
To Brush or Not to Brush: Product Rankings, Consumer Search, and Fake Orders
Abstract
Brushing—online merchants placing fake orders of their own products—has been a widespread phenomenon on major e-commerce platforms. One key reason why merchants brush is that it boosts their rankings in search results. Products with higher sales volume are more likely to rank higher. Additionally, rankings matter because consumers face search frictions and narrow their attention to only the few products that show up at the top. Thus, fake orders can affect consumer choice. We focus on this search-ranking aspect of brushing and build a stylized model to understand merchants’ strategic brushing behavior as well as how it affects consumers. We consider a high-type merchant (who sells a more popular product) and a low-type merchant (who sells a less popular product) competing on an e-commerce platform where product rankings evolve over time. We find that if brushing gets more costly for merchants (e.g., due to stricter platform policies), it may sometimes surprisingly harm consumers as it may only blunt brushing by the high-type merchant but intensify brushing by the low-type merchant. If search is less costly for consumers (e.g., due to improved search technologies), it may not always benefit consumers, either. Moreover, the design of the ranking algorithm is critical: placing more weight on sales-volume-related factors may trigger a nonmonotone change in consumer welfare; tracking recent sales only as opposed to cumulative sales does not always dial down brushing and, in fact, may sometimes cause the low-type merchant to brush more.
History: Ravi Bapna, Senior Editor; De Liu, Associate Editor.
Funding: C. Jin gratefully acknowledges the Singapore Ministry of Education Academic Research Fund [Tier 1, Grant R-253-000-144-133], The Wharton School Dean’s Postdoctoral Research Fund, and Mack Institute Research Fund. All authors gratefully acknowledge the 2019 Networks, Electronic Commerce and Telecommunications Institute (NET) Summer Research Grant.
Supplemental Material: The online appendices are available at https://doi.org/10.1287/isre.2022.1128.
Good wine needs no bush.
—William Shakespeare
1. Introduction
Brushing—online merchants placing fake orders of their own products—has been an increasingly pervasive practice witnessed on major e-commerce platforms such as Alibaba’s Taobao (Wong et al. 2015) and Tmall sites (Financial Times 2016), JD.com (Lim 2015) and Amazon (CBS 2018). Here is how brushing works: merchants reach out to (professional) brushers, who place orders and pay with the money received from the merchants; the merchants ship out empty parcels or boxes of worthless items; the brushers write good reviews about their fake orders; the merchants’ products rank higher in search results, generating more future traffic (Wong et al. 2015, Financial Times 2016). According to an estimate by Alibaba’s Vice President Yu Weimin, 1.2 million merchants on Taobao—or about 17% of all vendors—had faked 500 million transactions worth 10 billion Chinese Yuan in the year of 2013 alone; he further said those were “only the tip of the iceberg,” and his conservative estimate put the number of brushers in the tens of thousands (Wong et al. 2015).
What drives brushing? According to the Wall Street Journal (Wong et al. 2015), “faking orders, or ‘brushing,’ . . . let vendors pad their sales figures and, in theory, boost their standing on online marketplaces, which often give more prominence to high-volume sellers with good track records.” This is echoed by the Financial Times (2016), which contends that “shipping more goods would give [online sellers] better placement—and therefore a better chance to garner more real sales—on websites such as Alibaba-owned Taobao.” In the eyes of online merchants and industry observers, brushing almost becomes a necessary evil. “Without fake transactions, your product will end up at the very back of the search results, and people will never be able to find it,” said a Taobao merchant, who claimed that “faking several dozen transactions a day for a week could get his products within the first five pages of search results” (Wong et al. 2015). “The difference between being at the top of a page of results and buried at the bottom is night and day; brushing is a very tempting shortcut,” said an industry observer (Financial Times 2016). Alibaba also acknowledged the existence of brushing and said the following in its prospectus before the IPO: “sellers may engage in fictitious or phantom transactions with themselves or collaborators in order to artificially inflate their search results rankings” (Fountain et al. 2018).
These quotes consistently reveal one fundamental motivation of brushing. Consumers face search frictions, and thus often only consider prominent products that rank high in search results. At the same time, platforms’ ranking algorithm tends to give more visibility to products with higher sales volume and better reviews (which themselves tend to be correlated, as established by Chevalier and Mayzlin 2006, Chintagunta et al. 2010). Thus, there is a feedback loop between rankings and sales: a higher ranking drives more sales (due to search frictions), which, in turn, lead to a higher ranking (due to the ranking algorithm). Therefore, merchants are naturally under pressure to rack up fictitious sales to boost rankings in search results. This search-ranking perspective is at the heart of brushing. However, we should also acknowledge that it is not the only reason why merchants brush. Placing fake orders also allows merchants to generate glowing fake reviews that look more credible (because they are backed by real-world transactions), thereby deceiving consumers into believing the products are better than they actually are.
As a first cut, our paper focuses on the search-ranking aspect of brushing but abstracts away from the deception aspect of brushing. First, consumers must consider a product (through search) before they can possibly be deceived. Hence, consumer search is a foundational step. Second, consumers may be able to recognize fake reviews based on the actual content or with the aid of technology, or debias their perception based on their own independent investigation, whereas the ranking effect (which makes certain products more visible and easier to find than others) can be more ingrained and harder to root out. Third, the search-ranking aspect is a unique, defining (and hence arguably the most interesting) feature of brushing (the press articles cited earlier lend strong support to that), whereas fake reviews are a more generic problem that has been more extensively studied and can occur in other settings that do not require the evidence of real-world transactions. For these reasons, we focus our paper on the search-ranking aspect of brushing.
Platforms often claim they do not condone brushing. They deploy sophisticated data mining and machine learning techniques in an attempt to detect and remove fake transactions (Wall Street J. 2015, Bloomberg 2017), but are often met with limited success (Wall Street J. 2015, Financial Times 2016). One impediment is that these fake orders are backed by real shipping and delivery (Wong et al. 2015); another hindrance is that sophisticated brushers would mimic real shoppers’ browsing and clicking behavior before ordering to make the entire process look as real as possible (Fountain et al. 2018). A study by Xu et al. (2017) finds only a small proportion of the sellers involved in brushing are detected and materially penalized. Although platforms’ effort to crack down on brushing cannot easily eliminate brushing, it obviously makes brushing more costly for merchants, which is commonly believed to at least attenuate brushing and make consumers better off. Such a consumer-centric view is critical for platforms’ long-term success, but do consumers truly benefit?
Besides making brushing more difficult for merchants, platforms may instead consider improving search technologies to make search easier for consumers. Conventional wisdom suggests that reducing search frictions benefits consumers because consumers can incur less cost and also search more to find a product that better fits their need. Further, because a lower search cost implies consumers are less influenced by rankings (which motivate brushing), reducing search frictions is believed to further dampen brushing incentives and thus improve consumer welfare. Is it indeed a bulletproof idea to reduce search frictions?
Another lever platforms can pull is to fine-tune the design of the ranking algorithm, which can play a critical role in shaping merchants’ brushing behavior and consequently, consumer welfare. Specifically, because brushers home in on sales-volume-related factors (sales, ratings, etc.), it begs the question of how to best incorporate these factors into the ranking algorithm in light of brushing. How much should they be weighted, if at all? Should the rankings track the cumulative sales record or the recent history only?
To address these research questions, we build a stylized model that considers a high-type seller and a low-type seller competing on an e-commerce platform over two representative periods. In each period, one consumer arrives and is interested in buying one product. Upon arrival, each consumer is presented with a ranking (i.e., an ordered list) of two products (one from each seller). A consumer may prefer either product ex ante but is more likely to attach a higher prior value to the high-type seller’s product (which is henceforth referred to as the more popular product). However, upon arrival, a consumer is uncertain about the match value of each product and can conduct a sequential search to resolve such uncertainty. Motivated by the recent empirical evidence that rankings affect consumers through search cost (Ursu 2018), we capture the ranking effect by assuming that searching the bottom-ranked product is more costly. Product rankings are updated in each period. The ranking algorithm incorporates the platform’s own noisy information about product popularity and sales-volume-related factors. The latter can be manipulated by the sellers through costly fake orders (i.e., brushing) in a brushing game.
We characterize the brushing equilibrium. When the search cost is low, neither seller brushes because consumers search extensively and are hardly subject to the ranking effect, making brushing futile in our model. Otherwise, the sellers may engage in brushing and possibly differ in brushing intensities. Interestingly, it is possible that as brushing cost increases, the high-type seller brushes less (as expected), but the low-type seller (surprisingly) brushes more. Because the low-type seller sells a less popular product, it has an inherent disadvantage in the ranking evolution. As a consequence, the low-type seller sees brushing as the only means to counteract its disadvantage and must act more strategically: when the brushing cost is relatively low, knowing the high-type seller would brush aggressively, it capitulates and brushes modestly; when the brushing cost is relatively high, knowing the high-type seller would not brush much, it seizes the opportunity and brushes intensely to challenge the high-type seller’s entrenched position.
This result has managerial implications for the platform’s fight against brushing. It shows that by escalating the fight and making brushing more costly, the platform may only tame brushing from the high-type seller, which, in turn, prompts the low-type seller to brush even more. As a result, consumer welfare can decline with a higher brushing cost (because the less popular product may gain more prominence due to brushing). In fact, when the brushing cost is intermediately high, this effect can be so severe that consumer welfare can be even lower than if sales-volume-related factors were not incorporated into the ranking algorithm at all. This result can be particularly alarming considering that incorporating sales-volume-related factors into the ranking algorithm is meant to reinforce the platform’s knowledge about product popularity and benefit consumers.
