
Anatomy of the Edelman: Measuring the World’s Best Analytics Projects
Abstract
Each year, the INFORMS Edelman Award celebrates the best and most impactful implementations of operations research, management science, and analytics. As the Edelman Award approaches its 50-year mark, we provide a history and characterization of the award’s finalists and winners. We provide some basic descriptive analytics about the participating organizations and authors, the impact of their work, and the methods they employed. We also conduct predictive analytics on finalist submissions, gauging contributors to success in establishing winning entries. We find that predicting Edelman winners a priori is extremely difficult; however, given a set of finalists, predictive models based on monetary impact could have predicted the winner over half the time in recent years, but would have had less predictive success in the early years of the competition. We suggest that, by characterizing the finalists, we can give future entrants a better picture of what it takes to compete for the Edelman Award.
Introduction
In this paper, we characterize the finalists and winners in the past 48 years of the Edelman Award competition (1972–2019) in order to describe the characteristics needed to be an Edelman finalist and eventual winner. This characterization of finalists and winners promotes both the award and its contributions and gives potential organizations and authors knowledge about the attributes of a project worthy of entry and perhaps victory in the competition.
We characterize project size via a number of attributes, including authors, organizations, methods, and dollars saved. We evaluate participation by industry sector, country, and academic and consulting affiliation of supporting organizations. Based on this information, we attempt to predict the probability of winning for entrants in any given year. We think this research is useful to both researchers and practitioners alike as a useful source of “what it takes” to compete in the Edelman Award competition of INFORMS.
Background
The Edelman competition began in 1972, making the 2020 competition the 49th in the competition’s history. In discussing the purpose of the award, the INFORMS website states the following:
The Franz Edelman competition attests to the contributions of operations research and analytics in both the profit and non-profit sectors. Since its inception, cumulative benefits from Edelman finalist projects has topped the $292 billion mark. Edelman finalist teams have improved organizational efficiency, increased profits, brought better products to consumers, helped foster peace negotiations, and saved lives. The purpose of the Franz Edelman competition is to bring forward, recognize and reward outstanding examples of operations research, management science, and advanced analytics in practice in the world. (INFORMS 2019)
The website continues by providing information about Franz Edelman, the award’s namesake:
Franz Edelman is counted among the fathers of innovation in OR/MS. Coming of age in Hitler's Germany, Edelman dedicated his career to facilitating better decisions on matters great and small through operations research. Today, his discoveries, along with other OR/MS pioneers, inspire initiatives to help leaders get better results in every sector of management and operations. This top INFORMS practice prize was named after Franz Edelman shortly after his death in 1982. He established one of the earliest industrial OR/MS groups in North America at RCA, where he worked for over 30 years as O.R. director. (INFORMS 2019)
Additional information, critically important for competition applicants, are the judging criteria, as stated in the award’s policies and procedures:
The award is given for implemented work, not for a submitted paper or for the presentation describing the work. The Edelman criteria are: (1) Amount of beneficial impact on the client organization; (2) The level of innovation in both analytical methods and implementation; (3) Generalizability of the work for use in other organizations, especially in different kinds of organizations; (4) Difficulties surmounted — these can be technical, political, or managerial. Judges are free to assign their own degrees of importance to these criteria. Because the award has traditionally emphasized improvement in organizational performance, the heaviest weight is typically assigned to criterion (1): total beneficial impact, both absolute and relative to the size of the client, considering both quantified and non-quantified impacts. Testimonies from senior management constitute an influential source of information to confirm impact. (INFORMS 2019, pp. 6–7)
As the judging criteria indicate, the award recognizes only implemented work. The first-place winner is determined by a panel of expert judges who deliberate following an in-depth presentation by each finalist. No details of the judges’ deliberations are publicly disclosed. No ranking of “nonwinners” is provided after the judges’ deliberations; only the winner is announced.
Prior Research
A number of prior manuscripts evaluate the Edelman Award finalists based on several dimensions. Bell et al. (2003) is the only prior research paper that considers elements of Edelman finalists. They evaluate the presence of “strategic OR” within the 42 private sector Edelman finalists between 1989 and 1998 and the extent to which these projects provided continued, sustainable benefit to the companies at which they were implemented. The Edelman finalists are typically high profile, high investment, and high return; the authors find that approximately 60% of the Edelman finalists during this period continued to provide value to the organizations. As they point out, for OR to have a lasting and permanent impact on an organization, it must be “strategic” or permanent. Although we acknowledge that not all Edelman projects are permanent, we report on the benefits claimed at the time of the award and do not evaluate the actual or ongoing savings. On the other hand, Bell et al. (2001) discuss the longevity of Edelman projects and their organizations for some specific projects and note that not all persist.
Bell and Anderson (2002) characterize Edelman projects in a number of dimensions, including the intensity of OR content and whether the origins of the projects were problem resolution, crisis avoidance, or opportunity realization, and the like. In our case, we characterize projects by criteria, such as their results, methodology, and sector. Our objectives are to describe the attributes required to become an Edelman finalist and to try to predict winners based on those attributes.
Wynne and Robak (1989) compare 40 Edelman Award finalist papers, published between 1977 and 1986, on six dimensions:
A predisposition to change in the organization.
A dual organizational structure that allows for hierarchical and horizontal coordination.
A decentralized structure that allows for innovation and entrepreneurial behavior.
Generic business processes that allow information networks within the organization to interact.
A market focus that seeks to create value and efficiency.
An organization that is cooperative with a focus on reciprocity with access to information, tools, and support.
