
Modeling Financial Products and Their Supply Chains
Abstract
The objective of this paper is to explore how novel financial datasets and machine learning methods can be applied to model and understand financial products. We focus on residential mortgage backed securities, resMBS, which were at the heart of the 2008 US financial crisis. These securities are contained within a prospectus and have a complex waterfall payoff structure. Multiple financial institutions form a supply chain to create the prospectuses. To model this supply chain, we use unsupervised probabilistic methods, particularly dynamic topics models (DTM), to extract a set of features reflecting community (topic) formation and temporal evolution along the chain. We then provide insight into the performance of the resMBS securities and the impact of the supply chain communities through a series of increasingly comprehensive models. First, models at the security level directly identify salient features of resMBS securities that impact their performance. We then extend the model to include prospectus level features and demonstrate that the composition of the prospectus is significant. Our model also shows that communities along the supply chain that are associated with the generation of the prospectuses and securities have an impact on performance. We are the first to show that toxic communities that are closely linked to financial institutions that played a key role in the subprime crisis can increase the risk of failure of resMBS securities.
History: Olivia Sheng served as the senior editor for this article.
Funding: This research was partially supported by National Science Foundation [Grant CNS1305368] and National Institute of Standards and Technology [Grant 70NANB15H194].
Data Ethics & Reproducibility Note: No data ethics considerations are foreseen related to this article. The code capsule is available on Code Ocean at https://doi.org/10.24433/CO.8845455.v1 and in the e-Companion to this article (available at https://doi.org/10.1287/ijds.2020.0006).
1. Introduction
The 2008 U.S. financial crisis highlighted several challenges and limitations in monitoring systemic risk. Informally, systemic risk corresponds to risks that may be contagious across multiple financial markets and impact systemically important financial institutions. The residential mortgage-backed securities, resMBS, that were at the heart of the 2008 crisis were linked to massive defaults of subprime mortgages in the residential mortgage market. The risk was contagious because of the interconnectedness of resMBS with other financial products. For example, a resMBS may have been one arm of a collateralized debt obligation (CDO), whereas the other arm of the CDO could have leveraged a security tied to a foreign currency exchange rate. The crisis also exposed a major shortcoming: the gaps in data collection around financial products and the limited ability for synthesis across data sets, for example, the individual mortgages and the mortgage-backed securities. Multiple financial regulatory agencies are each responsible for monitoring individual lines of financial products. This results in silos and difficulty in synthesis and analysis across products and markets. These silos and gaps severely restricted the ability of regulators to manage a systemic crisis with data-informed actions.
The primary villains of the 2008 crisis were generally believed to be the financial institutions that were closely linked to the subprime residential mortgage market and that issued subprime loans to borrowers with poor credit scores. Many of these institutions filed for bankruptcy protection either before or during the 2008 crisis, or they faced financial penalties. The rating agencies were also vilified for assigning the coveted Aaa rating to many securities, including those that included subprime mortgages. However, an ex post study conducted 10 years after the crisis (Ospina and Uhlig 2018) paints a more nuanced picture. The research concludes that the majority of the resMBS actually performed well. As expected, securities issued closer to the financial crisis, that is, those issued from 2006 to 2007, suffered greater losses than those issued before the crisis, but it was only a small fraction of resMBS that incurred the greatest losses.
Given this scenario and the many challenges of monitoring these products, we believe that it would have been invaluable for regulators and analysts to have had access to the data and models that they needed in order to gain insight into the systemic risk associated with these products. A valuable strategic outcome of this research would be the ability to identify the subset of securities that were found to pose the greatest risk (Ospina and Uhlig 2018). The strategic contribution of our research and the design science impact as outlined in Gregor and Hevner (2013), focuses on the use of information extraction, text analytics, and machine learning methods to address this challenge. Our study also provides a proof of concept of how novel data sets and models that are built on a rich set of features can be synergistically exploited to help analysts understand the performance of financial products.
A key contribution of our research is an understanding of the impact of the supply chain on the performance of financial products. During the product development of resMBS, multiple financial institutions collaborate on complex tasks. These tasks included originating residential mortgages, creating a real estate trust or legal framework, issuing prospectuses that defined the contractual obligations of these products, selling securities to institutional investors, and finally servicing the resMBS, that is, managing the payouts. Performing these collaborative tasks successfully could incur significant overhead. Consequently, a successful collaboration and issuance of a prospectus could be an incentive to continue to collaborate and for a community to form. Such a community may benefit from staying together and may repeatedly issue hundreds of prospectuses over time. This is indeed our observation from this data set. At the same time, there is anecdotal knowledge that an association with the toxic financial institutions that were involved in the subprime market contributed to the failure of these securities. Our study is the first to extract and exploit a potential community structure. We hypothesize that identifying communities that include toxic financial entities could enable us to potentially isolate the subset of prospectuses and securities that contributed the greatest losses.
We study the performance of resMBS using two synergistic steps. First, we model the supply chain using unsupervised learning. We draw upon probabilistic topic models (Blei et al. 2003, Steyvers and Griffiths 2007) that have been successfully used to identify topics from a collection of documents. In our context, the topics represent communities of financial institutions that work together along the supply chain. We identify communities that capture complex relationships; for example, Company X is the issuer of securities for which Company Y originated the mortgages, and X issued prospectuses from 2002 through 2005. We use dynamic topic models (DTM) (Blei and Lafferty 2006) that use time slices to understand the evolution of topics, that is, communities, over time.
In the second step, we apply a series of increasingly comprehensive models to study the financial performance of resMBS. We label securities into classes based on their historical payment data. The labels include securities that meet expectations (ME) and make all of their payments fully and without delay. At the other extreme are securities that fail expectations (FE); they are securities that have stopped making payments and have failed. Between these two groups are securities that do not meet expectations (NME); they may have made late payments or incurred shortfalls in their payments, but they have not failed. These labels are explained in detail later in the paper. We use a machine learning approach to classify the securities using these labels. We note that there is significant quantitative finance research in predicting the performance of securities, such as stocks, using a variety of approaches, including sophisticated machine learning approaches. However, there is limited research on predicting the performance of over-the-counter (OTC) securities, including resMBS. Our research is, therefore, novel, and it builds a bridge between different research subdomains.
We summarize our findings as follows: First, models at the level of individual securities identify the salient features linked to their financial performance, that is, whether they meet or fail expectations. This includes the security class (from secured to unsecured debt), the year of issuance, and the Moody’s initial rating (MIR). We further account for the significant security-level features reflecting the often-complex waterfall payoff structure for these prospectuses (as detailed in Section 2). For example, the payoff to a security may be subordinated to the payoff to other senior securities; this is captured by a feature labeled senior subordinated debt (SSUP).
Our models reveal that the initial ratings may only be able to capture some of the nuanced risk arising from the complex waterfall payoff structure. Given this complex structure of payouts, it can be hypothesized that the performance of a security may be influenced by the structure of the prospectus. We, therefore, extend the model to include prospectus-level features. This includes composition features, for example, the count and the nominal principal (in US$) of the securities in the different security classes within a prospectus. Our model is the first to demonstrate that the composition of security classes within a prospectus can provide a quality signal. Further, the act of including securities labeled SSUP within the prospectus has an impact on performance for both the securities that carry the label and, more notably, other securities within the prospectus that do not carry this label.
Our final and most comprehensive model includes the community (topic) associated with each prospectus. This model highlights the fact that even after accounting for detailed security- and prospectus-level features, the community remains significant in predicting financial performance. This is especially notable because we do not include any features reflecting financial performance during the process of identifying financial communities.
We use real-world evidence to identify (toxic) financial institutions that were active in the subprime market and failed or faced significant difficulty. Based on the financial institutions that occur within the communities, we label the communities as toxic, partially toxic, or nontoxic. We compare toxic versus all topics with respect to the significance of topics in our comprehensive model. We demonstrate that toxic topics and some partially toxic topics increase the risk of failure, whereas all of the nontoxic topics decrease the risk of failure. This notable and novel finding from our research provides strong support for our recommendation, following design science guidance (Gregor and Hevner 2013) that the financial supply chain and corresponding models should be recognized as important modeling artifacts for this class of financial products. A further examination of partially toxic topics provides nuanced insights; for example, we can identify when some features of the prospectuses or securities within these topics can increase the risk of failure.
We note that we do not claim a causal connection between the toxic supply chain communities (toxic topics) and the performance of resMBS. Whereas causal estimation is important in many contexts, research by Fernandez-Loria and Provost (2022) and Fernandez-Loria et al. (2023) makes a case for the use of predictive models. In the context of our paper, predictive models can support the active monitoring of systemic risk.
We well-understand that the supply chain is only one of myriad factors that can influence the performance of these complex financial products. We further acknowledge that our retrospective data are not free from endogeneity concerns, including temporal dependencies, and we provide details on how we address this issue. Nevertheless, our approach to modeling these products may prove to be groundbreaking as it shows the synergistic potential of utilizing novel data sets and computational methods to understand the impact of the supply chain on the performance of financial products.
2. Background and Related Work
2.1. Background of the 2008 U.S. Financial Crisis
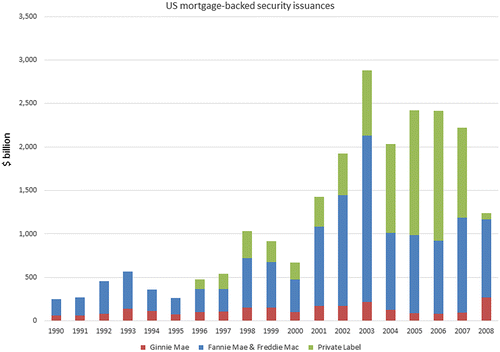
Mortgage-backed securities have had a long and successful history as versatile financial products and investment vehicles. They have been issued since 1990 by various government-sponsored enterprises, such as Fannie Mae, and by nonagency or private labels. Our focus is on the private-label securities because they played a major role in the 2008 crisis. Figure 1 provides the nominal value associated with such issuance from 1990 through 2008 (Securities Industry and Financial Markets Association 2018). As reflected in the figure, the early 2000s witnessed a boom in the issuance of private-label resMBS products. The issuance reached its peak around 2006, followed by a sharp decline in late 2007, in alignment with the financial crisis.