Besides, we find that reducing consumers’ search frictions does not always benefit consumers, either. In the absence of brushing, a lower search cost benefits the first-period consumer and encourages the consumer to search more, but due to the individual’s idiosyncratic taste, more search may lead to the purchase of the less popular product. Such a purchase (probabilistically) pushes the less popular product to the top, thereby hurting the interest of the second-period consumer. This distortion reveals negative externalities that early consumers may impose on later consumers as sales and rankings evolve. Moreover, in the presence of brushing, the distortion can be further strengthened by the fact that a lower search cost, by changing consumer search behavior, may disproportionately affect the brushing behavior of the two sellers who anticipate the change in consumer behavior. The adjustment of the sellers’ brushing strategies may not only harm the second-period consumer (as in the no-brushing case), but also the first-period one (different from the no-brushing case). Hence, the welfare distortion due to a lower search cost can be even more pervasive and pronounced when brushing kicks in. Platforms intent on reducing search cost should be particularly alert to such welfare distortion if the initial search cost and brushing cost are in lockstep (i.e., both are low/intermediate/high).
Further, changing the weight of sales-volume-related factors can trigger a nuanced brushing response from the sellers and consequently, consumer welfare may change in a nonmonotone fashion. On the one hand, sales-volume-related factors can provide useful information, and increasing their weight in the ranking algorithm can improve the algorithm’s efficiency in identifying the more popular product; on the other hand, because these factors are subject to brushing, an increased weight also gives the sellers a stronger brushing incentive. Hence, adjusting the weight of the sales-volume-related factors has nuanced welfare implications. We find that a platform intent on maximizing consumer welfare should set the weight to an intermediate level when the brushing cost is either on the low end or on the high end, but should attach all the weight to the sales-volume-related factors and make rankings purely based on sales when the brushing cost is intermediate.
We consider four major extensions in the main body of the paper to demonstrate robustness and generate additional insights. First, we extend the two-period base model (which captures the short run) to an infinite-horizon one that models the ranking evolution using a generalized random walk (which captures the long run). We find that even one-off brushing can have an enduring effect on long-run consumer welfare. The short-run distortion that a lower search cost can harm consumers is corrected in the long run in the absence of brushing, but persists once brushing kicks in.
Second, we extend the one-shot brushing game in the base model to a dynamic brushing model where the sellers can brush in both periods. Although our main insights continue to hold, we find that interestingly, when the brushing cost falls into an intermediate interval, the two sellers choose not to brush (even though they may brush when the brushing cost is outside this interval) because the threat of responsive brushing in the second period deters them from brushing in the first period. This implies that in a dynamic setting, increasing the brushing cost, instead of deterring brushing, may, in fact, trigger brushing from sellers who would not brush otherwise.
Third, we compare a ranking algorithm that tracks recent sales only with one that tracks cumulative sales. Conventional wisdom may suggest that tracking recent sales only can disincentivize brushing as the effect of brushing does not last as long. We find that whereas the high-type seller indeed brushes less in a system that tracks recent sales only, the low-type seller may take advantage of this opportunity and sometimes brushes even more. This result highlights the challenges the platform faces in the design of ranking algorithms—especially in terms of how to best incorporate sales-volume-related factors—when taking into account the impact of brushing.
Fourth, we endogenize the product prices of the two sellers. We find that either increasing brushing cost or decreasing search cost can soften the price competition between the two sellers, causing the equilibrium prices to rise and thereby hurting consumers. Indeed, because of the sellers’ price response to brushing, consumer welfare can sometimes be even lower than if sales-volume-related factors were not included in the ranking algorithm at all, which shows that the threat of brushing can undermine or even reverse the welfare advantage of a sales-dependent ranking algorithm. These welfare effects are indeed consistent with those identified in the base model (which treats prices as exogenous).
Our paper tells a cautionary tale that well-intentioned platform policies to address brushing, namely, making brushing more costly for sellers and search easier for consumers, may not always benefit consumers. We also caution that the design of the ranking algorithm may have subtle implications for sellers’ brushing behavior and consumer welfare. Our paper highlights the challenges platforms may face in each of these interventions against brushing.
2. Literature Review
One key premise of our paper is that online product rankings matter and specifically, a higher ranking attracts more traffic. Numerous empirical evidence lends strong support to such a ranking effect. Agarwal et al. (2011) show that in sponsored advertising, click-through rates (CTRs) decrease exponentially with rank in search results. Koulayev (2014) and De los Santos and Koulayev (2017) estimate the ranking effects to be significant and often sizable in online hotel search. Ursu (2018) quantifies the ranking effect in an Expedia data set by structurally estimating a sequential search model in the spirit of Weitzman (1979). In particular, Ursu (2018) empirically shows the rankings influence consumer search primarily through search cost, which motivates our modeling assumption.
To that end, our paper builds on the extensive consumer search literature. In addition to Weitzman (1979) and Ursu (2018), our paper is particularly related to those that capture firm prominence (Armstrong et al. 2009, Armstrong and Zhou 2011, Zhou 2011, Armstrong 2017). These papers assume that a more prominent firm will be searched earlier by consumers and that prominence is either exogenously specified or endogenously achieved through sales commissions or price advertising. A related stream of literature is that on position auctions in sponsored search advertising. In position auctions, advertisers bid for a more prominent ad slot. Edelman et al. (2007), Varian (2007), Katona and Sarvary (2010), Abhishek and Hosanagar (2013) assume exogenous CTRs that are decreasing from top to bottom, without modeling how CTRs are generated by consumer search behavior. Other papers integrate consumer search into position auctions as micro-foundations for the differences in CTRs across ad positions (e.g., Athey and Ellison 2011, Chen and He 2011, Jerath et al. 2011, Chu et al. 2020). Further, Katona and Sarvary (2010), Xu et al. (2012), Berman and Katona (2013) study the role of organic listing in sponsored search advertising.
These papers assume static prominence (or ad positions) that would not change over time. Whereas brushing is also a means to gaining prominence, one unique feature of our setting is that prominence (i.e., product rankings) can evolve over time. Incorporating this dynamic allows us to better understand the feedback loop between sales and rankings, as well as the search externalities that early consumers impose on later consumers, both of which are important building blocks of brushing. It also allows us to explore various design questions regarding ranking algorithms that one would not be able to explore otherwise, such as the impact of changing the weight of sales-volume-related factors in the ranking algorithms and how the recent-sales-based and cumulative-sales-based ranking algorithms differ in driving brushing behavior.
The fraudulent nature of brushing connects our paper to the literature on click fraud in search advertising (Wilbur and Zhu 2009, Chen et al. 2015), which focuses on a different problem setting. The typical motivation for committing click fraud, namely, deceptively clicking on search ads, is either to increase the third-party search engine’s revenue or to deplete a competitor advertiser’s budget. By contrast, the motivation for brushing we focus on in this paper is to manipulate the rankings and generate more sales of one’s own product. In a similar vein, our paper complements the literature on fake reviews (Mayzlin 2006, Anderson and Simester 2014, Mayzlin et al. 2014, Lappas et al. 2016, Luca and Zervas 2016) and false advertising (Corts 2013, 2014; Piccolo et al. 2015; Zinman and Zitzewitz 2016; Rao and Wang 2017; Piccolo et al. 2018; Rhodes and Wilson 2018). Fake reviews and false advertising are meant to influence consumers’ evaluation of a product, whereas the fake orders we focus on are meant to affect whether consumers consider a product, which is a prerequisite for how consumers evaluate a product.
The literature on fake reviews and false advertising typically assumes consumers are sophisticated Bayesian agents who update their beliefs about products or even infer sellers’ faking strategy based on fake reviews and ads, but does not consider consumer search cost or the design of ranking algorithms as we do. As a result, these papers cannot comment on the impact of search cost on brushing or consumer welfare; neither do they study the impact of adjusting ranking algorithms (e.g., varying the weight of sales-volume-related factors or tracking cumulative sales vs. recent sales). Besides, this literature typically considers one-shot static fakery, whereas our paper considers both static brushing (in the base model) and dynamic brushing (as an extension in Section 6.2).
Our paper is broadly related to the literature on observational learning. Seminal works include Banerjee (1992) and Bikhchandani et al. (1992). In their frameworks, customers are Bayesian agents who are uncertain about the state of the world (e.g., product value); they can directly observe the actions of previous customers (e.g., past purchases or historical sales volume) and thus update their belief about the state of the world accordingly. One key insight from this literature is the possibility of information cascades, that is, individuals may ignore their private signal about the state of the world and follow their predecessors’ decisions. In our setting, consumers do not infer from past purchases (and indeed many platforms do not disclose sales volume); instead, past purchases influence consumer search (which can fully resolve uncertainty about product fit) indirectly through rankings. Our long-run analysis in Section 6.1 finds a similar cascading effect: the product rankings will eventually stabilize, but if consumers’ search cost is high, then the wrong product may claim the top position in the long run. We complement the observational learning literature by bringing in the search and ranking perspectives not previously considered. We characterize how search cost modulates ranking evolution, and how sellers would manipulate this evolution through brushing.
To the best of our knowledge, although ours is the first analytical paper to formally model brushing, two papers have empirically investigated this practice. Xu et al. (2017) measure the scale of brushing on Taobao through web crawling and identify more than 11,000 sellers as faking transactions in a two-month period. They find that brushing can substantially increase an online seller’s reputation. Using a rich data set that consists of more than 300,000 products listed on a major e-commerce platform in a three-month period, Wang et al. (2018) find that brushing generates more traffic in the short run, but has a negative effect on product performance in the long run. Both papers focus on measuring the impact of brushing on the sellers (which is still inconclusive as the findings of the two papers are somewhat contradictory) given the variations in sellers’ endogenous brushing behavior, but they leave open the fundamental question of why sellers differ in how they brush in the first place and the implications of brushing for consumers and platform governance. We complement these empirical studies with a theoretical understanding of brushing.
