
Handling Missing Values in Information Systems Research: A Review of Methods and Assumptions
Abstract
In today’s big data environment, missing values continue to be a problem that harms data quality. The bias caused by missing values raises the highest concern, as it cannot be eliminated simply by increasing the sample size. Although the statistics literature has developed approaches to handling missing values and formulated assumptions regarding when these approaches generate valid statistical inferences, these prescriptions have yet to be broadly accepted by many social science disciplines, including the information systems (IS) discipline. By reviewing recently published empirical research in information systems, we find that missing values are indeed an important and pervasive problem. We believe that a review of missing value theory is necessary and timely for the IS community to understand the nature of missing values and to promote more rigorous research practice when missing values are often unavoidable. In addition, the missing not at random (MNAR) mechanism brings about challenges in parameter estimation. We contribute to research practice by proposing and demonstrating the superior performance of a Monte Carlo likelihood approach in correcting bias in parameter estimation. We conclude by suggesting that research validity can be enhanced through a reasoned adoption of the missing value handling method and structured missing value reporting practices.
History: Giri Kumar Tayi, Senior Editor; Pei-Yu Chen, Associate Editor.
Funding: This work was supported by the Singapore Ministry of Education [Grants R-253-000-136-114, R-253-000-149-490, and R-253-000-158-114] the National Natural Science Foundation of China [Approval No. 72201288], and the Program for Innovation Research in Central University of Finance and Economics. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not reflect the views of the Singapore Ministry of Education, the Singapore Government or the Central University of Finance and Economics.
Supplemental Material: The online appendices are available at https://doi.org/10.1287/isre.2022.1104.
1. Introduction
Today’s big data environment has ushered in many groundbreaking opportunities for both research and practice. The availability of massive amounts of data has allowed academic researchers to develop and test theories with important scientific and societal impact. Companies that have embraced big data analytics for fact-based decision making to help optimize their operations and devise strategies have also experienced tremendous value creation. However, despite such benefits, there are also major challenges. A perennial problem faced by everyone engaged with data analytics—both academic researchers and practitioners alike—is the handling of missing values. Missing values describes situations where meaningful values for data analysis are unobserved or hidden (Little and Rubin 2019). Academic researchers have historically handled missing values primarily by dropping the observations whose information is incomplete (called listwise deletion or complete case analysis) or by editing the data (e.g., substituting missing values with the mean of the variable in question or even with zeros) to lend an appearance of completeness.1 However, such handling of missing values may lead to inference problems where incorrect conclusions are drawn from the analysis.
Although the statistics literature has, since the 1970s, developed theoretical frameworks and guidelines for handling various types of missing value situations (Rubin 1976), these prescriptions have yet to diffuse to many social science disciplines, including the information systems (IS) discipline, that have a heavy empirical focus.2 The problem of missing data is perhaps critically important to the IS discipline, as IS researchers are at the forefront of leveraging big data in a variety of domains such as e-commerce and healthcare, among others, to draw high-impact insights (Chen et al. 2012, Chiang et al. 2018). However, missing values in databases and from IT applications continues to be a major challenge in data quality that adds complexity to and even jeopardizes the validity of research inference (Ballou et al. 2003, Cappiello et al. 2003, Li 2009, Grover et al. 2018). For instance, in electronic commerce, customers frequently neglect to provide ratings for products they have purchased and consumed (Ying et al. 2006), which creates missing data for product recommendation systems. In healthcare practice, medical tests are selectively performed on some patients due to limited medical resources (Hall et al. 2007), and paper-based medical records may not be fully digitized (Baird et al. 2017), which result in missing values in patients’ electronic health records. Moreover, missing values occur at different levels of data aggregation. Individuals are often reluctant to answer sensitive questions related to personal finances or their medical history in questionnaires (Brick and Kalton 1996), and firm-level archival databases such as Compustat (e.g., Havakhor et al. 2019) frequently encounter missing values because firms often strategically withhold data (e.g., research and development [R&D] expenses) due to concerns related to its proprietary nature (Koh and Reeb 2015). However, the challenges of dealing with missing data have received little attention in IS research. Our review of recently published empirical papers in major IS journals (presented in Section 3) suggests that missing values are indeed a pervasive problem in empirical IS research (i.e., many studies have missing values), the extent of missing values is nontrivial (i.e., the proportion of missing values in research data sets is significant), and the handling of missing values is often ill advised (i.e., methods that are known to lead to biased statistical estimates are still widely used).
The purpose of this paper is first and foremost to promote greater mindfulness with respect to the handling of missing values in IS research. Our intention is to stimulate conscientious adoption of appropriate methods for handling missing values in explanatory data analysis3 and of research practices in reporting information relating to missing values such that the empirical limitations can be heedfully appreciated.
Much of the prescriptions relating to appropriate methods for handling missing values come from the aforementioned statistics literature. However, these prescriptions are not all-encompassing. Missing value situations can be classified by the nature of the missingness mechanism (Rubin 1976). The (missing) data can be missing completely at random (MCAR), missing at random (MAR), or missing not at random (MNAR). The appropriateness of missing value handling approach depends on the missingness mechanism. Under the MCAR mechanism, listwise deletion will not introduce any bias into parameter estimates; while under the MAR mechanism, two broad approaches, maximum likelihood (ML; Rubin 1976, Dempster et al. 1977) and multiple imputation (MI; Rubin 1987) are well acknowledged to be valid methods by statisticians and econometricians. Unfortunately, under MNAR, the most general type of missingness mechanism, achieving unbiased parameter estimation is often difficult (Rotnitzky et al. 1998). The primary challenge with MNAR is that valid statistical inference requires that the missing data mechanism be modeled as part of the parameter estimation process (Rubin 1976). However, given that the missing data mechanism under MNAR is inherently unknown, it is difficult to specify the missing mechanism model.
Our second research objective, aimed at targeting this latter problem, is methodological. For parameter estimation under the MNAR mechanism, we propose a computational approach using a Monte Carlo likelihood estimation method that is able to correct biases in parameter estimation. Our proposed method is built upon recent theoretical advances showing that, for certain types of model specifications, parameters can be identified using maximum likelihood estimation incorporating the MNAR mechanism (Miao et al. 2016). Monte Carlo likelihood estimation has been employed in a variety of maximum likelihood estimation problems where the likelihood function is difficult to be calculated directly due to unobserved random effects (Ibrahim et al. 2001, Sung and Geyer 2007) or when latent variables are involved (Booth and Hobert 1999). We extend the application to handle missing values under the MNAR situation and provide evidence of its superior performance in parameter estimation.
The remainder of the paper is organized as follows. We first review and summarize the statistics literature on the missing value typology and approaches to handling missing values under the MCAR and MAR situations, as well as challenges and newer research developments with respect to the MNAR mechanism. In Section 3, we show the pervasiveness of the missing value problem in empirical IS research by reviewing how missing values are handled by IS researchers in recently published papers in leading IS journals. To enhance the understanding of the missingness mechanisms, we present six recurring scenarios where missing values have occurred in IS contexts. Based on our review of the missing value theory and IS research, we present actionable guidelines for proper missing value handling. Since the MNAR mechanism is the most problematic situation, in Section 4, we propose a computational Monte Carlo likelihood estimation approach that incorporates the missingness mechanism and thus is robust to the MNAR mechanism. Thereafter, in Section 5, we conduct a simulation-based validation of our proposed approach and compare it with commonly adopted/well-acknowledged missing data handling methods (i.e., listwise deletion, maximum likelihood assuming the MAR mechanism and a novel approach designed to handle the MNAR mechanism). Our simulation results show that without considering the missingness mechanism, regression coefficient estimates are generally biased, whereas our proposed approach consistently produces approximately unbiased estimates under different scenarios of missingness mechanisms. We conclude the paper with a discussion of the remaining challenges resulting from missing values, recommendations on the choice of missing value handling methods, and prescriptions for more rigorous research practice in reporting missing values.
2. Statistical Theory of Missing Values
The missingness mechanism is concerned with whether the fact that a variable has missing data is related to the underlying values of the variables in the data (Rubin 1976). Missingness mechanisms are crucial, since the effectiveness of different missing value handling methods rests on the nature of the dependencies arising from the mechanism. In this section, we introduce the typology of missingness mechanisms and elaborate on its implication on the choice of appropriate missing value handling methods. We also review current research progress and challenges that remain in handling the missing not at random (MNAR) mechanism.
2.1. Typology of Missingness Mechanisms
In his seminal study, Rubin (1976) proposed a typology of missingness mechanisms. Based on whether the missingness depends on the observed and/or the missing values, there can be three types of missingness mechanisms. If missingness does not depend on the values of the data, missing or observed, then the missing data are called missing completely at random (MCAR). An assumption less restrictive than MCAR is when missingness depends only on observed values, but not on the components that are missing, which is called missing at random (MAR). Finally, the mechanism is called missing not at random (MNAR) if the missingness depends on the missing values even conditional on the observed ones.
To better understand missingness mechanisms, it might be useful to borrow an example from Schafer and Graham (2002) and (Little and Rubin 2019, p. 18). Consider a data set with two variables y and z, where some of the values of variable z are missing. For variable z, one can define a response indicator variable r that identifies what is observed and what is missing, where r = 1 if the value of z is observed and r = 0 if missing. The missingness mechanism model is often described with a conditional probability function of the missingness indicator r given values of z and y, which is denoted by
missing completely at random (MCAR), if the probability of its missingness does not depend on variable y or z, namely, ;
missing at random (MAR), if the probability of its missingness depends on variable y but not z, namely, ;
missing not at random (MNAR), if the probability of its missingness depends on variable z itself, namely, .
The MCAR mechanism is more restrictive than MAR and MNAR since it excludes the dependency of r on both the observed values of y and the unobserved values of z. As such, research interest has long been focused on the MAR and MNAR mechanisms.5
In general, there is no way to test whether MNAR is the underlying missing mechanism in a data set, except in rare applications where researchers can fill the missing variables using follow-up data collection (Glynn et al. 1993). This is because testing MNAR would require comparing the distribution of observed z values to that of the missing z values, but the researcher does not have access to the unobservable missing values of z in the first place. Therefore, researchers need to make reasonable assumptions about MNAR versus other cases by theoretical arguments specific to the data context. The most common assumption in the theoretical and applied missing values literature is MAR. Under the MAR mechanism, the missing value problem is less challenging since we generally do not need to explicitly model the missingness mechanism; while under the MNAR mechanism, ignoring the missing mechanism will result in biased estimates (Rubin 1976). Recently, the missing values literature has begun to also focus on the MNAR mechanism, as there are many situations where one would suspect that certain variables with missing values are MNAR.6
2.2. Handling Missing Values Under MAR
It has been widely acknowledged that handling missing values using listwise deletion produces unbiased estimates under MCAR, whereas maximum likelihood (ML; Rubin 1976, Dempster et al. 1977) and multiple imputation (MI; Rubin 1987) produce unbiased estimates under both MAR and MCAR (Tsikriktsis 2005, Schlomer et al. 2010, Newman 2014). We briefly review these methods in an example data set with two variables y and z. The probability density function of variables y and z is denoted with the joint distribution , where θ is a vector of unknown parameters to be estimated. If we assume a joint-normal distribution of (y, z), then θ consists of a vector of means and the variance-covariance matrix. Suppose that variable z contains missing values. Without loss of generality, let (zi, yi), be the observation sampled from , but zi is missing for .
