
Does AI Cheapen Talk? Theory and Evidence from Global Entrepreneurship and Hiring
Abstract
Screening human capital based on signals such as job applications or entrepreneurial pitches is crucial for organizations. Signals are often informative insofar as they require differential knowledge and effort to produce. Generative AI (GAI) complicates screening by lowering the cost of producing impressive signals. We model the informational effects of GAI, showing that applicants’ access to GAI can increase—and also decrease—an evaluator’s screening mistakes. This result depends on how GAI affects experts’ signals compared with nonexperts’. Using experiments in hiring and start-up investing, we estimate that senders’ access to GAI (ChatGPT) lowers screening accuracy by 4%–9% for employers and start-up investors. Consistent with our model, senders’ access to GAI also improves screening accuracy in some settings, in our case, among senders from non–English-speaking countries. These results show that GAI can profoundly shape screening accuracy.
This paper was accepted by Anindya Ghose, information systems.
Funding: We are grateful for the Columbia Business School Digital Future Initiative Grant for helping fund this project. B. Cowgill thanks the Kauffman Foundation Emerging Scholars Program, the Columbia Center for Political Economy, the NET Institute, and the Stellar Development Foundation. P. Hernandez-Lagos thanks the Yeshiva University Sy Syms Dean’s Research Fund.
Supplemental Material: The online appendix and data files are available at https://doi.org/10.1287/mnsc.2024.07027.
1. Introduction
Screening talent and ideas is essential for organizations around the world to hire the right employees (Wiles et al. 2023b, Black et al. 2024) or to invest in promising ideas (Bapna 2019, Scott et al. 2019). Candidates generate various signals that organizations must evaluate to identify the candidate’s talent.1 Such signals are credible insofar as they require differential knowledge and effort to produce. Precisely because of the differential costs of acquiring knowledge and exerting effort, these signals can be informative about the candidate’s underlying quality (Spence 1973).
Generative artificial intelligence (GAI) presents a challenge to screening: it dramatically reduces the cost of generating signals that evaluators use to assess human capital.2 Some commentators forecast an “epistemic apocalypse” driven by cheap GAI “deepfakes” in domains spanning politics, hiring, investment, and the broader economy (Habgood-Coote 2023, p. 1).
How does GAI impact the accuracy with which evaluators identify a candidate’s true level of expertise? In this paper, we develop a method to measure the reduction in evaluators’ ability to distinguish expertise from a lack thereof. In other words, we quantify information loss from GAI. We present a simple model of how GAI affects evaluators’ learning and use it to propose a strategy for estimating information loss in the data. The model shows that the informational effects of GAI are ambiguous, contrary to the epistemic apocalypse prediction. We derive theoretical conditions in which GAI could decrease the accuracy of screening as well as increase it.
We then measure the size and direction of these effects with experiments in hiring and entrepreneurship. In the experiments, job candidates and entrepreneurs write pitches with and without accessing GAI to convince employers and investors, respectively. We observe each subject’s prior experience and expertise so that we can compare evaluators’ assessments of human capital versus the known facts.
On average, candidates’ access to GAI causes information losses equivalent to a 4%–9% increase in screening errors (the difference between predicted and actual expertise). When candidates can use GAI in our experiments, they produce higher quality pitches, but their signals become more compressed and homogenized, making it harder for evaluators to distinguish underlying expertise. We find that, when candidates can use GAI for their pitch text, evaluators increase their demand by about 6%–9% for other signals to evaluate candidates (e.g., background investigations or market research) that are costlier than text. Demand for these costlier signals reflects lower trust in the pitch as a signal of expertise.
We show that the effect of GAI on screening accuracy depends on a key theoretical parameter: how correlated each candidate’s signal boost from GAI and the candidate’s expertise are. Over the whole population, we find the covariance between the candidate’s signal boost and expertise to be slightly negative (, ), implying that GAI helps low-quality candidates in our setting slightly more than high-quality ones on average. In this case, GAI compresses signals between high and low applicants, thereby pooling them and making it more difficult for evaluators to separate them, which leads to information loss.
However, in different settings, GAI could help high-quality applicants boost their signals, providing little help to lower-quality candidates. Rather than destroying information, we show that GAI in these settings enhances the signal’s informational content, helping evaluators separate experts and nonexperts more effectively than without GAI. Although this finding may appear to be a theoretical curiosity, we find empirical evidence of this, particularly when senders are from non–English-speaking countries. For these subjects, GAI helps experts significantly more than nonexperts. This makes it easier for evaluators to detect the experts. Screening accuracy is, thus, higher when certain candidates can use GAI.
Our paper contributes to three bodies of literature. The first is about firms’ screening and selection processes (Bapna 2019, Chan and Wang 2018, Li et al. 2020, Kokkodis and Ransbotham 2023, Wright et al. 2023a, Hui et al. 2024). Several recent papers examine how evaluators’ adoption of artificial intelligence (AI) and machine learning for screening, both for hiring and investing, impacts screening outcomes (Horton 2017, Bhatia and Dushnitsky 2023). Machine learning algorithms can reduce the cost of evaluating disparate signals, improving screening accuracy (Cowgill 2020, Li et al. 2020). By contrast, there is less work on how the use of AI by the candidates themselves impacts screening accuracy. The work that does exist suggests both gains and losses to screening errors (Ghose and Ipeirotis 2010, Hong et al. 2021, Weiss et al. 2022, Wiles et al. 2023b).3 Our paper helps explain these apparently disparate findings by modeling and measuring the parameter—the correlation between signal gain from AI and expertise—that determines whether GAI increases or decreases such errors.
We also contribute to the literature on the productivity effects of AI (Agrawal et al. 2021, Allen and Choudhury 2021, El Sawy et al. 2021, Jia et al. 2024, Kim et al. 2024, Dell’Acqua et al. 2025, Gans 2025). Several recent papers suggest that AI boosts productivity, typically for the firm adopting the technology (Felten et al. 2023, Noy and Zhang 2023, Choi and Schwarcz 2024, Eloundou et al. 2024, Svanberg et al. 2024, Brynjolfsson et al. 2025).4 Because of the importance of information transmission, our paper also raises the possibility of productivity losses arising from increased screening errors by firms. Our model helps explain findings in which GAI raises workers’ productivity by supplying them with better information tools but lowers overall productivity because the people relying on that information trust it less (as in, e.g., Kim et al. 2024).
Lastly, this paper sheds light on the context-specific nature of AI. Recent work shows that AI can have different effects across contexts. Some papers find that AI is more helpful for firms or workers at the bottom of the performance distribution (Dell’Acqua et al. 2023, Brynjolfsson et al. 2025), whereas other work suggests that GAI helps workers at the top more (e.g., Choudhury et al. 2020, Otis et al. 2023, Conti and Messinese 2024). Our work provides an explanation for why we should expect variation in the distributional effects, for example, across industries or geographies. Our key parameter, the correlation between expertise and GAI signal boost, captures whether workers at the top or bottom of the skill distribution benefit more from the technology than others, and it varies across populations. This suggests that the distributional effects are not inherent to the technology. They depend on the context. Although GAI may seem like a globally standardized technology, our results suggest that companies may need to pursue context-specific strategies, for instance, when hiring or investing across borders (Bloom et al. 2012, Gupta and Khanna 2018, Carlson 2023, Wright 2026).
In the remainder of this paper, we provide a model of GAI and screening in Section 2. Section 3 discusses the experimental design and data to test the model. Section 4 provides results, and Section 5 discusses and concludes.
2. Theoretical Framework
We propose a model that helps assess how GAI impacts screening accuracy. The model features two players. One is a sender who spends effort generating a pitch (such as a cover letter or business plan). Senders with genuine expertise find it easier to generate a high-quality pitch. However, when GAI is available, senders of all types can use generative AI to enhance their pitch. The other player is a receiver who interprets the pitch and rewards the sender based on the receiver’s beliefs about the sender’s true level of expertise.
As in many real-world settings, the sender has incentives to manipulate the receiver’s beliefs, which means that the receiver faces a signal extraction problem. The receiver derives correct beliefs about expertise using an imperfect signal, which contains a mixture of information, noise, and spam (akin to, e.g., Holmström 1999). In the model below, we derive how the signal affects the receiver’s beliefs about the sender’s expertise. We can then evaluate the accuracy of those beliefs and see how this accuracy changes when senders can use GAI. After the preliminaries below, we summarize notation in Table 1 and proceed to the theoretical results.
|

Table 1. Glossary of Notation
| Symbol | Meaning/definition | Support/type |
|---|---|---|
| Players, types, and primitives | ||
| Sender’s true expertise (receiver ultimately values this) | ||
| Sender-specific GAI boost to the signal when GAI is available | ||
| F | Joint distribution of (bivariate normal) with means , variances , covariance | Distribution |
| Means of expertise and GAI-boost types | ||
| Variances of and | ||
| Covariance between expertise and GAI boost (key parameter) | ||
| Actions, technology, and noise | ||
| a | Sender’s signaling effort; cost | |
| s | Signal (pitch quality) | |
| Signal technology (Equation (1)) | Equation | |
| G | Indicator for GAI availability | {0,1} |
| Noise in the signal; | ||
| Variance of noise | ||
| Receiver’s posterior mean belief about expertise | ||
| Payment to sender | ||
| r | Sender’s revenue share | |
Notes. This table summarizes notation in the setup of our model. Online Table A.1 expands this table for use in our proofs.
2.1. Setup
2.1.1. The Sender.
The sender in our framework generates a signal by selecting a level of effort . The signal represents a pitch such as an outreach email or business plan. Higher signals require more effort to generate. Effort is costly and convex; exerting a effort reduces utility by . Senders’ signals can also increase or decrease according to the following privately known types:
Senders differ in expertise, denoted by . Senders with more expertise find it easier to produce higher signals.
Senders vary in how much GAI improves their pitch (when available). We denote this GAI boost as .
The sender privately observes these types . We assume they are drawn from a bivariate normal cumulative distribution function F with strictly positive means , variances , and a covariance term .5 The joint distribution of and is known to all players. The covariance between expertise and GAI boost—the term—can be positive or negative. This term becomes a key parameter that drives our qualitative results.
2.1.2. The Signal.
A sender of type using effort a can produce a signal
The availability of GAI ( or ) is an exogenous, publicly known parameter. As motivation for this setup, the state could represent a pre-GAI era, in which the absence of GAI availability is common knowledge. The could represent a post-GAI era, in which GAI is widely known to be available and integrated into content creation tools. G is publicly known because all parties know in which era they are.7 Although we raise this pre or post distinction as one motivating interpretation, our model only relies on the assumption that the availability of GAI ( or ) is exogenous and publicly known.8 We relax this assumption in our extensions, allowing the availability of GAI to be unobserved (Online Appendix A.2), and we endogenize GAI use in Online Appendix A.3.
Because of the assumption above, receivers in our setup are aware that all senders have access to GAI when (e.g., in our pre/post interpretation, they know that MS Word contains large language model (LLM) assistance). However, evaluators remain uninformed about any specific candidate’s , representing how much GAI helped that specific sender.
2.1.3. Sender’s Utility.
The sender gains a payment P from the receiver (e.g., being hired or funded) based on the receiver’s beliefs about the sender’s expertise. The sender chooses a to maximize
Choosing to provide higher effort a raises the sender’s signal (Equation (1)), but there are convex costs for higher effort (Equation (2)). Next, we show how the receiver formulates the receiver’s payment P.
