
Gradient Descent for Unbounded Convex Functions on Hadamard Manifolds and Its Applications to Scaling Problems
Abstract
In this paper, we study the asymptotic behavior of continuous- and discrete-time gradient flows of a “lower-unbounded” convex function f on a Hadamard manifold M, particularly their convergence properties to the boundary at infinity of M. We establish a duality theorem that the infimum of the gradient-norm of f over M is equal to the supremum of the negative of the recession function of f over the boundary , provided the infimum is positive. Further, the infimum and the supremum are obtained by the limit of the gradient flow of f. Our results feature convex optimization ingredients of the moment-weight inequality for reductive group actions, and are applied to noncommutative optimization. We show that gradient descent of the Kempf-Ness function for an unstable orbit converges to a destabilizing 1-parameter subgroup in the Hilbert-Mumford criterion, and the associated moment-map sequence converges to the minimum-norm point of the moment polytope. We show further refinements for operator scaling—the left-right action on a matrix tuple . We characterize the gradient-flow limit of operator scaling by a vector-space generalization of the classical Dulmage-Mendelsohn decomposition of a bipartite graph. For a special case of , we reveal that the limit determines the Kronecker canonical form of a matrix pencil .
Funding: H. Hirai was supported by the Japan Society for the Promotion of Science (KAKENHI [Grants JP21K19759 and JP24K21315]). K. Sakabe was supported by Deutsche Forschungsgemeinschaft (DFG, German Research Foundation [Grant 556164098]) and the European Research Council (ERC Starting Grant SYMOPTIC [Grant 101040907]).
1. Introduction
In convex optimization, it is typically assumed that the objective function f is bounded below. The performance of a minimization algorithm is evaluated by its convergence behavior to the minimum of f. This paper addresses the convergence behavior of minimization algorithms for a “lower-unbounded” convex function f, that is, . This may look meaningless, because the trajectory of an algorithm diverges to infinity, and goes to . The meta question of the paper is the following:
What can we gain from such a divergent sequence?
Let us formalize our setting and mention its background. Let M be a Hadamard manifold—a simply connected complete Riemannian manifold with nonpositive sectional curvature. Let be a (twice differentiable) geodesically convex function, that is, f is convex along any geodesic. We consider the following unconstrained convex optimization problem on M:
Such a problem setting is significant in the recent progress on operator scaling (Gurvits [27]) and generalizations (see Allen-Zhu et al. [1], Bürgisser et al. [12], Bürgisser et al. [13], Garg and Oliveira [21], Garg et al. [22, 23], and Hirai et al. [34]). In the classical matrix scaling (Sinkhorn [58]), the scalability is equivalent to the boundedness of (1.1) for some convex function f in . Further, it is also equivalent to the perfect-matching condition of the associated bipartite graph. Hayashi et al. [29] studied asymptotic behavior of the Sinkhorn algorithm for the unscalable (unbounded) case, and revealed that a combinatorial certificate (Hall blocker) of unscalability can be identified from divergent behavior of the Sinkhorn algorithm. Although a Hall blocker is easily obtained by network-flow algorithms, finding the corresponding certificate (shrunk subspace) for the operator scaling setting is possible but quite difficult (see Hamada and Hirai [28], Ivanyos et al. [37, 38]). Just recently, Franks et al. [19] modified the operator Sinkhorn algorithm—an alternating minimization algorithm for some convex function on the Hadamard manifold of positive definite matrices—to obtain a shrunk subspace in polynomial time, although it is still rather complicated. The matrix and operator scaling problems are generalized to a class of convex optimization involving reductive group actions, called noncommutative optimization (Bürgisser et al. [13]), which asks to minimize the Kempf-Ness function associated with an orbit of the action. This is formulated as a convex optimization problem on a representative class of Hadamard manifolds—symmetric spaces of nonpositive curvature. It is lower-unbounded if and only if the orbit is unstable, where a 1-parameter subgroup (destabilizing 1-PSG) in the Hilbert-Mumford criterion is the unboundedness certificate that generalizes a Hall blocker and a shrunk subspace. As mentioned in Bürgisser et al. [13], it is a great challenge to design polynomial-time algorithms for several noncommutative optimization problems, such as (un)stability determination, moment polytope membership, and orbit-closure intersection, which will bring fruitful applications to broader areas of mathematical sciences. Many of them involve (un)bounded determination of Kempf-Ness functions, though our current knowledge on such problems is limited.
Motivated by these considerations, we study minimization of lower-unbounded convex functions on Hadamard manifolds. Even in the Euclidean setting , there are few works (see, e.g., Auslender [4] and Obuchowska [50]) on such study. We focus on asymptotic behavior of the simplest algorithm—gradient descent. Accompanying this, we also consider its continuous version—gradient flow, that is, a trajectory produced by the differential equation .
The contributions and organization of this paper are summarized as follows. We begin with a general study of the asymptotic behavior of the gradient flow/descent for an unbounded convex function f on a Hadamard manifold M. As in the Euclidean setting, the recession function (asymptotic slope) of f (see Hirai [30] and Kapovich et al. [40]) is a basic tool of analyzing unboundedness, which is a function defined on the boundary at infinity of M . Intuitively, the boundary is the set of all directions from an arbitrary fixed point , and represents the slope of f along the direction at infinity. Then, Hadamard manifold M admits compactification , where the resulting topology is called the cone topology. These notions and related manifold terminologies are summarized in Section 2.
We focus on convergence properties, with respect to the cone topology, of the gradient flow/descent for an unbounded convex function f. In Section 3, under a sufficient condition of unboundedness, we establish in Theorem 3.1 that the gradient flow converges to a point of boundary with provision of the following min-max (inf-sup) relation:
The limit is the unique minimizer of over , and is a certificate of unboundedness. Further, we also show in Theorem 3.7 that the same result holds for the sequence produced by gradient descent applied to an L-smooth convex function f with step-size . These are the core results of the paper that drive the subsequent arguments.
Even in the Euclidean setting , these convergence results on the gradient flow/descent seem new, and bring an interesting ramification (Theorem 3.15): both and converge to the minimum-norm point of the gradient space (which is convex). This means that gradient descent is interpreted as a minimum-norm point algorithm in the gradient space. Other interesting connections to and implications for Hessian Riemannian gradient flow (Alvarez et al. [2]), mirror descent (Nemirovsky and Yudin [49]), and geometric programming are also mentioned.
In Section 4, we present applications. In Section 4.1, we deal with the norm-minimization problem for a reductive group action on a complex vector/projective space. As mentioned, this is the problem of minimizing the Kempf-Ness function associated with an orbit of the action. Then, gradient descent is essentially the first-order algorithm in Bürgisser et al. [13]. Applying our results, we show that for the unstable case the trajectory of the first-order algorithm converges, in cone topology, to the unique minimizer of , which yields a destabilizing 1-PSG in the Hilbert-Mumford criterion. Further, the spectrum of the moment map (= transported gradient of ) along the trajectory converges to the minimum-norm point of the moment polytope . For the gradient-flow setting, we reveal the connection to the theory of the moment-weight inequality for reductive group actions, developed by Georgoulas et al. [24], building upon the earlier work by Kempf, Kirwan, Mumford, and Ness in geometric invariant theory (GIT) and the recent work by Chen and Sun [15, section 4] in K-stability. Specifically, the weak duality in (1.2) becomes the moment-weight inequality, and the strong duality via the gradient flow can explain important parts of their theory. It may be fair to say that our results in Section 3 extract and discretize convex optimization ingredients of their theory.
