
Disclosing Product Availability in Online Retail
Abstract
Problem definition: Online retailers disclose product availability to influence customer decisions as a form of pressure selling designed to compel customers to rush into a purchase. Can the revelation of this information drive sales and profitability? We study the effect of disclosing product availability on market outcomes—product sales and returns—and identify the contexts where this effect is most powerful. Academic/practical relevance: Increasing sell-out is key for online retailers to remain profitable in the presence of thin margins and complex operations. We provide insights into how their information-disclosure policy—something they can tailor at virtually no cost—can contribute to this important objective. Methodology: We collaborate with an online retailer to procure a year of transaction data on 190,696 products that span 1,290 brands and 472,980 customers. To causally identify our results, we use a generalized difference-in-differences design with matching that exploits one policy of the firm: it discloses product availability only for the last five units. Results: The disclosure of low product availability increases hourly sales—they grow by 13.6%—but these products are more likely to be returned—product return rates increase by 17.0%. Because returns are costly, we also study net sales—product hourly sales minus hourly returns—which increase by 12.5% after the retailer reveals low availability. Managerial implications: The positive effects on sales and profitability amplify over wide assortments and when low-availability signals are abundantly visible and disclosed for deeply discounted products whose sales season is about to end. In addition, we propose a data-driven policy that exploits these results by using machine learning to prescribe the timing of disclosure of scarcity signals in order to boost sales without spiking returns.
History: This paper has been accepted as part of the 2019 Manufacturing & Service Operations Management Practice-Based Research Competition.
1. Introduction
“Don’t miss this deal!” is a time-worn sales pitch that online firms have refined to such a point that they now disclose availability information in real time. For instance, online travel agencies tell us that there are only a few seats left on a flight we are currently considering. And it does not come as a surprise when we receive a pop-up politely warning us that a hotel room we are after is, at that moment, being reserved by someone else. These practices are examples of pressure selling, a technique designed to make consumers rush into a purchase.
Can the use of such scarcity signals drive sales and profitability in online retailing? And, if so, what is the magnitude of the effect of such information provision? In what context is it more effective? These are the central questions of our research. Judging by the variety of disclosure policies we observe in the industry, there are no clear answers. At one end of the spectrum, Vente Privee never discloses product availability other than when it sells out. At the other end, Amazon discloses the availability of “Lightning Deals”—the company jargon for its limited-time offers—in real time and for the entire deal duration.
We partnered with an online retailer that operates in several countries to study the effect of disclosing product availability on market outcomes and identify the contexts where this effect is most powerful. The firm’s business model is that of flash sales, a type of online retailing in which heavily discounted branded products are sold for an extremely limited period of time. Typically, flash-sales operators—for example, Rue La La, Gilt, Vente Privee, and Woot—group same-brand or similar products committed by third parties into short-lived campaigns where the products are on sale until their stock is depleted or the campaigns expire. Characterized by slim margins and complex operations driven by discounts and wide, time-varying product portfolios, increasing sell-out is key for these retailers remaining profitable. In this study, we explore whether and how disclosing low product availability to customers can contribute to this objective.
We procured data pertaining to the operations of the retailer in a particular country during 2014; these data span 190,696 products, 1,290 brands, and 472,980 customers. Each data point includes (1) the product characteristics (e.g., final price, discount, initial inventory, sizes offered, and the category and campaign to which the product belongs), (2) the campaign characteristics (e.g., start date, end date, and the product categories the campaign comprises), and (3) the transaction characteristics (e.g., time stamp, number of units sold, and number of units returned).
We measure the dependent variables (market outcomes) by looking at product sales, returns, and net sales (i.e., sales minus returns). We also study the product return rate (i.e., the likelihood of a return).
We measure differences in the explanatory variable (the disclosure of product availability) by leveraging a distinctive feature of the firm with which we partnered: the website does not disclose the availability of a product until the inventory level drops down to a prespecified threshold that is identical for all products. Accordingly, this policy lets us observe products whose availability is never disclosed—we say that these products are untreated—and others whose remaining number of units is revealed once it hits the threshold—we say that these products are treated.
We must be cautious: The retailer discloses the availability of products that are more likely to be bestsellers than flops. This condition could make us confound the effect of disclosing availability with that of other factors that correlate with popularity. To address this problem, we identify the causal relationship between the disclosure of low product availability and market outcomes by using a generalized difference-in-differences (DID) design combined with matching. First, we form a suitable control group by pairing treated and untreated products of the same brand and product category and similar price and pretreatment popularity. Second, we estimate a generalized DID model to identify treatment effects. We verify that after matching, the pretreatment characteristics of the treatment and control groups, as well as their pretrends, are, on average, identical. We find, however, a change in market outcomes once the retailer discloses the low availability of a product: (1) hourly sales grow by 13.6%, (2) product return rates increase by 17.0%, and (3) hourly net sales rise by 12.5%.
The results for sales are in line with intuition—after all, who likes missing out on an exclusive deal? But there is a caveat to them: the purchases executed under the influence of scarcity signals are far more likely to be returned. The disclosure of product availability may pressure customers into impulse buying, only to find that most of their purchases do not eventually suit their real needs. Because returns involve additional operational costs, revealing product availability could negatively affect the retailer’s profitability—we study net sales precisely to shed light on this trade-off between sales and returns. Our results show that even in the adverse context of a return canceling out the entire economic contribution of a sale, the effect of scarcity signals is profitable overall.
We also find that the positive effect on sales and net sales is most prominent in the following instances:
The product is deeply discounted. Heavily discounted products not only sell better, but customers are also more sensitive to the disclosure of their limited availability. A deep discount decreases the cost of making a wrong choice; it also increases the value for money of a product. When combined with a low-availability signal, this makes it easier for customers to commit to a purchase instead of shopping around for longer.
The product is on sale for a short time. Campaigns of longer duration remaining mitigate the effect of disclosing product availability because customers have more time to explore alternative choices and consider other sources of information. This suggests that closer deadlines put an extra pressure on customers affected by a scarcity signal so as not to miss out on the scarce product.
The product belongs to a wide assortment. Facing (too) many options, customers who browse wide assortments may suffer a cognitive overload and thus rely on the most salient information—such as the low-availability signals that the firm displays noticeably—to make up their minds.
Scarcity signals are sufficiently abundant. This result suggests that customers with limited attention tend to overlook scarcity signals when they are sparse. Consequently, online retailers should not fear sending many conspicuous alerts to customers.
As an extension, we also examine how treatment effects relate to two customer habits. First, we find that scarcity signals make customers buy items that are 3.8% more expensive than what they normally purchase. Scarcity signals may create a thrill of exclusivity, making customers place more value on the products. This might lead customers to purchase more expensive items than they would do otherwise. Second, we study whether our insights are contingent on how customers engage with the firm. Interestingly, mobile customers seem to be less sensitive to availability information compared with those who purchase through a nonmobile device—a result that we speculate may be a consequence of smaller screens obstructing the visualization of scarcity signals. Mobile customers need to scroll up and down the screen continuously, making it difficult to gather information. In contrast, nonmobile customers can more easily browse through products and pay closer attention to the limited-availability signals.
Finally, we define a strategy that leverages our causal results to design data-driven policies that fine-tune the timing of disclosure of scarcity signals for each individual product according to an optimal stopping-time logic. Once a product is put on sale, we use machine learning to periodically compare the estimated profit-to-go if we disclosed its availability right away with the estimated profit-to-go if we postponed this decision one more period and make a decision accordingly. We tailor the model estimation to the specificity of our context, but the design principles of our policy apply to any retailer able to disclose product availability independently. In particular, by selectively reverting some of the treatment decisions of the firm, our model is able to lift all posttreatment net sales—our proxy of profitability—by an estimated average of 0.44%. The value of data-driven disclosure policies will be higher for online retailers who get frequent and costly returns and are able to disclose availability at variable inventory levels.
2. Literature Review
Our study is derived in the context of flash-sales retailing. Previous works in this space approach revenue maximization by optimizing data-driven pricing (Ferreira et al. 2015, Martínez-de Albéniz et al. 2018) and delivery outcomes (Calvo et al. 2018). We complement this research by exploring the retailer’s information-disclosure policy as another alternative to increase sell-out.
By focusing on the provision of inventory information to customers, our work relates to the literature on consumers’ strategic reactions to product availability. An important assumption in this literature is that inventory levels convey information to individuals. As a consequence, retailers can change consumers’ reactions by properly manipulating certain levers that influence inventories, such as service levels (Gaur and Park 2007), capacity rationing (Liu and Van Ryzin 2008), inventory allocation (Debo and Van Ryzin 2009), the use of cheap talk to share availability information (Allon and Bassamboo 2011), and the level of aggregation of the inventory information disclosed to customers (Cui and Shin 2018). Our paper complements this literature by exploring a different angle: how do customers react to the disclosure of low product availability?
We theorize about two mechanisms that may drive customers’ reactions in this context: the herding effect and the scarcity effect. Herding refers to a situation where an individual draws inferences from the decisions made by predecessors and copies them (Banerjee 1992). For instance, evidence of herding has been found in lenders on peer-to-peer lending platforms (Zhang and Liu 2012), in restaurant customers (Cai et al. 2009), and in retail consumers (Cui et al. 2019). Furthermore, theoretical contributions in capacitated service contexts show that uninformed customers can infer product quality from waiting times (Kremer and Debo 2015) and also that herding is the equilibrium solution to a queue-joining game (Veeraraghavan and Debo 2011).
