
A Data-Driven Educational Journey for Supply Chain Network Analytics
Abstract
This article presents a data-driven educational approach for supply chain network analytics, focusing on imparting students with a deep understanding of the subject and equipping them with the skills needed for applying data analytics in supply chain management. The framework includes defining learning objectives, designing a teaching plan, selecting effective delivery methods, and allocating necessary resources. Findings demonstrate a systematic teaching approach through real-world classroom experiences and student feedback. It highlights the effectiveness of the teaching methods and tools in preparing students for careers in supply chain management and data analytics. The article offers a blueprint for instructors to create engaging and effective educational programs by incorporating real-world data and industry guest speakers and fostering student engagement. Acknowledging context-specific findings, the study recognizes variations in effectiveness across institutions, student demographics, and cultural contexts. To assess the long-term impact, further research with diverse student cohorts and global perspectives is needed. Practical implications focus on preparing students for supply chain network analytics challenges by integrating data-driven techniques, practical application, collaboration, and industry relevance. The study provides educators a blueprint to prepare students for data-driven supply chain management careers, contributing to supply chain education’s evolution.
1. Introduction
Supply chain network analytics is a rapidly growing field that is essential for businesses looking to optimize their supply chain operations. The ability to collect, analyze, and interpret vast amounts of data has become a critical factor in supply chain management, and there is a growing demand for professionals with skills in both data analytics and supply chain management. As a result, there is a need for effective educational programs that can provide students with the knowledge and skills needed to succeed in this field. Businesses’ data collection has increased dramatically as insightful data are collected seemingly effortlessly by the now “normal” manner in which consumers increasingly interact with companies online. With this rising trend in consumer behavior, big data analytics (BDA) has rapidly earned important stature as a crucial business tool and has seen rapid growth across most industries in recent years. Similarly, BDA has become a powerful tool in the supply chain management process because a company’s ability to perform supply chain network analytics provides it with a competitive advantage in the current digital and global economy. The amount of data that collected in various sectors typically overpowers the ability and skills possessed by such businesses and their employees to utilize these data appropriately. Consequently, the need for robust infrastructures and skilled individuals to make sound data-driven decisions across departments is high. Unfortunately, the available talent is increasing slower than the demand for data analytics skills in supply chain management, creating a noticeable shortage in the workforce.
To reduce this educational gap, this paper aims to help instructors provide students with an end-to-end blueprint of what the data analysis process entails, in the hope of providing a tool for educational purposes and serving as a technical starter guide. To further emphasize the need for education in this matter, our literature review discusses big data analytics (BDA), supply chain networks analytics (SCNA), data analytics applications in supply chain management and supply chain analysis (SCA), and the capabilities and agility of supply chain analytics for data-rich environments.
This article presents a journey for instruction of a data-driven supply chain network analytics that utilizes a range of teaching methods and tools to provide students with a comprehensive understanding of the subject matter. We explore the use of data visualization; descriptive, predictive, prescriptive analytics (and introduce cognitive analytics); group decision-making tools; and other innovative techniques to teach supply chain network analytics. We also discuss the scope of the teaching plan, the delivery methods, and the resources needed to effectively implement the plan. Our ultimate goal is to provide a blueprint for instructors and educators looking to create and deliver effective course instruction and to engage in educational programs in supply chain network analytics.
As Waller and Fawcett (2013) predicted, there are “myriad of opportunities for research where supply chain management (SCM) intersects data science, predictive analytics, and big data, collectively referred to as DPB.” In this context, D stands for data science, P for predictive analytics, and B for big data. They called for research on skills that are needed by SCM data scientists and discussed how such skills and domain knowledge are related to the effectiveness of an SCM data scientist. They also mentioned that such knowledge is crucial to the development of future supply chain leaders. From a more general perspective, Dubey and Gunasekaran (2015) identified big data and business analytics (BDBA) skills and further proposed an education and training framework for a successful career in this field. These authors also proposed a theoretical framework that can further help an educational or training institute embrace the framework to train young undergraduates or graduates in BDBA skills. Rossman and Cochran (2018) mentioned that every student would be expected to understand three broad core statistical concepts: the nature of data and how characteristics of data determine the types of graphs, summary statistics, and analyses that are and are not appropriate; the concepts of probability necessary to establish the foundation for statistical inference; and the basics of statistical thinking and logic, particularly with respect to inference.
2. Literature Review
Big data analytics (BDA) (Tsai et al. 2015) refers to the use of advanced analytics techniques to extract valuable knowledge from vast amounts of data to facilitate data-driven decision-making. BDA consists of descriptive analytics, predictive analytics, and prescriptive analytics (Wang et al. 2016). Descriptive analytics is defined as describing and categorizing what has happened. Predictive analytics is used to anticipate future events and discover predictive patterns within data by using mathematical algorithms such as data mining, web mining, and text mining. Prescriptive analytics apply data and mathematical algorithms for decision-making. Multicriteria decision-making, optimization, and simulation are among the prescriptive analytics tools that help to improve the accuracy of forecasting.
Big data analytics (BDA) has garnered significant attention in recent years, holding the potential to revolutionize organizational and market operations. Its impact lies in introducing and educating entities on managing extensive, intricate data sets, influencing decision-making processes. The literature on data-driven decisions within supply chains, and more specifically within supply chain analytics (SCA), covers an array of topics that includes opportunities and challenges of integrating BDA, technologies and tools utilized to analyze large data sets, and various applications of big data analytics in a variety of supply chain management problems. The approach can efficiently collect, process, and analyze large amounts of data that can enhance our ability to help organizations unveil trends, patterns, and insight that would likely require additional resources and efforts through traditional data analysis methods (Biswas and Sen 2017) for supply chain analysis.
An extensive literature review was conducted to scan existing studies, briefs, and reports that illustrate big data analytics (BDA) as a comprehensive method to better serve the supply chain management industry (Nguyen et al. 2018). Our approach was to investigate what methods work, where improvements could be made, what gaps exist in the literature, and shortcomings in current practices. Throughout our review, we identified major themes to better understand where BDA currently stands in the supply chain industry and develop potential solutions to improve the quality of supply chain networks. The themes most frequently referenced in the literature were the benefits of BDA’s ability to analyze large quantities of data in rapid time for forecasting, the comparative analysis of BDA and traditional data analysis methods, and the lack of investment, knowledge, and training that prevent most industries from adopting BDA (Tatham et al. 2017).
Empirical evidence suggests multiple advantages of big data analytics in supply chain management, including reduced operational costs, improved supply chain agility, and increased customer satisfaction (Sheffi 2015, Ramanathan et al. 2017). Additionally, Talwar et al. (2021) exhibited an analysis of data sources for supply chains that discovered that 46% of firms had achieved 10% improvement in demand fulfillment using big data, followed by a more than $10 rise in supply chain efficiency for 36% of firms and better buyer-supplier relations for 28% of firms. With current technological development across the entities of the supply chain, data generated is increasing at a fast rate. Not too long ago, the information flow was documented by way of physical copies until the rise of information technology in recent decades. Thus, currently, most of the information flow linked to the material flow is documented in the form of digital structured data. Because the scope of the supply chain is currently worldwide, the volume of data collected from its various processes and the velocity at which is being generated can be qualified as big data. Therefore, the use of BDA can offer substantial value in all areas of the supply chain. Wang et al. (2016) underscored the necessity of supply chain analytics by highlighting its significance for companies. In particular, SCA plays a crucial role in enabling companies to consistently monitor their specified metrics, address underperformance issues, and identify root causes. Nguyen et al. (2018) brought a review of the extant literature on the use of big data analytics in supply chain management. Awwad et al. (2018) also presented a literature survey on the use of big data analytics in the supply chain.
Traditional methods of data analytics place limitations on the supply chain industries from fundamentally forecasting consumer behaviors, market trends, and supply chain performances. However, BDA can enhance the quality of efforts in demand forecasting, optimization in inventory levels, and reliability in identifying the most cost-effective suppliers (Zheng et al. 2023). Zheng et al. (2023) also described the potential limitations of BDA given supply chain managers’ unfamiliarity with it, which would require further investment in training to develop an efficient and effective skillset to properly apply BDA in day-to-day operations. Therefore, the pros outweigh the cons in that the literature describes the effectiveness if managers are adequately trained in BDA methods.
