explain patterns and magnitudes. It also shows that the standard CRRA model augmented by the same SEIRD epidemic propagation model with SIP-LIFT policy response (CRRA-SSL) performs poorly. Model specification tests reject the nested alternatives BDRA, CRRA-SSL, and BDRA-SSL-C. Model selection criteria show BDRA-SSL dominates all nested specifications, as well as the nonnested BDRA-SIRD-SL model. It also performs best before the pandemic based on 25 moment conditions. Hence, BDRA-SSL dominates alternatives in terms of simultaneously fitting short-term and long-term properties of the data. Last, we calculate model selection criteria using a rolling out-of-sample procedure, that is, a sequence of five-day-ahead volatility forecasts, restricting attention to the two best specifications: BDRA-SSL and BDRA-SIRD-SL. There are six rolling windows, each adding 30 days for estimation and producing 5-day-ahead forecasts. Results show BDRA-SSL dominates here as well, except for the forecast associated with the initial 30-day period.
Finally, we examine the economic impact of policies designed to mitigate the impact of the pandemic. In the estimated model, SIP causes volatility to jump up at the initiation date and down at the termination date. We show that a reduction in the duration of SIP, although shortening the period of high volatility associated with SIP, can amplify the reaction to news in the aftermath of SIP. Raising the compliance to SIP, for instance, through timely information dissemination, raises volatility throughout the SIP window and hence increases the size of the jumps up and down at initiation and termination times. In contrast, lowering the contamination rate, for instance, through health advisories, has mostly insignificant effects on volatility during the SIP window and thereafter.
The paper relates to five branches of the literature. First, it generalizes recent contributions seeking to examine the impact of pandemics on equilibrium asset prices (Detemple 2022). It differs in that it (i) integrates an epidemiology propagation model into the model with BDRA preferences, (ii) allows for unpredictable events such as the outbreak of a pandemic and the discovery of a vaccine, (iii) includes volatility and correlations in the analysis and focuses not only on patterns but also levels, and (iv) estimates a version of the model allowing for time-dependent contamination rate and examines its performance. The estimated model fits the data well both in-sample and out-of-sample: On the economic front, it correctly detects the short-lived recession period as declared by the NBER and explains the levels and adjustment patterns of the S&P500 volatility and of the number of cases during the COVID-19 outbreak.
Second, it contributes to the general equilibrium asset pricing literature. It extends, in particular, the BDRA model in Berrada et al. (2018) showing that market value and volatility inherit new components tied to the likelihood of occurrence of an outbreak and the likelihood of a vaccine discovery. Equilibrium formulas obtained are quasi-explicit allowing for estimation and straightforward calculations. It also complements earlier studies such as Merton (1973), Breeden (1979), and Cox et al. (1985) by incorporating an unexpected epidemic phenomenon into an equilibrium valuation framework.
Third, it connects to the growing literature dealing with the COVID-19 outbreak. Recent contributions have documented the empirical impact on the market (Gormsen and Koijen 2020) and volatility (Cheng 2020). The present paper explains the empirical evidence pertaining to volatility, along with other aspects, in an equilibrium setting. It shows in particular that BDRA is essential for rationalizing the data. Other recent articles examine the role and impact of mitigation policies (Eichenbaum et al. 2021, Hong et al. 2021, Jones et al. 2021). The first study investigates the implications of individual decisions and government policies for disease propagation mechanisms and economic aggregates dynamics. The second one focuses on optimal mitigation policies of firms in a partial equilibrium setting with stochastic transmission rate, unpredictable vaccine discovery rate, and fixed cost of mitigation. The last one incorporates similar elements but focuses on the implications of inefficient work-at-home policies, taking account of learning-by-doing and heterogeneity across sectors. The scope of our contribution differs as we explain short-run volatility dynamics during the COVID-19 outbreak along with the long-run behavior of a broad spectrum of economic variables in a setting with endogenous stochastic discount factor, unpredictable economic regimes, and unpredictable pandemic events.
Fourth, it relates to the literature seeking to reconcile statistics of model-implied asset volatilities, risk premia, and interest rates with the data. The origins of this literature go back to Shiller (1981) (excess volatility puzzle), Mehra and Prescott (1985) (risk premium puzzle), and Weil (1989) (risk free rate puzzle). Early contributions include Campbell and Shiller (1988), who study the role of dividend growth and the variations in expected returns to explain return volatilities; Rietz (1988), who examines the impact of disaster risk; and Epstein and Zin (1989, 1991), who develop a class of tractable recursive preferences and highlight the importance of the return on wealth. Subsequently, Sundaresan (1989), Constantinides (1990), and Detemple and Zapatero (1991) examine internal habits, Constantinides and Duffie (1996) study agent heterogeneity, and Campbell and Cochrane (1999) study internal habits to explain discrepancies with the data. Campbell (1999) provides an assessment of models in this literature. The last two decades have witnessed the development of models involving persistent macro-factors with stochastic volatility (Bansal and Yaron (2004), long-run risk factor; Bansal et al. (2014), relationship between macroeconomic volatility, long-run risk, predictability, and asset risk premia; and Campbell et al. (2018), Intertemporal Capital Asset Pricing Model (ICAPM) with stochastic factor volatility) and incomplete information (Brennan and Xia 2001, Ai 2010). Our model differs as it uses a different class of (time-separable) preferences (BDRA) to reconcile model implications with the data because fluctuations in regime probabilities play a critical role and unemployment risk is a driving source behind these fluctuations. In BDRA, unemployment serves as a purely informational variable that does not affect cash flows, and endogenous variables such as prices of risk and volatility components are in (quasi) closed form.2 Our primary focus, in addition, is the explanation of the S&P500 volatility behavior during the COVID-19 outbreak.
Last, it relates to the general literature on asset pricing with learning and incomplete information. The development of regime switching models with unobserved regimes goes back to David (1997), Veronesi (2000), and David and Veronesi (2013, 2014). Models with incomplete information were originally proposed by Detemple (1986) and Dothan and Feldman (1986) and subsequently extended by a variety of authors. Recent contributions include Andrei et al. (2019a, b), Hasler et al. (2019), and Andrei and Hasler (2020), among others. Relative to this literature, we develop a BDRA model with learning about unobserved economic regimes and show its relevance for the joint determination of the S&P500 volatility and the number of cases during the COVID-19 outbreak.
Section 2 presents the model and provides equilibrium formulas. Section 3 describes the estimation procedure and examines the fit to the data, both long term and during the early stages of the COVID-19 outbreak. Section 4 performs a comparison of models. Further discussion appears in Section 5. Section 6 examines mitigation policies. Conclusions follow. Appendix A details the SEIRD model under an SIP policy. Appendix B describes the decision-making process. Proofs are in Appendix C. Complementary results are in Appendix D.
2. Economic and Epidemiology Model
We extend the BDRA model in Berrada et al. (2018) to account for a pandemic outbreak triggered by an unpredictable initial infection event and a subsequent unpredictable vaccine discovery event.
2.1. Time-Dependent and Stochastic SEIRD Model
The epidemic propagation is assumed to be driven by a SEIRD model with time-dependent infection rate , unpredictable triggering event, and unpredictable vaccination discovery event.
The population is split in five categories: susceptible (), exposed (), infectious (), recovered (), and deceased (). Let be the fractions in each category, where the sum equals one. The infectious population further splits in three groups: asymptomatic , symptomatic mild , and symptomatic severe , so that . The last two categories consist of mildly sick and severely sick individuals, respectively. We assume , , , where fractions and are constants. Before the initial infection event, and . At the initial infection event date , the infectious population jumps up and the susceptible population jumps down: and . Thereafter, populations evolve as
A policy intervention such as SIP modifies the dynamics as follows. First, on implementation, it introduces an outflow at rate q, called the compliance rate, in each of the populations above (except for the deceased) to corresponding sheltered populations , identified by the superscript Q. Second, upon lifting (LIFT) of the policy, it induces a reverse flow from sheltered populations to those that are not. This reverse compliance rate is . In the remainder of this article, we refer to this model as the SEIRD-SIP-LIFT (SSL) model. A more detailed description of the model can be found in Appendix A. A flowchart of the epidemic propagation mechanism is displayed in Figure 1.
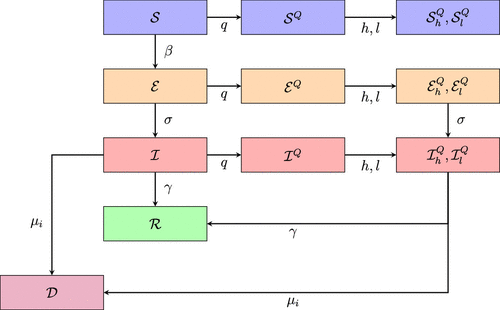
Notes. Populations are susceptible (, exposed (), infectious (), recovered (), and deceased (). Upon shelter-in-place (SIP), populations transition to quarantined categories () at the compliance rate q, which further split into work-at-home ( and laid off (). Lifting of the shelter-in-place policy (LIFT) reverses the direction of flows from quarantined to nonquarantined populations at the reverse compliance rate .
2.2. Regimes, Consumption, Dividends, and Information
We assume there are six regimes: expansion, recession, boom, no pandemic, pandemic, and vaccine. The first three regimes are unobservable. They are the outcomes of a Markov chain with three states, recession (), expansion (), or boom (), where is the -dimensional kth unit vector. The last three are observable and are the outcomes of an independent Markov chain with three states: no pandemic (), pandemic (), or vaccine (). The pandemic Markov chain is nonrecurrent: It evolves from state , to , and then , which is an absorbing state. The vaccine event is triggered when . In this event, the dynamics of the susceptible and infectious populations depend on the vaccination rate as described in and . To simplify derivations, we assume the pandemic is a one-time event, so it does not subsequently reoccur: is an absorbing state.
The Markov chains are independent continuous time switching processes:
The state variables in the model are , where C is aggregate consumption, D is aggregate dividend, and U is unemployment. The model for is
Appendix D shows how Equations (2.8)–(2.10) can be rewritten in terms of orthogonalized state variables , satisfying
2.3. Beliefs-Dependent Risk Aversion: BDRA(K,K)
To model economic processes during a pandemic, we extend the BDRA(K,K) model in Berrada et al. (2018). Let be a set of regime indices, where K is an arbitrary, but fixed, positive integer. The model has K unobserved economic regimes , K preference parameters and uses consumption C, orthogonalized dividends G, and orthogonalized macro variables Y as information sources. Let be the conditional regime probabilities based on public information. Instantaneous utility of consumption, for population j, is , where is a subjective discount rate and is a discount factor depending on the health and employment status of the population. The coefficients are parameters of the risk aversion function, as explained below. Let be the set of relevant populations.5 Marginal utility of consumption for population is
The processes are informational innovations associated with the underlying Brownian motions, the coefficients are sensitivities to news, and are the conditional means.
We also assume the supply of labor by households is inelastic. Aggregate labor supply is in the absence of an epidemic. During an outbreak, available supply is limited to individuals who do not exhibit symptoms: The workforce is . If SIP is implemented, and a fraction h of quarantined asymptomatic individuals is able to work at home, the effective labor supplied is , where is an efficiency factor and is the sheltered population able to work. The effective workforce impacts the growth rate of aggregate variables as described in (2.8)–(2.11).
Finally, we assume there is a representative agent (central planner) acting in the best interest of the overall population according to the preferences , where and is defined in the paragraph above (2.15). The inner summation over accounts for all relevant populations with distinct consumption discount factors (see Endnote 5).
The model combining the pandemic and economic dynamics described above is called the BDRA-SSL model, which stands for BRDA-SEIRD-SIP-LIFT.
2.4. Equilibrium
Standard results on effectively complete markets enable us to define equilibrium as follows.
The collection of processes is a rational expectations equilibrium if (i) the representative agent maximizes utility with respect to the consumption allocation c taking the state price density, that is, stochastic discount factor (SDF) as given, and (ii) the consumption good market clears: .
