
A Bandit-Based Approach to Educational Recommender Systems: Contextual Thompson Sampling for Learner Skill Gain Optimization
Abstract
In recent years, instructional practices in operations research, management science, and analytics have increasingly shifted toward digital environments, where large and diverse groups of learners make it difficult to provide practice that adapts to individual needs. This paper introduces a method that generates personalized sequences of exercises by selecting, at each step, the exercise most likely to advance a learner’s understanding of a targeted skill. The method uses information about the learner and their past performance to guide these choices, and learning progress is measured as the change in estimated skill level before and after each exercise. Using data from an online mathematics tutoring platform, we find that the approach recommends exercises associated with greater skill improvement and adapts effectively to differences across learners. From an instructional perspective, the framework enables personalized practice at scale, highlights exercises with consistently strong learning value, and helps instructors identify learners who may benefit from additional support.
1. Introduction
Over recent years, active learning has been increasingly adopted in operations research (OR), management science (MS), and analytics education, transforming how students engage with learning materials, receive feedback, and develop conceptual understanding (Fornasiero et al. 2021, Reeves et al. 2021, Maclean and Bayley 2024). One way active learning strategies have been implemented is through massive open online courses (MOOCs) and other digital learning environments that provide online access to instructional materials, practice activities, and assessments. Yet despite this digital shift in instructional practice, many courses continue to rely on standardized learning paths in which all learners progress through the same predetermined sequence of exercises, offering limited opportunity for personalized learning experiences. The need for adaptive sequencing becomes even more difficult to address in MOOCs, where the sheer number of learners severely constrains instructors’ ability to provide individualized learning trajectories. Moreover, students in OR/MS/analytics courses enter with widely differing levels of quantitative skills, yet scalable mechanisms for adapting practice to these varied skill levels remain limited.
Educational recommender systems (ERSs) offer a promising approach for supporting active learning by tailoring practice opportunities to learners’ evolving needs and guiding them along personalized learning paths. Within such systems, personalized recommendations function as a form of individualized feedback through scaffolding. Scaffolding is traditionally understood as an instructional practice in which a teacher provides structured support and gradually removes guidance as learners develop greater competence (van de Pol et al. 2010). It involves sequencing tasks so that each exercise offers an appropriate level of challenge relative to the learner’s current understanding. In our setting, the ERS operationalizes this principle by continuously updating its estimates of a learner’s skill state after each interaction and selecting subsequent exercises whose difficulty is aligned with that learner’s evolving proficiency. In doing so, the ERS provides individualized feedback in the form of targeted guidance about what to practice next.
In the ERS literature, the most commonly used approach for generating recommendations has been collaborative filtering (CF) techniques (Khanal et al. 2020). CF methods identify patterns in interaction logs to recommend relevant exercises to users, typically through the detection of similarity either between users (UserCF) or between exercises (ItemCF). Nevertheless, CF methods face important limitations in educational contexts. First, CF methods are not inherently personalized: recommendations are derived from aggregated behavioral patterns rather than the learner’s unique profile. User-based CF, for example, assumes that learners with similar past interactions will benefit from similar exercises, overlooking individual heterogeneity in learning needs or cognitive skill levels. Second, learners’ preferences and knowledge states evolve over time, yet CF approaches typically rely on static similarity measures. This makes CF ill suited to capture temporal dependencies or to adjust recommendations as learners progress. Third, without an explicit mechanism for exploration, CF also tends to reinforce historically popular exercises, limiting opportunities to identify exercises better aligned with a learner’s evolving profile.
Contextual bandit algorithms, by contrast, are inherently adaptive and address these shortcomings directly. They frame recommendation as a sequential decision problem in which the effectiveness of an exercise is uncertain ex ante and heterogeneous across learners, skills, and time. In a bandit setting, each recommendation step selects an exercise for a particular learner. The “context” is the information available at decision time about the learner and the candidate exercise (e.g., recent performance, affective state, topic, difficulty), and the resulting “reward” is the observed learning benefit after engagement, here operationalized as the change in estimated skill gain. The exploration–exploitation mechanism at the heart of bandit methods enables deliberate trialing of uncertain but potentially valuable exercises (exploration) while selecting those exercises expected to generate the greatest learning gains (exploitation). In this way, bandit algorithms can contribute to the construction of adaptive learning paths that respond to evolving learner needs. The literature study by Da Silva et al. (2023) highlights that, despite their promise, bandit-based methods remain underexplored in ERSs, underscoring a key avenue for future research.
This study addresses the identified literature gap by proposing a bandit-based framework for ERS and, to the best of our knowledge, is the first empirical evaluation of Thompson sampling (TS) for educational recommendation. TS is a Bayesian posterior sampling algorithm (Thompson 1933) with strong theoretical regret guarantees (Agrawal and Goyal 2012, 2013) and robust empirical performance across sequential decision-making tasks (Ferreira et al. 2018, Aramayo et al. 2023). At each decision step, TS maintains a posterior distribution over the expected utility of the available exercises and selects the next exercise by sampling from these distributions. In doing so, exercises are chosen in proportion to their probability of being optimal, which provides a principled mechanism for balancing exploration of uncertain exercises with exploitation of those exercises expected to yield high utility.
