
From Lexicons to Large Language Models: A Holistic Evaluation of Psychometric Text Analysis in Social Science Research
Abstract
Extracting psychological constructs from text is increasingly essential for social science researchers who study attitudes, perceptions, and traits across digital communication. This paper offers the first holistic comparison of four major approaches used for this purpose—lexicons, custom-built machine learning models, fine-tuned masked language models, and large language models (LLMs). We evaluate these paradigms across multiple performance dimensions and integrate insights from dual-process theory (DPT) to understand how cognitive and affective processes shape annotation quality. Our results show that LLMs match or exceed the performance of established supervised methods while producing more consistent and fair predictions, all without requiring specialized natural language processing (NLP) expertise or extensive labeled data. Using DPT, we further demonstrate that human annotation accuracy depends on the alignment between an annotator’s cognitive or emotional abilities and the psychological construct being coded. Misalignment reduces annotation quality and weakens downstream models. Drawing on this insight, we introduce a cognitive-affective prompting strategy for LLMs that emulates these human strengths, yielding performance gains beyond state-of-the-art prompting methods. Together, our findings offer practical guidance for method selection, illuminate how psychological constructs can be measured more reliably from text, and advance the design of psychometric NLP tools in social science research. To support immediate application, we also provide a researcher-friendly cookbook (in the Online Appendix) for using LLMs to annotate text data in practice.
History: Gautam Pant, Senior Editor; Gene Moo Lee, Associate Editor.
Funding: This work was supported by the McIntire School of Commerce at the University of Virginia. Financial support from the McIntire School of Commerce, University of Virginia, is gratefully acknowledged.
Supplemental Material: The online appendix and supplemental material are available at https://doi.org/10.1287/isre.2024.1143.
1. Introduction
Online platforms have greatly expanded the volume and variety of text data available to social science researchers, offering a direct and scalable view into people’s attitudes, perceptions, and traits (Ahmad et al. 2020). An important approach for distilling such psychological attributes from text is psychometric natural language processing (NLP), an umbrella term for the measurement of such latent constructs (Abbasi et al. 2018, Ahmad et al. 2020, Mousavi and Gu 2024). These techniques have proven indispensable across social science domains, from modeling how personality traits manifest in social media trace data (Yang et al. 2023), to using word-embedding trajectories in news to reveal evolving weight stigma (Arseniev-Koehler and Foster 2022), to linking affective language in Supreme Court exchanges to case outcomes (Black et al. 2011).
Modern psychometric NLP has evolved to enable understanding of nuanced, context-dependent aspects of language that earlier lexicon-based approaches may miss. However, despite significant progress fueled by machine learning (ML) and artificial intelligence (AI) over the past two decades, social science researchers still face three core challenges when measuring psychological constructs from text. Domain expertise gaps can limit the creation of labeled data sets tailored to highly specific topics. NLP expertise gaps may hamper the deployment of advanced or fine-tuned deep learning techniques capable of nuanced analysis. Identification of constructs for study may suffer from inaccuracies inherent in simpler methods or a lack in proficiencies required to effectively implement more robust NLP techniques. For social science researchers, overcoming these barriers is critical to realizing the promise of large-scale text data for understanding human psychology and behavior.
More recently, large language models (LLMs) show promise for resolving these barriers by offering high predictive performance alongside reduced demands for labeled data or specialized AI skills. Recognizing the importance of NLP methods in social science research, we conduct a holistic evaluation of LLMs against existing psychometric NLP paradigms: (1) lexicon-based methods, (2) custom-built models, and (3) fine-tuned masked language models (FLMs). Our holistic evaluation across four distinct data sets reveals that LLMs can meet or surpass other paradigms, including FLMs, in classifying psychological constructs along multiple dimensions, while requiring fewer resources and less technological expertise or domain-specific knowledge. This represents a significant contribution to the NLP literature by demonstrating a practical path to democratize access to state-of-the-art text analysis. More broadly, it signals a potential paradigm shift for social science research, enabling more ambitious and nuanced textual inquiry at scale without prohibitive technical overhead.
These advancements are especially relevant for coding constructs such as resilience, empathy, and sentiment polarity (hereafter, polarity), each of which demands distinct levels of cognitive and emotional engagement (Pennebaker and Francis 1996). Leveraging dual-process theory (Kahneman and Frederick 2002) to deepen our holistic evaluation, we demonstrate that cognitive and affective capacities of nonexperts substantially influence their ability to code these constructs in text, as well as performance of downstream models trained on these annotations. Our theoretically informed findings illustrate risks inherent in existing paradigms reliant on human annotation and potential avenues for improving the performance of LLMs by emulating enhanced cognitive and affective abilities through “cognitive-affective prompting.” This approach addresses the inconsistencies observed in the emerging research on persona-based prompting (see Tseng et al. 2024) and extends this body of work by introducing a generalizable practice for improving LLMs’ performance.
This study contributes to the literature on psychometric NLP by developing a theory-guided framework for holistic evaluation and applying it to demonstrate that LLMs exhibit comparable or superior predictive performance, consistency, and fairness relative to established approaches, while reducing demands for expertise and resources. We examine the cognitive and affective processes underlying the identification of psychological constructs and their effects on downstream models, as well as demonstrate how cognitive-affective prompting enables LLMs to emulate traits aligned with psychometric NLP tasks to improve performance. Salient design insights from our novel framework provide practical guidance for method selection and deployment, as well as support for emerging computationally intensive theory construction research (Miranda et al. 2022) and design of psychometric NLP-based artifacts (Abbasi et al. 2024), underscoring the promise of LLMs to enhance measurement reliability and uncover deeper psychological dynamics from digital text.
2. Background—NLP Methods for Identifying Psychological Constructs
2.1. Psychometric NLP Methods
Text classification is a foundational NLP task in which text is categorized into predetermined classes (e.g., “Empathetic” or “Nonempathetic”), often with assigned confidence scores, which may be dichotomized into labels or be used directly for subsequent analyses. These methods may be deployed for a variety of applications, although a prevalent use case, and the focus of our study, is the use of NLP to identify psychological constructs. These methods fall into four primary categories, each with distinct strengths and limitations.
Table 1 provides an overview of the landscape. Lexicon-based methods are the simplest and least resource-intensive to apply, requiring little domain or NLP expertise. Using predefined lists of words or phrases, researchers can aggregate scores based on term frequency to infer psychological constructs. Tools like Linguistic Inquiry and Word Count (LIWC) (Tausczik and Pennebaker 2010) and WordNet (Miller 1995) are widely used but criticized for their inability to incorporate contextual nuances. Domain-specific lexicons (e.g., Loughran and McDonald 2011) address some limitations but remain fundamentally constrained. Supervised Machine Learning models use labeled data sets to train algorithms for identifying labels in larger, unlabeled data sets. Innovations such as Recurrent Neural Networks (RNNs) (Rumelhart et al. 1986) and their derivatives such as Long Short-Term Memory networks (LSTMs) (Hochreiter and Schmidhuber 1997) enhanced the ability to handle sequential data. However, these architectures struggle with long-term dependencies and are computationally demanding. These custom-built models (CBMs) require substantial domain expertise to create a labeled training set and substantial NLP expertise to deploy.
|

Table 1. Psychometric NLP Paradigms for Text Classification
| Method | Brief description | Representative methods |
|---|---|---|
| Dictionary or lexicon methods | Text is labeled by counting/scoring specific terms associated with certain constructs, with the term list either manually labeled by experts or generated from data, such as using a vector space model to analyze texts with known labels (Salton et al. 1975). |
|
| Custom-built models (CBMs) | Custom-built machine learning models trained on labeled samples (ground truth) to classify a larger set of samples with unknown labels. |
|
| Fine-tuned masked language models (FLMs) | Fine-tuned pretrained masked language models that can be customized/adapted to a particular domain or task via additional pretraining (e.g., domain-specific BERTs) or via transfer learning (i.e., fine-tuning models based on a smaller set of labeled samples). |
|
| Large language models (LLMs) | Pretrained language models typically larger in size (parameters), pretrained on larger data, and trained as causal language models (e.g., autoregressive). Although they can be fine-tuned, they are adept at a variety of tasks without further training, a concept known as “zero-shot” or “few-shot” learning. |
|
Transformers revolutionized NLP by introducing self-attention mechanisms that process entire text sequences simultaneously. Transformer-based models like Bidirectional Encoder Representations from Transformers (BERT) (Devlin et al. 2019) leverage Masked Language Modeling to learn bidirectional representations of text. Fine-tuned models such as FinBERT (Araci 2019) demonstrate the adaptability of this approach for domain-specific tasks. Like CBMs, FLMs require high domain expertise for the creation of labeled data sets for fine tuning and high NLP expertise to deploy.
LLMs, the latest advancement, build on transformer architecture but employ autoregressive principles. LLMs predict each token based solely on preceding tokens, generating coherent and contextually relevant text incrementally. Examples include Generative Pre-Trained Transformer (GPT) (Brown et al. 2020), the Pathways Language Model (Chowdhery et al. 2022), Llama 3 (Grattafiori et al. 2024), and Mistral (Jiang et al. 2023). LLMs, exemplified by GPT’s 175-billion-parameter model, achieve superior performance even without fine-tuning, requiring minimal or no training data. Because of their natural language interface and low-cost commercial availability, LLMs may be deployed with very little NLP expertise. Moderate levels of domain expertise may be required to effectively communicate tasks to the LLM.
The performance of LLMs may be further amplified by prompt engineering techniques, which play a crucial role in optimizing their performance across various tasks. Few-shot prompting serves as a foundational method that provides limited input-output examples within prompts to facilitate in-context learning, enabling models to generalize from these examples effectively. Chain-of-thought (CoT) prompting enhances reasoning abilities by breaking down complex problems into simpler substeps, guiding models through a logical progression (Wei et al. 2023). Contrastive CoT introduces both valid and invalid reasoning demonstrations, allowing models to learn discernment between correct and flawed reasoning patterns (Chia et al. 2023). The Tree of Thoughts extends this framework by exploring multiple reasoning paths simultaneously, akin to a tree structure, thereby enabling more effective navigation through complex problem spaces (Yao et al. 2023). Finally, Self-Refine allows models to iteratively improve their responses by self-critiquing mechanisms, enhancing output quality by refining initial responses over successive iterations (Madaan et al. 2023).
Further advances, such as soft prompting and prompt tuning, have emerged as effective strategies for enhancing model performance. This involves introducing learnable, continuous input vectors—known as soft prompts—into the model’s input to guide its behavior for specific tasks without altering the model’s core parameters (Lester et al. 2021). In addition, although fine-tuning LLMs can be a computationally expensive task, Low-Rank Adaptation, which freezes the pretrained model weights and injects trainable rank decomposition matrices into each Transformer layer, provides an efficient way to fine-tune LLMs for downstream tasks with minimal computational overhead (Hu et al. 2021). These innovations highlight the ongoing evolution in how LLMs can be effectively utilized across domains, including psychometric NLP.
