
Efficiency of Parallel and Restart Exploration Strategies in Model-Free Stochastic Simulations
Abstract
We analyze the efficiency of parallelization and restart mechanisms for stochastic simulations in model-free settings, where the underlying system dynamics are unknown. Such settings are common in Reinforcement Learning (RL) and rare-event estimation, where standard variance-reduction techniques like importance sampling are inapplicable. Focusing on the challenge of reaching rare states under a finite computational budget, we model exploration via random walks and Lévy processes. Based on rigorous probability analysis, our work reveals a phase transition in the success probability as a function of the number of parallel simulations: an optimal number exists, balancing exploration diversity and time allocation per simulation. Beyond this threshold, performance degrades exponentially. Furthermore, we demonstrate that a restart strategy, which reallocates resources from stagnant trajectories to promising regions, can yield an exponential improvement in success probability. In the context of RL, these strategies can improve policy gradient methods by enabling more efficient state-space exploration, leading to more accurate policy gradient estimates.
Funding: This research was supported by the SticAmsud LAGOON project, ANR EPLER, IRL-CNRS IFUMI-2030, and Action international CNRS.
1. Introduction
The efficient simulation of stochastic systems is a cornerstone of many critical applications, ranging from rare-event estimation to gradient estimation in Reinforcement Learning (RL). In many practical scenarios, the underlying dynamics of a system are complex, poorly characterized, or entirely unknown, placing us essentially in a model-free setting. In such contexts, strategies for exploring the state space where the stochastic dynamics live and gathering informative samples are paramount. This work investigates two powerful and general mechanisms for enhancing the efficiency of stochastic simulations: parallelization and restarting. We aim to provide a rigorous probabilistic analysis of these strategies, with applications focused on key model-free problems such as estimating small probabilities for stochastic processes with unknown dynamics and the challenge of efficient exploration in RL.
A canonical problem in probability and statistics is the estimation of the probability that a stochastic process reaches a rare, distant state within a finite time horizon. Standard Monte Carlo methods fail as the event of interest is rarely observed. A common technique for accelerating rare-event simulation is importance sampling (Asmussen and Glynn 2007), which involves simulating the process under an alternative “twisted” measure that makes the rare event more likely, and then correcting this change of measure via likelihood ratios. However, importance sampling is not a viable solution in the model-free settings as its application requires exact knowledge of the underlying process dynamics to construct the optimal change of measure. When the dynamics are unknown or too complex to model—as is often the case in large-scale RL environments or with intractable stochastic processes—this precise knowledge is unavailable, rendering importance sampling inapplicable. Moreover, an estimation scheme for the change of measure is usually of very large variance. It is precisely this limitation that motivates the use of blind or model-free strategies, such as parallelization and restarting, which do not require explicit knowledge of the system dynamics.
Parallelization—running multiple independent simulations concurrently—seems a natural remedy, as it increases the chances of observing the rare event. However, under a fixed total computational budget, a critical trade-off emerges: should one allocate the entire budget to a single, long simulation, or distribute it among many shorter, parallel runs? The answer is not trivial, as splitting the budget too finely may deprive each simulation of the necessary time to reach the rare state. We analyze this trade-off quantitatively, identifying a sharp phase transition in the success probability as a function of the number of parallel runs.
Beyond parallelization, restart strategies offer another avenue for improvement. Instead of letting simulations run in potentially unfruitful regions of the state space, a restart mechanism halts them and reinitializes them from more promising states, effectively redirecting computational effort. This restarting mechanism is particularly powerful in scenarios where certain regions are more likely to lead to the target event. A well-designed restart policy can prevent the waste of resources on trajectories with a low probability of success and serves as a practical, model-free alternative to importance sampling.
Several recent works have addressed the efficient exploration challenge, in particular for RL. For example, the Go-Explore approach in Ecoffet et al. (2021) introduces an innovative solution by distinctly separating the exploration and exploitation phases. This method allows the algorithm to maintain a repository of promising states, which can be revisited for further exploration, significantly enhancing the ability to discover and leverage rare or hard-to-reach states. Another example is found in Mastropietro et al. (2025), based on the paradigm of the Fleming-Viot particle system, introduced by Burdzy et al. (1996). In this framework, a population of particles (which can represent different simulations in parallel) evolves over time, exploring the state space in parallel. When a particle falls into a less promising region, it is “restarted” by being replaced with a copy of another, more promising particle. This ensures that resources are concentrated on exploring the most fruitful areas of the state space.
Beyond RL, stochastic restarting has been studied extensively across disciplines such as statistical physics, computer science, and network theory, primarily to minimize expected task-completion times modeled via first-passage times (see, e.g., Luby et al. 1993, Avrachenkov et al. 2018, and Evans et al. 2020). In contrast, our work focuses on the asymptotic behavior of the full distribution of passage times, studying large deviation regimes and rare-event phenomena through asymptotic estimates, bounds, and threshold effects rather than expectations. Although related analytic frameworks for Markov processes with restart—addressing ergodicity, quasi-stationary distributions (QSDs), and connections to Fleming-Viot systems—are developed in Grigorescu and Kang (2013), our results concern finer asymptotics for more restricted process classes and different probabilistic questions. Our work also differs from Monthus (2021), which analyzes large deviations for the long-time asymptotics with stochastic restart to a fixed state. In contrast, we consider large deviations with respect to a spatial parameter modeling the complexity of exploring the state space.
Despite the promise of parallel simulation techniques and restart mechanisms, there is a lack of quantitative evidence of their potential benefits. Specifically, the extent to which these strategies improve exploration efficiency and yield better learning outcomes remains unclear. We aim to fill this gap by providing a detailed analysis of the impact of parallel simulations combined with restart mechanisms on the exploration process, modeled as the task of reaching a specific subset of the state space. To achieve this, we use a simplified model based on toy dynamics, specifically random walks and Lévy processes. These processes are chosen for their mathematical tractability and their ability to capture fundamental aspects of the problem, allowing explicit analytical results. Although these dynamics are simple, they provide crucial insights into the mechanisms that govern exploration, forming the basis for future work with more involved Markovian dynamics. By employing this framework, we examine two key aspects of exploration:
Exploration complexity, encapsulated by a parameter that quantifies the fluctuations necessary to achieve effective exploration and reach the target subset of the state space;
Exploration diversity, represented by the number of parallel simulations employed, which increases the breadth of the state-space search and enhances the likelihood of encountering rare, high-reward states within the target subset.
