
An Exact Solution to Wordle
Abstract
In this paper, we propose and scale a framework based on exact dynamic programming to solve the game of Wordle, which has withstood many attempts to be solved by a variety of methods ranging from reinforcement learning to information theory. First, we derive a mathematical model of the game, present the resultant Bellman equation, and outline a series of optimizations to make this approach tractable. We then outline how to extend the framework to solve variants of the game—such as Wordle Hard Mode, optimizing for the worst case, and optimizing under nonuniform word probabilities—and present results for all game variants considered. We show that the best starting guess is SALET, that the algorithm finds all hidden words in at most five guesses, and that the average number of guesses starting with SALET is 3.421. We conclude by presenting experiments that illuminate why some approximate methods have struggled to solve the game, which our framework successfully circumvents because of its exact nature. We have also implemented our algorithm at wordleopt.com, so that the reader may interact with the optimal policy.
1. Introduction
Over the past year, the explosive popularity of Wordle has attracted the efforts of many to solve the game using a variety of methods: from reinforcement learning to custom mathematical frameworks, such as in Anderson and Meyer (2022) and Katz and Conlen (2022). Yet at the same time, the lack of consensus on the “best” policies produced by these methods prompts interest in a framework that produces a certifiably optimal strategy. This lack of consensus has one main source; approaches to solving Wordle have always contained some degree of approximation because of the computational difficulties of the task, which Lokshtanov and Subercaseaux (2022) showed is NP-hard. Ultimately, this approximation breaks any guarantee of optimality.
Exact dynamic programming is one such method that holds the potential to provably solve the game because this field has seen success in a variety of domains from algorithm design to healthcare and fundamentally solves problems without any degree of approximation (Bertsekas 2005). Despite this, no work exists on applying exact dynamic programming to Wordle, likely because of scaling difficulties pertaining to the Curse of Dimensionality. In this paper, we present advances on all these fronts. Namely, we propose a methodology that provably solves Wordle via exact dynamic programming and present a series of computational and theoretical results for this framework that yield an algorithm capable of tractably solving the game.
1.1. Literature
The use of greedy heuristics and neural networks combined with reinforcement learning methods to generate a policy for Wordle is so pervasive that, indeed to the best of our knowledge, no prior work exists on using exact dynamic programming to certifiably solve Wordle. Furthermore, among the literature that exists to have found the “best” words to guess for Wordle, there is a contradiction—pointing again to the fact that no one has certifiably solved the game. For instance, Katz and Conlen (2022) introduced WordleBot and has claimed that CRANE is the best starting word for the game; however, their approach uses a combination of information theory-based metrics, a two-step greedy algorithm, and a reduced action space. Glaiel (2021), Anderson and Meyer (2022), Bonthron (2022), and Liu (2022) all proceeded via methods such as neural network-backed reinforcement learning, rank-one approximations with latent semantic indexing, or other heuristics but produced disparate best first guesses such as SLATE, ROATE, or SOARE—all of which we later disprove as optimal first-moves. Furthermore, although all of the aforementioned techniques are flexible enough to solve alternative versions of Wordle, no prior work exists on solving the popular variants of the game, such as the Hard Mode, optimizing for the worst case, and optimizing under nonuniform word probabilities, which we address in this work.
1.2. Contributions and Structure
In this paper, we derive a finite-state Markov decision process to model the game of Wordle, present a tractable algorithm to solve the game to optimality using dynamic programming, and extend the methodology to tackle variants of the game. We analyze and demonstrate the efficacy of the optimal strategy discovered by dynamic programming. Finally, we comment on why the prior application of reinforcement learning to this problem has struggled to produce an optimal policy.
The main contributions of this paper are as follows:
Derivation of a finite-state Markov decision process (MDP) for the game of Wordle and presentation of a tractable algorithm to solve the MDP for the optimal policy of the game using dynamic programming. To our knowledge, this is the first methodology that certifiably produces a globally optimal policy for Wordle. We show that the best starting word is SALET; it finds all hidden words in at most five guesses, and the average number of guesses starting with SALET is 3.421.
An extension of the aforementioned MDP to handle variants of the game; in particular, we consider variants with nonuniform solution probabilities that minimize the maximum number of moves needed to win the game as well as the Hard Mode of the game.
