
Microsoft Uses Machine Learning and Optimization to Reduce E-Commerce Fraud
Abstract
Many merchants conduct their businesses through e-commerce. One major challenge in tackling e-commerce fraud results from dynamic fraud patterns, which can degrade the detection power of risk models and can lead to them failing to detect fraud that has emerging unrecognized patterns. The problem is further exacerbated by the conventional decision frameworks that ignore the follow-up decisions made by other associated parties (e.g., payment-instrument-issuing banks and manual review agents). Microsoft developed a new fraud-management system (FMS) that effectively tackles these two challenges. It keeps features used by the machine learning (ML) risk models up to date by using real-time archiving, dynamic risk tables, and knowledge graphs. The FMS uses customized long-term and short-term sequential ML models to detect both historical and emerging fraud patterns. It also makes rapid real-time optimal decisions using a dynamic programming approach to optimize the long-term profit by taking into account the aforementioned multiple-party decisions. After implementing these innovations over a two-year period (2016–2018), Microsoft reduced its fraud loss by 0.52%, thus generating $75 million in additional savings; reduced the incorrect fraud rejection rate by 1.38%; and improved its bank authorization rate by 7.7 percentage points. The result was many millions of dollars in additional revenue. These innovations simultaneously prevent fraud and increase bank acceptance. In April 2019, Microsoft launched Microsoft Dynamics 365 Fraud Protection, a cloud-based service available for all e-commerce merchants.
Introduction
Microsoft is a software technology company that develops, licenses, and supports a wide range of software products, services, and devices. Many merchants, including Microsoft, today conduct much of their businesses online via e-commerce. E-commerce is growing at close to 20% annually and is expected to reach about $4 trillion by 2021 (eMarketer 2018). As one of the largest e-commerce merchants in the world, Microsoft derives a significant portion of its $100+ billion revenue from online sales of services, software, games, and physical goods to individual consumers and enterprises in more than 100 countries via online stores, applications, cloud service portals, and gaming consoles, and it accepts a wide variety of payment instruments and methods.
Although e-commerce reduces costs, promotes sales, and improves customers’ experiences, it also exposes merchants to serious threats from sophisticated fraudsters who take advantage of the relative anonymity and ease of use of the online channel to defraud and abuse it. The types of fraud and abuse merchants face are many and varied. These include e-commerce payment fraud, account takeover, first-party fraud, free-trial abuse, fake product reviews, warranty fraud, refund fraud, reseller fraud, abuse of program discounts, and many more, all of which endanger the merchants’ profitability and reputation. Some types of fraud have grave consequences for society at large, such as money laundering and proliferation of fake news. Unlike the nascent years of the Internet, fraudsters today are well-funded and well-equipped rings of professionals; hence, e-commerce fraud is growing fast. Currently, fraud losses are estimated at 1.8% of online revenue in 2018 (LexisNexis Risk Solutions 2018); after accounting for the considerable overhead of servicing fraud events, e-commerce merchants are losing $250 billion annually because of fraud costs.
Fraud Protection at Microsoft
Microsoft’s extensive online surface area is an attractive target for fraud attacks. Microsoft routinely sees fraudsters attempting various kinds of fraud on its properties. For example, they may attempt to sign up for free trials of its flagship products (e.g., Microsoft Office) to send large volumes of spam emails; they may attempt to sign up for Microsoft Azure trials and then use the cloud infrastructure to mine bitcoins; they may attempt to sign up for advertiser accounts with Bing ads to run phishing advertisements on the search-engine results page; or by using compromised accounts or stolen payment-instrument (PI) information, they may attempt to commit payment fraud in Microsoft online stores. These are but a few examples from a long list of attempted nefarious activities observed on a daily basis. If these activities are not curtailed, they can affect Microsoft’s reputation, the trust of its customers, and, ultimately, the profitability of its businesses. It is the mandate of the Microsoft fraud-protection team, along with several partners across the company, to prevent fraudsters from compromising the security of online transactions, legitimate customers’ shopping experiences, and the profitability of the company. Over the years, Microsoft has successfully overcome these challenges, and, in the process, Microsoft’s Dynamics 365 Fraud Protection team (DFP) developed an effective fraud-management system (FMS).
Fraudsters know no boundaries. One day, they attack a new product released in an e-commerce store; the next day, they try to abuse a free cloud service trial; and the following day, they attempt to commit device warranty fraud. It follows that, to be effective, the FMS should not be constrained by boundaries or silos. It should observe and connect knowledge globally across the company and fight fraud in its entirety. A major part of Microsoft’s success has come from driving such a paradigm shift in the company, where it takes a holistic view of all types of fraud and develops knowledge systems and artificial intelligence (AI) techniques that exploit synergies across domains. Although all types of fraud and their mitigations are of interest, this paper focuses on e-commerce payment fraud because it is a common denominator across all online businesses. The paper describes the techniques and strategies that the DFP has developed to improve both the profitability and customer experience of Microsoft’s e-commerce businesses.
