
Knowing (Not) to Know: Explainable Artificial Intelligence and Human Metacognition
Abstract
The use of explainable artificial intelligence (XAI) to render black-box artificial intelligence (AI) more interpretable to humans is gaining practical relevance. Prior research has shown that XAI can influence how humans “think”. Yet, little is known about whether XAI also affects how people “think about their thinking” (i.e., their metacognitive processes). We address this gap by investigating whether XAI affects metacognitive processes that guide human confidence judgments about their ability to perform a task and thereby, their decision whether to delegate the task to AI. We conducted two incentivized experiments in which domain experts repeatedly performed prediction tasks, with the option to delegate each task to an AI. We exogenously varied whether participants initially received explanations about AI’s overall prediction logic. We find that AI explanations improve how well humans understand their own ability to perform the task (metacognitive accuracy). This improvement causally increases both the frequency and effectiveness of human-to-AI delegation. Additional analyses show that these effects primarily occur when explanations reveal to humans that AI’s prediction logic diverges from their own, leading to a systematic reduction of overconfidence. Our findings highlight metacognitive processes as a central, previously overlooked channel through which AI explanations can influence human-AI collaboration. We discuss practical implications of our results for organizations implementing XAI to comply with regulatory transparency requirements as, for example, outlined in the European Union Artificial Intelligence Act.
History: Gordon Burtch, Senior Editor; Idris Adjerid, Associate Editor.
Funding: This research was supported by the Deutsche Forschungsgemeinschaft [Grant 449023539] and the Leibniz Institute for Financial Research SAFE.
Supplemental Material: The online appendix is available at https://doi.org/10.1287/isre.2024.1431.
1. Introduction
State-of-the-art artificial intelligence (AI) systems achieve high predictive performance by learning complex patterns from data (Jordan and Mitchell 2015). This complexity, however, often comes at the expense of transparency, rendering AI a “black box” whose inner workings remain opaque to human users. This opacity can impose notable limitations on human-AI collaboration, including reduced error and bias detection, lower adoption, and limited knowledge discovery (e.g., Bauer et al. 2021). Given the risks posed by opacity, regulators and industry leaders often advocate for explainable artificial intelligence (XAI) that reveals an AI’s prediction logic in ways that humans can understand (Goodman and Flaxman 2017). Major technology firms have adopted industry guidelines on transparent and explainable artificial intelligence (GoogleAI 2025); business consultancies highlight its key role for AI adoption (McKinsey 2024); and regulation, such as the European Union Artificial Intelligence Act, even mandates explainability for certain AI applications (European Union 2024).
As XAI becomes increasingly relevant in practice, a growing stream of research explores the consequences of rendering AI explainable. Although some empirical studies document that XAI improves the collaboration between humans and AI (Lebovitz et al. 2022, Senoner et al. 2024), there is also ample evidence on potential drawbacks that have been connected to unexpected effects on human cognition. For example, XAI may lead to information overload (Poursabzi-Sangdeh et al. 2021), induce reasoning errors (Chromik et al. 2021), or lead to confirmatory thinking (Bauer et al. 2023). Taken together, these findings suggest that explanations can fundamentally alter how humans “think” about both the AI and the task itself, shaping the effectiveness of human-AI collaboration.
However, beyond shaping how humans think, theories of human cognition (Ackerman and Thompson 2017) suggest that XAI may also influence how humans “think about thinking”. Specifically, research in psychology posits that cognition operates on two layers (Nelson and Narens 1990): object-level processes (thinking), which prior human-XAI work has primarily examined, and metacognitive processes (thinking about thinking), which have not yet been linked to XAI. This paper focuses on the interaction between XAI and metacognitive processes.
To get an idea about the functioning and role of metacognitive processes, it is useful to consider how they jointly operate with object-level processes during problem solving. These two layers form a continuous feedback loop that enables the cognitive system to regulate itself (Ackerman and Thompson 2017). Object-level processes actually solve the problem at hand (e.g., through remembering, processing of available information, developing a mental model of the task, and reasoning). Metacognitive processes aim to keep track of what and how well object-level processes are doing and can be divided into two distinct activities. First, metacognitive monitoring evaluates whether object-level processes function appropriately, forming and updating subjective confidence judgments about the likelihood of successfully performing a task. When metacognitive monitoring processes are accurate, confidence judgments closely track task performance, even without actually knowing the true performance. In this case, humans have a good understanding of their capability to perform the task. Second, metacognitive control uses these judgments to decide which object-level processes to execute next: for instance, whether to invest more or less mental effort in solving a problem. Most relevant to this paper, a common control decision involves delegating the task to someone or something else, such as an AI system (Ackerman and Thompson 2017). Taken together, metacognitive monitoring and control strongly shape problem-solving performance (Dunning 2011, Yeung and Summerfield 2012).
The potential role of metacognitive processes in human-AI collaboration has only recently begun to receive attention in information systems (IS) research. For example, prior studies have examined which types of metacognitive processes may occur during human-AI collaboration (Jussupow et al. 2021) and how these processes influence human delegation to AI (Fügener et al. 2022). However, it remains unclear whether technical features of AI, such as XAI, can endogenously shape metacognitive processes. Given emerging evidence that metacognition is central to effective human-AI collaboration, it is both practically and theoretically important to understand whether and how technical features of AI influence this fundamental aspect of cognition.
We aim to help fill this research gap by exploring how XAI, whose practical relevance in academia, industry, and policy continues to grow (e.g., Bauer et al. 2021, European Union 2024, GoogleAI 2025), may affect metacognitive processes. Building on the framework of Ackerman and Thompson (2017), we investigate whether explanations that reveal an AI’s overall prediction logic affect the extent to which humans’ confidence judgments align with their actual ability to perform a task (accuracy of metacognitive monitoring) and in turn, the effectiveness of human-to-AI delegation (effectiveness of metacognitive control decisions). We, therefore, pose the following research question.
RQ: How does XAI affect the accuracy of metacognitive monitoring and the effectiveness of metacognitive control decisions?
As a tangible example of a scenario that we have in mind, consider a loan officer with access to an XAI system to predict the creditworthiness of loan applicants. Upon reviewing explanations showing the AI’s overall prediction logic, she notices that the system places considerable weight on whether an applicant is a new client, a factor that she previously considered less relevant. This divergence from her own reasoning may prompt her to think: “Perhaps my assessment of new applicants is less reliable than I thought.” Metacognitive monitoring processes may pick up this recognition and translate it into a lowered confidence in her ability to assess creditworthiness for new applicants. The lowered confidence may then evoke the metacognitive control decision to rely more heavily on the AI for new applicants, anticipating that her own assessment would be less effective. If her confidence judgment becomes better aligned with her true performance (i.e., if her reduced confidence accurately reflects a true limitation of her assessment abilities), the effectiveness of her collaboration with the AI improves. Otherwise, explanations risk fostering overreliance on the AI by causing confidence to become poorly aligned with actual abilities.
To address our research question, we employed two complementary incentivized experimental studies designed to enable causal inference under controlled conditions. In our two experiments, we placed professionals in repeated prediction tasks without intermediary performance feedback. For every task, participants had to choose between performing the prediction themselves or delegating it to an AI whose prediction they only observed at the end of the experiment. We measured participants’ confidence in their own ability to perform the task. We randomly assigned participants to one of two between-subject conditions: XAI (access to the system’s overall prediction logic) or black box (no explanation). We presented the AI’s overall prediction logic using Shapley additive explanation’s (SHAP) global dependence plots (Lundberg and Lee 2017), one of the most popular methods for XAI (Gramegna and Giudici 2021), together with three illustrative examples. By observing the plots and examples, participants gained an understanding of how each input feature influenced the AI’s predictions on an aggregate level before they engaged with the prediction tasks. For Study 1, we recruited (n = 149) German real estate agents through industry partners. The task was to predict the listing prices of apartments in major German cities. Study 2 tested the generalizability of our findings and explored the underlying mechanisms and boundary conditions of XAI effects on metacognitive processes. We recruited (n = 200) finance and insurance professionals on Prolific to predict repayment outcomes of peer-to-peer loans.
Our experiments demonstrate that XAI systematically shapes metacognitive processes that shape task performance. Specifically, XAI causally enhances the accuracy of participants’ metacognitive monitoring. This improvement, in turn, enables more effective task delegation to AI: that is, more accurate metacognitive control decisions. Notably, the impact on metacognition emerges only when the AI’s prediction logic diverges from participants’ own reasoning, leading them to reduce their confidence. These effects arise without changes in participants’ task-solving strategies or their understanding of the AI. This highlights that the interaction between XAI and metacognition operates independently of previously documented effects of XAI on object-level processes.
This study adds to the IS literature in three ways. First, we broaden the debate on XAI and human cognition. Prior work emphasizes how XAI alters object-level processes applied to solve problems and engage in tasks, such as reasoning or learning (e.g., Bauer et al. 2023). We show that explanations can also affect metacognitive processes that guide these object-level processes.
Second, we complement emerging research on the role of metacognitive processes in human-AI collaboration (Jussupow et al. 2021, Fügener et al. 2022, Taudien et al. 2024). Our study contributes to this nascent work by showing that the technical features of AI systems may endogenously influence metacognitive processes, thereby shaping how well humans collaborate with AI.
Third, we contribute to the broader literature on transparency in human-AI collaboration, which has primarily examined decision support settings where humans retain formal decision-making responsibility (e.g., Lebovitz et al. 2022). In contrast, our work focuses on human-to-AI delegation, where humans cede formal responsibility to AI without knowing how the AI will act. Although the limited prior research on delegation has examined the role of information about expected AI performance (Taudien et al. 2022), we extend this line of work by showing that transparency about an AI’s overall prediction logic can also improve the effectiveness of delegation by shaping metacognitive processes. In doing so, we offer a complementary perspective on the conceptual delegation framework proposed by Baird and Maruping (2021).
From a managerial perspective, our findings suggest that XAI can improve employees’ accuracy in assessing their own ability to perform a task. This, in turn, may enhance organizational effectiveness by enabling employees to allocate tasks more appropriately between themselves and AI.
2. Theoretical Foundations
This section lays the theoretical foundation of our work. Section 2.1 offers an introduction to XAI and carves out the research gap on the interplay between XAI and metacognitive processes. Section 2.2 explains the metacognition theory. Section 2.3 draws on the metacognition literature to argue how XAI may affect metacognitive processes.
2.1. XAI and Object-Level Cognitive Processes
Contemporary AI is powered by machine learning and makes highly accurate predictions (Lebovitz et al. 2022). However, the learned logic that transforms input information into predictions typically remains unintelligible to stakeholders (Meske et al. 2022), possibly eroding trust, accountability, error detection, and knowledge discovery (Bauer et al. 2021). To counter these “black-box” risks, researchers have developed methods commonly referred to as explainable artificial intelligence. Put simply, XAI methods render a model’s prediction logic understandable to humans either to reveal the overall prediction logic that applies across observations in a data set (global explanations) or to show in isolation why a specific prediction was made for one observation (local explanations).
A widely used XAI approach is to offer post hoc feature-based explanations (Molnar 2020). These explanations illustrate the numerical contributions of input features to predictions, and they are constructed after the model has been trained. Although often, the aim is to explain individual predictions, aggregating feature contributions for various individual predictions yields insights into the model’s overall prediction logic. Hence, these methods not only can provide a “zoomed-in” view for understanding edge cases or studying unusual predictions in isolation, but also, they offer a broader understanding of the AI’s logic, helping users assess the AI’s capabilities (Naiseh et al. 2023). Given their popularity and intuitiveness (Molnar 2020), we operationalize XAI through feature-based explanations. More specifically, we rely on Shapley additive explanations (Lundberg and Lee 2017) to show users the AI’s overall prediction logic (global explanations). SHAP enjoys wide adoption both in research (Senoner et al. 2022) and in practice (Gramegna and Giudici 2021), and it is frequently referred to as a promising method for meeting legal requirements for XAI in the European Union Artificial Intelligence Act (Nannini et al. 2024), despite known limitations (see, e.g., Fernández-Loría et al. 2022).