Further BDA literature describes the growing need for customer behavior analysis and demand forecasting that is driven by increased market competition and the surge in supply chain digitization practices (Seyedan and Mafakheri 2020). Their study collected and examined seven mainstream techniques and pointed to optimization models or simulation that improve the transparency of forecasting through formulating and optimizing cost functions to fit predictions to their data (Seyedan and Mafakheri 2020). In addition, the literature also describes the ability for BDA to help organizations measure the performance of various areas in logistics and supply chain management that provide them with the ability to generate benchmarks to determine value-added operations (Wang et al. 2016).
Some additional impacts of BDA within supply chain analytics that are described in the literature include the drastic increase in the availability of raw data as a result of advancements in technology and collection techniques; combining different fields such as statistics and computation with data science, BDA allows supply chains to extract, improve, store, and monitor substantial components of data from the huge data sets for decision-making purposes (Gopal et al. 2024). Furthermore, Li (2020) illustrated ongoing transformations of traditional manufacturing and industrial processes through innovative technologies such as the Internet of Things (IoT), Artificial Intelligence (AI), Deep Learning (DL), and advanced robotics. The perspective provides evidence that supports our case that BDA would revitalize the supply chain industry to keep the organizations up to date with adapting their practices to meet the needs of learners in the 21st century (Li 2020).
Whereas traditional data analytics are feasible for analyzing data on a smaller scale, BDA is a comprehensive approach that deciphers large, unstructured, and complex data sets. Literature examines BDA and describes it as relying on advanced techniques such as deep learning to uncover patterns and insights that would be difficult to identify using traditional analytics. For example, Basole et al. (2017) described the importance of supply chain visualization that involves the use of visual tools and techniques to analyze complex relationships and interdependencies that exist; this is attainable with BDA, but supply chains would encounter limitations if operating under traditional data analytic methods that would hinder their ability to forecast consumer behaviors and patterns.
Moreover, a study conducted by Wang et al. (2016) reinforces our findings mentioned earlier in our literature that traditional approaches place limitations on industries’ ability to identify customer patterns and do not take into consideration the complexity of modern supply chain networks. The study used a combination of ML algorithms and network analysis techniques to assess a larger retailer that illustrated BDA’s ability to identify customer patterns and supply chain network performances (Wang et al. 2020). The method has been field tested using traditional methods and has yielded inconclusive findings that make it complicated and create setbacks for supply chain managers to understand customer trends and behaviors.
The comparison of literature for BDA and traditional SCA methods enables us to draw connections on findings. BDA has been field-tested, delivering comprehensive and more accurate analyses, which have been proven to enhance the quality of data production for supply chain managers and industries. Supply chain management has also a longtime tradition of using analytical methods for problem solving, too. Moreover, the combination of both fields exploits and identifies gaps in traditional approaches, revealing inconclusive findings. The shortcomings when the two fields are dealt with separately could eventually prove detrimental to the supply chain, hindering its ability to adapt and respond effectively to consumer patterns and behaviors. Lack of investment in BDA is one of the primary causes of gaps and limitations in current supply chain industries and organizations. If major companies invest in software, training, and personnel, the literature indicates that it would increase productivity, improve forecasting, and enhance the understanding of consumer behaviors. In contrast, the perception of cost is why many organizations could be reluctant to invest large sums of money into a process where they have minimal understanding of the benefits. According to Gopal et al. (2024), BDA investment would allow organizations to better analyze data through five characteristics that otherwise would be complex through traditional methods:
Velocity: how fast data can be produced
Volume: how much data is generated
Value: reliable data
Variety: types of data collection
Veracity: quality and accuracy of the data
With the understanding of costs, supply chain organizations should want to evaluate the tradeoffs through a cost-benefit analysis that would likely reveal the benefit of investment in BDA. Choosing the best supply chain network implementation with optimized cost can reduce the wastage from supplier end to end user (Gopal et al. 2024). Different methods bring different results, and the characteristics that big data can generate are considered to improve methods and practices for SCA.
Furthermore, according to Sun and Song (2018), who emphasized the need for innovative and interdisciplinary approaches that reflect the evolution of supply chains, the incorporation of BDA would keep supply chain analytics up to date with current practices. In addition to describing the lack of knowledge that prohibits organizations from investing in BDA, Sun and Song (2018)detailed the importance of leveraging partnerships with higher education. Noting that partnerships can provide valuable opportunities for students to garner practical experience and develop relevant skills to be successful in the supply chain industry (Sun and Song 2018). Consequently, by partnering with higher education and levering these partnerships, progress can be the disconnect between the theory behind supply chain best practices and concrete applications. Research reveals a gap between theory and supply chain practices, and even though there has been a significant increase in literature focusing on operations and supply chain management, it has largely failed to provide theory-driven explanations or algorithms that could help to extract meaningful insights from large data (Fosso Wamba and Akter 2019).
Earlier, Woodruff and Voβ (2006) described operations research (OR) as the yang and supply chain management (SCM) as the ying. They proposed that application of OR to problems in SCM provide good illustrations of OR. OR models also shed light on SCM. Wu (2022) discussed a global supply network design problem where the case company can source from multiple suppliers using multiple modes of transport (including the use of containers with different capacities), allowing lateral supply between warehouses, etc., tested in an undergraduate course. Dimitrov et al. (2013) presented a project with educational, research, and practical benefits. Through the course project students abstracted real-world problems into mathematics, evaluated the connection between the mathematics and reality, and reasoned about the model results. Dalal (2022) presented an exercise for teaching the transportation problem using a mix of spatial and randomly generated data illustrating the potential of using qualitative and quantitative data for undergraduate or introductory business school courses on operations research (OR), logistics, and supply chain management.
In the context of retail operations, Van Woensel et al. (2010) described the organization and teaching of retail operations in the classroom. Aksin and DeHoratius (2010) exemplified a multidisciplinary approach to teaching service and retail operations management, emphasizing the importance of utilizing field data drawn from actual operating contexts. Kulkarni et al. (2019) presented a sample of dashboard visualizations and discussed their implications for pedagogy of retail operations. They also discussed how optimization modeling and a single data set can be leveraged to expose students to multiple variants of covering models and, more importantly, how visualizations can be used to quickly demonstrate the differences in these models.
As with the topics to be taught in the class, the instructors could use open published data sets and case studies, their personal case studies and published work, or a combination of both, because it is the case for the course under which this article plays a role in, so as to narrow down the scope of the course, the topics to be analyzed, and the data sets to be used. For instance, in the courses where these concepts have been used at different levels at San Diego State University (MIS 753: Global Supply Chain Analytics; and BA 644: Operations and Supply Chain Management), we have ranged from supply chain network analysis accounting for specifics such as nonprofit organizations (Balza-Franco et al. 2017) and those involved in humanitarian logistics (i.e., food banking, disaster response, etc.) to analytics in port operations (Moros-Daza et al. 2019), shipyard operations (Solano-Charris and Paternina-Arboleda 2013), transportation (Gomez-Jacome et al. 2019, Moros-Daza et al. 2019, Jubiz-Diaz et al. 2021), inventory management (Paternina-Arboleda and Das 2005), warehousing (authorized data sources from consulting activities), or specifically for supply chain network analysis, such as in Ramírez et al. (2012), and Cure-Vellojin et al. (2011).
Woldt et al. (2020) reflected on this new reality, concluding that universities will need to modify course content and pedagogy to meet industry needs. In their article, they derived an empirical course mapping model for big data and supply chain analytics and offered recommendations to align academic programs with the needs of the industry, which is kind of what we propose in this research.
3. Learning Objectives
The learning objectives for a course in supply chain network analytics should be designed to equip students with the knowledge and skills needed to succeed in the field. First and foremost, students should gain a comprehensive understanding of supply chain management and the role of data analytics in performance improvement of supply chain operations. They should be able to identify key performance indicators and metrics that are relevant to supply chain performance, learn how to collect and prepare the data, and analyze data to gain insights (some would say wisdom) into supply chain operations.
