
Network Flow Models for Robust Binary Optimization with Selective Adaptability
Abstract
Adaptive robust optimization problems have received significant attention in recent years but remain notoriously difficult to solve when recourse decisions are discrete. In this paper, we propose new reformulation techniques for adaptive robust binary optimization (ARBO) problems with objective uncertainty. Without loss of generality, we focus on ARBO problems with “selective adaptability,” a term we coin to describe a common class of linking constraints between first-stage and second-stage solutions. Our main contributions involve reformulating and approximating these ARBO problems as network flow models by leveraging ideas from the decision diagram literature. We show that these models are versatile and easy to customize and can generate feasible solutions, primal bounds, and dual bounds. Furthermore, in contrast to existing approaches, they require no specialized algorithms and can be solved directly using standard optimization solvers. Through an extensive set of computational experiments, we show that our models generate high-quality solutions and dual bounds in significantly less time than popular benchmark methods.
History: Accepted by Andrea Lodi/Design & Analysis of Algorithms-Discrete.
Supplemental Material: The software that supports the findings of this study is available within the paper and its Supplemental Information (https://pubsonline.informs.org/doi/suppl/10.1287/ijoc.2024.0718) as well as from the IJOC GitHub software repository (https://github.com/INFORMSJoC/2024.0718). The complete IJOC Software and Data Repository is available at https://informsjoc.github.io/.
1. Introduction
Robust optimization (RO) has become a well-established paradigm for modeling and solving decision-making problems under uncertainty. It has found diverse applications, particularly in problem settings where the distribution of model parameters is difficult to estimate or when it is necessary to consider worst-case outcomes. Early research focused largely on static RO models, where a single robust solution is applied to all possible parameter realizations (Bertsimas et al. 2013). More recently, there has been significant interest in adaptive RO models, where recourse decisions can be made once additional information is revealed (Yanıkoğlu et al. 2019).
Adaptive RO models, particularly those with discrete recourse variables, are relevant in numerous application domains, such as routing (Eufinger et al. 2020), scheduling (Yan and Kung 2018), facility location (Hanasusanto et al. 2015), network design (Álvarez-Miranda et al. 2015), batching (Bayram et al. 2022), and matching problems (McElfresh et al. 2019). Despite their importance, these models can be significantly more challenging to solve relative to their static counterparts. Specifically, although there are standard techniques to reformulate and solve static RO models as tractable mixed-integer linear programming (MILP) problems, these techniques do not extend directly to adaptive RO models, where discrete recourse decisions must be defined for each and every parameter value lying within an uncertainty set. Few exact solution methods exist for solving these models, and most require specialized and carefully tuned algorithms (Zeng and Zhao 2013, Kämmerling and Kurtz 2020, Arslan and Detienne 2022). Instead, significant attention has been placed on approximation techniques, particularly ones that yield MILP formulations that can be solved directly using standard solvers (see, e.g., Hanasusanto et al. 2015).
In this paper, we consider adaptive robust binary optimization (ARBO) problems with objective uncertainty. We focus, without loss of generality, on ARBO problems with selective adaptability, a term we introduce to describe a class of linking constraints in which first-stage variables fix the values of one or several recourse variables but leave the others unrestricted, allowing the remaining recourse variables to adapt to new information. We show that this structure arises naturally in various planning and sequential decision-making tasks and can also be induced by adding auxiliary variables to general ARBO formulations that do not inherently exhibit this property. More importantly, we demonstrate that the structure of these linking constraints enables the development of new reformulation techniques and versatile solution methods for ARBO problems. Below, we provide a concise summary of our main contributions:
We introduce ARBO problems with selective adaptability and show how the structure of the linking constraints can be exploited when we have a description of the convex hull of the recourse feasible space (Section 3). We then leverage ideas from the decision diagram community to obtain such a description, demonstrating that ARBO problems can be reformulated as constrained network flow models (Section 4). In these models, recourse decisions are represented by continuous flows on certain links in a large, capacitated network and where capacity constraints are given by the values of first-stage decisions. Because these network flow models are MILPs, they can be solved directly using standard off-the-shelf solvers.
We present new techniques to generate more compact and tractable network flow models to approximate large ARBO problems (Section 5). The first technique utilizes approximate decision diagrams to formulate inner and outer approximations of the recourse feasible space, which enables the generation of both feasible solutions and primal and dual bounds on a given ARBO problem. The second technique, which we term as a generalized multinetwork flow model, pools together a collection of multiple constraints and networks to generate feasible solutions and dual bounds. We show the versatility of these approximation methods and outline new approaches for specifying the size and quality of these approximations.
We examine the performance of our exact and approximate network flow models in two sets of numerical experiments (Section 6). For smaller ARBO problems, we find that the exact network flow models can be solved efficiently. For larger ARBO problems, we show that approximate network flow models are essential and can reliably produce near-optimal solutions and high-quality dual bounds in solution times that are orders of magnitude faster than exact approaches and benchmark models. Furthermore, we show that the size and solution times of the approximate models can be reduced substantially while sacrificing very little in terms of solution quality, making these methods highly scalable to large ARBO problems.
All proofs can be found in the Electronic Companion. All vectors and matrices are presented in bold letters, whereas sets are denoted using calligraphic letters. Let be a feasible set described using linear and integrality constraints. We use to describe the relaxation of obtained by removing integrality constraints and to denote the convex hull of ; by definition, . The set of extreme points of any polyhedral set is denoted by .
2. Literature Review
We first review the relevant literature on robust binary optimization with objective uncertainty, followed by the literature on decision diagrams (DDs) and network flow models. We refer to Bertsimas et al. (2013) and Yanıkoğlu et al. (2019) for a broader overview of robust optimization.
2.1. Adaptive Robust Binary Optimization
Static robust binary optimization with objective uncertainty is well studied, where robust formulations of polynomially solvable problems can be NP-hard (see, e.g., Buchheim and Kurtz 2018). Nonetheless, these RO problems admit straightforward MILP formulations by reformulating the inner adversarial problem using standard optimality conditions.