3. The Model
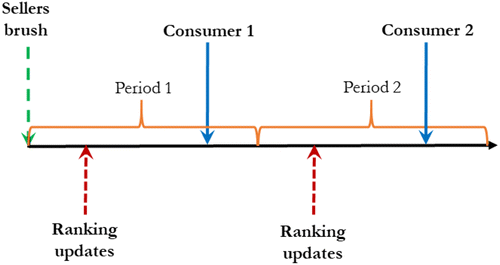
We consider two competing sellers, H and L, on an e-commerce platform, selling products H and L, respectively. The sellers operate over two time periods.1 In each period, one consumer arrives and is presented with an ordered list (ranking) of the two products; the consumer chooses one product to maximize the expected utility.
Each consumer’s net valuation of product is if it fits the consumer and otherwise. Each product independently fits each consumer with probability .2 Upon arrival, consumers know their own vi, the prior value they attach to product , but does not know the match value (ϵ or ), that is, whether a product fits. Consumers are heterogeneous in terms of with . For each consumer, with probability , and with probability . Because , we say product H is more popular than product L in the sense that a consumer is more likely to attach a higher prior value to product H.3 However, any individual consumer has no knowledge of which product is more popular in the market (i.e., the consumer does not know α nor does α affect the consumer’s expected utility for a given ranking). The platform does not know which product is more popular, either.
3.1. Consumer Search
To resolve the uncertainty about the match value, consumers conduct a costly sequential search, for example, navigating through the list page, clicking on the product links, going over the product page information (e.g., product descriptions and reviews). Consumers incur a search cost for each product they search, and after the search, they know whether the product fits and thus become aware of their net valuation of the product. Before consumers start, they decide which product to search first; after they search one product, they decide whether to purchase it or search the other one; if both products are searched, they purchase the one with a higher net valuation. Exactly one product is purchased at the end of each period.4
The search cost of a bottom-ranked product is c and that of a top-ranked product is normalized to zero. Searching a lower-ranked product presumably involves more search cost as consumers scroll down, navigate, or flip pages. This assumption parsimoniously captures a ranking effect whereby a higher-ranked product has more visibility and thus attracts more consumer attention. The empirical literature consistently finds the ranking effect significant. For example, Koulayev (2014) estimates ranking effects to range from $2.93 to $18.78; De los Santos and Koulayev (2017) find ranking effects range from $7.76 to $35.15. In particular, Ursu (2018) considers seven possible ways in which rankings affect consumer search and concludes that the only one consistently supported by her data is that rankings affect search costs. Our assumption is motivated by her empirical evidence and in the spirit of her model specification for structural estimation.
Consumer search determines the purchase probabilities of a given product under a given ranking. Let and denote the (endogenous) probability that a consumer purchases product H if it is top-ranked and that if it is bottom-ranked, respectively (we defer the characterization of these purchase probabilities to Section 4). Table 1 summarizes the main notation used in the paper.
|

Table 1. Glossary of Main Notation
| Symbol | Definition |
|---|---|
| Exogenous model parameters | |
| c > 0 | Search cost |
| Fit probability | |
| Prior value of a product before search | |
| Match value of a product after search | |
| Probability that a consumer has higher prior value of product H than L | |
| Cost of brushing one unit | |
| Parameter in the weight of sales-volume-related factors in the ranking algorithm | |
| Sales-volume-unrelated factors about product i in the ranking algorithm; | |
| Noise about product i in the ranking algorithm | |
| Sellers’ decision variables | |
| Brushing probability of seller in the base model | |
| First-period brushing probability of seller in the extension in Section 6.2 | |
| Brushing probability of seller under cumulative-sales-based ranking and recent-sales-based ranking in the extension in Section 6.3 | |
| Equilibrium price under sales-independent ranking, sales-dependent ranking, and brushing in the extension in Section 6.4 | |
| Other endogenous variables | |
| Ranking score of product | |
| Sales volume of product | |
| Probability of product H being ranked at the top when sales difference | |
| Purchase probability of product H when H is top-ranked (respectively bottom-ranked) | |
| Expected total profit of seller | |
| Consumer welfare under sales-independent ranking, sales-dependent ranking, and brushing | |
3.2. Ranking Algorithm
Next, we describe how product rankings are generated. In each period, the platform updates the product rankings according to a ranking score that incorporates both (1) sales-volume-related factors (subject to brushing) and (2) sales-volume-unrelated factors (not subject to brushing). We explain these two factors in more detail as follows:
Sales-volume-related factors include sales volume itself and other closely linked metrics. Sales volume is easy to track and often used as a key metric in the ordering of products. Wong et al. (2015) cite a source that estimates sales volume accounts for 25% of how listings are generated on Alibaba, carrying more weight than any other known metrics. Moreover, sales volume affects rankings indirectly as many other factors potentially used by ranking algorithms are also (sometimes implicitly) correlated with sales volume. For example, product ratings or consumer reviews are routinely used as an input for rankings and prior empirical evidence suggests that higher ratings/reviews are often associated with more sales (Chevalier and Mayzlin 2006, Chintagunta et al. 2010).5 Therefore, sales volume influences product rankings either directly or indirectly. These sales-volume-related factors are nevertheless often subject to brushing, that is, online sellers can place fake orders and write fake reviews for the orders placed to boost rankings (we will introduce the brushing game between the sellers in Section 3.3).
Sales-volume-unrelated factors reflect other information (e.g., offline reputation) that the platform gathers about the products through various data mining techniques. We assume that such factors give platforms informative but not perfect knowledge about product popularity, and cannot be manipulated through fake orders (or fake reviews therein).
Formally, product i’s ranking score Si is defined as follows:
ni is product i’s cumulative sales volume to date (the number of units sold so far) and captures the sales-volume-related factors;
represents the platform’s imperfect knowledge about product popularity based on the sales-volume-unrelated factors; μi is the informative part and we let and to reflect that product H is more popular than product L; δi is the noise term drawn from an independent and identically distributed (i.i.d.) standard Gumbel distribution; and
is the weight of the sales-volume-related factors in the ranking score. Note that if λ = 0, the ranking is sales-independent; if , the ranking is sales-dependent, and as λ increases, sales-volume-related factors carry more weight in the ranking; in an extreme case of , the ranking is purely sales-based.
The platform ranks the product with a higher score Si higher. The ranking is updated each time a new transaction (real or fake) comes in. Thus, given sales volume ni of products , the probability of product H being top-ranked (and product L being bottom-ranked) before the noise terms δi’s are realized is
3.3. Brushing Game
We now formulate a brushing game between the two sellers. We normalize the reward each seller earns from selling one unit of its own product (to an authentic consumer) to 1.6 Each seller incurs cost cB by brushing one unit (i.e., placing one unit of fake order of its own product). The brushing cost captures the following: (1) the physical cost of processing fake transactions and compensating third-party brushing professionals and (2) the difficulty of brushing in light of the regulatory environment: heftier penalties and tougher audits make brushing harder (namely, increasing the brushing cost) for sellers. We deliberately assume symmetry in unit reward and brushing cost across the two sellers such that the only difference between the two is how much consumers value them. This enables us to tease out the minimal nontrivial conditions for the two sellers to differ in their brushing strategies.7
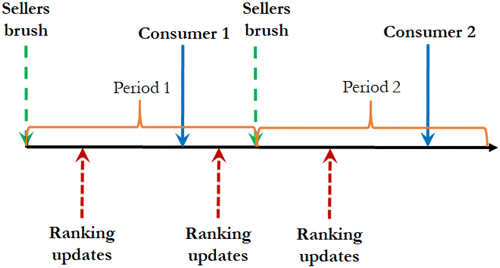
At the outset of the sales horizon, the two sellers simultaneously determine their respective brushing strategy to maximize their own expected total profit over two periods. Strategy qi stands for the probability of brushing one unit, and , the probability of not brushing. Any is a pure brushing strategy; any is a mixed strategy. Strategy qi captures the intensity of brushing: for example, implies seller L brushes (stochastically) more than seller H. After both sellers finish brushing, the ranking of the two products will be determined by their ranking scores specified in Section 3.2. Then, the period-1 consumer arrives and purchases one of the products, after which the rankings of the two products are updated again according to the latest ranking scores. Finally, the period-2 consumer arrives and purchases one of the products. The sequence of events is depicted in Figure 1.
Seller i’s expected total profit over two periods, , is equal to the expected total rewards from authentic sales less the expected total brushing cost, that is,
With probability , seller L brushes and seller H does not; in this case, R1 is seller H’s expected total rewards over two periods.
With probability , seller H brushes and seller L does not; in this case, R2 is seller H’s expected total rewards over two periods.
With probability , both sellers brush the same amount (i.e., either 0 or 1 unit); in this case, R3 is seller H’s expected total rewards over two periods.
A brushing strategy profile is a Nash equilibrium if
Note that we have made two simplifications to maintain analytical tractability and obtain clean results. First, we build a one-shot brushing game between the two forward-looking sellers who brush only at the outset of the sales horizon. As a first cut, the one-shot model reveals fundamental characteristics of the underlying strategic interactions between the sellers. In Section 6.2, we extend our analysis to dynamic brushing, where the two sellers have an additional opportunity to brush also at the start of the second period in response to what happens in the first period. Second, in our base model, we restrict possible brushing units to {0, 1} (i.e., each seller decides whether to brush, with mixed strategies allowed), which affords the simplest setting to cleanly identify the first-order effect of brushing. In online Appendix C.1, we allow for multiple brushing units and more general brushing strategies. Our main insights are robust to both extensions.
4. Analysis
In this section, we solve the consumer search problem to obtain the purchase probabilities of each product under a given ranking, and then feed the purchase probabilities into the sellers’ brushing game to characterize the brushing equilibrium.
4.1. Consumer Search
This subsection solves the consumer search problem. We focus on the case where the difference of prior values is neither too big nor too small (Assumption 1) to create the most tension between the two sellers for generating rich insights.
.
Recall that (respectively ) is the purchase probability of product H when it is top-ranked (respectively bottom-ranked). Proposition 1 characterizes consumers’ optimal search strategies and the resulting purchase probabilities.
