
Long-History Principal Component Analysis in a Dynamic Factor Model with Weak Loadings
Abstract
Estimated covariance and precision matrices of asset returns significantly influence the set of portfolios compliant with risk budgets and their potential losses. Statistical risk modeling approaches often assume temporal stability for consistency with a static factor structure, typically estimated within days of data history, resulting in finite-sample estimation error when the dimension of the population exceeds the number of observations. Our study investigates the application of Principal Component Analysis (PCA) over extended data histories (e.g., 1,500 trading days), an approach we term Long-History PCA, to forecast the daily risk profile based on dynamic factor structures with heterogeneous factor strengths. The use of a longer data history mitigates excess dispersion bias in the estimated factor loadings, particularly in the presence of weak factors. As shown in simulations and empirical data from the United States and European stock markets, our approach substantially mitigates second-order risk bias compared with traditional methods using medium horizons (), both with and without the augmentation of Responsive Covariance Adjustment using a short half-life () of 40 days.
Funding: R. M. Anderson gratefully acknowledges the financial support of Swiss Re through the Consortium for Data Analytics in Risk. B. Kim’s research is partially supported by a Korea University Business School Research Grant.
Supplemental Material: All supplemental materials, including the code, data, and files required to reproduce the results, are available at https://doi.org/10.1287/opre.2024.1134.
1. Introduction
In the classical mean-variance framework, second-order risk (SOR) arises from the uncertain nature of the joint distribution of asset returns, particularly due to inaccuracies in estimating the population covariance matrix or its inverse, the precision matrix . Small errors in these estimates can significantly distort efficient allocations in portfolio optimization,1 potentially biasing the optimized portfolio toward the deficiencies of the estimated model (Shepard 2009, Bernardi et al. 2019). Consequently, understanding and mitigating SOR bias is crucial for investors seeking admissible portfolio compositions that align with a predefined risk budget.
Nevertheless, quantifying and managing SOR remains challenging due to the unobservable and rapidly evolving nature of the true covariance structure of asset returns. Statistical factor-based risk modeling approaches, such as Principal Component Analysis (PCA), often rely on assumptions of temporal stability and uniform factor strengths2 to ensure consistent factor identification. These assumptions frequently fail to capture the dynamic complexities of real-world financial data. As a result, practitioners tend to limit their analysis to medium-length data histories (e.g., or 500 trading days)3 to estimate factor exposures, while using short half-life techniques, such as the Exponentially Weighted Moving Average (EWMA) with a half-life of days, to estimate current factor variances.4 For portfolios of practical relevance, which often include N ∼ 2,000 or more stocks, this mismatch leads to an inaccurate representation of the underlying covariance structure and exacerbates the SOR bias in portfolio optimization.
To address this challenge, this paper introduces the Long-History PCA (LH-PCA), a method designed to accurately forecast the precision matrix on a daily basis using an extended historical window (e.g., 1,500 trading days). It is important to clarify that LH-PCA is not a new statistical method or estimator. Rather, it represents the application of conventional PCA to a significantly longer history of data than is typical in financial risk modeling. Our primary contribution is the theoretical and empirical insight that this application yields useful and robust factor estimates, even when the underlying factor model exhibits time variation and weak factor loadings. We use the label “LH-PCA” as a convenient shorthand to refer to this specific application and its associated findings.
Building on the seminal contributions of Bates et al. (2013) and Bai and Ng (2023), we propose a dynamic factor model that accounts for variable factor volatilities and temporal instability in factor loadings, allowing for variations in their strength. We prove that PCA consistently estimates the underlying factor structure in the “large-N and large-T” framework, enabling precise risk forecasts for portfolios of practical and reasonable size. Beyond theoretical advancements, our study makes practical contributions by developing a robust framework for detecting and quantifying second-order risk bias in high-dimensional portfolios. Because the true return covariance structure is unobservable in practice, we propose an observable proxy of the SOR bias by constructing the Global Minimum Variance Portfolio (GMVP) using the empirically estimated precision matrix and comparing its out-of-sample realized volatility to its predicted volatility. This approach enables the development of reliable bias statistics that capture discrepancies between estimated and actual portfolio risk, providing an effective tool for risk-aware investment decisions.
Empirically, we validate the effectiveness of LH-PCA through Monte Carlo simulations and real-world stock market data, including U.S. and European equities. Compared with traditional benchmarks, such as variants of PCA with medium-length historical windows and shrinkage techniques (Ledoit and Wolf 2004b), we demonstrate that LH-PCA significantly reduces second-order risk bias by extending the data history from to . This improvement remains robust across diverse scenarios, including the use of responsive covariance adjustments (RCA) with short data histories (e.g., EWMA with a half-life of days). Our findings confirm that LH-PCA enhances risk estimation accuracy in fast-evolving financial markets, establishing it as a valuable tool for high-dimensional portfolio construction and risk management.
Overall, the proposed LH-PCA approach provides a robust and intuitive framework for analyzing high-dimensional financial data sets, particularly for portfolio optimization in the context of modern big data analytics. By effectively reducing dimensionality while retaining key factors, it facilitates accurate estimation of covariance and precision matrices, which are critical for constructing resilient and well-diversified portfolios. The adaptability of the proposed approach to both strong and weak factors, as well as dynamic and static loadings, renders it well-suited for the modeling of pragmatic dynamic factor structures, thereby addressing the limitations of traditional approaches.
2. Related Literature
Our study contributes to the literature on portfolio risk optimization, particularly in improving covariance matrix estimation for large portfolios. Traditional research on estimation errors in the Markowitz framework (Markowitz 1952) has largely focused on portfolio allocation strategies, such as constructing minimum-variance portfolios. Among various asset allocation models (see DeMiguel et al. 2009b, table 1), GMVP has been widely studied due to its ability to minimize risk while avoiding reliance on noisy mean return estimates (Jagannathan and Ma 2003). Moreover, GMVPs serve as foundational building blocks for other portfolio strategies (DeMiguel et al. 2009a) and are favored by investors for their attractive risk-adjusted returns. Recent refinements to GMVP have been proposed by Basak et al. (2009), Shi et al. (2020), and Ding et al. (2021).
Our approach diverges from this literature by focusing on daily forecasting of the precision matrix for large portfolios, a critical component in managing SOR. To achieve this, we emphasize identifying all relevant risk factors, regardless of their risk premiums. Including factors with negative or zero risk premiums can inadvertently increase portfolio volatility without enhancing expected returns. Although we do not assess whether factors are priced—because a factor can influence volatility without carrying a risk premium—our findings on SOR contribute to recent asset pricing discussions (Anderson et al. 2009, Bekaert et al. 2009a, Brenner and Izhakian 2018, Aït-Sahalia et al. 2025). Given the need for robust risk estimation, we leverage PCA-based methods, which are computationally efficient in capturing market dynamics.
We also build upon research improving PCA methodologies. Risk Premium-PCA (Lettau and Pelger 2020) extracts weak factors with high Sharpe ratios, Projected-PCA (Kim et al. 2021) constructs portfolios that hedge systematic risks, and Instrumental-PCA (Kelly et al. 2019) identifies latent factors explaining cross-sectional stock returns. These methods estimate low-dimensional factor structures under Arbitrage Pricing Theory (Ross 1976), prioritizing priced risks but often overlooking nonbenchmark assets’ time-series information (Pastor 2000), which is central to our study. Although fundamental risk factors such as ‘small minus big’ and ‘high minus low’ (Fama and French 1993) are interpretable, they often exhibit strong correlations. In contrast, PCA extracts orthogonal latent factors that efficiently capture market trends, despite limited interpretability.5 Given that capturing short-term trends—whether they persist long enough to be integrated into a fundamental factor model—is crucial for dynamic investment strategies, PCA-based models play a key role in adapting to evolving market conditions (Fan et al. 2016, Lettau and Pelger 2020).
The literature on Dynamic Factor Models (DFMs) has evolved to address challenges in modeling time-varying dynamics in high-dimensional data. Early contributions, such as Del Negro and Otrok (2008), introduced models with time-varying factor loadings and stochastic volatility, shedding light on international business cycle fluctuations. Su and Wang (2017) extended this work with a nonparametric approach to estimate DFMs with smoothly varying loadings, enabling tests for structural changes. More recently, Pelger and Xiong (2022b) developed an inferential framework for state-varying factor models, improving the estimation of time-dependent factor structures, while Barigozzi et al. (2021) advanced estimation methods for locally stationary DFMs, emphasizing financial connectedness and heterogeneous shock responses. Complementing these studies, our work leverages DFMs to estimate covariance and precision matrices for asset returns, a key component of portfolio risk management. Our proposed LH-PCA utilizes extended data histories to mitigate estimation errors from dispersion bias. This approach enhances traditional medium-horizon approaches by reducing second-order risk bias, as we elaborate on in subsequent sections.
