
Subcoalition Cluster Analysis: A New Method for Modeling Conflict in Organizations
Abstract
The renewed interest among managers and management researchers in stakeholder governance has also underscored the shortage of quantitative methods available for studying business firms as political systems. A critical problem for researchers applying coalition-based theories of organizational politics to observational data is that the units of analysis, coined “subcoalitions,” are often unobservable. This paper introduces subcoalition cluster analysis (SCA) as a new computational framework for analyzing intrafirm conflict that permits researchers to model groups of heterogeneous actors in terms of a smaller set of representative subcoalitions. The SCA approach to identifying latent fault-lines among groups of actors is based on widely held ideas in management research about the structure of intrafirm coalition politics, is computationally practicable in settings with many alternatives or actors, and can be straightforwardly applied to observational settings with incomplete data on actor preferences. We then apply SCA to two cases in which an organization characterized by multiple, partially inconsistent goals and stakeholders with heterogeneous preferences face a politically contested decision. In both cases, we first analyze preference data using SCA to identify the subcoalition structure that best characterizes the set of actors in the organization. We then use the SCA output as a dependent variable in an analysis of the predictors of subcoalition membership in the first case and as an independent variable in an analysis of the changing patterns of social influence in the second.
This paper was accepted by Lamar Pierce, organizations.
Supplemental Material: The data files are available at https://doi.org/10.1287/mnsc.2020.00013.
1. Introduction
The renewed interest among managers and management researchers in stakeholder governance has also underscored the shortage of quantitative methods available for studying business firms as political systems (Kaplan 2019, Joseph and Gaba 2020, Levinthal and Rerup 2021, Battilana et al. 2022). A critical problem for researchers applying existing theories of organizational politics to observational data is that the units of analysis of the study of “the business firm as a political coalition” (March 1962, p. 662)—subgroups of individuals with internally aligned preferences with respect to firm-level outcomes, coined “subcoalitions” in Cyert and March (1963, p. 27)—are often unobservable. Prior attempts to develop machine learning algorithms for subcoalition identification have long been stymied by well-known challenges related to equilibrium existence (does a stable subcoalition structure exist?) and computational practicability (if one exists, can we efficiently discover it?). Researchers interested in modeling large populations of heterogeneous actors in terms of a smaller set of representative subcoalitions in order to study the relationships between micro-level processes of individual preference formation, meso-level dynamics of intrafirm conflict, and macro-level outcomes of firm decision making thus lack a suitable quantitative toolkit.
In this paper, we introduce subcoalition cluster analysis (SCA) in order to fill this methodological gap. It returns a partition of actors into subcoalitions that have collective preferences that are (1) meaningful, (2) representative, and (3) stable. SCA thus satisfies the necessary requirements for modeling the business firm as a “conflict system,” an idea originally introduced in March (1962, p. 663) that has since become a pillar of the behavioral theory of the firm (BTOF) (Gavetti et al. 2007). The first property means that subcoalitions have collective preferences that can be represented by a weak ranking of alternatives. The second means that the subcoalition’s collective preferences are derived from the preferences of their membership. The third means that subcoalitions and their collective preferences can be treated as fixed (and identified independently from the higher-level outcomes of conflict among subcoalitions). Taken together, these requirements imply that SCA returns a partition for which actors are assigned to the subcoalition whose collective preferences they best align with while simultaneously defining the collective preferences of subcoalitions in terms of the outcome of this assignment process.
Similar to recent methodological innovations in cultural sociology designed for identifying latent schema such as relational class analysis (RCA) and correlational class analysis (CCA), SCA defines subcoalitions in terms of classes of actors with common patterns of response in preference data (Goldberg 2011, Boutyline 2017). However, whereas RCA and CCA identify classes “who agree on what the argument is about,” SCA instead identifies classes “who agree on the substance of issues” (DiMaggio et al. 2018, p. 32). SCA thus permits researchers to distinguish between the preferences of individuals, which are the units of observation in the study of a business firm as a conflict system, from the collective preferences of subcoalitions, which are the units of analysis. The SCA approach also relates to RCA/CCA and differs from commonly used structural approaches for identifying latent clusters in preference data like latent class analysis (LCA), in its “relational” approach to identifying subcoalitions (DiMaggio et al. 2018, p. 31). Whereas structural approaches envision a top-down process through which unobservable characteristics of actors and their environment predict patterns in actors’ preferences that induce group-based conflict, SCA instead envisions a bottom-up process in which actors with similar preferences form subcoalitions to agitate for commonly held goals.
SCA is designed to be broadly applicable for researchers across various management fields. The BTOF understanding of business firms as conflict systems—as the common ancestor of richer theories that have evolved in other management subfields—reflects a set of commonly held ideas about the mechanisms that define the structure of intrafirm conflict. Mithani and O’Brien (2021) trace how theories of coalition-based conflict in, for example, resource dependence theory, institutional theory, upper echelon theory, and the performance feedback model evolved from the original BTOF vision (Gavetti et al. 2012). These assumptions are also consistent with recent qualitative work on conflict in firms with multiple, partially conflicting goals (Kaplan 2008, Kellogg 2009, Zbaracki and Bergen 2010, Rerup and Zbaracki 2021). In addition, by modeling the subcoalition structure solely in terms of actors’ preferences with respect to firm-level outcomes rather than, for example, imputing subcoalition membership from other observable characteristics, the subcoalition structure returned by SCA can serve as a baseline model for evaluating these more complex theories. If the observed structure of organizational conflict departs significantly from that predicted by SCA, then this incongruity can be used by researchers to identify which characteristics of actors, networks, firms, and the external environment have additional explanatory power. In contrast, if the structure of conflict is well modeled solely based on data on what actors want, then SCA offers a more parsimonious representation of the structure of intrafirm politics than more complex theories do. Thus, those management researchers who might prefer to append an l for “latent” to SCA (Stevenson et al. 1985, p. 264) should still find it to be a useful tool for quantitative research.
The SCA algorithm can be straightforwardly applied to a broad range of organizational contexts. It is constructed to be computationally practicable, even in cases with many actors who face a wide range of alternatives. It is also designed to be flexible with respect to data requirements. Any observational data that can be transformed into a set of pairwise comparisons of alternatives for each actor can be straightforwardly accommodated by the SCA algorithm, including settings where the data are fairly sparse. SCA can accommodate data derived from, for example, revealed preferences, A/B tests, voting ballots, and ranked lists. In addition to returning a partition of actors into a recommended set of subcoalitions, SCA also reveals information about each subcoalition’s collective preferences, membership, and relative size, the strength of intrasubcoalition consensus and intersubcoalition conflict, and the strength of the attachment of each actor to their assigned subcoalition, information that can then be used by managers in order to manage intrafirm conflict and by researchers to study where divisions in firms emerge and how they evolve.
The paper proceeds as follows. We begin by placing SCA in the context of existing approaches used to model conflict in organizations. We focus, in particular, on how SCA complements recently proposed methods for identifying the latent dimensionality of conflict in groups. Then, we introduce the theoretical foundations of SCA, focusing in particular on how subcoalitions determine their collective preferences, how actors evaluate the desirability of subcoalitions, and the characteristics of stable partitions of actors. Next, we describe the SCA algorithm. Here, we emphasize how recent research in convex optimization on the “close rankings problem” (Hochbaum and Levin 2006, p. 1403) allows for the creation of new algorithms that adapt distance-based approaches for clustering points in Euclidean space to the problem of clustering actors based on their pairwise evaluations of alternatives. We then describe how SCA discovers a partition of actors for a fixed number of subcoalitions and also introduce several methods for determining the number of subcoalitions that is most consistent with the data.
We next analyze two cases in order to demonstrate how SCA can be used by managers and management researchers to better understand the structure and evolution of organizational conflict. Both cases analyze the structure of political conflict surrounding decisions faced by organizations whose members have heterogeneous preferences with respect to multiple, partially inconsistent goals. The first case analyzes the emergence of conflict at Wikipedia over how best to update the editing platform. It shows how the failure to identify the schism between experienced and inexperienced editors led the platform to underestimate the resistance to a strategic change intended to make the platform more inviting for novice editors. The second examines the emergence of conflict among baseball writers over whether candidates suspected of using performance-enhancing drugs deserve induction into the National Baseball Hall of Fame and then also demonstrates that social influence processes made this rift self-reinforcing. In both cases, we first analyze preference data using SCA to identify the subcoalition structure that best characterizes the set of actors in the organization. We then use the SCA output as a dependent variable in an analysis of the predictors of subcoalition membership in the Wikipedia case and as an independent variable in an analysis of the changing patterns of social influence among the baseball writers.
We conclude by discussing areas for future research. We describe opportunities to vary the utility function that actors use when evaluating their preferred subcoalition and the manner in which stable subcoalitions are identified in order to improve the predictive performance of the SCA algorithm. We also suspect that, much as there are some settings in which distance-based algorithms outperform model-based algorithms and vice versa for clustering problems defined in Euclidean space (Preud’homme et al. 2021), there are certain settings in which SCA will outperform structural approaches like LCA and other settings in which the opposite will be true. Identifying these conditions can be informative for researchers interested in predicting the structure of intrafirm conflict. It also may help distinguish between empirical settings in which the structure of organizational conflict is the product of bottom-up subcoalition building versus settings in which actor-level preference heterogeneity is driven by latent external or institutional factors.
2. Background
Although the vision of firms as sites of political contestation is a foundational concept in management theory (Selznick 1949, Dalton 1950, Thompson and McEwen 1958), it has been long under-emphasized relative to other aspects of the BTOF (Gavetti et al. 2007, 2012; Joseph and Gaba 2020; Ganz 2023; Levinthal and Pham 2024). Most commonly, behavioral research on firm decision making adopts the assumption that the organization can be represented by a single goal-oriented, boundedly rational actor. As a result, when the problem of goal multiplicity in firms is considered (and it usually is not), it is evaluated from the perspective of [intra]individual conflict, that is, difficulties in ordering alternatives by individual actors (Gaba and Greve 2019, Audia and Greve 2021) rather than from the perspective of organizational conflict, that is, difficulties in ordering alternatives among groups of actors who have no problem ordering alternatives themselves.
Existing empirical analyses of individual preference conflict, however, are of limited value to researchers interested in the structure and dynamics of organizational conflict. This is, in part, because strategic sites for studying individual conflict implicitly preclude the possibility that organizational conflict plays an important role in collective decision making. Actors who are unclear about what they want are unlikely to organize to agitate for shared goals (March and Simon 1958, p. 138). Further, although studies of individual conflict may assume that the firm itself can be characterized as a single, boundedly rational actor facing multiple firm-level goals, studies of organizational conflict necessarily must take patterns of heterogeneity in actors’ preferences into account. Ironically, then, whereas theories of individual conflict are capable of being interrogated by examining firm-level decisions, theories of organizational conflict require that the researcher look inside of the firm to explore the emergence of subcoalitions and, subsequently, how the interactions between subcoalitions produce firm-level decisions.