2.1.4. Receiver.
The receiver’s ex post value of the sender is equal to the sender’s expertise . Qualitatively, these payoffs correspond to a receiver seeking true expertise () and not the ability to artificially enhance a cover letter using GAI or through effort (a). The receiver, therefore, makes inferences from the signal about the sender’s expertise and bases the payment P on this expectation. To recruit the sender, the receiver splits the receiver’s expected profits (with the sender getting a portion ). The receiver’s payoff is, thus, equal to , where represents the receiver’s beliefs about the sender’s expertise (given the sender’s signal and availability of GAI). The payment to the sender from the receiver is
The receiver’s preferences are common knowledge. Given this setup, the sender has incentives to manipulate the receiver’s beliefs about the sender’s level of expertise. Table 1 summarizes the notation of the model.
2.2. Analysis
Before sharing our main results in Section 2.3, we present the key analytical steps. All proofs are in Online Appendix A. At the core of our results are the receiver’s posterior beliefs about the sender’s expertise (based on the signal s and availability of GAI G). This term is denoted . Online Lemma A.1 derives the formula for this term.
As is well-known for Bayes-updating normal random variables, the posterior belief is a weighted function of the prior and the signal. Our Online Lemma A.1 reflects this, and we use the term to represent the weight placed on the signal. Online Lemma A.1 allows us to derive two important implications about this weight.
(
Online Appendix A.1 presents results that establish exact conditions when the weight increases or decreases. The weight that the receiver places on the sender’s signal (i.e., pitch quality) is important because it influences screening accuracy and the other key outcome variables in which we are interested.
(
This result suggests that the substitution effect from GAI is theoretically ambiguous. GAI allows higher signals for less effort. This could make senders want to supply more effort to get ahead of other senders. However, senders might also think, if I can get higher signals with less effort, why work harder? This latter possibility is consistent with work showing that AI can lower incentives for effort (falling asleep at the wheel) (Athey et al. 2020, Dell’Acqua 2022).9 In an infamous federal lawsuit, for example, an attorney used ChatGPT to enhance his brief (supplying lower editing effort). The judge discovered fake quotes in the brief and sanctioned the attorney (Weiser 2023).
2.2.1. Accuracy Loss.
The key question for any evaluator is, how far are the receiver’s posterior beliefs from the actual expertise of a given sender? To answer this question, we examine the squared distance between the sender’s true expertise x and the receiver’s beliefs about it. Let denote a probability density function representing the receivers’ beliefs b about candidates whose true expertise is x. Accuracy loss is defined as the average squared deviations from true expertise:
In Online Lemma A.2, we derive an explicit and relatively simple formula for the accuracy loss as a function of true expertise x, generative AI availability G, and the distributional parameters. Errors are minimized when a sender’s true expertise equals the average expertise in the population: . We also show that the loss averaged across all senders takes a convenient, simplified form below.
(
Lemma 1 is important because it shows the useful equivalency that the average prediction error equals the variance of the receiver’s belief about the sender’s expertise (conditional on the signal and GAI availability). Our empirical section uses this equivalence. We collect data about the receiver’s squared error loss (inaccuracy) as well as the variance (uncertainty) of the receiver’s beliefs, using both as measures of information loss.
2.3. Main Results
We now proceed to derive our main results. We start by studying accuracy loss: when does GAI help or harm screening accuracy? GAI helps screening if and only if an expert’s signal boost from using GAI is typically extremely higher or extremely lower than a nonexpert’s GAI boost, that is, when the covariance between expertise and GAI boost () is extreme.
(
Proposition 1 raises the idea that GAI could improve the accuracy of screening. It shows that, if the covariance is extremely high (or low), GAI increases screening accuracy. Online Appendix A derives the exact cutoffs for extremely high and extremely low (i.e., and ). The intuition is simple. Suppose the covariance between expertise and GAI boost is extremely high. In that case, receivers can easily distinguish experts because experts send very high signals and nonexperts very low ones, and so accuracy improves. However, if the covariance is extremely negative, receivers can still distinguish experts (i.e., experts are the senders with very low signals), and so accuracy can also improve in this setting.
In other words, for GAI availability to help screening, GAI must boost experts’ signals significantly more than nonexperts’ signals, or GAI must hurt experts’ signals significantly more than nonexperts’ signals. In either case, receivers can infer expertise more accurately. By contrast, GAI reduces average accuracy when it benefits experts and nonexperts more similarly, particularly when it makes a pitch by a nonexpert resemble a pitch by an expert. In such a case, GAI does not help separate expertise. Figure 1 illustrates how GAI makes screening more accurate than without GAI for extreme covariances for some sample parameter values.
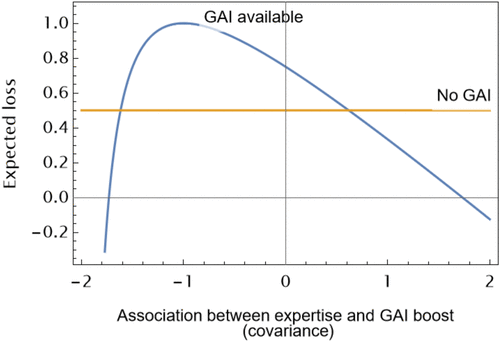
Notes. This figure plots the expected squared error loss under GAI (derived in Online Lemma A.2) as a function of different covariance parameters . GAI makes receivers’ inferences more accurate when the covariance between expertise and GAI is extreme. To visualize a specific relationship in this plot, we set variances equal to one except the variance of GAI boost, which is set to two.
In some environments, the opposite of an epistemic apocalypse is possible: better learning, not worse. We now discuss whether these extreme covariances are realistic (and, thus, more than a theoretical possibility). In practice, we suspect that the extremely low covariance is less likely.10 However, extremely high (positive) covariances may be possible.
There is evidence for this high positive covariance possibility in a 2023 experiment in AI art by popular science communicator Cleo Abram (2022a). Abram hired a visual artist (conventionally trained, pre-GAI) to develop art both without GAI help and later with the assistance of GAI, DALLE in that case. Simultaneously, Abram herself (no art background) completed the same task, developing art both with and without GAI.
The program then had 3,000 subjects blindly evaluate the professional’s and novice’s artwork both with and without GAI. Abram summarized the result, saying “[The GAI] boosted both of us,” but “It didn’t feel like the AI was leveling the playing field between us. It gave me new skills, but gave [the artist] superpowers” (Abram 2022b, emphasis added).
The conventionally trained artist developed sophisticated prompts about specific techniques and comparisons from art history, producing much more highly rated art. The novice’s art improved, but she was not able to leverage the power of GAI (DALLE) without subject matter expertise. The Abram experiment, thus, provides an example of GAI helping an expert more than a novice.
The DALLE experiment was an informal demonstration in a popular science program. Our experiments in this paper scale the Abram experiment under a controlled setting, using the context of hiring and entrepreneurship rather than AI art.
Our final set of results concerns the pitch. Does the availability of GAI necessarily produce higher signals (i.e., higher quality pitches)? Does GAI compress the level of signals, homogenizing them, or does it spread them out? We now show that the answer to both questions depends on the covariance . Let us denote the level of the signal s in equilibrium.
(
Intuitively, Proposition 2 says that, if is sufficiently high (i.e., experts benefit more), GAI makes pitches look better—that is, fancier, higher quality, more polished—or as if more effort has been put into developing them. This better average pitch result comes about for two reasons. The first is the direct lift from GAI. With GAI available, the sender’s message gets an additive boost on average. This lift is otherwise possible only by working harder.
The second factor is the incentive response. GAI not only makes it look as though the sender worked harder. It also changes the actual amount of effort the sender supplies. When GAI is available, the screeners adjust the amount of trust they place in the signal. Because the sender’s equilibrium effort is proportional to how much screeners trust the signal, GAI changes the returns to effort.
If GAI disproportionately helps experts (), the signal is more informative about true expertise, receivers increase the weight, and senders work a bit harder. If GAI helps nonexperts more (), the signal is less informative, receivers discount it, and senders optimally reduce effort. This reduction in effort can partially or fully offset the first force: the direct lift. Proposition 2 packages these two forces into a single cutoff (derived in Online Appendix A).
Our final result is about the dispersion or homogeneity of the signal. This directly tests the idea that GAI leads to compressing signals such that experts and nonexperts produce similar signal levels. The opposite of compressing is for pitch signals to be widely dispersed and varied so that they can possibly help distinguish human capital. To study this, we examine the signals’ population-wide variance.
(
Proposition 3 speaks to the widespread claim in popular and academic discourse that GAI homogenizes intellectual output. For example, a June 2025 New Yorker article (Chayka 2025) titled, “A.I. Is Homogenizing Our Thoughts,” cites Agarwal et al. (2025), Kosmyna et al. (2025), and other studies that “suggest that tools such as ChatGPT…make our writing less original.” Empirical studies by Bommasani et al. (2022), Doshi and Hauser (2024), and Toups et al. (2023) find similar results, and Kleinberg and Raghavan (2021) and Raghavan (2024) theorize about diversity and homogenization in AI.
In the stylized setup of our model, Proposition 3 shows that GAI does not necessarily lead to homogenization. It can also lead to higher dispersion and differentiation. The result shows that GAI’s impact on the dispersion of signals hinges on whether it narrows or widens the gap between experts and nonexperts. If GAI helps novices more (negative covariance), low-expertise senders are pulled up, whereas high-expertise senders are pulled less, bunching signals toward the middle. Everyone’s signals begin to look alike, compressing the range of quality and making it harder for evaluators to separate candidates.
Conversely, if experts reap the bigger gains (positive covariance), then high-expertise senders get the bigger lift, and dispersion grows. Rather than homogenizing, the signals spread out more, making it easier to distinguish between high- and low-quality candidates. Proposition 3, thus, shows that GAI can homogenize signals though not mechanically: it compresses or diversifies them depending on which group benefits more. As before, the result depends on . A negative covariance between expertise and GAI boost can actually decrease signal dispersion.
2.3.1. Theoretical Extensions.
Although the model above illustrates our main theoretical points, we can extend the model to several interesting adjacent questions. Some extensions require simple reinterpretations of the parameters. For example, because the GAI signal boost is unobserved by receivers, one could interpret it as uncertainty about whether GAI was used when available or uncertainty about the boost it gives to the signal when used. Both interpretations lead to the same qualitative results.
The Online Appendix describes more substantial extensions. Online Appendix A.2 studies exogenous but hidden use of GAI. Online Appendix A.3 endogenizes the use of GAI. Online Appendix A.4 studies binary types. These extensions help apply our setup to other theoretical settings, but the broad message about the pivotal role of the covariance term arises in all of these models. Section 5.2 discusses several other ways to extend our model along with some limitations and opportunities arising from our results.
3. Empirical Methodology
Our model suggests that GAI can either increase or decrease screening accuracy. The covariance term—capturing the heterogeneity in how GAI affects signals—is central to the receiver’s ability to learn from the availability of GAI. The covariance term may differ across populations and settings.
We now turn to measuring the size and direction of the informational effects of GAI. The negative epistemic effects of GAI are a common topic in public discourse. Our experiments aim to test and quantify the level of information loss. In applied settings—such as screening job applicants or entrepreneurs—does GAI help or harm screening? How big are the effects?
To answer these questions, we designed and executed a set of experiments outlined below.11 From the experiments, we can produce reduced-form estimates of how GAI changes signals, beliefs, and the accuracy of screening.
3.1. Overview of Experiments
Our experiments took place in spring/summer 2023. We recruited subjects into the role of senders tasked with developing a signal (pitch). A second set of receiver subjects evaluated the signal and interpreted the expertise of the senders. We recruited both sets of subjects from Prolific.12 In the hiring context, job candidates (senders) wrote cover letters to persuade employers (receivers) to hire them. In the entrepreneurship context, entrepreneurs (senders) wrote pitches to investors (receivers) to get funding for their venture idea.
