
Speed Up the Cold-Start Learning in Two-Sided Bandits with Many Arms
Abstract
Multiarmed bandit (MAB) algorithms are efficient approaches to reduce the opportunity cost of online experimentation and are used by companies to find the best product from periodically refreshed product catalogs. However, these algorithms face the so-called cold-start at the onset of the experiment due to a lack of knowledge of customer preferences for new products, requiring an initial data collection phase known as the burn-in period. During this period, standard MAB algorithms operate like randomized experiments, incurring large burn-in costs which scale with the large number of products. We attempt to reduce the burn-in by identifying that many products can be cast into two-sided products and then naturally model the rewards of the products with a matrix, whose rows and columns represent the two sides, respectively. Next, we design two-phase bandit algorithms that first use subsampling and low-rank matrix estimation to obtain a substantially smaller targeted set of products and then apply a Upper Confidence Bound procedure on the target products to find the best one. We theoretically show that the proposed algorithms lower costs and expedite the experiment in cases when there is limited experimentation time along with a large product set. Our analysis also provides insights into three experiment regimes of long, short, and ultra-short horizon, determined by the dimensions of the matrix. Empirical evidence from both synthetic data and a real-world data set on music streaming services validates the superior performance suggested by our theory.
This paper was accepted by J. George Shanthikumar, data science.
Supplemental Material: The online appendix and data files are available at https://doi.org/10.1287/mnsc.2022.03394.
1. Introduction
Online experimentation has become a major force in assessing different versions of a product, finding better ways to engage customers, and generating more revenue. These experiments happen on a recurring basis with periodically refreshed product catalogs. One family of online experimentation is the so-called multiarmed bandit (MAB) algorithms, where each arm models a version of the product. At each time period, the decision maker tests out a version, learns from the observed outcome, and proceeds to the next time period. It is well known that MAB algorithms balance exploration and exploitation to handle the lack of prior information at the onset of an experiment. They can dynamically allocate experimentation effort to versions that are performing well, in the meantime allocating less effort to versions that are underperforming. As a result, MAB algorithms can identify the optimal product under relatively low opportunity costs incurred from selecting suboptimal products. Consequently, fewer customers are subjected to potentially inferior experiences. We want to highlight that what is treated as a product in our context is not confined to merchandise in the e-commerce setting. It includes broader categories from ads campaign product in online advertisement to drug product in drug development.
However, when there is a large product set, even at the onset of the experimentation, MAB algorithms would face what is known as the cold-start problem: Many versions of a product are brand new to the customers. It is not yet clear to the algorithms how to draw any useful inferences before gathering some information. Therefore, many MAB algorithms involve an initial data collection phase, known as the burn-in period (Lu 2019).1 During this period, MAB algorithms operate as nearly equivalent to randomized experiments, incurring costs that scale with the number of products. Under such circumstances, the cumulative cost, or regret, of current practices is huge due to a costly and lengthy burn-in period.2
Our goal is to come up with a framework that can be cost-effective, which is achieved by first identifying a two-sided structure of the products. In many applications, because the products have two major components, the bandit arms can be viewed as versions of a two-sided product. To be more specific, let us provide two examples that will reappear in the later empirical studies.
Consider an online platform that wants to select one user segment and one content creator segment that interact the most to target an advertisement campaign (Lops et al. 2011, Geng et al. 2020, Bhargava 2022). Such an advertisement campaign is a two-sided product where user segment and content creator segment are its two sides. There are many user segments and many content creator segments. In each time period, the platform tests a pair of user segments and content creator segments and observes the amount of interaction between them, based on which, the platform decides which pair to test next. The number of products scales quickly: 10 user segments and 10 content creator segments already give rise to 100 pairs, and this is just an underestimate of how many segments there are for each side.
Consider an online platform that wants to design a homepage with a headline and an image. The platform’s goal is to select a pair of headlines and images that attracts the most amount of user engagement. The homepage design is a two-sided product with headline and image as two sides. Similar to Example 1, the number of pairs can easily be more than several hundred.
Besides the two examples above, there are plenty of other two-sided products: Airbnb experiences (activities and locations), Stitch Fix personal styling (tops and pants), Expedia travel (hotels and flights), car sales (packages and prices), drug development (composition of ingredients and dosages), and so on.
The task of finding the best version of a two-sided product can be translated into finding the maximum entry of a partially observed reward matrix, which can help accelerate the learning process. That is, we can model different choices of one side to be rows of the matrix, different choices of the other side to be the columns, and the unknown rewards for the corresponding row-column pairs (e.g., the amount of interaction in Example 1 and the amount of user engagement in Example 2) to be the matrix entries. Mathematically, suppose the first side of the product has number of choices and the second side has number of choices, then the reward matrix contains the rewards of versions of the two-sided product as entries. As mentioned previously, current algorithms will randomize on the initial number of periods, leading to a very costly burn-in period because and are often very large. Furthermore, when the time horizon T is rather small compared with the order , a large cumulative regret that scales with would arise because of the costly burn-in period.
By casting the rewards into a matrix and considering its low-rank structure, we can expedite the experiment and reduce the regret by orders of magnitude. To understand the low-rank structure, we note that the rewards for different versions of a two-sided product depend on the interactions between some latent features of the two sides. Low-rank simply means that, suppose is the rank of the matrix, then we only need as few as latent features to explain each side, such that . Because of such a low-rank property and with the help from low-rank matrix estimators, we only need to collect a small amount of data to have an estimate of the rewards for all arms of interest in the burn-in period. Such an estimate will be accurate enough to help screen out majority of the suboptimal arms, thus requiring substantially less subsequent exploration and greatly reducing the burn-in cost.
1.1. Our Contributions
1.1.1. Algorithm.
We design a new bandit algorithm called the low-rank bandit (
Moreover, we propose submatrix-sampled
1.1.2. Theory.
We establish nonasymptotic dependent and independent regret bounds of
Our theory sheds light on customized strategies given different time horizon lengths and the product set sizes, distinct from most existing bandit theoretical analysis that studies dependence of the regret on the time horizon asymptotically and results in suboptimal results for short horizons.
1.1.3. Empirics.
Empirical evidence from synthetic data validates the superior performance of our algorithm. In addition, we illustrate the practical relevance of our algorithms by proposing a data-driven approach to select experiment-dependent hyperparameters. We evaluate such an approach on an advertisement targeting problem for the music streaming service, where we want to learn the best combination of user group and creator group to target an advertisement campaign. We show that our bandit algorithm significantly outperforms existing ones in finding the best combination efficiently under various time horizon lengths.
1.1.4. Reduction Model for Contextual Bandits.
Additionally, we propose a new modeling framework to transform a stochastic linear bandit setting (a general class of bandit problems that contains contextual bandits) to the scope of our low-rank bandit problem. This allows us to empirically showcase
1.2. Related Literature
We first review the bandit literature relevant to online decision making under bandit feedback and then turn to related works on low-rank models and matrix-structured data.
