
Inventing with Machines: Generative AI and the Evolving Landscape of IS Research
Abstract
Generative artificial intelligence (AI) is not merely changing how information systems (IS) research gets done—it is reshaping what research can be. We stand at a pivotal moment where machines can help generate hypotheses, synthesize vast literatures, and identify patterns that would take human researchers months to uncover. Yet, this unprecedented capability presents equally unprecedented risks to scholarly integrity. Because the field is uniquely positioned to understand sociotechnical transformations, IS research faces an extraordinary opportunity to pioneer “inventing with machines” while preserving the human insight and oversight that gives scholarship, as currently defined, its meaning. This transformation demands more than tool adoption. It requires a reimagination of scholarly infrastructure, norms, and practice. However, this transformation of research tooling creates a dangerous paradox: Powerful AI tools are now accessible to researchers who lack the technical literacy to understand and use them responsibly, threatening everything from citation accuracy to theoretical validity. Yet within this paradox lies the potential for revolutionary advances in how we craft our future as scholars. Informed by the sociotechnical perspective, we argue that the path forward requires coordinated community action that goes far beyond individual skill development. The IS community must lead the development of specialized AI tools that consider our theoretical traditions, create educational frameworks that preserve scholarly values while embracing computational capabilities, and pioneer review processes that harness AI’s analytical power without ceding human control, at least, in the short run. Success will determine not only the future of IS scholarship but our field’s capacity to guide other disciplines through this fundamental transformation of academic practice. The era of human-AI collaboration in research has already begun. How we govern and guide it will define the next generation of scholarly discovery.
1. Introduction
The academic landscape is undergoing a transformation as profound as the shift from typewriter to word processor, from library card catalog to digital archives—but compressed into a timeframe that does not offer the luxury of gradual adaptation. Generative artificial intelligence (GenAI) systems can now draft coherent arguments, translate across languages, write sophisticated code, summarize vast literatures, and orchestrate complex workflows that span multiple tools and domains. For information systems (IS) scholars, this represents far more than an expanded toolkit—it demands a fundamental reconsideration of how knowledge is discovered, validated, and communicated across our discipline.
Just as earlier computational waves revolutionized data collection and statistical analysis, AI penetrates the traditionally human-dominated upstream stages of research: the formulation of theories, the design of studies, and the exposition of findings. What were once sequential, time-intensive processes—reading, thinking, writing, coding, analyzing—now collapse into rapid human-machine feedback loops that can compress months of traditional research activity into days or weeks. Throughout this discussion, we use “AI” to refer specifically to GenAI systems—text- and code-oriented large language models (LLMs), including those enhanced with tool use, retrieval-augmented generation (RAG), and reasoning—unless otherwise noted.
At the heart of this transformation lies the unprecedented prospect of automation of invention: the ability to close loops between hypothesis generation, experimental design, execution, interpretation, and evaluation at speeds and scales previously unimaginable. In practical terms, AI can dramatically expand the search space for research ideas, accelerate the assessment of massive literature, provide scaffolding for complex coding and data preparation tasks, and surface alternative theoretical framings that human researchers can then evaluate and refine. When properly harnessed, these capabilities promise to enhance both creativity and productivity by enabling researchers to explore vastly more possibilities within the same time constraints, to compare competing frameworks early in the research pipeline, and to subject nascent ideas to rapid simulation and critique before committing significant resources.
Recent demonstrations already show AI systems’ capacity to span the entire research loop. For instance, ResearchAgent helps define novel problems, propose methods, design experiments, and iteratively refine them using LLM-based reviewing agents (Baek et al. 2024). Such systems have a demonstrated ability to support the information-foraging and sensemaking loops: accelerating data gathering and aiding hypothesis generation and testing—even while surfacing issues such as prompt formulation and result verification (Susarla et al. 2023). More broadly, these systems have enabled a larger shift toward “agentic science,” in which AI systems are not merely used as tools but are being explored as autonomous agents across the scientific discovery process (Wei et al. 2025).
Yet AI remains intrinsically Janus faced—the same capabilities that can accelerate and enhance research carry equal potential to undermine its foundations. When AI systems blur the lines of intellectual authorship (Bozkurt 2024), propagate synthetic or misattributed evidence, introduce subtle but systematic biases (Xu et al. 2024), or gradually erode core scholarly practices through over-reliance, they threaten the very integrity they promise to enhance. Synthetically generated text and code can mask fundamental gaps in understanding; automated literature retrieval can systematically over-weight low-quality or fabricated sources (Walters and Wilder 2023); AI-generated summaries can background what is salient and important by favoring what is common and likely; the persuasive fluency of AI-generated content can outpace human capacity for verification and validation.
These risks extend far beyond individual research projects to pose community-level threats to the scholarly enterprise. When disclosure practices are weak, when intellectual provenance becomes unclear, and when verification standards deteriorate, the cumulative effect of employing AI threatens public trust in the academic record and undermines the peer-review processes that sustain rigorous scholarship. The challenge is not simply technical but fundamentally social: How do we preserve the cultural norms and institutional safeguards that make academic knowledge trustworthy while embracing AI tools that can genuinely advance human understanding?
This editorial advances a pragmatic framework grounded in the realities of current AI capabilities and existing research practices. Our perspective is consistent with a three-level usage model—Level I: Copy editor, Level II: Research Assistant, and Level III: “Supercollaborator” (Bhargava et al. 2025)—variations of which have been proposed earlier, which provides contingent guidance on appropriate forms of AI assistance, necessary control mechanisms, and critical boundaries that must not be crossed. Throughout, we maintain a fundamental principle: AI as research partner and not research driver. Although AI can legitimately assist with mechanical tasks and exploratory activities (Levels I and II), humans must retain ultimate responsibility for research framing, theoretical development, interpretive judgment, and scholarly contribution. Attempts to offload, outsource, or abdicate these higher-order intellectual functions to AI systems (Level III) without proper human supervision risk compromising both originality and integrity, regardless of how polished and convincing the resulting outputs may appear.
Our stance is deliberately proinnovation and prointegrity, rejecting both uncritical adoption of AI and automatic prohibition. We argue that responsible AI integration requires explicit commitments to three foundational principles: transparency in disclosing where and how AI provided assistance; provenance in tracking sources, prompts, and transformations, as well as documenting AI interaction as research transcripts to enable independent audit; and verification through systematic checking of claims, citations, and computational outputs. Far from slowing the pace of discovery, these principles make rapid research sustainable by maintaining and strengthening the trust and credibility essential to the cumulative building of knowledge. They also align naturally with the distinctive characteristic of IS as a field that bridges technical sophistication with a deep understanding of organizational, behavioral, and societal dynamics.
This editorial offers three interconnected contributions to the IS community. First, we name and bound the phenomenon of automation of invention for IS research, translating recent technical developments into a clear capability stack that distinguishes what current AI systems can reliably accomplish from what they cannot, at this time and with current technology. Second, we operationalize responsible AI use by providing a scaffolding of concrete control mechanisms and disclosure practices that authors, reviewers, and editors can implement immediately. Third, we demonstrate intellectual transparency by critically examining our own use of AI assistance in research and proposing specific innovations to editorial workflows that preserve human judgment while enhancing review consistency and auditability.
Our analysis proceeds in three steps that build systematically toward actionable guidance. Section 2 translates recent technical developments into a practical capability stack and operationalizes our three-level usage model with specific controls and disclosure requirements. Section 3 presents a transparent analysis of our own experimentation with AI in research, which aids in the development of this editorial. In Section 4, we discuss concrete implications for editorial and peer review practices, including immediately implementable safeguards and pilot-ready process innovations. We conclude with specific guidance for skill development and training programs, as well as provide guardrails to direct community norm evolution to ensure IS research remains both genuinely innovative and fundamentally trustworthy in an era of human-AI augmentation.
To ground the discussion, we begin by specifying our scope. We deliberately narrow our scope to avoid common conceptual confusions that plague discussions of AI in academia. We focus on text- and code-based LLMs and their RAG or tool-using variants as applied to core research activities: idea exploration, literature synthesis, academic writing, programming, mathematical proofs, data analysis, and peer review support. Although we address image, audio, and multimodal systems where relevant to IS phenomena, our normative guidance emphasizes scholarly integrity rather than artistic style or creative expression. Importantly, we make no claims that current AI models “think” or “understand” in any human sense. When we refer to AI reasoning, we mean computational procedures that generate plans, proofs, or programs through learned pattern recognition and completion, which are always subject to stochastic failure modes that require human oversight and validation.1
Finally, a note on our approach and evidence base. We write as IS scholars who are deeply committed to cumulative knowledge building and methodological pluralism. Our recommendations are designed for immediate practical application while remaining adaptable as AI capabilities continue their evolution. In contexts where best practices remain unsettled—as many currently do—we consistently favor disclosure and verification over blanket prohibition, and human accountability over delegation of agency to AI systems. We expect both community norms and supporting technologies to change/improve substantially over time. Meanwhile, clarity about boundaries, control mechanisms, and responsibility allocations enables productive experimentation without compromising the hard-earned credibility of the scholarly record.
1.1. Fundamental Concerns: Epistemic and Social Implications of AI Integration
Although this editorial ultimately advocates for thoughtful AI integration, we must first confront several fundamental concerns that demand serious consideration by the IS research community.
Epistemic Challenges: Epistemic assumptions are foundational beliefs about what constitutes valid knowledge or evidence in a given domain (e.g., objectivity, reproducibility, generalizability in scientific research). Foundational LLM models operate through probabilistic pattern matching rather than logical reasoning or genuine understanding. This creates a fundamental tension with scientific inquiry, which typically demands precision, creative thinking, verifiability, and causal reasoning. When AI tools generate plausible-sounding but potentially incorrect hypotheses, literature summaries, or methodological suggestions, they introduce epistemic uncertainty that may be difficult to detect. The risk is not just individual errors but systematic degradation of research quality as these uncertainties compound across studies.
