
An Optimization-Based Order-and-Cut Approach for Fair Clustering of Data Sets
Abstract
Machine learning algorithms have been increasingly integrated into applications that significantly affect human lives. This surged an interest in designing algorithms that train machine learning models to minimize training error and imposing a certain level of fairness. In this paper, we consider the problem of fair clustering of data sets. In particular, given a set of items each associated with a vector of nonsensitive attribute values and a categorical sensitive attribute (e.g., gender, race, etc.), our goal is to find a clustering of the items that minimizes the loss (i.e., clustering objective) function and imposes fairness measured by Rényi correlation. We propose an efficient and scalable in-processing algorithm, driven by findings from the field of combinatorial optimization, that heuristically solves the underlying optimization problem and allows for regulating the trade-off between clustering quality and fairness. The approach does not restrict the analysis to a specific loss function, but instead considers a more general form that satisfies certain desirable properties. This broadens the scope of the algorithm’s applicability. We demonstrate the effectiveness of the algorithm for the specific case of k-means clustering as it is one of the most extensively studied and widely adopted clustering schemes. Our numerical experiments reveal the proposed algorithm significantly outperforms existing methods by providing a more effective mechanism to regulate the trade-off between loss and fairness.
History: Rema Padman served as the senior editor for this article.
Data Ethics & Reproducibility Note: The code capsule is available on Code Ocean at https://doi.org/10.24433/CO.9556728.v1 and in the e-Companion to this article (available at https://doi.org/10.1287/ijds.2022.0005).
1. Introduction
Recent years have notably witnessed extensive adoption of machine learning applications in critical automated decision-making models. Clustering techniques, the most common unsupervised learning method (Liu et al. 2015), have been widely applied in many fields since the advent of the big-data era. With the incorporation of these techniques into a variety of critical decision-making models, particularly those that have a significant impact on human beings, ethical concerns about fairness arise. Despite its widespread success, numerous examples demonstrate unfavorable discrimination against protected groups (Sweeney 2013, Datta et al. 2015, Angwin et al. 2016, Buolamwini and Gebru 2018). Among these examples is a face-recognition model that achieves a higher level of face recognition accuracy in white males (Buolamwini and Gebru 2018). Another well-known example is a model that predicts recidivism that tends to incorrectly predict low-risk African Americans (Angwin et al. 2016). Such instances have recently triggered substantial interest in designing fair supervised and unsupervised machine learning algorithms (Chierichetti et al. 2017; Shaham et al. 2018; Ahmadian et al. 2019, 2020a; Baharlouei et al. 2019; Bera et al. 2019; Kleindessner et al. 2019a; Mary et al. 2019; Tang et al. 2019; Grari et al. 2020). These algorithms tend to minimize a certain loss (i.e., clustering objective) error, imposing a desirable level of fairness. Despite biases toward sensitive attributes that arise in supervised learning, as previously discussed, similar biases can also be observed in unsupervised learning, particularly clustering, and may have a significant impact on human lives. Clustering has several applications in fields such as market research, pattern recognition, data processing, and facility location (Von Luxburg et al. 2012, Ghosal et al. 2020). In contrast to applications such as image segmentation, in which data points are simply pixels in a variety of contexts, data points can represent human beings. This leads to the involvement of individuals’ sensitive information and may raise ethical questions. In what follows, we discuss three real-world concrete examples that illustrate the significance and necessity of establishing fair clustering techniques.
In the conventional facility location problem, the objective is to determine the optimal placement of facilities to minimize total transportation expenses for the entire population. Cluster analysis is a technique commonly used to tackle the problem. For example, the locations of houses in communities serve as data points, and the cluster center indicates where public facilities (such as parks, police stations, hospitals, etc.) would be built. It is important to ensure that facilities are provided equitably to serve the entire population. Micha and Shah (2020) provide an illustration of how clustering algorithms being used to identify the location of public facilities can lead to ethical concerns. For example, consider a large urban area with a population of 10,000 that is bordered by 10 small towns with a population of 100 each. A typical clustering algorithm (e.g., k-means) identifies the urban region and each small town as distinct clusters (when k = 11). However, the construction of a single park that serves 10,000 people in a metropolitan area, whereas each neighborhood of 100 gets its own park, violates the principle of equal entitlement. To ensure that each member of the population has similar equal entitlement rights, a fairness metric must be incorporated into the clustering decision.
As another example, consider the problem of forming committees (Thejaswi et al. 2021). Typically, the problem of selecting committee members is formulated as a clustering problem with the committee members determined by the centers of the clustering results. Despite the fact that the final decision may be optimal in terms of its loss value, a small percentage of the population may not be adequately represented in the formed committees. For instance, minority groups may not be present in certain committees, or certain groups may not have proportionate representation across seniority levels.
More recently, fairness consideration has seen a notable surge during the COVID-19 pandemic. This is well-demonstrated within the infectious disease management community. For example, an important decision is the effective distribution of medical resources. In the early stages of a pandemic, it is imperative that limited medical supplies, such as personal protective equipment (PPE) and vaccines, are distributed across the nation. This can be achieved by first clustering the population into different risk classes and then distributing the resources accordingly. However, the distribution may not be fair with respect to various sensitive attributes, such as gender and race. Numerous papers on vaccination and PPE distributions study this challenging problem (Mitchell et al. 2021, Munguía-López and Ponce-Ortega 2021, Sandrin and Simpson 2021). In addition to the distribution of medical resources, the construction of social separation policies is yet another example in which fairness plays a critical role. To build effective social separation policies, decision makers first conduct a clustering procedure to form social groups. The resulting solutions must minimize the disease spread, also ensuring that the assignment to social groups is independent of individuals’ sensitive attributes. For instance, it would not be desirable to let race be a driving factor in making such decisions as it might give the impression of racial segregation.
Fair clustering algorithms can be broadly classified into three categories: preprocessing, in-processing, and postprocessing. Preprocessing approaches modify the training data to remove discrimination prior to conducting any inference procedure (Chierichetti et al. 2017, Backurs et al. 2019, Bera et al. 2019, Schmidt et al. 2020). For instance, Chierichetti et al. (2017) propose a two-stage algorithm to solve the fair clustering problem. To begin, they define a novel fairlet structure for data preprocessing. Fairlets are defined as the smallest sets of items that satisfy fair representation. Then, a conventional clustering algorithm (i.e., one that does not consider fairness) is applied on the fairlets. For example, if the clustering problem is k-means, then Lloyd’s algorithm might be applied to cluster the fairlets. The second category is the postprocessing approach, which aims to modify the model output in order to enforce fairness, maintaining a low clustering loss (Ahmadian et al. 2019, Kleindessner et al. 2019a). For example, Kleindessner et al. (2019a) propose an algorithm that first focuses on the conventional k-center problem and then imposes fairness by swapping elements among groups. Finally, in-processing approaches impose fairness by enforcing additional constraints or including a regularization term that promotes independence between the model output and the sensitive attribute (Abraham et al. 2019, Baharlouei et al. 2019, Kleindessner et al. 2019b, Ziko et al. 2021). Among the methods discussed previously, both preprocessing and postprocessing methods decompose the fair clustering problem into two simpler subproblems: either construct a fair data structure first and then perform clustering or conduct clustering without considering fairness first and then adjust the solution to enforce fairness. Whereas these methods are relatively straightforward to implement, imposing a soft constraint on the solution is difficult. In contrast, in-processing methods are capable of balancing the loss value and fairness level according to the user’s specification. This additional flexibility of in-processing methods makes them more attractive than preprocessing and postprocessing methods; however, this flexibility also increases computational complexity. In this paper, we propose a novel in-processing approach for solving the fair clustering problem. Specifically, given a set of N data points, each of which is associated with a categorical sensitive attribute (e.g., gender, race, etc.), the fair clustering problem seeks to partition the data into k clusters in order to achieve a balance between the loss value and bias toward sensitive attributes. Similar to other in-processing approaches, our method allows for regulating the trade-off between the clustering objective and fairness.
Fair clustering is first introduced in Chierichetti et al. (2017), which considers a variant of classic clustering problems that involve binary sensitive attributes. The authors propose the concept of cluster balance to quantify fairness. This notion measures the fraction of points that correspond to less frequent protected groups in each cluster. A two-stage algorithm is constructed to solve the problem: in the first preprocessing stage, data points are grouped into fairlets, that is, small subsets that satisfy a desirable balance, and then clustering is performed on these fairlets in the second stage. A major drawback of the proposed method is mainly in the running time required to construct the fairlet decomposition, which is at least quadratic in the number of data points. This drawback is addressed in Backurs et al. (2019), which develops a near-linear time algorithm for heuristically constructing the fairlets. Similar two-stage methods are proposed in Bercea et al. (2018), Rösner and Schmidt (2018), and Schmidt et al. (2020) to solve fair variants of classic clustering problems. However, the presented preprocessing approaches as well as existing postprocessing approaches (Chierichetti et al. 2017, Backurs et al. 2019), impose fairness as a hard constraint and do not allow the user to regulate the trade-off between the clustering objective and fairness.