In contrast, few algorithms exist for solving ARBO problems with objective uncertainty, where optimal recourse decisions must be defined for any parameter drawn from the uncertainty set. The first and most well-known solution approach is the nested constraint-and-column generation algorithm, which iterates between a master problem and a subproblem that adds new variables and constraints into the master problem (Zeng and Zhao 2013). The second approach is a branch-and-price algorithm where, within each node of a branch-and-bound tree, the algorithm solves a series of iterative pricing problems to add columns that correspond to feasible recourse decisions under a fixed first-stage solution (Arslan and Detienne 2022). Finally, Kämmerling and Kurtz (2020) defined a specialized branch-and-bound algorithm that branches over first-stage solutions while using another algorithm to iteratively refine the dual bound in each node of the tree. The constraint-and-column generation approach is known to scale poorly to larger instances because each iteration of the algorithm adds a copy of all recourse variables and constraints to the master problem (see, e.g., Dumouchelle et al. 2023). On the other hand, the latter two approaches require carefully tuned intermediary steps and may be confined to specific software; for example, many commercial solvers limit the degree of user customization of specific branch-and-bound processes.
The challenges associated with these exact solution methods have motivated considerable interest in approximation techniques (Vayanos et al. 2011, Postek and Hertog 2016). For example, Bertsimas and Georghiou (2015) and Bertsimas and Dunning (2016) considered the use of piecewise constant decision rules to represent the binary recourse variables. Alternatively, Hanasusanto et al. (2015) and Subramanyam et al. (2020) proposed the K-adaptability method, which pre-identifies K recourse solutions to be implemented in the second stage, resulting in an MILP model that has become a commonly used benchmark (see, e.g., Dumouchelle et al. 2023 and Arslan and Detienne 2022).
In this paper, we present a new family of exact and approximate MILP reformulations for ARBO problems with objective uncertainty. We show that these formulations are highly versatile and can produce near-optimal solutions and bounds in significantly less time than existing methods.
2.2. Decision Diagrams and Network Flow Models
Decision diagrams are directed acyclic graphical structures that can be used to model and approximate the feasible space of discrete optimization problems. In recent years, DDs have been used to analyze, solve, and generate bounds and/or cuts for various discrete optimization problems (Bergman et al. 2016). Whereas most of the literature has focused on binary and integer programs, recent work has extended the use of DDs to nonlinear and mixed integer programs (see, e.g., Davarnia and Van Hoeve 2021 and Salemi and Davarnia 2023). With few exceptions, previous work focuses mainly on deterministic problems. Below, we highlight relevant literature on (approximate) decision diagrams and their applications in optimization problems under uncertainty and refer to Castro et al. (2022) for a more comprehensive survey of decision diagrams.
Although DDs can technically be used to model the feasible space of any discrete optimization problem exactly, one limitation is that the size of these diagrams may increase exponentially with problem size. In contrast, approximate DDs can encode inner and outer approximations of the feasible space, where the size of these DDs can be user specified. Many papers examine the tradeoff between the size of the DDs and the quality of the bounds and/or cuts that they generate, especially when compared with standard linear relaxations of various integer programs (Cire and Van Hoeve 2013; Bergman et al. 2014, 2016; Tjandraatmadja and van Hoeve 2019; Serra and Hooker 2020; Davarnia and Van Hoeve 2021). In this context, DDs are typically considered as a way to compete against, or enhance, standard MILP solution methods for deterministic problems and are used in their graphical form with shortest path algorithms. In contrast, we utilize DDs for their network flow representations to generate MILP-based reformulations and approximations of the ARBO problem. Compared with existing solution methods for ARBO problems, these MILP formulations are easier to formulate and solve using standard solvers.
Several works have examined the use of decision diagrams in two-stage stochastic programming with binary recourse decisions (Lozano and Smith 2018, Guo et al. 2021, MacNeil and Bodur 2023). Specifically, a decision diagram is associated with each scenario, making the two-stage problem amenable to standard Benders decomposition techniques that typically apply only to problems with continuous recourse; in the decomposition, shortest path algorithms are applied on the diagrams to generate cuts for the master problem. On the other hand, Serra et al. (2019) considered a monolithic formulation of a two-stage scheduling problem where a subset of constraints are replaced with DD-based network flow constraints. Integrality of the flows across these networks are then enforced using binary variables. Salemi and Davarnia (2023) extended DDs to represent mixed-integer optimization problems, which they used to reformulate the master problem of a Benders decomposition applied to solve the stochastic unit commitment problem. Hooker (2022) proposed the concept of stochastic decision diagrams for stochastic dynamic programming problems, where transition probabilities are associated with arcs of the decision diagram. To our knowledge, Lozano et al. (2022) has been the only application of DDs for robust optimization, where static RO models are reformulated into DD-based constrained shortest path problems for which specialized algorithms can be employed. In contrast to these works, we consider the first use of DD-based network flow models for adaptive robust optimization, which facilitates MILP reformulations and approximations for these problems.
3. Robust Binary Optimization with Selective Adaptability
In this section, we define the ARBO problem of interest, introduce the concept of selective adaptability, and derive several preliminary insights based on the structure of the ARBO problem.
3.1. Problem Definition
Consider an ARBO problem of the form
(
An ARBO problem with selective adaptability implies that the value of each binary recourse variable is either (i) fixed by the values of first-stage decisions (because of constraints corresponding to and those associated with and if is 0 or 1, respectively) or (ii) not restricted by the values of first-stage decisions (because the constraints associated with become redundant when and when for all and for all ). Practically, this implies that individual recourse variables not impacted by the first-stage decisions can be used to “adapt” to new information.
3.2. Models with Selective Adaptability
We give a few examples of ARBO problems with selective adaptability and then show that our examination of this problem structure comes without loss of generality. We begin with two examples of sequential decision-making problems that naturally exhibit this linking constraint structure:
In a facility location problem, a planner can make an assignment (or shipping) decision between a potential location j and an individual customer l only if a facility (e.g., hub, warehouse, factory) has been placed at location j (Kämmerling and Kurtz 2020). Assuming that customer demand is given by , the sequential nature of this decision-making process can be represented by linking constraints of the form , where is a particular location-customer assignment decision and determines whether a facility is placed in location j.
In a project investment problem, an investor with a limited budget aims to maximize investment returns across two decision stages by investing in different projects where early-stage investments come with risk but higher return rates (Arslan and Detienne 2022). For each project , the linking constraint captures early-stage commitment decisions. We revisit this problem in our numerical experiments in Section 6.