Finally, our work complements research on estimation error in covariance matrices, including model-free shrinkage methods (Ledoit and Wolf 2003, 2004a, 2004b), eigenvalue corrections (Ledoit and Péché 2011, Wang and Fan 2017), and eigenvector adjustments (Goldberg et al. 2022). By addressing the challenges of SOR in high-dimensional portfolios, our study provides a robust framework for improving precision matrix estimation and enhancing portfolio optimization.
3. Problem Formulation
Throughout the paper, we define the matrix norm of a matrix A as the Frobenius norm, represented by . Given , we define to be the matrix with the elements of b on the diagonal and zeros off the diagonal, while for some represents the vector in whose elements are the diagonal elements of B. We define the volatility function as the volatility of a given portfolio calculated under a covariance matrix . As usual, represents an identity matrix, and denotes the vector of ones, where all N entries are identical and equal to one.
3.1. Preliminaries
Over a finite time window of length days, we observe the dynamics of N tradable security returns in the market, where represents the column vector of daily security returns on each date . The true population covariance matrix and its estimate of
Estimating the precision matrix (the inverse of the covariance matrix) of stock returns is crucial in optimizing asset allocation to identify assets that reduce overall portfolio volatility and improve the effectiveness of hedging strategies. Although the precision matrix enables more informed decision making by balancing risk and return in a portfolio, misestimating it can lead to flawed conclusions, suboptimal portfolio construction, and increased exposure to unintended risks. Recognizing the critical role of the precision matrix managing portfolio-level risk, we define the SOR bias matrix as and set the SOR bias measure as
A fundamental challenge in detecting and addressing SOR bias lies in its measurement because the true precision matrix is unobservable in practice. We therefore need an observable proxy to quantify the extent of SOR bias resulting from the misrepresentation in . A reasonable approach is to construct optimized portfolios (such as the GMVP) based on the estimated and evaluate their out-of-sample performance by comparing it to the in-sample prediction.6 In the absence of the short-selling constraint within the classical mean-variance framework, the true GMVP and the estimated GMVP can be expressed as and , which are fully characterized by and , respectively.
Then, the true GMVP variance of is given by
In addition, the (in-sample) predicted variance of the estimated takes the form of
3.2. Excess Dispersion Bias from Finite Sample Error
Statistical risk modeling approaches typically assume temporal stability to ensure consistency with a static risk structure over the estimation horizon. However, when the number of observations (T) is significantly less than the dimension (N) of , finite-sample estimation error arises, and the estimated model is subject to the SOR bias. When , for example, the sample covariance matrix is singular,7 so its inverse matrix is not well-defined, and the GMVP is not unique and has estimated variance of zero. One of the most widely used methods to mitigate this bias is shrinkage estimation of the sample covariance matrix, as proposed by Ledoit and Wolf (2004b), which serves as one of our benchmark methods.
In practice, variants of PCA estimation for linear factor models are typically applied using a medium horizon of one or two years of historical data to ensure the temporal stability of the factor structure. Assuming where r represents the true number of factors, the factor structure is often represented by a static linear factor model in the form of
Let be the full-rank of and the time-normalized data admit the singular value decomposition expressed as
Although the factor-based approach is effective in mitigating finite-sample error problems when the number of factors (r) is effectively smaller than the number of observations, it still yields inaccurate estimated factor loadings when this medium horizon () is smaller than the number of securities. This discrepancy leads to what is known as excess dispersion bias in the estimated factor loadings, which remains one of the primary sources of second-order risk in factor-based models. More specifically, estimated factor loadings are contaminated by idiosyncratic returns when using static PCA with a medium data history , as we have with
In finite sample, with , the idiosyncratic returns of some of the stocks will appear to be very significantly correlated with the returns of some of the factors. The realized correlations between the factor returns and the idiosyncratic returns appear explicitly in the terms , adding dispersion to the estimated factor loadings.
3.3. Biased Estimation of Weak Factor Loadings
We next turn to an examination of weak latent factors. Standard factor models typically assume that the factors are strong, which implies that is asymptotically positive definite as . Recent literature has made efforts to relax this condition, allowing , where , to be asymptotically positive definite in the limit; for example, see Freyaldenhoven (2022), Bai and Ng (2023), and the references therein. Factors with , in particular, are commonly referred to as weak.
As noted by Freyaldenhoven (2022), a risk factor can be weak if its influence is limited to a subset of stocks in the market. We classify such weak factors in this context as narrow, whereas Freyaldenhoven (2022) refers to them as local. The crucial point is that PCA cannot accurately capture narrow factors because the extracted eigenfactors are supposed to be orthogonal to one another. That is, each eigenfactor may be an amalgam of several narrow factors with broad factors and idiosyncratic returns, while each true narrow factor may be partially captured in each of multiple (orthogonal) eigenfactors.
Although a narrow factor does not appear as an explicit factor in the output of PCA, it nonetheless is a source of risk. This risk will be captured in the estimated covariance matrix produced by PCA, as long as we extract enough eigenvectors to ensure that “the best rank K approximation” in the form of is sufficiently accurate.9 A portfolio that is concentrated in a single industry or country will, all else being equal, be riskier than a portfolio that is diversified over industries and countries. In order to properly evaluate the risk of a portfolio, and especially to produce optimized portfolios, we need our estimated covariance matrix to accurately reflect the narrow factors.
When , the idiosyncratic returns of some stocks will appear to be very significantly correlated with the returns of some narrow factors, just as is the case with the broad factors. For example, all European stocks are exposed to the market factor, with true factor loadings that are roughly equal. By contrast, only some stocks are exposed to each narrow factor, with true factor loadings that are roughly equal and comparable in magnitude to the true loadings on the market portfolio. The idiosyncratic return contaminates the narrow and market factor loadings essentially equally, but the relative contamination of the narrow factor is much greater than that of the market factor. This contamination assigns nonzero estimated factor loadings on the narrow factors, when the stocks are, in fact, not exposed to them. One can think of this as excess dispersion of the estimated factor loadings that are, in fact, zero.10
3.4. The SOR Bias Mechanism for GMVP
Consider how the excess dispersion affects the construction of the GMVP. The factor loadings of some stocks appear to be smaller than they actually are, and the optimizer will choose to increase their weights in the portfolio. Conversely, the factor loadings of some stocks appear to be larger than they actually are, and the optimizer will choose to decrease their weights in the portfolio.
(
As stated in Remark 1, the excess dispersion resulting from contamination by idiosyncratic volatility results in estimated GMVPs that have significantly higher variance than the true GMVP. Moreover, the estimated GMVP is substantially more volatile than predicted. In the presence of narrow factors, such as those driven by industry- or country-specific influences, an optimizer subject to excess dispersion may attempt to offset a narrow factor’s exposure. It does so by taking long positions in stocks that appear to be negatively correlated with the factor and short positions in stocks that appear to be positively correlated. However, if these stocks have no true exposure to the narrow factor, the positions fail to provide any actual offset to the factor exposure.12
To tackle the issue of excess dispersion bias, for example, Goldberg et al. (2022) proposed the Goldberg-Papanicolaou-Shkolnik (GPS) correction method that corrects the leading eigenvector based on PCA using the medium horizon . They show that the GPS correction can asymptotically mitigate this bias under the “large-N and fixed-T” framework. However, our preliminary simulation study indicates that the marginal benefit of using GPS correction is limited with a single layer of narrow factors (e.g., industries) and deteriorates further with multiple layers (e.g., countries and industries). Detailed results are available upon request.
Instead, our approach employs a longer history () of sample data to estimate the dynamic factor structure, with the goal of mitigating the SOR bias at the portfolio level under the “large-N and large-T” framework. This involves extending the history of the sample data to a longer horizon () in the hope that we can reduce the contamination of the estimated factor loadings. Of course, several challenges arise when extending covariance estimation into the temporal domain, presenting both theoretical and empirical hurdles. As the factor loadings of the securities change over longer horizons, extending the sample period creates challenges in ensuring consistent estimates of principal components in a dynamic factor model. In addition, detecting and extracting weaker (eigen-)factors, which typically contain multiple narrow factor components, poses a challenge due to inconsistencies in principal component estimates when weaker factors predominate. From this perspective, Bai and Ng (2023) argue that accurately estimating weaker loadings requires using a longer T.
3.5. Observable Measures of the SOR Bias
The volatility ratio (VR) is defined as the actual volatility, , divided by the predicted volatility of the estimated GMVP, . Simply put, the VR of captures the discrepancy between the in-sample and the out-of-sample . The VR of is an observable measure in a statistical sense, and its ideal value would be one when the estimation of the precision matrix is perfectly accurate. According to Proposition 1, the VR can be approximated by the square root of a ratio expression where the error term in the numerator is twice that in the denominator. This suggests that the VR is monotonically increasing in the magnitude of , subject to the SOR bias, as noted in Remark 1.
(
Refer to Section A of the Electronic Companions.