A Quick Primer on E-Commerce Payment Fraud
Although a credit/debit cardholder is always protected from the financial liability of unauthorized card transactions, there is a significant difference in how fraud losses are handled between merchants and card-issuing banks, depending on whether the fraud occurred online (Figure 1) or in a brick-and-mortar store. The numbers in Figure 1 refer to the 11 steps with e-commerce fraud, with the first 7 steps applying to both e-commerce and brick-and-mortar commerce. Suppose a shopper makes a purchase at a merchant and presents a credit or debit card for payment (step 1). Via some intermediaries, the merchant transmits this payment to the bank that issued the card (steps 2 and 3). The bank chooses whether to authorize that payment. If it authorizes the payment, the merchant receives the funds (steps 4 and 5), and the merchant provides the goods to the shopper (step 6). Unfortunately, if this shopper is a fraudster and has used stolen card information for this transaction, the true holder of the card will dispute this unrecognized transaction with the bank (step 7). This is called “chargeback.” This is where the difference between brick-and-mortar commerce and e-commerce becomes important. In the case of brick-and-mortar commerce, the bank takes the liability. That is, the bank withdraws the fraudulent charge from the cardholder’s billing statement and considers the resulting loss part of its cost of doing business. In e-commerce, however, the bank sends the chargeback to the merchant (steps 8 and 9), and the merchant is required, by law, to return the money to the bank (steps 10 and 11) if the merchant cannot prove it was a legitimate purchase transaction. In this case, the merchant must bear the loss of the cost of goods obtained by the fraudster. To make matters worse for the merchant, the bank will generally charge a fee for the chargeback, thus causing an additional loss. Furthermore, banks accept about 96% of the transactions (at step 3) when the buyer swipes a credit card at the merchant’s physical store, but they accept only 84% of the e-commerce transactions. Thus, even though the banks’ liabilities are lower with e-commerce, they accept a dramatically lower percentage of the transactions because they are concerned about negatively impacting the perception of cardholders regarding the security and fraud protection of their cards, which can cause them to abandon using the payment instrument.
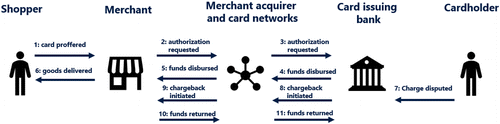
Annually, e-commerce payment fraud results in losses of tens of billions of dollars for e-commerce merchants in the United States. Added to that are penalties imposed by card networks and other fraud-handling costs, which lead to an overhead rate of 94 cents for each dollar of fraud loss. Therefore, e-commerce merchants have a strong incentive to control and manage fraud.
Challenges in Preventing E-Commerce Fraud
One might think that a simple way of thwarting e-commerce fraud is to put progressively more verification steps in the online shopping experience until fraudsters are dissuaded. Examples of this include requiring two-factor authentication for every transaction or requiring the shopper to solve a CAPTCHA (completely automated public Turing test to tell computers and humans apart) or short messaging service (SMS) challenges. Although this may reduce fraud, it also drives away legitimate customers who abandon their purchase attempts when they encounter the extra steps. This effect is significantly large but given little visibility, because this loss of legitimate business through fraud-protection efforts is difficult to measure and compare across various segments of the market. Nevertheless, it is well understood that an FMS needs to achieve and maintain a delicate (sharply poised) balance between thwarting fraudsters and providing a rapid and easy experience for valid customers.
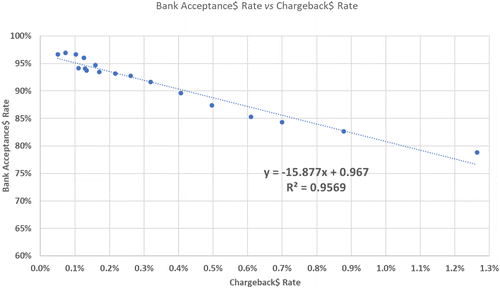
Even with this understanding, e-commerce fraud presents unique challenges that are unlike other decision-science problems. First, fraudsters actively attempt to stay below the radar of any FMS and change their attack vectors as soon those systems become good at thwarting them. Hence, every online merchant is under constant threat from innovations by fraudsters. This first challenge stems from dynamic fraud patterns, a consequence of the changing behavior of fraudsters. This degrades the performance of the fraud-detection models in the FMS. A second major challenge stems from the need to consider all the long-term and short-term impacts of making decisions once the fraud risk of a transaction has been determined. First-generation FMSs focused on driving fraud loss to low levels, which are usually dictated by cost of goods, fees, and penalties imposed by card networks, and largely ignored the opportunity loss due to wrongful rejections of legitimate transactions (i.e., false positives) by the FMS. Second-generation systems did somewhat better by optimizing the choice of the static thresholds applied on the fraud probability assessed by the fraud models. One of their objectives was to achieve a balance between fraud loss and opportunity loss, thus maximizing the total instantaneous profitability. However, these systems assumed that the environment was quasi-static and describable by long-term average measures. This resulted in decision policies that belied the dynamic nature of the fraud environment and ignored the multiple feedback-interaction loops involved in the decision of the fraud-risk model and the follow-up decisions made by other associated parties, such as payment-card issuing banks, which have their own FMSs. For example, a bank’s acceptance rates are impacted negatively by the fraud volumes it sees emanating from a merchant; see Figure 2 for empirical evidence observed by Microsoft. In Figure 2, the bank acceptance rate is the total dollar amounts accepted by banks divided by total dollar amounts submitted to banks by Microsoft; the chargeback$ rate is the total dollar amounts of those transactions that had chargebacks requested by banks divided by the total dollar amounts submitted to banks by Microsoft. If an e-commerce merchant submits purchase transactions with a high volume of fraud to banks, the banks will learn over time that transactions from this merchant are a higher fraud risk and will reject more transactions, including legitimate ones (resulting in lost revenue), from this merchant. Therefore, this long-term revenue loss should be considered along with the near-immediate loss due to fraud, while balancing against the desire for favorable customer experiences.