The proposed framework applies linear TS (LinTS) as the bandit strategy for educational recommendation. LinTS specifies a separate linear model for each available exercise, where the expected reward is expressed as a linear function of learner features. This formulation enables recommendations to adapt to evolving learner profiles and knowledge states. For benchmarking, we also consider standard TS, which operates in a noncontextual setting, alongside conventional CF approaches. This comparative design enables a systematic evaluation of the contribution of contextual modeling to sequential recommendation in ERSs.
The framework employs a reward signal based on learner skill gain, defined as the learner’s improvement in estimated knowledge state of a particular cognitive skill as computed by a Bayesian knowledge tracing (BKT) model (Corbett and Anderson 1994). BKT models skill acquisition as a latent probabilistic process, updating a learner’s knowledge state with each interaction based on observed responses, thereby providing a dynamic estimate of learning progress. The use of skill gain as reward contrasts with the predominant evaluation metrics in recommender studies, which rely on the correctness of recommended exercises (Manickam et al. 2017), ratings of recommended exercises (Nafea et al. 2019), or user satisfaction levels (Tarus et al. 2017). Correctness may lead to inflated performance estimates, as systems can achieve high accuracy by recommending exercises the learner is already able to solve, without necessarily promoting new learning. Similarly, ratings and satisfaction scores capture subjective perceptions of difficulty or enjoyment but may diverge from actual knowledge acquisition. These metrics are therefore limited as proxies for genuine learning progress, as they do not fully capture the cognitive development of a learner. Accordingly, skill gain is adopted as the reward signal because it more directly aligns the optimization process with the pedagogical objective of competence development.
Our experiment is performed on the ASSISTments data set (Patikorn et al. 2020), which provides interaction data from an online secondary-level tutoring system (Heffernan and Heffernan 2014). The reward signal is defined as the change in estimated skill between two consecutive interactions, based on the BKT proficiency measures included in the data set. Results show that LinTS achieves the highest performance, yielding a 15.2% improvement in average skill gain over the noncontextual TS baseline, as well as 16.5% and 20.7% improvements over CF baselines. This underscores the effectiveness of contextual modeling for adaptive educational recommendation.
The remainder of this paper is organized as follows. Section 2 reviews related work on ERS and bandit methods. Section 3 formalizes the problem setting and details the baselines (UserCF, ItemCF) and the bandit policies (TS, LinTS). Section 4 describes the experimental setup, including data set description, data preprocessing, data splitting, and validation strategy. Section 5 reports empirical results, and Section 6 discusses practical takeaways for OR/MS/analytics instructors. Section 7 ends with a conclusion and directions for future work.
2. Related Work
Research on active learning in OR/MS/analytics education has primarily focused on improving in-class teaching practices. For example, Maclean and Bayley (2024) examined efficient approaches for assessing higher-order thinking skills in an undergraduate business analytics course. Similarly, Fornasiero et al. (2021) introduced a puzzle-based learning method to support the development of optimization skills in high school students, whereas Reeves et al. (2021) designed hands-on, constructivist exercises to enhance learning in an introductory probability and statistics course. All these interventions remain largely classroom based. Importantly, none of these studies consider how active learning might be supported through personalized learning paths in digital environments, a domain that is becoming increasingly relevant as OR/MS/analytics courses move online.
Several approaches have been proposed to optimize sequences of exercises in ERSs, each aiming to guide learners through personalized educational trajectories. CF remains the most dominant approach in ERSs, with 5 of the 16 studies analyzed in the literature review by Da Silva et al. (2023) employing either pure CF methods or hybrid strategies that incorporate CF components. CF approaches are typically classified into two main variants: user-based and item-based filtering. The user-based approach infers preferences by identifying patterns of similarity among users, generating recommendations based on exercises previously interacted with by users exhibiting comparable behavioral profiles. Conversely, the item-based variant focuses on relationships between exercises, recommending exercises that are similar in content or usage patterns to those a given learner has already engaged with (Da Silva et al. 2023). Among CF approaches, user-based variants are more commonly adopted in the recommendation process, reflecting the growing pedagogical emphasis on student-centered learning (Krahenbuhl 2016). In the reviewed studies, various similarity metrics have been applied to operationalize these patterns, including cosine similarity (Wu et al. 2015, Tarus et al. 2017, Huang et al. 2019), Euclidean distance (Sergis and Sampson 2016), and Pearson correlation coefficient (Nafea et al. 2019), each offering different computational strategies for capturing relational proximity within interaction data.
Although CF has shown effectiveness in static recommendation scenarios, its reliance on historical similarity patterns constrains its pedagogical applicability. Recommendations are derived from aggregated interaction behavior rather than being informed by the learner’s evolving knowledge state, and the absence of an explicit exploration mechanism leads CF to reinforce familiar or popular exercises instead of identifying exercises that may more effectively promote sustained learning progress. These limitations create the need for methods that explicitly model sequential decision making.
Contextual bandit algorithms provide such a framework by conditioning recommendations on learner-specific features (personalization) and dynamically balancing the tradeoff between exploiting known effective exercises and exploring uncertain but potentially more beneficial ones. As highlighted in the systematic literature review by Da Silva et al. (2023), despite the prominence of bandit algorithms in general recommender system research, such methods remain underexplored in educational contexts, revealing a notable mismatch between the two domains and underscoring the need for further research.
