
Multivariate Functional Clustering with Variable Selection and Application to Sensor Data from Engineering Systems
Abstract
Multisensor data that track system operating behaviors are widely available nowadays from various engineering systems. Measurements from each sensor over time form a curve and can be viewed as functional data. Clustering of these multivariate functional curves is important for studying the operating patterns of systems. One complication in such applications is the possible presence of sensors whose data do not contain relevant information. Hence, it is desirable for the clustering method to equip with an automatic sensor selection procedure. Motivated by a real engineering application, we propose a functional data clustering method that simultaneously removes noninformative sensors and groups functional curves into clusters using informative sensors. Functional principal component analysis is used to transform multivariate functional data into a coefficient matrix for data reduction. We then model the transformed data by a Gaussian mixture distribution to perform model-based clustering with variable selection. Three types of penalties, the individual, variable, and group penalties, are considered to achieve automatic variable selection. Extensive simulations are conducted to assess the clustering and variable selection performance of the proposed methods. The application of the proposed methods to an engineering system with multiple sensors shows the promise of the methods and reveals interesting patterns in the sensor data.
History: Kwok-Leung Tsui served as the senior editor for this article.
Funding: The research by J. Min and Y. Hong was partially supported by the National Science Foundation [Grant CMMI-1904165] to Virginia Tech. The work by Y. Hong was partially supported by the Virginia Tech College of Science Research Equipment Fund.
Data Ethics & Reproducibility Note: The original data set is proprietary and cannot be shared. The full code to replicate the results in this paper, based on summary statistics of the original data, is available at https://github.com/jiem3/MultiFuncClustering. The code applied to a simplified version is available at https://codeocean.com/capsule/4041000/tree/v1, which covers the data analysis and part of the simulation scenarios with a single data set under each scenario using a fixed set of hyperparameters, for reducing computation time, and at https://doi.org/10.1287/ijds.2022.0034.
1. Introduction
3With the development of sensor and communication technologies, multisensor systems are now commonly deployed in many engineering systems to track both the system operating conditions and the system environment in a dynamic way. For example, sensors in aerospace play a vital role in navigation, detection, monitoring, and control of various air vehicles. Different types of aerospace sensors are located in the flight systems to measure the system states and vehicular environment (Nebylov 2012). Another example of multivariate sensor data are from automobiles, where multiple automotive sensors actively gather system and environment information, such as position, pressure, torque, exhaust temperature, and angular rate, from the powertrain, chassis, and body (Fleming 2001). In recent years, autonomous vehicles are targeting to operate without human involvement. To enable self-driving, a variety of sensors, such as radar, lidar, sonar, GPS, and odometry, are deployed in autonomous vehicles to perceive their surroundings (Kocić et al. 2018). In modern manufacturing systems, multiple sensors are installed to collect data (e.g., temperature, force, electrical signals, and vibration) from the manufacturing process, which can be used for different purposes such as the condition monitoring of machines, processes and tools, quality control, and resource management (Lee et al. 2013).
Thus, sensor data are common in modern engineering systems and offer tremendous opportunities for statistical research to develop new methods for analyzing such data. From a business analytics and decision making point of view, such new methods are much needed, for example, to answer questions such as, which sensor is important and what patterns there are in the sensor data. In the following, we describe one clustering application of sensor data to explore patterns in the data, which will be useful for exacting information from sensor data.
Sensor data are generally collected at a high rate (e.g., per second). Thus, it is reasonable to treat the measurements from each sensor during a certain period as the observation of a functional variable. Then, a system with multiple sensors correspondingly produces multivariate functional data. During the system operation, a certain type of event can occur over time (e.g., the start/stop of the system, system faults, and breakdowns). It is insightful to investigate the sensor data in a window prior to the occurrence of the event. For each occurrence of the event, we can extract one multivariate functional observation from the sensor data stream. One practical interest is to cluster these multivariate functional observations to study the system operating patterns (i.e., different patterns in the occurrences of the event). However, not all sensors contribute to the clustering. That is, some sensors in the system are irrelevant to the clustering. Thus, sensor selection is necessary.
This paper is motivated by a real engineering system application, which we call “System B.” To protect proprietary sensitive information, we had to disguise the system and sensor names and use rescaled data. In this system, 42 sensors are installed at various locations to monitor the operating status of the system. The sampling frequency of the sensors was two times per second at a regular grid. Figure 1 plots a subset of sensor data collected from System B. During the operation of the system, an event can occur due to various reasons, which is referred to as “Event S.” To investigate the occurrence patterns of Event S, engineers are particularly interested in 30 time points prior to the event occurrence (approximately 15 seconds). From the historical sensor data stream, there were 419 Event S occurrences. For each occurrence, we extract one multivariate functional observation over the window that was 30 time points prior to the event occurrence. Figure 1 shows the 30-time point data collected before the 419 event occurrences from 4 of the 42 sensors. The goal was to find out the event occurrence patterns through the clustering of these 419 observations as well as selecting the sensors that were important contributors to these event occurrences. Therefore, we propose a clustering method for multivariate functional data with automatic variable selection.

Notes. Measurements from four sensors are shown. Each line shows one observed functional curve from one sensor. (a) Sensor 1. (b) Sensor 2. (c) Sensor 3. (d) Sensor 4.