Production of a website—wordleopt.com—presenting the framework and results in an interactive format by allowing the user to query optimal guesses given the state of the game. To date, the website has more than 100,000 visits.
A discussion of why prior applications of reinforcement learning to Wordle have struggled to produce near-optimal policies.
The structure of the paper is as follows. In Section 2, we describe the game of Wordle and outline the framework of our approach—specifically, the derivation of the Markov decision process modeling Wordle, the dynamic programming algorithm to solve the game, computational optimizations making the game tractable to solve, and modeling extensions for game variants. In Section 3, we present a suite of results and analysis, in particular, the best starting guess to use across variants, lessons from the optimal policy beyond the first guess, an analysis of the strength of the optimal policy over typical human play, and a discussion of why reinforcement learning struggles to uncover a near-optimal policy. In Section 4, we summarize our findings and report our conclusions.
2. The Framework
In this section, we review the rules of Wordle, outline the dynamic programming formulation of the game and variants, and present the algorithm used to solve the game.
2.1. Wordle
Wordle is a word game that has exploded in popularity over the past few years, drawing in millions of players from around the world Malik (2022). The player’s objective is to guess a hidden, five-letter word in at most six guesses, and the player is given information after each guess they make indicating whether their guess’s characters match that of the hidden word. More specifically, each character of the players guess is highlighted as green, yellow, or gray—indicating that the character is in the hidden word and in the correct position, that the character is in the hidden word but in the incorrect position, or that the character does not appear in the hidden word, respectively. Note that a frequently unknown subtlety arises in the case of repeated characters. Namely, if a guess contains a particular letter k times and the hidden word contains it n < k times, then the final k – n tiles of that character are colored gray (indicating that the character doesn’t appear more than n times), even though the character appears in the word. Ultimately, if the player does not manage to guess the hidden word after six guesses, they lose the game; otherwise, they win! Finally, note that we consider the version of the game published by the original creators, which has 2,315 possible solutions and allows up to 12,972 possible guesses; so, importantly, there are words that may be guessed but cannot be the hidden word.
Figure 1 provides an example game of Wordle, in which the player wins the game after four guesses, as indicated by the five green tiles in the final guess. In the first guess, POKER, we see that all but the fourth tile are colored gray, precisely because the letters P, O, K, and R are not in the hidden word VIXEN; the E is colored green because it is indeed in the hidden word and occurs in the fourth spot. In the second and third guesses, the letters N and V are colored yellow because they are present in VIXEN but do not occur in the first and third spots, respectively.

We conclude this subsection by outlining the rules of Wordle Hard Mode, which is a variant of the game we also solve. This version is identical to the regular version of the game, except with the restriction that the player is forced to use information revealed in the green and yellow tiles. Specifically, new guesses must contain characters that have appeared in yellow tiles and contain characters in the same position as those that have appeared in green tiles. With this restriction, note that NORTH would not have been a valid second guess for the game in Figure 1, because NORTH does not contain the letter E. There are also two common points of confusion regarding the restriction in Hard Mode. First, characters in gray tiles may still be present in future guesses (again, restrictions apply only to information from green or yellow tiles). Secondly, if k green or yellow tiles appear for a character in the same guess, then future guesses must contain that character at least k times.
2.2. Dynamic Programming Formulation
The game of Wordle can trivially be modeled as a partially observable Markov decision process (POMDP), in which the hidden information is the word we try to guess; this formulation, however, does not lead to a scalable algorithm to solve the game. In this section, we provide a formulation of the game into a tractable problem with a finite state space by outlining the definition of a state s, control a, cost function c, and state transitions of the underlying Markov decision process (MDP); we then provide the resultant dynamic programming equation that we use to solve the game. Note for simplicity and to align with the game’s implementation that we assume that each of the possible solutions of the game is equally likely at the start. When discussing game variants in Section 2.3, we present a simple modification to handle nonuniform solution probabilities.
- State: We define a state st as an unordered collection of the guesses and corresponding tile colorings seen so far, which clearly captures all information given to the player. At the start of the game, the state is an empty collection because no guesses have been made; as the game progresses, this collection grows exactly with the information the player sees in the game. To give an example, consider again the illustrated game in Figure 1. After the third guess, SEVEN, the state is POKER,
 NORTH,
NORTH,  SEVEN,
SEVEN,  .