The dearth of quantitative methods for studying the structure and dynamics of organizational conflict is especially problematic in light of recent interest in redefining the purpose of the business firm in terms of multiple, diverse stakeholders with partially misaligned objectives (Battilana et al. 2022). Understanding the latent fault-lines among stakeholders can make the difference between successful resolution of internal disagreement and conflict-driven paralysis. For example, Battilana et al. (2019, p. 129) spotlight how the strategic creation of “spaces of negotiation” can offer dual-purpose firms a “safety valve” that ensures that disagreements over firm-level priorities among subcoalitions do not stand in the way of effective coordination. This is especially relevant in cases where the problem of multiple goals is reinforced by other possible sources of intrafirm conflict. For example, a challenging problem for firms considering a merger or joint venture is predicting whether organization members would naturally bifurcate into subcoalitions that reinforce their organizational identities as opposed to dividing into subcoalitions that span prior organizational boundaries—or, for that matter, whether coalition-based conflict is likely to emerge at all. SCA can thus help managers identify attractive acquisition targets or collaborative partners and ameliorate the problems of cultural integration that often plague these efforts (Hambrick et al. 2001, Li and Hambrick 2005).
Furthermore, by moving the unit of analysis from the individual or the firm to the subcoalition, SCA opens the door to examining research questions about individual or firm decision making through a political lens. At the individual level, SCA can be used, for example, to test theories about how subcoalition structures coevolve with other formal and informal institutions or intraorganizational social networks to impact actors’ beliefs or behavior (Centola et al. 2007, DellaPosta et al. 2015, Goldberg and Stein 2018). At the firm level, it can also be used to empirically test new theories that explore the complicated relationship between organizational conflict, collective decision making, and firm performance. Recent research exploring the interactions between organizational politics and organizational learning, for instance, emphasizes how intrafirm conflict among subcoalitions can generate desirable competition to produce better information (Rerup and Zbaracki 2021), innovative experimentation (Kaplan 2019), or adaptively rational search routines (Ganz 2023, Levinthal and Pham 2024).
2.1. Related Approaches for Modeling Preference Heterogeneity
SCA defines subcoalitions in terms of the latent alignment of preferences among groups of actors with respect to firm-level outcomes. It is thus a close complement of recent methodological innovations in sociology such as RCA and CCA directed toward identifying heterogeneity in cultural schema among populations of actors (Goldberg 2011, Boutyline 2017). RCA/CCA capture relationality, that is, “the principle that meaning emerges not from single entities but out of relations among them.” SCA instead captures multiplicity: “If different meaning systems are characterized by different relationships among survey items, and if these relationships form a limited number of patterns, then for any meaning domain, the population will often include two or more subpopulations who organize their attitudes in different ways” (DiMaggio et al. 2018, p. 32). Put differently, whereas RCA/CCA reveal latent dimensions in the evaluation of sets of alternatives, SCA reveals latent clusters.
SCA and RCA/CCA are also related in the microfoundations of their approaches for identifying latent patterns of preference heterogeneity. Rather than assuming that correlations in the data are the result of a set of latent dimensions or categorical variables, SCA and RCA/CCA assume that heterogeneity emerges from interdependent relationships among actors. In the case of RCA/CCA, this interdependence is the result of similar relationships among evaluations. For SCA, the interdependence is a result of the alignment of actors’ evaluations themselves. In this way, SCA differs from structural approaches for identifying clusters in preference data such as LCA (Linzer 2011) in the same manner as RCA/CCA differ from structural approaches like factor analysis and principal component analysis (PCA) (Inglehart and Baker 2000). As summarized in Table 1, SCA thus fills an important gap in the methodological toolkit for researchers seeking to model heterogeneity in preference data. While interdependent approaches to modeling relationality and structural approaches to modeling multiplicity both exist, SCA is the first method, to our knowledge, to offer an interdependent approach for modeling multiplicity in preference data.
|

Table 1. Methods for Evaluating Relationality and Multiplicity
| Structural | Interdependent | |
|---|---|---|
| Relationality | Factor analysis; Principal component analysis | Relational class analysis; Correlational class analysis |
| Multiplicity | Latent class analysis | Subcoalition cluster analysis |
2.2. Modeling Business Firms as Conflict Systems
The behavioral microfoundations of SCA draw on the theorized social structure of conflict systems in the BTOF, which is defined in March (1962) in terms of two attributes: (1) “There are consistent basic units: Each elementary unit in the system can be described as having a consistent preference ordering,” and (2) “There is conflict: the most preferred states of all elementary units cannot be simultaneously realized” (p. 663). Further, March (1962) assumes as “a reasonable approximation” that the preference orderings of the elementary units are “causally antecedent, and independent of, the decisions of the larger system” and, further, that conflict within each elementary unit “is trivial because of scale differences between the conflict within the [elementary unit] on the one hand and conflict among [elementary units] on the other” (p. 664). We reframe this definition so that it is also consistent with the concept of a hedonic coalition structure, which is a theory of group formation in coalitional game theory in which “the payoff to a player depends only on the composition of members of the coalition to which she belongs” (Bogomolnaia and Jackson 2002, p. 202). In our case, an actor’s payoff is a function of the alignment of the actor’s preferences with their assigned subcoalition’s collective preferences (which is itself defined by the individual preferences of its members). This reimagining of March (1962) permits the structure of the conflict system to be defined in terms of a stable partition among goal-oriented actors who desire to attach to the subcoalitions that make them best off.
The definition of stability used in the SCA algorithm is that no actor’s preferences are better aligned with the collective preferences of a different subcoalition than they are with the subcoalition to which the actor is assigned and that each subcoalition’s collective preferences are defined in a manner that maximizes their alignment with its members’ preferences. We define an actor’s alignment with their assigned subcoalition’s collective preferences according to a utility function, which is described in detail in Section 2.4. For now, it suffices to say that for each actor and for each pairwise comparison of alternatives, if the collective preferences of a subcoalition agree with the actor’s preferences, then the actor finds the subcoalition to be more desirable than if the subcoalition disagrees with the actor’s preferences. For example, if the subcoalition collectively prefers alternative i to alternative j and the actor prefers i to j, then the actor is better aligned with the subcoalition’s collective preferences than if the subcoalition preferred j to i. Furthermore, each subcoalition’s collective preferences maximize the aggregate utility of the actors assigned to it. The overall alignment of the subcoalition’s preferences with its members, then, is higher if the subcoalition prefers i to j and all of its members also prefer i to j than if some of its members preferred j to i. We describe a partition of actors into subcoalitions as unstable if there is an actor who prefers to defect to a different subcoalition from the one to which they are assigned or if there is a subcoalition with collective preferences that do not maximize the aggregate utility of its members.
This definition of a stable partition is attractive from a behavioral perspective because it implies that actors’ preferences over subcoalitions are defined with respect to each subcoalition’s collective preferences and not, for example, with respect to other actors’ individual preferences and subcoalition assignments. As discussed in Section 2.3, it is also computationally attractive because, for certain utility functions, a stable partition exists for any fixed number of subcoalitions and can be practicably computed in settings with many actors or alternatives. Whereas more demanding stability concepts could require that actors also predict how the preferences of other subcoalitions would change if they were to defect and then base their defection decisions on these what-if subcoalitions—or, for that matter, require that actors also predict how other actors would respond to their defection—these forward-looking stability concepts require heroic assumptions about actor rationality in large firms. Finally, except in special cases, there is neither a guarantee that an equilibrium partition exists that satisfies these forward-looking stability concepts (Bogomolnaia and Jackson 2002) nor that one can be efficiently discovered if it does (Aziz et al. 2016).
That said, the behavioral simplicity of the BTOF definition of stable subcoalitions brings with it important tradeoffs. First, SCA defines subcoalitions independently from the manner in which the conflict among the subcoalitions is eventually resolved. Further, unlike theories of coalition-based conflict in resource dependence theory or institutional theory, subcoalition structures defined by SCA are independent of considerations related to power, legitimacy, rivalry, or hierarchy (Mintzberg 1983). Also, there are no side payments or other inducements for actors who remain in a subcoalition or are part of a winning subcoalition, as is common in game-theoretic treatments of coalition formation in which actors have transferable utility (Von Neumann and Morgenstern 1944, Roth 1988). SCA is especially valuable in settings where the subcoalition structure or the specific social process through which subcoalitions are formed is unobservable to the researcher, as is often the case. However, alternative approaches to modeling the business firm as a conflict system may be desirable in situations where these data are available.
Second, the assumption that actors are incapable of predicting changes to collective subcoalition preferences resulting from defection brings with it the possibility that SCA will return knife-edge subcoalition structures in which the defection of an actor would produce an updated set of collective subcoalition preferences that would then generate a cascade of new defections by other actors. Alternative stability concepts overcome these disadvantages, but at a cost in terms of behavioral validity (and computational practicability). Nevertheless, we introduce the concepts of Nash stability and Pareto stability in order to help inform the interpretation of SCA’s results and because they highlight design features of the SCA algorithm that lead knife-edge partitions to be unlikely to be returned.
Nash stability requires that stable partitions also be robust to defection by any individual actor. Behaviorally, Nash stability requires that actors are capable of predicting the postdefection collective preferences of the subcoalitions they join. Computationally, there is neither a guarantee that a Nash stable partition exists for a given number of subcoalitions, nor are there practicable computational methods for discovering a Nash stable partition, except in special cases. That being said, in order for a stable partition to fail to satisfy Nash stability, the defection of a single actor must lead their new subcoalition to change their collective preferences. In practice, this means that if a firm is indeed well characterized as a conflict system, the coalitions returned by SCA will also tend to be Nash stable. Further, it is simple enough to check whether the partition of actors returned by SCA is also Nash stable by checking actor-by-actor if defection to any other subcoalition leads to a higher-utility match after collective preferences are recomputed. In addition, as described in Section 3.3, thoughtful initialization of the SCA algorithm that places actors with divergent preferences into different subcoalitions helps avoid knife-edge partitions and increases the likelihood that the subcoalitions returned by SCA are Nash stable.
Another related stability concept is Pareto stability. A partition is Pareto stable if there does not exist any other partition producing the same number of subcoalitions such that at least one actor is made strictly better off and no actors are made worse off. The limitations of Pareto stability are different from those of Nash stability. On the one hand, there does exist a Pareto stable partition given our setup, because the partition that maximizes aggregate utility is also Pareto stable by construction. On the other, there is no efficient algorithm for finding a Pareto stable partition or a way to check if a given partition is Pareto stable unless all potential partitions are enumerated.