Our work focuses on regret minimization in noncontextual bandit problems, with canonical algorithms including Thompson sampling (Thompson 1933, Agrawal and Goyal 2012, Gopalan et al. 2014, Russo et al. 2018) and upper confidence bound (Lai 1987, Kaelbling 1993, Katehakis and Robbins 1995, Auer et al. 2002a). Like ours, these algorithms explore and exploit without contextual information; that is, they make no assumptions on dependence of the arm rewards. Beyond the noncontextual setting, a large body of literature studies bandit problems with contextual information, where arm rewards are parametric functions of the observed contexts. In particular, extensive research has focused on the linear bandit (Auer et al. 2002b, Dani et al. 2008, Li et al. 2010, Rusmevichientong and Tsitsiklis 2010, Abbasi-Yadkori et al. 2011, Chu et al. 2011, Agrawal and Devanur 2014) and its extension under generalized linear models (GLMs; Filippi et al. 2010, Li et al. 2017, Kveton et al. 2020), in which the expected reward is a linear (or generalized linear) function of the context. We refer the readers to Lattimore and Szepesvári (2020) for a comprehensive overview.
Classical analysis of bandits focuses on asymptotic behavior of the regret bound under long experimentation horizons, assuming the number of arms is much smaller than the horizon. Specifically, the regret bound of a k-armed bandit consists of two terms: one linear in k but constant in T plus an order term.3 The former is typically ignored because, for large T, it is dominated by the latter term. But for large k problems such as our two-sided bandit setting with , this linear term, , can be as large as the latter term. This challenge, which creates a significant cold-start problem in short-horizon settings, has been the motivation for several approaches. These include combining clustering and MAB algorithms (Miao et al. 2022, Keskin et al. 2024), warm starting the bandit problem using historical data (Banerjee et al. 2022), or using an integer program to constrain the action set (Bastani et al. 2022).
A separate line of work on many-armed or infinitely armed bandit problems (Berry et al. 1997, Bonald and Proutiere 2013) addresses the cold-start challenge by employing subsampling to reduce the opportunity cost (Wang et al. 2009, Carpentier and Valko 2015, Chaudhuri and Kalyanakrishnan 2018, Bayati et al. 2020). The key distinction of our work from this line of research lies in leveraging the inherent matrix structure of the two-sided products, which allows for a more informed arm selection for targeted exploration + exploitation. Another way in the infinitely armed bandit literature to mitigate the cold-start issue is to impose structural assumptions on the reward function, such as linearity over a compact action set, as explored in Mersereau et al. (2009) and Rusmevichientong and Tsitsiklis (2010). In such cases as in the linear bandit setting, pulling any action provides information about the rewards of all actions.
Low-rank matrix estimators have become established tools for solving offline cold-start problems in recommendation systems (Lika et al. 2014, Zhang et al. 2014, Volkovs et al. 2017), and they are building blocks for many applications that have inherent low-rank models (Athey et al. 2021, Farias et al. 2022, Agarwal et al. 2023). We refer the readers to Davenport and Romberg (2016) and Chen et al. (2020) for a detailed discussion on low-rank matrix estimators.
Incorporating the low-rank matrix structure in bandit settings has been seen in many other works, which all consider different settings than ours. For example, Katariya et al. (2017) and Trinh et al. (2020) consider only rank 1 matrices, whereas our algorithm works for general low-rank matrices; Kveton et al. (2017) allow a decision maker to noisily choose and observe every entry of a submatrix (where is the rank of the underlying unknown matrix) in each period, but we only allow the selection of one entry each time and we assume the rank is unknown, which is a harder problem. Lu et al. (2018) provide an ensemble sampling based algorithm that lacks theoretical guarantees. Jun et al. (2019) address the contextual bilinear bandit setting where the reward function is a bilinear function of two feature vectors and an unknown low-rank parameter matrix. They propose an
Although the low-rank structure is utilized in all the above-mentioned works, we want to emphasize that our work focuses on a short-horizon learning problem with many arms, and the purpose of utilizing the low-rank property is to efficiently filter suboptimal arms in order to construct a more focused targeted set, under very limited experimentation time.
There are recent papers such as Gupta and Rusmevichientong (2021), Gupta and Kallus (2022), Allouah et al. (2023), and Besbes and Mouchtaki (2023) that focus on practical small data regime with limited sample size: The former group studies how to optimize decision making in a large number of small-data problems, whereas the latter group studies classical pricing and newsvendor problems and shows how a small number of samples can provide valuable information, leveraging the structure of the problems. Even though we focus on the burn-in period with small data, our bandit formulation with two-sided products and low-rank structure is completely different from their offline setups. Our problem is also different from the recent work of Xu and Bastani (2021) that studies how one can learn across many contextual bandit problems, because the contexts in our model are hidden and will be estimated through learning of the low-rank structure.
Finally, recent works such as Bajari et al. (2021) and Johari et al. (2022) also look at online experimentation for two-sided settings, but from a completely different angle. Specifically, their objective is to remove bias due to the spillover effect by using two-sided randomization.
1.3. Organization of the Paper
The remainder of the paper is organized as follows. We describe the problem formulation in Section 2. We present the
2. Model and Problem
In this section, we formulate our problem as a stochastic multiarmed bandit with (two-sided) arms and introduce notations and assumptions. These arms are represented as row-column pairs of a matrix, and the arm mean rewards are represented as entries of the matrix. We impose a low-rank structure to the reward matrix, which is a building block of our
2.1. Rewards as a Low-Rank Matrix
We work with a ground truth mean reward matrix , and our goal is to find the biggest reward entry as we sequentially observe noisy version of picked entries. As introduced earlier, the rows of this matrix correspond to different choices for the first side of the two-sided products and columns correspond to different choices for the second side. Entries of correspond to the mean rewards for different combinations of the two sides and we assume they are bounded as in the canonical bandit literature. This assumption is standard and makes sure that the maximum regret at any time step is bounded. It aligns with the real-world setting because user preferences are bounded in practice.
(
We use the two-sided product in Example 1, ads campaign, as a running example. In this case, the marketer needs to pick a pair of user segment and content creator segment to target the ads. Then we can model user segments as rows of matrix and content creator segments as columns of matrix . The amounts of interaction between different combinations of user segments and content creator segments are the entries of . The goal under this scenario is to find the pair that interacts the most to target the ads by experimenting with different pairs.
We model the ground truth mean reward matrix as a low-rank matrix. That is, let be the rank of , and we have . This means the reward for the entry corresponding to row j and column k is a dot product of two -dimensional latent feature vectors. Therefore, our reward model is a contextual reward with unobserved features. In Section 5.3, we show an alternative contextual bandit representation of our reward function that is motivated by the standard linear bandit setting framework.
We introduce an incoherence parameter and the condition number , which is known to be crucial for reliable recovery of the matrix in the low-rank matrix completion literature (Keshavan et al. 2010, Candes and Recht 2012, Chen 2015, Chen et al. 2020). The former measures how much information observing an entry gives about other entries in a matrix and the latter quantifies the numerical stability of a matrix.
For a matrix of rank with singular value decomposition , we denote the incoherence parameter as such that and .