We focus our analysis on a specific regime where the exploration complexity scales linearly with the simulation budget. The toy dynamics framework allows us to examine these parameters within finite time budgets systematically and to quantify how parallel simulations improve efficiency by leveraging diversity, whereas restarting mechanisms enable particles to avoid stagnation by redirecting effort toward more promising regions of the state space, ultimately facilitating the achievement of the exploration goal.
Our approach relies on the systematic analysis of these strategies under finite time budgets, using analytical techniques based on exponential martingales to quantify the effects of parallel simulations and restarting mechanisms. By addressing the interplay between exploration diversity and the power of parallelization and restarting mechanisms, our work provides novel insights into efficient exploration strategies and lays the groundwork for further investigations into more complex stochastic dynamics.
Through this investigation, our goal is not only to demonstrate the potential utility of these techniques but also to delineate their limitations. Understanding these nuances is crucial for developing more efficient stochastic simulations in model-free settings such as RL, particularly in environments characterized by sparse rewards. Ultimately, our findings aim to provide actionable insights into when and how to leverage parallel simulations and restarting strategies to optimize exploration, thereby advancing the field in both theory and practice.
1.1. Problem Statement and Contributions
In this work, we model exploration as a one-dimensional stochastic process, often referred to as a particle, aiming to reach a target subset of the state space. This target, represented as a barrier, captures a potentially informative state that is difficult to attain, making it essential to devise strategies that maximize the probability of success within a finite time budget and to quantify the resulting improvements. In the following we summarize our main findings and key take-away messages.
Phase Transition in Reaching Probabilities. We identify a striking phase transition in the probability of reaching the target subset of the state space as a function of the number of parallel simulations N. In Theorems 1 and 2, we rigorously show that when the time budget scales linearly with the barrier level, there is a sharp transition in performance. Our analysis is based on large deviations techniques, and the transition happens at a certain threshold which we present explicitly. Below this threshold, concentrating the entire budget on a single particle is optimal. If the budget, when split into N parts, remains above the threshold, then distributing it among N particles significantly improves the probability of success. However, using too many particles—thereby reducing the time available to each beyond the threshold—results in exponentially diminished performance.
Optimal Number of Parallel Simulations. In view of the previous point, a critical contribution is then the determination of an optimal number of parallel simulations, , that balances the trade-off between exploration diversity and the time allocated to each particle. This optimal depends intricately on the time budget and the large deviations characteristics of the particle dynamics, but in terms of the phase transition mentioned above, it can be characterized as the largest integer for which the split budget exceeds the threshold.
Exponential Boost via Restarting Strategy. To overcome stagnation and improve the probability of reaching the target, we introduce a restarting mechanism inspired by mechanisms described, for instance, in Mastropietro et al. (2025). We study an idealized situation in which this mechanism replaces particles with a low likelihood of success and restarts them at new initial positions sampled from a given measure. Our theoretical results (Theorem 3) demonstrate that this restarting strategy can substantially enhance the probability of success. The improvement is quantified by a factor proportional to the time budget and the exponential moments of the measure associated with the restarting mechanism. A particularly interesting restarting measure is a QSD over a set representing high-probability regions for successful trajectories. For these restarting measures, we can obtain sharper asymptotics using different methods that exploit the QSD properties. We note that this restarting strategy can be well approximated in practice by selection mechanisms such as the Fleming-Viot or Aldous-Flanary-Palacios algorithms (see Budhiraja et al. 2022 and the references therein). These schemes enable practical implementation and adequate sampling of initial positions, making the restarting mechanism computationally feasible in real-world scenarios. Finally, from a practical point of view, we present contributions in two directions for queueing systems. The first one corresponds to the problem of estimating small probabilities. We analyze the interplay between the probability of exploration and the efficiency of the associated estimation method. For the particular case of an M/M/1 queue, we show that the variance of the vanilla Monte Carlo estimator is essentially determined by the typical exploration time. The second, with broader impact, addresses efficient exploration in RL. In RL environments with sparse rewards, the core of the efficient exploration challenge lies in the inability of algorithms such as policy gradient methods to perform effective policy updates (see Ecoffet et al. 2021 and references therein). These methods estimate the gradient of the expected return with respect to the policy parameters. This estimation relies crucially on exploring the state space; if the agent fails to reach rewarding states, the gradient estimates are biased and ineffective. Our work addresses this specific issue: we aim to improve gradient estimation (hence policy evaluation under a fixed policy) not by changing the policy, but by enhancing the exploration process used to evaluate it. The M/M/1/K queue considered in Mastropietro et al. (2025) is reanalyzed here to illustrate our results.
1.2. Organization of the Paper
In Section 2, we introduce the models for the exploration process, which represent the dynamics of the exploration phase in RL. Like the rest of the paper, this section is divided into two parts. The first part analyzes the effects of parallel exploration, and the second part analyzes our restarting mechanism. Section 3 presents our main results for the two scenarios described above, after some necessary preliminaries. Main results are discussed in generality and illustrated through numerical simulations for concrete instances. In Section 4, we prove Theorems 1 and 2 related to parallel exploration. In Section 5 we prove Theorem 3 for exploration with a general restarting measure, and in Section 6 we prove Theorem 4 for a QSD restarting measure. Finally, appendices are devoted to practical applications of our work.
2. Exploration Strategies
We now formally introduce the models for exploration, using random walks and Lévy processes as simplified toy models. We focus on the probability of reaching a distant state x from an initial position of zero, with the drift component encoding the difficulty of exploration. The drift represents the inherent challenge in progressing toward the target state, where a stronger drift away from the target reflects a more difficult exploration task.
We consider scenarios where the total time budget scales with x, allowing us to examine how exploration strategies perform as the difficulty of reaching the target increases. Two specific strategies are explored: the first investigates parallel exploration under a fixed time budget, whereas the second examines the effects of restarting the process when it crosses a predefined threshold. Although these models are simplified, they provide critical insights into the fundamental principles that govern the effectiveness of exploration strategies in RL, particularly in challenging environments where reaching an unlikely target state is the goal.