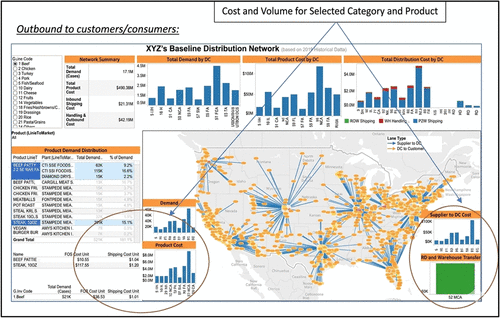
In addition, students should be able to use data visualization tools and techniques to communicate their findings effectively to different stakeholders in the organization. They should also learn how to collaborate effectively in group decision-making processes, leveraging cognitive analytics and other tools to make data-driven decisions. Students should also gain an understanding of how to apply best practices in data analytics to ensure that their analyses are accurate, unbiased, and ethically sound. Figure 1 illustrates a sample supply chain network analytics dashboard that integrates distribution costs, product demand, transportation flows, and geospatial visualization to support data-driven decision-making in supply chain operations.
Finally, students should be able to apply their knowledge and skills to real-world scenarios, working with case studies and simulations to gain practical experience in supply chain network analytics. By achieving these learning objectives, students will be well prepared to succeed in a career in supply chain management and data analytics. Upon completion of this case, students should be able to:
explain the concepts of supply chain network analytics and the importance of using data-driven approaches in decision-making;
understand the different types of data used in supply chain analytics, including structured and unstructured data;
use appropriate software to perform basic data analysis, such as data cleaning, manipulation, and data visualization on a realistic business data set;
apply data-driven approaches to optimize supply chain network performance, including inventory management, demand forecasting, and risk assessment;
communicate effectively about supply chain network analytics to both technical and nontechnical stakeholders, with the ability to present findings, make suggestions, and highlight insights.
4. Required Background
To effectively learn about supply chain network analytics, foundational understanding of several key topics is needed. These include basic concepts of supply chain management, such as procurement, inventory management, logistics, and distribution. In addition, knowledge of data analysis techniques and tools, such as statistics, data visualization, and programming languages, particularly Python, is important, as well as familiarity with data modeling and optimization techniques. With these foundational concepts in place, students can engage with the data-driven educational journey of supply chain network analytics presented in the research article with greater ease and effectiveness.
In this section, we highlight specific knowledge and skills required. A complete Python Notebook and Tableau project for this case is available from the instructor. This case can be utilized in a variety of courses because of the multiple tools utilized and the difficulty level aligned with those of introductory courses to these concepts.
4.1. Background in Python and Data Analysis
Students should have a solid Python foundation in Python, especially comfort with packages such as Pandas. Additionally, familiarity with packages such as NumPy and matplotlib can be of benefit but is not required as long as students have experience with data visualization tools such as Tableau. In terms of data analysis, students are expected to know how to join data from multiple tables and correctly group and aggregate data using their method of preference.
Python is currently an essential programming (scripting) language for data analysis and is widely used in the field of supply chain network analytics. Students in a course on supply chain network analytics should have foundations in Python programming, including knowledge of data structures, loops, functions, and object-oriented programming concepts. They should also be familiar with Python libraries such as NumPy, Pandas, Matplotlib, and Seaborn, which are commonly used for data manipulation, analysis, and visualization.
Notice in Figure 2 that we are using ChatGPT to generate code. Working alongside artificial intelligence will be “as inherent” as how we work with the Internet, and employees need to equip themselves with skills for this new future (Microsoft 2023). ChatGPT sparked a new wave of interest in generative AI technologies in recent months, and Big Tech firms like Google and Microsoft have since looked to infuse AI across their business.
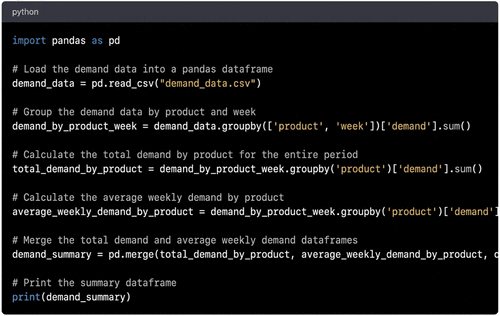
Students should also be familiar with database management systems and SQL queries because data retrieval and management are essential parts of data analytics. Students should be comfortable in using SQL to query databases, manipulate and join tables, and create views.
4.2. Background in Data Visualization
Data visualization at the level of Camm et al. (2022) is a critical skill for supply chain management, where teams must analyze and communicate complex data sets to make informed decisions about network design, sourcing, production, logistics, and more. Students are expected to perform exploratory data analysis (EDA) with the aid of data visualizations such as scatterplots, histograms, and boxplots, using Tableau as their data visualization software. Furthermore, students should have basic knowledge of using data visualizations and dashboarding properly. The course must introduce students to data visualization tools such as Tableau (as used in this article), Power BI, Excel, or more hardcore scripting in Python/R to help them create interactive dashboards, charts, and graphs. These tools can help students to identify patterns and trends in data and to communicate their findings effectively. Furthermore, we can teach students to use data visualization for storytelling. By using visuals to highlight key insights, students can make their analyses more compelling and engaging and communicate their findings more effectively to stakeholders. They can even be trained to use the newest AI tools to create videos that create the stories and interact/combine/compile with their dashboards for better conveying their stories.
In addition to proficiency in using these tools, students should be able to effectively choose the appropriate type of visualization for different types of data and analysis goals. They should understand how to design and create interactive dashboards that allow stakeholders to explore and analyze data in real time.
Data visualization can also be an effective tool for facilitating group decision-making in supply chain network analytics. By using data visualization to present complex data sets and visually communicate insights, teams at different places can collaborate more effectively and make more informed decisions. This particularly fosters online collaborative learning, where teams thousands of miles apart could participate in the process. We can use data visualization tools to create interactive dashboards that allow teams to collaborate and make decisions together to build consensus around decisions. We can use data visualization in a game format to encourage engagement and collaboration and even test game-theoretical collaborative frameworks in supply chain planning where students could be asked to design a supply chain network for a hypothetical company and present their findings in a game-like format, competing to make the most effective decisions.
For the case study in this article, we will present the use of Tableau. Tableau is a powerful data visualization tool that is widely used in the field of supply chain network analytics. Students in a course on supply chain network analytics should have a strong foundation in Tableau, including knowledge of data visualization principles, data preparation, and Tableau functionalities. Students should be able to use Tableau’s functionalities such as calculated fields, sets, and parameters to create interactive and dynamic visualizations. They should also be proficient in creating various types of visualizations, including charts, graphs, maps, and dashboards. Students should also be familiar with Tableau’s advanced features, including data blending, level of detail (LOD) expressions, and the Tableau server. These features enable students to analyze and visualize data from multiple sources and scale up their data visualization projects to enterprise-level solutions.
4.3. Optimization
Optimizing supply chains is a critical aspect for businesses, and it involves identifying the most efficient and cost-effective ways to move goods and services through the supply chain network. Data-driven optimization of supply chain networks is a rapidly growing field that uses data analytics and mathematical models to optimize supply chain networks.
One of the key benefits of data-driven optimization is the ability to make more informed decisions based on data analysis. By collecting and analyzing data from various sources, such as ERP systems and even real-time sensors, and IoT devices for performing more real-time optimization tasks, supply chain managers can gain insights into the performance of their supply chain networks. These insights can then be used to identify bottlenecks, optimize inventory levels, and reduce transportation costs, predict potential disruptions, and overcome them to improve (or maintain) performance.
Data-driven optimization also allows supply chain managers to simulate various scenarios and predict the outcomes of different decisions. This is particularly useful for supply chain networks that are complex and have multiple variables. By simulating different scenarios, managers can test different strategies and evaluate their potential impact on the overall performance of the supply chain network.
4.4. Basic Supply Chain Management Background
Supply chain management is the coordination of activities involved in the production and delivery of goods and services from raw materials to the end consumer. It encompasses all activities involved in sourcing, procurement, production, transportation, warehousing, and distribution. Effective supply chain management is critical for businesses to stay competitive and meet customer demands in today’s global marketplace. The supply chain management process involves a network of organizations, resources, activities, and technology that work together to deliver products and services to customers. It includes various stakeholders such as suppliers, manufacturers, distributors, retailers, and customers. Each of these stakeholders has a role to play in the supply chain management process, and their actions can have an impact on the entire network.
