
Directed Acyclic Graph-Type Distributed Ledgers via Young-Age Preferential Attachment
Abstract
Distributed ledger technologies provide a mechanism to achieve ordering among transactions that are scattered on multiple participants with no prerequisite trust relations. This mechanism is essentially based on the idea of new transactions referencing older ones in a chain structure. Recently, directed acyclic graph (DAG)-type distributed ledgers that are based on DAGs were proposed to increase the system scalability through sacrificing the total order of transactions. In this paper, we develop a mathematical model to study the process that governs the addition of new transactions to the DAG-type distributed ledger. We propose a simple model for DAG-type distributed ledgers that are obtained from a recursive young-age preferential attachment scheme (i.e., new connections are made preferably to transactions that have not been in the system for very long). We determine the asymptotic degree structure of the resulting graph and show that a forward component of linear size arises if the edge density is chosen sufficiently large in relation to the “young-age preference” that tunes how quickly old transactions become unattractive.
Funding: The research of C. Mönch is supported by the Deutsche Forschungsgemeinschaft [Grant 443916008].
1. Motivation and Background
1.1. Introduction
Distributed ledger technologies (DLTs), which are based on directed acyclic graphs (DAGs) such as the Tangle (Popov 2016) or Coordicide (Popov et al. 2020), generalize blockchain-based DLTs by weakening the ordering among the transaction blocks that constitute the ledger. Blockchain-based DLTs achieve total ordering of the transactions contained by the ledger through the rule of the longest chain as coined in Nakamoto (2006). Here, transactions are collected into blocks that each include a reference to the previous block such that a chain of ordered transactions emerges. When blocks are created concurrently such that only a partial order exists, the rule of the longest chain dictates that blocks that do not belong to the longest chain are discarded. This is a major factor that impairs the scalability of blockchain-based DLTs in terms of the rate of adding transactions to the ledger.
DAG-type distributed ledgers achieve scalability through allowing partially ordered transaction blocks (i.e., transaction blocks may reference more than one previous block). In this paper, we study the relation of design parameters for DAG-type DLTs based on the transient and limiting properties of the underlying transaction graph. We consider the graph of transaction blocks that emerges through block attachment (i.e., new blocks referencing preceding ones). We focus on two design choices for DAG-type DLTs.
How many preceding blocks should a new block reference?
How should the age of a preceding block impact the reference choice of a new block?
The rationale behind these two choices lies in the formulation of simple, probabilistic block reference rules that guarantee the existence of a giant forward component based on (i) a simple function of the number of preceding blocks to reference and (ii) an age preference parameter. A preference for old or high-degree vertices creates a graph architecture that is locally tree like and features vertices of arbitrary high degree, which differs extremely from the linear structure of blockchain-based DLT. Young-age preferential attachment (YAPA) interpolates between these two structural extremes and generates a sparse, locally tree-like graph in which there are no hubs (i.e., the maximal degree grows only weakly with the system). We provide a simple reference rule that allows us to study the two questions analytically and investigate some transient and asymptotic properties of the transaction block graph, such as the reference degree distribution, degree evolutions, the existence of a giant forward component, and the size of the “detached surface” of vertices in the transaction graph that do not connect to any previous transactions.
1.2. Related Literature About DLTs
Blockchain technology is based on the following fundamental principles. (i) Decentralization. Because of its distributed architecture, a blockchain does not rely on a central server but rather, stores data in a decentralized manner, and it can be updated by any node in the network. (ii) Transparency. Each node (peer) has a local copy of the blockchain, and updates are sent as a broadcast to all nodes. Therefore, any change to the blockchain is transparent to all members of the network. (iii) Open source. The original blockchain protocol introduced with Bitcoin is publicly available and can be used for development. (iv) Autonomy. All peers can update or transmit the stored data. Each node can verify the accuracy of all data received. This eliminates the need for trust between participants. (v) Immutability. Once a transaction block is part of the blockchain, it is stored publicly forever, and its contents (i.e., transactions) cannot be edited without changing the hash value stored in all subsequent blocks. (vi) Anonymity. Data transmission in the blockchain is done via addresses, and therefore, user identities remain hidden.
Current blockchain-based cryptocurrencies are often presented as an alternative to traditional currencies. However, there are questions about the scalability and performance of distributed ledgers compared with established payment systems (Croman et al. 2016, Pappalardo et al. 2017). Currently, the Bitcoin network is only capable of processing very few transactions per second (Blockchain Luxembourg S.A. 2021c), and it takes up to 20 minutes for a newly posted transaction to be processed (Blockchain Luxembourg S.A. 2021b). Established payment processors, on the other hand, process up to four orders more transactions per second, and new transactions are usually processed within a few seconds. A significant influence on the performance of the globally distributed peer-to-peer Bitcoin system (Donet et al. 2014) is the propagation speed of the blocks in the network (Decker and Wattenhofer 2013). For example, for a 1-MB block, which is roughly the average block size (Blockchain Luxembourg S.A. 2021a), it takes about 2.4 minutes (Croman et al. 2016) for 90% of the nodes to receive this block. With the block interval of 15 minutes used by the Bitcoin network, this poses a significant problem, which increasingly leads to the splitting of the blockchain—the so-called blockchain forks (Decker and Wattenhofer 2013). The emergence of such forks significantly decreases the performance of the distributed ledger system.