The fact that the partition with the highest aggregate utility is Pareto stable, nevertheless, points to the desirability of finding a partition for which aggregate utility is as close to its global maximum as possible. For sufficiently small sets of actors, this can be achieved by exhaustively searching over all of the possible partitions producing a specified number of subcoalitions. However, the number of potential partitions quickly exceeds computational limits for even modestly sized numbers of actors. For larger sets of actors, as described in Section 3.7, we instead recommend replicating the SCA algorithm many times with varying initial conditions and then selecting the partition with the highest aggregate utility in order to return a good approximation of a Pareto stable partition.
Another limitation of our stability concept is that we do not permit actors to defect to empty coalitions, which is commonly permitted in other coalitional games. Given our definition of a hedonic game, this restriction is necessary: If actors could defect to their own subcoalitions, then each actor would do so in order to maximize their individual utility. We instead assume the number of subcoalitions ex ante and then evaluate the relative fit of stable partitions producing various numbers of subcoalitions with the data. However, one could imagine an alternative setup in which the number of subcoalitions is endogenous to actors’ utility functions, for example, if the payoff for actors is an increasing function of subcoalition size. As noted previously, these additional features may come with the potential that stable subcoalitions do not exist or that they cannot be found efficiently. But, modifying the SCA algorithm so that the number of subcoalitions is endogenous is nevertheless an important potential direction for future research.
2.3. SCA as a Combinatorial Counterpart to k-Means Clustering
Some readers may recognize the close similarity between the definition of stability used in SCA and the definition of a stable partition used in k-means clustering, a popular unsupervised machine learning method for classifying observations into latent clusters in multidimensional Euclidean space (Hastie et al. 2009). k-means clustering identifies a partition of the data for which all observations are closer to the centroid of their assigned cluster than to the centroid of any other cluster, which is nearly identical to the definition of stability introduced in the previous section. SCA can therefore be viewed as an application of k-means–style clustering to a setting in which the objects to be clustered are actors with heterogeneous preferences defined in a combinatorial space (rather than observations associated with a vector of characteristics defined in Euclidean space) and stability is defined with respect to a set of collective subcoalition preferences (instead of a set of centroids).
This similarity between SCA and k-means clustering extends to the computational approach used to identify stable partitions as well. SCA searches for a stable partition by iteratively allowing actors to defect to subcoalitions that make them better off and then allowing subcoalitions to renegotiate their collective preferences in order to maximize the aggregate utility of their members. When a partition of actors is discovered such that no actors desire to defect, then the identified subcoalition structure satisfies the described stability criteria by construction. This algorithmic approach is closely related to Lloyd’s algorithm, which is commonly referred to as the k-means algorithm, in which observations are reassigned to clusters whose centroids they are closer to (the assignment step) and then centroids are recomputed based on this assignment (the updating step) and for which stability is achieved when no observations are reassigned over an assignment-and-updating iteration.
There are various benefits of the close similarity between SCA and k-means clustering. First, because of its widespread popularity, k-means clustering is extensively studied by researchers in machine learning and computer science. SCA adapts commonly used routines developed for k-means clustering in order to initialize clusters to avoid knife-edge, low-quality partitions (Arthur and Vassilvitskii 2007) and to evaluate the number of subcoalitions most consistent with the data (Tibshirani et al. 2001, von Luxburg 2010). Additionally, the ubiquity of k-means clustering in scientific, engineering, and management applications aids in the interpretability of the SCA algorithm. Users comfortable with the output of the k-means algorithm should be able to easily understand and apply the output of SCA, as well.
However, clustering actors in terms of their preferences poses computational challenges that do not apply to clustering observations according to their locations in Euclidean space. The guarantee that k-means clustering converges to a stable partition for any number of clusters derives from the coherence between the assignment step (in which observations are assigned to their closest centroid) and updating step (in which the centroid is adjusted to minimize the aggregate distance from the observations assigned to it). Because both the assignment step and updating step monotonically reduce the aggregate distance between the observations and their assigned centroids, a partition that globally minimizes the aggregate distance for a fixed number of clusters is stable by construction. Thus, the k-means algorithm is guaranteed to either discover this global optimum or to find a different stable partition along the way. Additionally, Euclidean distances and geometric means are extremely easy to compute, which makes the k-means algorithm computationally practicable, even in very large datasets.
The primary methodological contribution of SCA is the introduction of an approach for assigning actors to subcoalitions and for defining collective subcoalition preferences that shares these same desirable properties. Specifically, SCA utilizes a preference aggregation method that returns a collective weak ranking of alternatives that is (1) the unique solution to an optimization problem for which aggregate utility is maximized and (2) very fast to compute, even in settings with many actors or alternatives. The former property guarantees that a stable partition exists for any number of subcoalitions and can be discovered using the described defection-and-renegotiation algorithm. The latter is necessary for the algorithm to be practicable to use for observational data collected in settings with many actors or alternatives.
Given the close relationship between SCA and k-means clustering, it is worth considering conditions under which applying a dimensionality-reduction algorithm (like factor analysis or PCA) that projects combinatorial preference data into a lower-dimensional Euclidean space and then applying k-means clustering might be an appropriate alternative to SCA. There are various approaches for modeling the structure of partisanship in the U.S. legislature, for example, that summarize binary roll call data by identifying legislative ideal points in a two-dimensional political space (Poole and Rosenthal 1985, Jackman 2001, Potthoff 2018), which then permit the straightforward application of k-means in order to predict party affiliation (Jakulin et al. 2009). PCA and k-means have also been used together in nonlegislative contexts to analyze patterns of preference heterogeneity in survey data (Van Gunten et al. 2016) and mutual fund voting (Bubb and Catan 2022). If the researcher believes that the true structure of preference conflict in the population is well-characterized by ideal points arrayed in Euclidean space, then preprocessing preference data in this manner adds informative top-down structure to the quantitative analysis (Heckman and Snyder 1997). If the true structure of conflict is not well defined by a spatial model, then the researcher should be concerned that the partition returned by k-means clustering is biased by incorrect assumptions about the global structure of preferences.
An additional limitation of k-means clustering for analyzing intrafirm conflict arises in cases where the researcher wants to know the collective preferences of subcoalitions in addition to subcoalition membership. In this case, following the application of the k-means algorithm, a weak ranking of alternatives would subsequently need to be inferred from the geometric locations of the returned cluster centroids or the sets of ideal points assigned to each cluster. These repeated transformations from combinatorial preferences to low-dimensional Euclidean ideal points then back to combinatorial preferences complicates the interpretation of the output of the k-means algorithm. Additionally, although the partition returned by k-means clustering is stable with respect to ideal points arrayed in Euclidean space, it may not be stable with respect to these twice-transformed variables. Lastly, the transformation from individual preferences to Euclidean space required to use the k-means algorithm demands that there is either no missing data or that missing values are imputed, which further complicates inferences about the structure of conflict when k-means clustering is applied in settings with sparse data. The SCA algorithm, in contrast, does not involve a transformation from combinatorial to Euclidean space and is also designed to accommodate sparse observational data. The tradeoff is that SCA relies on a specific set of assumptions about the characteristics of stable partitions, as described in Section 2.2, and about actors’ utility functions, which is described in the next section.
2.4. Close Rankings Problem for Preference Ranking Data
The best-studied class of computationally efficient optimization-based methods for preference aggregation is generalized by the “close rankings problem,” in which the “the problem of finding a group ranking that is close to the rankings of individual reviewers…is formulated as a convex optimization problem” (Hochbaum and Levin 2006, p. 1403). However, to date, preference aggregation functions of this class have required that actors either submit a numeric score associated with each alternative or preference intensities that encode the strength of each pairwise comparison. In contrast, optimization-based preference aggregation algorithms for binary comparisons of alternatives, or “preference rankings,” face interrelated problems of computational complexity and multiple optimal solutions (Hochbaum and Levin 2006, p. 1394).
By far the most-studied optimization-based approach for aggregating preference rankings is Kemeny’s method (Kemeny 1959). Kemeny’s method is based on the following utility function: an actor receives one unit of disutility for every pairwise evaluation of alternatives that conflicts with the collective preferences. Optimal solutions for Kemeny’s method map from the set of alternatives to the set of consecutive integers. The best-evaluated alternative receives a rank of one, a less-preferred alternative receive a rank of two, and so on. Kemeny’s method thus returns an optimal ranking in which the collective [weak] preference for alternative i to alternative j is represented by the former being assigned a [weakly] lower integer rank than the latter.
However, Kemeny’s method is NP-hard to compute (Bartholdi et al. 1989, Fischer et al. 2016). Although practicable algorithms for computing exact optimal solutions exist for limited numbers of alternatives, heuristic approximations are required for settings where 15 or more alternatives are being ranked (see Rico et al. (2023) for a recent review). Furthermore, the optimal ranking for Kemeny’s method is not unique. In fact, it is easy to come up with examples where an alternative can be best-ranked or worst-ranked in different Kemeny-optimal rankings (Yoo and Escobedo 2021). This is a problem for our definition of stability because, depending on which Kemeny-optimal collective preferences are identified, a candidate partition may or may not be stable.
SCA adopts a method for aggregating preferences that is closely related to Kemeny’s, but is efficient to compute and returns a unique optimal ranking. Where our method differs from Kemeny’s is in the utility function used to determine actors’ preferences. In both methods, if an actor’s pairwise comparison of alternatives agrees with the collective preferences, then no disutility is assigned. But, whereas Kemeny’s method assigns one unit of disutility for each pairwise comparison of alternatives that disagrees with the collective preferences, ours assigns greater disutility if the disagreement occurs for alternatives whose ranks are more dissimilar than for alternatives whose ranks are more similar. In our method, if an actor prefers i to j and their subcoalition has j ranked first and i ranked second, the disutility for the actor is smaller than if their subcoalition had j ranked first and i ranked third. In Kemeny’s method, the disutility in the two cases would be the same.
Specifically, let preferences for actors over pairs of alternatives be represented by , where indicates that actor a prefers i to j and indicates that actor a does not prefer i to j. Define a ranking function to be a mapping from the set of alternatives A to the set of ranks, which are represented by consecutive integers , where . Let r correspond to a vector of ranks associated with the set of alternatives, where ri represents the rank of alternative i and ri < rj indicates that i is collectively preferred to j.