Power Concentration and Research Inequality: The advanced AI capabilities, such as creating bespoke RAG systems or fine-tuned LLMs, require substantial computational resources and specialized expertise, potentially concentrating research advantages among well-funded institutions and researchers. This risks creating a two-tiered system where AI-enabled researchers gain significant productivity advantages, whereas others face relative disadvantage (Abbasi et al. 2024). For a field committed to diverse perspectives and democratic knowledge creation, these power dynamics demand careful attention.
Disciplinary Identity and Methodological Homogenization: IS research’s strength lies partly in its sociotechnical framing of digital phenomenon and methodological pluralism (Sarker et al. 2019)—from econometric studies to qualitative, sometimes adopting interpretive or critical research approach, to design science innovations. Heavy reliance on AI tools, which are trained on existing literature and tend toward statistical patterns, may inadvertently push research toward mainstream approaches and conventional thinking. The risk is not just reduced innovation but erosion of the methodological diversity and distinctive theoretical positioning that enables IS to address complex contemporary phenomena.
Labor Market Implications: The automation of traditionally skilled research tasks raises serious questions about doctoral training and early-career development. If AI can support literature reviews, code analysis software, and draft theoretical frameworks, what skills should we be developing in future researchers? How do we ensure that efficiency gains don’t come at the cost of deep analytical capabilities that define scholarly expertise? Also, how do we make sure that AI use does not take away entry-level research assistant work that helps build a pipeline of candidates interested in entering doctoral programs or, more fundamentally, that provides employment for students to sustain themselves through an academic career?
Authenticity and Intellectual Contribution: Perhaps most fundamentally, extensive AI use raises questions about the nature of intellectual contribution and scholarly authorship. If an AI system generates key insights, theoretical frameworks, or methodological innovations with supervision, what constitutes an authentic and legitimate human contribution to knowledge? These are not merely technical questions but they touch on the core values that define academic scholarship.
These concerns do not necessarily argue against AI integration in research, but demand that we approach such integration with appropriate caution, transparency, and commitment to preserving the intellectual integrity that retains the essence of research that society would find valuable.
2. Overview of Advances in AI and Automation of Invention
Recent technical advancements have transformed AI into a pervasive general-purpose research tool rather than one capable of supporting a narrow single task. For IS research, the result is not a discrete technological shock but shifts in the layers that form academic research workflows, one that touches ideation, design, execution, and exposition. In this section, we take stock of the technical ingredients of modern AI and then map them to a pragmatic, responsibility-preserving usage model for scholarship.
As shown in the AI capability progression layer of Figure 1, GenAI has evolved through a sequence of technical augmentations that expand its role in research. This progression begins with foundation models trained on vast text and code corpora and extends through retrieval grounding, tool use, autonomous reasoning, and finally multiagent orchestration. Each step introduces new affordances but also presents new risks, requiring researchers to reconsider how human judgment and AI capabilities interact. The following subsections unpack these layers in turn, highlighting both their technical logic and their implications for IS research.
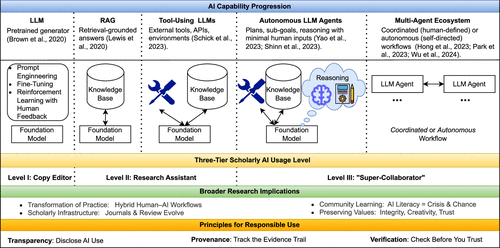
2.1. Evolving Capability Stack for AI
At the base of today’s systems are LLMs, or foundation models, built on the Transformer architecture (Vaswani et al. 2017) and pretrained on vast online text collections to understand and generate human language (Brown et al. 2020). There are several ways to align LLMs with certain domain. First, we can steer foundation models with prompt engineering (e.g., few-shot prompting or chain-of-thought prompting) to shape outputs without updating weights (Brown et al. 2020, Wei et al. 2022b). We can also adapt models with fine-tuning for domain tasks (Ziegler et al. 2019) and instruction tuning so models reliably follow natural-language directives (Wei et al. 2022a). To do this efficiently, low-rank adaptation (LoRA) updates only small adapter matrices rather than all parameters, enabling faster, cheaper customization (Hu et al. 2022). Reinforcement learning with human feedback (RLHF) further aligns outputs with human preferences (Ouyang et al. 2022), and direct preference optimization streamlines alignment without explicit reinforcement learning (Rafailov et al. 2023).
Regarding research affordances, LLMs are especially suitable for drafting texts, rewriting or refining arguments for clarity, summarizing complex materials, and performing multilingual editing or translation (Brown et al. 2020). Yet they still operate on static knowledge and encode information stylistically rather than faithfully (Riemer and Peter 2024) and are not epistemic agents despite strong anthropomorphic conversational fluency (Peter et al. 2025). As a result, they can produce plausible-sounding outputs without factual grounding—that is, hallucinations (Maynez et al. 2020, Ji et al. 2023). Overall, an LLM is like a vast encyclopedia written in probabilistic ink—rich in knowledge but unable to audit its own accuracy.
This observation motivates the first structural addition that reshaped AI capability: RAG, which combines language modeling with information retrieval so that LLMs can access external knowledge sources at the moment of response. Dense retrieval methods enable the system to locate relevant passages quickly (Karpukhin et al. 2020). The retrieved information is then summarized and integrated into coherent texts through architectures such as fusion-in-decoder (Izacard and Grave 2020). Recent approaches, such as GraphRAG, represent retrieved knowledge as interconnected graphs, allowing models to reason over relationships rather than isolated facts (Edge et al. 2024).
RAG expands the LLM capabilities from static recall to evidence-based synthesis—enabling scholars to trace sources, verify claims, and ground analyses in verifiable knowledge. When using RAG, human judgment remains essential to assess coverage and quality, as the tools cannot yet fully eliminate hallucinations because of errors tied to limitations of information retrieval—such as low recall, precision, or source quality—as well as from miscalibration in generation that leads to fabrication or misattribution even when high quality supporting evidence is retrieved (Ji et al. 2023). To summarize, if an LLM is an encyclopedia, RAG is a research assistant who can step outside the library to gather knowledge sources before answering.
A second addition is tool-using LLMs. Beyond retrieval, models now invoke external functions—search engines, code interpreters, data frames, statistical libraries, and domain-specific Application Programming Interfaces—and fold the results back into the task. Early demonstrations include Toolformer for self-supervised API use (Schick et al. 2023), Program-Aided Language Models for program-aided problem solving via code interpreters (Gao et al. 2023), web-grounded systems such as Language Models for Dialog Applications with tool hooks (Thoppilan et al. 2022), BlenderBot 3 with web search and memory (Shuster et al. 2022), Goedel with automated theorem proving (Lin et al. 2025), WebGPT with browser navigation and source citation (Nakano et al. 2021), and WebShop for goal-directed web interaction (Yao et al. 2022). Tool use is not merely convenience. It shifts the workflow from pure text generation into an interleaved cycle of generation and tool-driven action.
For research, this enables actions such as fetching scholarly articles, generating code for data visualizations, and exporting references to a BibTeX list. These early-stage systems remain nonautonomous—they act only when prompted—and thus require human oversight and intervention, since each generative planning step introduces an error rate that can lead to unintended or unhelpful actions. In summary, if RAG learns to look, the tool-using LLM learns to do—executing tasks while guided by human oversight.
A third addition pertains to planning and agentic behavior, namely, autonomous LLM agents, where an individual LLM will plan, reason, and act with minimal human input. These agents extend tool-using LLMs by integrating three core capabilities (Wu et al. 2025): reasoning to decompose complex tasks into steps, maintaining subgoals, and adjusting their plans when required; memory to maintain context across iterations; and tool-use to interact with external environments such as APIs, databases, or code interpreters. Frameworks like ReAct couple reasoning traces with external actions to make decision processes auditable (Yao et al. 2023), whereas Reflexion adds self-critique loops that enable agents to learn from previous errors (Shinn et al. 2023). Recent orchestration frameworks, such as LangChain and LangGraph, formalize these plan–act–reflect cycles through persistent state and checkpointing. Systems like Voyager and SWE agent demonstrate these principles in applied settings, with agents autonomously conducting extended workflows such as code refinement, literature triage, and simulation-based exploration (Wang et al. 2023, Yang et al. 2024). Such autonomous LLM agents offer many possible research affordances, such as mapping study plans into executable steps, conducting scoped literature searches with citation provenance, drafting and testing analysis code, performing data cleaning, estimation, and visualization, and launching simulations or replications.
The development of LLM-based agents is just beginning, and many reported capabilities are contested. First, any LLM application carries a nonzero error rate; in multistep task chains without checks and interventions, those errors can compound and compromise outputs. Second, “reasoning” in LLMs is still evolving (Mitchell and Krakauer 2023, Strachan et al. 2024). The faithfulness of LLMs’ self-generated reasoning traces has been questioned, as studies show that these explanations can diverge from the models’ underlying decision processes (Matton et al. 2025) and that intermediate chain-of-thought outputs often contain unreliable or misleading justifications (Chen et al. 2025). As a result, agentic autonomy can be fragile: agents will drift when objectives are poorly specified, when hallucinations and errors compound, when error signals are weak, or when optimization favors plausibility over validity. For scholarship, this means that agentic configurations must be paired with strong constraints: explicit success criteria, data set and citation provenance, and checkpoints at which humans read the primary evidence themselves. Overall, an autonomous LLM agent is like a strategist with hands, eyes, and a calendar—able to plan, act, and adapt over time with careful supervision.