2.1. Strategy I: Parallel Exploration
Let , where or , be a family of one-dimensional random walks or Lévy processes. Define further
First, the case of N parallel independent simulations is analyzed. We introduce as performance criterion for exploration the probability that starting from zero, one of the simulations reaches the rare state x within a given time budget , that is,
We aim at characterizing this probability (as a function of N) in the regime where the total simulation budget, , satisfies , for x large and C some positive constant. This is the focus of Theorem 1 for random walks and Theorem 2 for Lévy processes.
2.2. Strategy II: Exploration with Restart
Our second model incorporates a restart mechanism into the dynamics of a random walk or a Lévy process. The ingredients of the model are a positive number (the rare state we want the process to reach), a probability measure supported on , and a discrete random walk or a Lévy process . The trajectories of the process under study can be viewed as a concatenation in time of independent and identically distributed cycles, each consisting of sampling a state from and simulating the trajectory of until the first time it exits the interval .
Our goal is to analyze the first passage time over x of the restarted process, and compare it with the corresponding one for the process without restart. The conditions required on the family of restart measures to improve algorithmic performance are quite general. Essentially, it suffices that each be stochastically dominated by a nondegenerate measure possessing a finite second moment. We also examine in detail the case where restart occurs according to the unique quasi-stationary measure of the process Z absorbed at (see Subsection 3.4 for precise definitions). Our motivation for this particular mechanism (restarting from quasi-stationary distributions) is that the resulting process approximates complex particle dynamics built upon a given Markov process, a key example, as noted earlier, being the class of Fleming-Viot particle systems. Our model is indeed an approximation of the Fleming-Viot dynamics because the stationary distribution of the particle system approximates the quasi-stationary distribution associated with the underlying Markov process absorbed upon reaching A, as N goes to infinity (see Appendix B for more details).
3. Main Results
After introducing due notation, we present our results for each strategy.
3.1. Parallel Exploration Driven by a Random Walk
Let , be a random walk with independent increments all distributed as a random variable X. We will always assume that X is not deterministic, meaning that it is not concentrated on a single value, and that it may take both positive or negative values with positive probability. The moment-generating function (mgf) of X, , is strictly convex on the interior points of the set () where The following condition is usually referred to as the right Cramér condition:
We will work under further additional assumptions:
Note that and Assumptions (3), (4), and (5) imply that and , because and is strictly convex. Let denote the first time the random walk reaches level x, defined as
Furthermore, let represent the minimum of N independent random times, each distributed as , that is,
Our first main theorem states that the interesting behavior of and occurs while comparing them to functions of the following classes: for let
This set consists of functions that asymptotically behave like with an error term of order smaller than . The result below is stated for the class of functions defined above, but the reader can think of a specific example being for any .
We now state our main result regarding parallel exploration for random walks:
Let Z denote a random walk whose increments satisfy Assumptions (3), (4), and (5), and let belong to for some . Then for ,
(
In the regime in which the theorem is stated, probabilities decay exponentially as x goes to infinity (see Proposition 1 in Section 4). The result shows that using too many particles (thus giving too little time to each) entails an exponentially worse performance, meaning that decays with a faster exponential rate than . On the other hand, using too few particles comes only at a linear cost in performance.
The main intuition behind the results stated above is that within the (rare) event , the probability is concentrated on those trajectories with drift , for which the time needed to reach x is . This idea is formalized using exponential martingales and is at the core of Proposition 1. Our results show that allowing a budget smaller than substantially reduces the probability of success, whereas allowing too much budget results in no significant improvement. In the latter case, by splitting it into several independent particles, each one provides an “extra chance” of success.
Even though in general and (thus) the threshold depend in a nontrivial way on the distribution of the increments, in some cases it is possible to find simple expressions for these parameters. We present some of the important examples here.
(
(
3.1.1. Simulations for Parallel Random Walks.
Consider the random walk case described in Example 2. We use the parameters and , which imply . According to Theorem 1 the ratio
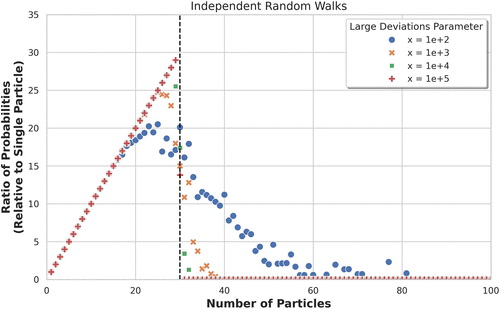
Notes. Estimated ratio between and as a function of number N with . The phase transition is observed at the expected threshold .
For the simulation we used the measure as defined in (20), under which the process is distributed as a birth-and-death random walk with interchanged parameters, namely, . Under this measure, passage over a given is not a rare event anymore, so simulations are feasible. For each large deviation parameter , and for each number of particles N between 1 and 100, we simulate and average over 1,000 random walks to get an estimate of . By reverting the measure change, we obtain estimates for the original ratio.
3.2. Parallel Exploration Driven by a Lévy Process
Random walks have an analogue in continuous time known as Lévy processes. Under analogous assumptions on the exponential moments, we can extend Theorem 1 to the case of Lévy processes on . This is based on the fact that the asymptotics for first passage times over high barriers are similar in the cases of random walks and Lévy processes; see Section 4. We now review some preliminaries on Lévy processes, all of which may be found in classical references such as Kyprianou (2006) and Bertoin (1998).
Let be a filtered probability space, where the filtration is assumed augmented and right-continuous. A Lévy process , is a stochastic process such that: for all , is measurable, , is independent of and has the same distribution as , and is continuous in probability, namely, that in probability if . We will always work with a càdlàg version of Z. Let denote the Lévy exponent of Z:
The Lévy-Khintchine formula introduces the characteristic triplet of Z:
Let and be defined as (6) and (7), respectively. Up to taking a continuous time parameter, our result on the number of particles under finite time budget constraints for Lévy processes is the same as for random walks:
Let Z denote a Lévy process such that satisfies Assumptions (3), (4), and (5). Let belong to the class for some (as defined in (8)). Then for ,
In view of the above result, we obtain an optimal number of particles for the Lévy process, in the same way as in Corollary 1.