The growing practical relevance of XAI (e.g., because of regulatory requirements) (European Union 2024) has (re-)sparked IS research on human-(X)AI collaboration. Early work in this domain studied explainability in knowledge-based expert systems (Gregor and Benbasat 1999, Ji-Ye Mao 2000, Wang and Benbasat 2007) before attention shifted toward modern XAI methods (e.g., Guo et al. 2025). In the context of contemporary machine learning-based AI (feature-based) explanations have been shown to affect trust (Bauer et al. 2023), fairness perceptions (Ochmann et al. 2024), technostress (Cram et al. 2022), and abilities to detect AI biases (Goyal et al. 2024). Crucially, XAI may also shift the way that humans think (“object-level processes” of cognition), affecting learning (Spitzer et al. 2024), information processing (Poursabzi-Sangdeh et al. 2021), and reasoning (Chromik et al. 2021), albeit sometimes in a biased way. Empirical evidence on how these effects translate into task performance remains mixed. Some studies report improvements (Senoner et al. 2024), others report negligible effects (Cecil et al. 2024), and still others report performance declines (Bauer et al. 2023).
Although prior studies have deepened our understanding of XAI’s consequences for human cognition, they focus on object-level processes, leaving open an important blind spot. Specifically, previous empirical studies have overlooked whether XAI may influence human metacognitive processes (i.e., humans’ “thinking about thinking”). For example, for object-level processes of cognition, Bansal et al. (2019) show that explanations can affect humans’ mental representation of how the AI works and trust. Relatedly, Bauer et al. (2023) find that observing explanations for individual predictions can shift human information processing and approaches of how to solve a task. However, these and related studies do not examine whether XAI can fundamentally shift metacognitive processes that monitor and control object-level processes, such as learning or reasoning. In doing so, they may overlook a more fundamental mechanism through which XAI may affect human cognition that may not only underpin the findings mentioned but also, help explain when and why humans choose to rely on AI more broadly.
2.2. Metacognition
Flavell (1979) introduced the concept of metacognition, which was later formalized by Nelson and Narens (1990). This line of research conceptualizes human cognition as operating on two layers: object-level processes and metacognitive processes. Object-level processes perform the primary cognitive operations directly related to the task, such as retrieving knowledge from memory, performing calculations, or reasoning to solve a problem. In contrast, metacognitive processes are higher-order operations that monitor, evaluate, and guide object-level processes. Put differently, like a manager, metacognitive processes keep track of object-level work and trigger adjustments, enabling the human cognitive system to self-regulate (Ackerman and Thompson 2017).
How does this self-regulation work during problem-solving? Ackerman and Thompson (2017) conceptualize object-level and metacognitive processes as operating in a continuous feedback loop (see Figure 1). Object-level processes analyze available information and the problem structure, drawing on memory and reasoning to sketch out an initial strategy. Metacognitive processes work in parallel, performing two essential activities.
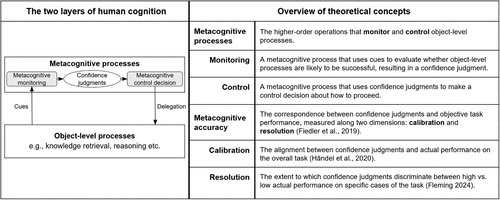
Notes. (Left panel) Schematic illustration of the interplay between the two layers of human cognition adapted from Nelson and Narens (1990), Ackerman and Thompson (2017), and Tankelevitch et al. (2024). Confidence judgments are one output of the metacognitive monitoring process. They are put into relation with humans’ actual ability to perform the task through multiple feedback loops between object-level processes, monitoring, and control. (Right panel) Tabular overview of key theoretical concepts. See Fiedler et al. (2019), Händel et al. (2020), and Fleming (2024).
First, metacognitive processes monitor object-level activities (referred to as metacognitive monitoring). They read and evaluate information to assess how likely it is that a solution attempt is on track. Thereby, metacognitive monitoring typically neither has nor needs direct access to “ground truth” (i.e., the actual task performance). Instead, it relies on heuristic cues that surface from object-level processes, such as experiences of fluency, familiarity, coherence, conflict, or surprise (Koriat and Levy-Sadot 2000, Thompson and Markovits 2025). These cues are weighted and integrated to form an overall (temporary) assessment of the likelihood of success, commonly referred to as a confidence judgment (Tankelevitch et al. 2024). Intuitively, when cues signal that something “feels right” (e.g., high fluency, quick retrieval, perceived task ease), confidence is higher. When cues convey that “something is off”, confidence is lower. Empirical research shows that such judgments, although imperfect, track objective task performance above chance and allow people to anticipate many of their own errors even without external feedback (Yeung and Summerfield 2012).
Second, metacognitive processes control object-level processes (referred to as metacognitive control decisions). Guided by confidence judgments, metacognitive control decisions choose the next object-level process among available alternatives, implicitly weighing the potential benefits and costs of further effort (Ackerman and Thompson 2017). Metacognitive control decisions’ function is to economize on mental effort: terminating work on problems judged too difficult or unsolvable, whereas sustaining effort when success appears within reach or the correct solution is known. For example, when confidence is extremely low, indicating a low likelihood of successful performance, the decision may be to abandon the task or delegate it rather than waste mental effort. Conversely, when confidence is very high, signaling a high likelihood to perform well, the decision may be to continue current processes without expending additional mental effort on second-guessing or information gathering (Yeung and Summerfield 2012). In our context, the pivotal metacognitive control decision is whether to invest effort in solving the task oneself or to delegate it to an AI. Once enacted, metacognitive control decisions are carried out by object-level processes, generating new cues that feed back into metacognitive monitoring. This ongoing exchange sustains the feedback loop between object-level and metacognitive processes in human cognition.
As indicated in Figure 1, confidence judgments are central to metacognitive processes (Ackerman and Thompson 2017), forming the link between metacognitive monitoring and control. The closer confidence judgments track true task performance, the better control decisions will be. The alignment between confidence judgments and true task performance is typically referred to as the accuracy of metacognitive monitoring or simply, metacognitive accuracy (Fiedler et al. 2019). Notably, previous research has shown that changes in metacognitive accuracy can result from adjustments in confidence alone (i.e., confidence may change without being accompanied by changes in humans’ ability to solve a task) (Fleming 2024). This finding underscores that the object-level and metacognitive processes of human cognition, although interacting, are distinct.
Although confidence judgments represent metacognitive processes’ best guess of actual task performance, it is a fallible one (i.e., metacognitive accuracy may be low). Overconfidence (believing that one is correct when one is not) and underconfidence (excessive doubt about one’s own solution) are common pitfalls that stem from the validity of cues and their evaluation during metacognitive monitoring (Koriat and Levy-Sadot 2000, Dunning 2011). Metacognitive accuracy is typically conceptualized and measured along two dimensions (Fiedler et al. 2019): (i) the alignment between confidence judgments and actual performance on the overall task (metacognitive calibration) (Händel et al. 2020) and (ii) the extent to which confidence judgments discriminate between high versus low actual performance on specific cases of the task (metacognitive resolution) (Fleming 2024).
Although related, metacognitive calibration and resolution may diverge. Following our previous example, a loan officer’s confidence may reflect that she subjectively believes to have correctly predicted the creditworthiness of two of three applicants, which indeed matches her actual success rate. Accordingly, her metacognitive calibration is high. However, her confidence in specific predictions may not systematically distinguish between her predictions that are actually correct and those that are incorrect. For example, she may show equally high confidence in one correct prediction and one incorrect prediction while showing low confidence in the other correct prediction. In this case, her metacognitive resolution is low. When confidence is appropriate along both dimensions, metacognitive accuracy is high, reflecting a well-tuned understanding of the limits of one’s ability both at the general task level and in specific cases of the task. Such accuracy is crucial for effective metacognitive control decisions, including whether to persevere with a task or delegate difficult cases to AI.
2.3. Metacognition and (X)AI
Researchers have recently begun to apply metacognition as a theoretical lens for understanding human-AI collaboration. Following Jussupow et al. (2021) and Tankelevitch et al. (2024), AI reliance can be viewed as a metacognitive control decision that follows metacognitive monitoring of one’s own problem-solving progress. From this perspective, humans with high (low) confidence in their ability to perform a task are, all else equal, less (more) likely to rely on AI. Although AI reliance is the result of multifaceted considerations, including intrinsic control motives (Bartling et al. 2014) and task enjoyment (Bouwer 2022), theory on metacognition conceptualizes its primary mechanism not as a comparative evaluation of one’s own abilities and those of the AI (as suggested by the literature on algorithm aversion, Jussupow et al. 2024) but as an absolute, self-referential confidence judgment. Put differently, humans rely on AI not because they believe that the AI is better or worse but because they perceive their own ability as sufficient or insufficient to perform the task.
When AI reliance takes the form of delegation, a metacognitive lens can complement the seminal framework of Baird and Maruping (2021) on delegating decision rights to agentic information systems. According to this framework, humans partly base delegation decisions on a simultaneous mental evaluation of the task and the self. These evaluations, termed “appraisals”, result in perceptions of how demanding the task appears and whether it should be delegated. In their conceptualization, Baird and Maruping (2021) deliberately abstract from specifying the mechanisms through which appraisals shape delegation, focusing instead on the subsequent delegation process itself.1 The metacognition framework makes this abstraction more concrete by interpreting appraisals as object-level cognitive processes. Metacognitive processes then read cues from these appraisals (e.g., perceived task difficulty or the ease with which a solution comes to mind) to form confidence judgments, which in turn, influence whether humans retain control or delegate the task to AI. In this way, metacognition provides a rationale for mechanisms underlying the delegation model of Baird and Maruping (2021) by specifying how exactly certain appraisals may translate into subsequent behavioral responses.
Empirically corroborating that there exists a relationship between human decisions to rely on AI and their confidence in being able to perform a task, results from controlled experiments suggest that inefficient delegation of decision rights to AI may stem from inflated or deflated confidence judgments (Fügener et al. 2022, Ma et al. 2024). Relatedly, Taudien et al. (2024) find that humans with high “metacognitive ability” (i.e., a strong capacity to monitor and control their own thought processes) are more likely to delegate to AI appropriately. This early evidence aligns with the theoretical view that effective delegation depends on metacognitive accuracy, including both metacognitive calibration and resolution (Ackerman and Thompson 2017).
We build on this stream of work and focus on human-to-AI delegation. Although delegation results from multifaceted considerations, we adopt a metacognition lens and conceptualize it primarily as a metacognitive control decision that is founded on confidence judgments. Our focus on human-to-AI delegation is motivated by two considerations. First, such delegation is becoming increasingly relevant as AI systems exhibit more agentic characteristics (Baird and Maruping 2021). Second, from a metacognitive standpoint, delegation functions as a central and common form of help-seeking behavior (Yeung and Summerfield 2012).
Although prior work in information systems has started to explore how metacognitive processes influence human-AI collaboration, it remains unclear whether technical features of AI can also shape users’ metacognitive processes. We address this gap by examining how providing explanations of an AI’s overall prediction logic influences metacognitive accuracy along both the calibration and resolution dimensions and in turn, influences delegation of tasks to AI.