.We provide a second definition of a state that is bijective to the first definition yet much more computationally convenient. Namely, we define a state as a collection of words, which represents the set of all possible solutions that are valid given the information presented to the player. Note that this is clearly equivalent to the first definition and satisfies the Markov assumption of dynamic programming because knowledge of future states depends only on the current understanding of which solutions remain valid. At the start of the game, the state is a set of 2,315 words, signifying that all possible solutions are valid; as the game progresses, this set decreases in size as information is revealed. To give an example, consider that the current state at time 4 is AWAKE, BLUSH, FOCAL, and the hidden word is FOCAL. If we make the guess THETA and see coloring
 , then from the coloring we know that the letters E and H are not present in the hidden word and thus that AWAKE and BLUSH are no longer possible solutions, transitioning us to the next state FOCAL, which reveals the hidden word.
, then from the coloring we know that the letters E and H are not present in the hidden word and thus that AWAKE and BLUSH are no longer possible solutions, transitioning us to the next state FOCAL, which reveals the hidden word.- Important Note: In all future discussions, we use the latter definition because it leads to more convenient and scalable algorithms for solving the game. Specifically, in calculating state transitions, one needs information regarding the potential colorings seen and their frequency, which requires knowledge of which solutions are still possible. As such, the latter representation seems more convenient as this information is readily available, whereas with the former definition we would need to check each of the 2,315 solutions for validity every time, which is expensive.
- Control: We define an action as a word in the set of all possible valid guesses A, which contains 12,972 words. Note, again, that it was a design choice of the game to make the set of guesses larger than the set of solutions.
- Cost Function: We define the cost of a guess as 1 and the cost of losing the game as . As such, , and . This way, if a policy has a finite cost, then we know that it wins the game with certainty (that is, regardless of the hidden word). Additionally, this cost structure directly allows us to minimize the expected number of guesses required to win the game, leading to the optimal policy for the game.
- Transition Function: For a given state st and guess a, denote as the collection of all states that we can transition into, given that we are in st and guess a. Note that , which represents the total number of colorings possible for the guess. For a fixed action a and state st, can be constructed by conditioning on each potential solution being the solution, observing the resultant coloring of a under w, and then iterating over st to remove solutions that are no longer valid; this produces one possible next-state , so repeating this for all yields . The associated transition probabilities are computed by counting the number of times a particular next-state appears while iterating through and dividing this count by . For a particular , we denote this transition probability as . Also, this entire process is enumerated in Algorithm 1.
Given this formulation of Wordle as a Markov decision process, we can apply the Bellman equation to solve for the optimal value of a state via
Before proceeding to the algorithm to solve this MDP, we note that our definition of an optimal solution here implicitly refers to winning the game in as few moves as possible on average, scoring all nonwinning games as infinity and given a uniform distribution of the solutions, which follows prior literature. However, given the flexibility of the formulation, this can be adapted to other cost structures and word distributions, some of which are considered (with examples) in Section 2.3.
2.2.1. Overview of the Algorithm.
First, observe that performing traditional back-propagation by enumerating all possible states at successively earlier times is computationally intractable, because the number of possible states at each time is exponential in the number of solutions, that is, . As such, we instead solve the equation for directly via recursion, in which s0 is the starting state with all 2,315 solutions present. Specifically, in evaluating , we iteratively search through the different guesses in A and recursively solve for states that can be transitioned into. Note that although this still involves a significant amount of computation (because of the large action space and the large number of possible states), a number of important computational optimizations make the problem feasible to solve, which we outline in the following subsection.
Finally, we note that a nice property of this algorithm is that it is trivially parallelizable. In particular, we can enumerate all possible next-states s1 from s0 and evaluate the value function of these next-states across many different processes.
2.2.2. Scaling the Algorithm.
In this section, we enumerate a number of observations that lead to significant speedups in solving the problem.
Observe that t = 5 corresponds to the situation in which the player has one guess left to make. If we denote s5 as an arbitrary state at t = 5, clearly, if , then because there is no action that can win the game with certainty; otherwise, when , then as per (1). This fact significantly reduces the amount of computation needed to solve Wordle because it effectively reduces the time-horizon of the game by 1; indeed, we encountered billions of states at t = 5 when solving the game, so having an explicit formula for their value likely reduced the computation needed by around a factor of 10.