It is well known that the rational expectations equilibrium can be implemented using the solution of the associated planning problem (Huang and Litzenberger 1988). Appendix B shows scaled optimal consumption allocations in the planning problem, , are identical across populations , and the planner’s instantaneous utility function is
Here is the consumption discount factor of the planner. The state price density in the rational expectations equilibrium is the shadow price of aggregate consumption in the planner’s problem, .
Let be the time marking the birth of the pandemic. At that time the infectious population becomes positive, , and all quantities related to jump. In particular, the equivalent population of normal consumers jumps from to .
As is also well known, the equilibrium state price density implies an interest rate r and a market price of risk . Here, the market price of risk consists of a market price for consumption risk , for orthogonalized dividend risk , for orthogonalized information risk , and for jump risk associated with the outbreak of a pandemic . Equilibrium is given by the following.
Consider the BDRA-SSL model and suppose that is before the pandemic. The equilibrium stochastic discount factor, interest rate, and market prices of risk are
The quantity is the drift of the aggregate consumption discount factor, its growth rate, is the expected consumption growth rate in the absence of a pandemic, is the expected value of , is the equilibrium pricing measure, and is the market price of jump risk. The interest rate has a jump component prior to the pandemic birth time .
The SDF is the planner’s marginal utility evaluated at aggregate consumption. Note that it is discontinuous: It jumps down at , and the relative jump size, that is, the negative of the market price of jump risk, is
Here, and is the size of the jump in at . Coefficient is the fraction of symptomatic mild in the infectious population, whereas is the fraction of asymptomatic. The expected relative jump is
The epidemic impact on the structure of the SDF is through , which can also be interpreted as the discount factor in an equivalent population of homogeneous consumers. A decrease in increases consumption per head and hence reduces the SDF. There are three effects on equilibrium coefficients. The first, encapsulated in the term , is structural in nature. It represents the net impact on the expected output growth rate and the growth rate of the equivalent population of normal consumers. The second arises through the adjusted probabilities that depend on . The third arises through the jump associated with the initial infection event. Variations in the equivalent consuming population combine with variations in consumption and regime probabilities to determine the behavior of these effects over time. The interest rate level and evolution reflect all effects. Market prices of risk reflect the second and third effects.
The next proposition extends the stock valuation formula in Berrada et al. (2018) to the epidemic context.
Define the matrix as in Proposition C.1 in the appendix and suppose that its elements are finite for all pairs . The stock price is then given by
The component is the volatility of due to consumption uncertainty, and the components are associated with beliefs uncertainty. The correlation between the stock return and the consumption growth rate (respectively, orthogonalized dividend growth rate) is (respectively, ). Correlations are stochastic.
Note that the equilibrium stock price and its volatility coefficients are continuous. In contrast, the state price density is discontinuous, because marginal utility jumps at the pandemic starting time. Market prices of diffusion risk are independent of the pandemic state variable and hence are continuous. The market price of jump risk is discontinuous. The equity premium, as the product of market prices of diffusion risk and volatility components, is continuous as well.
3. Empirical Results
We proceed in two stages. First we estimate the model without pandemic effects, based on prepandemic data. Second, we estimate pandemic-related parameters, using data during the COVID-19 outbreak.
3.1. Estimating the BDRA Model: Before the Pandemic
The estimation for the BDRA(K,K) model without pandemic effects follows the approach in Berrada et al. (2018). Estimation is based on longer time series with five additional years of data.
3.1.1. Data Description.
Throughout the analysis, we use data at quarterly frequency from January 1957 to December 2019. Per capita consumption is defined as
The price dividend ratio (PDR) is computed using the ratio of the current price index level and the sum of the 12 previous months of dividends.7 Log monthly returns are used to construct quarterly returns that are then adjusted for inflation using the seasonally adjusted consumer price index to obtain real returns. The construction of ex ante real 3-month rates and real 10-year rates follows the methodology of Beeler and Campbell (2012) (see Berrada et al. (2018)). We use the unemployment rate () obtained from the Saint-Louis Federal Reserve Bank as the information variable.
3.1.2. Estimation Procedure.
Following Berrada et al. (2018), the model parameters are estimated using a sequential Generalized Method of Moments (GMM) procedure (see Ogaki (1993)). There are three parameters subsets with
Subset contains parameters of the covariance matrix of consumption, dividends, and the information variable (unemployment). Its estimation relies on matching the corresponding sample moments.8 Subset contains parameters that define the steady-state behavior of the model. Its estimation relies on matching the corresponding sample moments. Steady-state equilibrium values are not affected by parameters in subset , which only influence the dynamics of equilibrium quantities. The estimation of relies on two moment conditions: (i) the correlation between log simple returns and changes in log PDR and (ii) the correlation between log simple returns and changes in log PDR lagged by one quarter.9 Using estimated parameters in the subset , these two moments within the model are calculated based on filtered values of state variables to generate sample paths that depend on the unknown parameters in . These are then estimated by minimizing the squared error of deviations of these two moments of sample paths within the model and in the sample. Table 1 summarizes the moment conditions employed in the estimation of the different sets of parameters. Additional details and justification of this procedure can be found in Berrada et al. (2018).
|

Table 1. Moment Conditions
| Moment condition | Invariant moment (definition) | Sample moments |
|---|---|---|
| Covariance of state variables: | ||
| 1. Vol. cons. | ||
| 2. Vol. div. | ||
| 3. Vol. unemp. | ||
| 4. Corr. cons., div. | ||
| 5. Corr. cons., unemp. | ||
| 6. Corr. div., unemp. | ||
| Steady state values: | ||
| 1. Exp. cons. | ||
| 2. Exp. div. | ||
| 3. Exp. unemp. | ||
| 4. Log-PDR | ||
| 5. Exp. 3-m. yield | ||
| 6. Exp. 10-y. yield | ||
| 7. Stock volatility | ||
| 8. Volatility of 10-y. yield | ||
| 9. Exp. excess return | ||
| 10. Corr. return, cons. | ||
| 11. Corr. return, div. | ||
| 12. Corr. 3-m. yield, cons. | ||
| 13. Corr. 3-m. yield, div. | ||
| 14. Corr. 10-y. yield, cons. | ||
| 15. Corr. 10-y. yield, div. | ||
| 16. Volatility log-PDR ratio | ||
| 17. Corr. log-PDR, cons. | ||
| Path dynamics: | ||
| 1. Corr. log-PDR, return | ||
| 2. Corr. log-PDR, return (1 lag) | ||
Notes. The table lists the moment conditions used for the just identified sequential GMM estimation of model parameters. Theoretical expressions for steady state values are in Berrada et al. (2018). Sample moments are based on standard sample statistics for means, standard deviations, correlation, and auto-correlation coefficients. The operator calculates the empirical correlation coefficient between and based on model trajectories of length T as a function of parameters .
3.1.3. Parameter and Moment Estimates.
Table 2 shows that estimates are close to their empirical values and typically lie within the 95% confidence bands or are close to the edges of these bands. Exceptions are the mean 3-month and 10-year yields and the volatility of the 10-year yield. Relative to the estimation results in Berrada et al. (2018), which is based on the shorter sample from 1957 to 2014, the mean consumption growth rate is further away from its sample value.10
|
Table 2. Moment Conditions and Confidence Intervals
| Moment condition | Model | Data | Confidence lower bound | Confidence upper bound |
|---|---|---|---|---|
| Mean | ||||
| Consumption growth | 0.01336 | 0.01878 | 0.01635 | 0.02095 |
| Dividend growth | 0.00862 | 0.02089 | 0.00881 | 0.03227 |
| Unemployment growth | 0.00586 | 0.00492 | −0.02870 | 0.03010 |
| Log PDR | 3.77885 | 3.61139 | 3.55770 | 3.65178 |
| Excess returns | 0.05318 | 0.05238 | 0.00972 | 0.09789 |
| Mean 10-year yield | 0.02919 | 0.02187 | 0.02088 | 0.02332 |
| Mean 3-month yield | 0.02968 | 0.00864 | 0.00676 | 0.01044 |
| Volatility | ||||
| Log PDR | 0.16681 | 0.17046 | 0.15423 | 0.19347 |
| Excess returns | 0.21168 | 0.16792 | 0.15025 | 0.19065 |
| 10-year yield | 0.02101 | 0.00902 | 0.00811 | 0.01003 |
| Correlations | ||||
| Stock returns/consumption | 0.08920 | 0.24046 | 0.10217 | 0.36067 |
| Stock returns/dividend | 0.26655 | 0.09437 | −0.04120 | 0.19922 |
| 10-year yield/consumption | 0.12260 | 0.14894 | 0.02145 | 0.27218 |
| 10-year yield/dividend | −0.04092 | −0.17219 | −0.27081 | −0.06591 |
| 3-month yield/consumption | 0.26685 | 0.25407 | 0.13267 | 0.35576 |
| 3-month yield/dividend | −0.02821 | −0.08680 | −0.20507 | 0.04195 |
| log PDR/consumption | 0.26323 | 0.22340 | 0.08045 | 0.35127 |
| Stock return and log(PDR) correlation | ||||
| 0.99742 | 0.96457 | 0.93910 | 0.97672 | |
| 0.06057 | 0.06030 | −0.07013 | 0.19272 | |
Notes. Model moment conditions are based on stationary values and estimated parameters. Confidence bounds are obtained using the bias corrected () bootstrap (DiCiccio and Efron 1996). The 95% confidence intervals are based on 1,000 replications.
Table 3 reports estimates for the drifts of consumption, unemployment, and dividends and for the preference parameters in the three growth regimes. Patterns for the coefficients pertaining to consumption and unemployment are the same as in Berrada et al. (2018), with reduction in some of the point values obtained. In contrast, dividend drift coefficients display an increasing pattern, as opposed to the previous U-shaped pattern, due to an increase in the estimate for regime 2. The risk aversion function implied by estimates of preference parameters displays the same inverted U-shape as in Berrada et al. (2018), but with a slight upward shift. Taken together, these results suggest the interpretation of regime 2 as a recession regime is also maintained, even though neither estimation imposed a priori restrictions on the ordering of regimes. Finally, standard deviation estimates for consumption, dividend, and unemployment are about the same, whereas the correlations between dividend and consumption (positive), and dividend and unemployment (negative) are both cut in half.
|
Table 3. Estimated Model Parameters and Standard Errors (in Parenthesis)
| Panel A: Expected growth rates of state variables | ||
|---|---|---|
| Normal | Low | High |
| Consumption | ||
| 0.00969 | 0.00572 | 0.03554 |
| (0.0079) | (0.0078) | (0.0102) |
| Dividend | ||
| 0.00672 | 0.00746 | 0.01707 |
| (0.0098) | (0.0094) | (0.0102) |
| Unemployment | ||
| −0.00067 | 0.12653 | −0.09982 |
| (0.0325) | (0.0455) | (0.0412) |
| Preferences: risk aversion | ||
| 2.06340 | 2.5699 | 2.2345 |
| (0.4008) | (0.0884) | (0.0570) |
| Preferences: subjective discount rate | |
|---|---|
| 0.01000 | |
| (0.0021) |
| Panel B: Standard deviations (σα on diagonal) and correlations (ραι on off-diagonal) of state variables | |||
|---|---|---|---|
| State variables | |||
| Consumption | Dividend | Unemployment | |
| Consumption | 0.0092 | 0.0799 | −0.3626 |
| (0.0616) | (0.1169) | (0.2308) | |
| Dividend | 0.0799 | 0.0449 | −0.1836 |
| (0.1169) | (0.0698) | (0.1978) | |
| Unemployment | −0.3626 | −0.1836 | 0.1214 |
| (0.2308) | (0.1978) | (0.9626) | |
| Panel C: Infinitesimal generator (Λ = [λij]) and Steady-State probability (P∞) | ||||
|---|---|---|---|---|
| Regimes | ||||
| Normal | Low | High | P∞ | |
| Normal | −0.07343 | 0.07343 | 3.859425 E-07 | 0.645 |
| — | (0.0147) | (1.82 E-06) | ||
| Low | 0.24417 | −0.25736 | 0.01320 | 0.184 |
| (0.0344) | — | (0.0038) | ||
| High | 0.01426 | 1.789710 E-07 | −0.01426 | 0.170 |
| (0.0049) | (1.82 E-06) | — | ||
Note. GMM parameter estimates with standard errors obtained from stationary bootstrap (Politis and Romano 1994).