Among in-processing methods, many add a regularization term to promote proportionate representations of protected groups in each cluster. For example, Ziko et al. (2021) penalize the difference between the proportions of protected groups in each cluster and the desired target proportions using the Kullback–Leibler (KL) divergence measure. A continuous relaxation of the underlying optimization problem is analyzed, and a majorization–minimization algorithm is used to identify a fair solution. Using a similar regularization framework, Abraham et al. (2019) penalize the square of absolute differences between the fractional representation of protected groups in clusters and the corresponding fractional representation in the entire population. A variant of Lloyd’s algorithm is proposed to find a fair solution. Whereas the preceding work quantifies the level of fairness by examining the proportionality of each protected group, other works approach the issue through the use of statistical independence measures to promote independence between the model output and the sensitive attribute. A commonly used measure of independence in statistics is the Pearson correlation coefficient (PCC) (Zafar et al. 2017). Although relatively simple to compute, PCC is incapable of capturing nonlinear dependencies between variables, hampering its usability. Another example is the Hilbert Schmidt independence criterion (HSIC) (Pérez-Suay et al. 2017), which requires kernel calculation and, thus, substantially increases computational complexity. Recently, another independence measure, the Hirschfeld–Gebelein–Rényi (HGR) correlation (Mary et al. 2019, Grari et al. 2020), has gained popularity because of its relative ease of calculation and ability to capture nonlinear dependencies. For example, Baharlouei et al. (2019) impose fairness through an HGR-based regularization term to penalize statistical dependence between clustering assignment and the sensitive attribute. Although Rényi correlation is closely related to the cluster balance notion defined by Chierichetti et al. (2017) in the case of binary sensitive attributes, it can be used to generalize the concept to impose fairness for categorical or even nondiscrete sensitive attributes.
In this paper, we use an upper bound on the Rényi correlation coefficient as a regularization term to formulate the fair clustering problem under a general clustering objective function that satisfies certain properties. Driven by findings from the field of combinatorial optimization, we propose an efficient and scalable in-processing algorithm that adopts an order-and-cut technique to find fair solutions for the clustering problem. More precisely, our proposed method first identifies an ordering of the items, then optimal cuts of the ordered solution are efficiently computed to form fair clusters. Our in-processing method includes a tunable parameter, λ, which allows for regulating the trade-off between the clustering objective and the fairness term. When λ = 0, the method returns an optimal clustering solution that does not impose any fairness constraints. On the other extreme, when , our scheme returns an ordering that constitutes consecutive blocks of items that have desirable proportionate representations of the protected groups. This ordering is then used to find optimal cuts that form fair clusters. In contrast to existing preprocessing methods that require each balanced block (fairlet) to be in a single cluster (Chierichetti et al. 2017), our optimal cuts offer more flexibility by allowing the placement of individual items of the same block in different clusters. Between the two extreme cases, we use a transition function, parameterized by λ, to identify a suitable ordering of the items and then compute optimal cuts of that ordering to form clusters with an appropriate level of fairness.
In summary, we approach the fair clustering problem through the lens of a novel optimization framework for clustering data sets and propose an order-and-cut heuristic algorithm that is inspired, in part, by results from the field of combinatorial optimization (Fisher 1958, Chakravarty et al. 1982). Our method exploits the specific structure of the problem at hand, leading to a scalable algorithm that yields fair clustering of data sets. In particular, we use an upper bound on Rényi correlation coefficient as a regularization term to balance the clustering objective and fairness. In the case of a binary sensitive attribute, the upper bound we use is exact. Unlike the formulation used in Baharlouei et al. (2019) for fair k-means, our proposed formulation allows for categorical sensitive attributes. Moreover, in contrast to the vast majority of existing work, we do not restrict the analysis to a specific objective function form. Instead, we consider a more general form that satisfies certain desirable properties. This, in turn, broadens the scope of the algorithm’s applicability. Whereas providing a lower bound performance guarantee for a general case—in which a balance between fairness and loss function is considered—is challenging, we demonstrate the effectiveness of the algorithm for the specific case of k-means clustering by comparing its performance to existing approaches on two benchmark data sets. Our experiments reveal that our method outperforms existing state-of-the-art approaches by achieving lower loss and similar levels of fairness.
The remainder of this paper is organized as follows: In Section 2, we provide some preliminary definitions and properties regarding the fairness notion and the set partitioning problem (SPP). Then, in Section 3, we present the model formulation, conduct an analysis of the problem, present our key findings, and detail the solution approach. Section 4 discusses findings from our numerical experiments for the specific case of fair k-means clustering. Finally, Section 5 brings the paper to a close and discusses potential future research directions. To facilitate the presentation, proofs and some discussions and results are relegated to the online appendix.
2. Preliminaries
In this section, we first introduce the notion of fairness and discuss different fairness measures proposed in the literature. Then, we relate the underlying clustering problem to a well-known combinatorial optimization problem, known as the set partitioning problem, and discuss a reformulation technique in which the problem is cast as a more tractable network problem.
2.1. Fairness Notion and Measures
Many recent works measure fairness under the disparate impact doctrine. We say a decision-making process suffers from disparate impact if its outcomes disproportionately hurt a protected group. In simpler words, disparate impact doctrine posits proportionate representations of protected classes in the decision-making process outcome. In fair clustering settings with discrete sensitive attributes, this translates to having equal proportions of the protected groups among clusters. Motivated by the former observation, Chierichetti et al. (2017) propose a cluster balance measure to quantify fairness when the sensitive attribute is binary. More specifically, given a set of data points, each associated with a binary sensitive attribute, the balance of a cluster is defined as the minimum of the fraction of ones to zeros and its reciprocal. The overall balance of the clustering solution is then computed as the minimum balance of all clusters. The higher the balance term, the fairer the clustering solution. Based on this cluster balance definition, the maximum balance is attained when the proportion of each sensitive attribute value is equal among different clusters. Many papers study fair clustering under the aforementioned cluster balance metric (Backurs et al. 2019, Li et al. 2020, Abbasi et al. 2021). Recently, however, relevant papers are examining the issue from the perspective of statistical independence. More precisely, by considering cluster assignment and sensitive attribute values to be two random variables, fairness is achieved when they are independent of one another. It is demonstrated that the maximum balance is attained when the conditional distribution of the sensitive attribute, given by the clustering solution, equals the distribution of the sensitive attribute in the whole data set, indicating the equivalence between the two different fairness concepts. In this paper, we take advantage of this equivalence and enforce fairness by requiring the partitioning to be independent of the sensitive attribute.
Various independence proxies, such as mutual independence (Kamishima et al. 2011), Pearson correlation coefficient (Zafar et al. 2017), and HSIC (Pérez-Suay et al. 2017) are used to impose fairness in machine learning algorithms. Unfortunately, many of these measures are computationally expensive and/or cannot capture nonlinear dependence between random variables, which significantly limits their applicability. Motivated by these limitations, Baharlouei et al. (2019) propose using the HGR correlation as a measure of independence to impose fairness; see Definition 1. Unlike Pearson correlation and HSIC, HGR captures nonlinear dependence between random variables and can be computed efficiently if these variables are categorical.
Given two random variables A and B, the HGR coefficient is defined as
Among its desirable properties, the HGR coefficient ranges between zero and one with a value of zero if and only if the two random variables are independent and a value of one if the variables are strictly dependent. In its most general case, the HGR coefficient is an abstract measure that needs to be approximated to be computed on a data set. For instance, Grari et al. (2020) estimate the HGR of two continuous random variables using a neural network. In the discrete case, Witsenhausen (1975) demonstrates that the HGR coefficient can be evaluated using the second largest singular value of a well-defined matrix as outlined in the following theorem.
(Restated Witsenhausen 1975). Let and be two discrete random variables. Then, is equal to the second largest singular value of matrix , where
Computing singular values of a matrix is computationally expensive. Generally, finding the singular values of a m × n matrix takes . This complexity is further compounded within an optimization setting. To overcome this limitation, in this paper, we consider a more tractable measure given by an upper bound on HGR. A direct consequence of Theorem 1, which we prove in the appendix, is shown as follows.
Let and be two discrete random variables. Then,
If at least one of the two discrete random variables is binary, then the upper bound of Equation (2) is attained. Moreover, if and only if
In light of Corollary 1, in this paper, we use the upper bound provided in Equation (2) to impose fairness by penalizing the dependency between a variable that assigns items to clusters and a categorical sensitive attribute . To simplify our notation, we denote by , where is a partition (set of assignments) of the data set into clusters. Unlike the exact HGR expression in Theorem 1, the upper bound is additively separable and allows for evaluating fairness per cluster, which is essential in our proposed algorithm.
2.2. Relation to Set Partitioning Problem and Reformulation Scheme
At the heart of clustering is a well-known combinatorial optimization problem known as SPP. The set partitioning problem is the task of partitioning a discrete set of items into mutually exclusive subsets in a manner that optimizes a certain objective function. This important combinatorial optimization problem arises in various applications such as inventory management, healthcare, system reliability, bin packing, and (of particular relevance to this paper) cluster analysis (e.g., Balas and Padberg 1976, Chakravarty et al. 1985, Hwang et al. 1985, Chan et al. 1998, Aprahamian et al. 2019, Aprahamian and El-Amine 2021). Given its relevance, the set partitioning problem is extensively studied within the operations research community with a rich body of literature (e.g., Chakravarty et al. 1982, 1985; Hwang et al. 1985; Hwang et al. 1999; Onn and Schulman 2001; Aviran and Onn 2002; Lewis et al. 2008; El-Amine and Aprahamian 2021). Although numerous variants of SPP exist, the literature demonstrates that even simple variations of the problem (e.g., univariate or standard linear model) are NP-hard (Chakravarty et al. 1982, Lewis et al. 2008). This perhaps explains why existing clustering algorithms, even ones that do not incorporate fairness, are heuristics that generally do not have any performance guarantees and depend on randomly generated initial conditions (Tang et al. 2012, Saxena et al. 2017). In this paper, our aim is to leverage the rich literature of set partitioning problems to construct an efficient clustering algorithm that is expected to perform well for a class of problems that satisfy certain properties.