The scarcity effect is the mechanism by which signs that a product may soon stock out create a buying frenzy among customers (DeGraba 1995). Sellers can thus use scarcity signals to attract demand because customers are afraid of missing out on the “hot product” in the future (Stock and Balachander 2005), but the effectiveness of this strategy depends on the conspicuity of customers (Tereyağoğlu and Veeraraghavan 2012). Cachon et al. (2018) find empirical evidence of the scarcity effect in the automotive industry by showing that adding inventory to car dealers increases sales only when it expands the variety of their stock. Our work is closer to that of Cui et al. (2019), who study Amazon “Lightning Deals.” Amazon’s approach to disclosing availability is to share the percentage claim of the deals; the authors show that a 10% increase in past sales—which implies lower product availability—leads to a 2.1% increase in cart add-ins in the next hour. Our paper, in contrast, focuses on a different disclosure policy—one that reveals product availability only when it is low. Hence, we can measure the value of sharing this information with customers. Moreover, thanks to our partnership with the firm, we can broaden the research questions by looking at several market outcomes (e.g., sales, returns, and net sales), as well as product- and retailer-specific moderators.
Our study also spans product returns. Past works have studied the determinants of returns—for example, return channels (Shulman et al. 2010), product variety, and customers’ past return patterns (Shang et al. 2019). Our work is close to that of Rao et al. (2014), where the authors use data from an online store selling personal accessories to show that the disclosure of inventory information is associated with more frequent returns. We complement their work by looking comprehensively at sales, returns, and net sales (and their moderators) and by leveraging a richer data set that allows us to obtain causal inference—and not just correlation—in a context that spans a myriad of brands and verticals.
We also study the effectiveness of scarcity signals as a function of the assortment width. Thus, our work relates to the theoretical literature on assortment (Talluri and Van Ryzin 2004, Caro and Gallien 2007, Wang and Sahin 2018), which we complement by showing that wider assortments bolster the effect of disclosing product availability.
Finally, we investigate customer reactions to scarcity signals across mobile and web channels. This connects our work to the stream of literature that studies the behavior of mobile consumers, as proxied by, for example, search costs and click-through rates (Ghose et al. 2012), data-usage patterns (Ghose and Han 2011), or the creation of review content (Ransbotham et al. 2019).
3. Institutional Setup
We partnered with a leading flash-sales retailer that leverages a large customer base to clear third-party branded stocks by running one-off, time-limited deals of discounted products—these deals are known as campaigns in the company jargon. The retailer spans a wide range of verticals—from apparel to toys and home appliances—and simultaneously operates several campaigns, usually one per brand, whose covers are presented on the homepage (see Figure 1(a)). Customers interested in a specific brand are directed to a separate page that shows the product categories that make up the campaign (see Figure 1(b), where the product categories segment the different ages of a kids’ clothing campaign). There the products of each category—along with their descriptions and original and final prices—are displayed together in an order that the company sets in advance1 and keeps fixed throughout the campaign.
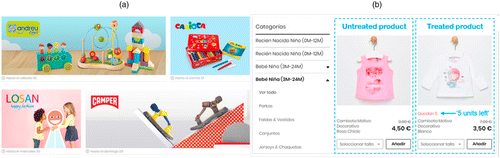
Notes. (a) Homepage: Campaigns. (b) Campaign page: Categories and products. The authors annotated Figure 1(b) by adding “untreated product,” “treated product,” and the translation of “Quedan 5” to “5 units left.”
Campaigns are ephemeral—they last from a few days to up to a month—and can start as soon as the brand commits the initial inventory level of each product and agrees on the pricing terms with the retailer. After launch, the products are available either until the firm depletes its initial inventory or until the campaign expires—that is, midcampaign replenishment is not possible.
A unique feature of the retailer’s operations is that it does not disclose product availability until the inventory level of a product drops down to five or fewer units.2 Right at that moment, and until the end of the campaign, the retailer displays product availability (e.g., “five units left”) in real time (see Figure 1(b)). The disclosure of low product availability is our treatment of interest.
The retailer’s business model is ideal for empirical identification. In particular, it has three characteristics that allow us to minimize biases and keep confounders at bay. First, campaigns are short—therefore, product sales are barely exposed to unobserved exogenous shocks. Second, prices and rankings are static—accordingly, managers cannot intervene in market outcomes after campaigns go live. Third, the site does not feature customer reviews or social interaction between customers—as a result, customer choices are not influenced by the opinions of their peers. All in all, this online retailer—with the myriad of brands and product categories it covers—provides a rich and clean context to study the effect of disclosing product availability.
4. Hypothesis Development
We study how retailers can drive customer behavior by disclosing product availability and what purchase contexts may amplify or mitigate this effect.
4.1. The Effect of Disclosing Product Availability
Online sellers display product availability to influence customer decisions. Focusing on market outcomes, we study the effect of disclosing inventory information on sales, returns, and net sales.
4.1.1. Sales
When making purchase decisions, customers are uncertain about product value, and they leverage information to update their beliefs about it. By revealing inventory information when availability is low, the firm signals simultaneously that certain products are both popular and in short supply, potentially unlocking the scarcity (Cialdini 2001, Park et al. 2020) and herding effects (Cui et al. 2019).
The scarcity effect occurs when shortage stress compels customers to make a purchase immediately because of fear of missing out in the future (DeGraba 1995). The disclosure of a low-availability signal warns that a product may soon sell out; this may induce customers to secure a purchase while they can (Inman et al. 1997), thereby increasing product sales.
The herding effect happens when customers mimic the choices of their predecessors because they understand product popularity for a proxy of product value (Banerjee 1992). The disclosure of a low-availability signal indicates that a product may be in high demand; this may trigger followers’ purchases that increase product sales.
The disclosure of low product availability increases product hourly sales.
Note that the validation of this hypothesis will not let us distinguish between the scarcity and herding effects—both point in the same direction. However, our analysis of moderating factors in Hypothesis 4 will provide some evidence of which of these two mechanisms is stronger in our research context.
4.1.2. Returns
Customers make return decisions by comparing their product valuations at the time of purchase and on receipt—that is, they will likely not return a product that meets or exceeds their initial expectations, but they will more probably do so if the product performs otherwise (Kopalle and Lehmann 1995). Purchases driven by scarcity or herding effects may raise product valuations at the time of purchase, and we thus study whether disclosing availability affects returns.
On disclosing product availability, scarcity customers feel the out-of-stock pressure and spend less time shopping around before they make an impulsive purchase that may be less aligned with their real tastes (Hong and Pavlou 2014). By contrast, disclosing product availability drives herding customers to make a purchase based on updated product valuations that—because they are rooted in popularity—may be inflated. As a result, both mechanisms incline customers to find the product disappointing once they receive it, thereby causing them to more often opt for a return.
The disclosure of low product availability increases product return rates.
4.1.3. Net Sales
Returned products not only give rise to reverse logistics costs but also must be salvaged at a further discount using alternative sales channels because the retailer generally receives them once the campaign is over. Returns are costly; for the firm with which we partnered, a return erodes the entire margin of a sale.3 Revealing product availability thus can be a double-edged sword: it will make little economic sense if it brings moderate additional sales at the expense of massive returns.
What, then, is the overall impact of showing this information on the profitability of a product? To answer this question with operational (but not financial) data of the retailer, we leverage the gross economics of our context and proxy product profitability by the difference between product sales and product returns—we call this net sales. The overall return rate faced by the retailer being just over 5%, we hypothesize the following.
The disclosure of low product availability increases net sales.
4.2. Moderating Factors
The revelation of low product availability can drive market outcomes only if customers rely on this information to guide their purchasing decisions. Because this is contingent on the purchase context, we study the characteristics that may moderate the effect of disclosing product availability. In particular, we examine the role of one product-specific factor—discount depth—and three campaign-specific factors—time pressure, assortment width, and disclosure ubiquity.
4.2.1. Discount Depth and Mechanisms
The retailer sells products at deep discounts—57.6%, on average—but whereas the top decile is generously discounted above 71.7%, the discounts of the bottom decile are below 41.2%. Are customers more sensitive to the low-availability signals of heavily discounted products? It depends on whether the scarcity or the herding effect is stronger because both effects result in different reactions in the presence of deep discounts.
When the scarcity effect is stronger, deep discounts strengthen the effect of low-availability signals. In the face of a scarcity signal, customers decide between waiting—at the cost of missing out on the current sales offering—and buying right away—at the cost of purchasing a suboptimal product by not searching long enough. This creates a trade-off between the opportunity cost of the current deal and the cost of an incorrect choice. Using laboratory experiments, Inman et al. (1997) find that individuals express higher purchase intents when exposed to scarcity signals—such as quantity constraints or deadlines—but only in the presence of substantial price reductions. This is because deep discounts reduce the cost of an incorrect choice, and this bolsters the scarcity effect further.
When the herding effect is stronger, deep discounts temper the effect of low-availability signals. Although imitative, herding is not irrational: customers can identify the observable triggers that unlock a herd and moderate their reactions accordingly (Zhang and Liu 2012). In our context, customers update their inference about the value of a product once the retailer discloses its availability. If the product is heavily discounted, customers may think that the discount—and not its value—is driving sales and will ignore the herd. Contrarily, if the product is only slightly discounted, customers may infer that their predecessors had some positive private information about the product value and will join the herd. As a result, deep discounts may weaken herding momentum (Cui et al. 2019). Note that Hypothesis 4 does not disentangle the causal mechanism between scarcity and herding and that its validation relies on the assumption that herding is rational.
If scarcity prevails over herding, the disclosure of low product availability has a greater effect on deeply discounted products, and vice versa.