Regarding literature for functional data with clustering, Abraham et al. (2003) applied the K-means algorithm to B-spline representations of functional data. James and Sugar (2003) represented sparsely sampled functional data by spline basis functions and assumed Gaussian mixture distributions for the coefficient vectors with cluster-specific means. Heard et al. (2006) applied Bayesian hierarchical clustering to the basis expansion coefficients of curve data generated from a genetic study on malaria-infected mosquitoes. Ray and Mallick (2006) considered wavelet decomposition of functional data and then used a mixture of Dirichlet processes to specify prior beliefs about the regularity of the functions and the number of clusters. Chiou and Li (2007) and Peng and Müller (2008) applied the K-means algorithm to functional data with distances, respectively, defined by the truncated Karhunen-Loève expansion and the functional principal component scores. Ma and Zhong (2008) studied a mixed-effects functional analysis of variance (ANOVA) model where cluster probabilities for each curve can be estimated to provide a soft clustering of the curve. Kayano et al. (2010) expanded multivariate functional data by ortho-normalized Gaussian basis functions and then applied the self-organized map procedure to the resulting coefficients. Jiang and Serban (2012) considered clustering for multilevel functional data. They applied hard and soft clustering methods to scores derived from the multilevel functional principal component analysis (FPCA). Chiou (2012) proposed to use a multiclass logit model to estimate the posterior probability that an observed curve is in one cluster. Giacofci et al. (2013) used wavelet decomposition with thresholding to reduce the functional clustering problem to a linear mixed-effects model with unknown label variables and proposed an expectation-maximization (EM) algorithm to estimate the parameters. Jacques and Preda (2014b) proposed using multivariate functional principal component analysis (MFPCA) for dimension reduction, assumed a mixture normal distribution for principal component scores, and used EM algorithm in estimation. Rodriguez and Dunson (2014) proposed to use splines and nested Dirichlet priors on spline coefficients in clustering Gaussian functional data where multiple curves were observed for each subject. Jacques and Preda (2014a) provided a comprehensive survey on functional clustering methods. Linton and Vogt (2017) modeled each curve by the Nadaraya-Watson estimator and then applied an iterative thresholding procedure to order pairwise L2 distances between curves to determine the number of clusters as well as cluster labels for individual curves. Chamroukhi and Nguyen (2019) introduced a model-based classification model for functional data.
More recently, Jadhav et al. (2021) used B-splines to estimate the function curves. Through penalizing all pairwise spline coefficients, they combined estimation of coefficients and clustering together. Zhong et al. (2021) proposed to cluster non-Gaussian curves using a nonparametric transformation function with no prior information on the number of clusters and estimated the transformation function, number of clusters, and the mean and covariance functions of clusters simultaneously using penalized EM algorithm. Guo et al. (2022) used multivariate state space model to represent the linear mixed effect model on functional data. Posterior probability is used to classify observations into different groups. Despite the rich literature on univariate functional clustering and multivariate functional clustering, none of the existing methods considered clustering and variable selection simultaneously.
In this paper, we propose a penalized likelihood approach to perform simultaneous clustering and variable selection on multivariate functional data. FPCA is applied to the observations of each functional variable to represent them by linear combinations of leading functional principal components. The coefficients of these representations are then modeled through a Gaussian mixture distribution to achieve clustering. Group lasso type of penalties with adaptive weights are used for variable selection. Three penalties, namely, the individual, variable, and group penalties, are considered, each penalizing the mean components of the combined coefficients in a different way. Specifically, the individual penalty penalizes individual mean components so that each component is kept in or removed from the model by itself. The variable penalty penalizes the (absolute) maximum of all the mean components belonging to the same functional variable so that all these components are kept in or removed from the model simultaneously. The group penalty assumes a natural group of the functional variables and penalizes the mean components belonging to all the variables in the same group simultaneously so that all the mean components in this group are kept in or removed from the model together.
To estimate the parameters, a complete log-likelihood is first formed with the inclusion of the latent cluster indicators and then one of the three penalties is added to form the penalized complete likelihood objective function. An EM algorithm is developed for the optimization, where closed-form expressions for parameter updates for each penalty are derived. The adjusted Bayesian information criterion (BIC) introduced by Xie et al. (2008) is used for selecting tuning parameters such as the number of clusters, the penalty parameter, and the power of the adaptive weights in the penalty. Extensive simulations are conducted to assess the clustering and variable selection performance of the methods in various settings of sample sizes, signal-noise ratios, and signal strengths. The application of the proposed methods to the System B data demonstrates that the proposed methods can reduce the number of sensors and reveal interesting patterns in the clustered event occurrences. Our method is the first functional clustering procedure that also incorporates variable selection.
The rest of the paper is organized as follows. Section 2 describes the details of the developed methods. Performances of the proposed methods are evaluated by a simulation study in Section 3. The engineering system sensor data are analyzed in Section 4. Conclusion and remarks are included in Section 5.
2. Multivariate Functional Clustering with Automatic Variable Selection
We first introduce some notation. Let p be the number of sensors (i.e., functional variables) and n be the number of observations. The functional curve observed from the sth sensor of the ith observation is denoted by , which is the observation period. In our engineering system study, p = 42, n = 419, and τ = 30. That is, we observe the values of for time points . Here, τ is the number of time points.
In the following, we introduce the proposed clustering method, which consists of two steps: (1) use FPCA to transform multivariate functional data to a coefficient matrix for data reduction and (2) use a model-based algorithm with penalty terms to perform clustering and automatic variable selection.
2.1. Functional Principal Component Transformation
In this section, we describe the details of the FPCA transformation. We focus on the transformation for observations on a single sensor. Let be the mean function of . Let and be the eigenvalues and eigenfunctions for , respectively. By the Karhunen-Loève expansion, we have
In practice, the expansion in (1) can be estimated through the FPCA (Ramsay and Silverman 1997). After applying the FPCA to the observed functional curves from sensor s, we can obtain the functional principal component (FPC) functions . In practice, only the leading FPCs are kept, which can represent a relatively large portion of the variation in the original data. In this paper, we choose the first FPCs such that a relatively large portion of the variation for data from sensor s is preserved. We will discuss the selection of the number of components in Section 2.4.