Intuitively, smaller means that we can get more information about other products from observing just a few entries, and the matrix completion problem is more tractable. Consequently, less experimentation cost is incurred while exploring a large product set. In contrast, matrices with bigger have most of their mass in a relatively small number of elements and are much harder to recover under limited observations.
For a matrix of rank with nonzero singular values , we denote the condition number as such that
Both and are assumed to be constants.
2.2. Bandit Under the Matrix-Shaped Rewards
We consider the following T-period horizon experiment with bandit feedback: At each time step t, the marketer has access to arms (ads campaigns), and each arm yields an uncertain reward (amount of interaction). At time t, if the marketer pulls arm , it yields reward where we assume the observation noises to be independent sub-Gaussian random variables with sub-Gaussian norm at most (see definition 5.7 in Vershynin (2010)). Natural examples of sub-Gaussian random variables include any centered and bounded random variable or a centered Gaussian.
Our task is to design a sequential decision-making policy that learns the underlying arm rewards (parameter matrix ) over time in order to maximize the expected reward. Let , an element of , and denote the arm chosen by policy at time . We compare with an oracle policy that already knows and thus always chooses the best arm (in expectation), . Thus, if the arm is chosen at time t, expected regret incurred is where the expectation is with respect to the randomness of and potential randomness introduced by the policy . This is simply the difference in expected rewards of and . We seek a policy that minimizes the cumulative expected regret
Note that throughout this paper, we assume the matrix is deterministic, which means our notion of regret is frequentist.
Together with policy , the observation model can be characterized by a trace regression model (Hastie et al. 2015). For a given subset of cardinality n, of [T], we define with observation operator (defined below), vector of observed values equal to , and noise vector equal to . The observation operator takes in a matrix and outputs a vector of dimension n (i.e., ). Elements of the output vector are the entries of at n observed locations, determined by . Specifically, is a vector in , and for each i in [T], its ith entry is defined by where design matrix has all of its entries equal to zero, except for the th entry, which is equal to one. The notation refers to the trace inner product of two matrices that is defined by The observation operator will appear in the matrix estimator we use.
3. LRB Algorithm
We first give an overview of our two-phase
Intuitively, our
As mentioned in Section 1.1, the
However, in our study, the two-phase procedure serves a different purpose. More specifically, in the first phase, we utilize the low-rank structure to filter suboptimal arms that are away from the highest estimated reward by forced-sample estimators. Although our first step seems similar to the aforementioned papers, our second phase is itself a
Furthermore, we want to emphasize that the two-phase approach in the aforementioned studies cannot be directly applied to our problem. They focused on long enough experimentation time horizons so that their algorithms can take time to learn arms well and leave only the optimal choice in the targeted set for some fixed h. However, as aforementioned, we face a short horizon under the many-arm circumstances. In our analysis, we will show that the filtering resolution h controls not only the size of the targeted set, but also the estimation error of using the forced samples. We need smaller h to filter out more arms to have a smaller targeted set, which in turn requires more forced-sampling rounds to achieve a good enough estimation to be more confident about the suboptimality of the filtered arms. Thus, it is unlikely to construct a targeted set with fine-enough filtering resolution that only contains the optimal choice as the single arm, because forced-sample estimation is not accurate enough under limited experimentation time to achieve that.
Finally, we note that one cannot use the low-rank estimator to construct confidence sets for the
3.1. Description of the LRB Algorithm
The main idea of our two-phase
The
3.1.1. Forced-Sampling Rule.
Our forced-sampling rule is . At time t, the forced-sampling rule decides between forcing the arm to be pulled or exploiting the past data, indicated by . We use to denote the set of time periods when an arm is forced to be pulled up to time t, that is, . The forced-sampling rule that we use is a randomized function that picks an arm with probability
3.1.2. Estimators.
At any time t,
The forced-sample estimates based only on forced samples.
The
UCB estimator based on all samples observed for each arm , where is a combination of the empirical mean reward estimation and a term that quantifies the uncertainty of the estimates, is the number of times entry has been played so far, and the function is defined by for the empirical experiment and for the analysis part for simplicity.
3.1.3. Low-Rank Estimator.
As mentioned before, our forced-sample estimator is based on a low-rank estimator. We use nuclear norm penalized least squares as our example for a low-rank estimator.
(
However, any low-rank estimator that satisfies the following tail bound can be used as our forced-sample estimator. For simplicity of presentation, we set .
(
Chen et al. (2020) provide the tail bound for square matrices to facilitate a clear presentation. In their paper, they note that it is straightforward to extend their discussions to general rectangular matrices of size . Similarly, we focus on square matrices for simplicity of presentation, whereas our proposed framework is not limited to square matrices. Given a tail bound for rectangular low-rank matrices of , all subsequent discussions can be easily extended accordingly. In addition, theorem 1 in Chen et al. (2020) proves for , but their result can be easily generalized to any large enough .
3.1.4. Execution.
We follow a two-phase process: If the current time t is in , then we are in the “pure exploration phases,” and arm is played; otherwise, we are in the “targeted exploration + exploitation phases," and this phase consists of the following two steps. As a preprocessing step, we use the forced-sample estimates to find the highest estimated reward achievable across all entries. We select a subset of arms whose estimated rewards are within of the maximum achievable (in step 6 of Algorithm 1). After this preprocessing step, we apply
(
1: Input: Matrix dimensions , forced-sampling rule f, filtering resolution h
2: for do
3: if then “pure exploration phase”
4: (forced-sampling)
5: else“targeted exploration + exploitation phases”
6: Define the set of near-optimal arms according to the forced-sample estimator:
(3.2)7: Choose the best arm within according to the
UCB estimator, that is,where is such that is the average observed value for entry , and is the number of times entry has been played so far.8: end if
9: Play arm , observe .
10: end for
3.1.5. Filtering Resolution h.
In our preprocessing step described above, we used h to filter the arm set as well as control how accurate the forced-sample estimator needs to be. As mentioned earlier, smaller h includes fewer arms in the targeted set, and thus more accurate forced-sample estimation is needed to have the optimal arm in the targeted set. Vice versa, bigger h leads to a larger targeted set that allows for more crude forced-sample estimation.
Recall that the parameter controls the quality of the forced-sample estimator. As the next lemma shows, the smaller h is, the bigger needs to be to ensure more forced samples. Its proof (in Section EC.1 in the Online Appendix) builds on Proposition 1 and Lemma EC.1 (in Section EC.1, which characterizes how many forced samples we can have given the forced-sampling parameter ). In our subsequent analysis, we assume for some , thus smaller values of correspond to shorter horizons.
For all where with where , it holds with probability at least that,
The above result states that the forced-sample estimator satisfies with probability at least for all arms when the forced-sampling parameter is big enough. To this end, we set
3.1.5.1. Range of h.
Filtering resolution h has a selection range. The upper bound of this range is controlled by the range of the arm rewards (entries of ) and is one per Assumption 1. To derive the lower bound, we notice that, given the time horizon T, we have number of forced samples per Lemma EC.1 in the Online Appendix. Because is a required condition for Lemma EC.1, we can let be such that to derive the minimum value that h can take, denoted by :
This shows that is of order .