(Consumer Search). Consumers’ optimal search strategies are as follows. [Selection rule]: each consumer searches the top-ranked product first; [stopping rule]: after knowing whether it fits, decides whether to continue to search the bottom-ranked product according to the rule specified in Table 2. The resulting purchase probabilities are summarized in Table 3.
|
Table 2. Consumer Search Strategies
| Prior value of top-ranked product | Search cost c | Fit of top-ranked product | Continue searching? |
|---|---|---|---|
| Fit | Not search | ||
| Not fit | Search | ||
| Regardless of fit | Not search | ||
| Regardless of fit | Search | ||
| Fit | Not search | ||
| Not fit | Search | ||
| Regardless of fit | Not search |
|
Table 3. Consumers’ Purchase Probabilities
| Search cost c | Purchase probabilities |
|---|---|
| Case 1: | |
| Case 2: | |
| Case 3: | |
| Case 4: |
Table 3 divides the search cost into four cases. In Case 1, the search cost is so low that consumers always search to the extent that they find the best product that fits their need. Hence, the purchase probabilities depend only on the product, but not the ranking (i.e., ). In Case 4, the search cost is so high that consumers always purchase the top-ranked product without search. Hence, the purchase probabilities only depend on the ranking, but not the product (i.e., ). In Cases 2 and 3, the purchase probabilities are both ranking- and product-dependent. In particular, the ranking effect can dominate in the sense that can be less than 1/2, which implies that consumers can be less likely to buy product H (the more popular product) than product L (the less popular product) when product H is placed at the bottom.
4.2. Brushing Equilibrium
Building on Proposition 1, Proposition 2 fully characterizes the brushing equilibrium of the two sellers.
(Brushing Equilibrium). The sellers’ equilibrium brushing strategies, qi, , are as follows:
When search cost is low, i.e., , neither seller brushes, i.e., .
When search cost is high, i.e., , there exist unique thresholds and on brushing cost cB with such that
ii-1. if brushing cost is low , then full brushing is the unique (dominant-strategy) equilibrium, i.e., ;
ii-2. if brushing cost is higher , then no brushing is the unique (dominant-strategy) equilibrium, i.e., ;
ii-3. if brushing cost is intermediate , then partial brushing is the unique (mixed-strategy) equilibrium, i.e., ; in particular, with a higher brushing cost, seller H (seller L) brushes less (more), i.e., qH (qL) is decreasing (increasing) in cB; additionally, and ;
ii-4. if is an equilibrium if and only if and ; and
ii-5. if is an equilibrium if and only if and .
When the search cost is low (part (i) of Proposition 2, corresponding to Case 1 of Proposition 1), there is no brushing in our model regardless of how inexpensive brushing is. Under such low search frictions, consumers are immune to the ranking effect (i.e., ) and can always find out their favorite product. Hence, manipulating the ranking through brushing would be futile for the sellers.8
When the search cost is not low (part (ii) of Proposition 2, corresponding to Cases 2–4 of Proposition 1), the brushing cost plays a crucial role in shaping the brushing equilibrium. When the brushing cost is sufficiently high, that is, , there is no brushing. When the brushing cost is sufficiently low, that is, , both sellers engage in full brushing (i.e., both brush one unit). When the brushing cost is intermediate (i.e., ), both sellers engage in partial brushing, randomizing between not brushing and brushing one unit. In such a mixed-strategy equilibrium, the two sellers differ in their brushing intensity. As brushing becomes more costly, seller H brushes less (which is intuitive), but seller L brushes more (which is counter-intuitive). Thus, seller L brushes more than seller H when the brushing cost is intermediately high but less when the brushing cost is intermediately low. See Figure 2 for an illustration.
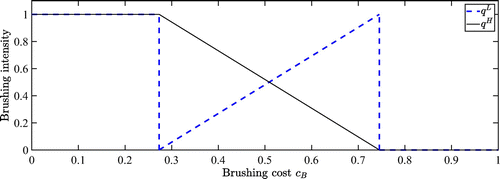
Note.
Next, we explain parts (ii-3)-(ii-5) of Proposition 2 in more detail. By and large, the brushing incentives are twofold: (1) to stay ahead of competition, termed the offensive incentive, and (2) to avoid lagging behind, termed the defensive incentive. Because seller H is more popular, the ranking algorithm is biased in favor of seller H in the sense that it is more likely to push seller H to the top all else equal (because of the platform’s knowledge about product popularity and sales volume’s reinforcement such knowledge). Thus, seller H has an innate advantage over seller L. Seller H brushes mostly to defend its advantage and therefore is primarily driven by the defensive incentive, whereas seller L sees brushing as the only opportunity to challenge its opponent’s entrenched position and therefore is mostly driven by the offensive incentive.
This distinction between the two sellers’ predominant brushing incentives has two gain-loss implications. First, an inter-gain-loss implication: if the other seller does not brush, then seller L has more to gain from brushing than seller H and thus is more willing to brush (as an offensive strategy); by contrast, if the other seller brushes, then seller H has more to lose from not brushing than seller L and thus is more willing to brush (as a defensive strategy). Second, an intra-gain-loss implication: seller L gains more from brushing (if seller H does not) than it loses from not brushing (if seller H brushes); by contrast, seller H loses more from not brushing (if seller L does) than it gains from brushing (if seller L does not).
The first (inter-gain-loss) implication explains the equilibrium behavior when the brushing cost is at the two thresholds, that is, when . Naturally, a sufficiently high brushing cost would deter both sellers from brushing, but seller L is more inclined to brush. When the brushing cost falls and reaches the upper threshold , the brushing cost becomes low enough to make seller L just indifferent between brushing and not brushing, but still not low enough to sway seller H to brushing. Due to seller L’s indifference, it may choose any brushing probability (0 and 1 included), but regardless of what seller L chooses, seller H always chooses no brushing as a dominant strategy. Hence the equilibrium in Proposition 2 (ii-5). On the other end of the spectrum, a sufficiently low brushing cost would naturally cause both sellers to brush, but seller L is not as motivated to brush as seller H. When the brushing cost rises and reaches the lower threshold , the brushing cost becomes high enough to make seller L just indifferent between brushing and not brushing, but still not high enough to discourage seller H from brushing. Due to seller L’s indifference, it may choose any brushing probability (0 and 1 included), but regardless of what seller L chooses, seller H always chooses brushing as a dominant strategy. Hence the equilibrium in Proposition 2 (ii-4).
The second (intra-gain-loss) implication explains the mixed-strategy equilibrium when the brushing cost is between the two thresholds, that is, when . When the brushing cost increases within this intermediate range, the two sellers stick to partial brushing. To sustain such a mixed-strategy equilibrium, both sellers must remain indifferent between brushing and not brushing. With an increase in brushing cost, a seller would strictly prefer not to brush if the other seller did not change its brushing strategy. Hence, to maintain a mixed-strategy equilibrium, the expected utilities from brushing and not brushing should be rebalanced to restore the sellers’ indifference between these two options. Specifically, the brushing strategies must change in a way to make a seller either gain more from brushing (when the other seller does not brush) or lose more from not brushing (when the other seller brushes). Recall that for seller L, the gain effect dominates, but for seller H, the loss effect dominates. Consequently, a mixed-strategy equilibrium can only be sustained if seller H decreases its brushing probability (so that seller L would gain more from brushing) and seller L increases its brushing probability (so that seller H would lose more from not brushing). Hence, as shown in Proposition 2 (ii-3) and illustrated in Figure 2, the equilibrium brushing probabilities of the two sellers change in opposite directions as the brushing cost changes within an intermediate range. It is noteworthy that seller L’s disadvantage in the ranking algorithm compels it to be a contrarian: it doubles down on brushing when doing so is expensive, but dials back brushing when doing so is cheap.
5. Implications for Consumer Welfare
This section studies the implications of brushing for consumer welfare, defined as the average utility per consumer. Let WI denote consumer welfare under sales-independent ranking (λ = 0). Naturally, in such a system, the sellers have no incentives to brush.9 Let WS denote consumer welfare in the sales-dependent ranking system () assuming the sellers would not brush. Let WB denote consumer welfare in the sales-dependent ranking system when the sellers’ brushing behavior is taken into account. The detailed expressions of WI, WS, and WB are presented in online Appendix A. Proposition 3 examines the impact of brushing on consumer welfare (i.e., comparing WB with WS and WI) and characterizes the moderating role of brushing cost cB for , that is, when the search cost is not too low (recall from Proposition 2 that neither seller brushes when ).
(Brushing Cost). The consumer welfare is not monotone increasing in cB. Specifically, when search cost is not low, that is, , WB is decreasing in cB if , where are introduced in Proposition 2; in particular, when , there exist unique thresholds and with such that
brushing improves consumer welfare (i.e., ) if and only if ;
brushing hurts consumer welfare but still achieves higher consumer welfare relative to sales-independent ranking (i.e., ) if and only if ; and
brushing results in even lower consumer welfare than that under sales-independent ranking (i.e., ) if and only if .
Proposition 3 first establishes that incorporating sales-volume-related factors into the ranking algorithm can increase consumer welfare (WS > WI) should the sellers be non-strategic. Sales volume is an indicator of consumer preference, and can help sharpen the platform’s knowledge of which product is more popular in the market, especially when the platform does not have a very good idea a priori. This result may explain why sales-volume-related factors are routinely used in product rankings.
However, this welfare gain is established under the caveat that the sellers would not manipulate rankings. Once their brushing behavior is considered, consumer welfare WB is generally nonmonotone in brushing cost cB, as illustrated by Figure 3. In particular, when the brushing cost is intermediately low, the welfare gain of sales-dependent ranking is further strengthened by brushing. However, a higher brushing cost can reduce consumer welfare. When the brushing cost is intermediate, the welfare gain is weakened but still preserved. When the brushing cost is intermediately high, the welfare gain is replaced by a welfare loss, that is, the presence of brushing can make consumer welfare in the sales-dependent ranking system even lower than that in the sales-independent ranking system—let alone the sales-dependent ranking system without brushing.