In Section 4.2, we focus on the left-right action on a matrix tuple , which corresponds to the operator scaling problem. In this setting, the middle equality in (1.2) is interpreted as a duality theorem for the scalability limitation (Theorem 4.20), which sharpens Gurvits’ characterization in the inf-sup form. We then study the limit of the gradient flow/descent for the Kempf-Ness function . Our focus is on the unscalable case, whereas the scalable case was studied in detail by Kwok et al. [45]. We show in Theorems 4.24 and 4.27 that the minimum-norm point of the moment polytope and the limit of the gradient flow/descent are characterized by a certain simultaneous block-triangularization of , which is a vector-space generalization of the classical Dulmage-Mendelsohn decomposition (DM-decomposition) (Dulmage and Mendelsohn [17]) of a bipartite graph. More specifically, the sequence of (normalized) scaling tuples along the gradient descent converges to a block-diagonal matrix modulo the left-right unitary group action, where the block structure is determined by our generalized DM-decomposition. This answers the gradient-descent variant of an open question by Garg and Oliveira [21, section 6] for asking asymptotic behavior of the operator Sinkhorn algorithm for unscalable instances. Finding this block structure itself is significant. We partially eliminate the unitary indeterminacy from , and exploit a convergent sequence to a coarse block-triangular structure (Theorem 4.28). This leads to a new construction of a shrunk subspace (certificate of unscalability) by gradient descent combined with the rounding procedure in Franks et al. [19].
In Section 4.3, for a special case of , we reveal that our DM-decomposition of coarsens and determines the well-known Kronecker canonical form of a matrix pencil . The Kronecker form plays important roles in systems analysis by a differential-algebraic equation (DAE) . Its computation has been studied for a long time in the literature of numerical computation (see, e.g., Demmel and Kåragström [16] and Van Dooren [59]). Our convergence result (Theorem 4.33) suggests a new iterative method for determining the Kronecker structure, which is based on simple gradient descent and is conceptually different from the existing ones.
These results may be positioned as attempts at detecting, by algorithms in M, hidden structures in the boundary at infinity, which have been little studied so far. We hope that our attempts lead to more serious studies from a computational complexity perspective. Particularly, it is an important future direction to improve the present convergence-type results to the ones having explicit iteration complexity.
After the submission of this paper, there have been several subsequent developments (Hirai [31, 32], Ohta [51], Sakabe [54], Sakabe et al. [55]).
2. Preliminaries
Let and denote the sets of real and nonnegative real numbers, respectively. We often add to and the infinity elements , where the topology and ordering are extended in the usual way. Let denote the set of complex numbers , where denotes the complex conjugate and Rez denotes the real part x. The same notation is used for a complex vector with as . For a matrix A over , let denote the transpose conjugate. For sets I and J of row indices and column indices of A, let A[I, J] denote the submatrix of A with row indices in I and column indices in J. For two matrices A, B (of possibly different sizes), let denote the block-diagonal matrix of block-diagonals A, B in order. For a vector , let denote the diagonal matrix with .
The general linear group and the special linear group over are simply denoted by and , respectively. The unitary group and the special unitary group are denoted by and , respectively. For a finite-dimensional vector space V over , let denote the group of linear isomorphisms on V.
For a positive integer n, let . For , let be defined by if and 0 otherwise, where is simply written as .
A sequence and function are simply denoted by and , respectively. For a real-valued sequence and continuous function , we will use several times the following:
This is a little exercise in calculus. For example, the leftmost in (2.2) follows from this: Suppose that . Then , , , , and hence, , . Because is arbitrary, we have .
2.1. Riemannian Geometry
We will utilize standard terminologies and notation on Riemannian geometry (see, e.g., Sakai [56]). See also a recent book (Boumal [8]) for the optimization perspective. We assume sufficient differentiability for manifolds, functions, maps, and vector/tensor fields on them. Let M be a Riemannian manifold. For , let denote the tangent space of M at x, where denotes the Riemannian metric at x and denotes the associated norm. Let and denote the unit sphere and ball in , respectively. The angle of two vectors is defined as . The product of two Riemannian manifolds is viewed as a Riemannian manifold by setting .
For a path and , let denote the tangent vector of at . The length of the path is defined by . The distance between is the infimum of the length of a path connecting x and y. We consider the Levi-Civita connection associated with the Riemannian metric. The connection determines the parallel transport along any path with , where . By using the parallel transport, the covariant derivative of a vector field by is given by , where is a path with and .
In this paper, any manifold M is assumed to be complete. That is, the metric space is complete. Then, the distance is always attained by a geodesic—a path satisfying for . By a unit-speed geodesic ray, we mean a geodesic with (and then for all t). For and , there is a unique geodesic with and , denoted by . By completeness of M, the map is defined on . This gives rise to a surjective map , called the exponential map.
For a map , where N is another manifold, let denote the differential of at . The differential of a function is given by , where is a path with and . The gradient of f is then defined via
The covariant differentiation of the gradient vector field gives rise to the Hessian :
The Hessian is a symmetric operator in the sense that .
2.1.1. Complex Projective Space.
We will consider the complex projective space as a Riemannian manifold. Let V be an n-dimensional vector space over . The complex projective space over V is a quotient manifold by the equivalent relation . The image of v by is denoted by [v]. A Riemannian structure on is given by the Fubini-Study form as follows. Let be a Hermitian inner product on V. Regard V as a 2n-dimensional Euclidean space by the real inner product . This induces a Riemannian structure on the sphere , where we set . Further, acts isometrically on by scalar multiplication . Then is viewed as the Riemannian quotient of with respect to this action. The resulting metric on is called the Fubini-Study metric. See, for example, Boumal [8, chapter 9] for Riemannian quotient manifolds.
2.2. Hadamard Manifold
A Hadamard manifold M is a simply connected complete Riemannian manifold having nonpositive sectional curvature everywhere (see Sakai [56, V.4]). For any two points in M, a geodesic connecting them is uniquely determined (up to affine rescaling). The exponential map is a diffeomorphism from to M. The parallel transport from to along the geodesic is simply denoted by .
In this paper, the boundary at infinity and the cone topology on play particularly important roles. See Sakai [56, V.4.2]) for a quick introduction to these notions. Two unit-speed geodesic rays are called asymptotic if for some constant . The asymptotic relation is an equivalence relation on the set of all unit-speed geodesic rays. Let denote the set of all equivalence classes. Let us fix an arbitrary point . Any unit vector defines an asymptotic class of unit-speed geodesic ray . This correspondence is a bijection between and , and induces a topology on that is isomorphic to the sphere . In fact, this topology is independent of the choice of x. Further, the topologies on M and on are extended to as follows. Because is a diffeomorphism, it holds that , where is the equivalence relation defined by or . With , we obtain the compact Hausdorff space (isomorphic to ). This topology on is called the cone topology. In this topology, a sequence in M converges to if and only if
, and
the sequence in determined by converges to , where the asymptotic class of geodesic is equal to .
The angle of two points is defined as , where u and are the representatives of and , respectively, at . The angle defines a metric on , which induces a different topology. By using the angle metric on , we can define a metric on the Euclidean cone of the boundary by . This space is viewed as the space of asymptotic classes of (not necessarily unit-speed) geodesic rays. It is identified with , though the metric space has a different topology from and is not necessarily a manifold. This metric space is a Hadamard space—a complete geodesic metric space satisfying the CAT(0)-inequality (Bridson and Haefliger [9]). It is uniquely geodesic, and its convexity is defined along geodesics. The unit ball around the origin 0 is a convex set, where the origin 0 is the image of point . Observe that can be identified with for any .
2.2.1. Manifold of Positive Definite Matrices and Symmetric Space.
A representative example of a Hadamard manifold is the space of positive definite Hermitian matrices (see Bridson and Haefliger [9, II.10]). The tangent space at is identified with the real vector space of Hermitian matrices, and the Riemannian metric is given by . In this space, several manifold notions are explicitly written (see, e.g., Hirai et al. [34, section 5.2]). The exponential map at x is given by , where is the matrix exponential. Particularly, any geodesic issuing at x is of form for some Hermitian matrix with , where is the Frobenius norm. An explicit formula of the geodesic parallel transport is also known. We will use one special case: .
