
Nonparametric Approximate Dynamic Programming via the Kernel Method
Abstract
This paper presents a novel, non-parametric approximate dynamic programming (ADP) algorithm that enjoys dimension-independent approximation and sample complexity guarantees. We obtain this algorithm by “kernelizing” a recent mathematical program for ADP (the “smoothed approximate linear program”). Loosely, our guarantees show that we can exchange the importance of choosing a good approximation architecture a priori (as required by existing approaches) with sampling effort. We also present a simple active set algorithm for solving the resulting quadratic program, and prove the correctness of this method. Via a computational study on a controlled queueing network, we show that our approach is capable of outperforming parametric linear programming approaches to ADP, as well as non-trivial, tailored heuristics for the same network, even when employing generic, polynomial kernels.
1. Introduction
Problems of dynamic optimization in the face of uncertainty are frequently posed as Markov decision processes (MDPs). The central computational problem is then reduced to the computation of an optimal “value” or “cost-to-go” function that encodes the value garnered under an optimal policy starting from any given MDP state. MDPs for many problems of practical interest frequently have intractably large state spaces precluding exact computation of the cost-to-go function. Approximate dynamic programming (ADP) is an umbrella term for algorithms designed to produce good approximations to this function. Such approximations then imply a natural “greedy” control policy.
ADP algorithms are often formulated in parametric settings. Here, the user specifies an “approximation architecture” (i.e., a set of basis functions), and the algorithm then produces an approximation in the span of this basis. The strongest theoretical results available for such algorithms typically share the following two features:
The quality of the approximation produced is comparable with the best possible within the basis (i.e., the parameterization or approximation architecture) specified.
The sample complexity or computational effort required for these algorithms scales, typically polynomially, with the dimension of the basis.
These results highlight the importance of selecting a “good” approximation architecture and remain somewhat dissatisfying in that additional sampling or computational effort cannot remedy a bad approximation architecture.
In contrast, an ideal nonparametric approach would, in principle, free the user from carefully specifying a suitable low-dimensional approximation architecture. Instead, the user would have the liberty of selecting a very rich architecture (whose specification is potentially implicit, such as via a kernel). The quality of the approximation produced by the algorithm would then improve—gracefully—with the extent of computational or sampling effort expended, ultimately becoming exact. Although they may fall short of the ideal notion of a nonparametric ADP algorithm, there are several existing proposals for nonparametric ADP available:
1.1. Kernelizing Policy Evaluation
These are approaches that are motivated by approximate policy iteration. The key computational step in approximate policy iteration methods is “policy evaluation.” The aim of this step is to find the cost-to-go function for a given policy. This step involves solving the projected Bellman equation, a linear stochastic fixed-point equation. Because of the curse of dimensionality, solving this exactly is infeasible, and a portion of the ADP literature focuses on approximately solving the policy-evaluation step. This usually involves approximating the cost-to-go function for a particular policy with a parametric approximation architecture. Nonparametric approaches of this flavor attempt to make this step nonparametric. Bethke et al. (2023) study the problem of minimizing Bellman errors from the point of view of kernel support vector regression and Gaussian processes. Engel et al. (2003) consider a generative model for the cost-to-go function, which is based on Gaussian processes. Xu et al. (2007) introduce the nonparametric version of the Least-Squares Temporal Difference- method, a numerically stable approach to do policy evaluation. Farahmand et al. (2009a) study regularized versions of some popular policy-evaluation methods and perform the sample-complexity analysis for one policy-evaluation step. It is difficult to provide convergence guarantees for approximate policy iteration schemes in parametric settings, and these difficulties remain in nonparametric variations. It is consequently difficult to characterize the computational effort or sample complexity required to produce a good approximation with such approaches. In practice, these theoretical shortcomings are often bypassed with heuristics, such as stopping after a fixed number of iterations. In contrast, the approach we study in this paper will admit sample complexity and approximation guarantees, but at the expense of assuming access to a certain idealized sampling distribution over states.
1.2. Local Averaging
Another approach to nonparametric ADP has been to use kernel-based local averaging to approximate the solution of an MDP with that of a simpler variation on a sampled state space (e.g., Ormoneit and Glynn 2002, Ormoneit and Sen 2002, and Barreto et al. 2011). Convergence rates for these local averaging methods are exponential in the dimension of the problem state space. As in our setting, Dietterich and Wang (2002) construct kernel-based cost-to-go function approximations. These are subsequently “plugged in” to various ad hoc optimization-based ADP formulations. This plug-in approach is inappropriate because it effectively translates to a nonparametric regression approach with no regularization whatsoever. One cannot expect generalization guarantees for the resulting function class, and, indeed, the authors are unable to provide guarantees. Practically, the absence of regularization is also likely to hurt performance, as is borne out in our experiments. Similarly, Ernst et al. (2005) replace the local averaging procedure used for regression by Ormoneit and Sen (2002) with nonparametric regression procedures, such as tree-based learning methods. This is done again without any theoretical justification. Pazis and Parr (2011) discuss a nonparametric method that explicitly restricts the smoothness of the value function. However, sample complexity results for this method are not provided, and it appears unsuitable for high-dimensional problems (such as, for instance, the queuing problem we consider in our experiments).
1.3. Feature Selection via -Penalty (Parametric)
Closely related to our work, Kolter and Ng (2009) and Petrik et al. (2010) consider modifying the approximate linear program with an -regularization term to encourage sparse approximations in the span of a large, but necessarily tractable, set of features. In contrast to this line of work, our approach will allow for approximations in a potentially full-dimensional (i.e., of dimension equal to the cardinality of the state space) approximation architecture, with a constraint on an appropriate -norm of the weight vector to provide regularization.
In addition, there are still other nonparametric proposals that do not quite fall into the three categories above. For example, Farahmand et al. (2009b) study what is effectively a kernelized version of a specific approximate value iteration algorithm. Again, it is not possible to provide performance guarantees of the type we present in this paper because doing so in the parametric case for approximate value iteration is already hard; see De Farias and Van Roy (2000).