The following is an example where all the parameters can be computed explicitly.
(
We assume further that . Because its distribution at time 1 is Gaussian with parameters , from Example 1 we conclude that and . The same conclusion on the optimal number of particles as in Example 1 holds.
3.2.1. Simulations for Parallel Lévy Processes.
For the simulations in Figure 2 we considered a Lévy process with positive and negative jumps. Positive (resp. negative) jumps occur at times distributed as a Poisson process of intensity (resp. ) and whose lengths are exponentially distributed with rate (resp. ). Following the notation in (12), we further take . It can be checked that the Lévy measure is given by
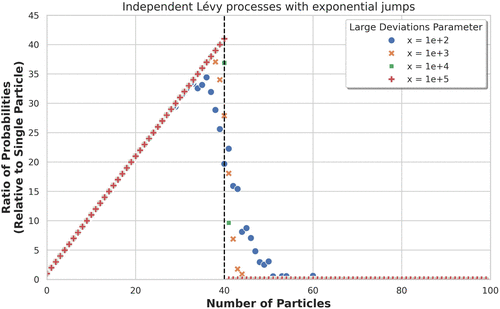
Note. Estimated ratio between and as a function of the number N of independent Lévy processes with exponential jumps, with parameters described in Subsection 3.2.1.
For the considered process, and its positive root turns out to be . Moreover, , which gives, for B taken as , an optimal number of particles.
For simulation purposes, as in the discrete-time case, we use the exponential martingale associated with and the measure , as defined in Section 4. Specifically, the parameters of the process were chosen in such a way that under the measure , the process is again Lévy with exponential jumps. Moreover, the time intensities and the jump rates are permuted: under the measure the parameters of the Lévy measure are , , , and .
(
On the other hand, the event may be decomposed into trajectories that reach x before the first reflection at and those that do not. The first subset may be treated as a process without reflection, thus contributing a term of the same order as that of the process without reflection. Trajectories of the latter subset have a last reflection time before , so there is an excursion of length during a shorter time. This provides an extra term of order at most . Thus,
3.3. Exploration with Restart for Random Walks and Lévy Processes
Our Strategy II consists of restarting a random walk or a Lévy process such as those studied in Theorems 1 and 2 upon leaving with a given probability measure supported in the interval . Our first result in this direction, stated in Theorem 3, gives asymptotic performance guarantees of restart strategies under mild assumptions on the restart measures , as .
In the next section we will specialize to a particularly interesting family of measures: quasi-stationary measures, for which better estimates are obtained (in particular matching bounds up to multiplicative constants). We remark that for the QSD case we rely exclusively on quasi-stationarity and related properties but not on Theorem 3.
Let be two positive finite measures on . is said to be stochastically dominated by , denoted , if for every measurable nondecreasing function u,
This notion is sometimes called first-order stochastic domination and is equivalent to being less than or equal to for every .
The next theorem provides estimates on the time it takes for the restarted process to reach the desired region (here an interval for large x) under mild assumptions on the restart measures , for which we assume without loss of generality that .
Let denote a random walk or a Lévy process satisfying Cramér’s condition, and letbe given by(5). For each , let be the restarted process with restart measures as described at the beginning of this section, and let be the first time a cycle of the process ends above x. Assume that there exists a finite positive measure with the following properties:
is not a delta measure on zero;
for every positive x;
has a finite second moment: .
Then, growing faster than but slower than , the ratio
A typical trajectory of the restarted process is a concatenation of independent cycles, each of which consists of a trajectory for some sampled according to and . An intuition behind the result is that adding as an initial distribution boosts the performance by a factor for each cycle. Because the cycles’ duration is stochastically bounded, we expect to observe an asymptotically linear number of cycles within time . However, a matching upper bound remains elusive for this general context.
Consider some fixed probability measure on such that and satisfying properties 1, 2, and 3 listed in Theorem 3. Now define the sequence as the conditional laws
Then , and Theorem 3 is applicable for this family of measures.
In a more general fashion than the previous example, one may wonder if the hypotheses of Theorem 3 are satisfied whenever the measures have a weak limit . This is indeed the case under some assumptions on the moments of the ’s, but the dominating measure need not be related to the weak limit. Define . Then defines a càdlàg function with . Because the ’s have a weak limit, also holds and defines a probability measure that dominates for every . Note as well that is not a delta measure at zero unless for all . Let us now give a precise condition under which satisfies property 3 in Theorem 3. Assume that the ’s have uniformly bounded moments of order p for some , that is,
We bound the tails of the by Markov’s inequality:
Then, using the Layer Cake Representation, the desired property holds:
As a final example for this section, we take a simple extension of Example 4 that shows that Theorem 3 covers cases beyond weak convergence:
Take and two (distinct) probability measures on satisfying the conditions of Theorem 3 and . We may build an alternating family of measures for as follows:
In this case Theorem 3 applies, but there is not a weak limit of the whole sequence of measures.
3.4. Restart with Quasi-stationary Measures
We now specialize to an important family of restarting measures for which we can obtain sharper asymptotic results than those provided by Theorem 3.
Throughout this section we assume that is the QSD of the process restricted to the interval . We begin with a few brief preliminaries on quasi-stationary distributions, and refer the reader to the monograph of Collet et al. (2013) for a comprehensive treatment of the subject.
(
The study of QSD for a given Markov process is a subtle matter; in general, they may not exist, and when they do, they may not be unique.
For the particular case of a one-dimensional Lévy process with absorbing set for some , by Kolb and Savov (2014, theorem 2.1 and remark 2.2) there is a unique QSD, provided the distribution of the process without absorption at any time is absolutely continuous with respect to Lebesgue in , which is satisfied because we are assuming a strictly positive diffusion coefficient. When there is a unique QSD, it is obtained as the Yaglom limit
The existence of a Yaglom limit for a Lévy process when the absorbing set is was proved in Kyprianou and Palmowski (2006),1 extending the case without jumps of Martinez and San Martin (1994).