Most existing applications of multiarmed bandit algorithms within the educational domain are situated in the context of educational games, where their capacity for adaptive, sequential decision making aligns well with the dynamic and interactive nature of game-based learning environments. Liu et al. (2014) apply an upper confidence bound (UCB)-explore strategy, a noncontextual bandit algorithm based on the UCB algorithm, in a physics-based educational game involving different ways of displaying number lines. Clément et al. (2014) employ the exponential-weight algorithm called EXP4, a context-free bandit strategy that incorporates expert knowledge to narrow the set of possible exercises when training a bandit policy. This method is applied within an educational game for seven- to eight-year-old schoolchildren, designed to support the development of numerical decomposition skills in the context of manipulating money. These studies are limited in two respects. First, they target narrow game-based case studies with bespoke mechanics and short interaction horizons; as a result, their findings may not transfer to broader settings such as MOOCs or large-scale tutoring platforms that involve heterogeneous content, longer trajectories, and diverse learner populations. Second, both methods are context free and therefore cannot condition recommendations on learner features, precluding meaningful personalization.
To date, only two studies have applied contextual bandits within the ERS domain. The first study by Manickam et al. (2017) employs a contextual linear UCB algorithm with context vectors representing latent concept knowledge profiles inferred from learners’ interaction histories in a college-level physics setting. The second study by Intayoad et al. (2020) incorporates past student behaviors and current learner state into a correlation analysis to preselect candidate exercises. As such, we argue that this approach cannot be considered a true contextual bandit model, as contextual information is confined to the prefiltering stage rather than being embedded within the bandit algorithm itself. The recommendation policy relies on a noncontextual -greedy strategy, with reward defined as whether the learner clicked on the suggested exercise. Although these approaches provide valuable empirical insights, the use of correctness on the next exercise in the first study and click-based feedback in the second as optimization criteria may be limiting for ERS. Such measures primarily capture short-term task performance or engagement and may fail to account for sustained learning gains or the incremental development of a learner’s knowledge state, which are particularly critical for constructing effective learning paths. In particular, the first study by Manickam et al. (2017) incorporated knowledge estimates as input features to guide recommendations. However, we argue that it would be more appropriate to optimize directly for improvements in these knowledge states, thereby aligning system objectives with sustained learning progress rather than immediate task performance.
To date, no studies on multiarmed bandits in ERS have incorporated TS (Thompson 1933), despite its well-documented effectiveness in general recommender system research (Ferreira et al. 2018, Aramayo et al. 2023, De Kerpel and Benoit 2025) and its empirically demonstrated superiority over frequentist strategies such as UCB (Chapelle and Li 2011). Its probabilistic exercise-selection mechanism facilitates a principled balance between exploration and exploitation while inherently accounting for uncertainty in reward estimation. The absence of TS in prior ERS research therefore constitutes a notable literature gap, which the present study seeks to address. In this study, we implement LinTS, a contextual bandit algorithm that models each exercise as a linear function of learner features, and evaluate it alongside the noncontextual TS baseline. Unlike prior approaches, we define the reward as skill gain, thereby directly optimizing for improvements in learners’ knowledge states rather than correctness on the next exercise.
3. Methodology
This section describes the algorithms and decision-making framework implemented in our ERS experiment. We first introduce the multiarmed bandit (MAB) problem and its contextual variant. We then detail the CF baselines (UserCF and ItemCF) and the two bandit-based methods TS and LinTS.
3.1. MABs in Educational Recommendation
In the MAB framework, a recommendation session unfolds over a sequence of T discrete interaction rounds. At each round , the ERS selects an exercise from a finite set of available exercises . Each exercise corresponds to a distinct learning activity, such as a practice exercise, instructional video, or interactive simulation. Once the learner engages with the recommended exercise, the system observes a reward , drawn from an unknown probability distribution specific to that exercise.
In this work, the reward is defined as the skill gain associated with the specific cognitive skill s targeted by the recommended exercise . Let denote the learner’s estimated mastery of skill s immediately prior to the interaction, and the mastery estimate immediately after, both estimated using a BKT model (Corbett and Anderson 1994). The reward is then computed as
The goal of the ERS is to choose exercises such that the sum of the learner’s realized rewards is maximized:
The contextual extension of MABs (CMAB) allows the ERS to incorporate side information about the learner and the exercise. At round t, the system observes a context vector that includes learner features such as demographic attributes, historical performance, or emotional state. The expected reward for an exercise is then modeled as
Figure 1 summarizes the contextual bandit interaction in our ERS. At time t, the learning platform (environment) provides a context vector describing the current learner state. The bandit policy (agent) selects an exercise , which is delivered to the learner. After the interaction, the platform returns a reward and the tuple is logged to update the policy.

Notes. The environment (learning platform) emits context ; the agent (bandit policy) recommends an exercise ; after the learner engages, the environment returns reward (skill gain). The resulting tuples support online learning and evaluation.
3.2. Collaborative Filtering Baselines
3.2.1. UserCF.
The user-based CF baseline estimates the expected effectiveness of a candidate exercise for a target learner by leveraging similarity in historical interaction profiles across the entire learner population. Let U denote the set of all learners, and let represent the observed skill-gain reward for learner u on exercise a. For a given target learner u, a similarity score is computed with every other learner based on the cosine distance between their respective interaction vectors in the learner–exercise space. Cosine-based similarity is the most common choice in distance-based CF, although alternative measures such as the Pearson correlation or the dot product are also used (Liu et al. 2017).