Solutions Considered
To address the challenge of estimating risk in the presence of dynamic fraud patterns, the members of the DFP team considered various ways in which they could update the features of the machine learning (ML) model and different strategies by which they could retrain the ML models to avoid model degradation. We considered fast incremental retraining cycles for a single ML model, which is trained on 12 months of the most recent data. The problem with this approach is that the data of newly evolving fraud patterns in the previous few weeks are overwhelmed by the more numerous historical patterns; hence, the model cannot learn them efficiently. On the other hand, if we were to retrain using only recent data, we would sacrifice accuracy, because all the historical knowledge would be forgotten quickly. Microsoft found that it needed an ML method that could learn to identify emerging fraud patterns without forgetting old patterns, referred to as progressive learning in literature (Venkatesan and Er 2016). We finally settled on using the long-term and short-term sequential model as a tractable instance of that paradigm (Jia et al. 2019b).
Once the risk of a transaction has been estimated, Microsoft needs to decide on whether to accept the transaction, reject it, or direct it for manual review. In addressing this real-time decision issue, the DFP team considered various control algorithms for setting decision policies to optimize the long-term profit. Below, we list the three approaches that the team considered and the data each uses.
Naïve control: Only historical mature data (i.e., confirmed fraud feedback).
Myopic control: Both the historical matured data and the most recent data with partial fraud feedback.
Prospective control: Historical mature data, most recent data with partial fraud feedback, and predictions of what might happen in the future, thus accounting for the feedback interactions between various decision-making players (e.g., banks and manual review agents).
Based on the nature and complexity of Microsoft businesses, we chose the appropriate control algorithm that worked best for each situation. For example, in Microsoft Advertising, the feedback about occurrence of fraud is usually available reliably within a very short period. In this case, naïve control works well, and the complexity of myopic and prospective control is unnecessary. However, this may not be true in other businesses, such as sales of hardware or games. Prospective control is a relatively complex model structure, which incorporates and generalizes both naïve and myopic control. To reduce unnecessary repetition in this paper, below we describe only prospective control to illustrate how it works, because it is the most generalized model.
Overview of the Solution Selected and Developed
This section provides a detailed overview of the solution, Prospective Dynamic Fraud Control. The decision at each current stage of the dynamic program is made based on the risk score, cost of goods, and margin of the current transaction, plus predicted future outcome of decisions made about the transaction. The prospective control model is trained by using fully matured data of past transactions, partially matured data of recent transactions, and predicted future outcomes.
Solution Details and Implementation
This section provides further detail about the technical solutions that Microsoft implemented to address the challenges of dynamic fraud patterns and the company’s need to consider the long-term implications of short-term decisions.
Knowledge Graph and ML Features
Fraud management is a knowledge-intensive task; therefore, it is worthwhile to have a clear way of talking about how this knowledge is organized. The DFP team found the property graph language most suitable for this purpose. The knowledge that the FMS uses is organized in a graph with an ontology (Figure 3). The nodes of this graph are entities and events, and the edges are relationships between those entities and events (West 2001, Cowan and Nicolas 2004). We allow only certain types of entities (e.g., users and devices), events (e.g., purchase transactions, chargebacks, and refunds), and relationships (e.g., shipped to and paid with) in the graph, as the ontology prescribes. For example, the ontology shown in Figure 3 allows the graph to have purchase nodes and PI nodes, with edges of type “paid with” connecting certain purchase nodes to certain PI nodes. Any such edge can be interpreted to be saying, “this purchase was paid with this PI.” This opens the possibility of revealing how multiple purchases were paid with a single PI, which can be a valuable clue in identifying potential fraud. Even more interesting, knowledge from multiple-hop queries can be accessed (where each hop is one portion of the path between two nodes), such as “the set of all the users who have used the same PI in making a particular type of purchase,” which can be useful in forming fraud islands, subgraphs of predominantly fraudulent transactions. Each node and each edge in the graph can have many attributes. For example, a purchase node can have attributes such as date and time of purchase and dollar amount. A device context node may have attributes such as operating system, IP address, and screen resolution. A user node may have attributes such as name, SMS number, and email ID. A paid-with edge may have attributes such as PI type. All these nodes and edges connected to a transaction, along with their attributes, constitute the knowledge about the transaction available to the FMS.
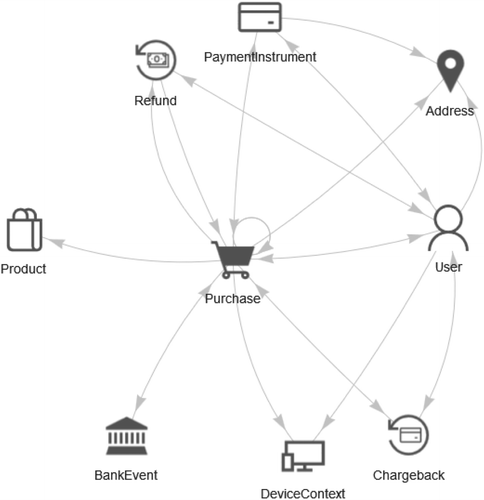
Figure 4 depicts how the FMS is embedded in the flow of transaction information between the various parties involved in the decision process. To score a purchase transaction, the FMS relies on a risk-score-evaluation engine that incorporates ML models. The ML models cannot directly use the semantic knowledge available in the graph. The input to these models is a vector of features pertaining to the purchase transaction, which can be viewed as quantitative functions (such as numbers, categories, and Boolean variables) built off of the semantic knowledge about the transaction. A feature can thus be any measurable characteristic of a transaction, ranging from something simple—such as product type, purchase amount, device type, or browser language—to something aggregated (i.e., comprehensive)—such as number of transactions the account associated with the current transaction has made during the previous day—and even something elaborate—such as an indicator on whether a transaction is connected via multiple hops to a known fraudster. Then, the customized ML model considers all those features to produce a fraud-risk score for this transaction, which represents the likelihood of a transaction being fraudulent. Next, using the collected features and risk score, the risk-control module in FMS makes a decision to approve, reject, or review the transaction. If a transaction is flagged for manual review, it is first sent to the bank for an authorization before the manual review takes place. Doing so saves manual-review costs, because there is no point in reviewing a transaction that the bank has already declined. The issuing banks’ decisions are made by using their FMSs and fraud-prevention strategies. Manual review agents make decisions based on information about the current transaction, the customer’s purchase history, past account activity, and additional information, such as the customer’s reputation, which may be available to them from extraneous sources.