But, how might XAI influence metacognitive accuracy? Explanations can convey the average relationships between input features and the predictions that an AI has learned. When reviewing such explanations, humans implicitly compare their own domain-specific reasoning with the AI’s prediction logic (Festinger 1957). If the AI’s reasoning aligns with their view, object-level processing tends to be fluent and evokes perceptions of correctness, coherence, or simplicity (Koriat and Levy-Sadot 2000). These perceptions serve as heuristic cues of solvability (Ackerman and Thompson 2017), which metacognitive processes interpret as signals that one is “on track”. As a result, confidence increases, and control decisions are likely to remain unchanged.
By contrast, if the AI’s reasoning diverges from a human’s own logic (e.g., by emphasizing features that the human had not considered), object-level processing may generate perceptions of discrepancy, incoherence, or difficulty, thereby lowering perceived solvability. According to Rozenblit and Keil (2002) and Abdel-Karim et al. (2023), such “surprise” is central to evoking the sense that one’s own approach may be flawed. Metacognitive processes interpret these cues, likely reducing confidence and triggering different control decisions: in our context, a shift in when to delegate to AI.
Thus, by making object-level processes recognize (mis-)alignments, explanations shape the heuristic cues that metacognitive monitoring draws on, thereby influencing confidence judgments. When explanations capture relevant, causal, or reliable regularities, they support appropriate confidence adjustments and enhance metacognitive accuracy. Conversely, when explanations reflect spurious correlations or overfitting patterns, they risk misleading users, prompting unwarranted confidence shifts and reducing metacognitive accuracy. Improvements (or deteriorations) in metacognitive accuracy, in turn, are likely to foster (or undermine) human-to-AI delegation.
From a theoretical standpoint, the notion that XAI can influence humans’ metacognitive accuracy through confidence adjustments and thereby, improve control decisions adds a novel dimension to existing research on how XAI affects human cognition. Prior studies have shown that XAI can shape users’ beliefs about an AI’s performance (Bansal et al. 2019) and influence how humans approach and understand tasks (Bauer et al. 2023) (i.e., object-level processes). This paper complements these findings by proposing a mechanism through metacognitive processes; explanations may prompt users to adjust their confidence judgments, which in turn, may evoke changes to mental models or beliefs about AI performance as control decisions in the specific decision environment.
3. Experimental Studies
We conducted two incentivized experimental studies to explore whether XAI affects metacognitive accuracy and subsequent delegation decisions. In both studies, participants solved a series of prediction tasks: predicting apartment listing prices in Study 1 and predicting peer-to-peer loan repayment in Study 2. For every case, they either made the prediction themselves or delegated it to an AI without ex ante knowing its prediction.
Both studies followed the same general three-stage structure (see Figure 2 for an overview). In stage 1, we familiarized participants with the task; exposed them to the XAI treatment; and measured their confidence in their own overall task-level performance, beliefs about the AI performance, and their understanding of how the task works. In stage 2, participants decided how to divide the prediction for each case (apartment or loan) between themselves and the AI before actually performing the prediction task in stage 3. Importantly, when deciding about delegation, the AI’s predictions remained hidden, and we did not provide feedback until the end of the session. We explain further details for both studies below.
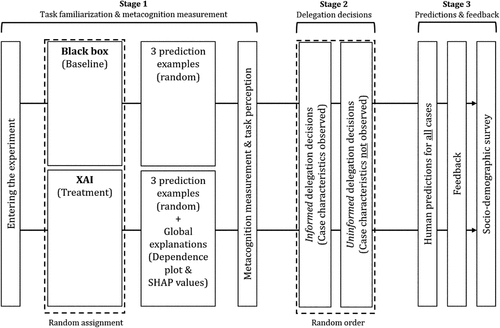
For both studies, we collected data to develop working machine learning models. We developed models in Python, employing common libraries, such as Pandas, NumPy, and XGBoost. Following standard data science practices (Hastie et al. 2009), we randomly divided the data into training (80%) and testing (20%) sets, and we optimized out-of-sample prediction accuracy using a fivefold crossvalidation approach to fine-tune hyperparameters. We provide details on preprocessing and descriptive statistics of the loan and real estate data as well as on the machine learning implementation and tuning in the Online Appendix.
Each study followed a between-subjects design. Treatment participants observed explanations that summarized the average marginal influence of each input feature on the model’s predictions, which were displayed as SHAP-based partial-dependence plots before making delegation decisions. The control group did not receive this information. Study 2 complements Study 1 by testing robustness in a domain that is more subjective and probing the underlying mechanisms.
We selected real estate pricing and consumer credit risk assessment for two reasons. First, both domains are already adopting algorithmic decision support and are expected to move toward even higher levels of automation (Tchuente and Nyawa 2022, Hurlin et al. 2024).2 Second, the high financial stakes in these domains place the use of AI in the “high-risk” category under current regulations, such as the European Union Artificial Intelligence Act, which mandates transparent and explainable systems (European Union 2024). Hence, studying XAI in this context has immediate practical relevance.
To identify the causal effect of explanations about an AI’s overall prediction logic on metacognitive monitoring and control, we conducted controlled experiments that hold constant potential confounds, such as prior AI engagement, access to external resources, and learning from feedback. We deliberately let participants make delegation decisions on a case-by-case basis, abstracting from industry practices where tasks are often delegated in bundles. This design controls for distorted beliefs about the characteristics of bundled tasks while still allowing cases to represent bundles of similar tasks in practice. Overall, our empirical strategy responds to prominent calls from IS researchers to employ quantitative experimental designs for causal identification (Gupta et al. 2018), even if it deliberately abstracts from typical real-world settings (Maruping et al. 2025).
3.1. Study 1
3.1.1. Design Study 1.
We invited professional real estate agents to participate in Study 1 via a link distributed by our industry partners to their employees by email. In collaboration with ABG Real Estate Group, Nassauische Heimstätte GmbH, and Norstat GmbH, we recruited 149 experts. The prediction task consisted of predicting the listing price of several German apartments that we collected from a popular real estate platform (refer to the Online Appendix for details). Experts completed the study in approximately 12 minutes.
3.1.1.1. Stage 1: Task Familiarization and Measurement of Metacognitive Calibration.
Upon entering the study, we randomly assigned participants to one of our two experimental conditions (which our randomization checks indicate was successful) (see Table 4 in the Online Appendix). On the first screen, participants learned that they needed to predict the listing prices (in euros) of four apartments located in major German cities (refer to the Online Appendix for exact instructions). To perform the prediction, they would observe eight apartment features, such as living space, year of construction, etc. We assigned the apartments randomly at the participant level, selecting them from a pool of 200 listings. We initially explained to participants that their compensation would depend on their task performance. A price prediction was deemed accurate if it deviated from the actual listing price by at most 10%. The 10 participants with the highest number of accurate predictions received a €50 bonus payment.
Participants learned that they could divide the four predictions between themselves and an AI on a case-by-case basis. Participants did not know in advance what price the AI would predict. They learned that they would not be able to reverse their delegation decision or change the AI’s prediction for delegated cases. We revealed that the AI is powered by a gradient-boosted forest (Chen and Guestrin 2016), and we provided a brief, intuitive description of the model’s architecture to mitigate concerns about variations in expectations about the technical implementation of the AI. We made participants aware that the AI’s prediction depends on the same eight apartment characteristics that they would also see themselves so that they would not expect the AI to have access to different or additional information.
We noted that the training data set included over 8,000 observations but did not contain the specific apartments to be predicted. We withheld information about the AI’s accuracy to assess how XAI affects beliefs about both human and AI performance without priming participants (You et al. 2022). Moreover, fixing initial beliefs rather than accounting for them in our analyses would have limited the generalizability of our results.
To familiarize participants with the prediction task and the AI, we showed them three randomly drawn apartments with their corresponding characteristics and the AI-generated price prediction as examples. We did not disclose the actual listing prices so that participants could not infer the AI’s accuracy.
In addition to this general information, we introduced XAI to participants in the treatment condition through SHAP (Lundberg and Lee 2017). We presented a SHAP dependence plot for each apartment characteristic as illustrated in the right panel of Figure 3, thereby visualizing the AI’s average prediction logic. These plots in the right panel of Figure 3 visualize the AI’s learned prediction logic by displaying how changes in a feature’s value (x axes) affect the predicted apartment price (y axes), holding all other features constant. We also offered guidance on interpreting these plots.3 To further support participants’ understanding of the AI’s logic, we also presented local SHAP explanations for the three example apartments (see the left panel of Figure 3). The examples served only to contextualize the global dependence plots, which constituted the main treatment manipulation. Importantly, participants did not receive local explanations for any of the cases used in the actual delegation tasks, nor did they receive feedback on prediction accuracy. In combination with the fact that example apartments were randomly drawn for each participant, the inclusion of local SHAP values is unlikely to have influenced the treatment beyond merely facilitating comprehension of the global explanation (for more details and a test that the treatment effect is independent of the specific examples viewed, see Table 5 in the Online Appendix). Treatment participants had to answer a control question about the AI’s prediction logic to ensure their comprehension. Participants in the baseline group did not receive any insights into the AI’s prediction logic.
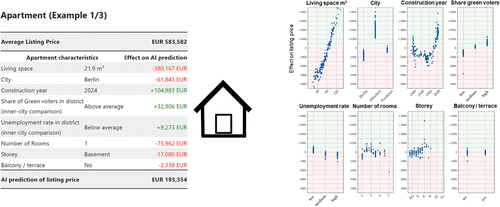
Note. EG, basement; EUR, euro.
On the final screen of stage 1, we measured agents’ confidence in their own performance and beliefs about the AI’s prediction performance using a percentage scale from 0% to 100%. We operationalized metacognitive calibration as the difference between participants’ confidence and their actual performance in predicting apartment prices in stage 3 (Fügener et al. 2022).
3.1.1.2. Stage 2: Four Delegation Decisions.
In stage 2, real estate agents divided the four price predictions between themselves and the AI. Participants did not see the AI’s prediction when making their delegation decision (i.e., they did not know what the AI would do in case they chose to delegate). They also knew that if they decided to assign a case to themselves, they would not observe the AI’s prediction when making their own prediction. To ensure that delegation decisions were not motivated by a desire to reduce the time spent in the experiment, we followed the procedure by Dietvorst et al. (2018), and we informed participants that they would also need to perform predictions for cases they delegated but that these predictions would not influence bonus payments.
Participants made delegation decisions for all apartments before predicting listing prices themselves in stage 3. Each of the four delegation decisions was presented on a separate screen (see Figure 11 in the Online Appendix). For three apartments, participants observed the eight apartment characteristics before delegating (“informed” delegation). For one apartment, they made the delegation decision without this information, seeing the characteristics only afterward (“uninformed” delegation). We randomized apartments and the sequence of informed and uninformed delegation at the individual level.
Although including uninformed delegation decisions may seem counterintuitive, we deliberately introduce this within-subject variation to disentangle the effects of XAI on metacognition from its effects on object-level cognition, such as learning from explanations. In uninformed delegation, participants lack case-specific information when dividing the task between themselves and AI. Hence, any improvements in task performance would reflect learning, not metacognitive processes. If XAI influences metacognition, we expect performance improvements only in informed delegation, where participants can exert metacognitive control based on available case information.
3.1.1.3. Stage 3: Price Predictions and Feedback.
In stage 3, participants performed the prediction task, received feedback, and completed a sociodemographic survey. Participants predicted the listing price for each apartment regardless of whether they had delegated the task to the AI following the procedure by Dietvorst et al. (2018). We also asked participants to guess the AI’s prediction for each apartment to explore whether explanations helped to better anticipate what AI would predict.
After participants made their own predictions for all four apartments, we provided them with feedback showing their own predictions, the AI’s predictions, and the actual listing prices. The experiment concluded with a questionnaire about participants’ age, gender, education level, risk aversion, and familiarity with and trust in AI (see Table 4 in the Online Appendix for an overview) and a summary of their earnings from the experiment.