Overall, the results obtained based on the augmented sample 1957–2019 are consistent with those in Berrada et al. (2018) for the period 1957–2014.
3.1.4. Discussion.
Table 2 shows that the model performs well in terms of matching the empirical values of unconditional moments of endogenous variables, including the first and second moments of the log PDR and the equity premium. It also matches the empirical value of the unconditional mean market volatility. To provide perspective on these results, and for comparison with the literature, note that the stock’s instantaneous risk premium, that is, the equity premium, is
Hence, the properties of the market prices of risk (the negatives of the volatility components of the SDF growth rate ) and of the return volatility components determine the properties of the risk premium. For a given , the equity premium increases if increases and . The volatility of the equity premium differs from zero if is stochastic. The market volatility , by the standard present value (Equation (2.29)), depends on the behavior of the aggregate dividend process and the stochastic discount factor. If the coefficients of the aggregate dividend process, the interest rate, and the market price of risk are nonstochastic, volatility stems from the volatility of dividends. Otherwise, there are additional volatility components related to their stochastic fluctuations.
The literature attempting to explain empirical regularities examines different specifications of the dividend process and the SDF. Campbell and Shiller (1988) use the expected (total) return to discount future dividends. With this specification, volatility is tied to the volatility of the expected return, the volatility of dividends, and the coefficients of the dividend process. They show the high volatility of stock returns stems from either the strong predictability of dividend growth or the large variations in expected returns. They find the model fails to explain a large part of the variation in the log dividend-price ratio.
With standard von Neumann-Morgenstern (vNM) preferences, aggregate consumption determines the structure and behavior of the SDF. With Epstein and Zin (1989) preferences, the return on wealth is an additional factor. Campbell (1999) examines different model specifications and highlights the tradeoffs involved. Bansal and Yaron (2004) develop a production-based model with Epstein and Zin (1989) preferences, a common persistent predictable factor in the consumption and dividend growth rates, and stochastic factor volatility, commonly called the long-run risk model. With relative risk aversion of 10 and elasticity of intertemporal substitution (EIS) of 1.5, the low-frequency risk in the model generates the size of the equity premium, the risk-free rate, and the volatilities of the market return, dividend yield, and risk-free rate. Bansal et al. (2014) investigate the relationship between macroeconomic volatility, long-run risk, and asset prices. Using a log-normality assumption for the return of the consumption asset and the stochastic discount factor, they establish a relation between the volatility and forecasts of consumption growth. In addition to linking volatility and predictability, using log-linearization, they identify a volatility risk premium, that describes the compensation for risk associated with macroeconomic uncertainty. Similarly, Campbell et al. (2018) enhance an intertemporal capital asset pricing model by integrating stochastic volatility. They show how low-frequency movements in equity volatility and associated risk premia are crucial to understand asset price dynamics.11
A related branch of literature highlights the role of incomplete information. Brennan and Xia (2001) consider a pure exchange economy with incomplete information and vNM preferences. They show that incomplete information about the drift of the dividend growth rate can explain the equity premium puzzle, the volatility puzzle, and the risk-free rate puzzle simultaneously. Their results are obtained with a risk aversion of 15 and a subjective discount rate of 10%. Ai (2010) considers a production economy from Bansal and Yaron (2004) but with incomplete information. With relative risk aversion and EIS parameters both equal to two, the model improves on Bansal and Yaron (2004). It produces an expected consumption-to-wealth ratio (CWR) as in the data, a standard deviation of the CWR closer to the data (compared with Bansal and Yaron (2004)), a volatility of the change in the CWR, and a standard deviation of the return on wealth that both match the data. It overestimates the equity premium by a small amount, but the standard deviation of the consumption growth rate, whereas closer than that of Bansal and Yaron (2004), is much higher than in the data.
Other contributions explore the effects of internal habits (Sundaresan 1989, Constantinides 1990, Detemple and Zapatero 1991), external habits (Campbell and Cochrane 1999), investor heterogeneity (Constantinides and Duffie 1996), and disaster risk (Rietz 1988). Although many of these models are able to explain some features of the data, they fail to address a comprehensive set of issues.
The BDRA model, in contrast, produces estimates that are consistent with 25 unconditional moments of economic time series. In our specification, the SDF is tied to aggregate consumption and the regime probabilities. The latter responds to innovations in consumption, dividend, and unemployment. As a result, there are three prices of risk that, combined with volatility coefficients of the market return, determine the size and properties of the equity premium. Stochastic fluctuations in consumption and probabilities also determine the size and properties of the volatility coefficients of the market return.
The equity premium generated by the model is 5.318% compared with 5.238% in the data. The components related to the three market prices of risk explain 14.87%, 1.08%, and 84.05% of the premium’s size. This shows that the main contributor is (orthogonal) unemployment risk, a determinant of regime probabilities risk. The unconditional expected variance generated by the model is compared with in the data. The respective contributions of the local variances associated with the three sources of risk are . Again, (orthogonal) unemployment risk emerges as the main driver of the average variance.
3.2. Estimating the BDRA Model: During the Pandemic
We now focus on the pandemic period, assuming that parameters are constant across economic regimes. We consider a version of the BDRA-SSL model where sheltered populations split into two groups; individuals apt to work at home and those laid off (Appendix A). Laid off populations, whether susceptible, exposed, or asymptomatic infectious, consume at a reduced rate reflecting their employment status. They discount consumption by factor . Mildly sick individuals in the infectious category consume at a reduced rate because of their health status. Their consumption discount factor is . Even if not laid off, they do not work; that is, they are on sick leave. Severely sick individuals neither consume nor work.
First, we complete the SSL model by specifying the transmission intensity. Second, we describe the estimation procedure for the pandemic-related parameters. Last, we present the results and discuss performance.
3.2.1. Transmission Intensity Specification.
We consider a version of the SSL pandemic model with time decay and threshold effects in the transmission intensity . We assume
3.2.2. Estimation Procedure for Pandemic Parameters.
In light of Sections 2.1 and 3.2.1, and Appendix A, the set of pandemic propagation parameters is .13
In addition, we have parameters in governing the impact of the pandemic on the time series of consumption, dividend and unemployment. Hence, the full set of pandemic-related parameters to be estimated is .
Estimation is based on the number of new COVID-19 cases and a measure of the index return volatility. Data for new cases are from the COVID Tracking Project (2021).14 Volatility is proxied by the average squared total return on the S&P500 index computed over a 10-day rolling window. The sample period is January 1, 2020, until August 7, 2020 and therefore covers the first and second waves of the COVID pandemic in the United States.15
All target quantities are available at daily frequency. Input quantities in the model, however, are available at different frequencies. Unemployment, consumption, and dividend are available at monthly frequency and are held constant between observations. This results in innovation processes that are updated at monthly frequency. The regimes conditional probabilities therefore change at monthly frequency. The drift processes of unemployment, consumption, and dividend are adjusted at daily frequency using the pandemic-related effect . The stock price level and volatility are functions of the conditional probabilities, the consumption, and dividend level. They also depend on the volatility coefficients of the conditional probabilities that are functions of the drift processes of unemployment, consumption, and dividend. It follows that through the updating procedure of the drift processes driven by the pandemic model, stock price level and volatility can also be updated at daily frequency. The entire process is displayed in Figure 2. The estimation is performed jointly by minimizing the weighted squared distance between model implied and observed (i) index volatility and (ii) number of new COVID cases, all measured at daily frequency. The weights applied ensure that time series have the same average.16 Joint estimation of parameters in is justified by the fact that populations behavior affects the pandemic propagation parameters, in particular, the infection rate (3.4) and its evolution through time.
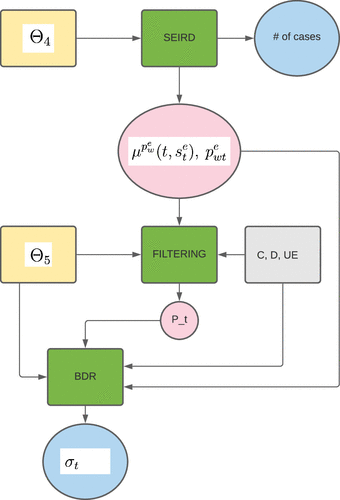
Note. Box colors are as follows: yellow, parameters; green, models; gray, data; pink, model output-intermediary quantities; blue, model output-target quantities.
3.2.3. Parameter Estimates.
The lower panel in Table 4 reports estimates of pandemic propagation and related policy parameters in . The initial transmission rate is found to decay at rate before SIP, decay/appreciate at rate during SIP, and to finally decay at rate after SIP. Estimates of elapsed times for infection regime changes since the beginning of the pandemic are (days) and (days), roughly in line with average times of SIP and LIFT implementations across states. The pandemic birth time is estimated at (days). The mean latency duration is days, and the mean infectious duration is days. Both values are consistent with estimates reported during the initial phases of the COVID-19 outbreak. The fraction of severe and asymptomatic cases are estimated at and , respectively, again consistent with reported values. The disease mortality parameter is commensurate with COVID-19 mortality statistics. As might be expected, the natural immunity rate is extremely low. Finally, the migration rates into and out of lockdown are, respectively, and . Compliance q is low because some states never went into lockdown, whereas others implemented SIP at various dates. In addition, the policy did not apply to essential workers. Reverse migration is even lower because businesses were slow to reopen or because firms continued operating using work-at-home.
|
Table 4. Estimated Coefficients and Standard Errors for the BDRA-SSL Model
| Parameters | Estimate | Standard error |
|---|---|---|
| Economic model | ||
| −0.225699987 | 0.000343447 | |
| −0.205206295 | 0.000309373 | |
| −1.010281569 | 0.017004253 | |
| 0.000361144 | 0.000065393 | |
| 0.004983284 | 0.001007257 | |
| 0.999998388 | 0.302882281 | |
| 0.870647382 | 0.258662682 | |
| 0.023494158 | 0.001518683 | |
| h | 0.482320207 | 0.030494020 |
| Pandemic model | ||
| 3.152666020 | 0.057393571 | |
| 0.032707404 | 0.000691162 | |
| 0.141244235 | 0.009444131 | |
| 0.016641559 | 0.005415440 | |
| 0.868235429 | 0.015268554 | |
| 0.000014448 | 0.000004421 | |
| 0.000006201 | 0.000002356 | |
| 0.000005195 | 0.000001749 | |
| 1.689756587 | 0.241127840 | |
| q | 0.090565497 | 0.000405423 |
| 0.000699006 | 0.000029186 | |
| 23.334514719 | 0.162969780 | |
| 18.249258086 | 0.407170015 | |
| 54.140625085 | 0.186541205 | |
| 121.043739540 | 0.261917872 | |
| 0.000000105 | 0.000000035 | |
| 15.820315698 | 0.182539417 | |
Notes. Sample period for estimation is January 1, 2020, to August 7, 2020. Standard errors are obtained from a wild bootstrap with degrees-of-freedom-adjusted resampled residuals using the Rademacher distribution (Davidson and Flachaire 2008).