If and t < 5, then . This is because guessing either of the words in the state will win the game with 50% probability or will transition into another state with cardinality 1, which has a value of 1. As such, Because we encounter millions of states of cardinality 2 when solving the game, and repeatedly so for each, this optimization likely reduces computation by a factor of 2.
Given a guess and a potential tile-coloring of that guess, it is straightforward to calculate whether an arbitrary solution to the game is still feasible given the information revealed by the tile-coloring. If we precompute this boolean for every combination of guess, coloring, and solution—resulting in a list of length —then we can compute the transition vector and associated probabilities in a number of array lookups linear to the state under consideration’s cardinality . Specifically, if we fix guess a and condition on being the solution to the game, we produce a tile-coloring; then, we check whether each possible solution in st is feasible under this by looking through the precomputed booleans and construct the next state from this information. Ultimately, this precomputation produces a very efficient methodology to calculate transitions. This optimization is one of the most important, because it reduces the computation required by more than a factor of 1,000 because we avoid recomputing the same type of information and can quickly perform this lookup using binary vectors.
When solving for in Equation (1), as we iterate through actions , we found it beneficial to prune suboptimal actions early, before evaluating each recursive term in the summation. To do so, first observe that for an arbitrary state st, a lower bound on is given by
Intuitively, this says that the best we can hope for is to guess the correct word in the state on the first guess with probability and otherwise only needing one more guess to win with probability (which corresponds to the first guess having been incorrect but determining the correct word with certainty). To perform pruning for a given guess a, we apply this lower bound to for every next-state . And as we progressively solve the different exactly, we update the summation in (1) with the exact values. If the lower bound on the objective ever exceeds the best guess seen thus far, we prune guess a and proceed to the next guess in A. We estimate that this optimization reduced the computation needed by a factor of 100, because it allows us to avoid computing the value functions of many states (in particular, large and costly states) and dampens the state-space blowup as we progress to future guesses.
Ultimately, we found that this pruning scheme can quickly filter out a strong majority of guesses in A, effectively reducing the large action space. We also found it helpful to exactly solve for next-states with the largest transition probabilities first, because they most significantly increase the summation.
Finally, after solving a large number of states, we found that the optimal guess to make in a state is often a possible solution to the state itself; that is, if is the argmin for a given state st in Equation (1), then a majority of the time we observe that . As such, while iterating through actions, we first evaluate those that lie in st first. We estimate that this reduces computation by a factor of around 3, because the algorithm filters out a large fraction of the actions by obtaining a good bound.
2.2.3. The Algorithm.
In this subsection, we provide descriptions of the algorithm used to generate the transition function and corresponding probabilities as well as the algorithm used to calculate with the aforementioned optimizations; these can be found in Algorithms 1 and 2, respectively.
(
Input: State st, String action
Output: Dictionary[Set → Float] next_states
transition_info Dict()
for solution , do
tile_coloring get_coloring(action, solution) ⊳ Coloring from action given solution
Set()
for temp_solution do
if is_valid_solution(action, tile_coloring, temp_solution), then
stemp.add(solution)
end if
end for
transition_info[stemp]
end for
return transition_info
We conclude this subsection by discussing the limits of feasibility. The current form of Wordle—with six rounds, five-letter words, and a guess and solution space of sizes 12,972 and 2,315, respectively—took days to solve via an efficient C++ implementation of the algorithm, parallelized across a 64-core computer. From inspection of (1), we see that scalability is dictated primarily by the number of rounds, vocabulary size, and word length. So, for instance, if we were tasked with solving a variant of Wordle with seven rounds, then the current form of the algorithm would likely not scale (because of the exponential blowup of (1)), and thus further optimizations would need to be implemented (such as proving time-independence of the value function, which we observed from the data but did not exploit or prove in this paper). However, increasing the vocabulary size within moderation would still result in a solvable game, because optimizations 3, 4, and 5 above would help avoid large increases in the computation by pruning suboptimal guesses and solutions.