Let be the coefficients in the truncated expansion of , where is the empirical mean function for sensor s. We have
For notation simplicity, we let . After the FPCA transformation is applied to the observations from all the sensors, we assemble all the coefficient vectors as follows:
The coefficient vectors, together with the FPC functions, now represent a reduction from the original multivariate functional observations. For notation convenience, we also represent in (3) as
Here, we use index j to represent the elements in .
In this paper, we apply separate FPCA for each sensor for data reduction, instead of applying MFPCA, because of the uniqueness of our problem. In literature, MFPCA is used for functional clustering when the number of functional variables is small (i.e., p is around 2 to 3). For example, the number of functional variables of the applications considered in Jacques and Preda (2014b) is p = 2. In our application, we have p = 42, which is much larger than those in existing applications. Using MFPCA will lead to a challenging covariance estimation problem under large p. Instead, we set a common set of B-spline basis functions across all p variables when we do separate FPCA. The basis functions ’s are linear combinations of these common B-spline basis functions, which can preserve the dependence among different functional variables to some extent. Similar ideas are also used in literature (Kowal et al. 2017).
2.2. Model-Based Clustering with Variable Selection
We introduce a model-based algorithm with a penalty term to cluster the q-dimension coefficient vectors obtained from Section 2.1. The coefficient matrix is , which is an n × q matrix. For convenience, we shall also call each column of the coefficient matrix as a variable.
To conduct model-based clustering, the distribution of the random vector is modeled by Gaussian mixture distributions, which are widely used in literature. The probability density function (pdf) of is
Here, m is the number of clusters, πk are proportions satisfying , and is the normal pdf for the kth cluster with mean and covariance matrix Σ. That is,
The Σ does not represent the correlations from the functional data, but it is related to the correlation of the coefficients in the Karhunen–Loève expansion. A diagonal structure of Σ is commonly used in the literature. In summary, the vector for unknown parameters is In some non–variable-selection context, separate covariance matrices are used for each cluster (Schmutz et al. 2020). In the variable selection setting, the number of variables can be large. We found separate covariance matrices can lead to robustness issues in covariance estimation when the numbers of observations assigned to some clusters are small.
Let δik be the indicator for observation i in cluster k such that if is from cluster k and 0 otherwise. Then the negative log-likelihood with the latent indicators δik is
To perform variable selection simultaneously with clustering, we consider the following penalized negative log-likelihood:
The penalty term in (6) can have different forms according to the need. In this paper, we consider three types of penalties: individual, variable, and group penalties. The individual penalty penalizes each mean component μkj separately, enforcing sparsity on individual means. The variable penalty penalizes the largest mean component corresponding to each variable in all clusters (i.e., ), enforcing variable-wise mean sparsity. The transformed data has q variables. The group penalty penalizes mean components from the same group simultaneously. Here we treat variables coming from the same sensor as one group.
Specifically, the individual penalty is defined as
In each penalty, the weights serve a role that is similar to those in the adaptive Lasso (Zou 2006). Specifically, λ controls at the universal level because it remains the same for all variables and clusters, and the weights adjust the penalization adaptively. In the individual penalty, one can define the weights according to mean components for each variable and cluster as in Zou (2006). That is,
Again, the element of , which is , is estimated when γ = 0. In both (7) and (8), γ is a hyperparameter for the weights. The calculations of in (7) and (8) are shown in Appendix A, Section A.1. With λ and γ, the penalties put more weights on variables with mean components close to zero. Conversely, variables with large mean components are not easily removed because the weights are small and the penalty terms. The hyperparameter γ adjusts the weights for mean components from each cluster. We need to choose hyperparameters λ and γ simultaneously, which will be discussed in Section 2.4.
Individual, variable, and group penalties all remove variables not contributing to the clustering procedure. However, according to the way each penalty is built, they act differently when removing variables. We now introduce more details on the principles behind all penalties.
The individual penalty term penalizes individual mean component μkj for each cluster and each variable. For example, μkj and for are two separate parameters in the estimation even though μkj and both correspond to the jth variable. In the individual penalty, we remove the jth variable from the clustering procedure when all the corresponding mean components for all m clusters are shrunk to zero, that is, For variables with little contribution to clustering, their mean components will be small across all the m clusters and will be removed automatically by the individual penalty.
The variable penalty sets the mean components μkj of the jth variable to zero for all , if its maximum mean component among m clusters is set to zero. As a result, the variable removal criterion is Compared with the individual penalty, the variable penalty considers the mean components from the same variable simultaneously since they share similar variable information. Note that is equivalent to . However, how the individual penalty and the variable penalty set μkj’s to zeroes are different. Individual penalty uses penalization on mean component for each variable, whereas variable penalty only applies penalization on the maximum mean component among different variables. For the jth variable, it is likely that some of the μkj’s are set to zero but not all. In this situation, using the individual penalty, the variable will not be removed. However, using the variable penalty, the variable is removed if the is set to be zero. More details are in Section 2.3.
For the group penalty, the removal criterion is when all the elements of are set to zero for . In such case, the sth sensor is removed. For the individual and variable penalties, the sth sensor is removed when all its mean μksl are set to zero under the indexing in (4).
With properly selected λ and γ, all three penalties can automatically set the mean components to zero for those variables without much contribution to the clustering. Closed-form parameter estimations exist for all penalty terms, as described in the next section.