A further leap is envisioned with multiagent ecosystems, in which several LLM agents, each with specialized roles, interact to carry out complex tasks (Hong et al. 2023, Guo et al. 2024). Unlike single-agent autonomy, robustness is sought via role differentiation and interaction: for example, one agent acts as a searcher, another as a coder, and another as a critic. Coordinated workflows rely on a hierarchical or supervisory controller that assigns roles, curates information flow, and enforces global objectives, exemplified by frameworks such as AutoGen (Wu et al. 2024). Autonomous workflows, in contrast, enable peer agents to negotiate, debate, or self-organize without central control, producing emergent consensus or behavioral diversity. Studies of deliberative debate (Du et al. 2023), social-simulation environments (Park et al. 2023), and cooperative reasoning benchmarks (Zhu et al. 2025) demonstrate how collective intelligence can outperform isolated agents.
For research, this would expand the scope to end-to-end research workflows, parallel theory exploration, and iterative design–evaluate–refine cycles. Yet the complexity of multiagent systems brings new hazards, including inherent reliability issues (Cemri et al. 2025), error cascades, emergent but unverifiable behaviors, and diffusion of authorship credit and accountability. Given that such agentic configurations boil down to interactions between multiple pattern-predicting entities, doubts will persist about the epistemic integrity of the generated outputs. Overall, multiagent systems function like a digital organization—specialized agents cooperating through either managerial control or peer negotiation.
In combination, these layers—foundation model, retrieval grounding, tool use, autonomous agent, and orchestration—constitute the capability stack we refer to throughout this editorial. The stack explains why AI feels qualitatively different from earlier “assistive” tools: it links support for search, synthesis, and action tightly enough that invention-like loops can be executed in hours rather than weeks, provided that the human remains in the loop as arbiter of sense and value. For this, the field will require the development of new guidance and new practices.
2.2. Automation of Invention: Three-Tier Usage Level and Core Human Controls
With the capability stack and research affordances, we ask where automation of invention is most consequential for IS research today or in the near future—and where boundaries must hold. As IS is a fundamentally social science, any such automation raises critical questions about epistemic integrity, when parts of the sense-making that guides research are abdicated to inscrutable AI models. Although automation offers dramatic process speed-ups, it also requires new duties of disclosure and control.
Table 1 outlines three scholarly usage levels—copy editor, research assistant, and “super-collaborator”—each aligned with corresponding AI capabilities (foundation models, retrieval grounding, tool use, agentic reasoning, and multiagent orchestration) and their associated research affordances. For each level, we specify the human role boundary to preserve, likely integrity hazards, and the core human controls anchored in three principles: transparency, provenance, and verification. By transparency, we mean clearly disclosing where and how AI was used. By provenance, we mean maintaining audit-ready records of sources, prompts, model versions/settings, workflows, and artifacts. By verification, we mean actively checking AI-generated claims, citations, code, and analyses for accuracy, reproducibility, and consistency with scholarly standards. Provenance functions as the critical link between Transparency and Verification: it bolsters transparent disclosure by systematically documenting how AI tools were used, and it enables rigorous verification by providing the traceable evidence necessary to audit, replicate, and validate each step of the workflow.
|

Table 1. Automation-of-Invention Framework: Usage Levels, Role Boundaries, Hazards, and Controls Across AI Capability Layers
| Level I: Copy editor | Level II: Research assistant | Level III: “Super-collaborator” | |
|---|---|---|---|
| AI capability | Base/aligned LLMs | RAG + tool-using LLMs | Single and multiagent systems |
| Typical research affordances | Drafting, rewriting, summarizing, multilingual edits | Focused literature Q&A; source-linked summaries; data processing and analysis | Iterative simulation; design–evaluate–refine loops; parallel theory/ model exploration; reviewer simulation |
| Human role boundary | Human authors decide content; AI polishes | Human authors define scope and analysis plan, curates and approves datasets and tools, interprets results, and gives final sign-off before use. | Human authors set objectives and success criteria, design and oversee agent roles, arbitrate synthesis, and retain final decision rights. |
| Integrity hazards | Hallucinated facts introduced; stylistic homogenization | Claim–source mismatches; biased or incomplete data coverage; silent computation errors; inappropriate or mis-specified methods; reproducibility drift from tool/version changes. | Goal drift; error cascades; opaque reasoning; coordination bias; diffuse accountability; unreliable outputs and epistemic confusion. |
| Core human controls | Transparency: Disclose AI editing Provenance: Record language-only use; capture model version, date/settings, and prompts; store with the manuscript for audit. Verification: Manual fact check; confirm that all claims are original and created by human authors | Transparency: Disclose data sources/tools; note access dates and versions; specify automated vs. manual steps. Provenance: Record data inclusion criteria; log prompts and retrievals with citations; archive code and configurations (replication package). Verification: Check citation–text correspondence; rerun key analyses; conduct code review. | Transparency: Disclose agentic setup: goals, roles, coordination structure, decision rights. Provenance: Keep auditable logs of prompts, hand-offs/checkpoints, tool/model versions, and data/config snapshots. Verification: Add human decision gates; use cross-agent checks/redundancy; reproduce key steps and trace errors to source. |
Level I—the copy editor—uses base/aligned LLM models that assist with local improvements to expression and mechanics. A researcher may request rewriting a paragraph for clarity, transforming passive voice to active voice, standardizing terminology, translating an abstract into a second language, or producing a concise summary of an author’s own text. The human role boundary is that ideas, claims, and argumentative structure originate with the human author, and any changes can be reviewed line by line.
Typical integrity hazards include accidental insertion of hallucinated facts and unwanted stylistic homogenization that dilutes the author’s voice. The core controls are as follows: transparency—disclose that AI was used only for copy-editing and describe its scope; provenance—record the model/provider and version, date/settings, and prompt context, and keep an auditable before/after diff (or tracked-changes file) with the manuscript; and verification—manually fact-check edited sentences, lock references, and confirm that all claims are original and created by the human authors.
Level II—the research assistant—extends model involvement to exploratory ideation and bounded technical support under human supervision. At this level, capabilities such as RAG and tool-using LLMs map naturally, because they enhance a researcher’s ability to retrieve, summarize, and operationalize information without replacing judgment or interpretation. Typical affordances include enumerating competing explanations, outlining a study design, triaging literature with citations, scaffolding code, or drafting a boilerplate for methods and data documentation. The human role boundary is that the researcher remains responsible for curating sources, reading the primary evidence, validating code on known cases, and deciding which suggestions to accept. The value of Level II lies in accelerated execution with retained flexibility: Scholars can explore multiple analytical paths and stress-test their reasoning before committing.
However, integrity hazards include over-delegation of intellectual tasks, claim–source mismatches, biased or incomplete data coverage, undetected computation or mathematical errors, and reproducibility drift from changing tool or package versions. These risks can be mitigated through three core controls. First, transparency requires clear disclosure of where AI assistance occurred, including data sources, models, and tools used. Second, provenance entails curating and documenting corpora and data sets, logging retrievals and prompts, and archiving notebooks, scripts, and configurations to enable audit and replication. Third, verification involves cross-checking citations and outputs against original sources, rerunning key analyses or unit tests, and conducting independent code reviews. Together, these practices ensure that automation supports rather than supplants scholarly expertise and accountability.
Level III—the “super-collaborator”—introduces the possibility of outsourcing creative choices that define a contribution, enabled by agentic and multiagent systems that can autonomously plan, coordinate, and iterate on research tasks. With agentic reasoning and autonomous workflows, such systems may propose the core framing, derive central hypotheses, design end-to-end empirical strategies, or produce arguments that the author does not fully understand. This division of labor crosses the line from partner to driver. Although it is valuable to solicit alternatives and adversarial critiques, delegating theorizing or interpretation in ways that sever the link between human authorship and scholarly claims is problematic. Accordingly, the human role boundary should ensure that humans set objectives and success criteria, design and oversee agent roles, arbitrate synthesis, and retain final decision rights.
Integrity hazards at this level include goal drift, error cascades, opaque reasoning, coordination bias, accountability gaps, and—critically—epistemic confusion about how conclusions were reached. To mitigate these risks, IS researchers should ensure transparency by disclosing the agentic setup (e.g., goals, roles, coordination structure, and decision rights); maintain provenance via auditable logs of prompts/messages, checkpoints and hand-offs, and pinned model/data versions; and enforce verification through human decision gates at key milestones (e.g., hypothesis selection and major analyses), cross-agent checks to surface inconsistencies, and reproducibility tests that rerun the analyses with fixed versions and multiple samples/holdouts.
Because AI is tireless and persuasive, fluency can be mistaken for truth and breadth for coverage, our stance is deliberately conservative. We encourage robust use of Level I (copy editor) and Level II (research assistant) assistance, always paired with disclosure, provenance, and verification; and, at this time, we strongly discourage any workflow in which a model’s unexamined synthesis becomes the locus of novelty characteristic of Level III (supercollaborator). The point of automating portions of invention is to widen the space of ideas we consider and to shorten the cycle between conjecture and test—not to relocate agency from scholar to system. When work drifts toward Level III, our current thinking is that the appropriate response is to step back into Level II, use the system to enumerate possibilities and counter-arguments, and then take human ownership of selection, justification, and explanation. This safeguard preserves accountability and makes the contribution clear to reviewers and readers. A key challenge, however, is the difficulty in detecting, if indeed, researchers/authors have harnessed AI as a supercollaborator in their work.
Across all levels, we believe that the core principle should remain unchanged until we have a complete rethinking of the research enterprise: AI may accelerate mechanics and expand exploration, but humans must own framing, interpretation, and accountability. In practical terms, that means authors must be able to explain their choices without appealing to model authority, must provide verifiable artifacts where AI materially contributed to analysis or evidence gathering, and must disclose assistance in a way that allows others to reproduce the workflow. Framed this way, the levels are not a moral ranking of tools but a division of labor that keeps invention human-led even when computation is abundant.