One might argue that comparing the realized risk of the estimated GMVP would be the primary criterion for assessing the degrees of SOR bias across different methodologies, rather than focusing on the “risk-prediction error” that the VR attempts to capture. The intuition is that a more accurately estimated precision matrix would result in lower realized volatilities of the estimated GMVP. However, we have discovered that this intuition may not always hold true and can be misleading in many realistic cases. Specifically, recall that the actual volatility is the product of the predicted volatility and the volatility ratio by definition. As a result, the actual volatility of may not have a monotone relationship with as
We conduct a numerical experiment to quantify the relationship between different SOR bias metrics and the excess dispersion bias in the estimated factor exposures specific to the GMVP. The data-generating process involves the contaminated mean-variance stock return model with mutually uncorrelated factors, where the idiosyncratic returns of N = 2,000 stocks are uncorrelated with each other, as well as with the factor returns. For simplicity, we assume homogeneous factor volatilities of 10% and idiosyncratic volatilities of 5%. The true factor loadings are drawn from a normal distribution with mean one, where the true dispersion is represented by . The estimated covariance matrix, , is subject to contamination by an excess dispersion parameter, , where the total dispersion is given by . Sample paths are generated from 1,000 different simulation seeds.
Figure 1 illustrates the results of our numerical experiment. As shown in panels (a) and (b), the ideal (or unobservable) SOR bias measure, computed using the average Frobenius norm of the estimation error in both the covariance and precision matrices, exhibits a monotonically increasing association with the excess dispersion parameter, . In particular, the estimation error in appears to be more sensitive to relatively small deviations from the true . Panels (c) and (d) confirm that VR serves as a more definitive measure of the accuracy of compared with the actual volatility of the estimated GMVP. The latter displays a nonmonotonic pattern influenced by the excess dispersion of the estimated factor loadings, along with its noisier reflection of the SOR bias, as indicated by relatively wider confidence intervals. Related to this observation, Proposition 2 draws attention to a potential SOR measurement problem concerning the actual volatility of , revealing that the true precision matrix may not be the unique minimizer of the GMVP’s actual volatility. This illustrates that a naive comparison of realized GMVP risks may result in an inaccurate assessment of the extent of the SOR bias across different methods employing the same data set.
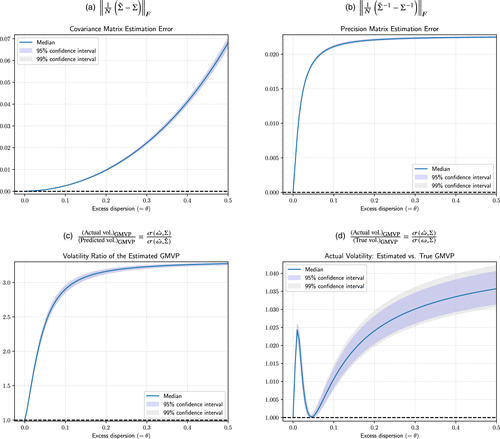
Notes. This figure illustrates the relationship between various SOR bias metrics and the excess dispersion bias in estimated factor exposures for the GMVP, using a contaminated mean-variance stock return model with mutually uncorrelated factors and N = 2,000 stocks with uncorrelated idiosyncratic returns and factor returns. Assuming homogeneous factor volatilities of 10% and idiosyncratic volatilities of 5%, the true factor loadings are drawn from a normal distribution with a mean of one, with true dispersion represented by . The estimated covariance matrix, , is contaminated by an excess dispersion parameter, , resulting in total dispersion . Panel (a) shows the average estimation error in the covariance matrix across different levels of excess dispersion. Panel (b) measures the error in the precision matrix, demonstrating that the inverse of the covariance matrix is significantly more sensitive to relatively small deviations from the true values. Panel (c) displays the volatility ratio, which captures the discrepancy between out-of-sample actual risk and in-sample predicted risk. Panel (d) compares the realized volatility of the estimated minimum-variance portfolio to the true minimum risk. Sample paths are generated from 1,000 different simulation seeds.
(
and the relationship between the SOR bias () and the actual (i.e., to-be-realized) volatility of the estimated GMVP may not be monotonic.
Refer to Section A of the Electronic Companions.
4. A Dynamic Factor Model with Weak Loadings
This section introduces our dynamic factor model with weak loadings for stock returns and outlines the key assumptions. Furthermore, it explores the identification approaches and the theoretical justification of Long-History PCA in an asymptotic framework, where both N and T are large.
4.1. Econometric Framework and Assumptions
The DFM of stock returns considered in this paper generalizes the standard definition by incorporating time-varying security sensitivities to factors and heterogeneous strengths in factor loadings. This setup builds on the frameworks of Bates et al. (2013), who propose a decomposition of factor loadings into a static term and a purely innovative component, and Bai and Ng (2023), who extend the assumption of homogeneous factor loading strengths to allow heterogeneity across factors. It also aligns with the local factor setup of Freyaldenhoven (2022), making it a versatile framework for capturing the empirical dynamics of observables with heterogeneous factor strengths.
(
Definition 1 establishes the econometric framework for our DFM. We presume that the daily log returns of N stocks are generated by a fixed number () of unobserved common factors () with the possibly time-varying factor loadings () and idiosyncratic errors on each date . Assumptions 1 and 2, which are central to our framework, rely on the existence of a finite to ensure that the DFM remains well-posed and robust across varying empirical contexts.
Latent factor and idiosyncratic returns
(Latent factor returns):
and .
For , , where is the nonrandom (but possibly time-varying) factor volatility of .
Define and the diagonal elements of
are strictly positive.
We have
(Idiosyncratic returns):
For , we have , and , where is the nonrandom idiosyncratic volatility of . For notational consistency, define and
Both and exist for all and .
We have for all , and
For all , holds for some , and we have
For all , we have
For all and , is independent of .
The conditions outlined in Assumption 1 align closely with those in Bai and Ng (2002), accommodating weak dependence between factors and idiosyncratic returns, as well as limited cross-sectional and temporal dependence among the idiosyncratic errors. As such, the dynamic nature of the factor model arises from two sources: (i) variable volatilities of both factor and idiosyncratic returns, and (ii) the time-varying factor loadings, with their conditions detailed in Assumption 2.
Assumptions on the factor loading dynamics
(Factor loading dynamics)
The dynamics of for is expressed as
(4)where specifies the (static) baseline factor loadings, is a deterministic scalar that may depend on the pair of , and is a (possibly degenerate) stochastic innovation process.
For all and , is independent of .
(Static baseline component):
has rank r, the columns of are orthogonal, and holds.
Allowing the strengths of baseline loadings to vary across factors, let
so that the weakest baseline loading has strength . Letting the normalization matrix
there exists some diagonal matrix such that
(Stochastic innovation component):
There exist envelope functions , , and such that the following conditions hold for all N, T and factor indices :
The following conditions hold:
Assumption 2 demonstrates that our approach significantly advances the conventional static framework by extending the setup of Bates et al. (2013) to account for time-varying security sensitivities to factors with heterogeneous strengths. The time-varying loadings () are decomposed into a static component () and a term driven by pure innovations (). A central implication of this structure, governed by the conditions in Assumptions 2 and 3, is that the noise term originating from the loading innovations, , can be treated analogously to an idiosyncratic error.13 Thus, the principal component estimator can tolerate significant instability in the factor loadings precisely because the effects of these shifts are mitigated by averaging across a large number of series (N) and a long time horizon (T). As inspired by Bates et al. (2013), the envelope conditions in Assumptions 2 and 3 formalize this by accommodating several empirically relevant forms of instability, such as “white noise” deviations, “random walk” innovations, and even discrete “single large break” events affecting a subset of series, under the key condition that these instabilities are sufficiently idiosyncratic to be diversified away. This structure, which facilitates the consistent estimation of factor models through PCA under mild regularity conditions, accommodates stylized features including mean-reverting14 stationary dynamics of factor exposures, occasionally interrupted by structural breaks, a feature commonly observed in empirical data sets. This enhancement builds on the contributions of Bai and Ng (2023), further expanding the local factor structure proposed by Freyaldenhoven (2022).15
Whereas the pure innovation component is structured to be diversified away, the static component of the factor loadings, , is the primary focus of our analysis, as it approximates the baseline factor sensitivities that cannot be diversified away. PCA-based estimation of such models typically assumes homogeneous factor loadings , a framework extended by Bai and Ng (2023) to allow heterogeneity using a parameter . We incorporate this extension in our normalization matrix , enabling the model to accommodate variations in factor strength across different securities and factors. Accordingly, we adhere to the assumptions of Bai and Ng (2023) for addressing heterogeneity in the strengths of the static component. These assumptions ensure consistency in estimation while allowing for flexibility in modeling empirical data. For example, when , and are independent of t, the model reduces to the standard definition of a static factor model with constant factor sensitivities, volatilities, and idiosyncratic terms over time. Overall, the proposed model combines the strengths of existing literature while providing greater flexibility to capture time-varying dynamics and heterogeneous strengths in factor loadings.