2.2.1. Maximum Likelihood Estimation (MLE).
Most modern statistical procedures and econometric estimations, including all maximum likelihood methods, view as a likelihood function. Given a complete data set with no missing values, we can simply substitute the realized values of z and y in the data set into and obtain a summation of the data’s evidence about parameter θ.
Under the assumption that the missing data follow the MAR mechanism, Rubin (1976) showed that it is valid to base statistical inferences on all of the observed values. Then, with missing values in z, the summation of the log-likelihood based on the observed values is
It is important to note that the MLE approach discussed here summarizes the likelihood of all observed values, including both complete and incomplete (n + m) observations, which makes it distinct from the listwise deletion method in which only complete cases (n) are included in the parameter estimation. However, MLE based on Equation (2) does not account for the missingness mechanism, which implicitly assumes that the missingness mechanism can be ignored (i.e., under MAR).
2.2.2. Multiple Imputation (MI).
(Bayesian) Multiple imputation (MI), proposed by Rubin (1987), is a flexible alternative to maximum likelihood methods. To implement this method, ideally, a researcher should draw multiple imputations (e.g., D imputations) for the missing values. The D repetitions of the missing component of the variable z, say , are often created sequentially by MCMC methods. For each imputation, an imputed value for , is drawn from the posterior distribution of z conditional on the value of yi and a properly sampled parameter θ, where the parameter θ is drawn from its posterior distribution given the observed data and the values just imputed. After D sets of imputations are generated, a researcher obtains the estimates of the parameters in each data set using standard complete-data estimation methods and then combines the estimates obtained from the multiple imputed data sets using a simple method.7
2.3. Handling Missing Values Under MNAR
Although maximum likelihood (ML) and multiple imputation (MI) are theoretically sound for large samples, they still rest on a critical assumption that the missingness mechanism is MAR. In most cases, however, departure from MAR can be expected (Schafer and Graham 2002). Typical instances of MNAR are abundant in clinical trials, in which participants may withdraw from the study for reasons related to the measured outcomes (Little 1995). Examples of MNAR in IS research are presented in detail in Section 3.2.
Under the MNAR mechanism, valid estimation requires that the missingness mechanism be modeled as part of the parameter estimation process (Rubin 1976). From a likelihood standpoint, the explicit specification of the missingness mechanism, , as shown in Equation (1), is required. For example, we could specify the missingness mechanism as a logit model, namely, . The joint distribution for the observed values and missingness can be factored as . This way of factorization is called the selection model. The full log-likelihood function based on the data and missingness is then given by the integral of the joint distribution over the unobserved missing values:
Likelihood estimation for MNAR models is computationally difficult. For incomplete observations, integration over the unobserved z value is required to compute the likelihood. As a result, researchers have long been concerned that, under the MNAR mechanism, parameter estimation is often difficult (Rotnitzky et al. 1998). However, recent theoretical developments show that it is possible to identify the parameters of interest for certain types of model specifications (Miao et al. 2016). Specifically, parameters are identifiable when we assume normality of the incomplete variable and a monotone missingness mechanism (e.g., the common logit or probit model).8
2.4. Conventional Methods for Handling Missing Values
In theory, ML and MI are more attractive than conventional techniques such as conditional mean imputation, mean/zero replacement, and listwise deletion. The shortcomings of these conventional techniques have been well documented (Little and Rubin 2019, chapters 3 and 4). We nonetheless briefly review and critique these commonly used methods.
2.4.1. Conditional Mean Imputation.
In the above example of the incomplete data set, a regression model that regresses z on y can be used for imputing z. First, the cases with observed z are used for fitting a linear regression model. Then, plugging the observed values of y into the regression model, we can obtain the predicted for the missing cases . Replacing the unknown zi with is called conditional mean imputation, because estimates the conditional mean of zi given yi.
Conditional mean imputation has commonalities with MI, in the sense that the relationship between y and z is used to impute z. This method employs only one value to impute each missing value, whereas MI uses multiple draws from a posterior distribution to impute each missing value. As a result, it underestimates the variance of the incomplete variable. Moreover, it overestimates the strength of the relationship between z and y—the correlation between z and y among the imputed cases is perfect () (Schafer and Graham 2002). Therefore, this method tends to result in bias in estimations involving covariances or correlations—even if the missingness mechanism is MCAR. MI overcomes these limitations by adding random noise to the imputed values and to the parameter estimation for θ. Although such randomness entails a loss of imputation accuracy, the extra noise is necessary so that the standard complete-data estimation method using imputed data sets becomes valid (Rubin 1996). The above analysis of the conditional mean imputation method suggests that simply promoting imputation accuracy does not guarantee unbiased parameter estimation. A valid missing value handling method should preserve the distribution of the incomplete variable and the relationship between this focal variable and other variables.
2.4.2. Unconditional Mean Imputation/Zero Substitution.
Another popular class of missing value handling practices is simple (global) replacement. First, (unconditional) mean imputation replaces all missing values with the average of the observed values for that variable. Although the mean of the variable is preserved under MCAR, other aspects of its distribution, such as variance and the correlation with other variables, are altered with potentially serious ramifications. Particularly, in the example data set, if there is association between z and y, then the conditional mean imputation will make the estimated correlation attenuate toward zero. Consequently, mean imputation may not improve on analyses that discard incomplete cases (Little and Rubin 1989).
Second, zero substitution replaces all missing values with zeros. However, unless the assumption of missing values being zero holds, zero substitution also results in serious distortion of the variable’s distribution and its correlation with other variables. In other words, zero imputation and unconditional mean imputation lead to biased estimations even under MCAR. There is no theoretical benefit unless the researcher is confident that the missing value is close to zero or the unconditional mean.
2.4.3. Listwise Deletion.
Listwise deletion (LD, also known as case deletion or complete-case analysis) is one of the most popular conventional approaches adopted by researchers and is the default setting of most statistical packages for handling missing values. However, the validity of LD depends on the type of missing mechanism. It is well acknowledged that under MCAR, LD results in valid estimation since the complete cases are still representative of the full population. Under MAR and MNAR, the complete observations will differ in some way from the observations with missing values and thus will be a biased subsample of the total sample, and the analysis will yield biased results (Tsikriktsis 2005, Schlomer et al. 2010, Newman 2014).
Overall, compared with the statistical-model-based methods, including MI, ML-MAR, and ML-MNAR, conventional methods generally lead to biased estimates (see Table 1).9
|

Table 1. Validity of Different Missing Value Handling Methods
| Missing value handling method | Missingness mechanisms | ||
|---|---|---|---|
| MCAR | MAR | MNAR | |
| MI/ML-MARa | Unbiased | Unbiased | Biased |
| ML-MNAR | Unbiased | Unbiased | Unbiased |
| Single-imputationb | Biasedc | Biased | Biased |
| LD | Unbiased | Biased | Biased |
aIn this table, we use the term “unbiased” to indicate the validity of MI/ML-MAR since these two methods are often viewed as unbiased under MCAR and MAR (e.g., Tsikriktsis 2005, Schlomer et al. 2010, Newman 2014). However, it is prudent to keep in mind that statistical inference of maximum likelihood or multiple imputation relies on large samples. In particular, when the model specification is correct, the consistency property of ML applies to incomplete data problems (Little 1992, Allison 2009). MI is shown to be approximately unbiased when the sample size and number of imputations are large (Rubin 1987, 1996).
bIncludes imputation using zero, unconditional mean, and conditional mean.
cSingle imputation methods under MCAR are often biased but can still produce unbiased estimates under certain circumstances. For example, unconditional or conditional mean imputation produces unbiased estimate of the mean.
3. A Review of Missing Value Handling in IS Research
3.1. Missing Values Reporting Practices in IS Research
Missing values are a perennial problem generally in quantitative empirical research regardless of discipline but are also a uniquely salient problem in the IS discipline. In this section, we review the recent empirical IS literature to examine how salient the missing data problem is in IS research and also assess current practices related to the handling of missing data. We find evidence that missing values are a recurring problem in empirical IS research, while at the same time little attention has been paid to adopting appropriate practices in reporting missing values and for handling missing values in the analysis. We examined recently published papers (between January 2017 and July 2019) in two of the leading information systems journals, namely, MIS Quarterly and Information Systems Research. We limit our scope to research that includes quantitative empirical studies, which results in a total of 181 research papers. Among these, 62 papers (34% of 181) mentioned the existence of missing values.10
Table 2 displays the different types of data sources employed among the examined papers, along with the number of papers having explicit mentions of missing values. To identify the papers mentioning missing values, we first reviewed the data description and data analysis sections of each of the papers for mentions of the existence of missing values. Moreover, we checked the result tables for any decreases in the number of observations being used in the analysis due to the inclusion of certain variables. Finally, to avoid omitting cases where missing values are discussed in other sections, we complemented our findings with keyword searches in the main text and appendix for words such as “missing,” “incomplete,” “impute,” “drop,” “delete,” and “exclude.”
|
Table 2. Distribution of Data Sources
| Data sources | Number of papers reviewed | Number of papers mentioning missing values | % | |
|---|---|---|---|---|
| Third-party data | 116 | 47 | 41% | |
| Survey | 37 | 14 | 38% | |
| Experiment | Laboratory | 30 | 6 | 20% |
| Field | 20 | 4 | 20% | |
| Total | 181 | 62 | 34% | |
Note. As there are papers employing more than one data source, the sum of the columns of number of papers reviewed and number of papers mentioning missing values exceeds the respective total number of unique papers.
We were able to verify that missing values are indeed a common problem across a variety of data sources with almost 40% of papers employing third-party data or surveys mentioning the presence of missing data, and even 20% of papers using data from laboratory or field experiments acknowledged missing data issues.11 These observations are quite striking, as the three types of data—namely, third-party databases, surveys, and experiments—are critical sources of data for empirical inquiry.
Having ascertained that the presence of missing values is indeed pervasive in empirical IS research, we next examined the extent of missing values within studies and how the missing data problems were handled. Figure 1 shows the extent of missing values, while Table 3 summarizes the methods used for handling them. Three observations can be drawn here. First, even though many papers mentioned the presence of missing values, many did not disclose sufficient relevant information.12 Out of the 62 papers that mentioned the presence of missing values, 23 (or 37.1%) did not identify which variable had missing values. Based on our review of the missing values literature, we highlight the importance of the missingness mechanism on the choice of missing value handling methods. However, only 2 of the 62 papers (or 3.2%) discussed the missingness mechanism. Without a clear articulation and justification of the missingness mechanism, it is not possible to ascertain whether the missing value handling method used was appropriate.

|
Table 3. Missing Values Methods in IS Research
| Missing value handling method | Frequency | % |
|---|---|---|
| Listwise deletion | 45 | 72.6% |
| Dropping incomplete variables | 7 | 11.3% |
| Mean/zero replacement | 6 | 9.7% |
| Conditional mean imputation | 5 | 8.1% |
| Using another variable or measurement as a proxy | 4 | 6.5% |
| Searching for information on missing values | 3 | 4.8% |
| Multiple imputation | 3 | 4.8% |
| Mean/zero replacement with missingness dummy | 1 | 1.6% |
| Pairwise deletion | 1 | 1.6% |
| Not reported | 5 | 8.1% |
Note. As there are papers employing more than one missing value handling method, the sum of the frequency exceeds the total number of unique papers mentioning missing values.