The concept of selective adaptability is also relevant when relaxing static robust optimization problems. Specifically, note that a static RO problem can be written as
3.3. Preliminary Model Insights
One possible reformulation of Problem (1) is as an infinite-dimensional MILP model, that is,
Arslan and Detienne (2022) observed that Problem (1) permits an alternative reformulation as
This observation can be made by noting that the inner minimization of Problem (1) is equivalent to optimizing over . Because this set is convex, we can apply the minimax theorem (Neumann 1928) to swap the order of the inner max and min operators, which leads to model (4).
We now show that there exists an even simpler reformulation when satisfies selective adaptability. This reformulation is shown in the next proposition, which relies on the following lemma.
If Problem (1) has selective adaptability, then
If Problem (1) has selective adaptability, then model (3) can be reformulated as shown, where becomes a vector of continuous variables:
The second and third constraints come directly from applying Lemma 1 to model (4), whereas the term in model (4) is reformulated using strong duality. Namely, recall that because , the dual of this maximization term can be rewritten as }. Thus, the new variables in model (5) correspond to the dual variables of this reformulation.
Proposition 1 is important for two reasons and motivates the rest of this paper. First, model (5) is equivalent to a static RO problem, that is, where both and represent “first-stage” decision variables. Practically, this implies that the original ARBO problem can be solved as an MILP if we have a polyhedral representation of . Section 4 focuses on representing in an extended network-based space. Second, Proposition 1 provides intuition for developing approximation methods, which are the focus of Section 5. In particular, replacing with an inner (or outer) approximation of it will generate a valid primal (or dual) bound on the optimal value of (5). For example, replacing with the continuous relaxation of , that is,
For the rest of this paper, we assume the ARBO problem has selective adaptability. This assumption is made for ease of exposition and comes without loss of generality. In particular, any ARBO problem without selective adaptability can be reformulated into one that has this property by adding auxiliary variables into the recourse problem. Specifically, let be a set of linking constraints that are not in the form of (2), and let be the indices of the variables that appear in these constraints. Now, let be a new set of auxiliary recourse variables. For each , we can replace in with the corresponding variable, making these constraints a part of , and redefine the linking constraints as . This technique is inspired by Arslan and Detienne (2022) and implies that all results derived in our paper are applicable to any ARBO problem with or without selective adaptability.
We conclude this section with two additional remarks on the generalizability of upcoming results.
The reformulations and approximations that are proposed in this paper apply to problems where first-stage decisions are mixed-integer, that is, , as long as only the binary variables defining appear in the linking constraints .
After Section 4, one may wonder whether we can use the network flow formulations to directly represent in constraint (4b) by building a decision diagram representation of the set rather than artificially inducing selective adaptability using new auxiliary variables. We note that these two ideas are in fact equivalent. A decision diagram for the decision region must by definition have m more layers than one for (see Section 4). This would be exactly the same as the decision diagram for the set , where are auxiliary variables introduced to reformulate a general ARBO problem into one with selective adaptability (where become the linking constraints).
4. Constrained Network Flow Reformulations
In this section, we present an MILP formulation for model (4) when . Specifically, in Section 4.1, we introduce DDs and the network flow formulation used to obtain a polyhedral description of . Then, in Section 4.2, we integrate the formulation with first-stage decisions.
4.1. Reformulating the Recourse Feasible Space
We first describe a general procedure for obtaining a decision diagram encoding of the feasible solutions in and then represent this diagram using a network flow formulation.
4.1.1. Decision Diagram Formulation.
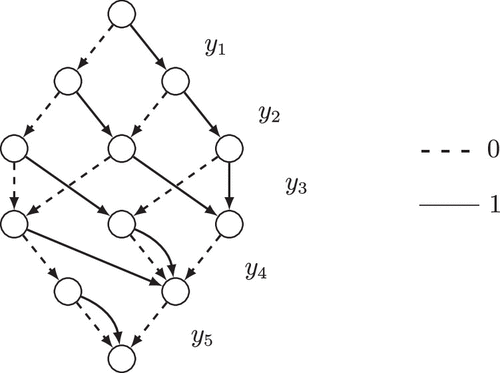
A binary decision diagram (BDD) is a graphical structure that can be used to encode the feasible space of a binary optimization problem (Bergman et al. 2016). Specifically, a BDD is a directed acyclic graph with nodes and arcs . The nodes are partitioned into nonempty layers , whereas the directed arcs connect nodes in adjacent layers from to for . The sets and are each composed of a single node, defined as the root node and terminal node, respectively. Each arc in the network has a label of either zero or one, and and define the subset of zero and one arcs leaving nodes in , respectively. A decision diagram is a valid representation of a feasible space if each path from root node r to terminal node t in can be mapped to a solution and vice versa. This mapping of paths to solution is defined by the zero-one label on each arc in the path. Specifically, for any arc j in the path, if , then , or if , then . For example, a decision diagram of is given in Figure 1. Finally, we note that the definition of BDDs in the literature generally includes arc weights that correspond to the value of objective coefficients of an optimization problem. Because these coefficients are not deterministic in our problem, we instead consider only “unweighted” decision diagrams.
DDs are closely related to the state-transition graph in the dynamic programming literature (Hooker 2013). In particular, nodes and arcs in the DD can be mapped to “states” and feasible “actions” of a recursive formulation where decisions are made sequentially. Many binary optimization problem structures admit simple recursive formulations that can be used to obtain decision diagrams (Bergman et al. 2016, 2022). In general, a recursive formulation of a deterministic binary optimization problem can be written as a Bellman equation of the form
Consider a feasible set that is defined by a knapsack constraint. The recursive formulation of is defined by feasible actions and state-transition function with an initial state . Each stage i in the recursive formulation thus corresponds to a layer i in the diagram. Each state in layer i represents the total amount of capacity used by the selection of items among , and feasible actions correspond to whether an additional item can be placed in the knapsack given the current state. To obtain a single terminal node in the decision diagram, we merge all nodes in layer , which is equivalent to replacing with in the recursive formulation. Note that this change in the state-transition matrix at the final stage n does not change the set of feasible actions in the recursive formulation.