3.1.2. Results of Study 1.
We present our results of Study 1 in two steps. First, we examine the effects of XAI on participants’ metacognitive accuracy with respect to metacognitive calibration (i.e., the alignment between confidence judgments and actual performance on the overall task). Subsequently, we show how changes in metacognitive calibration explain an adjustment of human-to-AI delegation (i.e., the control decision). Unless otherwise noted, all analyses focus on cases in which participants had access to relevant apartment characteristics at the time of making delegation decisions (i.e., informed delegation).
3.1.2.1. XAI and Metacognitive Calibration.
Aligned with Fügener et al. (2022), we operationalize participants’ metacognitive calibration as the difference between participants’ confidence to successfully perform the prediction task elicited in stage 1 and their average performance in predicting apartment prices themselves.4 A score of 0 indicates a perfect calibration (i.e., confidence matches average performance), whereas scores of −100 and 100 indicate the worst possible calibration (i.e., extreme underconfidence and overconfidence, respectively). For example, if a real estate agent estimated that her predictions would be correct in 75% of cases but was in fact accurate for only two of the four apartments (50%), her calibration would equal percentage points.
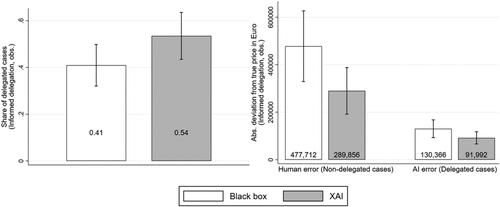
Figure 4 presents the distributions of calibration scores and averages for the baseline and treatment conditions. The results indicate that XAI improves metacognitive calibration. In the baseline condition, participants overestimated their own performance by an average of 43.3 percentage points. Among participants exposed to XAI, this discrepancy declined to 29.3 percentage points. The treatment effect is both economically meaningful (−32.3%) and statistically significant (, F-test). Importantly, this effect is driven by reduced confidence (54.2% versus 43.7%; , F-test) rather than improved performance in predicting listing prices (10.8% versus 14.4%; , F-test). In other words, participants adjusted their confidence downward to better reflect their true performance. Although real estate agents remained overconfident on average, initial exposure to XAI led to better metacognitive calibration.
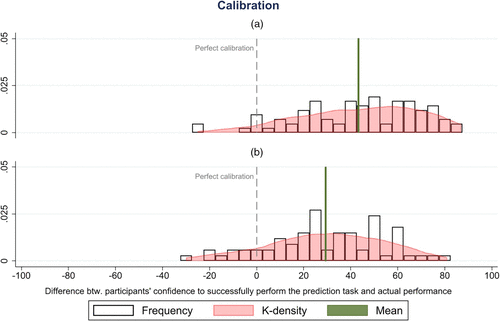
Notes. (a) Black box. (b) XAI. btw., between.
Exposure to XAI enhances real estate agents’ metacognitive calibration by reducing their confidence to more accurately reflect their actual performance.
Notably, exposure to explanations had no significant effect on participants’ beliefs about the AI’s predictive accuracy (63.8% versus 68.7%; , F-test). This suggests that the XAI-driven drop in confidence did not stem from a generalized belief that the task was difficult, even for the AI, but rather, from a reassessment of participants’ own abilities.
3.1.2.2. XAI and Delegation as Metacognitive Control.
Our first result supports the idea that XAI influences human metacognitive monitoring processes. We now examine how delegation frequency changes in response to XAI, assess the effectiveness of these adjustments, and explore how these behavioral shifts relate to XAI-induced changes in metacognitive calibration.
Figure 5 illustrates the average delegation frequency (left panel of Figure 5) and the average task performance conditional on whether real estate agents delegated the case (right panel of Figure 5). We first consider delegation frequency. The left panel of Figure 5 reveals that XAI increases delegation frequency from 41% to 54% (+31.7%; , F-test). Additional analyses indicate that this increase is largely driven by a greater willingness to delegate predictions for apartments located in Munich (+37 percentage points (pp.); , F-test) and Berlin (+30.9 pp.; , F-test) (see Table 8 in the Online Appendix).5
Note. Abs., absolute; obs., (case characteristics) observed.
To establish the theorized link between XAI-driven shifts in calibration and changes in delegation strategy, we conduct a causal mediation analysis following the methodology proposed by Li et al. (2022). Specifically, we employ a two-stage least squares approach. In the first stage, we instrument real estate agents’ calibration (column (1) in Table 1). In the second stage, we include the instrumented variable in a regression where the dependent variable is an indicator for whether the agent delegated the case (column (3) in Table 1). This instrumentation approach enables us to isolate the causal effect of exogenous variation in calibration (induced by our experimental manipulation) on delegation behavior, thereby mitigating concerns about confounding factors.
|

Table 1. Causal Mediation Analysis
| DV | Calibration | Delegation frequency | AI prediction error (abs.) | Human prediction error (abs.) | |||
|---|---|---|---|---|---|---|---|
| (1) | (2) | (3) | (4) | (5) | (6) | (7) | |
| XAI | −14.130*** | 0.205*** | 0.159*** | −47,011.379** | −43,302.048** | −176,903.314** | −108,942.564 |
| (4.676) | (0.058) | (0.059) | (19,150.781) | (19,830.103) | (71,997.351) | (66,924.815) | |
| Calibration (instrumented) | −0.003*** | 369.709 | 5,082.614*** | ||||
| (0.001) | (472.646) | (1,462.526) | |||||
| Total effect mediated (mean), % | 0.23 | — | 0.38 | ||||
| 95% CI (bootstrapped) | [0.08–0.38] | — | [0.21–1.33] | ||||
| Ind. controls | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Observations | 149 | 447 | 447 | 208 | 208 | 239 | 239 |
| R2 | 0.13 | 0.10 | 0.13 | 0.06 | 0.06 | 0.06 | 0.09 |
Notes. Two-stage least squares causal mediation analysis is shown. The first stage is depicted in column (1). The second stages examining the effect of the instrumented endogenous variables on delegation frequency and absolute prediction errors conditional on delegation decisions are depicted in columns (3), (5), and (7). Controls include agents’ age, task experience, sector experience, AI familiarity, risk aversion, gender, degree, and control question response. Robust standard errors are reported in parentheses. Significance levels are indicated with asterisks. abs., absolute; CI, confidence interval; DV, dependent variable; Ind., individual.
**; ***.
Our analysis shows that a substantial portion of the effect of XAI on delegation is mediated by shifts in agents’ calibration. When the instrumented calibration variable is added in the second stage, the estimated effect of XAI on delegation frequency declines in magnitude, although remaining statistically significant. The mediator itself is statistically significant () (column (3) in Table 1), providing strong evidence of a meaningful mediation effect. Quantitatively, approximately 23% of the total effect of XAI on delegation frequency can be attributed to changes in calibration (95% bootstrapped confidence interval (CI): [8%–38%]). These findings suggest that XAI influences metacognitive calibration, which in turn, causally alters their use of delegation as a metacognitive control strategy.
A looming question is now whether XAI not only affects delegation frequency but also, affects the effectiveness of delegation (i.e., the agents’ success in assigning cases to the better-suited prediction maker). Put in metacognitive terms, does XAI ultimately improve the effectiveness of the control strategy? The right panel of Figure 5 demonstrates that participants in the treatment condition allocate apartments between themselves and the AI in a manner that enhances overall predictive performance compared with their baseline counterparts. Specifically, real estate agents in the treatment condition exhibit improved predictive accuracy for cases that they retained, with a mean absolute prediction error of €289,856, which is substantially lower than the baseline error of €477,712. This reduction of 39.2% is both economically and statistically significant (, F-test). For apartments that the participants chose to delegate, the AI’s mean absolute prediction error in the treatment condition is €91,992 compared with €130,366 in the baseline condition. This corresponds to an economically meaningful reduction of approximately 29.4%, although this effect achieves only marginal statistical significance (-test), and thus, needs to be interpreted with care. We also find a significant decrease in mean absolute errors when considering delegated and nondelegated cases jointly (€183,929 versus €335,426, respectively; −45.2%; , F-test).
Columns (4) and (5) and columns (6) and (7) in Table 1 investigate the mediating role of metacognitive calibration in the relationship between XAI and delegation effectiveness. The results present a nuanced picture. Columns (4) and (5) in Table 1 show that calibration does not significantly mediate XAI’s marginal effect on the AI’s predictive performance. The estimated indirect effect is economically negligible in magnitude and statistically insignificant (, F-test). By contrast, for apartments that were not delegated but predicted by real estate agents, we find strong evidence that calibration significantly mediates the effect of XAI on agents’ predictive performance. When including instrumented calibration from column (6) to column (7) in Table 1, the direct effect of XAI on agents’ prediction error substantially diminishes in both magnitude (a reduction of approximately 38.4%) and statistical significance (from highly significant to insignificant). Quantitatively, approximately 38% of the total effect of XAI on agents’ prediction performance for not delegated cases is attributed to better calibration (-test (column (7) in Table 1); 95% bootstrapped CI: [21%–133%]).
Taken together, these findings suggest that XAI-driven improvements in metacognitive calibration not only increase the frequency of delegation but also, enhance its effectiveness. Real estate agents become more accurate in their predictions for cases that they retain, suggesting that they delegate predictions to the AI precisely when their own performance would otherwise be poor. By refraining from predicting such cases, their average prediction error is substantially reduced.
XAI not only increases the frequency of delegation to AI but more importantly, improves the effectiveness of delegation decisions. These shifts in delegation as a metacognitive control strategy are causally mediated by more accurate metacognitive calibration.
Although XAI improves task performance in our study, it does not produce complementarities in which humans and AI together outperform either party individually. In fact, the mean absolute error in our treatment is €183,929, which is significantly higher than when the AI makes all predictions alone (€113,524; , Wilcoxon signed-rank test) and more importantly, higher than that of an ideal agent who always assigns predictions to the party best suited to perform them (€92,450; , F-test). Thus, our findings show that although XAI-induced changes in metacognitive processes can mitigate ineffective delegation, they do not fully resolve it.
3.1.2.3. Ruling out Learning from XAI.
At this point, one may question whether the improvement for tasks that agents chose not to delegate is actually driven by them learning to make better predictions from previously observed AI explanations. In other words, does improved performance reflect changes in object-level processes (e.g., changes in humans’ strategy to make predictions)? To assess this alternative rationale, we examine real estate agents’ performance for apartments that they chose to predict themselves without access to apartment characteristics at the time of the delegation decision (i.e., uninformed delegation). Notably, delegation frequencies for such uninformed cases are similar to those for informed cases (48.3% versus 46.5%; , F-test), mitigating concerns about small sample biases. Any performance improvement for uninformed cases would most likely reflect learning effects from prior AI explanations. The reason is that agents made these delegation decisions without seeing the apartment characteristics such that by design, there are no cues that a metacognitive monitoring process could use to form a confidence judgment indicating how likely the participant is to solve this task successfully. Hence, any treatment effect on participants’ price prediction accuracy for uninformed cases could not be driven by more effective delegation as metacognitive control response to improved calibration. Instead, it would likely result from learning through XAI.