2.3. Estimation Procedure
In estimation, we maximizes the penalized negative log-likelihood. From a decision making point of view, the utility function is in (6). Because (6) contains latent cluster indicators δik, we use an EM algorithm to estimate the parameters θ. The parameter updating step varies for different penalties. In the following, we describe the EM algorithms for individual, variable, and group penalties. In estimation, we first use the EM algorithm described with γ = 0 to obtain an estimate of as , and then perform the EM again with nonzero γ to obtain the final estimates.
In general, the EM algorithm consists of an expectation step (E-step) and a maximization step (M-step). The E-step estimates the cluster indicators δik and updates the proportions πk through conditional expectations. The M-step updates the distributional parameters and Σ based on the estimated δik and πk from the E-step. The EM algorithm used in our method is shown as follows.
(i) Parameter Initialization: Given the number of clusters m and the coefficient vectors , we initialize parameters and for . We use the estimates from the K-nearest-neighborhood method to initialize the EM algorithm.
(ii) E-Step: For the rth EM iteration, the conditional expectations of the cluster indicators δik are estimated by
where and are the estimates from the previous step. The proportions are updated as(iii) M-Step: With the updated and , the distributional parameters can be updated. In particular, the elements of Σ are updated as
(9)The derivation of (9) is in Appendix A, Section A.2. The estimation of Σ is the same for all the three penalty terms because the penalty terms do not involve the covariance matrix. Conversely, the estimation procedures for the mean components vary for different penalties.
The M-steps for mean components under different penalties are as follows. We follow the framework in Xie et al. (2008) but tailored the formulas for our specific model formulation with adaptive weights.
(1) Individual Penalty: With adaptive weights, the sufficient and necessary condition for to globally minimize function is
Here, “iff” means “if and only if.” With the weight term wkj as specified in (7), the mean component update is different for each variable and cluster. In the rth step, we update μkj by
(10)where if x > 0 and 0 otherwise. In (10), both and are calculated from the previous step.(2) Variable Penalty: Let , and
(11)We update the parameter as follows:
(3) Group Penalty: In the group penalty, variables are grouped by sensors. The covariance matrix can be written as , where Σs is a diagonal matrix. With adaptive weights, we have the sufficient and necessary condition for being a unique minimizer of as
where is defined in (3). As a result, in the M-step for the group penalty, is updated as(12)whereand the element of is as in (11). Here, I is the identity matrix.
(iv) Convergence: We repeat the steps introduced in (ii) and (iii) until it converges. In this paper, we set the stopping criterion as when the parameter changes in two consecutive steps are negligible, that is, when
2.4. Hyperparameter Selection
For each type of penalty, it is important to select the value of hyperparameters. There are three hyperparameters: λ, γ, and m. Recall that λ and γ are for the penalty terms, and m is the number of clusters. Following Xie et al. (2008), we use the adjusted BIC to choose the hyperparameters, which is defined as Here is the effective degrees of freedom and n0 is the number of mean components that are forced to be zeros. Because we model all variables with a diagonal covariance structure, the information provided by data is not only related to the number of observations but also related to the number of variables. Therefore, we slightly modify the calculation of adjusted BIC as
In the literature, choices of λ and m are well studied, whereas the hyperparameter γ in the weights is often set to be one. To have more flexible weights, we use a grid search to find the hyperparameter combination with the minimum adjusted BIC. To avoid extreme behavior of weights, we fix the γ grid as .
Because the best λ value increases as the number of observations increases, we use different grids for different numbers of observations. In particular, the grid for λ is . To choose the best γ and λ combination, with each value of γ in γ grid, we first fix γ at zero, use adjusted BIC to choose the λ, and use the chosen λ to estimate which are used in the adaptive weights as in (7) and (8). Then, we perform estimation again with this at the nonzero γ we choose and go through the λ grid again using the adaptive Lasso. We use adjusted BIC to choose the best γ and λ combination.
It is easy to see from (13) that the adjusted BIC becomes smaller when more mean components are set to zeros. Because using more clusters and variables leads to a larger log-likelihood, the numbers of clusters and variables are controlled by the penalty term in (13). Therefore, the chosen hyperparameters reach a balance between the goodness-of-fit represented by the log-likelihood and model size restricted by the penalty.
Another specification that needs to be made is the number of FPCs, , which is a nontrivial issue. One commonly used strategy is to select the number of FPCs so that a high percentage, say 90%, of variation is explained by the FPCA, which works well when p is small. When p is large, requiring all functional variables achieve a high percentage of variation would require a large number of FPCs. Another strategy is to choose different for each functional variable according to some model criterion (Zhong et al. 2021). Doing that will create unequal weights across different functional variables in the likelihood calculation (i.e., those functional variables with more FPCs will contribute more to the likelihood), which does not fit the clustering problem considered in this paper. In this paper, we use a simple but practical solution. We set the number of FPCs so that at least of the functional variables have more than of their variations explained by the chosen number of FPCs. In the data analysis, we set proportions as and to select the number of FPCs. That is, we select such that at least 80% of the sensors have more than 80% of their variations explained by their first FPCs.
To link to the decision-making framework, the previous sections propose a functional data clustering method and provide criteria and suggestions in selecting the number of clusters, the penalty type, and the value of penalties. To obtain a satisfying clustering result, it is important to select the number of clusters, a proper type of penalty, and the values of penalties.