Senders received instructions to craft pitches intended to signal expertise regardless of their actual expertise. We asked receivers to evaluate the resulting messages and the expertise of the corresponding senders. Specifically, we tasked the receivers to assess the overall quality of the pitch and to discern which pitches were written by experts. Critically, we have direct measures of senders’ actual expertise in their respective domains. We can, therefore, assess the accuracy of the receivers’ beliefs about the senders’ expertise when senders can both use GAI and not.
Each sender in our design developed four pitches: two in a domain in which they have expertise and two in a domain in which they do not. Thus, we have a balanced number of pitches by senders with and without expertise. Within each domain, each sender first developed a pitch without using ChatGPT. After writing a pitch without ChatGPT assistance, every sender received instructions that they could use ChatGPT to rewrite or improve the pitch. Thus, we have a balanced number of pitches that could use ChatGPT (and not).
We recruited receivers with prior experience in the relevant domain to evaluate the senders’ pitches. Each receiver evaluated eight randomly assigned pitches, each with a 50% probability of being written with access to ChatGPT. They were informed whether the pitch was written with the assistance of GAI.13 Because senders produced multiple pitches in different domains, our specifications can use sender fixed effects. Because each receiver evaluated multiple pitches, we can also use receiver fixed effects. The unit of analysis of our data is, thus, the combination of sender receiver domain ChatGPT.
In the remainder of this section, we describe our two settings (hiring and entrepreneurship), participant recruitment, treatment compliance, and our full data set. In Section 3.8, we propose our regression specifications. We choose our two contexts below (hiring and entrepreneurship) to show the robustness of our findings across multiple contexts, and we do not have ex ante reasons to believe that they generate different effects. We later evaluate heterogeneous effects by setting and find no qualitative differences in the impact of ChatGPT. We provide more detailed information about the design and specific instructions in Online Appendix C.
3.2. Setting 1: Hiring
In the hiring context, we recruited candidates with prior work experience in exactly one of two possible expertise domains (industries): (a) data science or (b) management consulting. Although each sender had prior expertise in only one domain, the sender had to write a pitch for both roles separately. We tasked job candidates with developing a pitch for their candidacy for a job opening as would appear, for example, in a cover letter or email to a recruiter or employee at the target company.
On the receiver side, we recruited subjects with experience in hiring in the two industries we study. We then tasked these subjects with reviewing candidates’ pitches in the industry of their own prior experience. We informed the receivers about which pitches were developed by senders who could use ChatGPT.
We asked each receiver to evaluate whether the author of each pitch worked in the target role previously. Some senders had worked in the target role, and others had not. To answer, subjects used probability intervals. This is our measure of perceived expertise ( in our model). We also asked evaluators to rate the quality of the pitch on a one to five scale. We interpret this as a measure of the recruiting pitch’s quality in equilibrium ().
Finally, we asked receivers whether they would be willing to pay for a background verification of the sender’s expertise conducted by a third party, a proxy that captures demand for costlier signals. Demand for a costlier signal reflects lower trust in the pitch as a signal of expertise (low in the model).
3.3. Setting 2: Entrepreneurship
Our entrepreneurship setup has a parallel structure to the hiring one. We recruited subjects with experience as entrepreneurs and who had prior experience in only one of two potential sectors: (a) retail or (b) education. We then asked the entrepreneurs to write a pitch for a new business idea in both the sector in which they had expertise and the sector in which they did not. They did not have access to ChatGPT when writing these pitches. After writing them, we gave them access to ChatGPT and informed them they could use it to rewrite their pitches. As with our hiring setting, ChatGPT and other generative AI tools could be helpful when developing venture capital (VC) pitch materials. Pitch materials often constitute a deck of slides. As of 2024, ChatGPT could directly generate PowerPoint and LaTeX slides. Prior to that, it could generate content (such as graphics or text) that could be helpful for slides. Outside of pitch decks, text remains an important component of VC screening (and often the first step in the screening process).14
To review these pitches, we identified investors from around the world with experience in the two sectors. We asked them to evaluate the pitches in the domain of their prior experience. We then elicited their belief about whether the author of each pitch was an entrepreneur with experience in the requisite industry (representing in our model).
We also asked them to assess the quality of each pitch on a one to five scale. This allows us to measure the pitch quality, reflecting the signal level ( in our model). As with the hiring scenario, we elicited investors’ demand for costlier signals—in this case, a market analysis by a third party that would ask a set of potential customers to evaluate the idea—to validate the quality of the entrepreneurs. As before, demand for costlier signals should be inversely related to how much the investor trusts the signal (the weight in our model).
3.4. Heterogeneity: English Language Context
At the heart of our model is a covariance term . This term represents how much experts (versus nonexperts) gain a signal boost from GAI. The parameter does not appear directly in our data. In Online Appendix B, we develop a strategy to estimate from the experimental data.
Different populations may have different covariance terms () even for the same GAI technology. This is consistent with prior work showing differential effects of GAI by the English-speaking background of users (Brynjolfsson et al. 2025). In our empirical context, the GAI is a large language model (ChatGPT) developed originally in English (Radford et al. 2019). Effective LLM use can require follow-up questions and detecting “hallucinations” (Buchanan et al. 2024), and this requires sufficient command of the language. Filimonovic et al. (2025) describes LLMs as a “linguistic equalizer” in global science, and related work similarly shows how LLMs can be particularly useful for non-English experts (Del Giglio and da Costa 2023, Van Noorden and Perkel 2023, Prakash et al. 2025). The parameter could, therefore, vary by the sender’s fluency in English. Effectively using LLMs may be harder for nonnative speakers, particularly in domains in which they lack expertise. A nonnative speaker who does have expertise could possibly compensate for the lack of English with subject matter knowledge. The expertise might have created exposure to some English words at least in this domain, and through this mechanism, the nonnative-speaking expert could benefit from ChatGPT. For example, an entrepreneur from a non–English-speaking country who has spent a career in the education industry might be familiar with industry terms in English—such as the name of different educational software—even if the nonnative entrepreneur struggles with general English fluency. This industry-specific language knowledge can enable the nonnative entrepreneur to better iterate with ChatGPT to create an education start-up pitch than can a nonnative one without this education industry experience.
For these reasons, the covariance could be positive for senders from outside of an English-speaking background (i.e., ChatGPT helps boost the pitch quality of experts more than that of nonexperts). By contrast, the covariance could be the reverse (negative) among native speakers. For these speakers, ChatGPT might help improve the pitches of nonexperts more than those of experts. Nonexperts from an English-speaking background can ask follow-up questions to ChatGPT until their pitch sounds as convincing as that of an expert. To assess this variance, we recruited participants from around the world. Although our task and subject platform (Prolific) require some basic English fluency, we collected subjects from places where English both is a primary language and not a primary language.
3.5. Participant Recruitment
We recruited senders and receivers from Prolific. We filtered senders and receivers based on their industry, occupation, and entrepreneurship experience as provided by this platform. Both senders and receivers were compensated about $12/hour for completing the tasks. Note that our theory does not require that the Prolific experts be, say, world-class experts. It only requires that experts be more qualified than nonexperts. To validate our subjects’ relative expertise, we surveyed participants about their prior experience in a variety of domains. Online Appendix D.10 contains our results. Our subjects reported more years of education and work experience in domains relevant to their experimental context. For example, receivers in the entrepreneurial context reported more years of investing experience than other experimental subjects and the broader Prolific pool. This suggests that the experts we recruited satisfied the goal of being more qualified than the nonexperts. Later, we directly test whether evaluators rate higher experts’ pitches in a blind test.
3.6. Compliance
A potential concern with this platform is that senders might be using ChatGPT even if they are in the control condition. Although we instructed participants not to use ChatGPT in the experimental instructions (see Online Appendix C), some may have done so anyway. To address this concern, we asked participants at the end of the control (non-ChatGPT) questions whether they actually used ChatGPT in the control condition and exclude those who did. This does not eliminate the possibility that some senders used ChatGPT for the non-ChatGPT conditions. However, this form of noncompliance would bias our results toward zero (by equalizing treatment and control). If this were the case, our results could be interpreted as a lower bound of the true magnitude of effects. We also exclude pitches written by other senders who ignored the experiment’s instructions.15
3.7. Data
Our final data are on a sender–receiver evaluation level. In total, we have 343 unique senders and 801 unique receivers, about half of each in the entrepreneurship and hiring contexts.16 Each receiver evaluated eight pitches or cover letters as illustrated in Online Appendix C. Four receivers bridged the entrepreneurship and hiring domain, so they completed two sets of evaluations. This leaves our final data set with 6,440 evaluations.17 Pitches are randomly assigned to receivers within the same context (either entrepreneurship or hiring). Of our total observations, 3,192 come from the recruitment context, and 3,248 come from the entrepreneurship context. We pool observations across entrepreneurship and hiring in our main paper and test for heterogeneous effects in Online Appendix D. The senders come from a mixture of English- and non–English-speaking countries.18
3.8. Regression Specifications
Our specifications measure how GAI changes signals, beliefs, and accuracy. Our main specification is
The variable reflects whether the sender/pitching subject could use ChatGPT, corresponding to in our theory model. reflects sender fixed effects, and reflects receiver fixed effects. Because each receiver evaluated multiple senders, we include pitch order fixed effects ().19 Standard errors are clustered by receiver. The coefficient of interest is , which indicates whether and how ChatGPT shifts the outcome.
As mentioned, the model shows how the results depend on a latent parameter in the data-generating process, representing the covariance between the senders’ expertise and the signal increase from ChatGPT. Online Appendix B contains a strategy to estimate from our data. In our results section, we mention these estimates of alongside our reduced-form estimates of our main specification (Equation (3)).
3.8.1. Contingency Tables and Tests.
Although we present most of our results as linear regressions, we also present our results as two-dimensional contingency tables. On one axis, we have ChatGPT availability versus not, and on the other axis, we present different levels of the outcome. Within each cell, we present counts of observations. Many of our outcomes are in categorical format, and so we can transparently summarize our data this way. For hypothesis testing, we apply tests to the contingency tables. tests are advantageous because they are nonparametric; they do not assume normality, linearity, or homoscedasticity. They simply test whether variables are independent by comparing observed frequencies to expected frequencies. Consequently, these tests yield robust, nonparametric insights into the categorical association without risking the biases that arise from regression model misspecification.
|
Table 3. Confusion Matrix (Full Experiment)
| Variable | Predicted expertise | |||||
|---|---|---|---|---|---|---|
| [0,0.2] | (0.2,0.4] | (0.4,0.6] | (0.6,0.8] | (0.8,1] | Total | |
| Actual expert | 721 | 597 | 707 | 766 | 394 | 3,185 |
| Actual nonexpert | 926 | 648 | 651 | 688 | 340 | 3,253 |
| Total | 1,647 | 1,245 | 1,358 | 1,454 | 734 | 6,438 |
Notes. This table shows a confusion matrix for all predictions made by receivers/screeners in the data. The null hypothesis in the test is that the distribution of predicted expertise is statistically independent of the rater’s forecasts. Pearson , .
|
Table 4. Squared Error Contingency Table
| Variable | Error2 = (Predicted − Actual Expertise | |||||
|---|---|---|---|---|---|---|
| 0.01 | 0.09 | 0.25 | 0.49 | 0.81 | Total | |
| No ChatGPT | 703 | 679 | 643 | 599 | 546 | 3,170 |
| ChatGPT | 617 | 735 | 715 | 686 | 515 | 3,268 |
| Total | 1,320 | 1,414 | 1,358 | 1,285 | 1,061 | 6,438 |
Notes. This is a contingency table expressing raw counts of observations in all categories. We calculate predicted expertise by using the midpoint of all five probability bins (0–0.2), (0.2–0.4), (0.4–0.6), (0.6–0.8), and (0.8–1). The null hypothesis of the test is that the distribution of the errors is identical whether ChatGPT is available or not. Pearson , .
