
Estimating a Function and Its Derivatives Under a Smoothness Condition
Abstract
We consider the problem of estimating an unknown function and its partial derivatives from a noisy data set of n observations, where we make no assumptions about except that it is smooth in the sense that it has square integrable partial derivatives of order m. A natural candidate for the estimator of in such a case is the best fit to the data set that satisfies a certain smoothness condition. This estimator can be seen as a least squares estimator subject to an upper bound on some measure of smoothness. Another useful estimator is the one that minimizes the degree of smoothness subject to an upper bound on the average of squared errors. We prove that these two estimators are computable as solutions to quadratic programs, establish the consistency of these estimators and their partial derivatives, and study the convergence rate as . The effectiveness of the estimators is illustrated numerically in a setting where the value of a stock option and its second derivative are estimated as functions of the underlying stock price.
1. Introduction
We are concerned with the problem of estimating an unknown function and its partial derivatives over a domain of interest when there is no closed-form formula for ; hence, simulation must be conducted to estimate at , or only noisy data on are available. We make no assumptions about except that it has square integrable partial derivatives of order m.
To place the problem in a more rigorous setting, we consider the situation where we wish to estimate the unknown function and its partial derivatives by taking observations satisfying
Under the assumption that has square integrable partial derivatives of order m with , our goal is to estimate and its partial derivatives of order up to as functions over from the data set .
When the only information available on the unknown regression function is the fact that it is “smooth” so that it has square integrable partial derivatives of order m, one way to estimate is to fit a “smooth” function to the data set, that is, find the solution to the following problem:
is a d-tuple of nonnegative integers, is the order of defined by , and denotes the partial differential operator defined by
However, a question arises as to whether there exists a solution to (1). To guarantee the existence of a solution to (1), one of the properties that must have is the completeness with respect to a suitably chosen metric (or a pseudometric). It turns out that must be larger than to be complete. However, if we let be the set of “generalized functions” whose “weak” derivatives of order m are square integrable, then contains and is large enough to be a semi-Hilbert space in the seminorm, where ; see, for example, Meinguet [51, theorem 1 on p. 130]. (A weak derivative of a function f is a generalized version of the classical derivative in the sense that whenever the classical derivative exists, it is also a weak derivative of f.) Hence, throughout this paper, we will assume , where is the space of generalized functions whose weak partial derivatives of order m are square integrable; see Section 2 of this paper and Oden and Reddy [54] for the precise definitions of , generalized functions, and weak derivatives. We will further restrict our attention to the functions f whose smoothness is bounded by a certain constant. Thus, a natural candidate for the estimator of is the solution to the following problem:
The question now becomes how to compute the solution to Problem (A) numerically. As Proposition 6 of this paper states, the solution to Problem (A) can be found by solving a convex programming problem. However, it is not clear how to compute or estimate from the data set. This necessitates another approach that can estimate using a parameter that can be directly estimated from the data set. As an alternative to Problem (A), we consider the solution to the following problem:
In the context of nonparametric regression techniques in the statistics literature, Problems (A) and (B) are often contrasted with the following formulation:
This paper is motivated by a stock trader whose goal is to estimate “gamma,” which is the second derivative of the value, , of a stock option as a function of the underlying stock price. The only information that he has is the fact that gamma is a smooth function of the stock price. The trader can use Problem (C) to estimate and its second derivative, but he needs to estimate the smoothing parameter . Cross validation does not guarantee the consistency of the estimator of the second derivative of as . Moreover, the trader does not want to use any parameter that cannot be directly estimated from a data set. In this situation, Problem (B) better serves his purpose because its only parameter can be directly estimated from the data set. In fact, Problem (B) has been used widely within the numerical analysis community; see, for example, Cox [13, p. 530].
Despite its popularity in the numerical analysis community, little is known about how to compute and numerically and what statistical properties and possess. The contributions of this paper are showing that and are computable as solutions to convex programs, establishing the consistency of and as estimators of , establishing the consistency of and as estimators of for , and computing the convergence rate of when . The key contributions of this paper can be summarized as follows.
We identify the relationship between Problems (A) and (B). We prove that for within a certain interval, the solution to Problem (A) exists uniquely and becomes a unique solution to Problem (B) with . Conversely, for within a certain interval, the solution to Problem (B) exists uniquely and becomes a unique solution to Problem (A) with .
We discuss the computational aspects of Problems (A) and (B). We show that the solutions to Problems (A) and (B) can be found by solving convex programming problems. There exist numerous efficient algorithms that can successfully find the solutions to convex programs (see, for example, Boyd and Vandenberghe [6], Zangwill [76]), so this enables us to easily compute the solutions to Problems (A) and (B).
We establish the consistency of and as estimators of and the consistency of and as estimators of for as . Our main results for Problem (A) state that if for n sufficiently large and , we have
and we havefor as under modest assumptions. On the other hand, our main results for Problem (B) state that under some conditions on and , we havefor as .We compute the convergence rate of as . Specifically, when for n sufficiently large and , we have
under the assumption that the ’s are uniformly sub-Gaussian.
1.1. Literature Review
This paper is a contribution to the literature of nonparametric regression for smooth functions. Problem (C) has been studied extensively in the literature, whereas relatively less attention has been paid to Problems (A) and (B). For Problem (C), the existence of a solution is established by Duchon [19], and the convergence rates are derived by Cox [14], Rice and Rosenblatt [57], Utreras [67], and van de Geer [69]. Craven and Wahba [15] and Utreras [66] discuss how to choose the smoothing parameter through cross validation. Duchon [19] has shown that the solution to Problem (C) has an explicit representation as a sum of basis functions. However, this approach often requires solving a system of linear equations that involves a dense and highly ill-conditioned matrix (see Dierckx [17, p. 145]). Numerically more efficient algorithms are developed by Hutchinson and de Hoog [33] and Luo and Wahba [47]. Schoenberg [60] has shown that a solution to Problem (A) is also a solution to Problem (C) for some appropriately chosen, whereas Kersey [35] and Reinsch [56] studied the relationships between Problems (C) and (B). Green et al. [24] computed convergence rates of the Laplacian smoothing estimator, which can be viewed as a discrete approximation of Problem (C). For further references, see, for example, de Boor [16], Dierckx [17], Green and Silverman [23], Györfi et al. [27], Wahba [71], and Wegman and Wright [74]. For Problem (A), when , the existence and uniqueness of the solution are established by Schoenberg [60], and the convergence rates are derived by van de Geer [68]. When , we could not find any work concerning how to compute the solution to Problem (A) numerically or what statistical properties the solution to Problem (A) possesses. For Problem (B), when , the existence and uniqueness of the solution are established by Reinsch [56]. However, we could not find any work concerning how to compute the solution to Problem (B) and what statistical properties the solution to Problem (B) possesses either when or when . Therefore, the main contribution of this paper is to establish a theoretical foundation of Problems (A) and (B) for the case when by suggesting a convex programming formulation, establishing consistency, and computing the convergence rate.