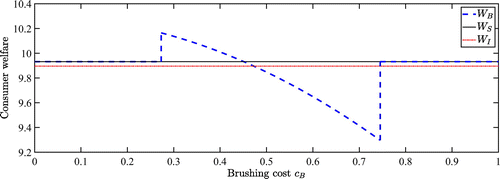
Note.
These welfare results follow from the equilibrium brushing strategies characterized in Proposition 2: in a partial-brushing equilibrium, an increase in brushing cost causes seller H to brush less and seller L to brush more, making consumers worse off. In particular, when the brushing cost is sufficiently high (but still low enough to sustain a partial-brushing equilibrium), seller L brushes almost a full unit whereas seller H brushes next to nothing, increasing the odds that seller L comes out at the top. In this case, the sales-volume-related factors in the ranking algorithm would be misleading, potentially causing consumers to be even worse off than if sales-volume-related factors were not included in the ranking algorithm at all. This welfare distortion is particularly alarming considering that sales-independent ranking might be dismissed as a low bar to beat.
Proposition 3 reveals an unintended consequence of sale-dependent ranking. Although it is meant to facilitate product discovery and improve consumer welfare, it may also trigger sellers’ strategic brushing behavior, which could undermine or even reverse the welfare advantage otherwise brought by incorporating sales-volume-related factors into the ranking algorithm. This result also has managerial implications for the platform as it fights brushing. Although conventional wisdom contends that making brushing harder (e.g., taking a more stringent view of what constitutes a sale) would deter such behavior and benefit consumers, we find that it may only deter high-quality sellers while inducing low-quality sellers to brush more, thereby reducing consumer welfare. Admittedly, if brushing cost keeps rising, then eventually the sellers stop brushing altogether (as indicated by Proposition 3), thus restoring the efficiency of sales-dependent ranking. However, to the extent that brushing is difficult to eradicate, Proposition 3 tells a cautionary tale about the combat against brushing.
Although Proposition 3 focuses on brushing cost as a lever to modulate consumer welfare, Proposition 4 investigates the impact of consumers’ search cost on consumer welfare.
(Search Cost). As search cost c decreases, the consumer welfare under brushing, , does not always monotonically increase; specifically, for , there exists δc such that , where is introduced in Proposition 2.
Conventional wisdom suggests that lower search frictions reduce consumers’ cost of effort and further encourage them to search more, enabling them to find a better product, both of which should be beneficial to consumers. However, Proposition 4 shows that in the presence of brushing, a lower search cost can reduce consumer welfare. We supplement Proposition 4 with Figure 4, which further shows that a lower search cost indeed benefits consumers when the ranking algorithm does not incorporate sales-volume-related factors (i.e., WI is decreasing in cB), but the reverse can be true in the sales-dependent ranking system, with or without brushing.
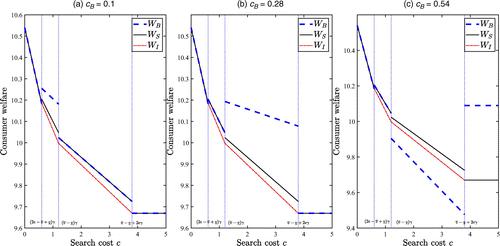
Note. .
The rationale is as follows. In the sales-dependent ranking system without brushing, whereas more search due to a lower search cost is helpful for the first-period consumer, it may increase the likelihood of product H being displaced from the top place (when the consumer finds product L to be a better fit), potentially hurting the second-period consumer. In other words, more search by early consumers can impose externalities on later consumers by potentially altering the product rankings. Due to heterogeneity in taste, such externalities can be negative.10 Empirically, externalities of this nature have been identified in the context of consumer reviews: for example, Park et al. (2021) find evidence that the first consumer review can significantly influence the fate of a product.
When brushing kicks in, as shown by both Proposition 4 and Figure 4, the potential welfare loss due to a lower search cost is more widespread in scope and more substantial in scale. In its standalone form, this result sounds striking: sellers brush to manipulate the rankings, which make a difference precisely owing to consumers’ search frictions; hence, one would expect reducing search costs to discourage sellers from brushing and improve consumer welfare.
Contrary to the previous intuition, a lower search cost—by changing consumer behavior—triggers nuanced, differential responses from the two sellers. It is possible that seller H responds by brushing less, which, in turn, motivates seller L to brush more, making consumers worse off. Another possibility is that both sellers brush less, but seller H is disproportionately discouraged from brushing, leading to lower consumer welfare. The latter scenario highlights the fact that not only does the absolute magnitude of brushing affect consumer welfare, but the relative intensity also does. Note that because brushing influences the rankings in both periods, not only can the second-period consumer be harmed by a lower search cost (as in the case without brushing), but the first-period consumer can also suffer (different from the case without brushing).
On a more granular level, we further observe from Figure 4 that the biggest drop in consumer welfare WB (due to a decrease in search cost) takes place when the initial search cost (before the decrease) and brushing cost are both low (as illustrated in Figure 4(a), where it takes place when the search cost switches from Case 2 to 1)11 or when both are intermediate (as illustrated in Figure 4(b), where it takes place when the search cost switches from Case 3 to 2), or when both are high (as illustrated in Figure 4(c), where it takes place when the search cost switches from Case 4 to 3). To see why, recall from Proposition 4 that the welfare drop occurs when, prior to the search cost reduction, the brushing cost is close to . Under such a brushing cost, seller L brushes little but seller H brushes almost at the maximum (see Proposition 2). Thus, when a reduction in search cost triggers a switch in consumer search behavior, seller H could only reduce its brushing intensity, making seller L’s relative brushing intensity increase by comparison, thereby hurting consumers. This welfare reversal arises when brushing cost and search cost are both high/intermediate/low because brushing cost threshold generally increases with search cost. An increase in search cost makes consumers more reliant on rankings, which incentivizes brushing, so sellers will still engage in (partial) brushing even under a higher brushing cost; as a result, brushing cost threshold increases.
These findings have managerial implications for the platform: making search easier for consumers (e.g., improving search technologies) is not necessarily a panacea that always improves consumer welfare; the platform should be particularly alert to the negative welfare consequence of reducing the search cost if the initial search cost and brushing cost are in lockstep (i.e., if both are low/intermediate/high).
In addition to the brushing cost (Proposition 3) and search cost (Proposition 4), another lever the platform can pull is to adjust the weight of sales-volume-related factors in the ranking algorithm (i.e., by adjusting λ). Proposition 5 examines the impact of λ on consumer welfare.
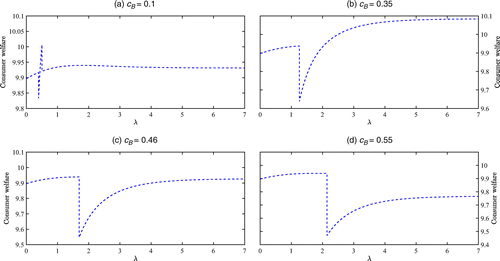
(Weight of Sales Volume in the Ranking Algorithm). Consider μ = 0. If , then there exist such that WB is nonmonotone in λ when . In particular, when and , setting will not generate the maximum consumer welfare.
Proposition 5 shows that changing the weight of sales-volume-related factors can have a nonmonotonic effect on consumer welfare. For tractability, the analytical result restricts attention to μ = 0 (i.e., the platform does not have any idea about product popularity). However, this assumption is not consequential and the insight holds for as well, as illustrated by Figure 5.
Note. .
On the one hand, placing more weight on the sales-volume-related factors (i.e., increasing λ) can reinforce the platform’s knowledge about consumer preference, helping push product H to the top, benefiting later consumers. On the other hand, more emphasis on these sales-volume-related factors also increases the sellers’ incentive to brush. Recall from Proposition 3 that when the other seller does not brush, seller L has a stronger incentive to brush. The same idea carries over here. Neither seller brushes if λ is sufficiently small (because the product rankings depend little on sales-volume-related factors, making brushing economically unjustifiable), but seller L has a stronger incentive to deviate. When λ reaches a certain threshold, seller L takes the lead on brushing. Hence, we see a dip in consumer welfare. As λ further increases, seller H also finds it increasingly rewarding to brush and thus increases its brushing intensity, which, in turn, discourages seller L from brushing. Hence, consumer welfare climbs back up. However, as λ increases beyond a point, brushing can become sufficiently lucrative for both sellers, prompting them to engage in full brushing (this occurs when brushing cost is low, as illustrated by Figure 5(a)). In this case, the effects of brushing cancel out, and consumer welfare falls again. However, when the brushing cost is not too low, as illustrated by Figure 5(b) through Figure 5(d), the two sellers may hold on to partial brushing despite a continued increase in λ. Sometimes, as illustrated by Figure 5(d), consumer welfare may never climb back to the level of sales-independent ranking (λ = 0).
More closely, Proposition 5 shows analytically that if the brushing cost is low, then the platform should set the weight of sales in rankings at an intermediate level to maximize consumer welfare, as illustrated by Figure 5(a). Figure 5(c) and Figure 5(d) supplement Proposition 5 by showing that if the brushing cost is on the high end, then the platform should do the same (setting λ at an intermediate level). In this case, seller H is reluctant to brush due to the high brushing cost, and an increase in λ is not a strong enough incentive that prompts seller H to catch up with seller L in brushing. Hence, consumer welfare is maximized when λ is set high enough that sales volume contributes as much useful information as possible but not too high to trigger brushing. By contrast, if the brushing cost is intermediate, then, as illustrated by Figure 5(b), consumer welfare is maximized as as seller H is more motivated to brush (given the more modest brushing cost) and may eventually catch up with seller L.