3.9. Outcomes
Below, we list and motivate all outcome variables. To link our experiments back to theory, we include a variable name next to each outcome. When interpreting our experiments through the lens of our model, we assume that our empirical measures represent equilibrium outcomes.
Several outcome variables are measured as a one to five ordinal rating. In these cases, we use the one to five rating as the dependent variable. In some cases, we give receivers five buckets of choices corresponding to specific numbers or intervals as described below.20 In these cases, we can either use the one to five rating as the dependent variable or we can use the midpoint of the interval.21 We mostly use this second approach (midpoints of intervals) to aid interpretation. Qualitatively, our results are robust to either approach as well as to using the tops or bottoms of the intervals (rather than the midpoint).
In addition, the magnitudes of some effects are not easily interpretable (i.e., squared error loss). To ease interpretation, we present results in both levels and logs. The log results can be interpreted as percentage increases (multiplicative). The five categories below summarize our outcome variables.
p: Receivers’ beliefs about sender expertise. We ask receivers to choose a probability bucket representing how likely a sender is to be an expert. This corresponds to in our theoretical model (the receiver’s posterior mean belief about the sender’s expertise). The probability buckets are in intervals of 20% (e.g., 0%–20%, 20%–40%). We use the midpoint of these intervals as the probability, but our results are robust to using the top or bottom of these intervals.
: Accuracy. We measure the accuracy of evaluations in two ways: the first approach uses the posterior variance (uncertainty) about expertise, following from Corollary 1. Because receivers’ beliefs are probabilities p that the sender is an expert, the variance of this belief is .
: Accuracy. In addition, we study accuracy by taking the square difference between the actual expertise of senders and the receiver’s probabilistic prediction (mentioned above).
Both (b) and (c) are measures of errors. This corresponds to L (loss) in our theoretical model. Thus, the positive coefficients indicate less accuracy. Because squared errors and variances are difficult to interpret, we also present results in logs (for percentage interpretation). We also measure the level of the signal in two ways.
: Level of the signal. We ask receivers to rate the pitch directly using a five-point scale.
: Natural language processing (NLP) level of the signal. We also obtain a more objective measure of the pitch quality using NLP and, specifically, the Flesch–Kinkaid reading score (Flesch 1948). This score measures the sophistication of written language according to the level of education necessary to understand it.22 For interpretability, we transform this variable so that higher values represent more sophisticated language.23 Our NLP variable is 100 minus the raw Flesch–Kinkaid score.
: Variance of the signal. To measure dispersion, we take the mean ratings of the signal by condition. Let represent the mean signal under ChatGPT and represent the mean signal with no ChatGPT. We then subtract each rating from the mean within its condition and square it. The average of these values, thus, has the interpretation of a variance (corresponding to Proposition 3).24 We do the same for the NLP rating: .
WTP: Demand for costlier signals: Finally, we measure evaluators’ demand for a signal that is costlier than text, for example, a background investigation in the hiring context and market research in the entrepreneurship context. This variable does not correspond to anything in the model but is meant to measure subjects’ demand for better signals. We elicited this directly in the experiments by asking subjects to choose from a range of dollar values ranging from $0 to $100.
We use these variables as the main outcome variables in Equation (3).
4. Results
Table 2 shows the summary statistics. Many of our main results are in this table although we later show full regressions with controls. When senders can use ChatGPT, screening accuracy is lower by 4%–9%. In other words, screeners are 4%–9% more likely to judge recruiters’ true expertise incorrectly.
|
Table 2. Summary Statistics by ChatGPT Availability
| Variable name | With ChatGPT | No ChatGPT | Difference |
|---|---|---|---|
| Sender’s true expertise (0/1) | 0.49 | 0.50 | −0.0011 |
| Receiver’s belief sender is an expert (p) | 0.45 | 0.45 | 0.0037 |
| Variance of receiver belief, | 0.18 | 0.17 | 0.0064*** |
| Log(variance of receiver belief) | −1.82 | −1.86 | 0.043*** |
| Squared error: (true expertise − receiver belief)2 | 0.31 | 0.30 | 0.003 |
| Log(squared error) | −1.90 | −1.99 | 0.092** |
| Level of signal (rating one to five by receiver) | 2.91 | 2.83 | 0.084*** |
| Log(level of signal, rating) | 0.96 | 0.92 | 0.044*** |
| Level of signal (NLP) | 69.95 | 53.04 | 17*** |
| Log(NLP rating) | 4.23 | 3.92 | 0.32*** |
| Variance of rating | 1.45 | 1.58 | −0.14*** |
| Log(variance of rating) | −1.07 | −0.53 | −0.54*** |
| Variance of NLP rating | 134.31 | 304.95 | −171*** |
| Log(variance of NLP rating) | 3.51 | 4.38 | −0.87*** |
| Receiver willingness to pay, $ | 39.37 | 37.27 | 2.1*** |
| Receiver willingness to pay (one to five rating) | 2.47 | 2.36 | 0.1*** |
| Log(receiver willingness to pay) | 3.39 | 3.31 | 0.079*** |
Notes. This table contains summary statistics for ChatGPT and non-ChatGPT messages. total sender receiver pairs. In observations, the sender had ChatGPT available to develop their pitch. The stars are given by the p-values of the t-test of a difference in means with zero.
*p < 0.1; **p < 0.05; ***p < 0.01.
The level of the signal (pitch quality) increases by 4% with ChatGPT when measured as the ratings by receivers. Roughly speaking, the text of the pitches appears more polished and to require higher effort and skill for a human to produce. Table 2 shows that ChatGPT lowers the dispersion of the signal by 54% when using the ratings by receivers and 87% when using the NLP score. These are consistent with GAI availability homogenizing the quality of pitches across people of different expertise.
Finally, we find that receivers are willing to pay more, on average, for additional information in the ChatGPT condition than in the control. This suggests that recruiters sense that the availability of ChatGPT has damaged their screening accuracy and are willing to pay for better signals.
On our main outcome variable (accuracy), Table 3 presents a confusion matrix that summarizes the accuracy of our screeners’ forecasts. The null hypothesis in the Table 3 test is that the distribution of predicted expertise is statistically independent of the rater’s forecasts. The low p-value () represents the rejection of this hypothesis. Together with our evidence, this suggests that our screeners were able to identify experts with a statistically detectable degree of accuracy. We later quantify how this changes as senders gain access to ChatGPT.
In Online Appendix D.1, we briefly explore differences between the entrepreneurship and hiring settings. Although there are differences in the overall level of outcomes, we find either no differences or small differences in the magnitude and direction of the ChatGPT effects. From here, we now go through our main results in detail using our pooled sample and the regression in Equation (3).
4.1. Screening Accuracy
How did accuracy change with ChatGPT? Table 4 reports a contingency table summarizing squared errors by ChatGPT availability. The test examines the null hypothesis that the distribution of the error is independent of ChatGPT availability. The low p-value rejects this null (nonparametrically). Online Table D.3 presents similar contingency tables for absolute error, and Online Table D.4 presents raw errors. Online Tables D.5 and D.6 separate out the error distributions for ChatGPT and non-ChatGPT senders. Together, these results consistently show that ChatGPT is associated with screening errors.
Table 5 presents our results about the effects of ChatGPT on accuracy with both no controls and the full set of controls in Equation (3). The outcomes in this table measure screening errors, so positive coefficients indicate greater inaccuracy. We use both the variance of receiver beliefs as well as squared error loss as measures of accuracy (as Lemma 1 derives their equivalence).
|
Table 5. ChatGPT Increases Screening Errors
| Coefficient | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) |
|---|---|---|---|---|---|---|---|---|
| Variance of receiver belief | Variance of receiver belief | Log variance of receiver belief | Log variance of receiver belief | Error2 | Error2 | Log(Error2) | Log(Error2) | |
| ChatGPT | 0.0064*** | 0.0059*** | 0.043*** | 0.041*** | 0.003 | 0.0011 | 0.092** | 0.077* |
| (0.0018) | (0.0019) | (0.012) | (0.012) | (0.0067) | (0.0074) | (0.039) | (0.041) | |
| Fixed effects | — | All | — | All | — | All | — | All |
| 0.0023 | 0.26 | 0.0024 | 0.26 | 0.000029 | 0.2 | 0.0009 | 0.22 | |
| Dependent variable mean | 0.17 | 0.17 | −1.8 | −1.8 | 0.31 | 0.31 | −1.9 | −1.9 |
| Observations | 6,438 | 6,438 | 6,438 | 6,438 | 6,438 | 6,438 | 6,438 | 6,438 |
Notes. The table shows results from our regression approach in Equation (3) to study how ChatGPT affects screening errors. As the outcome variable, we use measures of screening errors and regress them on ChatGPT. The columns using all fixed effects are outlined in Equation (3) and include sender, receiver, domain, and order fixed effects. Robust standard errors (in parentheses) are clustered at the receiver level.
*p < 0.1; **p < 0.05; ***p < 0.01.
Across our outcomes, we find that ChatGPT increases errors. We see this for all our results in logs and in levels for the variance of receiver beliefs measure. In regression format, our result on the level of squared errors cannot be detected at conventional levels but is highly significant at conventional levels in percentages and logs. We also find differences in squared errors in our most assumption-free tests (Table 4). Across the other outcomes, the decreases in accuracy are detectable at usual significance levels both with and without fixed effects. The magnitudes of screening errors are comparable to the ones in Table 2 at 4%–9%.
Why does accuracy go down? In Online Table D.7, we show that ChatGPT does not affect beliefs about the overall level of expertise. Specifically, when senders can use ChatGPT, on average, receivers think the senders have a 45% chance of being an expert. When senders cannot use ChatGPT, receivers also think that, on average, the sender has a 45% chance of being an expert (the same overall level). Our standard errors rule out differences greater than 1%.
In a sense, the receivers are correct: the true level of expertise does not change between ChatGPT and non-ChatGPT conditions. In both conditions, exactly 50% of senders are experts. Errors increase under ChatGPT because the receivers label expertise incorrectly (within the same overall amount of expertise). Online Table D.7 suggests that lower accuracy does not come from receivers naively believing that more senders using ChatGPT are experts. The overall level is the same. However, the screeners find it more difficult to separate experts and nonexperts when senders can use ChatGPT.
We can interpret our findings in Online Table D.7 through the well-known bias-variance decomposition.25 In this classic result, receivers’ average squared error equals the receivers’ bias (squared) plus the variance of their beliefs about the sender’s expertise. The results of Online Table D.7 show that receivers are slightly biased about the expertise of senders: they think that senders are 45% likely to be experts rather than 50% (a statistically significant difference). This bias is one source of screening errors.
However, this bias is constant across the two GAI conditions (Online Table D.7). Instead, what drives the increase in screening errors under GAI is the change in variance: receivers become more uncertain about expertise under GAI. Columns (1)–(4) of Table 5 measure this variance directly and show that it increases with GAI. Columns (5)–(8) show the same qualitative result when the variance is measured as the squared difference between the receiver’s beliefs and the sender’s true expertise although the estimates are less precise.