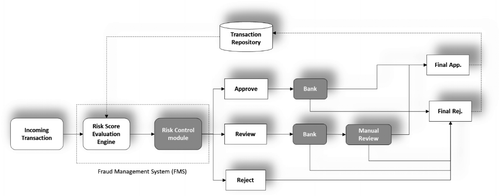
Note. App., approve; rej., reject.
Real-Time Archiving Using Dynamic Risk Features
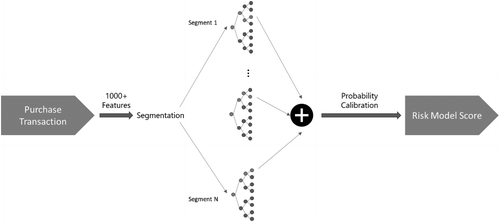
In the Microsoft FMS, the risk-score-evaluation engine consolidates various fraud patterns across different Microsoft business segments—for example, Xbox, Microsoft Azure, Office 365, and Bing ads. To maximize the overall performance of fraud detection, Microsoft’s risk-data scientist team built multiple-segment gradient-boosting decision-tree models (Friedman 2001) that fit the needs and business nature for each segment. Each segment may have a different set of input features. More than 1,000 features are used, and the training data include up to 100 million records. The models are retrained periodically (weekly or daily). In addition, a probability-calibration algorithm was designed to calibrate scores from all segments into one score (Figure 5), which provides a uniform meaning and a comparable unified score in the form of an intuitively understandable fraud probability.
Both fraudsters’ and legitimate customers’ online shopping behaviors change over time, either intentionally or unintentionally. The occurrence of such behavioral changes unfortunately leads to a degradation of the performance robustness of the risk models, hence causing their estimation of fraud likelihood to be inaccurate. To overcome this, we used the long-term and short-term sequential ML models illustrated in Figure 6. The long-term model captures the general trend of fraud and is trained weekly on at least one year’s worth of data, with the confirmed fraud status of the transactions providing the greatest accuracy, stability, and seasonal coverage. This long-term model score is then passed as a feature into the short-term model, which, in contrast, is designed to react quickly to emerging fraud patterns without impacting overall performance; that is, the model learns new patterns without forgetting old ones. It is trained on the most recent data with both confirmed and unconfirmed fraud labels. Figure 6 shows how long-term and short-term sequential models work in the risk-score-evaluation engine. Real-time archiving quantifies the shifts in fraud patterns and generates fresh features updated in both real-time mode and batch mode, which the long-term and short-term risk models use. The final fraud-risk model score is calibrated as an unbiased estimate of the fraud probability (Figure 7).
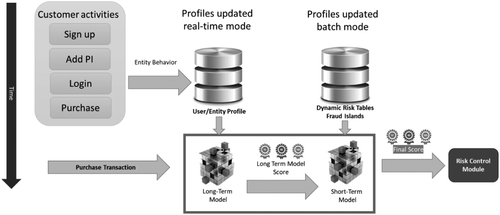
Note. PI, payment instrument.
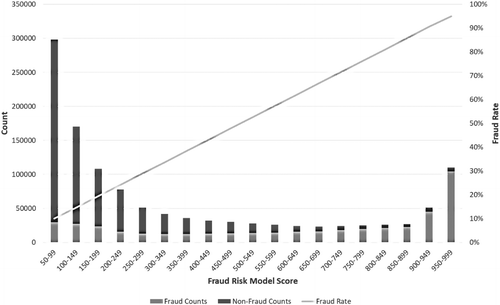
To ensure that the risk model can adapt to fraud-pattern changes, we developed real-time archiving using dynamic risk features with fraud feedback to resolve this problem (Jia et al. 2019a, Nanduri et al. 2020). Please refer to Nanduri et al. (2020) for details.
Fraud Island Linkage Features
Fraudsters are always trying to mimic legitimate customers’ purchase behaviors. Simple entity profiling such as velocity (i.e., arriving transaction volume in a short period) or recency cannot help with identifying these types of fraudulent transactions. Linking the known fraud transactions by entities—including account, email, PI, IP address, device, and shipping address—has helped us to prevent further damage from the same fraudsters. We define fraud islands as clusters of linked fraudulent transactions that are connected to each other through one or more hops. As the example in Figure 8 shows, one fraudster used 753 accounts and 591 PIs and caused $60,000 of fraud loss before we were able to prevent $300,000 of fraud loss using fraud island linkage features to boost its risk model scores. In this graph, each node is a transaction; the link (edge) is added when we find two transactions that share the same entity (e.g., email, PI, or device). The size of the node represents the density of links. The nodes in the figure represent each single transaction; the edge indicates the links through entities such as accounts, IPs, emails, and devices.

An account is considered as a fraudulent account if there is at least one fraudulent transaction associated with it in a past predetermined period (e.g., three months). From the historical data with partial fraud feedback, we construct the fraud islands (linked fraudulent transactions) when we find that transactions share any entities such as account, PI, device, or email address with multiple hubs. When the fraud islands are formed, we calculate statistics based on all transactions from each island; these include total bad transaction dollars and counts; total good transaction dollars and counts; and distinguished email, account, and PI counts. If a new transaction is linked to the existing islands based on its associated feature entities, then the calculated statistics of the linked island are used as additional feature inputs for the risk ML model to estimate the risk score.