To the best of our knowledge, there is no analogous existence-and-uniqueness result specific to discrete-time random walks conditioned on nonabsorption on bounded intervals. If the law of the increments of a random walk is absolutely continuous with respect to the Lebesgue measure, then one may consider the associated compound Poisson process (CPP) with rate 1, thereby obtaining a Lévy process with an absolutely continuous law for every time larger than its first jump. By checking that for large t the probability of not having jumped is negligible for the CPP even when conditioned on nonabsorption by time t, one obtains the same Yaglom limit as the conditioned CPP and in particular the existence and uniqueness given by Kolb and Savov (2014). This can be carried out using the asymptotics on passage times from Denisov and Shneer (2013). These asymptotics for conditioned processes are used in the proof of Lemma 4 of Section 6. Yaglom limits for random walks with absorption at were studied in Iglehart (1974), and under the Cramér condition in Doney (1985).
We may now state our main theorem for restarted processes:
Let Z be a random walk on discrete time or a Lévy process satisfying (3), (4), and (5) as in Theorem 1. For each positive , let denote the quasi-stationary probability measure on for the process Z absorbed upon exiting . Let be the restarted version of Z on with restart measure and the associated passage time over x. Let the time budget grow faster than as but slower than . Then there exist constants such that
In the particular case when Z is a linear Brownian motion, with a negative drift equal to , we have
The theorem states that the application of a restarting mechanism with quasi-stationary distributions improves performance by a factor comparable with the time budget times an exponential moment of the respective measure. In the Brownian motion case, this improvement factor is exponential in the complexity of the task. Indeed, although is of order , with the restarting mechanism we get order . For a general Lévy process, exponential moments of its quasi-stationary measures are not easy to estimate. We conjecture that they grow as , as , where is the positive solution of . Note that this is exactly the case for the linear Brownian motion. For spectrally negative Lévy processes, namely, when , the conjecture might be proved with the use of a Girsanov transformation of the process into a zero-drift one (thus providing the conjectured exponential factor) and applying the results of Lambert (2000). We do not pursue this further here; it is left as a direction of further study.
3.4.1. Simulations for Restarted Lévy Processes.
We now present numerical experiments for restarted processes. As a case study, we consider the Lévy process with exponential jumps introduced in Subsection 3.2.1, equipped with a restart mechanism activated upon exiting the interval .
For the process without restart, recall that the Cramér exponent is . Consequently, when the process is started from the origin, the probability of ever reaching the upper barrier at 50 is of order . As restart measure, we consider an exponential distribution with mean 10, truncated to , namely,
Its exponential moment of order satisfies
Multiplying by yields
Although this estimate is only heuristic, in view of Theorem 3 it suggests that the probability of exceeding the level within a finite time horizon under this restart strategy is no longer negligible. This behavior is confirmed numerically in Figure 3, which reports empirical mean estimates based on 100 independent replications for each time budget, together with confidence intervals. The figure illustrates how the restart mechanism makes the exceedance of the upper barrier observable on moderate time scales, with confidence intervals (CI) indicating the associated variability.
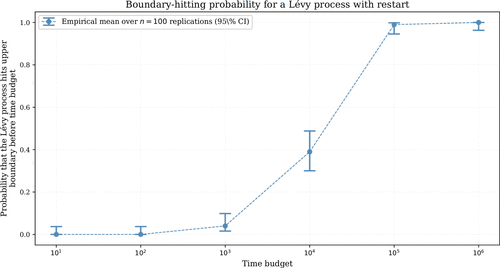
Notes. The underlying process combines a Brownian motion with drift and volatility with exponential jumps: positive jumps arrive at rate with jump sizes of rate 4, whereas negative jumps arrive at rate with jump sizes of rate 1. Whenever the process exits the interval , it is restarted according to a truncated exponential distribution with mean 10.
We emphasize that the simulations reported in this section do not rely on importance sampling or on any other variance-reduction technique. The numerical results therefore illustrate that introducing a restart mechanism alone can already lead to a significant improvement in the simulation of rare events. In particular, restarting makes it possible to turn probabilities that are extremely small for the original process into quantities that can be reliably estimated within reasonable computational time.
4. Proof of Theorems 1 and 2
We begin the section by introducing some preliminaries on exponential martingales, first for random walks and then for the Lévy process, which will be used in the proofs. They are standard techniques for the study of large deviations events for light tails, as is our case.
4.1. Preliminaries
By Assumption (3), the family of exponential martingales indexed by may be defined as
Indeed, is a martingale for every , which acts as a density for a new probability measure on the same probability space. Specifically, we define the measure as
We also observe that the density of with respect to is given by .
Exponential martingales are particularly useful for computing probabilities of rare events, as these events may become more frequent under if is appropriately chosen. Under the measure , the increments , , are i.i.d. (making Z a random walk), with mean and variance given by
The threshold in Theorem 1 can thus be interpreted in terms of the measure : the random time is -almost surely finite (because ) with mean , asymptotically as .
For the Lévy process we have analogous definitions: under Cramér’s condition the family of exponential martingales is defined as
Under any of the measures , Z is again a Lévy process with Lévy exponent
From (21) it is straightforward to check that the corresponding characteristic triplet is given by
The measure provides an intuition to Theorem 2 as in the random walk case: the law of the process conditioned to reach the high barrier is distributed as . We do not prove this exact result here, but it lies at the core of the references cited for our proof (Bertoin and Doney 1994, Palmowski and Pistorius 2009).
in (22) should not be confused with . If the jump measure is nonzero, they might not coincide.
4.2. Proofs
We introduce some pieces of notation: will be used to denote asymptotic equivalence and for for some constant for all .
Theorems 1 and 2 will follow from the following asymptotics of the passage times of random walks and Lévy processes with the assumptions on their exponential moments stated in Subsection 3.1.
The following proposition unifies Höglund (1990, corollary 2.2) for the case of random walks and Palmowski and Pistorius (2009, theorem 1) for Lévy processes:
Let be either a random walk () or a Lévy process () taking values in and assume that Conditions (3), (4), and (5) are satisfied (for in the case of a Lévy process). Fix some such that . If x and go to infinity in such a way that , then there exist positive constants C (independent of ) and such that
Some remarks are now in order:
The constants C and are given in Höglund (1990) and Palmowski and Pistorius (2009) in terms of the increments of the process in each case. Their explicit values are not relevant for our analysis.