Proposition 5 and Figure 5 have managerial implications for the platform. They show that incorporating the sales-volume-related factors can be a double-edged sword. It is generally not a good idea to eliminate these factors from the ranking algorithm altogether. Nor is it always recommended that product rankings be purely based on these factors. Rather, the platform may find it beneficial to fine-tune the weight of the sales-volume-related factors in the ranking algorithm. In particular, unless the brushing cost is intermediate, the platform may wish to set the weight of sales volume at an intermediate level to maximize consumer welfare.
6. Extensions
In this section, we study four extensions of our base model both to demonstrate robustness of our main findings and to generate additional insights. To maintain tractability, we make the following simplification: consumers share common prior values (i.e., α = 1); rankings in each period are purely based on sales volume (i.e., ) and updated only if a lower-ranked product strictly surpasses the higher-ranked product in sales volume. Note that imposing these simplifying assumptions on the base model does not affect our main insights.
6.1. Long-Run Impact
Our base model studies the impact of brushing in the short run (captured by our two-period model). This subsection studies the long-run impact of brushing by extending the two-period base model to an infinite-period one. We model the evolution of the sales-dependent ranking system as a generalized random walk in the spirit of Fleder and Hosanagar (2009). We relegate the technical details to online Appendix D.1 and summarize the main insights.
Our random-walk analysis shows that regardless of the initial sales volume, there will always be one product that eventually wins out, dominating the sales ranking with an unbeatable sales record, leading to a stable ranking (without oscillation) in the long run. However, there is no guarantee that product H will eventually secure the top position. If consumers face considerable search frictions, then product L may rise to the top in the long run; moreover, the likelihood that product L does so is sensitive to the initial sales volume, which gives the sellers an incentive to brush. It also implies that even one-shot brushing can have a long-run impact on consumer welfare. We confirm that the short-run welfare implications of brushing persist in the long run.
Nevertheless, there is one noteworthy difference between the short-term and long-term effects of search cost reduction. Recall that in the short run, even without brushing, a lower search cost may not benefit consumers in the sales-dependent ranking system as more search by early consumers can impose negative externalities on future consumers. In the long run, however, this distortion will be corrected: more search is more likely to push product H to the top eventually, improving long-run consumer welfare even though the interest of some consumers may be sacrificed along the way. By contrast, in the presence of brushing, the welfare distortion in the sales-dependent ranking system can still arise in the long run as a lower search cost disproportionately affects the two sellers’ brushing strategies, potentially making consumers worse off.
6.2. Dynamic Brushing
Our base model allows the two sellers to brush only at the beginning of the sales horizon (i.e., static brushing). In this subsection, we consider a dynamic brushing model where sellers can brush in both periods. Specifically, at the start of each period, both sellers simultaneously determine their respective brushing strategy, the probability of brushing one unit; each time the sales volume of either product increases (due to either real or fake orders), the ranking of the two products will be updated based on their ranking scores specified in Section 3.2. Thus, the two sellers play a dynamic game. Figure 6 illustrates the timeline of the game. We will solve the game via backward induction. Lemma 1 characterizes the sellers’ second-period brushing equilibrium.
(Second-Period Brushing). If (a) and (b) the two sellers have equal cumulative sales volume (fake plus real) at the end of the first period, then in the second period, the top-ranked seller brushes with probability and the bottom-ranked seller brushes with probability . Otherwise, neither seller brushes in the second period.12
Lemma 1 shows that the two sellers brush in the second period only if there is a tie in sales volume at the end of the first period. If the sales difference is too large, then it is hard for the laggard to catch up and surpass the leader via brushing; therefore, both sellers forgo brushing. Building on the brushing equilibrium of the second-period subgame, Proposition 6 characterizes the first-period brushing equilibrium. Let be the equilibrium brushing strategy of seller in the first period.
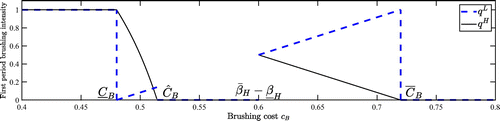
(First-Period Brushing). In the first period, when , neither seller brushes. When , if , both sellers conduct full brushing; if , neither seller brushes. When , there exists a unique threshold with (where are introduced in Proposition 2) such that
if , then is the unique equilibrium;
if or , then is the unique equilibrium; and
if or , then the unique equilibrium is a mixed-strategy one with ; additionally, (respectively ) is piecewise decreasing (respectively increasing) in cB.
Figure 7 illustrates Proposition 6. Comparing Proposition 6 to its static-brushing counterpart, Proposition 2 (illustrated in Figure 2), shows that sellers’ dynamic brushing strategies are largely similar to their static-brushing strategies. There is one noteworthy structural difference when the brushing cost is intermediately high (), in which case neither seller brushes in the first period in dynamic brushing (by Proposition 6) and the no-brushing stalemate continues in the second period (by Lemma 1). The possibility of brushing in the second period (because brushing is not too costly) acts a credible threat that deters the sellers from brushing in the first period (because brushing is not too cheap, either). In this case, brushing in the first period would be circumvented by the opponent’s responsive brushing in the second period and hence, the benefit of doing so is too short-lived to justify the cost. On the positive side, this result implies that in a dynamic setting, brushing cost does not have to be made exorbitantly high to eliminate brushing; on the negative side, it also implies that even when sellers do not brush originally, increasing the brushing cost may trigger brushing. Regardless, our high-level insights regarding consumer welfare remain robust. We refer the reader to online Appendix D.2 for more details.
Note. .
6.3. Ranking Based on Recent Sales
The ranking system in our base model ranks products by the cumulative sales volume; in this subsection, we consider an alternative system that ranks products by the most recent sales volume and examine how the change of the ranking algorithm affects the sellers’ brushing behavior. Specifically, we extend our two-period base model to a three-period model. In the cumulative-sales-based ranking system, the two products at the beginning of each period are ranked in descending order of the total historical sales volume recorded up to that period, whereas in the recent-sales-based ranking system, only the sales volume generated in the previous period is counted for ranking. In particular, in the former system, the rankings at the beginning of period 3 take into account sales volume generated in both periods 1 and 2; whereas in the latter, the rankings only include as input sales volume generated in period 2, but ignore that in period 1. Brushing still occurs at the outset of the sales horizon to be consistent with the base model.
We characterize the brushing equilibrium in both systems in online Appendix D.3. In either system, the structure of the brushing equilibrium is similar to the one in the base model (see Proposition 2). Let and be the equilibrium brushing strategy of seller in the recent-sales-based ranking system (R for recent) and cumulative-sales-based ranking system (T for total), respectively. Proposition 7 compares the equilibria of the two systems.
(Brushing Equilibrium Comparison: Recent vs. Cumulative Sales).
When , neither seller brushes, that is, .
When , in both systems, if , both sellers engage in full brushing, that is, ; if , neither seller brushes, that is, .
When , there exist unique thresholds on brushing cost cB with such that
Proposition 7 shows that the brushing equilibria in the two systems differ only when both the search cost and brushing cost are intermediate. Because the fake sales volume brought by brushing does not contribute to the third-period ranking in the recent-sales-based ranking system, brushing has less bang for the buck and thus a lower brushing cost is needed to motivate brushing. Consequently, the range of brushing cost that supports a partial-brushing equilibrium shifts to the left in the recent-sales-based ranking system. This implies that for the same brushing cost, seller H brushes less than it would in the cumulative-sales-based ranking system, but the same cannot always be said about seller L. When the brushing cost is in an intermediate range such that partial-brushing equilibrium emerges in both ranking systems (Case iii-3 of Proposition 7), seller L actually brushes more in the recent-sales-based ranking system (to strategically take advantage of the fact that seller H brushes less); otherwise, it brushes less (Cases iii-2 and iii-4 of Proposition 7). This result suggests that ranking algorithms can have subtle implications for brushing behavior. Importantly, whereas brushing is motivated by the fact that ranking algorithms take into account historical sales performance, discounting or disregarding the remote history does not necessarily tame brushing.
6.4. Endogenizing Prices
In this section, we endogenize the product prices to study the impact of ranking systems and brushing on the price competition between the two sellers. To generate clean insight, we focus on the case of symmetric sellers. We assume each consumer’s prior value and match value of each product are both independently drawn from a uniform distribution over . At the outset of the sales horizon, the two sellers first simultaneously determine their product prices and given the prices, and then simultaneously determine their brushing intensities (in the sales-based ranking system). Upon arrival, consumers observe the prices and rankings of the two products before they search.13 We focus on identifying symmetric equilibria of this pricing-brushing game where both sellers charge an identical price (because they are symmetric).
We note that even under the assumption of symmetric sellers, consumers still face two asymmetric products due to the ranking effect (the search cost of each product depends on where it is ranked). It is noteworthy that even without the complications of ranking evolution and brushing, characterizing the pricing equilibrium alone under asymmetric consumer search costs is notoriously difficult; little progress has been made until a recent paper by Choi et al. (2018). We build on their framework by closely following their modeling constructs.14 Proposition 8 characterizes the equilibrium prices in the sales-independent ranking system and the sales-based ranking system in the absence of brushing; it further compares the resulting consumer welfare.
(Price Equilibrium). For search cost , the (symmetric) equilibrium price under sales-independent ranking, pI, and that under sales-based ranking, pS, are given by:
Moreover, pS < pI and consumer welfare under sales-based ranking is higher than that under sales-independent ranking.
Proposition 8 shows that the sales-based ranking system (without brushing) intensifies price competition relative to sales-independent ranking. A lower price is more likely to lure the consumer in the current period, which, in the sales-based ranking system, translates into a higher likelihood of being placed at the top in the next period, thus increasing the chance of luring the consumer in the next period as well. This cascading effect gives the sellers a stronger incentive to cut price, resulting in a lower equilibrium price in the sales-based ranking system. As a result, consumer welfare is higher. Note that the welfare-enhancing effect of the sales-based ranking system is consistent with our finding from the base model, although the driving forces are markedly different.