Although approaches already exist to optimize the propagation speed of information in the distributed ledger network (Fadhil et al. 2016, 2017), these also do not reach the performance of current financial transaction systems. In addition to optimizing the propagation speed, other improvements arise in the communication protocol used (Croman et al. 2016, Gobel and Krzesinski 2017). One way to optimize the current Bitcoin protocol in terms of transmission speed is to minimize unnecessary transmissions by adjusting the sequence of exchanged messages needed to transmit new blocks. Instead of first publishing the availability of information, blocks that do not exceed a certain threshold in terms of size can thus be distributed directly to neighboring nodes. This can increase the effective transmission speed especially for small blocks, where the protocol overhead has a particularly large impact. Decker and Wattenhofer (2013) have shown that such protocol adaptations can reduce blockchain forks by about 50%.
To increase scalability and transaction throughput, nonlinear graph-based distributed ledgers (Lewenberg et al. 2015, Popov 2016, Sompolinsky et al. 2016, Yeow et al. 2017, Sompolinsky et al. 2021) replace the traditional blockchain with a global DAG that contains all recorded transactions. In this graph, the nodes are transaction blocks (consisting of one or more transactions), whereas the edges indicate the validation of previous blocks/transactions. Each added node should validate transactions, where k can be fixed or random. A key advantage of DAG-based systems is that by deviating from the linear longest blockchain rule, scalability can be greatly improved. The longest blockchain rule essentially requires all nodes to know about newly created blocks quickly, thus limiting the creation of blocks to allow for the propagation of this knowledge before a new block is created. Instead of trusting the longest-chain rule as given in blockchain-distributed ledgers, DAG-based distributed ledgers rely on metrics, such as the largest strongly connected cluster of transaction nodes in the transaction graph, to determine the trusted transactions (Sompolinsky et al. 2021).
Beyond financial transactions, there exist many application areas for distributed ledgers; for example, in the context of distributed and secure storage of personal data (Zyskind et al. 2015) or for asynchronous messaging services in the context of distributed computing (Yin et al. 2018). Particularly, the former use case is of high relevance because of increasingly frequent incidents in which personal data are publicly accessible because of security breaches or data misuse. Here, the use of distributed ledgers as a system for distributed access control offers a potential solution. Instead of storing data centrally and granting direct access, queries are mapped as well as sharing information via transactions. Combined with off-chain storage of sensitive data, it is thus possible to develop a distributed ledgers system in which each user retains full control over their own data. In addition to increased security, this has the advantage that laws and other regulations can be implemented directly in the protocol used in the form of policies (Zyskind et al. 2015).
1.2.1. Organization of the Paper.
In the following section, we introduce the model formally and present our mathematical main results. Section 3 contains further discussion of how our results relate to previous work and of the practical implication of our results for DLT applications. Section 5 contains numerical simulations. Finally, detailed proofs of our main results are provided in Section 6.
2. Model and Main Results
2.1. Model Definition
The model we propose is based on young-age preferential attachment. We study a recursive growth parametrized by two numbers, the edge density parameter and the reinforcement bias . We use the shorthand notations for and to denote and , respectively. At step n = 1, the graph G1 is initialized with a vertex labeled one. At any step n > 1, one vertex labeled n is added to the system, and Gn is obtained recursively from according to the following attachment rule. For each , n sends an arc to m independently of everything else with probability
We formally write with for the graph obtained upon adding the nth vertex. If n sends an arc to , we denote this event by . The notation is shorthand for the existence of a directed path from n to . Note that the direction of the arcs along any path can be recovered from the labels of the vertices that belong to the path (Figure 1).
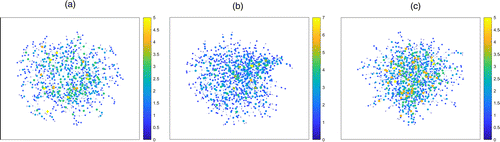
Notes. The node size and color correspond to the node indegree. (a) α = 3. (b) . (c) α = 4.
2.2. Key Properties of the YAPA Model
Ignoring the dynamical aspect of our model, it can be viewed as an instance of the directed inhomogeneous random graph model proposed in Cao and Olvera-Cravioto (2020), which allows us to infer some basic properties of the network from known results about this model class. We first establish that the young-age preferential attachment model produces a sparse graph (i.e., the number of arcs is of the same order as the number of vertices).
(Sparsity). It holds that
Next, we determine the distributional limit of the vertex degrees in Gn. For any vertex , we denote by its degree (vector) in Gn: that is,
Note that the outdegree of a vertex is determined once and for all upon its insertion (i.e., for all ). As can be guessed from the fact that connections occur independently and with probability of order , the asymptotic degree distribution is bivariate Poisson.
(Limiting Degree Distribution and Rate of Convergence). Let GN denote the young-age preferential attachment graph on N vertices. For uniformly chosen among the vertices of GN, the following asymptotic results hold:
Here, and are independent, and is distributed. The limiting indegree has distribution with mixing random variable , where V is . Moreover, we have that
The form of the limiting degree distribution in Theorem 1 is obtained rather directly by applying the machinery of Cao and Olvera-Cravioto (2020), but the error bound (2) is new and does not follow from previous results about inhomogeneous random graphs. Inspection of the proof further yields that an error of the same order can be achieved for any graph on N vertices in which edges are drawn independently with probability at most c/N for some universal c (cf. Lemma 3). We do not believe that the logarithmic term is asymptotically sharp, but the polynomial order is consistent with known results for other sparse models with independent edges, such as the Erdös–Rényi graph (cf. van der Hofstad 2017, theorem 5.12).