Second, it seems that the extent of missing values in the reviewed studies is not negligible. The proportion of missing values in a data column is important, as a greater percentage of missing values renders estimation more problematic and, as a result, drawing reliable conclusions more questionable. Of the 44 (out of 62) papers that provided information about the percentage of observations with missing values, the average percentage of missing values was 24.6% (see Figure 1). Experts have yet to reach consensus on a threshold for missing data above which the analysis would become problematic; Schafer (1999) recommends 5% as the cutoff, Newman (2014) recommends 10%, while Downey and King (1998) use the 20% threshold. An average of 24.6% missing is clearly above the rule-of-thumb thresholds recommended.
Third, we found that the prescribed missing data handling methods, such as MI and ML, are rarely employed. Only 3 out of 62 papers have used these methods. Instead, simple (and less rigorous) approaches, including LD, mean/zero imputation, conditional mean imputation, and so on, have been commonly used to handle the missing values, despite the fact that they are known to often produce biased estimates. Even in papers where more than one method is used to handle missing values, the more advanced and rigorous ML and MI methods are rarely used. Moreover, the choice of method often lacked adequate justification. For instance, the most popular method for handling missing values was LD (used in 45 of the 62 papers, or 72.6%, mentioning missing values); even though LD may generate unbiased coefficient estimates under special data situations (e.g., MCAR), the choice of LD was rarely justified by the potential missingness mechanism that is likely to be at play. Similarly, even though mean/zero substitution and conditional mean imputation often leads to biased statistical estimates, they were still commonly used (9.7% and 8.1% of the 62 papers, respectively). Finally, five papers (8.1%) that mentioned missing values did not clearly state how the missing data issue was handled.
Our review of recent empirical research published in the leading IS journals reveals two problems related to handling missing values. The first is the absence of prescriptions for information disclosure on missing values, including which variables contain missing values, what is the percentage of missing values, and so on. Despite the fact that missing values, if not handled properly, may lead to incorrect statistical inferences, it seems that the missing value problem in empirical IS research is not being treated systematically—information about missing values is often discussed with scant details. The second problem is that there seems to be a lack of clear guidelines on the choice of appropriate missing value handling method, which further inhibits the disclosure of information on missing values. Mean/zero replacement and conditional mean imputation are inappropriate regardless of the missingness mechanism, while dropping the incomplete variables may result in omitted variables bias.13 However, the proportion of papers adopting these three approaches amounts to 27.4% among the papers acknowledging the existence of missing values;14 72.6% (45 of 62 papers) of the papers that mentioned the presence of missing values used LD, which is also only appropriate when the missingness does not depend on the dependent variable for regression analysis or when the missing mechanism is MCAR for general statistical estimates, as discussed later in Section 3.3.1. The multiple imputation (MI) method, which is appropriate for the more general missingness mechanism of MAR was only used by three papers (4.8% of the papers). The ill-advised choice of missing value handling method will become more problematic as the extent of missing values increases (Newman 2014).
3.2. Common Reasons of Missing Values in IS Literature
Our quantitative review of recent empirical IS research with respect to the missing value problem raises alarming concerns about the pervasiveness of this problem. Next, we supplement this review with a qualitative one, with the aim of inferring a substantive understanding of whether there are any commonalities across studies. Unfortunately, as a consequence of most IS researchers not fully disclosing information about missing values, available information about the causes of missing values was scarce.
Among the 62 papers, 23 (37.1%) did not identify which variables suffered from missing values. Five papers (8.1%) did report the reason for the presence of missing values but did not relate this to its potential missingness mechanism. Only two papers explicitly stated MAR as the missing mechanism, and only one of these two papers justified why the mechanism was MAR. Despite the limited information on missing values from the published papers, we identified six common patterns following which missing values may occur in IS research so that we might infer the potential missingness mechanisms. The six patterns include survey research and five types of popular IS research. These patterns are not exhaustive, since causes of missing values will inevitably depend on the research context.
3.2.1. Type 1: Missing Values from Proprietary Surveys.
It has already been noted that survey-based IS research has not adequately disclosed relevant missing value information (Karanja et al. 2013). Specifically, among 749 survey-based research papers published between 1990 and 2010 in nine mainstream IS journals, only 167 papers (22.3%) reported information about the presence or treatment of missing data (Karanja et al. 2013). Further, only 39 out of 167 papers (23.4%) mentioned how missing values were handled, of which only a few papers applied advanced methods, such as MI.
Our review above is consistent with that of Karanja et al. (2013) with updated statistics from recent IS publications. In our review, most survey-based studies (12 out of 14) only mentioned the number of observations removed due to incomplete survey responses. It was not even possible to identify which variable(s) suffered from missing values. The reason for the missing values was mentioned in only one paper; thus, here we rely on the literature on the survey methodology to discuss the general causes of missing values in survey-based research.
The existing literature and textbooks on quantitative research methods summarize several causes of nonresponses or incomplete surveys (Brick and Kalton 1996). There are three types of missingness patterns in survey studies when categorized by the proportion of survey items with missing values. First, respondents may refuse to participate in the survey. Second, respondents may refuse to answer (or skip) parts of the survey questionnaire. Third, respondents may abort the survey such that starting with one survey item, all following items have missing values. This is particularly severe in longitudinal studies with multiple waves of surveys for the same participant. The main reasons for not answering survey items include: (1) machine error, the interviewer’s error to record the answer, or mistake of the respondent not to enter answers; (2) the survey is too long so that respondents may skip some survey items or abort the survey midway; (3) the survey questions are difficult to understand; (4) the respondent gives inconsistent answers, and thus answers to the related survey items are dropped by the researcher; (5) the respondent does not know the answer; and (6) the question is sensitive and therefore the respondent refrains from answering.
The missingness mechanism depends on the causes of missing values. The missingness mechanism for reason (1) is arguably most likely to be MCAR. Those for reasons (2), (3), and (4) could be MCAR in most surveys, but it is still possible that the missing mechanism is MAR or even MNAR. For example, if the survey question is too abstract, then participants without relevant education background, work experience, or comprehension ability may be more likely to refrain from answering. If the causes of missingness correlate with the complete items or missing items, then the mechanism is MAR or MNAR, respectively. Finally, we would argue that the missingness mechanisms for reasons (5) and (6) will likely be MAR or MNAR, because the missingness may correlate with the value of other survey items. For example, the knowledge to provide the answer may be lacking for certain groups of respondents. If missingness results from sensitive questions (e.g., about race, gender, senior participants, education level or income level), then certain types of users may feel offended and decline to answer. In any case, it seems unlikely that the missingness mechanism is MCAR for these two cases.
3.2.2. Type 2: Self-Reported User Information.
E-commerce has been the focus of much IS research since the inception of the internet. As long as the research design involves user-level regression analysis, the missing value problem seems inevitable. This is because most websites do not force users to provide all personal information, such as age, gender, marital status, education, and occupation, when signing up for an account. If users self-select what information to report online, then it is conceivable that missing values will occur in the databases of the e-commerce companies. From our review, especially with respect to papers on e-commerce, we suspect that this type of missing values scenario is so common that researchers may not even bother mentioning its existence. Thus, the underreporting of missing values could be more severe than with survey research.
From the perspective of the decision-making process of consumers, online users may provide the requested information when they expect the benefits to outweigh the potential costs (Dinev et al. 2015, Adjerid et al. 2018). On LinkedIn, for example, users self-report gender, a photo (possibly to signal race), education, and work experiences that are beneficial to their values on the job market. At the same time, users would typically not provide education background or upload photos on most other e-commerce sites. Roughly speaking, the causes of missing values in self-reported user information could be summarized as follows: (1) cognitive costs and efforts to provide information online is higher than the limited benefits of disclosing that information; and (2) users self-select not to disclose information because that information itself may intrude privacy or lead to adverse outcomes.
The missingness mechanisms of this scenario could be of two extremes. If the user does not disclose information just because of “laziness,” then the mechanism could be assumed to be MCAR, and LD may be acceptable as the missing value handling method. However, if users self-select not to disclose information to preserve privacy or to avoid adverse outcomes, then the missingness will likely correlate with the value of the missing variables (i.e., MNAR). For example, users with very high or low incomes may choose not to report income on various websites (Roth et al. 1999).
3.2.3. Type 3: R&D Data in the Compustat Database.
Of the 62 papers reviewed, 11 reported missing value issues because of limitations of the Compustat database. Eight papers include R&D expenses or R&D intensity in the regression analysis. R&D expenses are a primary measure of innovation and technology development activities in the firm. Koh and Reeb (2015) report that 42% of firms had missing values in R&D. The main idea of Koh and Reeb (2015) was to examine and compare the patenting activities of three groups of firms (missing R&D, zero R&D, and positive R&D) because, conceptually, patenting activities are highly relevant to R&D expenses. The authors argue that the cause of missing R&D data results from the manager’s discretion to hide the R&D expenses. Using rigorous difference-in-differences (DID) estimations, this paper also found that unexpected changes in auditors led firms with missing R&D values to alter their R&D reporting practices.
Koh and Reeb (2015) also show that firms with missing R&D have, on average, more patent applications and approvals than firms with zero R&D. This suggests that zero imputation will be inappropriate. Descriptive statistics show that the three groups of firms have different mean values in several accounting ratios, implying that missingness of R&D is unlikely to be MCAR. This paper’s main results imply that the missingness mechanism for R&D is likely to be MNAR. They compare firms with missing R&D but positive patenting (i.e., pseudo-blank firms) to firms with positive R&D. They found that positive R&D firms have substantially more patents; pseudo-blank firms correspond to the bottom 90th to 95th percentiles of patents in positive R&D firms. If patenting indeed correlates with the true value of R&D, then this finding provides strong evidence that the missingness of R&D is MNAR.
3.2.4. Type 4: IT Investment Data.
The business value of IT has been one of the most popular research topics in the IS literature—12 out of the 62 papers reviewed fall into this category. In the majority of these studies, the variables of interest include IT investment variables (i.e., hardware, software, or the number of IT employees). In the United States, these measures are not required to be disclosed in official annual reports. As a result, researchers rely on surveys conducted by consulting firms (e.g., Computer Intelligence and InformationWeek). It is well known that these data sets suffer from missing value problems on key IT investment variables. This problem is aggravated when the researchers typically need to merge an IT investment data set with the Compustat data set and the latter tends to contain more missing values for smaller firms (Chen et al. 2015).
Detailed information about the causes of missing values was not available in the reviewed papers, and thus it is difficult to accurately infer the missing mechanism for IT investment. The missingness could be MAR, because the consulting firms that collect the data may only focus on large and/or reputable firms (e.g., the missingness depends on firm size). If firms with very complicated IT governance or very limited IT resources do not report IT investment-related data during the surveys, then the missingness may correlate with the dollar value of IT investments, leading to the MNAR mechanism.
3.2.5. Type 5: Online Reviews.
There are 3 out of 62 papers that studied online word-of-mouth using data collected from websites. The three papers studied different products/services (e.g., restaurants, hotels, and movies) and mentioned two causes of missing values: (1) some records of the product/service do not have any online reviews or ratings, and therefore the authors cannot construct variables based on textual reviews or ratings; and (2) some records do not have complete product/service information.
It is quite unlikely that consumers provide product ratings by random chance. Theoretically, from the perspective of consumers, only those with a favorable predisposition acquire products and hence provide product ratings or reviews (Hu et al. 2017). Therefore, products that gain less favorable predispositions are less likely to be reviewed or rated. If they could have been rated by consumers, then the ratings may be lower than the average of observed ratings, and, similarly, the review valence may be more negative than the average valence of the products reviewed. This expectation is consistent with a study based on a random sample of ratings from users of an online radio service (Marlin et al. 2007). The ratings of products (i.e., songs) provided by users in the rating systems are much higher than those provided by randomly selected users during a survey. These studies provide strong arguments and evidence showing that the variable “mean rating/review valence” of the product is likely to be MNAR.