If , then realizes the supremum in the definition of , that is,
The case in the proposition shows that for t growing sufficiently fast with x, and have the same exponential order:
We begin by noticing that for any time t (discrete or continuous),
Case I: . In this case and are in the same regime of Proposition 1; thus, by (26),
For the remaining cases some considerations will be needed: for each such that , let
The set contains a (nontrivial) right neighbourhood of one as long as . We also note that for each as before, the map is continuously differentiable and
Case II: . As a subcase, assume first that , so that there exists such that
In this case, we have that , so the exponential rate of is given by Proposition 1:
On the other hand, . Then, for some constant ,
Using the Mean Value Theorem and the fact that is strictly increasing in the interval , we conclude that the limit in (31) is zero.
For the second subcase, let , so that is at a positive distance above the range of . A bound may be obtained from any by monotonicity of :
Case III: . As in the subcases considered above, assume first that . Now both and lie in the right-hand side (RHS) of the threshold in (23). It suffices to show that the function
It only remains to prove that is increasing, and using Remark 6 this is seen to hold:
The proof is finished by arguing in the same way as in Case II for . □
5. Proof of Theorem 3
For the proof of Theorem 3 we will need the following auxiliary lemmas:
Let
Then under the assumptions of Theorem 3,
Moreover, there exists a constant such that
Let and be random variables defined by
Under the assumptions of Theorem 3,
Let be as in Lemma 2 and consider an i.i.d. sequence with the same distribution as . For a fixed , define the events
In the setting of Theorem 3, the following holds:
Assuming these, we may now give the main result for restarted processes.
The first time the restarted process goes above x has a regenerative structure with cycles determined by the restart times. Formally,
Lemma 1 studies the behavior of for large x; in particular (36) shows that it becomes increasingly harder to observe the events of interest as x grows.
A lower bound for is given by the probability that in (39) takes an unusually small value. To this end, consider for a fixed small the events
Then by Lemma 3,
Finally, we can conclude the desired uniform lower bound for (15) because
The proof of Theorem 3 is now concluded. □
5.1. Proofs of Auxiliary Lemmas
We begin with the proof of the upper bound of (37) by a martingale argument. We have
We now turn to the lower bound. Our main ingredient is Bertoin and Doney (1994),3 who state that there exists a constant such that
Using that is almost surely finite, for every x and
We first claim that
Indeed, and equality cannot hold because otherwise the measures would converge (up to taking a subsequence) to the delta measure on zero, thus contradicting the positive limit of the absorption rates in Lemma 6, and the claim follows.
In view of the claim above, let be small enough such that , and let also be given by (40) such that for
Noticing that by the Markov property , we then have
It then suffices to find a strictly positive lower bound, independent of x for the following:
There are two cases to distinguish: whether is equal to one or not.
In the case , the first term in the RHS of (44) dominates the third and the desired lower bound is .
If we now assume that for some positive , then the middle term in (44) is at least for large x. The proof concludes by showing that either the first and third terms vanish or the first dominates the third: assume first that there exists a sequence such that
For such a sequence, the first and third terms on the RHS of (44) vanish as . On the other hand, if there is no such sequence (and hence ), the first term dominates the third one and is still a lower bound for (44).
Let us now observe that goes to zero as , so the events of interest are indeed rare events: for any , there is such that ; then for x big enough, we have that
Because is fixed, the above limit is upper bounded by , and is arbitrary. Hence, as .
The proof of Lemma 1 is then complete. □
The statement on follows easily from stochastic domination by noticing that the function is nondecreasing. Indeed,
We now turn to . For each denote by the overshoot at x: .
by means of the exponential change of measure and the asymptotics of
Using that has finite first moment, the last term above is seen to scale as up to multiplicative constants. □
To lighten the notation, let us denote by . We will show separately that
Together they imply (38).
Let us start with (46). For this part of the proof, we apply Chebyshev’s inequality:
The asymptotic equivalence of the last line above is justified by Doney and Maller (2004, theorem 3) once we note that decays exponentially to zero with t for every fixed (this is easily checked with an exponential martingale argument using any parameter such that ).
Because has finite second moment and does not equal , does not go to zero with and we conclude (46).
Let us now prove (47). On the one hand, the Strong Law of Large Numbers (see Kyprianou 2014, exercise 7.2, p. 224) implies that
Here as before denotes the overshoot at x. On the other hand, as seen in Lemma 2, for large x, is asymptotically equivalent to . Under Cramér’s condition converges to zero almost surely, so we conclude that
6. Proof of Theorem 4
In this section Z denotes either a random walk on discrete time or a Lévy process, satisfying Cramér’s condition, and we will consider as restarting measures the family of quasi-stationary distributions . The proof of Theorem 4 relies on some auxiliary results.
The sequence of QSD measures converges in distribution to the Yaglom limit on , given by
Once the sequence of measures admits a weak limit, Remark 2 provides a route to apply Theorem 3, thereby yielding the lower bound in Theorem 4. We adopt, however, a different approach that relies more heavily on properties associated with quasi-stationarity.
For the restarted process , has an exponential distribution with parameter , where is the exponential rate of absorption associated with and is defined in (35).
The function , as defined in Lemma 5, is decreasing in and has a positive limit as .
If we assume the lemmas above, we may prove the main result as follows:
By Lemma 5 we have that . Because grows slower than with x, and as , with the notation defined at the beginning of Subsection 4.2.
Also, by Lemma 6, has a positive limit, and because has order , by Proposition 1 we conclude that the ratio
Before proving the lemmas, we compute the quasi-stationary distribution, its exponential moment of order , and the absorption rate for a linear Brownian motion explicitly.
In the case in which Z is distributed as a Brownian motion, we can compute all ingredients explicitly. Brownian motion with constant drift has infinitesimal generator
By the spectral characterization of quasi-stationary measures (see, e.g., Méléard and Villemonais 2012, proposition 4), the measure
With the explicit form for the quasi-stationary distribution, and recalling that , the exponential moment follows:
The result now follows from Theorem 4. □
6.1. Proofs of Auxiliary Lemmas
We now turn to the proof of the auxiliary lemmas.