2.2. Psychometric NLP in Social Science Research
Psychometric NLP, which we define as the use of NLP methods to identify psychological constructs, has become a pivotal tool in research across diverse disciplines. Its applications span information systems (IS), business research, and social science more broadly. A comprehensive review of such work is infeasible, but to demonstrate the breadth of adoption and variety in use cases, we utilize Web of Science to systematically identify over 5,000 studies across 13 social science disciplines citing selected seminal NLP studies. Reviewing top-cited studies in each field, we note that NLP is used for a variety of purposes, but that identification of psychometric constructs is consistently a primary focus. See Online Appendix K for detailed analysis.
In IS research, psychometric NLP has been employed to examine technologies influencing communication and societal issues. For example, Zhang et al. (2024) used lexicons and transformers to identify suicidal ideation in social media; Adamopoulos et al. (2018) use psychometric NLP to show how personality traits influence the effectiveness of word-of-mouth; and Lee and Ram (2024) developed ML models to identify false information and its impact. In business research more broadly, marketing researchers utilize psychometric NLP for brand analytics, user engagement, and sales prediction (Rust et al. 2021, Xu et al. 2021). Finance researchers have largely focused on measuring polarity of news and other content related to financial markets, largely with lexicon-based methods, but have recently adopted more advanced tools, such as FinBERT (Loughran and McDonald 2011, Araci 2019, Huang et al. 2023). Management studies frequently apply psychometric NLP to analyze management communications (Gamache and McNamara 2019, Hyde et al. 2024).
In social science disciplines more broadly, psychometric NLP is utilized for a wide variety of goals. Archaeologists identify semantic characteristics of operas (Fan et al. 2023). Communication researchers analyze online dating profiles for psychometric traits related to deception (Toma and Hancock 2012). Criminologists analyze prisoners’ descriptions of depression symptoms (Willemsen et al. 2011). Education scholars identify cues of emotional and cognitive abilities, relating these with learning outcomes (Liu et al. 2022). Sociologists examine aspects of stigma and cultural views related to body weight (Arseniev-Koehler and Foster 2022).
These broad applications utilize a variety of methods, ontologies, and theoretical framings, yet share a common thread of utilizing NLP techniques to identify psychological constructs in order to understand the phenomena they research. Over the past few decades, the methods for performing psychometric NLP have evolved from lexicon-based techniques to FLMs, with researchers in various fields adopting newer methods at different rates, with some researchers increasingly favoring FLMs for their higher predictive performance, whereas others continue to consistently utilize lexicons for higher interpretability and ease of implementation.
3. Theory-Guided Framework for Holistic Evaluation of Psychometric NLP
In this section, we synthesize existing theory and research to develop a framework for holistically evaluating NLP paradigms for extracting psychological constructs from text. To guide our discussion, Figure 1 outlines this framework in three stages. First, we broadly compare and evaluate leading methods from primary NLP paradigms (lexicons, CBMs, FLMs, and LLMs) across a range of representative text classification tasks with a focus on outcomes critical for social science researchers, including predictive performance, consistency, and fairness. We then take a deeper dive to understand how cognitive and affective processes impact the inputs to NLP tools through the lens of dual-process theory. Finally, we apply this understanding to demonstrate how consideration of cognitive and affective perspectives can influence model performance.
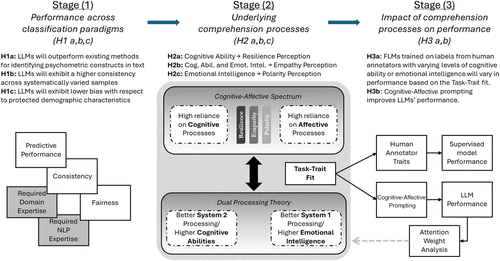
Note. H, hypothesis.
3.1. Performance of NLP Paradigms Across Critical Dimensions
Recently, the superior performance of LLMs in few-shot learning has drawn attention in psychometric NLP tasks. For instance, Rathje et al. (2023) found that GPTs’ accuracy excels in evaluating sentiment, discrete emotions, offensiveness, and moral foundations. Similarly, Peters and Matz (2023) studied GPT accuracy in inferring Big Five personality traits from Facebook status updates using zero-shot learning. Tan et al. (2024) further studied LLM-based annotation generation, LLM-generated annotations assessment, and LLM-generated annotations utilization tasks. Although initial studies show promise in LLMs for psychometric NLP compared with existing methods, they lack a comprehensive and systematic evaluation of psychometric NLP paradigms (including lexicons, CBMs, and FLMs) across tasks representative of a spectrum of psychological constructs (which we identify below). Expanding on this body of work, we propose:
(
Although previous studies have focused on the raw predictive performance of LLMs, consistency in performance remains underexamined. Consistent performance across data segments is crucial to avoid bias in downstream analyses such as econometrics. Prior research has highlighted how significant downstream biased estimation may be caused by measurement error in classification tasks performed by CBMs and FLMs (Yang et al. 2018, Qiao and Huang 2021). To our knowledge, no studies have examined the performance consistency of psychometric NLP methods across data segments. However, we hypothesize that LLMs may deliver more uniform performance across various data segments for two reasons: First, with their extensive parameters and training data, they often capture a broader range of linguistic nuances (Liu et al. 2024). This extensive pretraining enables them to generalize more effectively across diverse text segments, leading to more consistent performance. These leaps in performance at extreme architectural scale have been characterized as emergent abilities (Wei et al. 2022). Second, training or fine-tuning models on specific tasks (in CBMs and FLMs) can introduce variability, especially if training data are limited or not fully representative of all possible text segments, potentially leading to inconsistent performance across segments (Althammer et al. 2023). Hence, we propose:
(
Another critical, yet understudied, aspect of psychometric NLP is fairness, particularly how models handle texts from diverse demographic groups (Mehrabi et al. 2022). Systematic biases could lead to skewed conclusions that disproportionately affect certain demographics. Prior research shows that biases in lexicon-based methods might originate from initial seed word selections (Antoniak and Mimno 2021), whereas FLMs often inherit biases from the labeled data sets used for training (Rozado 2020, Bhardwaj et al. 2021). The broad, diverse data sets used to train LLMs suggest they may demonstrate lower demographic biases (e.g., BERT models: 3.3 billion tokens/30,000 (30K) vocabulary (Devlin et al. 2019) versus Llama 3: 15 trillion tokens/128K vocabulary (Grattafiori et al. 2024)). Significant efforts have also been made to enhance the alignment of foundation LLMs with fairness objectives (Eloundou et al. 2024, Ji et al. 2024), which should reduce biases in NLP applications of LLMs. We propose:
(
3.2. Dual-Process Theory
For the past several decades, text corpora annotated with psychological constructs have been central to the field of psychometric NLP. Ground-truth labels are typically supplied by human annotators, yet their judgments, as shaped by their individual cognitive and affective abilities (Pennebaker and Francis 1996, Panksepp 2003), vary in reliability. Dual‐Process Theory (DPT) offers a parsimonious lens for understanding this variability, relating discrepancies in annotation quality to the shifting balance between autonomous, low‐effort, affectively tinged Type 1 processes and working-memory-dependent, rule-based Type 2 processes that enable cognitive decoupling (Evans and Stanovich 2013, De Neys 2018). Because Type 2 processes require cognitive decoupling, their effectiveness covaries with cognitive ability (Evans 2003), whereas the efficiency of Type 1’s autonomous appraisal tracks emotional intelligence (Fiori 2009, Suslow et al. 2022). These dual routes generate clear, testable predictions for annotation performance: tasks that hinge more on reasoning and cognitive efforts (e.g., discerning nuanced resilience narratives) should benefit disproportionately from cognitive-driven Type 2 processing, whereas tasks dominated by affective resonance (e.g., labeling polarity) should benefit more from emotional intelligence-driven Type 1 processing. Critically, although excelling in both domains might seem ideal, empirical studies show that cognitive ability and emotional intelligence are distinct constructs that rarely co-occur at exceptionally high levels (Barbey et al. 2014). This distinction arises from different neurological underpinnings and developmental pathways, and empirical studies consistently show only a weak correlation between them (Joseph and Newman 2010, Khemlani et al. 2014). This dissociation is key because it implies that excelling in one domain does not predict excellence in the other, allowing cognitive ability and emotional intelligence to serve as differential predictors for tasks that lean on distinct cognitive or affective processes. For more detailed development of these concepts, please see Online Appendix M.
3.3. Cognitive-Affective Spectrum and Annotator Performance
We apply this dual-process framework by conceptualizing psychological annotation tasks along a cognitive-affective spectrum, reflecting the different blends of processing they demand (Pennebaker and Francis 1996, Panksepp 2003). To represent this spectrum, we examine constructs of resilience, empathy, and polarity, which are commonly studied in social science literature (see Online Appendix L for detail), and exemplify a range of cognitive and affective demands. At the cognitive pole are tasks demanding deliberative, analytical thought characteristic of Type 2 processing. The annotation of resilience exemplifies this because it is an act of demanding cognitive appraisal. An annotator must deconstruct a narrative, analyze coping strategies, and synthesize this information into a holistic judgment—a process reliant on working memory and “cognitive decoupling,” the ability to simulate another’s mental state (Evans and Stanovich 2013). At the affective pole are tasks dominated by the rapid, intuitive judgments of Type 1 processing. Annotation of sentiment polarity is representative of this end, guided primarily by the “affect heuristic,” where an annotator’s immediate “gut feeling” serves as the basis for evaluation (Slovic et al. 2007). This is a fast, automatic process of registering an internal affective state, rather than analyzing an external situation (Clore and Huntsinger 2007). Positioned between these poles, empathy annotation represents a hybrid task. As a multidimensional construct, its successful annotation requires both cognitive empathy (a controlled, Type 2 effort to understand another’s perspective) and affective empathy (an automatic, Type 1 resonance with another’s emotional state) (Decety and Jackson 2004, Singer and Lamm 2009). A successful annotator must synthesize both logical deduction and emotional reaction.