This paper presents what we believe is a practical, nonparametric ADP algorithm that enjoys approximation and sample complexity guarantees that serve as natural counterparts to those available for linear programming (LP) approaches to ADP. In greater detail, we make the following contributions:
A new mathematical programming formulation. We rigorously develop a kernel-based variation of the “smoothed” approximate LP (SALP) approach to ADP proposed by Desai et al. (2012). The resulting mathematical program, which we dub the regularized smoothed approximate LP (RSALP), is distinct from simply substituting the local averaging approximation above in the SALP formulation. We develop a companion active-set method that is capable of solving this mathematical program rapidly and with limited memory requirements.
Theoretical guarantees.1 Our algorithm can be interpreted as solving an approximate linear program in a (potentially infinite-dimensional) Hilbert space. We provide a probabilistic upper bound on the approximation error of the algorithm relative to the best possible approximation one may compute in this space, subject to a regularization constraint. We show that the sample complexity of our algorithm grows polynomially as a function of a regularization parameter. As this regularization parameter is allowed to grow, so does the set of permissible approximations, eventually permitting the best approximation within the architecture, which, for some of the architectures we consider, is exact.
The sampling requirements for our method are independent of the dimension of the approximation architecture. Instead, they grow with the allowed complexity of the approximation. This result can be seen as the “right” generalization of the prior parametric approximate LP approaches of de Farias and Van Roy (2003, 2004) and Desai et al. (2012), where, in contrast, sample complexity grows with the dimension of the approximating architecture.
A computational study. To study the efficacy of our approach, we consider an MDP arising from a challenging queueing network scheduling problem. We demonstrate that our method yields significant improvements over tailored heuristics and parametric ADP methods, all while using a generic high-dimensional approximation architecture. In particular, these results suggest the possibility of solving a challenging high-dimensional MDP using an entirely generic approach.
Relative to so-called “model-free” approaches to approximate DP based on simulation (such as temporal difference-learning), we note that the method we propose in the paper relies on the knowledge of the transition probabilities of the MDP. Further, we require that the number of possible next states for any state action pair to tractable. One can rely on sampling when this is not the case, but a rigorous analysis of that approach is beyond the scope of this paper; see Haskell et al. (2016) for a general analysis of so-called “empirical” Bellman operators. These issues are germane to linear programming-based ADP methods broadly.
The organization of the paper is as follows: In Section 2, we formulate an infinite-dimensional LP for our problem and present an effective approximate-solution approach. Section 3 provides theoretical guarantees for the quality of the approximations computed via our nonparametric algorithm. Theorem 1 in that section provides our main guarantee. In Section 4, we provide an active-set method that can be used to efficiently solve the required quadratic optimization problem central to our approach, while respecting practical memory constraints. We also establish the correctness of our active-set approach. Section 5 describes a numerical study for a criss-cross queueing system benchmarking our approach against approximate linear programming approaches and tailor-made heuristics. Section 6 concludes.
2. Formulation
2.1. Preliminaries
Consider a discrete-time Markov decision process with finite state space and finite action space . We denote by xt and at, respectively, the state and action at time t. For notational simplicity, and without loss of generality, we assume that all actions are permissible at any given state. We assume time-homogeneous Markovian dynamics: Conditioned on being at state x and taking action a, the system transitions to state with probability independent of the past. A policy is a map , so that
Because in practical applications, the state space is often intractably large, exact computation of is untenable. ADP algorithms are principally tasked with computing approximations to of the form where is referred to as an approximation architecture or a basis and must be provided as input to the ADP algorithm. The ADP algorithm computes a “weight” vector . One then employs a policy that is greedy with respect to the corresponding approximation .
2.2. Primal Formulation
The approach we propose is based on the LP formulation of dynamic programming. It was observed by Manne (1960) that the optimal cost-to-go can be obtained by solving the following linear program:
Here, is a penalty parameter, and is a strictly positive distribution on . In considering the above program, notice that if one insisted that the slack variables s were precisely zero, the Program (2) would be identical to (1), with the additional restriction to value-function approximations of the form . This case is known as the approximate linear program (ALP) and was first proposed by Schweitzer and Seidman (1985). de Farias and Van Roy (2003) provided a pioneering analysis that, stated loosely, showed
Now, consider allowing to map from to a general (potentially infinite-dimensional) Hilbert space . We use bold letters to denote elements in the Hilbert space ; for example, the weight vector is denoted by . We further suppress the dependence on and denote the elements of corresponding to their counterparts in by bold letters. Hence, for example, and . Denote the image of the state space under the map by ; . The analogous value-function approximation in this case would be given by
The only new ingredient in the program above is the fact that we regularize the weight vector using the parameter . Penalizing the objective of (5) according to the square of the norm anticipates that we will eventually resort to sampling in solving this program. In a sampled setting, regularization is necessary to avoid overfitting and, in particular, to construct an approximation that generalizes well to unsampled states. This regularization, which plays a crucial role both in theory and practice, is easily missed if one directly plugs in a local averaging approximation in place of , as is the case in the earlier work of Dietterich and Wang (2002), or a more general nonparametric approximation, as in the work of Ernst et al. (2005).
Because the RSALP of (5) can be interpreted as a regularized stochastic optimization problem, one may hope to solve it via its sample average approximation. To this end, define the likelihood ratio , and let be a set of N states sampled independently, according to the distribution π. The sample average approximation of (5) is then
We call this program the sampled RSALP. Even if were small, it is still not clear that this program can be solved effectively: If were infinite-dimensional, this is a semi-infinite linear program. We will, in fact, solve the dual to this problem.