Kemeny’s method returns a ranking that is a solution to the following integer program:
Our method returns a ranking that is instead the solution to the following program:
Among the set of optimal rankings for this maximization problem, define as the maximum optimal ranking for the set of actors A. The maximum optimal ranking is the ranking that maximizes the objective function that ranks every alternative as unfavorably as possible.1 In the appendix, we define a network flow-based algorithm for computing in strongly polynomial time that can be solved very quickly using standard optimization software.
Returning to the prior example, in a setting where the collective preferences have i top-ranked and j second-ranked, that is, and , and an actor prefers j to i, the actor would receive two units of disutility from the collective preferences: . If instead the collective preferences were and , then the actor would instead receive three units of disutility: . In contrast, if the actor preferred i to j, the actor would receive 0 units of disutility in both cases: and . Finally, if the collective preferences expressed indifference between i and j, for example, , then the actor would receive one unit of disutility if they preferred i to j or if they preferred j to i: and .
Note that our ranking method can also be recast as a utility-maximization problem, where the utility of actor a for ranking r is and maximizes the aggregate utility of all actors . This permits us to use it much in the same way that the k-means algorithm uses Euclidean distance to determine cluster assignment and the geometric mean to determine cluster centroids. In the defection step of the SCA algorithm, actors move to the subcoalition that maximizes their individual utility. In the renegotiation step, subcoalitions determine collective preferences that maximize the aggregate utility of their membership. This process of defection and renegotiation continues iteratively until no actors desire to defect.
To our knowledge, our paper is the first to apply this method to preference data and recognize its usefulness in clustering applications. In related work, Gupte et al. (2011) use the same objective function in order to return a minimum “agony” hierarchy in network data. Further, our algorithm for identifying the maximum optimal ranking is based on a well-known distance-labeling algorithm for computing node potentials in minimum cost flow problems (Ahuja et al. 1993, p. 316). Additionally, Atkinson et al. (2023) examines the close relationship between this ranking method and alternative methods based on eliminating maximum-cardinality preference cycles.
3. SCA Algorithm
Next, we describe SCA in detail. We begin by describing the computational approach implemented by SCA for discovering a fixed number of subcoalitions. We then introduce a series of methods for revealing the number of subcoalitions most consistent with the data.
3.1. Constructing Binary Preference Data
One of the advantages of SCA is its permissive data requirements. All that is needed is that the data can be transformed into a series of pairwise comparisons of alternatives for which an actor can prefer alternative i to alternative j, prefer j to i, or make no comparison between i and j. In other words, any data that can be transformed into an adjacency matrix over alternatives, where a 1 in a cell (i, j) represents a weak preference for i over j, can be analyzed using SCA.
For example, in a survey in which respondents are asked to compare alternatives i and j, when a respondent chooses option i instead of j, the adjacency matrix for that respondent records a one in the (i, j) cell and a zero in a (j, i) cell. If the respondent chooses j instead of i, this pattern is reversed. In settings where respondents only compare selected pairs of alternatives or in which they may decline to make a comparison, missing data are represented by a zero in both the (i, j) and (j, i) cells.
More structured sources of preference data are also easily managed. If actors submit a ranked list of alternatives, this can straightforwardly be transformed into an adjacency matrix that records a one in all cells (i, j) when i is better ranked than j. Along the same lines, if the respondent allocates points among or scores various alternatives, such as through use of a Likert scale, these data can be similarly transformed into a matrix in which alternatives allocated more points are preferred to those with fewer points. A setup where a respondent reveals their relative utility among alternatives, for example, by indicating their willingness-to-pay, can be represented as an adjacency matrix in the same fashion.
3.2. SCA’s structure
SCA is structured as a set of nested loops, including a body, inner loop, and outer loop.
The body of the algorithm initializes a partition π0 that defines K subcoalitions and then uses an iterative process of defection and renegotiation to search for a stable partition. The body of the algorithm concludes when a stable partition is discovered, which we denote .
The inner loop replicates the body of the algorithm B times, each time with a different initialized partition. Following the completion of the inner loop, then, the body has discovered as many as B stable partitions. The inner loop returns the partition with the highest aggregate utility out of this set, denoted . The outer loop then evaluates the inner loop for various values of K, where the set of possible K is denoted K. When the outer loop concludes, the algorithm has returned one for each value of K. Finally, as discussed in more detail in Section 3.8, in cases where the researcher is interested in identifying the number of subcoalitions most consistent with the data, which we denote , the researcher may apply an additional set of routines in order to estimate . We refer to this as the function.
Figure 1 is a visual depiction of the flow of the algorithm. The nested boxes depict the nested loops of the algorithm, with the top of each box indicating how many iterations of the inner boxes are executed as part of the loop and the bottom of the box representing the object that is returned once the loop is complete.

Next, we describe each of the parts of the SCA algorithm in greater detail, focusing on the implementation of each of the algorithm’s steps.
3.3. Body: Subcoalition Initialization
The body of the algorithm begins by initializing a partition of actors. Although the algorithm will discover a stable subcoalition structure for any initial partition defining K subcoalitions, it is preferable to begin the defection-and-renegotiation process with an intelligent partition, that is, one that reduces the chance of knife-edge solutions with low aggregate utility and reduces the number of defection-and-renegotiation iterations required until a stable partition is discovered.
We use a variant of the “k-means++” seeding algorithm, which has been shown to achieve both of these goals with k-means clustering (Arthur and Vassilvitskii 2007). In our adaptation of k-means++, we begin by selecting an actor at random to initialize the first subcoalition and define the subcoalition’s collective preferences according to that actor’s preferences. Then for every subsequent subcoalition to be initialized, we select a new actor whose probability of being selected is decreasing with respect to that actor’s utility if they were to join any of the already-seeded subcoalitions. Once all subcoalitions have been seeded, we compute the collective preferences for each subcoalition and then assign actors to the subcoalition whose collective preferences maximize their utility.
The following pseudo-code defines the initialization step in the SCA algorithm:
Choose an initial actor a1 uniformly at random from A. Let .
Choose the next actor a2, where the probability of actor being chosen is decreasing with respect to their utility with the existing initialized subcoalitions. Specifically, the probability that an actor is selected as a2 is .
Repeat step 2 until K initial actors have been chosen. Let π0 represent a partition of these actors into K subcoalitions with each subcoalition containing one actor. Let represent the set of actors in each subcoalition, where indexes subcoalitions.
Compute the initialized set of collective preferences given the singleton subcoalitions .
Assign the remaining actors to the subcoalition that maximizes their utility given . This defines a partition of all actors A, denoted π1.
3.4. Body: Renegotiation Step
After initializing the subcoalition structure, the SCA algorithm begins the search for a stable partition. Following the initialization step, each subcoalition’s collective preferences are utility maximizing for a single actor, but the subcoalitions are populated by many actors with heterogeneous preferences. The renegotiation step involves updating the collective preferences for each subcoalition so that they maximize the aggregate utility of their respective memberships.
Let t index iterations of the defection-and-renegotiation process. The renegotiation step inherits a partition of actors πt and an associated set of collective weak rankings for each subcoalition. It returns , the updated set of utility-maximizing collective preferences that are consistent with πt.
3.5. Body: Defection Step
Following the renegotiation step, some actors may no longer be in subcoalitions that maximize their utility. If any such actors exist, the defection step reassigns these actors to the subcoalitions whose collective preferences are strictly more desirable than the collective preferences of the subcoalition to which they are currently assigned.
The defection step inherits a partition πt and a set of collective weak orders . It assigns actors to the subcoalition that maximizes their utility given and returns , which is a partition for which all actors are in a subcoalition whose collective preferences maximize their utility.
3.6. Body: Algorithm Termination
The renegotiation and defection steps continue until the partitions in two consecutive iterations are identical, which means that the partition is stable under the definition described in Section 2.2. This partition is defined as .
3.7. Inner Loop: Searching for High-Quality Subcoalitions
Our concern that the body of SCA might discover a low-quality partition by chance leads us to recommend replicating the body of SCA multiple times. Thus, the inner loop returns the that has the highest aggregate utility after B replications of the body, denoted . In cases where the researcher exogenously determines the number of subcoalitions in the data, is the partition returned by SCA.
3.8. Outer Loop and Function
In many cases, the researcher may not know ex ante and may instead desire to estimate it from the data given candidate values of K. Therefore, we next describe a set of methods that can assist in determining conditional on having calculated for varying K.
One way to estimate involves calculating for each K and then returning the aggregate utility for each. Comparisons of aggregate utility given , which we represent as , inform how much better off actors are, on average, when K increases. If increases meaningfully given a one unit increase in K, it implies that partitions with one additional subcoalition make actors much better off, in which case the data are more consistent with the higher K. However, if increases only slightly, this instead implies that actors are roughly indifferent between the two partitions and that the data are instead consistent with the lower K.
But, how can we know what constitutes a meaningful difference? Two methods that are commonly used to evaluate the optimal K for the k-means clustering algorithm can also be applied here. One is to identify a K such that . This is often referred to as an “elbow” in the graph relating K to . The logic behind the elbow test is that, in the presence of unclustered data, the slope of the curve relating K to should be constant (Tibshirani et al. 2001).
The elbow test version of the function involves the following steps:
For each , calculate .
Return the minimum K such that .
However, there may be ambiguity regarding which K constitutes the elbow or whether an elbow exists at all. Further, the assumption that declines with a constant slope in the presence of unclustered data may not be valid for a given data set. A more robust version of the elbow test, called the gap statistic, addresses these shortcomings. The gap statistic version of the elbow test simulates as a function of K based on synthetic, unclustered data. It then uses this null distribution of partitions in the absence of subcoalitions as a control when executing the elbow test (Tibshirani et al. 2001).
When compared with the elbow test, the gap statistic has two advantages. The first advantage is that the gap statistic gives the analyst confidence that the observed elbow would not be so observed if no subcoalitions existed. A second advantage is that we can use the distribution of to develop tests for identifying that take into account not only the slope of the function relating K to , but also its variance. We recommend selecting the K such that the gap statistic for K is at least two standard deviations from the mean above the gap statistic for K + 1.
Our implementation of the gap statistic is as follows:
For b0 in 1, …, B0:
Construct a synthetic set of judgments for each actor by randomly permuting the identity of the actors associated with binary comparisons in the original data.
For all , compute a stable partition given the synthetic set of judgments, denoted .
For all , return .
For all , estimate and
Return the minimum K such that .
A different approach for identifying involves calculating the clustering stability of the partition rather than the aggregate utility. Clustering stability-based evaluation of a partition is based on the idea that meaningful partitions should be robust to small perturbations in the underlying data caused by sampling variability (von Luxburg 2010). If there are more subcoalitions estimated than actually exist in the data, small changes to the set of actors resulting from different samples will tend to produce substantially different partitions. Note that clustering stability differs from prior concepts of stability introduced in the paper. Clustering stability requires that the partition is robust to different sets of actors, rather than being robust to the presence of goal-oriented or (boundedly) rational actors.