The following section turns from prescription to evidence: we examine our own use of AI, the checkpoints we found necessary in practice, and how those experiences inform the editorial recommendations that follow.
3. Critical Self-Analysis: Accelerating/Automating Our Own Research
We now turn inward to critically assess AI’s implications for research practices within the IS field. The theoretical potential of AI is one thing, but understanding its tangible impact on the day-to-day work of IS scholars requires a more grounded perspective. To achieve this, we undertook a self-analysis exercise: members of our author team examined one of their recent research projects, reflecting on how current generative AI capabilities could have potentially accelerated or automated specific aspects of the research process involved in that particular study.
3.1. Research Questions and Evaluation Design
Our overarching question was: In which parts of IS research can AI augment or automate work without compromising interpretive judgment, methodological validity, or contribution clarity? To answer this, we designed a multi-case self-study across five representative modalities: analytical modeling, econometrics, qualitative research, scale/construct development, and computational design science. Each case documented (i) the tasks attempted with AI; (ii) the human–AI process we followed; (iii) the outputs produced; and (iv) the core controls needed for responsible use. We treated AI as a partner whose outputs must be grounded, verified, and archived alongside human work.
Used thoughtfully, AI expanded our search space, reduced setup friction, and improved the completeness of documentation. The gains were largest when models scaffolded work that we then verified and interpreted. The limits were equally clear: Interpretive judgment, construct definition, and identification choices remained human only.
3.2. Analytical Modeling: Using AI as a Research Assistant
AI demonstrates particular strength as a research assistant in specific technical tasks. In our analysis of a two-sided market model integrating Salop’s circular city framework with platform theory, AI served effectively as an “analytical assistant” for routine mathematical operations.
Where AI Excelled:
Proof Development: AI quickly produced fully worked proofs of key lemmas, including step-by-step algebraic derivations and first-order conditions
Computational Verification: Rapid checking of second-order conditions for concavity and uniqueness
Code Generation: Python scripts for implementing closed-form equilibria and generating publication-quality visualizations
Comparative Statics: Systematic exploration of parameter spaces and welfare implications
What Happened When We Pushed the Nonroutine Parts?:
Problem Formulation: When left to infer missing pieces, the system wrote inconsistent objective terms and mixed assumptions (e.g., transport cost and demand curvature), leading to infeasible setups.
Equilibrium Logic: It mishandled fixed points from cross-side network effects, imposed symmetry where corner solutions bind, and ignored boundary conditions (market coverage/entry), yielding interior solutions that violated constraints.
Global Versus Local Reasoning: It accepted critical points without feasibility or second-order checks across regions, and comparative statics were not consistent at regime boundaries.
Human Value-Add: The AI’s mathematical precision freed researchers to focus on higher-order activities: framing policy insights, interpreting economic intuition behind mathematical results, and connecting formal results to broader theoretical contributions. For instance, although AI computed equilibrium conditions, human insight was essential for understanding why consent-based regimes emerge and persist. At this point, it appears that AI cannot formulate suitable research questions, design appropriate models for specific contexts, or provide economic interpretation of mathematical results. The core intellectual work of theory development remains firmly in the human domain.
3.3. Econometric Analysis: Promise and Pitfalls in Causal Inference
In empirical research, AI shows significant potential as a research assistant, particularly in variable construction and identification strategy development.
Variable Construction Innovations: AI can transform traditionally labor-intensive text processing into prediction problems. For platform governance research, AI can
Analyze terms of service across hundreds of platforms to create standardized variables (e.g., restrictiveness scores, transparency indices)
Convert textual data into high-dimensional embeddings using models like Bidirectional Encoder Representations from Transformers or Generative Pre-trained Transformer
Enable large-scale comparative studies previously impossible to conduct manually
Causal Identification Support: Perhaps, most intriguingly, AI can suggest creative identification strategies:
Instrumental Variables: LLMs can propose plausibly exogenous variation in observational data
Difference-in-Differences: AI can identify treatment heterogeneity and suggest control variables
Research Design: Multistep role-playing prompts enable AI to “think” like economic agents, suggesting experimental setups
Example Application: When prompted to estimate causal effects of platform review moderation policy changes on seller conversion rates, AI suggested a credible difference-in-differences strategy, identifying treated groups (sellers with high unverified negative reviews) and control groups while recommending LLM-based embeddings for matching sellers with similar review distributions.
Critical Limitations: Although AI can suggest identification strategies, it cannot validate the fundamental assumptions underlying causal inference (parallel trends, excludability, etc.). Human expertise remains essential for assessing identification validity and interpreting causal estimates within appropriate theoretical frameworks.
3.4. Scale and Construct Development: Enhancing Rigor and Completeness
For methodological development and scale validation research, AI functions effectively as a research assistant, supporting specific tasks while preserving human control over construct definition and theoretical interpretation (Larsen et al. 2025).
Scale Development Support:
Item Generation: AI can produce lexical variants of theoretically defined items, expanding the initial pool for expert panel review
Bias Detection: Systematic review of survey items for potential gender, cultural, or technological bias
Methodological Completeness: AI can function as a checklist tool, ensuring alignment with community reporting standards
Quality Assurance Applications: Rather than replacing human judgment, AI serves as a methodological auditor, identifying areas where reporting clarity could be improved or essential details might be missing.
Boundary Conditions: AI cannot determine the theoretical distinctiveness of constructs, differentiate between related concepts (e.g., information technology mindfulness versus cognitive absorption), or interpret structural relationships. These remain fundamentally human tasks requiring domain expertise and conceptual clarity.
3.5. Qualitative Research: Promise and Perils of AI Partnership
Qualitative research presents perhaps the most complex and controversial application of generative AI, spanning all three models from copy editor to research assistant.
3.5.1. Data Collection and Augmentation
Synthetic Data Generation: AI can create rich, contextually grounded interview transcripts that provide diverse stakeholder perspectives on research phenomena. Some researchers may try to justify such synthetic data creation based on relative sparsity of certain data (e.g., projects that were failing, or had been declared failures) or lack of diverse stakeholder perspectives, or so-called “edge cases.”2 In our analysis of AI project failures, custom GPT assistants generated highly plausible stakeholder accounts with appropriate role-specific language and perspectives.
Limitations of Synthetic Data: AI-generated transcripts lack the conversational texture of authentic interviews—missing hesitations, repetitions, and authentic speech patterns. Even more critical are the dangers of defaulting to just studying the “typical” issues, potentially silencing the outlier or fringe voices, and even stereotyping – all of which careful theoretical sampling, intensive fieldwork, and in-depth interviewing, associated with certain genres of qualitative research seek to address. Furthermore, the mixing of real and synthetic data raises profound questions about authenticity and validity, especially within realist qualitative traditions.
3.5.2. Analytical Support
Coding Assistance:
Open Coding: AI can generate initial codes with supporting excerpts, although with tendencies toward hallucination and overweighting of certain data sources
Axial Coding: Effective at identifying higher-order categories and relationships
Constant Comparative Analysis: Can trace code evolution across iterations, providing transparency often missing in traditional GTM reporting.
Theoretical Development: AI shows capability in applying theoretical lenses (e.g., dialectical perspective, critical social theory) to generate initial theoretical analyses and even propositions, although these can initially lack the sophistication expected in high-quality scholarship.
Critical Concerns: The use of AI in qualitative analysis raises fundamental questions about the nature of qualitative research, particularly those based in the interpretive or critical traditions. Many scholars view the cognitive and creative activities of coding and theorizing as uniquely human endeavors that should not be automated or augmented by AI; this will be an issue that will be debated and discussed in future forums. At this time, there appears to be an agreement that, although AI tools can assist with mechanical aspects of qualitative research (transcription, initial coding, initial pattern identification), the core interpretive work—understanding meaning, developing theoretical insights, and ensuring cultural sensitivity—must remain under human control.
3.6. Computational Design Science Research: AI as a Design Turbocharger
Computational design science research provides a natural context for AI to act as a research assistant and, to a constrained extent, as a “supercollaborator.” Because the design cycle requires repeated iteration between problem framing, artifact building, and evaluation, AI’s speed in generating code, scaffolding prototypes, and documenting artifacts can significantly accelerate progress while still requiring human oversight for conceptual alignment and theoretical grounding.
AI-Supported Design Cycle:
Literature Review and Benchmarking Method Identification: AI rapidly synthesized prior methods into comparative tables of benchmarks, data sets, and evaluation metrics, providing a structured overview to guide design choices. This capability is particularly valuable in computational design science, which often requires integrating insights across multiple reference disciplines—such as computer science, IS, and problem-domain literatures (e.g., healthcare).
From Pseudocode to Code and Prototypes: When researchers expressed algorithms or procedures in pseudocode, AI translated them into executable modules with clear docstrings, inline comments, unit tests, and integration hooks for existing pipelines. Beyond backend functionality, AI also generated scaffolds for simple user interfaces, making it possible to deploy clickable prototypes rapidly. This accelerated the transition from conceptual design to testable artifact, enabling researchers to gather early feedback, conduct preliminary evaluations, and iterate more quickly on both functionality and user experience.
Evaluation Support: AI was able to propose evaluation protocols, identify design-relevant KPIs, generate test cases, and even suggest constructs for user studies (e.g., trust, usability, adoption). It can draft survey items, experiment designs, and simulation scenarios to probe artifact performance. Beyond setup, AI can analyze error patterns by highlighting systematically misclassified or underperforming cases and brainstorming potential remedies.
Documentation and Transparency: AI was able to generate README files, workflow notes, and code documentation following FAIR principles (findable, accessible, interoperable, reusable). These materials can support compliance with transparency requirements and enable code sharing with the broader community to promote adoption and reuse.