4.2. Identification Approaches
Our DFM specification can also be reformulated as a static factor model under additional restrictive conditions, accommodating the stochastic variation in the loadings by attributing some of this variability to the factors. Specifically, assume there exists with full column rank r. Let denote the Moore-Penrose pseudo-inverse of . Under these conditions, our DFM model can be interpreted as a static factor model with time-invariant loadings in the form of
Our approach also introduces a simplified representation of a linear factor model in the sense that the observed data process can be expressed as
In short, the representation in Equation (5) simplifies our DFM by assuming time-invariant loadings, while treating the composite noise as a combination of idiosyncratic and measurement errors that can be diversified away under mild assumptions, providing a robust, yet interpretable, formulation.
4.3. Theoretical Basis of Long-History PCA
To mitigate the realized correlation between idiosyncratic returns and factor returns, we consider a longer data history of length —for example, daily returns over six years. As a result, we cannot presume that the factor loadings remain constant over the entire (extended) sample period . Nevertheless, Theorem 1 and Corollary 1 confirm that, under the “large-N and large-T” framework, PCA can consistently estimate the covariance and precision matrices in a dynamic factor model under mild regularity conditions outlined in Assumptions 1 and 2.
(
Refer to Section A of the Electronic Companions.
Theorem 1 asymptotically justifies that the variation introduced by remains sufficiently small, ensuring that it does not dominate the factor structure in the limiting representations of the covariance and precision matrices. Note that the speed of convergence is governed by the minimum of N and T, emphasizing the importance of extending T for large N, while ensuring that T is not excessively large relative to N.
(
Then, as , we have
Refer to Section A of the Electronic Companions.
In particular, Corollary 1 justifies the use of LH-PCA in the setting of variable factor and idiosyncratic volatility, along with time-varying factor loadings with heterogeneous strengths under our assumptions. This implies that, accounting for time variation in both factor and idiosyncratic volatilities, changes in the values of the factor-loading matrix under our assumption do not pose an additional obstacle to the consistent estimation of the factor-driven covariance matrix. Furthermore, the estimation remains consistent under the dynamic factor model specification, even with weaker loadings in their static components.
Empirically, factor volatility is highly variable, even over short horizons. Factor loadings are also variable over long, and possibly medium, horizons. The presence of weak factors complicates the process of portfolio volatility prediction. Note that even if factor loadings were constant, and there were no weak factors, variation in factor volatility would alter the return correlation matrix over short horizons. PCA estimation over medium horizons makes sense only if factor loadings can be consistently estimated in the presence of rapidly varying factor volatility. PCA estimation over long horizons requires, in addition, that factor loadings can be consistently estimated in the presence of variable factor loadings and weak factors. For this reason, commercial latent factor models have avoided using long histories of daily return data. Our theoretical results justify estimation over longer histories, even when factor volatilities and factor loadings are varying and weak factors are present. Our empirical and simulation results show that the use of longer histories improves the prediction of portfolio volatility.18
4.4. Number of Eigenfactors
Implementing the PCA estimator requires selecting the appropriate number of eigenfactors to extract. Although data-driven criteria such as the Bai and Ng (2002) (hereafter “BN”) estimator have the theoretical advantage of adapting to the evolving structure of the stock market and reducing the misspecification risk associated with arbitrary fixed choices, they can exhibit practical instability in finite samples. To ensure the credibility and real-world applicability of our findings, our main analysis presents results using a fixed K, complemented by results where K is diagnosed dynamically.19
To validate that the performance of LH-PCA is not an artifact of the specific choice of K, we compare it against standard one-year PCA and GPS across both a wide fixed range () and varying deviations from the BN estimator ( for ), as shown in Figure 2. The results illustrate that although performance is similar at very low K (where the model is misspecified), the outperformance of LH-PCA widens significantly as K increases. This confirms that the primary source of LH-PCA’s advantage is the use of a long history (), which enables the model to effectively extract signal from the weaker factors found at higher K levels, rather than the specific choice of K itself.
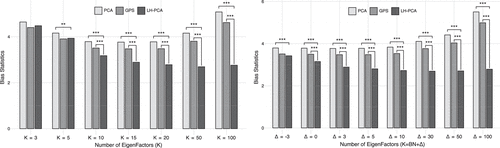
Notes. This figure illustrates the Bias Statistics across different choices of the number of extracted factors . In the right panel, “BN” represents the number of eigenfactors determined using the Bai and Ng (2002) estimator, and the variants are constructed by adding or subtracting a fixed increment . The data consist of CRSP daily returns from 2001 to 2021. The brackets denote the statistical significance of the difference in BS between LH-PCA and the benchmark schemes. **Significant at the 5% level; ***significant at the 1% level.
For our main empirical analysis, we set the representative fixed K to the median of the BN estimator calculated over the long-history window ( = 1,500). This choice is supported by simulation evidence confirming that enables the detection of weak, but structurally important, volatility-driving factors (consistent with Bai and Ng 2023), while filtering out nonsystematic signals that are often conflated with noise in medium windows . As such, using mitigates the finite-sample instability typically observed under , whose BN estimates tend to have higher dispersion and a lower median, as shown in Figure EC.1 of the Electronic Companions. The extended history improves the signal-to-noise ratio, allowing the estimator to suppress transient idiosyncratic shocks and converge toward the market’s effective rank.20
5. Simulation Study
In this section, we employ Monte Carlo simulations to assess the performance of the SOR bias. Having access to the true risk factor structure in the simulations, we can directly compute the difference between the true and estimated precision matrices. This not only supports the validation of our observable SOR bias metrics, but also provides a solid basis for our subsequent empirical analysis, as detailed in the following section.
5.1. Simulation Setup
In our simulation, we assume the presence of 4 broad factors, consisting of 1 market factor and 3 style factors, along with 27 narrow factors, which include 16 country factors plus 11 industry factors, to mimic the narrow factor structure of the European stock market. We set the annualized daily volatility of the market factor at 16% and the daily volatility of the three style factors at 8%, 8%, and 4%, respectively (Clarke et al. 2011, Morozov et al. 2012). The country and industry factor volatilities are calibrated from the European stock market data. We draw idiosyncratic volatilities uniformly from per annum. We randomly assign N = 2,000 stocks to countries and industries; see Table 1 for details. The true factors are normally distributed with mean zero, and they are assumed to be pairwise uncorrelated. The sample stock returns are generated across 1,000 different seeds.
|

Table 1. True Factor Structure in Simulation
| Factors | Volatility (%) | No. of stocks |
|---|---|---|
| Broad factors | ||
| Market | 16.00 | 2,000 |
| Style 1 | 8.00 | 2,000 |
| Style 2 | 4.00 | 2,000 |
| Style 3 | 4.00 | 2,000 |
| Industry factors | ||
| Industry 1 | 11.51 | 143 |
| Industry 2 | 12.74 | 291 |
| Industry 3 | 13.00 | 131 |
| Industry 4 | 15.08 | 144 |
| Industry 5 | 13.99 | 115 |
| Industry 6 | 17.80 | 251 |
| Industry 7 | 14.07 | 258 |
| Industry 8 | 12.22 | 53 |
| Industry 9 | 9.80 | 109 |
| Industry 10 | 13.11 | 171 |
| Industry 11 | 21.23 | 334 |
| Industry sum | 2,000 | |
| Country factors | ||
| Country 1 | 13.00 | 154 |
| Country 2 | 12.38 | 69 |
| Country 3 | 18.53 | 159 |
| Country 4 | 15.91 | 76 |
| Country 5 | 24.93 | 178 |
| Country 6 | 18.14 | 99 |
| Country 7 | 11.86 | 177 |
| Country 8 | 17.57 | 19 |
| Country 9 | 16.43 | 203 |
| Country 10 | 24.41 | 73 |
| Country 11 | 14.31 | 56 |
| Country 12 | 12.03 | 247 |
| Country 13 | 13.33 | 171 |
| Country 14 | 13.79 | 75 |
| Country 15 | 18.29 | 135 |
| Country 16 | 22.59 | 109 |
| Country sum | 2,000 | |
Notes. This table reports the true structure of broad, country, and industry factors in our simulation study. Factor volatilities are annualized, in percent. The true factors are assumed to be normally distributed with a mean of zero within the same regime and are considered pairwise uncorrelated.
5.1.1. Variable Volatility Structure.
We assume that the return-generating process follows a Markov regime-switching model (MRS). There is a latent Markov chain of the state process , in which denotes a normal factor-volatility structure, and denotes a crisis structure. This Markov chain is described by its transition matrix with the probabilities of switching from regime j at time to regime i at time t. In particular, we have
Furthermore, we assume that the initial distribution is given by . During the normal period (), the factor volatilities are drawn from the same distribution as the baseline setup. For the crisis regime (), we assume that the volatilities of the (market, style, country, industry, idiosyncratic) factors are multiplied by (2.0, 1.5, 1.5, 1.5, 1.25), respectively. The true factors are normally distributed with mean zero within the same regime, and they are assumed to be pairwise uncorrelated.