A straightforward way to test the clustering stability of a partition is to repeatedly resample actors (with replacement), reestimate the partitions from the resampled data, and then calculate the average proportion of actors who fall in the same subcoalition in the resampled data as in the real data. If large shares of actors fall in the same subcoalitions in both the synthetic and real data, it is indicative of meaningful subcoalitions. Similar to the elbow test, interpreting the mapping from K to average stability in order to determine requires judgment by the researcher regarding when the clustering stability level is deemed unacceptably low. When the elbow test, gap statistic, and clustering stability-based approaches all agree, however, it provides strong evidence for a given .
Our recommended clustering stability-based test for is implemented as follows:
For b0 in 1, …, B0:
Construct a synthetic set of actors by resampling uniformly from A with replacement. Define as the synthetic set of actors.
For all , compute , which is a stable partition defined for the synthetic data.
Define two partitions as equivalent if for all actors and for all actors if and for all and π assigns a1 and a2 to the same subcoalition, then assigns and to the same subcoalition. Define the minimum matching distance between partitions and as the minimum number of actors who must be moved to a new subcoalition for to be equivalent to . For all , return this minimum matching distance, denoted .
For all , calculate the clustering stability score:
Return the minimum K such that .
When these three methods identify the same number of subcoalitions as fitting the data best—and in our experience they often do—the researcher should feel confident that the returned partition captures the latent structure of conflict in the organization. In cases where they disagree, it is up to the researcher to determine whether changes to aggregate utility or changes to clustering stability more meaningfully identify subcoalitions in a given empirical setting. When the results of these tests are ambiguous, we generally recommend choosing the partition associated with fewer subcoalitions rather than more subcoalitions, which is based on our preference for a more parsimonious model, all else being equal.
4. Applying SCA to Two Cases
We next apply SCA to two cases. The primary purpose of the cases is to demonstrate the range of research questions to which SCA can be applied and, in the process, types of data that can be analyzed by SCA. Each case analysis is built around a politically contested question faced by an organization characterized by multiple, partially inconsistent goals and a diverse group of stakeholders with heterogeneous preferences. The first case uses SCA to model the structure of internal conflict over the future of Wikipedia based on a survey of editors that elicited recommendations for improving the platform. We then use the partition returned by SCA as a dependent variable in order to explain why an attempt to update the platform to make it easier for new editors led to a rebellion by experienced editors. The second uses SCA to understand the structure and evolution of conflict among baseball writers electing candidates for the National Baseball Hall of Fame. We then use the evolving structure of coalition-based conflict as an independent variable in an analysis of the dynamics of social influence among the writers.
4.1. Case 1: Wikipedia’s Editor Rebellion
4.1.1. Summary.
Following rapid growth in editor participation from 2003 to 2007, the number of new editors active on Wikipedia suddenly began to decline (Suh et al. 2009). Wikipedia responded with new tools and infrastructure designed to make editing easier, but with little impact. In his 2009 “State of the Wiki” address, founder Jimmy Wales argued that “if active contributors continue to decrease, there may not be a large enough cohort to ‘look after’ Wikipedia” (Wales 2009). Concerns that a smaller, more homogeneous editor population would jeopardize the future health of the Wikipedia project prompted a focus on editor recruitment and retention in the Wikimedia Foundation’s 2011–2015 strategic plan. As part of this effort, Wikipedia designed a series of surveys in order to better understand the experience of editors and recommend strategic changes.
Inside Wikipedia, there were competing theories about the causes of the weakening editor participation. The first theory was that editing Wikipedia articles was too technically demanding. By creating an easier user interface for editors, more people would be attracted to the community. The second theory was that the culture was hostile to new editors. Rather than welcoming new users and encouraging them to learn the norms of the platform, experienced editors would delete the edits of new editors that did not conform with Wikipedia’s guidelines without providing constructive feedback. The editor survey offered the potential to gather anonymous feedback from users in order to prioritize changes to the platform and community standards.
4.1.2. Data.
We analyze a question from the 2012 Wikipedia Editor Survey in which respondents were asked to identify “the most important problems that have affected you personally, making it harder for you to edit.” Editors were given a list of 10 potential problems and had the opportunity to select up to three they found most relevant to their experience. We encoded cases in which one problem was deemed relevant and the other problem not deemed relevant as a preference for the former over the latter. This approach takes advantage of SCA’s ability to accept incomplete data, because we do not record votes for problems that are either both deemed as relevant or both not deemed as relevant.
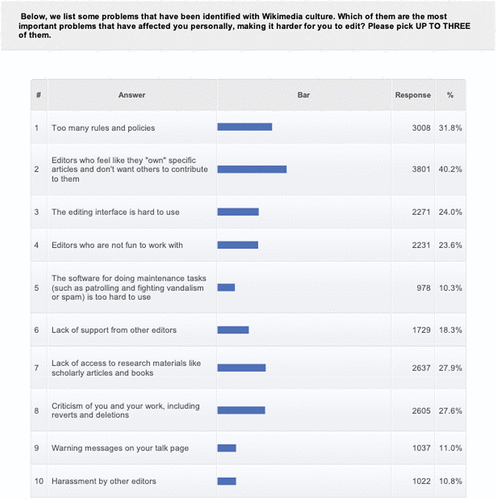
In Wikipedia’s topline analysis, approximately two-fifths of the more than 17,000 participants surveyed criticized “editors who feel like they ‘own’ specific articles and don’t want others to contribute to them.” Thirty-two percent felt that there were “too many rules and policies.” Between 20% and 30% responded affirmatively to four of the remaining eight options. The Wikimedia Foundation’s presentation of the results, which is displayed in Figure 2, supported the theory that Wikipedia’s editorial culture was its biggest problem but that the other concerns were valid as well.
4.1.3. Results.
We use SCA to model the internal disagreement over Wikipedia’s most important problems. We restrict the data set to editors who contribute primarily to English Wikipedia and who indicate that they at least sometimes participate as editors. After excluding editors who selected none of the problems, we are left with 1,416 individuals in our data set.
We present the collectively defined relative importance of problems conditional on the number of subcoalitions in Figure 3. When analyzed as a single group, our results are consistent with the results of Wikipedia’s topline analysis. The biggest problem is editors who “feel like they own specific articles.” Tied are “too many rules and policies,” the editing interface being “hard to use,” editors not being “fun to work with,” “lack of support from other editors,” “lack of access to research materials,” and “criticism of you and your work.” Lowest ranked were problems related to the software, “warning messages on your talk page,” and “harassment” by other editors.
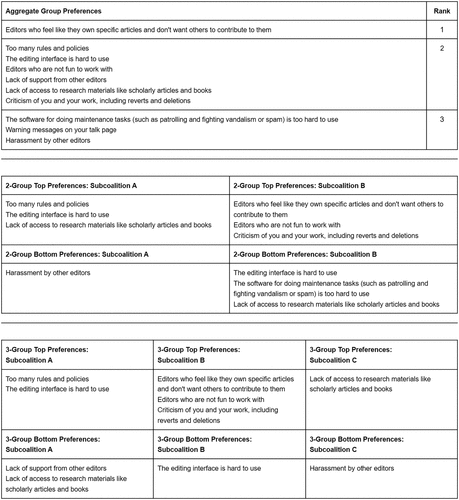
However, when we analyze Wikipedia as two subcoalitions, we identify substantial internal conflict. The first subcoalition (“A”), which includes 726 editors, points to the number of rules, difficulties using the editing interface, and lack of access to research materials as the most important problems. The other subcoalition (“B”), which includes 690 editors, instead identifies editorial ownership of articles, editors not being fun to work with, and criticism of one’s work as the most serious problems. Strikingly, two of the problems that were most important to the former group were least important to the latter.
The topline analysis thus obscures an important division among editors over perceived problems with the platform. Subcoalition A identifies technical problems as the most important problems for Wikipedia to address. Subcoalition B identifies cultural problems as more important. This divide is also reflected in the difference between the average utility of editors with the preferences of their own subcoalition—which are −8.3 and −8.8 for subcoalitions A and B, respectively—against the average utility of editors with the preferences of the other subcoalition—which are −21.6 and −23.8. When we instead allocate the editors among three subcoalitions, the third’s hierarchy of problems is a mix of the two identified previously. Their top problem is a lack of access to research materials, but their second tier of problems includes both issues with other editors and difficulties using the editing platform. For four subcoalitions, similarly, one group continues to emphasize cultural issues, one emphasizes technical ones, and the other two reflect a blend of priorities.
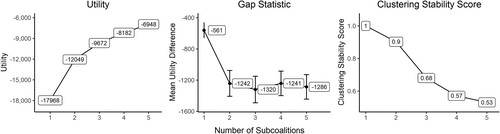
Next, we use the three methods described in Section 3.8 to identify the number of subcoalitions in the editor population from the data. The left panel of Figure 4 reports aggregate utility levels conditional on subcoalition count for partitions with one through five subcoalitions. The “elbow” that appears at two subcoalitions suggests that a meaningful second subcoalition may indeed be present. The center panel reports the gap statistic—that is, the difference between the aggregate utility when individual preferences are randomized in 100 synthetic data sets and the aggregate utility in the observed data—along with 95% confidence intervals. The gap statistic for two subcoalitions is significantly lower than when the editors are treated as a single group. In contrast, moving from two subcoalitions to three subcoalitions does not change the gap statistic significantly. The right panel reports the clustering stability score across 100 bootstrapped datasets. The score remains as high as 0.9 for two subcoalitions, dropping greatly if a third is added. All three of the methods therefore agree that the population of editors is well characterized by two subcoalitions. The two-subcoalition partition also satisfies Nash stability, offering additional confidence that the identified subcoalitions faithfully reflect the structure of conflict inside Wikipedia.
We next examine what types of editors are members of each subcoalition. We use logistic regression to predict membership in subcoalition B conditioned on the amount of time spent on Wikipedia, editorial experience, age, gender, and country of origin. We find that editors who spent more than an hour in the last week contributing to Wikipedia are 16% more likely to be a member of subcoalition B (, standard error (SE) = 0.012). Further, each additional year of editing experience makes an editor 3% more likely to be a member of subcoalition B (, SE = 0.022). Both effects are significant at the 0.01 significance level. Gender, age, and country-of-origin are not significant predictors of subcoalition membership. Experienced editors and avid users are more likely to be a member of the subcoalition who believes that other editors are the most significant problem with Wikipedia. In contrast, inexperienced and less frequent users are more likely to point to the problems associated with the editing platform itself.