Finally, we note that DDs can typically be reduced to encode the same set of feasible solutions with far fewer nodes and arcs. Figure 1 is a reduced DD for the knapsack set defined earlier. To obtain reduced DDs, we can use a simple bottom-up merging technique (Bryant 1992, Bergman et al. 2016). Starting with nodes in layer n, we can merge any nodes that have the same set of outgoing arc types and destinations, repeating this procedure from layers to 1.
4.1.2. Recourse Network Flow Formulation.
Let denote a DD representation of . Following the notation of Castro et al. (2022), we use to denote the network flow model of , which relates arc flows to values of in the recourse problem, that is,
4.2. A Complete Network Flow Reformulation
A key property of is that its projection onto the variables , denoted by , is equal to the convex hull of (Tjandraatmadja and van Hoeve 2019, Davarnia and Van Hoeve 2021). We can use this property to derive an MILP formulation of Problem (1), as shown next.
Problem (1) can be reformulated into the constrained network flow problem
Model (8) is an exact MILP reformulation of any ARBO problem with selective adaptability. It is derived by replacing the constraint in model (5) with the network flow formulation in (7). As we show in Section 6, this model can be tractably solved for problems of smaller sizes.
Consider the adaptive robust knapsack problem
Recall that the DD for is illustrated in Figure 1. Suppose . Then, problem (9) can be reformulated into model (8), where is the node-arc incidence matrix of the decision diagram given in Figure 1, and
The indices correspond to the solid lines in Figure 1 when labeled from left to right in each layer, starting with the first layer.
5. Network Flow Approximations
In this section, we present methods for constructing approximate decision diagrams, which in turn yield more tractable and compact network flow models. We then demonstrate that these models can generate both solutions and bounds for ARBO problems.
5.1. Approximate Decision Diagrams
A restricted decision diagram of contains paths that map to a strict subset of the feasible solutions in . On the other hand, a relaxed decision diagram contains paths that map to a superset of solutions that include all solutions in . Restricted and relaxed decision diagrams can be generated by merging states in the recursive formulation of (Castro et al. 2022). Next, we outline two general “top-down” approaches for building restricted and relaxed decision diagrams.
5.1.1. Merging with Width-Based Thresholds.
In Algorithm 1 we present a common approach that merges nodes whenever a threshold on the diagram’s “width” has been exceeded. Specifically, each layer in the diagram is constrained to have a width of at most W; that is, there can be at most W nodes per layer. Considering the recursive formulation, this width constraint is equivalent to having at most W number of different states at stage i. Note that if in Algorithm 1, then an exact decision diagram will be generated.
(
Input: A recursive formulation of , a width parameter W
Output: A decision diagram
1: Initialization: let denote the initial state of the system (at root node r),
2: for , do
3: for , do
4: for , do
5: if where , then add arc from u to with label
6: else add node with state to and add arc from u to with label
7: if , then
8:
9:
10: for , do
11: for , do add arc from u to t with label
12: Reduce
13: return
In step 8, the algorithm requires a rule for selecting nodes from the set . The simplest and most commonly used procedure is random selection (although designing node selection procedures has become a more active topic of research in recent years; see, e.g., van Hoeve 2022). Once this subset of nodes has been selected, they can be merged to create either restricted or relaxed DDs. To create relaxed DDs, merging operators must assign a new state to each merged node such that all subsequent feasible actions in the original recursive formulation remain feasible under this new state (Hooker 2013). Similarly, a restricted DD can be created by assigning a new state to the merged node such that a subset of feasible actions in the original recursive are retained without introducing infeasible actions. We give an example below.
Consider a feasible space defined by a single knapsack constraint (see Example 1). A relaxed (restricted) decision diagram can be generated by merging the nodes and assigning the new node a state that is the minimum (maximum) value of the states in the merged set.
We note that the node merge operation can be performed while building a layer, rather than after the layer is completely built, to reduce the memory requirement if desired. Furthermore, we note that we can also generate restricted diagrams simply by discarding nodes rather than merging them in Algorithm 1 because we are effectively removing all feasible actions associated with that state-stage combination in the recursive formulation. Finally, step 12 is to reduce the size of the decision diagram using the bottom-up approach described at the end of Section 4.1.1.
5.1.2. Merging with Distance-Based Thresholds.
We now propose a merging approach based on the similarity of states in each layer; that is, we merge two nodes only when their respective state values are within some “distance” of each another. Algorithm 2 outlines this approach, which revolves around a partitioning of nodes in each layer into subgroups, where nodes in each subgroup are then merged. Any suitable set partitioning method can be used, as long as two conditions are met: (i) within each subgroup, some predefined notion of distance between any pair of states does not exceed a user-specified parameter Q, and (ii) for any two subgroups, there exists a pair of nodes, one node in each subgroup, where the distance exceeds Q. The latter condition ensures the fewest number of partitions given Q. To the best of our knowledge, we are the first to outline and implement this distance-based approach for generating approximate decision diagrams.
(
Input: A recursive formulation of , a distance function , and distance parameter Q
Output: A decision diagram
1: Initialization: let denote the initial state of the system (at root node r),
2: for do
3: Steps 3–6 from Algorithm 1
4:
5: for , do
6:
7: Steps 10–13 from Algorithm 1
We give an example of a partition function (step 4 of Algorithm 2). Consider the feasible space defined in Example 3, for which we can define the following node partitioning procedure: (i) order nodes according to state values, from smallest to largest; (ii) starting with the smallest state, create a new subgroup for the next node if and only if its state is more than Q units larger than the smallest state in the current subgroup. Here, distance between states is simply defined as the absolute difference between state values.
The distance-based merging approach is motivated by our initial attempts at using width-based merging in preliminary experiments. We found that it was difficult to finely tune the size of the diagram and quality of the approximation through the use of the width threshold parameter W. In particular, when the width threshold is exceeded, it is often exceeded by a large margin, which typically results in the merging of hundreds or thousands of nodes into a single node. Furthermore, because the width constraint must be satisfied at each layer, there are essentially no restrictions on which nodes can or cannot be merged. In contrast, the key advantage of the distance-based approach is that both the size and the quality of the approximation is closely tied to the value of Q. In distance-based merging, Q determines precisely which nodes in each layer can and cannot be merged based on the similarity of their states. Furthermore, at each layer there may be many subgroups, but the number of nodes to be merged within each subgroup may be small. In general, we find that this distance-based merging procedure leads to approximations of higher quality and more precision in tuning the size and tractability of the corresponding models.