The goal of supply chain management is to optimize the flow of goods and services, minimize costs, and enhance customer satisfaction. This is achieved by managing the different activities in the supply chain, such as inventory management, transportation, and warehouse management. Effective supply chain management requires the use of advanced technology, data analytics, and strategic planning. Supply chain management has evolved over time, and today it is a complex and dynamic process that requires constant monitoring and optimization. Globalization, increased competition, and changing customer demands have led to the need for more agile and flexible supply chains. This has led to the development of new technologies and tools to enable businesses to better manage their supply chains.
Some of the key challenges faced by businesses in supply chain management include demand volatility, supply chain disruptions, and changing regulations. To address these challenges, businesses are increasingly turning to data-driven analytics to improve their supply chain management processes. Data analytics can help businesses to gain insights into their supply chain performance, identify potential bottlenecks, and make informed decisions.
Supply chain management is a critical aspect of business operations, and effective management of the supply chain can have a significant impact on a company’s bottom line. With the increasing availability of data and advanced analytics tools, businesses have an opportunity to optimize their supply chains and gain a competitive advantage in the marketplace.
5. Teaching Plan
The teaching plan for a data-driven educational journey for supply chain network analytics should be designed to equip students with the necessary knowledge and skills to analyze and optimize supply chain networks using data-driven approaches. The scope of a teaching plan for a data-driven educational journey for supply chain network analytics is quite broad because it covers various aspects of supply chain management, data analytics, and optimization techniques. The scope of the teaching plan may vary depending on the level of the course and the specific learning objectives. A suggested teaching plan for this course follows.
A Refresher to Supply Chain Management. This module should help students refresh their basic knowledge of supply chain management, its importance, and the various components of a supply chain network.
Data Collection and Management: This module should focus on the different sources of data that can be collected in a supply chain, such as point-of-sale data (Figure 3), inventory data, shipment data, route data (i.e., congestion), and data for potential of disruptions, among others. Students should learn how to collect, store, and manage supply chain data.
Descriptive Analytics: This module should focus on the use of descriptive analytics to understand the historical performance of a supply chain network. Students should learn how to use data visualization tools to analyze supply chain data and identify patterns and trends. We use Tableau as a visualization tool for this article, but Power BI, Excel, or Python/R dashboards could be analyzed as well (Figure 4).
Predictive Analytics: This module should focus on the use of predictive analytics to forecast future demand, identify potential supply chain disruptions, and optimize routes and inventory levels. Students should learn how to use statistical models to make associations, correlate, make predictions (Figure 5), and develop a forecast accuracy evaluation framework.
Prescriptive Analytics: This module should focus on the use of prescriptive analytics to optimize supply chain network performance. Students should learn how to use mathematical optimization techniques to solve supply chain problems such as inventory optimization, transportation optimization, and production planning.
Case Studies and Project Work: This module should provide students with the opportunity to apply the concepts and techniques learned in the course to real-world supply chain problems. Students should work on case studies and projects that require them to analyze supply chain data and develop optimization solutions. The instructor gave four data sets for the course, two with a large focus on network analytics, one for geospatial inventory analytics, and one for geospatial transportation analytics.
Industry Speakers: Inviting industry supply chain domain expert speakers from companies can be an excellent way to expose students to real-world supply chain challenges and opportunities. With virtual learning environments on the rise, this is a must-do activity for this course. The instructor invites two external speakers (one from industry, one from academia) to the classroom. One of the presentations breaks down the problem of optimizing food banking in the United States. At the end of the presentation, the students are then given the data set to play with and make discoveries, be creative, and present their results, benchmarked to those presented by the invited speaker or run by the instructor.
Assessment: The course assessment should be designed to evaluate the students’ understanding of the course material and their ability to apply the concepts and techniques learned in the course to real-world supply chain problems. In the context of this course structure, the assessment may include assignments, case studies, and project work, all of which could evolve to the writing of articles to be submitted to conferences or journals. Examinations are not among the tools that we propose for our course assessment.
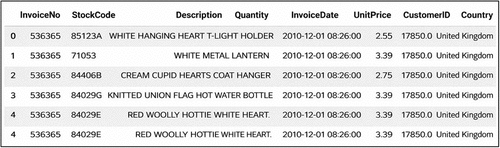
Figure 4 presents sample descriptive analytics dashboards developed in Tableau and enhanced with Gemini AI to visualize revenue trends, customer retention, sales forecasting, and product performance within a supply chain analytics context.
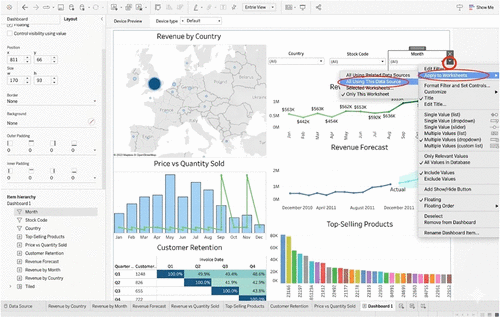
Figure 5 illustrates sample forecast and association dashboards used to support predictive analytics and market basket analysis within supply chain network analytics, highlighting projected sales trends and product association patterns through visualization techniques.
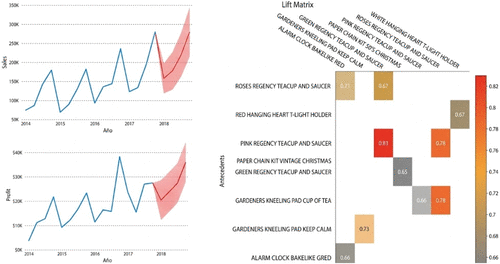
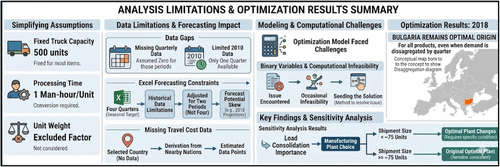
Figure 6 presents a sample analysis structure for optimizing supply chain networks, illustrating how data limitations, forecasting assumptions, computational challenges, and sensitivity analyses can be integrated into a decision-support framework for supply chain optimization.
For students who were able to submit results that were deemed good enough to be sent out for publication, then every other previous mark for the class was accounted the same as this submission, because the instructor would consider that the students have achieved the goals of the course in full.
We end the course by introducing cognitive analytics as an emerging field that can be applied to teaching supply chain network analytics. It involves using advanced algorithms and machine-learning techniques to analyze large amounts of data and extract insights that can be used to improve decision-making processes. Incorporating cognitive analytics into the classroom, it can help instructors to provide students with a more comprehensive understanding of the subject matter and equip them with the skills needed to make data-driven decisions in the supply chain network. For example, instructors can use cognitive analytics to analyze historical data on supply chain performance and identify patterns or trends that can be used to optimize the network or even help optimization models evolve in time, based on the learned patterns, identifying redundancies and limitations and finding new relations to enhance the quality of the original model. By teaching students how to use cognitive analytics tools and techniques, they can learn how to leverage data to improve supply chain performance and make more informed decisions.
A course in supply chain network analytics should focus on equipping students with the necessary knowledge and skills to analyze and optimize supply chain networks using data-driven approaches. The teaching plan should be designed to provide a comprehensive understanding of the supply chain management process, data analytics, and mathematical optimization techniques.
5.1. Delivery
This case is to provide students with hands-on experience in data analysis and modeling for supply chain networking analytics. Consequently, students are expected to dedicate serious time and effort to data cleaning and data mining, because these are crucial steps before diving into the data analysis, and start creating, working with the visualization tools to illustrate their findings. Given the time needed to preprocess data, we recommend presenting this case over multiple lessons, with a minimum of three lessons. This way, students will have the ability to work on this case as a multistep process. The delivery method would depend on various factors such as the level of the course, the availability of resources, and the preferences of the instructor and students. Some of the class delivery methods that we found useful are as follows:
Experiential Learning: entailing learning by doing. In this method, the instructor uses various case studies, simulations, and projects to provide hands-on experience in supply chain network analytics. These topics are more suitable for teaching through experience. Students who prefer a practical learning environment can apply the concepts and techniques learned in the course to real-world problems.