4.2.2. Time Pressure, Assortment Width, and Disclosure Ubiquity
Defining the value proposition of the retailer requires making strategic choices about the rate of new product introduction, the product variety, and the ubiquity of scarcity signals. We study how these characteristics moderate the effect of disclosing product availability. The availability of a product is constrained by its inventory level but also by the time left in the campaign. Is there any interaction between these two? Perhaps customers are more sensitive to scarcity signals in campaigns that are about to end because it is likely that they will lose their chance if they wait. Similarly, campaigns with longer time available may encourage customers to explore other available options more thoroughly, and this may increase the chances that they end up not purchasing anything. This leads us to hypothesize that higher time pressure amplifies the treatment effect.
The retailer displays together the products of the same category, but whereas small categories (the bottom decile) are made up of fewer than a dozen products, large categories (the top decile) host more than 50 products. Presenting a vast number of products together may backfire on the firm via the paradox of choice (Schwartz 2009). The evaluation of too many products—and their attributes—before a purchase makes customers anxious and distracts them. Therefore, wide assortments may compel customers to ground their decisions exclusively in the most noticeable information. Because previous research has shown that scarcity messages are a powerful tool for capturing customer attention (Cialdini 2009), we conjecture that wider product assortments strengthen the effect of revealing low availability.
The retailer can also modulate the ubiquity of scarcity signals by, for example, tuning the disclosure threshold—currently set to five units—across the board. Because the products drop their inventory levels independently, the retailer, within the same campaign, displays many low-availability signals simultaneously. In particular, an average of 16.7% of the products of a campaign already show low availability by the time the retailer discloses the availability of the next one—although this proportion varies considerably from 0.4% to 84.3%. Is the effect of these signals contingent on their ubiquity? Customers of the digital world, inundated with information and suffering from limited attention spans, may base their decisions only on the most salient data within reach. If product availability is seldom disclosed, it may go unnoticed—something that would not happen if such information were omnipresent.
The disclosure of low product availability has a greater effect on products with higher time pressure that belong to wider assortments with higher disclosure ubiquity.
5. Data
This study focuses on the operations of the retailer in one specific country during the year 2014. We obtained four databases from the company concerning campaigns, products, product sales, and product returns, and we fused them to acquire campaign, product, and customer data.
5.1. Campaign Data
The company classifies each product, category, and campaign using a unique code. We use this to gather the static and dynamic characteristics of the campaign context. The campaign static characteristics are the start and end dates, the duration, and the assortment width of each category. The campaign dynamic characteristics are, at any time, the percentage of products disclosing availability, the percentage of sold-out products, and the percentage of campaign completion.
5.2. Product Data
The company defines products at a model-color level—a product that is available in multiple sizes is composed of several stock-keeping units (SKUs). We use transaction data at the SKU level to collect, again, the static and dynamic characteristics of the product context. The product static characteristics are the original price, the final price, and the initial inventory level. The product dynamic characteristics are, at any time, the product sales, the product returns,4 the product net sales, and the percentage of unavailable sizes because of stockouts.
5.3. Customer Data
Each purchase transaction is tied to a unique customer identifier. We use this to glean the purchase history of each customer—from January 2014—and derive the average ticket value (i.e., the money spent in a purchase) up to any time. Finally, we also note whether a purchase occurred via a mobile device or otherwise.
5.4. Sample Selection
We construct our sample by including all the products that the retailer put on sale during 2014 and whose availability was undisclosed at the beginning of the campaigns. In particular, we restrict our sample to observations that meet the following criteria:
The products belong to campaigns that both begin and end in 2014.
The products’ initial inventory level is larger than five.
The products belong to campaigns in which product availability was disclosed for at least one product but not for all of them.
Criterion 1 ensures that we only include campaigns that we can observe from beginning to end. Criterion 2 removes all products that do not have any prehistory relative to the disclosure of their availability. Finally, criterion 3 removes useless data. Following these criteria, our final sample includes 1,290 campaigns (i.e., brands) that span 190,696 products and 472,980 customers. Table 1 shows the most relevant summary statistics.
|

Table 1. Summary Statistics
| Variable | Mean | Standard deviation | Minimum | Maximum | Observations |
|---|---|---|---|---|---|
| Campaign | |||||
| Campaign duration (days) | 5.00 | 2.52 | 2 | 30 | 1,290 |
| Number of products | 170.17 | 136.26 | 3 | 1,474 | 1,290 |
| Availability disclosures (%) | 14.23 | 15.05 | 0.08 | 98.39 | 1,290 |
| Product | |||||
| Initial inventory (units) | 71.62 | 194.13 | 6 | 20,847 | 190,696 |
| Sales (units) | 12.08 | 24.65 | 0 | 1,593 | 190,696 |
| Returns (units) | 0.47 | 1.44 | 0 | 98 | 190,696 |
| Return rate (%) | 5.38 | 14.10 | 0.00 | 100.00 | 160,993 |
| Original price (€) | 72.01 | 105.44 | 0.83 | 8,263.64 | 190,696 |
| Final price (€) | 29.94 | 47.21 | 0.82 | 4,958.67 | 190,696 |
| Discount depth (%) | 56.95 | 11.89 | 0.00 | 96.70 | 190,696 |
| Customer | |||||
| Average ticket value (€) | 28.77 | 31.04 | 1.00 | 1,319.00 | 472,980 |
| Mobile purchases (%) | 38.41 | 48.04 | 0.00 | 100.00 | 472,980 |
Note. The return rate is only defined for products that sell at least one unit.
6. Identification Strategy
We study whether and how the disclosure of low product availability—the treatment of interest—changes market outcomes. The retailer discloses the availability of a product when its inventory drops down to five or fewer units: Such treatment is neither random nor simultaneous to all products. Akin to Singh and Agrawal (2011), Xu et al. (2016), and Bavafa et al. (2018), we use a generalized DID design combined with matching to tackle treatment endogeneity and avoid biases.
6.1. Matching
Products with low initial inventory, or those that sell well, are more likely to receive treatment. The initial inventory of a product relates to the leftover stock from the brands’ main selling channels. We take this as exogenous because it is plausible that forecast errors will induce different order quantities for products of similar popularity. On the contrary, the treatment effect could be confounded by factors related to the product’s popularity. For instance, the product’s sales are likely to vary in accordance with the caliber of its brand and, as a result, to spuriously accentuate the effect of availability disclosure.
To address these endogeneity concerns, we exploit a unique feature in our data set: it contains thousands of product pairs (1) of the same brand and category, (2) that were put up for sale on the exact same dates, (3) with the same final price, and (4) that were equally popular—but only one of the two received treatment. Capitalizing on this fact, we match products that have identical (or similar) characteristics to create a suitable set of pairs—that we call cohorts—made up of one treated product and its best possible control (chosen from among the group of untreated products), over which the treatment assignment behaves as random.
First, we draw, for each treated product, a set of potential controls by selecting all the untreated products from the same campaign and product category; this controls for idiosyncratic differences between brands and product types. Then we classify these candidates according to their final price, pretreatment sales,5 and unavailable sizes at the time of treatment; these control for product popularity and broken assortment effects.6 We finally match the treated product with the nearest candidate in the Mahalanobis distance—but only if it lies within a prespecified caliper—and use the initial inventory level to break ties.
We perform matching without replacement to ensure enough variation in the control group. Ultimately, this matching procedure outputs a subsample of 8,691 cohorts—each one made up of one treated product and its untreated counterpart. We report in Table 2 the standardized mean differences and standardized quantile differences7 as indicators of balance between the treatment and control groups. The results indicate an effective balance of the treatment and control groups across all covariates except the initial inventory—after all, if we match two similar products that sell equally well, the only reason why one receives treatment and the other does not must be that their initial inventory levels differ significantly (otherwise, they would both be treated or untreated).
|
Table 2. Summary Statistics After Matching
| Variable | Treatment group | Control group | Smd | Sqd | ||
|---|---|---|---|---|---|---|
| Mean | Standard deviation | Mean | Standard deviation | |||
| Initial inventory (units) | 13.41 | 15.15 | 45.87 | 154.19 | 0.293 | 0.159 |
| Pretreatment sales (units) | 7.35 | 15.14 | 6.81 | 14.60 | 0.036 | 0.020 |
| Pretreatment returns (units) | 0.28 | 0.97 | 0.26 | 0.84 | 0.017 | 0.041 |
| Pretreatment net sales (units) | 7.07 | 14.84 | 6.55 | 14.29 | 0.036 | 0.026 |
| Final price (€) | 28.81 | 33.41 | 28.74 | 33.21 | 0.002 | 0.002 |
| Unavailable sizes (%) | 7.36 | 16.74 | 5.89 | 14.71 | 0.094 | 0.056 |
Notes. These statistics are taken at the product level for each of the 8,691 cohorts of our sample. To avoid biases, we derive them after removing all observations that take place at the exact treatment times. The variable Unavailable sizes refers to the percentage of unavailable sizes at the time of treatment. Smd and Sqd refer to the pooled standardized mean and quantile differences, respectively.
6.2. Generalized Difference-in-Differences
Our research context has three distinctive characteristics. First, some of the campaigns we observe do not overlap (our data set spans one year). Second, product-availability disclosures are not simultaneous inside a campaign (instead, these depend on the sample paths of inventory levels). Third, once disclosed, the products’ availability is displayed for a variable amount of time (until a stockout or the campaign end). As a result, we observe treatments that are taken at different times and last for different periods—this calls for a generalized DID design.
We base our design in two timelines: one absolute, indexed by , and another relative to treatment times, indexed by . Let index cohorts and denote the absolute time at which the retailer discloses the availability of the treated product in cohort (i.e., the product’s treatment time). We then define for the two products in cohort . By proceeding similarly across all cohorts, we obtain that refers to pretreatment and refers to posttreatment.