It follows from Theorem 1 that whereas the outdegree is asymptotically independent of the time at which a node enters the system, the indegree is not. Essentially, the limiting indegree distribution of a given node is also , but the time needed to collect all incoming links grows proportionally with network size. A node born at the beginning corresponds to V near zero, and a node born at a time close to the total age of the system corresponds to V close to one.
The indegree dynamics of fixed vertices are further characterized by the following bounds.
(Degree Evolutions). The maximal (total) degree of any vertex in GN is almost surely . We further have that
for any ,
for any
Let us now discuss the connectivity of the YAPA network. The forward component of after the arrival of vertex n, is given by
(Detached Surface). We have that
Although there is still a positive fraction of nodes with no left neighbors, this fraction is not very large; for instance, if we would like to make sure that with probability at least 0.995, a typical vertex sends an arc to at least one vertex, it suffices to choose .
Next, we would like to ensure that the vast majority of vertices that do connect upon arrival in the system are contained in the forward component of only a handful of vertices. This can only be achieved if there exist vertices m such that grows linearly with N. Our first result concerning such macroscopic components states that the forward component of a typical vertex is not of linear order.
(No Giant Forward Components for Typical Vertices). Let be uniformly chosen; then, for any , we have
As for Theorem 1, the neighborhood around a typically chosen vertex can be described by the local limit approach used in Cao and Olvera-Cravioto (2020). It is not hard to see that the weak local limit of is in fact the family tree obtained from the multitype Galton–Watson process given by the following recursion.
Sample uniformly. Generation 0 of the tree comprises the root, which has type V.
For any , given generation k − 1 of the tree, each member m in generation k − 1 of type Vm independently produces a ()-distributed number of offspring to obtain the kth generation, and each of the offspring thus produced is independently assigned a type drawn uniformly from .
The proof of Proposition 3 in Section 6 shows that the local limit tree dies out for any choice of . Contrary to the local behavior near a typical vertex, if , most vertices indeed belong to the forward components of a few old vertices. More precisely, let ; then, the vertices are always sequentially connected by construction, and we thus focus on the forward components of vertices added after n0.
(Existence of Giant Forward Components). Let be given. Then, almost surely,
Theorem 2 is the main result of this article. The apparent differences in the characterizations obtained in Proposition 3 and Theorem 2 are because of the reducibility of the graph. Proposition 3 is concerned with the forward component of a typical (i.e., uniformly chosen) vertex. Such a typical vertex has a birth time of order N and can simply not collect enough direct and indirect references up to time N to develop a large forward component. In particular, applying the machinery of Cao and Olvera-Cravioto (2020) (after some adaptations to account for irreducibility) yields that typical vertices do not have a giant forward component; see the proof of Proposition 3.
In contrast, Theorem 2 states that if an early vertex is kept fixed and the time horizon is extended to infinity, with positive probability, the selected vertex will be the root of a forward component of linear size eventually. We stress that it is not possible to derive statements of this type directly using the general theory of Cao and Olvera-Cravioto (2020), which uses the local weak limit of the graph (i.e., limit distributions of neighborhoods of typical vertices) and therefore, does not provide sufficient information about vertices with index .
3. Further Related Work and Discussion of Results
3.1. Design of Tip Selection for DAG-Type Distributed Ledgers
DAG-type distributed ledgers, such as IOTA (Popov 2016), utilize different algorithms for achieving consensus. State-of-the-art DAG-type DLTs repurpose the act of selecting transactions for validation (i.e., constructing arcs from an arriving node to previous ones for achieving consensus). In a nutshell, the tip selection algorithm in Popov (2016) is based on a biased random walk, and a transaction that is directly or indirectly validated by a large portion of the subsequent transactions is highly probable to be considered valid. Precisely, a tip on the surface of the DAG is selected based on a random walk from genesis to the surface. This random walk is biased in the sense that nodes possess a weight that resembles the number of subsequent nodes that are directly or indirectly attached to this node and that the jump probability of the random walk from a node i with weight wi to a node j with weight wj is with a given constant . For finite time, the value of the constant α may play a role to adjust the tip selection to mimic a uniformly random tip selection or to quickly concentrate the tip selection on a set of young nodes. However, this algorithm is different from our YAPA model as it concentrates the tip selection on certain walks where the node weights are large.
Further works, such as Kusmierz and Gal (2018) and Ferraro et al. (2020), analyze different properties of the DAG-type distributed ledgers, especially the IOTA DAG, which is denoted the Tangle. Kusmierz and Gal (2018) derive approximations of the probabilities that a node is left behind or that a node becomes a permanent tip. Specifically, the first approximation of the probability that a node is left behind is similar to the detached surface evolution in Corollary 1. Ferraro et al. (2020) provide a modified IOTA tip selection algorithm that is based on a combination of two Markov chain Monte Carlo algorithms with different parameters that aims to have all nodes validated. They prove this property using a fluid limit in the arrival rate of transactions.
In Coordicide (Popov et al. 2020), which is a follow-up work on IOTA constituting a modern DAG-type DLT, tip selection is fixed to validating two existing transactions. Here, the authors dispense with tip selection as a consensus mechanism and rather, consider it from a performance point of view (i.e., analyzing the impact of the tip selection on the DAG properties, especially in discouraging “lazy” behavior, which resembles the recurring validation of a fixed set of old transactions).