Let us recall the piece of notation and take any number in . We shall prove that the following limit holds for any bounded measurable function f:
The result relies on proving that when taking t and x to in the same order as in (52). To check this fact, we start by using the strong Markov property
In Denisov and Shneer (2013, theorem 3.5), it is proved that for Lévy processes, for large t,
Here we used the exponential martingale change of measure and the overshoot once more (recall Remark 7). In the case of a random walk under Cramér’s condition, Denisov and Shneer (2013, theorem 3.5) provide an analogous estimate but with a spatial factor , so all the above considerations still hold. We may now conclude (52):
We recall that for the process Z absorbed upon exiting , the absorption time is exponentially distributed with parameter if started with the quasi-stationary distribution (see, e.g., Collet et al. 2013, theorem 2.2). Observe that the can be decomposed into a sum of a geometric number of duration of cycles, namely,
Let be the first exit time from ; because the quasi-stationary measure is the unique Yaglom limit for the system under consideration, the rate of absorption is obtained as
7. Conclusion
This paper investigates various exploration strategies under time constraints in environments with unknown stochastic dynamics focusing on their impact on performance as measured by the time required to reach a set of rare states.
We aim for this work to be a foundational step toward developing a more qualitative theory of exploration, specifically by incorporating the time needed to observe meaningful signals for the first time. For example, in Reinforcement Learning environments with sparse rewards, exploration of the state space or action-state space is widely recognized as a critical bottleneck to efficiency. By addressing this crucial aspect, we seek to contribute to more efficient and effective exploration strategies in such contexts and beyond.
In this work, we focused on space-invariant one-dimensional dynamics, which provide highly interpretable results and for which we can provide explicit performance guarantees. Building on this understanding, future work will consider more general Markovian dynamics, providing a more comprehensive and realistic framework for exploring challenging environments. A natural extension of this work is to higher-dimensional settings. Although explicit hitting-time estimates of the kind used here are generally unavailable in that regime, the “too-many-particles” phenomenon and the core conclusions of our main results are expected to carry over to considerably more general settings.
The authors are grateful to the anonymous referees for their thorough and insightful reviews; their suggestions and observations led to substantial improvements in this work. P.B. and E.G. also express their deep gratitude to professors E. Mordecki and J. R. León for very valuable discussions.
Appendix A. M/M/1
In this section we investigate the interplay between the probability of exploration, under the time regime of interest, and the efficiency of the associated estimation procedure. In particular, we show that the variance of the natural Monte Carlo estimator mirrors the typical exploration time.
Consider an queue on the truncated state space with load parameter , and assume that almost surely. The chain is ergodic, and its invariant measure is geometrically decaying: for any with , the stationary weight is proportional to . By the Ergodic Theorem, the stationary measure satisfies
A Monte Carlo estimator for , based on a time horizon , is therefore
We focus on restrictive time budgets and assume that the estimation of for large k is performed with a linear-in-k horizon,
In such a regime, the process is expected to spend exceedingly little time in state k: indeed, the expected hitting time of k grows exponentially fast in k. As we show next, this scarcity of observations is the principal obstruction to reliable estimation, and it directly governs the variance of the Monte Carlo estimator.
Fix and introduce the surrogate estimator
Appendix B. The Fleming-Viot (FV) Particle System and FVRL
The approach found in Mastropietro et al. (2025) for defining a restarted mechanism is based on the paradigm of the FV particle system, introduced by Burdzy et al. (1996). In this framework, a population of particles (which can represent different simulations in parallel) evolves over time, exploring the state space in parallel. When a particle falls into a less promising region A, it is “restarted” by being replaced with a copy of another, more promising particle. This ensures that resources are concentrated on exploring the most fruitful areas of the state space. The FV strategy is particularly effective in scenarios where certain regions of the state space are more likely to yield valuable rewards, as it dynamically reallocates exploration effort toward these regions, thereby increasing the overall efficiency of the exploration process.
Note that various papers (Ferrari and Marić 2007, Asselah et al. 2011, Villemonais 2011) have shown that FV empirical measures converge as the number of particles tends to infinity to the conditioned evolution of the process, that is,
Appendix C. An Example in RL: The Control of Blocking in an Queue
This example has been considered in Mastropietro et al. (2025) and generalized to multidimensional settings (several coupled queues). It serves here as a canonical illustration of Reinforcement Learning in environments with sparse and rare rewards where the exploration is the main bottleneck. We summarize the model and the FVRL strategy introduced in Mastropietro et al. (2025) as a motivation for our theoretical results. Consider an queue with fixed buffer capacity K, arrival rate , service rate , and load . The state space is , representing queue occupancy. The control action determines whether to accept () or block () arriving jobs. The reward function is structured to penalize both the underutilisation of resource and large blocking probabilities
For threshold policies parameterized by , this simplifies to
C.1. The Gradient Estimation Problem
Given this framework, the RL strategy will be efficient if the gradient estimates can be informative. We discuss here only the estimate of the stationary probability . The stationary distribution for state , under the threshold policy , is given by the formula:
For typical parameters (, ), . Because , both are exponentially small.
Consequently,
Vanilla Monte Carlo (MC) estimators of exhibit prohibitive variance (in terms of multiplicative errors);
Much more importantly, the policy gradient in (C.2) becomes numerically zero under finite sampling. Hence, the learning signal vanishes, preventing convergence to an optimal .
C.2. Parallel Sampling
In order to compare our results with those of Mastropietro et al. (2025), we present a set of simulations for parallel queues under different time regimes. The hyperparameters used in Figure C.1 are total queue capacity , initial condition , arrival rate , and service rate . In this numerical illustration, , so that is the exponentially rare quantity identified in Subsection C.1.
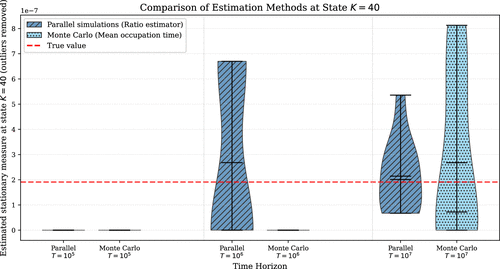
Notes. Simulation of parallel queues with , , , and , comparing renewal-based stationary probability estimates across time horizons , , and . The number of parallel copies to deploy in each time regime is computed using the results of our main theorems.