Their qualitative analysis provides point values in each of these six dimensions. They found that 5 of the winning papers appeared in the top 12 ranked papers, indicating that organizations with these attributes are more likely to succeed. Although we evaluate the probability of success, we do so on a project basis without an assessment of the organizational contribution to the probability of success.
To our knowledge, no prior analysis of Edelman finalists has sought to characterize attributes of all Edelman finalists nor to predict probabilities of those finalists to win the award.
Finalist Participation
In the award’s 48-year history, there have been 49 winners, including dual winners in 1984, and 296 finalists, averaging 6.17 finalists per year. “Finalist” in this sense is the client organization that benefited from the implementation of the analytical work described in a presentation to the judges. As Figure 1 shows, the maximum number of eight finalists was named in each of three years (1975, 1976, and 1992), and the minimum number of finalists, four, was named in one year (1988). Since 2009, the competition has converged on a norm of six per year, the mode number of finalists.
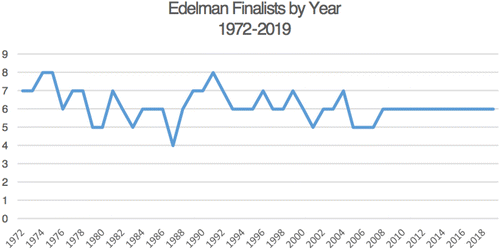
Note. The number of finalists ranges from four to eight and has standardized recently on six.
As Table 1 shows, only 18 organizations have been finalists multiple times. AT&T is the leader with nine finalist appearances and is followed closely by IBM with eight. (Side note: IBM is a finalist for the 2020 competition, tying with AT&T for the greatest number of appearances.) We make no attempt to normalize or control these statistics to account for mergers and acquisitions; rather, we use the organization name as reported at the time of the finalist appearance. For example, both Chessie Systems, a predecessor of CSX Railway, and CSX were finalists. However, each is counted separately in the finalist count. We also remove geographical or divisional distinctions. As examples, Hewlett-Packard and Hewlett-Packard Palo Alto were considered to be the same corporate organization, as were IBM and IBM Research. As a result, there are 256 unique finalist organizations (296 finalist presentations minus 40 duplicate appearances) in the history of the Edelman Award. Of these organizations, AT&T with two wins is the only multiple-time winner.
|

Table 1. Eighteen Organizations Have Been Edelman Finalists Multiple Times
| Organization | Finalist count | Wins |
|---|---|---|
| AT&T | 9 | 2 |
| IBM | 8 | 1 |
| Hewlett-Packard | 5 | 1 |
| General Motors | 3 | 1 |
| American Airlines | 3 | 1 |
| Procter & Gamble | 3 | 0 |
| U.S. Army | 3 | 0 |
| Bellcore | 3 | 0 |
| Xerox Corporation | 3 | 1 |
| RCA Corp. | 2 | 0 |
| UPS | 2 | 1 |
| United Airlines | 2 | 0 |
| Babcock & Wilcox Company | 2 | 1 |
| Pillsbury Company | 2 | 1 |
| Federal Aviation Administration | 2 | 0 |
| Syngenta | 2 | 1 |
| Getty Oil Company | 2 | 0 |
| Intel | 2 | 0 |
Note. The table totals are Organization (18), Finalist count (58), and Wins (11).
Support Organizations
In many cases, finalists turn to support organizations, which generally take technical and advisory roles in the development and implementation of the analytic methods. We define “support” organizations as those that are contributors to the Edelman work but are not the client organizations that implemented the analytical methods and derived benefits from their use. A support organization can be “primary” (i.e., it has a leading role in the submission) or “secondary” (i.e., it provides lesser support). The primary support organization is the one listed first in the list of authors; all other organizations listed are secondary. Primary and secondary support organizations are mutually exclusive and nonredundant based on this definition.
Primary support organizations were nonacademic software providers or consultants (44%) or academics (56%). Additional (not primary) support organizations were identified 90 times. We counted 179 additional support organizations, comprising academic support organizations (45%) and nonacademic support organizations (55%).
Overall, 63% (187/296) of the finalists have used at least one support organization, leaving 37% (109) of the finalists with a single organization, or no known support organization. Of the 109 single-organization finalists, 13 did not submit an acceptable paper or submitted no paper; thus, these papers have no readily identifiable support organization. Figure 2 shows an annual timeline with the number of single-organization and support-organization finalists.
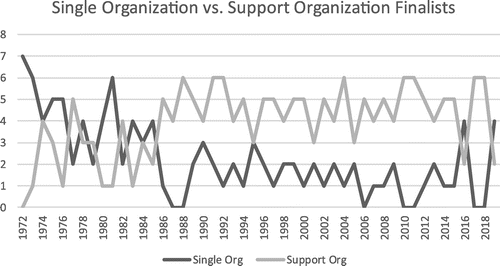
Note. The norm has shifted toward more frequent use of support organizations in recent years.