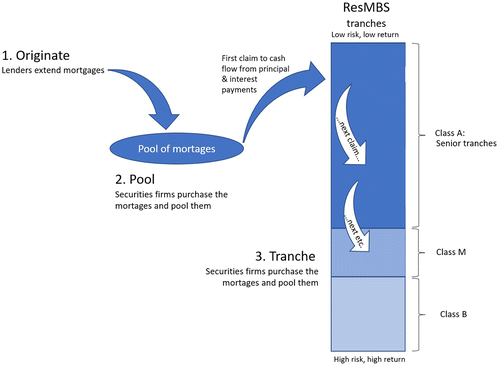
A residential mortgage-backed security is a financial product constructed by pooling cash flows from a collection of residential mortgage loans. The cash flows from the pool of mortgages, both the principal and interest payments, are allocated to a set of resMBS, based on a complex waterfall payoff priority. Figure 2 provides an illustration of the pool of mortgages and the waterfall payment structure (adapted from The Financial Crisis Inquiry Commission 2011). The securities served first, at the top of the waterfall, are referred to as investment-grade senior secured debt or class _A_ securities. This is followed by mezzanine (class _M_) securities and then discounted or unsecured (class _B_) securities. The securities are packaged within a prospectus—a legal contract—and rated for their creditworthiness. The prospectus is issued, and the securities are then sold to investors.
Since the 2008 financial crisis, several papers have described resMBS and their role in the crisis. We refer the reader to studies by Ashcraft and Schuermann (2008), Ashcraft et al. (2010), Gerardi et al. (2010), Hunt et al. (2014), and Levitin and Wachter (2012), which explicitly address how the residential mortgage registration and transfer systems and the subprime crisis contributed to the 2008 U.S. financial crisis. The financial institutions that played a major role in the subprime crisis and the incentives that guided their behavior and actions are documented by Pavlov and Wachter (2011) and The Financial Crisis Inquiry Commission (2011). We note, however, that our research is the first to accomplish the following: (1) Propose criteria to label toxic financial institutions and communities that include toxic institutions. (2) Create a corpus of prospectuses, extract the supply chain, and track the persistence of communities across the corpus. (3) Empirically study the impact of toxic financial communities on the performance of the securities.
We briefly report on the waterfall structure and the ratings of securities that are issued between 2001 and 2007 (Ashcraft et al. 2010). The fraction of highly rated securities in each prospectus decreases with increasing mortgage credit risk (measured either ex ante or ex post). This suggests that ratings indeed contain useful information for investors. However, there is also evidence of significant time variation in credit ratings, including a progressive decline in maintaining strict rating standards between 2005 and 2007. We note that this was the peak period for the issuance of low-performing (toxic subprime) mortgages. The researchers observed high mortgage defaults and losses and large rating downgrades for securities with observably higher risk mortgages based on a simple ex ante model. They also observed securities with a high fraction of opaque (low-documentation) loans. These findings held over the entire sample period.
2.2. Text Analytics in Finance
There is a long history of applying text analytics to understand company behavior and financial product performance. Loughran and McDonald (2016) offer an extensive survey of text-analytics approaches in the accounting, finance, and economics literature. Their survey covers methods to determine topics in documents, find hidden structures, and determine sentiment. As an example of text-mining applications in finance, Hoberg and Phillips (2018) study a collection of 10-K statements1 filed with the Securities and Exchange Commission (SEC) to determine how companies utilize product descriptions and product differentiation in comparison with their competitors. As a result of the study, the authors provide a new set of industries, competitor sets, and corresponding new measures of industry competition.
There is growing interest in exploiting financial big data and computational tools to better model and predict the behavior of financial ecosystems. The success of text-extraction tools (Hernández et al. 2010; Burdick et al. 2011, 2014, 2016) lowers the barriers to such research as does the increased availability of public financial documents that are typically filed with the SEC.
Latent semantic analysis (LSA) (Landauer and Dumais 1997) is one of the earliest approaches developed to obtain semantic information from the word-document co-occurrence matrix of some (large) document collection. LSA uses dimensionality reduction based on matrix factorization and represents words and documents as points in a Euclidean space. Our research draws upon unsupervised probabilistic topic models (Blei et al. 2003, Steyvers and Griffiths 2007). Both unsupervised topic models and their extensions are successfully used to identify topics from a range of web and social media corpora; the topics are used to understand user behavior and make predictions (Das et al. 2015, Chen et al. 2021, Hu 2021, Liu et al. 2021, Yang et al. 2022). We use DTM (Blei and Lafferty 2006) that use time slices to understand the evolution of topics over time.
The state of the art for language understanding and document processing is represented by large language models (LLMs), for example, bidirectional encoder representations from transformers (BERT) (Devlin et al. 2019). Recently, topic-modeling approaches that use embeddings have been introduced (Dieng et al. 2020, Grootendorst 2022). The Business Open Knowledge Network project successfully constructed document embeddings over the online web text of company websites to construct competitor networks (Hoberg et al. 2021). We report on an evaluation that uses a BERT-like model for the task of clustering resMBS prospectuses to identify supply chain communities comprising financial entities and their roles. Whereas BERT-like models are very successful in exploiting general document similarity, there are limitations of the resMBS data set that hinder the task of identifying the supply chain communities. Our evaluation in Online Appendix D discusses these limitations and identifies opportunities for further research.
2.3. Machine Learning Models for Prediction with Financial Products
Machine learning approaches have long been used in quantitative finance; a major focus of the research is on predicting the behavior of the stock market. Recent research on prediction models is summarized in Kaur and Dharni (2022) and Kumbure et al. (2022). These prediction models exploit a variety of data, including historical performance data, information about the underlying company and industry sector, economic indicators, financial news, and even nonfinancial signals such as rumors, external events, Twitter sentiment, etc.
In contrast, corporate bonds, asset-based securities, etc., are less well-studied. One major reason is the difficulty in obtaining relevant data from OTC markets in which trading is controlled by dealers. Recent research on bonds is summarized in Nazemi et al. (2022) and research on currency exchange predictions is summarized in Islam et al. (2020). A range of models, including analytical models, game-theoretic models, and econometric time-series approaches are utilized. Research on these fixed-income securities and trading in the secondary OTC market typically studies price volatility or bond liquidity.
Specialty products, such as the resMBS, are less well-studied by academic researchers. In addition to the challenge posed by the lack of data from OTC markets, these specialty products often require domain-specific knowledge that is more readily available to regulators, large institutional investors, or credit rating agencies. For example, models using proprietary data may be used to study the behavior of financial products under varying economic conditions with a focus on recommending a credit rating or making a decision when assembling a portfolio of securities.
Following the 2008 U.S. financial crisis, researchers examined the performance of resMBS from many different angles, including the variation in their credit rating over time (Ashcraft et al. 2010), the effect of issuer size on initial prices (He et al. 2012) and ratings (He et al. 2011), and the role of accounting rules on resMBS sales (Merrill et al. 2012). Levitin and Wachter (2012) argue that information failure caused by the complexity and heterogeneity of private label resMBS contributed to the crisis, and they propose that mortgage securitization and origination be standardized as a way of reducing complexity and heterogeneity.
An ex post study by Ospina and Uhlig (2018) provides a detailed picture of the payoff performance of the resMBS. The authors find that the misrating of Aaa debt was modest; most notably, only a small share of resMBS contributed the greatest losses. They further conclude that after controlling for the decline in home prices, the boom in the housing market was beneficial for the performance of the resMBS.
A framework for knowledge contribution in design science research (DSR) identifies exaptation: contributions for which design knowledge already known in one field is extended or adapted to another (Gregor and Hevner 2013). Our contribution of research artifacts described in this paper, both the creation of novel data sets and the proposed analytical models, are exemplars of exaptation. A focus of our research is the impact of the supply chain—communities of financial entities and their roles—on performance. A single previous study (Demiroglu and James 2012) focuses on the supply chain. The authors study the impact when a particular financial institution is both an originator of mortgages and either a sponsor or a servicer; in these cases, the default rates are significantly lower. No other research attempts to construct the supply chain for resMBS products or to estimate its impact on performance. Our research fills that gap.
Our research is also novel in its use of historical payment data to label resMBS into classes based on their performance. The labels include securities that meet expectations and make all of their payments fully and without delay. At the other extreme are securities that fail expectations; they are securities that have stopped making payments and have failed. Between these two groups are securities that do not meet expectations; they may have made late payments or have incurred shortfalls in their payments, but they have not failed. These labels are explained in detail later in the paper. Our models use a machine learning approach to classify the securities using these labels.
3. Pipeline for Data Curation and Analysis
Figure 3 summarizes the data curation and analysis pipeline. The data set for this paper is a set of approximately 5,000 prospectuses for resMBS that were issued by private labels and filed with the Securities and Exchange Commission between 2002 and 2007. We use text extraction and named entity recognition (NER) to construct the supply chain of financial institutions and the roles that these institutions play in each prospectus. We construct a proxy data set of (role–financial entity) pairs to represent the supply chain. Our data set is unique; few financial product data sets are associated with a supply chain. As an example, the extensive Bloomberg repository, which contains the resMBS and their payment history, does not provide the details of the resMBS supply chain. This knowledge is not proprietary, but it is not widely available, nor is it typically used for financial analysis; this contributes to the novelty of our research.

Notes. DTM is used to identify topics representing supply chain communities. The performance history of the securities is used to label the securities.
We apply DTM (Blei and Lafferty 2006) to the proxy data set of (role–financial entity) pairs to identify topics representing communities in the supply chain. We augment the securities within a prospectus with multiple features, including the payment history of each security that is obtained from the Bloomberg repository (Bloomberg). We use the payment history to label the securities as meeting, failing, or not meeting expectations. Features at the level of the individual security, the prospectus, and the topic are then used for the task of classifying the performance of the securities.
We note that, whereas there is no explicit discussion or acknowledgement in the academic or practitioner literature of communities across this supply chain, there are several signals that suggest a community structure, including the following: (1) The title/name of a prospectus typically indicates that it is part of a series. This is also reflected in tools such as Bloomberg, in credit ratings and in investor analysis reports. (2) Prospectuses within the series or those issued by the same entity often use the same template to generate the text of the prospectus. (3) Companies, their subsidiaries, and/or their affiliates often participate together within a prospectus.