Following Mastropietro et al. (2025), we estimate the stationary probability via a renewal-type decomposition based on successive returns to J. More precisely, we estimate (i) the expected return time to state J, which in our setting is of order , and independently (ii) the probability of hitting K starting from J. For the latter we report estimators under time horizons of magnitudes , , and , and we compare them with the true stationary value shown in Figure C.1.
To ensure a fair comparison with the experiment of Mastropietro et al. (2025, section 4.1), we remark that the total number of events observed in our simulations—counting both arrivals and departures—is one to two orders of magnitude larger than theirs. Indeed, across our time regimes we record approximately events for , which exceeds the event counts reported in Mastropietro et al. (2025, figure 2). This discrepancy is natural: correlations in the Fleming-Viot particle system substantially facilitate the exploration of the rare state K.
In summary, and as expected, the estimation accuracy with independent particles lies between that of naive Monte Carlo (which rarely reaches K even for time of order ) and that of the Fleming-Viot particle system.
C.3. Fleming-Viot Solution
The FVRL method addresses this by introducing an absorption set, where prior knowledge is used on the fact that no rewards are granted in with . The Fleming-Viot particle system consists of N particles evolving in , with a resetting mechanism: particles hitting jump to positions of randomly selected surviving particles. This particle system approximately estimates the quasi-stationary distribution
For , :
Vanilla MC estimates even with samples;
FV provides accurate estimates with particles;
FVRL converges to whereas MC-based policy gradient fails completely.
The method effectively trades the rare-event probability for the substantially larger quasi-stationary probability , overcoming the exponential sample complexity of vanilla approaches. We do not compare here our results with the estimates constructed in Mastropietro et al. (2025) because those are more complex than the idealized situation described in Subsection 3.4, which can, however, serve as a rule of thumb for practitioners.
1 The processes we consider fall in their class A category with parameter .
2 The notation was introduced in Remark 4.
3 See Borovkov (2013) for the analogous result for discrete-time random walks.
References
- (2007) Stochastic Simulation: Algorithms and Analysis, Stochastic Modelling and Applied Probability, vol. 57 (Springer, New York).Google Scholar
- (2011) Quasistationary distributions and Fleming-Viot processes in finite spaces. J. Appl. Probab. 48(2):322–332.Google Scholar
- (2018) Hitting times in Markov chains with restart and their application to network centrality. Methodology Comput. Appl. Probab. 20(4):1173–1188.Google Scholar
- (1998) Lévy Processes,
Cambridge Tracts in Mathematics , vol. 121 (Cambridge University Press, Cambridge, UK).Google Scholar - (1994) Cramér’s estimate for Lévy processes. Statist. Probab. Lett. 21(5):363–365.Google Scholar
- (2013) Probability Theory (Springer, London).Google Scholar
- (2022) Approximating quasi-stationary distributions with interacting reinforced random walks. ESAIM Probab. Statist. 26:69–125.Google Scholar
- (1996) Configurational transition in a Fleming-Viot-type model and probabilistic interpretation of Laplacian eigenfunctions. J. Phys. A Math. General 29(11):2633–2642.Google Scholar
- (2013) Quasi-stationary Distributions., Markov Chains, Diffusions and Dynamical Systems (Springer, Berlin).Google Scholar
- (2013) Asymptotics for the first passage times of Lévy processes and random walks. J. Appl. Probab. 50(1):64–84.Google Scholar
- (1985) Conditional limit theorems for asymptotically stable random walks. Zeitschrift Wahrscheinlichkeitstheor. Verwandte Gebiete 70:351–360.Google Scholar
- (2004) Moments of passage times for Lévy processes. Ann. Inst. Henri Poincaré Probab. Statist. 40(3):279–297.Google Scholar
- (2021) First return, then explore. Nature 590:580–586.Google Scholar
- (2020) Stochastic resetting and applications. J. Phys. A Math. Theoret. 53(19):193001.Google Scholar
- (2007) Quasi stationary distributions and Fleming-Viot processes in countable spaces. Electronic J. Probab. 12:684–702.Google Scholar
- (2013) Markov processes with redistribution. Markov Processes Related Fields 19(3):497–520.Google Scholar
- (2009) The maximum of a Lévy process reflected at a general barrier. Stochastic Processes Appl. 119(7):2336–2356.Google Scholar
- (1990) An asymptotic expression for the probability of ruin within finite time. Ann. Probab. 18(1):378–389.Google Scholar
- (1974) Random walks with negative drift conditioned to stay positive. J. Appl. Probab. 11(4):742–751.Google Scholar
- (2014) Exponential ergodicity of killed Lévy processes in a finite interval. Electronic Comm. Probab. 19:1–9.Google Scholar
- (2006) Introductory Lectures on Fluctuations of Lévy Processes with Applications (Springer, Berlin).Google Scholar
- (2014) Fluctuations of Lévy Processes with Applications, Introductory Lectures, 2nd ed. (Springer, Berlin).Google Scholar
- (2006) Quasi-stationary distributions for Lévy processes. Bernoulli 12(4):571–581.Google Scholar
- (2000) Completely asymmetric Lévy processes confined in a finite interval. Ann. Inst. Henri Poincaré Probab. Statist. 36(2):251–274.Google Scholar
- (1993) Optimal speedup of Las Vegas algorithms. Inform. Processing Lett. 47(4):173–180.Google Scholar
- (1994) Quasi-stationary distributions for a Brownian motion with drift and associated limit laws. J. Appl. Probab. 31(4):911–920. Google Scholar
- (2025) Fast-exploring reinforcement learning with applications to stochastic networks. Queueing Systems 109(3):23.Google Scholar
- (2012) Quasi-stationary distributions and population processes. Probab. Surveys 9:340–410.Google Scholar
- (2021) Large deviations for Markov processes with stochastic resetting: Analysis via the empirical density and flows or via excursions between resets. J. Statist. Mech. Theory Experiment 2021(3):033201.Google Scholar
- (2009) Cramér asymptotics for finite time first passage probabilities of general Lévy processes. Statist. Probab. Lett. 79(16):1752–1758.Google Scholar
- (2011) Interacting particle systems and Yaglom limit approximation of diffusions with unbounded drift. Electronic J. Probab. 16:1663–1692.Google Scholar