(
Input: Integer t, State st, Dictionary[(Set,Integer) → Float] Vmemory
Output: Float
if t = 6 or , then ⊳ Optimization 1
return
else if t = 5 then
return 1
else if , then
return 1
else if , then ⊳ Optimization 2
return 1.5
else if , then
return
end if
state_value
for action , do ⊳ Optimization 5
temp, next_states , Get_Transition_Info(st, action) ⊳ Optimization 3
if next_states.size and next_states, then
continue ⊳ Skip action, no info revealed
end if
for , next_states do
temp temp ⊳ Optimization 4
end for
for , next_states do
if temp state_value, then
break
else if {action}, then
continue
end if
temp temp
end for
if temp < state_value, then
state_value temp
end if
end for
return state_value
2.3. Adapting the Framework for Wordle Variants
Here, we exemplify how to extend the framework to handle variants of Wordle. In particular, we discuss the needed changes for three common variants: handling nonuniform solution probabilities, minimizing the maximum (rather than average) number of guesses needed to win, and the Hard Mode of Wordle (see Section 2.1 for details on the rules).
2.3.1. Handling Non-Uniform Solution Probabilities.
Motivated by Wordle’s implementation, all prior discussions assumed that each possible solution has a uniform probability of being the hidden word; that is to say, all words in the solution set s0 have probability of being the hidden word at the start of the game. However, some implementations assign higher probabilities to more difficult words, so as to vary the difficulty of the game.
Before starting, denote as an arbitrary solution to the game, and assume that we know pw: the probability of w being the hidden word at the start of the game; note that , and in the regular version of the game, we have .
Now, in order to handle nonuniform solution probabilities, the definition of state, control, and cost function all remain the same as before; only the details of the transition function change. In particular, Line 12 in Algorithm 1 needs to become
This appropriately weighs the probability of each possible solution in a state st relative to the remaining solutions in that state.
We conclude by noting that although the computational optimizations from Section 2.2 still work in this case, two slight modifications are needed. First, for the second optimization, we write the value function for a state of size 2 as follows: If , then ; this intuitively says that the best we can do is to first guess the more likely solution of the two. Similarly, we need to update the lower bound in optimization 4 by an identical scheme.
2.3.2. Minimizing the Maximum Guesses Needed.
Variations of the cost structure or Bellman equation defined in Section 2.2 may also be of interest, so we consider such modifications in this subsection. In particular, we derive an MDP yielding a policy that minimizes the maximum number of guesses needed to win, rather than the average number of guesses. In other words, in this MDP, we deterministically transition to the next-state with the worst (highest) value.
To handle this situation, the definition of a state, control, cost function, and transition function all remain the same as in the regular version of Wordle. Rather, the Bellman equation replaces the summation in (1) with a max-operation and assigns a unit probability to this transition:
Regarding scaling techniques, we found that pruning was by far the most useful, resulting in a solve-time several orders of magnitude faster than for the regular version of Wordle. Specifically, solving the regular version of Wordle yields a policy that can win in at worst five moves; so, in solving this variant, we can prune any policies that result in five or more guesses to win by setting if t = 5. In this situation, we can also set the value function to for any states at t = 4 that do not have cardinality 1, because there is no way to win the game in one move. As such, this effectively becomes a dynamic program with a small time-horizon of 3, which is exponentially easier to solve.
2.3.3. Wordle Hard Mode.
Finally, we consider the popular variant of Wordle named” Hard Mode.” Recall from Section 2.1 that in this version the player is required to use information that has been revealed to him or her from green and yellow tiles. Thus, the set of actions the player can choose from is not fixed throughout the game.
To handle this situation, we modify the original formulation’s state definition and then update the control and transition function accordingly. As such, we have the following MDP formulation:
- State: We define a state st to be a pair of sets , in which keeps track of the valid solutions remaining, whereas keeps track of the valid actions remaining. Note, then, that this is still very similar to the original definition of the state, simply with an added component, so that we may keep track of the valid actions remaining in a computationally convenient manner.
- Control: As before, we define an action as a word; however, the set of actions is now dependent on the state st such that .
- Cost Function: As before, we define the cost of a guess as 1 and the cost of losing as .
- Transition Function: For a given state st and guess a, we again denote as the collection of all states that we can transition into. In Hard Mode, the construction of requires an extra step to update (in addition to as before). More specifically for a fixed action , conditioning on a potential solution , we can compute the coloring observed from this action and then iterate over both and and remove any words that are no longer potential solutions or valid actions, respectively. This produces a next-state ; repeating this across all yields .