2.3. Dual Formulation
We begin by establishing some notation. Let denote the set of states that can be reached starting at a state given an action . For any states and action , define . Now, define the symmetric positive semidefinite matrix according to
Notice that Q, R, and S depend only on inner products in (and other easily computable quantities). The dual to (6) is then given by:
Assuming that Q, R, and S can be easily computed, this quadratic program is tractable—its size is polynomial in the number of sampled states. We may recover a primal solution (i.e., the weight vector ) from an optimal dual solution:
Programs (6) and (9) have equal (finite) optimal values. The optimal solution to (9) is attained at some . The optimal solution to (6) is attained at some with
The proof of Proposition 1 is presented in Appendix A. Having solved this program, we may, using Proposition 1, recover our approximate cost-to-go function as3
A policy greedy with respect to is not affected by constant translations; hence, in (11), the value of can be set to be zero arbitrarily. Again, note that given , evaluation of only involves inner products in .
2.4. Kernels
As pointed out earlier, the sampled RSALP is potentially difficult to work with. Proposition 1 establishes that solving this program (via its dual) is a computation that scales polynomially in N, so that it can be solved efficiently, provided that inner products in can be evaluated cheaply. Alternatively, we may have arrived at a similar conclusion by observing that in any optimal solution to (6), we must have that , where denotes the set of states that can be reached from the sampled states of in a single transition. Then, one can restrict the feasible region of (6) to this subspace. In either approach, we observe that one need not necessarily have explicitly characterized the feature map ; knowing for all would suffice, and so the algorithm designer can focus on simply specifying these inner products. We will see that when , these inner products are effectively cheap to compute for practically interesting choices of and . This leads us to what is popularly referred to as the “kernel trick,” which we discuss next without the assumption that is necessarily a finite set.
A kernel is a map ; we will call such a kernel positive definite if, for any finite collection of elements in , the Gram matrix defined by is symmetric and positive semidefinite. Given such a kernel, we are assured of the existence of a Hilbert space and a map such that4 . The kernel trick then allows us to implicitly work with this space by replacing inner products of the form in (7), (8), and (11) by K(x, y). Of course, the quality of the approximation one may produce depends on and, consequently, on the kernel employed.
One case of special interest is where is finite and the Gram matrix corresponding to this set is positive definite. A kernel satisfying this condition is known as full-dimensional or full-rank. In this case, we may take to be the -dimensional Euclidean space. Working with such a kernel would imply working with an approximation architecture where any function can be exactly expressed in the form , for some weight vector .
There are a number of kernels one can specify on the state space; we give two examples here for the case where . The polynomial kernel is defined according to
A corresponding Hilbert space is given by the span of all monomials of degree up to d on . A Gaussian radial basis kernel is defined according to
The Gaussian kernel is known to be full-dimensional (see, e.g., theorem 2.18 in Scholkopf and Smola 2001), so that employing such a kernel in our setting would correspond to working with an infinite-dimensional approximation architecture. A thorough exposition on this topic, along with many more examples, can be found in the text of Scholkopf and Smola (2001).
2.5. Overall Procedure
Our development thus far suggests the following nonparametric algorithm that requires as input a kernel, K; a state sampling distribution, π; and a distribution that allows us to weight approximation across states, ν. Recall that we defined by w the likelihood ration between ν and π; . Lastly, recall that denotes the set of states reachable with positive probability in one step from state x, having taken action a. Our procedure requires that we set the parameters κ (which we recall penalizes the one sided Bellman error across states) and Γ (which regularizes the set of approximations allowed). Finally, we must specify the number of samples N.
Sample N states from a distribution π.
Solve (9) with
(12)and(13)The value of S may be set to be zero.
Let be the dual optimal. Define an approximate value function by
(14)
In the next section, we will develop theory to characterize the sample complexity of our procedure and the approximation quality it provides. This theory will highlight the roles of the kernel K and the sampling distributions used.
3. Approximation Guarantees
3.1. Overview
Recall that we are employing an approximation of the form
Here, rather than regularizing by penalizing according to the weight vector in the objective as in (5), we regularize by restricting the size of the weight vector as a constraint. This regularization constraint is parameterized by the scalar . It is easy to see that (15) is equivalent to the original Problem (5), in the following sense: For any , there exists a so that for all B sufficiently large, (5) and (15) have the same optimal solutions and value.5 Let be any such value of C, corresponding to a particular Γ.
Now, let
The best approximation to within this set has -approximation error
Now, observe that if has dimension (i.e., if the kernel is full-dimensional), there exists a satisfying . Consequently, for sufficiently large and any value of , we have that —the approximation error in (16) reduces to zero. More generally, as and B grow large, we expect the approximation error in (16) to monotonically decrease; the precise rate of this decrease will depend, of course, on the feature map , which, in turn, will depend on the kernel we employ.
Loosely speaking, in this section, we will demonstrate that:
For any given and B, the exact solution of the RSALP (15) will produce an approximation with -error comparable to the optimal -error possible for approximations with and .
Under a certain set of idealized assumptions, solving a sampled variation of the RSALP (15) with a number of samples that scales gracefully with , B, and other natural parameters produces a near-optimal solution to the RSALP with high probability. These sample complexity bounds will not depend on the dimension of the approximation architecture .
Because and B are parameters of the algorithm designer’s choosing, these results will effectively show that with the ability to use a larger number of samples, the designer may choose larger values of and B and, consequently, produce approximations of improving quality. Under mild assumptions on the kernel, the approximation error can be made arbitrarily small in this fashion.
3.2. Preliminaries and an Idealized Program
Before proceeding with our analysis, we introduce some preliminary notation and define an idealized sampling distribution. For a vector and a weight vector , we denote by the weighted 1-norm of x. We next define an idealized sampling distribution. Let ν be an arbitrary distribution over and denote by and an optimal policy and the transition probability matrix corresponding to this policy, respectively. We define a distribution over according to
This idealized distribution will play the role of the sampling distribution π in the sequel.
As before, let be a set of N states drawn independently at random from ; here, we pick a specific sampling distribution . Given the definition of in (4), the “idealized” sampled program we consider is:
Here, T is the Bellman operator defined in (3).