We perform two interventions to ensure that the comparison between the treatment and control groups is fair. First, we remove, cohort by cohort, all observations that take place at the exact treatment time (i.e., at ). By definition, all treated products sell at least one unit right at , and if not removed, these transactions could bias our results. Second, we delimit a different observation window for each product. We observe the treated product of each cohort from the beginning of the campaign until it sells out or the campaign ends—that is, we stop just before the sales of this product would be undefined. We observe the untreated product of each cohort from the beginning of the campaign until it sells five units posttreatment or the campaign ends8—that is, we drop all observations that correspond to sales never achievable by the treated product of the cohort. Finally, we build an hourly panel data set indexed by and keep the cohort-wise correspondence between and to facilitate taking absolute time fixed effects subsequently.9
To obtain the causal inference, we estimate the treatment effects by using the following generalized DID model specification:
Unavailable sizes. This variable measures the percentage of sold-out sizes of a product.
Disclosure ubiquity. This covariate gauges the percentage of products of a campaign that received treatment but did not sell out yet.
Soldouts. This variable quantifies the percentage of sold-out products of a campaign.
Completion. This covariate gathers the percentage of completion of a campaign.
We perform three variations to the main model specification of Equation (1). The first one is related to the dependent variable. We analyze each individual purchase transaction and estimate the following binary fixed-effect logit model to identify the treatment effect on the product return rate (i.e., the probability that a sale is returned):
The second variation is related to the critical assumption of the parallel trends. Although we matched products to construct a balanced subsample of cohorts, we need to verify that the pretreatment trends of the outcome variables do not differ across the treatment and control groups—otherwise, this would bias the estimates and invalidate our results. We validate this assumption by performing a similar test to that of Autor (2003), where we expand Equation (1) to estimate the treatment effect hour by hour during a band of five hours pretreatment and posttreatment:12
Our third variation has to do with moderators. To identify the moderating effect of discount depth, time pressure, assortment width, and disclosure ubiquity on sales, we add these variables as interactions to the treatment effect in a three-way generalized DID:
7. Estimation Results
In this section, we present the estimation results of our models. First, we look at the treatment effect—the effect of disclosing low product availability—and then at the moderating factors.
7.1. Treatment Effect
7.1.1. Main Results
Table 3 shows the baseline estimates for product sales, returns, net sales, and return rate. We find a positive and statistically significant effect across all specifications. Our estimates show that relative to the pretreatment average outcomes, disclosing product availability (1) increases hourly sales by 13.6%, (2) increases hourly returns by 42.6%, and (3) increases hourly net sales by 12.5%,13 thus validating Hypotheses 1 and 3. Furthermore, the results show that the increase in product returns is not entirely driven by the increase in sales: we also find a positive and statistically significant effect on the return rate—this validates Hypothesis 2. In particular, our estimates show that disclosing product availability increases product return rates by 0.59 percentage points and 17.0%, marginally and relative to the pretreatment average, respectively.14
|
Table 3. The Effect of Disclosing Product Availability
| Dependent variable | ||||
|---|---|---|---|---|
| Sales (units/hour) | Returns (units/hour) | Net sales (units/hour) | Return rate (%) | |
| TREAT | 0. | 0. | 0. | −0.050 |
| (0.001) | (0.000) | (0.001) | (0.031) | |
| AFTER | 0. | 0.000 | 0. | 0.018 |
| (0.002) | (0.000) | (0.002) | (0.057) | |
| TREAT AFTER | 0. | 0. | 0. | 0. |
| (0.002) | (0.000) | (0.002) | (0.062) | |
| Time-invariant fixed effects | Cohort | Cohort | Cohort | Cohort |
| Time fixed effects | Hour | Hour | Hour | None |
| Controls | Yes | Yes | Yes | Yes |
| Number of products | 17,382 | 17,382 | 17,382 | 14,690 |
| Observations | 2,089,302 | 2,089,302 | 2,089,302 | 158,315 |
| R2 | 0.156 | 0.030 | 0.154 | 0.270 |
Notes. This table reports (1) the estimated coefficient values and robust standard errors (in parentheses) of Equation (1) for product Sales, Returns, and Net sales and (2) the estimated coefficient values and standard errors of Equation (2) for Return rate. The first three regressions cluster standard errors at the product category level; the last regression performs analytic bias correction. All regressions include the following controls: Unavailable sizes, Disclosure ubiquity, Soldouts, and Completion. The return-rate regression does not include time fixed effects to leave enough variation of the dependent variable and reports pseudo-R2 instead of R2.
5%; 1%; 0.1%.
7.1.2. Robustness Checks
We perform five robustness checks to the main results. First, we test the parallel-trends assumption by estimating the more nuanced model of Equation (3). Table 4 shows the estimates of the treatment effect across time, which we also plot in Figure 2, both in absolute and in relative terms. Our results reassure that after matching there are no pretreatment differences between the treatment and control groups (i.e., the treatment leads are insignificant)—this validates the parallel-trends assumption. Furthermore, the results show that treatment effects are strongest in the hour following the disclosure of product availability: at that point, the effect on market outcomes peaks nearly twice as much as that achieved in the long term.
|
Table 4. The Effect Across Time of Disclosing Product Availability
| Dependent variable | |||
|---|---|---|---|
| Sales (units/hour) | Returns (units/hour) | Net sales (units/hour) | |
| TREAT | 0.002 | 0.001 | 0.001 |
| (0.006) | (0.001) | (0.006) | |
| TREAT | 0.010 | 0.001 | 0. |
| (0.005) | (0.001) | (0.005) | |
| TREAT | 0.009 | 0.000 | 0.009 |
| (0.005) | (0.001) | (0.005) | |
| TREAT | 0.010 | 0.0000 | 0.010 |
| (0.005) | (0.001) | (0.005) | |
| TREAT | 0.002 | 0.001 | 0.003 |
| (0.005) | (0.001) | (0.005) | |
| TREAT | 0. | 0.003 | 0. |
| (0.007) | (0.002) | (0.007) | |
| TREAT | 0. | 0.003 | 0. |
| (0.007) | (0.002) | (0.006) | |
| TREAT | 0. | 0. | 0. |
| (0.006) | (0.001) | (0.006) | |
| TREAT | 0. | 0. | 0. |
| (0.006) | (0.001) | (0.005) | |
| TREAT | 0. | 0. | 0. |
| (0.002) | (0.000) | (0.002) | |
| Time-invariant fixed effects | Cohort | Cohort | Cohort |
| Time fixed effects | Hour | Hour | Hour |
| Controls | Yes | Yes | Yes |
| Number of products | 17,382 | 17,382 | 17,382 |
| Observations | 2,089,302 | 2,089,302 | 2,089,302 |
| R2 | 0.156 | 0.030 | 0.154 |
Notes. This table reports the estimated coefficient values and robust standard errors (in parentheses) of Equation (3) for sales, returns, and net sales. All regressions cluster standard errors at the product category level and include the following controls: Unavailable sizes, Disclosure ubiquity, Soldouts, and Completion.
5%; 1%; 0.1%.
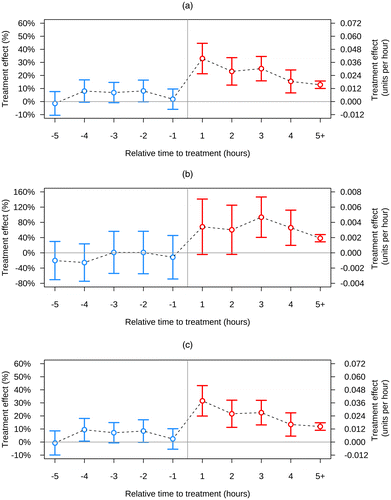
Notes. (a) Product sales. (b) Product returns. (c) Product net sales. Percentage estimates are obtained by normalizing the estimated coefficient values of Table 4 with respect to the pretreatment average outcomes. The vertical bands span a 95% confidence interval.
Second, we address the legitimate concern that by using hourly sales—and not total sales—as the dependent variable, we can infer that treatment makes products sell faster but not necessarily more. Indeed, very popular treated products that sell out long before the end of a campaign would probably also sell well in the absence of treatment but perhaps at a slower pace. We may pair such products with other very popular—but untreated—products that also sell five units after treatment but over a longer period. As a result, in these situations, a direct extrapolation of the treatment effect on hourly sales might lead us to overestimate the treatment effect on total sales. But we could also find the opposite case in our sample: we may pair untreated products that sell five units after treatment with treated products that take longer to sell out. As a result, in these situations, a direct extrapolation of the treatment effect on hourly sales might lead us to underestimate the treatment effect on total sales. How can we then be sure that the treatment effect on hourly sales is indicative of a similar effect on sales? The answer lies in two subsamples.
The first subsample contains the 5,170 cohorts of our data set whose products never sell out. In these cohorts, which account for 59.5% of the total, we observe the products from the beginning and until the end of the campaigns—as a result, the treatment effects on both hourly sales and total sales should coincide. We rerun the analysis over this subsample and verify that the direction, significance, and size of treatment effects remain invariant (we report the results in Table A.1 in the appendix). Consequently, we can safely extrapolate the treatment effects on hourly sales to treatment effects on total sales.
The second subsample contains the 1,669 cohorts whose products all sell out.15 In these cohorts, which account for 19.2% of the total, each pair of products sells the same exact number of units posttreatment, although perhaps at a different pace—as a result, this could misalign hourly sales and total sales. We rerun the analysis over this subsample and find that treatment effects in hourly sales are not statistically significant—reassuringly, our design captures that treatment is futile for these products. Furthermore, we find a negative and statistically significant effect in hourly net sales driven by an increase in returns. This result shows that treatment effects are not universally positive and motivates the data-driven policies we explore in Section 9.