Given this formulation of Wordle Hard Mode as an MDP, we can explicitly write the Bellman equation as
Note that although this variant is named Hard Mode, it is ironically computationally easier to solve because of the ever-shrinking action space. In addition, all of the scaling techniques from Section 2.2 are still applicable.
3. Results and Discussion
In this section, we present a detailed analysis of the optimal policy and discuss the results of why prior heuristics have struggled to uncover the optimal policy.
3.1. The Best Starting Word
A common question for Wordle is what the best first guess is. Table 1 answers this for Normal and Hard Mode by presenting the five best initial guesses to take in Wordle. From the table, we see that SALET is the best first guess in both versions, yielding an expected number of guesses of 3.421 and 3.508, respectively. Note that this expectation assigns equal probability to each of the 2,315 solutions being the hidden word.
|

Table 1. Listing of the Five Initial Guesses in Wordle Yielding the Lowest Expected Number of Guesses to Win If an Optimal Policy Is Followed
| Initial guess | Expected no. of guesses |
|---|---|
| (a) Regular Wordle | |
| SALET | 3.42117 |
| REAST | 3.42246 |
| TRACE | 3.42376 |
| CRATE | 3.42376 |
| SLATE | 3.42462 |
| (b) Wordle hard mode | |
| SALET | 3.50842 |
| LEAST | 3.51064 |
| REAST | 3.51361 |
| CRATE | 3.51749 |
| TRAPE | 3.51788 |
Note. Results are for the regular (left) and Hard Mode (right) versions.
Interestingly for both versions, from the top-five options, we see that it is highly valuable to have the letters A, E, and T in your initial guess because all top words contain these letters; including an S, L, or R appears to also be of high importance because these letters appear in most of the top words. As such, including these letters in an initial guess appears to yield the best results, as opposed to other common strategies such as including as many vowels as possible in the first guess, which is followed by avid player Bill Gates (Kain 2022). Indeed, to corroborate this, note that guessing SALET reveals an average of 1.683 colored tiles in the first move, whereas a word such as AUDIO, containing four vowels (the most that a single five-letter word can contain), reveals an average of only 1.320 colored tiles in the first move.
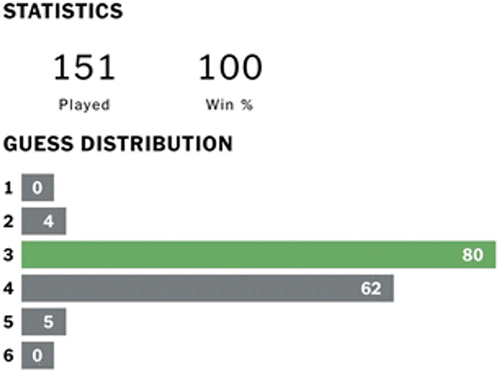
We conclude this subsection with results demonstrating the real-life performance of the policy. Namely, we played Wordle on the official New York Times website for the past 151 days using the policy, and we portray the performance statistics in Figure 2. As expected, we win the game every time, never need the sixth guess, and from these games need an average of 3.45 moves to win.
3.2. The Optimal Policy Beyond the First Guess
For the reader’s reference, Table 2 provides a glimpse into the optimal policy for the second guess, assuming that SALET was the first guess. To use the lookup table, each possible coloring from SALET is followed by the best second guess to make. Also note that portraying such a lookup table for the third, fourth, and fifth guesses takes up considerable space given the exploding number of possibilities, so we do not include these here. However, the reader may see and interact with the full policy at wordleopt.com.
|
Table 2. (Color online) A Lookup of the Optimal Second Guess Given the Feedback from Using SALET as the First Guess
 |
Figure 3 demonstrates the efficacy with which the optimal policy plays the regular and hard versions of Wordle. More specifically, it shows at most how many guesses are needed to win the game, conditioned on each of the 2,315 possible solutions to the game. For instance, after just two guesses, the optimal policy will have won the game 4.0% of the time in the normal mode, and after just one more guess, that probability increases to 57.1%. Interestingly, we also see that the optimal policy will never need to use all six guesses because it wins the game with certainty in at most five guesses, with just 3.3% of situations requiring that final fifth guess. This fact—that not all rounds are even necessary to win the game with certainty—highlights the advantage of optimality because some prior heuristic approaches (such as Bonthron 2022) produce policies that do not even win the game with certainty despite utilizing all six guesses; see Section 3.4 for further discussion on the trouble of applying heuristics to Wordle. For the Hard Mode, we see that the policy more aggressively uncovers the hidden word in the earlier guesses but then struggles to get the remaining hidden words relative to the normal mode; this is, of course, expected behavior given the more constrained action space. Also, we see that the Hard Mode policy does indeed need all six guesses to win.