Any totally geodesic subspace M of is also a Hadamard manifold. Here, a submanifold is said to be totally geodesic if every geodesic in M is also geodesic in . It is known (Bridson and Haefliger [9, II.10.58]) that for a connected Lie group defined by polynomials and satisfying , the submanifold is a totally geodesic subspace. Such a group G is called self-adjoint (or symmetric), and is a reductive algebraic group (see Wallach [61, sections 2.2, 3.1.3, and 3.2]). Here is known as a symmetric space (of nonpositive curvature). A particular case we will face is and , where the tangent space at I is given by . It is known (Bridson and Haefliger [9, II.10.71]) that the boundary at infinity of becomes a spherical building, and the associated Euclidean cone becomes a Euclidean building. We will consider convex functions on these spaces in Section 4.
2.3. Convex Function
In a Hadamard manifold M, by uniqueness of geodesics, convexity is naturally introduced. A function is said to be convex if for every geodesic one-dimensional function is convex. We will assume twice differentiability for the smoothness of f. Then the convexity condition is equivalent to . From , convexity of f is equivalent to positive semidefiniteness of Hessian :
We next introduce an important tool for studying the unboundedness of convex functions. Let us fix . The recession function (asymptotic slope) (Hirai [30], Kapovich et al. [40]) is defined by
The second property is included in Kapovich et al. [40, lemma 3.2 (vi)]. Moreover, it is known (Hirai [30]) that is a positively homogeneous convex function on Hadamard space .
In particular, both and are sufficient conditions for unboundedness of f. In fact, they are equivalent.
(
(1) if and only if .
(2) If , then there uniquely exists with .
The existence in Proposition 2.1 part (2) follows from the lower semicontinuity of on the compact space with respect to the cone topology. The uniqueness of in part (2) can be seen from the positively homogeneous convexity of on , as in the Euclidean case.2
As a sharpening of the easier part (the only-if part) in part (1), we here mention the following weak duality relation between the gradient-norm and the recession function.
(
For and , it holds that
In Section 3, we show, via the gradient flow of f, that the equality (strong duality) always holds. This technique may be viewed as a refinement of the proof of the if-part in Kapovich et al. [40, proposition 2.1 (1)], in which the limit of the normalized gradient flow of f constructs with . A similar gradient-flow approach can be found in the setting of GIT (Chen and Sun [15], Georgoulas et al. [24], Woodward [62]) (see Section 4.1).
3. Asymptotic Behavior of Gradient Flow
3.1. Continuous-Time Gradient Flow
Throughout, M denotes a Hadamard manifold. Let be a twice differentiable convex function. Consider the following differential equation—the gradient flow of f,
It is clear that the trajectory is going to minimize f; see Lemma 3.2 part (2) below. In fact, if a minimizer of f exists, then converges to a minimizer. This convergence is known for the general setting of Hadamard spaces (see, e.g., Bačák [5, theorem 5.1.16] and Mayer [47, theorem 2.41]). Our focus is on the case where f is unbounded below, particularly the case where the minimum gradient-norm is positive. We establish the following convergence of an unbounded gradient flow and strong duality between the gradient-norm and the recession function.
Suppose that . Let be the solution of (3.1).
(1) converges to the minimum gradient-norm , and
(2) converges, in cone topology, to the unique minimizer of over ,
We should mention related results. In the general setting of Hadamard space X, Caprace and Lytchak [14, proposition 4.2] showed that the gradient-flow curve of a Lipschitz convex function with converges to a point in the boundary of X. Their proof relies on a very general result of Karlsson and Margulis [41, theorem 2.1] for semicontraction semigroups in uniformly convex spaces. Here it is well-known3 that the gradient-flow semigroup satisfies the (semi)contraction property:
We start with the following well-known properties of gradient flows.
(1) The solution of (3.1) is defined on .
(2) is nonincreasing.
(3) is nonincreasing.
We describe a proof because the intermediate equations will be used.
Lemma 3.2 part (2) follows from
Part (3) follows from by convexity of f (positive semidefiniteness of ).
Part (1). Suppose that is defined on for finite . For , it holds that
Let . First, we note
Define via For , by convexity of f along the geodesic from to , it holds that
From this, we have
Choose any convergence subsequence with and . Then it holds that
For , we have Then, we have
Even if , the strong duality holds (because ).
The velocity of escape (3.4) coincides with the minimum gradient-norm.
Suppose that . Let denote the representative of the unique minimizer of over . Then the following hold:
(1) .
(2) .
Part (1). For , it holds that (by Lemma 3.2 part (3)). Hence,
Part (2). By Theorem 3.1, it holds that . Therefore, by part (1), we have
We next consider “convergence” of the gradient . Because the space varies, the convergence concept of is less obvious. In our intuition, and would have opposite directions in the limit. The following partially justifies this intuition.
Suppose that . Let denote the representative of the unique minimizer of over . Then it holds that
Does hold?
We will see in Section 4 that this property has important consequences.
Let be the unit-speed geodesic from to . Let . Then, by Sakai [56, chapter III, proposition 4.8 (1)], it holds that Therefore, we have
On the other hand, by Proposition 3.4, it holds that , where the inequality follows from (2.2) with . Thus, the equality holds in (3.9). Necessarily, we have
By , we have . With parallel transport and , we have the claim. □
3.2. Discrete-Time Gradient Flow (Gradient Descent)
Next, we consider the discrete version. Suppose that is an L-smooth convex function. Consider the following sequence:
This is nothing but the trajectory generated by gradient descent with initial point and step-size ; we discuss in Remark 3.13 another type of discrete gradient flow. The convergence/accumulation of to a minimizer of f can be shown under several reasonable assumptions (see, e.g., Boumal [8, theorem 11.29]). For the unbounded case, as in the continuous setting, we establish the following.
Suppose that . Let be the sequence in (3.11).
(1) converges to the minimum gradient-norm , and
(2) converges, in cone topology, to the unique minimizer of .
Hence, the following holds:
Our original attempt proving this was to establish the contraction property
The proof goes in a way analogous to Theorem 3.1. Corresponding to Lemma 3.2, the following properties hold.
(1) .
(2) .
Contrary to the well-known inequality (see Boumal [8, (11.15)]), our inequality Lemma 3.8 part (1) seems less well-known; see Remark 3.14 for further discussion.
Part (2). Let . Then we have
We now prove part (1). From (3.14), we have
By squaring this and applying the rearrangement , we have , particularly,
From convexity, it holds that
The proof is similar to that of Theorem 3.1. Let . For , we have
Let be defined via For , by convexity of f along geodesic , it holds that
From this, we have
Choose any convergent subsequence of , which converges to . The second term of (3.18) vanishes as . Then it holds that
By , we have The rest is the same as the last part of the proof of Theorem 3.1. □
We note the limiting behavior of the decrement of and the change of .
(1) .
(2) .
Part (1). By convexity and Lemma 3.8 part (1), we have
By with Theorem 3.7, we have the claim.
Part (2). The inequality (3.15) is also written as
By , we have , and the claim follows. □
The discrete version of Proposition 3.4 is the following.
Suppose that . Let denote the representative of the unique minimizer of over .
(1) .
(2) .
Part (1). As in (3.17), it holds that . Hence, with (2.1) for , we have
On the other hand, for arbitrary , we have
Part (2). As in the proof of Proposition 3.4 part (2), by Theorem 3.7 and the above part (1), we have
For convergence of , the same property of Proposition 3.5 holds:
Suppose that . Let denote the representative of the unique minimizer of over . Then it holds that
Does hold?
Let . We first show
Indeed, by the triangle inequality and Theorem 3.7 part (1), we have . On the other hand, by Proposition 3.10 part (1), it holds that , where the inequality follows from (2.1) for .