To test this, we regress the absolute error for each prediction on a treatment indicator, a dummy for whether the delegation decision was uninformed, and their interaction term. In this specification, captures the estimated treatment effect for informed delegation cases, and quantifies the treatment effect for uninformed cases. The results (see column (1) in Table 2) show that the significant treatment effect on prediction performance arises only when participants had access to apartment characteristics before deciding not to delegate (; , F-test). In contrast, for uninformed delegation decisions, no significant treatment effect is found (; , F-test). The absence of a treatment effect in the uninformed condition suggests that XAI does not generally improve participants’ prediction skills. Therefore, the performance gains observed for informed cases are unlikely to reflect participants’ learning from XAI. Instead, they most likely stem from a more effective metacognitive control response that (at least partly) originates from improved calibration.
|
Table 2. Delegation Performance
| DV: Absolute prediction error | Not delegated | Delegated |
|---|---|---|
| (1) | (2) | |
| XAI () | −173,565.24** | −46,655.48** |
| (70,508.320) | (20,083.752) | |
| Uninformed delegation () | −138,968.18* | 1,822.44 |
| (77,581.771) | (28,355.115) | |
| XAI Uninformed delegation () | 174,283.07* | 37,977.27 |
| (104,906.298) | (43,246.167) | |
| 717.83 | −8,678.21 | |
| p-value (F-test) | 0.993 | 0.829 |
| Controls | Yes | Yes |
| Observations | 316 | 280 |
| R2 | 0.018 | 0.004 |
Notes. Ordinary least squares (OLS) regression analyses are shown. Recall that for uninformed delegation, agents could not view the apartment characteristics at the time of delegation, which means that any improvements through XAI cannot be attributed to more effective delegation. Controls include agents’ age, task experience, sector experience, AI familiarity, risk aversion, gender, degree, and control question response. Robust standard errors are in parentheses. Significance levels are indicated with asterisks. DV, dependent variable.
*; **.
Further analyses also show that treatment exposure neither alters how real estate agents weigh apartment characteristics in their own price predictions nor affects their beliefs about how the AI weighs these characteristics in its predictions (see Tables 6 and 7 in the Online Appendix).
These results strengthen the conclusion that the previously observed improvement in agents’ prediction performance for nondelegated cases is unlikely to be driven by learning effects. Instead, the evidence supports the interpretation that performance gains stem from agents’ improved metacognitive calibration, allowing them to recognize and delegate tasks that they would otherwise perform poorly on.
3.2. Study 2
Study 1 shows that XAI can influence metacognitive processes, improving both calibration and subsequent control decisions. However, the design of Study 1 has limitations. In particular, it does not capture case-level confidence judgments (i.e., confidence judgments for specific apartments). As a result, we cannot formally assess the effect of XAI on metacognitive resolution, defined as the degree to which participants’ confidence distinguishes between cases that they are likely to solve correctly and those that they are not. To address this limitation, we conducted a second experimental study in a different domain, with additional measurements designed to capture resolution.
Study 2 pursues three main objectives: (i) test whether the effects observed in Study 1 replicate in an arguably more subjective prediction task, where humans might be less likely to expect the AI to outperform them; (ii) examine the effect of XAI on metacognitive accuracy with a focus on resolution; and (iii) examine the role of perceived alignment between the AI’s and human’s prediction logic as a potential boundary condition, which according to theory, should be central to the impact of XAI on metacognitive accuracy.
3.2.1. Design Study 2.
We conducted Study 2 in April 2025 with 200 participants on Prolific. To ensure some level of familiarity with the task, we only recruited individuals working in the finance and insurance industry. Participants’ task was to predict whether a borrower would pay back a P2P loan, for which we used historical data on matured loans from the LendingClub platform. They could perform the prediction themselves or delegate it to an AI. Mirroring Study 1, we varied whether participants initially observed explanations about the average relation between features and AI predictions. Randomization checks suggest that the allocation to conditions was successful (see Table 12 in the Online Appendix). On average, recruited participants required 47 minutes to complete the experiment.
The previous task of predicting listing prices concerns the quantitative evaluation of objects in euros, whereas the prediction of another person’s repayment behavior in P2P lending blends quantitative factors with social and moral inference, such as subjective expectations of trustworthiness (see, e.g., Duarte et al. 2012). This makes the setting well suited to examine whether XAI influences metacognitive processes and delegation behavior when perceptions of AI superiority are less pronounced because the task involves an interhuman dimension that AI is often perceived to lack. In line with this reasoning, participants expect AI performance to exceed their own by an average of 16.44 percentage points in Study 1 but only by 5.5 percentage points in Study 2.
Before the main experiment, we conducted a prestudy to assess participants’ unaided performance on the repayment prediction task. Based on the results, we curated a stratified set of prediction cases for the main study, with cases that participants were highly likely to perform well on and others that they were highly unlikely to perform well on (see the Online Appendix for details). This stratification enabled us to examine whether and how XAI affects participants’ metacognitive resolution, an analysis not possible in Study 1.
3.2.1.1. Stage 1: Task Familiarization and Measurement of Metacognitive Calibration.
Upon entering the study, participants learned that their task was to predict whether a P2P borrower repaid the loan. We informed participants that the loans that they would encounter were real matured P2P loans described by the following six borrower and loan characteristics: borrower’s annual income (in U.S. dollars (USD)) and job title, the loan’s amount (in USD), term (in months), purpose, and monthly installment (in USD).
Closely mirroring Study 1, we informed participants that they could, for each loan, choose whether to complete the prediction task themselves or irrevocably delegate it to an AI without disclosing the AI’s predictions in advance. We again provided a brief, intuitive description of the AI model’s training data and architecture, clarifying that the loans used in the experiment were not part of its training set. Participants were randomly assigned to the treatment condition in which they additionally observed explanations about the AI’s prediction logic (using SHAP dependence plots with three contextualized example loans that showed local SHAP values as in Study 1) along with text-based explanations of the visualized relationships to improve accessibility, whereas the AI’s prediction logic remained a “black box” to baseline participants.
To familiarize themselves with the task and the AI, participants in both conditions viewed three randomly drawn loans from the test set along with the AI’s repayment predictions. We did not reveal actual repayment outcomes for these loans. Notably, we stratified the examples such that they consisted of at least one “repayment” prediction and one “no repayment” prediction. To control for potential variation in participants’ prior beliefs about the average repayment frequency of borrowers, we truthfully informed participants that 50% of the loans in our sample ultimately defaulted.
At the end of stage 1, we asked participants to report their confidence in their own performance as well as their beliefs about the AI’s performance and the average participant’s performance using percentage scales from 0% to 100%. We operationalized metacognitive calibration as the difference between participants’ confidence in stage 1 and their actual performance in stage 3. We also employed an established self-report measure from psychology (van Rensburg et al. 2022) to capture the perceived alignment between participants’ mental models and the AI’s prediction logic.
3.2.1.2. Stage 2: Thirty Delegation Decisions and Measurement of Metacognitive Resolution.
Participants began stage 2 by dividing 30 cases between themselves and the AI. Consistent with Study 1, they made each delegation decision without knowing the AI’s prediction, could not reverse their choices, and did not receive intermediary feedback. We presented each of the 30 loans on separate screens and informed participants in advance that they would provide repayment predictions for all loans in stage 3. Similar to Study 1, participants made 25 delegation decisions while observing loan characteristics and 5 delegation decisions without observing loan characteristics, resulting in 25 “informed” and 5 “uninformed” delegation decisions. We again randomized the order in which participants encountered these sets of informed and uninformed delegation decisions.
Importantly, in Study 2, for each case, participants additionally indicated their confidence in their own ability to make a correct prediction and their confidence in the AI’s ability to make a correct prediction using a percentage scale from 0% to 100%. By examining the former conditional on participants’ likelihood to perform the prediction successfully themselves as measured by the performance of prestudy participants, Study 2 can extend our analyses of the impact of XAI on metacognitive processes to resolution.
3.2.1.3. Stage 3: Predictions and Feedback.
In stage 3, participants provided repayment predictions for all 30 individual loans, received feedback on both their own performance and the AI’s performance, and completed a sociodemographic survey.
3.2.2. Results of Study 2.
We present the results of Study 2 in three parts. First, we replicate and validate the key findings from Study 1. Second, we examine the effect of XAI on resolution. Third, we explore how the impact of XAI on metacognitive accuracy depends on the alignment of human and AI logic, offering further insight into when and why explanations may affect metacognition.
3.2.2.1. Replication of Findings from Study 1.
In line with our earlier findings, we observe that XAI results in better metacognitive calibration (see Figure 8 in the Online Appendix). In the baseline condition, the average gap between participants’ expected performance and actual performance is 11.8 pp. This gap shrinks to 4.2 pp. in the treatment condition. This reduction amounts to 64.4%, and it is statistically significant (, F-test). As in Study 1, this improvement is mainly driven by a reduction in participants’ confidence in their own ability to perform the task (, F-test). Again, we do not find a treatment effect on beliefs in AI ability in Study 2 (69.7% in the baseline condition versus 68.8% in the treatment condition; -test).
We also replicate our findings on the effect of XAI on delegation behavior. XAI significantly increases the frequency of delegation (53.5% versus 59.1%; +10.5%; , F-test) and improves delegation effectiveness as reflected in higher task performance (63.2% versus 66%; +4.4%; , F-test). Causal mediation analyses confirm that these effects are mediated by changes in calibration, with approximately 104% of the effect on delegation frequency (95% bootstrapped CI: [78%–129%]) and 57% of the effect on delegation effectiveness (95% bootstrapped CI: [29%–83%]) explained by the effects of XAI on case-level confidence judgments (see Table 15 in the Online Appendix). Consistent with Study 1, we find no evidence that the XAI treatment leads to learning effects (see Tables 13 and 14 in the Online Appendix).
Taken together, Study 2 broadly replicates the findings from Study 1, showing that the impact of XAI on metacognition is robust in a task domain where human perceptions of the AI’s advantage are found to be less prominent.
3.2.2.2. XAI and Metacognitive Resolution.
Next, we explore whether XAI also affects metacognitive resolution (i.e., the degree to which confidence judgments discriminate between high versus low actual task performance on specific cases of the task). To detect whether confidence judgments better discriminate between cases of the task that participants perform well and those of the task that they do not perform well, we divide our sample into two subsamples of loans based on the average prediction performance of prestudy participants. Specifically, we classify a loan as a “high human performance” loan (hereafter H-loan) if at least 70% of prestudy participants accurately predicted the repayment outcome without AI assistance. All other loans are classified as “low human performance” loans (L-loans). We chose the 70% threshold because it just exceeds both average human and AI performance across all loans. By classifying task performance independently of participants’ own predictions, we aim to mitigate endogeneity concerns. Moreover, average performance on H-loans and L-loans does not differ significantly between participants in the prestudy and the main study, alleviating concerns that sample composition biases this classification. We examine treatment effects on confidence separately for cases where participants are expected to perform well (H-loans: 30% of sample) and those where participants are expected to perform poorly (L-loans: 70% of sample). We regress participants’ confidence scores for individual loans on a treatment dummy and controls using a fixed-effects regression specification with robust standard errors. Asymmetries in estimated treatment effects for these subsamples will give us insights into the impact of XAI on metacognitive resolution.
We illustrate the results for different loan types in Figure 6 (based on Table 16 in the Online Appendix). For L-loans, where prestudy participants exhibit relatively low task performance (46.2% prediction accuracy), confidence declines from 67.5% to 61.0% (−9.6%; , F-test). For H-loans, where prestudy task performance is substantially higher (80.5% accuracy), the average case-level confidence drops from 69.8% to 66.2% (−5%; , F-test). Thus, XAI reduces confidence across both loan types, but the decline is nearly twice as large for the more challenging tasks (, F-test), increasing the gap between confidence judgments for L-loans and H-loans. This pattern suggests that XAI renders participants less overconfident, especially for tasks that they are unlikely to solve well. At the same time, they become slightly more underconfident for tasks that they are likely to solve successfully. As the former effect is notably more pronounced in magnitude than the latter, confidence judgments become indeed better at discriminating cases where participants are expected to perform well and poorly. Hence, XAI, at least partially, improves metacognitive resolution.