Even at the more granular level of individuals’ ratings (rather than ratings at the product level), the missingness mechanism for the rating variable will still likely be MNAR. For instance, in a study that examined the determinants of users’ perceptions on adopting a new IT product, the variable of interest could be the rating at the individual level. It has been shown that consumers with extreme (either positive or negative) ratings are more likely to write reviews than consumers with moderate product ratings (Hu et al. 2017). In the context of song ratings of an online radio service, 64.85% of users responded that their preferences affect their choice of song to rate, which violates the MAR assumption (Marlin et al. 2007).
An implication of the above discussions on missing online reviews is that the missingness of a variable could be driven by self-selection. That is, missing values are caused by the data holder’s self-selection decisions that maximize their own utility. The famous Heckman selection model depicts well the self-selection problem. One motivational self-selection situation is that women may choose not to join the work force when the market wage is lower than their latent home wage at zero hours of work, and thus their wage becomes missing (Heckman 1979). As such, wage data are also typically considered as MNAR in the missing values literature. Our current example about online reviews is a similar case. Users may post an online review only when they feel that posting reviews creates positive utility for them. The self-selection decision of whether to participate in the activity results in the well-known endogenous sample selection bias if it is related to the dependent variable of interest (Wooldridge 2015). Although Heckman correction can be used to correct the endogenous sample selection bias, its application is typically limited to the situation where the key dependent variable is missing due to self-selection, and the missing mechanism is MNAR.
3.2.6. Type 6: Country-Level Macroeconomic Variables.
It is not uncommon for IS research to conduct econometric analysis at the country level. In these studies, data from developing countries frequently contain missing values (Kanat et al. 2018). The missingness mechanism for this case is not MCAR because the missingness correlates with the economic status of the country. The missingness may also correlate with several other important economic indicators, which are typically included as control variables in such studies. In general, both MAR and MNAR are possible, depending on the nature of the incomplete variables. If the focal variable correlates with macroeconomic development (e.g., literacy/education, average income, family size, IT literacy, IT assets at home, etc.), then it is likely that the missing mechanism is MNAR.
Finally, we acknowledge that missing values are also common in other databases or data collection contexts, and it is difficult to provide a comprehensive identification of all possible reasons and mechanisms of missing values. For instance, in healthcare practice, medical records often contain missing values. Missing values have long been investigated in medical and clinical research. It is unlikely that medical records or measurements of outcomes are MCAR (Carpenter and Kenward 2007). With limited clinical and financial resources, some medical tests can be preferentially administered to sicker patients or those with more complicated medical conditions (Hall et al. 2007), which suggests that the missingness of medical records is at least MAR. Patients may drop out of clinical trials depending on the outcome being measured (Little 1995, Enders 2011), in which case the missingness is MNAR. We expect that the reasons for missing values in medical care and clinical trials are of great interest to healthcare IT researchers, and we thus refer researchers to the aforementioned literature.
3.3. Recommendations for Handling Missing Values
3.3.1. When Should LD Be Used?
An ongoing debate in the literature is whether MI and ML really outperform LD in general (White and Carlin 2010, Garg 2013, Pepinsky 2018). The current consensus can be summarized as follows:
For the general purpose of parameter estimation, LD does not introduce bias to parameter estimation under MCAR but results in bias under MAR or MNAR (Schlomer et al. 2010, Newman 2014). Particularly for regression analysis, LD does not introduce bias in regression coefficients when the missingness does not depend on the dependent variable (Little 1992, Schafer and Graham 2002, Allison 2009).
LD is less efficient than MI/ML-MAR methods because it does not utilize full information of the data.15
Under MCAR and MAR, MI/ML-MAR methods are superior to LD in unbiasedness and efficiency. However, under MNAR, MI and ML may not outperform LD. Therefore, when the missing mechanism is not MCAR, the choice of missing value handling method is complicated because it is practically difficult to differentiate between MAR and MNAR.
Given the discussions above, the pros and cons of using LD and the conditions under which LD is unbiased seem clear-cut in theory. LD’s main advantages are (1) ease of implementation and (2) less chance of error if the researchers are not familiar with MI or ML methods. The disadvantage of LD is the reduced efficiency because incomplete records are removed and the final sample size is smaller. Loss of efficiency is decreasing in total sample size and increasing in the proportion of incomplete data. Different rules of thumb for acceptable proportions of missing values, ranging from 5% to 20%, have been proposed (Downey and King 1998, Schafer 1999, Newman 2014). As a result, if the sample size is large (such as with individual-level data sets in e-commerce studies) and the missing proportion is smaller than 20%, then LD can be acceptable.
More importantly, to employ LD as the main missing value handling method, researchers should carefully scrutinize the missing mechanism. For general purposes of parameter estimation (e.g., mean, variance-covariance matrix), researchers should first conduct statistical tests for the null hypothesis of MCAR (e.g., the MCAR test by Little 1988). If the null hypothesis is rejected, then missingness is likely to be MAR or MNAR and LD should not be employed. If the null hypothesis is not rejected, then it is still possible that MAR or even MNAR is the true case (i.e., a type II error of the MCAR test). Researchers will still need to provide theoretical arguments to justify the MCAR mechanism.
For regression analysis, LD may not result in bias, even if the underlying mechanism is not MCAR. LD yields unbiased regression coefficients when the missingness does not depend on the dependent variable (Little 1992, Schafer and Graham 2002, Allison 2009). Therefore, although the assumption regarding the typology of missing mechanism is often not verifiable, fortunately, when missing values only occur in a right-hand side (RHS) variable, the validity of LD can be supported by testing the association between the missingness and the dependent variable. Among the 62 IS papers mentioning the existence of missing values, we find that 27 papers mention missing values in the RHS variable, while 15 papers mention missing values in the dependent variable. When missing values occur in the dependent variable, the test of the association between the dependent variable and its missingness (i.e., essentially differentiating between MAR and MNAR for the dependent variable) is not feasible, and thus this type of test lends limited support to the unbiasedness of LD as a missing value handling method.
3.3.2. When Should MI or ML-MAR Be Used in Lieu of ML-MNAR?
MI and ML-MAR are considered the state-of-the-art methods under MCAR and MAR. Under the MCAR and MAR mechanisms, both methods are unbiased and highly efficient (Schafer and Graham 2002, Allison 2009). Simulation studies that compare the performance of MI and LD also show that even when the distributional assumption of MI or ML-MAR is misspecified, they generally outperform LD in many scenarios under MCAR and MAR (Azen et al. 1989, Schafer 1997, Enders 2001, Garg 2013). In other words, MI and ML-MAR are recommended under MCAR and MAR in most references.
However, the main drawback of using MI or ML-MAR is the bias under MNAR (Schafer and Graham 2002, Newman 2014). Theoretical results relating to bias under MNAR are limited, but various simulation studies show that, under MNAR, MI is not much better than LD (Newman 2003) or could even be more biased than LD (Pepinsky 2018). We expect this to be the same for ML-MAR, which is corroborated in our own simulation study to be presented later in Section 5. It is often noted in the missing values literature that, since we cannot differentiate MAR and MNAR by data and there arguably exist cases where the missingness mechanism is MNAR, MI and ML-MAR should be used with caution.
Our review of missing value problems in the recent empirical IS literature found that the missingness mechanism for all six types of data could potentially be MNAR. Three types of studies (i.e., studies based on IT investment, R&D investment, and online reviews) were found to be more prone to the MNAR mechanism, but the missingness mechanism for the three other types of studies will still depend on the variable used and the research context. Therefore, we also recommend that MI should be used with caution when the missingness could be MNAR. Researchers are advised to provide convincing theoretical arguments as to why the missingness may not depend on the value of the focal variable if they employ MI or ML-MAR in lieu of ML-MNAR or other methods for MNAR. Among the 62 papers reviewed, three papers employed MI but only one paper provided relevant justification. However, this kind of theoretical argument is not possible to be empirically verified by data or statistical tests. We recommend that sensitivity analysis using ML-MNAR (or other methods for MNAR) should be conducted to show that the results presented can also be supported under the MNAR mechanism.
In summary, the recommended actions for researchers are as follows:
When theory and statistical tests support LD as unbiased (e.g., MCAR) and the sample size is large enough, researchers can use LD for simplicity.
When evidence suggests MNAR, researchers should use ML-MNAR or other methods for MNAR.
In other cases, researchers should use both MI/ML-MAR and ML-MNAR or other methods for MNAR as sensitivity analysis, except under rare cases in which the researchers can provide convincing arguments that the underlying missingness mechanism is MAR. In this case, MI/ML-MAR can be used.
Mean/zero imputation and conditional mean imputation are not recommended unless the authors have strong confidence that the imputation is close to the unobservable data-generating process.
4. Handling MNAR by Monte Carlo Likelihood Estimation
As we have mentioned, MLE is difficult when the likelihood model incorporates the MNAR missingness mechanism in the parameter estimation process. In this paper, we propose a Monte Carlo approach using expectation maximization (EM) to overcome the computational difficulty of ML-MNAR. The proposed Monte Carlo–based approach to ML-MNAR is denoted as ML-MNAR(MC). During the estimation, we first estimate parameters that depict the conditional distribution of the incomplete variable given the complete variables. Other parameters of interest, such as the regression coefficients, are computed after the parameter estimation process.
Consider a data set with three variables of interest x, y, and z, where the regression model of interest has y as the dependent variable, x and z are RHS variables, and the variable z has missing values, whereas variable x is complete. We are interested in obtaining regression coefficients. Before proceeding with estimating coefficients for the regression model, we estimate parameters in the conditional distribution of the incomplete variable z. More specifically, the conditional distribution of z given variables (x, y) is assumed to be a normal model and the probability density function is given by
The missingness mechanism is modeled as the conditional distribution of r given variables (x, y, z) (e.g., specified as a logit model). The unknown parameters in the missingness mechanism then consist of the intercept and slopes. Then parameters are estimated by maximizing the full likelihood based on the two models through MCMC approaches. In the example above, the full likelihood is
In Equation (5), θ consists of parameters and ψ consists of parameters in the missingness mechanism (e.g., coefficients in the logit model). The first term denotes the summation of log-likelihood over the complete observations (), and the second term denotes the summation of log-likelihood over the incomplete observations (). The second term involves the integration over the density function with respect to z. Note that variables x and y are always conditioned, since they are complete variables without missing values.
The likelihood function of Equation (5) can be maximized using the expectation maximization (EM) algorithm (Dempster et al. 1977). During each iteration, the expectation (E) step involves the calculation of the expected log-likelihood over the posterior distribution of z given observed values of (x, y, r) as well as the estimation of at the current iteration. The maximization (M) step maximizes the expectation outcome in the E step and obtains updated parameter estimation for . Due to the difficulty in obtaining a closed-form formula for the expectation step, we employ the Monte Carlo EM algorithm (Wei and Tanner 1990, Neath 2013) to numerically approximate the expectation outcome by sampling from the posterior distribution of z using the Metropolis-Hastings algorithm, an MCMC method.17 We check the convergence of the EM algorithm, and the iterations are terminated when the absolute difference between a prespecified number of iterations (e.g., between the tth and the (t + 20)th) is less than a prespecified threshold (e.g., ) for all parameters contained in θ and ψ. After obtaining the estimation of , we derive the mean, variance, and correlation with other variables of z. These estimates can be substituted to the estimation of the regression coefficients of the linear regression model.