We notice that the range of h gets bigger with the time horizon, because decreases in the time horizon. Hence, for shorter time horizons, the best achievable accuracy of the low-rank estimator is less refined than that for longer time horizons, but more arms will be included in the targeted set to ensure that high-reward arms are not filtered out due to a lower quality estimation. Such intuition is formalized in Proposition 2 in Section 3.3.1, where we examine the optimality of h. We discuss further about the range of h when comparing our bound to the existing literature in Section 3.3.2.
3.1.5.2. Near-Optimal Arms.
An important step in our regret analysis is to show the following: When the estimation is accurate enough, the targeted set will be a subset of “near-optimal” arms, which we define below as a function of h. Notation-wise, we use to denote the near-optimal set of arms parameterized by an arbitrary h, where denotes a subset of row indices and denotes a subset of column indices; denotes the set of entries of the submatrix constructed from and .
(
That is, it contains elements in that are at most h smaller than the best arm in .
We next introduce the near-optimal function , which characterizes the cardinality of the near-optimal set.
(
In such cases, for brevity, we often use shortened notation and for and , respectively. The more general case with will be considered in Section 4. When entries of are sampled from certain distributions, we can describe the expected value of the near-optimal function in a closed form (see Section EC.6 in the Online Appendix). We also provide empirical examples, on the near-optimal functions for low-rank matrices in Section EC.7 in the Online Appendix.
The following lemma shows that a targeted set is a subset of the near-optimal set when the forced-sample estimation is accurate enough. Its proof is in Section EC.2.3.3 in the Online Appendix.
If , then the largest entry belongs to the targeted set defined in Equation (3.2) of Algorithm 1. Furthermore, .
Our next section provides the regret analysis of the
3.2. Regret Analysis of LRB
We present both a gap-dependent bound and a gap-independent bound on our
(
(
As emphasized earlier, we use low-rank estimators rather than the empirical mean of the arms to select the targeted arms in the first phase so that we can learn the arms faster and keep the regret low. Indeed, to ensure that the optimal arm is selected into the targeted set, we need to control the estimation error to be within (Lemma 2). When there are number of arms, low-rank estimators only use number of explorations to achieve the aforementioned estimation accuracy (shown earlier by Lemma 1), whereas empirical mean estimator needs number of explorations. This is because empirical mean estimator for each arm only focuses on information for that particular arm, ignoring helpful information from other arms. We elaborate further on this point in Remark 2 in Section 3.3.2 after more in-depth analysis.
3.3. Balancing Regrets of Two Phases with h
Our algorithm can adjust the filtering resolution h to balance the cost of forced-sampling and the cost of targeted exploration + exploitation after the filtering. Finer filtering resolution incurs more costs in the first phase due to more forced-sampling rounds to achieve more accurate estimates but alleviates the burden in the second phase as more suboptimal arms have been filtered out. Vice versa, less refined filtering resolution results in a larger targeted set and thus incurs more costs in the second phase, but saves costs in the first phase.
To explain further mathematically, recall the regret decomposition we have discussed in the beginning of Section 3.2. According to the proof of Theorem 2 in Section EC.2 in the Online Appendix (we use the gap-independent regret analysis to illustrate), the regret from the pure exploration phase can be bounded above by and the regret from the targeted exploration + exploitation phase can be bounded above by , where
Note that we ignore the constant term for above (and in subsequent expressions we omit this term for simplicity). The upper bound of the regret, , can be expressed as
Note that the quantity increases in h. Indeed, as described in Lemma 1, the bigger the h, the fewer rounds of forced-sampling are needed to achieve the forced-sample estimation accuracy. Consequently, less regret is incurred in the first phase which leads to smaller . The quantity depends on h via the near-optimal function , which is nondecreasing in h. This is because more arms may be included in the targeted set as h gets bigger. Consequently, more regret is incurred in the second phase to find the best arm in the targeted set, which makes bigger. Next, we discuss how to choose h optimally.
3.3.1. Optimality of h.
Based on the interaction between and , we characterize the best filtering resolution that optimizes the regret bound in the following lemma.
(
If for any , then is optimal up to a factor of two, that is, .
If for some , then is optimal up to a factor of two.
If for any , then is optimal up to a factor of two.
Similar arguments hold for the gap-dependent bound in (3.5).
The proof of Lemma 3 can be found in Section EC.3 in the Online Appendix. Although Lemma 3 only analyzes the regret upper bounds and rather than the actual regret of the two phases, we empirically show that the actual regret follows the same behavior in numerical simulations. In Section EC.5 in the Online Appendix, we plot the cumulative regret from the two phases for low-rank matrices that are with rank 3 with respect to a sequence of h, and observe that with 225 number of forced samples gives the lowest cumulative regret. Further, the regret curves of the two phases cross at around , and the cumulative regret at is within a factor of two of the lowest cumulative regret.
We discussed in Section 3.1.1 that the range of h becomes bigger in the time horizon T due to the functional form of . Next, we show that the optimal filtering resolution in fact monotonically decreases in the time horizon T.
The optimal filtering resolution monotonically decreases in the time horizon T when .
The proof of Proposition 2 is in Section EC.3 in the Online Appendix. This proposition aligns with our earlier finding that finer filtering resolution is achieved over longer time horizons.
Next, we show that our upper regret bounds improve on those in the existing literature by balancing and through h.
3.3.2. Benefits of Low-Rank Structure and the Targeted Exploration + Exploitation.
We compare the gap-independent bound in Theorem 2 against the upper regret bounds for standard noncontextual bandits to show that our bound achieves better rates in Proposition 3. This analysis also holds for comparison against gap-dependent bounds in the literature.
From this section, we focus on the order of d and T and treat as a constant when we discuss the regret order because . We first show in Proposition 3(1) that our regret bound under any time horizon is no worse than the regret bound of those standard noncontextual bandit algorithms (e.g.,
Recall that . For any structure of :
For all values of , Algorithm 1 achieves no worse regret than .
In particular, when , Algorithm 1 can achieve regret of order . More specifically, it can achieve the regret of order .
The proof of Proposition 3 is relegated to Section EC.3.2 in the Online Appendix. We want to emphasize that the improvement of our algorithm stems from leveraging the low-rank structure. Without assuming any special structure, no algorithm is able to achieve a lower regret than the regret lower bound of of the standard noncontextual bandit algorithms like
(
In Proposition 3, we have not yet considered any structure of in our discussion and have only worked with a very loose bound of for any h to show how the sole use of low-rank estimation and the element-wise error bound already helps with reducing regret upper bound of the existing literature.
We illustrate how to further tighten the regret bound by leveraging the structure of determined by its shrinkage rate defined below.
(
The inequality in the set constraint naturally holds when because . Because , then shrinks faster for larger values of , which implies that the low-rank structure can filter out more arms. When , Definition 6 yields .
Theorem 3 then works with Definition 6 to give a tighter regret bound for our algorithm. We defer its proof to Section EC.3.2 in the Online Appendix.
For , it holds that
When , and
when ,
We next present Example 3 in which we plug in empirical estimated values of to show more concrete improvement.