We consider this work in the same vein (i.e., our YAPA model provides a relationship between the parameters of the tip selection algorithm (that is, the edge density α and the reinforcement bias β) and the DAG-distributed ledger properties). We establish the YAPA model in (1) as a rule to encourage the validation of young transactions. From the calculation of the asymptotic distribution of the outdegree (which turns out to be ) as well as the nonasymptotic expected outdegree at a given time point , we know the expected number of transactions that are validated given parameters α, β. Further, the reinforcement bias is understood as a forgetting factor, precisely a parameter to set the preference for validating young transactions (i.e., larger leads to a stronger preference of younger transactions over older ones). Hence, by choosing α, β while ensuring , the properties of the distributed ledger can be controlled. As is reflected in our results, we study the following properties: (i) the emergence of “giant” components (i.e., a linear increase of the number of direct and indirect validations that a transaction receives over time), (ii) the average number of direct validations received by a transaction over time, and (iii) the number of orphan transactions.
3.2. Related Mathematical Results
Our model is similar in spirit to the one introduced in Lyon and Mahmoud (2020) but with two important differences. First, their model produces a tree, whereas our model produces a directed acyclic graph that is typically not a tree. Second, we modulate the attachment via the parameters α and β to obtain a whole range of instances. This flexibility allows us to tune the model to specific applications and also allows us to observe the connectivity phase transition of Theorem 2. The young-age preferential attachment tree of Lyon and Mahmoud (2020) corresponds to running our model with β = 1 and conditioning on the creation of precisely one arc per time step. As explained in Section 2, our model can be analyzed in the general framework of Cao and Olvera-Cravioto (2020), who adapted the very general framework of inhomogeneous random graphs developed in Bollobás et al. (2007) to directed graphs, thereby generalizing earlier results of Bloznelis et al. (2012). We use some techniques from the (directed) inhomogeneous random graph world to obtain the degree sequence and analyze the emergence of a giant connected component for our model in Proposition 3. However, because is not reducible and we investigate connected components in terms of directed paths, our main result in Theorem 2 cannot be obtained by a direct application of the results in Bloznelis et al. (2012) and Cao and Olvera-Cravioto (2020). We also emphasize the dynamic nature of our model, which is not captured by the inhomogeneous random graph framework. Furthermore, if we were to ignore the direction of the arcs and consider GN as an undirected graph, then it is straightforward to deduce that the limit in Proposition 3 would be positive whenever (cf. Bollobás et al. 2007).
The limiting case β = 0 of the YAPA model corresponds to a directed version of the uniformly grown random graph investigated in Bollobás and Riordan (2004) and Bollobás et al. (2005); this is a very natural recursive model that was first studied by Dubins in the 1980 s (cf. Kalikow and Weiss 1988, Shepp 1989, Durrett and Kesten 1990). Although we exclusively consider positive values of β, choosing would lead to a preference for old-age vertices and produce an effect similar to degree-based preferential attachment models, such as the Barabási–Albert model (Barabási and Albert 1999). Models of this type have been investigated thoroughly in the last 20 years (see, e.g., Bollobás et al. 2001; Dereich and Mörters 2009, 2013; and the references therein). Old-age preferential attachment models produce graphs with entirely different features, such as a scale-free degree distribution, whereas the degrees in the YAPA model are fairly sharply concentrated around their expectation as is exemplified by Proposition 2.
4. Simulation
In the following, we describe evaluation results that are based on simulating the model with attachment probabilities given by (1). Transaction blocks arrive according to a Poisson process with rate λ = 1. We fix the reinforcement bias β = 2 and variate the edge density parameter α. Figure 2 shows the evolution of the connected component size starting at the genesis node (transaction) for the first 105 transactions for different α. Note the linear growth rate of the connected component for . The figure shows the empirical average in addition to the standard deviation (which is depicted as the shaded area) from 20 independent simulation runs. Note that the standard deviation for the subcritical regime α = 2 is large because there is no natural scaling (in N) for the component size.
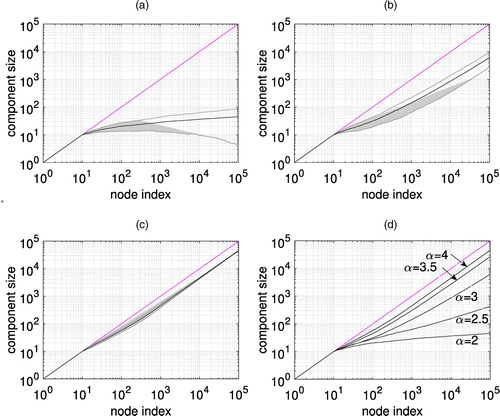
Notes. As an initial condition, we assume that the first 10 nodes reference the genesis node. (a) α = 2. (b) α = 3. (c) α = 4. (d) Variable α.
Figure 3 shows the error as calculated from Theorem 2 for . The figure shows clearly the convergence of the ratio to Z(m) with a growing number of vertices N.
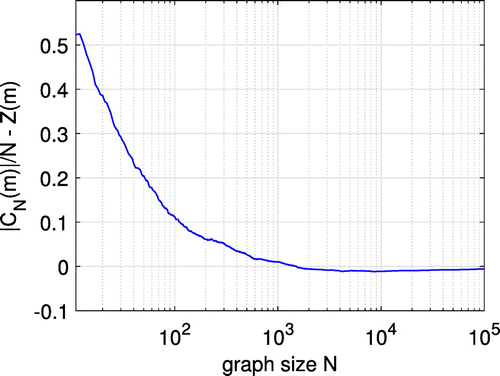
Note. The error diminishes with an increasing number of vertices N.