5. Simulation Analysis
5.1. Data Generation
To illustrate the operating characteristics of different missing value handling methods, we conduct a simulation study for the estimation of regression coefficients in the following model:
One thousand data samples of the values of (x, z, y) are drawn from the above data-generating process. Missing values are imposed on variable z according to the missingness mechanism represented by the following logistic model:
In our simulation experiments, we fix the value of ψx and vary the values of ψz and ψy since the dependence of the missingness with z or y covers all of the important missing data scenarios for estimating the regression coefficients, as we elaborate further in the next section. We let coefficient parameters ψz and ψy take values in . The value of ψx is fixed at zero so that the MCAR mechanism is covered when . The missing value percentage (i.e., the amount of missing values in the data set) is set to 10%, 20%, 30%, and 40% by solving the intercept term ψ0 (King and Zeng 2001). It is worth noting that although our example illustrates the missing value scenario where a RHS variable is incomplete, our method is also applicable when the dependent variable is incomplete, as noted in Section 4 and also demonstrated in our discussion of alternative simulation settings in Section 5.4.4.
Panels (a) and (b) of Figure 2 show the distribution of z under different values of ψy and ψz, respectively, where the missing value percentage is set to 30% and other parameters in the missing mechanism are fixed at zero in each subplot. We see that the distribution of observed z is severely distorted under the MNAR mechanism (). In our simulations, the variable z theoretically follows a normal distribution. Untabulated results show that, when , the deviation from normal distribution can be statistically detected. More importantly, from the perspective of statistical inference, the main concern is how to correct the possible bias caused by the MNAR mechanisms.

5.2. Evaluation Methods
We compare our proposed ML-MNAR(MC) with the commonly used LD, the well-established maximum likelihood estimation assuming MAR (ML-MAR).18
As discussed in Section 4, to implement ML-MNAR(MC), we first estimate parameters for the conditional distribution of the incomplete variable z given the complete variables. Then we derive the regression coefficients from the results estimates. Similarly, we employ ML-MAR to estimate coefficients through two steps. We first estimate the summary statistics including means and variance-covariance matrix for all the variables, which are then used to obtain the regression coefficients.19
When ψz is nonzero, the missingness mechanism becomes MNAR, which renders ML-MAR invalid. When ψy is nonzero, the coefficient estimation, if dropping incomplete observations (using LD), is subject to the endogenous sample selection problem. In other words, ML-MAR and LD generate unbiased estimation only under the special cases of and , respectively. This observation is illustrated in Figure 3. The key observation here is that, in general situations where and , neither LD nor ML-MAR will be valid approaches to handling missing values.
5.3. Estimation Results
To demonstrate the above conclusion, we present the coefficient estimation results from LD, ML-MAR, and ML-MNAR(MC) under different values of ψz and ψy with 30% missing value percentage in Figure 4. The spectrum from light (white) to dark (black) represents increasing absolute bias averaged across the three regression coefficients. Results are based on 400 replications of the simulation.
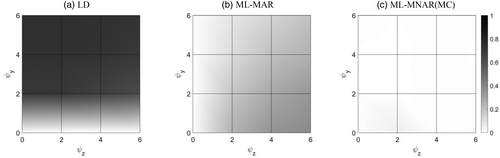
Figure 4(a) shows that, under LD, the bias is approximately zero for regardless of the value of ψz. This corresponds to the horizontal axis in Figure 3. It is also well known that estimations of coefficients are unbiased under LD if the missingness results from exogenous sample selection. However, the potentially detrimental effects of LD are evident when ψy becomes nonzero.
Figure 4(b) shows that departure from MAR also adversely affects the performance of ML-MAR. With ML-MAR, bias is approximately zero for regardless of the value of ψy. This corresponds to the vertical axis in Figure 3. However, this property of ML-MAR does not hold when . In addition, when we compare panels (a) and (b) of Figure 4, we can observe that the bias from ML-MAR estimation under the MNAR mechanism tends to be less than the bias from LD under endogenous sample selection. Although our results depend on the parameter settings of the simulation, there has been much evidence to show that principled methods such as ML and MI tend to perform better than conventional methods (Rubin 1996, Schafer and Graham 2002, Newman 2014).
Figure 4(c) shows the coefficient estimation results using ML-MNAR(MC), our Monte Carlo likelihood estimation method that incorporates the missingness mechanism. Results shows that the estimations of regression coefficients are approximately unbiased across different combinations of ψz and ψy.
In summary, we demonstrate that the missingness mechanism plays an important role in determining the appropriateness of missing value handling methods. A stronger MNAR mechanism makes the ML-MAR approach generate biased estimation; endogenous sample selection makes LD invalid. We illustrate the bias of the above missing value handling methods with missing value percentages from 10% to 40% in Figure A1 of Online Appendix 2). Results show that, as the proportion of missing values increases, the chosen method will exert a higher degree of influence over the results, and differences among competing methods will be magnified.
Table 4 provides detailed results of each of the three regression coefficients with 30% missing value percentage.20 The results show that LD generates unbiased parameter estimation when , while ML-MAR is unbiased when . When or , the bias could be severe for both LD and ML-MAR. A rule of thumb is that problematic levels of bias occur when the absolute value of the bias is greater than one half of the estimate’s standard error, since then the coverage of a 95% confidence interval starts to reduce (Schafer and Graham 2002). Therefore, when or , LD and ML- MAR could result in problematic bias in coefficient estimation. ML-MNAR(MC) incorporates the missingness mechanism into the likelihood model, which makes it robust to the MNAR mechanism. Estimation results are approximately unbiased under different values of ψy and ψz. Although there are several cells with slightly shaded values of bias, they are unlikely to result in problematic estimates based on the benchmark of one half of the standard error (Schafer and Graham 2002).
|
Table 4. Mean Bias and Standard Deviation of Coefficient Estimates (30% Missing Values)
| β0 | β1 | β2 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | 0 | 2 | 4 | 6 | 0 | 2 | 4 | 6 | 0 | 2 | 4 | 6 | |
| LD | 0 | 0.004 | 1.190 | 1.230 | 1.240 | −0.012 | −0.315 | −0.328 | −0.341 | 0.015 | −0.628 | −0.671 | −0.678 |
| (0.098) | (0.102) | (0.101) | (0.102) | (0.114) | (0.096) | (0.103) | (0.097) | (0.116) | (0.105) | (0.109) | (0.104) | ||
| 2 | −0.001 | 1.120 | 1.190 | 1.210 | 0.006 | −0.251 | −0.297 | −0.305 | −0.001 | −0.750 | −0.734 | −0.731 | |
| (0.109) | (0.111) | (0.102) | (0.104) | (0.119) | (0.097) | (0.098) | (0.102) | (0.132) | (0.117) | (0.114) | (0.108) | ||
| 4 | 0.000 | 1.030 | 1.150 | 1.180 | −0.001 | −0.204 | −0.263 | −0.294 | 0.005 | −0.776 | −0.790 | −0.749 | |
| (0.120) | (0.107) | (0.110) | (0.102) | (0.117) | (0.110) | (0.102) | (0.100) | (0.135) | (0.128) | (0.118) | (0.112) | ||
| 6 | −0.001 | 0.940 | 1.090 | 1.150 | −0.005 | −0.163 | −0.236 | −0.267 | −0.001 | −0.768 | −0.795 | −0.779 | |
| (0.121) | (0.109) | (0.102) | (0.107) | (0.116) | (0.107) | (0.099) | (0.100) | (0.142) | (0.133) | (0.118) | (0.112) | ||
| ML-MAR | 0 | 0.004 | 0.001 | 0.001 | 0.007 | −0.008 | −0.007 | 0.000 | −0.005 | 0.013 | 0.006 | −0.002 | −0.002 |
| (0.089) | (0.099) | (0.099) | (0.100) | (0.101) | (0.115) | (0.125) | (0.111) | (0.110) | (0.111) | (0.124) | (0.114) | ||
| 2 | −0.484 | −0.194 | −0.119 | −0.084 | 0.135 | 0.184 | 0.117 | 0.081 | 0.113 | −0.154 | −0.089 | −0.070 | |
| (0.093) | (0.091) | (0.094) | (0.096) | (0.111) | (0.113) | (0.116) | (0.118) | (0.125) | (0.135) | (0.129) | (0.124) | ||
| 4 | −0.646 | −0.306 | −0.206 | −0.150 | 0.211 | 0.288 | 0.204 | 0.136 | 0.187 | −0.237 | −0.178 | −0.108 | |
| (0.099) | (0.087) | (0.096) | (0.095) | (0.110) | (0.124) | (0.120) | (0.117) | (0.137) | (0.155) | (0.141) | (0.134) | ||
| 6 | −0.705 | −0.379 | −0.273 | −0.202 | 0.235 | 0.351 | 0.259 | 0.199 | 0.206 | −0.274 | −0.215 | −0.166 | |
| (0.101) | (0.090) | (0.088) | (0.091) | (0.105) | (0.121) | (0.113) | (0.114) | (0.140) | (0.166) | (0.144) | (0.137) | ||
| ML-MNAR | 0 | 0.011 | 0.003 | 0.006 | 0.007 | −0.006 | −0.005 | −0.002 | −0.004 | 0.010 | 0.001 | −0.003 | −0.005 |
| (MC) | (0.094) | (0.113) | (0.104) | (0.104) | (0.100) | (0.120) | (0.130) | (0.115) | (0.110) | (0.115) | (0.126) | (0.117) | |
| 2 | −0.083 | 0.003 | −0.001 | 0.003 | 0.045 | −0.001 | 0.007 | 0.002 | −0.021 | −0.003 | 0.000 | −0.007 | |
| (0.252) | (0.100) | (0.101) | (0.101) | (0.150) | (0.114) | (0.115) | (0.116) | (0.146) | (0.110) | (0.114) | (0.114) | ||
| 4 | −0.011 | 0.009 | 0.001 | 0.003 | 0.006 | −0.011 | 0.003 | −0.009 | 0.006 | 0.000 | −0.013 | 0.010 | |
| (0.127) | (0.092) | (0.100) | (0.099) | (0.107) | (0.117) | (0.116) | (0.113) | (0.119) | (0.111) | (0.113) | (0.111) | ||
| 6 | 0.003 | 0.006 | 0.001 | 0.008 | −0.003 | −0.003 | −0.008 | −0.004 | −0.007 | −0.006 | 0.000 | −0.001 | |
| (0.100) | (0.093) | (0.093) | (0.098) | (0.099) | (0.111) | (0.108) | (0.109) | (0.111) | (0.107) | (0.106) | (0.108) | ||
Notes. To facilitate interpretation, each cell is shaded with a darker background when the contained absolute bias value increases. The color scale is from 0% up to 50% dark background. The 0% dark background corresponds to 0 absolute value. The 50% dark background corresponds to (absolute) values equal to or larger than 0.355, which is the average of the 96 cells for LD and ML-MAR. The standard deviation of the estimated coefficient over the repeated simulations is presented in parentheses.