Let the low-rank matrices , where the entries of follow uniform distribution on [0,1]. From the empirical evidence in Section EC.7 in the Online Appendix, when , that is, the shrinkage rate . Then from Theorem 3, when , the regret is of order , which is lower than ; when , the regret is of order , lower than the regret needed by standard noncontextual bandit like
The above example shows that we can construct the empirical and thus fit if we have access to the reward distribution from abundant related historical data. Consequently, we can obtain the optimal h via the recipe provided in the proof of Theorem 3. We elaborate on a more data-driven approach for obtaining the optimal h in Section 5.2, where we use a prespecified grid to search for optimal values based on a historical data set.
(
3.3.3. Effectiveness of LRB Under Different Horizons.
Proposition 3, Theorem 3, and Example 3 bring an important implication: Our algorithm
When , Proposition 3 shows that our algorithm performs no worse than those standard noncontextual bandits, and we call this time regime the long horizon. Furthermore, when we know the near-optimal function as in Example 3,
When , our algorithm achieves a regret upper bound that is strictly better than that of standard noncontextual bandits even without specifying (as shown in Proposition 3), and we call such a time regime the short horizon. In such a short horizon regime, we have seen that
The remaining time horizons, that is, , will be called the ultra-short regime. In this regime,
4. LRB with Submatrix Sampling
In this section, we propose to perform a subsampling prestep that can potentially incur less cost than a regular
4.1. Description of the Submatrix-Sampled Low-Rank Bandit Algorithm
The subsampling prestep samples a submatrix of , and our
(
1: Decide the submatrix size as a function of .
2: Draw a set of number of row indices, denotes as , and a set of number of column indices, denoted as , uniformly at random (without replacement) from [d], respectively.
3: Run
LRB (algorithm Algorithm 1) on the submatrix indexed by (, ).
For simplicity of presentation, we set , but we can optimize for selecting nonsquare submatrices. Note that
Our motivation comes from Bayati et al. (2020), who suggest that subsampling may help when the time horizon is ultra-short. Their work states that, when the number of arms , it is optimal to sample a subset of arms and execute
Noticeably, we cannot ensure that the biggest element in this submatrix is necessarily the biggest element of the entire matrix. If not, then in each period, we would at least incur a subsampling cost defined as the difference between the biggest element of the entire matrix and the biggest element of a random submatrix. Such a subsampling cost is a function of the matrix size, the submatrix size and the rank of the full matrix.
(
When the arm rewards follow certain common distributions, the subsampling cost function has closed forms, which is presented in Section EC.6 in the Online Appendix. We also provide empirical evidence for how the subsampling cost functions look like for low-rank matrices in Section EC.7 in the Online Appendix.
4.2. Regret Analysis Under Submatrix Sampling
In this section, we first give a general regret upper bound analysis for
Recall that , where is a constant. Similarly, we define
The total regret of
The first term describes the regret incurred from the difference between the biggest element in the submatrix and the biggest element in the entire matrix, per the definition of the subsampling cost function (Definition 7). The remaining sum, , bounds the regret of running
To bring the unknown subsampling cost function into the analysis, we let , where is called the subsampling ratio which is a decision variable. We assume a structure of the subsampling cost in Assumption 2 such that the subsampling cost is equal to zero when ; that is, there is no subsampling cost if the submatrix is the entire matrix. Further, the subsampling cost increases when reduces.
(
We show in Section EC.6 of the Online Appendix that subsampling cost functions for matrices whose entries are drawn from some common distributions satisfy Assumption 2, and we provide further empirical evidence in Section EC.7 of the Online Appendix to show that Assumption 2 holds for a variety of low-rank matrices.
Under Assumption 2, we provide regret upper bounds of the subsampling version of LRB, namely the
Suppose Assumption 2 holds. Recall that is defined in Theorem 3.
When ,
When ,
Moreover, to achieve this regret order, we select the subsampling ratio in the following way:
When :
If , we choose ;
If , we choose such that .
When :
If , we choose such that ;
If , we choose .
The proof of Theorem 5 is relegated to Section EC.4 in the Online Appendix. Compared with Theorem 3, the subsampling strategy has reduced the regret from in Theorem 3 to . We notice that, although the optimal subsampling ratio depends on all parameters in Assumption 2 (i.e.,, , , and ), the improvement of the subsampling strategy depends solely on the value of . Next, we provide an example to present more concrete improvement.
Let the low-rank matrices , where the entries of follow uniform distribution on [0,1]. From the empirical evidence in Section EC.7 in the Online Appendix, , , , and . In this case, . Moreover, as discussed in Example 3, that is, . By applying Theorem 5, when , the regret is of order ; when , the regret is of order . Compared with Example 3, when , the regret can be reduced from to with the subsampling strategy.
The above example shows that
Similar to the comments we made in Remark 3, we see via Example 4 that we can estimate if we are given historical data and fit and to decide the optimal subsampling ratio . We elaborate on a more data-driven approach in Section 5.2, where we search over a prespecified grid to find the optimal subsample size based on a historical data set.
4.3. Visualizing the Benefits of Low-Rank Structure, Targeted Exploration + Exploitation, and Subsampling
We visualize the potential benefits of leveraging low-rank structure, having a targeted exploration + exploitation phase, and subsampling, by plotting the sum of dominating terms (ignoring the constants) in the regret bound of several approaches, namely, for
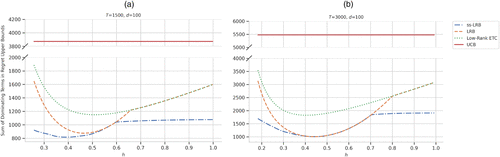
First of all, the curve for
Next, when comparing
Finally, the gap between
5. Empirical Results
We compare the performance of
5.1. Synthetic Data
5.1.1. Synthetic Data Generation.
In Figure 2, we evaluate
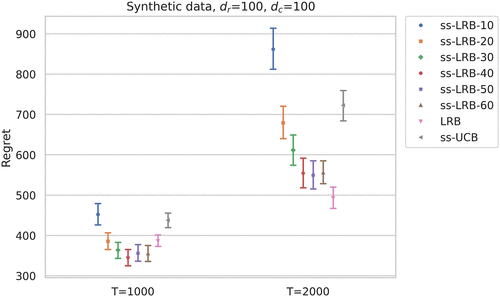
5.1.2. Results.
We compare the
5.2. Data-Driven Approach to Select Experimentation Parameters for a Music Streaming App
In a real-world setting, we can tune the experimentation parameters in a data-driven manner by using related historical data. To illustrate, we utilize a real-world data set to simulate an advertising campaign setting as described in Example 1. That is, an advertiser needs to specify which pair of user group and content creator group to target for the advertisement campaign to be most effective.5 The number of combinations of a user group and a creator group can be large, as we can distinguish user groups with many different information such as demographics, geographic information, and behavior. Likewise, we can distinguish creator groups with many distinct features. Our algorithm (and other benchmark algorithms) would seek to find the best combination of a user group and a creator group to maximize overall interaction between the two groups. As such, we choose an application in the music streaming industry, where we have access to user and creator interaction data. More details on the data can be found in Zhang et al. (2022). We suppress the interaction data information and let different algorithms learn such information over time. We provide more background on music streaming services in Section EC.8.4 in the Online Appendix.