Consider the geodesic triangle of vertices . Let denote the unit-speed geodesic from to . Let denote the angle at vertex of this triangle. Then
By the law of cosines in CAT(0) space M (see, e.g., Bridson and Haefliger [9, II.1.9 (2)]), we have
Take in this inequality. By , (from Theorem 3.7 part (1)), (seen from Proposition 3.10 part (1)), and (3.21), we have , and By Lemma 3.9 part (2), it holds that and
By taking parallel transport and , we have the claim. □
Another type of discrete gradient flow, well-studied in the literature of nonpositively curved space (see Bačák [5], Mayer [47], and Ohta and Pálfia [52]), is defined via the resolvent map ,
For our manifold case, it can be written as an implicit difference scheme:
Several nice (convergence) properties are known for the sequence of (3.23). For example, the contraction property (3.13) holds for the semigroup of (3.23) (see Bačák [5, theorem 2.2.23]). On the other hand, solving (3.22) is a nontrivial task from an algorithmic point of view.
In the case of , Lemma 3.8 part (1) can be easily obtained from a known inequality. For an L-smooth convex function f in , the following inequality holds (e.g., Beck [6, theorem 5.8 (iii)]):
3.3. Euclidean Specialization
Here, we present refinements of the above results for the Euclidean setting . As far as our knowledge, the above convergence results on the gradient flow/descent seem new even in this special case, and are further sharpened as follows. In the Euclidean space , the tangent space is also identified with for every , where the inner product is given by . The parallel transport for any path is the identity map. Let be a (smooth) convex function. We assume L-smoothness of f when Gradient Descent (3.11) is considered. The gradient and Hessian are obtained by and , respectively.
In this setting, the strong duality (Corollary 3.3) is written as
Then, the gradient space is equal to the closure of the domain of . Indeed, this is because , where the first inclusion follows from and the second from . Also, it is known in convex analysis (Rockafellar [53, theorems 13.1 and 13.3]) that is equal to the support function of . Summarizing, it holds that
In particular, the gradient space is (closed) convex. Now, the equality in (3.25) is attained by the (uniquely determined) minimum-norm point of and its negative direction ; see the proof of the next theorem. By Theorems 3.1 and 3.7, both and converge to , and both and converge to in cone topology.
Let denote the minimum-norm point of . Suppose that .
(1) converges to , and converges to .
(2) converges to , and converges to .
It suffices to show the claims for and . We first verify that the unique minimizer of over the unit sphere is written as . Observe from the KKT-condition that is a supporting hyperplane of at . Then, for any unit vector v, it holds that . In particular, and attain the equality in (3.25).
Then, by Theorem 3.1, we have “in cone topology.” This implies that
Because , the expected convergence in Questions 3.6 and 3.12 holds in this case. We end this section with other interesting aspects.
3.3.1. Hessian Riemannian Gradient Flow.
Here we point out that the convergence of to the minimum-norm point can also be explained via the theory of Hessian Riemannian gradient flows by Alvarez et al. [2]. Suppose for simplicity that the Hessian is nonsingular for every . Then, by the inverse mapping theorem applied to (with the inverse ), we see that is an open (convex) set.
Consider the continuous gradient flow , and let . One more differentiation in (3.1) yields
From , we have the following ordinary differential equation (ODE) obeyed by :
This can be interpreted as a gradient-flow ODE on a Riemannian manifold. Define a Riemannian metric on open convex set by
In this metric, the gradient of is given by . Then (3.28) is viewed as the gradient flow of the squared-norm function :
This is a particular instance of Hessian Riemannian gradient flow in Alvarez et al. [2]. Then, by Alvarez et al. [2, proposition 4.4], the solution of (3.30) minimizes over in limit , which proves , the first part of Theorem 3.15 part (1).
3.3.2. Mirror Descent.
On the other hand, the discrete version (Theorem 3.15 part (2)) can be explained from the framework of mirror descent (Nemirovsky and Yudin [49]), where we consult Bubeck [10, chapter 4] for it. Consider a general optimization problem
Under several assumptions on , the solution (or the average solution or the best solution ever) is shown to converge to a minimizer of g (see, e.g., Lu et al. [46], Vishnoi [60, chapter 7], Bubeck [10, theorem 4.2], and Beck [6, section 9.2]).
Now, consider the setting and . That is, (3.31) is the minimum-norm point problem on . As a mirror map, we can choose the Legendre-Fenchel conjugate . Then, the update (3.32) becomes
Define by . Because , (3.34) becomes
This is nothing but gradient descent, where the above Hessian Riemannian gradient flow is viewed as the continuous limit of (3.34). Then, the first part of Theorem 3.15 part (2) can be deduced from Lu et al. [46, theorem 3.1]. Furthermore, an convergence rate is obtained if ( ). See Sakabe [54] for details.
It may be interesting to develop a manifold analogy of these observations, which may use the space in Hirai [30]. Related to this issue, in Section 4.1, we will consider an analogous gradient flow (Kirwan’s flow) in the complex projective space .
3.3.3. Matrix Scaling and Geometric Programming.
The matrix scaling problem (Sinkhorn [58]) is this: For a given nonnegative matrix , find positive diagonal matrices (scaling matrices) X, Y such that XAY approximates a doubly stochastic matrix, that is, and . Define a convex function by
From for , the required scaling matrices X, Y are obtained from having small gradient-norm . Particularly, such a point is obtained by minimizing .
This matrix scaling optimization falls into a more general class of convex optimization, called geometric programming, to which our results are applicable. A geometric program asks to minimize a function of the following form:
f is L-smooth convex with , and
.
Therefore, with , by Gradient Descent (3.11) applied to (3.36), the gradient sequence converges to the minimum-norm point of .
We will show in Section 4.2 for the general setting of operator scaling that the point and the limit of XAY are characterized by a canonical block-triangular form of A, known as (an extended version of) the DM-decomposition (Dulmage and Mendelsohn [17]; see also Murota [48, section 2.2.3]). A similar convergence property was earlier shown by Hayashi et al. [29] for the Sinkhorn algorithm (Sinkhorn [58]), the standard alternating minimization algorithm for (3.36), in which the gradient and the scaled matrix XAY oscillate between two limit points described by the DM-decomposition.
4. Application
4.1. Norm-Minimization in Reductive Group Action
We consider the formulation of noncommutative optimization in Bürgisser et al. [13]; see also Hirai et al. [34]. Let be a connected reductive algebraic group over , where we assume that it is self-adjoint (via conjugation (Wallach [61, theorem 3.13])). Its Lie algebra is the complexification of the Lie algebra of a maximal compact subgroup as , where . The inner product on is defined by . Let V be a finite-dimensional vector space over . Let be a rational representation, where denotes its Lie algebra representation: . Consider a K-invariant Hermitian inner product and the associated norm on V. The norm-minimization problem over the orbit of is given by
It turned out (e.g., Bürgisser et al. [13]) that this class of optimization problems has numerous, sometimes unexpected, applications and connections in various fields of mathematical sciences. The most fundamental problem is to ask whether the infimum is zero, that is, whether the origin 0 is in the orbit closure . This is the semistability problem in GIT. The representation gives rise to a Hamiltonian action on the complex projective space . The corresponding (modified4) moment map is given by
(
(i) .
(ii) .
(iii) There is a 1-parameter subgroup of G such that .
The orbit in this situation is called unstable. Otherwise, it is called semistable. Accordingly, we call the 1-parameter subgroup in (iii) a destabilizing 1-PSG.
The unstability corresponds to the lower-unboundedness of the Kempf-Ness function on the group G defined by
Because is K-invariant, the Kempf-Ness function is viewed as a function on the symmetric space . By and by , we may consider the following version of the Kempf-Ness function on :
It is clear that . Then, is an L-smooth convex function such that the transported gradient of provides the moment map :
(
(1) is -smooth convex, where is the maximum of the norm of a weight for .
(2) .
The second property (2) is implicit in Bürgisser et al. [13] and follows from and . In particular, for the Kempf-Ness function , the unboundedness is equivalent to the positivity of the minimum gradient-norm. Applying Corollary 3.3, we have:
. If , then is a destabilizing 1-PSG.
follows from for , the polar decomposition for , , and (because G is algebraic). The latter part can be seen from the definitions of the Kempf-Ness function (4.4) and the recession function (2.4). □
As seen below, this is a part of the theory of moment-weight inequality (Georgoulas et al. [24]), in which the recession function is essentially Mumford’s numerical invariant, called the -weight; see Lemma 4.13.