4.2. The Level of the Signal (Pitch)
4.2.1. Expertise and Signal Levels.
We now study how ChatGPT affects the level of the signal. In our model, higher level signals require more effort to produce but less so for experts. Before we study the effect of ChatGPT, we first use our data to assess a key assumption of the model: that expert subjects generate higher quality signals because it is easier for them to do so (e.g., Equation (1)). In Table 6, we show that subjects with prior experience indeed produce pitches that receivers rate as higher quality (column (1)) both in our ChatGPT subsample (column (2)) and outside it (column (3)). Although we see a positive relationship between our measure of expertise and the ratings, some readers may ask why the relationship is not stronger. Decades of prior research about selection (starting at least with Dawes 1979) suggests that detecting talent in hiring and entrepreneurship settings is very hard. In fact, many employers and investors are relatively bad at it (McDaniel et al. 1994, Schmidt and Hunter 1998, Scott et al. 2019, Nanda et al. 2020, Sackett et al. 2022). What textual features did evaluators reward with higher signal levels and beliefs of expertise to pitches? To assess this, we conduct topic modeling on the sender pitches in each context using latent Dirichlet allocation (LDA). The LDA model detects clusters of words in the corpus of text that constitute different topics (Pritchard et al. 2000, Blei et al. 2003). We then use ChatGPT to help us label these topics based on the cluster of words. This approach allows us to categorize the pitches within each context into categories of topics.
|
Table 6. Expert Signal Quality is Higher
| Coefficient | (1) | (2) | (3) |
|---|---|---|---|
| Signal level (rating) | Signal level (rating) | Signal level (rating) | |
| Expertise | 0.16*** | 0.13*** | 0.18*** |
| (0.031) | (0.045) | (0.046) | |
| Fixed effects | All | All | All |
| Senders’ sample | All | ChatGPT | No ChatGPT |
| 0.37 | 0.51 | 0.55 | |
| Dependent variable mean | 2.9 | 2.9 | 2.8 |
| Observations | 6,438 | 3,239 | 3,135 |
Notes. In this table, we predict the level of the signal using whether senders are experts. Column (1) shows the full sample. Column (2) shows pitches that can use ChatGPT. Column (3) shows pitches that cannot use ChatGPT. Robust standard errors (in parentheses) are clustered at the receiver level.
*p < 0.1; **p < 0.05; ***p < 0.01.
Our results in Online Appendix D.4 validate the receivers’ judgments. Receivers give higher ratings to pitches that discuss topics appropriate for the context (education, retail, data science, or management). For example, in the consulting recruitment context, evaluators give higher ratings to cover letters that mention strategic consulting and client management topics and give lower ratings to ones that mention data science topics.
4.2.2. ChatGPT and Signal Levels.
We now turn to the effect of ChatGPT. Table 7 shows how ChatGPT impacts the level of the signal both with controls and without. The results show that ChatGPT increases the level of the signal by 4%–6% when using the evaluators’ rating as the measure of level (columns (1)–(4)).
|
Table 7. ChatGPT Increases the Level of the Signal
| Coefficient | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) |
|---|---|---|---|---|---|---|---|---|
| Rating by receiver | Rating by receiver | Log rating by receiver | Log rating by receiver | NLP rating | NLP rating | Log NLP | Log NLP | |
| ChatGPT | 0.084** | 0.12*** | 0.044*** | 0.056*** | 17*** | 17*** | 0.31*** | 0.32*** |
| (0.034) | (0.031) | (0.014) | (0.014) | (0.41) | (0.34) | (0.0075) | (0.0065) | |
| Fixed effects | — | Full | — | Full | — | Full | — | Full |
| 0.0012 | 0.37 | 0.0018 | 0.37 | 0.25 | 0.7 | 0.26 | 0.7 | |
| Dependent variable mean | 2.9 | 2.9 | 0.94 | 0.94 | 62 | 62 | 4.1 | 4.1 |
| Observations | 6,438 | 6,438 | 6,438 | 6,438 | 6,440 | 6,440 | 6,440 | 6,440 |
Notes. The table shows results from our regression approach in Equation (3) to study how ChatGPT affects the level of the signal. As the outcome variable, we use the level of the signal (as measured by evaluators’ ratings and NLP) and regress it on ChatGPT. The columns using all fixed effects are outlined in Equation (3) and include sender, receiver, domain, and order fixed effects. Robust standard errors (in parentheses) are clustered at the receiver level.
*p < 0.1; **p < 0.05; ***p < 0.01.
When using the NLP-created measure (columns (5)–(8)), we find larger percentage effects of around +32%. The base rate in the non-ChatGPT control group is 53 (a Flesch–Kinkaid score of 47), which corresponds to the reading level of a high school senior. The average in the ChatGPT condition is 70 (or 30 on the Flesch–Kinkaid scale), which is around the reading level of a college senior.
In percentage terms, the result is a higher increase (+32%) than that for the receivers’ ratings of the signal (+4%–6%). Whereas the NLP-created measure captures language sophistication, receivers seem to believe there is more to a good pitch than the sophistication of language. When pitching for a job or start-up idea, other aspects (e.g., qualifications and ideas) presumably also matter. ChatGPT may not be able to provide these as effectively, and thus, the effect of ChatGPT on the receivers’ ratings is lower than that on the NLP score.
But how were the ChatGPT pitches different? We can use our LDA topic models to study this. Online Appendix D.5 shows that ChatGPT shifts the topics of the pitches. For example, in the education start-up context, ChatGPT pitches mention “specialized training” significantly less than non-ChatGPT pitches. Our results on this (summarized in Online Appendix D.5) generally suggest that ChatGPT shaped the content of the pitch rather than simply correcting spelling and grammar.
Although the signal was higher for pitches that could use ChatGPT, did receivers believe that the ChatGPT senders had more expertise? Online Table D.7 suggests that they were not fooled: average beliefs about the level of expertise did not increase. Together, these results suggest that the pitches looked better in the ChatGPT condition (Table 7), but they also suggest that receivers discounted the better pitches, attributing the difference to ChatGPT.
4.3. Dispersion of the Signal
ChatGPT increases the level of signals. But how does it affect the dispersion of the signal? Table 8 shows that ChatGPT homogenizes or compresses the level of the signal, lowering the variance between different senders’ pitches. Using the receivers’ rating of signals, the variance decreases by about 9%. In logarithms, it decreases by up to 56%. Using the NLP measure, the variance decreases by up to 92%. Our signal results fit intuitively with our overall result about screening errors, suggesting that screeners use varied signals to distinguish expert from nonexpert candidates or entrepreneurs.
|
Table 8. ChatGPT Lowers Dispersion of Signals
| Coefficient | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) |
|---|---|---|---|---|---|---|---|---|
| Variance of rating | Variance of rating | Log variance of rating | Log variance of rating | Variance of NLP | Variance of NLP | Log variance of NLP | Log variance of NLP | |
| ChatGPT | −0.14*** | −0.13*** | −0.54*** | −0.56*** | −171*** | −186*** | −0.87*** | −0.92*** |
| (0.041) | (0.043) | (0.057) | (0.062) | (16) | (16) | (0.054) | (0.053) | |
| Fixed effects | — | All | — | All | — | All | — | All |
| 0.002 | 0.27 | 0.015 | 0.23 | 0.019 | 0.51 | 0.036 | 0.48 | |
| Dependent variable mean | 1.5 | 1.5 | −0.8 | −0.8 | 218 | 218 | 3.9 | 3.9 |
| Observations | 6,438 | 6,438 | 6,438 | 6,438 | 6,440 | 6,440 | 6,440 | 6,440 |
Notes. The table shows results from our regression approach in Equation (3) to study the dispersion of signals. As the outcome variable, we use the variance of the signal as measured by evaluators’ ratings and NLP and regress it on ChatGPT. The columns using all fixed effects are outlined in Equation (3) and include sender, receiver, domain, and order fixed effects. Robust standard errors (in parentheses) are clustered at the receiver level.
*p < 0.1; **p < 0.05; ***p < 0.01.
Together, our results suggest that ChatGPT raised the average level of the signal, significantly reducing variation in it. Before ChatGPT, signals were lower on average and highly dispersed (i.e., many high signals, many low signals). After ChatGPT, signals are higher but more similar.
4.4. Demand for Costlier Signals
Our final result is about how screeners might react to the loss of information. Our results above suggest that screeners trust pitches less when senders can use ChatGPT. For that reason, they may prefer an alternative way to screen altogether. To test this, we ask evaluators how much they would be willing to pay for costlier signals, such as a background investigation (in the recruitment setting) or market research (in the entrepreneurship setting). Table 9 reports the results. We find that receivers increase their willingness to pay by about 6%–9% when senders can use ChatGPT regardless of the specification. For example, from columns (1) and (2), this translates into an additional $2.10–$2.40 per pitch. Consistent with the reduced accuracy of the pitches, this result suggests that receivers find the pitches less informative.
|
Table 9. ChatGPT Increases Demand for Costlier Signals
| Coefficient | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) |
|---|---|---|---|---|---|---|---|---|
| WTP | WTP | Log WTP | Log WTP | WTP, one to five scale | WTP, one to five scale | Log WTP, one to five scale | Log WTP, one to five scale | |
| ChatGPT | 2.1*** | 2.4*** | 0.079*** | 0.089*** | 0.1*** | 0.12*** | 0.055*** | 0.061*** |
| (0.73) | (0.62) | (0.022) | (0.019) | (0.036) | (0.031) | (0.016) | (0.014) | |
| Fixed effects | — | All | — | All | — | All | — | All |
| 0.0016 | 0.47 | 0.0023 | 0.46 | 0.0016 | 0.47 | 0.0022 | 0.47 | |
| Dependent variable mean | 38 | 38 | 3.3 | 3.3 | 2.4 | 2.4 | 0.72 | 0.72 |
| Observations | 6,438 | 6,438 | 6,438 | 6,438 | 6,438 | 6,438 | 6,438 | 6,438 |
Notes. The table shows results from our regression approach in Equation (3) to study the demand for costlier signals. As the outcome variable, we use receivers’ willingness to pay for costlier signals, which we regress on ChatGPT. The columns using all fixed effects are outlined in Equation (3) and include sender, receiver, domain, and order fixed effects. Robust standard errors (in parentheses) are clustered at the receiver level.
*p < 0.1; **p < 0.05; ***p < 0.01.
If screeners migrate away from text and toward different signals, what does this mean in context? Online Appendix D.6 reports the results of a supplemental survey sent to our subjects as well as a broader pool of Prolific subjects. We find that, in the recruitment context, receivers most commonly prefer interviews. In the entrepreneurship context, receivers most commonly prefer market research. After these signals, receivers also value those related to the candidate’s personal background.
4.5. Covariance: How Much Is Expertise Correlated with ChatGPT Signal Boost?
We have thus far shown that ChatGPT: (a) decreases screening accuracy, (b) increases signal levels, and (c) decreases signal dispersion. According to Propositions 1–3, these results suggest that the covariance should be negative because of (b) and (c), but its magnitude should not be too large because of (a). Otherwise, GAI would improve nonexperts’ signals so much that they would be more easily distinguished from experts than without GAI.
Applying our strategy for estimating as outlined in Online Appendix B reveals a negative covariance with a point estimate of and a bootstrapped standard error of 0.0066. Our p-value for testing this estimate against zero is 0.072. The negative (and significant) value suggests that overall, ChatGPT helped nonexperts more than experts, and the GAI-induced boost makes nonexperts more similar to experts.
The above estimate of uses our entire data set. In our experimental design, we discuss the possibility that could differ by population, particularly according to English familiarity. Among subjects from non–English-speaking backgrounds, we hypothesized that experts could use ChatGPT more effectively (than nonexperts) to boost their pitches.