Given the difficulty of solving general set partitioning problems, researchers primarily focus on analyzing special instances of the problem in an effort to establish structural properties that hold in an optimal solution. Of particular interest is the set partitioning problem with additive objectives, that is, the total objective function value is equal to the sum of the contributions of each subset. Chakravarty et al. (1982) introduced a reformulation scheme that casts this variation of the set partitioning problem as a more tractable shortest path problem, enabling the efficient identification of the global optimal solution in polynomial time. The reformulation scheme, however, requires knowledge of a so-called optimal ordering, which is an indexing of the items such that the optimal partition is only made up of subsets containing items with consecutive indices. In general, identifying an optimal ordering prior to solving the problem is a challenging task. Consequently, much effort has been put toward identifying optimal orderings for different problem instances. For example, in their original paper, Chakravarty et al. (1982) identified an optimal ordering for problem instances with objectives that are only a function of the sum of attribute values and that are concave in the subset sum (for fixed cardinality). Existing studies can be broadly categorized into two parts: the univariate and multivariate cases.
Studies of the univariate case are extensive (Fisher 1958, Chakravarty et al. 1982, Hwang et al. 1985, Jin 2017, Aprahamian et al. 2019, Lin et al. 2023), and under these circumstances, optimal orderings are relatively easy to define and are based on the attribute values of the items. For example, Fisher (1958) analyzes the one-dimensional k-means problem and showed that an optimal ordering can be obtained by indexing the items according to the attribute values. The work in Jin (2017) focuses on maximizing a specific class of objective functions that rely on the weighted product of attribute values. Assuming nonnegative weights, the author demonstrates that the optimal ordering corresponds to the order of the attribute values of the items. Building on this work, Aprahamian et al. (2019) extend the objective function to include both the subset sum and weighted product of attribute values. Through their analysis, they find that, when the weights are nonpositive, optimal orderings can still be identified by simply indexing items according to their attributed values. Whereas these studies impose a specific objective function structure, some studies look into a broader class of objective functions that possess certain properties. For instance, Hwang et al. (1985) consider a general composite objective function and show that, if the inner and outer components possess certain properties, then an optimal ordering can be efficiently identified. In a more recent study, Lin et al. (2023) extend the analysis to an even broader family of objective functions that are characterized by elementary symmetric polynomials, which are building blocks of symmetric polynomial functions. In their work, they identify sufficient conditions to efficiently construct optimal orderings.
In addition to studying the univariate case, researchers also investigate multivariate functions (Chakravarty et al. 1982, Gal and Klots 1995, Hwang et al. 1999, Onn and Schulman 2001, Aviran and Onn 2002). Similar to the univariate case, these studies typically impose certain structural constraints on the objective function. For example, Gal and Klots (1995) study the bivariate set partitioning problem in which items have two attribute values. They considered an objective function consisting of a sum of weighted averages. In their study, each item had a frequency p and a weight w, and optimal partition policies could be identified through a simple threshold characterization in which the thresholds could be efficiently obtained. Similarly, Chakravarty et al. (1982) also study the bivariate set partitioning problem. By assuming that the objective function is concave in the subset sum of the attribute values, they are able to efficiently identify an optimal ordering. More recently, the work in El-Amine and Aprahamian (2022) extends the technique in Chakravarty et al. (1982) to heuristically identify optimal orderings for higher dimensional set partitioning problems. Hwang et al. (1999) study the multivariate set partitioning problem for an objective function that is a function of the sum of the attribute vectors. Their paper identifies a polynomial-time algorithm capable of solving the problem to optimality when certain conditions are satisfied (e.g., when the objective function is convex on the sum of the attribute vectors in each group in the partition). The efficiency of this algorithm is later improved by Aviran and Onn (2002) and Onn and Schulman (2001).
In summary, the existing research on optimal orderings is both comprehensive and extensive, covering a wide range of potential loss functions and their respective applications. This vast literature explores various algorithms, methodologies, and theoretical foundations, laying a solid foundation for researchers investigating optimal orderings. In this paper, we build upon this wealth of knowledge and consider clustering problem instances whose nonfair variants have a known and well-defined optimal ordering. Let denote the optimal ordering of the items when λ = 0, where represents the rank of item in the optimal ordering when λ = 0. Although the assumption of a known optimal ordering restricts the analysis, the methodology presented in this paper is generalizable to situations in which it is possible to identify near-optimal orderings of the nonfair variant of the problem. For example, one can use existing algorithms and approaches that have been developed to accurately (yet heuristically) solve the conventional nonfair variant to construct near-optimal orderings. Once identified, the proposed approach can be adopted to solve the fair variant of the problem. This highlights a key advantage of the considered approach as it allows the utilization of existing conventional algorithms to solve the corresponding fair variant of the problem. We demonstrate one example of this in Section 4 in which we analyze the fair k-means clustering problem.
Before we present the main algorithmic approach of this paper, we first provide a brief description of the reformulation scheme that casts the set partitioning problem as a shortest path problem (see Chakravarty et al. 1982 for details). To this end, consider an additively separable set partitioning problem instance with N items and a known optimal ordering. Assume that items are indexed according to this optimal ordering; that is, the first item that appears in the optimal ordering has an index of one, whereas the last item has an index of N. Consider an auxiliary graph, , comprising a set of N + 1 vertices, , and a set of edges with edge (i, j) representing a subset comprising items i to j − 1. In this graph representation of the problem, a path from vertex 1 to N + 1 corresponds to a partition that follows the optimal ordering, and more importantly, the set of all paths from 1 to N + 1 is equivalent to the set of all partitions that follow the optimal ordering. As such, because the optimal partition must follow the optimal ordering (by definition), then one of these paths must represent the global optimal solution of the original problem. By setting the weight of each edge in G to the contribution of its corresponding subset to the objective function (which is possible because the objective function is additively separable by subset), finding the shortest path from vertex 1 to N + 1 identifies the optimal ordered partition. Given that the graph is acyclic and directed, solving the resulting shortest path problem can be done in (Cook et al. 1997). This order-and-cut reformulation scheme is extensively utilized throughout the proposed algorithmic procedure.
3. Model Formulation and Algorithmic Approach
Consider a data set comprising data points, which is characterized by a vector of nonsensitive attributes , where represents the vector of d nonsensitive attribute values of data point . We seek to find a partition of comprising at most K clusters that minimizes a certain objective function. Let denote a clustering solution, which is a set of sets with g representing the number of subsets (i.e., ). Here, set Ωk, , represents the kth cluster that contains the indices of data points that belong in that cluster. For a given clustering solution, , denote by the clustering loss (i.e., a metric that quantifies the performance of a clustering solution) that we aim to minimize. This leads to the following clustering optimization problem that does not yet factor in fairness:
In addition to the nonsensitive attribute value, suppose that each item is characterized by a categorical sensitive attribute , where is the number of categories (e.g., M = 2 represents a binary sensitive attribute). As discussed in Section 2.1, a clustering solution is considered fair whenever the choice of the partition is independent of the sensitive attribute. We incorporate this factor into the framework by adding a regularization term to the objective function to get the following optimization problem:
Adding the fairness component to the optimization problem significantly complicates the analysis because the optimal ordering of the underlying problem is no longer known. Such multivariate set partitioning problems are known to be difficult to solve as the characterization of an optimal ordering becomes challenging (Chakravarty et al. 1985, Gal and Klots 1995, Hwang et al. 1999, Onn and Schulman 2001, Aviran and Onn 2002). Whereas some studies provide interesting results that characterize an optimal ordering with respect to multiple variables (e.g., Chakravarty et al. 1985, El-Amine and Aprahamian 2021), they often impose restrictive assumptions on the objective function that are not easy to meet. This is especially true within the considered fairness context as the two terms in the objective function of (4) compete with one another, violating the required assumptions. In this paper, we take advantage of the specific structure of (4) by noting that the extreme cases (i.e., when λ = 0 or ) reduce to set partitioning problems with interesting properties. In what follows, we detail the algorithmic approach, which comprises three main components: the first two analyze the problem at the two extreme cases (Sections 3.1 and 3.2), whereas the last component bridges these two extreme cases to handle any fairness level (Section 3.3).
3.1. Optimal Cuts When No Fairness Is Imposed
We first consider analyzing the problem without imposing any fairness considerations, that is, λ = 0. Whereas this step reduces the problem to the conventional clustering problem, which is not the main focus of this paper, it serves as the foundation point for the algorithm. As discussed in Section 2.2, we consider clustering problem instances that, when fairness is not considered, have a well-defined and known optimal ordering given by . Given this, solving (4) to global optimality when λ = 0 can be achieved via the shortest path reformulation detailed in Section 2.2. In particular, because an optimal ordering is known, the corresponding auxiliary graph can be constructed, and the shortest path on this graph from vertex 1 to N + 1 represents the global optimal solution to the conventional clustering problem.
It is important to note that the reformulation technique described in Section 2.2 does not consider any constraints. To factor in the constraints of (4), one can adopt a similar reformulation technique; however, the problem reduces to a constrained shortest path problem. Whereas, in general, constrained shortest path problems are quite challenging to solve (Handler and Zang 1980, Ziegelmann 2007, Abbasi et al. 2021), the specific structure of our constraint allows us to solve it efficiently. More precisely, we need to limit the number of subsets of the partition to K. Because each edge within the graph representation of the problem corresponds to a subset, this translates to limiting the number of arcs of the shortest path to at most K. This can be achieved by running a modified implementation of the Bellman–Ford algorithm in which at most K passes of the edge set are performed (Cook et al. 1997, Magzhan and Jani 2013). For fixed K, the running time of the resulting algorithm is , where N is the number of items in the data set. Because the method first arranges the items to follow the optimal order and then identifies the optimal cuts to form clusters, we refer to it as an order-and-cut approach. As is discussed in subsequent sections, this order-and-cut approach is extensively utilized throughout the algorithm. However, the ordering of the items is informed by the imposed level of fairness λ (e.g., when λ = 0, the ordering reduces to ).