Finally, we remark that the distance-based approach can be customized to generate even more refined approximations by merging subgroups with some probability . This additional feature can generate approximations that lie in between those generated solely by incrementally increasing the value of Q (which could be discrete when all states are integer-valued, as in Example 3).
5.2. Generating First-Stage Solutions and Dual Bounds
In this section, we focus on the use of (relaxed) decision diagrams to formulate MILP models that simultaneously generate first-stage solutions and dual bounds for the ARBO problem. A brief discussion of restricted diagrams can be found in Section EC.2 of the Electronic Companion.
Let denote a relaxed decision diagram of . Then, the model
The proposition follows from the observation that represents a superset of , which implies that . Furthermore, (10) includes the additional term to tighten the dual bound that is generated because, in general, and (i.e., can have fractional extreme points, whereas is an integral polyhedron but includes solutions that are not in ). The intersection of and can thus yield a better outer approximation of compared with either sets alone (see Section EC.3.3 for details).
Whereas (10) uses a single decision diagram to generate an outer approximation of , we propose a generalization using a collection of diagrams and feasible sets.
Suppose that , and let denote the set of constraint indices. Now, suppose we are given a collection of subsets of indices and , where and . For an arbitrary set , let and denote an exact and relaxed decision diagram for the feasible set described by the constraints with indices in , respectively. Then, the model
As a proof of concept, consider the model from Example 2 but with an additional constraint of . Rather than formulating an exact or relaxed decision diagram of
In practice, multinetwork approximations can be useful when single-network representations are too large or when the underlying problem structure does not admit an obvious recursive formulation. In these settings, we can generate exact or relaxed DDs for subsets of constraints that do admit a simple recursive formulation (Tjandraatmadja and van Hoeve 2019, Davarnia and Van Hoeve 2021). Furthermore, in many decision-making problems, a large subset of constraints defining may have a totally unimodular constraint coefficient matrix and integer right-hand sides and thus define a feasible space for which its relaxation is an integral polytope. In this setting, we can generate DDs only for the remaining constraints. The corresponding multinetwork flow approximations may potentially be smaller in size, easier to implement, or better in quality than single-network approximations. We will further explore these models in the numerical experiments in Section 6.2.
5.3. Evaluating the Quality of a Solution
All models presented earlier generate a feasible first-stage solution . The true objective value of this solution, which we denote using , can be computed by solving
Problem (12) can be solved using a simple constraint generation algorithm where, at an iteration k, a master problem solves a relaxation of (12) over an enumerated set of recourse solutions , whereas a subproblem solves the inner problem for a fixed and generates a new solution to add to ; for brevity, we refer to Kämmerling and Kurtz (2020) for details.
Because the approximation models presented in Section 5.2 produce both a solution and a dual bound, we can compute a model-based optimality gap for the solution, defined as
6. Numerical Experiments
In this section, we examine the performance of the exact and approximate network flow models for two different ARBO problems. All experiments and models were coded in Python 3.7 and solved using Gurobi 9.1.1 under default settings on a Macbook Pro (M1 Chip) with 16GB of RAM. The code can be found at Bodur et al. (2025).
6.1. Capital Budgeting Problems
We first consider a capital budgeting problem, which seeks to compute a robust investment plan for a set of n projects under an investment budget constraint. Several variants of this problem have been studied in the adaptive robust optimization literature (Hanasusanto et al. 2015, Kämmerling and Kurtz 2020, Subramanyam et al. 2020, Arslan and Detienne 2022, Dumouchelle et al. 2023). In this problem, investment decisions are binary and can be made in two stages; that is, projects can be invested in at either an early stage (denoted using ) or a later stage (denoted using ). The profitability of a project is not known with certainty in the first stage and is revealed only in the second stage. Early-stage investors are rewarded with a first-mover advantage that entails a higher percentage on the final profit generated by each project.
We follow the model formulation from Arslan and Detienne (2022) and use their publicly available problem instances.1 Specifically, we consider the adaptive capital budgeting problem:
In this model, denotes the cost of investing in project i, h is the total investment budget, captures the first-mover advantage, and is the payoff of project i, which is unknown in the first stage. The payoff of each project depends on a set of M common risk factors . Specifically, it is assumed that , where describes the impact that each risk factor has on the payoff . The risk factors are assumed to reside in , that is,
We consider 300 instances of varying size where and where each value of n is associated with 60 different instances (Arslan and Detienne 2022). Each instance is characterized by a random sample of project costs and payoffs as well as an investment budget defined as a fraction of total project costs, that is, with .
In (14), the linking constraint satisfies selective adaptability, and the remaining two constraints can be reformulated using DDs. Because is a knapsack constraint, we generate the exact decision diagram by following the steps in Example 1; from this, we can obtain an exact network flow reformulation of (14). We also derive approximate network flow models based on relaxed DDs generated using the distance-based merging approach discussed in Section 5.1.2. Recall that in this approach, a user-specified value Q bounds the distance between state values of nodes that are to be merged. In the capital budgeting problem, the state value of a node in layer i defines the amount of weight that has been added to the knapsack based on decisions , and Q represents the maximum difference in weight values between any two nodes to be merged. We follow the procedure described in Example 4 to determine which nodes should be merged. Once merged, the new node is assigned the minimum state value of the nodes that were merged. Finally, recall that the resulting network flow models generate first-stage solutions and dual bounds.
6.1.1. Model Formulation and Solution Time.
Table 1 highlights the average number of arcs in the exact () and approximate () decision diagrams used to represent . These numbers convey the size of the corresponding network flow models because each arc in a decision diagram corresponds to a continuous variable in the model. All decision diagrams took no more than a few seconds to generate, and most were generated within a fraction of a second.
|

Table 1. The Average Number of Arcs in the Reduced Decision Diagrams Under Different Q Values
| 166 | 164 (99%) | 151 (91%) | 134 (81%) | 109 (65%) | |
| 2,992 | 1,972 (66%) | 1,198 (40%) | 894 (30%) | 554 (19%) | |
| 12,334 | 6,726 (55%) | 3,600 (29%) | 2,463 (20%) | 1,359 (11%) | |
| 28,121 | 14,621 (52%) | 7,374 (26%) | 4,912 (17%) | 2,622 (9%) | |
| 48,285 | 24,589 (51%) | 12,180 (25%) | 7,954 (16%) | 4,160 (9%) |
Note. The percentage of each value relative to that of the exact decision diagram (i.e., ) is given in parentheses.