This framework (further detailed in Online Appendix M) provides a clear basis for predicting how annotation accuracy varies with an individual’s cognitive and affective abilities (Salovey and Mayer 1990, Stanovich and West 1998, Joseph and Newman 2010). Accordingly, we propose the following hypotheses:
(
(
(
3.4. Cognitive-Affective Spectrum and Model Performance
3.4.1. Effects of Annotator Cognitive-Affective Traits on Downstream Model Performance.
Building upon the premise that human annotation accuracy is influenced by the alignment between individual traits and task demands, we posit that fine-tuning NLP models with data labeled by annotators whose cognitive abilities or emotional intelligence align with specific task requirements will enhance model performance. Supporting this, research indicates that high-quality data sets are essential for robust model training, because models trained on superior data show improved generalization (Mishra et al. 2020), and that the quality of training data critically affects model outcomes, especially in specialized domains (Bras et al. 2020). Aligning annotator traits with task demands is expected to yield higher-quality annotations, thereby enhancing fine-tuning and overall model performance. Thus, we hypothesize:
(
3.4.2. Cognitive-Affective Prompting for LLMs.
Given that individuals’ cognitive ability and emotional intelligence affect their performance in text annotation tasks, it is pertinent to investigate whether focusing on cognitive-affective processes may likewise be used to influence the performance of LLMs. A number of studies provide theoretical rationales for why LLMs calibrated to incorporate both cognitive and affective signals may outperform more conventional prompting approaches. For example, Kong et al. (2024) observe that LLMs exhibit a strong capacity for role-playing: their experiments demonstrate that role-playing prompts (e.g., “You are an excellent math teacher”) outperform standard zero-shot prompting across multiple data sets, corroborating the earlier findings of Wu et al. (2023) on the positive impact of role-playing on LLMs’ performance. This line of research suggests that, by incorporating personas, LLMs can generate more contextually appropriate responses and thereby enhance their utility and effectiveness for specific tasks (Chen et al. 2023, 2024; Tseng et al. 2024).
Shen et al. (2024) extend this stream of research by conducting extensive experiments that reveal stable differences in four aspects of decision-making abilities across distinct role emulations, indicating a robust correlation between these roles and the LLMs’ decision-making abilities. Despite this progress, the performance of LLMs when adopting particular personas depends on how well those personas align with the task at hand, as illustrated by Zheng et al. (2024) in extensive experiments using 162 personas. Their findings show that although choosing the best persona for each question significantly increases prediction accuracy, identifying this persona automatically remains difficult, often yielding performance no better than random selection.
This difficulty in identifying the most suitable persona for a downstream task continues to be a focus of current NLP research (Fröhling et al. 2024). In response, we seek to extend this body of work by integrating the cognitive-affective framework. Because humans’ ability to annotate text depends on their cognitive-affective capacities and alignment with the task, we propose that LLMs could likewise be prompted based on the interplay between a task’s cognitive and affective requirements. Specifically, LLMs could be prompted to assume superior cognitive abilities when working on tasks that involve cognitive processes and superior emotional intelligence when working on tasks that involve affective processes. Given that most tasks can be situated along the cognitive-affective spectrum, researchers can then determine whether emphasizing cognitive abilities, emotional intelligence, or both would yield the best performance for a given task.
Based on dual-process theory and the distinctions between cognitive and affective processes, we propose the following hypothesis regarding how individual differences in cognitive ability and emotional intelligence affect annotation accuracy across resilience, empathy, and polarity tasks:
(
4. Analysis and Results
4.1. Comparing LLMs with Other Psychometric NLP Methods
Guided by our framework, we begin our analysis by evaluating performance and practicality of various approaches to text classification for three representative case studies along the cognitive-affective spectrum, referring to psychological constructs of resilience (case 1), empathy (case 2), and polarity (case 3). We selected these three constructs because, although all three draw on both cognitive and affective processes, they vary in extent, allowing us to examine the impact of individual abilities. We first report our findings regarding the comparison of LLMs with the other psychometric NLP methods: (1) lexicons, (2) custom-built machine learning models, and (3) fine-tuned language models (details are in Online Appendices A, B, and C). We then focus on cognitive and affective processes and test whether LLMs’ performance can be enhanced using this theoretical perspective.1
For case 1, we use the data set from Mousavi and Gu’s (2024) work on measuring resilience content, a concept defined as the ability to adapt and recover from disruptions. We predict whether tweets are labeled as “resilience” or “nonresilience” content by trained annotators.
For case 2, we utilize a data set developed from corporate earnings calls in which we measured empathy content. Sentences extracted from these calls were manually labeled by trained annotators, as described in Online Appendix B. We predict whether the sentences contain or do not contain empathetic language.
For case 3, we use a data set which was used to create the FinBERT model (Araci 2019), in which excerpts from financial news and press releases were categorized for polarity by trained annotators. We predict the polarity label for each phrase.2
4.1.1. Results: Predictive Performance.
Table 2 reports the area under the receiver operating characteristic curve (AUC) scores for each method across cases, tested on held-out samples. As noted, we focused on text classification, which measures the (degree of) presence or absence of a psychological construct in text. The main objective in classification is to separate samples that contain the psychological construct (i.e., positive samples) from others (i.e., negative samples). We focus on AUC because it evaluates a model’s ability to separate classes irrespective of class imbalance.
|
Table 2. Evaluation of Predictive Performance Across Psychometric NLP Paradigms
| Paradigm | Case 1: Resilience | Case 2: Empathy | Case 3: Polarity |
|---|---|---|---|
| Lexicon-based methods | 71.62a | 67.08b/65.76c | 71.64d |
| Custom-built model (LSTM) | 87.12 | 80.57 | 90.28 |
| FLM (fine-tuned BERT) | 98.59 | 92.21 | 99.90 |
| LLMs | |||
| Standard | |||
| GPT-4o (via API) | 94.92 | 94.35 | >99.99 |
| Llama 3.1 8B | 79.72 | 84.15 | 96.49 |
| Llama 3.1 70B | 88.50 | 85.08 | 99.95 |
| Mistral | 93.28 | 86.69 | 99.46 |
| Adapted | |||
| Llama 3.1 8B soft prompting | 92.93 | 83.87 | 97.79 |
| Llama 3.1 8B fine-tuned | 93.43 | 86.11 | 99.97 |
| Llama 3.1 70B soft prompting | 91.39 | 88.10 | 99.97 |
| Llama 3.1 70B fine-tuned | 91.03 | 87.78 | 99.91 |
| Mistral soft prompting | 80.26 | 86.09 | >99.99 |
| Mistral fine-tuned | 90.84 | 87.41 | 99.98 |
Notes. See Online Appendices D and E for details of CBMs and FLMs. In Online Appendix F, we outline five prompting techniques attempted before selecting the best for each task, as well as details on soft prompting and fine-tuning. Bold text reflects the best predictive performance for each case, as determined by AUC score.
To provide a comprehensive assessment of LLMs, we include OpenAI’s proprietary GPT-4o alongside several open-weight models (Llama 3.1, Mistral) of varying sizes. We test these LLMs in a standard few-shot inference setting, as well as with two common adaptation techniques for Llama and Mistral: soft prompting (adapting the model via learnable input vectors (Xu et al. 2023)) and fine-tuning (further training the model on our task-specific labeled data (Hu et al. 2021)).
As shown in Table 2, the fine-tuned BERT (FLM) sets a strong benchmark, achieving the top score on the resilience task (AUC = 98.59). However, GPT-4o demonstrates a small improvement over BERT on the more affective empathy and polarity tasks. This demonstrates that standard LLMs can perform nearly as well or better than FLMs (partially supporting Hypothesis 1(a)). A closer look at the various LLMs tested reveals several consistent patterns: First, model size correlates with performance, as the Llama 3.1 70B model consistently outperformed its 8B version. Second, fine-tuning proves to be a reliable enhancement strategy, boosting performance for nearly every model. In contrast, soft-prompting produced mixed results—improving some models while degrading others. Finally, model architecture is a significant factor, with Mistral’s Mixture-of-Experts (MoE) design consistently outperforming the similarly sized dense transformer of Llama 3.1 8B. This finding is aligned with established research showing that MoE architectures achieve greater computational efficiency, allowing them to leverage a vast number of parameters with the computational cost of a much smaller dense model, thereby providing a more effective path to high performance (Shazeer et al. 2017, Fedus et al. 2022).
4.1.2. Results: Consistency in Predictive Performances.
Social science researchers often use the psychological constructs extracted from text in a subsequent downstream task. For instance, Mousavi and Gu (2024) used psychometric NLP to measure resilience content in a large collection of text samples and then used this as a variable in an econometric model to show that leaders’ resilience communication improves community compliance. Natural variance within such corpora means that text samples can range widely, from those that are highly typical or representative of the overall corpus to those that are highly distinct or unique. Because these features are frequently used in subsequent analytical processes, such as in econometric and regression models, it is imperative that the extraction method for these psychological features maintains a consistent level of performance across different samples in the data. For example, financial headlines vary greatly; some follow conventional patterns and language typical of financial reporting, whereas others might use unique or unconventional expressions to grab attention or convey nuanced perspectives. If the chosen method for measuring polarity is more adept at accurately identifying sentiment in conventional headlines but struggles with those that are less typical (but more engaging), this discrepancy can lead to skewed polarity scores, causing biased estimates in subsequent econometric models. Such systematic measurement error that varies with document characteristics is especially problematic because it is difficult to accommodate using econometric techniques (Yang et al. 2018).
Borrowing from the parallel coordinates technique (Inselberg 2009), we implemented a novel method to assess performance consistency across different segments of data. First, we employed pretrained language model “all-mpnet-base-v2”3 from the Python package “sentence-transformers” for converting each text sample (e.g., sentence, tweet, news headline) to a vector representation with 768 dimensions. We computed cosine similarity to gauge the degree of resemblance between each sample vector and a composite mean vector computed across all samples. The data set was then stratified into quartiles based on these cosine similarity scores, with the most distinct samples in the lowest quartile (Q1) and the most typical samples in the highest quartile (Q4). We computed AUC scores for each quartile in each case along with standard deviations (SDs) and coefficients of variation (CVs; CV = SD/mean). Results are presented in Table 3, comparing GPT-4o (the best-performing LLM) with established methods. Across the three cases, GPT-4o exhibited the lowest CV by a sizable margin, showing the highest level of consistency in measurement across different segments of data (supporting Hypothesis 1(b)).
|
Table 3. Evaluation of Consistency Across Psychometric NLP Paradigms
| Construct | Method | Mean | SD | Coeff. var. |
|---|---|---|---|---|
| Resilience | GPT-4o | 0.95 | 0.03 | 0.03 |
| FLM (fine-tuned BERT) | 0.97 | 0.09 | 0.09 | |
| Custom-built model (LSTM) | 0.86 | 0.12 | 0.14 | |
| Resilience dictionary (Mousavi and Gu 2024) | 0.72 | 0.06 | 0.08 | |
| Empathy | GPT-4o | 0.95 | 0.03 | 0.03 |
| FLM (fine-tuned BERT) | 0.92 | 0.06 | 0.07 | |
| Custom-built model (LSTM) | 0.77 | 0.24 | 0.32 | |
| EmoBank lexicon (Sedoc et al. 2020) | 0.78 | 0.21 | 0.27 | |
| LIWC empathy (Sergent and Stajkovic 2020) | 0.64 | 0.19 | 0.29 | |
| Polarity | GPT-4o | >0.99 | <0.01 | <0.01 |
| FLM (fine-tuned BERT) | >0.99 | <0.01 | <0.01 | |
| Custom-built models (LSTM) | 0.90 | 0.03 | 0.03 | |
| LM lexicon (Loughran and McDonald 2011) | 0.71 | 0.08 | 0.12 |
Note. Bold text denotes the minimum coefficient of variation (coeff. var.) for each construct (lower indicates more stability across quartiles).