5.2.1. Our Problem.
The company has been providing services to older-aged users and now wants to expand their services to younger-aged ones. It has also attracted new creators to the platform and plans to run an experiment to find a younger-aged user group and a new creator group that interact the most to target an advertisement campaign. The experimentation parameters can be found via historical data on interaction between older-aged user groups and seasoned creator groups.
5.2.2. Bandit Formulation.
To simulate such a setting, we gather the data that correspond to the older-aged users and seasoned creators as a “historical” data set and keep the data that correspond to the younger-aged users and new creators on the side as a “test” data set. For each data set, we cluster the samples into 53 user groups and 39 creator groups, so that we have a 2,067-armed stochastic bandit. We bucket users using different locations (provinces) and activity intensity levels. We bucket creators using the anonymous creator types and activity intensity levels. We obtain the same user groups and creator groups for the two data sets. For each (user group, creator group)-pair, we take the average of all interaction data between this user group and this creator group (including clicks, likes, shares, whether the user commented, whether the user viewed the comments, and whether the user visited the creator’s homepage) and treat it as the reward for this pair.
5.2.3. Selecting Experimentation Parameters.
The experimentation on finding a pair of younger-aged user group and new creator group needs input parameters such as the number of forced samples, denoted as f, the filtering resolution h, and the submatrix sampling size m for different experimentation horizon length T. We work with a prespecified grid of parameters (listed in Section EC.8.3 in the Online Appendix) and simulate a bandit experiment for each combination of the parameters using the historical data set. We pick the set of parameters that achieves the lowest regret on the historical data set averaged over 30 trials. Essentially speaking, we assume that the historical data and test data share similar reward distributions; hence, the optimal parameters learned for the historical data can be used for the experiment we want to run for the test data.
5.2.4. Results and Evaluation.
In Figure 3, we report the regret of using test data to conduct experiments using our algorithm (
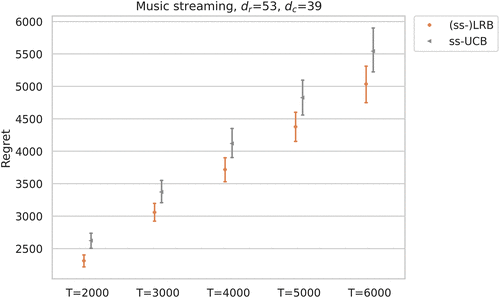
Notes. Parameters of our algorithm (ss-)LRB are selected based on historical data.
In this real data experiment, without knowing whether the data generation produces low-rank matrix of rewards, we still see the effectiveness of our algorithm. Further, even though the historical data distribution may differ from the test data, our experiment results show that using the optimal parameters learned from the historical data still yields better performance than the benchmark. This shows that our data-driven approach of selecting the experiment parameters provides a practical solution to real-world scenarios, such that we can train the parameters on related historical data sets prior to starting an experiment. In practice, when no past data are available to tune these parameters, one can select parameters using the insights provided in Section 3 and 4.
Thus far, we did not use any contextual information. In the next section, we show that
5.3. Fast Learning in the Contextual Setting
In this section, we consider a classical contextual bandit setting and show how we use
5.3.1. Contextual Bandit Setting.
We consider a bandit setting with number of arms whose parameters are unknown. We index the arms by for every and every . We denote each arm feature with a p-dimensional vector . At time t, by selecting arm , we observe a linear reward , where is the (population-level) known context. The expected regret incurred at period t is We want to minimize the cumulative expected regret and find the arm that has the highest reward.
To match this bandit formulation with an example, we consider the case of tailoring a homepage of an app to a user segment with a known context X mentioned in Example 2. The home page consists of a welcome text message and a picture background and thus can be considered as a two-sided product. We have choices of welcome text messages and choices for picture backgrounds. is the unknown ground truth arm feature of homepage indexed by .
5.3.2. Low-Rank Reward Matrix.
The mean rewards can be shaped into the following matrix :
The low-rank structure of attributes to the modeling detailed next. Let , where and . Then Under this design, the mean reward matrix is of rank because is in and is in . We assume is small, so the mean reward matrix is of low rank. This is because we only need very few features to explain each welcome text message and each picture background.
In the example of designing homepage, each row of can be interpreted as the feature vector of a text message, and each column of can be interpreted as the feature vector of a picture background. Welcome text messages are more straightforward and the interpretation would be the same across different user segments, so they are assumed to be independent of X. Picture backgrounds, on the other hand, are more subjective and up to each user segment’s interpretation. Thus, the representation depends on X.
5.3.3. LRB Policy.
To use our
5.3.4. OFUL Policy.
To apply
5.3.5. Synthetic Experiment Setup.
Our goal is to seek a policy that minimizes the cumulative expected regret over time horizon . We set , , , and . We evaluate different policies over 10 simulations. The error bars are 95% confidence intervals. Other experiment details can be found in Section EC.8.5 in the Online Appendix.
5.3.6. Results.
In Figure 4, focusing on time , the average cumulative regret of
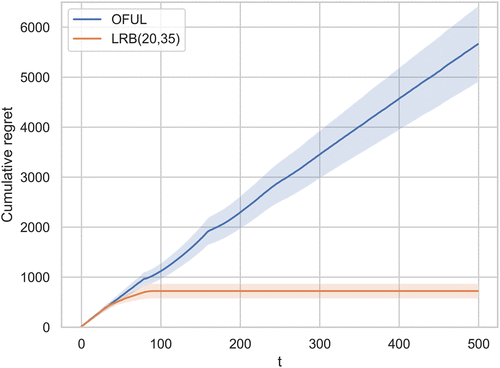
It is possible to design a variation of
6. Conclusion
This work introduced novel two-sided bandit algorithms,
Our framework offers practical guidance for the design of large-scale online experiments. In many industrial settings, such as A/B testing systems, recommender algorithms, or marketing experiments, the number of potential interventions (e.g., user-item pairs, ad-audience combinations, or headline-image variants) is combinatorially large. A common workflow is to first use heuristics or manual curation to filter this vast action space down to a manageable subset and then run an experiment on this reduced set. Our
6.1. Future Directions
Besides the low-rank estimator, prediction methods that leverage other problem structures may benefit from pairing with our targeted exploration + exploitation and/or subsampling strategy for enhanced performance as well. Such a heuristic may be of independent interest. For example, when we want to leverage more dimensions to characterize a product, we can formulate a tensor version of our LRB. As a real-life application, Airbnb Experiences can be modeled as three-sided products by including a temporal side in addition to the content and the location of an activity as mentioned in Section 1. On a related note, for settings such as Stitch Fix personalized styling, we have a unique reward profile for each user and different user reward matrices might share similarity. To find the best outfit for each user, we can form a tensor version of our
Our work also gives new perspectives on how to leverage potential low-rank matrix structure for product bundling (Stigler 1963) because the basic two-product bundling case considered in canonical works (Adams and Yellen 1976, Schmalensee 1984, McAfee et al. 1989) can be viewed as two-sided products. The entries of the matrix can be the expected rewards or purchase probabilities of bundles of two products. Through customer’s purchase behaviors, the preference regarding each bundle can be learned, which ultimately informs the pricing scheme.