This paper is also a contribution to the literature on shape constrained estimation. Many researchers have studied the problem of estimating the unknown regression function when is known to possess shape properties, such as monotonicity or convexity. One of the most popular approaches is least squares estimation under shape restrictions. For instance, when is known to be monotone, one can fit a monotone function to the data set by solving the following quadratic program:
This paper can be viewed as a contribution to the literature on metamodel estimation or response surface estimation, which has been an important subject of research in the simulation community. A common goal in this setting is to fit a metamodel to a simulation output, where the simulation runs are time consuming. Therefore, most work has focused on a setting where n is relatively small. One of the earlier works is the response surface methodology that is based on the idea of fitting a polynomial function to the data set locally; see, for example, Myers and Montgomery [52]. When the ’s are possibly correlated, the kriging-based methods serve as good alternatives; see, for example, Ankenman et al. [3]. The kriging-based methods, in general, do not assume that the regression function is m times differentiable, where . Hence, they do not produce any estimator of the derivatives of . Rather, the kriging estimator of at any is expressed as the weighted sum of the ’s. The weights are dependent on and calculated in a way in which the mean squared deviations are minimized. In Chen et al. [9], under the assumption that the regression function is differentiable, the gradient estimates are observed along with the ’s, and they are used to obtain an estimator of that shows superior performance to the stochastic kriging estimator (see Ankenman et al. [3]). In the radial basis function estimators, the regression function is approximated by a linear combination of radially symmetric functions, where the coefficients and other parameters are estimated from the data set; see, for example, Franke [21]. The orthogonal series estimators or wavelet estimators represent the regression function by its Fourier series and estimate the coefficients from the data set; see, for example, Donoho and Johnstone [18]. Nonparametric regression methods, such as the kernel regression method (Nadaraya [53], Watson [73]), the local polynomial regression estimators (Cleveland [12]), the smoothing splines (Reinsch [55]), the weighted least squares regression estimators (Ruppert and Wand [58], Salemi et al. [59]), and the nearest neighbor estimators (Shapiro [62], Stone [64]), have received considerable attention in the statistics literature; see, for example, Eubank [20], Green and Silverman [23], Härdle [29], and Wand and Jones [72] for comprehensive surveys. Most of these estimators invariably require the estimation of smoothing parameters that cannot be estimated directly from the data set. In this regard, Problem (B) has the advantage of estimating only one parameter, , which has a direct meaning and can be estimated from the sample variances computed from the data set.
1.2. Organization of This Paper
This paper is organized as follows. Section 2 introduces some definitions and preliminaries. We precisely describe the relationship between Problems (A) and (B) in Section 3, whereas Section 4 is concerned with the convex programming formulations of Problems (A) and (B). Section 5 states the main results regarding consistency and convergence rates, and the numerical results can be found in Section 6. Section 7 provides discussions on future research topics. The proofs of all theorems, corollaries, lemmas, and propositions are provided in the Appendix.
2. Definitions and Preliminaries
For , its norm is given by . For a sequence of random variables and a sequence of positive real numbers , we say as if for any , there exist constants C and N such that for all .
When , we define by the space of generalized functions whose weak partial derivatives of order m are square integrable, that is,
It should be also noted that is a seminorm on , but a norm on the equivalence classes in , and is a Hilbert space under ; see Meinguet [51, theorem 1, p. 130] for details.
For any open-bounded subset , we define by the set of functions f defined on satisfying . Its norm is defined as follows:
Its norm is defined as follows:
3. Relationships Between Problems (A) and (B)
In this section, we study the relationship between Problems (A) and (B). When , Schoenberg [60] established some results similar to Lemma 1, Proposition 3, Proposition 4, and Proposition 5 of this paper. Thus, some of our results in this section can be viewed as extensions of those in Schoenberg [60] to the multidimensional case. Throughout this section, we assume that are given and that the following assumption holds.
m is a positive integer satisfying , and is a set of mutually distinct points containing a -unisolvent set. A set of points is called -unisolvent if for any , the condition for all implies for all . In particular, when , is -unisolvent if and are mutually distinct.
Propositions 1 and 2 establish the existence of the solutions to Problems (A) and (B) under Assumption 1.
Let be given. Under Assumption 1, there exists a solution to Problem (A). Furthermore, if and are two solutions to Problem (A), then for .
Let be given. Under Assumption 1, there exists a solution to Problem (B). Furthermore, if and are two solutions to Problem (B), then they differ by a polynomial of total degree less than or equal to (i.e., ).
Our next propositions, Propositions 3, 4, and 5, are concerned with the uniqueness of the solutions to Problems (A) and (B). For our analysis, we need to define the following function: . For any nonnegative real number u, let , where is a solution to Problem (A) with . The following lemma characterizes the shape of .
There exists a minimizer, say , of over . Under Assumption 1, there exists a unique solution, say , to the following problem:
Under Assumption 1, is nonnegative, convex, and strictly decreasing over with and for all .
The following propositions discuss the uniqueness of the solutions to Problems (A) and (B) and the relationship between them.
Assume Assumption 1. Let be given. Then, there exists a unique solution to Problem (A), and satisfies . In other words, if and are two solutions to Problem (A), then for all . Furthermore, is also a solution to Problem (B) with .
Assume Assumption 1. Let be given. Then, there exists a unique solution to Problem (B), and satisfies . In other words, if and are two solutions to Problem (B), then for all . Furthermore, is also a solution to Problem (A) with .
Combining Propositions 3 and 4 yields the following proposition.
Assume Assumption 1.
Let be given. Then, there exists a unique solution to Problem (A), and satisfies . Furthermore, is also a unique solution to Problem (B) with .
Let be given. Then, there exists a unique solution to Problem (B), and satisfies . Furthermore, is also a unique solution to Problem (A) with .
The proofs of Lemma 1 and Propositions 1–5 are provided in Appendix A.
4. Convex Programming Formulations for Problems (A) and (B)
In this section, we discuss the question of how to compute the solutions to Problems (A) and (B) numerically. The following propositions, Propositions 6 and 7, reveal that we can find the solutions to Problems (A) and (B) by solving convex programs. Their proofs are provided in Appendix A.