Prospective Control Model
To make fraud-risk decisions, conventional fraud-control systems apply risk cutoff score thresholds, approve transactions with risk scores lower than a specific low-score threshold, reject transactions with scores higher than a specified high-score threshold, and utilize manual review agents for further investigations on transactions with risk scores in between. The cutoff threshold scores are set so that the inline FMS can optimally and instantaneously prevent fraudsters’ attacks. However, this mechanism gives little consideration to the dynamic looping effects induced by the system’s decision (i.e., approve, reject, or review) and the follow-up decisions made by associated parties such as issuing banks and manual review agents (Figure 9). Neither rejection nor approval of a transaction is determined solely by any single decision maker. A transaction is considered to be settled if the transaction has been approved by FMS, the bank, and manual review agents (if applicable), and the charge has been approved by all. A transaction is not settled in any of the following situations:
The FMS rejects the transaction, which is immediately deleted from the decision system.
The FMS approves the transaction and submits a payment authorization request to the bank; however, the bank declines the request.
The FMS and the bank approve the transaction; however, a manual review agent rejects it.
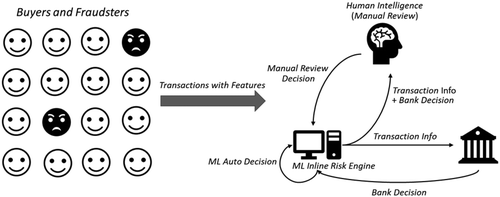
In addition, as we mention above, a transaction is labeled as fraudulent if a manual review agent has rejected it as being a fraud or the merchant has received a chargeback from the bank. These fraud labels are used later to train the fraud model. This means that the decisions of the manual review agents will influence the decisions that the FMS makes through the updated fraud-detection model. If the merchant rejected almost all fraud transactions and almost no confirmed fraud labels are available for future model training, the future fraud decisions made by the new risk-score-evaluation model, which is trained by using few labels, will likely be inaccurate. This cycle could get progressively worse if it is not attenuated carefully. To prevent this potential problem, we applied a dynamic programming and control-based approach (Bertsekas 2005, Puterman 2014); we specifically applied dynamic optimal control with incomplete information (Smallwood and Edward 1973, Lin et al. 1998) as the foundation of this project. The risk-control module, Microsoft’s novel fraud-control framework, uses the estimated interactive effects of decisions made by different parties. It can adjust fraud-control strategies according to the availability of data attributes and labels, applying data analytics and dynamic optimization techniques using a model it calls the Prospective Control Model to make automated decisions (i.e., approval, rejection, or manual review) for each transaction (Li et al. 2018). The decision made at the current period (t) is not based solely on the features of the transaction (i.e., risk score, cost, or margin), but is also based on the expected return of the transactions in the near future period (t + 1), which results from the decision made in the current period. Figure 10 provides a general summary of the prospective control algorithm. It shows that this system is purely data-driven and self-adaptive in real time. However, it needs to be tuned based on the unique nature of Microsoft’s various businesses. For example, for Xbox, no manual review is involved in risk decision making. Therefore, when we apply the prospective control algorithm to this segment, any model elements that involve manual review decisions could be removed, and no manual review cost is considered. We describe this algorithm in additional detail in the appendix.
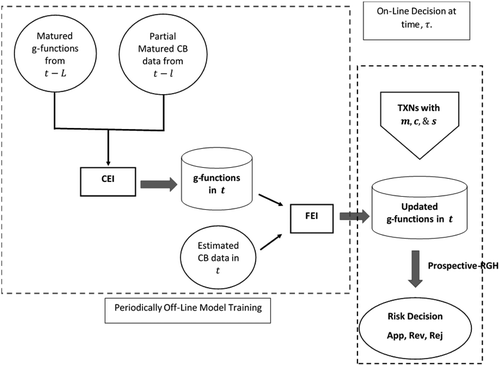
Note. App, approve; CB, chargeback; CEI, current environment inference; FEI, future environment inference; Rej, reject; Rev, review; RGH, real-time greedy heuristic; TXNs, transactions.
Impact on Microsoft Business
Over a two-year period (2016–2018), while the business continued to expand, this work reduced Microsoft’s fraud loss by 0.52% ($75 million savings), reduced the false-positive rate by 1.38%, improved the bank acceptance rate of legitimate purchases by 7.69%, and reduced the number of manually reviewed transactions by 70%. We elaborate on the beneficial impacts below. We calculated these impacts based on only a portion of Microsoft’s e-commerce business. Because of confidentiality requirements, we cannot discuss the total impact on all Microsoft’s e-commerce business.
Preventing Trial Fraud and Abuse
As we mention above, in addition to payment fraud, the FMS also protects Microsoft from other types of abuse, such as abuse of free trials. For example, Azure cloud services has shown double-digit growth in recent quarters and are Microsoft’s fastest-growing business. These services attract many fraudsters, a far higher number than attempt payment fraud. From 2017 to 2018, the FMS fraud-detection rate for these cloud services improved by about 10 percentage points. During this period, the business was growing; hence, the total number of fraudulent sign-up attempts that the FMS prevented in real time rose by more than 300,000. This was achieved while keeping the false-positive rate, as measured by reactivations, below 0.15%, thus ensuring that legitimate customers were not being impacted significantly. Microsoft conservatively estimates that each fraudulent Azure sign-up costs it about $50 in cost-of-goods-sold (COGS) loss on average because of the consumption of computing power, bandwidth, and storage. This implies that the COGS loss saved by the FMS was about $15 million from 2017 to 2018. Even more importantly, the FMS reduced the fraudulent occupancy of the platform by 1.2%, which improved the availability of the platform for peak customer demand.