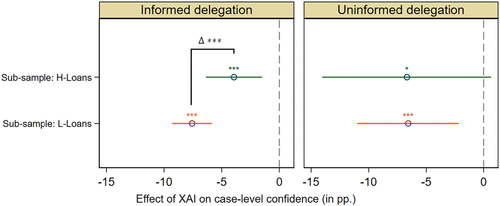
Notes. We show estimated treatment effects of XAI on participants’ case-level confidence from fixed-effects regressions estimated separately for loans with high (H-loans) and low (L-loans) human task performance. See Table 16 in the Online Appendix. pp., percentage points. *p < 0.1; ***p < 0.01.
Notably, when comparing confidence levels for H-loans and L-loans in cases of uninformed delegation, where participants made delegation decisions without seeing any loan characteristics (the right panel of Figure 6), we observe an approximately equal-sized decline in confidence for cases with expected high and low human performance. Similarly to our findings discussed in Section 3.1.2, we interpret this as evidence that without cues arising from observing loan characteristics, the metacognitive monitoring process is not able to form accurate confidence judgments that align with participants’ expected performance on specific cases of the task. Hence, confidence declines overall but not distinctly for H-loans and L-loans.
XAI, at least partially, improves metacognitive resolution such that participants’ confidence for specific cases of a task more accurately discriminates between tasks that they are likely and unlikely to perform successfully.
When looking at the impact of XAI on delegation frequency and effectiveness for the two loan types, we only find significant treatment effects for L-loans ( and , respectively) but not for H-loans ( and , respectively). Causal mediation analyses confirm that XAI-induced changes in confidence mediate the effect of XAI on delegation frequency and effectiveness for L-loans (see Table 18 in the Online Appendix). This pattern supports the interpretation that XAI helps participants delegate, especially those tasks that they are unlikely to perform well themselves. Interestingly, XAI only slightly reduces participants’ expectations of the AI’s performance on individual loans (see Table 17 in the Online Appendix), and this reduction does not vary by loan type (−2.359 pp. for L-loans versus −2.337 pp. for H-loans; , F-test). This suggests that the observed XAI-driven changes in delegation decisions are unlikely to be confounded by shifts in participants’ beliefs about the AI’s predictive performance, corroborating the notion that XAI primarily affects human-AI collaboration by affecting humans’ own metacognitive accuracy.
3.2.2.3. Mechanisms and Boundary Conditions.
Results from our two studies demonstrate that XAI improves metacognitive accuracy. These improvements consistently stem from reductions in participants’ confidence judgments. However, as outlined in Section 2.3, theory predicts that XAI could in principle either increase or decrease confidence judgments, conditional on whether humans perceive an alignment or misalignment between their own and the AI’s task-solving logic, respectively. There are two competing rationales for the deviation of our empirical findings from this theoretical perspective. Either participants predominantly perceive a misalignment between their own reasoning and that of the AI, or contrary to theoretical expectations, alignment does not actually raise confidence. The latter would point to a notable boundary condition wherein XAI may reduce confidence in the face of misalignment but is not effective at boosting confidence when alignment is perceived. In this case, our findings could be interpreted as XAI nudging individuals toward more accurate metacognitive monitoring by drawing attention to aspects of the task that they would otherwise overlook.
To analyze the role of perceived alignment between participants’ prediction logic and AI’s prediction logic in XAI’s impact on metacognition, we follow prior research in psychology (e.g., van Rensburg et al. 2022) and rely on self-reported perceptions of alignment. Specifically, after treatment exposure in stage 1, participants expressed their agreement with the following statement on a seven-point Likert scale: “The way the AI makes its predictions is similar to my approach of estimating loan repayment.”
Contrary to the notion that XAI generally reveals a misalignment of participants’ own prediction logic and the AI’s prediction logic, treatment participants report an average perceived alignment of 4.9 of 7 (standard deviation = 1.29), with a median of 5. Hence, a meaningful share of treatment participants seems to perceive an alignment between their own logic and that of the AI. But, do these participants refrain from adjusting their confidence? To answer this question, we next repeat previous regression analyses on separate subsamples of our data. Specifically, we split treatment participants based on whether their reported alignment exceeds the median of the baseline (median = 5). This approach follows the logic that under random assignment, a treatment participant reporting alignment above the baseline median is more likely to have recognized a strong overlap of their own reasoning and the AI’s reasoning, whereas those below the baseline median are more likely to have recognized a contradiction.6 Accordingly, we classify treatment participants with perceived alignment scores above the baseline median as having recognized a “high alignment” and those below or at the median as having recognized a “low alignment”. We then compare these two treatment subsamples separately with the full baseline sample and estimate distinct treatment effects on our key confidence measures.
Figure 7 summarizes the estimated treatment effects (based on regression results in Table 19 in the Online Appendix). The left and right panels of Figure 7 show how confidence changes when explanations likely cause participants to realize that the AI’s prediction logic either aligns with or contradicts their own, respectively. We report separate treatment estimates for beliefs about their own performance (), calibration (), and case-level confidence for both H-loans () and L-loans ().
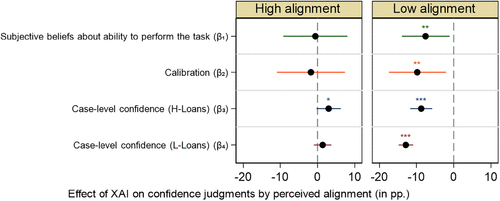
Notes. Coefficient plot showing estimated coefficients from ordinary least squares and fixed-effects regressions of participants’ confidence in their ability to perform the task (), calibration ( ), and case-level confidence in correctly predicting repayment behavior (H-Loans ( ) and L-Loans ( )) on a treatment indicator and control variables. See Table 19 in the Online Appendix. pp., percentage points. *p < 0.1; **p < 0.05; ***p < 0.01.
Our results indicate that the documented effects of XAI on calibration occur primarily among participants who perceive a low alignment between their own prediction logic and the AI’s prediction logic. Specifically, participants who perceive a high alignment exhibit no meaningful adjustment in confidence judgments. The only exception is a marginally significant increase in case-level confidence for H-loans, which is modest in magnitude. By contrast, among participants who perceive a low alignment, XAI substantially reduces confidence, which in turn, improves calibration. In this group, we observe a decline in case-level confidence for both L-loans and H-loans, with the reduction being significantly more pronounced for L-loans (, Z-test). These analyses suggest that XAI enhances metacognitive accuracy primarily when it confronts participants with a contradiction to their own logic, indicating that XAI’s potential to reinforce confidence may be limited.
XAI primarily affects metacognitive accuracy when it makes individuals recognize a misalignment between their own prediction logic and the AI’s prediction logic, causing them to decrease their confidence. Recognized alignments may marginally increase confidence in tasks that individuals are likely to perform well but otherwise, have no significant effect.
3.3. Additional Robustness Checks for Study 1 and Study 2
In Study 1, we follow conceptualizations of metacognitive processes (Fleming 2024), and we propose that XAI improves humans’ calibration and thereby, changes subsequent delegation decisions. However, we acknowledge that additional mechanisms may affect delegation. For instance, beliefs about the AI’s performance could influence delegation choices and outcomes, and thus, they could potentially confound our results regarding human-to-AI delegation. To mitigate this concern, we repeat our main analyses while controlling for participants’ beliefs in the AI’s prediction performance. More specifically, we replicate our causal mediation analyses showing how changes in calibration account for changes in delegation frequency and performance (Table 1) and our regression analyses of delegation performance for informed delegation versus uninformed delegation (Table 2) while additionally controlling for participants’ beliefs about the AI’s performance. Our findings prove to be robust (see Tables 10 and 11 in the Online Appendix), corroborating our core insights into the importance of metacognitive calibration for delegation.
Relatedly, two other mechanisms may also mediate XAI’s impact on human-AI collaboration in Study 1: the ability to correctly anticipate what the AI will predict for a given case and cognitive trust in the AI. We measure the latter using established trust measures by Komiak and Benbasat (2006), and we measure the former using the absolute difference between participants’ estimate of the AI’s price prediction for a given apartment and its actual prediction. Our analyses (see Table 9 in the Online Appendix) show that XAI does not seem to affect the human ability to correctly anticipate AI predictions, suggesting that our results are not confounded by humans learning to better understand what the AI is doing. With respect to trust, we find that our treatment does modestly increase cognitive trust in the AI (+0.93 points on a 7-point Likert scale; , F-test). Causal mediation analyses further reveal that the increase in cognitive trust accounts for 31.4% of the change in delegation frequency (95% bootstrapped CI: [14%–49%]). However, cognitive trust does not mediate the effect of XAI on delegation effectiveness. Therefore, although the explanation-driven increase in delegation frequency is partly attributable to enhanced cognitive trust (consistent with findings by Taudien et al. 2022), it does not explain why agents become more effective at dividing tasks between themselves and the AI. This observation further corroborates our main finding that improved metacognitive accuracy enables more effective human-to-AI delegation.
Finally, given our relatively small sample size in Study 1 (n = 149), we conducted an ex post power analysis revealing that the power for identifying the effect of XAI on metacognitive calibration (effect size = 13.96 pp.) amounts to 91.4%. Based on this analysis, we identify the required sample size of Study 2 to detect an effect of a similar size. After excluding inattentive participants, our final sample in Study 2 consists of 152 participants (77 baseline participants and 75 treatment participants), which exceeds the required minimum of 53 participants per condition to satisfy a minimum power of 80%.
4. Discussion and Conclusion
Our studies reveal that XAI can improve the accuracy of metacognitive monitoring measured through calibration and resolution, which in turn, improves the metacognitive control decision to delegate tasks to the AI. This metacognitive shift primarily occurs when XAI reveals to humans that their own reasoning and AI reasoning diverge, suggesting that explanations reduce overconfidence by nudging humans to pay attention to aspects of the task that they would otherwise overlook. We rule out alternative explanations for these effects, including learning from AI explanations, increased trust in the AI, or stronger beliefs in the AI’s performance.
4.1. Theoretical Contribution
By linking empirical and conceptual frameworks on human-XAI interaction, metacognition, and human-to-AI delegation, we make several theoretical contributions. First, we broaden the theoretical understanding of how XAI affects human cognition. Prior research has largely focused on how XAI influences object-level cognition, such as reasoning, learning, or trust in AI predictions (e.g., Bauer et al. 2023). However, empirical results have been mixed. Some studies find that explainability improves human-AI collaboration (Rader et al. 2018), whereas others suggest that it can impair decision quality (Poursabzi-Sangdeh et al. 2021). One reason for this inconsistency may be the field’s narrow focus on object-level cognition while overlooking metacognitive processes that govern how humans monitor and control their own thinking (Nelson and Narens 1990). We introduce metacognition as a complementary theoretical lens in the XAI literature, and we show that explanations affect not only how people think but also, how they think about their thinking. Conceptually, we identify XAI-enabled adjustments in the accuracy of metacognitive monitoring and subsequent control decisions as a key mediator of XAI’s impact on performance.
From this perspective, our study relates to that of Bauer et al. (2023), who show that mental model updates, reflecting object-level cognitive processes, occur only when local explanations confirm human prior beliefs. Viewed through a metacognitive lens, this finding can be interpreted as metacognitive processes reinforcing confidence in response to repeated confirmatory local explanations, thereby prompting control decisions that sustain existing task-solving strategies. The confidence adjustments that we observe may similarly underlie the documented impact of local explanations in decision support settings, which evoke mental model updates (Bauer et al. 2023). Differences between the results reported by Bauer et al. (2023) and those presented here may stem from the type of explanations and the way that humans collaborate with AI: repeated exposure to distinct local explanations for isolated predictions in decision support versus global explanations of the AI’s overarching prediction logic in a delegation setting. Global explanations, by providing an aggregate-level view, may be more effective in helping users recognize aspects of a problem that they might otherwise overlook. By revealing broader patterns, they can trigger a more comprehensive adjustment of confidence, which in our case, affects the delegation of cases to AI. Hence, XAI may produce distinct effects on object-level and metacognitive processes depending on the type of explanation, the content that it conveys, and the mode of human-AI collaboration.