We start with some definitions. Let be any -unisolvent set of M fixed points in . (M is given in (3).) Let be the unique polynomials of total degree less than m satisfying if and if , that is,
Let be given. Under Assumption 1, a solution to Problem (A) exists by Proposition 1. Furthermore, for any solution to Problem (A), there exists a solution to Problem (A), satisfying for , which can be represented by
Conversely, any function of form (4), where is any solution to (6), is a solution to Problem (A).
Let be given. Under Assumption 1, a solution to Problem (B) exists by Proposition 2. Furthermore, is a solution to Problem (B) if and only if is represented by
It should be noted that when , the representation in (4) coincides with the form of a natural spline; see Greville [25, equation 4.1 on p. 3] for the details.
Proposition 6 reveals that for any solution to Problem (A), there exists a solution to Problem (A) satisfying for , which is a linear combination of the ’s and ’s. In addition, Proposition 7 implies that a solution to Problem (B) is always a linear combination of the ’s and ’s.
5. Consistency and Rates of Convergence
In this section, we focus on the consistency and convergence rates of the solutions to Problems (A) and (B). Toward this goal, we need the following assumptions.
.
are iid -valued random vectors having a common positive continuous density function . This implies that there exist such that for all .
.
is a sequence of iid -valued random vectors satisfying and for .
and for .
are uniformly sub-Gaussian random variables (i.e., there exist positive real numbers A and B such that for any ).
.
, restricted to , is not a polynomial of degree less than or equal to .
is continuous on .
We need Assumption 2(i) for the following reason. When is not assumed, a function in is not well defined on a set of measure 0 because the functions in are determined only outside a set of measure 0. Under the assumption , it is known that the functions in are continuous, so the point evaluation is well defined; see Meinguet [51, theorem 1 on p. 130].
The next lemma shows that Assumption 2 guarantees a very important property of the ’s, the so-called -unisolvency. The proof of Lemma 2 is provided in Appendix A.
Under Assumption 2, is a set of mutually distinct points containing a -unisolvent set for n sufficiently large a.s. In other words, Assumption 2 implies Assumption 1 for n sufficiently large a.s.
Lemma 2 ensures that the solutions to Problems (A) and (B) exist for n sufficiently large a.s. under Assumption 2.
We are now ready to present our main results. Theorems 1 and 2 reveal that and are consistent estimators of and that and are consistent estimators of for . Theorem 3 computes a lower bound on the rate of convergence of . We discuss the rate of convergence of in Remark 4.
Theorems 1 and 2 use the following assumptions on and .
There exists a constant such that for all n sufficiently large a.s.
There exists a constant such that for all n sufficiently large a.s.
Although Assumptions 6–9 are somewhat hard to verify, we can establish them by imposing some conditions on and . For example, Assumptions 6, 8, and 9 are implied by Assumptions 10, 11, and 12, respectively.
.
for all n sufficiently large a.s.
.
We are now ready to present Theorem 1, Theorem 2, Corollary 1, and Corollary 2.
Under Assumptions 2, 3, 6, and 8,
Under Assumptions 2, 3, 7, and 9,
We now turn to the convergence rate of . We need Assumption 13, which is implied by Assumption 11.
Under Assumption 13, the convergence rate of is established in Theorem 3.
Under Assumptions 2, 3, 4, 6, and 13,
It should be noted that the rate established in Theorem 3 is identical to the optimal rate of convergence for the estimation of a function of smoothness of order m, which was established by Stone [65]. However, as Corollary 3 states, this rate is achieved under Assumptions 10 and 11, which may be hard to verify if sufficient information on is not available. One should also note that there are many estimators that achieve this optimal rate. See Kohler et al. [38] for a kernel estimator; Cox [14] for a smoothing spline estimator; Györfi et al. [27, theorems 4.3, 5.2., and 6.2] for partitioning, kernel, and nearest neighbor estimators, respectively; and Kohler et al. [37] for partitioning and nearest neighbor estimators. Furthermore, Stone [65] established that the optimal rate of convergence for the estimation of the rth derivative of a function of smoothness of order m is for , and this rate is achieved by the smoothing spline estimator proposed by Cox [14].
We next discuss a situation where the solution to Problem (B) exists uniquely.
Consider the problem:
The proofs of Theorems 1–4 and Corollaries 1–3 are provided in Appendix B.
The same convergence rate as in Theorem 3 can be obtained for under the assumption
In the case where the error is dependent on , our results in Theorems 1, 2, 3, and 4 hold with light modifications in the proofs.
In many practical situations, the variance of the ’s is heterogeneous (i.e., is dependent on ). A natural candidate for in such a case is , where is the density function of . When the ’s are uniformly distributed, can be estimated by computing the average of across .
6. Numerical Results
In this section, we observe the numerical behavior of the solutions to Problems (A), (B), and (C). To describe the detailed procedure, we start by noticing that, in practice, we can often observe multiple times at a fixed design point . Thus, we assume that we can collect iid observations , where for and and the ’s, conditional on , are iid copies of conditional on X. We then compute the average of the ’s across multiple replications (i.e., for each ). Next, the ’s will be used in place of the ’s in Problems (A), (B), and (C).
Next, we provide more detailed descriptions on how the solutions to Problems (A)–(C) are obtained.
6.1. Problem (B)
In order to estimate , we observe that Remark 6 suggests using the average of the ’s as an estimate of when the ’s are uniformly distributed. Because we use the ’s in place of the ’s, we use the average of across as an estimate of . Therefore, our estimate of is
We then solve the convex programming problem in Proposition 7 with the ’s replaced by the ’s and replaced by (14) using CVX, a package for solving convex programs developed by Grant and Boyd [22]. The solution obtained this way is denoted by , and its objective value is denoted by . is used as an estimate of when solving Problem (A).
6.2. Problem (A)
We next solve the convex programming problem in Proposition 6 by using as an estimate of and the ’s in place of the ’s. CVX is used to solve the convex programming formulation.
6.3. Problem (C)
The key issue here is how to determine the smoothing parameter . We use cross validation to determine the smoothing parameter. We also use a fixed sequence of real numbers decreasing to zero as . The smoothing parameter chosen by cross validation depends on the observed data set , whereas does not depend on the observed data set and depends on n only.
To define the cross validation function, let be the minimizer of
We also solve Problem (C) with the ’s replaced by the ’s and replaced by for . The specific choice of is given in Sections 6.5 and 6.6.
6.4. How to Select m
One needs a priori knowledge on m to determine the right value of m. It should be noted that the smoothness of a function is measured by . Thus, if itself is believed to be smooth, then we set . If is believed to have smooth partial derivatives of order 2, then we set .