Figure 4 shows the properties of the shortest paths to the genesis node for various values of the reinforcement bias β and the edge density parameter α. In light of the impact of the tip selection algorithm parameterization through α and β, the figure reflects the shape of the transaction DAG (i.e., its depth and width in terms of the length of the shortest paths to genesis). In comparison, note that the extreme cases of a DAG of depth 1 or a totally ordered chain produce sum lengths of the shortest paths of size n and , respectively. The figure also shows markers for the values of that correspond to a mean outdegree , which is used in the context of DAG-type DLT (Popov 2016, Popov et al. 2020) as a deterministic guideline for the number of validated nodes per new node. Although the fraction of nodes not connected to genesis remains constant as given by the detached surface approximation in (5), the shape of the DAG DLT can be controlled by the choice of α, β. Note that a similar argument can be made in terms of the shortest paths to some arbitrary genesis cluster of nodes.
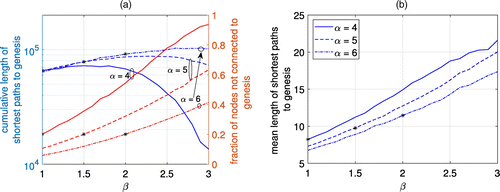
Notes. The width and depth of the constructed graphs show a strong dependency on β. The figures are obtained from 102 simulation runs each, including transactions. The black markers correspond to a mean outdegree . (a) Cumulative length of the shortest paths to genesis in hops. (b) Mean length of the shortest paths to genesis in hops.
5. Implications for DLT Applications
Our work is motivated by questions on the design choices of DAG-based DLT applications, in particular on how the analyzed YAPA referencing scheme that relates newly generated blocks to previously generated ones affects the DLT properties. In the following, we discuss the implications of the obtained results for some design aspects of DLT applications.
5.1. Tip Selection
Tip selection is often convolved with consensus as in Popov (2016) and Müller et al. (2022). In Popov et al. (2020), tip selection is considered separately and set to referencing a fixed number of previous blocks. When tip selection is convolved with consensus, it is usually based on some aggregate weight of the blocks that must be tracked (Popov 2016, Müller et al. 2022). Some works also propose uniform random tip selection on a subset of (nonconflicting) blocks, such as Müller et al. (2022).
The first implication of the YAPA model definition is that users that generate blocks do not have to track or calculate block weights according to more or less complex and time-consuming algorithms. The configuration model is entirely determined by the YAPA parameters α, β. In turn, these determine the required storage and computation capacity for reference operations (i.e., the number of references (hashes) that are required on average as in Proposition 1). Note that each reference is usually tied to one hash operation as well as a linear growth of storage space. This stands in contrast to the deterministic number of references as well as the weight-based referencing methods.
5.2. Laziness and Permanent Tips
The reviewed state of the art makes great effort to avoid lazy behavior (i.e., preventing users from referencing a fixed set of old blocks). The temptation to do this is based on the reuse of computed hashes in old blocks in referencing for new blocks. The YAPA configuration readily dispenses with this problem for . On the other hand, the risk of a block becoming a permanent tip is shown for our model in Corollary 1. This can be considered the cost of using the simple YAPA configuration model as the detached surface contains transaction blocks that are never verified.
5.3. Consensus and Time to Confirmation
The results of this work emphasize that consensus in a DAG-based DLT that uses the proposed YAPA configuration model can be reached. Theorem 2 shows that a consensus method based on the so-called heaviest weighted subchain (Wang et al. 2022) or the so-called heaviest sub-DAG (Müller et al. 2022) is viable under a proper YAPA configuration of . The simulation results validate this behavior for a range of realistic parameters (i.e., average number of references/hashes of and β = 2). Further, the simulation results provide insights in the form if the DLT is controlled by the YAPA configuration α, β. Related works, such as Popov (2016) and Müller et al. (2022), assume a constant Tangle width and that the numbers of tips of the Tangle are stationary with a given mean. Note that in Müller et al. (2022), this is justified by a number of chosen tips equal to one. Our simulations show, on the other hand, that the shape of the Tangle can be controlled by adjusting α and β at a fixed average outdegree (i.e., number of referenced previous blocks). In turn, the shape of the Tangle implicates the causal relations of transaction blocks (i.e., for a given number of blocks, N having a few long chains of blocks (approaching line topologies) with crossreferences is semantically different from having many short chains of blocks (approaching a star topology)). The former form distributes the cumulative weight required for consensus, whereas the latter concentrates this weight on a few blocks. Nevertheless, the result in Theorem 2 shows that consensus can be achieved after long-enough time.
Time to confirmation is a performance metric for the consensus protocol of the DLT. As discussed, the YAPA configuration model for a DLT provides two guarantees. First, the confirmation time in terms of the rate of convergence of the distribution of the number of direct block references received is bounded in Theorem 1. This stands in contrast to heuristics to obtain estimates of the time to confirmation as, for example, in Popov (2016) and Müller et al. (2022), where some difficulty stems from the intractability of the referencing rule.