Hybrid Classroom: combining traditional classroom instruction with online learning. With this method, students attend some classes in person and some classes online. The instructor can use various online tools such as video conferencing, online forums, and learning management systems (LMS) to deliver the online portion of the course. This is relevant because it will allow for the topics to be recorded and left in the LMS to be accessed as many times as is required by the students.
Computer Labs and Software are essential resources for teaching supply chain network analytics. The software should be up to date and should cover a range of topics, such as optimization, simulation, and data analysis. The instructor should choose the level of coding needed to convey the class, depending on the level of the course. The instructor should also provide access to online resources such as data repositories and supply chain network analysis tools. An introductory level course would tend to use more end-user software tools. Examples of such would be the Log-Hub add-ins to Excel, as shown in Figure 7 and end-user digital twins, but many more could be used. A more advanced level course would need to convey more Python/R scripting and tools like GUROBI or CPLEX. Meta-modeling analytics/optimization tools such as OPTEX from Hypothalamus AI could be used as an all-level course based on its versatility to model using Lego-style blocks of constructs or to allow the user to model from scratch more complex routines and then transfer the optimization code to the solver of preference (i.e., GUROBI, CPLEX, etc.) or to a modeling platform such as AIMMS or ILOG and then store them in the OPTEX knowledge base. In addition, tools such as Log-Hub Add-In for Excel would work better for more end-user-oriented courses, which would be the case for MBA courses.
As for the introductory class (e.g., BA 644) we currently use open solver (Mason 2011) as the course main optimization tool, but the instructor is now heavily working with AI-generated Python codes so that students may have a more automated experience and understanding of how to use the tool with the help of (data-modified) real-life examples. AI automated python code generates programs of mathematical models in high-level algebraic languages and in general-purpose languages, making it in a generic meta-platform that works as an interface for multiple mathematical programming technologies. This is part of a future study.
5.2. Data, Python Notebook
Students will be given one data file to follow along with (data.csv), the E-Commerce Data data set. This data set was downloaded as a CSV file from the public website Kaggle.com; it has eight attributes and 541,909 instances, which are described in Table 1. We will also provide a complete Jupyter Notebook (SupplyChainNetworkAnalytics.ipynb) that includes every step of the data cleaning process, as well as the solution, with an explanation. This notebook can be used as a technical guide for students to follow along during the data cleaning process and the analytics and can be run in any regular Python Coding environment. The PDF includes a step-by-step guide on how to create visualizations using Tableau.
|

Table 1. Description (Sample) of the Attributes
| Attribute | Values |
|---|---|
| Invoice no. | 536365 to 581587 A563185 to A563187 C536379 to C581569 |
| Stock code | 10002 to 90208 10123C to 90214Z AMAZONFEE, BANK CHARGES B, C2, D, M, S CRUK, DOT, POST DCGS0003 to DCGS0076 DCGSSBOY, DCGSSGIRL gift_0001_10 to gift_0001_50 |
| Description | 4 PURPLE FLOCK DINNER CANDLES, 50’S CHRISTMAS GIFT BAG LARGE, DOLLY GIRL BEAKER, I LOVE LONDON MINI BACKPACK, NINE DRAWER OFFICE TIDY, OVAL WALL MIRROR DIAMANTE, RED SPOT GIFT BAG LARGE, SET 2 TEA TOWELS I LOVE LONDON, etc. |
| Quantity | −80,995 to 80,995 |
| Invoice date | 12/1/10 8:26 to 12/9/11 12:50 |
| Unit price | −11,062.06 to 38,970 |
| Customer ID | 12346 to 18287 |
| Country | Australia, Austria, Bahrain, Belgium, Brazil, Canada, Channel Island, Cypress, Czech Republic, Denmark, EIRE, European Community, Finland, France, German, Greece, Hong Kong, Iceland, Israel, Italy, Japan, Lebanon, Lithuania, Maltha, Netherlands, Norway, Poland, Portugal, RSA, Saudi Arabia, Singapore, Spain, Sweden, Switzerland, United Arab Emirates, United Kingdom, Unspecified, United States |
5.3. Description of the Case Study
This case study demonstrates the application of descriptive, predictive, and prescriptive analytics techniques in the context of online retail global distribution for a U.K.-based corporation using a data set publicly available at kaggle.com. By analyzing the behavior of the supply network, predicting future sales per country, optimizing the distribution network with near-shoring practices, and developing interactive dashboards, the company can gain valuable insights, optimize operations, and make informed decisions to enhance supply chain efficiency, customer satisfaction, and overall business performance.
Title: Online Retail Global Distribution for a U.K.-based Corporation
Introduction: This case study, based on the Kaggle.com E-commerce data set, focuses on an online retail corporation based in the United Kingdom. The company has a vast database containing more than 500,000 registries for online sales across 38 countries or territories, with the largest share of sales in the U.K. market. The objectives of the case study are to deploy descriptive analytics to analyze the behavior of the supply network on a country-wise basis and over a timeline, predict future online sales per country, model the distribution network considering near-shoring practices, and develop interactive dashboards for tracking relevant metrics. The student is asked to perform:
Descriptive Analytics for Supply Network Behavior: Using the available database, descriptive analytics will be employed to analyze the behavior of the supply network. This analysis will involve examining key metrics such as sales volume, revenue, product preferences, and market trends on a country-wise basis. Visualizations and statistical measures will be used to identify patterns, trends, and outliers in the online sales data across different countries and territories. This analysis will provide insights into the performance and behavior of the supply network over time and help identify key factors driving sales in each country.
Predicting Future Online Sales per Country: Building upon the descriptive analytics, predictive analytics techniques will be applied to forecast future online sales per country. Time series analysis, regression models, or machine-learning algorithms will be utilized to analyze historical sales data and predict future sales trends. The models will consider various factors such as seasonality, economic indicators, customer behavior, and marketing campaigns. The predicted sales figures will enable the company to make informed decisions regarding inventory management, marketing strategies, and resource allocation for each country or territory.
Modeling the Distribution Network: To optimize the distribution network, the case study will consider near-shoring practices by bringing manufacturing back from South Asia to Europe. Optimization techniques, such as mathematical programming or network optimization models, will be employed to determine the optimal location of manufacturing facilities among three potential countries. Gravity models could also be implemented. Factors such as production costs, transportation expenses, labor availability, and market proximity will be considered to identify the most advantageous locations for manufacturing. The optimized distribution network will enhance supply chain efficiency, reduce lead times, and potentially lower costs associated with international manufacturing.
Table 2 shows the difference between running a year-long mathematical model for the design of the supply chain network, after all the analyses have been performed, as compared with a more dynamic run with network links designed on a quarterly basis.
It is important to mention here that once we set the manufacturing facility location with the year-long model, we fixed it for each one of the independent runs for each quarter, so transportation links were variable. The reader can observe that building a more dynamic supply chain network yields more than 4% in projected savings.
We argue that this could be further improved once you drill down to the molecular level of day-to-day transport operations, but this is a matter of future work.
Building Interactive Dashboards with a Timeline: To provide stakeholders with a comprehensive view of the supply chain and relevant metrics, interactive dashboards will be developed. These dashboards will present key performance indicators (KPIs), sales trends, inventory levels, production capacity, and other relevant metrics in a visually appealing and user-friendly format. The dashboards will feature timeline functionality, allowing users to explore historical data and track performance metrics over time. This interactive visualization will enable executives, managers, and other stakeholders to monitor the supply chain’s performance, identify bottlenecks, and make data-driven decisions to optimize operations. The Tableau project for this case study is available upon request.
|
Table 2. Results for Supply Chain Network Optimization Analysis
| Network time structure | Network total cost to serve (€) | Savings |
|---|---|---|
| Year around data single network model | 73,053,293.69 | |
| Quarter-by-quarter more dynamic network model | 70,042,425.72 | 4.1% |
Teaching the presented case study to graduate business students holds several practical implications in terms of its applicability to real-world problems. By engaging with this case study, students can develop valuable skills and knowledge that can be directly applied in their future careers in supply chain management and data analytics. The case study reflects current trends and challenges in the online retail industry, making it highly relevant to the real-world business context. It exposes students to the practical considerations and complexities associated with managing global distribution networks. This industry relevance enhances students’ understanding of the dynamic nature of supply chain management and equips them with the knowledge and skills necessary to address real-world supply chain problems. The case study enables students to understand the impact of supply chain decisions on business performance and global operational strategy. By modeling the distribution network and considering near-shoring practices, students learn how to optimize the supply chain to improve efficiency, reduce costs, and enhance customer satisfaction (if customer feedback data exist). This enhances their ability to make informed decisions that align with the overall strategic objectives of the organization. The case study’s applicability to real-world scenarios enhances students’ preparedness for future careers and equips them with the necessary tools to contribute effectively to the field of supply chain management.