Consider applying gradient descent to :
This is the first-order algorithm in Bürgisser et al. [13]. Each of the two updates (4.5) and (4.6) has its own advantage. Their relation is given by:
If and for , , then it holds that , where the third inequality follows from and the fourth from Lemma 4.2 part (2). □
For the semistable case, Bürgisser et al. [13] showed its iteration complexity to compute and to find with . For the unstable case, our result (Theorem 3.7) implies that Gradient Descent (4.5) constructs a destabilizing 1-PSG in the limit, which is maximally destabilizing in the sense that it is obtained from the unique minimizer of over (recall that denotes the unit sphere in ). This special 1-PSG is the same as the one shown by Kempf [42].
Suppose that . Let be the sequence of (4.5), and let be the sequence defined by . Then converges to the unique minimizer of over , where is a maximally destabilizing 1-PSG.
Unfortunately, because is not necessarily (upper semi)continuous, this theorem does not imply the algorithmic statement that is a destabilizing 1-PSG for some large k. Therefore, we need a certain rounding idea to obtain a destabilizing 1-PSG from . We see in Section 4.2 that such a rounding is possible for the left-right action.
We also consider convergence of the moment-map sequence . Let denote a positive Weyl chamber: it is a convex cone with the property that for any there is a unique point in , denoted by , satisfying for some . The moment polytope is defined as the closure of the image of :
The convexity theorem by Guillemin and Sternberg [25], Guillemin and Sternberg [26], and Kirwan [43] says that it is a convex polytope.
(
By Lemma 4.2 part (2), the polar decomposition for , , , and , it holds that
By Theorem 3.7, we have the convergence of along the gradient-descent trajectory, which is an analogue of Theorem 3.15 part (2).
Let be the minimum-norm point of , and let be the sequence defined by . Suppose that . Then, both and converge to for .
It suffices to show the claim for . By Proposition 3.10 part (2), Proposition 3.11, and Lemma 4.2 part (2), it holds that
Because converges to and converges (to ), it must hold that converges to . □
Question 3.12, if it is true, would imply the stronger convergence .
4.1.1. Moment-Weight Inequality and Gradient Flow of Moment-Map Squared.
Clearly, via Theorem 3.1, the above results (Theorems 4.5 and 4.7) hold for the gradient flow:
Our consideration of this case falls into the theory of moment-weight inequality by Georgoulas et al. [24], which builds upon the earlier work by Kempf, Kirwan, Mumford, and Ness in GIT, and the recent work by Chen and Sun [15] in K-stability. Here, we briefly summarize the relation by deducing an important part of the theory from our results in Section 3.1. We use notation for the action on . According to Georgoulas et al. [24, chapter 3], consider the gradient flow (Kirwan’s flow) of the squared-norm of the moment map on :
This is the gradient flow of a real analytic function on a compact Riemannian manifold (with respect to the Fubini-Study metric). By the standard argument of the Łojasiewicz gradient inequality, the limit of exists.
(
Further, the limit attains the infimum of the moment-map norm over the orbit in .
(
The equality (4.10) can be understood from Theorem 3.1 as follows. Regard G as a Riemannian manifold by the right-invariant Riemannian metric for , and consider the gradient flow of on G:
Then, the solution is obtained from the action of as follows:
(
Define by . Then, by adapting Georgoulas et al. [24, (4.3)] with our notation, it holds that . Thus, , implying that is the solution of (4.9). □
We can see that and (4.6) is the discretization (gradient descent) of (4.11). Analogously to Lemma 4.4, the relation between and is given by:
For , it holds that . Hence, it holds that , and
Thus, satisfies (4.8). □
Therefore, the moment-limit theorem (Theorem 4.9) follows from . Accordingly, an analogue of Theorem 3.15 part (1) (or the continuous version of Theorem 4.7) is the following.
Let be the minimum-norm point of , and let be the function defined by . Suppose that . Then, both and converge to for .
It suffices to show the claim for . By Proposition 3.4 part (2), Proposition 3.5, and Lemma 4.2 part (2), it holds that
The rest is the same as in the proof of Theorem 4.7. □
Contrary to , we do not know whether converges.5 At least, if Question 3.6 is affirmative, then converges. On the other hand, converges to , converges to , and they have the same spectrum . Therefore, there is such that . This fact is a part of the generalized Kempf existence theorem (Georgoulas et al. [24, theorem 10.4, (10.9)]). In particular, Theorem 4.7 can be viewed as a discrete version of the moment-limit theorem, though we do not know whether converges.
We next explain the moment-weight inequality. The (restriction of) -weight is defined by
(
By recalling (2.4), it holds that , where the second equality follows from Lemma 4.2 part (2). □
We now state the main part of the theory of moment-weight inequality (for linear actions).
(
Suppose that . Then the equality in (4.14) holds, and the supremum is attained by unique with , obtained as follows: Let be defined by for solution of (4.8). Then the limit exists, , and .
From our convex optimization perspective, the moment-weight inequality (4.14) is explained by the weak duality (Lemma 2.2). The equality case is explained by the strong duality (Theorem 3.1), the gradient-flow construction of the unique minimizer of , and the formula of the velocity of escape (Proposition 3.4).
We finally state one well-known important uniqueness property of minimizers of the moment-map norm over ,
(
In the next subsection, we characterize such minimizers for the left-right action.
4.2. Operator Scaling and Its Gradient-Flow Limit
Let be an N-tuple of matrices over . Let , be nonnegative vectors with the same sum , where p, q are arranged as
The operator scaling problem, originally introduced by Gurvits [27] for and extended by Franks [18] for general p, q, is to ask: For a given accuracy , find such that
In view of the previous section, the operator scaling is interpreted as the moment polytope membership of the left-right action defined by
A positive Weyl chamber is taken as the set of diagonal matrices with p, q satisfying (4.15) and . We regard it as a subset of . Then the moment polytope consists of vectors of eigenvalues of over (the closure of the -orbit of A). Comparing (4.18) with (4.16), we have:
A is -scalable if and only if belongs to , where .
We consider the operator scaling problem for the most basic case: . Then, it holds that
Accordingly, the Kempf-Ness theorem (Theorem 4.1) links with the -scaling problem, and is sharpened as follows. Let denote the family of pairs of vector subspaces , such that for all , , . This is (essentially) the same as the family of independent subspace pairs in Franks [18] and Franks et al. [19]. Although is an infinite set, it turns out in Lemma 4.22 that a certain maximal subset of is a finite set.
(
(i) .
(ii) A is -scalable.
(iii) For all , it holds that .
This theorem was originally stated for the case , in which the condition (iii) is simply written as for every subspace Y. A subspace violating this condition is called a shrunk subspace in Franks et al. [19], Garg et al. [23], and Ivanyos et al. [37, 38]. The generalization is straightforward and is included in more general results for the operator scaling with marginals by Franks [18].
A vector-space pair violating part (iii) actually gives rise to a destabilizing 1-PSG as follows: Choose and such that the first r rows of span X and the first s rows of span Y, where . Then one can see that is a destabilizing 1-PSG.
Further, the strict inequality in part (iii) brings exact scalability.
(
The exact case corresponds to the existence of g, h with . By Lemma 4.2 part (2), this is the case where the Kempf-Ness function has an optimum (= a point of zero gradient). Then, Theorem 4.18 can be deduced from General Property (2.5) of the recession function (given explicitly in (4.21) below). Here, the Kempf-Ness function is written as
(
Now Theorem 4.3 (Corollary 3.3, or the moment-weight inequality (Theorem 4.14)) sharpens (ii) (iii) of Theorem 4.17 in the following min-max (inf-sup) form:
(
where the infimum in the left-hand side (LHS) is taken over all , with and the supremum in the right-hand side (RHS) is taken over all , , , with and .
Inspired by this formula, Hirai [32] obtained a cleaner formula by using the trace norm instead of the Frobenius norm.