4.1.3. Fairness in Psychometric NLP.
Beyond variation in performance across individual samples within corpora, there may be more systematic variation in the ability of models to consistently perform across distinct subpopulations. In addition to issues this may cause for downstream models, it may also result in bias or lack of fairness. In order to evaluate fairness across subpopulations, we required a context where significant disparities could be present and impactful, as well as a data set that captured demographic characteristics of content authors. Unfortunately, the three cases examined thus far do not meet these criteria, and therefore, we turn to a data set explicitly created for evaluating fairness in NLP models. This distinctive data set captures user-generated content regarding the highly sensitive context of healthcare, along with a variety of related psychological constructs (trust, anxiety, numeracy, and literacy) and demographic details, “affording opportunities for measuring bias and benchmarking fairness of text classification methods” (Abbasi et al. 2021, p. 3748). Demographic factors of race and sex facilitate our examination of potential biases and the evaluation of fairness across NLP methods.
To assess and compare the fairness of various methods, we applied each one to the four psychological constructs—trust, anxiety, numeracy, and literacy. We then measured each method’s fairness using the Disparate Impact (DI) metric, as described in Abbasi et al. (2021, equation 1). DI compares the proportion of positive predictions (e.g., high trust, high anxiety, etc.) for a protected group (often referred to as the “nonprivileged” group) to the proportion of positive predictions for a reference group (“privileged” group):
A DI value of one indicates perfect equity, meaning that both groups are receiving positive predictions at the same rate. This is seen as the ideal scenario under the concept of fairness known as “demographic parity,” which emphasizes equal predictions across groups. A DI value below one indicates that the nonprivileged group is less likely to receive positive predictions compared with the privileged group, suggesting potential bias against the nonprivileged group. Conversely, a DI value above one would indicate bias in favor of the nonprivileged group, with this group receiving a disproportionately higher rate of positive predictions.
4.1.4. Results: Comparing Fairness.
We used DI to measure fairness with respect to sex and race. Consistent with prior work (Abbasi et al. 2021), we defined groups of sex (“male” versus “female”) and race (simplified to “white” versus “nonwhite,” following Friedler et al. 2018). Table 4 reports the AUC and DI values (additional details in Online Appendix G), which are aligned with those reported in prior research (Abbasi et al. 2021), as well as the trends noted in our performance analysis. In comparing DI outcomes, we find that across all four cases, the LIWC lexicon is the most biased and LLM is the most fair method by a significant margin with respect to both sex (with mean deviations 40%–60% lower than all other methods) and race (20%–40% lower), supporting Hypothesis 1(b).
|
Table 4. Evaluation of Fairness Across Psychometric NLP Paradigms
| Case | LIWCa | LSTM | Fine-tuned BERT | GPT-4o | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUC | DI sex | DI race | AUC | DI sex | DI race | AUC | DI sex | DI race | AUC | DI sex | DI race | |
| Anxiety | 0.667 | 0.967 | 0.845 | 0.655 | 1.034 | 0.900 | 0.729 | 1.143 | 0.905 | 0.717 | 1.082 | 0.960 |
| Trust | 0.669 | 1.119 | 1.064 | 0.748 | 0.971 | 1.085 | 0.848 | 0.996 | 1.078 | 0.844 | 0.970 | 1.021 |
| Numeracy | 0.702 | 0.794 | 0.665 | 0.716 | 0.896 | 0.647 | 0.769 | 0.887 | 0.662 | 0.757 | 0.937 | 0.713 |
| Health Lit. | 0.672 | 1.130 | 1.036 | 0.708 | 1.150 | 1.148 | 0.799 | 1.084 | 0.928 | 0.788 | 1.015 | 0.988 |
| RMSDb | 0.323 | 0.137 | 0.188 | 0.295 | 0.094 | 0.202 | 0.218 | 0.100 | 0.183 | 0.228 | 0.054 | 0.145 |
| MADb | 0.323 | 0.122 | 0.148 | 0.293 | 0.079 | 0.172 | 0.214 | 0.086 | 0.146 | 0.224 | 0.048 | 0.090 |
Note. Bold text indicates best sex/race DI performance per row.
aEnhanced using a supervised method as detailed in Online Appendix G.
bThese report root mean squared deviation (RMSD) and mean absolute deviation (MAD) from 1.0 across cases—smaller values indicate higher performance (AUC) and better fairness (DI).
4.2. Role of Cognitive-Affective Abilities in Text Annotation
Our preceding analysis established the superior performance, consistency, and fairness of LLMs compared with established paradigms. Yet, many of these methods, particularly custom-built models and fine-tuned language models, are fundamentally dependent on human-labeled data to establish a “ground truth” for training and evaluation. This reliance raises a critical question about the very foundation of these benchmarks: do individuals’ traits (i.e., cognitive abilities and emotional intelligence) affect their ability to annotate psychological constructs. To answer this question, we recruited 600 participants through CloudResearch Connect each to annotate 12 samples—4 samples with respect to resilience, 4 for empathy, and 4 for polarity. This study was preregistered (https://aspredicted.org/ggwp-jn8t.pdf) and received Institutional Review Board (IRB) approval from one of the author’s institutions (IRB-SBS 6999). A total of 240 samples per construct were drawn from our original testbed.
After consenting to take the survey, the participants first answered a commitment question (“Do you commit to providing thoughtful answers to the questions in this survey?”) and then answered socio-demographic questions related to age, gender, race, education, and household size and income. We then provided instructions (including definitions) for annotating the data with respect to the construct of interest (i.e., resilience, empathy, and polarity) and then asked them to annotate the data. We used the same annotation instruments that were used in previous studies to create the ground-truth data (Strapparava and Mihalcea 2007, Mousavi and Gu 2024).4 In addition to the annotations, we asked the participants to highlight “the key words or phrases that influenced” their annotation decisions. This data set allows us to identify more nuanced patterns. The order of constructs was also randomized. After the annotations, we asked the participants to take questions from the Quality of Life in Neurological Disorders Short Form (Cella et al. 2012, Gershon et al. 2012) to measure cognitive abilities; Wong and Law’s Emotional Intelligence Scale (Wong and Law 2002) to measure their emotional intelligence; and the Positive and Negative Affect Schedule (Crawford and Henry 2004) to measure current positive and negative mood (see Online Appendix H for instrument validity). The last two constructs (positive and negative mood) were used as control variables, consistent with the recommendations of Podsakoff et al. (2003).
4.2.1. Results: Cognitive-Affective Abilities in Human Data Annotations.
After the data collection, we removed anyone who did not pass our attention checks, bot detection check (reCAPTCHA score below 51%), and finished the survey faster than the first percentile in terms of duration of completion, per preregistered conditions. This resulted in 571 valid participants who coded 4 sample items per task, for a total of 2,284 user-task-level observations. Table 5 reports summary statistics for key variables.
|
Table 5. Summary Statistics of the Key Variables in the Data Annotation Survey
| Variable | Definition | Mean | SD | Min | Max |
|---|---|---|---|---|---|
| HE_Match | Annotator-expert annotation match | 0.660 | 0.474 | 0 | 1 |
| Cog_Ability | Annotator’s cognitive ability | 49.0 | 8.593 | 24.4 | 64.2 |
| Emo_Intel | Annotator’s emotional intelligence | 5.502 | 0.879 | 1 | 7 |
| Pos_Mood | Annotator’s positive mood | 3.299 | 0.877 | 1 | 5 |
| Neg_Mood | Annotator’s negative mood | 1.718 | 0.733 | 1 | 4.3 |
| Education_category | Annotator’s education level | 1.835 | 0.701 | 1 (No HS diploma) | 7 (Doctorate) |
| Age_category | Annotator’s age category | 3.406 | 1.188 | 1 (18–19) | 7 (70 or over) |
| Gender_encoded | Annotator’s gender category | 1.884 | 0.989 | 1 (Man) | 3 (Woman) |
| Race_encoded | Annotator’s race category | White/Caucasian: 1,636; Black/African American: 376; Other: 272 | |||
To examine the impacts of cognitive abilities and emotional intelligence on the quality of annotation by participants, we ran logistic regressions using the following equation:
Here, i denotes the sample to be annotated; h represents the participant; indicates alignment between participant (nonexpert) annotations and those of experts (trained annotators who generated the original ground truth data) with a value of one indicating a match and zero indicating no match; controls include education, age, gender, and race-related factors; represents sample fixed effects; and is the error term. It is worth noting that in constructing , participants’ responses were binarized by averaging the scores they assigned to each item (e.g., “the text focuses on the tendency to perceive others as in need,” “the text focuses on adopting others’ perspectives,” and “the text focuses on valuing others’ welfare” for annotating Empathy samples). A score of one was assigned if the mean was equal to or exceeded 5 (representing “somewhat agree” on our 7-point Likert scale; 4 was “neutral”), and zero otherwise. We employed two specifications: a conditional logistic regression with as the grouping variable and robust standard errors; and a logistic regression where was included as dummy variables, with robust errors clustered at the annotator level. The primary distinction between the two approaches is that the first uses robust standard errors, whereas the second applies clustered robust standard errors. Table 6 reports the results of these regression models.
|
Table 6. Regression Results for Comparing Experts and Nonexperts
| (1) | (2) | (3) | (4) | (5) | (6) | |
|---|---|---|---|---|---|---|
| Variables | Resilience HE match (robust) | Resilience HE match (cluster robust) | Empathy HE match (robust) | Empathy HE match (cluster robust) | Polarity HE match (robust) | Polarity HE match (cluster robust) |
| Cog_Ability | 0.03*** (0.01) | 0.03*** (0.01) | 0.04*** (0.01) | 0.04*** (0.01) | 0.02 (0.01) | 0.02 (0.01) |
| Emo_Intel | −0.03 (0.08) | −0.04 (0.09) | −0.40*** (0.10) | −0.45*** (0.12) | 0.28** (0.09) | 0.32** (0.11) |
| Pos_Mood | −0.32*** (0.08) | −0.36*** (0.10) | −0.30*** (0.08) | −0.34** (0.11) | −0.14 (0.09) | −0.16 (0.11) |
| Neg_Mood | −0.04 (0.08) | −0.04 (0.10) | −0.21* (0.08) | −0.24* (0.11) | −0.02 (0.09) | −0.03 (0.12) |
| edu_category | −0.17* (0.08) | −0.19* (0.09) | 0.01 (0.07) | 0.02 (0.09) | 0.03 (0.10) | 0.03 (0.11) |
| age_category | 0.07 (0.05) | 0.08 (0.06) | 0.04 (0.05) | 0.05 (0.06) | 0.10 (0.05) | 0.11 (0.07) |
| Constant | 3.12* (1.32) | 3.40* (1.67) | −1.24 (1.57) | |||
| Gender and race categories | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Observations | 2,027 | 2,024 | 2,114 | 2,110 | 1,698 | 1,696 |
| Sample-fixed effects | Yes | Yes | Yes | Yes | Yes | Yes |
Note. In each specification, some observations were dropped due to no variations in the outcome.