3. Simulation Study
In this section, we conduct simulations on various scenarios to evaluate the performance of clustering and variable selections. We simulate data that mimic the real data from System B with enough sampling points to represent the true functional curves of all the sensors. After generating data, we apply the FPCA and conduct clustering and variable selection under the optimal hyperparameters chosen by the adjusted BIC. Estimated results are compared with true values, and model performances with different penalties are discussed. To illustrate the advantage of variable selection in clustering, we also compare the results from clustering with variable selection with the results from clustering without penalty (i.e., no variable selection).
3.1. Setup
In the simulation, we investigate the effects of three factors on clustering and variable selection, which are the sample size, the signal-noise ratio, and the signal strength. The signal-noise ratio is reflected by the number of signal sensors and the number of noisy sensors. In particular, we consider both signal sensors (i.e., have effects on clustering) and noisy sensors (i.e., have no effects on clustering). Let be the number of signal sensors and be the number of noisy sensors. The total number of sensors is . Signal strength refers to the variability of functional curves around its cluster center.
To allow for investigating those factors in the simulation in a relatively simple manner, certain structures are used in the data simulations. For both signal sensors and noisy sensors, we use B-splines with bases of order 3. The domains of all simulated sensor data are from 0 to 30, where there are 31 measurements on each unit. With the same basis functions, coefficients are used for each sensor. The spline coefficients for an observation i are with elements
Here, and are spline coefficients for signal sensors and noisy sensors, respectively. To simulate multiple functional clusters, we use a Gaussian mixture distribution to generate , whose pdf is
The simulation model in (14) is similar to, but different from, the fitted model in (2). In this way, data simulated from (14) can mimic the main features in the real data but are not necessarily in favor of the fitted model, because the simulated data still need to go through the FPCA for data reduction. Also, before performing the analysis, we rescale the data of each sensor to have mean 0 and variance 1.
To simplify the setting, we set the number of clusters m = 3 and use equal proportions with , k = 1, 2, 3. The mean component for cluster k is with elements
Here, and are the mean components for signal sensors and noisy sensors, respectively. The covariance matrix for cluster k is specified as , and
Here, δ is a value used to control the magnitude of variance (i.e., control the signal strength), and and are the variance terms for signal sensors and noisy sensors, respectively. For signal sensors, we choose the value of and to mimic the real data. For all m clusters of noisy sensor data, we set elements in to all be zero and assign the same value to all the diagonal elements in . The value is chosen so that variances of spline coefficients for noisy sensors have a similar magnitude to the variances of spline coefficients for signal sensors. As an illustration, Figure 2, (a)–(c), shows examples of simulated functional data from a strong signal sensor, a weak signal sensor, and a noisy sensor, respectively.

Notes. Each line shows one observed functional curve from one sensor. The solid bold lines represent cluster means. (a) Strong signal sensor. (b) Weak signal sensor. (c) Noisy sensor.
In our simulations, we consider three scenarios that investigate the effects of sample size, the signal-noise ratio, and the signal strength on clustering and variable selection. To see the effect of sample size, we vary 50, 200, 350, and 500 to generate data and fix , and .
We study the effect of the signal-noise ratio by varying the number of noisy sensors while the number of signal sensors is fixed. We set while using , and 64. We fix n = 200 and for all cases in this scenario.
We investigate the effect of signal strength by varying , and 2.5. A larger δ leads to a smaller coefficient variance, which generates functional curves that are closer to each other. Conversely, a smaller δ generates functional curves that are more spread out. We fix , and n = 200 for all the cases in this scenario.
3.2. Results
In this section, we present simulation results with different sample sizes, signal-noise ratios, and signal strengths. Under each setting, we repeat 200 times and obtain the results. For the 200 simulated samples under each setting, we calculate the mean absolute error of the estimated number of clusters as where is the estimated number of clusters for the ith sample, and is the true number of clusters. In this study, is three across different setups. For clustering accuracy, we also compute the adjusted Rand index (ARI), which is a nonparametric correlation estimation (Hubert and Arabie 1985), where a higher similarity between two variables returns an ARI closer to one.
To evaluate the performance of variable selection, we calculate the mean number of variables removed, sensors removed correctly, and sensors removed falsely. Signal sensors are considered removed falsely if they are identified as noises. In the simulation, the number of FPCs is chosen as three (i.e., three variables for one sensor).
Table 1 shows the summary of simulation results, and Figure 3 shows the boxplots of ARI for 200 data sets under different sample sizes for various methods. The ’s using different penalties are similar. From the ARI plot, we can see that the performance of the individual penalty and the group penalty are similar, but the ARI of the variable penalty is worse than the individual and group penalties. Regarding variable selection, the number of falsely removed sensors is generally small. The variable penalty tends to have more falsely removed sensors compared with the individual and group penalties. The number of correctly removed sensors is close to the true value (i.e., 16) for all the cases and all the three different penalties.