Second, our research contributes to the growing literature on metacognition in human-AI collaboration. Prior work has shown that metacognitive processes influence how users evaluate AI systems (Jussupow et al. 2021, Abdel-Karim et al. 2023, Ma et al. 2024) and whether they choose to delegate tasks to AI (Fügener et al. 2022, Taudien et al. 2024). More recently, scholars have begun theorizing about the role of metacognition in interactions with generative AI, which imposes new cognitive and metacognitive demands (Tankelevitch et al. 2024).
We complement this line of work by extending our understanding of the interplay between metacognitive monitoring and technical system features. Rather than viewing it solely as an individual trait or factor influencing human-AI interaction (Taudien et al. 2024), we show that metacognitive processes can be actively shaped by the design of AI systems. This adds to the metareasoning literature in psychology (Ackerman and Thompson 2017) by examining more complex, socially embedded decision contexts that involve coordination between two autonomous agents (a human and an AI).
On a broader level, our study provides empirical support for the idea that metacognition is critical to realizing the complementary value of AI systems. Specifically, we show that metacognitive calibration and resolution enable more effective delegation decisions as humans become more adept at identifying which cases are difficult for them. Importantly, this metacognitive change does not lead to a blanket increase in delegation. Instead, humans become better at discerning when to retain control and when to rely on the AI. This highlights the role of accurate metacognitive monitoring as a mechanism that enhances decision quality by enabling more precise task allocation as a metacognitive control response.
Third, our study extends the broader literature on the role of transparency in human-AI interactions by focusing on an aggregate level of transparency about an AI’s functioning in the context of human-to-AI delegation. Most prior studies examine the role of isolated explanations for individual predictions (local explanations) in decision support contexts, where humans evaluate case-specific AI predictions and retain decision authority (e.g., Lebovitz et al. 2022). Genuine delegation, however, requires humans to make a binary choice to either fully transfer or retain decision-making responsibility. Accordingly, explanations serve a different role in delegation settings; instead of allowing humans to better assess the accuracy of individual AI predictions, explanations provide an overarching understanding of the AI’s logic, enabling humans to assess more generally when they are not suited to perform a task. Our results show that global explanations as a form of aggregate-level transparency can affect metacognitive processes, which can improve the effectiveness of human-AI collaboration when humans can choose to transfer decision-making rights to AI.
By adopting a metacognitive lens, our study extends the seminal framework of Baird and Maruping (2021), which conceptualizes human delegation of tasks to agentic systems, such as AI. In this framework, delegation decisions partly rest on a simultaneous mental evaluation of the task and the self. These evaluations or appraisals reflect perceptions of task demands and competence that inform whether delegation occurs. Our findings provide empirical evidence that metacognitive processes are a central channel through which appraisals translate into delegation decisions, a facet not yet incorporated in this framework. At the same time, our findings are consistent with the broader claim of Baird and Maruping (2021) that delegation is shaped by multiple factors, including preferences, cognitive traits, and appraisal mechanisms. Although metacognitive changes account for a substantial share of the effect of explainability on delegation, they do not fully explain it, pointing to the existence of additional mechanisms beyond metacognition.
4.2. Practical Implications
Our findings relate directly to explainability mandates, such as Article 13 of the European Union Artificial Intelligence Act, requiring certain AI systems to be transparent so that those using them can understand and use them correctly (European Union 2024). Across both studies, we find that explanations can reduce overconfidence, helping humans better recognize their knowledge gaps and delegate more effectively to AI. Thus, implementing XAI to meet legal transparency obligations can impose compliance costs, but also, it can deliver operational gains by improving human-AI collaboration. However, sometimes this XAI-enabled confidence adjustment may overshoot; some experts begin to undervalue their own abilities when they are actually well suited for the task and let AI perform it for them. In that sense, XAI may inadvertently risk that humans become excessively cautious in their decision making, which may deteriorate the speed and quality of decision making (e.g., Desender et al. 2019), and overrely on AI, which may undermine learning and control and may diminish the capacity for innovation (e.g., Goddard et al. 2012).
If XAI can evoke these problems, ultimately by diminishing appropriate human confidence, organizations may be well advised to introduce complementary measures that enable employees to use their skills and knowledge if feeling sufficiently confident. Given that recent research has found evidence that AI literacy may help humans better understand their strengths and weaknesses relative to those of AI (cf. Pinski and Benlian 2024), the implementation of explainability measures may position AI literacy trainings (e.g., workshops, courses, and industry resources) as a particularly valuable complementary investment. Similarly, organizations may draw from a rich literature on measures for enhancing employee self-efficacy and confidence in organizational settings (see, e.g., Spreitzer 1995), which outlines strategies to help employees build confidence in their judgment under uncertainty, including feedback mechanisms and leadership communication strategies.
4.3. Limitations and Future Research
Our study has limitations that we hope will inspire future research. First, our experiments are conducted in a static environment where participants delegate tasks without receiving feedback on their own performance or the AI’s performance. This setup reflects practical scenarios in which humans and AI work in parallel, requiring an up-front decision about which tasks to retain or delegate. It also isolates the causal effect of explainability on metacognition and delegation by removing learning effects. However, such learning effects are likely to shape behavior over time. In dynamic settings with repeated interactions and feedback, humans may revise their interpretation of AI explanations and adjust their confidence accordingly. Prior work suggests that people may be reluctant to trust AI after it makes an error (Dietvorst et al. 2015), indicating that observed AI performance may moderate the impact of explanations. Future research should investigate how intermediate feedback shapes metacognitive processes and delegation decisions in repeated decision-making contexts.
Second, consistent with observations in prior research (Lichtenstein et al. 1982, Rozenblit and Keil 2002), participants in both our studies entered the experiment with overconfidence (see Figure 4 and Figure 8 in the Online Appendix). Our finding that XAI is successful at reducing such overconfidence is, therefore, reminiscent of earlier research on the illusion of explanatory depth (Rozenblit and Keil 2002). This work shows that humans often overestimate the depth of their knowledge until they attempt to explain it. In our setting, XAI may trigger similar object-level processes: prompting overconfident individuals to articulate their own task understanding, compare it with the AI’s reasoning, and nudge humans to attend to task aspects that they would otherwise overlook. By reading resulting heuristic cues (e.g., experiences of incoherence), metacognitive processes adjust confidence judgments. Despite distinct degrees of initial overconfidence in our two experiments, the exact role of overconfidence in the relationship between XAI and metacognition remains unclear as we did not exogenously vary it. Likewise, we did not manipulate participants’ perceived alignment between their own reasoning and that of the AI. Hence, one may naturally wonder about the individual roles of overconfidence and perceived alignment as well as their interaction for XAI’s impact on metacognition. A seemingly fruitful avenue for future research would be to exogenously manipulate overconfidence and the perceived alignment between humans’ own reasoning and the AI’s reasoning. With respect to the latter, using an exact measurement of perceived alignment is crucial. Although we rely on an established self-reported alignment measure from psychology (van Rensburg et al. 2022), there may be value in unpacking this construct further (e.g., by measuring it for distinct feature-label relationships).
Third, we refrain from using prediction tasks in our experiment that are highly morally or ethically charged, such as predicting the risk of recidivism in the criminal justice system or rejecting loans based on sensitive attributes. Although there is abundant empirical evidence of discriminatory lending practices based on sensitive borrower characteristics (e.g., Iyer et al. 2009), we deliberately excluded such attributes in Study 2, and instead, we provided both participants and the AI with fundamental financial characteristics. This design choice minimizes the risk that participants perceive the AI as biased or inappropriate. As a result, even though credit approval decisions can carry moral weight, our design limits this dimension. At the same time, AI is increasingly deployed in high-stakes settings, where users may feel a moral responsibility for outcomes. In such contexts, the impact of explainability may depend on anthropocentric beliefs about human superiority (Millet et al. 2023). Strong convictions that humans are uniquely qualified to decide in these domains can trigger psychological reactance when an AI relies on different reasoning (Clayton 2022). Users may reject otherwise useful explanations, not despite but because of the AI’s divergence, interpreting it as validation of their moral stance. Exploring these dynamics of metacognition in morally or ethically charged situations offers a promising direction for future research.
Finally, our experimental design deliberately forces participants to choose between full delegation and full autonomy. If participants retain control, they do not have access to the AI’s output. This clear separation allows for precise identification of causal effects, aligning with recent calls in the IS field for stronger causal inference in experimental designs (Maruping et al. 2025). However, many real-world scenarios involve partial delegation or decision support. For example, real estate agents in Study 1 might retain control while still viewing AI predictions to inform their judgment. Future studies should examine the role of explainability in such hybrid settings, where the boundary between delegation and support is more fluid.
The authors thank Wanxue Dong, Carlos Fernández-Loría, Stefan Feuerriegel, Alok Gupta, Jenny Jin, Anna Taudien, and the entire review team for their helpful comments and suggestions. The authors also benefited from the comments of participants at the Workshop on Information Systems and Economics 2024 in Bangkok, the Human-Algorithm Interaction Workshop in Oxford, and various seminars.
1 Specifically, the authors note: “While there is much to be said about appraisals, the main point is that they are an essential mechanism for understanding why, when, and how delegation to and from agentic IS artifacts may occur” (Baird and Maruping 2021, p. 328).
2 For anecdotal evidence on the use of AI in real estate pricing, see https://www.houseprice.ai/ or https://ascendixtech.com/, and for anecdotal evidence on the use of AI in consumer credit risk assessment, see https://www.zest.ai/ or https://ginimachine.com/risk-management/credit-scoring/.
3 For example, the dependence plot for “living space” (the first plot in the upper right panel of Figure 3) shows a straightforward relationship; more living space contributes to higher price predictions. The dependence plot for “construction year” (the third plot in the upper right panel of Figure 3) shows a more sophisticated, U-shaped relationship; very old apartments and very new apartments contribute to higher price predictions, whereas middle-aged apartments from the 1960s contribute to lower price predictions.
4 Mathematically, the calibration of participant i is defined as , where represents i’s initial belief about the percentage of N tasks that they will make correct predictions for. indicates whether i correctly predicted the true outcome of case j.
5 Interestingly and perhaps offering a partial explanation for the changing role of apartment location in delegation decisions, XAI reveals that location, particularly Munich and Berlin, contributes notably and variably to the AI’s predictions (see SHAP dependence plots in Figure 3). For Munich, this variance is the highest among all categorical apartment features. Real estate agents may interpret this as a signal that predicting listing prices for apartments in these cities is especially complex, reducing their confidence in their ability to manually perform the prediction and increasing their willingness to delegate these cases to the AI.
6 Note that our results are robust to using the baseline mean instead of the median. Despite this robustness, we acknowledge that the individual-level measurement of changes in the alignment for treatment participants before and after they observe explanations would have been more precise. However, given that we wanted to avoid a repeated measurement that may have induced issues, such as priming, anchoring, or consistency pressure, we opted for our arguably intuitive and statistically justifiable approach.