Third, we turn our attention to the valid concern that we paired substitute products. After all, we constructed the cohorts by matching products of the same campaign, category, price, and popularity. It might be the case that by inducing customers to focus more on the products that display availability, the treatment negatively affects the outcomes of the control group. We address this potential issue by rerunning the study using a different subsample of 16,059 cohorts that match products of the same campaign, price, and popularity but do not belong to the same product category.16 The direction and magnitude of the results obtained with this alternative subsample, which we report in Table A.2 in the appendix, are consistent with those derived by using our original data set.
Fourth, we rerun the analysis by changing the granularity of the time-invariant fixed effects: from the current cohort level to the product, category, and campaign levels. All our results hold, but their significance degrades as we take coarser fixed effects (we report these model variations in Table A.3 in the appendix).
Fifth, and last, we rerun the analysis by logging the dependent variables. The results are also robust to this alternative definition of outcomes. Note that we use linear models in all our regressions. This is because with linear models we can leverage a within estimator to include a massive number of fixed effects—nearly 9,000 when taken at the cohort level—without risking the computability of results. This number of fixed effects, combined with the size of our sample (+2 million observations), would make it very hard, if not impossible, for any alternative nonlinear model to handle.
7.2. Moderating Factors
What strategic levers can retailers manage to boost the effect of disclosing product availability on sales and profitability? To answer this question, we interact the treatment effect with several product- and campaign-specific attributes. Table 5 shows the estimates for all of them.
|
Table 5. The Effect of Disclosing Product Availability: Moderating Factors
| Discount depth | Time pressure | Assortment width | Disclosure ubiquity | |||||
|---|---|---|---|---|---|---|---|---|
| Sales (units/hour) | Net sales (units/hour) | Sales (units/hour) | Net sales (units/hour) | Sales (units/hour) | Net sales (units/hour) | Sales (units/hour) | Net sales (units/hour) | |
| TREAT | 0. | 0. | 0. | 0. | 0. | 0. | 0. | 0. |
| (0.004) | (0.004) | (0.002) | (0.002) | (0.001) | (0.001) | (0.001) | (0.001) | |
| AFTER | 0. | 0. | −0.049*** | −0.047*** | −0.020*** | −0.020*** | −0.026*** | −0.025*** |
| (0.008) | (0.008) | (0.003) | (0.003) | (0.003) | (0.003) | (0.003) | (0.003) | |
| TREATAFTER | −0.018** | −0.017** | 0.005 | 0.003 | 0.001 | 0.002 | 0.002 | 0.003 |
| (0.006) | (0.006) | (0.003) | (0.003) | (0.002) | (0.002) | (0.002) | (0.002) | |
| Discount depth | 0. | 0. | ||||||
| (0.024) | (0.023) | |||||||
| TREATAFTER Discount depth | 0. | 0. | ||||||
| (0.010) | (0.010) | |||||||
| Completion | −0.096*** | −0.093*** | ||||||
| (0.009) | (0.009) | |||||||
| TREATAFTER Completion | 0. | 0. | ||||||
| (0.004) | (0.004) | |||||||
| Assortment width | 0.000 | 0.000 | ||||||
| (0.000) | (0.000) | |||||||
| TREATAFTER Assortment width | 0. | 0. | ||||||
| (0.000) | (0.000) | |||||||
| Disclosure ubiquity | −0.496*** | −0.459*** | ||||||
| (0.045) | (0.043) | |||||||
| TREATAFTER Disclosure ubiquity | 0. | 0. | ||||||
| (0.045) | (0.043) | |||||||
| Time-invariant fixed effects | Category | Category | Category | Category | Campaign | Campaign | Category | Category |
| Time fixed effexts | Hour | Hour | Hour | Hour | Hour | Hour | Hour | Hour |
| Time fixed effexts | 17,382 | 17,382 | 17,382 | 17,382 | 17,382 | 17,382 | 17,382 | 17,382 |
| Observations | 2,089,302 | 2,089,302 | 2,089,302 | 2,089,302 | 2,089,302 | 2,089,302 | 2,089,302 | 2,089,302 |
| R2 | 0.128 | 0.127 | 0.129 | 0.128 | 0.092 | 0.091 | 0.129 | 0.127 |
Notes. This table reports the estimated coefficient values and robust standard errors (in parentheses) of the model of Equation (4) for Sales and Net sales and several moderating factors. All regressions cluster standard errors at the product category level and include the following controls: Unavailable sizes, Disclosure ubiquity, Soldouts, and Completion. We report the main effect and the interacted effect of causal interest of each moderator—note that our three-way DID model also includes other two-way interaction terms that we omit for brevity. The regressions that study product static characteristics (i.e., Discount depth) and campaign dynamic characteristics (i.e., Time pressure and Disclosure ubiquity) include time-invariant fixed effects at the category level. The regressions that study category static characteristics (i.e., Assortment width) include time-invariant fixed effects at the campaign level.
5%; 1%; 0.1%.
7.2.1. Discount Depth
Products sell more when the retailer discloses their availability to customers, and greater discounts magnify this effect further and significantly. To be specific, we find that—all other things being equal—a deep discount (i.e., one in the top quartile of the distribution) amplifies the treatment effect by a factor of 2.4 both in sales and in net sales compared with a low discount (i.e., one in the bottom quartile of the distribution). This validates Hypothesis 4 and suggests that the scarcity effect outweighs the herding effect in our research context.
7.2.2. Time Pressure
We proxy time pressure with the variable Completion—the percentage of completion of the duration of a campaign. Our results indicate that sales are significantly lower for campaigns that are about to end, but these strengthen the treatment effect significantly. A case in point is a campaign whose duration is 75% completed, which bolsters the treatment effect by a factor of 1.8 in sales and 1.9 in net sales compared with a campaign 25% completed. This validates Hypothesis 5 and is in line with our conjecture that closer deadlines reinforce the effect of availability constraints.
7.2.3. Assortment Width
To study the mediating role of assortment size on the treatment, we construct the variable Assortment width, which measures the number of products in each category. Our results show that the treatment effect is significantly accentuated in wide assortments, which validates Hypothesis 5. This result is compatible with two conjectures. On the one hand, customers may cut across wide, cluttered assortments by relying more on scarcity signals to make purchase decisions. On the other hand, facing many available options, customers may be more willing to rely on the decisions of their peers—as these are revealed via product-availability disclosures—and the treatment effect is bolstered.
7.2.4. Disclosure Ubiquity
How does the number of active scarcity signals moderate the treatment effect? Interestingly, we find that the standalone effect of disclosure ubiquity is significantly negative, but, by contrast, its moderating effect is positive and highly significant. This result supports Hypothesis 5 and is compatible with our conjecture that scarcity signals need to be sufficiently abundant that customers notice them.
8. Customer-Level Extensions
We extend our main results by studying two additional questions: (1) Can the retailer effectively increase customers’ willingness to pay by disclosing low-availability signals? and (2) is the reaction to these signals contingent on whether customers engage with the retailer via mobile devices?
8.1. Purchase Value
By uncovering inventory information when availability is low, the retailer simultaneously signals that certain products are both popular and in short supply. We found strong evidence that the provision of such information increases both sales and net sales. To what extent are these additional sales performed by customers who used to buy cheaper products in the past? Perhaps the disclosure of low product availability creates a thrill of exclusivity, making customers buy more expensive items than what they normally do. This leads us to hypothesize that the disclosure of low product availability drives customers to buy more expensive products.
To validate this, we construct the variable for each purchase transaction, indexed by . This variable is the ratio between the price of the product purchased in transaction by a given customer and the average price of the products purchased by the same customer in the past. Consequently, when a value of this variable is larger than one, it indicates that the product now purchased by the customer is above his or her historical willingness to pay. If the variable of the transactions that involve the treated products increases once the retailer discloses the low-availability information, this will imply that the treatment helps in reaching customers with lower historical spending. Similar to our analysis of return rates, we identify this effect by estimating the model of Equation (1) at the transaction level17 using as the dependent variable:
|
Table 6. Disclosing Product Availability Increases Customers’ Purchase Value
| Dependent variable | |
|---|---|
| Value | |
| TREAT | −0.002 |
| (0.007) | |
| AFTER | 0.002 |
| (0.013) | |
| TREAT AFTER | 0. |
| (0.014) | |
| Time-invariant fixed effects | Cohort |
| Time fixed effects | Yes |
| Controls | Yes |
| Number of products | 15,545 |
| Observations | 75,629 |
| R2 | 0.561 |
Notes. This table reports the estimated coefficient values and robust standard errors of Equation (5). The regression includes the following controls: Unavailable sizes, Disclosure ubiquity, Soldouts, and Completion.
1%.
8.2. Mobile vs. Web Channels
Customers engage with the retailer via an app from a mobile device or through a regular web browser from a nonmobile device.18 The retailer curates the look and feel such that the customer experience is virtually identical across both channels (see Figure 3), but still, mobile devices are smaller than nonmobile ones and can be accessed constantly and ubiquitously. Will this fact amplify or mitigate the treatment effect for mobile customers?
Notes. (a) Mobile app. (b) Web browser.
The smaller screens of mobile devices obstruct customers’ learning (Chae and Kim 2004, Chittaro 2006). By having to scroll up and down the screen continuously, mobile customers may overlook scarcity signals and react less vividly than if they were engaging via a nonmobile device. We speculate that mobile customers may pay less attention to product-availability information than web customers, and thus the disclosure of such information will have a lower effect on them. To validate this, we first disaggregate product sales by channel type: mobile versus web. We then subtract web sales from mobile sales to capture the relative treatment effect across these channels. Finally, we reestimate the model of Equation (1) using the new sales covariates as dependent variables.