*p < 0.05; **p < 0.01; ***p < 0.001.
The results demonstrate a positive and significant coefficient for cognitive ability in the resilience annotation, indicating that participants with higher cognitive ability scores exhibited greater accuracy in annotating resilience-related samples. In contrast, emotional intelligence does not exhibit a significant relationship with accuracy in resilience annotation, suggesting that participants’ emotional intelligence levels do not influence their ability to correctly label these samples. These findings align with our theoretical expectation that cognitive processes, rather than affective ones, are critical for annotating resilience.
In Table 6, the third and fourth columns provide the results for empathy annotation. Here, the coefficients for cognitive ability remain positive and significant, reaffirming the association between higher cognitive abilities and greater accuracy in this domain. Interestingly, emotional intelligence also emerges as a significant predictor, albeit with a negative coefficient. This counterintuitive finding suggests that participants with higher levels of emotional intelligence were less accurate in annotating empathy-related samples.
A robustness check confirming that our findings are not contingent on task complexity or difficulty is detailed in Online Appendix N.
A potential explanation for this result lies in the nature of emotional intelligence. Individuals with heightened emotional intelligence may be more susceptible to the emotional tone of the text, potentially misinterpreting authorial intent and focusing less on perspective-taking or the welfare of others. This pattern highlights a significant challenge of overattribution in annotations driven by emotional intelligence. We posit that for empathy annotation, which requires a delicate balance between cognitive and affective processing, a high degree of emotional intelligence can paradoxically degrade performance through affective dominance, where potent emotional responses overshadow the requisite cognitive appraisal. This aligns with dual-process theory’s predictions about Type 1 processing dominance: fast, intuitive, emotion-laden responses can generate powerful initial judgments that slower, more deliberative Type 2 processing fails to correct or override (Kahneman 2011). To further investigate this finding, we conducted a careful qualitative examination of tokens participants highlighted as key words or phrases that influenced their decisions during annotation (please see Online Appendix H). Our analysis reveals that participants with higher emotional intelligence seem to have systematically misinterpreted superficial affective language—such as apologies, expressions of gratitude, or mentions of concern—as genuine empathy, while overlooking the deeper empathic markers that experts used to assess perspective-taking and altruistic intent. This finding underscores the need for future research on hybrid cognitive-affective constructs, where processing system interactions create complex dynamics beyond simple additive models.
In Table 6, the final two columns are for polarity. Unlike the previous tasks, cognitive ability does not exhibit a significant relationship with accuracy in this domain. However, emotional intelligence is positively and significantly associated with performance, suggesting that individuals with higher emotional intelligence are better suited for tasks requiring sensitivity to polarity, which likely involves affective discernment.
Overall, these results support our hypothesis regarding the cognitive-affective spectrum of annotation tasks. Specifically, tasks that rely heavily on cognitive processes (e.g., resilience annotation) are shaped predominantly by participants’ cognitive abilities, whereas those requiring affective judgments (e.g., empathy and polarity annotation) are strongly impacted by emotional intelligence. Notably, the unexpected negative relationship between emotional intelligence and empathy annotation accuracy underscores a more intricate interplay between affective processes and task demands, meriting additional inquiry (see Online Appendix H).
A key finding from our analysis is that individual annotators’ characteristics can lead to variability in the labels they assign. Such variability has significant implications for psychometric research reliant on human-labeled data because inconsistent annotations can affect downstream measurements and models.
Our conclusions are based on responses from nonexpert annotators who received minimal training, an unavoidable limitation given the challenges that preclude recruiting a large cohort of experts for analysis. To further clarify this, we conducted an additional analysis contrasting data from trained experts with data from nonexperts who varied in cognitive ability and emotional intelligence (see Online Appendix I for details regarding the data preparation and fine-tuning processes). The main results of this analysis are presented in Table 7. Our results show that whereas nonexpert participants with above-median levels of relevant traits for each task (cognitive ability for resilience, emotional intelligence for polarity, and a combination of the two for empathy) performed at levels comparable to experts, those with lower levels performed significantly worse. Although further research is needed to determine whether experts can better compartmentalize or mitigate biases tied to their underlying traits and skills, our findings suggest that underlying traits can impact labeling tasks, supporting Hypothesis 3(a).
|
Table 7. Using Nonexpert Data in FLMs
| Training data | Resilience AUC | Empathy AUC | Polarity AUC |
|---|---|---|---|
| Experts | 0.8065 | 0.8061 | 0.9914 |
| Nonexperts with above median cognitive abilities | 0.8025 | ||
| Nonexperts with below median cognitive abilities | 0.7511 | ||
| Nonexperts with above median cognitive abilities and emotional intelligence | 0.7722 | ||
| Nonexperts with below median cognitive abilities and emotional intelligence | 0.6643 | ||
| Nonexperts with above median emotional intelligence | 0.9844 | ||
| Nonexperts with below median emotional intelligence | 0.9674 |
4.3. Cognitive-Affective Prompting
Building on our findings that human annotators’ performance varies according to task fit with their cognitive abilities and emotional intelligence, we examined how LLMs might emulate this effect. Specifically, we asked LLMs to assume the role of a human annotator with higher levels of cognitive abilities and/or emotional intelligence while labeling text samples for resilience, empathy, and polarity.
We tested five prompting strategies (Online Appendix F) and identified the one that consistently yielded the best classification performance (i.e., highest AUC scores). We then refined the best-performing strategy by embedding a “cognitive-affective” component in each prompt. In each prompt, we asked the model to “assume the role of an expert human coder who possesses [X or Y or X and Y],” where X is “exceptional emotional intelligence” (Table 8, “High Emo”) and Y is “superior cognitive abilities” (Table 8, “High Cog”). We then annotated the data using each prompt.
|
Table 8. Predictive Performance of GPT-4o Across Various Prompting Strategies
| Strategy | AUC | F1 (Macro) | Accuracy | Positive recall | Positive precision | Negative recall | Negative precision | Threshold |
|---|---|---|---|---|---|---|---|---|
| Resilience | ||||||||
| Few-shot | 0.9363 | 0.8418 | 0.9093 | 0.8421 | 0.6575 | 0.9214 | 0.9702 | 0.76 |
| Chain-of-thought (CoT) | 0.9386 | 0.8026 | 0.8693 | 0.9474 | 0.5400 | 0.8553 | 0.9891 | 0.76 |
| Contrastive CoT | 0.9492 | 0.8611 | 0.9253 | 0.8070 | 0.7302 | 0.9465 | 0.9647 | 0.76 |
| Tree of thought | 0.9409 | 0.8345 | 0.9147 | 0.7193 | 0.7193 | 0.9497 | 0.9497 | 0.76 |
| Self-refine | 0.9415 | 0.8298 | 0.9067 | 0.7719 | 0.6667 | 0.9308 | 0.9579 | 0.76 |
| High cog | 0.9544 | 0.8775 | 0.9307 | 0.8947 | 0.7183 | 0.9371 | 0.9803 | 0.76 |
| High emo | 0.9472 | 0.8697 | 0.9253 | 0.8947 | 0.6986 | 0.9308 | 0.9801 | 0.76 |
| High cog & emo | 0.9505 | 0.8775 | 0.9307 | 0.8947 | 0.7183 | 0.9371 | 0.9803 | 0.76 |
| Empathy | ||||||||
| Few-shot | 0.9247 | 0.6840 | 0.9862 | 0.2500 | 0.7500 | 0.9986 | 0.9876 | 0.86 |
| Chain-of-thought | 0.9407 | 0.6539 | 0.9711 | 0.4167 | 0.2632 | 0.9804 | 0.9901 | 0.76 |
| Contrastive CoT | 0.9435 | 0.6475 | 0.9752 | 0.3333 | 0.2857 | 0.9860 | 0.9887 | 0.76 |
| Tree of thought | 0.9239 | 0.6144 | 0.9587 | 0.4167 | 0.1786 | 0.9678 | 0.9900 | 0.66 |
| Self-refine | 0.8970 | 0.5747 | 0.9378 | 0.4167 | 0.1163 | 0.9466 | 0.9897 | 0.76 |
| High cog | 0.9464 | 0.6541 | 0.9766 | 0.3333 | 0.3077 | 0.9874 | 0.9888 | 0.76 |
| High emo | 0.9494 | 0.6657 | 0.9739 | 0.4167 | 0.2941 | 0.9832 | 0.9901 | 0.76 |
| High cog & emo | 0.9498 | 0.6723 | 0.9752 | 0.4167 | 0.3125 | 0.9846 | 0.9902 | 0.76 |
| Polarity | ||||||||
| Few-shot | 0.9995 | 0.9927 | 0.9936 | 0.9968 | 0.9937 | 0.9868 | 0.9934 | 0.41 |
| Chain-of-thought | 0.9976 | 0.9951 | 0.9957 | 0.9968 | 0.9968 | 0.9934 | 0.9934 | 0.26 |
| Contrastive CoT | 0.9941 | 0.9903 | 0.9914 | 0.9904 | 0.9968 | 0.9934 | 0.9805 | 0.31 |
| Tree of thought | >0.9999 | 0.9976 | 0.9979 | 0.9968 | 1.0000 | 1.0000 | 0.9935 | 0.31 |
| Self-refine | >0.9999 | 0.9976 | 0.9979 | 1.0000 | 0.9968 | 0.9934 | 1.0000 | 0.26 |
| High cog | >0.9999 | 0.9976 | 0.9979 | 1.0000 | 0.9968 | 0.9934 | 1.0000 | 0.26 |
| High emo | >0.9999 | 0.9976 | 0.9979 | 0.9968 | 1.0000 | 1.0000 | 0.9935 | 0.35 |
| High cog & emo | >0.9999 | 0.9976 | 0.9979 | 1.0000 | 0.9968 | 0.9934 | 1.0000 | 0.26 |
Notes. Bold text among basic prompting strategies indicates highest AUC and the strategy used as a base for cognitive-affective prompting. Bold italic text among cognitive-affective strategies indicates the hypothesized best performance.
Together, these strategies address challenges in eliciting complex reasoning from LLMs. By systematically comparing them, we identified the optimal approach for combining cognitive-affective cues within prompts.