3.1. Data-Extraction Protocol
The resMBS data set comprises prospectuses—legal contracts—that are hundreds to thousands of pages of noisy, semistructured data in varying formats, including ASCII text, PDF files, and tokenized HTML documents. Each document comprises a mix of legal contractual language, for example, covenants, details of the financial securities, and on occasion some details of mortgage loans.
We considered the following sections of the prospectuses:
Cover page: This page occurs in all prospectuses and varies in structure. This page was used in our pipeline across all prospectuses.
Summary section: This section occurs in almost all prospectuses. It was often aligned in column or tabular format, and this layout could sometimes pose difficult extraction challenges. This section was used across a majority of the prospectuses except in cases in which the alignment was very confusing, for example, a varying count of columns.
Some prospectuses included separate sections discussing the financial institutions that play key roles along the supply chain. It was typically difficult to extract this information, so these sections were rarely used.
In summary, the relevant knowledge was contained in the cover page and summary within tables, itemized lists, and/or other document elements. Whereas the relevant text made up to less than 1% of the prospectus, identifying these pages posed a big data scalability challenge of volume. A high-quality extraction from these pages further introduced challenges of variety and veracity along our pipeline. The statistics for the tokens extracted from the prospectuses are found in Online Table 5.
We briefly discuss the protocol to extract the mentions of financial institutions and the role that they played in the supply chain from the prospectuses; details are available in Burdick et al. (2016) and Xu et al. (2016). The extraction pipeline was developed using the rule-based algebraic information extraction system, IBM SystemT (Chiticariu et al. 2010) and was executed within the IBM Discovery cloud infrastructure.
We develop a named entity recognizer, Dict NER (Xu et al. 2016), which is tuned to extract the names of financial institutions from text. Note that we use the terms “financial institution” and “financial entity” in an interchangeable manner. The former is more commonly used in the finance and economics literature, whereas “named entity” is the term used in the information-management community. Financial institution names are typically composed of a root term, which is usually unique, and a suffix term, which is drawn from a small corpus of suffix terms. For example, U.S. Bank National Association is composed of the root term “U.S. Bank” and the suffix term “National Association.” Dict NER utilizes both a root dictionary and a suffix dictionary to recognize such names. We also develop an entity resolution tool, Rank ER (Xu et al. 2016), to map the extracted name to a corpus of standardized financial institution names. For example, there are multiple variants of names in Figure 4 that are all matched to the standard financial institution name Wachovia. The standardized corpus of names was curated from multiple resources, including the ABSNet portal (ABSNet 2018) (now archived) and the National Information Center of the Federal Reserve System (NIC 2018). A role extraction module uses keyword matching to extract roles such as issuer, depositor, originator, and sponsor. A role to financial entity matching module pairs a role with one or more financial institution names.

Figure 4 illustrates the summary section of a sample resMBS prospectus. Example names in this summary include Wachovia Bank, National City, and HSBC Bank. We can also extract the role played by a financial institution, for example, depositor, issuing entity, seller, sponsor, originator, servicer, or trustee. As the figure demonstrates, it is necessary to correctly interpret the tabular structure in order to align the originator or servicer role with the correct set of financial institution names.
Consider the three columns in the lower part of the figure, which contain the role, extracted name of the mentioned entity, and matching standardized name (determined after entity resolution). For this exemplar supply chain, Wachovia plays the role of depositor, issuing entity, seller, and sponsor. Similarly, National City plays the role of originator and servicer. The example prospectus in Figure 4 finally is associated in the data set with a set of pairs, for example, (issuing entity, Wachovia) and (originator, National City).
Details about the quality of Dict NER and role to financial institution matching are in Burdick et al. (2016) and Xu et al. (2016). The extraction precision of the data set is typically between 85% and 95%. There is a wide range in precision across the documents as is typical for text-extraction methods. We, therefore, take several additional steps to improve data quality. For example, we use a second extraction pipeline with a different named entity recognizer, ORG NER (Chiticariu et al. 2010), and only consider extracted pairs, associating roles with financial institution names when the two pipelines show agreement. This extension to the protocol increases the precision of the extracted data to 90% or higher.
The final step of the protocol is to obtain performance data for each security identified in each prospectus. Although each security has a unique identifier (CUSIP 2018), these CUSIP values are typically not generated at the time of issuance and are, thus, not included in a prospectus. The name of the issuing entity for each resMBS prospectus is, therefore, matched against the (issuer) names of securities available through the Bloomberg repository (Bloomberg 2018). When this automated match retrieves multiple entries, a human selects the correct matching entry. Finally, based on anecdotal evidence and the literature, we consider the roles of issuer and originator to be most important, so we filter the prospectuses to only include those for which the issuer of the securities and the originator of the mortgages was successfully extracted.
We extract multiple descriptive properties from the Bloomberg repository, including information on the structure of the security and tranche type, payment contingencies, and waterfall payoff details. For example, some securities are interest-paying or linked to floating interest rates or, in the case of SSUP, payment may be subordinated to the payment of other securities in the prospectus. We also obtain the MIR at issuance as well as updated ratings. Summary statistics for the frequencies of the different roles extracted are found in Online Table 4, and details on the attributes available from the Bloomberg repository are in Online Table 6.
Table 1 presents summary statistics of the prospectus and security counts from the Bloomberg repository. These statistics are partially presented in Figure 5, which highlights trends in the issuance of the three security classes over time. The issuance of securities grows rapidly from 2002 and peaks in 2006 with the issuance in 2007 falling below 2005 levels. We note that the count of _M_ securities increases very rapidly over this period, growing from fewer than 200 (less than 7% of all securities) in 2002 to a peak of more than 5,000 (approximately 34% of all securities) in 2006.
|

Table 1. Summary Statistics for Prospectuses and Securities in resMBS with Performance Data in the Bloomberg Repository
| 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | |
|---|---|---|---|---|---|---|
| Count of prospectuses | 173 | 262 | 394 | 566 | 849 | 535 |
| Count of securities | 2,529 | 3,694 | 5,531 | 9,069 | 14,154 | 9,865 |
| Count of _A_ securities | 1,519 | 2,127 | 2,835 | 4,267 | 6,653 | 5,263 |
| Count of _M_ securities | 149 | 406 | 1,016 | 2,577 | 4,849 | 2,594 |
| Count of _B_ securities | 861 | 1,161 | 1,680 | 2,225 | 2,652 | 2,008 |
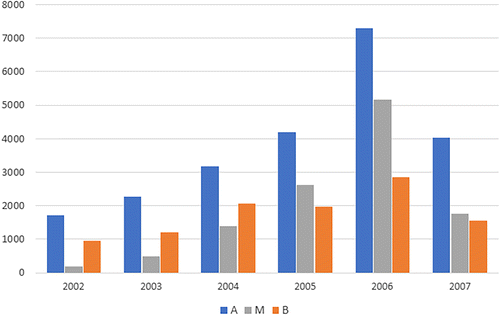
Note. The summary count for the data set is in Table 1.
3.2. Labels to Reflect Financial Performance
We model the financial performance of the resMBS as a classification task. We use historical payment data to create the following labels that reflect financial performance:
ME: Securities that meet all payments in full and on time are labeled ME. At the time of data collection, some securities may have met all expectations and terminated.
FE: Securities that do not meet their payment conditions and stop making payments prior to fulfilling the underlying financial contract terms are labeled FE. Securities in this class failed at some time prior to the time of historical data collection.
NME: Between meeting and failing expectations, there are securities that do not meet their payment conditions with payment shortfalls or delays in making payment. However, they continue to perform, and they have not failed (at the time of historic data collection). They are labeled NME.
FNE: We combine the classes of FE and NME securities into a single class: failing or not meeting expectations (FNE), reflecting all securities that do not meet expectations.
We utilize historic payment information from the Bloomberg repository to estimate the financial performance of each security and label the security. This includes information on the original mortgage amount (principal), the current principal balance, the sum of principal and interest payments, and shortfall and loss information. The history also indicates any early termination of payment before the principal payoff or maturity of the bond. In consultation with several investment experts, we define some (approximate) maximum shortfall and loss thresholds for each class, as follows:
For investment grade (class _A_) securities, to label a security as ME, neither the shortfall in the principal that is repaid nor the sum of the other shortfalls and losses should exceed the maximum threshold of 100 basis points (a basis point is 0.01% of principal). A threshold of 2,500 basis points is the cutoff to label an _A_ security as FE. Securities whose performance lay between these two thresholds are labeled as NME.
For noninvestment-grade discounted securities (class _M_ and _B_ securities), we use a threshold of 500 basis points as ME and a threshold of 5,000 basis points as FE. Securities whose performance lay between these two thresholds are labeled as NME.
The models in this paper consider two tasks. The first is to predict those securities that have the label FE. The second is to predict those securities that have the label FE or NME; this combined group is labeled FNE.
Figure 6 illustrates performance over time. Figure 6(a) shows the trend over all securities, whereas (b), (c), and (d) correspond to the trends for _A_, _M_, and _B_ securities, respectively. The rates for both FE and FNE increase over time for all securities. For _A_ securities, the rate is flat from 2002 to 2004 and then increases slowly after 2004. For _M_ securities, the rate starts increasing more sharply in 2003. In contrast, for _B_ securities, the rate of failure starts increasing much earlier, in 2002, and by 2005, these securities reach a 95% rate of failing or not meeting expectations.
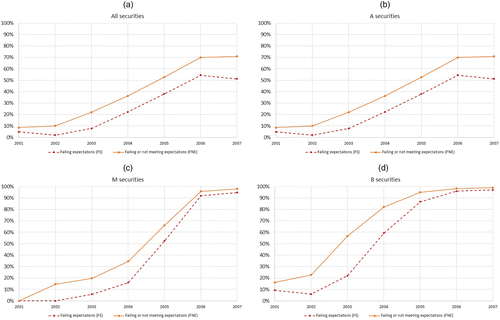
Notes. FE: failing expectations (dashed line) and FNE: failing or not meeting expectations (solid line). Panel (a) shows the trend over all securities, whereas (b), (c), and (d) correspond to _A_, _M_, and _B_ securities, respectively. (a) All securities. (b) _A_ securities. (c) _M_ securities. (d) _B_ securities.