5.1.2. Time-Varying Factor Loadings.
We further extend the simulation setup by allowing variable factor loadings over time, following Adrian and Franzoni (2009) and the references therein. We first assume that the broad factor exposures (i.e., the market beta and the style factor loadings) are time-varying based on a discretized version of the mean-reverting Ornstein-Uhlenbeck process given by the following stochastic differential equation:
5.2. Main Findings
Table 2 summarizes the simulation results within the setup characterized by the MRS volatility structure and the mean-reverting factor loading dynamics. We compare the performance of four distinct approaches—that is, LW denotes the shrinkage estimation of the sample covariance matrix, proposed by Ledoit and Wolf (2004b) using one year of historical data;21 PCA represents the plain PCA estimation based on one year () of data history; GPS refers to the PCA method adjusted by the GPS correction in accordance with the guidelines of Goldberg et al. (2022) to correct the leading eigenvector; and LH-PCA represents the PCA estimation utilizing a six-year history ( = 1,500) of sample data. The simulation results are obtained from 1,000 simulation runs with varying seeds, acquired through bootstrapping with replacements for cross-validation.
|
Table 2. The 99% Confidence Intervals for the Expected Performance Metrics (without RCA)
| Expected performance statistics (bootstrapped) | |||
|---|---|---|---|
| Ideal SOR bias | Volatility ratio | Actual volatility | |
| (%, p.a.) | |||
| LW | [51.5739, 56.4899] | [22.0352, 24.4072] | [9.5471, 9.8187] |
| PCA | [5.5964, 5.8933] | [2.9599, 3.0431] | [7.1718, 7.3970] |
| GPS | [5.5829, 5.8793] | [2.7943, 2.8709] | [7.1195, 7.3338] |
| LH-PCA | [4.6756, 4.9940] | [2.6009, 2.6842] | [7.3720, 7.6024] |
Notes. This table shows the 99% confidence intervals of the estimated GMVP’s expected performance metrics obtained from 1,000 different seeds under the simulation setup with the MRS volatility structure and the mean-reverting factor loading dynamics. The performance statistics are calculated from a sample of N = 2,000 stocks. LW denotes the shrinkage estimation of the sample covariance matrix proposed by Ledoit and Wolf (2004b) with . PCA stands for the plain PCA method with ; GPS indicates the methodology proposed by Goldberg et al. (2022) with . We employ = 1,500 for LH-PCA. These results are obtained from 1,000 simulation runs with varying seeds, acquired through bootstrapping with replacements for cross-validation.
As indicated by the ideal SOR bias defined in Equation (1), which is quantified by the average Frobenius norm of the estimation error in the precision matrix and is only available in simulation, the factor-based approach demonstrates approximately 10 times superior performance to the use of the shrunk sample covariance matrix. This observation is corroborated by both metrics for expected volatility ratio and actual volatility, though the performance differentials in terms of actual volatility become much less pronounced. Moreover, the actual volatility measure exhibits a contrasting direction compared with the observations from the other two metrics within the factor-based approaches. This is consistent with our observations in Proposition 2 and Figure 1, in that the actual volatility may lose its monotone relationship with the estimation error when the estimated is reasonably close to the true .
In a dynamic factor model, the covariance matrix estimated by PCA (and its variant) is distinct from the covariance matrix encountered on the following day of estimation. Such discrepancies have the potential to result in empirically inaccurate out-of-sample predictions of the true factor structure on a daily basis. Understanding these discrepancies underscores the potential necessity for responsive covariance adjustments in empirical analysis; see Section C of the Electronic Companions for more details of its implementation under the factor model approaches. Nevertheless, similar patterns can be observed in the enhanced box plots in Figure 3, where the estimated covariance matrices are adjusted by RCA with days for PCA, GPS, and LH-PCA. Specifically, the enhanced box plots consistently illustrate the distributions of the expected metrics within each panel, specific to the estimated GMVPs across different estimation schemes.
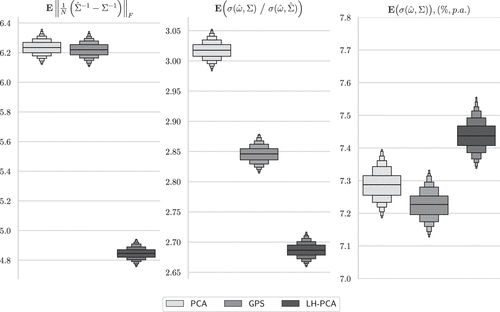
Notes. This figure shows the distributions of the estimated GMVP’s expected metrics obtained from 1,000 different seeds under the extended setup with the MRS volatility structure and the mean-reverting factor loading dynamics. The performance statistics are calculated from a sample of N = 2,000 stocks. PCA stands for the plain PCA method with ; GPS indicates the methodology proposed by Goldberg et al. (2022) with . We employ = 1,500 for LH-PCA. The estimated covariance matrices are adjusted by RCA with days. These results are obtained from 1,000 simulation runs with varying seeds, acquired through bootstrapping with replacements for cross-validation.
The fact that expected VR statistics are not adversely affected by the introduction of variable factor volatility and mean-reverting stock factor exposures is a direct consequence of Corollary 1, which asserts that (LH-)PCA consistently estimates the baseline factor exposures in the presence of (potentially) unstable factor structure dynamics under mild regularity conditions. In addition, the outcomes demonstrate that the use of a longer data history leads to a significant improvement in the estimation of factor loadings. This is evidenced by the fact that LH-PCA outperforms one-year PCA and GPS in the presence of narrow factors under both the ideal SOR bias and the volatility ratio metrics.22 Overall, our numerical results confirm that the use of long histories such as = 1,500 trading days, or six years, substantially improves the performance of the unconstrained GMVPs, compared with using a medium history of days, indicating superior SOR bias mitigation.
6. Empirical Analysis
6.1. Data and Samples
In our empirical study, we investigate two financial markets: the United States and Europe. Daily stock return data in the United States are obtained from the Center for Research in Security Prices (CRSP), and European stock return data from 16 countries23 are obtained from Compustat-Capital IQ’s Global Daily (henceforth EURO). Our database spans from 2001 to 2021. We selected this period for several reasons: (i) it provides a substantial timeframe for estimating the plane spanned by factor returns over a long history (); (ii) it encompasses major market shocks, including the global financial crisis and COVID-19; and (iii) most European countries transitioned from their national currencies to the Euro in the late 1990s and early 2000s. One particular feature of our empirical setting is that we consider the entire universe of stocks at a given point in time. This is crucial because small stocks, which tend to be highly volatile, can make the estimation problem more challenging than focusing on more established samples, such as the S&P 500 constituents.
As in the previous section, we fix = 250 × 6 = 1,500 and trading days. Our decision to use = 1,500 trading days (approximately six trading years) is based on observed stock market patterns in the United States and Europe. For instance, the U.S. stock market experienced a bull market from late 2002 to 2007, followed by the Global Financial Crisis in 2008–2009 and a recovery afterward. Similarly, from 2013 to 2019, markets underwent a prolonged period of sustained growth, which was disrupted by the COVID-19 crash in 2020. In Europe, the Eurozone debt crisis (2010–2012) was preceded by a postcrisis recovery and followed by a stabilization phase from 2013 to 2018. Taken together, our choice of six trading years as the long-history window is grounded in the stock market cycles observed during our main sample period, 2001–2021. In Section D.3 of the Electronic Companions, we cross-check our empirical results using alternative lengths for the moving window to ensure that our main findings are not sensitive to this parameter choice.
Table 3 provides a comprehensive overview of our sample, presenting the number of stocks and the yearly realized volatility across countries and industries. On average, a moving window in the CRSP data set contains approximately 2,260 stocks, with the total number of firms in the sample being N = 6,516. At the start of our moving window analysis, around 2,800 securities are available, but this number gradually declines to approximately 1,800 by the end of the sample period, consistent with the listing gap argument in Doidge et al. (2017). In the EURO data set, a total of N = 7,350 firms are included in our sample, with an average of about 2,500 stocks available in each moving window. Unlike in CRSP, the number of available securities in EURO has increased over the sample period, likely due to the broader coverage of the database and the expanding stock market.