Table 2 summarizes the solution time of the network flow models, from which we make two observations. First, when n increases, the time it takes to solve the exact model grows exponentially, implying that the exact models are generally intractable beyond small values n. In contrast, as we increase Q for a fixed value of n, the solution time can be reduced drastically. For example, when , the solution time of the models can be reduced by several orders of magnitude when .
|
Table 2. The Average Solution Time (in Seconds) of the Network Flow Models Under Different Values of Q
| 0.1 s | 0.1 s | 0.1 s | 0.1 s | 0.1 s | |
| 1 s | 0.5 s | 0.3 s | 0.2 s | 0.1 s | |
| 87 s | 11 s | 3 s | 1 s | 0.3 s | |
| 534 s | 45 s | 8 s | 3 s | 1 s | |
| >3,600 s | 117 s | 22 s | 8 s | 2 s |
6.1.2. Quality of Model Solutions.
For each solution generated by the network flow model, we calculate its model-based optimality gap as well as the true optimality gap where possible (see Section 5.3). Table 3 summarizes these values. Note that only the model-based optimality gap is shown for the instances because the exact models (i.e., where ) could not be solved within the time limit. We also note that because the solution times of the exact models are generally negligible for and (see Table 2), we focus our discussion on the instances with and 50, where tractable approximations become more critical.
|
Table 3. The Average True Optimality Gap and Model-Based Gap (Shown in Parentheses) of the Solutions
| Instances | |||||
|---|---|---|---|---|---|
| 0% | 1.2% (1.5%) | 3.0% (4.3%) | 2.6% (4.6%) | 4.4% (7.6%) | |
| 0% | 1.2% (1.5%) | 1.5% (2.1%) | 1.0% (1.7%) | 1.1% (2.2%) | |
| 0% | 0.3% (0.5%) | 0.4% (0.7%) | 0.5% (0.8%) | 0.9% (1.4%) | |
| 0% | 0.1% (0.2%) | 0.2% (0.3%) | 0.2% (0.4%) | 0.2% (0.5%) | |
| — | −(0.08%) | −(0.2%) | −(0.3%) | − (0.5%) |
The main takeaway from Table 3 is that both the true and the model-based optimality gaps remain very small, even with the significant reduction in solution times shown in Table 2. For example, when and , the average optimality gap of solutions is less than 0.5% despite the models taking two orders of magnitude less time to solve compared with the exact model (i.e., 3 versus 534 seconds; Table 2). Similarly, when , the average model-based optimality gap is when and when , the latter of which requires an average solution time that is three orders of magnitude less than the exact model (i.e., 2 versus 3,600+ seconds; Table 2).
These observations highlight that the approximate network flow models are able to simultaneously generate both (i) near-optimal solutions and (ii) near-exact dual bounds. In Section EC.3.3 of the Electronic Companion, we provide a more in-depth analysis of the dual bounds and also compare our results to the K-adaptability approach from Hanasusanto et al. (2015) as well as the branch-and-price approach from Arslan and Detienne (2022).
6.2. Robust Assignment Problems
In this section, we consider a problem setting in which there are numerous linking constraints between first-stage and second-stage decisions. Specifically, we examine robust and adaptive assignment problems and focus on the use of multinetwork flow models (discussed in Section 5.2).
Assignment problems encompass numerous decision-making tasks that span many applications. A standard assignment problem can be modeled as a bipartite graph of agents , tasks , and directed links . Let denote the subset of agents for which there exists a directed link to task , and similarly, let denote the subset of tasks that can be assigned to agent . Depending on the context, agents can represent people, products, resources, funding, or jobs, whereas tasks can represent locations, facilities, projects, or machines. Each agent is associated with weight , and each task m has capacity , whereas the reward (e.g., match quality) of a specific agent-task pairing is unknown (e.g., varies day to day or must be estimated from data). Figure 2 illustrates this assignment problem.
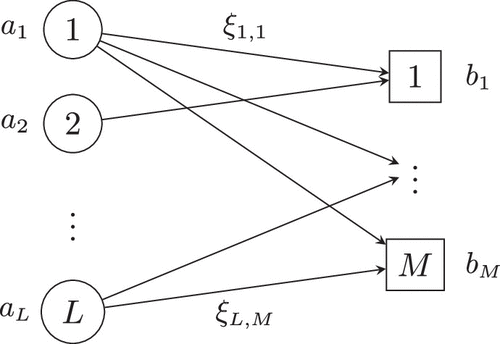
Note. Agents are associated with weight , tasks are associated with capacity , and agent-task pairings generate reward .
Using this notation, recall that a static robust assignment problem can be formulated as
We now consider a setting where a planner desires a limited degree of flexibility in the assignment planning process by pre-identifying a subset of potential agent-task pairings from which assignments can be made once rewards become known. Practically, this may arise when there is a need to train people for specific tasks, inform individuals about potential assignments, or inspect match quality before making a final decision. We assume that we have a cardinality constraint limiting the number of preidentified pairings and formulate the adaptive robust assignment problem as
6.2.1. Experimental Setup.
We consider assignment problems of five sizes where is equal to (20,2), (20,3), (20,4), (25,5), and (25,8). For each problem size, we randomly generate 10 instances. Each instance is characterized by (i) a randomly generated bipartite graph with 50% sparsity (such that and 100, respectively) and (ii) randomly generated vectors of agent weights and task capacities , where each element of is a random integer from [1, 10] and each element of is a random integer from .
For each instance, we generate the uncertainty set as follows. Let denote a vector representing the nominal reward of each link. With slight abuse of notation, each element is a random number generated from [0.5 a, a], where a is the weight of the agent associated with this link. Then, the uncertainty set is defined on the percentage of deviation from , namely,
We consider both an exact network flow formulation and a multinetwork flow approximation, abbreviated as Exact NF and Multi NF:
Exact NF. Model (15) can be represented as an exact network flow model by reformulating based on a straightforward extension of the procedure outlined in Example 1. Specifically, the state in the recursive formulation of is a vector of size (rather than scalars) that captures the amount of capacity remaining in the constraints of based on previous decisions of . Details are given in Section EC.4.1 of the Electronic Companion.