In Online Appendix D.7, we examine the use of ChatGPT among non-English speakers. Although we do not know how much time each subject spent iterating with ChatGPT, we can measure the differences between their pitch before and after being able to use ChatGPT. This suggests different intensity of usage and possibly a higher perceived value in the use of ChatGPT. In Online Table D.18, we look at all subjects from non-English backgrounds. Among these subjects, pitches by experts changed more after being able to use ChatGPT (compared with those by nonexperts). This is consistent with our hypothesis that among non-English speakers, experts can more effectively use ChatGPT.
We now estimate the covariance by these subpopulations. We find that, for senders from non–English-speaking countries,26 was +0.056 (positive) with a bootstrapped standard error of 0.013 and a p-value below 0.001 when tested against zero. This indicates that ChatGPT helps experts more than nonexperts and, thus, could possibly increase screening accuracy. By contrast, for senders who do come from English-speaking countries, we find a more strongly negative estimate of : a point estimate of −0.034 with a bootstrapped standard error of 0.0075 and a p-value below 0.001 when tested against zero.
Figure 2 illustrates the differences in our estimate of across populations. Given that the sign of the covariance differs across these two populations, we now examine heterogeneity in our reduced-form treatment effects of ChatGPT.
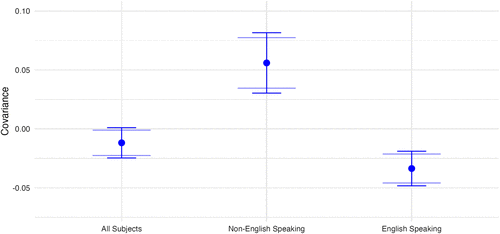
Notes. This figure shows 90% and 95% confidence intervals for our covariance estimates across the three populations we study. The covariances are estimated using the econometric strategy detailed in Online Appendix B.
4.6. Heterogeneity: ChatGPT and Non-English Sender Contexts
From here, we can now revisit our treatment effects. In Table 10, we study our main outcomes and add an interaction term for non–English-speaking sender countries. We find some evidence that ChatGPT introduces gains to accuracy when screening senders from non–English-speaking contexts for whom experts’ signals increase more than nonexperts’ ( is positive). Consistent with Proposition 1, the coefficient on the interaction is negative and significant at conventional levels in column (1) for our accuracy outcome. The results are qualitatively similar though not significant when using variance of receiver beliefs as a proxy of accuracy (column (2)).
|
Table 10. ChatGPT and Non–English-Speaking Sender Contexts
| Coefficient | (1) | (2) | (3) | (4) | (5) | (6) | (7) |
|---|---|---|---|---|---|---|---|
| Log(Error2) | Log variance of receiver belief | Log rating by receiver | Log NLP | Log variance of rating | Log variance of NLP | Log WTP | |
| ChatGPT | 0.17*** | 0.051*** | 0.069*** | 0.34*** | −0.6*** | −0.96*** | 0.1*** |
| (0.049) | (0.014) | (0.015) | (0.0075) | (0.07) | (0.062) | (0.022) | |
| ChatGPT Non- English | −0.34*** | −0.038 | −0.048* | −0.092*** | 0.15 | 0.14 | −0.048 |
| (0.096) | (0.027) | (0.028) | (0.012) | (0.13) | (0.12) | (0.04) | |
| Fixed effects | All | All | All | All | All | All | All |
| 0.22 | 0.26 | 0.37 | 0.7 | 0.23 | 0.48 | 0.46 | |
| Dependent variable mean | −1.9 | −1.8 | 0.94 | 4.1 | −0.8 | 3.9 | 3.3 |
| Observations | 6,438 | 6,438 | 6,438 | 6,440 | 6,438 | 6,440 | 6,438 |
Notes. The table shows results from our regression approach in Equation (3), adding an interaction between Non–English-speaking subjects and ChatGPT. We study all of the main dependent variables. The columns using all fixed effects are outlined in Equation (3) and include sender, receiver, domain, and order fixed effects. Robust standard errors (in parentheses) are clustered at the receiver level.
*p < 0.1; **p < 0.05; ***p < 0.01.
However, ChatGPT’s impact on the average signal level is lower for senders from non–English-speaking contexts, using the subjective and NLP ratings (columns (3) and (4)), which is inconsistent with Proposition 2. ChatGPT’s impact on the signal’s dispersion is higher in magnitude but not statistically different in non–English-speaking contexts relative to others, which is qualitatively consistent with Proposition 3 (columns (5) and (6)). Lastly, the impact of ChatGPT on willingness to pay for costlier signals is lower in magnitude but not statistically significant in non–English-speaking contexts. This is qualitatively consistent with our theory (column (7)).
Together, these analyses suggest that the effects of GAI are not unidirectional. There are cases in which GAI can increase screening accuracy. Consistent with the model, when experts benefit substantially more than nonexperts—as we see among senders in non–English-speaking contexts—ChatGPT helps evaluators screen candidates.
4.7. Robustness Analyses
There are a few ways we can extend our experimental results. For example, our experiments were designed to capture both within-subject and between-subjects variation. However, we can modify our analysis to capture only the between-subjects variation. We implement this analysis in Online Appendix D.9 and find qualitatively similar results as in our full sample. In addition, we can study the effects of ChatGPT on rankings. Most of our results so far study the level of signals or perceived expertise. However, candidates often compete in a ranking. Online Appendix D.8 studies the effects on rankings. We also find that expertise increases the ranking of the level of the sender’s signal by 2.8–3.5 percentiles. Experts have 4.0–4.8 percentiles higher perceived expertise. However, ChatGPT increases the sender’s ranking by only about two percentiles and has no effect on perceived expertise. These results are generally in line with our findings in levels (rather than rankings).
5. Discussion and Conclusion
Our paper aims to contribute a deeper conceptual understanding of GAI’s impact on information loss and empirical estimates of the degree of information loss at least in a few key settings. We propose a model of the data-generating process behind GAI information loss as well as a research design for measuring it. When we implement this design empirically, we can quantify both the degree of information loss (of 4%–9%) and the magnitude of the parameters generating that change (a negative ).
5.1. Theoretical Implications
Our study offers a theory, rooted in the covariance parameter, of when GAI leads to information loss. In doing so, it helps reconcile prior work on the impact of GAI on screening that suggests either gains or losses (Wiles et al. 2023a, Gans 2024) to screening accuracy when candidates can use GAI. Ultimately, the study tackles a crucial problem that this literature outlines: “the problem of deciding what’s real or not” (Horton 2024, Campante et al. 2025).
By showing how generative AI correlates with expertise in different ways across geographies, the paper also helps explain seemingly conflicting findings on the distributional effects of AI. Indeed, some papers find that AI is more helpful for firms or workers at the bottom of the performance distribution (rather than the top) (Dell’Acqua et al. 2023, Brynjolfsson et al. 2025). Other work reveals the opposite: GAI helps those at the top more (Choudhury et al. 2020, Otis et al. 2023, Conti and Messinese 2024). Our model embraces this distributional distinction as a parameter that profoundly shapes the accuracy of screening. In doing so, it reveals the context-specific nature of GAI, which makes it important for firms to pursue differentiated strategies across markets.
This work further contributes to research on how technology shapes firm growth and innovation disparities across geographies (Bloom et al. 2012, Tambe 2014, Nagaraj et al. 2020, AlShebli et al. 2022, Wright et al. 2023b). Our findings suggest that GAI presents both opportunities and limitations in reducing the gap between English-speaking hubs that have historically held a competitive advantage (Bloom et al. 2012, Kerr and Robert-Nicoud 2020, Conti and Guzman 2023) and others. Because GAI improves screening accuracy in non–English-speaking contexts it can enable higher quality companies from there to raise venture capital and choose expert talent. Access to this funding and talent can be crucial for growth and innovation (Conti and Guzman 2023). At the same time, we find that GAI improves the pitch quality of entrepreneurs in non–English-speaking contexts less than that of entrepreneurs in English-speaking contexts. Future research may further examine the conditions under which GAI mitigates or reinforces such disparities.
5.2. Limitations and Opportunities
Our study is not without its limitations, ones that can open the door to several lines of future research.
5.2.1. Empirical Setting.
We chose our empirical setting for its ability to support a clean experiment though it has limitations. For example, our measure of expertise captures a binary rather than continuous distribution, our subjects participated in an artificial intelligence exercise that may not fully capture behavior in higher stakes situations, and all subjects in the GAI condition had access to the technology. This paper seeks to be a wave 1 study (List 2020), focusing on establishing initial causality and producing first tests of theory. Future work may explore this framework with finer grained measures in field settings with costlier signals, such as grant funding applications, and in contexts in which AI adoption is unequal (McElheran et al. 2024, Otis et al. 2024). Working papers by Galdin and Silbert (2025) and Cui et al. (2025) find similar results in a natural experiment on Freelancer.com.
5.2.2. Vertical vs. Horizontal Differentiation.
The model and empirics focus on vertical differentiation only (high- versus low-quality candidates, experts versus not). However, many labor markets feature match-specific preferences or productivity. Future research could study how GAI impacts signaling on horizontal features for which market participants have different tastes. This setting may be promising for GAI although there may still be some incentive to fake one’s horizontal type in some cases.
5.2.3. Endogenous .
In our model, the covariance parameter is an exogenous parameter. However, in real life, firms can shape the of their GAI products. GAI firms can choose to make their technology help low-expertise workers evade screeners, or they can build GAI to help higher quality workers signal their expertise. Deciding which customers to prioritize is a classic entrepreneurial dilemma (Gans et al. 2019). Endogenizing is a valuable area for future research.
5.2.4. Multidimensional Screening.
In our model, the reviewer is screening for one characteristic. We call this expertise; however, it can generalize to screening for any single variable. Of course, in many settings, reviewers are assessing multiple characteristics (e.g., both technical expertise as well as the ability to speak clearly to the client). In these settings, a single signal could be informative about multiple traits. GAI could boost signals on some of these traits and be neutral on others. Although we do not explicitly show this, it is a natural extension of our model.
5.2.5. Multitasking.
Investors and employers evaluate candidates on the basis of one dimension of expertise in our model and experiments. However, they might want to screen candidates on two dimensions, one important and a second less important (Holmstrom and Milgrom 1991). GAI may asymmetrically dilute the signal quality for the important one, leading firms to focus on the second one that is now relatively more measurable though less crucial for productivity. This would reflect the “the folly of rewarding A, while hoping for B” (Kerr 1975). Future work may explore this potential implication.
5.2.6. Static vs. Dynamic Model.
Our model studies one-shot learning and transfers. In some real-world situations, a screener who is disappointed with an employee’s on-the-job performance could do something to discipline the candidate. The threat of such ex post punishment might constrain the incentives to fake expertise through ChatGPT.
5.2.7. How GAI Changes Pitches.
Our study reveals that GAI improves the average level of the signals. This could be for a variety of reasons. For example, GAI can prompt subjects to simply think more clearly and edit their original pitches. Or GAI can offer new information, for example, about problems in the education sector or skills crucial for a consultant that addresses subjects’ preexisting knowledge gaps. Precisely disentangling refinement from new knowledge is difficult. Future work can explore the channels behind GAI’s boost to pitch quality.
5.2.8. Alternative Signals.
Our research additionally suggests that evaluators demand costlier signals than text when ChatGPT is available. But what is the nature of these costlier signals? Whereas our supplementary survey suggests an important role for market research and job interviews, we do not directly observe this choice in our data nor incentivize it. Will screeners turn to nuanced investigations of individual quality, for example, through a full background investigation or market analysis? Will they leverage more advanced spam-proofing techniques such as cryptography with existing text-based signals (Horton 2024)? Or will they focus on demographic variables and protected categories as occurred after U.S. “ban the box” reforms that eliminated criminal history signals (Agan and Starr 2018, Doleac and Hansen 2020)? Future work may investigate these possibilities.