|
Table 3. Empirical Data Description
| United States | Europe | |||||
|---|---|---|---|---|---|---|
| Sources: | CRSP | Compustat-Capital IQ Global | ||||
| Dimensions: | T = 5,284, N = 6,516 | T = 5,359, N = 7,350 | ||||
| Category | Classification | Volatility (%) | No. of stocks | Classification | Volatility (%) | No. of stocks |
| Industry | 1. Consumer Nondurables | 19.32 | 346 | 1. Consumer Nondurables | 12.08 | 679 |
| 2. Consumer Durables | 26.65 | 155 | 2. Consumer Durables | 13.12 | 216 | |
| 3. Manufacturing | 26.30 | 614 | 3. Manufacturing | 12.21 | 1,082 | |
| 4. Energy | 39.02 | 302 | 4. Energy | 13.00 | 344 | |
| 5. Chemicals | 23.67 | 134 | 5. Chemicals | 13.94 | 218 | |
| 6. Business Equipment | 21.82 | 1,400 | 6. Business Equipment | 12.37 | 1,764 | |
| 7. Telecom | 23.75 | 278 | 7. Telecom | 12.92 | 250 | |
| 8. Utilities | 18.94 | 157 | 8. Utilities | 13.94 | 151 | |
| 9. Shops | 23.28 | 719 | 9. Shops | 11.83 | 767 | |
| 10. Health | 20.80 | 812 | 10. Health | 12.30 | 746 | |
| 11. Money (Finance) | 23.91 | 1,599 | 11. Money (Finance) | 11.98 | 1,347 | |
| Country | United States | 6,516 | 1. Austria (AUT) | 14.46 | 98 | |
| 2. Belgium (BEL) | 13.01 | 151 | ||||
| 3. Switzerland (CHE) | 12.16 | 337 | ||||
| 4. Germany (DEU) | 11.14 | 997 | ||||
| 5. Denmark (DNK) | 13.76 | 231 | ||||
| 6. Spain (ESP) | 15.25 | 201 | ||||
| 7. Finland (FIN) | 11.92 | 203 | ||||
| 8. France (FRA) | 12.70 | 909 | ||||
| 9. United Kingdom (GBR) | 11.70 | 2,148 | ||||
| 10. Greece (GRC) | 14.75 | 239 | ||||
| 11. Ireland (IRL) | 15.87 | 78 | ||||
| 12. Italy (ITA) | 16.47 | 487 | ||||
| 13. Netherland (NLD) | 16.04 | 226 | ||||
| 14. Norway (NOR) | 15.33 | 356 | ||||
| 15. Portugal (PRT) | 17.88 | 48 | ||||
| 16. Sweden (SWE) | 15.35 | 855 | ||||
Notes. In each dataset, the Category reflects a narrow factor classification (industry or country), with the Classification column identifying the specific industries or countries within each category. Annualized realized volatility is reported for each factor in percentage terms, along with the number of stocks represented in each classification. Industry classifications follow the definitions provided on Kenneth French’s website.
6.2. Empirical Assessment of SOR Bias
In Section 3.5, we introduced the Volatility Ratio, the ratio of the GMVP’s actual (out-of-sample) volatility to its predicted (in-sample) volatility, as a definitive, albeit unobservable, measure of SOR bias. As shown in Proposition 1, the VR is an excellent theoretical metric that is monotonically increasing with the magnitude of the SOR bias. However, the VR cannot be calculated directly in empirical applications, when the true population covariance matrix, , is unobservable.
To overcome this limitation, we require an observable and statistically robust proxy for the VR that can be computed from realized returns. As proposed by Shepard (2009), the building block of our performance statistics is Z-score of , defined as
A potential pitfall of the BS measure lies in the time-resolution problem, which arises because the statistic may appear overly optimistic, nearing one, due to cyclical prediction errors. These errors may alternatively overestimate or underestimate the predicted risk, but offset each other over the long term. The Mean Rolling Absolute Deviation (MRAD) is an alternative way to mitigate this problem because it computes the bias statistic over the u-day horizon subperiods and then calculates the average of those rolling windows until we exhaust the sample. The MRAD metric is defined as
We further employ Q-statistics, which is a QLIKE loss function proposed in Patton (2011). As mentioned in Menchero et al. (2013), the Q-statistics address both time-resolution and portfolio-resolution issues by penalizing both underprediction and overprediction of risks, defined as
6.3. Main Findings
Similar to the simulation section, we assess the predictive performance of the four estimation methods. Our main empirical measure is the Bias Statistics, defined in Equation (7). For our benchmark specification, we use the median of Bai and Ng (2002) estimator computed over as the fixed number of PCA eigenfactors to extract, without applying RCA.26
Figure 4 presents enhanced box plots27 using 1,000 bootstrapped Z-score samples with replacement. In the CRSP sample, the median Bias Statistic for the Ledoit-Wolf method (white) is 5.63, which is significantly higher than the median Bias Statistic of the standard PCA estimation of 3.77 (light gray). We see that eigenvector correction of GPS (dark gray) shows a modest improvement to 3.49. Our proposed method, LH-PCA (black), shows the best performance at the median Bias Statistic of 3.02. Our analysis now turns to the empirical results from the EURO data set. In Figure 4, the right panel conveys the same overall message as in the CRSP case: despite practitioners’ reluctance to apply PCA to data histories longer than one or two years, using a long-history approach (LH-PCA) improves portfolio volatility prediction.28
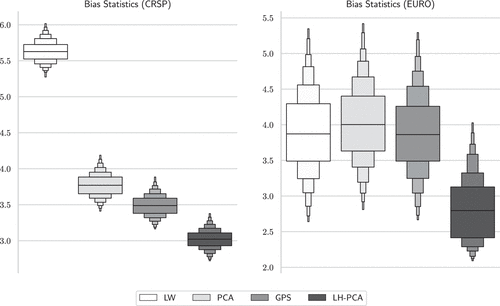
Notes. This figure shows the distributions of the estimated GMVP’s Bias Statistics obtained from daily CRSP (left panel) and EURO (right panel) stock returns data. LW stands for Ledoit-Wolf shrinkage method; PCA stands for the plain PCA method with ; GPS indicates the methodology proposed by Goldberg et al. (2022) with . We employ = 1,500 for LH-PCA. These results are obtained from bootstrapping with replacement for cross-validation, using 1,000 different random seeds. For the European data, we cap Z-scores at 100 and −100 to mitigate the impact of a small number of extreme days that cause factor models based on medium-length windows (such as LW, PCA, and GPS) to become overly sensitive to outliers. This conservative treatment favors competing methods over LH-PCA.
The realized (or actual) volatility results are depicted in Figure 5. Here, we observe a slight deterioration in LH-PCA’s realized volatility performance in both CRSP and EURO. In the CRSP sample, the median realized volatility of LH-PCA is 7.33% per annum, which is comparable to the 7.36% achieved by LW. It is slightly higher than the medians for PCA and GPS, although these differences are empirically indistinguishable. In the case of EURO, LH-PCA achieves lower median realized volatility (2.91%) than other benchmark schemes. However, other methods exhibit a wider distribution of realized volatility, which at times results in lower realized volatility in the lower quantiles. This mixed result is exactly what we documented in Section 3.5, where the level of actual volatility is not a monotonic function of SOR bias . Putting this together, LH-PCA demonstrates powerful performance in mitigating SOR bias in both the U.S. and European stock markets, as indicated by Figure 4. However, because of the nonmonotonic nature between the degree of SOR bias and realized volatility, Figure 5 produces less-clear-cut results.
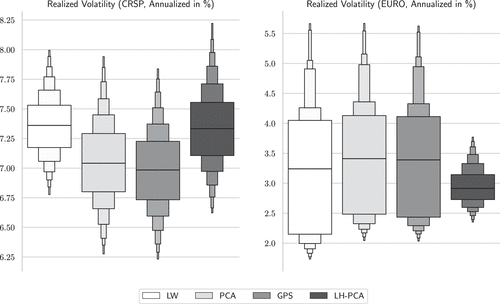
Notes. This figure shows the distributions of the estimated GMVP’s Realized Volatility obtained from daily CRSP (left panel) and EURO (right panel) stock returns data. LW stands for Ledoit-Wolf shrinkage method; PCA stands for the plain PCA method with ; GPS indicates the methodology proposed by Goldberg et al. (2022) with . We employ = 1,500 for LH-PCA. These results are obtained from bootstrapping with replacement for cross-validation, using 1,000 different random seeds. For the European data, we cap Z-scores at 100 and −100 to mitigate the impact of a small number of extreme days that cause factor models based on medium-length windows (such as LW, PCA, and GPS) to become overly sensitive to outliers. This conservative treatment favors competing methods over LH-PCA.
Figures EC.3 and EC.4 in Section D.4 of the Electronic Companions present the empirical comparison using an alternative performance metrics, MRAD and Q-statistics, demonstrating that LH-PCA consistently outperforms competing methods in estimating factor models. Overall, the results in this section provide strong evidence that adopting a long-history approach such as LH-PCA leads to more accurate GMVP risk forecasts and substantially reduces second-order risk.