|

Table 1. Summary of Simulation Results Under n = 50, 200, 350, and 500, with , and for All Settings
| n | Penalty | Variable removed | Sensor removed correctly | Sensor removed falsely | (no penalty) | |
|---|---|---|---|---|---|---|
| 50 | Individual | 0.29 | 49.88 | 15.84 | 0.05 | 1.70 |
| Variable | 0.20 | 49.37 | 15.32 | 0.19 | ||
| Group | 0.36 | 47.55 | 15.74 | 0.11 | ||
| 200 | Individual | 0.26 | 49.95 | 15.91 | 0.02 | 0.46 |
| Variable | 0.28 | 50.15 | 15.76 | 0.08 | ||
| Group | 0.20 | 47.56 | 15.84 | 0.01 | ||
| 350 | Individual | 0.32 | 49.50 | 15.82 | 0.01 | 0.25 |
| Variable | 0.26 | 49.99 | 15.78 | 0.06 | ||
| Group | 0.28 | 47.42 | 15.80 | 0.00 | ||
| 500 | Individual | 0.43 | 48.96 | 15.59 | 0.03 | 0.22 |
| Variable | 0.42 | 49.48 | 15.51 | 0.17 | ||
| Group | 0.28 | 46.81 | 15.60 | 0.01 |
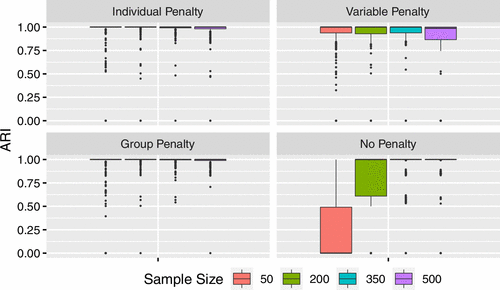
Table 2 shows the summary of simulation results, and Figure 4 shows the boxplots of ARI for 200 data sets under different signal-noise ratios for various methods. The group penalty method performs better than the individual and variable methods in terms of and the number of falsely removed sensors. Also, the number of correctly removed sensors is close to the true value for all the cases and all the three different penalty methods, and the variable penalty tends to have more falsely removed sensors. The ARI plots show that the individual and group penalties are better than the variable penalty.
|
Table 2. Summary of Simulation Results Under and 64, with n = 200, , and for All Settings
| Penalty | Variable removed | Sensor removed correctly | Sensor removed falsely | (no penalty) | ||
|---|---|---|---|---|---|---|
| 8 | Individual | 0.28 | 25.96 | 7.93 | 0.01 | 0.12 |
| Variable | 0.20 | 26.29 | 7.89 | 0.09 | ||
| Group | 0.18 | 23.85 | 7.94 | 0.00 | ||
| 16 | Individual | 0.26 | 49.95 | 15.91 | 0.02 | 0.46 |
| Variable | 0.28 | 50.15 | 15.76 | 0.08 | ||
| Group | 0.20 | 47.56 | 15.84 | 0.01 | ||
| 32 | Individual | 0.34 | 98.12 | 31.98 | 0.06 | 1.17 |
| Variable | 0.27 | 97.94 | 31.67 | 0.10 | ||
| Group | 0.26 | 95.64 | 31.84 | 0.04 | ||
| 64 | Individual | 0.32 | 189.09 | 62.26 | 0.02 | 1.81 |
| Variable | 0.32 | 184.74 | 60.65 | 0.14 | ||
| Group | 0.29 | 182.44 | 60.80 | 0.01 |
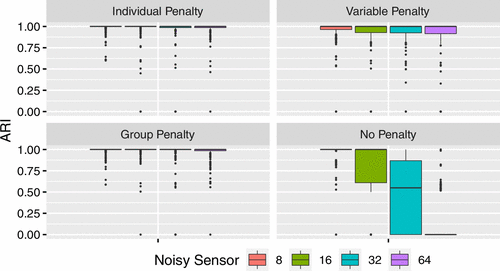
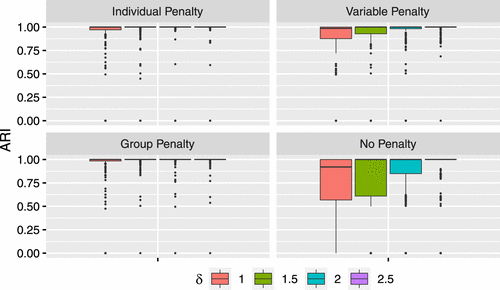
Table 3 shows the summary of simulation results, and Figure 5 shows the boxplots of ARI for 200 data sets under different signal strengths for various methods. The results show that stronger signals return better clustering results for all variable selection methods. In all cases, the group penalty method outperforms the variable and individual penalty methods in terms of and the number of sensors removed falsely. The number of correctly removed sensors is close to the true value for all the cases and all the three different penalty methods. Similarly, the ARI plots show that the individual and group penalties are better than the variable penalty.
|
Table 3. Summary of Simulation Results Under , and 2.5, with n = 200, , and for All Settings
| δ | Penalty | Variable removed | Sensor removed correctly | Sensor removed falsely | (no penalty) | |
|---|---|---|---|---|---|---|
| 1 | Individual | 0.36 | 49.98 | 15.88 | 0.04 | 0.62 |
| Variable | 0.31 | 50.06 | 15.69 | 0.12 | ||
| Group | 0.28 | 47.87 | 15.92 | 0.04 | ||
| 1.5 | Individual | 0.26 | 49.95 | 15.91 | 0.02 | 0.46 |
| Variable | 0.28 | 50.15 | 15.76 | 0.08 | ||
| Group | 0.20 | 47.56 | 15.84 | 0.01 | ||
| 2 | Individual | 0.26 | 49.98 | 15.91 | 0.04 | 0.34 |
| Variable | 0.24 | 50.24 | 15.72 | 0.10 | ||
| Group | 0.10 | 47.91 | 15.96 | 0.01 | ||
| 2.5 | Individual | 0.20 | 49.92 | 15.89 | 0.02 | 0.24 |
| Variable | 0.21 | 50.12 | 15.70 | 0.07 | ||
| Group | 0.10 | 48.02 | 15.99 | 0.01 |
In summary, the group penalty performs the best in terms of ARI, , and the number of falsely removed sensors. Based on the simulation results, we recommend using the group penalty for the clustering of functional data with variable selection.
3.3. Comparison with Clustering Without Variable Selections
Our focus is on functional clustering with variable selection. Because there are no existing methods for direct comparisons, we compare our methods with the method without variable selection. For clustering without variable selection, our approach is similar to Jacques and Preda (2014b), but we use separate FPCA to handle a relatively large p.