Table 7 shows the estimates for mobile sales, web sales, and their difference. We find a positive and statistically significant effect across both channels. Our estimates show that relative to the pretreatment average outcomes, the disclosure of low product availability increases mobile sales by and web sales by .19 Consistent with this result, we also find a negative and statistically significant effect on the difference between mobile and web sales. This suggests that the effect of disclosing product availability is relatively lower on mobile users.
|
Table 7. The Effect Across Channels of Disclosing Product Availability
| Dependent variable | |||
|---|---|---|---|
| Mobile sales (units/hour) | Web sales (units/hour) | (Mobile – web) sales (units/hour) | |
| TREAT | 0.007*** | 0.007*** | 0.000 |
| (0.001) | (0.001) | (0.001) | |
| AFTER | 0.002 | 0.003* | −0.001 |
| (0.001) | (0.001) | (0.001) | |
| TREAT AFTER | 0.006*** | 0.011*** | −0.006*** |
| (0.001) | (0.001) | (0.001) | |
| Time-invariant fixed effects | Cohort | Cohort | Cohort |
| Time fixed effects | Hour | Hour | Hour |
| Controls | Yes | Yes | Yes |
| Number of products | 17,382 | 17,382 | 17,382 |
| Observations | 2,089,302 | 2,089,302 | 2,089,302 |
| R2 | 0.090 | 0.107 | 0.020 |
Notes. This table reports the estimated coefficient values and robust standard errors (in parentheses) of Equation (1) for Mobile sales, Web sales, and Mobile sales minus web sales. All regressions cluster standard errors at the product category level and include the following controls: Unavailable sizes, Disclosure ubiquity, Soldouts, and Completion.
5%; 0.1%.
A potential concern of this last extension is that customers may self-select across channels. Almost the entire customer base downloaded the app, but this only means that most customers can engage with the retailer through both channels—not that they actually do it.20 However, if customers of different types self-selected into channels, we would probably observe idiosyncratic differences in mobile versus web customer activity patterns. To verify that this is not the case, we examine some statistics—disaggregated on a per-channel basis—that proxy purchase seasonality and intensity at the customer level. Reassuringly, the results, reported in Table 8, show no relevant differences between the activity patterns of mobile and web customers, thereby alleviating customer self-selection concerns.
|
Table 8. Customer Activity Patterns Across Channels
| Variable | Mobile app | Web session | ||||
|---|---|---|---|---|---|---|
| Mean | Standard deviation | Observations | Mean | Standard deviation | Observations | |
| Weekend sales (%) | 29.82 | 45.75 | 69,355 | 24.27 | 42.87 | 91,801 |
| Evening sales (%) | 33.49 | 47.20 | 69,355 | 28.59 | 45.18 | 91,801 |
| Mean hour of sales (hh:mm:ss) | 14:42:47 | 04:24:19 | 69,355 | 14:24:40 | 04:16:19 | 91,801 |
| Purchase frequency (purchases/year) | 4.84 | 6.31 | 69,355 | 4.76 | 6.76 | 91,801 |
| Items per purchase (units/purchase) | 2.75 | 1.60 | 69,355 | 2.96 | 1.76 | 91,801 |
| Average ticket value (€) | 51.55 | 33.21 | 69,355 | 54.63 | 38.02 | 91,801 |
Notes. This table reports the summary statistics that describe the mobile and web activity patterns of the set of 126,075 customers that purchased any of the products of our sample. We consider the entire sales activity of these customers—and not just that related to the products of our sample—to construct the variables. Evening sales is the fraction of sales transacted after 7 p.m.
9. Data-Driven Disclosure Policy
So far, we have provided causal evidence of the effect of disclosing low-availability signals on sales, returns, and profits and studied the factors that mediated this reaction. We now design data-driven policies that leverage these insights to prescribe the timing of disclosure of such signals.
Disclosing product availability boosts sales but also returns, and hence, a fixed disclosure threshold becomes suboptimal: any value will be too high for the bestsellers that would probably sell out anyway and too low for the slow movers that most need a push to avoid a sales standstill. By tuning the disclosure of product availability according to the unique context of each product, we can exploit our understanding of the treatment effects to lift sales while minimizing returns.
The ideal disclosure policy is the solution to an optimal stopping problem. Once a product is put on sale, we would periodically compare the profit-to-go if we treated that product right away with the profit-to-go if we postponed this decision one more period. A nonnegative difference between both quantities would mean that we should treat the product immediately—that is, disclose its availability from that moment onward—and stop comparing potential outcomes; otherwise, we should wait and repeat the same procedure one period later. As a result, rather than treating all products once their inventories hit a predetermined low, we would only intervene for products that benefit from treatment, when they most need it.
In practice, we would first estimate, for each untreated product and period, the profit-to-go if we treat now versus wait one period. Then we would construct a dummy to indicate whether “treating now” is preferred to “waiting one period.” Finally, we would train a model that, by taking this dummy as dependent variable, would predict the optimal decision—for each product and period—as a function of certain product and campaign covariates.
Generally, one can estimate the profit-to-go by combining backward induction and data with enough heterogeneity of disclosure thresholds. Because the firm we partnered with treats all products once they hit five units, it is impossible for us to estimate the effect of delaying (nor anticipating) treatment by a number of periods. That is, we lack proper counterfactuals to the event of start disclosing availability when inventory levels are different from five.
However, we can estimate what would have happened if the retailer never disclosed the availability of a treated product. We resort to matching to predict the outcome of reverting a treatment decision: for each product in the treatment group and at the time of treatment, (1) we take its posttreatment net sales as a proxy of the profit-to-go in case of treatment (the baseline decision of the retailer), (2) we take the posttreatment net sales of its control product (i.e., the untreated product to which it was matched) as a proxy of the profit-to-go in case of nontreatment,21 and (3) we infer that the treatment is beneficial when the difference between the two is nonnegative. Accordingly, we can use this to train a binary model that decides whether to disclose its availability until the end of the campaign or to never disclose it once the inventory of a product drops down to five units.
We use 70% of our sample of 8,691 cohorts to run a random forest that predicts the differences in profits-to-go as a function of some of the moderating factors that we study in Section 4.2 and the control variables we include in all our regressions. We run a number of machine learning methods, including linear regression, among which random forest shows the strongest predictive power. In fact, a random forest’s ability to generate highly accurate predictions makes it one of the most popular statistical learning methods in practice (Breiman 2001). In our model specification, a random forest is built on 10,000 regression trees. The random forest model first determines the best number of variables to include in a tree;22 it then grows a regression tree by picking the best variable as a split point, which generates a diverse set of trees; in this way, we grow a vast number of trees and average those trees to yield a prediction.
We use the remaining 30% of our sample to make the out-of-sample treatment decisions based on our model predictions. We then compare the out-of-sample value of net sales achieved by the treatment decisions of our algorithm with the actual net sales of the retailer’s baseline policy and measure the relative improvement in the profitability of the data-driven disclosure policy with respect to the baseline. We cross-validate our results by repeating 300 rounds of the preceding estimation and prediction analysis with a random 70%–30% split in the training and testing data sets in each round. We present the distribution of relative profitability improvements in Figure 4.
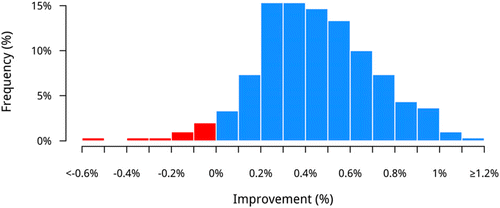
Notes. We compute the relative improvement of the out-of-sample net sales achieved by the treatment decisions of our algorithm with respect to the actual net sales of the retailer’s baseline policy in each round of analysis. The y-axis plots the frequency of each improvement bin in 300 rounds of analysis.
By selectively reverting some of the treatment decisions of the retailer, our model is able to lift the value of all posttreatment net sales—our proxy of profits—by an average of 0.44%. Three factors constrain the potential of data-driven disclosure policies in our setting. First, we can only reverse treatment decisions by the time five units are left, and it is likely that these few units would have sold anyway—conversely, we cannot use treatment to speed up slow movers. In other words, our proposed algorithm would be more powerful if the retailer could start signaling scarcity at variable inventory levels larger (but also smaller) than five. Second, our data do not let us implement a dynamic model to decide on the disclosure of product availability by the hour—instead, we must decide all (i.e., treat until the end) or nothing (i.e., never treat). Finally, because the firm’s returns are infrequent (slightly above 5%) and economical (the cost of a return compares with the margin of a sale), the average treatment effect is very large (+12.5% in net sales) and thus difficult to improve on. Consequently, the value of data-driven disclosure policies will be highest for online retailers that see frequent and costly returns and are able to disclose the products’ availability at variable inventory levels.
10. Conclusions
We show that revealing low product availability to customers is an effective tool for boosting sales and profits in online retail. Moreover, we point at the factors that accentuate—or temper—the value of this technique: Scarcity signals are most powerful when they are abundantly released and involve deeply discounted products sold within wide assortments and whose campaigns are close to the end. Conversely, these signals are least useful when they are seldom released and involve moderately discounted products sold within narrow assortments and whose campaigns have plenty of time left.
These insights, derived in the context of flash-sales retailing, can be generalized across many situations because we do not study just one brand—we examine the operations of a company that involves thousands of brands, dozens of verticals, and millions of active customers over the span of a year. Thus, companies competing in the online retailing space can leverage this study by tailoring their information-disclosure policies as a function of these characteristics. We caution them to (perhaps) expect lower treatment effects—after all, flash-sales products are gone once they sell out, and this may augment customers’ reactions to scarcity signals, especially when compared with a context where product replenishment is possible.