6. Proofs
The proofs of our main results are divided into three sections. The first section contains the derivation of results that can be obtained in the general framework of Cao and Olvera-Cravioto (2020). The second section provides concentration bounds for degree properties, which are needed in the last section or are interesting in their own right, and the final section contains the proof of our main result, Theorem 2.
6.1. Directed Inhomogeneous Random Graphs and Branching Process Approximation
We call
Then,
Setting also
It is straightforward to verify the regularity assumptions listed in Cao and Olvera-Cravioto (2020, assumption 3.1) for our model using κ and as defined and interpreting together with the Lebesgue measure as the ground space. Proposition 1 is now a special case of the corresponding statement in Cao and Olvera-Cravioto (2020).
By Cao and Olvera-Cravioto (2020, proposition 3.3), we have
Each
In particular, because for all m, n, we have
The limiting distribution described in Theorem 1 is obtained as a special case of the statement of Cao and Olvera-Cravioto (2020, theorem 3.4) when applied to the kernel κ given in (3). □
The detached surface
Using that , we obtain that and thus,
The outdegrees of different vertices are independent, and therefore, Δn is a sum of independent -distributed random variables. The corresponding variances are uniformly bounded by one; thus, another invocation of Kolmogorov’s Strong Law of Large Numbers yields almost sure convergence of to □
In Cao and Olvera-Cravioto (2020, section 4.3.1), it is shown that the forward exploration started in a uniform vertex can be coupled to a multitype branching process with family tree . It is straightforward to deduce from the form of κ that this branching process is the Galton–Watson process described in Remark 2. It is well known and not hard to prove that if almost surely, then we have as for any and additionally, see, for example, van der Hofstad (2021, corollary 2.27). The survival probability of the Galton–Watson process can be characterized via the Volterra-type operator on given by
Our goal is to show that for any choice of , we have that , and hence, ζ = 0. Let Ut denote the type of vertex , and let U0 denote the type of the root; then,
Note that because types must increase along any genealogical path in . On the event , the evolution of the branching process is represented by the operator . More precisely, we have that , where denotes constant unit function and describes the expected number of offspring of type in the kth generation of ; hence,
We assume for the moment that is quasinilpotent for any (i.e., , where denotes the operator norm on ). In particular, this implies that vanishes as , and hence,
Thus, it only remains to show that for any fixed is quasinilpotent. Because is bounded on , it is straightforward to verify that is a compact operator on ; hence, is quasinilpotent precisely if zero is its only eigenvalue (see, e.g., Dunford and Schwartz 1988, section VII 5.13). Assume for contradiction that has the eigenvalue : that is, that there is some satisfying for almost every
Because f is integrable, the right-hand side is a continuous function of x by dominated convergence, and we may thus assume that f has a continuous version g that satisfies (7) for all . Because g is continuous, it follows from Lebesgue’s differentiation theorem that exists and is equal to for every . It follows that is differentiable and thus, that is differentiable (even smooth) on . In fact, we have, for ,
Furthermore, we have
We conclude that g is a solution to the final value problem
Because g is an eigenfunction for λ, the term in parentheses must vanish (i.e., , which is a contradiction). We conclude that has only the eigenvalue 0 and is thus, quasinilpotent. □
6.2. Concentration Bounds
We begin by stating a straightforward concentration bound on the maximal degree in GN, which applies not only to our model but also, to any directed inhomogeneous random graph in which κ and are bounded.
Let GN denote a random graph in which each arc (m, n) is included independently with probability Suppose that uniformly in m, n for all sufficiently large N and some ; then, the maximal total degree ΔN in GN satisfies
Let Dn denote the total degree of . By assumption, Dn is dominated by a random variable; hence,
The statement about the maximal degree is an immediate consequence of Lemma 1. Let us now establish the stated bounds on the degree evolutions. The evolution of the indegree of a fixed vertex m after the arrival of vertex k > m can be modeled using a counting process that jumps by one upon the arrival of the jth vertex after k if this vertex attaches to m. Hence, jumps occur with probability
In particular, we have
The moment-generating function of is given as
A bound on the tail of the indegree distribution can now be derived using Markov’s inequality
We obtain
We only provided the detailed calculation for the indegree distribution; a similar but simpler argument yields the same bound for the outdegree distribution. Let us set, for each ,
Note that the first error is probabilistic and that the second error is essentially just a discretization error because
We have that
First note that only if , and thus, the error induced in the calculation of the probability weights by ignoring the truncation is and may thus be ignored. A straightforward integral approximation yields
To approximate the discrete outer sum by an integral, we use that if is continuously differentiable, then
We have that almost surely
Fix k, and write . Note that the are independent, and thus, another invocation of Chernoff’s inequality (see, e.g., Chung and Lu 2006, theorem 3.2) yields that
Arguing as in the proof of Lemma 1, we may choose C so large that and such that
Choosing now for some sufficiently large D and setting allow us to apply (15) to obtain
Combining the previous lemmas concludes the proof of Theorem 1.
6.3. Forward Component Size and Weight Evolution—Proof of Theorem 2
Let ; then,
Hence, transitions of the processes depend on the weight structure of the forward component of m, not only on its present size. In particular, each is a Markov process with respect to the filtration generated by the graph sequence but not with respect to the smaller filtration generated by the sequence itself. It is, therefore, more convenient to study the weight processes , which have the dynamics
To eliminate the slightly unwieldy products structure of the transition probability, we formulate a stochastic domination result. We use the notation
Let denote the Markov chain given by and
Then, stochastically dominates .