6.5. M/M/1 Queue
We consider the case where is the steady-state mean waiting time of a customer in a single-server queue under the first come, first served discipline with infinite capacity buffer, exponential service times, exponential interarrival times, unit arrival rate, and a service rate of . is known to be ; see Hillier and Lieberman [31, p. 781]. We chose an M/M/1 queue because there exists a closed-form formula for the steady-state waiting time of a customer, so we can compare our estimators with the true values. We set for . For each and with , we generated by averaging the waiting times of the first 1,000 customers arriving at the queue when the queue is initialized empty and idle. We next computed the solution to Problem (B) and the solution to Problem (A) with the ’s replaced by the ’s and . is estimated from (14), and is estimated from . Both Problems (A) and (B) are solved using CVX.
For Problem (C), we computed by minimizing in (15) over . In addition to , we used three sequences of real numbers, , , and , for . To select , we tried several sequences of real numbers and selected the one generating the lowest empirical integrated mean square error (EIMSE) values for and . The rate of decay for was chosen to be of order based on the suggestion made by Cox [13].
To measure the accuracy of , the solution to Problem (B), we computed the EIMSE of as follows:
We also computed the EIMSE of as follows:
Table 1 reports the 95% confidence intervals of the EIMSE values of the estimators of computed from Problems (A)–(C) based on 400 iid replications for each n value. The columns labeled as (A) and (B) report the results obtained from Problems (A) and (B), respectively. The columns labeled as CV, , , and report the results obtained from Problem (C) when is set as , , , and , respectively. The values in Table 1 are measured in . Table 2 reports the 95% confidence intervals of the EIMSE values of the estimators of computed from Problems (A)–(C) based on 400 iid replications for each n value.
|

Table 1. The 95% confidence intervals of the EIMSE values for the estimators of computed from Problems (A)–(C) when is the steady-state mean waiting time of a customer in an M/M/1 queue. All values are measured in .
| n | (A) | (B) | (C) | |||
|---|---|---|---|---|---|---|
| CV | ||||||
| 15 | ||||||
| 25 | ||||||
| 35 | ||||||
|
Table 2. The 95% confidence intervals of the EIMSE values for the estimators of computed from Problems (A)–(C) when is the steady-state mean waiting time of a customer in an M/M/1 queue.
| n | (A) | (B) | (C) | |||
|---|---|---|---|---|---|---|
| CV | ||||||
| 15 | ||||||
| 25 | ||||||
| 35 | ||||||
6.6. Stock Trader’s Problem
We consider the stock trader’s problem that motivated this paper. Consider a trader who trades stock options on a daily basis. Each day, his decision is either buy or sell a stock option, and he bases his decision on gamma, which is the second derivative of the value of the stock option as a function of the underlying stock price. The value of the stock option, , typically has no closed-form formula, so simulation is required to estimate the value of the stock option and its second derivative with respect to the underlying stock price. Because simulation takes a long time to conduct, the estimation of and is done a day before any decision is made. Because and depend on the underlying stock price and because we cannot precisely predict the underlying stock price for the next day, and are typically estimated over a range of possible values of the underlying stock price. Hence, the trader’s goal is to estimate gamma, , over a range of possible values of the underlying stock price. Furthermore, in his estimation, he does not want to use any parameter that is not estimated from the data set.
To place this problem in a more specific setting, we consider the case where is the price of a European call option on a nondividend-paying stock when the underlying stock price is . We chose a European call option because there exists a closed-form formula for its price, so we can compare our estimates with the true values. Specifically, we consider the case where the strike price is , the risk-free annual interest rate is , the stock price volatility is 0.3, the underlying stock has a drift of 0.03, and the time to maturity of the option is year. It is known that the price of this option is given by
To compute our estimators, we set for . For each , we assumed that the current stock price is and simulated a sample path of a geometric Brownian motion up to time T with a drift of 0.03 and a volatility of 0.3. We then computed , the price of the option by computing , where is the value of the geometric Brownian motion we generated at time T. This procedure was repeated times, generating . We next computed the solutions to Problems (A) and (B) with the ’s replaced by the ’s and . is estimated from (14), and is estimated from . Both Problems (A) and (B) are solved with CVX.
For Problem (C), we computed by minimizing in (15) over . In addition to , we used three sequences of real numbers, , , and , for . To select , we tried several sequences of real numbers and selected the one generating the lowest EIMSE values for and . The rate of decay for was chosen to be of order based on the suggestion made by Cox [13].
Table 3 reports the 95% confidence intervals of the EIMSE values of the estimators of computed from Problems (A)–(C) based on 400 iid replications for each n value. The columns labeled as (A) and (B) report the results obtained from Problems (A) and (B), respectively. The columns labeled as CV, , , and report the results obtained from Problem (C) when is set as , , , and , respectively. The values in Table 3 are measured in .
|
Table 3. The 95% confidence intervals of the EIMSE values for the estimators of computed from Problems (A)–(C) when is the price of a European call option. All values are measured in .
| n | (A) | (B) | (C) | |||
|---|---|---|---|---|---|---|
| CV | ||||||
| 15 | ||||||
| 25 | ||||||
| 35 | ||||||
Table 4 reports the 95% confidence intervals of the EIMSE values of the estimators of computed from Problems (A)–(C) based on 400 iid replications for each n value. The values in Table 3 are measured in .
|
Table 4. The 95% confidence intervals of the EIMSE values for the estimators of computed from Problems (A)–(C) when is the price of a European call option. All values are measured in .
| n | (A) | (B) | (C) | |||
|---|---|---|---|---|---|---|
| CV | ||||||
| 15 | ||||||
| 25 | ||||||
| 35 | ||||||
6.7. Observations from Numerical Experiments
When we compare Problems (A) and (B) with Problem (C) with the smoothing parameter estimated from cross validation, Problem (B) shows superior performance when estimating the second derivative of . Problem (C) generates extreme estimates in a few percents of time, thereby degrading the overall performance. This phenomenon has been observed by other researchers; see the discussion in Wahba [71, p. 65].
When we compare Problems (A) and (B) with Problem (C) with a fixed smoothing parameter for , Problem (C) shows superior performance. However, it should be noted that to select , we tried several sequences of real numbers and selected the one generating the lowest EIMSE values for and . This was possible because we already knew what and were in all of our numerical examples. In reality, one does not have a priori knowledge of the exact values of and for , so finding this way is not feasible. However, in our numerical experiments, the results from Problem (C) with a fixed smoothing parameter give us a sense of how well Problems (A) and (B) perform compared with the best possible performance of Problem (C). Tables 1–4 report that the performance of Problems (A) and (B) is as good as that of Problem (C) with the best possible choice of .