3.2. Block-Based Fair Ordering
This section analyzes the second extreme case (i.e., ) in which the main goal is to identify a fair clustering solution without any consideration for the loss function. Unlike the previous section, which has a well-defined and known optimal ordering of the items given by , the optimal ordering when (denoted by ) is not known beforehand. Here, we present an efficient block-based ordering scheme that attempts to identify an ordering of the items (based on their sensitive attribute values) that, when optimally cut, results in a fair clustering solution. The main principle behind the approach is based on the equivalence between minimizing independence metrics and preserving the proportionality of the sensitive attributes across the clusters. Given this, the method generates an ordering from blocks of items that satisfy the desired proportion of sensitive attribute values. This is achieved in two steps: First, using the sensitive attribute values, construct blocks of items such that the distribution of the sensitive attribute within each block matches that of the entire data set (with minor exceptions of remainders). Second, using knowledge of the optimal ordering when λ = 0, arrange the blocks as well as the items in each block to obtain a final ordering of the items. This procedure, which we elaborate on in detail as follows, is similar to the fairlet concept of Chierichetti et al. (2017). However, a key differentiator is that, in our case, we take advantage of the knowledge we have regarding the optimal ordering when λ = 0. This, in turn, results in a much more computationally efficient block construction procedure. Another important difference worth highlighting is that, unlike Chierichetti et al. (2017), our procedure is not restricted to binary variables and is efficiently generalizable to categorical sensitive attributes with a large number of categories. Moreover, in contrast to Chierichetti et al. (2017), our clustering algorithm does not enforce the block structure to be preserved, which improves flexibility and allows the user to attain more appropriate fairness levels based on λ.
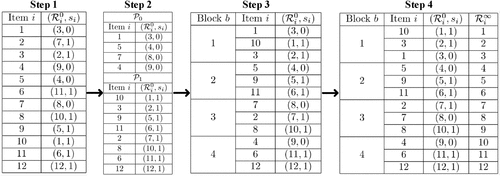
Recall that associated with each item is a sensitive attribute value that has M categories. Denote by , the set of items that have a sensitive attribute of m with . We refer to the collection of s as the category sets of . For example, suppose the sensitive attribute is gender with m = 0 representing males and m = 1 representing females. Then, category set () corresponds to the set of male (female) data entries. Let B denote the cardinality of the smallest category set, that is, , which also represents the number of blocks considered in our block-based ordering procedure. Our choice of B is primarily motivated by the desire to maximize the number of blocks, ensuring that each block contains at least one item from each sensitive category. Maximizing the number of blocks is desirable because it provides a more granular decomposition of , which increases flexibility, allowing us to attain better fairness. For each category m, we begin by sorting the items in according to the optimal ordering when λ = 0. For instance, going back to our gender example, the first item in set represents the first male item that appears in the optimal ordering when λ = 0. The ordered items of each set are then uniformly distributed across the B blocks, which is achieved sequentially for each category . More precisely, the distribution procedure works as follows: For any given category set , first identify the number of items from that set that will be placed in each block (this is equal to ). Then, place the first items of in block 1, the next in block 2, and so on until all items are assigned. This is repeated for all category sets in order for every item of to be assigned to a block. Once this assignment is complete, each block has a distribution of sensitive attributes that closely aligns with that of the entire data set. To illustrate this concept, consider a data set with 90 items and a binary sensitive attribute (i.e., either 0 or 1). Suppose the data set comprises 30 items with sensitive attribute 0 and the remaining 60 with sensitive attribute 1. As such, the ratio of 0 s to 1 s in the entire data set is 0.5. In this case, the aforementioned block-based procedure leads to 30 blocks, each having a single item with sensitive attribute 0 and two items with sensitive attribute 1. Notice that the ratio of 0 s to 1 s in each of the blocks is 0.5, which matches that of the entire data set (i.e., the representation of the items with respect to the sensitive attribute is identical). In certain situations, however, some remainders are expected. In such a case, we propose to distribute the remainders across the blocks in a uniform manner (see Online Appendix B for details and a complete example). Once all blocks have been formed, items within each block are arranged to follow , which leads to the final ordering of the items (i.e., ). This last step essentially ensures that the identified block-based ordering is as close as possible to (which is desirable as it reduces the loss), preserving the identified block-based structure. The final block-based ordering procedure is provided in Algorithm 1.
(Block-Based Ordering Procedure)
input: Set of items, ; optimal ordering when λ = 0, ; sensitive attribute values, .
output: An ordering of the items, , where each block has a distribution of the sensitive attribute that closely matches that of the original data set.
for do
for do
if si = m then
;
for do
for do
.
if then
for do
for do
for do
place first unassigned items of in block b
sort block b according to
return , which follows the order of the items from block 1 until block B.
Figure 1 provides a simple and complete example of the block-based ordering procedure. The example comprises a data set with 12 items (step 1) with a single nonsensitive attribute and a single binary sensitive attribute. Consequently, each item is characterized by a pair (, where represents the location of the item in the optimal ordering when λ = 0 and si represents the value of the binary sensitive attribute. In step 2, the category sets ( and ) are first formed and then ordered to follow . Notice that the cardinality of the smallest category set in this case is 4 (i.e., B = 4), which results in 4 blocks. In step 3, items are assigned to blocks. Because is the category set with the smallest cardinality, we start by assigning its items to the blocks. In particular, the first item of , (3, 0), is assigned to block 1; the second, (4, 0), is assigned to block 2; the third, (8, 0), is assigned to block 3; and the last item, (9, 0), is assigned to block 4. For the remaining category set, each block has two items from (because =2). Consequently, the first two items of , (1, 1) and (2, 1), are assigned to block 1; the next two items, (5, 1) and (6, 1), are assigned to block 2; and so on until all items of are assigned to blocks. Finally, in step 4, items in each block are ordered according to (to further reduce the loss function) to obtain the final ordering . Observe that in steps 3 and 4, there are numerous ways of assigning items to blocks, and each of these assignments results in different orderings. The blocked-based procedure, however, only considers assignments that preserve the optimal ordering of the loss function (i.e., ) as much as possible. Doing so results in more favorable orderings. Once the ordering is identified, the procedure described in Section 2.2 can be utilized to form the clusters.
In the special case when , the objective function only consists of the fairness metric, that is, . Because the objective is now only a function of the sensitive attributes (and is not impacted at all by the nonsensitive attributes), all the orderings that are generated by permuting different blocks lead to identical fairness levels. As a result, the user can arbitrarily select any one of these orderings, and our order-and-cut algorithm provides the same objective function value. For this special case, it can be shown that the ordering generated by our block-based fair ordering is guaranteed to be an optimal ordering when certain conditions are satisfied as summarized in the following theorem.
Consider a data set comprising n items. If, for all for some , and , then the block-based fair ordering is guaranteed to be an optimal ordering when .
Theorem 2 demonstrates that, for certain problem instances, one can exactly obtain by utilizing the proposed block-based ordering.
3.3. Procedure for the General Case
In this section, we analyze the clustering problem between the two extreme cases, that is, . This part of the analysis represents the most general case, and our aim is to use the knowledge of the two extreme orderings, discussed in Sections 3.1 and 3.2, to identify good performing orderings for a general λ, which we denote by . Once identified, the corresponding shortest path formulation can be solved to identify optimal clusters. In most existing in-processing fair clustering techniques, the choice of λ, which is a tunable parameter that regulates the trade-off between loss and fairness, is data dependent. This is because different data sets result in substantially different values for the loss value, whereas the HGR-based fairness metric is consistently between zero and one. Consequently, the value of λ across data sets is not comparable, which makes the choice of λ less interpretable and often arbitrary based on trial and error. In an effort to improve the interpretability of λ, we consider a normalized version of Problem (4) given by the following optimization problem:
Here, and ( and ) are lower and upper bounds on the loss function (fairness measure), respectively. Notice that, when λ = 1, the loss and fairness components in (4) are equally weighted irrespective of the input data. When , on the other hand, more weight is placed on the loss term, whereas a indicates a higher weight on the fairness term. This normalization procedure enhances the interpretability of the tuning parameter by asserting λ = 1 as a data-independent reference point. As becomes clear later, this data-independent reference point serves an important role in calibrating the considered transition function. The bounds , and are obtained by solving the following two extreme problems:
Solve and evaluate and .
Solve , where is chosen such that , and evaluate and .
Computing and ( and ) can be done in by applying the approach detailed in Section 3.1 (Section 3.2). Because an ordering is known beforehand, the entire procedure reduces to constructing the auxiliary graph, calculating the weight of the corresponding edges, and solving the corresponding shortest path problem. This follows because there are edges in the graph and by noting that the complexity of the modified implementation of the Bellman–Ford algorithm is . For calculating and , additional steps are required to construct the block-based ordering. These additional steps can be computed in because, for each block and category, we need to select the corresponding items from the ordering. By noting that B < n and , we can conclude that the overall complexity is .