It suffices to show that is equal to the objective function of the RHS in (4.20). Here is written as for , , with . Then we have
In the sequel, we assume that A is not -scalable, and analyze the asymptotic behavior of gradient descent for :
Then by Lemma 4.4. We address the following problem.
Characterize the following (A), (B), and (C):
(A) The limit of (= the minimum-norm point of ).
(B) The limit of in cone topology (= the unique minimizer of ).
(C) The limit of in (= the minimizer of the moment-map norm over ).
We show that these are characterized by a certain simultaneous block-triangular form of A. This block-triangular form is a vector-space generalization of the classical Dulmage-Mendelsohn decomposition (Dulmage and Mendelsohn [17]) for a bipartite graph and its associated matrix. We introduce our generalized DM-decomposition in a way analogous to Hayashi et al. [29, section 3] for the classical setting, where the essential idea of the construction can be partly found in Ito et al. [36]. Iwamasa et al. [39] pointed out that our DM-decomposition is a special case of the Harder-Narasimhan filtration for generalized Kronecker quivers.
Recall the family defined before Theorem 4.17. Define a map by
Consider the convex hull ; see the left of Figure 1. Let denote the subset of such that is an extreme point of not equal to .
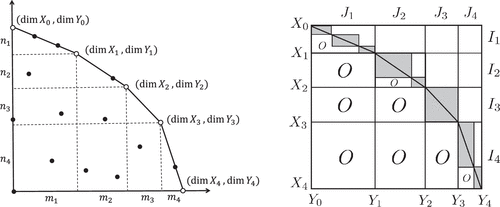
For , if and , then and . In particular, is a finite set, and is injective on .
We may suppose that and are equal or on an adjacent pair of extreme points. Observe . By the dimension identity of vector spaces, it holds that
We claim that and , which implies the statement. Otherwise, by (4.24), or goes beyond , which contradicts . □
Therefore, can be arranged as
If , then . In particular, is a modular lattice with respect to the partial order , where the minimum and maximum elements are given by and , respectively.
For each , consider a maximal chain (flag) of :
For abuse of notation, , , , and also denote the index sets of the corresponding rows and columns of B. Define ordered partitions of [n], of [m], and their refinements , by
Let denote the matrix tuple of block-diagonal matrices obtained from by replacing each (upper) off-diagonal block with the zero matrix. We call a diagonalized DM-decomposition of A. A diagonalized version of a coarse DM-decomposition is defined analogously.
Let and . By convexity of , it holds that
Define by
Recalling , define by
(1) is the minimum-norm point of , and
(2) is the unique minimizer of over , where it holds that
(4.33)
Let and be the sequences in (4.23) and (4.22), respectively.
(1) converges to for .
(2) converges, in cone topology, to . More precisely, the sequence defined by converges to for .
We first show (4.33). From the definitions of and , we have
By the last equation in (4.31), we have
On the other hand, is a coarse DM-decomposition, that is, for each with . By (4.21) in the proof of Theorem 4.20, the value of the recession function is given by
Observe from (4.28)–(4.30) that
Hence, the maximum in (4.34) is attained by the index of any nonzero element of any diagonal block of , which implies , and (4.33).
To complete the proof, it suffices to show because and would attain . This is done in the next proposition. □
Let be a diagonalized DM-decomposition of A.
(1) is exactly -scalable.
(2) .
In particular, it holds that .
Part (1). We first show:
Claim. is exactly -scalable.
We can assume that A is already equal to a DM-decomposition B, where all , are coordinate subspaces. Suppose indirectly that is not exactly -scalable. Then, by Theorem 4.18, there is nontrivial such that . Then belongs to . However, goes beyond or lies on the interior of the segment between and . The former case is obviously impossible. The latter case is also impossible because of the maximality of the chain in . □
We observe from that is a constant multiple of . By the claim, for each , we can choose scaling matrices to make an exact -scaling. Then, for , , the scaling is a desired -scaling.
Part (2). Let B be a DM-decomposition of A, where . For each and , by , it holds that
Let and . For , define and by
By (4.36), the scaling is written as
Now the sequence of the scaled matrices along the gradient-descent trajectory accumulates to the -orbit of a diagonalized DM-decomposition , providing a (partial) solution of Problem 4.21 part (C):
Let be a diagonalized DM-decomposition of A, and let be a -scaling of . Then accumulates to points in for .
It holds that . Thus, attains the infimum of over , which is also the limit of . By the second Ness uniqueness theorem (Theorem 4.15), we have the claim. □
For the gradient flow of the Kempf-Ness function on the group , because of the convergence theorem (Theorem 4.8), converges to a point for some , .
Although is also a diagonalized DM-decomposition of A, it is not clear how to remove the unitary indeterminacy from and to extract the DM-structure of . This is possible for the coarse DM-structure as follows:
Let be the sequence defined by . Suppose that and for unitary matrices , and nondecreasing and nonincreasing vectors and , respectively. Then accumulates to coarse DM-decompositions. The convergence is linear in the following sense: there are , such that for all , it holds that
By Theorems 3.7 and 4.24 and Lemma 3.9 part (1), it holds that
Because we have
Suppose that the index is in a lower triangular block. By (Corollary 4.25 part (2)) and (4.37), it holds that
Suppose that converges, or more strongly, the convergence of Question 3.12 is true. Then it holds that This implies
Because , the scaling sequence accumulates to -scalings. From the coarse DM-structure of in the limit, one can see that accumulates to diagonalized coarse DM-decompositions. Although our numerical experiment supports such convergence, our results imply only in (4.38).
We end this subsection with some implications of these results.
4.2.1. On Finding a Destabilizing 1-PSG.
Suppose that A is not -scalable. Consider mapped to the extreme point of with the property that it maximizes r among all extreme points maximizing . The subspace pair violates (iii) in Theorem 4.17 and is a special certificate of unscalability, called dominant in Franks et al. [19]. By Theorem 4.28, after a large number k of iterations, the last rows of and the first rows of become bases of an -approximate dominant pair in the sense that for all and all unit vectors . Franks et al. [19] devised a procedure to round such an -approximate dominant pair into the exact dominant pair , where p is a polynomial and b is the bit complexity of A. Hence, if we would establish global linear convergence in Theorem 4.28, a polynomial number of iterations of Gradient Descent (4.22) would suffice to recover the dominant pair and a destabilizing 1-PSG.
4.2.2. Matrix Scaling Case.
An matrix is viewed as a matrix tuple . Consider the left-right action on A, in which the group is restricted to the subgroup consisting of diagonal matrices. The corresponding scaling problem is nothing but the matrix scaling problem of the nonnegative matrix ; see Section 3.3. The above results are also applicable to this setting. Indeed, the gradient is a pair of diagonal matrices. Then, the gradient flow/descent belongs to the diagonal subspace in , and is viewed as the gradient flow/descent for the geometric programming objective (3.36) in matrix scaling. Here, all subspaces are coordinate subspaces. Hence, a DM-decomposition B is obtained by row and column permutations, and is equivalent to the original (extended) DM-decomposition of M. In Remark 4.29, the unitary matrices and are permutation matrices, and all lower triangular blocks of become zero matrices after finitely many iterations. Also, all upper triangular blocks of converge to zero matrices. In particular, the expected convergence to the diagonalized DM-decomposition is true. This convergence property is almost the same as the one for the Sinkhorn algorithm. Indeed, Hayashi et al. [29] showed that this limit (Sinkhorn limit) oscillates between the -scaling and -scaling of .
4.2.3. On the Limit of the Operator Sinkhorn Algorithm.
This suggests an expectation of the limiting behavior of the operator Sinkhorn algorithm (Gurvits’ algorithm), the standard algorithm for the operator scaling problem. The operator Sinkhorn algorithm is viewed as alternating minimization of , where each step scales with and with alternatively. When it is applied to the -scaling of a diagonalized DM-decomposition , the resulting scaling sequence oscillates between the -scaling and -scaling of . With the view of Theorem 4.27 and the matrix scaling case above, it is reasonable to conjecture that it oscillates between orbits and , where (resp. ) is a -scaling (resp. -scaling) of .