Limitations Observed: Although AI proved valuable for accelerating code generation, prototyping, evaluation, and documentation, it was less effective in producing genuinely novel artifact designs or anticipating the broader sociotechnical implications of a system. Generated code, although often executable, typically requires debugging, optimization, and adaptation to meet efficiency and scalability requirements. Most importantly, AI lacked the ability to justify how an artifact addressed the meta-requirements of a design problem, justify its novelty in terms of design principles, situate it within an existing body of kernel theories, or clarify the design pathways that encompass abstract spectrum, artifact typology, desirable traits, and necessary characteristics. These limitations confirm long-standing Design Science Research insights that the intellectual core of design science—problem relevance, theoretical grounding, evaluation rigor, and contribution articulation—remains firmly the responsibility of human researchers.
Suggested Human–AI Augmentation Workflow: A more productive balance emerges when AI is leveraged for routine but time-intensive tasks—literature benchmarking, pseudocode translation, code scaffolding, and documentation—whereas human researchers take on higher-order intellectual work. Human expertise is essential for adapting artifacts to domain-specific contexts, ensuring conceptual relevance, and grounding evaluation in sociotechnical realities. Researchers also provide the creativity and judgment needed to connect computational artifacts to IS theory, interpret evaluation outcomes, and refine designs according to normative criteria such as fairness, trust, and usability. In this division of labor, AI serves as a rapid prototyping partner, while human scholars safeguard rigor, theoretical meaning, and knowledge contribution—ensuring that design science research delivers not just functional artifacts but actionable and generalizable design knowledge.
3.7. Cross-Methodological Insights: Common Patterns and Persistent Challenges
Our self-critical analyses map the benefits and limits of automation of invention across methods, highlighting where AI assists and where human judgment must prevail.
In quantitative work, the healthiest uses of automation of invention are those that expose assumptions rather than obscure them. AI is already useful for refactoring code, narrating diagnostics, and stress-testing designs before data are locked. It can surface alternative specifications, contrast parameters of interest across related literatures, and suggest edge cases that challenge a preferred model. These accelerations are compatible with Level II (research assistant) because they widen the space of options and make premortems routine. What must remain human are the choice of identification strategy, the interpretation of discrepancies, and the argument for why a given empirical pattern adjudicates between theories. A model can enumerate reasons; it cannot be the reason we believe a claim.
In qualitative research, automation of invention helps when it accelerates mechanics without diluting meaning. Transcription, anonymization, and structured memoing are valuable so long as researchers engage with the raw materials and treat generated labels or themes as provisional codes/categories and patterns to be checked against the corpus. Risks grow when synthetic text substitutes for field experience, when retrieval pipelines overweight constructed summaries relative to primary artifacts, or when persuasive fluency outpaces verification. Returning to original notes, transcripts, or recordings at analytic inflection points—paired with citation of exact excerpts and transparent coding histories—keeps interpretation grounded in lived texture rather than in fluent generalization. These practices preserve the partner-not-driver stance: AI assists the mechanics of seeing and organizing; humans do the seeing and thinking.
Design science and artifact-centric work benefit from rapid prototyping enabled by AI. Interfaces can be scaffolded, test harnesses generated, and user-journey variants proposed, making it feasible to explore multiple concepts before committing serious resources. The limit appears when evaluation drifts from measuring properties of a human-designed artifact to accepting one that the model happened to produce. In such settings, the more the AI system participates in generation, the more evaluation must emphasize traceability, benchmarking against explicit requirements, and human-interpretable rationales for design choices. Outputs should be treated as candidate designs to be critiqued and iterated, not as authoritative solutions.
These method-specific opportunities are reflective of the Janus-faced nature of contemporary systems. AI models are probabilistic pattern-matchers: They excel at encoding and reproducing structure from training data but lack genuine understanding, common sense, and the capacity for causal reasoning. As a result, they sometimes produce fluent fabrications, they can perpetuate or amplify biases in their sources, and they complicate reproducibility when intermediate steps are not logged. Tool use, retrieval grounding, and orchestration improve reliability by interleaving generative planning with verifiable actions, yet none of these removes the need for human judgment. The opacity of complex models can make it hard to explain why a particular output was generated, which is precisely why provenance and audit trails—prompts, retrievals, code executions, and decisions—must accompany AI-assisted work.
Several themes emerge across our methodological analyses.
3.7.1. Partnership Model.
Across all methodologies, AI functions most effectively as a research partner rather than research driver. In other words, most scholars are not comfortable with the supercollaborator model today. Although AI can aid in and accelerate specific tasks—from mathematical proofs to literature synthesis—the intellectual work of research question formulation, the creative formulation of solutions, theoretical interpretation, and contribution framing in IS research should remain human for the near future.
3.7.2. Validation Imperative.
The probabilistic nature of AI outputs demands rigorous human verification across all applications. Whether checking mathematical derivations, validating literature summaries, or reviewing code functionality, human oversight and accountability are nonnegotiable. Such verification can be supported by AI on an elementary level, but not replaced. For example, some computer science conferences experiment with automated presubmission feedback or additional generated reviews, but such feedback does not replace the human review process; rather, it supports it.
3.7.3. Skill Evolution, Not Replacement.
Rather than deskilling researchers, effective AI integration requires new competencies: prompt engineering, context engineering, output validation, bias detection, and strategic task allocation between human and artificial intelligence.
Our self-analysis shows that AI can speed up legitimate parts of the workflow while also creating new failure modes. The near-term task is to use assistance as scaffolding—and pair it with human verification and interpretation. It also shows that AI may be applied in ways that are not considered legitimate at the present time. Authors should be aware that there could be severe sanctions for the use of AI for certain tasks (e.g., generating interview data for qualitative research).
3.7.4. Immediate Opportunities.
Streamlined literature mapping and evidence integration. An example is as follows: use RAG tools to assemble a focused corpus, de-duplicate references, and extract rival mechanisms with source links; authors then read the primary texts and write the synthesis themselves.
Enhanced methodological reporting and completeness checking. An example is as follows: checklist passes that flag missing sampling frames, item wordings, invariance tests, or decision rules; authors decide and document the fixes.
Accelerated coding and preliminary analysis (when appropriate). An example is as follows: refactor data-cleaning scripts, generate unit-tested transformations, and create diagnostic plots for outliers/imbalance before confirmatory modeling.
Improved accessibility for nonnative English speakers. An example is as follows: targeted rewriting for clarity and tone, plus consistent terminology and LaTeX/typesetting clean-up without adding claims.
3.7.5. Persistent Challenges.
Hallucination and error propagation. An example is as follows: unsupported statements in related work or mis-computed coefficients carried from drafts into tables.
Bias amplification in analysis and integration. An example is as follows: over-reliance on English-language or mainstream-venue corpora that skews what gets cited or retrieved.
Authenticity/validity in qualitative contexts. An example is as follows: auto-transcription and auto-coding that bypass researcher immersion, reflexivity, and participant meaning; fabricated or de-contextualized quotes.
Over-reliance and skill atrophy. An example is as follows: accepting model-suggested constructs/specifications without justification; optimizing metrics over meaning.
Detection of inappropriate use of AI with certainty remains a challenge.
AI can expand the search space of ideas, reduce setup friction, and improve documentation completeness. Gains are largest when assistance scaffolds work that scholars then verify and interpret. Limits are equally clear: question and hypothesis formulation, theorizing, construct definition, creative interpretation, and identification choices remain human only. Credible claims about AI-enabled productivity or quality require transparency about where assistance entered, provenance that permits audit, and verification artifacts (prompts, retrievals, code, and checkpoints) that explain how results came to be, as illustrated in Table 2.
|
Table 2. Critical Self-Analysis of Automating Research Practices Across IS Paradigms
| Analytical modeling: AI as mathematical co-pilot | |
| Objective | Specify and analyze a formal model to examine how a policy or technology choice reshapes incentives and welfare. |
| AI’s role | Draft proof scaffolds, propose algebraic steps, check second-order conditions, and generate simulation code to explore parameter spaces. |
| Process | We began by writing the economic environment and equilibrium concept in natural language, then prompted AI for candidate proof outlines and code stubs. We grounded derivations by re-deriving critical steps manually and by using independent symbolic tools where needed. |
| Outputs | Candidate lemmas, step-wise derivations, and Python code for simulation and comparative statics. |
| Controls | All core math was re-derived by the authors; simulations reproduced analytical predictions within tolerances. |
| Econometrics: Design enumeration under human identification | |
| Objective | Estimate causal effects when multiple designs are plausible. |
| AI’s role | Enumerate design options (e.g., DiD variants, event studies, IV strategies), generate starter analysis scripts, and triage related literatures via retrieval. |
| Process | We provided a design brief (units, timing, outcomes, threats), asked AI to list viable designs and diagnostics, and generated code skeletons. Humans then evaluated identification assumptions (parallel trends, exclusion restrictions), selected estimators, and set pre-registered specifications. |
| Outputs | A short-listed set of designs, code templates, and a diagnostic plan. |
| Controls | Assumptions were adjudicated by researchers |
| Qualitative research: Assistive, not involving creative interpretation and theorizing | |
| Objective | Develop grounded insights from interviews, documents, and field notes. |
| AI’s role | Transcript tidying, candidate codebook creation, cross-document retrieval, and suggestion of rival interpretations. |
| Process | We anonymized transcripts, used AI to propose initial codes and memos, and iteratively reconciled them with human coding. We explicitly treated interpretation and theorization as human-only activities. |
| Outputs | Cleaned transcripts, draft codebooks, retrieval trails, and memos enumerating alternative explanations. |
| Controls | Researchers checked emergent findings against audio/original notes, and recorded adjudication rationales (when there were contradictions). |
| Scale and construct development: Facilitating lexical breadth, ensuring human boundaries | |
| Objective | Define constructs and craft appropriate items. |
| AI’s role | Generate lexical variants, flag jargon or sensitive terms, and suggest readability edits. |
| Process | Starting from theory- or evidence-based construct definitions and exemplar items, we asked AI to propose variants and to run basic bias scans over public corpora. |
| Outputs | Candidate item sets and flagged terms |
| Controls | Domain experts screened items; pilots tested reliability/validity; inclusion/exclusion decisions remained theory-anchored and human-led. |
| Computational design science: Design turbocharger | |
| Objective | To design, implement, and evaluate computational artifacts that address IS problems while accelerating the traditional build–evaluate–refine cycle. |
| AI’s role | Foundation models serve as the backbone for problematization, design and evaluation. AI conducts rapid literature triage and benchmarking, translates pseudocode to code, scaffolds user interfaces for evaluation, and generates comprehensive documentation. |
| Process | Researchers specify the problem environment and design goals in natural language. AI assists by synthesizing relevant literature, identifying benchmarking methods and drafting pseudocode. Humans refine and select designs, then prompt AI to translate pseudocode into functional code modules and scaffold prototypes with UI components for user evaluation. Finally, use AI to generate comprehensive documentation for code-sharing and transparency materials. |
| Outputs | Benchmark tables and literature maps, executable modules with reproducible notebooks, data processing pipelines, clickable prototypes with UI, and transparent documentation including model cards, READMEs, and code comments. |
| Controls | Transparency: log prompts, versions, and AI contributions; Provenance: archive datasets, code artifacts, and workflow histories; Verification: unit tests, reproducibility checks, robustness analyses, and human rederivation of critical design and evaluation steps. |
4. Landscape of IS Research with GenAI in the Not-so-Distant Future
The integration of GenAI into IS research will transform how our discipline produces, validates, and disseminates knowledge in the next few years. This transformation will extend far beyond the adoption of new tools, and will demand a fundamental reimagining of scholarly practice, community learning, institutional infrastructure, and the preservation of appropriate academic values underlying research. The following exploration examines how human-AI collaboration is revolutionizing research workflows, why the resulting technical literacy gap represents both crisis and opportunity for our community, how journals and professional development systems must evolve together to support responsible AI integration, and ultimately, how the IS research community can embrace these powerful capabilities while preserving the intellectual rigor and ethical foundations that give scholarly work its meaning and legitimacy.