This program is a sampled variant of (15) and is closely related to the sampled RSALP (6) introduced in the last section. Before proceeding with an analysis of the quality of approximation afforded by solving this program, we discuss its connection with the sampled RSALP (6) of the previous section:
The distributions ν and π: We allow for an arbitrary distribution ν, but, given this distribution, require that . In particular, the distribution ν might be chosen as the empirical distribution corresponding to N independent draws from under some measure; one would then draw N independent samples under to construct the second term in the objective. In a sense, this is the only “serious” idealized assumption we make here. Given the broad nature of the class of problems considered, it is hard to expect meaningful results without an assumption of this sort, and, indeed, much of the antecedent literature considering parametric LP-based approaches makes such an assumption. When the sampling distribution π is a close approximation to (say, the likelihood ratio between the two distributions is bounded), then it is possible to provide natural extensions to our results that account for how close the sampling distribution used is to the idealized sampling distribution.
Regularization: We regularize the weight vector with an explicit constraint on ; this permits a transparent analysis and is equivalent to placing the “soft” regularization term in the objective. In particular, the notation makes this equivalence explicit. In addition, we place a separate upper bound on the offset term B. This constraint is not binding if , but, again, permits a transparent analysis of the dependence of the sample complexity of solving our idealized program on the offset permitted by the approximation architecture.
The choice of κ: The smoothing parameter κ can be interpreted as yet another regularization parameter, here on the (one-sided) Bellman error permitted for our approximation. Our idealized program chooses a specific value for this smoothing parameter, in line with that chosen by Desai et al. (2012).
3.3. The Approximation Guarantee
Let be an optimal solution to the idealized sampled Program (18) and let . Further, define
Notice that scales as the square of C, K, and B and, further, is . The following result will constitute our main approximation guarantee:
For any , let . If is an optimal solution to (18), then with probability at least ,
The result is proved in Appendix B. There, we prove a more refined result, replacing the max-norm in the bound above with an “optimally weighted” variant, which can provide a substantially stronger guarantee (Desai et al. 2012). The remainder of this section is dedicated to parsing and interpreting this guarantee:
Optimal approximation error: Ignoring the ϵ-dependent error term in the guarantee, we see that the quality of approximation provided by is essentially within a constant multiple (at most ) of the optimal (in the sense of -error) approximation to possible using a weight vector and offsets b permitted by the regularization constraints. This is a “structural” error term that will persist, even if one were permitted to draw an arbitrarily large number of samples. It is analogous to the approximation results produced in parametric settings, with the important distinction that one allows comparisons to approximations in potentially full-dimensional sets, which might, as we have argued earlier, be substantially superior.
Dimension-independent sampling error: In addition to the structural error above, one incurs an additional additive “sampling” error that scales like . The result demonstrates that
This is an important contrast with existing parametric sample complexity guarantees. In particular, existing guarantees typically depend on the dimension of the space spanned by the basis function architecture . Here, this space may be full-dimensional, so that such a dependence would translate to a vacuous guarantee. Instead, we see that the dependence on the approximation architecture is through the constants C, K, and B. Of these, K can, for many interesting kernels, be upper-bounded by a constant that is independent of , whereas C and B are user-selected regularization bounds. Put another way, the guarantee allows for arbitrary “simple” (in the sense of being small) approximations in a rich feature space, as opposed to restricting us to some a priori fixed, low-dimensional feature space. This yields some intuition for why we expect the approach to perform well, even with a relatively general choice of kernel. Although the dependence on C, K, and B in the bound above is likely loose, the guarantees above show that for a fixed approximation architecture—that is, choice of kernel, C, and B—the sampling error ϵ improves with the number of samples. We see in our experiments that, keeping other parameters fixed, policy performance improves with the number of samples, N.
A nonparametric interpretation: As we have argued earlier, in the event that is full-dimensional, there exists a choice of C and B for which the optimal approximation error is, in fact, zero. A large number of kernels would guarantee such feature maps. More generally, as C and B grow large, will decrease. In order to maintain the (bound on) sampling error constant, one would then need to increase N at a rate that is roughly . In summary, by increasing the number of samples in the sampled program, we can (by increasing C and B appropriately) hope to compute approximations of increasing quality, approaching an exact approximation. Although the rate at which the structural error term goes to zero with B remains unclear, this is a substantially weaker requirement than choosing a low-dimensional approximation architecture that provides a small approximation error.
4. Numerical Scheme
This section outlines an efficient numerical scheme that we use to solve the regularized SALP. In particular, we would like to solve the sampled dual Problem (9), introduced in Section 2.3, in order to find an approximation to the optimal cost-to-go function. This approach requires solving a quadratic program (QP) with N × A variables, where is the number of sampled states and is the number of possible actions. Furthermore, constructing the coefficient matrices Q and R for (9) requires arithmetic operations, where H is the maximum number of states that can be reached from an arbitrary state-action pair; that is,
These computationally expensive steps may prevent scaling up solution of the QP to a large number of samples. Also, an off-the-shelf QP solver will typically store the matrix Q in memory, so that the memory required to solve our QP with an off-the-shelf solver effectively scales like .
In this section, we develop an iterative scheme to solve the Program (9) that, by exploiting problem structure, enjoys low computational complexity per iteration and attractive memory requirements. Our scheme is an active-set method in the vein of the approaches used by Osuna et al. (1997) and Joachims (1999), among others, for solving large support vector machine (SVM) problems. The broad steps of the scheme are as follows:
At the tth iteration, a subset of the decision variables of (9)—the “active set”—is chosen. Only variables in this set may be changed in a given iteration; these changes must preserve feasibility of the new solution that results. Our algorithm will limit the size of the active set to two variables—that is, . The methodology for choosing this active set is crucial and will be described in the sequel.
Given the subset , we solve (9) for , where all variables except those in must remain unchanged. In other words, for all . This entails the solution of a QP with only decision variables. In our case, we will be able to solve this problem in closed form.
Finally, if the prior step does not result in a decrease in objective value, we conclude that we are at an optimal solution; Proposition 2 establishes that this is, in fact, a correct termination criterion.