Finally, our work can be extended to use offline collected historical data (if any) to warm start our two-sided bandit under limited online experiment horizon. For example, we can leverage the offline data for low-rank matrix estimation,6 by adopting a meta-algorithm called artificial replay proposed by Banerjee et al. (2022) and previously cited in Section 1.2 to incorporate selected historical data into our bandit algorithm.
All authors contributed equally.
1 We use this term to describe the initial nonadaptive data collection phase, where the algorithm operates like a randomized experiment. This is analogous to its use in the Markov chain Monte Carlo (MCMC) literature for the initial period before convergence (Brooks et al. 2011). We distinguish this from another common use of “burn-in” in online experimentation, which typically refers to a period for time-varying treatment effects (e.g., novelty effects) to stabilize; that is not the context here.
2 It should be noted that, although standard MAB algorithms are recognized for addressing cold-start problems in certain studies (Ye et al. 2023) through effective exploration and exploitation, this capability is contingent on a relatively short burn-in period compared with the total experimentation horizon. As we have discussed, given a substantial number of arms and a constrained time horizon, standard MAB algorithms cannot manage the cold-start problem effectively.
3 Theorem 7.2 of Lattimore and Szepesvári (2020).
4 We treat
5 In Section EC.8.4 of the Online Appendix, we discuss other related modes of advertisement campaigns that are not necessarily two-sided products.
6 Depending on whether the offline samples are uniformly or nonuniformly sampled, we can keep using the entry-wise bound from Chen et al. (2020) or switch to Xi et al. (2023) who have derived an entry-wise bound for sampling a matrix under a nonuniform pattern.
References
- (2011) Improved algorithms for linear stochastic bandits. Adv. Neural Inform. Processing Systems, vol. 24 (Curran Associates Inc., Red Hook, NY), 2312–2320.Google Scholar
- (1976) Commodity bundling and the burden of monopoly. Quart. J. Econom. 90(3):475–498.Google Scholar
- (2014) Bandits with concave rewards and convex knapsacks. Babaioff M, Conitzer V, Easley D, Nisan N, eds. Proc. 15th ACM Conf. Econom. Comput. (ACM, New York), 989–1006.Google Scholar
- (2012) Analysis of Thompson sampling for the multi-armed bandit problem. Mannor S, Srebro N, Williamson RC, eds. Proc. Conf. Learn. Theory, vol. 39 (PMLR, New York), 1–26.Google Scholar
- (2023) Causal matrix completion. Neu G, Rosasco L, eds. Proc. 36th Ann. Conf. Learn. Theory (PMLR, New York), 3821–3826.Google Scholar
- (2023) Optimal pricing with a single point. Management Sci. 69(10):5866–5882.Link, Google Scholar
- (2021) Matrix completion methods for causal panel data models. J. Amer. Statist. Assoc. 116(536):1716–1730.Crossref, Google Scholar
- (2002a) Finite-time analysis of the multiarmed bandit problem. Machine Learn. 47(2):235–256.Crossref, Google Scholar
- (2002b) The nonstochastic multiarmed bandit problem. SIAM J. Comput. 32(1):48–77.Crossref, Google Scholar
- (2021) Multiple randomization designs. Preprint, submitted December 27, https://arxiv.org/abs/2112.13495.Google Scholar
- (2022) Artificial replay: A meta-algorithm for harnessing historical data in bandits. Preprint, submitted October 1, https://arxiv.org/abs/2210.00025.Google Scholar
- (2020) Online decision making with high-dimensional covariates. Oper. Res. 68(1):276–294.Link, Google Scholar
- (2022) Learning personalized product recommendations with customer disengagement. Manufacturing Service Oper. Management 24(4):2010–2028.Link, Google Scholar
- (2020) Unreasonable effectiveness of greedy algorithms in multi-armed bandit with many arms. Adv. Neural Inform. Processing Systems 33:1713–1723.Google Scholar
- (1997) Bandit problems with infinitely many arms. Ann. Statist. 25(5):2103–2116.Google Scholar
- (2023) How big should your data really be? Data-driven newsvendor: Learning one sample at a time. Management Sci. 69(10):5848–5865.Link, Google Scholar
- (2022) The creator economy: Managing ecosystem supply, revenue sharing, and platform design. Management Sci. 68(7):5233–5251.Link, Google Scholar
- (2013) Two-target algorithms for infinite-armed bandits with Bernoulli rewards. Adv. Neural Inform. Processing Systems 26:2184–2192.Google Scholar
- (2011) Handbook of Markov Chain Monte Carlo (CRC Press, Boca Raton, FL).Crossref, Google Scholar
- (2012) Exact matrix completion via convex optimization. Comm. ACM 55(6):111–119.Crossref, Google Scholar
- (2015) Simple regret for infinitely many armed bandits. Bach F, Blei D, eds. Proc. Internat. Conf. Machine Learn. (PMLR, New York), 1133–1141.Google Scholar
- (2018) Quantile-Regret Minimisation in Infinitely Many-Armed Bandits (UAI).Google Scholar
- (2015) Incoherence-optimal matrix completion. IEEE Trans. Inform. Theory 61(5):2909–2923.Crossref, Google Scholar
- (2020) Noisy matrix completion: Understanding statistical guarantees for convex relaxation via nonconvex optimization. SIAM J. Optim. 30(4):3098–3121.Crossref, Google Scholar
- (2011) Contextual bandits with linear payoff functions. Proc. 14th Internat. Conf. Artificial Intelligence Statist. (PMLR, New York), 208–214.Google Scholar
- (2008) Stochastic linear optimization under bandit feedback. Servedio RA, Zhang T, eds. Proc. Conf. Learn. Theory (Omnipress, Madison, WI), 355–366.Google Scholar
- (2016) An overview of low-rank matrix recovery from incomplete observations. IEEE J. Selected Topics Signal Processing 10(4):608–622.Crossref, Google Scholar
- (2022) Uncertainty quantification for low-rank matrix completion with heterogeneous and sub-exponential noise. Camps-Valls G, Ruiz FJR, Guyon I, eds. Proc. Internat. Conf. Artificial Intelligence Statist. (PMLR, New York), 1179–1189.Google Scholar
- (2010) Parametric bandits: The generalized linear case. Adv. Neural Inform. Processing Systems 23:586–594.Google Scholar
- (2020) Online evaluation of audiences for targeted advertising via bandit experiments. Proc. AAAI Conf. Artificial Intelligence 34(1):13273–13279.Crossref, Google Scholar
- (2013) A linear response bandit problem. Stochastic Systems 3(1):230–261.Link, Google Scholar
- (2014) Thompson sampling for complex online problems. Proc. Internat. Conf. Machine Learn. (PMLR, New York), 100–108.Google Scholar