The predicted effectiveness of an exercise a is then obtained as a similarity-weighted average of the recorded rewards from all other learners:
The system then selects the exercise with the maximal predicted value . The UserCF algorithm is formally defined in Algorithm 1.
(
1: Input: Target learner u, candidate exercise set , interaction matrix R (skill gain)
2: Compute for all
3: for each do
4:
5: end for
6: Return
3.2.2. ItemCF.
The item-based CF baseline instead exploits similarities between exercises, as derived from their historical usage patterns across learners. As in the user-based variant, stores the skill-gain reward for learner u on exercise a. For a target learner u and a candidate exercise a, the cosine similarity is computed with every other exercise . The predicted skill-gain reward for a is then given by the similarity-weighted average of the learner’s own past rewards on other exercises:
The algorithm then recommends the exercise with the highest predicted value. The ItemCF algorithm is formally defined in Algorithm 2.
(
1: Input: Target learner u, candidate exercise set , interaction matrix R (skill gain)
2: Compute for all
3: for each do
4:
5: end for
6: Return
3.3. Bandit Policies
3.3.1. TS.
TS is a Bayesian algorithm based on probability matching (Thompson 1933), where exercises are selected proportionally to their probability of being optimal given the current belief state. At each round t, the algorithm samples a reward value for each exercise from its posterior distribution and selects the exercise with the highest estimated reward. This approach naturally balances exploration and exploitation by favoring exercises with high estimated rewards while still exploring uncertain options.
In the standard formulation of TS, the reward is binary, and the posterior distribution over the mean reward of each exercise follows a Beta distribution. In contrast, in the proposed ERS, the reward signal is continuous, representing the learner’s skill gain after engaging with an exercise. We therefore model rewards as Gaussian-distributed with unknown mean and variance. The conjugate prior for this case is the Normal–Inverse–Gamma distribution:
At each round, TS samples from the posterior for every exercise a, selects the exercise with the highest sampled mean, observes the reward signal, and updates the corresponding hyperparameters. The TS algorithm is formally defined in Algorithm 3.
(
1: Input: Exercise set , hyperparameters
2: for do
3: for each do
4: Sample
5: Sample
6: end for
7: Select
8: Recommend and observe continuous reward
9: Update for
10:
11:
12:
13:
14:
15: end for
3.3.2. LinTS.
LinTS (Agrawal and Goyal 2013) extends TS to contextual bandits by assuming that the expected reward of each exercise is a linear function of the context vector. It balances exploration and exploitation by sampling parameter vectors from a Bayesian posterior distribution that captures uncertainty in the estimated parameters.
In LinTS, each exercise a is associated with an information matrix and a reward vector . The posterior mean parameter vector is given by
Exploration in LinTS arises naturally from the parameter sampling process. At each time step t, a parameter vector is sampled for each exercise a according to
In this work, we adopt a Gaussian LinTS variant as formalized in Algorithm 4. Consistent with the approach of Agrawal and Goyal (2013), the posterior variance scaling factor v is held fixed rather than estimated adaptively.
(
1: Input: Regularization parameter , exploration scaling factor v, context space , set of exercises
2: Initialize: For each exercise ,
3: for each time step do
4: Observe context vector
5: for each exercise do
6: Sample parameter vector:
7: Compute the expected reward:
8: end for
9: Select exercise
10: Recommend exercise and observe reward
11: Update the selected exercise:
12: end for
4. Experimental Setup
4.1. Data Set
The data set used for this experiment is the ASSISTments 2017 data set (Patikorn et al. 2020), a large-scale clickstream corpus collected from the web-based ASSISTments tutoring system (Heffernan and Heffernan 2014), which records middle-school students’ mathematics exercise-solving activities between 2004 and 2006. The data set is widely used in learning analytics research, for example, in learner performance prediction (Hakkal and Lahcen 2024) and knowledge tracing estimation (Cully and Demiris 2020, Neshaei et al. 2024). It contains 935,638 interaction records from 1,708 unique learners across 3,162 distinct exercises, with 37.4% of all attempts answered correctly.
The data set provides three complementary types of inputs. First, clickstream records capture the raw sequence of learner–system interactions. Second, exercise information describes the exercises themselves, including the associated cognitive skill(s) and exercise type (e.g., multiple choice, open response). Third, student profiles encode both background information and behavioral characteristics. Background attributes include sociodemographic indicators such as gender, the middle school attended, and the academic year in which the system was used. Behavioral characteristics are derived from historical interaction logs and summarized over the learner’s past activity. These include the following:
Academic proficiency indicators, which include the learner’s average knowledge mastery across all mathematical skills targeted by the system, performance on the Massachusetts Comprehensive Assessment System (MCAS) mathematics test and the learner’s overall correct response rate. These academic proficiency indicators capture complementary dimensions of learner ability. The MCAS mathematics score provides a stable, externally validated measure of baseline competence, whereas average knowledge mastery reflects broader conceptual understanding as inferred during system interaction. The overall correctness rate indicates how efficiently and accurately learners apply their knowledge.
Affective state indicators that capture internal emotions or psychological states that can influence learning, which include the averaged tendencies toward confusion, frustration, boredom, and engaged concentration.