4.1. Transformation of Scholarly Practice
The familiar arc of scholarship—reading to frame questions, designing studies with suitable methods, assembling and analyzing data, and interpreting results—now runs alongside assistants that can draft prose, retrieve and ground evidence, refactor code, and narrate diagnostics. It can even generate data and aid in conceptual development, which deserves extreme caution on the part of researchers. The immediate effect is a change in pace and breadth. We can canvass a wider set of alternatives before committing, and we can instrument routine steps so they are less fragile and better documented. What must not change is authorship over ideas: scholars still ask the questions, own the choices, and stand behind the claims.
Consider qualitative work. In an AI-augmented grounded-theory project, assistants can help with mechanical tasks that often absorb early cycles of attention: segmenting transcripts into candidate incidents, harmonizing a codebook, or generating concordance views that surface recurring phrases and unexpected co-occurring terms. These aids can keep materials organized and make it easier to notice tensions. But the engine of the method—memoing, theoretical sampling, and the adjudication of competing interpretations—remains human. Researchers decide when two categories are genuinely distinct, which distinctions matter conceptually, and what kinds of additional evidence are needed to resolve a disagreement. Used this way, the assistant does not “do grounded theory.” It helps maintain procedural completeness while preserving the space in which human interpretation unfolds.
Quantitative workflows display a similar division of labor. Before data are locked, assistants can stress-test designs by enumerating rival specifications, suggesting edge cases that would challenge a preferred model, and writing brief diagnostics that make assumptions explicit. Tool-using systems can produce unit-tested transformations, generate tidy data summaries, and create visual checks for outliers, imbalance, or seasonality. After estimation, assistants can verify that tables correspond to code outputs, that coefficient labels are consistent across text and figures, and that robustness claims match models actually present in the repository. None of this replaces identification strategy or inference; humans must still choose estimators, weigh tradeoffs, and interpret magnitudes. The value of assistance lies in the speed and breadth with which we examine defensible paths and not in offloading the responsibility to select one.
Literature review work can be recast in the same key. RAG-based LLM systems can assemble focused corpora with traceable links to sources, de-duplicate references that differ only in citation style, and highlight rival mechanisms that recur in adjacent literatures. They can suggest contrasts among parameters (quantities) of interest—for example, whether comparable studies report treatment-on-the-treated, intent-to-treat, or local average treatment effects, or, in noncausal settings, whether reported quantities are marginal means, conditional effects, or elasticities under particular functional forms. These are maps, not verdicts. Authors must still read primary texts, adjudicate between explanations, and write the integrative argument in their own voice.
The worry that speed will erode deliberation is legitimate. A practical countermeasure is to build deliberation into the workflow. When an assistant proposes multiple specifications, the research team concisely records why the final choice was made and what would change under an alternative. When the tool surfaces an edge case or conflicting evidence, the team captures the reason for inclusion or exclusion. Small habits like these convert acceleration into transparency. They also create artifacts that help other humans audit how results came to be: short decision logs, prompt histories, and retrieval trails that travel with the manuscript.
In laboratory and field contexts, a similar pattern plays out. Assistants can help run design–evaluate loops for interface variants, simulate congestion regimes before deployment, or generate checklists to ensure that materials, protocols, and analysis notebooks are archived. But it remains the investigator’s job to choose constructs, justify measurement strategies, and determine whether observed effects carry the interpretive weight the paper claims. What changes is the seam where automation ends and interpretation begins. We gain leverage by making that seam explicit: The tool proposes, the human scholar disposes, and the record shows the difference.
4.2. Community Learning Challenge
Because capable tools are broadly available, a literacy gap has opened between what systems can produce and what scholars can responsibly accept. Fluent prose and tidy figures can mask fabricated citations, spurious links, method shortcuts, and, more broadly, intellectual laziness. The difficulty is not simply technical competence—it is also cultural fit. IS research often interrogates implicit norms in sociotechnical systems—tacit rules, role expectations, and institutional logics—not merely patterns in text or data. Recognizing, naming, and theorizing norms requires domain knowledge, reflexivity, and situational understanding, which is not equivalent to identifying correlations. Moreover, the black box character of modern systems sits uneasily with norms of transparency and reproducibility, even as adoption pressure grows.
The risks show up in ordinary practice. A junior scholar approaches an assistant with the query habits learned from web search, unaware that prompt design and context formulation fundamentally shape output quality, bias, and reliability. They receive confident responses filled with plausible but incorrect connections across literatures, along with citations that look real but lead nowhere. Because the system presents information with unwavering certainty, verification is especially difficult for those who do not grasp the probabilistic and stylistic nature of these models. The result is a subtle drift in the direction of convenience: mechanically produced structure is mistaken for understanding.
A concrete example helps. In a model-assisted review of “algorithmic governance in gig platforms,” a naive retrieval can over-weight computer-science fairness metrics and under-represent labor studies and Global South scholarship. The resulting summary normalizes a managerial framing and sidelines worker agency. The problem is not simply that the sample is unbalanced, but that the downstream theoretical lens quietly shifts. We do not solve this by forbidding assistance. We solve it by building literacies and habits that make such shifts visible and corrigible.
What does such literacy look like? It begins with evidence-based reading, where model-generated summaries are checked directly against the source PDF, with unsupported claims and misattributions explicitly annotated. It then requires pluralized retrieval, meaning every literature search is run through multiple query paths, corpora, and languages, with scholars documenting what is missing—not just what is found. Literacy also includes minority reporting, where researchers record counter-evidence, edge cases, and alternative mechanisms so that synthesis becomes an argument with evidence rather than a fluent collage. In addition, scholars must maintain transparent assistance trails by archiving prompts, tool calls, and retrieval logs so others can reconstruct how AI shaped the search and selection of materials. Finally, literacy entails governance in action: checking data provenance and licensing, avoiding the upload of sensitive materials to closed systems, and using explicit stopping rules for when to return to manual reading, hand calculation, or independent derivation.
Equity belongs in the literacy conversation. Colleagues outside well-resourced institutions may have limited access to commercial tools or paywalled corpora. A community answer includes open models and indexers tuned to IS domains, teaching resources that do not presume expensive subscriptions, and shared datasets, prompts, and notebooks that enable replication regardless of institutional wealth. The goal is not merely to make scholars faster, but to make the field fairer by distributing the benefits of augmentation.
4.3. Reimagining Scholarly Infrastructure
Peer review concentrates the scarcest resource in research: expert attention. Thoughtful AI augmentation can help use that attention where it matters most. Assistants can prepare targeted summaries keyed to a manuscript’s questions, scan methods for standard validity threats, and map adjacent literatures so reviewers arrive better oriented. The goal is not to replace judgment but to clear away mechanical checks and make space for interpretation—assessing theoretical contribution, methodological fit, and broader implications.
To do this responsibly, we encourage building pluralism into the workflow. Algorithmic filters can freeze the canon and squeeze out new ideas, so search should reach beyond top venues and beyond English. Weighting should lift work from underrepresented regions, fields, and methods. Summaries should note conflicting findings and edge cases, not just the majority view. Rotate appraisal prompts across different lenses—economic, sociotechnical, and critical—and keep suggestions “blind” so prestige signals do not sway decisions.
Example: A manuscript on platform governance cites only North American IS studies and concludes that ratings increase trust. A pluralist assistant would flag this bias, retrieve labor relations and Global South work showing ratings as tools of control, and produce a one-page counter-view. The reviewer remains responsible for weighing the evidence and justifying their recommendation.