4.3.1. Results: Cognitive-Affective Prompting.
Table 8 reports the results of this analysis. We used “gpt-4o-2024-11-20” with identical settings (temperature = 0) in all cases. We also used a custom Python function to identify the threshold that results in the highest F1 score and used that threshold to report F1, accuracy, positive and negative recall, and precision.
As outlined in the results, GPT-4o achieved its highest performance using the contrastive chain-of-thought prompting strategy for resilience and empathy annotations, whereas the tree-of-thoughts prompting strategy proved most effective for annotating polarity cases. More significantly, our results reveal that tailoring the prompting strategy based on a cognitive-affective framework leads to even greater performance improvements. For resilience annotations, which predominantly require cognitive reasoning, appending the phrase “assume the role of an expert human coder who possesses superior cognitive abilities” to the prompt significantly enhanced performance. For empathy annotations, where both affective and cognitive dimensions are crucial, prompts that included both “exceptional emotional intelligence” and “superior cognitive abilities” yielded the best results. Polarity annotations, which rely more on affective judgment, benefited marginally from prompts emphasizing “exceptional emotional intelligence,” due to almost perfect baseline performance in this case. Overall, if we consider the gap between the baseline performance for both resilience (i.e., 0.9492) and empathy (i.e., 0.9435) and perfect ranking (i.e., AUC = 1), the proposed approach closes more than 10% of that gap. These meaningful performance improvements can be achieved when including such cognitive-affective prompting aligned with task demands, as proposed in Hypothesis 3(b).5 It is notable that simply prompting a model to exhibit both high emotional intelligence and cognitive ability is not universally beneficial (e.g., “high cog” is better than “high cog and emo” for the resilience task). From a human psychological standpoint, this might be attributed to hypersensitivity of emotion hindering the application of cognitive skills to a cognitively aligned task (e.g., Truninger et al. 2018, Fiori and Ortony 2021) or possibly to challenges introduced by multigoal pursuit (Neal et al. 2017) or role conflict (Biddle and Thomas 1966, Anglin et al. 2022). Further research is required to determine if such phenomena translate to LLM performance as well.
4.3.2. Analysis of Attention Weights.
To deepen our understanding of how LLMs leverage concepts such as “cognitive abilities” and “emotional intelligence” during annotation tasks, we conducted a comprehensive analysis of attention weights (see Online Appendix J for detailed methodology). Using Meta’s Llama 3.1 70B Instruct model, we tracked the attention paid to the phrases “cognitive abilities” and “emotional intelligence” as the model generated annotations for resilience, empathy, and polarity samples in our validation sets. By analyzing how attention to these key phrases varied during the generation process, we were able to identify patterns that correlate with annotation accuracy.
As reported in Table 9, a discernible pattern emerges regarding the differential impact of attentional focus on annotation accuracy.6 For resilience and empathy samples, enhanced performance correlates with increased attention directed toward the phrase “cognitive abilities” relative to “emotional intelligence.” Conversely, annotation accuracy for polarity samples demonstrates a positive relationship with heightened attention to “emotional intelligence” compared with “cognitive abilities.” These observations corroborate our central hypothesis: the inclusion of these conceptual anchors within the prompt modulates LLM performance, with heightened accuracy contingent upon attentional alignment with the contextually appropriate concept, as prescribed by our cognitive-affective prompting strategy. Furthermore, consistent with our a priori expectations, increased instance hardness—a measure of inherent sample annotation difficulty—is associated with diminished model performance. It is noteworthy that the coefficient for instance hardness did not attain statistical significance in the polarity sample analysis. This can be attributed to the exceptionally high AUC achieved by the model for this specific data set, indicating near-perfect performance and thus limiting the observable impact of instance hardness on the already robustly accurate annotations.
|
Table 9. Attention Weights Analysis
| Variables | (1) Resilience LLM-expert match | (2) Empathy LLM-expert match | (3) Polarity LLM-expert match |
|---|---|---|---|
| CognitiveAttention | 1.38* (0.57) | 2.55*** (0.48) | −0.30 (0.26) |
| EmotionalAttention | 0.96* (0.38) | 1.83*** (0.30) | 1.12* (0.57) |
| InstanceHardness | −0.72*** (0.14) | −0.56*** (0.15) | −0.22 (0.18) |
| Constant | 3.47*** (0.40) | 5.66*** (0.57) | 5.37*** (0.80) |
| Observations | 375 | 727 | 466 |
Notes. Robust standard errors are in parentheses. Scaled to mean = 0 and SD = 1.
*p < 0.05; ***p < 0.001.
5. Discussion and Conclusion
Empirical research in social science has been markedly influenced by the adoption of NLP techniques to measure psychological constructs in text and the evolution (and revolutions) in these methods over time. Despite advancements, social science researchers still grapple with challenges in data collection, ground-truth labeling of training sets, and mastering NLP techniques to effectively utilize advanced methods. The dilemma often lies in choosing between simple, but less accurate, lexicon-based methods and the demanding process of labeling data and deploying FLMs. In contrast, LLMs offer a revolutionary approach. They eliminate the need for manual labeling or technical expertise7 required to develop NLP models, while still delivering results comparable (or superior) to FLMs. Stage 1 of our holistic evaluation demonstrates LLMs have predictive performance on par with FLMs (Hypothesis 1(a)), make more consistent predictions over different segments of data (Hypothesis 1(b)), and provide more fair predictions (Hypothesis 1(c)), despite requiring less domain or NLP expertise (see Table 10). These benefits also come at extremely low cost. Each application programming interface (API) request to GPT-4o cost approximately $0.001, yielding a total expenditure of $3.35 for processing a data set of 3,000 items. At the time of writing, the published rates for more advanced models such as GPT-5 and Gemini 2.5 Pro are marginally lower than the costs we incurred. Comparable pricing is also available through third-party platforms, including replicate.com and fireworks.ai, which host a range of open- and closed-source models. By contrast, human annotation of the same 3,000-item data set required an outlay of roughly $300 to produce ground-truth labels for the empathy training set, after which CBMs or FLMs remain necessary to generalize beyond the labeled subset.
|
Table 10. Holistic Evaluation of Psychometric NLP Paradigms
| Paradigm | Required domain expertise | Required NLP expertise | Aggregate predictive performance | Consistency in predictive performance | Fairness in predictive performance |
|---|---|---|---|---|---|
| Lexicon-based | Low | Low | Low | Low | Low |
| Custom-built Models | High | High | Medium | Low | Medium |
| FLMs | High | High | High | Medium | Medium |
| LLMs | Medium | Low | High | High | High |
In stages 2 and 3 of our holistic evaluation, we further demonstrate that human annotators’ abilities in identifying psychological constructs depend on their cognitive and affective abilities (Hypotheses 2(a), (b), and (c)) and task-trait fit along these dimensions has a significant influence on the predictive performance of downstream FLMs (Hypothesis 3(a)). Inspired by these findings, we introduce a cognitive-affective prompting strategy that improves LLM performance (Hypothesis 3(b)). These findings suggest that when utilizing LLMs for psychometric NLP tasks, considering cognitive-affective demands and crafting prompts that encourage alignment with those demands can improve performance. This contributes to the research on persona-based prompting by offering a strategy that addresses discrepancies in prior studies and enhances LLM performance across psychometric tasks. Practically, it gives social scientists a direct lever to enhance the validity of automated coding, moving beyond generic prompts to ones tailored for psychological measurement.
Positioned toward the “data science and analytics” end of the abstraction spectrum defined in Abbasi et al. (2024) and inspired by studies they identify (Liu et al. 2020, Lee et al. 2025), our theory-guided framework for holistic evaluation of paradigms for psychometric NLP affords three notable salient design insights. First, we elucidate five key dimensions for evaluating the different paradigms. Using these dimensions, we note that LLMs may exhibit comparable performance, and better fairness and consistency, with lower requirements for domain and NLP expertise (Hypothesis 1). Second, our framework and evaluation underscore the importance of the interplay between annotators’ cognitive-affective abilities and task-trait fit on labeling performance as well as downstream performance for FLMs (Hypothesis 2 and Hypothesis 3(a)). Third, we empirically demonstrate how cognitive-affective considerations may positively inform LLM-based scoring (Hypothesis 3(b)).
These design insights have important implications for future social science research leveraging psychometric NLP. As specific examples, design insights from our framework can inform computationally intensive theory construction research in deriving psychometric information from text (Miranda et al. 2022), as well as design of novel psychometric NLP artifacts for social science research extracting information from technology-enabled communication (e.g., Liu et al. 2020, Yang et al. 2023, Kitchens et al. 2024). Our work highlights how LLMs can be incorporated into future artifacts and also provides a high-performing, easy to implement, objective, and consistent benchmark for comparison in evaluating proposed artifacts. Considering required domain and NLP expertise, predictive performance, consistency, fairness, and interpretability, we advocate for the acceptance of LLMs as a standard for psychometric NLP in social science research.
6. Limitations and Future Research
Our study has inherent limitations that, in turn, suggest promising avenues for future research. To begin, beyond those we investigate in this study, there are a variety of other dimensions in which LLMs may (or may not) exhibit superior performance over established psychometric NLP approaches. For instance, the ability of LLMs to provide rationale for their outputs has potential impacts for interpretability. The practical relevance of identified constructs may also be improved by the ability to customize prompts and focus LLMs on the precise definition of constructs that researchers wish to identify. Similarly, although we find that GPT-4o has desirable consistency and fairness benefits over other paradigms, we did not examine the impact of cognitive-affective prompting on these dimensions. This also seems to be a rich area for future inquiry. Our findings regarding the benefits of cognitive-affective prompting strategy for LLM annotations suggests additional future research potential: this type of benefit may also accrue to human annotators through behavioral nudging to emphasize cognitive or affective abilities, which may be examined in future studies. Regarding our findings for annotation and personal traits, as with any study surveying human subjects, we had to make choices regarding ordering and length of the survey instrument. Although we followed best practices, future replications with alternative formats could improve the evidence relative to our findings. Although we have proposed and preliminarily examined possible mechanisms, the counterintuitive result that higher emotional intelligence negatively influences empathy annotation merits further study. We suggest that further investigating psychological constructs demanding high levels of both cognitive and affective processes is a promising future direction. It may also be interesting to explore targeted training interventions designed to help compensate for annotator trait-task misalignment.
1 We considered potential data contamination in LLMs for each data set. The resilience and empathy data sets are constructed based on publicly available information (tweets and earnings calls, respectively). However, the labels for these data sets are proprietary (developed for this study or obtained from the authors of prior studies for which they were developed) and have never been published. Therefore, there is no possible contamination of the data sets including labels. The labeled polarity data set was, however, made public prior to the training dates for the LLMs we use. To ensure that contamination did not drive our results, we reperformed our analysis on an additional polarity data set published after the training date for LLMs, noting similar results.