Disengaged behavior indicators that reflect behavioral patterns that indicate that a learner is not productively engaged, which include the averaged tendencies for carelessness (e.g., slipping an exercise), gaming the system, and disengaging from the learning task.
The affective and disengagement indicators are obtained via a two-stage process: manual labeling through in-class field observations on a representative subsample, followed by the training of automated detectors using supervised machine learning methods to the full data set (Pardos et al. 2014). In addition, cognitive measures in the form of BKT estimates of mastery are included in the data set. After each exercise attempt, the system recalculates the learner’s probability of mastery for the specific cognitive skill targeted by the exercise, thereby providing a fine-grained, time-varying representation of the learner’s knowledge state. In this study, reward is defined as skill gain, computed from the difference between the BKT mastery estimate after and before the interaction for a specific skill targeted by the exercise. This continuous-valued signal measures the incremental change in the learner’s estimated mastery due to engaging with the recommended exercise, providing a pedagogically grounded target for optimization.
4.2. Data Preprocessing
Prior to partitioning the data set into training, validation, and test subsets, we apply the following preprocessing pipeline.
Reward calculation and filtering. Any interaction in which either the preinteraction mastery estimate or the postinteraction mastery estimate for the skill associated with the attempted exercise is missing is removed. Only interactions with strictly positive rewards are retained, focusing the learning process on exercises that have demonstrably advanced a learner’s mastery of the targeted skill and also reducing computation time. The empirical distribution of these computed rewards is shown in Figure 2(a). The pronounced peak around zero reflects the large share of interactions that do not yield measurable improvements in estimated skill gain. Moreover, the distribution is positively skewed: most interactions correspond to small to moderate gains, with a long right tail representing relatively larger skill gain improvements.
Duplicate user–exercise interactions. For any user–exercise pair with multiple recorded interactions, only the most recent chronologically observed attempt is retained. This situation often arises on the ASSISTments platform when learners request hints, retry after incorrect responses, or reopen an exercise within the same session. Retaining only the final attempt ensures that the postinteraction mastery estimate reflects the learner’s ultimate knowledge state for that exercise, avoiding inflated counts from partial or intermediate states.
Learner activity threshold. Learners with fewer than 50 interactions are excluded to preserve sufficient historical data for personalized modeling, because shorter histories produce highly unstable skill gain estimates and provide too little signal for meaningful contextual differentiation. The resulting student activity levels, measured as the number of retained interactions per learner, are summarized in Figure 2(b).
Warm-start enforcement. After the temporal split, any validation or test interactions involving a user or exercise unseen in the training set are removed. This ensures that evaluation occurs in a warm-start setting, where all entities at test time have prior representation in the training data, thereby avoiding cold-start scenarios.
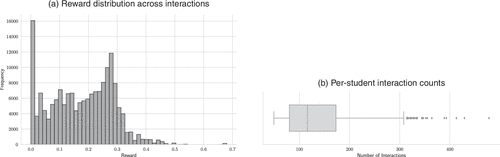
Notes. (a) Distribution of skill-gain rewards. (b) Variability in student activity levels.
A summary of the final preprocessed data set, including the number of unique users, exercises, skills, and total number of interactions is provided in Table 1.
|

Table 1. Summary Statistics of the Preprocessed ASSISTments 2017 Data Set
| Statistic | Value | Description |
|---|---|---|
| Unique users | 1,250 | Number of distinct learners in the data set. |
| Unique exercises | 2,600 | Number of distinct exercises available for recommendation. |
| Interactions | 167,585 | Total number of recorded learner–exercise interactions after preprocessing. |
| Number of skills | 102 | Number of distinct knowledge concepts, for example, supplementary angles, Pythagorean theorem. |
For the contextual bandit setting, we construct a context vector for each interaction by concatenating user features as listed in Table 2. Categorical variables are one-hot encoded, and continuous features are standardized.
|
Table 2. Features Used to Construct the Context Vector
| Feature | Description |
|---|---|
| Sociodemographic characteristics | |
| Academic year | Year(s) during which the learner used the platform (categorical). |
| School | Anonymized middle-school identifier (categorical). |
| Gender | Gender of the learner (categorical). |
| Academic proficiency | |
| Average knowledge mastery | Average student knowledge level across all skills the learner has attempted. |
| Overall correctness rate | Fraction of correct responses across all attempted exercises. |
| MCAS mathematics score | Standardized MCAS math assessment score. |
| Affective state | |
| Confusion | Mean predicted probability of confusion over past interactions. |
| Frustration | Mean predicted probability of frustration over past interactions. |
| Boredom | Mean predicted probability of boredom over past interactions. |
| Engaged concentration | Mean predicted probability of being focused/engaged. |
| Disengaged behavior | |
| Carelessness | Mean predicted probability of careless errors. |
| Gaming the system | Mean predicted probability of exploiting system loopholes. |
| Off-task | Mean predicted probability of disengagement from the learning task. |
4.3. Data Splitting
We adopt a temporal user split strategy, a commonly used evaluation approach that splits the historical interactions by percentage based on the interaction timestamps (Meng et al. 2020). For each learner, interactions are ordered chronologically, with the first assigned to training, the next to validation, and the final to test. This preserves the natural temporal sequence of interactions, ensures user overlap across splits, and mirrors real-world online deployment where future learner states are unknown at recommendation time.