Table 2 lists the 22 primary support organizations that have supported a finalist multiple times. We have seen 149 unique primary support organizations (187 appearances of support organizations minus 38 organizations with more than one appearance). To avoid double counting of a finalist entry, we identify only one “primary” support organization for each finalist—the support organization with the most authors listed on the paper or, in case of a tie, those who are listed first. To avoid double counting of finalist and support organizations, a company (e.g., IBM or GE) is not a support organization for itself; such a company is considered “internal” support or a finalist with only one associated organization. For example, the IBM Thomas J. Watson Research Center could be listed on a submission from IBM Global Business Services but is considered internal IBM support. Thus, each appearance as a support organization is in addition to that as a primary organization with no double counting. Finally, universities are listed without differentiating departments (e.g., engineering or school of business), as are consulting and software companies, without differentiating by division or geographic region (e.g., IBM and IBM China).
|
Table 2. A Number of Primary Support Organizations Are Associated with an Edelman Finalist Entry Multiple Times
| Primary support organization | Appearances | Winning entry |
|---|---|---|
| University of Pennsylvania | 7 | 3 |
| Georgia Institute of Technology | 5 | 1 |
| IBM | 5 | 0 |
| The Massachusetts Institute of Technology | 4 | 0 |
| Sandia National Laboratories | 3 | 0 |
| University of Texas | 3 | 1 |
| University of Michigan | 3 | 0 |
| Boston University | 2 | 0 |
| ACT Systems | 2 | 0 |
| University of California at Berkeley | 2 | 1 |
| University of Chile | 2 | 1 |
| Stanford University | 2 | 0 |
| Columbia University | 2 | 1 |
| Tilburg University | 2 | 1 |
| General Electric | 2 | 0 |
| Naval Postgraduate School | 2 | 0 |
| Sabre Decision Technologies | 2 | 1 |
| Northwestern University | 2 | 1 |
| University of Southern California | 2 | 0 |
| Yale University | 2 | 2 |
| Rensselaer Polytechnic Institute | 2 | 0 |
| Princeton University | 2 | 0 |
Notes. University of Pennsylvania is the leader in appearances and participation in winning entries as the primary support organization. The table totals for the 22 support organizations are 60 appearances and 13 winning entries.
Among primary support organizations, University of Pennsylvania is the leader with seven appearances; IBM and Georgia Institute of Technology are second with five. The majority of the multiple finalists are universities. Only University of Pennsylvania and Yale University are associated with a winning entry more than once, with three and two wins, respectively. Overall, 35 of the 49 winners (71%), including two winners in 1984, have at least one support organization; of these support organization winners, 21 (60%) are academic in nature and 14 (40%) are nonacademic.
It is worthy of comment that 179 of the 187 finalists with support organizations have additional support organizations (i.e., organizations other than the primary). There are 366 total (primary and secondary) support organizations for the 296 finalists, for a total of 662 nonunique organizations that have participated. This averages to 2.24 organizations per finalist overall and implies a mean of 2 support organizations for those with outside support (i.e., over 3 organizations in those competitors with outside support). Figure 3 shows that the number of participating support organizations has grown over time.
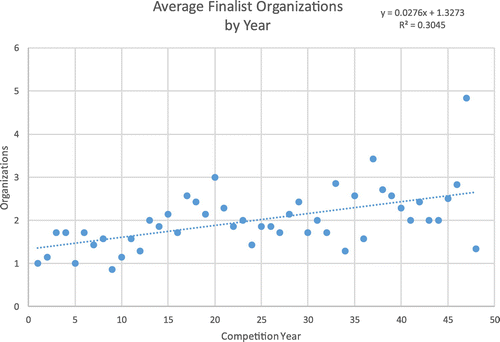
Authorship
Over the life of the Edelman Award, 278 papers have been written (12 early finalists did not submit formal papers and the 6 finalist papers from the 2019 competition had not been published as of this writing). Those papers have 1,316 nonunique authors, for an average of 4.73 authors per paper.
As one might expect, given the expanding organizational participation that Figure 3 shows, the number of authors per paper has increased over the years (Figure 4). The average over the past 10 years has been 8.4 authors per paper; the average over the first 10 years in which papers were written was 1.8 authors per paper.

Sector Participation
As Table 3 shows, the finalists include 211 (71%) private companies, 81 (27%) public or governmental organizations, and four (1%) nongovernmental organizations (i.e., NGOs, which are essentially charities). Although the finalists exhibit strong diversity, manufacturing, technology, and energy companies lead the private sector, whereas national and city organizations lead the public sector.
|
Table 3. The Plurality of Edelman Finalists Are from the Private Sector and Manufacturing Categories, Whereas Public Sector Entries Are Frequently National in Scale
| Private sector | 211 | 71% |
|---|---|---|
| Manufacturing | 39 | 18% |
| Technology | 27 | 13% |
| Energy | 23 | 11% |
| Consumer goods | 17 | 8% |
| Financial | 17 | 8% |
| Freight transportation | 16 | 8% |
| Telecommunications | 15 | 7% |
| Transportation | 10 | 5% |
| Agriculture | 10 | 5% |
| Hospitality | 10 | 5% |
| Other (10 categories) | 27 | 13% |
| Public sector | 81 | 27% |
| National | 46 | 57% |
| City | 16 | 20% |
| State/regional | 12 | 15% |
| Other (4 categories) | 7 | 9% |
| Nongovernmental organizations | 4 | 1% |
Note. Adding the totals from the three sectors, we arrive at 296 (211 + 81 + 4), which represents the number of finalist presentations.