6.8. When Multiple Observations Cannot Be Made at a Fixed Design Point in
Throughout Section 6, we assumed that multiple observations can be made at any fixed design point in . These multiple observations were used to empirically estimate . In many applications, multiple observations at a point may not be available. In such cases, one needs to use other ways to empirically estimate . One possible approach is partitioning into a finite number of hyperrectangles, computing the sample variance of the ’s whose ’s fall within each hyperrectangle, and computing the average of these sample variances (weighted by the density function of X evaluated at each hyperrectangle) as an estimate of . This approach is based on the observation that should ideally be .
To illustrate this approach numerically, we consider the following example: is given by for , , for , and for , where the ’s follow a uniform distribution over . We assumed that only one observation is made for . To estimate , we partitioned [0, 1] into the five intervals , and and computed the sample variances, say and , in which is the sample variance of the ’s whose ’s fall in for . We set equal to the average of , and . We then solved Problem (B) to obtain and . This procedure was repeated 1,600 times independently. Using these 1,600 replications, we computed the 95% confidence intervals of the EIMSE values of and , respectively. Table 5 reports the 95% confidence intervals for a variety of n values. The EIMSE values in Table 5 decrease as n increases, indicating that the choice of is appropriate.
|
Table 5. The 95% confidence intervals of the EIMSE values for and when was set as the average of sample variances across five intervals.
| n | EIMSE for | EIMSE for |
|---|---|---|
| 30 | ||
| 40 | ||
| 50 |
7. Conclusions
We conclude this paper with some discussions on future research topics.
7.1. How to Choose When Multiple Observations Are Not Available
In Section 6.8, we discussed a way to empirically estimate when multiple observations are not available at a design point in . In this approach, we divide into smaller hyperrectangles, compute the sample variance of the ’s whose ’s fall within each hyperrectangle, and compute the average of these sample variances (weighted by the density function of X evaluated at each hyperrectangle) as an estimate of . We conjecture that this approach will generate an asymptotically consistent estimator if the volume of the hyperrectangles decreases to zero and the number of ’s within each hyperrectangle increases to infinity as . A more rigorous study on this conjecture is a good future research topic.
7.2. Combining the Smoothness Condition with Shape Constraints
Because our proposed formulations, Problems (A) and (B), impose only the smoothness condition on the underlying function , the proposed estimators do not necessarily produce a function that satisfies additional shape conditions on , such as convexity or monotonicity. For example, even if is convex, our estimators are not necessarily convex. Figure 1 shows the solution to Problem (B) when is given by for , , , for , and for , where the ’s follow a uniform distribution over and . Even if is convex, is not necessarily convex.
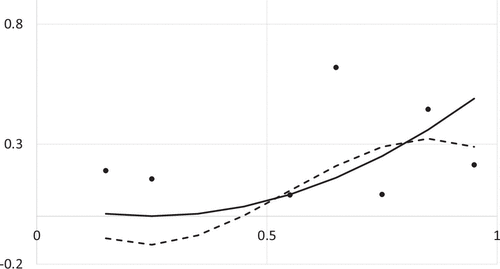
One possible fix to this phenomenon is incorporating additional conditions to our formulation. A good topic for future research is combining shape constraints, such as convexity and monotonicity, with the smoothness condition in our proposed formulations.
7.3. Establishing Consistency Under a Condition That Is Easier to Verify
Corollary 2 is established under Assumption 7, which is hard to verify. We conjecture that the conclusions of Corollary 2 hold under a more natural condition that as . This remains as an open question. Another open question is computing the convergence rate of under suitable conditions on .
7.4. Extending Our Formulations to Shape-Constrained Estimation Problems
Problem (A) can be seen as an estimation problem of a smooth function by minimizing the sum of squared errors under the smoothness condition . This type of formulation has been used for shape-constrained estimation problems, such as convex regression. For example, Mazumder et al. [49] proposed estimating an unknown convex function by minimizing the sum of squared errors over convex functions satisfying a Lipschitz condition. An interesting question for future research is how to extend Problem (B) to shape-constrained problems, such as convex and isotonic regression problems.
Appendix A. Proofs of Propositions 1–7 and Lemmas 1 and 2
To establish the existence of the solutions to Problems (A) and (B), we define the following functions and . For any , consider the following problem:
Under Assumption 1, the solution to Problem (I) exists uniquely; see Meinguet [50, equation 29 and theorem 3 on p. 299]. We will denote the solution to Problem (I) by . Define . On the other hand, is defined by for . It can be easily seen that is convex over and that is strictly convex over .
For any and , we define and by
Both and are nonempty, closed, and convex subsets of .
We recall that is defined as follows. For any nonnegative real number u, , where is a solution Problem (A) with .
Because is nonempty, closed, and convex and because is strictly convex over , there exists a unique minimizer of over and is a solution to Problem (A).
To prove the second part, let and be two solutions to Problem (A). Then, and are two minimizers of over . By the uniqueness of the minimizer of over , it follows that for .
Because is nonempty, closed, and convex and because is convex, there exists a minimizer of over and is a solution to Problem (B).
To prove the second part, we note that for any , , and is a seminorm in and a norm in . We will denote an equivalence class in by [f] for .
Let and be minimizers of over . Because
The existence of follows from the fact that
The only nontrivial part is that is strictly decreasing over . Let be given. We need to show that . Suppose, on the contrary, that
Let and be the solutions to Problem (A) with and , respectively. Note that and minimizes over because of (A.2).
We will construct an n-dimensional ball around that is contained in . If this is proven, it will follow that for , and hence, interpolates the ’s, so . Together with the facts and , we will reach a contradiction.
To construct such a ball, we notice that the ’s are distinct, so we can find such that for . For any , we will show that is in . ( will be specified later.) Define by
and for all ;
the ’s are infinitely differentiable; and
for all and some constant C.
It follows that for , and
Let be given. By Proposition 2, there exists a solution to Problem (B). Let and be a solution to Problem (A) with . We will first show that is also a solution to Problem (A) with and satisfies . By definition, minimizes over all functions f satisfying and satisfies
By (A.3), is a feasible solution to Problem (B), so we should have
Also, is a feasible solution to Problem (B), so we should have
By (A.3), (A.7), and (A.8), we can conclude
Next, we turn to the uniqueness of the solution to Problem (B). Let and be two solutions to Problem (B). By Proposition 1, we have
Let be given. By Proposition 1, there exists a solution to Problem (A). Let and be a solution to Problem (B) with . We will first show that is also a solution to Problem (B) with and satisfies . First, we will prove that
To prove (A.11), we note that by Proposition 4, is a solution to
By Proposition 4, is a solution to Problem (A), so we have
By (A.12), is a feasible solution to Problem (B) with , so we should have
Because is a feasible solution to Problem (A), we have
By combining (A.11), (A.13), and (A.14), we have
By (A.12) and (A.15), is also a solution to Problem (B) with and satisfies .