Policy and education must evolve with infrastructure. Journals can require authors to show the process, including what tools were used, which prompts and versions were run, and where human judgment entered the workflow. They can also reject outcome-only claims that amount to “the model says so,” and publish clear examples of good practice across methods and domains. Reviewer rubrics can explain how to interpret minority reports or conflicting agent outputs, when to ask for a human-run replication, and what evidence counts as adequate provenance for code, data, and decisions. Editors and programs can back this up with training so that authors, reviewers, and students share a common standard for transparency, provenance, and verification.
4.3.1. Where Venues Are Evolving: aiXiv and Agents4Science.
Two experiment-ready venues preview what scholarly infrastructure may look like in agentic research of the future: the aiXiv platform for human–AI coauthored work and the Agents4Science conference that explicitly positions AI systems as both authors and reviewers.
aiXiv (Zhang et al. 2025) proposes a closed-loop, multiagent workflow in which research proposals and papers are submitted, reviewed, and iteratively revised by both human and AI scientists. Its architecture exposes APIs, including model context protocol (MCP) interfaces—an open standard that lets AI agents connect to external tools, data sources, and other agents through a common schema—so heterogeneous agents can coordinate. The authors report quality gains after iterative revision cycles on the platform.
Agent4Science (2025) is the first conference to require AI as the primary (first) author and to run a review pipeline that includes multiple AI reviewers with a human oversight committee. The call for papers mandates an AI Contribution Disclosure checklist within the LaTeX template, encourages a Reproducibility Statement, and adopts NeurIPS-style ethics and review templates—making the evaluation criteria and model details transparent.
aiXiv’s closed-loop, multiagent submission→review→revision model and Agents4Science’s deliberate use of AI as authors and reviewers illustrate a pragmatic path: enable agentic participation, but insist on disclosure, artifacts, and nondelegable human responsibility. Besides the experimental character of these approaches, it remains to be seen if they yield interesting results and to what extent such results will be trusted. It is also important to carefully assess whether work within different theoretical and methodological traditions can benefit equally from these paths.
4.3.2. Experiments with AI-Generated Reviews.
A growing number of conferences have begun experimenting with AI-generated reviews and review-support tools. Below, we summarize several prominent initiatives that have sparked extensive discussion within their respective communities.
The International Conference on Learning Representations (ICLR) 2025 introduced a “review feedback agent,” an LLM-based system designed to improve review clarity, actionability, and professionalism. Implemented as a large-scale randomized controlled trial, the system provided optional feedback to more than 20,000 randomly selected reviews. The results were notable: 27% of reviewers who received feedback chose to update their reviews, incorporating more than 12,000 of the agent’s suggestions. Those updates resulted in substantially longer and more informative reviews—on average, 80 words longer—according to blinded evaluations.
The AAAI Conference on Artificial Intelligence (AAAI) 2026 piloted a different approach. Each paper received one AI-generated review during Phase 1, alongside the standard human reviews. The LLM did not assign scores but produced detailed summaries, literature checks, and balanced discussions of strengths, weaknesses, and technical issues. Although many researchers were initially skeptical, postconference surveys found that roughly 40% of authors considered the AI-generated reviews helpful—although often overwhelming in their level of detail. Persistent concerns include hallucinated claims, formulaic phrasing, and the reinforcement of biases embedded in training data.
The ACM Symposium on Theory of Computing (STOC) 2026 has taken yet another route by offering optional automated presubmission feedback. Authors can use a Gemini-based LLM tool optimized for verifying mathematical rigor and identifying technical inconsistencies before formal review. The tool’s use is voluntary, and the generated feedback is not shared with the program committee. Importantly, submitted papers are neither stored nor used for model training, ensuring confidentiality.
AI offers intriguing possibilities for improving peer review, but skepticism dominates: Questions of motivation, validity, and fairness persist, and human judgment remains indispensable. Studies confirm clear efficiency gains but also reveal shallow understanding of domain knowledge, factual errors and hallucinations, bias in scoring, loss of confidentiality, and homogenization of comments (Zhuang et al. 2025). Progress depends on gathering rigorous evidence and developing thoughtful deployment strategies before wider adoption (Naddaf 2025).
4.4. Preserving Scholarly Values
The main risk is cultural drift. We start to equate fluent output with understanding, and convenience crowds out core scholarly habits: patience with complexity, tolerance for ambiguity, systematic method, and a willingness to challenge assumptions. Those virtues are cultivated by engagement with primary sources, by slow thinking alongside fast iteration, and by accountability for claims. AI assistance does not automatically erode these virtues, but it can when we treat speed as a substitute for care.
A more attractive alternative is disciplined adoption. We use AI to handle routine analytical tasks, widen the option set, and expose assumptions, and we reserve the essential work of interpretation, contextualization, and theory-building for humans. We normalize visible process so that readers can reconstruct how results came to be: prompts, retrievals, notebooks, and checkpoints travel with the paper; boundary statements clarify what the assistant did and what the authors decided. We expect reviewers to read minority reports and to request additional human-run checks when the stakes are high. Also, we invest in literacies that help scholars recognize when model fluency masks gaps in evidence or leaps in logic.
Disciplined use of AI is not about self-denial. It is a way to produce better scholarship. In the near term, success means papers that show how the results were generated, that compare reasonable alternatives before choosing one, that acknowledge competing explanations and explain why they were set aside, and that share code, data, and logs so others can audit and build on the work. The real benefit is not faster writing but clearer claims and stronger evidence. If AI is to count as augmentation, it should help us produce arguments that are easier to follow, methods that others can reproduce, and findings that accumulate rather than disappear into one-off results.
This editorial does not assume a radical break with scholarly culture. Will the current academic system of scholarly journals, based on human (or human-led) peer review, be upended, with the increasing capabilities of AI to incorporate human values and judgment, apart from a variety of cognitive skills? For this editorial, we side-step this question and the radical changes that may occur, and, instead, discuss an adaptive approach in which practices, policies, and tools remain coherent over the next few years. The point is to pace integration so that values and infrastructure move together: journals piloting pluralist review aids and artifact requirements; departments teaching boundary-aware use; communities building open, domain-tuned tools; and authors keeping meaning-making where it belongs—with humans, accountable for claims. What matters is not the slogan attached to the moment, but the workmanship of the path we choose to walk.
5. Conclusion: Toward Responsible AI Integration in IS Research
GenAI marks an inflection point for IS scholarship—not for the novelty of the tools alone, but for how we choose to integrate them into the craft of making reliable, useful knowledge. The opportunity is real: faster iteration, broader canvassing of alternatives, and better documentation. The risk is equally real: a slow erosion of judgment if fluent outputs are mistaken for understanding. The task before us is to turn capability into credible scholarship without compromising the intellectual practices that make research worth trusting.
Our editorial makes three commitments. First, we treat AI as augmentation, not substitution. Models can draft, retrieve, refactor, and stress-test, but humans choose questions, define constructs, set identification strategies, and own claims. Second, we recommend a visible process as the price of trust—transparency about where assistance entered, provenance that allows audit, and verification that demonstrates results survive scrutiny. Third, we argue for adaptive change in venues and training so the community learns together rather than delegating judgment to opaque systems. These commitments reframe the boundary between tool and author while keeping meaning-making squarely human.
Carrying this stance into practice requires specific actions from each actor in the ecosystem, and we believe that in the near future:
Authors might start using AI to widen the option set and to expose assumptions, although not to outsource interpretation. In quantitative work, that means letting tools enumerate rival specifications and edge cases while the research team justifies final choices and documents counterfactual paths not taken. In qualitative work, that means letting tools tidy materials and surface tensions while the researcher does the memoing, adjudicating, and theorizing. Across methods, manuscripts should “show their work” with short decision logs, prompt histories, retrieval trails, links to code, and notebooks, the iterative nature of interpretation or constant comparative analysis employed by some qualitative research traditions, so others can see how claims were formed and reproduce key steps, as illustrated in the control mechanisms in Table 1.
Reviewers will move toward conserving judgment for high-value tasks and welcome assistant-prepared orientation—question-aligned summaries, method checklists, and corpus maps—while insisting on pluralism in what is surfaced as appropriate. Similarity metrics and citation maps are context, not gatekeepers; minority-report views and nonprestige sources belong in the reviewer’s option set. AI-generated reviews are being piloted across multiple conferences, and there are lively discussions on whether they meaningfully enhance the review process. Above all, reviewers should retain intellectual ownership of recommendations and expect process-visible artifacts when AI materially shaped a submission.
Editors and journals will increasingly go beyond blanket prohibitions or perfunctory disclosures. Practical steps include piloting process-visible submissions and assistant-aided review; requiring artifact bundles (prompts, retrieval logs, code, checkpoints) when AI assistance is claimed; and publishing short exemplars that illustrate acceptable use by authors and reviewers. Such policies educate while they govern, reinforcing that outcome-only assertions (“the model says so”) are not evidence.
Programs and professional development should teach two things in tandem: tool literacy and human judgment. Students need hands-on practice with retrieval sensitivity, prompt design, audit trails, and bias checks—and equally, they need a curated, human-taught corpus of anchor texts and debates that sits outside the model. The aim is not merely competence with software, but durable habits of framing, interpretation, and value judgment, and a deep appreciation of human-machine collaboration within the framework considered legitimate for a particular community or outlet.
The community at large should invest in open domain-adapted AI assistance that reflects IS values—methodological pluralism, sociotechnical awareness, and ethical attention—rather than remain passive consumers of general-purpose commercial tools. Building and maintaining shared corpora, indexers, prompts, templates, and exemplars is a practical route to equity as well as quality, ensuring that colleagues outside elite institutions can participate fully in the benefits that AI brings to the table.