Having normalized the optimization problem, our remaining goal is to construct a method, parameterized by λ, that transitions between the two extreme orderings and . We achieve this by multiplying the ranking of the items in by scalars generated by a scaled and shifted logistic function. Specifically, we perturb the ranking of item i, , by multiplying with a scalar that is a function of λ, denoted by . This transition function is designed such that it matches the extreme orderings identified when λ = 0 and . That is, when λ = 0, ordering the items according to the metric reduces to the ordering of , and when , ordering the items according to the metric reduces to the ordering of . We start the analysis by first considering the multiplicative factors when λ = 0, which can be set to 1 for all items, that is, . This is because simply ordering the items according to leads to the ordering . As for the multiplicative factors when , we consider an ordering of the items represented by the blocks identified by the procedure discussed in Section 3.2, that is, . To this end, for each block Cb, , define
Although the terms κb’s can be theoretically computed based on Equation (6), one problem that may arise when numerically implementing the procedure is that the value of κb’s can potentially blow up when the ratio is large. This issue can potentially distort the ordering procedure and negatively impact the performance of the algorithm. To overcome this numerical limitation, we modify Equation (6) as follows:
Having determined the multiplicative scalars and for all items , we identify the multiplicative scalars for a general λ, , through a scaled and shifted logistic function. In general, for a given item i, this transition function is given by
The basic idea for doing so is simple: higher values of ρ indicate more emphasis on fairness, and hence, the transition rate to from must also be higher. Finally, the scale and shift parameters, L1 and L2, are obtained by solving a system of equations that ensure the multiplicative scalars reduce to and when λ = 0 and , respectively. This leads to the following transition function:
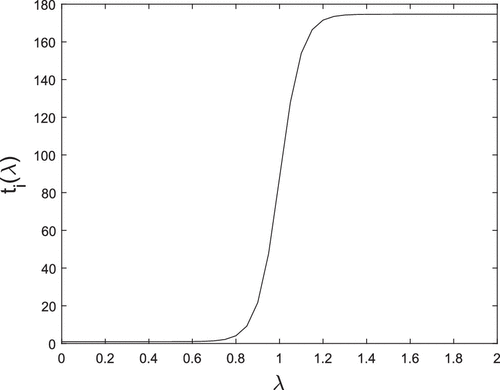
Figure 2 provides an example of a transition function for an arbitrary item in a dummy data set. The observed S-shaped structure of the function has a number of desirable properties: first, when λ is sufficiently small or large, minor perturbations in λ do not result in large variations in the multiplicative scalars. This is desirable because small variations in λ are not expected to impact the optimal clustering solution when λ is sufficiently small or large. Consequently, the resulting ordering of the items maintains the structure of () when λ is sufficiently small (large). In contrast, as λ approaches 1, the transition function attains its steepest rate of change, which is intuitive in our setting because a value of λ = 1 represent the transition point between loss and fairness (i.e., when , the emphasis is on loss, and when , the emphasis is on fairness; see the normalization procedure at the beginning of this section). Consequently, as λ approaches 1 the rate of transition needs to increase in order to transition from to . All of the aforementioned characteristics, coupled with the fact that the extreme cases are matched, motivate us to consider the scale and shifted logistic function as the transition function. Now that the transition function is completely characterized, the algorithm (at a high level) has three basic steps: First, for a given value of λ, compute, for all , and order the items according to to obtain . Second, construct the auxiliary graph that corresponds to the ordering (see Section 2.2), and compute all the arc values. Third, solve the shortest path problem from node 1 to node N + 1 on the resulting graph to obtain a clustering solution that is representative of the fairness level λ. Algorithm 2 provides a much more granular and detailed decomposition of the algorithm.
The overall complexity of the algorithm is quadratic in the number of data points, that is, . The algorithm can essentially be decomposed into two stages: First, for a given λ, it determines the corresponding ordering, . Second, the algorithm formulates the problem as a shortest path problem and solves it using a modified implementation of the Bellman–Ford algorithm. As discussed, the time complexity for calculating each of , and is , and the time complexity for calculating is . Hence, the time complexity of the first stage is . For the second stage, calculating the edge weights of the graph takes , and solving the shortest path problem takes (Cook et al. 1997). As a result, the overall complexity of the order-and-cut algorithm is . The quadratic complexity of the algorithm might pose computational issues when dealing with large data sets. To overcome this limitation, Online Appendix C details a scalable divisive hierarchical clustering scheme that heuristically identifies the cuts.
(Final Order-and-Cut Clustering Algorithm)
input: Regulating parameter λ; number of groups K; set of items, ; optimal ordering when λ = 0, ; sensitive attribute values, .
output: A clustering solution, , with K clusters.
run Algorithm 1 to identify the block-based ordering
for do
for do
for do
sort in nondecreasing order to obtain
initialize the cost matrix of the auxiliary graph and the optimal objective function value matrix to infinity and the predecessor matrix to zero
compute , and
for to N do
for to N + 1 do
set the first column of matrix O to the first row of c
for to K do
for to N − 1 do
for to N + 1 do
if then
construct the shortest path, denoted by vector path, using the predecessor matrix P
for to K do
for to do
return .
4. Empirical Results for Fair k-Means Clustering
In this section, we run a series of numerical experiments to demonstrate the effectiveness of the algorithm for the specific case of k-means clustering. We consider k-means because it is one of the most extensively studied and widely adopted clustering schemes with uses in market segmentation, computer vision, astronomy, and many other domains (Kuo et al. 2002, Coates and Ng 2012, Baron 2019). The k-means problem, or k-means clustering, is concerned with minimizing the variances within clusters. The problem in its most general form is demonstrated to be NP-hard (Dasgupta 2008), and numerous heuristic solutions (e.g., Lloyd’s (1982) algorithm) have been developed in the machine learning field to solve the conventional k-means problem. The loss function for k-means clustering is given by
Recall that our approach relies on knowledge of an optimal ordering when no fairness is imposed. Whereas the optimal ordering for the general k-means problem has not yet been fully characterized, for the one-dimensional k-means problem, an optimal ordering can be obtained by simply indexing the items according to their scalar nonsensitive attribute values (Fisher 1958). Given this, we split the analysis of this section into two parts: In Section 4.1, we first discuss the one-dimensional k-means problem whose optimal ordering when λ = 0 is fully characterized. Then, in Section 4.2, we extend the discussion to consider higher dimensional problem instances. Because the optimal ordering for such cases is not known, we take advantage of existing conventional k-means algorithms (namely Lloyd’s (1982) algorithm) and dimensionality reduction techniques (namely, multidimensional scaling (MDS); Mead 1992) to develop a systematic method that identifies good performing orderings when λ = 0. As is detailed in Section 4.2, this procedure is tailored for the k-means problem as it takes advantage of its specific structure. In both sections, the performance of the algorithm is evaluated on two standard real data sets (Adult and Bank data sets of the University of California, last accessed May 2023) and compared with two existing state-of-the-art approaches that focus on solving the fair k-means problem (Baharlouei et al. 2019, Ziko et al. 2021).
Our choice of the Adult and Bank University of California (last accessed May 2023) data sets is primarily motivated by the fact that these are the standard data sets used within the fair clustering community; see, for example, Chierichetti et al. (2017), Backurs et al. (2019), Bera et al. (2019), Schmidt et al. (2020), Thejaswi et al. (2021), Abbasi et al. (2021), Böhm et al. (2020), Ahmadian et al. (2020b), Chhabra and Mohapatra (2022), and Anderson et al. (2020). In an effort to align with their work and have a fair comparison, we decided to continue using the same data sets and protected attributes. There could be several explanations as to why fair clustering of these two data sets is relevant. For example, the Bank data set is associated with marketing campaigns of a Portuguese financial institution. Using clustering techniques, the target population can be subdivided into multiple groups in order to personalize the marketing campaigns. Because marital status is listed in personal information banks, the government considers marital status as personal information. As such, banks are prohibited from disclosing this information to third parties. If the clustering results are dependent on sensitive information, then it is possible to extract the marital status of customers, resulting in the disclosure of private information. Hence, the bank must ensure that the clustering decision is independent of marital status. The Adult data set, on the other hand, is derived from U.S. Census information from 1994. Census Bureau data can help private institutions and federal agencies fairly distribute limited resources and identify underserved communities. For example, the decision maker may decide to cluster the population to determine how to effectively distribute resources to different communities. This must be done in a manner that ensures all communities receive their fair share of resources. For instance, males and females must have similar access to schools, hospitals, roads, and public works. These discussions merely serve as examples of why fair clustering of the Adult and Bank data sets is relevant. Other motivations include but are not limited to clustering for bank loan disbursement, employment short-listing, college admissions, and prisoner recidivism (Chhabra et al. 2021). Collectively, these needs are the primary motivation for developing effective fair clustering techniques.
4.1. One-Dimensional k-Means Clustering
We first consider the extreme case when λ = 0 and provide formal statements on the structure of an optimal ordering. In this problem instance, we show that an optimal ordering for the one-dimensional k-means problem can be achieved by indexing the items according to their nonsensitive attribute values. This result is formally presented in the following theorem.
Consider a problem instance consisting of a data set comprising n items, each of which is associated with a scalar attribute value. When λ = 0, indexing the items based on their scalar attribute values leads to an optimal ordering for the one-dimensional k-means problem.
In light of Theorem 3, one can obtain by directly utilizing the reformulation scheme presented in Section 2.2, and our order-and-cut algorithm can then be implemented to solve the underlying fair k-means problem. As mentioned earlier, we run the experiment on two standard real data sets: Adult and Bank from the University of California (last accessed May 2023). The Adult data set was extracted from the 1994 Census database and contains 14 attributes (10 categorical and 4 continuous). The complete data set includes 48,842 samples. To avoid entries with incomplete data, we eliminate samples that contain missing values. We consider gender as the sensitive attribute and arbitrarily select the attribute “fnlwgt” as the nonsensitive attribute in our one-dimensional analysis. The Bank data set from the University of California (last accessed May 2023), on the other hand, contains information from direct marketing campaigns of a Portuguese banking institution. The complete data set contains 41,188 instances with 17 attributes. Among the 17 attributes, marital status (married, unmarried)1 was chosen as the sensitive attribute. For the one-dimensional analysis, the attribute duration is arbitrarily selected as the nonsensitive attribute. The first 10,000 records, according to the attribute age, are used to demonstrate the performance of the algorithm for both data sets. The reason for only selecting 10,000 records is based on the fact that we are solving the problem using three methods, each of which is solved 40 times (for a range of λ values). Consequently, just for the one-dimensional analysis, we are solving the underlying problem 240 times, and utilizing the entire data set would require a substantial amount of time. Numerical results for the remaining components of the data sets portray similar behaviors, and the results are summarized in Online Appendix I.