Next, we study the impact of brushing in the sales-based ranking system on the price competition. The two-stage pricing-brushing game is too complicated to be solved analytically, so we study it numerically via backward induction (see online Appendix D.4 for details).
Figure 8 illustrates our numerical findings. We observe from Figure 8(a) that when the brushing cost is intermediate, the equilibrium price with brushing, pB, deviates from that without brushing, pS; further, we numerically find that neither seller brushes in this case, which implies brushing acts as a threat that alters the sellers’ pricing behavior. Moreover, when the brushing cost is intermediate, the equilibrium price pB is increasing in the brushing cost. In particular, pB can be even higher than pI, but in other cases, it can be lower than pS. This implies that brushing can soften or intensify price competition.
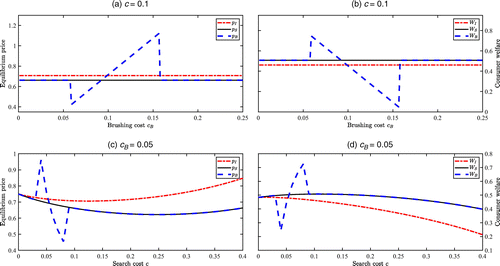
We provide some intuition for these observations. The threat of brushing can soften price competition because an attempt to undercut one’s competitor with a low price would be circumvented by the competitor who could brush to the top and sustain a high price that exploits the ranking effect. It occurs when brushing cost is intermediately high, in which case brushing is cheap enough to make the threat of brushing credible but not so cheap as to induce the competitor to counteract with both brushing and charging an even lower price (because low profit margins due to low price would render relatively costly brushing economically unviable). By contrast, when brushing cost is intermediately low, the threat of brushing can intensify price competition as the sellers are compelled to lower their price to deter (relatively cheap) brushing.
The price response has welfare implications, as illustrated by Figure 8(b), which shows that with an increase in brushing cost, consumer welfare can fall (due to a higher equilibrium price); in fact, consumer welfare can be even lower than that under sales-independent ranking. Note that these observations are consistent with our findings from the base model (Proposition 3), although the driving forces are markedly different.
Figure 8(c) and Figure 8(d) illustrate the impact of search cost on the equilibrium price and consumer welfare, respectively. We observe that even equilibrium prices pI and pS are not monotone in search cost, let alone pB. In particular, a lower search cost can lead to a higher equilibrium price, and this nonmonotonicity effect is only amplified once the threat of brushing is factored in. These observations contradict the common belief that reducing search frictions promotes competition. In the context of price-directed search, as explained in Choi et al. (2018), a reduction in search cost makes it harder for a seller to retain consumers after search, but easier to attract consumers when they decide where to search in the first place. These two opposing forces drive the nonmonotonic relationship between search cost and equilibrium price, which further causes consumer welfare to be nonmonotone in search cost. This is consistent with our findings from the base model (Proposition 4), although the driving forces are markedly different.
7. Conclusion and Discussion
This paper studies brushing on e-commerce platforms, where sellers place fake orders of their own products to inflate sales. Among others, consumers’ search frictions and platforms’ ranking algorithms are two drivers for brushing. On the one hand, consumers face search frictions and tend to be fixated only on the few most prominent products at the top of search results. On the other hand, online marketplaces often incorporate sales-volume-related factors into their ranking algorithms: a product that sells well in the past may obtain a higher placement, which, in turn, drives more future sales. We focus on this search-ranking aspect of brushing and shed light on the diverging brushing incentives of sellers who differ in popularity.
Our results generate managerial implications for platforms and highlight the challenges in fighting brushing. First, as platforms crack down on brushing, they should be wary that making brushing harder for sellers may, in fact, harm the interest of consumers, and consumers may be even worse off than if sales-volume-related factors were not included in the product rankings at all. Second, whereas brushing is partially attributed to the presence of search frictions, making search easier for consumers can subtly change sellers’ brushing behavior, and sometimes undermine consumer welfare, especially when the brushing cost and search cost are in lockstep. Third, in light of brushing, platforms should carefully design their ranking algorithms. It may be worthwhile to fine-tune the weight of sales-volume-related factors; from a consumer-welfare standpoint, it may be best to set the weight to an intermediate level when the brushing cost is on the low or high end, but make the rankings purely based on sales when the brushing cost is intermediate. Further, tracking only recent sales rather than cumulative sales may not always alleviate brushing, but rather sometimes trigger more brushing from less popular sellers.
Next, we discuss some of our modeling assumptions, limitations of our work, and future research directions.
First, the ranking effect in our paper can be broadly construed as the platform directing traffic to certain products, making them easier to find than others. In light of this interpretation, search frictions can be present in a variety of settings, even those that seem to be non-search-related on the surface. Second, one limitation of our model is that search can fully resolve consumers’ valuation uncertainty (a standard assumption in search theory). Although consumers in our model face search frictions only, consumers in practice can be subject to other information frictions and thus unable to fully determine their own valuation of a product even after search. As a consequence, consumers may try to infer the value of a product by looking at its sales volume (provided that the platform discloses such information) or reading consumer reviews, both of which can be manipulated by sellers through brushing (i.e., fake orders can allow sellers to inflate sales volume consumers observe and inject glowing fake reviews15 without being easily identified because these reviews are backed by real transactions). Future research can incorporate these additional features into the model. We conjecture that some of the fundamental differences between high-type and low-type sellers in terms of their brushing incentives may still carry over. Although the current paper explores the implications of search cost reduction and ranking algorithm design, future research may examine how much information about sales volume and consumer reviews platforms should share with consumers (in light of brushing).
An alternative to brushing is sponsored advertising. Indeed, when covering brushing, Wong et al. (2015) acknowledge that “one way to get products in front of customers’ eyes is to buy advertising.” However, they go on to say “some ecommerce consultants and sellers say ad prices in competitive product categories have risen 10% to 20% a year recently, making them unaffordable for small merchants.” One reason why sponsored ads are expensive is their short supply: typically, only a limited number of ad slots are available, making them heavily sought after. A merchant who does not win one of the few coveted sponsored spots will not get any exposure. By contrast, a merchant who brushes more can presumably always make some incremental improvement in one’s visibility in search results. Another challenge in sponsored advertising is that merchants may be confused about the best keywords to bid on. Some keywords can be too broad to be relevant, and bidding on those keywords may only be a waste of their marketing budget. By contrast, brushing spares merchants the headache of selecting the right keywords to bid on. All of these imply that brushing can be a viable alternative to sponsored advertising. Future research can examine how merchants should jointly determine these two strategies and whether brushing acts as a complement or a substitute to sponsored advertising.
Because brushing inflates the platform’s gross merchandise volume (GMV), an indicator often used by investors to gauge a platform’s financial performance, some worry that the platform may lack incentives to stem brushing (Wall Street J. 2015). In fact, there are allegations of JD.com giving merchants organizational support for brushing (Lim 2015); relatedly, Alibaba’s reported revenue was probed by the U.S. Securities and Exchange Commission amid concerns of fictitious transactions (Bomey and Weise 2016). Future research can take the perspective of a platform and investigate how it balances consumer welfare, GMV, and the capital market when deciding on strategies against brushing.
Finally, although we set our paper in the context of e-commerce platforms to fix ideas, brushing, as a phenomenon, transcends e-commerce and finds its way in other business applications as well. Examples include film distributors buying movie tickets to artificially boost a movie’s box-office rankings (Bloomberg 2017); podcasters pumping up subscription totals via fake accounts to manipulate the iTunes podcast charts (Leswing 2018); pop music artists allegedly faking sales to rig the iTune store rankings (Shih 2018); and app developers inflating the number of downloads to be ranked higher on the leaderboard in the App Store and Google Play (Zhu et al. 2015). Broadly, these ranking systems can be viewed as learning algorithms that try to learn and earn from data (i.e., sales volume) as they come in, but in doing so, they create a distortion in the data (i.e., brushing). Our paper is among the first attempts to shed light on how learning algorithms trigger strategic manipulation of the data-generating process. We hope it will inspire more future research on this front.
The authors are grateful to the senior editor, the associate editor, and four anonymous reviewers for their detailed comments that have greatly improved the paper. The authors also thank Yossi Spiegel for being a discussant of the paper at the 2019 NET Institute Conference on Network Economics and Stefanos Zenois for being a discussant of the paper in a spotlight session of the 2019 INFORMS Revenue Management and Pricing Section Conference. The paper was a finalist of the 2019 INFORMS Service Science Best Cluster Paper Award. The first two authors contributed equally to this work.
1 We relax this assumption and consider an infinite-horizon model in Section 6.1.
2 We consider an extension where the two products differ in their fit probabilities in online Appendix C.3.
3 When , consumers can disagree on which product has a higher prior value.
4 Our consumer search model (e.g., prior value and match value) closely follows the consumer-search literature (e.g., Weitzman 1979, Choi et al. 2018).
5 Conceptually, if a product has higher ratings, then consumers are more likely to purchase it, which translates into higher sales volume. Conversely, if a product has higher sales volume, then it is indicative of desirability (otherwise consumers would not buy), which implies that consumers are more likely to leave positive reviews.
6 We endogenize product prices in Section 6.4.
7 We extend our results to asymmetric brushing costs in online Appendix C.2.
8 One may argue that sellers in practice may still brush even if consumers face negligible search frictions. This is because consumers in practice can face other information frictions that our model assumes away. In our model, search fully resolves consumers’ valuation uncertainty (a common assumption in the search literature), but in practice, consumers may still be uncertain about how to value a product even after search and rely on information that can be manipulated by brushing to form their opinion. For example, consumers may update their belief about a product upon reading fake reviews.
9 As argued earlier, if consumers in practice face other information frictions besides search frictions, then brushing may still occur even when rankings are sales-independent.