- (2022) Data pooling in stochastic optimization. Management Sci. 68(3):1595–1615.Link, Google Scholar
- (2021) Small-data, large-scale linear optimization with uncertain objectives. Management Sci. 67(1):220–241.Link, Google Scholar
- (2019) Personalizing many decisions with high-dimensional covariates. Adv. Neural Inform. Processing Systems 32:11469–11480.Google Scholar
- (2015) Statistical Learning with Sparsity: The Lasso and Generalizations (Taylor & Francis, Boca Raton, FL).Crossref, Google Scholar
- (2022) Experimental design in two-sided platforms: An analysis of bias. Management Sci. 68(10):7069–7089.Link, Google Scholar
- (2019) Bilinear bandits with low-rank structure. Chaudhuri K, Salakhutdinov R, eds. Proc. Internat. Conf. Machine Learn. (PMLR, New York), 3163–3172.Google Scholar
- (1993) Learning in Embedded Systems (MIT Press, Cambridge, MA).Crossref, Google Scholar
- (2020) Dynamic assortment personalization in high dimensions. Oper. Res. 68(4):1020–1037.Link, Google Scholar
- (2017)
Stochastic rank-1 bandits . Singh A, Zhu J, eds. Proc. Artificial Intelligence Statist. (PMLR, New York), 392–401.Google Scholar - (1995) Sequential choice from several populations. Proc. Natl. Acad. Sci. USA 92(19):8584.Crossref, Google Scholar
- (2010) Matrix completion from a few entries. IEEE Trans. Informs. Theory 56(6):2980–2998.Crossref, Google Scholar
- (2024) Data-driven clustering and feature-based retail electricity pricing with smart meters. Oper. Res. 73(5):2636–2660.Link, Google Scholar
- (2017) Stochastic low-rank bandits. Preprint, submitted December 13, https://arxiv.org/abs/1712.04644.Google Scholar
- (2020) Randomized exploration in generalized linear bandits. Proc. Internat. Conf. Artificial Intelligence Statist., 2066–2076.Google Scholar
- (1987) Adaptive treatment allocation and the multi-armed bandit problem. Ann. Statist. 15(3):1091–1114.Crossref, Google Scholar
- (2020) Bandit Algorithms (Cambridge University Press, Cambridge, MA).Crossref, Google Scholar
- (2017) Provably optimal algorithms for generalized linear contextual bandits. Precup D, Teh YW, eds. Proc. 34th Internat. Conf. Machine Learn., vol. 70 (PMLR, New York), 2071–2080.Google Scholar
- (2010) A contextual-bandit approach to personalized news article recommendation. Proc. 19th Internat. Conf. World Wide Web (ACM, New York), 661–670.Google Scholar
- (2014) Facing the cold start problem in recommender systems. Expert Systems Appl. 41(4):2065–2073.Crossref, Google Scholar
- (2011)
Content-based recommender systems: State of the art and trends . Ricci F, Rokach L, Shapira B, Kantor P, eds. Recommender Systems Handbook (Springer, Berlin), 73–105.Crossref, Google Scholar - (2019) Beyond A/B testing: Multi-armed bandit experiments. Medium (April 4), https://medium.com/data-science/beyond-a-b-testing-multi-armed-bandit-experiments-1493f709f804.Google Scholar
- (2021) Low-rank generalized linear bandit problems. Banerjee A, Fukumizu K, eds. Proc. Internat. Conf. Artificial Intelligence Statist. (PMLR, New York), 460–468.Google Scholar
- (2018) Efficient online recommendation via low-rank ensemble sampling. Pera S, Rendle S, Vlachos M, eds. Proc. 12th ACM Conf. Recommender Systems (ACM, New York), 460–464.Google Scholar
- (1989) Multiproduct monopoly, commodity bundling, and correlation of values. Quart. J. Econom. 104(2):371–383.Crossref, Google Scholar
- (2009) A structured multiarmed bandit problem and the greedy policy. IEEE Trans. Automated Control 54(12):2787–2802.Crossref, Google Scholar
- (2022) Context-based dynamic pricing with online clustering. Production Oper. Management 31(9):3559–3575.Crossref, Google Scholar
- (2015) A UCB-like strategy of collaborative filtering. Bui TD, Ho TB, eds. Proc. Asian Conf. Machine Learn. (PMLR, New York), 315–329.Google Scholar
- (2023) Online low rank matrix completion. Proc. 11th Internat. Conf. Learn. Representations (ICLR, Appleton, WI).Google Scholar
- (2010) Linearly parameterized bandits. Math. Oper. Res. 35(2):395–411.Link, Google Scholar
- (2018) A tutorial on thompson sampling. Foundations Trends® Machine Learn. 11(1):1–96. Crossref, Google Scholar
- (2023) Overcoming the long horizon barrier for sample-efficient reinforcement learning with latent low-rank structure. Proc. ACM Measurment Anal. Comput. Systems 7(2):1–60.Crossref, Google Scholar
- (1984) Gaussian demand and commodity bundling. J. Bus. 57(1):S211–S230.Crossref, Google Scholar
- (1963) United States v. Loew’s Inc.: A note on block-booking. Supreme Court Rev. 1963:152–157.Crossref, Google Scholar
- (1933) On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika 25(3/4):285–294.Crossref, Google Scholar
- (2020)
Solving Bernoulli rank-one bandits with unimodal Thompson sampling . Algorithmic Learning Theory (PMLR, New York), 862–889.Google Scholar - (2010) Introduction to the non-asymptotic analysis of random matrices. Preprint, submitted November 12, https://arxiv.org/abs/1011.3027.Google Scholar
- (2017)
Dropoutnet: Addressing cold start in recommender systems . Adv. Neural Inform. Processing Systems 30:4957–4966.Google Scholar - (2009)
Algorithms for infinitely many-armed bandits . Koller D, Schuurmans D, Bengio Y, Bottou L, eds. Adv. Neural Inform. Processing Systems, vol. 21 (Curran Associates, Inc., Red Hook, NY), 1729–1736.Google Scholar - (2023) Entry-specific bounds for low-rank matrix completion under highly non-uniform sampling. Proc. IEEE Internat. Sympos. Inform. Theory (IEEE, Piscataway, NJ), 2625–2630.Google Scholar
- (2021) Multitask learning and bandits via robust statistics. Management Sci. 71(9):7752–7773.Google Scholar
- (2023) Cold start to improve market thickness on online advertising platforms: Data-driven algorithms and field experiments. Management Sci. 69(7):3838–3860.Link, Google Scholar
- (2014) Addressing cold start in recommender systems: A semi-supervised co-training algorithm. Berkovsky S, Bennett PN, Murdock V, Moffat A, eds. Proc. 37th Internat. ACM SIGIR Conf. Res. Development Informat. Retrieval (ACM, New York), 73–82.Google Scholar
- (2022) Netease cloud music data. Manufacturing Service Oper. Management 24(1):275–284.Link, Google Scholar
- (2025) Stochastic low-rank tensor bandits for multi-dimensional online decision making. J. Amer. Statist. Assoc. 120(549):198–211.Google Scholar
- (2022) Learning markov models via low-rank optimization. Oper. Res. 70(4):2384–2398.Link, Google Scholar