4. Dynamic Topic Models for Financial Supply Chains
We use topic models to represent the communities of financial entities and the roles that they play along the supply chain. A topic model (Blei et al. 2003, Steyvers and Griffiths 2007) is a probabilistic model based on the idea that a collection of documents can be described using a set of topics. At a high level, it is assumed that, to create a document, one first randomly chooses a distribution over a collection of (unobserved) topics. Then, for each word in a document, one independently and randomly chooses a topic from the previously sampled mix of topics assigned to the document and then, again independently and randomly, draws a word from the (unobserved) word distribution for that topic. Based on these assumptions about the generative mechanism and the associated underlying probability distributions, topic models aim to extract the underlying topic structure via maximum likelihood estimation. For resMBS, the prospectuses are the documents, and the pairs of (role–financial institution) are the keywords.
However, the financial institutions, roles, and communities were not static over our time horizon. Some institutions left a community or played a different role, whereas other financial institutions may have joined the community. To capture this evolution of topics over time (ToT), we adopt time series extensions to the topic models. This includes a continuous non-Markovian model of ToT (Wang and McCallum 2006) and DTM (Blei and Lafferty 2006). We use the DTM extension in which the document collection is also divided by time: in our case, one time slice for each year. Details about latent Dirichlet allocation (LDA) topic models and the DTM extension are provided in the online appendix.
4.1. DTM Experimental Results
4.1.1. Configuration.
We used the Python gensim implementation of DTM (Rehurek and Sojka 2010), which represents each document (prospectus) as a bag of words over a vocabulary of (role–financial institution) pairs. We filtered the data and eliminated financial institutions that appeared in fewer than 20 prospectuses as well as prospectuses that had fewer than five pairs. This created a subset of 4,472 prospectuses. Additional statistical information on these prospectuses is provided in Online Tables 7 and 8.
Some roles, such as issuer and originator, are particularly important in the supply chain. Others, such as servicer, may occur very frequently but do not play a central role in creating prospectuses nor significantly impact financial performance. To address this variation in role importance, we doubled the token weight associated with pairs that involve the roles of issuer or originator.
We created annual time slices from 2002 to 2007 using the date of the prospectus issuance. (We note that the data are insufficient for us to consider both month and year.) We varied the hyperparameter α, which affects sparsity of the topics in each time slice; however, this parameter did not have much impact. We also varied the count of topics from 20 to 50 in increments of five. We did not observe much change in the community structure beyond 30 topics, so we report results for 30 topics.
The hyperparameter is significant because it controls the rate at which the topic evolves with each new time slice. Setting the parameter at one extreme converts DTM to a static topic model, whereas setting it at the other extreme results in independent topics in each time slice. We used two settings for this parameter, 0.005 and 0.75. A low value of 0.005 results in slow evolution, whereas a high value of 0.75 results in fast evolution. We labeled the results with = 0.005 as DTMslow and = 0.75 as DTMfast. To set a baseline for topic evolution, we computed the static LDA topics, labeled as LDA.
Completeness is an intrinsic problem for unsupervised methods such as topic models, in which there is often no independent ground truth data. Human evaluation is typically used as a basis for evaluating both the accuracy and completeness of topics over document corpora. Here, we performed an indirect evaluation of accuracy and completeness as follows. First, we noted that a large number of prospectuses are strongly associated with a single topic; this indicates that the topics capture strong co-occurrence patterns in the data. For example, 71% of the prospectuses/securities in the data set are associated with a single topic with a topic weight of at least 0.7. Second, our models demonstrate that topics/communities are found to be significant when predicting financial performance. Together, these observations imply the following: the topics are strongly associated with a significant fragment of the data set, the topics provide good coverage of the securities and prospectuses, and the topics are associated with financial performance. This, then, suggests that there is no evidence of missing topics and the topics are reasonably accurate and complete.
4.1.2. DTM Result Summary.
The DTMslow model showed minimal temporal evolution, and the topics were very similar to LDA (by experiment design). We, therefore, compare the topics in the DTMfast model with the (union of) topics in LDA and DTMslow. We observe three types of communities:
Stable: Twelve topics that appear in DTMfast are conserved and appear to be well-aligned to topics in both LDA and DTMslow. There is very low evolution of topic composition across the time slices for these stable topics. In other words, these topics represent communities in the supply chain that do not evolve over the time period.
Evolving: These are topics that appear in DTMfast and show some overlap with topics in LDA and DTMslow; however, the topics are not fully aligned. In several evolving DTMfast topics, we observe an evolution of the issuer associated with the topic.
Dynamic: Of most interest are eight topics that only emerge in DTMfast. In several cases, these topics may be associated with smaller financial institutions that issued a moderate volume of prospectuses. Consequently, these topics may have been merged with some other topics in the LDA or DTMslow models. The additional modeling flexibility of DTM, which explicitly models the community structure for each time slice, facilitates their appearance. Hence, the emergence of dynamic topics clearly highlights the benefits of using DTM.
Seven small topics (with fewer than 25 prospectuses each) were not studied further.
4.2. Exemplar Topics
4.2.1. The Supply Chain.
We note that some evolving or dynamic communities may be focused on the issuer, whereas the originators of mortgages or service providers may join or leave a community over time. Alternatively, some communities may focus on the originators of the mortgages; as the community evolves, different issuers may engage with these originators, and their loans may be pooled within prospectuses from these different issuers. In some cases, there may be a continuous evolution of financial institutions across the roles.
Figure 7 summarizes two topics (topics 8 and 26) with different time dynamics. The illustration is a Sankey diagram rendering of a bipartite graph. Each of the nodes on the left represents the community for that year. The nodes on the right are the (role–financial institution) pairs. The thickness of the edge represents the weight or significance of the financial institution and role to the topic. The supply chain represented by topic 8 in Figure 7(a) is stable over the time slices. Wilmington Trust is the issuer, and Countrywide participates in many roles, including servicer, seller, depositor, and sponsor across all time slices.
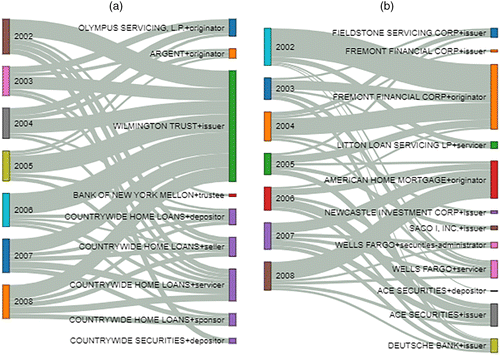
Notes. The nodes on the left represent the community for that year and link to the (role–financial institution) pairs on the right; the thickness of the edge represents the strength of the connection. (a) Topic 8. (b) Topic 26.
The supply chain represented by topic 26 in Figure 7(b) is dynamic. Fremont served as the originator in the early time slices, but that role was then assumed by American Home Mortgage starting in 2005. There is also an evolution of issuers. Fremont and Fieldstone are issuers in the early time slices, and Ace Securities and Deutsche Bank join as issuers in later time slices.
4.2.2. Communities and Financial Products.
We highlight four communities. As previously discussed, topic 8 is a large stable topic, whereas topic 26 is dynamic. We also consider topics 11 and 28. Topic 11 is a stable topic in which Bank of America is active in multiple roles through the different time slices. Topic 28 is dynamic with Renaissance and Principal Residential as issuers. These four communities are each associated with 100 to 200 prospectuses and an average of approximately 1,500 securities. The largest (topic 8) is associated with approximately 200 prospectuses and more than 3,000 securities.
These communities represent a range of behavior. Their activity level related to issuing prospectuses varies across the time slices, and the composition of the prospectuses (by security class) varies across topics. Figure 8(a) highlights the peak activity of each topic based on the normalized fraction of prospectuses issued per year (normalized based on the overall count of prospectuses for that topic). We note that topic 11 peaks early in 2004, whereas the other three topics peak in 2006.
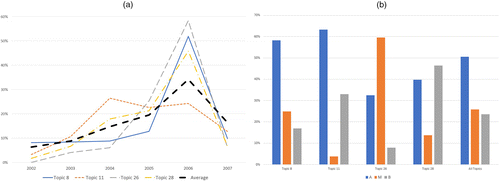
Notes. Panel (a) shows the normalized fraction of securities issued per year for each topic, contrasted with the sample average. Panel (b) shows the normalized fraction of securities by class, again contrasted with the sample average. (a) Activity per year. (b) Composition by class.
The varied composition of the prospectuses is even more interesting. Figure 8(b) summarizes the composition by security class for each topic. The overall composition across all topics is shown at the far right of the figure. When contrasting the securities composition of each topic, we observe that topic 8 most resembles the overall composition across all topics. Topic 11 produces very few class _M_ securities, whereas topic 26 produces an excess. Almost 60% of topic 26 securities are class _M_ securities; the sample average is approximately 25%. Topic 28 produces an excess of approximately 50% class _B_ securities; the sample average is just over 20%. Clearly, the types of prospectuses that are produced vary from one community/topic to the next.
Figure 9 summarizes the overall financial performance of each topic. The x-axis represents the percentage of securities that fail expectations, and the y-axis represents the percentage labeled SSUP (which, as we highlight in the next section, is a key indicator of financial performance). The FE percentage across topics ranges from the single digits to more than 50%, and the percentage of securities that are SSUP ranges from 0% to 15%.
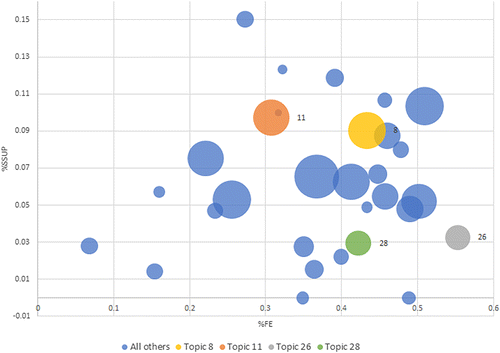
Note. The x-axis represents the percentage of securities that fail expectations (FE), and the y-axis is the fraction of securities labeled SSUP.
For our focal topics, we note that topics 8 and 11 both issue a large fraction of SSUP securities but differ significantly in their FE rate. Topic 8 has a high FE failure percentage of 47%, whereas topic 11 has a moderately high percentage of 33%. In contrast, topics 26 and 28 issue a smaller fraction of _A_ and SSUP securities. Recall that SSUP is a label for _A_ securities, so a low _A_ issuance necessarily leads to low SSUP issuance. We note, however, that the failure rate of topic 26 is more than 50%, the highest of all the topics. This high failure rate can, in part, be explained by the high proportion of _M_ securities issued. The failure rate for topic 28 is lower at just over 40%.