Multi NF. To form the multinetwork flow model, we generate an exact decision diagram for each knapsack constraint ; we leave the constraints as is because they satisfy the integral polyhedron property (see Proposition 4). The resulting model generates a feasible first-stage solution and a dual bound.
The Multi NF model defined above can be considered as one of the most natural or straightforward approximations of the ARBO problem, and we will show that it performs well in the numerical experiments. Nonetheless, we remark that there are many possible variations of this model that we could use to tighten or loosen the approximation. For example, instead of generating one exact decision diagram for each knapsack constraint, we could generate one for each pair of constraints, which would tighten the approximation quality but potentially lead to larger formulations. On the other hand, we could also generate an approximate decision diagram for each knapsack constraint (like in Section 6.1), which leads to a worse approximation but could significantly reduce the size and solution time of the model. In summary, various Multi NF models could be defined that will trade off between lower solution times and better solution quality.
Finally, for each network flow model, we enforce a one-hour time limit to build and reduce each diagram. Similar to Section 6.1, we also consider the K-adaptability model with and as a point of reference; the complete MILP formulation can be found in Section EC.4.3 of the Electronic Companion. For all models, we enforce a 30-minute time limit for the solver.
6.2.2. Computational Results.
Table 4 provides an overview of the size and the time taken to generate and reduce the DDs. The size and time for exact DDs increases rapidly with the size of the assignment problem; on average, it takes one second for the (20,2) instances, 73 seconds for the (20,3) instances, and more than one hour for all the other instances. Because the set of all solutions in must be represented by an exact DD, the size of this DD may grow exponentially with the number of constraints used to define . In contrast, the average size and time for the multinetwork models is far smaller and generally negligible (<1 second). Because the Multi NF model is simply a collection of individual DDs that are each exact reformulations of only one constraint in , the size and formulation time scales linearly in the number of constraints defining .
|
Table 4. The Build Time and Attributes of the Decision Diagrams
| Model | BDD attributes | (20,2) | (20,3) | (20,4) | (25,5) | (25, 8) |
|---|---|---|---|---|---|---|
| Exact NF | Average build time | 0.5 s | 67 s | — | — | — |
| Average reduction time | 0.2 s | 6.2 s | — | — | — | |
| Average no. of arcs (unreduced) | 11,994 | 199,856 | — | — | — | |
| Average no. of arcs (reduced) | 498 | 5,506 | — | — | — | |
| Multi NF | Average build time | 0.1 s | 0.1 s | 0.1 s | 0.1 s | 0.1 s |
| Average reduction time | 0.1 s | 0.1 s | 0.1 s | 0.1 s | 0.2 s | |
| Average no. of arcs (unreduced) | 1,262 | 2,577 | 3,911 | 8,855 | 20,365 | |
| Average no. of arcs (reduced) | 287 | 884 | 1,385 | 3,669 | 7,742 |
Note. Values for Multi NF are given as a summation over all the diagrams used to generate the multinetwork formulation for a particular instance.
Table 5 highlights the average solution time of the models over different problem instances. We observe that the Multi NF models can be solved relatively efficiently even as the size of the assignment problem grows larger. This is in direct contrast to the K-adaptability model.
|
Table 5. Average Solution Times Across the Different Models
| Model | (20,2) | (20,3) | (20,4) | (25,5) | (25,8) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Exact NF | 0.1 s | (50) | 1.1 s | (50) | — | — | — | |||
| Multi NF | 0.1 s | (50) | 0.3 s | (50) | 1.8 s | (50) | 81 s | (50) | >633 s | (33) |
| 3-Adapt | 1.2 s | (50) | 48 s | (50) | >324 s | (46) | >1,634 s | (5) | >1,800 s | (0) |
| 4-Adapt | 26 s | (50) | >342 s | (46) | >1,134 s | (24) | >1,749 s | (3) | >1,800 s | (0) |
Note. The value in the parentheses denotes the number of instances, out of 50, that could be solved within the 30-minute time limit given to each instance.
Figure 3 shows the model-based optimality gap of solutions generated by the Multi NF models; as we discussed in Section 5.3, these values are upper bounds on the true optimality gap of the solution. First, we note that 86 out of the 250 problem instances had an optimality gap of 0%. In these instances, the Multi NF model found the optimal solution and verified its optimality. Most of these cases pertained to problem instances that were smaller in size. Second, 223 out of 250 instances had an optimality gap that was less than 1%, 247 out of 250 instances had a gap that was less than 2%, and no solution had an optimality gap that was greater than 3%. These statistics include solutions of the Multi NF instances that could not be solved within the time limit.
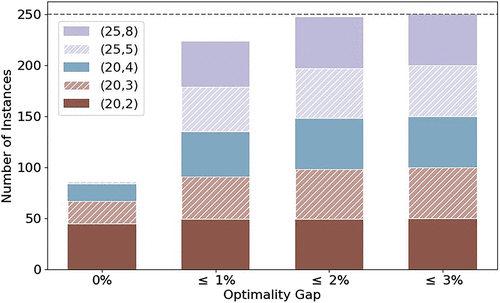
Note. The histogram is stacked according to the legend ordering, with the smallest instances appearing at the bottom.
6.3. Summary of Numerical Results
We briefly summarize the main takeaways of the numerical section. First, we show that exact network flow formulations can be tractably formulated and solved for smaller instances of ARBO problems. Second, for larger instances, the approximate network flow formulations are tractable and simultaneously generate (i) near-optimal first-stage solutions and (ii) high-quality dual bounds. Finally, the size and solution times of the approximate network flow models can often be reduced drastically while sacrificing very little in terms of the quality of solutions and dual bounds.
7. Conclusion
In this paper, we examine ARBO problems with objective uncertainty. We leverage ideas from the decision diagram community to reformulate and approximate these problems as constrained network flow models, which can be solved using standard solvers. Our numerical experiments show that they can efficiently generate near-optimal solutions and high-quality bounds.