10 As a further explanation, a lower search cost can create two opposite forces. On the one hand, consumers are better off for a given ranking, which puts an upward pressure on welfare. On the other hand, the second-period consumer may be less likely to see product H being ranked at the top (due to the first-period purchase), which puts a downward pressure on welfare. The latter effect may outweigh the former effect, causing consumer welfare to decline. Note that the driving force of this reversal is exactly the same as that of the celebrated Simpson’s paradox (Blyth 1972).
11 Cases are defined in Table 3; Case 1 (4) corresponding to the lowest (highest) search cost.
12 In this subsection, for succinctness, we do not write out as expressions of the model primitives, which can be easily obtained from Proposition 1.
13 In an e-commerce setting, online shoppers typically observe the prices before search.
14 For example, consistent with Choi et al. (2018), we assume that consumers are heterogeneous in their prior and match values, and capture this heterogeneity by a continuous distribution, which enables us to solve in closed form the equilibrium prices under sales-independent ranking and sales-based ranking without brushing.
15 Fake reviews can have two effects: one is to bias consumers’ perception of a product; and the other is to allow the product to rank higher (as ranking algorithms take consumer reviews into account). Our model does not capture the first effect, but captures the second effect because consumer reviews can be characterized as sales-volume-related factors considered in the ranking algorithm (see Section 3.2). As for the first effect, future research can investigate how effective fake reviews are in deceiving consumers. A challenge in producing fake reviews is that consumers may be suspicious of overly positive reviews, yet unmoved by mildly positive ones. Further, consumers may be increasingly able to tell real and fake reviews apart, especially with the aid of artificial intelligence (AI) technology.
References
- (2013) Optimal bidding in multi-item multislot sponsored search auctions. Oper. Res. 61(4):855–873.Link, Google Scholar
- (2011) Location, location, location: An analysis of profitability of position in online advertising markets. J. Marketing Res. 48(6):1057–1073.Crossref, Google Scholar
- (2014) Reviews without a purchase: Low ratings, loyal customers, and deception. J. Marketing Res. 51(3):249–269.Crossref, Google Scholar
- (2017) Ordered consumer search. J. Eur. Econom. Assoc. 15(5):989–1024.Crossref, Google Scholar
- (2011) Paying for prominence. Econom. J. 121(556):F368–F395.Google Scholar
- (2009) Prominence and consumer search. RAND J. Econom. 40(2):209–233.Crossref, Google Scholar
- (2011) Position auctions with consumer search. Quart. J. Econom. 126(3):1213–1270.Crossref, Google Scholar
- (1992) A simple model of herd behavior. Quart. J. Econom. 107(3):797–817.Crossref, Google Scholar
- (2013) The role of search engine optimization in search marketing. Marketing Sci. 32(4):644–651.Link, Google Scholar
- (1992) A theory of fads, fashion, custom, and cultural change as informational cascades. J. Political Econom. 100(5):992–1026.Crossref, Google Scholar
Bloomberg (2017) China is finally going after click farms and fake online sales. (November 6), https://www.bloomberg.com/news/articles/2017-11-06/china-is-finally-going-after-click-farms-and-fake-online-sales.Google Scholar- (1972) On Simpson’s paradox and the sure-thing principle. J. Amer. Statist. Assoc. 67(338):364–366.Crossref, Google Scholar
- (2016) SEC probes Alibaba’s singles day; stock drops. USA Today (May 25), https://www.usatoday.com/story/money/2016/05/25/securities-and-exchange-commission-alibaba-singles-day-sec/84898944/.Google Scholar
CBS News (2018) Couple swamped by Amazon deliveries that they didn’t order. (February 9), https://www.cbsnews.com/news/amazon-brushing-scam-couple-receives-packages-they-didnt-order/.Google Scholar- (2011) Paid placement: Advertising and search on the Internet. Econom. J. 121(556):F309–F328.Google Scholar
- (2015) Can payment-per-click induce improvements in click fraud identification technologies? Inform. Systems Res. 26(4):754–772.Link, Google Scholar
- (2006) The effect of word of mouth on sales: Online book reviews. J. Marketing Res. 43(3):345–354.Crossref, Google Scholar
- (2010) The effects of online user reviews on movie box office performance: Accounting for sequential rollout and aggregation across local markets. Marketing Sci. 29(5):944–957.Link, Google Scholar
- (2018) Consumer search and price competition. Econometrica 86(4):1257–1281.Crossref, Google Scholar
- (2020) Position ranking and auctions for online marketplaces. Management Sci. 66(8):3617–3634.Link, Google Scholar
- (2013) Prohibitions on false and unsubstantiated claims: Inducing the acquisition and revelation of information through competition policy. J. Law Econom. 56(2):453–486.Crossref, Google Scholar
- (2014) Finite optimal penalties for false advertising. J. Indust. Econom. 62(4):661–681.Crossref, Google Scholar
- (2017) Optimizing click-through in online rankings with endogenous search refinement. Marketing Sci. 36(4):542–564.Link, Google Scholar
- (2007) Internet advertising and the generalized second-price auction: Selling billions of dollars worth of keywords. Amer. Econom. Rev. 97(1):242–259.Crossref, Google Scholar
Financial Times (2016) China’s e-commerce sites try to sweep away ‘brushing’. (November 22), https://www.ft.com/content/735722e6-aca6-11e6-9cb3-bb8207902122.Google Scholar- (2009) Blockbuster culture’s next rise or fall: The impact of recommender systems on sales diversity. Management Sci. 55(5):697–712.Link, Google Scholar
- (2018) A series of mysterious packages. NPR Planet Money (April 27), https://www.npr.org/sections/money/2018/04/27/606528176/episode-838-a-series-of-mysterious-packages.Google Scholar
- (2011) A “position paradox” in sponsored search auctions. Marketing Sci. 30(4):612–627.Link, Google Scholar
- (2010) The race for sponsored links: Bidding patterns for search advertising. Marketing Sci. 29(2):199–215.Link, Google Scholar
- (2014) Search for differentiated products: Identification and estimation. RAND J. Econom. 45(3):553–575.Crossref, Google Scholar
- (2016) The impact of fake reviews on online visibility: A vulnerability assessment of the hotel industry. Inform. Systems Res. 27(4):940–961.Link, Google Scholar
- (2018) It looks like Apple fixed a problem with ‘manipulation’ on the top podcast charts. Business Insider (October 9), https://www.businessinsider.com/apple-podcast-charts-manipulation-fixed-2018-10.Google Scholar
- (2015) JD.com fires employee for encouraging ‘brushing’ fake orders to inflate sales. Forbes (April 11), https://www.forbes.com/sites/jlim/2015/04/11/jd-com-brushing-fake-orders-to-inflate-sales.Google Scholar
- (2016) Fake it till you make it: Reputation, competition, and Yelp review fraud. Management Sci. 62(12):3412–3427.Link, Google Scholar
- (2006) Promotional chat on the Internet. Marketing Sci. 25(2):155–163.Link, Google Scholar
- (2014) Promotional reviews: An empirical investigation of online review manipulation. Amer. Econom. Rev. 104(8):2421–2455.Crossref, Google Scholar
- (2021) The fateful first consumer review. Marketing Sci. 40(3):481–507.Link, Google Scholar
- (2015) How limiting deceptive practices harms consumers. RAND J. Econom. 46(3):611–624.Crossref, Google Scholar
- (2018) Deceptive advertising with rational buyers. Management Sci. 64(3):1291–1310.Link, Google Scholar
- (2017) Demand for “healthy” products: False claims and FTC regulation. J. Marketing Res. 54(6):968–989.Crossref, Google Scholar
- (2018) False advertising. RAND J. Econom. 49(2):348–369.Crossref, Google Scholar
- (2018) Fans of pop star Ariana Grande accuse Chinese star of gaming iTunes rankings. Washington Post (November 8), https://www.washingtonpost.com/world/2018/11/08/fans-pop-star-ariana-grande-accuse-chinese-star-gaming-itunes-rankings/.Google Scholar
- (2018) The power of rankings: Quantifying the effect of rankings on online consumer search and purchase decisions. Marketing Sci. 37(4):530–552.Link, Google Scholar
- (2007) Position auctions. Internat. J. Indust. Organ. 25(6):1163–1178.Crossref, Google Scholar
Wall Street J. (2015) ‘Cat-and-mouse game’: Alibaba exec on fake transactions. (March 3), https://www.wsj.com/articles/BL-CJB-26092.Google Scholar- (2018) An empirical investigation of sales cheating effect in e-commerce. International Conference on Information Systems (ICIS) 2018 Proc. (Association for Information Systems), article 11, https://aisel.aisnet.org/icis2018/economics/Presentations/11/.Google Scholar
- (1979) Optimal search for the best alternative. Econometrica 47(3):641–654.Crossref, Google Scholar
- (2009) Click fraud. Marketing Sci. 28(2):293–308.Link, Google Scholar
- (2015) Inside Alibaba, the sharp-elbowed world of Chinese e-commerce. Wall Street J. (March 2), https://www.wsj.com/articles/inside-alibaba-the-sharp-elbowed-world-of-chinese-e-commerce-1425332447.Google Scholar
- (2012) Effects of the presence of organic listing in search advertising. Inform. Systems Res. 23(4):1284–1302.Link, Google Scholar
- (2017) An empirical investigation of ecommerce-reputation-escalation-as-a-service. ACM Trans. Web 11(2):1–35 (TWEB).Crossref, Google Scholar
- (2011) Ordered search in differentiated markets. Internat. J. Indust. Organ. 29(2):253–262.Crossref, Google Scholar
- (2015) Discovery of ranking fraud for mobile apps. IEEE Trans. Knowledge Data Engrg. 27(1):74–87.Crossref, Google Scholar
- (2016) Wintertime for deceptive advertising? Amer. Econom. J. Appl. Econom. 8(1):177–192.Crossref, Google Scholar