Note. Results are presented for both the Normal and Hard Modes of the game.
Furthermore, solving the variant of Wordle from Section 2.3 that minimizes the maximum number of guesses needed reveals that a policy that wins in at most five guesses is the best we can do. In other words, there does not exist a policy that wins in four or fewer guesses across all starting words.
3.3. The Optimal Policy’s Strength over Human Play
A key property of the optimal policy is that it finds the absolute best guess to make. As such, the next guess is derived from a consideration of all possible actions and the information that each of these tells. In many situations, this intelligent global search can make the difference between winning the game with certainty or losing. For instance, consider the situation depicted in Figure 4, left, in which a human guesses the word LIGHT, revealing four green tiles in the final four characters. The human then proceeds to try finding the solution by changing only the first character, a strategy that ultimately loses him or her the game. Although this greedy, local-search behavior is intuitive and represents a first instinct to many, it can clearly be problematic because winning can be left to luck. On the other hand, in Figure 4, right, we depict the optimal strategy given that LIGHT was the initial guess and revealed four green tiles. As we can see from the figure, instead of greedily searching through possible solutions, the optimal strategy makes a second guess that is not a possible solution but rather aims to ascertain the first letter from an array of potential solutions. That is, by guessing FERMS second, it tests whether FIGHT, EIGHT, RIGHT, MIGHT, and SIGHT are the hidden word and is able to determine that EIGHT is the hidden word, winning the game with just three moves.

Ultimately, this demonstrates the clear edge that following an optimal policy gives. Interestingly, the Hard Mode of Wordle tends to prevent such intelligent forms of play, instead forcing a more greedy search as intended. In the above-depicted situation, in particular, a player would be forced to act as in the situation on the left; therefore, the initial guesses in Wordle Hard Mode are even more crucial to guarantee a win because the player more easily gets cornered into low-valued guessing.
3.4. On the Difficulty of Heuristics and Reinforcement Learning to Uncover the Optimal Policy
In this section, we present a series of experiments aimed to help the reader understand why prior heuristics and applications of reinforcement learning to Wordle struggled to uncover an optimal policy or even reach a consensus on an optimal first guess. To preface this section, as discussed in the Literature section (Section 1.1), many prior attempts to solve Wordle have claimed to find “best” first words, yet many of these papers and works do not even converge to the same answer.
One common feature of these prior works—such as Glaiel (2021), Anderson and Meyer (2022), or Katz and Conlen (2022)—is that they directly seek future states that are “good” in the sense of requiring a minimal number of moves to win. Indeed, as discussed in Section 2.2, in this work we also seek the same objective but do so in a certifiably exact manner, whereas prior work has no certification because of the use of heuristics. As we illustrate via experiments shortly, this becomes problematic when combined with the large action space of Wordle, which admits objective values (see (1)) that are very fine-grained. Namely, small errors in estimating the objective value cause suboptimalities in the policy at later time steps, and these errors compound as the policy and state values are back propagated.
To illustrate this point, we performed an experiment in which we added noise to the value function V of states at t = 3 and attempted to recover the optimal policy given that SALET was the first word guessed. Specifically, for a given state at , we perturbed by up to of its value and sought to compute the optimal policy under these noisy estimates of the value function. We note that this experiment sought to emulate prior work, as it used approximate methods (such as two-step greedy heuristics) to compute their policy.
Figure 5 presents the results of this experiment, which we rerun 25 times to account for randomness in the perturbations. On the y-axis, we have the expected number of moves needed to win Wordle under the policy uncovered, and on the x-axis we have the percent perturbation of the value function at t = 3. For the reader’s reference, we plot a horizontal red line at value 3.42 to emphasize that an optimal policy for Wordle wins the game in 3.42 guesses on average. Finally, the blue line plots the median expected number of moves to win of the uncovered optimal policy, and the blue shaded region around this plots the maximum and minimum expected moves to win across the 25 simulations.