Observe that, although our order-and-cut algorithm is general enough to handle nonbinary sensitive attributes, we restrict the numerical study to binary sensitive attributes. The key reason for doing this is because existing benchmark algorithms are limited to binary sensitive attributes. As a result, to be able to compare our algorithm to benchmark methods, we decided to limit the attention to binary sensitivity attributes. However, to investigate the performance of our algorithm when the sensitive attribute is nonbinary, Online Appendix F provides additional numerical experiments for such cases. The main observations are consistent with those of the binary case.
To evaluate the performance of our order-and-cut algorithm, we consider three existing fair clustering algorithms, Baharlouei et al. (2019), Ziko et al. (2021), and Chierichetti et al. (2017), as benchmark algorithms. In particular, we first select the method in Baharlouei et al. (2019) (which we refer to as BNR) because the approach utilizes the same fairness metric as ours, that is, the HGR coefficient. Second, we choose the method in Ziko et al. (2021) (which we refer to as ZYGB) because both BNR and ZYGB also incorporate a tuning parameter λ, which allows us to balance the clustering performance and the fairness level. Although ZYGB uses a different fairness metric, that is, KL divergence, the alternative metric possesses similar properties to our fairness metric. The similarity of BNR and ZYGB to our approach is the main reason for choosing them as benchmark algorithms. The remaining approaches impose fairness as a hard constraint and, hence, do not allow the user to control the fairness level. This makes the comparison much more difficult. In addition to BNR and ZYGB, we also compare our method to the earliest work on fair clustering, Chierichetti et al. (2017) (which we refer to as Fairlet). In their work, Chierichetti et al. (2017) formulate the fair clustering problem through the balance fairness metric. Although Fairlet imposes fairness as a hard constraint (i.e., it does not have a tuning parameter), we still decided to include it as a benchmark algorithm because it is one of the first fair clustering approaches. In the remaining three methods (order-and-cut, BNR, and ZYGB), λ is a tunable parameter that is used to adjust the balance between the loss and the fairness level. As a result, λ has the same meaning in these three approaches. To achieve a fair comparison, we ensure that the tunable parameter λ is equivalent across these three algorithms and evaluate the k-means loss function and the HGR coefficient fairness metric of the resulting solutions.
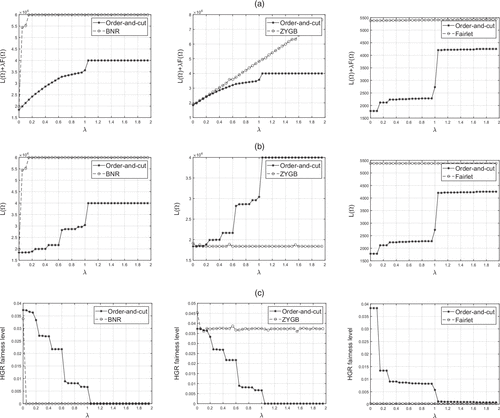
The numerical experiments are conducted for various fairness level values ranging from zero to two, that is, . The upper bound of two is chosen because steady-state behavior is already attained, and higher values result in similar observations. We investigate a range of λ values because of its relevance in dictating the fairness of the solutions. As a result, such an analysis can be used to observe the trade-off between loss and fairness across the different methods. The results for the Adult and Bank data sets are summarized in Figures 3 and 4, respectively. Each figure plots, as a function of λ, the total objective function value (top), loss value (mid), and HGR-based fairness metric (bottom). The figures on the left compare the performance of the proposed order-and-cut approach to BNR, the plots in the center compare the performance of the order-and-cut to ZYGB, and the plots on the right compare the performance of the order-and-cut to Fairlet. We adopt the codes provided by BNR, ZYGB, and Fairlet to implement their approaches. The results reveal a number of interesting observations. First, looking at the total objective function value, the order-and-cut approach of this paper outperforms the remaining methods by consistently providing a lower objective function value. Comparing the loss value across the methods (mid), we can see that BNR quickly leads to a solution with a poor loss value, whereas the ZYGB method does a better job in maintaining a favorable loss value (especially for higher λ values). However, looking at the HGR-based fairness metric across the methods (bottom), we can see that BNR rapidly converges to a completely fair solution (indicated by the near-zero fairness metric), whereas ZYGB struggles to converge to a fair solution. As a result, BNR appears to place much more emphasis on fairness, which does not allow the user to regulate the trade-off between fairness and loss, which is a disadvantage shared with preprocessing and postprocessing methods. In contrast, whereas ZYGB maintains favorable loss values, it fails to obtain fair clustering solutions, which defeats the purpose of their algorithm. The proposed order-and-cut approach, on the other hand, provides more reasonable results in which the loss gradually increases and the HGR-based fairness metric gradually decreases with λ. On the right-hand side, we can observe that the loss and fairness values of Fairlet are independent of λ. This is not surprising as Fairlet imposes fairness as a hard constraint, and hence, it is not possible to balance the trade-off between loss and fairness. In terms of fairness, Fairlet can provide relatively fair solutions. However, this comes at the cost of a large loss value. In fact, in both data sets, the proposed order-and-cut approach is able to identify a solution that is both fairer and has a considerably lower loss value.
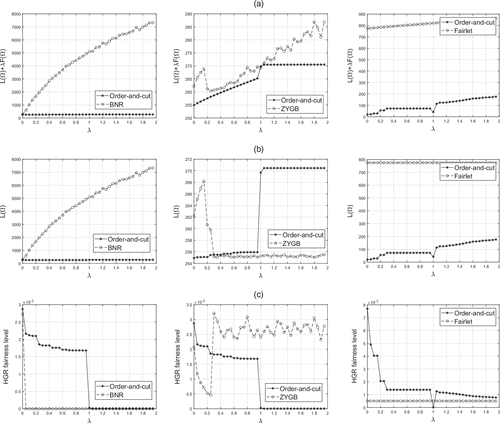
Notes. The figures compare order-and-cut to BNR (left), ZYGB (center) and Fairlet (right). (a) Objective value. (b) Loss value. (c) Fairness level.
Notes. The figures BNR (left), ZYGB (center) and Fairlet (right). (a) Objective value. (b) Loss value. (c) Fairness level.
It is worth noting that the reason why the scales of the vertical axes in Figures 3 and 4 are different from one another is because we are comparing BNR, ZYGB, and Fairlet with our order-and-cut method in separate graphs. For example, by looking at the results of BNR, we observe that the y-axis values range from 0 to 8,000. Such a wide range is observed because BNR is failing to maintain adequate loss values as λ increases. In contrast, looking at the results of ZYGB, we can see that it attains much more favorable loss values, which is why a narrower range of y-axis values is observed.
It is important to note that, in both numerical experiments, the order-and-cut approach provides near perfect fair solutions (indicated by an almost zero value of the fairness metric) as λ grows. This demonstrates that the block-based ordering procedure of Section 3.2 is highly effective in constructing near-optimal orderings when . Moreover, notice that, as λ approaches 1, the order-and-cut approach experiences a sudden shift. This is expected because λ = 1 represents a data-independent transition point between fairness and loss, that is, at this point, both components of the objective function are equally weighted. Consequently, as λ surpasses 1, a reduction in the HGR-based metric is observed at the cost of an increased loss value. Because these scenarios represent situations in which fairness is more important, this shift is well-justified (as demonstrated by the performance of the overall objective function in the top portion of the figure). In summary, our numerical experiments reveal that the order-and-cut approach of this paper provides a more effective mechanism in regulating the trade-off between loss and fairness. This, in turn, allows the user to identify a more appropriate clustering solution that attains a desirable level of fairness. In contrast, existing methods either fail to provide fair solutions (e.g., ZYGB) or they provide a fair solution but at the cost of very poor clustering performance (e.g., BNR).
4.2. Multidimensional k-Means Clustering
In this section, we extend the numerical experiments of Section 4.1 to analyze the performance of the algorithm for higher dimensional k-means problem instances. Unlike the analysis in Section 4.1, an optimal ordering when λ = 0 is not readily available. As such, before implementing the order-and-cut algorithm of this paper, we first present a mechanism that uses conventional k-means clustering algorithms along with dimensionality reduction techniques to construct . More precisely, we use Lloyd’s (1982) algorithm to solve the conventional k-means problem (i.e., without imposing fairness). Lloyd’s (1982) algorithm is chosen because of its simplicity, efficiency, and effectiveness in identifying near-optimal clustering solutions that minimize the loss function. Notice that a clustering solution in itself does not fully characterize an ordering of the items (e.g., the order of the clusters as well as the order of the items in each cluster are not defined by a clustering solution). As a result, we need to complement the clustering solution identified by Lloyd’s (1982) algorithm with an additional procedure to obtain an ordering, which we achieve through a dimensionality reduction technique. To motivate this, we present an interesting behavior (Property 1) that the k-means loss function possesses.
For any clustering solution, , the k-means loss can be rewritten as a function of pairwise distances as follows:
In light of Property 1, the pairwise distances of all items in the data set are the only relevant characteristics required for k-means clustering. As a result, we consider MDS, which is a dimensionality reduction technique that aims at optimally maintaining the pairwise distances of all items in the data set. In particular, we propose to utilize MDS to reduce the dimension of the nonsensitive attributes to a single dimension. This, in turn, enables us to fully characterize based on Lloyd’s (1982) solution. This is achieved by ordering the clusters from Lloyd’s (1982) algorithm based on their average reduced MDS scalar values and ordering items in each cluster according to their reduced MDS scalar values. A detailed description of the steps involved in this procedure is provided in Online Appendix D. Whereas MDS is not guaranteed to perfectly maintain pairwise distances, a perfect reduction is not required as the clusters are already informed by Lloyd’s (1982) algorithm. If the MDS procedure happens to perfectly maintain pairwise distances, then by Property 1, clustering according to the reduced one-dimensional vector yields an optimal clustering solution to the original data set.