We next turn to the uniqueness of the solution to Problem (A). Let and be two solutions to Problem (A). By the previous arguments, and are also two solutions to Problem (B) with . By Proposition 4, the solution to Problem (B) with is unique, so .
Combine Propositions 3 and 4.
Let and be the reproducing kernel Hilbert space with the ’s as the reproducing kernels. Then, is the direct sum of and ; see Meinguet [50, equation 13 on p. 295 and equation 20 on p. 296]. Any element f of has the following representation:
Let and be the reproducing kernel Hilbert space with the ’s as the reproducing kernels. Then, is the direct sum of and ; see Meinguet [50, equation 13 on p. 295 and equation 20 on p. 296]. Any element f of has the following representation:
From the assumption that is continuous on , the ’s are mutually distinct a.s. By Chui [10, theorem 9.4 on p. 135] or Chung and Yao [11], there exists a -unisolvent set in with some fixed positive integer r.
Define a function by
Then, at because , is positive definite. Because H is continuous, there exists such that
Appendix B. Proofs of Theorems 1–4 and Corollaries 1–3
We start by defining a set of functions that will play an important role in the proofs of Theorems 1–4. We define by
In Lemmas B.1 and B.2, we will establish that Assumption 7 guarantees that , restricted to , belongs to for n sufficiently large a.s. In the proof of Lemma B.3, we will use the fact that can be covered by a finite number of balls with radius in metric for any . In the proof of Theorem 3, we will use the fact that the number of balls of radius needed to cover in metric is of order .
To prove Theorems 1 and 2, we need Lemmas B.1, B.2, B.3, and B.4. Here is our first lemma.
Let be an open-bounded subset of containing . Under Assumptions 2, 3, 7, and 9, there exists a constant , depending on , such that
The proof is divided into three steps.
Step 1. We prove is bounded for n sufficiently large (uniformly on n) a.s. To see this, one notices that by Assumption 3, Assumption 9, and the strong law of large numbers, we have
(B.2)for n sufficiently large a.s. We used the fact that and , and hence, is continuous on and is bounded over .Step 2. We use the Sobolev integral identity to express as the sum of a polynomial of degree less than m and a bounded function over . To fill in the details, note that is continuous over and hence, belongs to when it is restricted to . By Assumption 7 and Adams and Fournier [1, theorem 2 on p. 717], , restricted to , belongs to for n sufficiently large a.s. The Sobolev integral identity (see Oden and Reddy [54, theorem 3.6 on p. 78]) allows us to express
for all , where is a polynomial of degree less than m,for , and , , are bounded infinitely differentiable functions of and . Hölder’s inequality implies(B.3)for .Let be the radius of the smallest ball, centered at the origin, containing . Then, changing to the spherical coordinate system yields
(B.4)by the fact that .By Assumption 7, (B.3), and (B.4), there exists a constant such that
(B.5)for n sufficiently large a.s.Step 3. We use (B.5) and the -unisolvency of to show that is bounded uniformly on n for n sufficiently large a.s.
First, combining (B.2) and (B.5) yields
(B.6)for n sufficiently large a.s.
Second, we consider the following matrix:
By the -unisolvency of the ’s, the matrix is positive definite because with implies for all , which then implies for all . Let be the positive eigenvalues of W, and let be the corresponding eigenvectors with for . Let be the minimum of .
We next prove that
Note that is a nonempty closed subset of , and
By Shapiro et al. [63, proposition 5.2 on p. 157],
We finally prove that is bounded on uniformly on n for n sufficiently large. Let be given by for some . Let and note that the Rayleigh–Ritz theorem implies
Combining (B.6), (B.7), and (B.8) yields
Combining (B.5) and (B.10) completes the proof of Lemma B.1.
Under Assumptions 2, 3, 7, and 9, there exists a constant such that
We consider two cases separately: the case when and the case when .
Case 1. . Because , it follows that . The fundamental theorem of calculus and the continuity of imply
where is the weak derivative of of the first order. By Assumption 7 and Hölder’s inequality,for and n sufficiently large a.s., proving Lemma B.2.Case 2. . Let be a bounded open subset of containing .
We first prove that with is bounded uniformly on n and for n sufficiently large a.s. By Oden and Reddy [54, equation 3.48 on p. 81] and Lemma B.1, a.s. Assumption 7 and Adams and Fournier [1, theorem 2 on p. 717] imply that there exists a constant such that
When is restricted to , with belongs to for n sufficiently large a.s. Applying the Sobolev integral identity (Oden and Reddy [54, theorem 3.6 on p. 68]) to with yields
We next note that by the extended mean-value theorem, for any and , satisfying , we have
This is for some constant and n sufficiently large a.s.
Combining the two cases, we complete the proof of Lemma B.2.
Under Assumptions 2, 3, 7, and 9,
Let be given. Let be defined as in (B.1). Assumption 7, Lemma B.1, and Lemma B.2 imply that under Assumptions 2 and 3, any solution to Problem (B), restricted to , belongs to for n sufficiently large a.s. By Kolmogorov and Tihomirov [39, theorem 13], there exist and in such that for any , there is satisfying
For each , we have
Under Assumptions 2, 3, 7, and 9,
Note that
Lemma B.4 follows from Assumption 9 and Lemma B.3.
We first use Lemma B.4 and the fact that is continuous over to conclude that converges to uniformly over a.s.
Fix . We can find a finite number of sets covering , each having a diameter less than (i.e., ) and having a nonempty interior. Because and hence, is continuous over , Lemma B.2 implies that we can find a constant, say c, satisfying
For each and ,
By Lemma B.4 and Assumption 2, we conclude that
We next use Lemmas B.1, B.2, and B.4 to establish
We need to use the truncated value defined as follows. For any and , the truncated value of x, denoted by , is defined by
Note that for , for , and for . Together with the fact that for , we obtain
We will prove that
For each , we have
To prove the last part of Theorem 2, let be fixed. By Assumption 2(ii), for any with ,
By Adams and Fournier [1, third equality in theorem 2 on p. 717], there exists a constant C such that the right-hand side of (B.20) is less than or equal to
By Adams and Fournier [1, first equality of theorem 2 on p. 717] and the fact that for n sufficiently large a.s. and as ,
We apply arguments similar to those in Theorem 2 and Lemmas B.1–B.4 to establish the following claims.
Step 1. By Assumption 6, for n sufficiently large a.s.
Step 2. Use arguments similar to those in the proof of Lemma B.1 to establish that Assumptions 2, 3, 6, and 8 imply that there exists a constant such that for all and n sufficiently large a.s. for any bounded open subset of containing .