This conflict between the subcoalitions erupted when English Wikipedia introduced its new Visual Editor in 2013 in order to make it easier for new editors on the site. Existing editors complained that the bug-marred rollout was disrespectful to dedicated users, a waste of donated money, and that it reflected a lack of commitment to Wikipedia’s core mission. In response, editors “staged a rebellion” by adopting user-written code that allowed them to circumvent the new editing platform, leading Wikipedia to grudgingly change the Visual Editor interface from opt-out to opt-in (Orlowski 2013, Sampson 2013). Had leadership been aware that the rationale for this major change to the editing interface was in conflict with the desires of its most avid users, they would also have known they needed to be more careful during the new Visual Editor’s introduction.
This case emphasizes how excessive attention to aggregated preferences or topline survey results may lead managers to overlook the potential for conflict over important decisions. Because Wikipedia’s leadership lacked insight on the structure of conflict within the organization, they could not appreciate the sharp divergence in preferences across the two subcoalitions and, as a result, underestimated the internal resistance to a strategic change. The case also shows how the information returned by SCA about subcoalition membership and preferences can be used to understand the major sources of organizational conflict and the correlates of subcoalition membership. Moreover, this case reiterates how SCA can be applied in the presence of sparse data and demonstrates the application of algorithms for identifying the number of subcoalitions in the data.
4.2. Case 2: Baseball Writers’ Association of America Tosses a Shutout
4.2.1. Summary.
The most important public function of the Baseball Writers’ Association of America (BBWAA) is determining which retired baseball players are inducted into the National Baseball Hall of Fame. Beginning in 2013, however, the election process became embroiled in controversy when none of the candidates received the 75% of votes required for induction. For the first time in a half-century, the National Baseball Hall of Fame had a summer induction ceremony with no living inductees. The BBWAA considers Hall of Fame voting to be “the ultimate privilege” for its members (Chappell 2014). Yet rumors swirled that, if the BBWAA continued to be unable to serve its purpose of selecting candidates for the Hall of Fame, the Hall of Fame would begin to explore other options for determining who should be inducted (Keri 2013).
Prior to the election, baseball writers acknowledged that 2013’s crop of new candidates was particularly controversial. Barry Bonds and Roger Clemens, two players who are among the most distinguished in the game’s history but whose candidacies were shrouded in rumors of performance-enhancing drug (PED) use, were submitted to the baseball writers for consideration for the first time. Absent the PED question, both Bonds and Clemens would be near-consensus Hall of Fame picks. Although other marginal Hall of Fame candidates suspected of PED use had been considered by the writers in prior years, this was the first time they had to judge players with such extraordinary on-the-field performance who were also suspected of using PEDs. Despite many baseball writers acknowledging a crowded, controversial ballot with many qualified newcomers, few suspected that no candidates would be inducted.
New York Times columnist Nate Silver hypothesized that the tenor of the debate had changed during the 2013 voting process: “Instead of the typical friendly arguments about how a player’s lifetime accomplishments might be weighed against how dominant he was in his best seasons, or how to compare players at different positions, the writers are now spending most of their time arguing about who used steroids and when, and how this should affect Hall of Fame consideration” (Silver 2013). Disagreements over players prior to 2013 tended to be idiosyncratic, as each voter applied slightly different criteria for measuring greatness. The 2013 disagreement, instead, felt more like competing factions within the BBWAA: the writers who felt that PED rumors disqualified a player from Hall of Fame induction against those willing to weigh possible PED use against on-the-field performance.
4.2.2. Data.
Many baseball writers voluntarily make their Hall of Fame ballots public. Beginning with the 2009 class of candidates, Twitter user @leokitty began tracking these public votes. In 2013, Ryan Thibodeaux took over the ballot tracking effort in a public spreadsheet posted on his website. In addition, starting in 2013, the BBWAA began to publish the votes of willing writers. Over time, the number of public ballots has increased, from 60 in 2009, to 168 in 2013, to 311 in 2016.
We use these public ballots to study the nature and evolution of the conflict among the baseball writers over Hall of Fame candidates. From each writer’s ballot, we create a series of binary comparisons between players, assuming that writers prefer players for whom they voted to those for whom they did not. We do not record binary preferences over candidates when a writer either voted for both candidates or excluded both candidates from their ballot.
4.2.3. Results.
We analyze whether the nature of disagreement over which candidates deserve induction into the Hall of Fame changed in 2013, the first year that Bonds and Clemens were on the Hall of Fame ballot. Then, we examine whether subcoalition conflict in the BBWAA has changed how voters use other writers’ prior votes to update their beliefs about which candidates to vote for in future years.
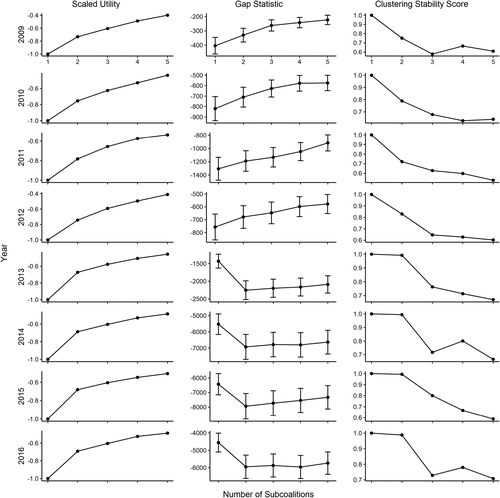
We begin by examining the aggregate utility conditional on the number of subcoalitions for each year from 2009 through 2016, displayed in the first column of Figure 5. Because there are different numbers of writers and candidates in each year, we scale utility so that it equals −1 when the writers are treated as a single group. The longitudinal data identify a clear elbow beginning with the 2013 ballot that did not exist in the earlier years. From 2009 through 2012, the relationship between the number of subcoalitions and aggregate utility is roughly linear. From 2013 through the present, however, it is highly nonlinear, with an elbow at two groups. This supports the hypothesis that there is one subcoalition from 2009 through 2012, but two distinct subcoalitions from 2013 on.
The results from the 2013 election are illustrative of the nature of the conflict. When the writers are treated as a single bloc, Clemens and Bonds are ranked in the second-highest tier behind five other candidates with no ties to PED use. When writers are divided into two subcoalitions, however, writers are nearly evenly split between a PED-sensitive subcoalition that ranks Bonds and Clemens as tied for last place and a PED-insensitive coalition that ranks Bonds first and Clemens second, ahead of all other candidates.
The second column of Figure 5 reports the gap statistic, which also indicates a clear shift beginning in 2013. Prior to 2013, the gap statistic is monotonically increasing with respect to the number of subcoalitions. After 2013, it is lower for two subcoalitions than for one, then remains roughly constant when we partition the writers into 3, 4, or 5 subcoalitions.
The third column of Figure 5 reports the clustering stability score. Again, the pattern changes after 2013. Prior to 2013, when the writers are divided into two subcoalitions, many voters who are identified as a part of the same subcoalition in the observed data are part of different subcoalitions in the bootstrap samples. After 2013, the subcoalitions produced by the bootstrap samples almost exactly align with those produced by the actual data when the writers are divided into two subcoalitions. Once again, the three methods agree that the BBWAA becomes well characterized as two competing subcoalitions after 2013. And, as in the previous cases, the two-subcoalition partitions after 2013 satisfy Nash stability.
We next use these results to examine whether changes to patterns of social influence are contributing to the ossification of subcoalition boundaries and subsequent difficulty reaching consensus on candidates. Baseball writers frequently cite each other’s analysis and prior voting behavior when publicly justifying their voting choices, creating a bandwagon effect for some candidates. Although some candidates are elected in their first year on the ballot, most face a slower process through which writers gradually become convinced of a candidate’s merit following many years of debate, balloting, and re-evaluation (James 1994). This multiyear conversation about whether a player is worthy of induction has tended to generate coordination among the electorate. As a result, prior to rule changes in 2014 that shortened the maximum number of years that a new candidate would remain on the ballot, every player but one who has ever received 50% of the vote from the writers has eventually been inducted.
However, if baseball writers’ evaluations of candidates are influenced more strongly by writers in their own subcoalition than by writers outside their subcoalition, then the social influence of the out-group writers would be weakened and the cross-subcoalition divergence in evaluation of the candidates would be self-reinforcing. Goldberg and Stein (2018) refer to this mechanism for explaining self-reinforcing conflict as associative diffusion. In contrast, if baseball writers are influenced equally by members of their own subcoalition as by members of the opposing one, then the divergence would be more likely to weaken over time.
We examine these dynamics of social influence among the writers using a series of regression analyses. These models estimate whether a writer, i, voted for a candidate j in year t, where a vote by a writer for a candidate in a year, vijt, is represented by a one and the absence of a vote is represented by a zero. In all years, we divide the writers into two subcoalitions. We estimate linear probability models of the following form:
The variable β1 measures the influence of in-subcoalition writers on a writer’s voting decision in the subsequent year; β2 measures the influence of out-subcoalition writers on a writer’s voting decision in the subsequent year; δ measures the persistence of a writer’s voting decision; and λt is a set of year fixed effects. Then, we examine whether the pattern of influence changes after 2013 using the following model:
The variables β3 and β4 measure the change in in- and out-subcoalition influence, respectively, after 2013. Two-way cluster-robust standard errors are reported for all regressions, where errors are clustered on the level of the writer and candidate.
The results, which are presented in Table 2, are consistent with a self-reinforcing split among the writers after 2013. Model 1 indicates that writers are more influenced by in-subcoalition writers than by out-subcoalition writers, because β1 exceeds β2. However, Model 2 demonstrates that this difference is isolated to the post-2013 period. Prior to 2013, writers are about equally influenced by in- and out-subcoalition writers, consistent with the absence of meaningful subcoalitions in the data. After 2013, however, they become significantly less influenced by out-subcoalition writers. The strength of the influence from in-subcoalition writers does not significantly change. The difference between β3 and β4 is significant at the 0.05 level, which indicates that the change in influence from out-subcoalition writers is different from the change in influence from in-subcoalition writers.
|
Table 2. BBWAA: Linear Regression Results
| (1) | (2) | |
|---|---|---|
| 0.633*** | 0.633*** | |
| (0.0175) | (0.0175) | |
| β1 | 0.308*** | 0.288*** |
| (0.0319) | (0.0344) | |
| β2 | 0.107** | 0.228*** |
| (0.0329) | (0.0425) | |
| β3 | 0.0205 | |
| (0.0506) | ||
| β4 | −0.154** | |
| (0.0545) | ||
| Observations | 15,665 | 15,665 |
| R2 | 0.571 | 0.572 |
Note. Robust standard errors in parentheses.