In the following section, we will establish an approach for selecting the active set at each iteration and show how Step 2 above can be solved while maintaining feasibility at each iteration. We will establish that Steps 1 and 2 together need no more than arithmetic operations and comparisons and, moreover, that the memory requirement for our procedure scales like O(NA). Finally, we will establish that our termination criterion is correct: In particular, if no descent direction of cardinality at most two exists at a given feasible point, we must be at an optimal solution.
4.1. Subset Selection
The first step in the active-set method is to choose the subset of decision variables to optimize over. Given the convex objective in (9), if the prior iteration of the algorithm is at a suboptimal point , then there exists a direction such that is feasible with a lower objective value for sufficiently small. To select a subset to optimize over, we look for such a descent direction d of low cardinality —that is, a vector d that is zero on all but at most q components. If such a direction can be found, then we can use the set of nonzero indices of d as our set .
This problem of finding a “sparse” descent direction d can be posed as
Here, is the gradient of the objective of (9) at a feasible point λ; thus, the objective seeks to find a direction d of steepest descent. The first three constraints ensure that d is a feasible direction. The constraint is added to ensure that the direction is of cardinality at most q. Finally, the constraint is added to ensure that the program is bounded and may be viewed as normalizing the scale of the direction d.
The Program (20) is, in general, a challenging mixed-integer program because of the cardinality constraint. Joachims (1999) discusses an algorithm to solve a similar problem of finding a low-cardinality-descent direction in an SVM classification setting. Their problem can be easily solved, provided that the cardinality q is even; however, no such solution seems to exist for our case. However, in our case, when q = 2, there is a tractable way to solve (20). We will restrict attention to this special case—that is, consider only descent directions of cardinality two. In Appendix D, we will establish that this is, in fact, sufficient: If the prior iterate λ is suboptimal, then there will exist a direction of descent of cardinality two.
To begin, define the sets
Consider the following procedure:
Sort the set of indices according to their corresponding component values in the gradient vector . Call this sorted list .
Denote by (x1, a1) the largest element of such that , and denote by (x2, a2) the smallest element of such that . Add the tuple to the list .
Consider all . For each such x, denote by the largest element of such that , and denote by the smallest element of . Add each tuple to .
Choose the element of that optimizes
(21)Set , and all other components of d to zero.
This procedure finds a direction of maximum descent of cardinality two by examining candidate index pairs , for which is minimal. Instead of considering all such pairs, the routine selectively checks only pairs that describe feasible directions with respect to the constraints of (20). Step 2 considers all feasible pairs with different states x, whereas Step 3 considers all pairs with the same state. It is thus easy to see that the output of this procedure is an optimal solution to (20)—that is, a direction of steepest descent of cardinality two. Further, if the value of the Minimal Objective (21) determined by this procedure is nonnegative, then no descent direction of cardinality two exists, and the algorithm terminates.
In terms of computational complexity, this subset selection step requires us to first compute the gradient of the objective function . If the gradient is known at the first iteration, then we can update it at each step by generating two columns of Q, because λ only changes at two coordinates. Hence, the gradient calculation can be performed in O(NA) time and with O(NA) storage (because it is not necessary to store Q). For Step 1 of the subset-selection procedure, the component indices must be sorted in the order given by the gradient . This operation requires computational effort of the order . With the sorted indices, the effort required in the remaining steps to find the steepest direction via the outlined procedure is O(NA). Thus, our subset-selection step requires a total of arithmetic operations and comparisons.
The initialization of the gradient requires effort. In the cases where such a computation is prohibitive, one can think of many approaches to approximately evaluate the initial gradient. For example, if we use the Gaussian kernel, the matrix Q will have most of its large entries close to the diagonal. In this case, instead of the expensive evaluation of Q, we can only evaluate the entries , where , and set the rest of them to zero. This block diagonal approximation might be used to initialize the gradient. Another approach is to sample from the distribution induced by λ to approximately evaluate . As the algorithm makes progress, it evaluates new columns of Q. With a bit of bookkeeping, one could get rid of the errors associated with the gradient initialization. The convergence properties of the active-set method with approximate initialization is an issue not tackled in this paper.
4.2. QP Subproblem
Given a prior iterate and a subset of decision variable components of cardinality two, as computed in Section 4.1, we have the restricted optimization problem
This subproblem has small dimension. In fact, the equality constraint implies that is constant; hence, the problem is, in fact, a one-dimensional QP that can be solved in closed form. Further, to construct this QP, two columns of Q are required to be generated. This requires computation effort of order .
Note that the subset is chosen so that it is guaranteed to contain a descent direction, according to the procedure in Section 4.1. Then, the solution of (20) will produce an iterate that is feasible for the original Problem (22) and has lower objective value than the prior iterate .
Finally, we state a proposition establishing the correctness of our active-set method: If the prior iterate is suboptimal, then there must exist a direction of descent of cardinality two. Our iterative procedure will therefore improve the solution and will only terminate when global optimality is achieved.
If is feasible, but suboptimal, for (9), then there exists a descent direction of cardinality two.
This result is proved in Appendix D.
5. Case Study: A Queuing Network
This section considers the problem of controlling the so-called “Rybko-Stolyar” queuing network illustrated in Figure 1, with the objective of minimizing long-run average delay. There are two “flows” in this network: the first through server 1 followed by server 2 (with buffering at queues 1 and 2, respectively), and the second through server 2 followed by server 1 (with buffering at queues 4 and 3, respectively). Here, all interarrival and service times are exponential with rate parameters summarized in Figure 1.