5.2.9. Using GAI at Work.
Finally, the assumption in our model is that employers want to hire true experts rather than effective users of GAI. There are, however, a variety of ways that GAI could substitute for some (or all) parts of human capital. This may result in employers screening for expertise less and screening instead for other qualities. Thus, the nature of expertise could change with GAI. Understanding these future screening scenarios has important implications for accuracy and bias in hiring, entrepreneurial finance, and many other economic transactions. We hope that future work investigates these possibilities using incentive-based experiments.
5.3. Practical Implications
Our findings have implications for talent evaluators, candidates, and GAI companies. Our average information loss results suggest that, as GAI permeates all forms of media (text, pictures, video, audio, etc.), these conventional signals could become useless for screening.27 Still, GAI could help with screening if it enables high-quality candidates to improve their signals much more than low-quality ones. In any case, our results suggest that evaluators could seek alternative screening approaches. This could create a new market for products that can evaluate human capital and resist GAI’s garbling of traditional signals.
Despite the epistemic apocalypse intuition, we show that GAI does not necessarily destroy information. If GAI disproportionately helps experts—as the DALLE experiment and our non–English-speaking subjects indicate—then GAI can actually increase the accuracy of screening. Whereas these instances may be relatively rare in the current environment, GAI companies could shape this outcome in the future (Hernández-Lagos 2025). These companies have some control over whether their products are more helpful for novices or experts () and, thus, may be able to shape the covariance terms and ultimate signaling value of the content that their software produces.
Ultimately, screening extends far beyond the hiring and start-up settings that we study. News, consumers, educators, students, apartment renters, shoppers, singles, educators, medical patients (and more) all heavily rely on screening and signaling. Our paper suggests that GAI could profoundly change how these agents learn and screen. Many signals are useful for evaluators because of their costliness. However, their informational content fundamentally changes if GAI makes these signals cheaper with implications for a variety of transactions across the global economy.
The authors thank Hemant Bhargava, Nandil Bhatia, Natalie Carlson, Avi Goldfarb, Nan Jia, Ginger Jin, Mike Luca, Nick Otis, Neil Thompson, and Emma Wiles for helpful discussion and feedback as well as seminar participants at Boston University (Digital Initiative), Johns Hopkins (Carey), University of California, Los Angeles (Anderson), and Yeshiva (Sy Syms). The authors also thank participants at the Academy of Management Annual Meeting; the Columbia Management, Analytics, and Data Conference; the Conference on Field Experiments in Strategy; the Utah Conference in Memory of John Morgan; and the Wharton AI and the Future of Work Conference for comments and suggestions. The authors further thank Daniel Creech and Noa Rosinplotz for excellent research assistance. Lastly, the authors are grateful to Anindya Ghose as well as the anonymous Associate Editor and reviewers for their thoughtful feedback. All authors contributed equally to this paper. All errors remain the authors’ own.
1 Signals are observable pieces of information, such as pitches or cover letters, that enable organizations to infer the expertise of candidates.
2 In other knowledge tasks, GAI has similarly lowered costs, for example, see Brynjolfsson et al. (2025), Choi and Schwarcz (2024), Eloundou et al. (2024), Felten et al. (2023), and Noy and Zhang (2023).
3 See also Gans (2024), Marinescu and Wolthoff (2020), Martin-Lacroux and Lacroux (2017), Sajjadiani et al. (2019), and Sterkens et al. (2023) in labor markets.
4 The literature is mostly empirical and often relies on the labor augmentation versus substitution framing (e.g., Noy and Zhang 2023). One exception is Agrawal et al. (2021), who present a model in which AI helps decision making by providing information about an external state of nature. The paper analyzes the interplay between information gains from using AI and information transmission between functional units within the firm.
5 The normality assumption on types is for tractability. The main qualitative result in the model holds for a class of discrete distributions as well. See Online Appendix A.4.
6 We assume that the noise realization is the same for a given sender irrespective of the availability of GAI.
7 This characterization may not be a good description of recent years when GAI remains relatively new. In recent years, some senders might not use GAI despite its availability. Similarly, some receivers may be unaware that senders are using GAI. The use of GAI in today’s environment could include considerations that we do not model here.
8 For this reason, we do not mention the pre-GAI and post-GAI distinction to subjects in our experiment.
9 The exact conditions for effort to increase or decrease are in Online Appendix A.1. The conditions coincide with those that make the weight on the signal increase or decrease in Corollary 1 because the optimal effort in equilibrium is proportional to that weight.
10 To get an extremely negative covariance, GAI would need to reduce experts’ signals (or leave them unaffected entirely), giving a very high boost to nonexperts.
11 The preregistration may be found here, https://osf.io/rfbu6/?view_only=68c735abdda543be9c8db502e24d68a4.
12 Using a controlled context such as Prolific is crucial to be able to get pitches from subjects on areas in which they do and do not have expertise as further discussed below.
13 The experiments were designed following the interpretation of the model in which receivers are told if senders used ChatGPT rather than only if they had access to ChatGPT. We do this to empirically isolate the impact of a sender’s ChatGPT use on receivers’ beliefs from the effects of uncertainty around ChatGPT use.
14 For example, YCombinator has a text-based application that start-ups have to fill out even to be considered (https://www.ycombinator.com/apply). Even when entrepreneurs send a pitch deck, they often first send a text-based pitch via an introductory email directly to the investor or another contact who then introduces them to the investor. In addition, many entrepreneurs are not able to get a face-to-face meeting with a VC at which one could present a deck and, thus, make pitches over email (with introductory text, possibly with attachments). The topic of written communication in VC and/or accelerator pitches have appeared in other papers, for example, Wright et al. (2023a).
15 For example, some disregarded the prompts altogether by writing a pitch about the retail industry when the prompt instructed them to do so about the education and training industry.
16 We dropped two of the receivers who were also senders and evaluated at least one of their own pitches.
17 This total number reflects 797 unique receivers who evaluate eight pitches each and four unique receivers who evaluate 16 pitches each (797 × 8 + 4 × 16 = 6,440). These receivers evaluated pitches in one of the entrepreneurship and one of the hiring contexts. We lose two sender–receiver observations of subjective quality and predicted expertise.
18 English-speaking countries include Australia, Canada, South Africa, the United Kingdom, and the United States. Non–English-speaking countries include countries such as France, Mexico, Poland, and South Korea.
19 For each domain setting, we allocated the pitches across eight buckets for each ChatGPT condition, so the order fixed effects also account for differences in expert probabilities within each bucket.
20 For example, in our question about the sender’s expertise, we asked receivers to choose from five buckets of probability in 20% intervals: 0%–20% probability that the sender is an expert, 20%–40%, etc.
21 For example, 10% for a 0%–20% probability bucket.
22 A concern with the readability measure is that it is only capturing the extremes of the actual quality distribution. Reassuringly, the readability scores in our final sample follow a fairly normal distribution, suggesting that they are capturing quality differences in the middle of the distribution in addition to the extremes.
23 In the Flesch–Kinkaid score, higher numbers require less education to understand. The maximum score is 100, which corresponds to a fifth grade reading level, and the lowest score is 0, referring to text readable by professional school graduates. To make higher scores better, we transformed the raw Flesch–Kinkaid score to our NLP variable, which is equal to 100 minus the raw Flesch–Kinkaid score.
24 That is, , where is the mean.
25 For example, see Hastie et al. (2017), James and Stein (1961), and Stein (1956).
26 In robustness tests, whether the sender is from an English-speaking country highly correlates (about 0.8) with English being the sender’s first language based on demographic data that Prolific collects about subjects. However, several subjects withheld data about their first language from Prolific, so we use the country—which is available for all senders in our data—as the main measure in our results.
27 Online ratings and reputation are other signals that may have lost informational content over time through inflation, particularly when reviews are public and reciprocal (Bolton et al. 2013, Nosko and Tadelis 2015, Filippas et al. 2018).
References
- (2022a) The REAL fight over AI art. Accessed November 19, 2024, https://www.youtube.com/watch?v=NiJeB2NJy1A.Google Scholar
- (2022b) Tweet by @cleoabram. Twitter (September 14), https://x.com/i/status/1570043396961476609.Google Scholar
- (2018) Ban the box, criminal records, and racial discrimination: A field experiment. Quart. J. Econom. 133(1):191–235.Crossref, Google Scholar
- (2025) AI suggestions homogenize writing toward western styles and diminish cultural nuances. Yamashita N, Evers V, Yatani K, Ding X(S), Lee B, Chetty M, Dugas PT, eds. Proc. 2025 CHI Conf. Human Factors Comput. Systems (Association for Computing Machinery, New York), 1–21.Google Scholar
- (2021) AI adoption and system-wide change. NBER Working Paper No. 28811, National Bureau of Economic Research, Cambridge, MA.Google Scholar
- (2021) Algorithm-augmented work and domain experience: The countervailing forces of ability and aversion. Organ. Sci. 33(1):149–169. Link, Google Scholar
- (2022) Beijing’s central role in global artificial intelligence research. Nature Sci. Rep. 12(1):21461.Google Scholar
- (2020) The allocation of decision authority to human and artificial intelligence. AEA Papers Proc. 110:80–84.Google Scholar
- (2019) Complementarity of signals in early-stage equity investment decisions: Evidence from a randomized field experiment. Management Sci. 65(2):933–952.Link, Google Scholar
- (2023) The future of venture capital? Insights into data-driven VCs. California Management Rev.Google Scholar
- (2024) Hunting for talent: Firm‐driven labor market search in the United States. Strategic Management J. 45(3):429–462.Crossref, Google Scholar
- (2003) Latent Dirichlet allocation. J. Machine Learn. Res. 3:993–1022.Google Scholar
- (2012) Americans do IT better: US multinationals and the productivity miracle. Amer. Econom. Rev. 102(1):167–201.Crossref, Google Scholar
- (2013) Engineering trust: Reciprocity in the production of reputation information. Management Sci. 59(2):265–285.Link, Google Scholar
- (2022) Picking on the same person: Does algorithmic monoculture lead to outcome homogenization? Koyejo S, Mohamed S, Agarwal A, Belgrave D, Cho K, Oh A, eds. Adv. Neural Inform. Processing Systems, vol. 35 (Neural Information Processing Systems Foundation, Inc., San Diego), 39114.Crossref, Google Scholar
- (2025) Generative AI at work. Quart. J. Econom. 140(2):889–942.Crossref, Google Scholar
- (2024) ChatGPT hallucinates non-existent citations: Evidence from economics. Amer. Econom. 69(1):80–87.Crossref, Google Scholar