Table 4 shows the breakdown of major public and private sector categories. Military, computer, telephone, automotive, and banking subsectors lead in the number of entries in their sectors, whereas most other sectors are somewhat evenly distributed among subsectors. The NGOs, such as the American Red Cross, are entirely within the healthcare sector.
|
Table 4. Major Public and Private Sectors Are Broken Down into Major Subsectors
| Public sector breakdown of major sectors | Major private sector breakdown of major sectors | ||||
|---|---|---|---|---|---|
| National | 44 | Manufacturing | 44 | Telecommunications | 17 |
| Military | 15 | Automotive | 10 | Telephone | 11 |
| Healthcare | 6 | Metals and steel | 8 | Communications networks | 4 |
| Air safety | 5 | Electronics | 7 | Other | 2 |
| Health and safety | 3 | Healthcare | 3 | Financial | 17 |
| Postal service | 2 | Aircraft | 2 | Banking | 9 |
| Natural gas | 2 | Paper products | 2 | Investment | 6 |
| Other | 11 | Energy transmission | 2 | Other | 2 |
| City | 14 | Other | 10 | Consumer goods | 16 |
| Fire and safety | 3 | Technology | 24 | Food | 6 |
| Police | 2 | Computer | 13 | Consumer packaged goods | 3 |
| Waste management | 2 | Equipment | 3 | Marketing | 2 |
| Healthcare | 2 | Professional services | 2 | Apparel | 2 |
| Other | 5 | Electronics | 2 | Other | 3 |
| State/Regional | 12 | Other | 4 | Freight transportation | 15 |
| Highway | 3 | Energy | 21 | Rail freight | 6 |
| Healthcare | 2 | Petroleum | 6 | Truck freight | 4 |
| Other | 7 | Oil | 5 | Water freight | 2 |
| Utility | 3 | Other | 3 | ||
| Natural gas | 3 | ||||
| Other renewable | 4 | ||||
Note. This breakdown covers 180 finalist presentations.
Geography
Table 5 shows the primary national affiliation of the winning organizations. Assigning a country to each organization is not always clear-cut. For example, the Athens Olympic planning committee was assigned a location of Greece, although the committee is ongoing and not housed in that nation. Given the multinational flavor of many competing organizations and the frequently regional or subdivisional nature of such entries, the assignment of a location is sometimes unclear. In most cases, we use the country of primary operations; for example, we assign IBM and HP to the United States. In some cases, the predominant affiliation of the authors or location of the project takes precedence. For example, BHP Group, a Melbourne, Australia, company, was a finalist for its analysis of potash mining operations in Canada; therefore, we assigned Canada as the country because all authors and activities were affiliated with Canada. We suggest that Table 5 broadly indicates the frequency of country participation, although some individual decisions could be debated.
|
Table 5. Twenty-Six Countries Have Had Finalists in the Edelman Competition and Nine Countries Boast Winners
| Country | Frequency | Percent | Winner |
|---|---|---|---|
| United States | 229 | 77.4% | 37 |
| Canada | 10 | 3.4% | 2 |
| Netherlands | 6 | 2.0% | 3 |
| China | 5 | 1.7% | 0 |
| Chile | 3 | 1.0% | 1 |
| Mexico | 3 | 1.0% | 1 |
| Japan | 3 | 1.0% | 0 |
| Norway | 3 | 1.0% | 0 |
| Brazil | 3 | 1.0% | 0 |
| France | 3 | 1.0% | 1 |
| Spain | 3 | 1.0% | 0 |
| England | 3 | 1.0% | 0 |
| Australia | 3 | 1.0% | 0 |
| Greece | 2 | 0.7% | 0 |
| South Africa | 2 | 0.7% | 1 |
| Israel | 2 | 0.7% | 0 |
| Kuwait | 2 | 0.7% | 0 |
| Germany | 2 | 0.7% | 0 |
| New Zealand | 2 | 0.7% | 0 |
| South Korea | 1 | 0.3% | 0 |
| Sweden | 1 | 0.3% | 0 |
| Belgium | 1 | 0.3% | 0 |
| Saudi Arabia | 1 | 0.3% | 0 |
| India | 1 | 0.3% | 1 |
| Egypt | 1 | 0.3% | 0 |
| Ireland | 1 | 0.3% | 1 |
| Total | 296 | 100.0% | 48 |
Notes. Of the finalist organizations, 77% are from the United States, which with its 37 winners has significantly more than the two other countries with multiple winners (Canada and the Netherlands with 2 and 3 winners, respectively). The table totals are Country (26), Frequency (296), and Winner (48).
In total, 26 countries have had finalists in the Edelman competition. The United States, which represents 77% (229/296) of all finalists, is by far the predominant participant in the Edelman. Canada (10), the Netherlands (6), and China (5) are well represented, and a number of countries had finalists two or three times. The United States also has the most winners (37), followed by the Netherlands (3), and Canada (2), with six other countries each owning one win. Winners are distributed similarly to finalists, with 77% (37/48) of the winners from the United States and 23% (11/48) of the winners from outside the United States. Proportionally, 16.2% (37/229) of U.S. finalists are winners, and 16.4% (11/67) of finalists from countries other than the United States are eventual winners.
Methods
In our analysis, we summarize the general methods identified by the authors of all 278 papers submitted. Figure 5 presents the top 22 methods (after some standardization of naming conventions) that appear at least 1% of the time. These account for 71.4% of the keywords. When taken together, optimization methods (e.g., integer, linear, nonlinear, network and math programming-based optimization), which are by far the most common methodologies, provide 28.1% of the keywords. We note that these methods are not mutually exclusive; for example, integer and linear programming are part of math programming. We report them individually to give the reader a sense of their relative frequency.
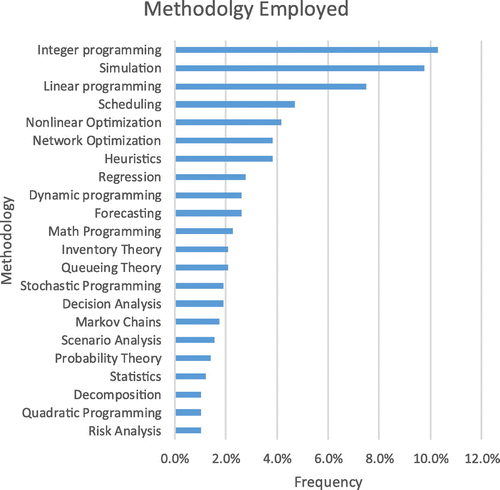
Notes. The most common methods that Edelman finalists use are typically some form of optimization. The figure totals include 410 observations of 22 methods (71.3% of the total).