***p < 0.01; **p < 0.05; *p < 0.1.
SCA thus reveals a noteworthy change in the social structure of Hall of Fame voting following the 2013 election. Prior to 2013, conflict over candidates was idiosyncratic and writers were influenced equally by those with whom they had similar preferences as those with whom they had differing preferences. After 2013, not only did the writers split into two subcoalitions, one sensitive to PED use and one insensitive to it, but this split also appears self-reinforcing, because writers’ future voting decisions are no longer as strongly influenced by voters outside of their subcoalition as by voters inside their subcoalition.
These analyses exemplify how SCA can reveal the evolution of conflict within organizations. By applying SCA over multiple years, we are able to explore the emergence and persistence of conflict systems. Further, applying SCA longitudinally enables additional analyses that explore the social dynamics of conflict. In this case, a bifurcation of the BBWAA emerged in 2013 based on divergent views about suspected PED users that persisted through at least 2016. By embedding the results of SCA in a dynamic regression model, we also show that conflict among the PED-sensitive and PED-insensitive subcoalitions was self-reinforcing, implying that the structure of the conflict among the writers was likely to continue to persist.
5. Discussion and Conclusion
In the 60 years since March (1962) first proposed the subcoalition concept as a key unit of analysis in the study of firm decision making, managers and management researchers have lacked the quantitative methods necessary to apply the BTOF vision of the business firm as a conflict system to observational data on individual preferences. SCA fills this void by offering a computational framework for modeling a heterogeneous group of actors in terms of a set of subcoalitions with internally consistent, externally conflicting preferences. Similar to recent innovations in cultural sociology for identifying latent dimensions in preference data such as RCA and CCA, SCA adopts a bottom-up approach in which subcoalitions form among interdependent groups of actors with similar preferences who seek to agitate for collective goals. This distinguishes SCA from alternative structural approaches like LCA, which instead envision patterns in preference data as emerging from latent exogenous factors that produce correlations in actors’ preferences.
We illustrate in two case studies how SCA identifies latent fault-lines among actors. In these settings, SCA reveals a subcoalition structure that appears to reflect important schisms in each population. In the case of Wikipedia, it predicts the conflict between experienced and newer editors that erupted after the introduction of the new editing platform. In the study of the baseball writers, SCA shows the emergence of conflict in a longitudinal setting in which writers became divided into PED-sensitive and PED-insensitive camps. The case studies also show how SCA can be leveraged in subsequent analyses of the structure of social conflict through the inclusion of the SCA output in statistical models that predict subcoalition membership and how subcoalition structure impacts individual and firm-level decision making.
That said, SCA is just a first step in building a broader set of computational tools for revealing the social structure of conflict systems in organizations. To start, we suspect there are opportunities to integrate different utility functions or methods for initializing clusters that could improve the speed or predictive ability of SCA in certain contexts, for example, in settings where respondents report complete ranked lists of alternatives or the intensity of their pairwise preferences. Further, we suspect that using a wider assortment of initialization algorithms including, for example, groups of actors inferred by the latent categories estimated by LCA, could lead to increased (and more rapid) discovery of higher-quality partitions. Along these lines, a promising avenue for future research would be to analyze the relative performance of variations on the SCA algorithm proposed here and also to benchmark the performance of SCA against structural approaches such as LCA to see the settings and performance criteria for which each algorithm performs best, perhaps following the grid-search methodology proposed in Sotoudeh and DiMaggio (2023). In addition to improving predictive accuracy, we are also hopeful that we can leverage observed variability in the performance of various interdependent and structural algorithms to differentiate between empirical settings in which the BTOF vision of coalition-based conflict is more appropriate and those in which an institutional theory-based approach offers better predictive power.
We are also cautiously optimistic that new developments in computer science and coalitional game theory will permit more complex political interactions to be analyzed in which actor preferences are endogenous to intersubcoalition interactions and in which actors’ decisions to attach to subcoalitions are driven in part by the desire to secure side payments or achieve individual goals. Perhaps by relying on different utility functions or different algorithms for finding stable partitions, methods can also be discovered that improve upon our stability concept in behaviorally valid and computationally efficient ways. Finally, new innovations in community detection and machine learning may suggest ways to endogenously reveal the number of coalitions in the data in place of ex post routines like the elbow test, gap statistic, and clustering stability score. That said, these are hard problems with mathematical constraints related to equilibrium existence and computational constraints related to the massive combinatorial space that potentially needs to be searched.
However, we cannot overemphasize the potential value of a simplified model of coalition-based conflict for testing theories that integrate more complex individual incentives, formal structures, social networks, and institutions. We look to the field of legislative studies in political science as inspiration for how SCA can be used in this manner. Empirical research on legislative bargaining in political science exploded after Poole and Rosenthal (1985) proposed a framework for using roll call votes to assign legislators ideal points on the left-right spectrum. By assuming sincere voting and unidimensional spatial preferences—and thus ignoring strategic voting, party influence, parliamentary rules, and legislative organization—these [DW-]NOMINATE scores reflect a much-simplified model of legislative decision making. However, precisely for this reason, this framework became the dominant analytical engine for evaluating richer theories of legislative bargaining. We hope that SCA (or a more worthy successor) can serve this same purpose for the study of coalition-based politics in nonlegislative settings.
Along these lines, there exists the potential for SCA to be used to study coalition structure and formation in other research settings. SCA can be straightforwardly applied to modeling interorganizational conflict, for example, within social movement industries (McCarthy and Zald 1977) or business groups (Zuckerman and Sgourev 2006). SCA can also be used, more generally, to identify multiplicity in observational data on the preferences of any group or population. We hope, for instance, that future studies examining heterogeneity in cultural attitudes that apply interdependent methods like RCA/CCA to identify groups of individuals who share schematic representations of issues will also use SCA to identify groups of individuals who share positions on those issues (DiMaggio et al. 2018). Lastly, we cannot ignore the potential for SCA to also be applied to legislative decision making, particularly in parliamentary settings where the structure of conflict has many dimensions and in which parties enter into coalitions in order to agitate for their platforms.
We conclude by spotlighting the extraordinary opportunity for future work that brings research on organizational conflict together with new methods in computational social choice and related fields. Our paper shows how tying theoretical results from social choice and game theory in political economics together with efficient algorithms for combinatorial optimization in operations research and computer science brings about a new solution to the decades-old problem of modeling business firms as conflict systems. We suspect that Richard Cyert, James March, and others at the Carnegie School in the 1950s and 1960s could not foresee how hard it would be to design a computer program to do something as simple as partitioning actors into subcoalitions according to their divergent desires for the future of their firms. The good news for managers and management researchers interested in modeling processes of contestation and compromise in firms with multiple, diverse stakeholders is that at least a few of the conceptual and computational challenges that previously stood in the way of the development of “computer models of organizational decision making [that] expose both the theory of the firm as a coalition and the theory of political coalitions in general to new analytic attention” (March 1962, p. 677) are finally being overcome.
The authors thank the department editor Lamar Pierce, an anonymous associate editor, and three excellent reviewers for insightful comments and questions during the review process that improved this paper and Nathan Atkinson, Dorit Hochbaum, and James Orlin for help in adapting ideas from network flow and combinatorial optimization to this setting; the authors are particularly indebted to James for his assistance in defining the properties of the procedure for producing a weak ranking. The authors received helpful comments and feedback of various forms from a long list of individuals, including Kieran Allsop, Jasmina Chauvin, John-Paul Ferguson, Thorbjorn Knudsen, John Mantus, Metin Sengul, Craig Tovey, and John Walsh.
Appendix
Below, we define a procedure for producing the weak ranking described in Section 2.4.
Define a weak ranking as a mapping from the set of alternatives to the set of integers with the following properties:
The minimum ranking is one, which corresponds to an alternative that is socially preferred to all other alternatives.
The maximum ranking is less than or equal to N.
Alternatives are assigned ranks that correspond to consecutive integers, where ri < rj indicates that i is collectively preferred to j.
Consider the following optimization problem:
Define as the optimal values of r for the following maximization problem.
We begin by describing an algorithm for computing and then prove it is optimal for the described problem. We then transform such that is satisfies the properties of a weak ranking.
First, we express P1 as the following dual network flow problem. In order to ensure that for all , we append a new attribute t and arcs (i, t) for all and we add a constraint that rt = 0. Additionally, let for all .
As the matrix is totally unimodular, there exists an optimal integer-valued solution, and we can drop the integrality constraints.
The dual of P3 is a minimum cost flow problem in which the costs assigned to each arc are −1.
For any feasible solution, for all i. To see this, note that and by (A.13). Therefore, . Because for all i, it follows that for all i.
Note that after fixing for all i, note that P4 reduces to the problem of finding a minimum cost circulation.
Based on P4, the following procedure finds .
optimal flow for P4.
In the residual network find a tree of shortest paths directed to note t.
for each node : let be the length of the path in from i to t.
In computing the lengths of a path in , the cost of each forward arc is −1 and the cost of each backward arc is +1.
The algorithm produces .
Let . We first note that is feasible for the ranking problem because and for all .
To show that is optimal, we will show that satisfies the complementary slackness conditions.
If , then and , in which case . That is, .
If , then , in which case and . That is, .
We next show that for any optimal ranking and for all . This is by induction on the number of arcs in on the path from i to t. If there is exactly one arc, then it is the arc (i, t). Then and thus .
Suppose that the claim is true whenever the number of arcs on the path is k or fewer. Suppose that the path P from i to t has k + 1 arcs. Let be the node that succeeds i on P. Then by the induction hypothesis.
If is a forward arc of , then by complementary slackness, , in which case . If is a backward arc of , then . By complementary slackness, , where and thus . In this case . □
Finally, as is defined on the consecutive integers with a maximum value of −1, satisfies the properties of a ranking and is maximum among all weak rankings defined on the integers .
Legend
r; r*: A weak ranking; the optimal r defined in Section 2.4.
N: The number of alternatives.
z; z*: Objective value of (P1); optimal z for (P1).
pi,j: Number of pairwise preferences for i over j.
η: Dual variables for minimum cost flow problem (P4).
x, y: Flow values for minimum cost flow problem (P4).
x*: Optimal flow values for x.
G(x*): Residual network given x*.
T*: Tree of shortest length paths in G(x*).
ℓ: The node that succeeds i on a path P in T*.