- Campante FR, Durante R, Hagemeister F, Sen A (2025) GenAI misinformation, trust, and news consumption: Evidence from a field experiment. NBER Working Paper No. 34100, National Bureau of Economic Research, Cambridge, MA.Google Scholar
- (2023) Differentiation in microenterprises. Strategic Management J. 44(5):1141–1167.Crossref, Google Scholar
- (2018) Hiring preferences in online labor markets: Evidence of a female hiring bias. Management Sci. 64(7):2973–2994.Link, Google Scholar
- (2025) A.I. is homogenizing our thoughts. The New Yorker (January 25), https://www.newyorker.com/culture/infinite-scroll/ai-is-homogenizing-our-thoughts.Google Scholar
- (2024) AI assistance in legal analysis: An empirical study. 73:384.Google Scholar
- (2020) Machine learning and human capital complementarities: Experimental evidence on bias mitigation. Strategic Management J. 41(8):1381–1411.Crossref, Google Scholar
- (2023) What is the US comparative advantage in entrepreneurship? Evidence from Israeli migration to the United States. Rev. Econom. Statist. 105(3):528–544.Crossref, Google Scholar
- (2024) The selective tailwind effect of A.I. on startups: Predictions and anomalies. Preprint, submitted October 24, https://dx.doi.org/10.2139/ssrn.4958898.Google Scholar
- (2020) Bias and productivity in humans and algorithms: Theory and evidence from resume screening. Preprint, submitted March 21, https://conference.iza.org/conference_files/MacroEcon_2017/cowgill_b8981.pdf.Google Scholar
- (2025) Signaling in the age of AI: Evidence from cover letters. Preprint, submitted September 29, https://arxiv.org/abs/2509.25054.Google Scholar
- (1979) The robust beauty of improper linear models in decision making. Amer. Psych. 34(7):571–582.Crossref, Google Scholar
- (2023) The use of artificial intelligence to improve the scientific writing of non-native English speakers. Revista da Associação Médica Brasileira 69(9):e20230560.Google Scholar
- (2022) Falling asleep at the wheel: Human/AI collaboration in a field experiment on HR recruiters. Working paper, University of Michigan, Ross School of Business, Ann Arbor, MI.Google Scholar
- (2025) Super Mario meets AI: Experimental effects of automation and skills on team performance and coordination. Rev. Econom. Statist. 107(4):951–966.Crossref, Google Scholar
- (2023) Navigating the jagged technological frontier: Field experimental evidence of the effects of AI on knowledge worker productivity and quality. Preprint, submitted September 18, https://dx.doi.org/10.2139/ssrn.4573321.Google Scholar
- (2020) The unintended consequences of “ban the box”: Statistical discrimination and employment outcomes when criminal histories are hidden. J. Labor Econom. 38(2):321–374.Crossref, Google Scholar
- (2024) Generative AI enhances individual creativity but reduces the collective diversity of novel content. Sci. Adv. 10(28):eadn5290.Crossref, Google Scholar
- (2024) GPTs are GPTs: Labor market impact potential of LLMs. Science 384(6702):1306–1308.Crossref, Google Scholar
- (2023) How will language modelers like ChatGPT affect occupations and industries? Preprint, submitted March 2, https://arxiv.org/abs/2303.01157.Google Scholar
- (2025) Generative AI as a linguistic equalizer in global science. Working paper, Faculty of Business and Economics, University of Basel, Basel, Switzerland.Google Scholar
- (2018) Reputation inflation. Tardos E, Elkind E, Vohra R, eds. Proc. 2018 ACM Conf. Econom. Comput. (Association for Computing Machinery, New York), 1–699.Google Scholar
- (1948) A new readability yardstick. J. Appl. Psych. 32(3):221.Google Scholar
- Galdin A, Silbert J (2025) Making talk cheap: Generative AI and labor market signaling. Preprint, submitted November 11, https://arxiv.org/abs/2511.08785.Google Scholar
- (2024) How will generative AI impact communication? Econom. Lett. 242:111872.Crossref, Google Scholar
- (2025) The Microeconomics of Artificial Intelligence (MIT Press, Cambridge, MA).Crossref, Google Scholar
- (2019) Foundations of entrepreneurial strategy. Strategic Management J. 40(5):736–756.Crossref, Google Scholar
- (2010) Estimating the helpfulness and economic impact of product reviews: Mining text and reviewer characteristics. IEEE Trans. Knowledge Data Engrg. 23(10):1498–1512.Crossref, Google Scholar
- (2018) A recombination-based internationalization model: Evidence from Narayana health’s journey from India to the Cayman Islands. Organ. Sci. 30(2):405–425.Link, Google Scholar
- (2023) Deepfakes and the epistemic apocalypse. Synthese 201(3):103.Crossref, Google Scholar
- (2017) The Elements of Statistical Learning: Data Mining, Inference, and Prediction, vol. 2 (Springer, New York).Google Scholar
- (2025) The transparency of AI and the profits of the firm. Preprint, submitted October 19, https://doi.org/10.2139/ssrn.5627150.Google Scholar
- (1999) Managerial incentive problems: A dynamic perspective. Rev. Econom. Stud. 66(1):169–182.Crossref, Google Scholar
- (1991) Multitask principal–agent analyses: Incentive contracts, asset ownership, and job design. J. Law Econom. Organ. 7:24–52.Crossref, Google Scholar
- (2021) Just DM me (politely): Direct messaging, politeness, and hiring outcomes in online labor markets. Inform. Systems Res. 32(3):786–800.Link, Google Scholar
- (2017) The effects of algorithmic labor market recommendations: Evidence from a field experiment. J. Labor Econom. 35(2):345–385.Crossref, Google Scholar
- (2024) Blockchain as a solution to trust issues. ThreadReaderApp. Accessed February 16, 2024, https://threadreaderapp.com/thread/1758537324709732549.html.Google Scholar
- (2024) The short-term effects of generative artificial intelligence on employment: Evidence from an online labor market. Organ. Sci. 35(6):1977–1989.Link, Google Scholar
- (1961) Estimation with quadratic loss. Neyman J, ed. Proc. Fourth Berkeley Sympos. Math. Statist. Probab. Vol. 1 Contributions Theory Statist., vol. 4 (University of California Press, Cambridge University Press, Berkeley and Los Angeles, London), 767.Google Scholar
- (2024) When and how artificial intelligence augments employee creativity. Acad. Management J. 67(1):5–32.Crossref, Google Scholar
- (1975) On the folly of rewarding A, while hoping for B. Acad. Management J. 18(4):769–783.Crossref, Google Scholar
- (2020) Tech clusters. J. Econom. Perspect. 34(3):50–76.Crossref, Google Scholar
- (2024) Decision authority and the returns to algorithms. Strategic Management J. 45(4):619–648.Crossref, Google Scholar
- (2021) Algorithmic monoculture and social welfare. Proc. Natl. Acad. Sci. USA 118(22):e2018340118.Crossref, Google Scholar
- (2023) Learning to successfully hire in online labor markets. Management Sci. 69(3):1597–1614.Link, Google Scholar
- (2025) Your brain on ChatGPT: Accumulation of cognitive debt when using an AI assistant for essay writing task. Preprint, submitted June 10, https://arxiv.org/abs/2506.08872.Google Scholar
- (2020) Hiring as exploration. NBER Working Paper No. 27736, National Bureau of Economic Research, Cambridge, MA.Google Scholar
- (2020) Non est disputandum de generalizability? A glimpse into the external validity trial. NBER Working Paper No. 27535, National Bureau of Economic Research, Cambridge, MA.Google Scholar
- (2020) Opening the black box of the matching function: The power of words. J. Labor Econom. 38(2):535–568.Crossref, Google Scholar
- (2017) Do employers forgive applicants’ bad spelling in résumés? Bus. Professional Comm. Quart. 80(3):321–335.Crossref, Google Scholar
- (1994) The validity of employment interviews: A comprehensive review and meta-analysis. J. Appl. Psych. 79(4):599–616.Crossref, Google Scholar
- (2024) AI adoption in America: Who, what, and where. J. Econom. Management Strategy 33(2):375–415.Crossref, Google Scholar
- (2020) Improving data access democratizes and diversifies science. Proc. Natl. Acad. Sci. USA 117(38):23490–23498.Crossref, Google Scholar
- (2020) The persistent effect of initial success: Evidence from venture capital. J. Financial Econom. 137(1):231–248.Crossref, Google Scholar
- (2015) The limits of reputation in platform markets: An empirical analysis and field experiment. NBER Working Paper No. 20830, National Bureau of Economic Research, Cambridge, MA.Google Scholar
- (2023) Experimental evidence on the productivity effects of generative artificial intelligence. Science 381(6654):187–192.Crossref, Google Scholar
- (2024) Global evidence on gender gaps and generative AI. Technical report, Center for Open Science, Washington, DC.Google Scholar
- (2023) The uneven impact of generative AI on entrepreneurial performance. Working paper, University of Toronto, Rotman School of Management, Toronto.Google Scholar
- (2025) Writing without borders: AI and cross-cultural convergence in academic writing quality. Humanities Soc. Sci. Comm. 12(1):1–11.Google Scholar
- (2000) Inference of population structure using multilocus genotype data. Genetics 155(2):945–959.Crossref, Google Scholar
- (2019) Language models are unsupervised multitask learners. OpenAI Blog 1(8):9.Google Scholar
- (2024) Competition and diversity in generative AI. Preprint, submitted December 11, https://arxiv.org/abs/2412.08610.Google Scholar
- (2022) Revisiting meta-analytic estimates of validity in personnel selection: Addressing systematic overcorrection for restriction of range. J. Appl. Psych. 107(11):2040–2068.Crossref, Google Scholar
- (2019) Using machine learning to translate applicant work history into predictors of performance and turnover. J. Appl. Psych. 104(10):1207–1225.Crossref, Google Scholar
- (2021)
Digital platform ecosystems: The coming context for AI . Pagani M, ed. Artificial Intelligence for Sustainable Value Creation (Edward Elgar Publishing, Cheltenham, UK), 55–69.Crossref, Google Scholar - (1998) The validity and utility of selection methods in personnel psychology: Practical and theoretical implications of 85 years of research findings. Psych. Bull. 124(2):262–274.Crossref, Google Scholar
- (2019) Entrepreneurial uncertainty and expert evaluation: An empirical analysis. Management Sci. 66(3):1278–1299.Link, Google Scholar
- (1973) Job market signaling. Quart. J. Econom. 87(3):355–374.Crossref, Google Scholar
- (1956) Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. Neyman J, ed. Proc. Third Berkeley Sympos. Math. Statist. Probab., vol. 1 (University of California Press, Cambridge University Press, Berkeley and Los Angeles, London), 208.Google Scholar
- (2023) Costly mistakes: Why and when spelling errors in resumes jeopardise interview chances. PLoS One 18(4):e0283280.Crossref, Google Scholar
- (2024) Beyond AI exposure: Which tasks are cost-effective to automate with computer vision? Preprint, submitted February 8, https://doi.org/10.2139/ssrn.4700751.Google Scholar
- (2014) Big data investment, skills, and firm value. Management Sci. 60(6):1452–1469.Link, Google Scholar
- (2023) Ecosystem-level analysis of deployed machine learning reveals homogeneous outcomes. Oh A, Naumann T, Globerson A, Saenko K, Hardt M, Levine S, eds. Adv. Neural Inform. Processing Systems, vol. 36 (Neural Information Processing Systems Foundation, Inc., San Diego), 80772.Google Scholar
- (2023) AI and science: What 1,600 researchers think. Nature 621(7980):672–675.Crossref, Google Scholar
- (2023) Here’s what happens when your lawyer uses ChatGPT. The New York Times Online (May 27), https://www.nytimes.com/2023/05/27/nyregion/avianca-airline-lawsuit-chatgpt.html.Google Scholar
- (2022) Effects of using artificial intelligence on interpersonal perceptions of job applicants. Cyberpsychology Behav. Soc. Networking 25(3):163–168.Crossref, Google Scholar
- (2023a) Algorithmic writing assistance on jobseekers’ resumes increases hires. NBER Working Paper No. 30886, National Bureau of Economic Research, Cambridge, MA.Google Scholar
- (2023b) Generative AI and labor market matching efficiency. Working paper, Boston University, Questrom School of Business, Boston.Google Scholar
- (2026) When local learning scales: Entrepreneurs’ initial users and market expansion. Organ. Sci. 37(1):377–401.Link, Google Scholar
- (2023a) Judging foreign startups. Strategic Management J. 44(9):2195–2225.Crossref, Google Scholar
- (2023b) Open source software and global entrepreneurship. Res. Policy 52(9):104846.Crossref, Google Scholar