Monetary Impact
A hallmark of Edelman finalist projects is the real-world impact that resulted in benefits—either monetary or nonmonetary. For convenience here, we call monetary benefits “savings,” although monetary benefits sometimes result from sources other than savings. In such cases, we call monetary benefits “dollar impact.”
Nonmonetary sources that result in real-world impact include social benefits, such as improved safety, air quality, or lives saved. To the extent that finalists monetize such benefits, we capture them as dollar impact, which we describe above. However, such benefits are often difficult to quantify accurately and often evoke “feel-good” responses from judges. For these reasons, projects with social benefits sometimes are valued by judges in a manner not reflected in dollar impact. However, these factors are not included in our analysis.
Our data summarize the cumulative savings of projects since the inception of the award. To ensure consistency in reporting, for each finalist, we conservatively estimate monetary impact by combining reported realized savings with at most two years of anticipated savings. All savings estimates are expressed as inflation-adjusted U.S. dollars.
Of the 296 finalists, 264 include estimated dollar impact. Other finalists include projects that report zero savings; that is, they include only nonmonetary impacts. For example, 10 finalist submissions address space flight, religious pilgrimage, disease control, water quality, or plutonium disposition, whereas 22 submissions deal with impacts that are not published or for which no official record is available or they represent the 2019 finalists’ projects, which have not been published as of this writing.
Figure 6 (Alden 2019) shows the cumulative all-finalist total savings over time; as of 2018, these projects have generated $292 billion in inflation-adjusted savings. As we can see in the quadratic line of best fit, the size of claimed savings has increased since the inception of the award, even after we adjust for constant dollars.
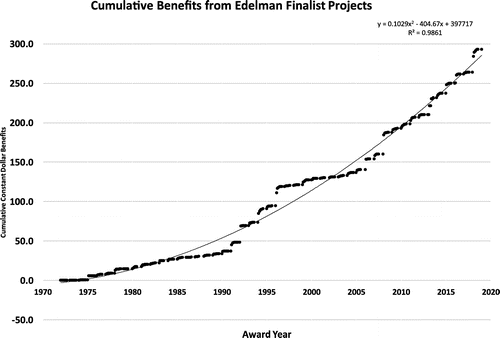
Note. The word “benefits” in the graph’s title represents total quantified monetary benefits.
Perhaps more interesting than cumulative savings is the distribution of savings for finalists. The mean constant-dollar savings reported is $1.1 billion; the median is only $200 million, which indicates a strong positively skewed distribution (skew = 5). Figure 7 shows the histogram of constant-dollar (i.e., inflation-adjusted) savings of all projects with savings reported. The plurality of projects report less than $50 million in savings and 80% report less than $1 billion.
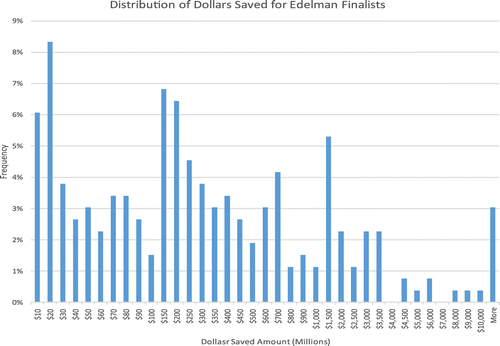
Notes. Over one-third of the finalist projects report savings of less than $100 million; almost one-third report savings between $100 million and $500 million; and nearly one-third more report savings between $500 million and $1 billion. Less than 3% report savings over $1 billion. To create an informative graph in the presence of heavy skewness, the x-axis scale is nonlinear; it grows at increments of $10 million, $50 million, $100 million, $500 million, and $1 billion.
Other sources of project value beyond monetary impact include improved health, numbers of lives saved, new industry paradigm shifts, breadth of application, new areas of application, and challenges of work and/or implementation.
Because the amount of savings can be an important factor in becoming an Edelman finalist, one might expect projects that demonstrate larger savings to win a disproportionate fraction of the time. Figure 8 shows that larger dollar-amount projects have won a higher percentage of the time; however, although the figure shows that a big dollar impact clearly does not ensure a win, as savings grow, larger projects have a definite advantage. In this example, 17% of finalists win overall. The 37% of finalist projects that generate less than $100 million in savings win only 12% of the time; the 19% of finalists with over $1 billion in savings win 24% of the time; the remaining 44%, which generate between $100 million and $1 billion in savings, win 19% of the time.
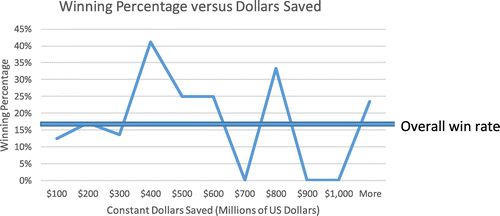
Of course, two projects that have resulted in large savings could enter in the same year, thereby rendering one large-savings project less impressive relative to the other. Surprisingly, looking at a period of 46 years over which savings have been reported, the highest reported savings actually won the award only 11 of 46 times (24%). During this 46-year interval, the winning entry has a median reported dollar saving of $859 million less in savings than the maximum nonwinning entry.