2 We utilize the polarity data set to represent an affective task. Theory and evidence have shown that even within the finance domain, which can be somewhat technical in nature, affective processes are dominant in determining sentiment. See Online Appendix O for details.
3 This Microsoft-developed pretrained model demonstrates robust capabilities in generating sentence embeddings. For details, please see https://www.sbert.net/docs/pretrained_models.html.
4 A review of 23 instruments across 50 studies found no agreed-upon “gold standard” for measuring empathy (de Lima and Osório 2021). Adopting Batson’s view of empathy as an other-oriented, congruent emotional response, we capture it through three facets: recognizing others’ need, taking their perspective, and valuing their welfare (Salovey and Mayer 1990, Batson 2016, König et al. 2020). See Online Appendix B for details.
5 Although as a single summary metric, the AUC is not suitable for direct statistical testing, we performed a paired, one-sided Wilcoxon signed-rank test on per-case log-loss differences (Gneiting and Raftery 2007, Dror et al. 2018), confirming the statistical significance of the superior performance of cognitive-affective prompting for resilience (p < 0.01) and empathy (p < 0.001). For polarity, baseline performance is too high for meaningful improvement.
6 We also estimated the models in Table 9 with an interaction term between cognitive and emotional attention. The results were substantively unchanged for resilience and polarity (the interaction term was insignificant). For empathy, which benefitted from both cognitive and emotional attention, main effects remained stable, but a negative interaction term indicated that the respective benefits may not be additive. Our hypotheses do not address this interaction, but it may represent an interesting topic for further research.
7 The level of NLP expertise required when using LLMs can vary based on two key factors: the mode of access and the prompting strategy. Accessing a proprietary model through a simple API call (e.g., OpenAI’s GPT-4o) requires minimal setup, whereas deploying (and modifying) an open-weight model like Llama 3.1 via Python demands greater technical proficiency. In addition, although prompting techniques can depend on technical skills, results in Table 8 show that even a simple few-shot prompt is relatively effective. In contrast, fine-tuning in FLMs is highly sensitive to selecting the pretrained model (see Table E in Online Appendix E) and hyperparameter choices like learning rate and batch size (Devlin et al. 2019), making it a considerably more complex task, as is building a CBM from scratch.
References
- (2018) Text analytics to support sense-making in social media: A language-action perspective. MIS Quart. 42(2):427–464.Crossref, Google Scholar
- (2024) Pathways for design research on artificial intelligence. Inform. Systems Res. 35(2):441–459.Link, Google Scholar
- (2021) Constructing a psychometric testbed for fair natural language processing. Proc. 2021 Conf. Empirical Methods Natural Language Processing (Association for Computational Linguistics, Stroudsburg, PA), 3748–3758.Google Scholar
- (2018) The impact of user personality traits on word of mouth: Text-mining social media platforms. Inform. Systems Res. 29(3):612–640.Link, Google Scholar
- (2020) A deep learning architecture for psychometric natural language processing. ACM Trans. Inform. Systems 38(1):1–29.Crossref, Google Scholar
- (2023) Annotating data for fine-tuning a neural ranker? Current active learning strategies are not better than random selection. Proc. Annual Internat. ACM SIGIR-AP ‘23 (Association for Computing Machinery, New York), 139–149.Google Scholar
- (2022) Role theory perspectives: Past, present, and future applications of role theories in management research. J. Management 48(6):1469–1502.Crossref, Google Scholar
- (2021) Bad seeds: Evaluating lexical methods for bias measurement. Proc. 59th Annual Meeting Assoc. Comput. Linguistics and 11th Internat. Joint Conf. Natl. Language Processing, vol. 1: Long Papers (Association for Computational Linguistics, Stroudsburg, PA), 1889–1904.Google Scholar
- (2019) FinBERT: Financial sentiment analysis with pre-trained language models. Preprint, submitted August 27, https://arxiv.org/abs/1908.10063.Google Scholar
- (2022) Machine learning as a model for cultural learning: Teaching an algorithm what it means to be fat. Sociol. Methods Res. 51(4):1484–1539.Crossref, Google Scholar
- (2010) SentiWordNet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. Proc. Seventh Internat. Conf. Language Resources Evaluation LREC’10 (European Language Resources Association, Paris), 2200–2204.Google Scholar
- (2014) Architecture of fluid intelligence and working memory revealed by lesion mapping. Brain Structure Function 219(2):485–494.Crossref, Google Scholar
- (2016)
Empathy and altruism. Brown KW, Leary MR, eds. The Oxford Handbook of Hypo-Egoic Phenomena (Oxford University Press, Oxford, UK), 161–174.Google Scholar - (2019) SciBERT: A pretrained language model for scientific text. Preprint, submitted September 10, https://arxiv.org/abs/1903.10676.Google Scholar
- (2021) Investigating gender bias in BERT. Cognitive Comput. 13(4):1008–1018.Crossref, Google Scholar
- (1966) Role Theory: Concepts and Research (John Wiley & Sons, Hoboken, NJ).Google Scholar
- (2011) Emotions, oral arguments, and Supreme Court decision making. J. Politics 73(2):572–581.Crossref, Google Scholar
- (2020) Adversarial filters of dataset biases. Preprint, submitted July 11, https://arxiv.org/abs/2002.04108.Google Scholar
- (2020) Language models are few-shot learners. Adv. Neural Inform. Processing Systems 33:1877–1901.Google Scholar
- (2012) Neuro-QOL: Brief measures of health-related quality of life for clinical research in neurology. Neurology 78(23):1860–1867.Crossref, Google Scholar
- (2016) XGBoost: A scalable tree boosting system. Proc. 22nd ACM SIGKDD Internat. Conf. Knowledge Discovery Data Mining (Association for Computing Machinery, New York), 785–794.Google Scholar
- (2023) When large language models meet personalization: Perspectives of challenges and opportunities. Preprint, submitted July 31, https://arxiv.org/abs/2307.16376.Google Scholar
- (2024) From persona to personalization: A survey on role-playing language agents. Preprint, submitted October 9, https://arxiv.org/abs/2404.18231.Google Scholar
- (2023) Contrastive chain-of-thought prompting. Preprint, submitted November 15, https://arxiv.org/abs/2311.09277.Google Scholar
- (2022) PaLM: Scaling language modeling with pathways. Preprint, submitted October 5, https://arxiv.org/abs/2204.02311.Google Scholar
- (2007) How emotions inform judgment and regulate thought. Trends Cognitive Sci. 11(9):393–399.Crossref, Google Scholar
- (1995) Support-vector networks. Machine Learn. 20(3):273–297.Crossref, Google Scholar
- (2004) The Positive and Negative Affect Schedule (PANAS): Construct validity, measurement properties and normative data in a large non-clinical sample. British J. Clin. Psych. 43(3):245–265.Crossref, Google Scholar
- (2004) The functional architecture of human empathy. Behav. Cognitive Neurosci. Rev. 3(2):71–100.Crossref, Google Scholar
- (2021) Empathy: Assessment instruments and psychometric quality—A systematic literature review with a meta-analysis of the past ten years. Front Psychol. 12:781346.Crossref, Google Scholar
- (2018) Dual Process Theory 2.0 (Routledge/Taylor & Francis Group, New York).Google Scholar
- (2019) BERT: Pre-training of deep bidirectional transformers for language understanding. Proc. 2019 Conf. North Amer. Chapter Assoc. Comput. Linguistics: Human Language Technologies, vol. 1: Long and Short Papers (Association for Computational Linguistics, Stroudsburg, PA), 4171–4186.Google Scholar
- (2018) The Hitchhiker’s guide to testing statistical significance in natural language processing. Gurevych I, Miyao Y, eds. Proc. 56th Annual Meeting Assoc. Comput. Linguistics, vol. 1: Long Papers (Association for Computational Linguistics, Stroudsburg, PA), 1383–1392.Google Scholar
- (2024) First-person fairness in chatbots. Preprint, submitted October 16, https://arxiv.org/abs/2410.19803.Google Scholar
- (2003) In two minds: Dual-process accounts of reasoning. Trends Cognitive Sci. 7(10):454–459.Crossref, Google Scholar
- (2013) Dual-process theories of higher cognition: Advancing the debate. Perspect. Psych. Sci. 8(3):223–241.Crossref, Google Scholar
- (2023) Multimodal knowledge graph construction of Chinese traditional operas and sentiment and genre recognition. J. Cultural Heritage 62:32–44.Crossref, Google Scholar
- (2022) Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Preprint, submitted June 16, https://arxiv.org/abs/2101.03961.Google Scholar
- (2009) A new look at emotional intelligence: A dual-process framework. Personality Soc. Psych. Rev. 13(1):21–44.Crossref, Google Scholar
- (2021) Initial evidence for the hypersensitivity hypothesis: Emotional intelligence as a magnifier of emotional experience. J. Intelligence 9(2):24.Crossref, Google Scholar
- (2018) A comparative study of fairness-enhancing interventions in machine learning. Preprint, submitted February 12, https://arxiv.org/abs/1802.04422.Google Scholar
- (2024) SubData: A Python library to collect and combine datasets for evaluating LLM alignment on downstream tasks. Preprint, submitted December 21, https://arxiv.org/abs/2412.16783.Google Scholar
- (2019) Responding to bad press: How CEO temporal focus influences the sensitivity to negative media coverage of acquisitions. Acad. Management J. 62(3):918–943.Crossref, Google Scholar
- (2012) Neuro-QOL: Quality of life item banks for adults with neurological disorders: Item development and calibrations based upon clinical and general population testing. Quality Life Res. 21(3):475–486.Crossref, Google Scholar
- (2007) Strictly proper scoring rules, prediction, and estimation. J. Amer. Statist. Assoc. 102(477):359–378.Crossref, Google Scholar
- (2024) The Llama 3 herd of models. Preprint, submitted November 23, https://arxiv.org/abs/2407.21783.Google Scholar
- (1997) Long short-term memory. Neural Comput. 9(8):1735–1780.Crossref, Google Scholar
- (2021) LoRA: Low-rank adaptation of large language models. Preprint, submitted October 16, https://arxiv.org/abs/2106.09685.Google Scholar
- (2023) FinBERT: A large language model for extracting information from financial text. Contemporary Accounting Res. 40(2):806–841.Crossref, Google Scholar
- (2024) The tangled webs we weave: Examining the effects of CEO deception on analyst recommendations. Strategic Management J. 45(1):66–112.Crossref, Google Scholar
- (2009)
Parallel coordinates . Liu L, Tamer Özsu, eds. Encyclopedia of Database Systems (Springer US, New York), 2018–2024.Crossref, Google Scholar - (2024) AI alignment: A comprehensive survey. Preprint, submitted May 1, https://arxiv.org/abs/2310.19852.Google Scholar