6.4. Robustness Checks
As a robustness check, we verify that our results remain consistent when using the extended CRSP sample (1961–2021). Table 4 reports subsample estimates based on this extended data set, which provides 61 years of daily stock returns. We partition the sample into three periods: 1961–1980, 1981–2000, and our main CRSP sample of 2001–2021. Although this is not a strict three-fold validation, it serves a similar purpose for robustness analysis. This extension is particularly informative because the earlier periods encompass major market disruptions, including the 1973 oil crisis, 1970s stagflation, and the 1987 Black Monday crash.
|
Table 4. CRSP Longer Sample Results
| Periods | PCA | LH-PCA | Difference |
|---|---|---|---|
| Panel A: Excess bias statistics | |||
| CRSP 1961–1980 | 1.39 | 0.70 | 0.69*** (21.10) |
| CRSP 1981–2000 | 2.73 | 1.36 | 1.38*** (5.22) |
| CRSP 2001–2021 | 2.77 | 2.02 | 0.75*** (8.71) |
| CRSP 1961–2021 | 2.31 | 1.32 | 0.99*** (12.10) |
| Panel B: Excess MRAD | |||
| CRSP 1961–1980 | 0.98 | 0.43 | 0.55*** (14.73) |
| CRSP 1981–2000 | 1.89 | 0.88 | 1.01*** (11.34) |
| CRSP 2001–2021 | 1.92 | 1.31 | 0.61*** (8.20) |
| CRSP 1961–2021 | 1.61 | 0.81 | 0.80*** (22.98) |
| Panel C: Excess Q-statistics | |||
| CRSP 1961–1980 | 3.34 | 1.17 | 2.17*** (12.79) |
| CRSP 1981–2000 | 10.98 | 3.29 | 7.69*** (3.81) |
| CRSP 2001–2021 | 11.15 | 6.55 | 4.60*** (6.76) |
| CRSP 1961–2021 | 8.14 | 3.22 | 4.92*** (8.55) |
Notes. This table presents robustness checks using an extended CRSP sample, covering 61 years of daily data (1961–2021). The data set is divided into three periods: 1961–1980, 1981–2000, and 2001–2021, with the 2001–2021 results corresponding to our main sample period. Additionally, we analyze results for the entire 1961–2021 period. PCA refers to the standard PCA method using , whereas LH-PCA employs = 1,500. For each panel, we report the deviation of the corresponding test statistics from their ideal values under the assumption of normally distributed daily returns, adopting a conservative perspective. Specifically, the reported figures include Excess Bias Statistics (Panel A), Excess MRAD (Mean Rolling Absolute Deviation) (Panel B), and the Excess mean of Q-statistics (Panel C), all computed using Global Minimum Variance Portfolios across different subsamples and estimation methods. The last column (Difference) reports the difference in the test statistic, along with the associated t-statistics shown in parentheses.
***Significant at the 1% level.
Each panel employs a different test statistic to ensure that our findings are not driven by any single performance measure. Table 4, Panel A reports the Excess Bias Statistic (Excess BS), defined as the deviation of the empirical BS from its ideal value of one under normally distributed daily returns and perfectly accurate volatility forecasts. Table 4, Panel B presents the Excess MRAD, which subtracts the MRAD implied by the ideal normal benchmark (0.17), and Table 4, Panel C provides the Excess Q-statistic, obtained by removing the theoretical Q-stat value associated with a standard normal distribution (2.27). Across all three subsamples, as well as the full 61-year data set, we consistently find that LH-PCA outperforms standard PCA because its volatility predictions are consistently closer to the ideal values suggested by each test statistic. Therefore, we conclude that the performance advantage of LH-PCA is neither sample-specific nor method-specific.
In Section D.3 of the Electronic Companions, we detail our choices of tuning parameters. We describe how we select the benchmark number of factors (K) and demonstrate that the outperformance of LH-PCA is robust to variations in the long-history window .
7. Conclusion
This paper introduces Long-History Principal Component Analysis, a robust framework for estimating precision matrices in high-dimensional portfolios under dynamic factor structures with weak loadings. By extending the data history used for PCA estimation from traditional short-to-medium horizons (e.g., days) to a long history ( = 1,500 days), LH-PCA mitigates second-order risk bias more effectively than competing methodologies, including Ledoit-Wolf shrinkage, standard PCA, and the GPS eigenvector correction (Goldberg et al. 2022). Theoretically, we show that LH-PCA maintains consistency in estimating the factor-driven covariance and precision matrices, even under variable factor volatilities and time-varying loadings. Empirically, both simulation results and real-world stock return data from the U.S. (CRSP) and European markets demonstrate that LH-PCA produces more accurate forecasts of GMVP volatility, as measured by bias statistics, volatility ratios, MRAD, and Q-statistics.
Our findings have important implications for portfolio risk management in the presence of high-dimensional and dynamically evolving return structures. The superior performance of LH-PCA is particularly evident in environments where narrow factors are prominent and traditional PCA-based estimators are vulnerable to dispersion bias. Moreover, the method remains effective, even when responsive covariance adjustments are incorporated, further validating its applicability in fast-changing financial markets. In light of increasing investor reliance on data-driven risk models, LH-PCA offers a scalable, theoretically grounded, and empirically validated approach to improving portfolio construction and volatility forecasting under realistic and noisy conditions.
The authors thank Jeffrey Bohn, Young Ho Eom, Lisa Goldberg, Markus Pelger, Raman Uppal, and seminar participants at 2023 Financial Management Association Annual Meeting, the INFORMS Annual Meeting 2024, Korea University Business School, Southwestern University of Finance and Economics, the University of California Berkeley, University of Oxford Saïd Business School, and Yonsei University Business School for many valuable comments. B. Kim gratefully acknowledges that a significant portion of this work was completed while he was a visiting scholar at the University of California, Berkeley.
1 Neglecting the misestimation of expected returns can have a significant impact, similar to the mismeasurement of the covariance matrix. However, this study focuses solely on covariance matrix estimation, leaving expected return estimation errors for future research. Notably, the significance of expected return estimation errors may diminish in short-horizon optimization scenarios.
2 We use the terms strong and weak factor loadings within the framework of Bai and Ng (2023), which extends and generalizes the concepts introduced in Lettau and Pelger (2020), Freyaldenhoven (2022), and Uematsu and Yamagata (2023), among others.
3 Throughout the paper, we use , , and to represent Long, Medium, and Short historical windows, respectively.
4 An exception is Northfield, which employs a hybrid model using 60 months of exponentially weighted regressions on fundamental factors and PCA factors derived from residuals. However, it still contends with SOR bias due to high dimensionality—that is, typically .
5 Pelger and Xiong (2022a) discuss interpretation of latent PCA factors.
6 As illustrated by Proposition 2, achieving the minimum realized variance of the constructed GMVP, which is a practically important goal, may be a conceptually different objective from measuring SOR in our context.
7 Because mean daily returns of stocks are small, and the sample mean is a very noisy estimate of the true mean, it is customary not to demean, and therefore to divide by T rather than .
8 The Eckart and Young (1936) theorem implies that is the best rank-r approximation of .
9 If the approximation is poor, then the risk of the narrow factor will not be captured by PCA. As a consequence, an optimizer will not attempt to diversify away the risk of that narrow factor and potentially expose the investor to unnecessary and unexpected risk.
10 Goldberg et al. (2022) (GPS) propose a correction to the estimated eigenvector corresponding to the largest eigenvalue (i.e., market factor). But they do not address this excess dispersion in the narrow (or weak) factors.
11 When is estimated by the sample covariance matrix with and the true covariance matrix is time-invariant, the estimated precision matrix is characterized by the inverse-Wishart distribution.
12 When over 90% of the stocks have zero true exposure to a given narrow factor, the number of false positives—stocks that falsely appear to have nonzero exposure at the 5% confidence level—will be about half the number of true positives. As a consequence, about one-third of the stocks in our estimate (embedded in the PCA output) of the narrow factor will be false positives, and we cannot capture the narrow factor as cleanly as we would wish. Because the longer history () reduces the correlation between factor and idiosyncratic return, it reduces the estimated loadings of the false positives, but does not reduce the number of false positives. This suggests that the factor return model is misspecified in the presence of two layers of narrow factors, most likely because it does not allow for interaction terms between narrow factors in the two layers.
13 The envelope conditions outlined in Assumptions 2 and 3 align with those in Bates et al. (2013, corollary 1), serving as sufficient criteria for the envelope functions specified in Bates et al. (2013, assumption 4).
14 Empirical evidence suggests that the factor loadings of individual stocks exhibit mean-reverting behavior over time (Blume 1971, Alexander and Chervany 1980).
15 More specifically, Freyaldenhoven (2022) states that a factor can be considered weak if it influences only a subset of the observables, where such factors are referred to as local.
16 The positive recurrence of and mild conditions of ensure that the term does not drift indefinitely, provided that the deterministic function is well-behaved.
17 The average Frobenius norm serves as a measure of the average error within the entries of the approximated population covariance and precision matrices.
18 In Bai and Ng (2023), proposition 6 proves that the average error in estimating asymptotically vanishes provided that and , where is the weakest factor strength out of the r factor loadings in .
19 We acknowledge and appreciate the advice of the anonymous Associate Editor on this matter.
20 Robustness checks for different BN penalty functions are provided in Section D.3 of the Electronic Companions.
21 See Section B of the Electronic Companions for details.
22 It is noteworthy that the performance of one-year GPS is fairly decent when only broad factors are present. However, the performance of the method deteriorates with the inclusion of a single layer of narrow factors and deteriorates further with the addition of a second layer of narrow factors. Details are available upon request.