4.3. Kronecker Form of a Matrix Pencil
Finally, we discuss the special case of , that is, . In this case, A is naturally identified with a matrix pencil , where s is an indeterminate. Here we reveal a connection to the Kronecker canonical form of , and suggest a new numerical method for finding the Kronecker structure based on gradient descent.
A pencil is called regular if and for some . Otherwise, is called singular. For simplicity, we assume (again) that and . The Kronecker form is a canonical form of a (singular) pencil under transformation by , . The standard reference of the Kronecker form is Gantmacher [20, chapter XII]; see also Murota [48, section 5.1.3] for its importance in systems analysis. For a positive integer , define matrix by
(
is the minimum degree of a polynomial vector in that is linearly independent from over .
is the minimum degree of a polynomial vector in that is linearly independent from over .
The indices , called the minimal indices, are uniquely determined. If and is singular, then the Kronecker form has a zero block with the sum of row and column numbers greater than n. Therefore, by Theorem 4.17, we have:
A pencil is regular if and only if and is -scalable.
We point out a further connection that the Kronecker form (4.39) is viewed as almost a DM-decomposition. Let b denote the number of diagonal blocks of in (4.39). For , let and denote the row and column index sets, respectively, of the -th diagonal block of . Define by the vector subspace spanned by the rows of g of indices in . Similarly, define by the vector subspace spanned by the rows of h having indices in . We let (and . Suppose that exists and is an upper triangular matrix. Let denote the vector space spanned by the rows of g having the last indices in , and let denote the vector space spanned by the rows of h having the first indices in . Let and , where + is the direct sum. Consider all indices with , and suppose that they are ordered as .
(1) is the coarse DM-flag of .
(2) Suppose that is an upper triangular pencil. Then the union of and is a DM-flag of .
Part (1). Suppose that consists of for , arranged as in (4.25). We show for . Consider the convex hull of and for all . Then belongs to , and the maximal faces of are composed of the line segments connecting points from to b with bending points .
We show by induction on the number b of diagonal blocks. Consider the base case where the Kronecker form consists of a single block. It suffices to show that . Suppose that is an regular pencil . By regularity, there is no with (otherwise is singular over ). This means no point in beyond the line segment between and . Therefore, we have . Suppose that . Suppose to the contrary that there is with . By basis change, we may assume that
Consider a general case of . We can choose such that , , and the line segment between and meets with only at . Consider and . By the construction and (4.24), one of and is outside of . Suppose that . Consider the submatrix , which is also a Kronecker form with a smaller number of blocks. From , , and , it necessarily holds that . However, this is a contradiction to the inductive assumption. The case is similar; consider the sub-Kronecker form .
Part (2). Observe that all integer points in the maximal faces of are obtained by the images of and . This implies that is a maximal chain of . □
The matrix pencil corresponding to a coarse DM-decomposition , which we call a coarse Kronecker triangular form, is a refinement of a quasi-Kronecker triangular form in Berger and Trenn [7] and generalized Schur form in Demmel and Kåragström [16] and Van Dooren [59] if g, h are unitary matrices and is triangular.
Then, the convergence (Theorem 4.28) of Gradient Descent (4.22) can be applied as follows:
(
A coarse Kronecker triangular form is enough for determining the structure of the Kronecker form. Indeed, each (nonsquare) rectangular diagonal block is a or matrix for some integers , from which all minimal indices , can be identified.
The above theorem suggests an iterative method for determining the minimal indices of a singular pencil, which is based on simple gradient descent and is conceptually different from the existing algorithms, for example, Demmel and Kåragström [16] and Van Dooren [59]. It is an interesting future direction to develop a numerically stable algorithm based on this approach.
The authors thank Shin-ichi Ohta, Harold Nieuwboer, and Michael Walter for discussion; Yuni Iwamasa, Taihei Oki, and Tasuku Soma for comments; and Shun Sato for suggesting Sanz Serna and Zygalakis [57]. The authors also thank the referees for numerous helpful comments. The conference version appeared as Hirai and Sakabe [33].
1 Proof sketch: Let and , and define by . By convexity of f along the geodesic between and , it holds that for . By the triangle inequality, we have for . By the CAT(0)-inequality on the geodesic triangle of vertices and by being bounded, it holds that for . Thus, we have . By symmetry, it holds that , and hence, .
2 If , then by convexity, it holds that for the midpoint m of and in , and by it holds that .
3 It is found in Ambrosio et al. [3, theorem 4.0.4] for the general setting of gradient flows in metric spaces. For our manifold case, it is an easy consequence of the first variation formula (Sakai [56, proposition 2.2]) as follows: , where is a geodesic from to .
4 The formal definition of the moment map is given by (Georgoulas et al. [24, lemma 8.2]).
5 In the earlier versions of this paper, the convergence of was stated but the proof was false.
6 The classical DM-decomposition restricts to coordinate subspaces and to the sublattice of the coordinate subspaces X, Y maximizing , where g, h are chosen as permutation matrices. In this setting, a block-triangular form obtained by using the maximal chain of the entire was considered by N. Tomizawa (unpublished) in the development of principal partitions in the 1970’s; see Hayashi et al. [29, section 3]. For this reason, our decomposition may be more precisely called a DMT-decomposition.
References
- [1] (2018) Operator scaling via geodesically convex optimization, invariant theory and polynomial identity testing. Diakonikolas I, Kempe D, eds. Proc. 50th Annual ACM SIGACT Sympos. Theory Comput. STOC 2018 (Association for Computing Machinery, New York), 172–181.Google Scholar
- [2] (2004) Hessian Riemannian gradient flows in convex programming. SIAM J. Control Optim. 43(2):477–501.Crossref, Google Scholar
- [3] (2008) Gradient Flows: In Metric Spaces and in the Space of Probability Measures, 2nd ed. (Birkhäuser, Basel, Switzerland).Google Scholar
- [4] (1997) How to deal with the unbounded in optimization: Theory and algorithms. Math. Programming 79(1–3):3–18.Crossref, Google Scholar
- [5] (2014) Convex Analysis and Optimization in Hadamard Spaces (De Gruyter, Berlin).Crossref, Google Scholar
- [6] (2017) First-Order Methods in Optimization (Society for Industrial and Applied Mathematics, Philadelphia).Crossref, Google Scholar
- [7] (2012) The quasi-Kronecker form for matrix pencils. SIAM J. Matrix Anal. Appl. 33(2):336–368.Crossref, Google Scholar
- [8] (2023) An Introduction to Optimization on Smooth Manifolds (Cambridge University Press, Cambridge, UK).Crossref, Google Scholar
- [9] (1999) Metric Spaces of Non-Positive Curvature (Springer-Verlag, Berlin).Crossref, Google Scholar
- [10] (2015) Convex optimization: Algorithms and complexity. Foundations Trends Machine Learn. 8(3–4):231–357.Crossref, Google Scholar
- [11] (2020) Interior-point methods for unconstrained geometric programming and scaling problems. Preprint, submitted August 27, https://arxiv.org/abs/2008.12110.Google Scholar