- (2023) Mistral 7B. Preprint, submitted October 10, https://arxiv.org/abs/2310.06825.Google Scholar
- (2010) Emotional intelligence: An integrative meta-analysis and cascading model. J. Appl. Psych. 95(1):54–78.Crossref, Google Scholar
- (2011) Thinking, Fast and Slow (Farrar, Straus and Giroux, New York).Google Scholar
- (2002)
Representativeness revisited: Attribute substitution in intuitive judgment . Gilovich T, Griffin D, Kahneman D, eds. Heuristics and Biases: The Psychology of Intuitive Judgment (Cambridge University Press, New York), 49–81.Crossref, Google Scholar - (2014) Causal reasoning with mental models. Front. Human Neurosci. 8:849.Crossref, Google Scholar
- (2024) Timely, granular, and actionable: Designing a social listening platform for public health 3.0. MIS Quart. 48(3):899–930.Crossref, Google Scholar
- (2024) Better zero-shot reasoning with role-play prompting. Preprint, submitted March 14, https://arxiv.org/abs/2308.07702.Google Scholar
- (2020) A blessing and a curse: How CEOs’ trait empathy affects their management of organizational crises. Acad. Management Rev. 45(1):130–153.Crossref, Google Scholar
- (2024) Explainable deep learning for false information identification: An argumentation theory approach. Inform. Systems Res. 35(2):890–907.Link, Google Scholar
- (2025) Guided Diverse Concept Miner (GDCM): Uncovering relevant constructs for managerial insights from text. Inform. Systems Res. 36(1):370–393.Link, Google Scholar
- (2021) The power of scale for parameter-efficient prompt tuning. Preprint, submitted September 2, https://arxiv.org/abs/2104.08691.Google Scholar
- (2020) Predicting labor market competition: Leveraging interfirm network and employee skills. Inform. Systems Res. 31(4):1443–1466.Link, Google Scholar
- (2020) Finding useful solutions in online knowledge communities: A theory-driven design and multilevel analysis. Inform. Systems Res. 31(3):731–752.Link, Google Scholar
- (2022) Automated detection of emotional and cognitive engagement in MOOC discussions to predict learning achievement. Comput. Ed. 181:104461.Crossref, Google Scholar
- (2024) Measuring spiritual values and bias of large language models. Preprint, submitted October 15, https://arxiv.org/abs/2410.11647.Google Scholar
- (2011) When is a liability not a liability? Textual analysis, dictionaries, and 10-Ks. J. Finance 66(1):35–65.Crossref, Google Scholar
- (2023) Self-refine: Iterative refinement with self-feedback. Preprint, submitted May 25, https://arxiv.org/abs/2303.17651.Google Scholar
- (2022) A survey on bias and fairness in machine learning. Preprint, submitted January 25, https://arxiv.org/abs/1908.09635.Google Scholar
- (1995) WordNet: A lexical database for English. Comm. ACM 38(11):39–41.Crossref, Google Scholar
- (2022) Computationally intensive theory construction: A primer for authors and reviewers. MIS Quart. 46(2):3–18.Google Scholar
- (2020) DQI: Measuring data quality in NLP. Preprint, submitted May 2, https://arxiv.org/abs/2005.00816.Google Scholar
- (2024) Resilience messaging: The effect of governors’ social media communications on community compliance during a public health crisis. Inform. Systems Res. 35(2):505–527.Link, Google Scholar
- (2017) Dynamic self-regulation and multiple-goal pursuit. Annual Rev. Organ. Psych. Organ. Behav. 4(1):401–423.Crossref, Google Scholar
- (2003) At the interface of the affective, behavioral, and cognitive neurosciences: Decoding the emotional feelings of the brain. Brain Cognition 52(1):4–14.Crossref, Google Scholar
- (1996) Cognitive, emotional, and language processes in disclosure. Cognition Emotion 10(6):601–626.Crossref, Google Scholar
- (2023) Large language models can infer psychological dispositions of social media users. Preprint, submitted September 13, https://arxiv.org/abs/2309.08631.Google Scholar
- (2003) Common method biases in behavioral research: A critical review of the literature and recommended remedies. J. Appl. Psych. 88(5):879–903.Crossref, Google Scholar
- (2021) Correcting misclassification bias in regression models with variables generated via data mining. Inform. Systems Res. 32(2):462–480.Link, Google Scholar
- (2023) GPT is an effective tool for multilingual psychological text analysis. Preprint, submitted May 19, https://osf.io/sekf5.Google Scholar
- (2020) Wide range screening of algorithmic bias in word embedding models using large sentiment lexicons reveals underreported bias types. PLoS One 15(4):e0231189.Crossref, Google Scholar
- (1986) Sequential thought processes in PDP models. Parallel Distributed Processing: Explorations in the Microstructure of Cognition, vol. 2: Psychological and Biological Models (MIT Press, Cambridge, MA), 7–57.Google Scholar
- (2021) Real-time brand reputation tracking using social media. J. Marketing 85(4):21–43.Crossref, Google Scholar
- (1990) Emotional intelligence. Imagination Cognition Personality 9(3):185–211.Crossref, Google Scholar
- (1975) A vector space model for automatic indexing. Comm. ACM 18(11):613–620.Crossref, Google Scholar
- (2020) Learning word ratings for empathy and distress from document-level user responses. Proc. Twelfth Language Resources Evaluation Conf. (European Language Resources Association, Paris), 1664–1673.Google Scholar
- (2020) Women’s leadership is associated with fewer deaths during the COVID-19 crisis: Quantitative and qualitative analyses of United States governors. J. Appl. Psych. 105(8):771–783.Crossref, Google Scholar
- (2017) Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. Preprint, submitted January 23, https://arxiv.org/abs/1701.06538.Google Scholar
- (2024) On the decision-making abilities in role-playing using large language models. Preprint, submitted February 29, https://arxiv.org/abs/2402.18807.Google Scholar
- (2009) The social neuroscience of empathy. Ann. NY Acad. Sci. 1156:81–96.Crossref, Google Scholar
- (2007) The affect heuristic. Eur. J. Oper. Res. 177(3):1333–1352.Crossref, Google Scholar
- (1998) Individual differences in rational thought. J. Experiment. Psych. General 127(2):161–188.Crossref, Google Scholar
- (1966) The General Inquirer: A Computer Approach to Content Analysis (MIT Press, Oxford, UK).Google Scholar
- (2007) SemEval-2007 Task 14: Affective text. Agirre E, Màrquez L, Wicentowski R, eds. Proc. Fourth Internat. Workshop Semantic Evaluations SemEval-2007 (Association for Computational Linguistics, Stroudsburg, PA), 70–74.Google Scholar
- (2022) Positive attentional bias mediates the relationship between trait emotional intelligence and trait affect. Sci. Rep. 12(1):20733.Crossref, Google Scholar
- (2024) Large language models for data annotation: A survey. Preprint, submitted December 2, https://arxiv.org/abs/2402.13446.Google Scholar
- (2010) The psychological meaning of words: LIWC and computerized text analysis methods. J. Language Soc. Psych. 29(1):24–54.Crossref, Google Scholar
- (2012) What lies beneath: The linguistic traces of deception in online dating profiles. J. Comm. 62(1):78–97.Crossref, Google Scholar
- (2018) The power of EI competencies over intelligence and individual performance: A task-dependent model. Front. Psych. 9:1532.Crossref, Google Scholar
- (2024) Two tales of persona in LLMs: A survey of role-playing and personalization. Preprint, submitted October 5, https://arxiv.org/abs/2406.01171.Google Scholar
- (2017) Attention is all you need. 31st Conf. Neural Inform. Processing Systems (NIPS 2017) (Curran Associates, Inc., Red Hook, NY).Google Scholar
- (2023) Chain-of-thought prompting elicits reasoning in large language models. Preprint, submitted January 10, https://arxiv.org/abs/2201.11903.Google Scholar
- (2022) Emergent abilities of large language models. Preprint, submitted October 26, https://arxiv.org/abs/2206.07682.Google Scholar
- (2011) Psychopathy and lifetime experiences of depression. Criminal Behaviour Mental Health 21(4):279–294.Crossref, Google Scholar
- Wong CS, Law KS (2002) Wong and Law Emotional Intelligence Scale (WLEIS) [Database record]. APA PsycTests. https://doi.org/10.1037/t07398-000.Google Scholar
- (2023) Large language models are diverse role-players for summarization evaluation. Preprint, submitted September 19, https://arxiv.org/abs/2303.15078.Google Scholar
- (2021) The interplay between online reviews and physician demand: An empirical investigation. Management Sci. 67(12):7344–7361.Link, Google Scholar
- (2023) Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment. Preprint, submitted December 19, https://arxiv.org/abs/2312.12148.Google Scholar
- (2023) Getting personal: A deep learning artifact for text-based measurement of personality. Inform. Systems Res. 34(1):194–222.Link, Google Scholar
- (2023) SDTM: A supervised Bayesian deep topic model for text analytics. Inform. Systems Res. 34(1):137–156.Link, Google Scholar
- (2018) Mind the gap: Accounting for measurement error and misclassification in variables generated via data mining. Inform. Systems Res. 29(1):4–24.Link, Google Scholar
- (2023) Tree of thoughts: Deliberate problem solving with large language models. Preprint, submitted December 3, https://arxiv.org/abs/2305.10601.Google Scholar
- (2024) KETCH: A knowledge-enhanced transformer-based approach to suicidal ideation detection from social media content. Inform. Systems Res. 36(1):572–599.Link, Google Scholar
- (2024) When “a helpful assistant” is not really helpful: Personas in system prompts do not improve performances of large language models. Preprint, submitted October 9, https://arxiv.org/abs/2311.10054.Google Scholar
Reza Mousavi is an associate professor at the University of Virginia’s McIntire School of Commerce. His work examines the inner workings and societal impacts of AI, specifically LLMs and NLP. He holds a PhD in computer information systems from the W. P. Carey School of Business, Arizona State University; an MBA from the University of Tehran; and a BSc in Engineering from Sharif University of Technology.
Brent Kitchens is the William Stamps Farish Associate Professor and IT and Innovation Area Coordinator at the McIntire School of Commerce, University of Virginia. He holds a PhD in Information Systems from the University of Florida Warrington College of Business and a BBA in Management Information Systems from the University of Mississippi.
Abbie Griffith Oliver is an assistant professor at the McIntire School of Commerce, University of Virginia. Her research explores the intersection of corporate governance and social evaluations. She holds a PhD in Business Administration (Strategy) from the University of Georgia Terry College of Business, an IMBA from the University of South Carolina, and a BA in Economics from Wake Forest University.
Ahmed Abbasi is the Joe and Jane Giovanini Professor of IT, Analytics, and Operations in the Mendoza College of Business at the University of Notre Dame. He serves as director of the Analytics PhD program and co-director of the Human-centered Analytics Lab.