We further emphasize that the differing prospectus composition and performance range across the four communities is notable because we do not use any of this information in the DTM model. The question remains whether the topics are significant in predicting financial performance, and we explore this question in the following section.
5. Models to Predict Performance
In this section, we present a sequence of increasingly comprehensive models to help us understand the factors that impact the financial performance of resMBS. We start with a model that includes the features of individual securities. Next, we consider a model that further includes prospectus-level features. The final model includes supply chain features, represented by the topic weights.
We construct classification models for two binary outcomes: (i) Securities that fail expectations and (ii) securities that either fail or do not meet expectations. Details and statistics related to these outcome labels are provided in Section 3.2 and Figure 6. We report on the results of a regularized logistic regression least absolute shrinkage and selection operator (LASSO) model (Tibshirani 1996). The LASSO approach benefits from ease of regularization and the interpretability of the resulting models. It also compares favorably with other machine learning approaches ranging from simple classification trees to ensemble approaches for this data set and task(s). For each model, we report on two metrics: accuracy and the F1 score. The F1 score is defined as the harmonic mean of precision (positive predictive value) and recall (sensitivity) of the positive labels.
5.1. Model Design and Potential Limitations
We first discuss the motivation for our modeling approach and then its limitations. In a context such as ours, in which potentially hundreds of features must be evaluated, feature engineering must be carefully considered. The information about the supply chain that is extracted from prospectuses can be represented in a number of different ways. For example, we could use a binary indicator that directly reflects whether a financial institution participated in the supply chain for a particular security. Alternatively, we could use a binary indicator to represent a specific financial institution playing a specific role, for example, servicer. However, we chose to represent the supply chain with a topic weight feature serving as a proxy for the community with the community comprising multiple financial institutions and their roles. This topic weight feature can be viewed as a summary statistic for the supply chain, and it has the added benefit of being more dense than the individual binary indicators.
Another key concern when choosing a model is the ease of interpreting results. The major motivation for selecting our three increasingly comprehensive models is that these models accurately reflect our understanding of how the features of the securities, the composition and complex waterfall payment structure of the prospectuses, and finally the financial supply chain all impact performance. The relationships among features at the different levels may be complementary and/or correlated. These three models assist in our increasingly nuanced understanding and explanation of the financial insights that we obtain from the data set.
First, each resMBS is characterized by a set of features that reflects the security class within the waterfall structure, the rating, and the year of issuance. In the absence of other factors, these features are the drivers of financial performance, and we indeed find these security-level features to be significant in the security-level model.
Our summary statistics show that the distribution of securities across the three security classes, _A_, _M_, and _B_, varies across each of the prospectuses. Further, there are temporal trends in this variation, and these trends appear to impact performance. After consultation with experts, we constructed a set of features that captures these prospectus-level variations. For example, within a prospectus, the presence of even a single security with the label SSUP could impact the financial outcome for all other securities in that prospectus, independent of whether these other securities are labeled SSUP. Thus, the presence of an SSUP security is an overall quality signal for a prospectus. It was through a deep dive into the waterfall model of the payouts and extensive consultation with experts that we were able to identify these important prospectus-level features that impact performance.
In this context, it is noteworthy that we experimented with a hurdle model. First, we built a model to predict the overall performance of the prospectus, followed by a model of the performance of the individual securities. This more sophisticated model performed well, but it did not lead to significant improvements in our performance measures; thus, we could not justify the increased modeling complexity.
Next, we addressed our representation of the supply chain. As discussed earlier, when we constructed our security- and prospectus-level models, we considered categorical features reflecting the participation of a financial institution. However, with hundreds of financial institutions playing a number of different roles, the data were too sparse to yield meaningful results. Thus, the direct inclusion of the financial institution as a feature (or financial institution playing a specific role) was not helpful. We also experimented with representing the key players, for example, issuers, and their level of involvement in the supply chain, for example, the count of different roles played by one issuer. We determined that the topic weight was the best feature to be a proxy for the communities, and it was able to provide real-world financial insights.
The key motivation for our use of the three models is that each of these models focuses on a set of financial features (security or prospectus or topic) that represents some aspects of the data set. By providing three separate models, we can connect each model and its outcomes to specific financial insights. This allows us to provide more detailed explanations. For example, we can highlight the fact that many toxic and partially toxic topics are associated with an increased risk of failure even after accounting for security- and prospectus-level features.
We note that, as we move from the security- to the prospectus-level models, the significant features and their coefficients from the security-level model appear to be conserved in the prospectus-level model. The features at these two levels appear to be complementary in their impact on financial performance. However, this is not the case when we move to the third comprehensive model; there is a change in the significant features and their coefficients. This suggests that some communities or topics in the supply chain may be correlated with the underlying prospectus and security features. We use the three models and this potential correlation to provide more nuanced insights for some partially toxic topics.
The models were implemented using the glmnet package in R. Tuning was done using 10-fold cross-validation and a mean square error loss. When splitting the data across folds, we ensured that we did not train on securities from a particular prospectus, which would lead to subsequent testing on securities from the same prospectus. We note that the search range for the regularization parameter had to be changed significantly from the default values.
Because of the shrinkage of the LASSO model, the model is not unbiased, and the regression coefficients cannot be directly interpreted as the log odds of the outcome. Almost all the features are binary or have values between zero and one; the only exception is the original mortgage amount. Thus, despite the estimation bias, the magnitude of the resulting regression coefficient can be an approximate indicator of the relative importance of that feature in predicting the outcome. We note that many features may be correlated, and this may contribute to the presence and magnitude of the regression coefficients.
In addition to the models presented in this section, we developed more detailed models. For example, we built independent models for each security class and year of issuance. Additionally, we incorporated time-varying security features, hypothesizing that the impact of features such as SSUP were not constant over the study horizon. Although these additional models were comparable in performance (as measured by accuracy and F1 score), they did not provide additional insights, and we could not justify the additional modeling complexity.
We note that, whereas many variations of deep learning models have been very successful, we did not consider them for the following reasons: (1) We have a limited sample count of prospectuses in comparison with the typical large corpora used in deep learning. (2) Attention-based learners and other variations have a significant advantage when the data includes temporal features, but this is not the case for our data set. (3) Most important, our major contribution is being able to interpret the models and to show the impact on performance from the supply chain topics. Such intuition would not be possible when the model is a black box that represents a deep learning model.
Finally, we carefully considered the many limitations of our retrospective data, including the potential for endogeneity. This included investigating the time-varying effects of all of the independent variables as discussed. Yet, in considering how we would test for potential endogeneity issues, we note that there is no obvious choice of an instrumental variable for the resMBS data set. Most financial research uses a portfolio of assets (stocks or bonds) to create treatment and control data sets, but such a portfolio approach is not feasible here as we cannot directly manipulate the resMBS data set.
However, we also recognize that the year 2007 is critical in the timeline of the financial crisis, and this feature value may be a proxy for many unobserved real-world factors that affect the securities’ performance. We, therefore, include an annual control variable, the year of issue for the securities, to capture, for example, the time-varying effect from the economy. Without these annual controls, financial communities operating in 2007 would appear worse than communities that were active in, say, 2002. In other words, in order to observe whether financial communities had any impact beyond their operating environment and the product characteristics, we included the annual controls as well as all the other key product features. Because of the use of this annual control variable, we could not use a traditional time-dependent training/testing split such that the training data for each year precedes the testing data. For example, there was insufficient data to use the month of issuance to create the train/test split.
We note that endogeneity can also result when some treatment is not applied randomly and when there is selection bias in data set sampling. In this study, we considered all of the prospectuses issued in the period of the experiment with the caveat that there was a limited number of prospectuses from which we were unable to extract data or which we otherwise filtered out because they had insufficient data. Thus, we do not introduce a selection bias that may lead to additional endogeneity concerns.
5.2. Insights from the Security-Level Model
Features of this model include the security class, the year of issuance, the MIR, and several characteristics of the waterfall payoff structure. There are more than 60 values for the MIR. We aggregated these values to a higher level rating, for which Aaa represents the securities that have the lowest credit risk. The Aaa rating is followed, in increasing order of risk, by Aa, A, Baa, Ba, B, Caa, Ca, and C. Some securities were evaluated but did not have a rating; we label this value MIR_NR. Finally, securities that were not evaluated for an MIR value are labeled MIR_null.
The waterfall payoff characteristics for the security class or tranche are captured using 73 binary variables. As an example, the following two features are key to identifying the placement of the security in the waterfall payoff structure shown in Figure 2: super senior bond (SSNR) indicates that the principal and/or interest distributions for this security have priority over other senior securities, whereas SSUP indicates that the principal and/or interest distributions are subordinated to other senior bonds within the prospectus.
Figure 10 summarizes the results of the security-level model for the two outcome variables, FE and FNE. The x-axis has the values of the coefficients for FE, and the y-axis has the values of the coefficients for FNE. The accuracy of the FE and FNE models are 91.3% and 84.7%, and the F1 scores are 0.891 and 0.857, respectively.
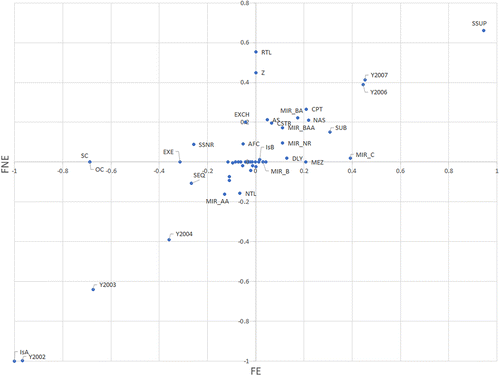
Notes. The regression coefficients are normalized such that the magnitude of the largest coefficient is one for each model. IsA is an indicator variable for class _A_ securities. The regression coefficients are found in Online Table 11.
A significant effect is that the annual controls for both 2007 and 2006 increase the predicted probability of FE and FNE. Meanwhile, the annual controls for 2002 and 2003 and the _A_ security class decrease the predicted probability of FE and FNE. This is consistent with the trends observed in Figure 6.
The MIR value of MIR_NR increases the probability of both FE and FNE. The MIR values of Baa, Ba, and C all increase the predicted probability of FE, whereas a value of Aa decreases the same probability. The MIR value Aa was primarily assigned to _M_ securities. More than 75% of _M_ securities have this rating, and they are, on average, less risky than _M_ securities in general.