4.4. Algorithms
Both UserCF and ItemCF maintain a user–exercise reward matrix that is updated in buffered batches every 1,000 interactions, with pending updates applied at the end of training. UserCF estimates candidate effectiveness by computing cosine similarity between the target learner and all others. ItemCF instead relies on similarities between candidate exercises and those previously attempted by the learner. For the bandit models, TS represents each exercise with a Gaussian reward distribution under a Normal–Inverse–Gamma prior initialized with noninformative hyperparameters, and it updates exercise-specific statistics incrementally after each interaction. LinTS maintains a separate linear model per exercise with ridge regularization fixed at . To reduce computational overhead, matrix inversions and parameter estimates are recomputed only every 1,000 steps. Both TS-based models (TS and LinTS) include a short warm-start phase of random exercises to ensure initial coverage. Finally, in all methods, once a learner has attempted an exercise, it is excluded from future recommendations, reflecting realistic tutoring scenarios where repeating the same exercise yields negligible learning gains.
4.5. Validation Strategy
We tune the bandit hyperparameters using grid search on the validation split, using mean instantaneous reward as the evaluation criterion. LinTS is tuned over different values of the variance-scaling parameter v, whereas TS is tuned over the Normal–Inverse–Gamma prior parameters with a fixed prior mean . Table 3 summarizes the respective search spaces. The best-performing configuration for each model is then retrained on the combined training and validation data and evaluated once on the held-out test split, without further adaptation during testing. The CF baselines have no hyperparameters and are directly trained on the combined data set before final evaluation, whereas TS-based strategies require hyperparameter tuning, which incurs additional computational cost.
|
Table 3. Hyperparameter Grids Used for LinTS and TS
| Model | Hyperparameter | Candidate values |
|---|---|---|
| LinTS | v | |
| TS | ||
5. Results
All model hyperparameters were selected by maximizing the average instantaneous reward on a validation set. The best configuration for TS was , which corresponds to a neutral prior mean , a low prior precision yielding a diffuse prior over exercise means, and hyperparameters that maintain posterior uncertainty during the initial learning phase. For LinTS, the optimal exploration scale was , and because v scales the posterior covariance of sampled coefficients, this relatively small value reduces injected sampling noise and thus favors exploitation of the informative learner context once sufficient evidence has been accumulated.
Figure 3 presents the evolution of cumulative average reward on the held-out test set across all models. The results show that bandit-based approaches outperform CF baselines. Both TS variants yield higher rewards than UserCF and ItemCF, confirming that exploration–exploitation strategies can generate more effective recommendations than neighborhood-based heuristics.
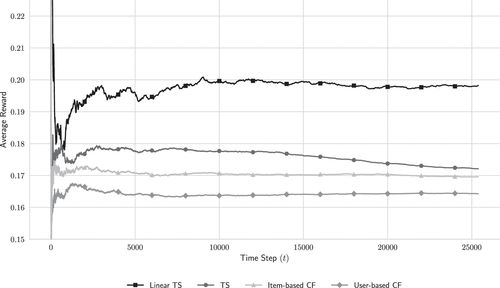
Note. LinTS outperforms all noncontextual baselines, including TS and CF baselines, underscoring the value of contextual modeling in adaptive educational recommendation.
Among the tested models, LinTS achieves the highest performance, converging to a final average reward of 0.198. This corresponds to a 15.2% improvement over standard TS (0.172), a 16.5% improvement over ItemCF (0.170), and a 20.7% improvement over UserCF (0.164). Although standard TS already performs better than both CF baselines, the contextual extension embodied in LinTS produces substantially larger gains, highlighting the added value of incorporating learner features into the exercise-selection process.
Figure 4 shows exercise-selection frequency distributions, with the x axis denoting exercise identifiers and the y axis denoting the number of selections during testing. ItemCF (Figure 4(a)) spreads choices widely across the exercise space, reflecting the absence of adaptive prioritization. UserCF (Figure 4(b)), by contrast, concentrates almost exclusively on a few exercises, illustrating premature convergence and overexploitation. TS (Figure 4(c)) distributes exercises more broadly than UserCF, avoiding the premature lock-in observed in that model. At the same time, its selections are less diffuse than ItemCF and hence concentrate more on consistently rewarding exercises. LinTS (Figure 4(d)) goes further by identifying a narrower set of high-value exercises, indicating more effective balancing of exploration and exploitation in the contextual setting.
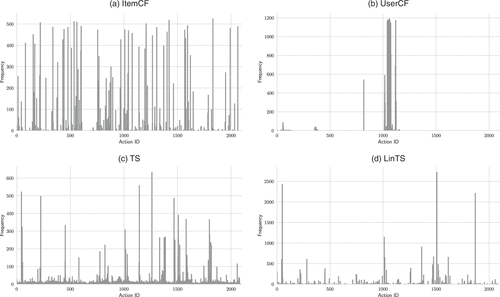
Note. Contextual modeling (LinTS) concentrates selections on a narrower set of informative exercises, whereas noncontextual strategies spread choices more diffusely across the exercise space.