Admittedly, the managerial prescriptions of our results should be honestly executed: there are limits to how far retailers can go when engineering their disclosure policies with the aim of encouraging a purchase. However tempting it might be, manipulating scarcity signals to a point at which they become untrustworthy is not only unethical but also illegal.23
Can we expect the retailer we partnered with to find value in and implement the recommendations of our work? The answer is yes. The company we worked with was recently acquired by a larger group that owns other competing sites with radically different information-disclosure policies. In the words of the retailer’s chief marketing officer, this project “provides us with fact-based insights that help us to discuss and subsequently implement changes in our other sites, as well as test alternative models of reinforcing this scarcity effect in our company.”
But perhaps more important, we provide the online retailing community with a clear implementation path to convert our causal findings into enhanced practice via the use of data-driven policies. Contingent on the availability of data with enough variation, we show how retailers can use machine learning to prescribe the timing of disclosure of scarcity signals in light of the ever-changing context of each individual product. The fact that our algorithm improved the profitability of the retailer we partnered with will hopefully spur other companies to explore this promising avenue as well.
The authors thank Jérémie Gallien, Benedict Paul, Rik Pieters, Giovanni Valentini, the anonymous associate editor, and the anonymous referees for their constructive and helpful feedback. The authors are also grateful to the M&SOM Practice-Based Research Competition.
Appendix
|
Table A.1. The Effect of Disclosing Product Availability: Hourly Sales vs. Total Sales
| Dependent variable | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Sales (units/hour) | Returns (units/hour) | Net sales (units/hour) | Sales (units/hour) | Returns (units/hour) | Net sales (units/hour) | Sales (units/hour) | Returns (units/hour) | Net sales (units/hour) | |
| TREAT | 0.013*** | 0.001*** | 0. | 0. | 0. | 0. | 0. | 0.001 | 0. |
| (0.001) | (0.000) | (0.001) | (0.001) | (0.000) | (0.001) | (0.004) | (0.001) | (0.004) | |
| AFTER | 0.004* | 0.000 | 0. | 0. | 0.000 | 0. | 0.006 | 0.000 | 0.006 |
| (0.002) | (0.000) | (0.002) | (0.002) | (0.000) | (0.001) | (0.011) | (0.001) | (0.011) | |
| TREAT AFTER | 0.017*** | 0. | 0. | 0. | 0. | 0. | 0.017 | 0. | −0. |
| (0.002) | (0.000) | (0.002) | (0.002) | (0.000) | (0.001) | (0.009) | (0.001) | (0.008) | |
| Time-invariant fixed effects | Cohort | Cohort | Cohort | Cohort | Cohort | Cohort | Cohort | Cohort | Cohort |
| Time fixed effects | Hour | Hour | Hour | Hour | Hour | Hour | Hour | Hour | Hour |
| Controls | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Number of products | 17,382 | 17,382 | 17,382 | 10,340 | 10,340 | 10,340 | 3,338 | 3,338 | 3,338 |
| Observations | 2,089,302 | 2,089,302 | 2,089,302 | 1,435,366 | 1,435,366 | 1,435,366 | 235,978 | 235,978 | 235,978 |
| R2 | 0.156 | 0.030 | 0.154 | 0.114 | 0.017 | 0.113 | 0.176 | 0.057 | 0.173 |
| Sample | Original | Original | Original | Sub 1 | Sub 1 | Sub 1 | Sub 2 | Sub 2 | Sub 2 |
Notes. This table reports the estimated coefficient values and robust standard errors (in parentheses) of Equation (1) for product Sales, Returns, and Net sales. “Sub 1” refers to the 5,170 cohorts whose products never sell out, whereas “Sub 2” refers to the 1,669 cohorts whose products all sell out. All the regressions cluster standard errors at the product category level and include the following controls: Unavailable sizes, Disclosure ubiquity, Soldouts, and Completion.
5%; 1%; 0.1%.
|
Table A.2. The Effect of Disclosing Product Availability: Robustness to Same-Category Controls
| Dependent variable | ||||
|---|---|---|---|---|
| Sales (units/hour) | Returns (units/hour) | Net sales (units/hour) | Return rate () | |
| TREAT | 0. | 0. | 0. | −0. |
| (0.001) | (0.000) | (0.001) | (0.020) | |
| AFTER | -0.015 | -0.001 | -0.0013 | −0.046 |
| (0.001) | (0.000) | (0.001) | (0.038) | |
| TREATAFTER | 0. | 0. | 0. | 0. |
| (0.002) | (0.000) | (0.002) | (0.042) | |
| Time-invariant fixed effects | Cohort | Cohort | Cohort | Cohort |
| Time fixed effects | Hour | Hour | Hour | None |
| Controls | Yes | Yes | Yes | Yes |
| Number of products | 32,118 | 32,118 | 32,118 | 28,700 |
| Observations | 3,776,951 | 3,776,951 | 3,776,951 | 345,095 |
| R2 | 0.160 | 0.024 | 0.158 | 0.242 |
Notes. This table reports (1) the estimated coefficient values and robust standard errors (in parentheses) of Equation (1) for product Sales, Returns, and Net sales, and (2) the estimated coefficient values and standard errors of Equation (2) for Return rate. The first three regressions cluster standard errors at the product category level; the last regression performs analytic bias correction. All regressions include the following controls: Unavailable sizes, Disclosure ubiquity, Soldouts, and Completion. The return-rate regression does not include time fixed effects to leave enough variation of the dependent variable and reports pseudo-R2 instead of R2.
0.1%.
|
Table A.3. The Effect of Disclosing Product Availability: Robustness to Time-Invariant Fixed Effects
| Dependent variable | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Sales (units/hour) | Sales (units/hour) | Sales (units/hour) | Returns (units/hour) | Returns (units/hour) | Returns (units/hour) | Net sales (units/hour) | Net sales (units/hour) | Net sales (units/hour) | Return rate (%) | Return rate (%) | |
| TREAT | 0. | 0. | 0. | 0. | 0. | 0. | −0.052 | −0. | |||
| (0.001) | (0.001) | (0.000) | (0.000) | (0.001) | (0.001) | (0.029) | (0.027) | ||||
| AFTER | 0. | 0.002 | −0. | 0.000 | 0.000 | −0. | 0. | 0.001 | −0. | 0.010 | 0.020 |
| (0.002) | (0.002) | (0.002) | (0.000) | (0.000) | (0.000) | (0.002) | (0.002) | (0.002) | (0.048) | (0.042) | |
| TREAT AFTER | 0. | 0. | 0.002 | 0. | 0. | 0. | 0. | 0. | 0.001 | 0. | 0. |
| (0.002) | (0.002) | (0.001) | (0.000) | (0.000) | (0.000) | (0.002) | (0.001) | (0.001) | (0.057) | (0.052) | |
| Time-invariant fixed effects | Product | Category | Campaign | Product | Category | Campaign | Product | Category | Campaign | Category | Campaign |
| Time fixed effects | Hour | Hour | Hour | Hour | Hour | Hour | Hour | Hour | Hour | None | None |
| Number of products | 17,382 | 17,382 | 17,382 | 17,382 | 17,382 | 17,382 | 17,382 | 17,382 | 17,382 | 14,690 | 14,690 |
| Observations | 2,089,302 | 2,089,302 | 2,089,302 | 2,089,302 | 2,089,302 | 2,089,302 | 2,089,302 | 2,089,302 | 2,089,302 | 158,315 | 158,315 |
| R2 | 0.173 | 0.128 | 0.092 | 0.046 | 0.023 | 0.013 | 0.170 | 0.127 | 0.091 | 0.198 | 0.106 |
Notes. This table reports (1) the estimated coefficient values and robust standard errors (in parentheses) of Equation (1) for product Sales, Returns, and Net sales and (2) the estimated coefficient values and standard errors of Equation (2) for Return rate. The first six regressions cluster standard errors at the product category level; the last two regressions perform analytical bias corrections. All regressions include the following controls: Unavailable sizes, Disclosure ubiquity, Soldouts, and Completion. The return-rate regressions do not include time fixed effects to leave enough variation of the dependent variable and report pseudo-R2 instead of R2.
5%; 1%; 0.1%.
1 Company managers described the ordering of products within a category as “purely random.”
2 The threshold of five units, untouched since the firm was founded, applies across all brands and categories.
3 In our research context, products are unconditionally refundable (“14-day unconditional money-back guarantee”), but customers who opt for a return have to pay a €6.95 flat shipping fee. In private conversations with the authors, the retailer’s chief marketing officer shared that returned products are salvaged at their cost in ephemeral physical outlets and that, on average, the return flat shipping fee covers the reverse logistics costs. Therefore, each product return cancels the contribution of a sale.
4 Product returns are observed long after campaigns end. We use the purchase transaction identifier associated with each return to anticipate, at the moment of a purchase, whether that transaction will eventually be returned.
5 We compute the pretreatment sales of a potential control—which never receives treatment—by adding this product’s sales from the campaign start to the time of treatment of the treated product we want to pair it with.
6 Because products uptake treatment when their inventory level hits five units, it is likely that one or more of their sizes are sold out by then. We avoid broken assortment biases by matching products with a similar percentage of sizes unavailable at the time of treatment.
7 The standardized average distance between the empirical quantile distributions of the treatment and control groups.
8 In 95.3% of the cohorts, the treated items had five units left just after treatment. In 4.7% of the cohorts, the treated items had strictly fewer than five units left just after treatment as a result of multiple sales transactions taking place at exactly the treatment time. In such cases, we observe the untreated product from the beginning of the campaign until it sells the number of units that the treated product had just after treatment.
9 For instance, in a cohort where the treated product receives treatment at 10:35:00 a.m., we construct the panel data observation that corresponds to by gathering all transactions (i.e., sales and returns) that fall between 10:35:01 a.m. and 11:35:00 a.m. We also keep the correspondence that in this cohort, means t = 11:00:00 a.m., means t = 10:00:00 a.m., and so on (absolute times are recorded using an hourly scale as well).