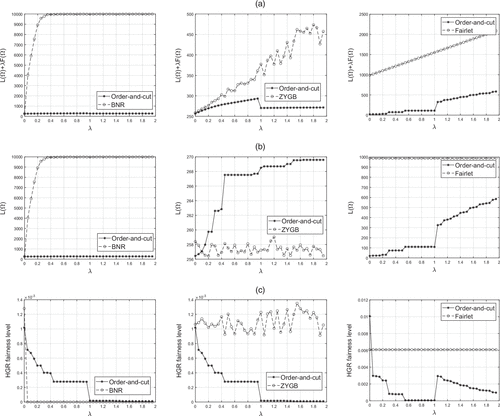
Having identified , we are now in a position to directly implement the order-and-cut approach to solve the underlying fair clustering problem. We perform numerical experiments similar to that of Section 4.1, that is, on the Adult and Bank data sets and compare the performance to BNR, ZYGB, and Fairlet. Instead of selecting only one attribute, as demonstrated in the previous experiment, we use all 6 numerical attributes for the Adult data set and all 10 numerical attributes for the Bank data set. We still select gender (marital status) as the sensitive attribute for the Adult (Bank) data set. Figures 5 and 6 summarize the results by plotting, as a function of λ, the total objective function value (top), the loss value (mid), and the HGR-based fairness metric (bottom). The figures on the left are for the Adult data set, and the figures on the right are for the Bank data set. The results reveal similar findings to that of Section 4.1. In particular, the considered order-and-cut approach consistently outperforms both BNR and ZYGB in terms of the total objective function value. Moreover, BNR continues to place much more emphasis on fairness by quickly converging to a completely fair solution with an almost zero independence value. However, this comes at a cost of a poor loss value. In a similar vein, ZYGB either maintains desirable loss values but fails to converge to a fair clustering solution or achieves a relatively fair solution, but its performance falls short compared with the order-and-cut approach in terms of both fairness and loss value. Fairlet, which enforces fairness as a rigid constraint, struggles to strike a balance between loss and fairness. As a result, it yields substantial loss values even though its solutions are relatively fair. These results demonstrate that the order-and-cut approach continues to outperform existing methods in higher dimensional settings by more effectively regulating the trade-off between loss and fairness. One potential concern is the effect of high dimension on the proposed procedure to construct . This concern arises from the fact that reducing higher dimensional vectors to a single dimension ultimately results in more loss of information. Consequently, this may lead to inaccurate orderings, which would negatively impact the performance of the order-and-cut approach. Online Appendix E provides numerical results to observe the impact of dimension on the performance of the algorithm. The analysis reveals that a high dimension of the data set does not seem to have a negative impact on the performance of the considered procedure. Furthermore, in our efforts to validate the efficacy of our order-and-cut algorithm, we conducted numerical experiments to evaluate the optimality gaps on small-scale synthetic data sets across various dimensions as detailed in Online Appendix G. The results reveal that the optimality gaps remain remarkably narrow even when the dimension reaches up to d = 500. Additionally, we carried out similar numerical experiments on a practical high-dimensional data set, Parkinson’s Disease Classification, which comprises up to 753 dimensions (from the University of California, last accessed May 2023). This serves to provide insights into the performance of our algorithm when applied to practical high-dimensional data sets with detailed findings presented in Online Appendix H.
Notes. The figures compare order-and-cut to BNR (left), ZYGB (center) and Fairlet (right). (a) Objective value. (b) Loss value. (c) Fairness level.
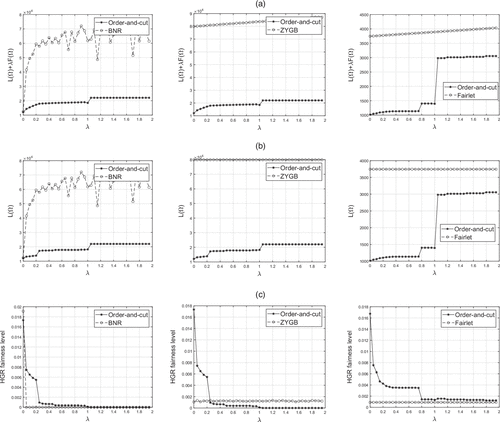
Notes. The figures compare order-and-cut to BNR (left), ZYGB (center) and Fairlet (right). (a) Objective value. (b) Loss value. (c) Fairness level.
5. Conclusions and Future Research Directions
In this paper, we consider the problem of clustering data sets with the goal of minimizing a certain loss with respect to a vector of nonsensitive attributes, maintaining fairness, measured by an HGR-based metric with respect to a categorical sensitive attribute. We construct a novel order-and-cut algorithm, which is driven by findings from the field of combinatorial optimization that heuristically solves the underlying optimization problem more efficiently and accurately than existing methods. Unlike preprocessing and postprocessing fair clustering methods, which impose fairness as a hard constraint, the considered in-processing method allows the user to regulate the trade-off between the clustering objective and fairness. The approach takes advantage of the knowledge of optimal orderings when no fairness is considered. This, when coupled with a block-based fair ordering procedure, enables us to identify good-performing optimal orderings for any fairness level. Whereas it is challenging to offer a lower bound on the performance guarantee for a general case, our extensive results demonstrate the effectiveness of our order-and-cut algorithm in comparison with three benchmark algorithms. To overcome potential scalability concerns that may arise owing to the quadratic complexity of the algorithm, we present a scalable hierarchical divisive algorithm that heuristically identifies the cuts.
We run a series of numerical experiments that demonstrate the effectiveness of the algorithm for one of the most commonly adopted clustering schemes, namely, k-means. Although the optimal ordering for the general k-means problem is not known, we capitalize on existing algorithms that solve the nonfair k-means problem and use dimensionality reduction techniques to accurately identify the optimal ordering when no fairness is imposed. This procedure highlights a key advantage of the considered approach as it allows the utilization of existing conventional algorithms in order to solve the corresponding fair variant of the problem. Our numerical experiments reveal that the proposed order-and-cut approach outperforms existing methods by providing a more effective mechanism to regulate the trade-off between fairness and clustering performance.
This work can be expanded in a number of important directions. For example, all methods and approaches of this paper are limited to discrete sensitive attributes. An important extension is to consider fair clustering with continuous sensitive attributes. Whereas the HGR-based fairness metric considered in this paper is (in theory) extendable to continuous sensitive attributes, the computations of the metric are more challenging. This, within an optimization setting, leads to tractability concerns. Another research direction is the utilization of the order-and-cut approach to solve fair variants of other popular clustering schemes (beyond k-means). The dimensionality reduction approach is specifically tailored for the k-means loss, and other techniques may be needed for other clustering schemes. This is worthy of exploration as doing so allows the utilization of existing algorithms to solve the corresponding fair variant of the problem. This work can also be extended to settings beyond fair clustering. In particular, the approach can be used to solve a class of set partitioning problems with objective functions that are a weighted sum of two competing terms. If the optimal ordering of each term is known (analogous to the two extreme cases), then similar concepts can be utilized to solve the problem for intermediate values of the weights.
The authors are grateful to the senior editor, Rema Padman, and the two referees for their excellent comments and suggestions that greatly improved both the analysis and presentation of the results in this paper.
1 The marital status of the original data set comprised four categories: single, married, divorced, and unknown. In our analysis, we converted this into a binary by integrating single and divorced as unmarried. To avoid missing data, unknown instances are eliminated from the data set.