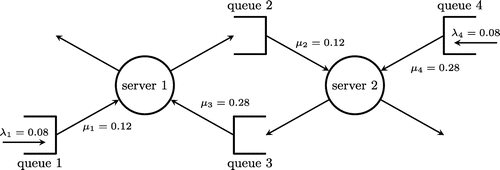
This specific network has been studied by de Farias and Van Roy (2003), Chen and Meyn (1998), and Kumar and Seidman (1990), for example, and closely related networks have been studied by Harrison and Wein (1989), Kushner and Martins (1996), Martins et al. (1996), and Kumar and Muthuraman (2004). It is widely considered to be a challenging control problem. As such, a lot of thought has been invested in designing scheduling policies with networks of this type in mind. Our goal in this section will be two-fold. First, we will show that the RSALP, used “out-of-the-box” with a generic kernel, can match or surpass the performance of tailor-made heuristics and state-of-the-art parametric ADP methods. Second, we will show that the RSALP can be solved efficiently.
5.1. MDP Formulation
Although the control problem at hand is nominally a continuous time problem, it is routinely converted into a discrete time problem via a standard uniformization device; see Moallemi et al. (2008), for instance, for an explicit example. In the equivalent discrete time problem, at most a single event can occur in a given epoch, corresponding either to the arrival of a job at queues 1 or 4 or the arrival of a service token for one of the four queues with probability proportional to the corresponding rates. The state of the system is described by the number of jobs in each of the four queues, so that , whereas the action space consists of four potential actions, each corresponding to a matching between servers and queues. We take the single-period cost as the total number of jobs in the system, so that . Finally, we take as our discount factor.
5.2. Approaches
The following scheduling approaches were considered for the queueing problem:
5.2.1. RSALP (This Paper).
We solve (9) using the active-set method outlined in Section 4, taking as our kernel the standard Gaussian kernel , with the bandwidth parameter6 . Note that this implicitly corresponds to an full-dimensional-basis function architecture. Because the idealized sampling distribution, , is unavailable to us, we use in its place the geometric distribution
5.2.2. SALP (Desai et al. 2012).
The SALP Formulation (2) is, as discussed earlier, the parametric counterpart to the RSALP. It may be viewed as a generalization of the ALP approach proposed by de Farias and Van Roy (2003) and has been demonstrated to provide substantial performance benefits relative to the ALP approach. Our choice of parameters for the SALP mirrors those for the RSALP to the extent possible, so as to allow for an “apples-to-apples” comparison. Thus, as earlier, we solve the sample average approximation of this program using the same sampling distribution π as in (23), and we set . Being a parametric approach, one needs to specify an appropriate approximation architecture. Approximation architectures that span (at least quadratic) polynomials are known to work well for queueing problems. We use the basis functions used by de Farias and Van Roy (2003) for a similar problem modeled directly in discrete time. In particular, we use all monomials with degree at most 3, which we will call the cubic basis, as our approximation architectures.
5.2.3. Longest Queue First (Generic).
This is a simple heuristic approach: At any given time, a server chooses to work on the longest queue from among those it can service.
5.2.4. Max-Weight (Tassiulas and Ephremides 1992).
Max-Weight is a well-known scheduling heuristic for queueing networks. The policy is obtained as the greedy policy with respect to a value-function approximation of the form
5.3. Results
Policies were evaluated by using a common set of arrival-process sample paths. The performance metric we report for each control policy is the long-run average number of jobs in the system under that policy,
Further, in order to generate SALP and RSALP policies, state sampling is required. To understand the effect of the sample size on the resulting policy performance, the different sample sizes listed in Table 2 were used. Because the policies generated involve randomness to the sampled states, we further average performance over 10 sets of sampled states. The results are reported in Tables 1 and 2 and have the following salient features:
RSALP outperforms established policies: Approaches such as the Max-Weight or “parametric” ADP with basis-spanning polynomials have been previously shown to work well for the problem of interest. We see that the RSALP with more than 3,000 samples achieves performance that is superior to these extant schemes.
Sampling improves performance: This is expected from the theory in Section 3. Ideally, as the sample size is increased, one should relax the regularization. However, for our experiments, we noticed that the performance is quite insensitive to the parameter Γ. Nonetheless, it is clear that larger sample sets yield a significant performance improvement.
RSALP is less sensitive to state sampling: We notice from the standard deviation values in Table 2 that our approach gives policies whose performance varies significantly less across different sample sets of the same size.
|

Table 1. Performance Results in the Queueing Example
| Policy | Performance |
|---|---|
| Longest queue | 32.36 |
| Max-Weight | 26.20 |
|
Table 2. Performance Results in the Queueing Example
| Sample size | 1,000 | 3,000 | 5,000 | 10,000 | 15,000 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| SALP, cubic basis | 28.76 | (7.04) | 31.56 | (7.04) | 27.76 | (4.60) | 26.52 | (3.68) | 26.32 | (4.48) |
| RSALP, Gaussian kernel | 26.88 | (1.56) | 25.24 | (0.44) | 24.52 | (0.32) | 24.16 | (0.20) | 24.08 | (0.24) |
Note. For the SALP and RSALP methods, the number in parentheses gives the standard deviation across sample sets.
In Figure 2, we see how performance varies for the RSALP method, as a function of the discount factor α and the regularization parameter Γ.

First, consider the choice of regularizer Γ. From Figure 2, we see that performance degrades for large choices of the parameter (presumably because this restricts the richness of the approximation architecture), as well as for very small choices of the parameter (presumably due to poor generalization). Although there is degradation in performance for small values of Γ, this degradation is meaningful, but limited, in our experiments (average cost is worse for small choice than the optimal choice).
Now, consider the choice of discount factor α. Note that we are concerned with (and report) average cost performance, but solve a discounted problem formulation. Although this may appear to be inconsistent at first glance, note that the average cost criterion can be seen as a weighted average, across states, of the discounted cost incurred starting at those states. The weights in this average correspond to the steady-state distribution induced by the policy in question. This is in keeping with Desai et al. (2012) and de Farias and Van Roy (2003), for example.
Moreover, we view the choice of α as an algorithmic tuning parameter that implicitly regularizes a bias-variance tradeoff in the learning algorithm. Specifically, if α is too low, there is “bias” introduced through the misalignment of discounted and average cost objectives. On the other hand, if α is too large, the sample complexity degrades, and many more samples are needed. This is consistent with the approximation guarantees we have developed and also consistent with the results in Figure 2: Values of α closer to one result in degraded average cost performance. This is in keeping with the view of the discount factor as a regularizer in the broader reinforcement-learning literature (e.g., Jiang et al. 2015, Amit et al. 2020, and Dewanto and Gallagher 2021).