We start by analyzing the transition probabilities of
Noting that is uniformly bounded by , we can estimate
We conclude that
To obtain a stochastic upper bound is only slightly more tricky.
Let be defined as in Lemma 4, and let . There exits n1 such that for all , we can couple and conditionally on such that
We argue by induction. The claim holds by construction at any given initial time Now, assume that the coupling has been established for times . Then,
Lemmas 4 and 5 indicate that the dynamics of can be analyzed in the terms of the simple processes defined in Lemma 4. To this end, fix and Ym = y, and define for ,
It follows from a straightforward calculation or alternatively, by invoking Brightwell and Luczak (2012, lemmas 2.1 and 2.2) that is a martingale and that is a supermartingale adapted to the filtration defined by .
If , then almost surely.
Because is a nonnegative supermartingale, converges almost surely to some random variable satisfying Because , it thus follows from
Let us now focus on the case . Performing a Taylor expansion, we see that
Using the Martingale , we can represent Yn as
In view of (18) and (19), the recursion (20) is a stochastic approximation of the stable point We recall the following well-known result about stochastic approximations.
(Special Case of Pemantle 2007, lemma 2.6). Suppose that is a stochastic process adapted to a filtration satisfying the recurrence relation
;
for all ; and
either or for some and some open interval (l0, r0).
Then, we have for any interval that
We now have all of the ingredients to complete the proof of Theorem 2.
Let and . We estimate
Approximating the sums by integrals yields
6.3.1. The Subcritical Case .
By Lemma 5, is eventually dominated by for some y if . Because almost surely by Lemma 6, we conclude that
6.3.2. The Supercritical Case .
We first employ Lemma 4 to dominate from below by the random limit
We wish to apply Lemma 7 with , and
Let us first check that the condition on ξn is satisfied. Clearly, because is a martingale difference. To see that is bounded, we simply note that
We say survives if and that it dies out if . We are going to show now that p > 0 (i.e., survives with positive probability). Observe that we have
Note that if almost surely, then we have that almost surely. Because as vanishes, it follows that for every , there exists some K0 such that
Denoting and setting , it follows that dominates the unique solution of the difference equation
Combining Lemmas 4 and 5, we obtain that
Note that and that for any ,
6.3.3. The Critical Case .
From the supercritical case, we infer that almost surely γ = 0 in this case because γ is a monotone function of α and .
The original version of lemma 7 in Pemantle (2007) also allows us to include an error term Rn in the recursion as long as . In principle, one can apply this version of the stochastic approximation result directly to . We have chosen to include the intermediate step via Yn because it breaks up the error estimates into several parts and makes the argument easier to follow because has a rather simple form.
Note that the subcritical result also follows from the supercritical/critical case by monotonicity, but we gave a standalone argument because the supercritical case is more involved than the direct proof. Unfortunately, this simple argument does not carry over to the critical case.
References
- (1999) Emergence of scaling in random networks. Science 286(5439):509–512.Google Scholar
Blockchain Luxembourg S.A. (2021a) Average block size—Blockchain. Accessed May 19, 2023, https://blockchain.info/de/charts/avg-block-size.Google ScholarBlockchain Luxembourg S.A. (2021b) Median confirmation time—Blockchain. Accessed May 19, 2023, https://www.blockchain.com/charts/median-confirmation-time.Google ScholarBlockchain Luxembourg S.A. (2021c) Transaction rate—Blockchain. Accessed May 19, 2023, https://blockchain.info/de/charts/transactions-per-second.Google Scholar- (2012) Birth of a strongly connected giant in an inhomogeneous random digraph. J. Appl. Probab. 49(3):601–611.Google Scholar
- (2004)
The phase transition and connectedness in uniformly grown random graphs . Leonardi S, ed. Algorithms and Models for the Web-Graph (WAW 2004), Lecture Notes in Computer Science, vol. 3243 (Springer, Berlin), 1–18. https://doi.org/10.1007/978-3-540-30216-2_1.Google Scholar - (2005) The phase transition in the uniformly grown random graph has infinite order. Random Structures Algorithms 26(1–2):1–36.Google Scholar
- (2007) The phase transition in inhomogeneous random graphs. Random Structures Algorithms 31(1):3–122.Google Scholar
- (2001) The degree sequence of a scale-free random graph process. Random Structures Algorithms 18(3):279–290.Google Scholar
- (2012) Vertices of high degree in the preferential attachment tree. Electronic J. Probab. 17(14):1–43.Google Scholar
- (2020) Connectivity of a general class of inhomogeneous random digraphs. Random Structures Algorithms 56(3):722–774.Google Scholar
- (2006) Concentration inequalities and martingale inequalities: A survey. Internet Math. 3(1):79–127.Google Scholar