Predictive Analysis
Potential entrants who want to understand how they might compare with other entrants may try to predict likely outcomes, given project attributes. In that light, we tried to predict the probability of success of a submission based on the measurable attributes that we identified. We note that many of the explanatory variables are not known to the entrant for the current year’s other entries (these are held in confidence until the competition); however, an entrant might gauge an entry’s probability of having won in prior years’ competitions, given the information known about prior entrants and winners. This information is invaluable for assessing the plausibility of winning.
We tried to capture award criteria (impact, technical difficulty, implementation challenges, and transferability) in our measurable project attributes. We also allowed for other attributes that may affect judging but are not explicitly part of the award criteria.
Hypothesized project attributes that are related to the award criteria include the following:
Impact (dollars). This variable sums both realized and projected savings, based on the method for capturing benefit that we describe above. We transform dollars saved with the log function to account for a wide range and scale of savings reported and to achieve better predictive accuracy.
Number of organizations. The number of organizations is indicative of the scale of the problem and the implementation challenges that these organizations may have faced. It may also be indicative of transferability, because more organizations are likely to be involved in a project that can be reused in other settings and organizations.
Number of authors. The number of authors on the final paper is indicative of the complexity of the problem, and perhaps the scale of the project and its implementation challenges.
Number of methods employed. This variable attempts to capture the technical difficulty of the problem. Does the approach require only descriptive, predictive, or prescriptive methods or a combination?
Other factors that may affect outcomes include the following:
Predictive or prescriptive variable. This binary variable reflects whether the method used was predictive or prescriptive. Most finalists and award winners used prescriptive methods. This variable tests for potential bias toward a particular general methodology.
Geographic location-based bias. The objective is to discern the presence of any bias toward or away from projects based in the United States. This variable tests whether being a U.S. entrant has a positive effect on probabilities (e.g., tradition), a negative one (e.g., novelty of an entrant from outside the United States), or no effect (i.e., no bias based on the entrant’s geographic location).
Primary support organization affiliation. This variable tests if academic or private sector (e.g., software or consulting firms) support provides an increased chance of winning. On one hand, academic support might improve the research, writing, and presentation component of the entrant; on the other hand, private sector support might improve the implementation and production software component of a project. We suggest that the presence of consulting or software companies also implies an increase in transferability, both due to the resulting work product and the prior belief by private sector support organizations that the work can be used elsewhere.
At the time of submission and until the finalists are announced, no entrant knows with certainty who the competition is. Thus, we might like to predict the probability of success of a submission that is blind to other competitors. However, our data cover only entrants that are finalists: in effect, submissions that are all “winners.” We have no data on those projects that did not reach the finalist stage.
Of course, our explanatory models are limited to what we can reasonably glean from the competition data. In all cases, we cannot account for the specific deliberations of the judging panel, the quality of the exposition or presentation of a finalist, or the participation of high-level executives; thus, it may not be a surprise that predictive lift in the probability of a win is relatively low.
We applied logistic regression to predict winners. A priori to knowing the other finalists, the method did not result in a substantial improvement in the ability to predict a winner. In summary, the probability of winning was only marginally increased from the basic assumption that every entrant who becomes a finalist has an equal chance to win. (Usually, this is a 1/6 chance, given the norm of six finalists, which has most frequently been the case.)
However, once the finalists’ attributes are known, the conditional probability of a win, given the strength and attributes of the competitors, can be assessed. We implement this by first assessing each entrant’s overall probability of winning; for each year, we then identify the finalist with the highest overall probability of winning the competition. In this way, we need not necessarily predict a high probability of winning, but we can choose the entrant with the highest probability among the six finalists. Of course, we cannot assess well the probability of winning until finalists’ attributes are known using this method; thus, it may be of less value. But, it is hardly surprising that an entrant cannot easily gauge the probability of winning without first knowing details about the competitors.
To implement this, we made the following changes to the predictor variables.
The monetary savings reported by each finalist show a large spread and also show a tendency to increase with each year. Because, in any particular year, the winner is determined solely by the attributes of the other contestants, there is a need to mitigate the influence of this trend of increasing average yearly monetary savings on the predictive model. We address this by applying a natural logarithm transformation on the reported monetary savings.
To normalize the data within each year, we divide each numeric variable with the maximum reported for that year. This enables us to standardize the spread among the contestants and to compare relative positions of contestants within one award year with contestants from other award years.
Table 6 shows results from different models, which we assessed to develop a predictive model for selecting the Edelman Award winner. We estimated all models on the entire data set specific to each model and made predictions “within sample” (i.e., no held-out testing data set) due to the low number of total observations. We note that many early finalist submissions had low (even adjusting for inflation) or missing savings estimates. As the Edelman Award has grown in stature and recognition, the finalists’ entries have included larger and more sophisticated projects. It could also be true that, with more staunch competition, the dollar impact has grown in importance over time. To test this possibility, we tested our observation by truncating the training data at award year 1999 and using data for award years 2000 through 2019. Overall, we see that Model 2 with three explanatory variables offers the best predictive capability as described by “Precision” in Table 6. All the models considered in Table 6 perform on average better than a random assignment for predicting winners in the data set. Table 6 also includes the computations for lift for each model relative to a random assignment. All the values greater than one suggest better precision in selecting winners relative to a random assignment.