5.4. A Step-by-Step Journey to Supply Chain Network Analytics
In what follows, we present a step-by-step procedure outlining the methodologies used to solve the case study on the online retail global distribution for a U.K.-based corporation. With a database containing more than 500,000 registries for online sales in 38 countries or territories, this case study aims to provide a comprehensive understanding of the supply network behavior, predict future sales, model the distribution network, and build interactive dashboards. The case study delves into descriptive analytics, predictive analytics, optimization modeling, and data visualization techniques. The methodologies employed in this procedure enable the analysis of country-wise sales behavior, the prediction of future sales trends, the optimization of the distribution network, and the construction of interactive dashboards for tracking relevant metrics over time. At the end, the students are asked to give valuable insights and recommendations derived from the development of the whole process to address real-world challenges in online retail global distribution.
The first step is data collection and exploration. This data set was retrieved from kaggle.com. In real life there should be a step zero that involves getting the data from a database. The students would be asked to collect the online sales data from the company’s database, which contains more than 500,000 registries for online sales in 38 countries or territories. Then, one should explore the data set to understand its structure, variables, and quality and preprocess the data by handling missing values, outliers, and data inconsistencies.
The second step is to perform descriptive analytics for supply network behavior, where the students are required to analyze the behavior of the supply network on a country-wise basis and over a timeline, followed by the calculation of key metrics such as sales volume, revenue, customer demographics, product preferences, and market trends for each country. There are many options to perform these analyses. We chose to follow a more user-oriented framework to work this section integrated with visualizing the data using graphs, charts, and other visual representations to identify patterns, trends, and outliers.
The third step is to prepare predictive analytics for future sales, where the student should prepare the data for predictive analysis, ensuring that it is properly formatted and divided into training and testing sets. Then, they should apply suitable time series analysis, regression models, or machine-learning algorithms to forecast future online sales per country. Evaluating the performance of the models using appropriate metrics such as mean squared error or R-squared value is of the highest relevance so that the best-performing model could be selected and used to predict future sales trends for each country.
The fourth step is to model the distribution network. Here, students are asked to search for data such as cost of transportation per unit, per distance, per mode, and per country. They are asked to search for manufacturing wages for potential countries to (re)locate facilities (for near-shoring practices) and tariffs (if they exist). These data sets are available from the instructor, but we foster the self-construction of data sets by the students. With all the data sets in place, students are then asked to identify three potential countries for near-shoring manufacturing practices, considering factors such as production costs, transportation expenses, labor availability, and market proximity. What follows is the modeling stages, namely defining the objectives and constraints for optimizing the distribution network, incorporating the near-shoring locations. Then, the students formulate an optimization model to determine the optimal location of manufacturing facilities. Then they solve the optimization model using appropriate optimization techniques (opensource or commercial solvers in our case) to obtain the optimal distribution network configuration. Then they run sensitivity and post-optimality analyses to explore the what-if potentials for the problem under study. Then they document the entire process and report the insights for the case study to bring wisdom to the intended audience. An Excel file with an open solver solution, including the different data sets to be prepared by the students, in addition to the online sales data set originally given (retrieved from kaggle.com), is available upon request.
The fifth step is to build the interactive dashboards, where students are asked to select a suitable data visualization tool (e.g., Tableau, Power BI) to build the interactive dashboards. In this case study, we used Tableau as our tool for building dashboards. Determine the relevant metrics and KPIs to be tracked on the dashboards. Design the dashboards to present the selected metrics and KPIs in a visually appealing and user-friendly manner. Last, incorporate timeline functionality to enable users to explore historical data and track performance metrics over time.
The last step is to evaluate, interpret, and present the results to the audience (the instructor in the classroom setup, the leadership in a real company setting). Students are asked to evaluate the results and insights obtained from the descriptive and predictive analytics, distribution network modeling, and interactive dashboards and assess the practical implications and recommendations derived from the analysis, considering the company’s goals, market conditions, and strategic objectives. All of the findings must go into a comprehensive report and the corresponding executive presentation summarizing the findings, methodologies, and insights from the case study. The findings should be prepared depending on who the relevant stakeholders are. They could be executives, managers, or decision-makers or (in this case) the instructor. The presentation should emphasize the value and applicability of the solutions proposed.
6. Classroom Experience
Creating a conducive classroom experience for effective teaching of any subject, including supply chain network analytics, is essential. We praise ourselves in using incorporate active learning strategies, such as case studies, group projects, and simulations, to engage students and facilitate their understanding of the subject matter. Active learning promotes critical thinking and encourages students to take ownership of their learning processes.
Encouragement of collaborative learning strategies can foster a supportive learning environment and enable students to learn from one another. Furthermore, when this collaboration is online with geographically remote groups, it improves the reasoning and group decision-making capabilities of students. The use of technology to enhance the classroom experience, such as online discussion forums, virtual classrooms, or data visualization tools, facilitates learning and provides a platform for collaborative learning and engagement. Active instructor involvement also creates a positive learning environment and fosters student engagement and motivation.
Engaging with students in special topics of current interest is an activity that yields the most attention from students to the class. An example of this relates to taking advantage of current events in the world, associating them with potential effects on any given supply chain. During the spring of 2022, the students were encouraged to jointly run models to counter the problems of disruptions on agricultural commodities due to the Russia-Ukraine conflict, among the largest producers of commodities such as corn, sunflower oil, and more. How the world should react to such disruption drew a lot of interest from the students and made them engage in a more productive class environment.
6.1. Courses Where This Case Was Used
We have used this case study in a three- to four-session structure (2 hours and 40 minutes each session) as part of the MIS 753–Global Supply Chain Analytics course at San Diego State University, a minority serving institution. This course provides a comprehensive framework on managing global supply chains. Students learn supply chain strategies and the global impacts on the strategies. This course addresses global supply chain networks, demand management and production planning, global sourcing, stakeholder collaborations, supply chain inventory management, logistics and channel management, drivers and metrics, and supply chain analytics. Cases and readings drawn from real-world situations are used to discuss each one of these issues. The instructor has also used this case study for executive education for ESAN, a university in Peru, focusing on the use of these tools for industry but not in the step-by-step project development as it was presented in the preceding sections.
Every student shall prepare for all case studies and actively participate in case discussions. Students may be called to ask or answer questions related to the case. One case is assigned to a team. The team shall turn in a case report, and a 250-word executive summary on the cover page. The report shall analyze the key issues, propose alternative solutions, discuss the pros and cons of each alternative, and then make recommendations. The rationale of such recommendations must consider capabilities of the organization and the business environment at the time of the case study, that is, if the time frame takes place during the years 2020–2021, then students should consider aspects related to global supply chains in the times of COVID-19, such as resilience, disruptions, and so on, or if the case runs in the years 2022–2023, then students are encouraged to seek for experiences that relate to world conflicts in global supply chains, such as the impact of the Russia-Ukraine conflict on agricultural supply chains. A list of suggested discussion questions is posted on the LMS. These questions can be used as the starting point to analyze each case, but students are encouraged to produce their own knowledge base because they shall conduct further analyses. The assigned team also needs to make a formal presentation in class and respond to questions. There is a rule for each member of the team to have equal “airtime” for the case presentation and the Q&A session. The final report shall be around 6,000 words, excluding tables and figures, using APA style for in-text citation and references. The APA format guide is posted on the LMS. The paper shall use at least 25 scholarly references, dated within the last 10 years, and more if needed for seminal contributions from authors, which are not bound by time.