The top panel of Table 4 reports estimates of the economic effects of the pandemic on the drifts of consumption, dividend, and unemployment. The sensitivity of consumption, assumed to be constant across economic regimes, is estimated at , showing an extremely low response to the propagation via . The sensitivity of dividend, also assumed constant, is higher at , albeit still very low. Estimates of both these coefficients are positive, indicating a negative impact as the growth rate of the effective workforce falls. In contrast, the sensitivity of unemployment, assumed to depend on the economic regime in the estimation, is negative in all these regimes and large in comparison. Its greatest magnitude is in the boom regime at , followed by the normal regime at and the recession regime at . Hence, unemployment responds strongly to the growth rate of the workforce in all regimes when the pandemic takes off but very strongly if the economy is in a boom regime. Uncertainty about the regime implies that the actual response of unemployment is determined by the average of these sensitivities, which is unambiguously negative. A negative expected growth in the effective workforce therefore translates into an expected increase in unemployment, and that response becomes stronger if regime probabilities shift toward the normal and boom regimes as the pandemic unfolds. The efficiency of work-at-home is estimated at a low , and the fraction of individuals working at home is . The efficiency loss associated with work-at-home can be attributed to frictions in the organization of work, the transmission of information, and the implementation of decisions and processes. Last, the consumption discount factors of ill and laid-off individuals are estimated at and , respectively. Individuals stricken by the pandemic shift their consumption basket toward medical goods and services, leading to a moderate reduction in overall expenditures. Laid-off individuals consume at nearly the same rate during the pandemic due to government subsidies and related support schemes.
3.3. Model Performance
Section 3.3.1 analyzes the model’s performance relative to targeted variables. Section 3.3.2 assesses the behavior of model-implied regime probabilities in light of the NBER-declared recession during the pandemic. Section 3.3.3 explains the sources of volatility during and after the spike. Out-of-sample performance is studied in Section 4.
3.3.1. Model Performance: Targeted Variables.
We first examine the performance of the BDRA-SSL model relative to variables that were targeted in the estimation procedure, that is, the number of new COVID-19 cases and the volatility of the S&P500.
Figure 3 shows that the estimated model stays close to the observed number of cases in the data and picks up the timing of changes in the propagation pattern. The most significant deviation occurs at the beginning of the epidemic, between days 50 and 80, and there is a minor discrepancy toward the end of the first wave of the outbreak, between days 130 and 160, counting from January 1, 2020. The match during the first wave and through most of the second wave, between days 180 and 220, is very close.
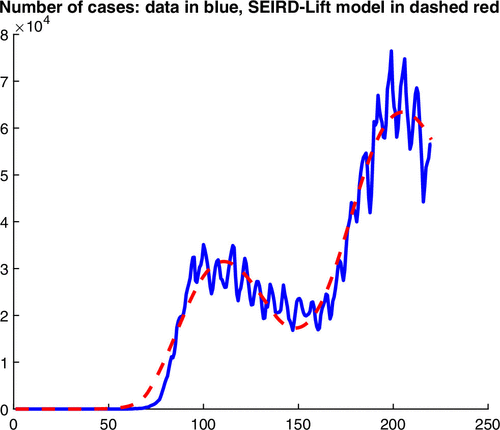
Notes. The sample period is January 1 through August 7. The x axis displays the day number.
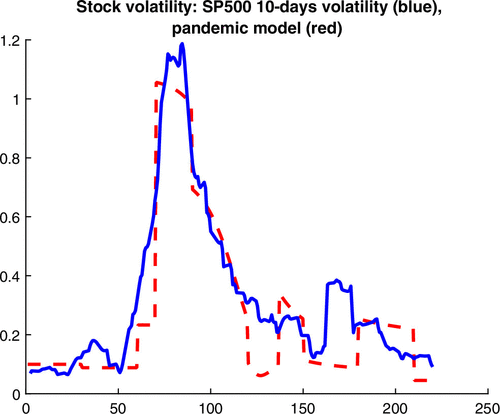
Figure 4 demonstrates that the BDRA-SSL model is able to replicate the rapid increase and decrease in volatility that took place during the first wave of the COVID-19 pandemic, as well as the magnitude and inverted V-shape of the effect recorded, that is, the volatility spike. In comparison, the standard BDRA model without pandemic effect, called the base model hereafter, only generates an increase in volatility with a significant delay and of smaller amplitude (Figure 5). It is also unable to reproduce the spike of the volatility event. The reason for the discrepancy between the performances of the two models is because the base model reacts only when the recession probability reaches a peak, whereas the pandemic model reacts immediately following an increase in the number of COVID-19 cases. This discrepancy is examined in more detail in the next section.17
Notes. The sample period is January 1 through August 7. The x axis displays the day number.
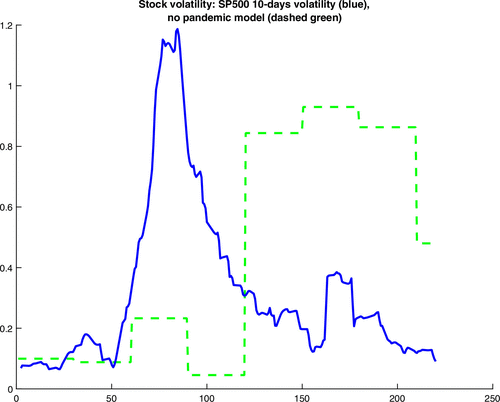
Notes. The sample period is January 1 through August 7. The x axis displays the day number.
3.3.2. Regime Probabilities and Pandemic Model.
To better understand the performance of BDRA-SSL, it is informative to focus on the dynamics of the conditional regime probabilities. Figures 6 and 7 display their evolution for the model with pandemic (BDRA-SSL) and the base model (BDRA). The shaded area corresponds to the brief recession period February through April identified by NBER, which is a nontargeted event. The base model overestimates the duration of the recession and has a major reaction with a delay of two months. The volatility in the base model, illustrated in Figure 5, increases with a delay exceeding two months and stays high for several months thereafter. It therefore completely misses the observed spike in volatility during the first wave of the pandemic. In contrast, the conditional probabilities in BDRA-SSL react sooner and with smaller magnitudes (Figure 6). The increase in the recession probability is mostly confined to the NBER recession period, and it almost goes to zero immediately when this recession is assessed to be over. Symmetrically, the normal regime probability decreases during the NBER-declared recession, but rapidly increases and, for the most part, varies in the 90%–100% range thereafter. The volatility implied by BDRA-SSL is directly impacted by the variations in the number of COVID cases through the pandemic factor ; through changes in the expected drifts of consumption, dividend, and mostly unemployment; and through associated changes in the regime probabilities.18 The model’s ability to rapidly reflect short-term variations tied to the epidemic not only generates a high level of volatility at the onset of the crisis but is also able to capture its rapid decrease as the number of new cases decreases. The introduction of this pandemic channel in BDRA-SSL allows it to correctly estimate the duration of the recession, perfectly time the spike in volatility, and match the magnitude and profile of the volatility event.
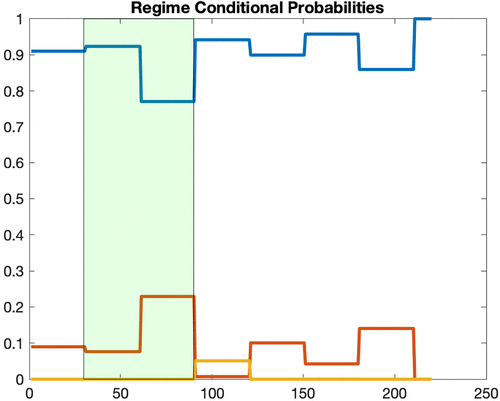
Notes. Normal regime in blue, recession regime in red, and boom regime in yellow. The shaded area corresponds to the NBER recession period. The sample period is January 1 through August 7. The x axis displays the day number.
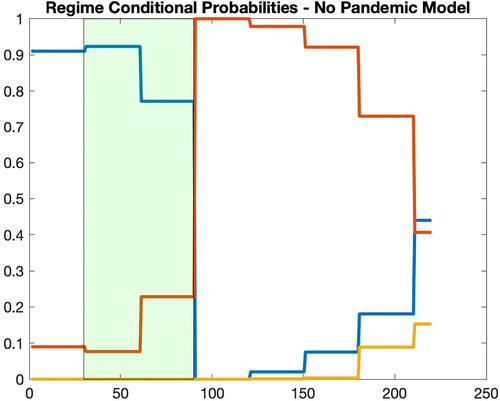
Notes. Normal regime in blue, recession regime in red, and boom regime in yellow. The shaded area corresponds to the NBER recession period. The sample period is January 1 through August 7. The x axis displays the day number.
Figure 4 shows there is a second volatility event in the data, very short lived and of small magnitude, between days 165 and 180 of the sample. This event is not picked up in a timely manner by BDRA-SSL even though the pandemic flares again during the second wave, roughly between days 160 and 220 in the sample. As Figure 6 indicates, the recession (normal regime) probability is low (close to one) during that period, implying the model becomes unresponsive to pandemic shocks. The reason why volatility does not spike in the model is because the pandemic factor is small and does not vary much; that is, is nearly flat, during that period, implying the absence of a significant reaction in the underlying factors and the regime probabilities (Figure 8).
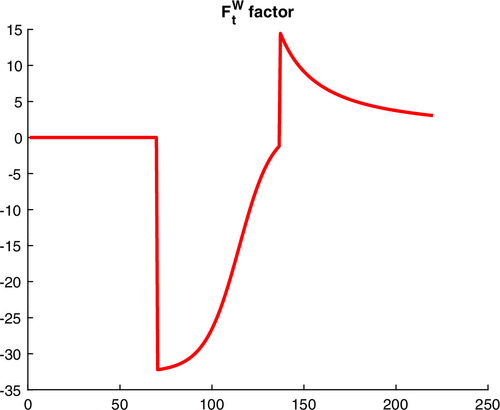
Notes. The sample period is January 1 through August 7. The x axis displays the day number.
3.3.3. Explaining the Source of the Volatility Spike.
Figure 9 displays the evolution of the volatility (relative to its maximum level) along with the decomposition in terms of its three sources: consumption, orthogonal dividend, and orthogonal unemployment. First, we observe that the spike in volatility is almost entirely due to the unemployment component; that is, it has an informational origin because unemployment is only used to update regime probabilities. Second, although dividend- and consumption-implied volatilities explain up to about 85% of volatility prerecession and in the early stages of the recession, unemployment-implied volatility nevertheless plays an important role. After the recession, they very briefly explain all the volatility behavior before reverting to levels lower than before the recession between days 140 and 210. After day 210, consumption and dividend volatility components explain 100% of the volatility behavior.
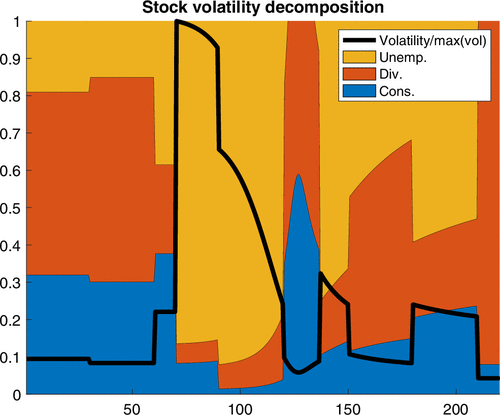
Notes. The three components correspond to consumption source (blue), dividend source (red), and unemployment source (yellow). The sample period is January 1 through August 7. The x axis displays the day number.
The explanation for these patterns stems from (i) the sudden drop in the pandemic factor at the peak of the recession followed by its subsequent adjustment (Figure 8), (ii) the fact that the economy is more likely to be in the normal regime upon entering and after exiting the recession (Figure 6), and (iii) the large response of to variations in in the different regimes compared with the unresponsiveness of and (see Remark 3.1). The combination of these elements implies unemployment behavior dominates during the recession. It also plays a dominant role after the recession, in periods during which the pandemic factor does not vanish. Finally, it plays an important role before the recession, even though the pandemic factor is null, because the deviation from the mean unemployment drift is large when the probability of a recession or the normal state is large (see the composition of in (6.1)).