After accounting for the security class and the year of issuance, many of the waterfall payoff features associated with a security class or tranche were retained. Notably, the presence of the label SSUP significantly increases the probability of both FE and FNE. The impact of SSUP on performance is consistent with the waterfall structure. Several other waterfall payoff features also increase the predicted probability of both FE and FNE. This includes CPT, which is an indicator that each component of the payback may vary, and sequential pay (SEQ), an indicator that the principal will be paid in sequence after the principal of higher priority securities reaches zero.
Some features decrease the predicted probability of FE but do not impact FNE. This includes overcollateralization (OC) and excess (EXE)‚ both indicators that these securities have the rights to certain excess interest and principal payments—and SC, which indicates securities that are backed by structured collateral. These features reflect some middle ground because they decrease the probability of FE, but they also do not guard against the shortfalls and payoff losses of FNE. Finally, some features have no impact on FE, but they increase the probability of FNE. These features include retail (RTL), an indicator that the security is designated for sale to retail investors, and accrual (Z), which indicates that the accruing interest is added to the outstanding principal balance (for some period).
We note that the impact of the label SSUP is the largest of any individual feature after accounting for the security class and the year of issuance. In addition, several waterfall payoff features also have a major impact. This may indicate that, given the complexity of the resMBS waterfall payoff structure, the MIR values alone cannot fully represent the nuanced risk.
To summarize, the security-level model is consistent with the observed trends of Figure 6 and provides valuable insight into the waterfall payoff structure. The model is accurate in its predictions for individual securities. However, we are interested in gaining more insights into the drivers of poor financial performance for resMBS. To do this, we next introduce prospectus- and supply chain–level features into our models.
5.3. Prospectus-Level Model
We hypothesized that prospectus-level features may provide additional insight into financial performance. We, therefore, used 13 variables to capture the composition of a prospectus. These variables include the count and fraction of securities and the nominal volume and fraction of the volume (in US$) in each of the three security classes. In addition, given the significance of the SSUP feature, we further hypothesized that the presence of SSUP securities within a prospectus may be significant; we used a binary indicator (HasSSUP) to signal when a prospectus contains at least one SSUP security.
The accuracy and F1 scores for the prospectus-level model are similar to those for the security-level model. Figure 11 provides the normalized coefficients. Many of the observations from the security-level models hold: the security class, the year of issuance, MIR values, some waterfall payoff features, and SSUP continue to have a strong impact on both FE and FNE.
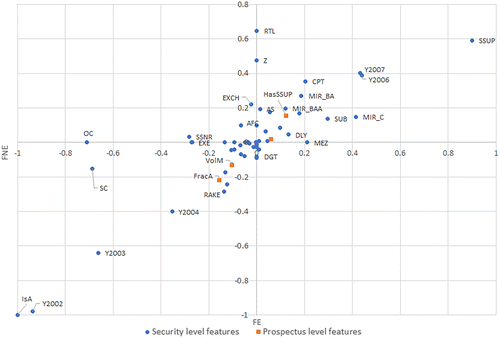
Notes. The regression coefficients are normalized such that the magnitude of the largest coefficient is one for each model. The regression coefficients are found in Online Table 12.
We observe that, new to this model, the fraction of securities in class _A_ decrease the predicted probability of FE and FNE, which is to a smaller extent counterbalanced by the impact of the nominal value (in US$) in these same securities. The nominal volume (in US$) in _M_ securities decreases these probabilities. Most notably, the indicator HasSSUP increases the probability of both FE and FNE. This is because, if the model indicates the presence of even one security with the label SSUP within a prospectus, it can increase the probability of both FE and FNE for all other securities in that prospectus, independent of whether these other securities are labeled SSUP.
In summary, the model reflects the significance of prospectus composition in predicting the financial performance of the securities. Prospectuses that include SSUP securities and prospectuses with an excess of class _M_ and _B_ securities increase the predicted probability of FE and FNE for all securities within the prospectus. We note that the impact of the fraction of class _M_ securities is counterbalanced by their volume. This is a notable finding as one may reason that the excess of class _B_ (or _M_) securities may serve as a buffer to reduce the risk for the senior class _A_ securities. Our model and observations show the opposite effect: an excess of class _B_ (or _M_) securities is a negative signal that increases the risk for senior class _A_ securities.
We further hypothesize that the prospectus may be a surrogate for the supply chain that produced the securities. This suggests that some supply chains may have produced prospectuses with varying composition across the security classes and correspondingly varying risk profiles. We study the supply chain in the next model.
5.4. Comprehensive Model
Our final comprehensive model includes all features of the security and prospectus models. In addition, we used 30 indicator variables, one for each topic. The DTM model assigns a weight vector over the 30 topics to each prospectus. We selected the largest topic weight for each prospectus and its securities. The coefficients of this model are summarized in Figure 12. The x-axis shows the values of the coefficients for FE, and the y-axis shows the values of the coefficients for FNE.
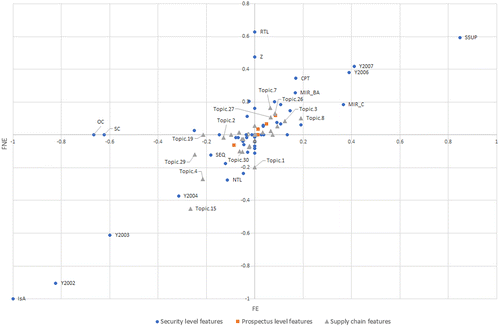
Notes. The regression coefficients are normalized such that the magnitude of the largest coefficient is one for each model. The full regression coefficients are found in Online Table 13.
Of the 30 binary indicators for the communities, 23 were retained by the FE model and 24 were retained by the FNE model. The coefficients for the topics have similar weights in comparison with features in the security- and prospectus-level models. In other words, after accounting for the security and prospectus features, the supply chain has additional significant impact on the predicted performance. We discuss the financial insights obtained from the impact of the topics on performance in the next section.
6. Financial Insight from the Topics in the Comprehensive Model
Recall that our strategic goal is to use the topics (communities) to obtain financial insights into the performance of subsets of prospectuses and securities. In this section, we take a deep dive into the financial impact of communities. Using a variety of real-world evidence (e.g., Bloomberg company profiles, news articles, financial press articles, Wikipedia), we identify institutions that were active in the subprime market and failed or faced penalties during or after the crisis. We label these institutions as toxic. A community that is closely associated with one or more such toxic institutions is labeled as toxic or partially toxic. We next review the financial impact of the topics based on their significance in our comprehensive model. We demonstrate that the toxic topics and some partially toxic topics increase the risk of failure, whereas all of the nontoxic topics decrease the risk of failure. Some partially toxic topics are not significant in the comprehensive model and display more nuanced behavior; we explore them in more detail in this section.
We conducted a comprehensive review of the prominent financial institutions for each topic. We excluded (six) topics that were small (fewer than 40 prospectuses). We further excluded (two) evolving topics for which no financial institution appeared to play a prominent role; these topics appeared to reflect a high turnover of financial institutions and the presence of multiple communities. We used the following protocol to label the remaining 22 topics, for which we identify the following factors as contributing toward toxicity:
An institution filed for bankruptcy or was subject to regulatory fines.
An institution underwent an involuntary merger.
An institution received federal bailout funds from the Troubled Asset Relief Program (TARP).
An institution was closely associated with the subprime market and encountered financial difficulty but may have survived the financial crisis.
An institution was labeled as toxic if it satisfied either of the first two criteria. The third and fourth criteria were used to label an institution as partially toxic.
The protocol for labeling communities based on the toxic or partially toxic labels for the financial institutions is as follows: A community is considered toxic if there was a significant presence of toxic institutions in the community in the key roles of issuer or originator. We use a threshold of at least two different toxic institutions participating in the community over the time interval or one toxic institution playing many roles over multiple years. A community is labeled nontoxic if it was not associated with any toxic institutions. A community is labeled partially toxic if it was neither toxic nor nontoxic. For example, a community associated with a single toxic financial institution playing a single role may be labeled as partially toxic.
The results of this labeling are as follows: 8 topics had no association with toxic financial institutions and were labeled as nontoxic (topics 2, 4–6, 16, 17, 28, 30). Of the remaining 14 topics, 5 are labeled as toxic (associated with multiple toxic institutions), whereas the remaining 9 are partially toxic.
To confirm our manual labeling, we constructed a (simpler) model that only considers the security class, the topic, and the annual control as independent variables; that is, the model did not use the additional security- and prospectus-level features that were included in the comprehensive model. This simpler model confirmed that the nontoxic topics all either decreased the risk of failure or had no impact on performance for both FE and FNE. Similarly, the toxic or partially toxic topics all either increased the risk of failure or had no impact on performance for both FE and FNE. Further, all eight nontoxic topics were found to decrease the risk of failure for both FE and FNE in the comprehensive model.