10 By clustering standard errors at the category level, we allow for within-category correlations of the error terms that naturally account for (a) potential substitution effects among similar products, and (b) temporal correlation of market outcomes. In contrast, clustering standard errors at the campaign level would not make as much sense because, for instance, the error terms of products in the “men’s wear” and “women’s wear” categories of the same campaign will likely be uncorrelated. Warned by Abadie et al. (2017, p. 1), who argue that “there is in fact harm in clustering at too aggregate a level,” we decided to stay at the product category level—which already gives rise to clusters.
11 We control at the finest possible level that leaves sufficient variation of the causal variable of interest.
12 A bandwidth of five hours of pretreatment and posttreatment is adequate given that in our data set two lags of the outcome variables of any given product show no significant correlation when spaced more than three hours apart.
13 The pretreatment average outcomes are as follows: (a) product sales: 0.1246 unit/hour; (b) product returns: 0.0047 unit/hour; and (c) product net sales: 0.1199 unit/hour.
14 The pretreatment average return rate is 3.5%.
15 Note that control products have more initial inventory than treated products, and thus they could potentially sell more than five units after treatment—something impossible for a treated product. Because we drop these problematic observations to enable an apples-to-apples comparison, a control product that “sells out” in our sample indicates that it is very likely that the treated product of its cohort, had it not taken treatment, would have sold out as well.
16 We base this robustness check on the assumption that customers do not substitute products across categories. This seems to be a reasonable guess given that the retailer implements product categories to segment products according to types (e.g., shoes and accessories), customer gender, or customer age (e.g., as in kids’ clothing).
17 We work at the transaction level because is defined at the customer (and not product) level.
18 According to the retailer’s management team, the number of customers engaging with the retailer via a web session on a mobile device is negligible.
19 The pretreatment averages are (a) mobile product sales: 0.054 units/hour; and (b) web product sales: 0.0706 units/hour.
20 In fact, of the 126,075 different customers who purchased any of the products in our sample, only 27.9% of them purchased through both channels.
21 Recall that products were matched on price.
22 Based on Gini importance (Louppe et al. 2013), the top relevant features in our random forest model include price discount, percentage of campaign completion, percentage of sold-out products within a campaign, percentage of unavailable sizes because of stockouts, and pretreatment sales rate.
23 In November 2015, Reuters reported that the Centre for Protection against Unfair Competition, a German private-sector competition watchdog, filed for an injunction against online fashion retailer Zalando, accusing the group of false advertising (Thomasson 2015). It stated that “Zalando had in its online shop misrepresented how many pieces of certain items of clothing were still available, creating the impression that customers needed to act fast to buy them.”
Along the same lines, the BBC reported in October 2017 that the Competition and Markets Authority, a UK competition watchdog, probed hotel booking sites to see if they were misleading consumers. According to the BBC, one “area being looked in this investigation is the way sites display how many rooms are left, how many people are viewing a particular hotel and messages that claim to state the last time at which a similar room was booked.” The watchdog is concerned that “this is used for pressure selling, creating a false impression of room availability to rush customers into making a booking decision” (BBC 2017).
References
- (2017) When should you adjust standard errors for clustering? NBER Working Paper 24003, National Bureau of Economic Research, Cambridge, MA.Google Scholar
- (2011) Buying from the babbling retailer? The impact of availability information on customer behavior. Management Sci. 57(4):713–726.Link, Google Scholar
- (2003) Outsourcing at will: The contribution of unjust dismissal doctrine to the growth of employment outsourcing. J. Labor Econom. 21(1):1–42.Crossref, Google Scholar
- (1992) A simple model of herd behavior. Quart. J. Econom. 107(3):797–817.Crossref, Google Scholar
- (2018) The impact of e-visits in primary care: Evidence on visit frequencies and patient health. Management Sci. 64(12):5461–5480.Google Scholar
- (2017) Watchdog takes aim at hotel booking sites. BBC (October 27), https://www.bbc.com/news/business-41769488.Google Scholar
- (2001) Random forests. Machine Learn. 45(1):5–32.Crossref, Google Scholar
- (2018) Does adding inventory increase sales? Evidence of a scarcity effect in U.S. automobile dealerships. Management Sci. 65(4):1469–1485.Link, Google Scholar
- (2009) Observational learning: Evidence from a randomized natural field experiment. Amer. Econom. Rev. 99(3):864–882.Crossref, Google Scholar
- (2018) Fast or furious: Delivery outcomes and customer engagement in online retail. Working paper, IESE Business School, University of Navarra, Barcelona, Spain.Google Scholar
- (2007) Dynamic assortment with demand learning for seasonal consumer goods. Management Sci. 53(2):276–292.Link, Google Scholar
- (2004) Do size and structure matter to mobile users? An empirical study of the effects of screen size, information structure, and task complexity on user activities with standard web phones. Behav. Inform. Tech. 23(3):165–181.Crossref, Google Scholar
- (2006) Visualizing information on mobile devices. Computer 39(3):40–45.Crossref, Google Scholar
- (2001) Harnessing the science of persuasion. Harvard Bus. Rev. 79(9):72–81.Google Scholar
- (2009) Influence: The Psychology of Persuasion (HarperCollins, New York).Google Scholar
- (2018) Sharing aggregate inventory information with customers: Strategic cross-selling and shortage reduction. Management Sci. 64(1):381–400.Link, Google Scholar
- (2019) Learning from inventory availability Information: Evidence from field experiments on Amazon. Management Sci. 65(3):1216–1235.Google Scholar
- (2009) Creating sales with stock-outs. Working paper, Dartmouth College, Hanover, NH.Google Scholar
- (1995) Buying frenzies and seller-induced excess demand. RAND J. Econom. 26(2):331–342.Crossref, Google Scholar
- (2015) Analytics for an online retailer: Demand forecasting and price optimization. Manufacturing Service Oper. Management 18(1):69–88.Link, Google Scholar
- (2007) Asymmetric consumer learning and inventory competition. Management Sci. 53(2):227–240.Link, Google Scholar
- (2011) An empirical analysis of user content generation and usage behavior on the mobile internet. Management Sci. 57(9):1671–1691.Link, Google Scholar
- (2012) How is the mobile internet different? Search costs and local activities. Inform. Systems Res. 24(3):613–631.Link, Google Scholar
- (2014) Product fit uncertainty in online markets: Nature, effects, and antecedents. Inform. Systems Res. 25(2):328–344.Link, Google Scholar
- (1997) Framing the deal: The role of restrictions in accentuating deal value. J. Consumer Res. 24(1):68–79.Crossref, Google Scholar
- (1995) The effects of advertised and observed quality on expectations about new product quality. J. Marketing Res. 32(3):280–290.Crossref, Google Scholar
- (2015) Inferring quality from wait time. Management Sci. 62(10):3023–3038.Link, Google Scholar
- (2008) Strategic capacity rationing to induce early purchases. Management Sci. 54(6):1115–1131.Link, Google Scholar
- (2013) Understanding variable importances in forests of randomized trees. Burges CJC, Bottou L, Welling M, Ghahramani Z, Weinberger KO, eds. NIPS’13: Proc. 26th Internat. Conf. Neural Inform. Processing Systems, vol. 1 (Curran Associates, Red Hook, NY), 431–439.Google Scholar
- (2018) Using clickstream data to improve flash sales effectiveness. Working paper, IESE Business School, University of Navarra, Barcelona, Spain.Google Scholar
- (2020) The impact of disclosing inventory-scarcity messages on sales in online retailing. J Oper. Management 2020:1–19.Google Scholar
- (2019) Creation and consumption of mobile word-of-mouth: How are mobile reviews different? Marketing Sci. 38(5):773–792.Link, Google Scholar
- (2014) The role of physical distribution services as determinants of product returns in Internet retailing. J. Oper. Management 32(6):295–312.Crossref, Google Scholar
- (2009) The Paradox of Choice (HarperCollins, New York).Google Scholar
- (2019) Where should I focus my return reduction efforts? Empirical guidance for retailers. Decision Sci. 50(4):877–909.Crossref, Google Scholar
- (2010) Optimal reverse channel structure for consumer product returns. Marketing Sci. 29(6):1071–1085.Link, Google Scholar
- (2011) Recruiting for ideas: How firms exploit the prior inventions of new hires. Management Sci. 57(1):129–150.Link, Google Scholar
- (2005) The making of a “hot product”: A signaling explanation of marketers’ scarcity strategy. Management Sci. 51(8):1181–1192.Link, Google Scholar
- (2004) Revenue management under a general discrete choice model of consumer behavior. Management Sci. 50(1):15–33.Link, Google Scholar
- (2012) Selling to conspicuous consumers: Pricing, production, and sourcing decisions. Management Sci. 58(12):2168–2189.Link, Google Scholar
- (2015) German private-sector watchdog accuses Zalando of false advertising. Reuters (November 5), https://www.reuters.com/article/us-zalando-court/german-private-sector-watchdog-accuses-zalando-of-false-advertising-idUSKCN0SU1FJ20151105.Google Scholar
- (2011) Herding in queues with waiting costs: Rationality and regret. Manufacturing Service Oper. Management 13(3):329–346.Link, Google Scholar
- (2018) The impact of consumer search cost on assortment planning and pricing. Management Sci. 64(8):3649–3666.Link, Google Scholar
- (2016) Battle of the channels: The impact of tablets on digital commerce. Management Sci. 63(5):1469–1492.Link, Google Scholar
- (2012) Rational herding in microloan markets. Management Sci. 58(5):892–912.Link, Google Scholar