The following aspects of the volatility components of the stock return are noteworthy:
The behavior of the volatility of the stock return associated with consumption innovations, , is displayed in the upper left panel of Figure 10. The first term stemming from the volatility of dividends is small and constant. The second term is also small and nearly insensitive to fluctuations because of the small difference between risk aversion parameters across regimes (this term is null if ). The last term is small and nearly constant, because is small as it does not depend on when is constant. As a result, both the size of and the amplitude of its variations are small.
The volatility of the stock return associated with dividend innovations, , is shown in the upper right panel of Figure 10. It is also small and nearly constant over time, for the same reasons as those explaining the behaviors of the first and last term of .
In contrast, the volatility stemming from unemployment innovations, is large and exhibits significant variations over time (lower panel of Figure 10). The sensitivity to unemployment news contributes to these properties. This term reflects the behavior of because the estimated coefficients differ across regimes (see Equation (6.1)). Variations in over time affect the volatility of probabilities associated with unemployment news and explain the behavior of , and ultimately of .
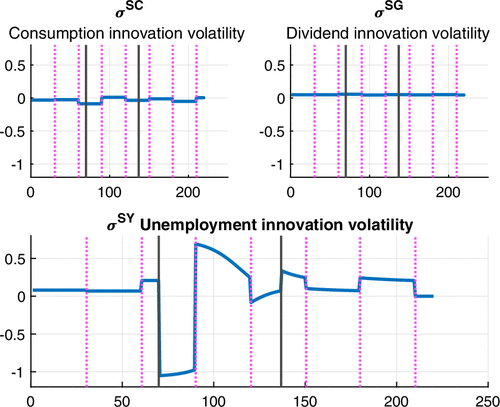
Notes. (Top left) Volatility component associated with consumption innovations. (Top right) Volatility component associated to dividend innovations. (Bottom) Component associated with unemployment innovations. The sample period is January 1 through August 7. The x axis displays the day number. Vertical lines display the information arrival dates in magenta and the beginning and end of SIP in black.
4. Comparison of Models
Section 4.1 describes the models to be compared. Section 4.2 explains the comparison methodology. Section 4.3 analyzes the results. Section 4.4 carries out out-of-sample tests.
4.1. Models Descriptions
We now compare the performances of different models with BDRA-SSL. Contenders are the nested alternatives, CRRA-SSL, BDRA, and BDRA-SSL-C, and the nonnested BDRA-SIRD-SL model. The model CRRA-SSL has constant parameters across regimes. In BDRA, the economic model does not depend on the SSL component: and . BDRA-SSL-C has constraints on efficiency and work-at-home fraction. The nonnested BDRA-SIRD-SL model has SIRD pandemic dynamics instead of SEIRD. In this specification, contaminated individuals transition directly from the susceptible category to the infectious category. The remainder of the model, in particular, the policy components SIP (S) and LIFT (L), remain the same.
4.2. Estimation and Comparison Methods
All models are estimated using the procedure described in previous sections. Parameter estimates are in Table 5. As expected, estimates of pandemic parameters, which are jointly estimated, display small variations across models, reflecting structural changes in models, including behavioral feedback effects.
|
Table 5. Estimated Coefficients for BDRA-SSL, CRRA-SSL, BDRA, BDRA-SIRD-SL, and BDRA-SSL-C (Constrained)
| Parameters | BDRA-SSL | CRRA-SSL | BDRA | BDRA-SIRD-SL | BDRA-SSL-C |
|---|---|---|---|---|---|
| Economic model parameters | |||||
| −0.225699987 | −0.338038755 | 0.000000000 | −0.223064349 | −0.229568310 | |
| −0.205206295 | −0.120434706 | 0.000000000 | −0.192356267 | −0.157732990 | |
| −1.010281569 | −0.843161274 | 0.000000000 | −0.872292363 | −1.238391188 | |
| 0.000361144 | 0.000503377 | 0.000000000 | 0.000322987 | 0.000347659 | |
| 0.004983284 | 0.004836171 | 0.000000000 | 0.005257631 | 0.005202975 | |
| 0.999998388 | 0.997659820 | 1.000000000 | 0.906362197 | 0.906367982 | |
| 0.870647382 | 0.825955929 | 1.000000000 | 0.939919562 | 0.997379434 | |
| 0.023494158 | 0.023670607 | 1.000000000 | 0.023308220 | 0.714220655 | |
| h | 0.482320207 | 0.242233577 | 1.000000000 | 0.231886452 | 0.913435513 |
| Pandemic model parameters | |||||
| 3.152666020 | 3.244041477 | 2.262868406 | 0.349183873 | 3.397179601 | |
| 0.032707404 | 0.028815729 | 0.047651367 | 0.029633000 | ||
| 0.141244235 | 0.074761862 | 0.094102904 | 0.013680354 | 0.135072072 | |
| 0.016641559 | 0.009445437 | 0.021186155 | 0.063100964 | 0.008364380 | |
| 0.868235429 | 0.869548138 | 0.810637484 | 0.675365163 | 0.874389944 | |
| 0.000014448 | 0.000013980 | 0.000023156 | 0.000007847 | 0.000014335 | |
| 0.000006201 | 0.000003603 | 0.000002384 | 0.000003159 | 0.000003577 | |
| 0.000005195 | 0.000005234 | 0.000014305 | 0.000007851 | 0.000007686 | |
| 1.689756587 | 1.905648885 | 3.292112442 | 1.629043349 | 1.681568270 | |
| q | 0.090565497 | 0.088976961 | 0.084756362 | 0.061431596 | 0.100584742 |
| 0.000699006 | 0.000715303 | 0.000498207 | 0.000193004 | 0.000607208 | |
| 23.334514719 | 23.239457246 | 22.999992457 | 19.059137853 | 25.834294286 | |
| 18.249258086 | 18.199482007 | 12.366558517 | 2.540410448 | 18.399096295 | |
| 54.140625085 | 53.437581942 | 59.814919272 | 63.984375000 | 54.843750000 | |
| 121.043739540 | 122.648112289 | 122.341882473 | 146.250000000 | 118.829431654 | |
| 0.000000105 | 0.099596431 | 0.000007479 | 0.039565862 | 0.000008381 | |
| 15.820315698 | 16.189452828 | 13.723105952 | 6.679687500 | 16.006268628 | |
Note. Sample period is January 1, 2020, to August 7, 2020.
Parameters of the pandemic model are estimated using a quasi-log-likelihood ratio (QLR) estimator. Let denote time series at sampling times . BDRA-SSL-C, CRRA-SSL, and BDRA are all nested in BDRA-SSL. The QLR estimator minimizes the sum of squared errors over multiple time series:
|
Table 6. Model Specification Tests and Model Selection Criteria
| Model | BDRA-SSL | BDRA-SSL-C | CRRA-SSL | BDRA | BDRA-SIRD-SL |
|---|---|---|---|---|---|
| Np | 26 | 24 | 24 | 17 | 25 |
| SSE | 5.83 | 17.46 | 13.25 | 87.35 | 7.99 |
| Model specification tests | |||||
| neg. QLR statistic | 11.63 | 7.42 | 81.53 | ||
| Critical value | 5.99 | 5.99 | 16.92 | ||
| p-value | 0.00 | 0.02 | 0.00 | ||
| Model selection criteria | |||||
| BIC | 1,206.14 | 3,764.58 | 2,842.32 | 19,108.70 | 1,681.49 |
| AIC | 1,250.20 | 3,801.86 | 2,879.60 | 19,122.25 | 1,723.86 |
Notes. Models are nested and nonnested. Specification tests are based on the negative quasi-log-likelihood ratio statistic , where N is the number of observations and () is the constrained (unconstrained) sum of squared errors (negative quasi-log-likelihood function). The model selection criteria are (Bayesian), respectively, (Akaike), where is the quasi-log-likelihood function and np is the difference between the total number of model parameters and the number of constrained model parameters.
4.3. Results
Table 6 shows that model specification tests reject the hypothesis that any of the nested alternatives, BDRA-SSL-C, CRRA-SSL, and BDRA, dominate BDRA-SSL. This is confirmed by both the Bayesian Information Criterion (BIC) and the Akaike Information Criterion (AIC) for model selection. The table also shows that the nonnested BDRA-SIRD-SL model is dominated. Both the BIC and AIC model selection criteria, which penalize overparametrized models, choose BDRA-SSL as the best model among all alternative specifications, nested and nonnested, despite it being least parsimonious.
The table also reveals that performance deteriorates substantially when the SSL pandemic component does not feed back into the economic model, as for the stripped model (BDRA). The main reason is because BDRA fails to capture the inverse V-shaped pattern in the volatility adjustment. It also shows that the SSL model and BDRA are essential ingredients for good performance during the pandemic. Figure 11 illustrates performance along one dimension by displaying the volatility fits of the candidate models.19
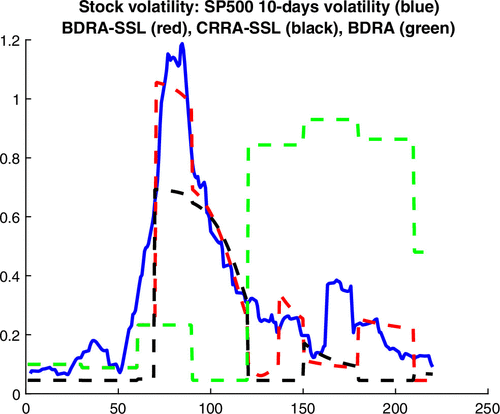
Notes. Red and green line sometime overlap, and only the red line is visible. The sample period is January 1 through August 7. The x axis displays the day number.
4.4. Model Comparison: Out-of-Sample
The model selection criteria in Table 6 suggest that the best model is BDRA-SSL (with SEIRD pandemic propagation) followed by BDRA-SIRD-SL (with SIRD propagation). To further investigate the out-of-sample performance of these two models, we estimate the models using 30, 60, 90, 120, 150, and 180 days of data and then forecast both the number of COVID cases and the index volatility for the subsequent 5 days following the sample period used for estimation. At time t, the volatility forecast for the next five days is constructed using factors and . It is entirely driven by model implied quantities and does not rely on new observations. The forecast for the number of cases is implied by the SSL model and does not use new observations.
Table 7 shows that, except in the first 30 days, both BIC and AIC model selection criteria favor BDRA-SSL. The overall dominance of the BDRA-SSL model is illustrated by the forecasts of five-day-ahead realized volatility in Figure 12 and five-day-ahead number of COVID cases in Figure 13.
|
Table 7. Model Selection Criteria for BDRA-SSL vs. BDRA-SIRD-SL Using Varying Sample Sizes for Five-Day-Ahead Forecasts
| Model | Days | |||||
|---|---|---|---|---|---|---|
| 30 | 60 | 90 | 120 | 150 | 180 | |
| BDRA-SSL (SEIRD) | ||||||
| BIC | 42.40 | 759.23 | 387.15 | 468.15 | 651.60 | 1,006.34 |
| AIC | 60.18 | 786.24 | 419.50 | 504.28 | 690.65 | 1,047.77 |
| BDRA-SIRD-SL | ||||||
| BIC | 34.63 | 879.03 | 480.27 | 658.22 | 948.85 | 1,502.72 |
| AIC | 51.72 | 905.00 | 511.38 | 692.96 | 986.40 | 1,542.56 |
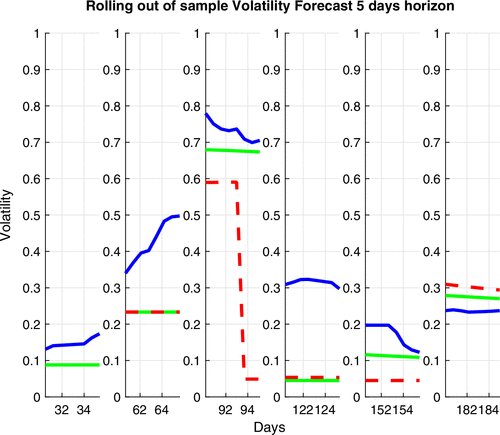
Notes. BDRA-SSL forecast (solid green), BDRA-SIRD-SL forecast (dash red), and realized volatility (solid blue). Red and green lines sometimes overlap, and only the green line is visible.