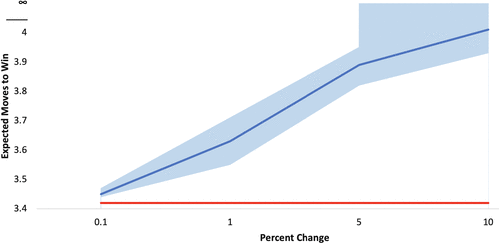
Interestingly, from the graph we see that as the perturbations become bigger, the deviation of the resultant optimal policy from the true optimal policy grows, so much so, in fact, that if we perturb the value function around 10%, then some of the simulations result in a policy that does not win with certainty. Additionally, we see that even if the perturbations are as small as 0.1%, we still cannot recover the true policy, because the lowest point of the shaded region is still greater than the expected value of the true optimal policy. Finally, it is important to point out that this degradation in the policy occurs in just three time-steps from first guess, that is, that the error propagations are significant for just three guesses from the start. Ultimately, then, this experiment again highlights and reveals why approximate methods—such as prior applications of reinforcement learning—struggle to uncover an optimal policy.
4. Conclusion
In this paper, we derive a novel, exact dynamic programming-based model for the game of Wordle and present an algorithm that tractably solves the game and, to the best of our knowledge, produces the first certifiably optimal policy for the game. The crux of the algorithm comes from a series of theoretical and computational observations from the Bellman equation solving the game, which can be found in Section 2.2. In Section 2.3, we also exemplify how to extend the framework to apply to variants of the game, such as Hard Mode.
Finally, we perform experiments to illustrate why prior approximate approaches to solving the game have struggled to uncover an optimal policy. Ultimately, we find that a large sensitivity to approximating state values contributes to difficulty in uncovering a true optimal policy for the game.
References
- (2022) Finding the optimal human strategy for Wordle using maximum correct letter probabilities and reinforcement learning. Preprint, submitted February 1, https://arxiv.org/abs/2202.00557.Google Scholar
- (2005) Dynamic Programming and Optimal Control, 3rd ed., vol. I (Athena Scientific, Belmont, MA).Google Scholar
- (2022) Rank one approximation as a strategy for Wordle. Preprint, submitted April 11, https://arxiv.org/abs/2204.06324.Google Scholar
- (2021) The mathematically optimal first guess in Wordle. Accessed May 31, 2023, https://medium.com/@tglaiel/the-mathematically-optimal-first-guess-in-wordle-cbcb03c19b0a#:∼:text=ROATE.Google Scholar
- (2022) Who has the best Wordle starting word: Bill Gates, Wordle bot or MIT? Accessed May 31, 2023, https://www.forbes.com/sites/erikkain/2022/09/15/who-has-the-best-wordle-starting-word-bill-gates-wordle-bot-or-mit/?sh=3a16deb02266.Google Scholar
- (2022) Introducing WordleBot, the upshot’s daily Wordle companion. Accessed May 31, 2023, https://www.nytimes.com/2022/04/07/upshot/wordle-bot-introduction.html.Google Scholar
- (2022) Using Wordle for learning to design and compare strategies. 2022 IEEE Conference on Games (CoG) (IEEE, Piscataway, NJ), 465–472.Google Scholar
- Lokshtanov D, Subercaseaux B (2022) Wordle Is NP-hard. Fraigniaud P, Uno Y, eds. 11th International Conference on Fun with Algorithms (FUN 2022), Leibniz International Proceedings in Informatics (LIPIcs), vol. 226 (Schloss Dagstuhl – Leibniz-Zentrum für Informatik, Dagstuhl, Germany), 19:1–19:8.Google Scholar
- (2022) Popular puzzle game Wordle is being purchased by the New York Times. TechCrunch (February 1), https://tcrn.ch/3HletQK.Google Scholar
Dimitris Bertsimas is the Boeing Professor of Operations Research and the associate dean of business analytics at the Sloan School of Management, MIT. His research interests include optimization, machine learning (ML), and their applications. He is currently editor-in-chief of INFORMS Journal on Optimization.
Alex Paskov is currently a PhD student at the MIT Operations Research Center. Prior to his graduate work, he studied applied mathematics and computer science at Columbia University, where he graduated salutatorian of his class. His research interests include optimization and machine learning with a focus on reinforcement learning.