Less Fraud and More Bank Acceptance
In Figure 11, key performance indices are normalized relative to year 2016. The bank acceptance rate by dollar amount increased by nearly 7.70%. In addition, because the next-generation FMS prevents more fraud, the bank’s authorization rate increases commensurately. Recall from Figure 2 that a 1-percentage-point decrease in chargeback rate in fraud detection can yield about a 15-percentage-point increase in bank authorization rates.
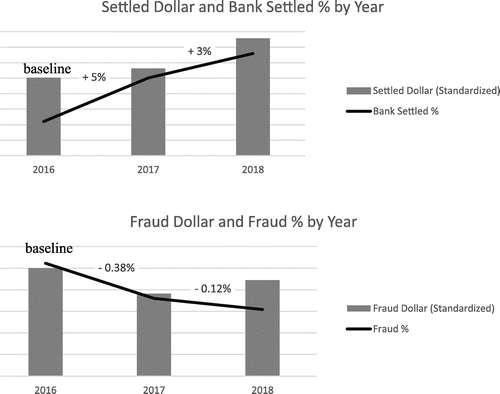
Our approach goes further in improving bank authorization rates. Some card-issuing banks use an automated process to allow merchants to communicate knowledge about the transaction outside of the regular authorize–settle flow messages. Microsoft uses these facilities to communicate transaction features, such as risk score and anonymized geolocation of the transaction, to the issuing bank. This helps the bank’s risk model make more accurate decisions, which further increases its acceptance rate. For example, using the American Express enhanced authorization application programming interface, Microsoft has, by conservative estimates, seen an additional 0.3-percentage-point lift in the American Express acceptance rate.
High bank acceptance rates also benefit the issuing bank by increasing its revenue and profit from the card-lending business and avoiding the dreaded “back of the wallet” effect. (This refers to the commonly seen behavior where a shopper will stop using a particular credit card after multiple rejections and will switch to an alternate card.) Microsoft has therefore seen strong collaborative interest from banks to drive up the acceptance rate of legitimate transactions.
Fewer False Positives
In addition to reducing the negative impact of false negatives (i.e., wrongful acceptances), Microsoft has strived to reduce false positives (i.e., wrongful rejections). A higher false-positive rate means more lost revenue and poorer customer experiences. As we illustrate in Figure 12, with the new FMS, Microsoft has decreased the overall false-positive rate by nearly 1.38 percentage points as denominated by purchase dollars and by nearly 0.36 percentage points as denominated by transaction count.
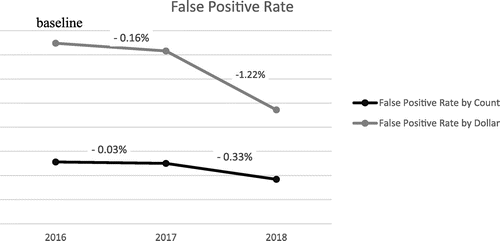
Fewer Manual Reviews
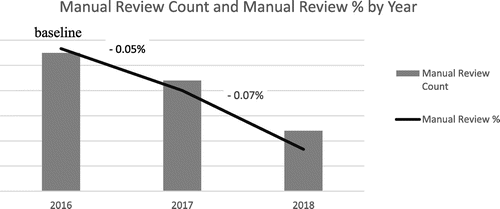
Microsoft selectively employs manual review agents to review specific types of transactions that involve high-COGS/high-risk products, including physical goods, or transactions that the automatic ML models find difficult to categorize and that require a human to conduct further investigation before a decision can be made. However, the average cost of each manual review ranges from $3 to $20. To optimize the company’s overall profitability, without sacrificing false negatives and false positives, Microsoft needed to reduce this labor-intensive option. Because of the tremendous improvements that the FMS made on automatic decisions, Microsoft reduced the number of transactions submitted for manual review (Figure 13). Over a two-year period (2016–2018), the manual-review volume count decreased from 0.55 million to 0.24 million reviews, despite increases in overall business volume. Under the most conservative manual-review cost ($3 per review), this saved over $1.44 million. Furthermore, because a manual review increases the time to decide on acceptance or rejection by 2–6 hours, customer experiences improved for the 70% of those customers who previously would have had to wait 2–6 hours for a decision on acceptance.
Paradigm Shifts Across Microsoft Businesses on Viral Launches
Microsoft’s next-generation FMS has caused a paradigm shift in how its businesses think of new product releases. Typically, new products are prime targets for fraud attacks, because they are highly coveted and easily sold by fraudsters on the black market. In previous years, Microsoft’s launches of new products were accompanied by concerns of massive fraud attacks; hence, the company took intensive precautions to prevent these attacks, including a very gradual product rollout across market segments and the application of very conservative risk thresholds for decision rules. This conservatism inhibited the virality of launch, an important factor in launching technology products. With the new FMS, Microsoft is confident that the system can adapt to any emerging fraud patterns and new shopping behaviors, while automatically using an optimal control policy at every point in time. Microsoft has seen a vindication of this conviction over the past two years, during which it released several groundbreaking and popular new products, including a new generation of Microsoft Surface devices, office-productivity software, and hugely successful Xbox games like the FIFA series and Fortnite. Using its FMS, Microsoft successfully controlled fraud without damaging the buying experience of its valued customers, which helped encourage viral product launches.