Successful experiences from this course that are worth listing are (a) an ASCM live event presentation led by the instructor, with small pieces of information presented by one of the group students for this last case study approaching the reshaping of some food world commodities, and (b) articles that were latter submitted by the instructor with the respective students for publication in book series (as part of the International Conference in Computational Logistics in Berlin, 2023) or a journal (such as this one).
6.2. Student Feedback
Student feedback, beyond the typical college-led student feedback survey, is crucial for improving the quality of a course in supply chain network analytics. It provides the instructor with valuable insights into what is working well and what needs to be improved. The instructor can organize focus groups to obtain more in-depth feedback from students, providing a platform for students to express their opinions, ideas, and concerns about the course, and can help to identify areas for improvement. The instructor should also encourage students to provide informal feedback throughout the course, such as through class discussions, email, or one-on-one meetings. This can provide immediate feedback and enable instructors to adjust the course material or teaching style as needed.
Some of the general feedback received in the MIS 753 class at San Diego State University follows. To the question of, What was the best thing about this course?, the students answered the following (text within parentheses is the authors’):
“Use of real-world data.”
“The project made us dive deep into supply chain analytics and I think we learned a ton from it. Show the depth of a single problem.”
“The lectures, the real-world examples, and the concepts.”
“The topic is very relevant.”
“Working assignments in groups.” We (the authors) want to point out that this is a strong orientation of this course because it brings the best of each member.
“Exposure to tools that can analyze (large and varied) data sets.” The use of a variety of tools such as Python, R for data analytics, as a choice by the student, and the choice of optimization tools such as GUROBI/CPLEX, a meta-modeling tools such as OPTEX, or the ADD-INS to Excel or Google sheets such as Open Solver, were of great help. The instructor also brought availability to the students of the ADD-INS from Log-hub (https://log-hub.com/supply-chain-apps/) for all students but especially for those students who are more prone toward user-oriented tools.
“He (the instructor) arranges guest lectures for giving insights on specific topics, and it helps to understand the problem and solve it.”
At the time this lecture was given, it was the first time delivered with this strong orientation to analytics of real-world large data sets. It was pointed out by students that the topic was strong and better organization of it was needed, which the authors of this paper (one of which was the instructor at the time) agreed with. Students also mentioned in the feedback reviews that more class examples using large data sets would help them understand better the ups and downs of data cleansing, preprocessing, and preliminary and in-depth analysis, including but not limited to data visualization, data mining, clustering, forecasting and prediction, and (large-scale) optimization techniques.
Of course, there were comments in the class, such as “a better organization of the course was needed,” and “while the professor was heavily using the LMS, the modules could be better organized in the LMS,” but in general, the course was well accepted and yielded great results. Two of the course students sought graduate mentorship from the instructor in topics related to the class. One of them even got to start the supply chain analytics program at work and use (authorized) real data sets from the company to work on the culminating experience project, which in turn yielded class materials on supply chain network design on how to mitigate the impact of decoupling from current global trade partner countries.
The methodology employed in this case study offers numerous benefits, not only in terms of enhancing student performance but also in improving the instructor’s effectiveness, as measured by student feedback surveys. By engaging students in a practical and data-driven approach, the methodology fosters a deeper understanding of supply chain network analytics and its real-world applications. This experiential learning enables students to develop essential skills in data interpretation, problem-solving, and decision-making. Through the application of this methodology, students can actively engage with the case study, fostering a more immersive and impactful learning experience. As a result, student feedback surveys are likely to reflect increased satisfaction, improved understanding of the subject matter, and higher confidence in applying the learned concepts to real-world scenarios. The student feedback surveys conducted over multiple semesters, encompassing fall 2021 through spring 2023, serve as a valuable data set for evaluating the impact of incorporating case studies within an educational context. The collected feedback revolves around two key aspects: the global student experience and the effectiveness of the instructor’s communication in conveying course concepts.
This methodology was first introduced in the spring of 2022 and fully integrated in the fall of 2022 to accommodate the learning needs for students at the college of business at San Diego State University. The student’s perceptions for both the use of relevant examples as well as for the global feedback dramatically improved after the implementation of this case study. These results collectively highlight the potential of the data-driven case study integration to positively influence both students’ overall educational experience and their perception of the instructor’s pedagogical proficiency. When teaching full-time graduate engineering students (at Universidad del Norte, Colombia) the protocol was not implemented. The protocol was used with full-time working business students from the MBA and the MSIS programs and master students for the Big Data Analytics program at San Diego State University. We wanted to wait until both the fall 2023 and the spring 2024 results came. The evidence shows that the methodology provided more stable results from student feedback surveys, where all five courses taught yielded median values for overall course scores from 4.1 (4.1 being an undergraduate course) to 5.0.
In addition, an impactful review was received from the participants on the online executive course in supply chain analytics from ESAN in Peru, which included students from at least three different Latin-American countries. The most representative narrative comments came for the “applicability of the case study,” for which we could see that eight out of the 17 total feedbacks had a similar comment.
In our assessment, graduate students enrolled in a full-time engineering program generally demonstrate a tendency to achieve positive academic outcomes and offer more favorable feedback in student surveys when compared with their peers who are concurrently pursuing an MBA or an MSIS while engaged in full-time work. It is important to note that these observations are rooted in the distinct academic and professional commitments associated with each program and should be considered in the broader context of individual circumstances and goals. Also, students enrolled in the Master of Science in Information Systems program typically exhibit a performance level and provide student evaluations that fall somewhere between those of engineering and MBA students, reflecting the unique blend of technical and business-oriented skills emphasized in our curriculum.
7. Conclusions and Further Research
The future of supply chain management is highly intertwined with data analytics. This article highlights essential components for preparing students for a career in supply chain management with a twist in data management. It provides them with the skills and knowledge needed to succeed in the dynamic and challenging world of supply chain management and equips them with the tools and techniques needed to make informed data-driven decisions and drive success in their organizations. Such a course bridges the existing gap in supply chain management education, which often lacks depth in preparing next-generation students for the complex, dynamic, and data-rich nature of modern supply chains.
The course outlined in this research paper is designed to provide students with a comprehensive understanding of the principles and practices of supply chain network analytics as well as the technical skills required to apply data-driven techniques to real-world problems in supply network analytics at the various levels: descriptive, diagnostics, predictive, prescriptive, adding visualization power to decision-making. We propose strategies for different levels of learning to accommodate introductory courses as well as the more advanced ones. Through a combination of lectures, hands-on exercises, and case studies, students will learn about various topics such as supply chain optimization, network design, demand forecasting, optimizing inventory from the data, routing goods and services through a network, and managing risks. They will also learn how to use various data analysis tools and software to collect and analyze data, simulate scenarios, and optimize supply chain networks.
The teaching plan outlined in this research paper is designed to be flexible and adaptable to different learning styles and needs. It includes a range of delivery methods, resources, and assessment tools that are designed to enhance the learning experience and promote student engagement. By completing this course, students will be well prepared for a career in supply chain management and equipped with the skills and knowledge needed to navigate the challenges of the rapidly changing global data-driven marketplace. They will be able to use data-driven techniques to optimize supply chain networks, reduce costs, and improve overall performance, making them valuable assets to any organization.
Although this paper has outlined a comprehensive teaching plan for a data-driven educational journey for supply chain network analytics, there is still much room for future work in this field. An area where further investigation could be valuable is the integration of sustainability because it has become an increasingly important consideration for supply chain managers. We can explore how to set up educational tools to show how data-driven techniques can be used to optimize supply chain networks while also reducing their environmental impact. Another topic to further explore relates to cross-functional collaboration because supply chain networks involve multiple stakeholders across different functions, including procurement, logistics, and operations. Future research can investigate how data-driven techniques can facilitate collaboration and communication between these stakeholders to improve overall performance, in a group decision-making environment. Group decision-making is an essential skill in supply chain management, where teams must work together to make informed decisions about network design, sourcing, production, logistics, and more. Strategies such as role playing, group discussions, brainstorming, and the use of perhaps remote connected visualization tools for geographically apart groups could enhance this last experience to the global level. Furthermore, there is a growing need for more advanced analytics such as machine learning and artificial intelligence. Future research can explore how these techniques can be used in supply chain network analytics to improve efficiency and accuracy. Because the field of data analytics will most likely continue to evolve, new techniques and tools will emerge. Researchers can explore how these new approaches can be applied to supply chain network analytics to improve performance and reduce costs.