If we succeed, the markers of progress will be obvious. Papers will compare plausible alternatives before settling on a path, and they will say why. Tables and text will align because the analysis is scripted and checked. Literature positioning will include a short minority report rather than burying conflicting findings. Repositories will travel with submissions so that others can audit and extend. Review will feel less like triage and more like interpretation because assistants have cleared the brush (such as format checks, citation verifications, basic robustness checks) while editors enforce artifact expectations on theory, method and rigor. Together, these practices raise the ceiling on what our field can credibly claim.
IS is well placed to lead. Our field adopts a sociotechnical perspective to studying contemporary phenomena (Sarker et al. 2019), such as digital transformations—including the very transformation now touching academia. That vantage should make us early exemplars of responsible augmentation: pairing capability with culture and speed with skepticism. Other disciplines will watch how we balance efficiency and rigor and equity and access, and how we ensure that human accountability remains nondelegable.
The path forward is neither a romantic return to pre-AI workflows nor a headlong rush to automate judgment. It is a disciplined, adaptive integration—one that treats models as powerful assistants, insists on visible process, invests in shared infrastructure, and preserves the human work of framing, interpretation, and accountable claims. If we get this right, the payoff is not simply more output; it is clearer contributions, stronger evidence, and a more cumulative record that others can trust and build on. That is a future worth choosing—and building—together.
1 Tools such as AlphaGeometry are symbolic-neural hybrids that link LLM-style reasoning with formal verifiers.
2 For the time being, we would consider the creation and use of such data as unacceptable for research and a significant ethical violation.
References
- (2024) Pathways for design research on artificial intelligence. Inform. Systems Res. 35(2):441–459.Link, Google Scholar
Agent4Science (2025) Open conference of AI agents for science. Retrieved September 24, https://agents4science.org.Google Scholar- (2024) ResearchAgent: Iterative research idea generation over scientific literature with large language models. Preprint, submitted April 11, https://arxiv.org/abs/240407738.Google Scholar
- (2025) Guidelines on the Use of AI/Gen AI: Recommendations for INFORMS Journals (INFORMS, Catonsville, MD).Google Scholar
- (2024) GenAI et al. Cocreation, authorship, ownership, academic ethics and integrity in a time of generative AI. Open Prax 16(1):1–10.Crossref, Google Scholar
- (2020) Language models are few-shot learners. Adv. Neural Inform. Processing Systems, vol. 33 (Curran Associates Inc., Red Hook, NY), 1877–1901.Google Scholar
- (2025) Why do multi-agent LLM systems fail? Preprint, submitted March 17, https://arxiv.org/abs/250313657.Google Scholar
- (2025) Reasoning models don’t always say what they think. Preprint, submitted May 8, https://arxiv.org/abs/250505410.Google Scholar
- (2023) Improving factuality and reasoning in language models through multiagent debate. Preprint, submitted May 23, https://arxiv.org/abs/2305.14325.Google Scholar
- (2024) From local to global: A graph RAG approach to query-focused summarization. Preprint, submitted April 24, https://arxiv.org/abs/240416130.Google Scholar
- (2023) Pal: Program-aided language models. Proc. Internat. Conf. Machine Learn. (PMLR, New York), 10764–10799.Google Scholar
- (2024) Large language model based multi-agents: A survey of progress and challenges. Preprint, submitted January 21, https://arxiv.org/abs/240201680.Google Scholar
- (2023) MetaGPT: Meta programming for a multi-agent collaborative framework. Preprint, submitted August 1, https://arxiv.org/abs/2308.00352.Google Scholar
- (2022) Lora: Low-rank adaptation of large language models. Proc. Internat. Conf. Learn. Representation 1(2):3.Google Scholar
- (2020) Leveraging passage retrieval with generative models for open domain question answering. Preprint, submitted July 2, https://arxiv.org/abs/200701282.Google Scholar
- (2023) Survey of hallucination in natural language generation. ACM Comput. Survey 55(12):1–38.Crossref, Google Scholar
- (2020) Dense passage retrieval for open-domain question answering. Proc. Conf. Empirical Methods Natural Language Processing (Association for Computational Linguistics, Stroudsburg, PA), 6769–6781.Google Scholar
- (2025) The ITEM ontology: A tool to elucidate the anatomy of psychometric indicators. Inform. Systems Res., ePub ahead of print August 13, https://doi.org/10.1287/isre.2023.0257.Google Scholar
- (2025) Goedel-prover: A frontier model for open-source automated theorem proving. Preprint, submitted February 11, https://arxiv.org/abs/250207640.Google Scholar
- (2025) Walk the talk? Measuring the faithfulness of large language model explanations. Preprint, submitted April 19, https://arxiv.org/abs/250414150.Google Scholar
- (2020) On faithfulness and factuality in abstractive summarization. Proc. 58th Annual Meeting Assoc. Comput. Linguist. (Association for Computational Linguistics, Stroudsburg, PA).Google Scholar
- (2023) The debate over understanding in AI’s large language models. Proc. Natl. Acad. Sci. USA 120(13):e2215907120.Crossref, Google Scholar
- (2025) AI is transforming peer review—And many scientists are worried. Nature 639(8056):852–854.Crossref, Google Scholar
- (2021) WebGPT: Browser-assisted question-answering with human feedback. Preprint, submitted December 17, https://arxiv.org/abs/211209332.Google Scholar
- (2022) Training language models to follow instructions with human feedback. Adv. Neural Inform. Processing Systems (Curran Associates Inc., Red Hook, NY), 27730–27744.Google Scholar
- (2023) Generative agents: Interactive simulacra of human behavior. Proc. 36th Annual ACM Sympos. User Interface Software Tech (UIST '23) (Association for Computing Machinery (ACM), New York), 1–22.Google Scholar
- (2025) The benefits and dangers of anthropomorphic conversational agents. Proc. Natl. Acad. Sci. USA 122(22):e2415898122.Crossref, Google Scholar
- (2023) Direct preference optimization: Your language model is secretly a reward model. Preprint, submitted May 29, https://arxiv.org/abs/2305.18290.Google Scholar
- (2024) Conceptualizing generative AI as style engines: Application archetypes and implications. Internat. J. Inform. Management 79(C):102824.Google Scholar
- (2019) The sociotechnical axis of cohesion for the IS discipline: Its historical legacy and its continued relevance. MIS Quart. 43(3):695–720.Crossref, Google Scholar
- (2023) Toolformer: Language models can teach themselves to use tools. Adv. Neural Inform. Processing Systems, vol. 36 (Curran Associates Inc., Red Hook, NY), 68539–68551.Google Scholar
- (2023) Reflexion: Language agents with verbal reinforcement learning. Preprint, submitted March 20, https://arxiv.org/abs/2303.11366.Google Scholar
- (2022) Blenderbot 3: A deployed conversational agent that continually learns to responsibly engage. Preprint, submitted August 5, https://arxiv.org/abs/220803188.Google Scholar
- (2024) Testing theory of mind in large language models and humans. Nature Human Behav. 8(7):1285–1295.Crossref, Google Scholar
- (2023) The Janus effect of generative AI: Charting the path for responsible conduct of scholarly activities in information systems. Inform. Systems Res. 34(2):399–408.Link, Google Scholar
- (2022) Lamda: Language models for dialog applications. Preprint, submitted January 20, https://arxiv.org/abs/220108239.Google Scholar
- (2017) Attention is all you need. Preprint, submitted June 12, https://arxiv.org/abs/1706.03762.Google Scholar
- (2023) Fabrication and errors in the bibliographic citations generated by ChatGPT. Sci. Rep. 13(1):14045.Crossref, Google Scholar
- (2023) Voyager: An open-ended embodied agent with large language models. Preprint, submitted May 25, https://arxiv.org/abs/230516291.Google Scholar
- (2022a) Finetuned language models are zero-shot learners. Internat. Conf. Learn. Representation (ICLR 2022) (OpenReview).Google Scholar
- (2022b) Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inform. Processing Systems, vol. 35 (Curran Associates Inc., Red Hook, NY), 24824–24837.Google Scholar
- (2025) From AI for science to agentic science: A survey on autonomous scientific discovery. Preprint, submitted August 18, https://arxiv.org/abs/250814111.Google Scholar
- (2025) Agentic reasoning: A streamlined framework for enhancing LLM reasoning with agentic tools. Proc. 63rd Annual Meeting Assoc. Comput. Linguist. (Association for Computational Linguistics, Stroudsburg, PA).Google Scholar
- (2024) Autogen: Enabling next-gen LLM applications via multi-agent conversations. First Conf. Language Modeling (COLM 2024) (OpenReview).Google Scholar
- (2024) Hallucination is inevitable: An innate limitation of large language models. Preprint, submitted January 22, https://arxiv.org/abs/240111817.Google Scholar
- (2024) SWE-agent: Agent-computer interfaces enable automated software engineering. Adv. Neural Inform. Processing Systems, vol. 37 (Curran Associates Inc., Red Hook, NY), 50528–50652.Google Scholar
- (2022) Webshop: Towards scalable real-world web interaction with grounded language agents. Adv. Neural Inform. Processing Systems, vol. 35 (Curran Associates Inc., Red Hook, NY), 20744–20757.Google Scholar
- (2023) React: Synergizing reasoning and acting in language models. 11th Internat. Conf. Learn. Representation (ICLR 2023) (OpenReview).Google Scholar
- (2025) A next-generation open access ecosystem for scientific discovery generated by AI scientists. Preprint, submitted August 20, https://arxiv.org/abs/250815126.Google Scholar
- (2025) MultiAgentBench: Evaluating the collaboration and competition of LLM agents. Preprint, submitted March 3, https://arxiv.org/abs/250301935.Google Scholar
- (2025) Large language models for automated scholarly paper review: A survey. Preprint, submitted January 17, https://arxiv.org/abs/2501.10326.Google Scholar
- (2019) Fine-tuning language models from human preferences. Preprint, submitted September 18, https://arxiv.org/abs/190908593.Google Scholar