Paradigm Shifts Across the Industry on Bank Acceptance
Microsoft’s FMS is also driving another kind of paradigm shift across the industry. The fraud-management systems of card-issuing banks rely principally on the behavior of the payment instrument and do not have any insights into the context of the transaction. Hence, they tend to be conservative and prioritize low fraud over high acceptance. Microsoft has demonstrated that, rather than relying exclusively on these bank systems, merchants can do the bulk of their fraud-detection and -prevention tasks themselves. For this, merchants can use the broad data they have about each transaction around “who?” (buyer identity), “how?” (device used by the customer requesting the transaction), “where?” (geolocation and shipping information), and “what?” (product) information that is complementary to the information the banks have. Thus, by doing a risk check and then providing informative “trust” signals for the bank’s fraud-management system, banks can simultaneously have low fraud and high acceptance. Because doing so is also in the best interest of the banks, they are highly supportive of this approach.
Portability
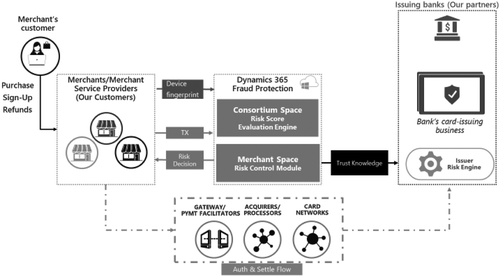
Microsoft’s strong success in first-party fraud protection built on a portable new cloud-based system encouraged the company to provide this capability to its enterprise customers. The company’s mission is to use its own experiences to enable other digitally transformed enterprises to fight fraud while keeping their doors open for legitimate customers and partners. In April 2019, Microsoft launched a preview of a cloud-service product called Microsoft Dynamics 365 Fraud Protection, which serves all e-commerce merchants. As of this writing, the product is planned for general availability in October 2019. Figure 14 illustrates the high-level architecture of the product. Dynamics 365 Fraud Protection initially focuses on payment fraud protection and related scenarios in e-commerce. The product enables e-commerce merchants to decrease fraud loss, increase bank acceptances to yield higher revenue, and improve the online shopping experience of their customers. The product’s core differentiators include device fingerprinting, prospective dynamic fraud control, a fraud-protection network (a consortium of merchant customers) with advanced AI for risk-scoring evaluation, and trust knowledge exchange with participating issuing banks.
Conclusions
We have developed a next-generation fraud-management system called Prospective Dynamic Fraud Control to protect Microsoft’s e-commerce business from payment fraud and trial abuse. The system is highly self-adaptive, which allows it to rapidly detect and mitigate emerging fraud patterns. This is achieved by using innovative real-time dynamic-risk features generating techniques and customized long-term and short-term sequential machine learning models. The system also applies dynamic optimization techniques, called prospective control modeling, to optimize the decisions of the risk-control module for maximum long-term profitability. The impact of these innovations on Microsoft businesses has been multifold: lower fraud loss, lower wrongful rejections, higher bank acceptance, higher availability of our cloud platform, and improved customer experiences. These successes have engendered a paradigm shift in the way the company tunes its fraud-control policies to achieve viral launches of products across the company. Microsoft’s innovative FMS has also started a paradigm shift in the industry at large by demonstrating that merchants can simultaneously have low fraud and high acceptance by performing the bulk of the fraud protection themselves using contextual signals about a transaction and sending trust signals to issuing banks. Finally, we have been purposeful in ensuring that the new FMS is highly portable so it can be applied to fraud control outside Microsoft. In April 2019, Microsoft launched a preview product called Microsoft Dynamics 365 Fraud Protection, which is available for all e-commerce merchants to help them achieve the same benefits that Microsoft has attained in its own business: lower fraud, higher bank acceptance, and a better customer experience.
Appendix. Prospective Control Algorithm
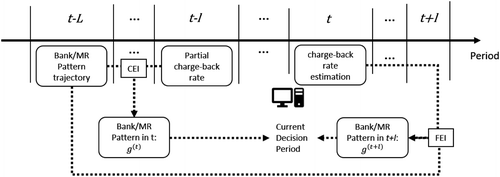
Fully mature data include transactions that occurred before t − L; partially mature data include transactions that occurred between t − L and t − l; and the predicted outcomes are for the period from t to t + 1 (Figure A.1). This prospective control model is designed to resolve the pattern-recognition lag issue due to the delay true fraud label obtained from banks (we call it “delay of label maturity”). The g-functions in the figure are short for gold functions that represent profit-related probabilities associated with different risk decisions. For example, for a transaction, w, to estimate the expected profit/reward of the decision being “approval” or “review,” we use Equation (A.1) and Equation (A.2), respectively:
Note. CEI, current environment inference; MR, manual review.
where m is the margin earned from an approved nonfraudulent transaction, c is the cost of goods, c0 is the unit cost for each manual review, and s is the predicted risk score for this specific transaction.
In Figure A.1, CEI is an acronym for current environment inference. It represents the interaction effect of decisions made by the FMS, banks, and manual review agents during the current decision period, t. CEI maps g-function trajectories (t′ < t − L), and partially mature chargeback to estimate the g-function , and at the current decision period, t.
where (k = 1, 2, …, 5) denote the prediction function for using risk score, g-function trajectory (, and partially mature chargeback as predictor variables.
Using the real-time greedy heuristic (RGH) (Bonet 1998) allows us to update the estimation of the g functions and to dynamically calculate the expected profit of each possible decision.
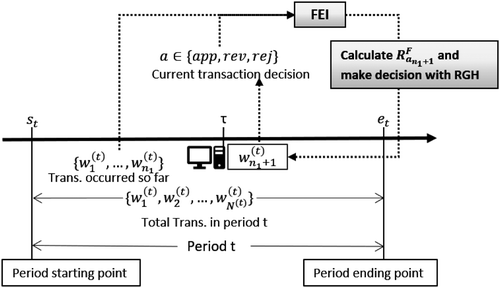
Figure A.2 illustrates the logic of RGH within period t. Let time τ be a decision time point in period t where transaction occurs, and the FMS needs to make a decision to approve, reject, or manually review this transaction. Suppose from st, starting point of period t, to current decision point τ, n1 transactions in the period have been observed. Hence, the chargeback rate of period t can be estimated, if are approved or reviewed using Equation (A.3):
Note. FEI, future environment inference; trans., transactions.
where δ(.) is an indicator function, and is the decision made (approve or review) on transaction j in period t.