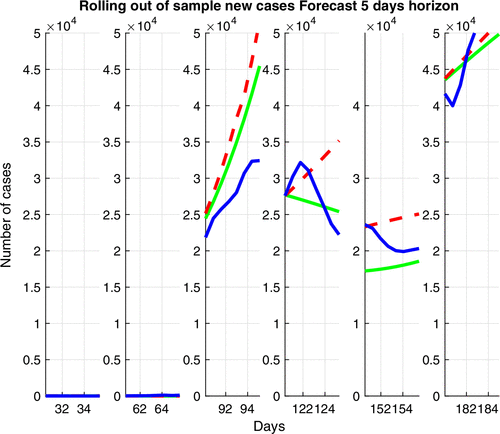
Notes. BDRA-SSL forecast (solid green), BDRA-SIRD-SL forecast (dash red), and realized number of cases (solid blue). Red, blue, and green lines sometimes overlap, and only the green line is visible.
5. Further Discussion
An important element emerging from the previous results is the ability of BDRA-SSL to quickly capture the occurrence of a recession. The quick reaction of the recession probability was highlighted as the reason why the volatility spike generated by the model coincides with the spike in the data. This section provides further perspective on the source of the reaction.
The NBER dates the COVID-19 recession from February 2020 to April 2020. The unemployment rate stood at 3.5% in February 2020, increased to 4.4% in March 2020, and peaked at 14.7% in April 2020. By itself, the monthly innovation in the unemployment rate between February and March is too small to have a significant impact on the March recession probability. The large innovation from March to April arrives too late to move the recession probability in a timely fashion consistent with the data This is why BDRA (without pandemic) indicates the recession occurs too late, after April 2020 (Figure 7). The inability of BDRA to time the recession is consistent with the behavior of the Anxiety Index, published by the Philadelphia Fed, that measures recession forecasts of professional forecasters. The Anxiety Index also suggests the recession occurs after April, that is, after the NBER declared the recession over. In contrast, during the Great Financial Crisis (GFC), dated by the NBER from December 2007 to June 2009, the unemployment rate increased from 5% in December 2007 to 9.5% in June 2009, sufficient to accurately update the BDRA recession probability.
Turning to BDRA-SSL, we first note that the labor force participation rate (LFPR) decreased from 63.3% in February 2020% to 60.1% in April 2020, a variation of −3.2% over only 2 months. In fact, the March 2020 LFPR stood at 62.6%, showing the real drop occurs in April. In BDRA-SSL, the factor tied to the growth rate of the effective workforce ensures the recession probability adjusts almost instantaneously. In comparison with the GFC, the drop in LFPR over two COVID months is significantly larger than during the GFC over two years. Indeed, during the GFC, the LFPR dropped by only 0.3%, from 66% in December 2007 to 65.7% in June 2009. Incorporating the effective labor force as an element associated with the pandemic, only present during the COVID recession, is supported by the data.
The BDRA-SSL recession probability is accurate and fares well compared with other measures of economic conditions such as the Aruoba-Diebold-Scotti (ADS) index published by the Philadelphia Fed and based on Aruoba et al. (2009) or the Chicago Fed National Activity Index (CFNAI) based on Stock and Watson (1999). The CFNAI captures the principal component of 85 macro variables. The ADS index is more parsimonious, currently using (1) Initial jobless claims (weekly), (2) payroll employment (monthly), (3) industrial production (monthly), (4) real personal income less transfer payments (monthly), (5) real manufacturing and trade sales (monthly), and (6) real gross domestic product (GDP; monthly) to construct the first eigenvector of a state-space system estimated by Kalman filtering. None of these indicators of the current economic state relies on financial market data (the ADS index initially used the term spread).20 In contrast, BDRA-SSL is more parsimonious as it only uses low-frequency consumption, dividend, and unemployment data; daily frequency S&P500 volatility; and COVID case data. Its ability to capture the COVID recession regime shows the informational efficiency of financial markets combined with a measure of the effective labor force permits the identification of economic conditions at a high frequency. As such, it can provide important information for policy makers who decide on fiscal or monetary interventions contingent on the state of the economy.
6. Counterfactuals: Policy Responses to COVID-19
In this section, we use the BDRA-SSL model specification to study how the forecasted volatility and the evolution of the number of COVID cases would be affected by changes in what we call COVID policy. To that end, we focus on a version of the model estimated 90 days after the start of the pandemic. We then examine the impact of policy changes taking place on day 90, on the variables of interest, from day 91 to day 140. It follows that the forecasted variables are entirely model based and do not rely on observations after the 90-day sampling period.
6.1. Parameter Estimates
Table 8 shows the parameter estimates based on the 90-day sample. Several items stand out when compared with the estimates for the full sample. First, estimates of the pandemic propagation parameters are of the same order of magnitude as the full sample values, but smaller, except for , which is slightly greater. The initial growth rate of the infection rate is only about 20% of its full sample value , reflecting the slow growth of the pandemic during the restricted sample period.
|
Table 8. Estimated Coefficients and Standard Errors (SE) for the BDRA-SSL Model
| Parameter | 90-day estimate | 90-day SE | 220-day estimate | 220-day SE |
|---|---|---|---|---|
| Economic model parameters | ||||
| −0.134924598 | 0.029572802 | −0.225699987 | 0.000343447 | |
| −0.091688930 | 0.026782613 | −0.205206295 | 0.000309373 | |
| −0.938349279 | 0.544321910 | −1.010281569 | 0.017004253 | |
| 0.000337497 | 0.000612275 | 0.000361144 | 0.000065393 | |
| 0.002203412 | 0.004677995 | 0.004983284 | 0.001007257 | |
| 0.995104732 | 1.367843618 | 0.999998388 | 0.302882281 | |
| 0.900391474 | 1.366977705 | 0.870647382 | 0.258662682 | |
| 0.044926476 | 0.073941992 | 0.023494158 | 0.001518683 | |
| h | 0.307635547 | 0.560847830 | 0.482320207 | 0.030494020 |
| Pandemic model parameters | ||||
| 2.989608782 | 0.312903446 | 3.152666020 | 0.057393571 | |
| 0.029225264 | 0.003143854 | 0.032707404 | 0.000691162 | |
| 0.146379924 | 0.039652250 | 0.141244235 | 0.009444131 | |
| 0.005990826 | 0.009221702 | 0.016641559 | 0.005415440 | |
| 0.797629762 | 0.083301484 | 0.868235429 | 0.015268554 | |
| 0.000010517 | 0.000022988 | 0.000014448 | 0.000004421 | |
| 0.000002461 | 0.000004365 | 0.000006201 | 0.000002356 | |
| 0.000002630 | 0.000004317 | 0.000005195 | 0.000001749 | |
| 0.336971286 | 0.910780505 | 1.689756587 | 0.241127840 | |
| q | 0.043552344 | 0.015198718 | 0.090565497 | 0.000405423 |
| 0.001449279 | 0.001970921 | 0.000699006 | 0.000029186 | |
| 15.412895478 | 9.627534229 | 23.334514719 | 0.162969780 | |
| 10.391159185 | 18.890498725 | 18.249258086 | 0.407170015 | |
| 56.250002230 | 0.519035551 | 54.140625085 | 0.186541205 | |
| 136.384365514 | 125.755107575 | 121.043739540 | 0.261917872 | |
| 0.000041698 | 0.000070962 | 0.000000105 | 0.000000035 | |
| 15.126819175 | 0.374330522 | 15.820315698 | 0.182539417 | |
Notes. The sample period for the 90-day estimate is January 1, 2020 to March 30, 2020 (day 90). The 220-day estimate uses the full sample.
Second, the start of the pandemic is estimated at , virtually the same as for the full sample and the estimates of the elapsed times to the first break point, respectively, and , which are close to each other. In contrast, estimates for the second break point differ more clearly, in the 90-day sample versus for the full sample. The restricted sample significantly overestimates the second break point. The values of these elapsed times to break points determine the timing of pandemic-related events in the model and therefore volatility.
Third, the compliance rate and reverse compliance rate are now versus the previous . The compliance rate q thus drops by about 50%, ensuring a smaller impact at the break point and a shortening of the time at which the pandemic reaches its endemic state.
Finally, the magnitudes of all sensitivity parameters decrease, but the parameter becomes less negative in all regimes, whereas become less positive. One of the most relevant changes pertains to that goes from based on the full sample to with the restricted one. Pandemic effects through the employment channel are weaker based on the restricted sample. This will tame the impact on volatility and volatility forecasts given that, as shown in Figure 9, the informational unemployment component determines volatility during the pandemic.
6.2. Policy Interventions
We examine the impact of three types of policy interventions. The first consists in shortening the duration of SIP. This is accomplished by reducing the parameter , which is under direct control of the regulatory authority. The second consists in increasing the compliance rate . In the United States, compliance is neither instantaneous nor uniform because states are not bound by Centers for Disease Control and Prevention (CDC) and Federal Government recommendations. Information dissemination, however, can influence compliance. To simplify, we assume direct control over . The third pertains to the contamination rate , which is also not under direct control of authorities but can be influenced by proper messaging of the dangers associated with unsafe practices.21 We again assume direct control to simplify.22
6.2.1. Volatility Behavior in the Absence of Policy Intervention.
Although our focus is on the forecast window from days 90 to 140, it is useful to keep in mind the behavior of volatility over the period from days 70 to 140 in the absence of an intervention. As shown in the left panels of Figure 14, volatility jumps up on day , when SIP is declared. On that day, populations migrate to work-at-home, implying a jump down in the effective workforce and the associated pandemic factor , that is, an increase in the magnitude of the pandemic factor, as displayed in the right panels of Figure 15. The latter feeds into the sensitivities to news:
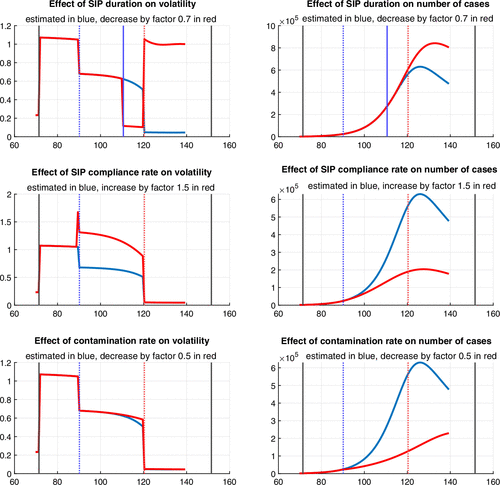
Notes. Policy intervention on day 90. Variables under the modified policy (red) and without policy change (blue). Vertical lines indicate estimated SIP dates (black), information arrival dates (dash blue and red), and policy intervention date (dash blue).
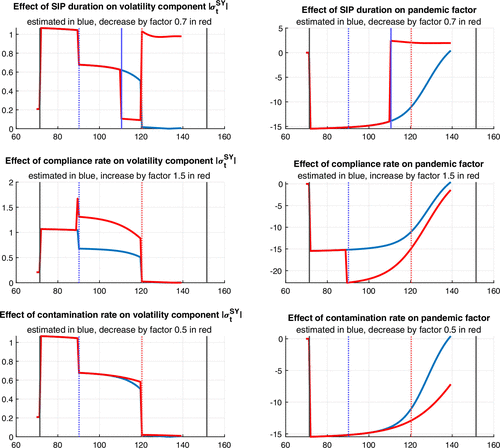
Notes. Variables under the modified policy (red) and in the absence of a policy change (blue). Vertical lines indicate estimated SIP dates (black), information arrival dates (dash blue and red), and policy intervention date (dash blue).