23 These are Austria (AUT), Belgium (BEL), Switzerland (CHE), Germany (DEU), Denmark (DNK), Spain (ESP), Finland (FIN), France (FRA), United Kingdom (GBR), Greece (GRC), Ireland (IRL), Italy (ITA), Netherland (NLD), Norway (NOR), Portugal (PRT), and Sweden (SWE). These 16 countries are commonly studied in analyses of European stock markets (see Fama and French 1998 and Bekaert et al. 2009b).
24 Under the assumption of normally distributed daily returns, the ideal value of MRAD is approximately 0.17. In the presence of leptokurtic return distributions, this value tends to increase, implying that our evaluation based on the normal benchmark adopts a conservative perspective.
25 Patton (2011) shows that the Q-statistic is the unique loss function that solely relies on the Z-scores. The ideal value of the expected Q-statistic is approximately 2.27 assuming the normal distribution of daily returns.
26 Refer to Section D.4 of the Electronic Companions for the empirical analyses with RCA.
27 We use the Python library Seaborn to produce enhanced box plots. This enhanced version plots more quantiles than the standard, providing more information about the shape of the distribution, particularly in the tails.
28 The gains in the EURO case appear less pronounced than those in the CRSP case, but this is largely attributable to our treatment of outliers. Unlike the CRSP data set, the European stock market data are less comprehensive and require additional filtering, which likely removes many small and volatile stocks. Even after cleaning, short-window methods (LW, PCA, and GPS) occasionally produced highly inaccurate daily risk forecasts, resulting in extremely large Z-scores (e.g., a Z-score of 400 under the standard PCA factor model). Such distortions undermine meaningful comparisons across forecasting methods. To address this, we capped Z-scores at 100 and −100 for the affected observations—an adjustment that effectively biases the evaluation in favor of short-history algorithms. Despite this conservative treatment, LH-PCA consistently outperforms the alternative approaches; without these caps, its relative advantage would appear even more substantial.
References
- (2009) Learning about beta: Time-varying factor loadings, expected returns, and the conditional CAPM. J. Empirical Finance 16(4):537–556.Crossref, Google Scholar
- (2025) When uncertainty and volatility are disconnected: Implications for asset pricing and portfolio performance. J. Econom. 248:105654.Crossref, Google Scholar
- (1980) On the estimation and stability of beta. J. Financial Quant. Anal. 15(1):123–137.Crossref, Google Scholar
- (2009) The impact of risk and uncertainty on expected returns. J. Financial Econom. 94(2):233–263.Crossref, Google Scholar
- (2002) Determining the number of factors in approximate factor models. Econometrica 70(1):191–221.Crossref, Google Scholar
- (2023) Approximate factor models with weaker loadings. J. Econom. 235:1893–1916.Crossref, Google Scholar
- (2021) Time-varying general dynamic factor models and the measurement of financial connectedness. J. Econom. 222(1):324–343.Crossref, Google Scholar
- (2009) Jackknife estimator for tracking error variance of optimal portfolios. Management Sci. 55(6):990–1002.Link, Google Scholar
- (2013) Consistent factor estimation in dynamic factor models with structural instability. J. Econom. 177:289–304.Crossref, Google Scholar
- (2009a) Risk, uncertainty, and asset prices. J. Financial Econom. 91(1):59–81.Crossref, Google Scholar
- (2009b) International stock return comovements. J. Finance 64(6):2591–2626.Crossref, Google Scholar
- (2019) Second-order risk of alternative risk parity strategies. Risk 21(3):1–25.Google Scholar
- (1971) On the assessment of risk. J. Finance 26(1):1–10.Crossref, Google Scholar
- (2018) Asset pricing and ambiguity: Empirical evidence. J. Financial Econom. 130(3):503–531.Crossref, Google Scholar
- (2011) Minimum-variance portfolio composition. J. Portfolio Management 37(2):31–45.Crossref, Google Scholar
- (2008) Dynamic factor models with time-varying parameters: Measuring changes in international business cycles. Federal Reserve Board of New York Staff Report 326, Federal Reserve Board of New York, New York.Google Scholar
- (2009b) Optimal versus naive diversification: How inefficient is the 1/N portfolio strategy? Rev. Financial Stud. 22(5):1915–1953.Crossref, Google Scholar
- (2009a) A generalized approach to portfolio optimization: Improving performance by constraining portfolio norms. Management Sci. 55(5):798–812.Link, Google Scholar
- (2021) High dimensional minimum variance portfolio estimation under statistical factor models. J. Econom. 222(1):502–515.Crossref, Google Scholar
- (2017) The U.S. listing gap. J. Financial Econom. 123(3):464–487.Crossref, Google Scholar
- (1936) The approximation of one matrix by another of lower rank. Psychometrika 1(3):211–218.Crossref, Google Scholar
- (1993) Common risk factors in the returns on stocks and bonds. J. Financial Econom. 33(1):3–56.Crossref, Google Scholar
- (1998) Value versus growth: The international evidence. J. Finance 53(6):1975–1999.Crossref, Google Scholar
- (2016) Projected principal component analysis in factor models. Ann. Statist. 44(1):219–254.Crossref, Google Scholar
- (2022) Factor models with local factors: Determining the number of relevant factors. J. Econom. 229(1):80–102.Crossref, Google Scholar
- (2022) The dispersion bias. SIAM J. Financial Math. 13(2):521–550.Crossref, Google Scholar
- (2003) Risk reduction in large portfolios: Why imposing the wrong constraints helps. J. Finance 58(4):1651–1684.Crossref, Google Scholar
- (2019) Characteristics are covariances: A unified model of risk and return. J. Financial Econom. 134(3):501–524.Crossref, Google Scholar
- (2021) Arbitrage portfolios. Rev. Financial Stud. 34(6):2813–2856.Crossref, Google Scholar
- (2011) Eigenvectors of some large sample covariance matrix ensembles. Probab. Theory Related Fields 151:233–264.Crossref, Google Scholar
- (2003) Improved estimation of the covariance matrix of stock returns with an application to portfolio selection. J. Empirical Finance 10(5):603–621.Crossref, Google Scholar
- (2004a) A well-conditioned estimator for large-dimensional covariance matrices. J. Multivariate Anal. 88(2):365–411.Crossref, Google Scholar
- (2004b) Honey, I shrunk the sample covariance matrix. J. Portfolio Management 30(4):110–119.Crossref, Google Scholar
- (2020) Estimating latent asset-pricing factors. J. Econom. 218(1):1–31.Crossref, Google Scholar
- (1952) Portfolio selection. J. Finance 7(1):77–91.Google Scholar
- (2013) Predicting risk at short horizons: A case study for the USE4D Model. MSCI Model Insight, MSCI Barra documentation, MSCI Barra, New York.Google Scholar
- (2012) The Barra global equity model (GEM3). MSCI Barra model documentation, MSCI Barra, New York.Google Scholar
- (2000) Portfolio selection and asset pricing models. J. Finance 55(1):179–223.Crossref, Google Scholar
- (2011) Volatility forecast comparison using imperfect volatility proxies. J. Econom. 160(1):246–256.Crossref, Google Scholar
- (2022a) Interpretable sparse proximate factors for large dimensions. J. Bus. Econom. Statist. 40(4):1642–1664.Crossref, Google Scholar
- (2022b) State-varying factor models of large dimensions. J. Bus. Econom. Statist. 40(3):1315–1333.Crossref, Google Scholar
- (1976) The arbitrage theory of capital asset pricing. J. Econom. Theory 13(3):341–360.Crossref, Google Scholar
- (2009) Second order risk. Working paper, MSCI Barra, New York.Google Scholar
- (2020) Improving minimum-variance portfolios by alleviating overdispersion of eigenvalues. J. Financial Quant. Anal. 55(8):2700–2731.Crossref, Google Scholar
- (2017) On time-varying factor models: Estimation and testing. J. Econom. 198(1):84–101.Crossref, Google Scholar
- (2023) Estimation of sparsity induced weak factor models. J. Bus. Econom. Statist. 41(1):213–227.Crossref, Google Scholar
- (2017) Asymptotics of empirical eigenstructure for high dimensional spiked covariance. Ann. Statist. 45(3):1342–1374.Crossref, Google Scholar
Robert M. Anderson is a Long-Term Visiting Professor at the Institute for Advanced Study in Mathematics at Harbin Institute of Technology; and the Coleman Fung Professor Emeritus of Risk Management and a Distinguished Professor Emeritus of Economics and Mathematics at the University of California, Berkeley. His research bridges advanced mathematics and economic theory, applying rigorous mathematical modeling to the fields of mathematical economics and quantitative finance.
Baeho Kim is a professor of finance and business analytics at Korea University Business School. His research integrates financial analytics, risk management, and derivatives pricing and hedging through quantitative modeling of financial risk.
Dean Ryu is an assistant professor of finance at ITAM Business School. His research focuses on asset pricing, with particular emphasis on understanding volatility dynamics using statistical methods and machine learning techniques.