With this estimated chargeback rate, all five current gold functions, , could be estimated with mature g-function trajectories as
where t < t − L. This is the future environment inference (FEI) module shown in both Figures A.1 and A.2.
The g-functions in the FEI are trained by machine learning models with estimated chargeback rate and mature g-functions from previous periods as inputs.
Using the RGH described above, the prospective control module can make the optimal risk decision for transaction with features of score, margin, and cost of goods (at time t, which maximizes the total expected profit of N(t) transactions occurring in period t with the following equations:
s.t.
where λ is a discount factor and Δ is a referential future profit of t + l.
s.t.
We describe additional details of the prospective control algorithm in Table A.1.
|

Table A.1. Prospective Control Algorithm
| Process repeated at periodical time : |
|
|
|
|
|
|
|
|
|
References
- (2005) Dynamic Programming and Optimal Control, 3rd ed., vol. 1 (Athena Scientific, Belmont, MA).Google Scholar
- (1998) Solving large POMDPs using real time dynamic programming. Proc. AAAI Fall Sympos. POMDPs (Association for the Advancement of Artificial Intelligence, Palo Alto, CA), 61–68.Google Scholar
- (2004) Network structure and the diffusion of knowledge. J. Econom. Dynam. Control 28(8):1557–1575.Google Scholar
eMarketer (2018) Worldwide retail and ecommerce sales: eMarketer’s forecast and new ecommerce estimates for 2016–2021. Report, eMarketer, New York.Google Scholar- (2001) Greedy function approximation: A gradient boosting machine. Ann. Statist. 29(5):1189–1232.Google Scholar
- (2019b) Long-term short-term cascade modeling for fraud detection. U.S. Patent US20190066109, filed August 22, 2017, issued February 28, 2019.Google Scholar
- (2019a) Hierarchical profiling inputs and self-adaptive fraud detection system. U.S. Patent US20190087821, filed September 21, 2017, and issued March 21, 2019.Google Scholar
LexisNexis Risk Solutions (2018) 2018 true cost of fraudSM study. Accessed August 29, 2019, https://risk.lexisnexis.com/-/media/files/financial%20services/research/2018-true-cost-of-fraud-overall-rep%20pdf.pdf?la=en-us.Google Scholar- (2018) Discriminative data-driven self-adaptive fraud control decision system with incomplete information. Microsoft J. Appl. Res. 10(November):14–27.Google Scholar
- (1998) A hybrid genetic/optimization algorithm for finite horizon partially observed Markov decision processes. Technical Report 98-25, University of Michigan, Ann Arbor.Google Scholar
- (2020) Adaptive fraud detection system using dynamic risk features. J. Systems Sci. Inform. Forthcoming.Google Scholar
- (2014) Markov Decision Processes: Discrete Stochastic Dynamic Programming (John Wiley & Sons, Hoboken, NJ).Google Scholar
- (1973) The optimal control of partially observable Markov processes over a finite horizon. Oper. Res. 21(5):1071–1088.Link, Google Scholar
- (2016) A novel progressive learning technique for multi-class classification. Neurocomputing 207(May):310–321.Google Scholar
- (2001) Introduction to Graph Theory, vol. 2 (Prentice Hall, Upper Saddle River, NJ).Google Scholar
Jay Nanduri is a distinguished engineer in Dynamics 365 and part of the Cloud & Enterprise Division at Microsoft. He has over 25 years' experience in entrepreneurship, driving strategy-technical vision and product development and leading large impactful initiatives. He is currently driving the cloud learning graph platform that powers many solutions across consumer and commercial scenarios. He holds an MTech in computer science from National Institute of Technology, India, and an MBA from The Wharton School of Business.
Yuting Jia is director of the risk data science team in Dynamics 365 at Microsoft. He and his team protect against fraud on purchase transactions and fight abuse of web services. He has over 14 years of experience for fraud detection and decision optimization. He was senior manager leading a team at Fico to build consortium Falcon models. He was a postdoc at Supercomputer Center at the University of California San Diego. He holds a PhD in mathematics and an MSc in computer science from the Queen's University.
Anand Oka is senior director of program management in Dynamics 365 at Microsoft. He drives innovative applications of connected customer knowledge and AI to solve challenges, for example, fraud/abuse for e-commerce enterprises. Previously, he worked on user value measurement at Microsoft and machine intelligence for search/recommendation at Blackberry. He holds a PhD from the University of British Columbia and an MS from the Technion–Israel Institute of Technology, both in electrical engineering. He is a senior member of the IEEE.
John Beaver is senior director of engineering in Dynamics 365 at Microsoft. With experience in high-scale distributed systems solving real-time optimization problems, he helps lead the engineers and data scientists for anti-fraud/abuse solutions. For 27 years at Microsoft, he has worked on the Visual FoxPro DBMS, the TransPoint e-bill presentment/payment, and Microsoft Display Advertising's ad delivery/optimization platform. He has a BS in computer science with honors from the University of Michigan.
Yung-Wen Liu is senior data scientist in the risk data science group in Dynamics 365 at Microsoft working on e-commerce fraud-detection projects. He has expertise in data analysis, machine learning, and systems engineering. Before joining Microsoft in 2017, he was an associate professor of industrial engineering at the University of Michigan–Dearborn. He holds a PhD in industrial engineering from the University of Washington and two MAs, in statistics and economics, from the University of Michigan.