The results are consistent with the implication of the missingness mechanism on the validity of different missing value handling methods, as discussed in Sections 2 and 3.3. Given that ψx is fixed at zero, the MCAR mechanism corresponds to the setting where , the MAR mechanism when and , and MNAR to the more general situation where . LD is valid under the MCAR mechanism. Moreover, a special case for LD being unbiased under MNAR is when the missingness of z does not depend on y (i.e., and ). Maximum likelihood estimation ignoring the missingness mechanism eliminates the bias under the MCAR and MAR mechanisms but leads to biased estimation under the MNAR mechanism. The method which is robust to different missingness mechanisms is ML incorporating the missingness mechanism, wherein parameters are estimated using the Monte Carlo likelihood approach (ML-MNAR(MC)).
In our study, we highlight the concern of bias since, in general, unbiasedness is more important than efficiency in econometrics (i.e., a “less efficient and unbiased estimator” is preferred to a “more efficient but biased estimator”). Among the methods being evaluated, ML-MNAR(MC) is the only method that generates almost unbiased estimates under different settings. When it comes to comparing the variance of different missing value handling approaches, theoretical guidance is currently lacking in the literature. We expect that ML-MNAR(MC) could be highly efficient since it is an MLE-based method. To investigate efficiency, we computed the root mean square error (RMSE) of the coefficient estimates (see Table 5), as a smaller RMSE is associated with greater efficiency (assuming that the estimators are unbiased). Combining results in Tables 4 and 5, we can see that the proposed ML-MNAR(MC) sometimes leads to increased variance, since this estimation method involves more parameters to be estimated after incorporating the missingness mechanism. However, the slight increase in variance should not outweigh the reduction in bias. Results of the overall root mean squared error (RMSE) show that the RMSE of ML-MNAR(MC) is still the smallest in most cases in our simulations. Finally, in addition to bias and efficiency of parameter estimation, missing values also raise concern of estimating the standard error of estimates. We defer the discussion of this challenge to Section 6.
|
Table 5. RMSE of Coefficient Estimates (30% Missing Values)
| β0 | β1 | β2 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | 0 | 2 | 4 | 6 | 0 | 2 | 4 | 6 | 0 | 2 | 4 | 6 | |
| LD | 0 | 0.098 | 1.190 | 1.231 | 1.246 | 0.115 | 0.329 | 0.344 | 0.354 | 0.117 | 0.637 | 0.680 | 0.686 |
| 2 | 0.109 | 1.126 | 1.196 | 1.216 | 0.119 | 0.269 | 0.313 | 0.322 | 0.131 | 0.759 | 0.743 | 0.738 | |
| 4 | 0.120 | 1.032 | 1.151 | 1.185 | 0.117 | 0.232 | 0.282 | 0.311 | 0.135 | 0.786 | 0.798 | 0.758 | |
| 6 | 0.120 | 0.946 | 1.090 | 1.155 | 0.116 | 0.195 | 0.256 | 0.285 | 0.142 | 0.779 | 0.804 | 0.787 | |
| ML-MAR | 0 | 0.089 | 0.099 | 0.099 | 0.101 | 0.101 | 0.116 | 0.125 | 0.111 | 0.110 | 0.111 | 0.124 | 0.114 |
| 2 | 0.493 | 0.214 | 0.152 | 0.128 | 0.174 | 0.216 | 0.165 | 0.143 | 0.169 | 0.205 | 0.157 | 0.142 | |
| 4 | 0.654 | 0.318 | 0.227 | 0.178 | 0.238 | 0.313 | 0.236 | 0.179 | 0.232 | 0.283 | 0.227 | 0.172 | |
| 6 | 0.712 | 0.389 | 0.287 | 0.221 | 0.257 | 0.371 | 0.282 | 0.229 | 0.249 | 0.320 | 0.259 | 0.216 | |
| ML-MNAR | 0 | 0.095 | 0.113 | 0.104 | 0.104 | 0.101 | 0.120 | 0.130 | 0.115 | 0.110 | 0.115 | 0.126 | 0.117 |
| (MC) | 2 | 0.265 | 0.100 | 0.101 | 0.100 | 0.156 | 0.114 | 0.115 | 0.116 | 0.148 | 0.110 | 0.113 | 0.114 |
| 4 | 0.127 | 0.092 | 0.100 | 0.099 | 0.107 | 0.117 | 0.116 | 0.113 | 0.119 | 0.111 | 0.114 | 0.112 | |
| 6 | 0.100 | 0.093 | 0.093 | 0.098 | 0.099 | 0.111 | 0.108 | 0.109 | 0.111 | 0.107 | 0.106 | 0.108 | |
Notes. Cells with darker shades mean larger values. The color scale is from 0% up to 50% dark background. The 0% dark background corresponds to the minimum value in the whole table (i.e., 0.089). The 50% dark background corresponds to values equal to or larger than 0.400, which is the average of the 96 cells for LD and ML-MAR. The smallest RMSE for estimating the coefficient in each missing mechanism setting is in bold font.
5.4. Robustness Analysis
As summarized earlier (see Table 1), the validity of missing value handling methods rests on the underlying missingness mechanism. However, in practice, the missingness mechanism is unknown and cannot be inferred from the data. Moreover, although the proposed ML-MNAR(MC) is robust to the MNAR mechanism, it still requires explicit specification of the model for the missingness mechanism. Finally, statistical-model based methods, including MI, ML-MAR, and even the proposed ML-MNAR(MC), generally impose normality assumptions on the distributions of the variables. When the assumptions on the missingness mechanism and data distribution are violated, the extent of bias that may result from these methods is difficult to quantify. To further test the robustness of these methods, we conduct additional experiments involving the misspecification of the distributional assumptions and the missingness mechanism. For all subsequent robustness tests reported, we vary the missingness mechanism by allowing the coefficients ψy and ψz to take values in {0, 2, 4}. The missing value percentage is set to 10% and 30%.
5.4.1. Robustness to Misspecification of Distributional Assumptions.
First, with respect to the misspecification of distributional assumptions, we conduct two sets of robustness checks. First, we simulate scenarios where the conditional distribution of z on x and y is skewed. To achieve this, we generate a random residual term drawn from a skewed distribution and add this residual term to the conditional mean of z. We experiment with four distributions: three different Pearson type I distributions (a generalization of the beta distribution) with skewness set at 0.2, 0.4, and 0.6, respectively, and a gamma distribution with skewness set at 0.67. Second, we let the regression model of interest to be a logit model with binary dependent variable y (i.e., a generalized linear model). Under this setting, the relationship among the variables is not exactly linear. Thus, the normality assumption required by statistical models including MI, ML-MAR, and ML-MNAR(MC) does not hold. For this analysis, we employ MI rather than ML-MAR, since MI can be implemented flexibly by modeling the conditional distribution of the incomplete variable given the complete variables, rather than imposing a joint distribution for all variables.
The results (see Table A5 in Online Appendix 2) show that LD leads to sizable bias in all the settings. This is because the results are averaged over different values of ψy (0, 2, or 4). The statistical-model-based methods, ML-MAR and ML-MNAR(MC), generally outperform LD, even if the conditional distribution is skewed or when the relationship among variables is not linear. When , ML-MAR leads to the minimum bias, whereas when , ML-MAR generates more biased estimates and ML-MNAR(MC) generally obtains the smallest bias across different settings.
5.4.2. Robustness to Misspecification of the Missingness Mechanism.
With respect to the misspecification of the missingness mechanism, we conduct three sets of robustness checks. First, we examine misspecification of the logit function in Equation (7) by adding a squared term of the incomplete variable into the underlying missingness mechanism. Incorporating the squared term into the missingness mechanism has real-world implications. For instance, consumers with extreme (either positive or negative) underlying ratings are more likely to provide the ratings. We experiment with (1) omitting the term , (2) omitting the term , and (3) incorporating z2 while the true function includes a term . Second, we examine omitted variable bias in the logit function. The underlying missingness mechanism is modeled to include a variable u (with ) that is correlated with x and/or z (with ). We experiment with (1) omitting the variable u that is correlated with both x and z, (2) omitting the variable u that is correlated only with x, and (3) incorporating u into the missingness mechanism when u is correlated with both x and z (i.e., no omitted variable bias).
The results of these simulations (see Table A6 in Online Appendix 2) show that ML-MNAR(MC) is relatively robust to the above misspecification in the missingness mechanism and leads to relatively small bias in different simulation settings. When the squared term is omitted, ML-MAR leads to bias under . This observation suggests that the MAR assumption of ML-MAR involves not only the linear term but also the squared term in the missingness mechanism. ML-MNAR(MC) leads to bias if the squared term is ignored, but the bias can be eliminated if the squared term is incorporated into the missingness mechanism. When there is an omitted variable that is correlated with the variable(s) of interest, ML-MAR leads to bias under , but the magnitude of the bias is much less than the standard deviation since the correlation is at a low level. ML-MNAR(MC) leads to the minimum bias, even without including the omitted variable. If the related variable is incorporated during the estimation process of ML-MNAR(MC), then the bias can be eliminated.
The third robustness check is about the possible misspecification of the probability function. In particular, the missingness of z may not follow a logit model. The logit model can be formulated as a latent-variable model, where the error variable follows a standard logistic distribution. However, the error variable could follow (1) a standard normal distribution (the Probit model); (2) a student’s t-distribution with two degrees of freedom (also called a Robit model); (3) a Pearson type I distribution with variance, skewness and kurtosis being 1, 0.3, and 3, respectively; and (4) a gamma distribution with the shape and scale parameters being 9 and 1/3, respectively. The results (see Table A7 in Online Appendix 2) show that ML-MNAR(MC) is still relatively robust to the above misspecification in the functional form of the missingness mechanism and leads to relatively smaller bias across different simulation settings.
5.4.3. Representativeness of Simulation Parameters to Real-World Settings.
To alleviate the concerns about representativeness of our simulations to real-world analysis settings, we set the simulation parameters as close to a real-world data set as possible. To achieve this, we examined the model fit and correlation coefficients reported in the IS literature to ensure that the simulation settings are similar to real data sets. In the simulation results reported in Section 5.3, R2 = 0.5, and ρ = 0.5. These are reasonable values for IS research. As a robustness check, we systematically varied the R2 value of the linear model and the correlation between explanatory variables x and z as follows: (1) (low) and (low); (2) (low) and (high); (3) (high) and (low); and (4) (high) and (high). Results are robust with these alternative settings.
5.4.4. Regression Analysis with Missing Values in the Dependent Variable.
The simulation setting in Section 5.1 presents the situation that a RHS variable contains missing values. In fact, our method is also applicable to missing values in the dependent variable since we estimate parameters in the conditional distribution of the incomplete variable given complete variables, regardless of whether the incomplete variable is an RHS variable or a dependent variable. When missing values occur in the dependent variable following a normal model, the conditional distribution of the dependent variable implies a linear regression model.21
To demonstrate the performance of ML-MNAR(MC) in handing missing values in the dependent variable, we conduct a simulation analysis with the dependent variable being missing. The models of data generation and missing mechanism are the same as the main simulation setting, except that the missing values occur in the dependent variable. Results show that LD and MI lead to bias when . This is because when , the missing mechanism is MNAR, and LD leads to endogenous sample selection. We evaluate two approaches for MNAR, our proposed method and miceMNAR. ML-MNAR(MC) generates approximately unbiased estimation, and miceMNAR generates estimates close to the true values of parameters. However, since miceMNAR is particularly designed for the Heckman’s model, it still leads to bias to some extent (e.g., when and , the bias of β2 is −0.076, whose absolute value is greater than one half of the estimate’s standard error (0.131); see Table A8 in Online Appendix 2).