The results for clustering without variable selections are shown in the last columns of Tables 1–3. In general, the is much worse than those from variable selections. With larger sample sizes, does become smaller for the method without variable selection, which shows it is necessary to consider variable selection, especially when the sample size is small. When the number of noisy sensors increases, the for the method without variable selection becomes worse, which shows it is important to consider variable selection when the number of noisy sensors is large. The results show that stronger signals return better clustering results using the method without variable selection.
The last panel of Figures 3–5 shows the ARI plots for the method without variable selection. We observe similar patterns to those shown in the . In summary, both the results in the tables and ARI plots show that it is necessary to do variable selection when clustering functional data with noisy functional variables and when the sample size is small.
4. Application to System B Data
In this section, we apply the proposed methods to the sensor data from System B. The background of the application is introduced in Section 1. Based on the simulation results, we apply the proposed method with the group penalty to this engineering system sensor data because the group penalty has the best performance.
We first rescale the data to mean 0 and variance 1 before the analysis. That is, we first compute the sensor mean and standard deviation using the data from all curves from a sensor. Then, for each curve from the sensor, we subtract the curve by the sensor mean and then divide it by the sensor standard deviation. In the analysis, we use three FPCs to represent each sensor under the empirical rule proposed in Section 2.4. In this case, we have 84% of the sensors having more than 80% of their variations explained by their first three FPCs. The hyperparameters chosen by the adjusted BIC are m = 4, , and γ = 2 for the group penalty. The numbers of sensors removed and kept in the model are 23 and 20, respectively.
We visualize the result from the group penalty method. Figure 6 shows observations for a subset of four sensors that are not removed by the group penalty method, and Figure 7 shows observations for a subset of two sensors that are removed by the group penalty. The columns represent four different clusters using the group penalty method. The solid bold line in each panel shows the mean functional curve for each cluster.

Notes. Four clusters are represented by different columns, and each line shows one observed functional curve from one sensor. The solid bold lines represent cluster means.

Notes. Four clusters are represented by different columns, and each line shows one observed functional curve from one sensor. The solid bold lines represent cluster means.
Clearly, the removed sensors in Figure 7 exhibit no group features, and the selected sensors in Figure 6 show similar patterns within the same cluster. For example, the first row of Figure 6 shows an interesting pattern. The measurements of Sensor 1 decrease as time approaches the time point 30. Cluster 1 corresponds to a pattern that Sensor 1 readings were high and dropped drastically fast before time point 30. Cluster 2 corresponds to an event pattern that Sensor 1 readings dropped gradually. Cluster 3 shows the readings dropped more slowly, and cluster 4 shows Sensor 1 readings kept at a lower value until time point 30. In the real application, our proposed methods provide engineers with an automatic way to extract information from large-scale sensor data.
5. Conclusions and Areas for Future Research
In this paper, we propose a clustering method for multivariate functional data with the unique feature of simultaneous variable selection. Three penalty terms are introduced for variable selection: individual, variable, and group penalties. All three penalties perform well in both clustering and variable selection in our simulation studies. However, the group penalty shows the best performance. Also, from the decision-making point of view, we used the EM method to optimize the utility function, which is the penalized negative log-likelihood. We suggest using the modified adjusted BIC to select the number of clusters and the hyperparameters in the clustering method.
A sensor data application is considered in this paper, where sensors in the engineering system provide multivariate functional data. Selected sensors highlight important sensors contributing to the clustering of functional patterns. Our proposed methods can be used in the initial screening process of sensor scheduling and selection. The identification of important sensors and patterns through clustering provides an effective way to extract information from sensor data, which can be important for business owners of such data.
Our method is applicable to applications other than engineering sensor systems. It can be applied to other studies with multivariate functional variables that have the need for clustering and variable selection. For example, a study on implantable body devices for identifying life-threatening events was presented in Van Laerhoven et al. (2004), where only a K-means clustering is used. Our method could enhance the clustering with the incorporation of variable selection. In addition, indoor environmental safety issues occur more frequently because of the increased use of home appliances. Usually, multiple devices are deployed to monitor possible emergencies such as fire and smoke appearances (Wu and Clements-Croome 2007). Our method could be applied to recognize various risks at home.
As for future research, the robustness of clustering methods has been of interest in literature (Tupper et al. 2018, Park and Simpson 2019). It will be interesting to study the robustness of functional clustering methods under the setting of variable selection, which is nontrivial. In another direction, misalignment of the functional data can be challenging in clustering (Slaets et al. 2012). Although our sensor data are well aligned, it will be interesting to consider functional clustering with variable selection under functional data with misalignment.
In some applications, the sampling frequencies may vary among different sensors. Sampling frequencies may influence the clustering results through the estimated values of the truncated coefficients of the Karhunen-Loève expansion in FPCA. When some sensors do not have enough samples, the clustering results may change. Investigating and solving the inadequate sample problem is an interesting future research topic in functional data clustering. Another potential future research direction is selecting the number of clusters and useful sensors using methods other than the adjusted BIC. Previously, Huang et al. (2002) and Hurvich et al. (1998) developed model selection criteria for selecting the smoothing hyperparameters in estimating functional curves. Those two papers can bring insights into improving the adjusted BIC selection method in our case. Thus, it is worthy to further explore the improvement opportunity in the future.
The authors thank the editor-in-chief, a senior editor, an associate editor, and three anonymous referees for providing helpful comments and suggestions that significantly improved this paper. The authors acknowledge Advanced Research Computing at Virginia Tech for providing computational resources.