|
Table 6. We Use Logistic Regression to Predict the Probability of Winning the Edelman Competition (Award Years Covered: 1974–2000)
| Variables | Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | Model 6 |
|---|---|---|---|---|---|---|
| Starting year (training data) | 2000 | 2000 | 1974 | 1974 | 1974 | 1974 |
| Intercept | −9.434** | −10.611** | −6.166*** | −6.557*** | −6.392*** | −6.650*** |
| (3.393) | (3.498) | (1.785) | (1.845) | (1.908) | (1.955) | |
| Normalized log [Dollars saved by submission] | 8.684* | 8.561* | 5.125** | 5.121** | 5.317** | 5.281** |
| (3.654) | (3.651) | (1.956) | (1.959) | (2.000) | (2.003) | |
| Number of authors (normalized) | 1.215 | −0.039 | 0.081 | |||
| (0.958) | (0.600) | (0.610) | ||||
| Number of organizations (normalized) | 0.873 | 0.641 | 0.450 | |||
| (0.888) | (0.608) | (0.691) | ||||
| Use of both prescriptive and predictive methods (Factor, both = 1) | −0.146 | −0.204 | ||||
| (0.385) | (0.394) | |||||
| Country of primary institution (Factor) | 0.085 | 0.104 | ||||
| (0.400) | (0.402) | |||||
| Prescriptive (1) or Predictive (0) method used (Factor) | −0.343 | −0.366 | ||||
| (0.335) | (0.337) | |||||
| Academic entry (Factor) | 0.555 | 0.460 | ||||
| (0.342) | (0.375) | |||||
| Pseudo-R2 | 0.081 | 0.111 | 0.05 | 0.054 | 0.065 | 0.067 |
| Precision of the identifying winner | 35% | 50% | 23.9% | 26.1% | 23.9% | 23.9% |
| Lift (relative to random prediction) | 2.1 | 3 | 1.4 | 1.57 | 1.4 | 1.4 |
Notes. The coefficients for different models are given along with the standard errors, which we show in parentheses. Model 2 improves the probability of predicting a winner by 300% over a naïve equal-probability approach.
***p < 0.001; **p < 0.01; *p < 0.05.
Table 7 illustrates the confusion matrix for our predictive model based on Model 2. The predictions for all finalists based on the posterior probabilities from the logistic regression model along with their relative standing in their peer group are shown along the vertical axis on the left. The actual outcomes are shown horizontally. For a total of 118 finalists, the true negatives are 88, and true positives, false positives, and false negatives are each 10.
|
Table 7. The Confusion Matrix for Model 2 in Table 6 Results in the Best Precision for Predicting Winners
| Actual | |||
|---|---|---|---|
| Lost | Won | ||
| Predicted | Lost | 88 | 10 |
| Won | 10 | 10 | |
The precision of our model (i.e., the fraction of time it correctly predicts a winner) is 10/20 (50%). The sensitivity or the true positive rate is also 50%. The true negative rate (TN/actual), also called the specificity, is 88/98 (89.8%). The accuracy, or the fraction of time the model correctly classifies a finalist is 98/118 (83%). The error rate or the misclassification rate is then 17%.
Figure 9 shows the predicted probabilities of winning for finalists that submitted entries during years 2014–2018. For each year, we compute the predicted probability of winning for each finalist, using the logistic regression model (i.e., Model 2 from Table 6). The finalist with the highest probability is then predicted to be the winner for that year. In the plot, for each year, the actual winner is represented by a solid black circle. Note that, for years 2014 and 2018, this methodology gives a correct prediction. An interesting feature, which we show in Figure 9, is that hypothetical inferences can be now made on the probabilities that a finalist in a particular year would win in a different year. For example, the finalist with the largest probability in the year 2017 would be ranked second in years 2016 and 2018 and would not be predicted to win. Similarly, the winner in 2014 would not be predicted to win in 2015.
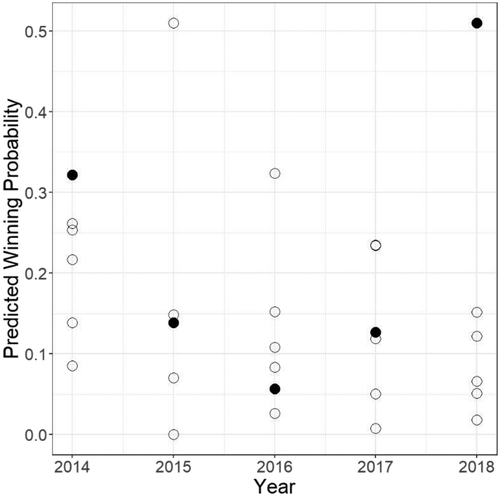
Notes. For each year, the actual winner is shown in the shaded black circle. The model is correct two out of five years.
As an illustration of model usefulness, we show how potential future participants can assess their chances of winning the Edelman competition. Calculation details are described in the appendix. In a given year, contestants can evaluate their chances of winning for different scenarios. For example, our analysis offers insight into how the probability of winning shifts according to the attributes of the project. By hypothesizing different scenarios for the attributes of the competition, it is possible to estimate the likelihood of winning in each case. By inspecting the most recent data, current contestants can also gain some insight into the “competitive landscape.” In any scenario, if a contestant has the maximum overall probability of winning, then that contestant has a 50% chance of winning the Edelman competition using that scenario.
Overall, the key insight from the analysis of the Edelman Award finalists and winners is that the most significant predictor for winning the award is the dollar impact reported. Although statistically insignificant, the number of authors and number of organizations also improved predictive accuracy in the years tested. For more recent years, the role of impact was larger and predictive accuracy improved. Although this finding can seem to neglect the impact of the number of authors involved and the organizations involved, we observe significant correlations of these variables with project impact; this connection is intuitive, because more people and organizations are likely to be associated with projects of higher value. A related interpretation can also be that high impact is also strongly associated with more collaboration.