By forming this connection between robust optimization and decision diagrams, our framework can also take advantage of independent contributions that emerge from the decision diagram research community. For example, recent literature has explored the use of DDs to solve deterministic integer and/or nonlinear optimization problems (see Section 2). This suggests that it may be possible to extend our framework to more general adaptive robust optimization problems.
1 See https://github.com/borisdetienne/RobustDecomposition (accessed February 2024).
References
- (2015) The recoverable robust facility location problem. Transportation Res. Part B: Methodology 79:93–120.Crossref, Google Scholar
- (2022) Decomposition-based approaches for a class of two-stage robust binary optimization problems. INFORMS J. Comput. 34(2):857–871.Link, Google Scholar
- (2022) Optimal order batching in warehouse management: A data-driven robust approach. INFORMS J. Optim. 4(3):278–303.Link, Google Scholar
- (2022) Network models for multiobjective discrete optimization. INFORMS J. Comput. 34(2):990–1005.Link, Google Scholar
- (2014) Optimization bounds from binary decision diagrams. INFORMS J. Comput. 26(2):253–268.Link, Google Scholar
- (2016) Decision Diagrams for Optimization, vol. 1 (Springer, Cham, Switzerland).Crossref, Google Scholar
- (2016) Multistage robust mixed-integer optimization with adaptive partitions. Oper. Res. 64(4):980–998.Link, Google Scholar
- (2015) Design of near optimal decision rules in multistage adaptive mixed-integer optimization. Oper. Res. 63(3):610–627.Link, Google Scholar
- (2013) Robust and adaptive network flows. Oper. Res. 61(5):1218–1242.Link, Google Scholar
- (2025) Network flow models for robust binary optimization with selective adaptability. INFORMS J. Comput. (INFORMS, Cantonsville, MD).Google Scholar
- (1992) Symbolic boolean manipulation with ordered binary-decision diagrams. ACM Comput. Surveys (CSUR) 24(3):293–318.Crossref, Google Scholar
- (2018) Robust combinatorial optimization under convex and discrete cost uncertainty. EURO J. Comput. Optim. 6(3):211–238.Crossref, Google Scholar
- (2022) Decision diagrams for discrete optimization: A survey of recent advances. INFORMS J. Comput. 34(4):2271–2295.Link, Google Scholar
- (2013) Multivalued decision diagrams for sequencing problems. Oper. Res. 61(6):1411–1428.Link, Google Scholar
- (2021) Outer approximation for integer nonlinear programs via decision diagrams. Math. Programming 187:111–150.Crossref, Google Scholar
- (2023) Neur2RO: Neural two-stage robust optimization. Twelfth Internat. Conf. Learn. Representations (OpenReview.net).Google Scholar
- (2020) A robust approach to the capacitated vehicle routing problem with uncertain costs. INFORMS J. Optim. 2(2):79–95.Link, Google Scholar
- (2021) Logic-based Benders decomposition and binary decision diagram based approaches for stochastic distributed operating room scheduling. INFORMS J. Comput. 33(4):1551–1569.Abstract, Google Scholar
- (2015) K-adaptability in two-stage robust binary programming. Oper. Res. 63(4):877–891.Link, Google Scholar
- (2013) Decision diagrams and dynamic programming. Internat. Conf. Integration Constraint Programming, Artificial Intelligence, and Oper. Res. (Springer, Cham, Switzerland), 94–110.Google Scholar
- (2022)
Stochastic decision diagrams . Schaus P, ed. Internat. Conf. Integration Constraint Programming, Artificial Intelligence, and Oper. Res. (Springer, Cham, Switzerland), 138–154.Crossref, Google Scholar - (2020) Oracle-based algorithms for binary two-stage robust optimization. Comput. Optim. Appl. 77(2):539–569.Crossref, Google Scholar
- (2018) A binary decision diagram based algorithm for solving a class of binary two-stage stochastic programs. Math. Programming 191(1):381–404.Google Scholar
- (2022) Constrained shortest-path reformulations for discrete bilevel and robust optimization. Preprint, submitted June 26, https://arxiv.org/abs/2206.12962v1.Google Scholar
- (2023) Leveraging decision diagrams to solve two-stage stochastic programs with binary recourse and logical linking constraints. Eur. J. Oper. Res. 315(1):228--241.Google Scholar
- (2019) Scalable robust kidney exchange. Proc. AAAI Conf. Artificial Intelligence 33(1):1077–1084.Crossref, Google Scholar
- (1928) Zur theorie der gesellschaftsspiele. Math. Ann. 100(1):295–320.Crossref, Google Scholar
- (2016) Multistage adjustable robust mixed-integer optimization via iterative splitting of the uncertainty set. INFORMS J. Comput. 28(3):553–574.Link, Google Scholar
- (2023) On the structure of decision diagram–Representable mixed-integer programs with application to unit commitment. Oper. Res. 71(6):1943–1959.Link, Google Scholar
- (2020) Compact representation of near-optimal integer programming solutions. Math. Programming 182(1):199–232.Crossref, Google Scholar
- (2019) Last-mile scheduling under uncertainty. Internat. Conf. Integration Constraint Programming, Artificial Intelligence, and Oper. Res. (Springer, Cham, Switzerland), 519–528.Google Scholar
- (2020) K-adaptability in two-stage mixed-integer robust optimization. Math. Programming Comput. 12(2):193–224.Crossref, Google Scholar
- (2019) Target cuts from relaxed decision diagrams. INFORMS J. Comput. 31(2):285–301.Link, Google Scholar
- (2022) Graph coloring with decision diagrams. Math. Programming 192(1):631–674.Crossref, Google Scholar
- (2011)
Decision rules for information discovery in multi-stage stochastic programming . 2011 50th IEEE Conf. Decision Control Eur. Control Conf. (IEEE Computer Society, Washington, DC), 7368–7373.Crossref, Google Scholar - (2018) Robust aircraft routing. Transportation Sci. 52(1):118–133.Link, Google Scholar
- (2019) A survey of adjustable robust optimization. Eur. J. Oper. Res. 277(3):799–813.Crossref, Google Scholar
- (2013) Solving two-stage robust optimization problems using a column-and-constraint generation method. Oper. Res. Lett. 41(5):457–461.Crossref, Google Scholar