References
- (2023) How AI-based systems can induce reflections: The case of AI-augmented diagnostic work. MIS Quart. 47(4):1395–1424.Crossref, Google Scholar
- (2017) Meta-reasoning: Monitoring and control of thinking and reasoning. Trends Cognitive Sci. 21(8):607–617.Crossref, Google Scholar
- (2021) The next generation of research on IS use: A theoretical framework of delegation to and from agentic IS artifacts. MIS Quart. 45(1):315–341.Crossref, Google Scholar
- (2019) Beyond accuracy: The role of mental models in human-AI team performance. AAAI Conf. Human Comput. Crowdsourcing, vol. 7 (University of Washington, Seattle).Google Scholar
- (2014) The intrinsic value of decision rights. Econometrica 82(6):2005–2039.Crossref, Google Scholar
- (2023) Expl(AI)ned: The impact of explainable artificial intelligence on users’ information processing. Inform. Systems Res. 34(4):1582–1602.Link, Google Scholar
- (2021) Expl(AI)n it to me—Explainable AI and information systems research. Bus. Inform. Systems Engrg. 63(2):79–82.Crossref, Google Scholar
- (2022) Under which conditions are humans motivated to delegate tasks to AI? A taxonomy on the human emotional state driving the motivation for AI delegation. Marketing Smart Tech. Proc. ICMarkTech 2021, vol. 1 (Springer, Berlin), 37–53.Google Scholar
- (2024) Explainability does not mitigate the negative impact of incorrect AI advice in a personnel selection task. Sci. Rep. 14(1):9736.Crossref, Google Scholar
- (2016) XGBoost: A scalable tree boosting system. Proc. 22nd ACM SIGKDD Internat. Conf. Knowledge Discovery Data Mining (ACM, New York), 785–794.Google Scholar
- (2021) I think I get your point, AI! The illusion of explanatory depth in explainable AI. 26th Internat. Conf. Intelligent User Interfaces (ACM, New York), 307–317.Google Scholar
- (2022) On the psychophysiological and defensive nature of psychological reactance theory. J. Comm. 72(4):461–475.Crossref, Google Scholar
- (2022) Examining the impact of algorithmic control on Uber drivers’ technostress. J. Management Inform. Systems 39(2):426–453.Crossref, Google Scholar
- (2019) Confidence predicts speed-accuracy tradeoff for subsequent decisions. eLife 8:e43499.Crossref, Google Scholar
- (2015) Algorithm aversion: People erroneously avoid algorithms after seeing them err. J. Experiment. Psych. General 144(1):114–126.Crossref, Google Scholar
- (2018) Overcoming algorithm aversion: People will use imperfect algorithms if they can (even slightly) modify them. Management Sci. 64(3):1155–1170.Link, Google Scholar
- (2012) Trust and credit: The role of appearance in peer-to-peer lending. Rev. Financial Stud. 25(8):2455–2484.Crossref, Google Scholar
- (2011)
The Dunning–Kruger effect: On being ignorant of one’s own ignorance . Olson JM, Zanna MP, eds. Advances in Experimental Social Psychology, vol. 44 (Elsevier, Amsterdam), 247–296.Google Scholar European Union (2024) Proposal for a regulation of the European Parliament and of the council laying down harmonised rules on artificial intelligence (Artificial Intelligence Act) and amending certain union legislative acts. Accessed April 9, 2024, https://data.consilium.europa.eu/doc/document/ST-5662-2024-INIT/en/pdf.Google Scholar- (2022) Explaining data-driven decisions made by AI systems: The counterfactual approach. MIS Quart. 46(3):1635–1660.Crossref, Google Scholar
- (1957) Social comparison theory. Selective Exposure Theory 16(401):3.Google Scholar
- (2019)
Metacognition: Monitoring and controlling one’s own knowledge, reasoning and decisions . Sternberg RJ, Funke J, eds. The Psychology of Human Thought: An Introduction (Heidelberg University Publishing, Heidelberg, Germany), 89–111.Google Scholar - (1979) Metacognition and cognitive monitoring: A new area of cognitive–developmental inquiry. Amer. Psychologist 34(10):906–911.Crossref, Google Scholar
- (2024) Metacognition and confidence: A review and synthesis. Annual Rev. Psych. 75(1):241–268.Crossref, Google Scholar
- (2022) Cognitive challenges in human–artificial intelligence collaboration: Investigating the path toward productive delegation. Inform. Systems Res. 33(2):678–696.Link, Google Scholar
- (2012) Automation bias: A systematic review of frequency, effect mediators, and mitigators. J. Amer. Medical Informatics Assoc. 19(1):121–127.Crossref, Google Scholar
- (2017) European Union regulations on algorithmic decision-making and a “right to explanation”. AI Magazine 38(3):50–57.Crossref, Google Scholar
GoogleAI (2025) Responsible AI progress report. Accessed June 13, 2025, https://ai.google/static/documents/ai-responsibility-update-published-february-2025.pdf.Google Scholar- (2024) The impact of explanations on fairness in human-AI decision-making: Protected vs proxy features. Proc. 29th Internat. Conf. Intelligent User Interfaces (ACM, New York), 155–180.Google Scholar
- (2021) SHAP and LIME: An evaluation of discriminative power in credit risk. Frontiers Artificial Intelligence 4:752558.Crossref, Google Scholar
- (1999) Explanations from intelligent systems: Theoretical foundations and implications for practice. MIS Quart. 23(4):497–530.Crossref, Google Scholar
- (2025) An explainable artificial intelligence approach using graph learning to predict intensive care unit length of stay. Inform. Systems Res. 36(3):1478–1501.Link, Google Scholar
- (2018) Economic experiments in information systems. MIS Quart. 42(2):595–606.Crossref, Google Scholar
- (2020) Individual differences in local and global metacognitive judgments. Metacognition Learn. 15(1):51–75.Crossref, Google Scholar
- (2009) The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed. (Springer, New York).Crossref, Google Scholar
- (2024) The fairness of credit scoring models. Management Sci., ePub ahead of print November 14, https://doi.org/10.1287/mnsc.2022.03888.Link, Google Scholar
- (2010) Screening in new credit markets: Can individual lenders infer borrower creditworthiness in peer-to-peer lending? Preprint, submitted March 15, http://dx.doi.org/10.2139/ssrn.1570115.Google Scholar
- (2000) The use of explanations in knowledge-based systems: Cognitive perspectives and a process-tracing analysis. J. Management Inform. Systems 17(2):153–179.Crossref, Google Scholar
- (2015) Machine learning: Trends, perspectives, and prospects. Science 349(6245):255–260.Crossref, Google Scholar
- (2024) An integrative perspective on algorithm aversion and appreciation in decision-making. MIS Quart. 48(4):1575–1590.Crossref, Google Scholar
- (2021) Augmenting medical diagnosis decisions? An investigation into physicians’ decision-making process with artificial intelligence. Inform. Systems Res. 32(3):713–735.Link, Google Scholar
- (2006) The effects of personalization and familiarity on trust and adoption of recommendation agents. MIS Quart. 30(4):941–960.Crossref, Google Scholar
- (2000) Conscious and unconscious metacognition: A rejoinder. Consciousness Cognition 9(2 Pt 1):193–202.Crossref, Google Scholar
- (2022) To engage or not to engage with AI for critical judgments: How professionals deal with opacity when using AI for medical diagnosis. Organ. Sci. 33(1):126–148.Link, Google Scholar
- (2022) How do recommender systems lead to consumer purchases? A causal mediation analysis of a field experiment. Inform. Systems Res. 33(2):620–637.Link, Google Scholar
- (1982)
Calibration of probabilities: The state of the art to 1980 . Kahneman D, Slovic P, Tversky A, eds. Judgment Under Uncertainty: Heuristics and Biases (Cambridge University Press, Cambridge, UK), 306–334.Crossref, Google Scholar - (2017) A unified approach to interpreting model predictions. Conf. Neural Inform. Processing Systems (NIPS) (University of Washington Seattle, Seattle), 1–10.Google Scholar
- (2024) “Are you really sure?” Understanding the effects of human self-confidence calibration in AI-assisted decision making. Proc. 2024 CHI Conf. Human Factors Comput. Systems (ACM, New York).Google Scholar
- (2025) Editor’s comments: Quantitative behavioral IS research—A look back and a look forward. MIS Quart. 49(1):iii–xviii.Crossref, Google Scholar
McKinsey (2024) Building AI trust: The key role of explainability (November 26), https://www.mckinsey.com/capabilities/quantumblack/our-insights/building-ai-trust-the-key-role-of-explainability.Google Scholar- (2022) Explainable artificial intelligence: Objectives, stakeholders, and future research opportunities. Inform. Systems Management 39(1):53–63.Crossref, Google Scholar
- (2023) Defending humankind: Anthropocentric bias in the appreciation of AI art. Comput. Human Behav. 143:107707.Crossref, Google Scholar
- (2020) Interpretable Machine Learning: A Guide for Making Black Box Models Explainable (Christoph Molnar, Munich, Germany).Google Scholar
- (2023) How the different explanation classes impact trust calibration: The case of clinical decision support systems. Internat. J. Human-Comput. Stud. 169:102941.Crossref, Google Scholar
- (2024) Operationalizing explainable artificial intelligence in the European Union regulatory ecosystem. IEEE Intelligent Systems 39(4):37–48.Crossref, Google Scholar
- (1990) Metamemory: A theoretical framework and new findings. Psych. Learn. Motivation 26:125–173.Crossref, Google Scholar
- (2024) Perceived algorithmic fairness: An empirical study of transparency and anthropomorphism in algorithmic recruiting. Inform. Systems J. 34(2):384–414.Crossref, Google Scholar
- (2024) AI literacy for users—A comprehensive review and future research directions of learning methods, components, and effects. Comput. Human Behav. Artificial Humans 2(1):100062.Crossref, Google Scholar
- (2021) Manipulating and measuring model interpretability. Proc. 2021 CHI Conf. Human Factors Comput. Systems (ACM, New York).Google Scholar
- (2018) Explanations as mechanisms for supporting algorithmic transparency. Proc. 2018 CHI Conf. Human Factors Comput. Systems (ACM, New York).Google Scholar
- (2002) The misunderstood limits of folk science: An illusion of explanatory depth. Cognitive Sci. 26(5):521–562.Crossref, Google Scholar
- (2022) Using explainable artificial intelligence to improve process quality: Evidence from semiconductor manufacturing. Management Sci. 68(8):5704–5723.Link, Google Scholar
- (2024) Explainable AI improves task performance in human-AI collaboration. Sci. Rep. 14:31150.Google Scholar
- (2024) Transferring domain knowledge with (X)AI-based learning systems. Avital M, Karahanna E, Themistocleous M, Constantiou ID, Fitzgerald B, Seidel S, eds. 32nd Eur. Conf. Inform. Systems (ECIS).Google Scholar
- (1995) Psychological empowerment in the workplace: Dimensions, measurement, and validation. Acad. Management J. 38(5):1442–1465.Crossref, Google Scholar
- (2024) The metacognitive demands and opportunities of generative AI. Proc. 2024 CHI Conf. Human Factors Comput. Systems (ACM, New York), 1–24.Google Scholar
- (2022) Calibrating users’ mental models for delegation to AI. Proc. 43rd Internat. Conf. Inform. Systems (Association for Information Systems, Atlanta).Google Scholar
- (2024) Know thyself: The relationship between metacognition and human-AI collaboration. Internat. Conf. Inform. Systems (Association for Information Systems, Atlanta).Google Scholar
- (2022) Real estate price estimation in French cities using geocoding and machine learning. Ann. Oper. Res. 308:571–608.Crossref, Google Scholar
- (2025) Fast reasoning and metacognition. Psychonomic Bull. Rev. 32(4):1915–1921.Crossref, Google Scholar
- (2022) The five-factor perceived shared mental model scale: A consolidation of items across the contemporary literature. Frontiers Psych. 12:784200.Crossref, Google Scholar
- (2007) Recommendation agents for electronic commerce: Effects of explanation facilities on trusting beliefs. J. Management Inform. Systems 23(4):217–246.Crossref, Google Scholar
- (2012) Metacognition in human decision-making: Confidence and error monitoring. Philos. Trans. Roy. Soc. London Ser. B Biol. Sci. 367(1594):1310–1321.Google Scholar
- (2022) Algorithmic versus human advice: Does presenting prediction performance matter for algorithm appreciation? J. Management Inform. Systems 39(2):336–365.Crossref, Google Scholar