Next, we took a deep dive into the 14 toxic and partially toxic topics; they are summarized in Tables 2 and 3. The summary includes the count of prospectuses, ranging from 40 to more than 300 prospectuses per topic. It also indicates the years when the prospectuses were active or when there was a spike in activity. The third column identifies the key financial institutions and roles in the supply chains; we focus on the issuer and originator roles. This column also identifies all cases of financial stress and failure.
|
Table 2. Summary of Topics That Are Labeled Toxic or Partially Toxic and Increase Risk of Failure in the Comprehensive Model
| Topic | DTM topic type | Supply chain | Toxic | Model |
|---|---|---|---|---|
| 3 | Dynamic DTM topic. 41 prospectuses. Active all years. | Ameriquest and Weyerhauser and PHH are the issuers. Ameriquest failure in 2007. Weyerhauser was prosecuted. | Yes | ↑↑ |
| 7 | Stable DTM topic. 92 prospectuses. Active in 2006, 2007. | IndyMac is the issuer and is also in many roles. IndyMac failure in 2008. | Yes | ↑↑ |
| 26 | Dynamic DTM topic. 85 prospectuses. Peak in 2006. | Fremont and American Home are the originators. Fremont and Fieldstone and Ace Securities and Deutsche Bank are the issuers. American Home, Fieldstone failures in 2007 and 2008, respectively. | Yes | ↑↑ |
| 27 | Stable DTM topic. 144 prospectuses. Peak in 2005. | Structured Asset and Lehman are the issuers. Aurora is an originator. Lehman failure in 2008 and Aurora failure in 2012. | Yes | ↑↑ |
| 8 | Stable DTM topic. 192 prospectuses. Peak in 2006. | Wilmington Trust is issuer. Countrywide in many roles. Argent and Olympus are originators. Argent failure in 2007. | Partial | ↑↑ |
| 10 | Dynamic DTM topic. 45 prospectuses. Peak in 2003. | GMAC is the issuer. Encore Credit Corp. is originator. GMAC faced financial difficulty and rebranding in 2009. Encore was purchased by Bear Stearns, which failed in 2008. | Partial | ↑ - |
| 18 | Stable DTM topic. 80 prospectuses. Peak in 2006. | Morgan Stanley is the issuer and in many roles. Long Beach is originator; owned by Washington Mutual. Flagstar Bank is originator; very active in the subprime market. Washington Mutual failure in 2009. | Partial | ↑↑ |
|
Table 3. Summary of Topics That Are Labeled Partially Toxic and Have a Nuanced Impact in the Comprehensive Model
| Topic | DTM topic type | Supply chain | Toxic | Model |
|---|---|---|---|---|
| 9 | Dynamic DTM topic. 107 prospectuses. Active across all years. | Merrill Lynch in multiple roles. American Home Mortgage is an issuer. American Home failure in 2007. | Partial | – – |
| 12 | Evolving DTM topic. 167 prospectuses. | Bear Stearns is the issuer. EMC is an originator; other roles. Bear Stearns failure in 2008. | Yes | – – |
| 14 | Stable DTM topic. 307 prospectuses Active all years. | Large topic. Countrywide in many roles. Homecomings Financial (GMAC) is an originator. Homecomings Financial failure in 2008. | Partial | – – |
| 25 | Dynamic DTM topic. 131 prospectuses. Peak in 2006. | Maia Mortgage Finance is the issuer. Financial difficulties in 2009. | Partial | – – |
| 11 | Stable DTM topic. 125 prospectuses. Active all years. | Large topic. Bank of America in many roles. Bank of America received TARP funding. | Partial | – ↓ |
| 20 | Stable DTM topic. 40 prospectuses. | Small topic. Wells Fargo dominant in many roles. EMC Mortgage failure. Equity One failure. | Partial | ↓↑ |
| 22 | Stable DTM topic. 40 prospectuses. | Small topic. First Horizon in many roles. First Horizon received TARP funding in 2008. | Partial | - ↓ |
The findings for these 14 toxic or partially toxic topics from the comprehensive model are as follows: Four toxic topics (3, 7, 26, and 27 in Table 2) increase the risk of failure for both FE and FNE in the comprehensive model. Three partially toxic topics (8, 10, and 18 in Table 2) similarly increase the risk of failure for both FE and FNE in the comprehensive model.
One toxic topic (12) and three partially toxic topics (9, 14, and 25), summarized in Table 3, are not significant in the comprehensive model. Further, three partially toxic topics (11, 20, and 22), also summarized in Table 3, have mixed significance; they are not significant in one model but slightly lower the risk of failure in the other. This group of seven topics provides more nuanced findings as discussed next.
Consider topic 14 with more than 300 prospectuses and almost 4,000 securities; it is the largest community that we identified. Countrywide, a major player in the resMBS market, dominates this community and plays multiple roles. Homecomings Financial (GMAC), a toxic financial institution, originated some mortgages. This topic was active and issued prospectuses across all years. We posit that, in this large and partially toxic topic, not all of the prospectuses and securities may have been equally impacted by the toxic supply chain. Potentially, there is some subset of prospectuses and securities that are directly associated with the failed Homecomings Financial (GMAC) and that were issued in the throes of the housing bubble, and this subset may experience a higher risk of failure. However, because this subset of securities is merged in this topic within a very large group of securities, the toxic performance of the subset may be somewhat diluted. Thus, despite topic 14 being partially toxic, it is not significant in the comprehensive model.
Finally, we consider the toxic topic 12 and the two partially toxic topics 20 and 22. They are all small(er) topics, each with approximately 600+ securities. They are closely associated with multiple toxic financial institutions (Bear Stearns, GMAC, EMC Mortgage, Equity One). We posit that the security- and prospectus-level features, including the initial ratings for these securities, may have well-captured the increased risk of failure. Consider the following observations:
Topics 20 and 22 had the highest fraction of _B_ securities issued by any topic, 44% and 38%, respectively. The sample average was 24%.
More than 34% of the securities issued by topic 12 were _B_ securities; this too is well above the sample average of 24%.
Topic 20 had the highest percentage of _A_ securities with the SSUP label at 33%; the sample average was 13%.
These security- and prospectus-level features very likely captured the increased risk associated with these topics. Combined with the small size of the topics, the topics themselves may not have added significant additional risk of failure. Consequently, the topics were not significant in the level 3 model. Nonetheless, we posit that these three toxic topics and their securities, remain prime candidates for poor performance and higher risk of failure.
To summarize, we observe that many toxic and partially toxic topics are associated with an increased risk of failure even after accounting for security- and prospectus-level characteristics. In other words, the securities produced by these communities are riskier than we would expect when looking at the level 1 and 2 features. On the other hand, for some toxic and partially toxic topics that are not significant in the comprehensive model, the level 1 and 2 features of the securities capture the increased risk of failure.
7. Summary, Generalizability, and Future Research
This study is based on the novel resMBS prospectus data set. It is the first to examine the financial supply chain of financial institutions and the roles that they played in managing these securities. We identify communities along the supply chain, comprising (role–financial entity) pairs, in which a community may manage multiple prospectuses over time. The research aims to evaluate the impact of the communities on the financial performance of these securities. We presented three complementary models to gain insights into the drivers of financial performance. We demonstrate that both security level features, and prospectus level features such as the presence of SSUP securities, are drivers of financial performance. Using a variety of real-world evidence, we identified toxic institutions that were active in the subprime market and failed or faced penalties during or after the crisis. We then compared the financial performance of the securities vis-à-vis the significance of topics in our comprehensive model. We are the first to show that toxic communities that are closely linked to toxic financial institutions that played a key role in the subprime crisis can increase the risk of failure of resMBS. We demonstrate that toxic topics increase the risk of failure, whereas nontoxic topics decrease the risk of failure. This finding is noteworthy as no financial information was used when identifying the topics.
We can extend our research along the following directions: The first is prediction. Whereas the models in this paper rely on post mortem labels, the payment history for these securities, including various shortfalls and delayed payments, is also gathered on a real-time basis. The availability of such contemporaneous data could result in the development of prediction models or time to failure models. The next possible research direction is the design of a monitoring framework for financial products. The resMBS data set presents interesting temporal dynamics across multiple dimensions. There is constant change of financial institutions and roles across the supply chain. We observe an evolution in prospectus composition, and anecdotal research indicates diminishing quality control over the ratings of these products. Outcomes also change over time. An ability to account for these dynamics needs to be at the heart of any monitoring system.
We briefly discuss the generalizability of our research. Our novel contributions lie in using communities along the financial supply chain to construct models of financial performance. There are many potential data sets to which this approach can be applied, such as the securitization of any asset-backed product, including student loans, automobile loans, etc. More recently, there is significant interest in understanding the exposure of financial contracts to climate change–related triggering events. In this scenario, additional features capturing potentially complex ownership relationships augment the information on the financial supply chain. Similar to the temporal evolution of the financial supply chain, mergers and acquisitions may change the ownership relationships. We note that, in all of these cases, whereas the data may be available to the public, creating and curating the data set would require significant effort.
A framework for knowledge contribution in DSR identifies exaptation: contributions in which design knowledge already known in one field is extended or adapted to another (Gregor and Hevner 2013). Our contribution is the synergistic application of machine learning with text corpora, for example, dynamic topic modeling, together with more traditional analytical modeling, for example, logistic regression. A very successful similar approach is applied to the Business Open Knowledge Network (BOKN) data set (Hoberg et al. 2021). In that project, word embeddings are constructed over the web text of company websites and temporal evolution is captured using data from archival sources, such as the WayBack Machine from the Internet Archives. The project builds on our use of topic models and generates more sophisticated embeddings, such as Doc2Vec and RoBERTa (Devlin et al. 2019). Similar to the way we model the financial supply chain, the embeddings of the BOKN data are used to construct competitor networks for companies. These corporate competitor networks are then used for multiple downstream tasks, including (i) predicting the profitability of (public) companies, (ii) predicting the industry sector of companies, and (iii) predicting the reported actual competitors of companies. Both unsupervised and supervised approaches (Siamese networks) are used for these prediction tasks. Preliminary results indicate that the language embeddings over the web text can indeed play a successful role in constructing competitor networks and making accurate predictions.
An interesting future line of research is exploring the use of word embeddings and LLMs to extract knowledge, including but not limited to supply chains, from financial documents. We report on the results of a first attempt to use sentence embeddings and document similarity to cluster prospectuses that potentially share supply chain features in the online appendix. We use all-mpnet-base-v2, a sentence-embedding approach that has been trained using Siamese BERT networks. We chose this model because it has been extensively evaluated and found to provide efficient performance in assessing sentence similarity (Reimers and Gurevych 2019).
Whereas BERT-like models are very successful in exploiting general document similarity, there are limitations of the resMBS data set that hinder the task of exploiting supply chain similarity and identifying communities along the supply chain; details are in Online Appendix D. Despite these limitations, the preliminary study provides insights into opportunities for future research in neuro-symbolic machine learning, in which the neural learning model must additionally satisfy symbolic constraints (Hitzler and Sarker 2022). In this case, the symbolic constraints are that prospectuses that are clustered together must exhibit both document similarity and supply chain similarity; that is, there must be an overlap of the communities comprising specific (role–financial entity) pairs across two similar prospectuses.
An alternate path for future research is to extract (role–financial entity) pairs using the OpenAI ChatGPT API (or similar tools). Recall that we used special information extraction and named entity recognition tools for this task; this created a high entry barrier for similar research. An initial exploration using the ChatGPT 3.5 API yielded interesting, yet mixed, results. The interesting result was that, when the prospectus included sentences that explicitly mentioned a (role–financial entity) pair, then ChatGPT was often able to extract this pair without the need for any tuning. This positive outcome can dramatically lower the entry bar for text extraction from documents. However, as noted earlier, the cover page and summary section of the prospectuses often contain tabular data, aligned in columns. In these circumstances, the ChatGPT API would often return plausible, yet incorrect, pairs. They were plausible pairs in that they may correctly identify a financial entity or role. However, they were incorrect because that particular (role–financial entity) pair was not mentioned in the prospectus. The API does not provide confidence in the extracted results; this complicates the task of differentiating correct and incorrect pairs.