In summary, we view these results as indicative of the possibility that the RSALP may serve as a practical and viable alternative to state-of-the-art parametric ADP techniques.
6. Conclusions
This paper set out to present a practical nonparametric algorithm for approximate dynamic programming, building upon the success of linear programming-based methods that require the user to specify an approximation architecture. We believe that the RSALP, presented and studied here, is such an algorithm. In particular, the theoretical guarantees presented here establish the “nonparametric” nature of the algorithm by showing that increased sampling effort leads to improved approximations. On the empirical front, we have shown that our essentially “generic” procedure was able to match the performance of tailor-made heuristics as well as ADP approaches using prespecified approximation architectures. Nevertheless, several interesting directions for future work are evident at this juncture:
The choice of kernel: The choice of kernel matters insomuch as the feature map it encodes allows for approximations with small Hilbert norm (i.e., small C). Thus, a good choice of kernel would require fewer samples to achieve a fixed approximation accuracy than a poor choice of kernel. That said, picking a useful kernel is an apparently easier task than picking a low-dimensional architecture—there are many full-dimensional kernels possible, and with sufficient sampling, they will achieve arbitrarily good value-function approximations. Nevertheless, it would be valuable to understand the interplay between the choice of kernel and the corresponding value of C for specific problem classes (asking for anything more general appears rather difficult).
The active-set method: In future work, we would like to fine-tune/build more extensible software implementing our active-set method for wider use. Given the generic nature of the approach here, we anticipate that this can be a technology for high-dimensional MDPs that can be used out of the box.
Appendix A. Duality of the Sampled RSALP
We begin with a few observations about the primal program, (6):
Because the objective function is coercive,8 weight vector can be restricted without loss of generality to some finite ball in . The optimal value of the primal is consequently finite.
The primal has a feasible interior point: Consider setting
for some .The optimal value of the primal is achieved. To see this, we note that it suffices to restrict to the finite-dimensional space spanned by the vectors , where denotes the set of states that can be reached from the sampled states of in a single transition. Then, the feasible region of the primal can be restricted, without loss of optimality, to a compact subset of . Because the objective function of the primal is continuous, we know that its optimal value must be achieved by the Weierstrass theorem.
We next derive the dual to (6). As in (Luenberger 1997, chapter 8), we define the Lagrangian:
It follows immediately that on the set defining the feasible region of the Program (9), we must have that
The first conclusion of Luenberger (1997, theorem 1, pp. 224–225) and the first and second observations we made at the outset of our proof then suffice to establish that Programs (6) and (9) have equal optimal values (i.e., strong duality holds) and that the optimal value of the dual program is achieved at some . Our third observation, (A.1) and the second conclusion of Luenberger (1997, theorem 1, pp. 224–225) then suffice to establish our second claim. □
Appendix B. Proof of Theorem 1
Here, we state and prove a refined version of Theorem 1; specifically, Theorem 1 is implied by Theorem B.1. First, however, we introduce a certain “weighted” max norm and the notion of a Lyapunov function: Let be the set of all functions on the state space bounded from below by one. For any , let us define the weighted -norm by
Our use of such weighted norms will allow us to emphasize approximation error differently across the state space. Further, we define
For a given ψ, gives us the worst-case expected gain of the Lyapunov function ψ for any state action pair (x, a).
Recall that we let be an optimal solution to the Idealized Sampled Program (18) and let . Further, we defined,
The following result will constitute our main approximation guarantee:
For any , let . If is an optimal solution to (18), then with probability at least ,
Note that this result implies Theorem 1 by choosing to be the vector of all ones. The proof will broadly proceed in two steps. First, we prove a uniform concentration guarantee that allows us to show that the one-sided expected Bellman error minimized by the RSALP is well approximated in its sampled counterpart. The main part of the proof then essentially leverages the structure of the feasible region of the RSALP and properties of the Bellman operator to establish the result.
B.1. Uniform Concentration Bounds
We begin with defining the empirical Rademacher complexity of a class of functions from to R as
We begin with the following abstract sample complexity result: Let be a class of functions mapping to that are uniformly bounded by some constant . Moreover, denote for any function the empirical expectation , where the Xi are i.i.d. random draws from as above. We then have the following sample complexity result:
This result is standard;9 for completeness, the proof may be found in Appendix C. Next, we establish the Rademacher complexity of a specific class of functions. Fixing a policy μ, consider then the set of functions mapping to defined according to:
We have:
For any policy μ,
Observe that, due to triangle inequality
Now, consider the class of functions mapping to , defined according to:
Now, , where and . It is easy to show that , so that with the previous lemma, the results of Bartlett and Mendelson (2002, theorem 12, parts 4 and 5) allow us to conclude
Now, define
We have:
For every and every , we have that . Moreover,
For the first claim, observe that
For the second claim, Hoeffding’s inequality applied now to the sum of independent random variables, each in , yields
Corollary B.1, Lemma B.1, and the first part of Lemma B.3 yields the following sample complexity result:
Provided , we have
By the first part of Lemma B.3, we have for any that . Recall also that by Corollary B.1, . Consequently, by Lemma B.1,
But, when
This completes the proof.
Theorem B.2 will constitute a crucial sample complexity bound for our main result; we now proceed with the proof of Theorem 1.
B.2. Proof of Theorem 1
Let be the optimal solution to the Sampled Program (18). Define
Observe that we may assume, without loss of generality, that
The second equality follows by our observation that and because . The second inequality above holds with probability at least by virtue of Theorem B.2 and the fact that The subsequent inequality follows from our observation that . The fourth inequality follows from the assumed optimality of for the Sampled Program (18) and the feasibility of for the same. The fifth inequality holds with probability and follows from the Hoeffding bound in Lemma B.3 because . The final inequality follows from the observation that for any , and probability vector ν,
Now, the proof of theorem 2 of Desai et al. (2012) establishes that for any and , we have,
Applied to (B.2), this yields
Because our choice of was arbitrary (beyond satisfying ), the result follows.