Step 3. Use arguments similar to those in the proof of Lemma B.2 to establish that Assumptions 2, 3, 6, and 8 imply that there exists a constant such that for and n sufficiently large a.s., where when and when .
Step 4. Use arguments similar to those in the proof of Lemma B.3 to establish that Assumptions 2, 3, 6, and 8 imply as a.s.
Step 5. Use arguments similar to those in the proof of Lemma B.4 to establish that Assumptions 2, 3, 6, and 8 imply as a.s.
Step 6. Use arguments similar to those in the proof of Theorem 2 to establish as a.s., as , and as for any satisfying .
It suffices to prove that Assumption 10 implies Assumption 6 and that Assumption 11 implies Assumption 8. Because for all n, under Assumption 10, we have , so Assumption 6 holds. Note that Assumption 11 implies that is a feasible solution to Problem (A) for all n sufficiently large a.s., so , or equivalently, .
It suffices to prove that Assumption 12 implies Assumption 9. Because ,
So, Assumption 12 implies Assumption 9.
Let be a solution to
We note that
By Assumption 13, we have
Hence, if we can prove
To establish (B.23), we introduce the notion of -covering sets and the covering number of a metric or pseudometric space as follows. For any , an -covering set of is a class of functions in T such that for any , there exists satisfying . The covering number of is the number of elements of a minimal covering set. In other words,
We note that there exists a positive constant such that for each ,
(B.25) together with Step 2 in the proof of Theorem 1 and Assumption 4 implies (B.23) by van de Geer [69, lemma 8.4], which completes the proof of Theorem 3.
In the proof of Corollary 2, we already proved that Assumption 10 implies Assumption 6. It suffices to prove that Assumption 11 implies Assumption 13. Under Assumption 11, is a feasible solution to Problem (A) for n sufficiently large a.s., so , or equivalently, for all n sufficiently large a.s.
Let be equipped with the seminorm for . It should be noted that is a semi-Hilbert space and that is a closed subspace of . By Assumption 5(i), . By the projection theorem, there exists minimizing over . Let . To prove that , suppose, on the contrary, that . By Assumption 5(iii) and Assumption 2, we reach for , which contradicts Assumption 5(ii).
To prove the second part of Theorem 4, let be defined as in Lemma 1. We will show that for n sufficiently large,
To show (B.26), we will first show that
References
- [1] (1977) Cone conditions and properties of Sobolev spaces. J. Math. Anal. Appl. 61(3):713–734.Crossref, Google Scholar
- [2] (2003) Sobolev Spaces, 2nd ed. (Academic Press, Amsterdam).Google Scholar
- [3] (2010) Stochastic kriging for simulation metamodeling. Oper. Res. 58(2):371–382.Link, Google Scholar
- [4] (2020) Sparse convex regression. INFORMS J. Comput. 33(1):262–279.Link, Google Scholar
- [5] (1967) Piecewise-polynomial approximations of functions of the classes . Math. USSR-Sbornik 2(3):295–317.Crossref, Google Scholar
- [6] (2004) Convex Optimization (Cambridge University Press, Cambridge, UK).Crossref, Google Scholar
- [7] (1958) On the estimation of parameters restricted by inequalities. Ann. Math. Statist. 29(2):437–454.Crossref, Google Scholar
- [8] (1970)
Estimation of isotonic regression . Puri ML, ed. Nonparametric Techniques in Statistical Inference (Cambridge University Press, London), 177–197.Google Scholar - [9] (2013) Enhancing stochastic kriging metamodels with gradient estimators. Oper. Res. 61(2):512–528.Link, Google Scholar
- [10] (1988) Multivariate Splines (SIAM, Philadelphia).Crossref, Google Scholar
- [11] (1977) On lattices admitting unique Lagrange interpolations. SIAM J. Numerical Anal. 14(4):735–743.Crossref, Google Scholar
- [12] (1979) Robust locally weighted regression and smoothing scatterplots. J. Amer. Statist. Assoc. 74(368):829–836.Crossref, Google Scholar
- [13] (1983) Asymptotics for M-type smoothing splines. Ann. Statist. 11(2):530–551.Crossref, Google Scholar
- [14] (1984) Multivariate smoothing spline functions. SIAM J. Numerical Anal. 21(4):789–813.Crossref, Google Scholar
- [15] (1979) Smoothing noisy data with spline functions: Estimating the correct degree of smoothing by the method of generalized cross-validation. Numerische Mathematik 31:377–403.Crossref, Google Scholar
- [16] (1978) A Practical Guide to Splines (Springer, New York).Crossref, Google Scholar
- [17] (1993) Curve and Surface Fitting with Splines (Oxford University Press, New York).Crossref, Google Scholar
- [18] (1994) Ideal spatial adaptation via wavelet shrinkage. Biometrika 81(3):425–455.Crossref, Google Scholar
- [19] (1979)
Splines minimizing rotation invariant semi-norms in Sobolev spaces . Schempp W, Zeller K, eds. Multivariate Approximation Theory (Birkhäuser-Verlag, Basel, Switzerland), 85–100.Google Scholar - [20] (1999) Nonparametric Regression and Spline Smoothing (Marcel Dekker, New York).Crossref, Google Scholar
- [21] (1982) Scattered data interpolation: Tests of some methods. Math. Comput. 38(157):181–200.Google Scholar
- [22] (2014) CVX: MATLAB software for disciplined convex programming, version 2.1. Accessed April 17, 2024, http://cvxr.com/cvx.Google Scholar
- [23] (1994) Nonparametric Regression and Generalized Linear Models: A Roughness Penalty Approach (Chapman & Hall, London).Crossref, Google Scholar
- [24] (2021) Minimax optimal regression over Sobolev spaces via Laplacian regularization on neighborhood graphs. Banerjee A, Fukumizu K, eds. Internat. Conf. Artificial Intelligence Statist. (PMLR, New York), 2602–2610.Google Scholar
- [25] (1969) Theory and Applications of Spline Functions (Academic Press, New York).Google Scholar
- [26] (2001) Estimation of a convex function: Characterization and asymptotic theory. Ann. Statist. 29(6):1653–1698.Crossref, Google Scholar
- [27] (2002) A Distribution-Free Theory of Nonparametric Regression (Springer, New York).Crossref, Google Scholar
- [28] (1976) Consistency in concave regression. Ann. Statist. 4(6):1038–1050.Crossref, Google Scholar
- [29] (1990) Applied Nonparametric Regression (Cambridge University Press, Cambridge, UK).Crossref, Google Scholar