1 For example, consider two optimal rankings and , where and . Because i and j are ranked the same in and .
References
- (1993) Network Flows: Theory, Algorithms, and Applications (Prentice Hall, Englewood Cliffs, NJ).Google Scholar
- (2007) k-means++: The advantages of careful seeding. Proc. 18th Annual ACM-SIAM Sympos. Discrete Algorithms (Society for Industrial and Applied Mathematics, Philadelphia), 1027–1035.Google Scholar
- (2023) The strong maximum circulation algorithm: A new method for aggregating preference rankings. Preprint, submitted July 28, https://arxiv.org/abs/2307.15702.Google Scholar
- (2021) Organizational Learning from Performance Feedback: A Behavioral Perspective on Multiple Goals: A Multiple Goals Perspective (Cambridge University Press, Cambridge, UK).Crossref, Google Scholar
- (2016)
Hedonic games . Brandt F, Conitzer V, Endriss U, Lang J, Procaccia AD, eds. Handbook of Computational Social Choice (Cambridge University Press, Cambridge, UK), 356–376.Crossref, Google Scholar - (1989) Voting schemes for which it can be difficult to tell who won the election. Social Choice Welfare 6(2):157–165.Crossref, Google Scholar
- (2022) Beyond shareholder value maximization: Accounting for financial/social trade-offs in dual-purpose companies. Acad. Management Rev. 47(2):237–258.Crossref, Google Scholar
- (2019) The dual-purpose playbook. Harvard Bus. Rev. 97(2):124–133.Google Scholar
- (2002) The stability of hedonic coalition structures. Games Econom. Behav. 38(2):201–230.Crossref, Google Scholar
- (2017) Improving the measurement of shared cultural schemas with correlational class analysis: Theory and method. Sociol. Sci. 4(15):353–393.Crossref, Google Scholar
- (2022) The party structure of mutual funds. Rev. Financial Stud. 35(6):2839–2878.Crossref, Google Scholar
- (2007) Homophily, cultural drift, and the co-evolution of cultural groups. J. Conflict Resolution 51(6):905–929.Crossref, Google Scholar
- (2014) Sportswriter who let readers fill out hall of fame ballot is banned. Accessed December 19, 2024, https://www.npr.org/sections/thetwo-way/2014/01/09/261229164/sportswriter-who-let-readers-fill-out-hall-of-fame-ballot-is-banned.Google Scholar
- (1963) A Behavioral Theory of the Firm (Prentice Hall, Englewood Cliffs, NJ).Google Scholar
- (1950) Unofficial union-management relations. Amer. Sociol. Rev. 15(5):611.Crossref, Google Scholar
- (2015) Why do liberals drink lattes? Amer. J. Sociol. 120(5):1473–1511.Crossref, Google Scholar
- (2018) Culture out of attitudes: Relationality, population heterogeneity and attitudes toward science and religion in the U.S. Poetics 68:31–51.Crossref, Google Scholar
- (2016)
Weighted tournament solutions . Brandt F, Conitzer V, Endriss U, Lang J, Procaccia AD, eds. Handbook of Computational Social Choice (Cambridge University Press, New York), 85–102.Crossref, Google Scholar - (2019) Safe or profitable? The pursuit of conflicting goals. Organ. Sci. 30(4):647–667.Link, Google Scholar
- (2023) Conflict, chaos, and the art of institutional design. Organ. Sci. 35(1):138–158.Google Scholar
- (2007) Perspective–neo-Carnegie: The Carnegie School’s past, present, and reconstructing for the future. Organ. Sci. 18(3):523–536.Link, Google Scholar
- (2012) The behavioral theory of the firm: Assessment and prospects. Acad. Management Ann. 6(1):1–40.Crossref, Google Scholar
- (2011) Mapping shared understandings using relational class analysis: The case of the cultural omnivore reexamined. Amer. J. Sociol. 116(5):1397–1436.Crossref, Google Scholar
- (2018) Beyond social contagion: Associative diffusion and the emergence of cultural variation. Amer. Sociol. Rev. 83(5):897–932.Crossref, Google Scholar
- (2011) Finding hierarchy in directed online social networks. Proc. 20th Internat. Conf. World Wide Web (ACM, New York), 557–566.Google Scholar
- (2001) Compositional gaps and downward spirals in international joint venture management groups. Strategic Management J. 22(11):1033–1053.Crossref, Google Scholar
- (2009) The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Springer Series in Statistics, 2nd ed. (Springer, New York).Crossref, Google Scholar
- (1997) Linear probability models of the demand for attributes with an empirical application to estimating the preferences of legislators. RAND J. Econom. 28:S142.Crossref, Google Scholar
- (2006) Methodologies and algorithms for group-rankings decision. Management Sci. 52(9):1394–1408.Link, Google Scholar
- (2000) Modernization, cultural change, and the persistence of traditional values. Amer. Sociol. Rev. 65(1):19.Crossref, Google Scholar
- (2001) Multidimensional analysis of roll call data via Bayesian simulation: Identification, estimation, inference, and model checking. Political Analysis 9(3):227–241.Crossref, Google Scholar
- (2009) Analyzing the U.S. Senate in 2003: Similarities, clusters, and blocs. Political Analysis 17(3):291–310.Crossref, Google Scholar
- (1994) The Politics of Glory: How Baseball’s Hall of Fame Really Works (Macmillan, New York).Google Scholar
- (2020) Organizational structure, information processing, and decision-making: A retrospective and road map for research. Acad. Management Ann. 14(1):267–302.Crossref, Google Scholar
- (2008) Framing contests: Strategy making under uncertainty. Organ. Sci. 19(5):729–752.Link, Google Scholar
- (2019) The 360-Degree Corporation: From Stakeholder Trade-offs to Transformation (Stanford Business Books, an imprint of Stanford University Press, Stanford, CA).Google Scholar
- (2009) Operating room: Relational spaces and microinstitutional change in surgery. Amer. J. Sociol. 115(3):657–711.Crossref, Google Scholar
- (1959) Mathematics without numbers. Daedalus 88(4):577–591.Google Scholar
- (2013) The fallacy of the baseball hall of fame. http://grantland.com/the-triangle/the-fallacy-of-the-baseball-hall-of-fame/.Google Scholar
Levinthal DA, Pham DN (2024) Bringing politics back in: The role of power and coalitions in organizational adaptation. Organ. Sci. 35(5):1704–1720 .Google Scholar- (2021) The plural of goal: Learning in a world of ambiguity. Organi. Sci. 32(3):527–543.Link, Google Scholar
- (2005) Factional groups: A new vantage on demographic faultlines, conflict, and disintegration in work teams. Acad. Management J. 48(5):794–813.Crossref, Google Scholar
- (2011) Reliable inference in highly stratified contingency tables: Using latent class models as density estimators. Political Analysis 19(2):173–187.Crossref, Google Scholar
- (1962) The business firm as a political coalition. J. Politics 24(4):662–678.Crossref, Google Scholar
- (1958) Organizations (Wiley, New York).Google Scholar
- (1977) Resource mobilization and social movements: A partial theory. Amer. J. Sociol. 82(6):1212–1241.Crossref, Google Scholar
- (1983) Power in and Around Organizations. The Theory of Management Policy Series (Prentice Hall, Englewood Cliffs, NJ).Google Scholar
- (2021) So what exactly is a “coalition” within an organization? A review and organizing framework. J. Management 47(1):171–206.Google Scholar
- (2013) Revolting peasants force Wikipedia to cut’n’paste Visual Editor into the bin. https://www.theregister.co.uk/2013/09/25/wikipedia_peasants_revolt/.Google Scholar
- (1985) A spatial model for legislative roll call analysis. Amer. J. Political Sci. 29(2):357.Crossref, Google Scholar
- (2018) Estimating ideal points from roll-call data: Explore principal components analysis, especially for more than one dimension? Social Sci. 7(2):12.Crossref, Google Scholar
- (2021) Head-to-head comparison of clustering methods for heterogeneous data: A simulation-driven benchmark. Scientific Rep. 11(1):4202.Crossref, Google Scholar
- (2021) The politics of learning from rare events. Organ. Sci. 32(6):1391–1414.Link, Google Scholar
- (2023) Reducing the time required to find the Kemeny ranking by exploiting a necessary condition for being a winner. Eur. J. Oper. Res. 305(3):1323–1336.Crossref, Google Scholar
- (1988)
Introduction to the Shapley value . Roth AE, ed. The Shapley Value: Essays in Honor of Lloyd S. Shapley (Cambridge University Press, Cambridge, UK), 1–30.Crossref, Google Scholar - (2013) Will Wikipedia’s pretty new editing software solve its recruitment crisis? Accessed December 24, 2024, https://www.dailydot.com/business/wikipedia-visual-editor-wysiwyg/.Google Scholar
- (1949) TVA and the Grass Roots: A Study in the Sociology of Formal Organization (University of California Press, Berkeley).Google Scholar
- (2013) In Cooperstown, a crowded waiting room. Accessed December 24, 2024, https://fivethirtyeight.blogs.nytimes.com/2013/01/12/in-cooperstown-a-crowded-waiting-room/.Google Scholar
Sotoudeh R, DiMaggio P (2023) Coping with plenitude: A computational approach to selecting the right algorithm. Sociol. Methods Res. 52(4):1838–1882 .Google Scholar- (1985) The concept of “coalition” in organization theory and research. Acad. Management Rev. 10(2):256–268.Crossref, Google Scholar
- (2009) The singularity is not near: Slowing growth of Wikipedia. Proc. 5th Internat. Sympos. Wikis Open Collaboration (ACM, New York).Google Scholar
- (1958) Organizational goals and environment: Goal-setting as an interaction process. Amer. Sociol. Rev. 23(1):23.Crossref, Google Scholar
- (2001) Estimating the number of clusters in a data set via the gap statistic. J. Roy. Statist. Soc. Ser. B 63(2):411–423.Crossref, Google Scholar
- (2016) Consensus, polarization, and alignment in the economics profession. Sociol. Sci. 3:1028–1052.Crossref, Google Scholar
- (2010) Clustering stability: An overview. Foundations Trends Machine Learn. 2(3):235–274.Google Scholar
- (1944) Theory of Games and Economic Behavior (Princeton University Press, Princeton, NJ).Google Scholar
- (2009) State of the Wiki. Accessed December 24, 2024, https://commons.wikimedia.org/wiki/File:State_of_the_Wiki.pdf.Google Scholar
- (2021) A new binary programming formulation and social choice property for Kemeny rank aggregation. Decision Analysis 18(4):296–320.Link, Google Scholar
- (2010) When truces collapse: A longitudinal study of price-adjustment routines. Organ. Sci. 21(5):955–972.Link, Google Scholar
- (2006) Peer capitalism: Parallel relationships in the U.S. economy. Amer. J. Sociol. 111(5):1327–1366.Crossref, Google Scholar