6. Discussions and Conclusions
Today’s big data environment has provided both opportunities and challenges to IS researchers in making scientific and societal impacts that are relevant and long-lasting (Chen et al. 2012). As empirical researchers, we cannot avoid missing values in most data sets. Bias caused by missing values raises great concerns, since it cannot be eliminated simply by increasing the volume of data. Although several social science disciplines have begun to pay closer attention to the missing value problem and embrace methods from statistics to enhance statistical inference validity, this problem has not received adequate attention from the IS community, as shown by our review of recent empirical studies published in the major IS journals. Such lack of attention was also reflected in our review, as evidenced by the scarce information on the rate of missing values in the data sets and the dearth of explicit discussion on missing value handling methods.
In this study, we present a systematic and theoretical discussion on the missing values problem. Starting from the typology of missingness mechanisms, the missing values problem is then modeled in a systematic way. The important implication drawn from the missing values literature is that, under the MAR mechanism, maximum likelihood estimation or multiple imputation without considering the missingness mechanism are valid for general parameter estimation purposes. However, in many practical real-world situations, we should expect departure from the MAR assumption. We provide reasons to suspect MNAR in six types of commonly used data and methods in IS research in Section 3. However, a rigorous statistical test of the MNAR mechanism is difficult to achieve except by obtaining follow-up data (Glynn et al. 1993).
We also propose an estimation process that is robust to MNAR, the most general missingness mechanism, by jointly modeling the distribution of the incomplete variable and the missingness mechanism. This estimation process generates approximately unbiased estimation under both MAR and MNAR mechanisms. Generating unbiased parameters is necessary and critical for both economic interpretation and statistical inference. The magnitude of coefficients (i.e., the economic significance) often has profound practical implication in empirical studies. Without incorporating the missingness mechanism or simply dropping the incomplete observations (i.e., via LD), bias could be severe. We acknowledge the limitations of the simulation analysis where we could not exhaustively explore all possible settings, such as varying the correlations among the variables of interest, the magnitude of the beta coefficients of the regression model, and the explanatory power (e.g., R2) of the regression model, and so on. Although the simulation setting would determine the magnitude of the bias, we expect that the results will be qualitatively similar given the theoretical properties of the missing value problem.
It is worth noting that, although the implemented method is robust to different types of missingness mechanisms, it inherits the assumption typically required by likelihood estimation approaches. For the likelihood approach incorporating the missingness mechanism (also called full likelihood by Little and Rubin 2019), its validity relies on the specification of the parametric missing data mechanism whose ground truth is unfortunately not “testable” from the data; therefore, the method implemented in this study can be viewed as a tool for sensitivity analysis. Moreover, the ML-MNAR(MC) method aims at obtaining unbiased regression coefficients but is not designed for imputing missing values most accurately. Conducting random draws for each missing value via the MCMC method is an intermediate step for obtaining unbiased parameter estimations. This is similar to the multiple imputation method, whose multiple imputations for each missing value is an intermediate step to obtain parameter estimation. However, the ML-MNAR(MC) method may be adapted to be an imputation method. Whether incorporating the missing mechanism generates more accurate imputation would be a promising direction for future research.
In addition to unbiased estimates, accurate estimation of standard errors of these estimates is crucial for minimizing type I and type II errors in hypothesis testing in social science studies (Newman 2014). Missing values unavoidably result in information loss due to the unobserved values. A valid estimation of the standard error should then take the information loss into account. There have been multiple solutions for rectifying the standard error estimation under the MAR mechanism, such as standard errors based on the information matrix, bootstrapping by computing standard errors from the estimation results based on sampling with replacement, and supplemented EM, which calculates the large-sample covariance matrix based on the E and M steps of EM (Meng and Rubin 1991). Under the MNAR mechanism, standard errors can similarly be obtained using the information matrix or via bootstrapping (Little and Rubin 2019). Developing alternative computationally efficient solutions to obtain standard errors under MNAR is a nontrivial but promising direction for future research.
Given these unsolved issues in the missing values literature, we are still far from reaching an omnipotent solution for handling missing values. As the number of incomplete variables increases and econometric models grow more complex, tracking the bias caused by missing values is almost not possible. In our preliminary experimentation, we have successfully extended the ML-MNAR(MC) method to handle two variables with missing values, which demonstrates the possibility that the proposed method can be used to handle more than one incomplete variable. However, with more variables having missing values, the computation complexity of ML-MNAR(MC) inevitably increases. Moreover, theoretical support for the applicability of ML-MNAR(MC) to any number of variables with missing values is far from attained. Prior research has demonstrated the theoretical identifiability property of ML incorporating the MNAR mechanism when there is one variable with missing values (Miao et al. 2016), but extending this theoretical guarantee to multiple variables has yet to be done. Therefore, we also recommend missing value handling outside of the statistical paradigm. In our review, we found three papers using information from other data sources to impute missing values.
Regarding research practice, when collecting data, it is important to formulate a strategy to capture the missingness mechanism if missing values are unavoidable, such as measuring covariates that can predict the missingness of a certain variable. During the data analysis phase, we encourage researchers to consider maximum likelihood (ML) and multiple imputation (MI) to handle missing values and to obtain preliminary statistics, such as the correlation measures, and then proceed with subsequent econometrics analysis. When there is strong evidence showing that the missingness mechanism is MNAR, the likelihood should incorporate the missingness mechanism into the model.
Finally, we propose that disclosure of missing value–related information should be a compulsory part of summary statistics reporting. Researchers should also explicitly discuss the method used in handling the missing values. To be specific, we recommend that researchers (1) add a column in the summary statistics that describes the missing value percentage of each variable in the incomplete data set and (2) justify the choice of the missing value handling method by discussing the reasons for missing values or through statistical analysis with follow-up data. To avoid unnecessarily lengthening manuscripts, such discussions on missing values can be provided in mandatory supplementary publication materials to enhance research transparency (Burton-Jones et al. 2021). The purpose of this paper is not to cast doubt on published results in the literature. To the extent that most empirical researchers would agree that it is almost impossible for any large-scale data analysis to not have missing values, we argue that discussion of the missing values problem should enhance research rigor instead of exposing researchers to questions and doubts.
The authors thank the senior editor, the associate editor, and the anonymous reviewers for their constructive comments and valuable suggestions on this research.
1 We were not able to find any literature on how practitioners handle missing values. However, our discussions with practitioners suggest that most practitioners simply drop observations with missing values.
2 Several social science disciplines such as psychology (Schafer and Graham 2002), political science (Honaker and King 2010), operational management (Tsikriktsis 2005), and organizational research (Newman 2014) have recently begun to embrace the prescriptions on handling missing values from the statistics literature.
3 Since explanatory data analysis is the more mainstream approach in the empirical IS literature, we limit our attention to the handling of missing values in explanation-oriented empirical research. The guidance of handling missing values in predictive analytics would be different (Shmueli and Koppius 2011), which is beyond the scope of this paper.
4 A commonly used concrete example of the missingness mechanism is the logistic model in which ψ consists of the intercept and slope coefficients. It is worth noting that, although the regression model often uses y to denote the dependent variable, this probabilistic model of missing mechanism does not distinguish between the dependent and right-hand side variables as in the regression model. In this model, y and z are just two variables, with y being completely observed but z has missing values. Correspondingly, the typology of missing mechanisms by Rubin (1976) is for general statistical analysis of variables in the data set, such as the estimation of common summary statistics, rather than specifically for regression analysis.
5 Although the MCAR mechanism is unlikely to hold in a real-world data set, a test of the MCAR mechanism could still be useful to support the popular listwise deletion method. Little (1988) proposed a global test for MCAR that uses all of the available data. However, since the power of this test may be weak, Little (1988) reminds us that accepting the null hypothesis of MCAR does not imply its correctness. For instance, with two variables x and z in a data set where z contains missing values, the power may be high if missingness of z depends on the fully observed x. On the other hand, if missingness of z depends on z (i.e., the MNAR situation), then the test only has acceptable power if x and z are highly correlated.
6 Concrete examples of MNAR in IS research will be provided in Section 3.2. Handling missing values under MNAR is the focus of the methodological contribution of this paper.
7 A detailed review of MI computations is beyond the scope of this study. Chapters 5 and 10 of Little and Rubin (2019) provide comprehensive documentation on creating multiple imputations and combining the statistical inference for each of the imputed data sets. Both ML and MI have been implemented in common statistical software applications such as Stata (StataCorp 2013), SAS (Yuan 2010), S-PLUS (Schimert et al. 2001), and LISREL (Jöreskog and Sörbom 2007).
8 As we need to distinguish between ML estimation that ignores the missingness mechanism and ML estimation that incorporates the missingness mechanism, we will henceforth refer to the former as ML-MAR and to the latter as ML-MNAR. Unless specifically mentioned, the general term ML is used to refer to ML-MAR, which is more frequently discussed in the extant missing values literature than ML-MNAR.
9 In empirical IS research, researchers are often concerned about the validity of estimated coefficients in regression analysis, where dependent variables and right-hand side (RHS) variables are specified in econometric models. It is worth noting that the above discussion is for general statistical analysis of variables in the data set (e.g., estimating common summary statistics), and it holds regardless of whether the method is used to handle missing values in the dependent variable or in RHS variables. However, in regression analysis, LD may be valid when the missing mechanism is not MCAR—when the missingness does not depend on the dependent variable, LD does not result in biased regression coefficients (Little 1992, Schafer and Graham 2002, Allison 2009). We provide more detailed discussion of LD for regression analysis in Section 3.3.1.
10 Most empirical researchers would acknowledge that it is extremely rare for any large-scale data analysis to not have any missing values, and thus we expect some underreporting and that 34% underestimates the extent of the missing values problem in the reviewed studies.
11 One would expect that studies employing experiments, where data collection is under tight control of the researcher, would not suffer from missing values. However, missing data still occurred for laboratory or field experiments due to participants not completing all parts of the experiment.
12 In our review, the research papers typically did not explicitly report information about the percentage of observations with missing values. Moreover, most articles often briefly mention only the number of cases being deleted due to incomplete observations, which makes it difficult to judge the missing values percentage for specific variables. To make best informed judgments about the missing value percentage, we made inferences based on two sources of information: (1) the analysis results tables that present different samples, such as for an imputed data set, when dropping incomplete observations and when dropping incomplete variables, and (2) the authors’ description of the number of observations dropped during the study sample formation process.
13 In addition to mean/zero substitution, sometimes researchers include a missingness indicator in the estimation, with the intention of controlling for systematic differences between the observations with missing values and those without missing values. However, this method is still not able to alleviate bias (Schafer and Graham 2002). By filling the missing values with a constant, the variance of the focal variable and the relationship between the incomplete and other variables are not preserved among incomplete observations.
14 There is a paper using both mean/zero replacement and conditional mean imputation. Therefore, although the sum of the counts for these three approaches is 18, there are 17 unique papers (i.e., 27.4%).
15 There are scenarios where LD can still be efficient. Consider a data set with two variables y1 and y2, where some of the values on variable y2 are missing. Since the incomplete observations provide no information for the coefficient of the regression of y2 on y1, the LD is efficient with respect to the estimation of the coefficient. However, ML-MAR is still more efficient than LD in estimating the mean values of the variables (see Little and Rubin 2019, example 3.1).
16 It is worth noting that if the missing value scenario is that y is incomplete while other variables are complete, then parameters in the conditional distribution of the incomplete variable y include the regression coefficients of interest.