- [30] (1954) Point estimates of ordinates of concave functions. J. Amer. Statist. Assoc. 49(267):598–619.Crossref, Google Scholar
- [31] (1967) Introduction to Operations Research, 9th ed. (Holden-Day, San Francisco).Google Scholar
- [32] (2006) Options, Futures, and Other Derivatives (Prentice Hall, Hoboken, NJ).Google Scholar
- [33] (1985) Noisy data with spline functions. Numerische Mathematik 47:99–106.Crossref, Google Scholar
- [34] (2018) Shape constraints in economics and operations research. Statist. Sci. 33(4):527–546.Crossref, Google Scholar
- [35] (2003) On the problems of smoothing and near-interpolation. Math. Comput. 72(244):1873–1885.Crossref, Google Scholar
- [36] (2018) Segmented concave least squares: A nonparametric piecewise linear regression. Eur. J. Oper. Res. 266(2):585–594.Crossref, Google Scholar
- [37] (2006) Rates of convergence for partitioning and nearest neighbor regression estimates with unbounded data. J. Multivariate Anal. 97(2):311–323.Crossref, Google Scholar
- [38] (2009) Optimal global rates of convergence for nonparametric regression with unbounded data. J. Statist. Planning Inference 139(4):1286–1296.Crossref, Google Scholar
- [39] (1961) -Entropy and -capacity of sets in functional spaces. Amer. Math. Soc. Translations 2(17):277–364.Crossref, Google Scholar
- [40] (2008) Representation theorem for convex nonparametric least squares. Econom. J. 11(2):308–325.Crossref, Google Scholar
- [41] (2010) Data envelopment analysis as nonparametric least squares regression. Oper. Res. 58(1):149–160.Link, Google Scholar
- [42] (2017) Modeling joint production of multiple outputs in StoNED: Directional distance function approach. Eur. J. Oper. Res. 262(2):792–801.Crossref, Google Scholar
- [43] (2013) A more efficient algorithm for convex nonparametric least squares. Eur. J. Oper. Res. 227(2):391–400.Crossref, Google Scholar
- [44] (2020) The limiting behavior of isotonic and convex regression estimators when the model is misspecified. Electronic J. Statist. 14(1):2053–2097.Crossref, Google Scholar
- [45] (2021) Consistency of penalized convex regression. Internat. J. Statist. Probab. 10(1):69–78.Crossref, Google Scholar
- [46] (2012) Consistency of multidimensional convex regression. Oper. Res. 60(1):196–208.Link, Google Scholar
- [47] (1997) Hybrid adaptive splines. J. Amer. Statist. Assoc. 92(437):107–116.Crossref, Google Scholar
- [48] (1991) Nonparametric regression under qualitative smoothness assumptions. Ann. Statist. 19(2):741–759.Crossref, Google Scholar
- [49] (2019) A computational framework for multivariate convex regression and its variants. J. Amer. Statist. Assoc. 114(525):318–331.Crossref, Google Scholar
- [50] (1979) Multivariate interpolation at arbitrary points made simple. Z. Angew. Math. Phys. 30:292–304.Crossref, Google Scholar
- [51] (1984)
Surface spline interpolation: Basic theory and computational aspects . Singh SP, Burry JWH, Watson B, eds. Approximation Theory and Spline Functions, NATO ASI Series, vol. 136 (Springer, Dordrecht, Netherlands), 127–142.Crossref, Google Scholar - [52] (2002) Response Surface Methodology: Process and Product Optimization Using Designed Experiments (Wiley, New York).Google Scholar
- [53] (1964) On estimating regression. Theory Probab. Appl. 9(1):141–142.Crossref, Google Scholar
- [54] (1976) An Introduction to the Mathematical Theory of Finite Elements (Wiley, New York).Google Scholar
- [55] (1967) Smoothing by spline functions. Numerische Mathematik 10:177–183.Crossref, Google Scholar
- [56] (1971) Smoothing by spline functions II. Numerische Mathematik 16:451–454.Crossref, Google Scholar
- [57] (1983) Smoothing splines: Regression, derivatives and deconvolution. Ann. Statist. 11(1):141–156.Crossref, Google Scholar
- [58] (1994) Multivariate locally weighted least squares regression. Ann. Statist. 22(3):1346–1370.Crossref, Google Scholar
- [59] (2016) Moving least squares regression for high-dimensional stochastic simulation metamodeling. ACM Trans. Model. Comput. Simulation 26:16:1–16:25.Crossref, Google Scholar
- [60] (1964) Spline functions and the problem of graduation. Proc. Natl. Acad. Sci. USA 52(4):947–950.Crossref, Google Scholar
- [61] (2011) Nonparametric least squares estimation of a multivariate convex regression function. Ann. Statist. 39(3):1633–1657.Crossref, Google Scholar
- [62] (2000) On the asymptotics of constrained local M-estimators. Ann. Statist. 28(3):948–960.Crossref, Google Scholar
- [63] (2009) Lectures on Stochastic Programming: Modeling and Theory (SIAM, Philadelphia).Crossref, Google Scholar
- [64] (1977) Consistent nonparametric regression. Ann. Statist. 5(4):595–645.Crossref, Google Scholar
- [65] (1980) Optimal rates of convergence for nonparametric estimators. Ann. Statist. 8(6):1348–1360.Crossref, Google Scholar
- [66] (1981) Optimal smoothing of noisy data using spline functions. SIAM J. Sci. Statist. Comput. 2(3):349–362.Crossref, Google Scholar
- [67] (1988) Convergence rates for multivariate smoothing spline functions. J. Approx. Theory 52(1):1–27.Crossref, Google Scholar
- [68] (1990) Estimating a regression function. Ann. Statist. 18(2):907–924.Crossref, Google Scholar
- [69] (2000) Empirical Process in M-Estimation (Cambridge University Press, Cambridge, UK).Google Scholar
- [70] (1985) Non-parametric analysis of optimizing behavior with measurement error. J. Econometrics 30(1):445–458.Crossref, Google Scholar
- [71] (1990) Spline Models for Observational Data (SIAM, Philadelphia).Crossref, Google Scholar
- [72] (1995) Kernel Smoothing (Chapman & Hall, London).Crossref, Google Scholar
- [73] (1964) Smooth regression analysis. Sankhya Ser. A 26(4):359–372.Google Scholar
- [74] (1983) Splines in statistics. J. Amer. Statist. Assoc. 78(382):351–365.Crossref, Google Scholar
- [75] (2020) Shape-constrained kernel-weighted least squares: Estimating production functions for Chilean manufacturing industries. J. Bus. Econom. Statist. 38(1):43–54.Crossref, Google Scholar
- [76] (1969) Nonlinear Programming: A Unified Approach (Prentice-Hall, Hoboken, NJ).Google Scholar