Future Research
This research characterizes attributes of Edelman finalists and attempts to identify key contributors to success in winning the Edelman Award. Similar approaches might be applied to other major awards, such as the Wagner Prize, which has a considerably shorter history than the Edelman. Further, although we evaluated a number of models and methods, our ability to predict the winner successfully was generally low. Future research could include more nonmonetary benefits, such as improved safety, lives saved, and air quality. Part of the reason for low predictive lift could be due to the unpredictability of decision by committee, which is the method used to determine Edelman Award winners. However, if one were to characterize other attributes of the contestants, such as the quality of exposition or presentation, level of organizational support, or factors suggested by Wynne and Robak (1989), as we describe above, these factors might lead to a higher predictive ability. Finally, we found little lift in predictive ability from random selection in our predictions from our models; our results are mildly successful, given that one knows the attributes of the competitors in that cohort. This is not the case during the application process. Thus, a model that provides insight into the probability of success a priori would have greater value to prospective competitors.
Conclusion
The Edelman Award is the premier INFORMS award on the application of advanced analytics. We characterized the finalists in a number of dimensions, noting historical frequencies of finalists and among the winners. Based on those casual observations, we built predictive models for winning. We found only marginal increases in probabilities based on a number of project attributes. For each year, however, a simple model based on dollar impact, number of authors, and number of organizations predicted the highest probability of winning among the finalists; the highest-probability finalist was predicted the winner approximately one-third of the time over the history of the award and nearly half the time in recent years. For prospective competition entrants, the message is twofold. First, to be competitive the entry should be on a par with the project attributes presented here; second, once the competition has begun, the winner is determined by a number of factors that we have not identified, and every entrant has a chance.
Appendix
Part 1
The following expression can be used to compute the overall winning probability. The coefficients from Model 2 in Table 6 in the main text are used for the computations:
where
A finalist in any year can assess the chance of being the winning entry by comparing how its entry stacks up with respect to the overall probability of winning. If its entry generates the maximum overall probability relative to its peer group for that year, then that finalist has a 50% chance of winning the Edelman. As noted in the main text, a finalist usually does not have information on other finalists. However, the model we present here can be used to assess various hypothetical scenarios about the competition and estimate the probability of winning.
Part 2
The confusion matrices for Model 2 in Table 6 are included in the main text. The matrices for other models are shown in Table A.1.
|
Table A.1. Confusion Matrices for Models 1, 3, 4, 5, and 6
| Model 1 | |||
|---|---|---|---|
| Actual | |||
| Predicted | Model 1 | Lost | Won |
| Lost | 85 | 13 | |
| Won | 13 | 7 | |
|
Model 3
| Actual | |||
|---|---|---|---|
| Predicted | Model 3 | Lost | Won |
| Lost | 200 | 35 | |
| Won | 36 | 11 | |
|
Model 4
| Actual | |||
|---|---|---|---|
| Predicted | Model 4 | Lost | Won |
| Lost | 202 | 34 | |
| Won | 34 | 12 | |
|
Table A.1. (Continued)
| Model 5 | |||
|---|---|---|---|
| Actual | |||
| Predicted | Model 5 | Lost | Won |
| Lost | 201 | 35 | |
| Won | 35 | 11 | |
|
Model 6
| Actual | |||
|---|---|---|---|
| Predicted | Model 6 | Lost | Won |
| Lost | 201 | 35 | |
| Won | 35 | 11 | |
References
- (2019) Operations research: Billions and billions of benefits. 2019 Edelman Gala Recognizing Distinction in the Practice of Analytics, Operations Research, and Management Science (INFORMS, Catonsville, MD), 18–19.Google Scholar
- (2002) In search of strategic operations research/management science. Interfaces 32(2):28–40.Link, Google Scholar
- (2003) Strategic operations research and the Edelman prize finalist applications 1989–1998. Oper. Res. 51(1):17–31.Link, Google Scholar
- (2001) Is there life after Edelman? OR/MS Today 27(June):26–31.Google Scholar
INFORMS (2019) Franz Edelman award for achievement in advanced analytics, operations research, and management science. Accessed May 1, 2020, https://www.informs.org/Recognizing-Excellence/INFORMS-Prizes/Franz-Edelman-Award.Google Scholar- (1989) Entrepreneurs enabled: A comparison of Edelman prize-winning papers. Interfaces 19(2):70–78.Link, Google Scholar
Michael F. Gorman is a professor of operations management and analytics at the University of Dayton. He has 10 years of experience leading systems development at BNSF Railway and regularly consults for both shippers and carriers in transportation and logistics issues as the president of MFG Consulting, Inc. Throughout his 25 years of corporate and consulting experience, he has focused on delivering value to the organizations for which he works. Dr. Gorman graduated from Indiana University with a PhD in business and economics in 1994, and he has a master’s in economics from Indiana.
Lakshminarayana Nittala is an assistant professor at the University of Dayton with research interests in the areas of innovation, new product development, healthcare, and applications of data analytics. Prior to academia, he worked in the semiconductor industry as a technologist leading research and development projects.
Jeffrey M. Alden is a technical fellow in the Chief Data and Analytics Office at General Motors and an INFORMS fellow. His research covers many topics, including plant planning and operations, vehicle portfolio, electric vehicle infrastructure, new business analysis, complexity reduction and quality. He holds six patents, seven trade secrets, and authored over 50 papers. He has won eight GM awards for excellence. He was on a team that saved GM more than $2 billion and won the 2005 Edelman competition.