Finally, we note that there has also been significant successful research on applying word embeddings to improve the results of topic models (Das et al. 2015, Dieng et al. 2020, Grootendorst 2022). Such approaches have the potential to augment information about the communities along the supply chain, and these augmented communities may provide more insight on the performance of the securities.
The authors thank the following individuals: Nancy Wallace and Paolo Issler (University of California Haas School of Business) and Joe Langsam for their help in identifying the resMBS prospectuses and labeling the performance of these securities; Doug Burdick and Rajasekar Krishnamurthy (IBM Research) for supporting the text extraction task using the IBM SystemT platform; Soham De, Zheng Xu, and Minchao Shao for implementing the resMBS extraction pipeline; and Zheng Xu, Elena Zotkina, Aaron Hunt, Chi-Hung Chen, Prabhath Kollimarla, and Aditya Shenoy for technical support with data cleaning, data integration, and topic model analytics.
1 10-K statements are comprehensive financial reports that publicly traded companies are required to produce.
References
ABSNet (2018) Accessed January 10, 2017, https://www.absnet.net/ABSNet.Google Scholar- (2008) Understanding the securitization of subprime mortgage credit. Staff Report 318, Federal Reserve Bank of New York, New York.Google Scholar
- (2010) MBS ratings and the mortgage credit boom. Staff Report 449, Federal Reserve Bank of New York, New York.Google Scholar
- (2006) Dynamic topic models. Cohen W, Moore A, eds. Proc. 23rd International Conf. Machine Learning (ACM, New York), 113–120.Google Scholar
- (2003) Latent Dirichlet allocation. J. Machine Learn. Res. 3:993–1022.Google Scholar
Bloomberg (2018) Bloomberg l.p. Accessed February 25, 2021, https://en.wikipedia.org/wiki/Bloomberg_Terminal.Google Scholar- (2016) resMBS: Constructing a financial supply chain from prospectus. Krishnamurthy R, Raschid L, Vaithyanathan S, eds. Proc. Second Internat. Workshop on Data Science for Macro-Modeling (ACM, New York), 7:1–7:6.Google Scholar
- (2014) Data science challenges in real estate asset and capital markets. Krishnamurthy R, Raschid L, Vaithyanathan S, eds. Proc. Internat. Workshop on Data Science for Macro-Modeling, DSMM’14 (ACM, New York), 1–15.Google Scholar
- (2011) Extracting, linking and integrating data from public sources: A financial case study. Data Engineering, 60.Google Scholar
- (2021) Mining bilateral reviews for online transaction prediction: A relational topic modeling approach. Inform. Systems Res. 32(2):541–560.Link, Google Scholar
- (2010) Hajič J, Carberry S, Clark S, Nivre J, eds. Proc. 48th Annual Meeting of the Association for Computational Linguistics (Association for Computational Linguistics, Kerrville, TX), 128–137.Google Scholar
CUSIP (2018) Cusip global services. Accessed January 10, 2018, https://www.cusip.com/cusip/index.htm.Google Scholar- (2015) Gaussian LDA for topic models with word embeddings. Chengqing Z, Michael S, eds. Proc. 53rd Annual Meeting of the Association for Computational Linguistics and the 7th Internat. Joint Conf. Natural Language Processing, vol. 1 (Association for Computational Linguistics, Kerrville, TX), 795–804.Google Scholar
- (2012) How important is having skin in the game? Originator-sponsor affiliation and losses on mortgage-backed securities. Rev. Financial Stud. 25(11):3217–3258.Google Scholar
- (2019) BERT: Pre-training of deep bidirectional transformers for language understanding. Burstein J, Doran C, Solorio T, eds. Proc. 2019 Conf. North American Chapter of the Association for Computational Linguistics: Human Language, vol. 1 (Association for Computational Linguistics, Kerrville, TX), 4171–4186.Google Scholar
- (2020) Topic modeling in embedding spaces. Trans. Assoc. Comput. Linguistics 8:439–453.Google Scholar
- (2022) Causal decision making and causal effect estimation are not the same…and why it matters. INFORMS J. Data Sci. 1(1):4–16.Link, Google Scholar
- (2023) A comparison of methods for treatment assignment with an application to playlist generation. Inform. Systems Res. 34(2):786–803.Link, Google Scholar
- (2010)
Making sense of the subprime crisis . Kolb R, ed. Lessons from the Financial Crisis: Causes, Consequences, and Our Economic Future (John Wiley & Sons, Inc., Hoboken, NJ).Google Scholar - (2013) Positioning and presenting design science research for maximum impact. Management Inform. Systems Quart. 37(2):337–355.Google Scholar
- (2022) Bertopic: Neural topic modeling with a class-based tf-idf procedure, Preprint, submitted March 11, https://arxiv.org/abs/2203.05794.Google Scholar
- (2011) Credit ratings and the evolution of the mortgage-backed securities market. Amer. Econom. Rev. 101(3):131–135.Google Scholar
- (2012) Are all ratings created equal? The impact of issuer size on the pricing of mortgage backed securities. J. Finance 67(6):2097–2137.Google Scholar
- (2010) Unleashing the Power of Public Data for Financial Risk Measurement, Regulation, and Governance, Preprint, submitted November 16, http://dx.doi.org/10.2139/ssrn.1814232.Google Scholar
- (2022) Neuro-symbolic artificial intelligence: The state of the art. Frontiers in Artificial Intelligence and Applications (IOS Press, Amsterdam).Google Scholar
- Hoberg G, Knoblock C, Phillips G, Pujara J, Qiu Z, Raschid L (2021) Filling the private firm void: Using learned representations to identify competitor relationships between businesses. Information Sciences Institute Technical Report, University of Southern California, Los Angeles.Google Scholar
- (2018) Text-based network industries and endogenous product differentiation. J. Political Econom. 124(5):1423–1465.Google Scholar
- (2021) Characterizing social TV activity around televised events: A joint topic model approach. INFORMS J. Comput. 33(4):1320–1338.Abstract, Google Scholar
- (2014)
U.S. residential mortgage transfer systems: A data management crisis . Brose M, Flood M, Krishna D, Nichols B, eds. Handbook of Financial Data and Risk Information II: Software and Data (Cambridge University Press, Cambridge, UK).Google Scholar - (2020) A review on recent advancements in forex currency prediction. Algorithms (Basel) 13(8):186.Google Scholar
- (2022) Application and performance of data mining techniques in stock market: A review. Intelligent Systems Accounting, Finance Management 29(4):219–241.Google Scholar
- (2022) Machine learning techniques and data for stock market forecasting: A literature review. Expert Systems Appl. 197:116659.Google Scholar
- (1997) A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction and representation of knowledge. Psych. Rev. 104(2):211–240.Google Scholar
- (2012) Information failure and the U.S. mortgage crisis. University of Pennsylvania Institute for Law & Economics Research Series 10, Philadelphia.Google Scholar
- (2021) Content-based model of web search behavior: An application to TV show search. Management Sci. 67(10):6378–6398.Link, Google Scholar
- (2016) Textual analysis in accounting and finance: A survey. J. Accounting Res. 54(4):1187–1230.Google Scholar
- (2012) Did capital requirements and fair value accounting spark fire sales in distressed mortgage-backed securities? NBER Working Paper No. 18270, National Bureau of Economic Research, Cambridge, MA.Google Scholar
- (2022) Intertemporal defaulted bond recoveries prediction via machine learning. Eur. J. Oper. Res. 297(3):1162–1177.Google Scholar
National Information Center (2018) Accessed January 10, 2018, https://www.ffiec.gov/nicpubweb/nicweb/NicHome.aspx.Google Scholar- (2018) Mortgage-backed securities and the financial crisis of 2008: A post mortem. NBER Working Paper No. 24509, National Bureau of Economic Research, Cambridge, MA.Google Scholar
- (2011) Subprime lending and real estate prices. Real Estate Econom. 39(1):1–17.Google Scholar
- (2010) Software framework for topic modelling with large corpora. Witte R, Cunningham H, Patrick J, Beisswanger E, Buyko E, Hahn U, Verspoor K, Coden AR, eds. Proc. New Challenges for NLP Frameworks, A Workshop at LREC 2010 (Malta), 46–50.Google Scholar
- (2019) Sentence-BERT: Sentence embeddings using Siamese BERT-networks. Inui K, Jiang J, Ng V, Wan X, eds. Proc. 2019 Conf. Empirical Methods in Natural Language Processing and the 9th Internat. Joint Conf. Natural Language Processing (EMNLP-IJCNLP) (Association for Computational Linguistics, Kerrville, TX), 3982–3992.Google Scholar
Securities Industry and Financial Markets Association (2018) US mortgage-related issuance and outstanding. Accessed June 28, 2018, https://www.sifma.org/resources/research/us-mortgage-related-issuance-and-outstanding/.Google Scholar- (2007)
Probabilistic topic models . Landauer TK, McNamara DS, Dennis S, Kintsch W, eds. Handbook of Latent Semantic Analysis (Routledge, London), 424–440.Google Scholar The Financial Crisis Inquiry Commission (2011) Final report of the national commission on the causes of the financial and economic crisis in the United States. Accessed January 10, 2018, https://www.govinfo.gov/content/pkg/GPO-FCIC/pdf/GPO-FCIC.pdf.Google Scholar- (1996) Regression shrinkage and selection via the LASSO. J. Roy. Statist. Soc. B 58(1):267–288.Google Scholar
- (2006) Topics over time: A non-Markov continuous-time model of topical trends. Eliassi-Rad T, Ungar LH, Craven M, Gunopulos D, eds. Proc. 12th ACM SIGKDD International Conf. Knowledge Discovery and Data Mining (ACM, New York), 424–433.Google Scholar
- (2016) Exploiting lists of names for named entity identification of financial institutions from unstructured documents. Technical report, University of Maryland, College Park, MD.Google Scholar
- (2022) sDTM: A supervised Bayesian deep topic model for text analytics. Inform. Systems Res. 34(1):137–156.Google Scholar