Appendix A. Some Derivations
A.1. Mean Component Estimates
Let be the minimizer for (5), when there is no constraint on the likelihood, and satisfies
The partial derivative of the likelihood is then
With a nonsingular covariance matrix Σ, we obtain the estimator of by setting (A.1) to zero and multiplying Σ on both sides of the equation. That is, Then, the estimate for the mean component from cluster k is
A.2. Covariance Matrix in the EM Algorithm
Similar to the mean component estimate calculation, ’s are calculated by setting the partial derivative of the penalized log-likelihood function with respect to Σ to be zero. We have
References
- (2003) Unsupervised curve clustering using B-splines. Scandinavian J. Statist. 30(3):581–595.Google Scholar
- (2019) Model-based clustering and classification of functional data. Wiley Interdisciplinary Rev. Data Mining Knowledge Discovery 9(4):e1298.Google Scholar
- (2012) Dynamical functional prediction and classification, with application to traffic flow prediction. Ann. Appl. Statist. 6(4):1588–1614.Google Scholar
- (2007) Functional clustering and identifying substructures of longitudinal data. J. Roy. Statist. Soc. B 69(4):679–699.Google Scholar
- (2001) Overview of automotive sensors. IEEE Sensing J. 1(4):296–308.Google Scholar
- (2013) Wavelet-based clustering for mixed-effects functional models in high dimension. Biometrics 69(1):31–40.Google Scholar
- (2022) Functional mixed effects clustering with application to longitudinal urologic chronic pelvic pain syndrome symptom data. J. Amer. Statist. Assoc. 117(540):1631–1641.Google Scholar
- (2006) A quantitative study of gene regulation involved in the immune response of anopheline mosquitoes: An application of Bayesian hierarchical clustering of curves. J. Amer. Statist. Assoc. 101(473):18–29.Google Scholar
- (2002) Varying-coefficient models and basis function approximations for the analysis of repeated measurements. Biometrika 89(1):111–128.Google Scholar
- (1985) Comparing partitions. J. Classification 2:193–218.Google Scholar
- (1998) Smoothing parameter selection in nonparametric regression using an improved akaike information criterion. J. Roy. Statist. Soc. Ser. B. Statist. Methodology 60(2):271–293.Google Scholar
- (2014a) Functional data clustering: A survey. Adv. Data Anal. Classification 8:231–255.Google Scholar
- (2014b) Model-based clustering for multivariate functional data. Comput. Statist. Data Anal. 71:92–106.Google Scholar
- (2021) Pan-disease clustering analysis of the trend of period prevalence. Ann. Appl. Statist. 15(4):1945–1958.Google Scholar
- (2003) Clustering for sparsely sampled functional data. J. Amer. Statist. Assoc. 98(462):397–408.Google Scholar
- (2012) Multilevel functional clustering analysis. Biometrics 68(3):805–814.Google Scholar
- (2010) Functional cluster analysis via orthonormalized Gaussian basis expansions and its application. J. Classification 27(2):211–230.Google Scholar
- (2018) Sensors and sensor fusion in autonomous vehicles. Proc. 26th Telecommunications Forum (IEEE, Piscataway, NJ), 420–425.Google Scholar
- (2017) A Bayesian multivariate functional dynamic linear model. J. Amer. Statist. Assoc. 112:733–744.Google Scholar
- (2013) Predictive manufacturing system-trends of next-generation production systems. IFAC Proc. Vol. 46(7):150–156.Google Scholar
- (2017) Classification of non-parametric regression functions in longitudinal data models. J. Roy. Statist. Soc. B 79(1):5–27.Google Scholar
- (2008) Penalized clustering of large-scale functional data with multiple covariates. J. Amer. Statist. Assoc. 103(482):625–636.Google Scholar
- (2012) Aerospace Sensors (Momentum Press, New York).Google Scholar
- (2019) Robust probabilistic classification applicable to irregularly sampled functional data. Comput. Statist. Data Anal. 131:37–49.Google Scholar
- (2008) Distance-based clustering of sparsely observed stochastic processes, with applications to online auctions. Ann. Appl. Statist. 2(3):1056–1077.Google Scholar
- (1997) Functional Data Analysis (Springer-Verlag, Berlin).Google Scholar
- (2006) Functional clustering by Bayesian wavelet methods. J. Roy. Statist. Soc. B 68(2):305–332.Google Scholar
- (2014) Functional clustering in nested designs: Modeling variability in reproductive epidemiology studies. Ann. Appl. Statist. 8(3):1416–1442.Google Scholar
- (2020) Clustering multivariate functional data in group-specific functional subspaces. Comput. Statist. 35:1101–1131.Google Scholar
- (2012) Phase and amplitude-based clustering for functional data. Comput. Statist. Data Anal. 56:2360–2374.Google Scholar
- (2018) Band depth clustering for nonstationary time series and wind speed behavior. Technometrics 60:245–254.Google Scholar
- (2004) Medical healthcare monitoring with wearable and implantable sensors. Proc. 3rd Internat. Workshop on Ubiquitous Comput. for Healthcare Appl (CiteSeerX, University Park, PA).Google Scholar
- (2007) Understanding the indoor environment through mining sensory data: A case study. Energy Building 39(11):1183–1191.Google Scholar
- (2008) Penalized model-based clustering with cluster-specific diagonal covariance matrices and grouped variables. Electronic J. Statist. 2:168.Google Scholar
- (2021) Cluster non-gaussian functional data. Biometrics 77(3):852–865.Google Scholar
- (2006) The adaptive lasso and its oracle properties. J. Amer. Statist. Assoc. 101(476):1418–1429.Google Scholar