- (2016) On scaling decentralized blockchains. Clark J, Meiklejohn S, Ryan P, Wallach D, Brenner M, Rohloff K, eds. Financial Cryptography and Data Security. FC 2016, Lecture Notes in Computer Science, vol. 9604 (Springer, Berlin, Heidelberg), 106–125. https://doi.org/10.1007/978-3-662-53357-4_8.Google Scholar
- (2013) Information propagation in the Bitcoin network. IEEE 13th Internat. Conf. Peer-to-Peer Comput. (P2P) (IEEE, Piscataway, NJ), 1–10. https://doi.org/10.1109/P2P.2013.6688704.Google Scholar
- (2009) Random networks with sublinear preferential attachment: Degree evolutions. Electronic J. Probab. 14(43):1222–1267.Google Scholar
- (2013) Random networks with sublinear preferential attachment: The giant component. Ann. Probab. 41(1):329–384.Google Scholar
- (2014) The Bitcoin P2P network. Böhme R, Brenner M, Moore T, Smith M, eds. Financial Cryptography and Data Security. FC 2014, Lecture Notes in Computer Science, vol. 8438 (Springer, Berlin, Heidelberg), 87–102. https://doi.org/10.1007/978-3-662-44774-1_7.Google Scholar
- (1988) Linear Operators. Part II (John Wiley & Sons, Inc., New York).Google Scholar
- (1990) The Critical Parameter for Connectedness of Some Random Graphs. A Tribute to Paul Erdős (Cambridge University Press, Cambridge, UK), 161–176.Google Scholar
- (2016) A Bitcoin model for evaluation of clustering to improve propagation delay in Bitcoin network. 2016 IEEE Internat. Conf. Comput. Sci. Engrg. (CSE) and IEEE Internat. Conf. Embedded Ubiquitous Comput. (EUC) and 15th Internat. Sympos. Distributed Comput. Appl. Bus. Engrg. (DCABES) (IEEE, Piscataway, NJ), 468–475. https://doi.org/10.1109/CSE-EUC-DCABES.2016.226.Google Scholar
- (2017) Locality based approach to improve propagation delay on the Bitcoin peer-to-peer network. IFIP/IEEE Sympos. Integrated Network Service Management (IM) (IEEE, Piscataway, NJ), 556–559. https://doi.org/10.23919/INM.2017.7987328.Google Scholar
- (1950) An Introduction to Probability Theory and Its Applications, vol. I (John Wiley & Sons, Inc., New York).Google Scholar
- (2020) On the stability of unverified transactions in a DAG-based distributed ledger. IEEE Trans. Automatic Control 65(9):3772–3783.Google Scholar
- (2017) Increased block size and Bitcoin blockchain dynamics. 27th IEEE Internat. Telecomm. Networks Appl. Conf. (ITNAC) (IEEE, Piscataway, NJ), 1–6. https://doi.org/10.1109/ATNAC.2017.8215367.Google Scholar
- (1988) When are random graphs connected. Israel J. Math. 62(3):257–268.Google Scholar
- (2018) Probability of being left behind and probability of becoming permanent tip in the Tangle v0.2. Working paper, IOTA Foundation.Google Scholar
- (2015) Inclusive block chain protocols. Böhme R, Okamoto T, eds. Financial Cryptography and Data Security. FC 2015, Lecture Notes in Computer Science, vol. 8975 (Springer, Berlin, Heidelberg), 528–547. https://doi.org/10.1007/978-3-662-47854-7_33.Google Scholar
- (2020) Trees grown under young-age preferential attachment. J. Appl. Probab. 57(3):9111–927.Google Scholar
- (2022) Tangle 2.0 leaderless Nakamoto consensus on the heaviest DAG. IEEE Access 10:105807–105842. https://doi.org/10.1109/ACCESS.2022.3211422.Google Scholar
- (2006) Bitcoin: A peer-to-peer electronic cash system. White paper.Google Scholar
- (2017) Blockchain inefficiency in the Bitcoin peers network. EPJ Data Sci. 7:30. https://doi.org/10.1140/epjds/s13688-018-0159-3.Google Scholar
- (2007) A survey of random processes with reinforcement. Probab. Surveys 4:1–79.Google Scholar
- (2016) The Tangle. Working paper, IOTA Foundation.Google Scholar
- (2020) The Coordicide. Working paper, IOTA Foundation.Google Scholar
- (1989) Connectedness of certain random graphs. Israel J. Math. 67(1):23–33.Google Scholar
- Sompolinsky Y, Wyborski S, Zohar A (2021) Phantom Ghostdag: A scalable generalization of Nakamoto consensus. Proc. 3rd ACM Conf. Adv. Financial Tech. (AFT ’21) (Association for Computing Machinery, New York), 57–70. https://doi.org/10.1145/3479722.3480990.Google Scholar
- (2016) Spectre: A fast and scalable cryptocurrency protocol. IACR Cryptology ePrint Archive 1159. Working paper. https://eprint.iacr.org/2016/1159.Google Scholar
- (2017) Random Graphs and Complex Networks, vol. 1, Cambridge Series in Statistical and Probabilistic Mathematics (Cambridge University Press, Cambridge, UK).Google Scholar
- (2021) Random Graphs and Complex Networks, vol. 2, Cambridge Series in Statistical and Probabilistic Mathematics (Cambridge University Press, Cambridge, UK).Google Scholar
- (2022) SoK: Diving into DAG-based blockchain systems. Preprint, submitted October 29, https://doi.org/10.48550/arXiv.2012.06128.Google Scholar
- (2017) Decentralized consensus for edge-centric Internet of things: A review, taxonomy, and research issues. IEEE Access 6:1513–1524. https://doi.org/10.1109/ACCESS.2017.2779263.Google Scholar
- (2018) Hyperconnected network: A decentralized trusted computing and networking paradigm. IEEE Network 32(1):112–117.Google Scholar
- (2015) Decentralizing privacy: Using blockchain to protect personal data. 2015 IEEE Security Privacy Workshops (IEEE, Piscataway, NJ), 180–184.Google Scholar