To better understand these dynamics, Figure 5 analyzes LinTS behavior during training. In the first 10,000 rounds (Figure 5(a)), the distribution is broad and relatively uniform, reflecting an exploratory phase in which the agent samples widely across the exercise space. In contrast, during the final 10,000 rounds (Figure 5(b)), the frequency distribution becomes highly concentrated on a small subset of exercises, indicating focused exploitation of high-value learning opportunities. These findings highlight that contextual linear modeling not only improves reward performance but also produces qualitatively different exploration–exploitation dynamics, enabling more principled exploration and more focused exploitation of high-reward exercises.
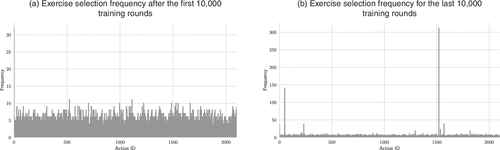
Notes. (a) Early exploration behavior. (b) Later-stage exploitation dynamics.
6. Discussion
From an instructional perspective, the proposed bandit-based ERS offers three key benefits for OR/MS/analytics courses. First, many such courses still rely on instructor-centered teaching practices in which all learners progress through the same fixed sequence of exercises predetermined by the instructor. This structure limits the ability to adjust difficulty, pacing, or feedback to individual needs and often reproduces typical drawbacks of fixed exercise paths: exercises that are too easy may induce disengagement, whereas overly difficult tasks can cause frustration and reduced persistence. The proposed ERS addresses these limitations by adaptively selecting exercises based on each learner’s evolving skill profile. For example, the system could be embedded into an introductory optimization or probability course to automatically recommend additional practice on duality or conditional probability for students who struggle while advancing more prepared students to more difficult exercises. By personalizing the learning trajectory in this way, LinTS supports scalable learning environments in which instruction becomes responsive rather than prescriptive, enabling individualized practice without requiring instructors to manually construct multiple parallel exercise pathways. This adaptivity is particularly valuable in large enrollment courses and other digital learning environments where instructors cannot feasibly monitor or tailor learning trajectories for all students.
Second, as shown in Figures 4 and 5, LinTS concentrates its recommendations on a relatively small set of exercises. This provides empirically grounded feedback to support course design: The learned policy highlights which exercises consistently generate large skill gains and are therefore strong candidates for in-class discussion, worked examples, or graded assignments. The same mechanism can underpin an instructor dashboard that identifies which prerequisite skills learners are struggling with, such as matrix operations in linear programming or probability rules in stochastic models, and highlights which exercises produce the strongest gains for specific student subgroups. Such information supports targeted intervention during classroom hours or tutorial sessions.
Third, learners in OR/MS/analytics courses often enter with widely varying quantitative competencies in areas such as statistics, linear algebra, and optimization. Because LinTS can condition its recommendations on learner background, it can identify students who struggle with standard exercise sets, for example, because of limited prerequisite skills, and recommend more suitable practice exercises. This enables instructors to provide differentiated remediation. Collectively, these insights underscore the potential of contextual bandit–based ERS to support individualized data-driven instruction and remediation in OR/MS/analytics courses, including large-scale digital learning environments where traditional personalized feedback is difficult to provide at scale.
7. Conclusion
ERS provide a scalable mechanism for supporting active learning in digital OR/MS/analytics settings, where large and heterogeneous learner populations make individualized guidance difficult to provide manually. CF remains widely used in ERS, but its reliance on historical similarity patterns, lack of adaptivity, and absence of an exploration mechanism limit its ability to support effective personalized learning trajectories. This work introduces a contextual bandit framework based on LinTS, which models exercise effectiveness as a function of learner features and optimizes directly for skill gain. Experiments on the ASSISTments 2017 data set show that LinTS outperforms both noncontextual TS and CF baselines, achieving higher average skill gains and exhibiting desirable exploration–exploitation dynamics. The results highlight several instructional benefits: adaptive sequencing that responds to learners’ evolving skill profiles, data-driven insights into which exercises most effectively promote learning, and the ability to identify students who may require targeted support.
Some limitations of this study must be acknowledged. The work relies on simplifying assumptions, which may limit the extent to which the findings generalize beyond the present setting. For example, learners with fewer than 50 interactions were excluded, limiting the applicability of the proposed approach in sparse data settings involving many new or infrequent users. Future work should incorporate richer contextual signals, explore nonlinear model classes, and consider multiobjective formulations that balance learning progress with other pedagogical goals. Such extensions would further enhance the applicability of contextual bandits in adaptive learning systems.