Two more dates, namely and , are relevant for the interpretation of some of the figures. On these dates, corresponding to the end of months 3 and 4, information comes out, leading to a jump in innovations and in the regime probabilities. Jumps in probabilities are also a source of jumps in the responses because and depend on regime probabilities. Given the direction of innovations and probability jumps, volatility decreases on these days, as shown in the plots.
6.2.2. Lifting Shelter in Place: .
The upper panels of Figure 14 display the responses of volatility and cases to a 30% decrease in the parameter (elapsed time to the end of SIP) relative to a no policy change benchmark, that is, . The left panel shows that, in the absence of a policy intervention, volatility slowly decreases from the beginning of the forecast window on day 90 and then jumps down to a low level on the news release at day 120, where it stays for the remainder of the period up to day 140. In contrast, the number of cases, shown in the right panel, continues to increase for a while before eventually abating, explained by the fact that the pandemic is in an expansion phase and that SIP has a delayed impact. The reason for the volatility behavior is explained in Section 6.2.1. A policy intervention that reduces the duration of SIP and the associated inflection point of the propagation mechanism facilitates the spread of the pandemic and hence has a negative impact on the path of the number of cases, as displayed in the upper right panel. It also has the effect of shortening the downward drift of the effective workforce and advancing the inflection point of , resulting in a sharp drop in volatility on the lifting date 110.60, followed by a large increase on the news release date 120. The reason for the sharp drop is because the magnitude of the pandemic factor, which jumps from negative to positive, decreases substantially. The reason for the subsequent increase is because the magnitude of , which jumps to a large negative value, increases at the news release date. Finally, volatility exhibits a mild decrease until day 140, which reflects the slow decline in the pandemic factor after the lifting date.
6.2.3. Raising the Compliance Rate: q.
The middle panels of Figure 15 display the effects of a 50% increase in the compliance rate q taking place on day 90, the intervention date. The benchmark case without policy intervention is the same as above. An increase in compliance rate raises the subsequent sheltered population and slows down the spread of the disease. The number of cases therefore decreases, rather substantially, relative to the no intervention benchmark, as displayed in the middle right panel. The pandemic factor jumps down immediately upon intervention because the effective workforce jumps down when the compliance rate q increases, as shown in the right panel of Figure 15. Volatility therefore jumps up relative to the no-intervention case. The almost simultaneous revision in probabilities associated with the arrival of information at date 90 causes a downward jump as in the benchmark model. Volatility, however, rests at a level higher than the benchmark case due to the policy intervention. At the next news release date, on day 120, it jumps down to its level without intervention. The policy effectively increases volatility at the implementation time and the magnitude of the downward jump at the second news release date.
6.2.4. Reducing the Contamination Rate: .
The bottom panels in Figures 14 and 15 describe the impact of a 50% decrease in the contamination rate . The impact of the policy change on the pandemic factor is to tame its subsequent increase, but the effect only appears with a delay. The impact on the return volatility is extremely small. The reason is because depends on which is independent of the contamination rate. The effects that occur take place at later dates driven by the progressive changes in the working population. However, these later changes are insignificant leaving volatility mostly unaffected. In contrast, the number of cases, in the right panel of Figure 14, displays a sharp decrease relative to the benchmark throughout the forecast period. A reduction in the contamination rate slows down the spread of the disease during the initial stages of the pandemic, leading to a stabilization in the number of cases. As time progresses, this initial taming effect wanes, and the increase in the number of cases accelerates before eventually slowing down.
The patterns in the upper versus middle and lower panels of Figures 14 and 15 highlight the tradeoff between the increase in COVID cases associated with a return of the sheltered population to the workplace and the stabilization resulting from the reduced contamination rate or the increased compliance rate. This tradeoff is directly reflected in the path of the number of cases. It also shows up in the path of volatility that decreases in the period following the discontinuation of SIP (days 91–119), but significantly (mildly) increases if the compliance (contamination) rate increases (decreases).
7. Conclusion
In this paper, we extended the BDRA model to accommodate unpredictable pandemic events such as the onset of an outbreak and the discovery of a vaccine, as well as associated mitigating policies such as SIP and LIFT. The BDRA-SEIRD-SIP-LIFT model, called BDRA-SSL, was estimated using economic and disease data from the COVID-19 outbreak. The estimated model was found to provide a close fit to the realized trajectories of variables targeted in the estimation, that is, the number of new cases and the index volatility, to capture salient aspects of the recession event identified by the NBER, a nontargeted quantity, and to explain the source of the volatility spike in the data. Model specification tests and model selection criteria showed it dominates nested and nonnested alternatives such as BDRA, CRRA-SSL, and BDRA-SIRD-SL during the pandemic. Tests also showed it outperforms the best alternative specification out-of-sample. Counterfactual analysis provided insights about the potential impact of policy changes. At the same time, the model generated a close match to 25 unconditional moments of economic time series, hence displayed consistency with long-run statistical properties of economic and financial time series. Beliefs-dependent risk aversion was found to be critical for explanations of phenomena pre– and intra–COVID-19 outbreak.
The evidence provided in this paper shows that the volatility spike during the first wave of the COVID-19 outbreak is explained by pandemic propagation phenomena, specifically supply and demand factors associated with the evolution of the effective workforce, which determined the response to unemployment shocks. Effects from the natural propagation of the pandemic were exacerbated by policy responses. Policies designed to mitigate the health consequences of the outbreak often have damaging effects on financial markets. SIP, for instance, raises volatility and actions seeking to extend it or accelerate the transition to shelter-at-home can either increase the persistence of high volatility episodes or increase the levels of volatility during such episodes and the magnitudes of jumps when SIP is discontinued. This tradeoff between human and economic consequence leaves regulators with a stark choice between conflicting objectives.
Although the model developed provides a comprehensive explanation for long-term and short-term features of the data, it leaves room for further improvements. First, although the model explains the volatility spike during the COVID-19 pandemic, it is unable to simultaneously explain the V-pattern of the stock market index. Tension between these two quantities, which rely on the same parameters, prevents a good fit on both accounts. Second, the model does not explain the level and behavior of the short rate and of the term structure of interest rates, both in the long run and during the COVID-19 outbreak. In that regard, the average interest rate and bond yields generated by the model are too high, and short-term fluctuations too large to properly capture the data. A critical ingredient for that purpose is likely to be monetary policy. Actions by the Federal Reserve, for example, pertaining to the federal funds rate, have undoubtedly shaped the response of fixed income markets during the outbreak. More generally, quantitative easing has had a profound effect on these markets since its inception in 2008. Extending the model to capture these aspects and providing corroborating international evidence are avenues for future research.
The authors thank Daniel Andrei, Syed Hassan, Matthias Lassak, and seminar participants for comments. This paper was presented at Soochow University (Suzhou), University of Toronto, the 2022 Financial Engineering and Banking Society conference, the 2022 European Financial Management Association conference, the 2022 World Finance Conference, the 2022 EUROFIDAI-Ecole Superieure des Sciences Economiques et Commerciales conference and the 2023 Multinational Finance Society conference. It won Best Paper awards at the 2022 World Finance Conference and the 2023 Multinational Finance Society conference.
Appendix A. Stochastic SEIRD-SIP-LIFT Model
This appendix describes the SEIRD model under a SIP-LIFT policy, that is, a shelter-in-place (SIP) policy followed by a lifting (LIFT) of the restriction. Combining these three elements gives the SSL model. The SSL model developed here extends Detemple (2022) by incorporating the unpredictable nature of pandemics and vaccine discoveries, captured by the Markov chain in Section 2.1. For generality we allow all the coefficients to be time dependent.
In this model, populations in transition to a sheltered stay-at-home state upon implementation of SIP and stay put until the policy is lifted. Sheltered (quarantined) populations are denoted with a superscript Q. Sheltered populations further split between work-at-home and laid-off populations, according to the fractions h, l where . Work-at-home and laid-off populations are subscripted by h and l, respectively. All infectious populations, sheltered and nonsheltered, were split into three subgroups: asymptomatic, symptomatic mild, and symptomatic severe. Figure 1 illustrates the propagation mechanism across populations under SIP. Subgroups in the infectious category are not displayed.
We assume implementation of SIP takes time. The migration rate from to the corresponding sheltered categories takes place at the constant rate q. Likewise when SIP is lifted, that is, during LIFT, reverse migration from the sheltered categories to nonsheltered ones occurs at the constant rate . In both cases, delays in implementation occur for a variety of reasons including the fact that policy recommendations are typically not uniformly adopted across states and, even when they are uniformly adopted, implementation may not be synchronous or instantaneous.
The evolution of populations in the SSL model is described by the following system of differential equations with stochastic component due to the unpredictable vaccine event:
Several additional aspects of the propagation model under SIP are worth highlighting. First, all births are assigned to the susceptible classes. For sheltered susceptible , as the birth rate equals the death rate, natural growth is null. For nonsheltered susceptible , natural growth is determined by the excess of birth in the surviving population net of birth assigned to the sheltered susceptible over death in the nonsheltered susceptible . Aggregating over sheltered and nonsheltered populations gives a flow of birth equal to . Second, populations in remain isolated, until the policy is lifted or they transition to due to natural immunity or vaccination. Hence, they cannot be contaminated during that period. Third, includes all recovered, naturally immune and vaccinated populations. Such individuals are immune to the disease and therefore apt to rejoin the workforce.25 Fourth, includes all the deceased from an infection: The fraction is the cumulative death toll as a fraction of the initial population . Last, the transition from to does not depend on sheltered individuals. Contamination, in fact, is entirely driven by nonsheltered asymptomatic individuals.
As previously indicated, lifting SIP, that is, applying LIFT, reverses the migrations from to in the model above. The negative of the reverse compliance rate replaces q. Applying that rate to sheltered symptomatic infectious populations does not affect the economic properties of the model, because such populations are not able to work by assumption; that is, they are on sick leave.
Appendix B. Decision Making in the Pandemic Model
We consider the problem of an egalitarian central planner acting in the best interest of the populations comprising the economy and treating each population equally, that is, according to its size. The economy has a unique, homogeneous population at the outset. This initial population branches out into the subpopulations displayed in Figure 1, as well as finer subpartitions, such as asymptomatic, symptomatic mild and symptomatic severe categories, as the epidemic unfolds. We assume the set of subpopulations is . The planner acts as a representative agent for this initially homogeneous population and its descendants. Let
Substituting instantaneous utilities and exchanging to order of operations gives
Performing the optimization gives the necessary and sufficient (by concavity) conditions
Appendix C. Proofs
The equilibrium state price density is the marginal instantaneous value function of the planner up to a normalizing constant
The jump in the SDF at is
Given the observed filtration, the SPD has dynamics,
For generality, we let be regime dependent in what follows.
Define , and the state variable . The price-dividend ratio is where the matrix is defined in (C.13).
Define the stopping times and and note that on the interval , , on , , and on , . The time partition will be used to show that where Z is an observed state variable. The stock price and price dividend ratio are then obtained by integrating over the densities of the switching times. Note that on each subinterval , and the population weights in the SSL model are deterministic functions of time, switching times and their known initial values.
Using where (see Appendix D), we can define
First, P is continuous, and H is continuous except at where jumps. As , for and at , we then obtain
Second, the martingale can be decomposed into a continuous and discontinuous part: . The jumps in the discontinuous part only depend on the jumps in the regime indicator . However, as in the jump times and therefore the increments are known, it follows that . If the conjecture holds, it must therefore be the case that , implying is continuous for and at the boundaries,
Ito’s formula and the -martingale property then imply
Canceling terms on the right-hand side in the first and second lines shows that if solves the ODE
Integrating over v then shows that the matrix satisfies,
The linear backward ordinary differential equation (BODE) for v can be solved. Define
Note that and therefore
If , where denotes the smallest eigenvalue of A, letting then gives
We conclude with
If the pandemic model reaches the endemic state at , for and therefore under the eigenvalue condition, and
Define the matrix with element , and , we then get
This completes the proof. □
Appendix D. Orthogonalization
The state variables are orthogonalized state variables derived from macro variables , where is per capita consumption, aggregate dividends, and unemployment. Macro state variables have covariance matrix and dynamics
To find the orthogonalized state variables, define and note that
Finally, set and note that
Let be the element in row i and column j of the matrix K. Because , we also get, from the second row, that . It follows , equivalently with . Likewise, from the third row, we obtain .