- [12] (2018) Efficient algorithms for tensor scaling, quantum marginals, and moment polytopes. Thorup M, ed. Proc. 59th IEEE Annual Sympos. Foundations Comput. Sci. FOCS 2018 (IEEE, New York), 883–897.Google Scholar
- [13] (2019) Towards a theory of non-commutative optimization: Geodesic 1st and 2nd order methods for moment maps and polytopes. Proc. 60th IEEE Annual Sympos. Foundations Comput. Sci. FOCS 2019 (IEEE, New York), 845–861.Google Scholar
- [14] (2010) At infinity of finite-dimensional CAT(0) spaces. Math. Ann. 346(1):1–21.Crossref, Google Scholar
- [15] (2014) Calabi flow, geodesic rays, and uniqueness of constant scalar curvature Kähler metrics. Ann. Math. 180(2):407–454.Crossref, Google Scholar
- [16] (1993) The generalized Schur decomposition of an arbitrary pencil —Robust software with error bounds and applications. I. Theory and algorithms. ACM Trans. Math. Software 19(2):160–174.Crossref, Google Scholar
- [17] (1958) Coverings of bipartite graphs. Canadian J. Math. 10:517–534.Crossref, Google Scholar
- [18] (2018) Operator scaling with specified marginals. Diakonikolas I, Kempe D, eds. Proc. 50th Annual ACM SIGACT Sympos. Theory Comput. (STOC 2018) (Association for Computing Machinery, New York). 190–203.Google Scholar
- [19] (2023) Shrunk subspaces via operator Sinkhorn iteration. Bansal N, Nagarajan V, eds. Proc. 2023 Annual ACM-SIAM Sympos. Discrete Algorithms (SODA) (SIAM, Philadelphia), 1655–1668.Google Scholar
- [20] (1959) The Theory of Matrices, vol. 1–2 (Chelsea Publishing Co., New York).Google Scholar
- [21] (2018) Recent progress on scaling algorithms and applications. Bull. Eur. Assoc. Theoret. Comput. Sci. (125):14–49.Google Scholar
- [22] (2018) Algorithmic and optimization aspects of Brascamp-Lieb inequalities, via operator scaling. Geometric Funct. Anal. 28(1):100–145.Crossref, Google Scholar
- [23] (2020) Operator scaling: Theory and applications. Foundations Comput. Math. 20(2):223–290.Crossref, Google Scholar
- [24] (2021) The Moment-Weight Inequality and the Hilbert-Mumford Criterion—GIT from the Differential Geometric Viewpoint, Lecture Notes in Mathematics, vol. 2297 (Springer, Cham, Switzerland).Google Scholar
- [25] (1982) Convexity properties of the moment mapping. Inventiones Math. 67(3):491–513.Crossref, Google Scholar
- [26] (1984) Convexity properties of the moment mapping. II. Inventiones Math. 77(3):533–546.Crossref, Google Scholar
- [27] (2004) Classical complexity and quantum entanglement. J. Comput. System Sci. 69(3):448–484.Crossref, Google Scholar
- [28] (2021) Computing the nc-rank via discrete convex optimization on CAT(0) spaces. SIAM J. Appl. Algebra Geometry 5(3):455–478.Crossref, Google Scholar
- [29] (2023) Finding Hall blockers by matrix scaling. Math. Oper. Res. 49(4):2166–2179.Link, Google Scholar
- [30] (2024) Convex analysis on Hadamard spaces and scaling problems. Foundations Comput. Math. 24(6):1979–2016.Crossref, Google Scholar
- [31] (2025) Generalized gradient flows in Hadamard manifolds and convex optimization on entanglement polytopes. Preprint, submitted November 15, https://arxiv.org/abs/2511.12064v1.Google Scholar
- [32] (2026) A scaling characterization of nc-rank via unbounded gradient flow. Linear Algebra Appl. 730:525–545.Crossref, Google Scholar
- [33] (2024) Gradient descent for unbounded convex functions on Hadamard manifolds and its applications to scaling problems. Proc. 65th IEEE Sympos. Foundations Comput. Sci. (FOCS 2024) (IEEE, New York), 2387–2402.Google Scholar
- [34] (2023) Interior-point methods on manifolds: Theory and applications. Proc. 64th IEEE Sympos. Foundations Comput. Sci. (FOCS 2023) (IEEE, New York), 2021–2030.Google Scholar
- [35] (2001) Fundamentals of Convex Analysis (Springer-Verlag, Berlin).Crossref, Google Scholar
- [36] (1994) Block-triangularizations of partitioned matrices under similarity/equivalence transformations. SIAM J. Matrix Anal. Appl. 15(4):1226–1255.Crossref, Google Scholar
- [37] (2017) Non-commutative Edmonds’ problem and matrix semi-invariants. Comput. Complexity 26(3):717–763.Crossref, Google Scholar
- [38] (2018) Constructive non-commutative rank computation is in deterministic polynomial time. Comput. Complexity 27(4):561–593.Crossref, Google Scholar
- [39] (2025) Algorithmic aspects of semistability of quiver representations. Censor-Hillel K, Grandoni F, Ouaknine J, Puppis G, eds. 52nd Internat. Colloquium Automata Languages Programming (ICALP 2025) (Schloss Dagstuhl - Leibniz-Zentrum für Informatik, Wadern, Germany), 99:1–99:18.Google Scholar
- [40] (2009) Convex functions on symmetric spaces, side lengths of polygons and the stability inequalities for weighted configurations at infinity. J. Differential Geometry 81(2):297–354.Crossref, Google Scholar
- [41] (1999) A multiplicative ergodic theorem and nonpositively curved spaces. Comm. Math. Phys. 208(1):107–123.Crossref, Google Scholar
- [42] (1978) Instability in invariant theory. Ann. Math. 108(2):299–316.Crossref, Google Scholar
- [43] (1984) Convexity properties of the moment mapping. III. Inventiones Math. 77(3):547–552.Crossref, Google Scholar
- [44] (2006) Rigidity of invariant convex sets in symmetric spaces. Inventiones Math. 163(3):657–676.Crossref, Google Scholar
- [45] (2021) Spectral analysis of matrix scaling and operator scaling. SIAM J. Comput. 50(3):1034–1102.Crossref, Google Scholar
- [46] (2018) Relatively smooth convex optimization by first-order methods, and applications. SIAM J. Optim. 28(1):333–354.Crossref, Google Scholar
- [47] (1998) Gradient flows on nonpositively curved metric spaces and harmonic maps. Comm. Anal. Geometry 6(2):199–253.Crossref, Google Scholar
- [48] (2000) Matrices and Matroids for Systems Analysis (Springer-Verlag, Berlin).Google Scholar
- [49] (1983) Problem Complexity and Method Efficiency in Optimization (John Wiley & Sons, Inc., New York).Google Scholar
- [50] (2004) On the minimizing trajectory of convex functions with unbounded level sets. Comput. Optim. Appl. 27(1):37–52.Crossref, Google Scholar
- [51] (2025) Discrete-time gradient flows for unbounded convex functions on Gromov hyperbolic spaces. Comm. Contemporary Math., ePub ahead of print December 11, https://doi.org/10.1142/S0219199726500033.Crossref, Google Scholar
- [52] (2015) Discrete-time gradient flows and law of large numbers in Alexandrov spaces. Calculus Variations Partial Differential Equations 54(2):1591–1610.Crossref, Google Scholar
- [53] (1970) Convex Analysis (Princeton University Press, Princeton, NJ).Crossref, Google Scholar
- [54] (2026) Nesterov’s accelerated gradient for unbounded convex functions finds the minimum-norm point in the dual space. Preprint, submitted February 9, https://arxiv.org/abs/2602.08618.Google Scholar
- [55] (2026) Strassen’s support functionals coincide with the quantum functionals. Preprint, submitted January 29, https://arxiv.org/abs/2601.21553.Google Scholar
- [56] (1996) Riemannian Geometry (American Mathematical Society, Providence, RI).Crossref, Google Scholar
- [57] (2020) Contractivity of Runge-Kutta methods for convex gradient systems. SIAM J. Numer. Anal. 58(4):2079–2092.Crossref, Google Scholar
- [58] (1964) A relationship between arbitrary positive matrices and doubly stochastic matrices. Ann. Math. Statist. 35(2):876–879.Crossref, Google Scholar
- [59] (1979) The computation of Kronecker’s canonical form of a singular pencil. Linear Algebra Appl. 27:103–140.Crossref, Google Scholar
- [60] (2021) Algorithms for Convex Optimization (Cambridge University Press, Cambridge, UK).Crossref, Google Scholar
- [61] (2017) Geometric Invariant Theory (Springer, Cham, Switzerland).Crossref, Google Scholar
- [62] (2011) Moment maps and geometric invariant theory. Preprint, submitted June 29, https://arxiv.org/abs/0912.1132.Google Scholar