References
- (2012)
Analysis of Thompson sampling for the multi-armed bandit problem . Mannor S, Srebro Nathan, Williamson RC, eds. Proc. 25th Ann. Conf. Learn. Theory, vol. 23 (PMLR, Cambridge, MA), 39.1–39.26.Google Scholar - (2013)
Thompson sampling for contextual bandits with linear payoffs . Dasgupta S, McAllester D, eds. Proc. 30th Internat. Conf. Machine Learn., vol. 28 (PMLR, Cambridge, MA), 127–135.Google Scholar - (2023) A multiarmed bandit approach for house ads recommendations. Marketing Sci. 42(2):271–292.Link, Google Scholar
- (2011) An empirical evaluation of Thompson sampling. Shawe-Taylor J, Zemel R, Bartlett P, Pereira F, Weinberger KQ, eds. Advances in Neural Information Processing Systems, vol. 24 (Curran Associates, Red Hook, NY), 1–9.Google Scholar
- (2014) Online Optimization of teaching sequences with multi-armed bandits. Stamper J, Pardos ZA, Mavrikis M, McLaren BM, eds. Proc. 7th Internat. Conf. Ed. Data Mining (International Educational Data Mining Society, Worcester, MA), 269–272.Google Scholar
- (1994) Knowledge tracing: Modeling the acquisition of procedural knowledge. User Modeling User-Adapt. Interactions 4(4):253–278.Crossref, Google Scholar
- (2020) Online knowledge level tracking with data-driven student models and collaborative filtering. IEEE Trans. Knowledge Data Engrg. 32(10):2000–2013.Crossref, Google Scholar
- (2023) A systematic literature review on educational recommender systems for teaching and learning: Research trends, limitations and opportunities. Ed. Inform. Tech. (Dordrecht) 28(3):3289–3328.Google Scholar
- (2025) A reward-informed semi-personalized bandit approach for enhancing accuracy and serendipity in online slate recommendations. ACM Trans. Recommender Systems (ACM, New York).Google Scholar
- (2018) Online network revenue management using Thompson sampling. Oper. Res. 66(6):1586–1602.Link, Google Scholar
- (2021) Empowering optimization skills through an orienteering competition. INFORMS Trans. Ed. 22(1):1–8.Link, Google Scholar
- (2024) XGBoost to enhance learner performance prediction. Comput. Ed. Artificial Intelligence 7:100254.Crossref, Google Scholar
- (2014) The ASSISTments ecosystem: Building a platform that brings scientists and teachers together for minimally invasive research on human learning and teaching. Internat. J. Artificial Intelligence Ed. 24(4):470–497.Crossref, Google Scholar
- (2014)
Optimality of Thompson sampling for Gaussian Bandits depends on priors . Kaski S, Corander J, eds. Proc. 17th Internat. Conf. Artificial Intelligence Statist., vol. 33 (PMLR, Cambridge, MA), 375–383.Google Scholar - (2019) A score prediction approach for optional course recommendation via cross-user-domain collaborative filtering. IEEE Access 7:19550–19563.Crossref, Google Scholar
- (2020) Reinforcement learning based on contextual bandits for personalized online learning recommendation systems. Wireless Personal Comm. 115(4):2917–2932.Crossref, Google Scholar
- (2020) A systematic review: Machine learning based recommendation systems for e-learning. Ed. Inform. Tech. (Dordrecht) 25(4):2635–2664.Google Scholar
- (2016) Student-centered education and constructivism: Challenges, concerns, and clarity for teachers. Clearing House 89(3):97–105.Crossref, Google Scholar
- (2017) Collaborative filtering algorithm based on rating distance. Kim CH, Lee HW, Lee DH, Sakurai K, eds. Proc. 11th Internat. Conf. Ubiquitous Inform. Management Comm. (Association for Computing Machinery, New York), 1–7.Google Scholar
- (2014) Trading off scientific knowledge and user learning with multi-armed bandits. Accessed August 7, 2025, https://api.semanticscholar.org/CorpusID:4103970.Google Scholar
- (2024) That’s incorrect and let me tell you why: A scalable assessment to evaluate higher order thinking skills. INFORMS Trans. Ed. 25(1):23–34.Link, Google Scholar
- (2017) Contextual multi-armed bandit algorithms for personalized learning action selection. Proc. IEEE Internat. Conf. Acoustics Speech Signal Processing, 6344–6348.Google Scholar
- (2020) Exploring data splitting strategies for the evaluation of recommendation models. Proc. 14th ACM Conf. Recommender Systems (Association for Computing Machinery, New York), 681–686.Google Scholar
- (2019) On recommendation of learning objects using Felder-Silverman learning style model. IEEE Access 7:163034–163048.Crossref, Google Scholar
- (2024) Towards modeling learner performance with large language models. Proc. 17th Internat. Conf. Ed. Data Mining (International Educational Data Mining Society, Worcester, MA), 759–768.Google Scholar
- (2014) Affective States and state tests: Investigating how affect and engagement during the school year predict end-of-year learning outcomes. J. Learn. Analytics 1(1):107–128.Crossref, Google Scholar
- (2020) ASSISTments longitudinal data mining competition special issue: A preface. J. Ed. Data Mining 12(2):i–xi.Google Scholar
- (2021) Game—Constructivist exercises to enhance teaching of probability and statistics for engineers. INFORMS Trans. Ed. 22(1):55–64.Link, Google Scholar
- (2016) Learning object recommendations for teachers based on elicited ICT competence profiles. IEEE Trans. Learn. Tech. 9(1):67–80.Crossref, Google Scholar
- (2017) A hybrid knowledge-based recommender system for e-learning based on ontology and sequential pattern mining. Future Generation Comput. Systems 72:37–48.Crossref, Google Scholar
- (1933) On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika 25(3–4):285–294.Crossref, Google Scholar
- (2010) Scaffolding in teacher–student interaction: A Decade of research. Ed. Psych. Rev. 22(3):271–296.Crossref, Google Scholar
- (2015) A fuzzy tree matching-based personalized e-learning recommender system. IEEE Trans. Fuzzy Systems 23(6):2412–2426.Crossref, Google Scholar