Our assessment suggests that full-time engineering graduate students generally excel academically and provide more positive feedback in comparison with peers pursuing an MBA or MSIS while working full time. However, it is crucial to recognize that these findings are influenced by the unique demands of each program and should be considered alongside individual circumstances and objectives. Additionally, students in the Master of Science in Information Systems program typically achieve performance levels and provide evaluations that bridge the gap between engineering and MBA students, reflecting the program’s emphasis on a distinct blend of technical and business skills.
We acknowledge that this article’s findings and recommendations are based on a specific context and implementation, and we recognize that the effectiveness of this work may vary across different educational institutions, student populations, and cultural contexts. We also recognize that to assess the long-term impact of such an educational approach on students’ knowledge retention, skill development, and career outcomes, more research is needed with different cohorts of students and maybe with students from different geographical locations around the world. For future analysis, we propose to include evaluations of our graduates that go into the supply chain analytics field to assess their fitness to work with BDA for SCM.
Lastly, with new AI tools appearing in the market, coding has become a highly automated task, which can help students to succeed. However, with great power comes great responsibility, because the ethics of AI must be considered into any research that involves its use in education. By the way, banning AI is not how we are going to get ethical decisions. If we ban the use of technology, then we are only letting our students lag behind those who do use it. The balance for responsible use of AI needs further investigation, because the future that we see is one with AI in the forefront.
We express their sincere gratitude to Log-hub for providing permission to use the Log-hub Excel add-in in the development of this study.
References
- (2010) Introduction to the special issue, Part 2: Teaching service and retail operations management. INFORMS Trans. Ed. 11(1):1–2.Google Scholar
- (2018) Big data analytics in supply chain: A literature review. Proc. Internat. Conf. Indust. Engrg. Oper. Management (IEOM Society International, Washington, DC), 418–425.Google Scholar
- (2017) A collaborative supply chain model for non-for-profit networks based on cooperative game theory. Internat. J. Logist. Systems Management 26(4):475–496.Crossref, Google Scholar
- (2017) Visualization of innovation in global supply chain networks. Decision Sci. 48(2):288–306.Crossref, Google Scholar
- (2017) A proposed architecture for big data driven supply chain analytics. Preprint, submitted May 14, https://arxiv.org/abs/1705.04958.Google Scholar
- (2022) Data Visualization: Exploring and Explaining with Data (Cengage Learning, Mason OH).Google Scholar
- (2011) A Fictitious Play algorithm applied to a retailer’s replenishment decision problem in a two-echelon supply chain. Internat. J. Logist. Systems Management 8(3):247–266.Crossref, Google Scholar
- (2022) An exercise for teaching transportation problem using spatial data. INFORMS Trans. Ed. 23(1):12–26.Link, Google Scholar
- (2013) A real-world network modeling project. INFORMS Trans. Ed. 14(1):4–12.Link, Google Scholar
- (2015) Education and training for successful career in Big Data and Business Analytics. Indust. Commercial Training 47(4):174–181.Crossref, Google Scholar
- (2019) Understanding supply chain analytics capabilities and agility for data-rich environments. Internat. J. Oper. Production Management 39(6/7/8):887–912.Crossref, Google Scholar
- (2019)
Caribbean ports, inland logistics, and the Panama Canal expansion: A mode and port choice analysis . Paternina-Arboleda C, Voβ S, eds. Computational Logistics. ICCL 2019. Lecture Notes in Computer Science, vol. 11756 (Springer, Cham), 154–170.Crossref, Google Scholar - (2024) Impact of big data analytics on supply chain performance: An analysis of influencing factors. Ann Oper Res. 333(2):769–797.Crossref, Google Scholar
- (2021) Effect of infrastructure investment and freight accessibility on gross domestic product: A data-driven geographical approach. J. Adv. Transportation 2021:1–22. Crossref, Google Scholar
- (2019) Dynamic interactive visualizations: Implications of seeing, doing, and playing for quantitative analysis pedagogy. INFORMS Trans. Ed. 19(3):121–142.Link, Google Scholar
- (2020) Education supply chain in the era of Industry 4.0. Systems Res. Behav. Sci. 37(4):579–592.Crossref, Google Scholar
- (2011) OpenSolver—An open-source add-in to solve linear and integer progammes in excel. Oper. Res. Proc. 2011: Selected Papers Internat. Conf. Oper. Res. (Springer Berlin Heidelberg, Berlin, Heidelberg), 401–406.Google Scholar
- Microsoft (2023) What can copilot’s earliest users teach us about generative AI at work? Work Trend Index Special Report, November 15, 2023. https://www.microsoft.com/en-us/worklab/work-trend-index/copilots-earliest-users-teach-us-about-generative-ai-at-work.Google Scholar
- (2019)
Using advanced information systems to improve freight efficiency: Results from a Pilot Program in Colombia . Paternina-Arboleda C, Voβ S, eds. Computational Logistics. ICCL 2019. Lecture Notes in Computer Science, vol. 11756 (Springer, Cham), 22–38.Crossref, Google Scholar - (2018) Big data analytics in supply chain management: A state-of-the-art literature review. Computers Oper. Res. 98:254–264.Crossref, Google Scholar
- (2005) A multi-agent reinforcement learning approach to obtaining dynamic control policies for stochastic lot scheduling problem. Simulation Model. Practice Theory 13(5):389–406. Crossref, Google Scholar
- Ramanathan R, Philpott E, Duan Y, Cao G (2017) Adoption of business analytics and impact on performance: A qualitative study in retail. Production Planning Control 28(11–12):985–998.Google Scholar
- (2012) The dynamic demand game: A Markov state fictitious play approach to a two-echelon supply chain problem under demand uncertainty. Internat. J. Indust. Systems Eng. 10(3):319–335.Google Scholar
- (2018) Interview with James J. Cochran. J. Statist. Ed. 26(2):149–159.Crossref, Google Scholar
- (2020) Predictive big data analytics for supply chain demand forecasting: Methods, applications, and research opportunities. J Big Data 7(1):53.Crossref, Google Scholar
- (2015) The Power of Resilience: How the Best Companies Manage the Unexpected (MITPress, Cambridge, MA).Google Scholar
- (2013) Simulation model of the supply chain on a naval shipyard. Internat. J. Indust. Systems Engrg. 13(3):280–297.Google Scholar
- (2018) Current state and future potential of logistics and supply chain education: A literature review. J. Internat. Ed. Bus. 11(2):124–143.Crossref, Google Scholar
- (2017) Supply chain management skills to sense and seize opportunities. Internat. J. Logist. Management 28(2):266–289.Crossref, Google Scholar
- (2015) Big data analytics: A survey. J. Big Data 2:21Crossref, Google Scholar
- (2010) Teaching retail operations in business and engineering schools. INFORMS Trans. Ed. 11(1):29–34.Link, Google Scholar
- (2013) Data science, predictive analytics, and big data: A revolution that will transform supply chain design and management. J. Bus. Logist. 34(2):77–84.Crossref, Google Scholar
- (2020) A hybrid big data analytical approach for analyzing customer patterns through an integrated supply chain network. J. Ind. Inf. Integr. 20:100177.Google Scholar
- (2016) Big data analytics in logistics and supply chain management: Certain investigations for research and applications. Int. J. Production Econom. 176:98–110.Crossref, Google Scholar
- (2020) Big data and supply chain analytics: Implications for teaching. Oper. Management Ed. Rev. 14:155–176.Google Scholar
- (2006) Introduction to the special issue: Integrating OR in teaching supply chain management. INFORMS Trans. Ed. 6(3):1–2.Link, Google Scholar
- (2022) Case Article: Integrating network design models for a global supply network. INFORMS Trans. Ed. 22(3):172–175.Link, Google Scholar
- (2023) Big data analytics in flexible supply chain networks. Computers Indust. Engrg. 178:109098.Crossref, Google Scholar