1 Alternative propagation mechanisms can be substituted without affecting the solution procedure and the main structural results.
2 Campbell and Shiller (1988), Campbell (1999), Bansal and Yaron (2004), Bansal et al. (2014), and Campbell et al. (2018) rely on log-linearizations and log-normality assumptions on the return of the consumption asset and the stochastic discount factor to derive components of the volatility risk premium and its connection to consumption growth forecasts.
3 At this stage the labeling of economic regimes is arbitrary. Estimation will show that regime 1 corresponds to a normal expansion regime, regime 2 to a recession regime, and regime 3 to a boom regime.
4 The linear functional forms are selected to simplify the model and limit the number of coefficients to be estimated. Polynomial functions could be substituted at the cost of increasing the number of parameters.
5 The set depends on the specification. In the model without SIP and a homogeneous infectious group . If the infectious populations splits into asymptomatic, mildly sick and severely sick with different consumption discount factors . With SIP and layoffs, we may have a further partitioning of where populations that are in principle able to work, but are laid off, have a distinct discount factor .
6 The data are obtained from the Saint-Louis Federal Reserve Bank.
7 We use the log of the price dividend ratio.
8 These variables have constant volatility, so the procedure is equivalent to a maximum likelihood approach.
9 A large literature following Campbell and Shiller (1988) analyzes the link between stock returns and PDR.
10 Table 4 in Berrada et al. (2018), shows that the fit for nontargeted moments in the estimation, such as the correlations and auto-correlations of the log price-dividend ratio and the stock market return at various lags, is good in their sample. The fit for these moments in the extended sample considered here is almost identical and is not reported. Additionally, the correlation between the change in the log-price-dividend ratio and the change in the unemployment rate prepandemic is in the data and in the model, which is well within the 95% confidence interval, . We further note, as emphasized in Berrada et al. (2018) and in Sections 3.3–5 of this paper, that the informational factor related to changes in the unemployment rate plays a key role in generating volatility spikes both during the financial crisis and the pandemic. However, given that unemployment is only observed monthly and the pandemic volatility spike is short, we lack an empirical benchmark for the conditional correlation during the pandemic.
11 In long-run risk models, the correlation between consumption and asset returns is too high (see Beeler and Campbell (2012) on this correlation puzzle). In contrast, the information channel that explains the excess volatility dynamics with BDRA preferences is orthogonal to consumption and dividend risk and resolves the correlation puzzle (Berrada et al. 2018).
12 Because there is no vaccine discovery event in our sample, we consider a version of the model with . We also assume the pandemic birth at is a sure event that we estimate from the data.
13 We estimate a version of the model with .
15 The quantitative easing program started in March 2020 with a significant inflation of the FED balance sheet. There is strong empirical evidence that QE affected stock prices, but with a significant delay. We focus on the immediate real effect of the pandemic and do not extend the analysis to a period where the market is too heavily biased by QE.
16 The reference average is arbitrary. We use the average volatility in our implementation. Thus, we adjust time series as where is the mean volatility over the sample period, is the mean of and the subscript j denotes the sampling time .
17 We also examined BDRA-SSL 2-step, a variation of BDRA-SSL, which uses a two-step procedure for estimation of the parameters in . Here, parameters in , pertaining to the SEIRD model, are estimated based on the number of new cases only. Parameters in , pertaining to consumption, dividend and unemployment, are estimated based on the path of market volatility. The two procedures yield indistinguishable results.
18 Because are at least three orders (respectively, two orders) of magnitude smaller than (respectively ), the effects of the pandemic factor on consumption and dividend are insignificant relative to those on unemployment. Moreover, as explained in Remark 3.1, the pandemic factor does not impact the sensitivities to consumption news () and dividend news (), which eliminates this volatility transmission channel.
19 A nested version of BDRA-SSL with constant dividend growth rate was also estimated. This constrained version is able to explain the volatility spike during the pandemic, albeit not as well as BDRA-SSL. This result provides additional confirmatory evidence that the model’s ability to capture the spike is unrelated to uncertainty in the dividend growth rate. Formal specification tests, however, reject the model with constant dividend growth rate, both before and during the pandemic. During the pandemic, the negative QLR statistic is 426.43 compared with a critical value of 5.996 for a test of size 5%.
20 Both indices are updated in real time.
21 The contamination rate is an attribute of the pandemic that is not under the direct control of the policy maker. However, the information policy of the decision maker can influence the perceptions and behaviors of individuals which feed back into the propagation mechanism.
22 All policies considered affect the time at which the pandemic reaches its endemic state, implying they have non-linear effects on forward-looking endogenous variables such as volatility.
23 On that day, when jumps up, the correlation and the coefficient become negative.
24 See also Figure 10 for the behavior of with the 220-day parameter estimates.
25 The formulation abstracts from issues of incomplete information pertaining to the health status of populations, in particular asymptomatic infectious ones.
26 See Huang and Litzenberger (1988).
27 The Kronecker product of matrices A and B, of dimensions and , is the matrix of dimension where each element of A is multiplied by matrix B.
28 The -operator, , applied to an matrix, , is such that .
References
- (2010) Information quality and long-run risk: Asset pricing implications. J. Finance 65(4):1333–1367.Crossref, Google Scholar
- (2020) Dynamic attention behavior under return predictability. Management Sci. 66(7):2906–2928.Link, Google Scholar
- (2019a) Asset pricing with persistence risk. Rev. Financial Stud. 32(7):2809–2849.Google Scholar
- (2019b) Why did the q theory of investment start working? J. Financial Econom. 133(2):251–272.Crossref, Google Scholar
- (2009) Real-time measurement of business conditions. J. Bus. Econom. Statist. 27(4):417–427.Crossref, Google Scholar
- (2004) Risks for the long run: A potential resolution of asset pricing puzzles. J. Finance 59(4):1481–1509.Crossref, Google Scholar
- (2014) Volatility, the macroeconomy, and asset prices. J. Finance 69(6):2471–2511.Crossref, Google Scholar
- (2012) The long-run risks model and aggregate asset prices: An empirical assessment. Critical Finance Rev. 1(1):141–182.Crossref, Google Scholar
- (2018) Asset pricing with beliefs-dependent risk aversion and learning. J. Financial Econom. 128(3):504–534.Crossref, Google Scholar
- (1979) An intertemporal asset pricing model with stochastic consumption and investment opportunities. J. Financial Econom. 7(3):265–296.Crossref, Google Scholar
- (2001) Stock price volatility and equity premium. J. Monetary Econom. 47(2):249–283.Crossref, Google Scholar
- Campbell JY (1999) Chapter 19: Asset prices, consumption, and the business cycle. Taylor JB, Woodford M, eds. Handbook of Macroeconomics, 1st ed., vol. 1 (Elsevier, Amsterdam), 1231–1303.Google Scholar
- (1999) By force of habit: A consumption‐based explanation of aggregate stock market behavior. J. Political Econom. 107(2):205–251.Crossref, Google Scholar
- (1988) The dividend-price ratio and expectations of future dividends and discount factors. Rev. Financial Stud. 1(3):195–228.Crossref, Google Scholar
- (2018) An intertemporal CAPM with stochastic volatility. J. Financial Econom. 128(2):207–233.Crossref, Google Scholar
- (2020) Volatility markets underreacted to the early stages of the COVID-19 pandemic. Rev. Asset Pricing Stud. 10(4):635–668.Crossref, Google Scholar
- (1990) Habit formation: A resolution of the equity premium puzzle. J. Political Econom. 98(3):519–543.Crossref, Google Scholar
- (1996) Asset pricing with heterogeneous consumers. J. Political Econom. 104(2):219–240.Crossref, Google Scholar
- (1985) A theory of the term structure of interest rates. Econometrica 53(2):385–407.Crossref, Google Scholar
- (1997) Fluctuating confidence in stock markets: Implications for returns and volatility. J. Financial Quant. Anal. 32(4):427–462.Crossref, Google Scholar
- (2013) What ties return volatilities to price valuations and fundamentals? J. Political Econom. 121(4):682–746.Crossref, Google Scholar
- (2014) Investors’ and central bank’s uncertainty embedded in index options. Rev. Financial Stud. 27(6):1661–1716.Crossref, Google Scholar
- (2008) The wild bootstrap, tamed at last. J. Econometrics 146(1):162–169.Crossref, Google Scholar
- (1986) Asset pricing in a production economy with incomplete information. J. Finance 41(2):383–391.Crossref, Google Scholar
- (2022) Asset prices and pandemics: The effects of lockdowns. Quart. J. Finance 12(1):2240002.Crossref, Google Scholar
- (1991) Asset prices in an exchange economy with habit formation. Econometrica 59(6):1633–1657.Crossref, Google Scholar
- DiCiccio TJ, Efron B (1996) Bootstrap confidence intervals. Statist. Sci. 11(3):189–228.Google Scholar
- (1986) Equilibrium interest rates and multiperiod bonds in a partially observable economy. J. Finance 41(2):369–382.Crossref, Google Scholar
- (2021) The macroeconomics of epidemics. Rev. Financial Stud. 34(11):5149–5188.Crossref, Google Scholar
- (1989) Substitution, risk aversion, and the temporal behavior of consumption and asset returns: A theoretical framework. Econometrica 57(4):937–969.Crossref, Google Scholar
- (1991) Substitution, risk aversion, and the temporal behavior of consumption and asset returns: An empirical analysis. J. Political Econom. 99(2):263–286.Crossref, Google Scholar
- (2020) Coronavirus: Impact on stock prices and growth expectations. Rev. Asset Pricing Stud. 10(4):574–597.Crossref, Google Scholar
- (2019) Should investors learn about the timing of equity risk? J. Financial Econom. 132(3):182–204.Crossref, Google Scholar
- (2021) Implications of stochastic transmission rates for managing pandemic risks. Rev. Financial Stud. 34(11):5224–5265.Crossref, Google Scholar
- (1988) Foundations for Financial Economics (North-Holland, Amsterdam).Google Scholar
- (2021) Optimal mitigation policies in a pandemic: Social distancing and working from home. Rev. Financial Stud. 34(11):5188–5223.Crossref, Google Scholar
- (1985) The equity premium: A puzzle. J. Monetary Econom. 15(2):145–161.Crossref, Google Scholar
- (1973) An intertemporal capital asset pricing model. Econometrica 41(5):867–887.Crossref, Google Scholar
- (1993) Generalized method of moments: Econometric applications. Handbook Statist. 11:455–488.Crossref, Google Scholar
- (1994) Large sample confidence regions based on subsamples under minimal assumptions. Ann. Statist. 22(4):2031–2050.Crossref, Google Scholar
- (1988) The equity risk premium: A solution. J. Monetary Econom. 22(1):117–131.Crossref, Google Scholar
- (1981) Do stock prices move too much to be justifed by subsequent changes in dividends? Amer. Econom. Rev. 71:421–436.Google Scholar
- (1999) Business cycle fluctuations in US macroeconomic time series. Handbook of Macroeconomics. vol. 1 (Elsevier, Amsterdam), 3–64.Crossref, Google Scholar
- (1989) Intertemporally dependent preferences and the volatility of consumption and wealth. Rev. Financial Stud. 2(1):73–88.Crossref, Google Scholar
- The Covid Tracking Project (2021) The Atlantic. https://covidtracking.com/data/national.Google Scholar
- (2000) How does information quality affect stock returns? J. Finance 55(2):807–837.Crossref, Google Scholar
- (1989) The equity premium puzzle and the risk-free rate puzzle. J. Monetary Econom. 24(3):401–421.Crossref, Google Scholar