17 The technical details of implementing the Monte Carlo likelihood estimation are provided in Online Appendix 1.
18 A more stringent evaluation would entail benchmarking the performance of our proposed method against existing methods designed specifically to handle MNAR missing values rather than comparing it against conventional methods known to produce biased results. A novel method, miceMNAR (https://cran.r-project.org/web/packages/miceMNAR/; Galimard et al. 2018), was developed for handling MNAR missing values. However, this method was developed only for handling missing values in the dependent variable. In this analysis, we are subjecting the missing value handling methods to missing values in RHS variables under different missingness mechanisms. Therefore, miceMNAR is not a valid benchmark. To conduct a fair evaluation of our proposed methods, we compare it with miceMNAR when there are missing values in the dependent variable later in our robustness analysis (Section 5.4.4).
19 Here, the implementation of ML-MAR is based on the joint multivariate normal distribution of all the variables. This distributional assumption is valid in our simulation setting. ML-MAR is implemented with the MATLAB function ecmmvnrmle (https://www.mathworks.com/help/finance/ecmmvnrmle.html). To avoid distributional assumptions for the complete variables (which may be nonnormal), researchers can implement ML-MAR with the normality assumption only on the incomplete variable conditional on other complete variables (Little 1992).
20 Online Appendix 2 presents the results for different missing value percentages from 10% to 40%. Results of multiple imputation and other commonly used conventional missing value handling methods (i.e., conditional mean imputation, zero/mean substation, and zero/mean substation with missingness indicator) are also provided in Online Appendix 2. Multiple imputation is implemented with the MICE R package (https://cran.r-project.org/web/packages/mice/), and it behaves qualitatively the same way as ML-MAR. For the above conventional methods, bias was observed regardless of the missingness mechanism.
21 This can be seen from Equation (4), where we model the conditional distribution of the incomplete variable.
References
- (2018) Beyond the privacy paradox: Objective vs. relative risk in privacy decision making. MIS Quart. 42(2):465–488.Crossref, Google Scholar
- (2009)
Missing data . Millsap RE, Maydeu-Olivares A, eds. The Sage Handbook of Quantitative Methods in Psychology (Sage, Thousand Oaks, CA), 72–89.Crossref, Google Scholar - (1989) Estimation of parameters and missing values under a regression model with non–normally distributed and non–randomly incomplete data. Statist. Medicine 8(2):217–228.Crossref, Google Scholar
- (2017) Reflective technology assimilation: Facilitating electronic health record assimilation in small physician practices. J. Management Inform. Systems 34(3):664–694.Crossref, Google Scholar
- (2003) Assuring information quality. J. Management Inform. Systems 20(3):9–11.Google Scholar
- (1999) Maximizing generalized linear mixed model likelihoods with an automated Monte Carlo EM algorithm. J. Royal Statist. Soc. Ser. B. Statist. Methodology 61(1):265–285.Crossref, Google Scholar
- (1996) Handling missing data in survey research. Statist. Methods Medical Res. 5(3):215–238.Crossref, Google Scholar
- (2021) Advancing research transparency at MIS Quarterly: A pluralistic approach. MIS Quart. 45(2):iii–xviii.Google Scholar
- (2003) Time-related factors of data quality in multichannel information systems. J. Management Inform. Systems 20(3):71–92.Crossref, Google Scholar
- (2007) Missing Data in Randomised Controlled Trials: A Practical Guide. (Health Technology Assessment Methodology Programme, Birmingham, UK).Google Scholar
- (2012) Business intelligence and analytics: From big data to big impact. MIS Quart. 36(4):1165–1188.Crossref, Google Scholar
- (2015) A new measure of disclosure quality: The level of disaggregation of accounting data in annual reports. J. Accounting Res. 53(5):1017–1054.Crossref, Google Scholar
- (2018) Strategic value of big data and business analytics. J. Management Inform. Systems 35(2):383–387.Crossref, Google Scholar
- (1977) Maximum likelihood from incomplete data via the EM algorithm. J. Royal Statist. Soc. Ser. B. Statist. Methodology 39(1):1–38.Google Scholar
- (2015) Informing privacy research through information systems, psychology, and behavioral economics: Thinking outside the “APCO” box. Inform. Systems Res. 26(4):639–655.Link, Google Scholar
- (1998) Missing data in Likert ratings: A comparison of replacement methods. J. General Psych. 125(2):175–191.Crossref, Google Scholar
- (2001) The impact of nonnormality on full information maximum-likelihood estimation for structural equation models with missing data. Psych. Methods 6(4):352–370.Crossref, Google Scholar
- (2011) Missing not at random models for latent growth curve analyses. Psych. Methods 16(1):1–16.Crossref, Google Scholar
- (2018) Heckman imputation models for binary or continuous MNAR outcomes and MAR predictors. BMC Medical Res. Methodology 18:90.Crossref, Google Scholar
- (2013) Robustness of multiple imputation under missing at random (MAR) mechanism: A simulation study. Unpublished doctoral dissertation, Georgia Southern University.Google Scholar
- (1993) Multiple imputation in mixture models for nonignorable nonresponse with follow-ups. J. Amer. Statist. Assoc. 88(423):984–993.Crossref, Google Scholar
- (2018) Creating strategic business value from big data analytics: A research framework. J. Management Inform. Systems 35(2):388–423.Crossref, Google Scholar
- (2007) Thyroid and parathyroid operations in Veterans Affairs and selected university medical centers: Results of the patient safety in surgery study. J. Amer. College Surgeons 204(6):1222–1234.Crossref, Google Scholar
- (2019) Relationships between information technology and other investments: A contingent interaction model. Inform. Systems Res. 30(1):291–305.Link, Google Scholar
- (1979) Sample selection bias as a specification error. Econometrica 47(1):153–161.Crossref, Google Scholar
- (2010) What to do about missing values in time series cross section data. Amer. J. Political Sci. 54(2):561–581.Crossref, Google Scholar
- (2017) On self-selection biases in online product reviews. MIS Quart. 41(2):449–472.Crossref, Google Scholar
- (2001) Missing responses in generalised linear mixed models when the missing data mechanism is nonignorable. Biometrika 88(2):551–564.Crossref, Google Scholar
- (2007) Lisrel. V. 8.80. Scientific Software International, Chicago.Google Scholar
- (2018) Surviving in global online labor markets for IT services: A geo-economic analysis. Inform. Systems Res. 29(4):893–909.Link, Google Scholar
- (2013) How do MIS researchers handle missing data in survey-based research: A content analysis approach. Internat. J. Inform. Management 33(5):734–751.Crossref, Google Scholar
- (2001) Logistic regression in rare events data. Political Anal. 9(2):137–163.Crossref, Google Scholar
- (2015) Missing R&D. J. Accounting Econom. 60(1):73–94.Crossref, Google Scholar
- (2009) A Bayesian approach for estimating and replacing missing categorical data. J. Data Inform. Quality 1(1):1–11.Crossref, Google Scholar
- (1988) A test of missing completely at random for multivariate data with missing values. J. Amer. Statist. Assoc. 83(404):1198–1202.Crossref, Google Scholar
- (1992) Regression with missing X’s: A review. J. Amer. Statist. Assoc. 87(420):1227–1237.Google Scholar
- (1995) Modeling the drop-out mechanism in repeated-measures studies. J. Amer. Statist. Assoc. 90(431):1112–1121.Crossref, Google Scholar
- (1989) The analysis of social science data with missing values. Sociol. Methods Res. 18(2-3):292–326.Crossref, Google Scholar
- (2019) Statistical Analysis with Missing Data (Wiley, Hoboken, NJ).Google Scholar
- (2007) Collaborative filtering and the missing at random assumption. Proc. 23rd Conf. Uncertainty Artificial Intelligence, Washington, DC.Google Scholar
- (1991) Using EM to obtain asymptotic variance-covariance matrices: The SEM algorithm. J. Amer. Statist. Assoc. 86(416):899–909.Crossref, Google Scholar
- (2016) Identifiability of normal and normal mixture models with nonignorable missing data. J. Amer. Statist. Assoc. 111(516):1673–1683.Crossref, Google Scholar
- (2013)
On Convergence Properties of the Monte Carlo EM Algorithm . Jones G, Shen X, eds. Modern Statistical Theory and Applications: A Festschrift in Honor of Morris L. Eaton (Institute of Mathematical Statistics, Beachwood, OH), 43–62.Crossref, Google Scholar - (2003) Longitudinal modeling with randomly and systematically missing data: A simulation of ad hoc, maximum likelihood, and multiple imputation techniques. Organ. Res. Methods 6(3):328–362.Crossref, Google Scholar
- (2014) Missing data: Five practical guidelines. Organ. Res. Methods 17(4):372–411.Crossref, Google Scholar
- (2018) A note on listwise deletion vs. multiple imputation. Political Anal. 26(4):480–488.Crossref, Google Scholar
- (1999) Missing data in multiple item scales: A Monte Carlo analysis of missing data techniques. Organ. Res. Methods 2(3):211–232.Crossref, Google Scholar
- (1998) Semiparametric regression for repeated outcomes with nonignorable nonresponse. J. Amer. Statist. Assoc. 93(444):1321–1339.Crossref, Google Scholar
- (1976) Inference and missing data. Biometrika 63(3):581–592.Crossref, Google Scholar
- (1987) Multiple Imputation for Nonresponse in Surveys (Wiley, New York).Crossref, Google Scholar
- (1996) Multiple imputation after 18+ years. J. Amer. Statist. Assoc. 91(434):473–489.Crossref, Google Scholar
- (1997) Analysis of Incomplete Multivariate Data (CRC Press, New York).Crossref, Google Scholar
- (1999) Multiple imputation: A primer. Statist. Methods Medical Res. 8(1):3–15.Crossref, Google Scholar
- (2002) Missing data: Our view of the state of the art. Psych. Methods 7(2):147–177.Crossref, Google Scholar
- (2001) Analyzing Data with Missing Values in S-PLUS (Insightful Corporation, Seattle).Google Scholar
- (2010) Best practices for missing data management in counseling psychology. J. Counseling Psych. 57(1):1–10.Crossref, Google Scholar
- (2011) Predictive analytics in information systems research. MIS Quart. 35(3):553–572.Crossref, Google Scholar
StataCorp (2013) Stata Multiple-Imputation Reference Manual, v. 13 (StataCorp LP, College Station, TX)Google Scholar- (2007) Monte Carlo likelihood inference for missing data models. Ann. Statist. 35(3):990–1011.Crossref, Google Scholar
- (2005) A review of techniques for treating missing data in OM survey research. J. Oper. Management 24(1):53–62.Crossref, Google Scholar
- (1990) A Monte Carlo implementation of the EM algorithm and the poor man’s data augmentation algorithms. J. Amer. Statist. Assoc. 85(411):699–704.Crossref, Google Scholar
- (2010) Bias and efficiency of multiple imputation compared with complete-case analysis for missing covariate values. Statist. Med. 29(28):2920–2931.Crossref, Google Scholar
- (2015) Introductory Econometrics: A Modern Approach, 6th ed. (Cengage Learning, Boston).Google Scholar
- (2006) Leveraging missing ratings to improve online recommendation systems. J. Marketing Res. 43(3):355–365.Crossref, Google Scholar
- (2010) Multiple Imputation for Missing Data: Concepts and New Development, v. 9.0 (SAS Institute Inc., Rockville, MD).Google Scholar