References
- (2021) Fair clustering via equitable group representations. Proc. 2021 ACM Conf. Fairness Accountability Transparency (Association for Computing Machinery, New York), 504–514.Google Scholar
- (2019) Fairness in clustering with multiple sensitive attributes. Preprint, submitted October 11, https://arxiv.org/abs/1910.05113.Google Scholar
- (2019) Clustering without over-representation. Proc. 25th ACM SIGKDD Internat. Conf. Knowledge Discovery Data Mining (Association for Computing Machinery, New York), 267–275.Google Scholar
Ahmadian S, Epasto A, Kumar R, Mahdian M (2020a) Fair correlation clustering. Chiappa S, Calandra R, eds. Proc. 23rd Internat. Conf. Artificial Intelligence Statist., vol. 108 (PMLR, New York), 4195–4205 .Google Scholar- (2020b) Fair hierarchical clustering. Larochelle H, Ranzato M, Hadsell R, Balcan M, Lin H, eds. Adv. Neural Inform. Process. Systems, vol. 33 (Curran Associates, Inc., Red Hook, NY), 21050–21060.Google Scholar
- (2020) Distributional individual fairness in clustering. Preprint, submitted June 22, https://arxiv.org/abs/2006.12589.Google Scholar
- (2016) Machine bias. ProPublica Online (May 23), https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing.Google Scholar
- (2021) Optimal clustering of frequency data with application to disease risk categorization. IISE Trans. 54(8):728–740.Google Scholar
- (2019) Optimal risk-based group testing. Management Sci. 65(9):4365–4384.Link, Google Scholar
- (2002) Momentopes, the complexity of vector partitioning, and Davenport–Schinzel sequences. Discrete Comput. Geometry 27(3):409–417.Google Scholar
- (2019) Scalable fair clustering. Chaudhuri K, Salakhutdinov R, eds. Proc. 36th Internat. Conf. Machine Learn., vol. 97 (PMLR, New York), 405–413.Google Scholar
- (2019) Rényi fair inference. Preprint, submitted June 28, https://arxiv.org/abs/1906.12005.Google Scholar
- (1976) Set partitioning: A survey. SIAM Rev. 18(4):710–760.Google Scholar
- (2019) Machine learning in astronomy: A practical overview. Preprint, submitted April 15, https://arxiv.org/abs/1904.07248.Google Scholar
- (2019) Fair algorithms for clustering. Wallach H, Larochelle H, Beygelzimer A, d’Alch é-Buc F, Fox E, Garnett R, eds. Adv. Neural Inform. Process. Systems, vol. 32 (Curran Associates, Inc., Red Hook, NY), 4955–4966.Google Scholar
- (2018) On the cost of essentially fair clusterings. Preprint, submitted November 26, https://arxiv.org/abs/1811.10319.Google Scholar
- (2020) Fair clustering with multiple colors. Preprint, submitted February 18, https://arxiv.org/abs/2002.07892.Google Scholar
- (2018) Gender shades: Intersectional accuracy disparities in commercial gender classification. Friedler SA, Wilson C, eds. Proc. 1st Conf. Fairness, Accountability Transparency, vol. 81 (PMLR, New York), 77–91.Google Scholar
- (1982) A partitioning problem with additive objective with an application to optimal inventory groupings for joint replenishment. Oper. Res. 30(5):1018–1022.Link, Google Scholar
- (1985) Consecutive optimizers for a partitioning problem with applications to optimal inventory groupings for joint replenishment. Oper. Res. 33(4):820–834.Link, Google Scholar
- (1998) Worst-case analyses, linear programming and the bin-packing problem. Math. Programming 83(1):213–227.Google Scholar
Chhabra A, Mohapatra P (2022) Fair algorithms for hierarchical agglomerative clustering. Proc. 2022 21st IEEE Internat. Conf. Machine Learn. Appl. (IEEE, Piscataway, NJ), 206–211 .Google Scholar- (2021) An overview of fairness in clustering. IEEE Access 9:130698–130720.Google Scholar
Chierichetti F, Kumar R, Lattanzi S, Vassilvitskii S (2017) Fair clustering through fairlets. Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, Garnett R, eds. Adv. Neural Inform. Process. Systems, vol. 30 (Curran Associates, Inc., Red Hook, NY), 5029–5037 .Google ScholarCoates A, Ng AY (2012) Learning feature representations with k-means. Montavon G, Orr GB, Müller KR, eds. Neural Networks: Tricks of the Trade, 2nd ed. (Springer, Berlin), 561–580 .Google Scholar- (1997) Optimal trees and paths, chapter 2. Combinatorial Optimization (John Wiley & Sons, Hoboken, NJ).Google Scholar
- (2008) The Hardness of k-Means Clustering (Department of Computer Science and Engineering, University of California, Berkeley, CA). Google Scholar
- (2015) Automated experiments on ad privacy settings: A tale of opacity, choice, and discrimination. Proc. Privacy Enhancing Tech. 2015(1):92–112.Google Scholar
- (2021) A heuristic scheme for multivariate set partitioning problems with application to classifying heterogeneous populations for multiple binary attributes. IISE Trans. 54(6):537–549.Google Scholar
- (2022) A heuristic scheme for multivariate set partitioning problems with application to classifying heterogeneous populations for multiple binary attributes. IISE Trans. 54(6):537–549.Google Scholar
- (1958) On grouping for maximum homogeneity. J. Amer. Statist. Assoc. 53(284):789–798.Google Scholar
- (1995) Optimal partitioning which maximizes the sum of the weighted averages. Oper. Res. 43(3):500–508.Link, Google Scholar
- (2020) A short review on different clustering techniques and their applications. Mandal JK, Bhattacharya D, eds. Emerging Technology in Modelling and Graphics (Springer, Singapore), 69–83.Google Scholar
- (2020) Fairness-aware neural Rényi minimization for continuous features. Bessiere C, ed. Proc. 29th Internat. Joint Conf. Artificial Intelligence (IJCAI-20), 2262–2268.Google Scholar
- (1980) A dual algorithm for the constrained shortest path problem. Networks 10(4):293–309.Google Scholar
- (1999) A polynomial time algorithm for shaped partition problems. SIAM J. Optim. 10(1):70–81.Google Scholar
- (1985) Optimal set partitioning. SIAM J. Algebraic Discrete Methods 6(1):163–170.Google Scholar
Jin K (2017) Optimal partitioning which maximizes the weighted sum of products. Xiao M, Rosamond F, eds. Frontiers in Algorithmics (Springer International Publishing, Cham, Switzerland), 127–138 .Google Scholar- (2011) Fairness-aware learning through regularization approach. 2011 IEEE 11th Internat. Conf. Data Mining Workshops (IEEE, Piscataway, NJ), 643–650.Google Scholar
- (2019a) Fair k-center clustering for data summarization. Chaudhuri K, Salakhutdinov R, eds. Proc. 36th Internat. Conf. Machine Learn., vol. 97 (PMLR, New York), 3448–3457.Google Scholar
- (2019b) Guarantees for spectral clustering with fairness constraints. Chaudhuri K, Salakhutdinov R, eds. Proc. 36th Internat. Conf. Machine Learn., vol. 97 (PMLR, New York), 3458–3467.Google Scholar
- (2002) Integration of self-organizing feature map and k-means algorithm for market segmentation. Comput. Oper. Res. 29(11):1475–1493.Google Scholar
- (2008) A new modeling and solution approach for the set-partitioning problem. Comput. Oper. Res. 35(3):807–813.Google Scholar
- (2020) Deep fair clustering for visual learning. Proc. IEEE/CVF Conf. Comput. Vision Pattern Recognition, 9070–9079.Google Scholar
- (2023) Optimal unlabeled set partitioning with application to risk-based quarantine policies. IISE Trans. Forthcoming.Google Scholar
- (2015) Toward nonlinear multimaterial topology optimization using unsupervised machine learning and metamodel-based optimization. 41st Design Automation Conf. Internat. Design Engrg. Technical Conf. Comput. Inform. Engrg. Conf., vol. 2B (American Society of Mechanical Engineers, New York).Google Scholar
- (1982) Least squares quantization in PCM. IEEE Trans. Inform. Theory 28(2):129–137.Google Scholar
- (2013) A review and evaluations of shortest path algorithms. Internat. J. Sci. Tech. Res. 2(6):99–104.Google Scholar
- (2019) Fairness-aware learning for continuous attributes and treatments. Chaudhuri K, Salakhutdinov R, eds. Proc. 36th Internat. Conf. Machine Learn., vol. 97 (PMLR, New York), 4382–4391.Google Scholar
- (1992) Review of the development of multidimensional scaling methods. Statistician 41(1):27–39.Google Scholar
- (2020) Proportionally fair clustering revisited. Czumaj A, Dawar A, Merelli E, eds. Proc. 47th Internat. Colloquium Automata Languages Programming, vol. 168, Leibniz International Proceedings in Informatics (Schloss Dagstuhl–Leibniz-Zentrum für Informatik, Dagstuhl, Germany), 85:1–85:16.Google Scholar
- (2021) Ethical management and implementation of COVID-19 immunity passports and vaccination certificates: Lawfulness, fairness, and transparency. Linguistic Philos. Investigations 20:45–54.Google Scholar
- (2021) Fair allocation of potential COVID-19 vaccines using an optimization-based strategy. Process Integration Optim. Sustainability 5(1):3–12.Google Scholar
- (2001) The vector partition problem for convex objective functions. Math. Oper. Res. 26(3):583–590.Link, Google Scholar
- (2017) Fair kernel learning. Ceci M, Hollmén J, Todorovski L, Vens C, Džeroski S, eds. Machine Learning and Knowledge Discovery in Databases (Springer International Publishing, Cham, Switzerland), 339–355.Google Scholar
- (2018) Privacy preserving clustering with constraints. Preprint, submitted February 7, https://arxiv.org/abs/1802.02497.Google Scholar
- (2021) Public assessments of police during the COVID-19 pandemic: The effects of procedural justice and personal protective equipment. Policing 45(1):154–168.Google Scholar
- (2017) A review of clustering techniques and developments. Neurocomputing 267:664–681.Google Scholar
- (2020) Fair coresets and streaming algorithms for fair k-means. Bampis E, Megow N, eds. Approximation and Online Algorithms (Springer International Publishing, Cham, Switzerland), 232–251.Google Scholar
- (2018) Spectralnet: Spectral clustering using deep neural networks. Preprint, submitted January 4, https://arxiv.org/abs/1801.01587.Google Scholar
- (2013) Discrimination in online ad delivery. Queue 11(3):10–29.Google Scholar
- (2019) Kernel cuts: Kernel and spectral clustering meet regularization. Internat. J. Comput. Vision 127(5):477–511.Google Scholar
- (2012) Integrating nature-inspired optimization algorithms to k-means clustering. Seventh Internat. Conf. Digital Inform. Management (IEEE, Piscataway, NJ), 116–123.Google Scholar
- (2021) Diversity-aware k-median: Clustering with fair center representation. Oliver N, Pérez-Cruz F, Kramer S, Read J, Lozano JA, eds. Machine Learning and Knowledge Discovery in Databases. Research Track (Springer International Publishing, Cham, Switzerland), 765–780.Google Scholar
- (2012) Clustering: Science or art? Guyon I, Dror G, Lemaire V, Taylor G, Silver D, eds. Proc. ICML Workshop Unsupervised Transfer Learn., vol. 27 (PMLR, New York), 65–79.Google Scholar
- (1975) On sequences of pairs of dependent random variables. SIAM J. Appl. Math. 28(1):100–113.Google Scholar
- (2017) Fairness constraints: Mechanisms for fair classification. Singh A, Zhu J, eds. Proc. 20th Internat. Conf. Artificial Intelligence Statist., vol. 54 (PMLR, New York), 962–970.Google Scholar
- (2007) Constrained Shortest Paths and Related Problems: Constrained Network Optimization (Verlag Dr. Muller, Saarbrucken, Germany).Google Scholar
Ziko IM, Yuan J, Granger E, Ben Ayed I (2021) Variational fair clustering. Proc. AAAI Conf. Artificial Intelligence 35(12):11202–11209 .Google Scholar