B.3. A Remark on Nonidealized Sampling Distributions
Say is an approximation to the idealized sampling distribution , and let minimize the RSALP using this sampling distribution. Then, the expression in the fourth inequality in (B.2) in the proof of Theorem B.1 could instead be replaced by the expression
Alternatively, if, instead, we had finer control on the approximation provides to (say, for all s), then the additional error term permits a computable bound, because we would have (through an appropriate coupling of the sample under and ) that
Appendix C. Proof of Lemma B.1
We begin with some preliminaries: Define
Notice that
McDiarmid’s inequality (or, equivalently, Azuma’s inequality) then implies:
Now,
With (C.1), this immediately yields the result. □
Appendix D. Correctness of Termination Condition
The proof of Proposition 2 requires the following lemma:
Suppose are vectors such that and . Then, there exist coordinates {i,j}, such that yi < yj, , and .
Define the index sets and . Under the given hypotheses, both sets are nonempty. Using the fact that , define
Because the weighted average of y over S– is more than its weighted average over S+, we can pick an element in S+, i, and an element of S–, j, such that yi < yj. □
If λ is suboptimal, because (9) is a convex quadratic program, there will exist some vector which is a feasible descent direction at λ. Let be the gradient at that point. We must have that , so that it is a descent direction, and that d satisfies the first three constraints of (20), so that it is a feasible direction.
Define
First, consider the case of . In this case, for all x such that , we have . Because d is a descent direction, we have . Lemma D.1 can be applied to get a pair (x1, a1) and (x2, a2) such that and , with . Further, x1 is such that , and (x2, a2) is such that . These conditions ensure that if (x1, a1) and (x2, a2) are increased and decreased, respectively, in the same amount, then the objective is decreased. And, hence, we obtain a descent direction of cardinality two. By assuming that , we have avoided the corner case of not being able to increase due to .
For , without loss of generality, assume that for each ; that is, d has exactly two nonzero components corresponding to the state x. This is justified at the end of the proof. Denote these indices by and , so that and . From the first constraint of (20), we must have that .
There are two cases:
Suppose , for some . Then, we can define a descent direction of cardinality two by setting , and all other components of to zero.
Suppose that , for all . For all , define . Then, the fact that implies that
(D.1)At the same time, for all , we have that
Then, because d is a descent direction, we have that
(D.2)Now, define the vector by
Applying Lemma D.1 to (D.1) and (D.2), there must be a pair of indices (x1, a1) and (x2, a2) such that and . For such (x1, a1) and (x2, a2), we have a descent direction where we can increase and decrease by the same amount and get a decrease in the objective. Note that because , we have that and ; hence, . Also, by construction, (x2, a2) is chosen such that , implying that . Thus, the specified direction is also feasible, and we have a feasible descent direction of cardinality two.
Finally, to complete the proof, consider the case where there are some with ; that is, d has more than two nonzero components corresponding to the state x. For each , define
Define a new direction by
It is easy to verify that is also a feasible descent direction. Furthermore, has only two nonzero components corresponding to each start .
1 These guarantees come under assumption of being able to sample from a certain idealized distribution. This is a common requirement in the analysis of ADP algorithms that enjoy approximation guarantees for general MDPs (de Farias and Van Roy 2004, Van Roy 2006, Desai et al. 2012). It is possible to enhance these guarantees by showing how they degrade when the sampling distribution to which one has access differs from this idealized distribution; we do not pursue this extension here.
2 Separating the scalar offset b from the linear term parameterized by will permit us to regularize these two quantities differently in the sequel.
3 Note that the form of (11) is similar to what one might expect from the Representer Theorem; see, for example, theorem 4.2 in Scholkopf and Smola (2001).
4 A canonical such space is the so-called “reproducing kernel” Hilbert space, by the Moore-Aronszajn theorem. For certain sets , Mercer’s theorem provides another important construction of such a Hilbert space.
5 Note that the choice of C corresponding to a given Γ will be problem-dependent, and a precise conversion is nontrivial. This does not pose an issue in practical applications, however, because Γ can easily be optimized via a crude line-search. Moreover, the numerical results in Section 5 suggest that the method is insensitive to the choice of Γ over several orders of magnitude. Further, observe the constraint has no counterpart in (5). As we shall see shortly, the value of B can be chosen so that this constraint is not binding and the two formulations are equivalent. However, by introducing this additional constraint, we obtain sharper sample complexity bounds.
6 The sensitivity of our results to this bandwidth parameter appears minimal.
7 Specifically, we tried values of the form , for k between –12 and 2.
8 As , the objective value goes to .
9 Indeed, the calculations in Lemmas B.1 and B.2 are routine; see Bartlett and Mendelson (2002).
References
- (2020) Discount factor as a regularizer in reinforcement learning. Proc. 37th Internat. Conf. Machine Learning (PMLR), 269–278.Google Scholar
- (2011)
Reinforcement Learning Using Kernel-Based Stochastic Factorization , Advances in Neural Information Processing Systems, vol. 24 (MIT Press, Cambridge, MA), 720–728.Google Scholar - (2002) Rademacher and Gaussian complexities: Risk bounds and structural results. J. Machine Learning Res. 3:463–482.Google Scholar
- (2023) Kernel-based reinforcement learning using Bellman residual elimination. J. Machine Learning Res. Forthcoming.Google Scholar
- (1998) Value iteration and optimization of multiclass queueing networks., 1998. Proc. 37th IEEE Conf. Decision and Control, vol. 1 (IEEE, Piscataway, NJ), 50–55.Google Scholar
- (2005) Maximum pressure policies in stochastic processing networks. Oper. Res. 53(2):197–218.Link, Google Scholar
- (2000) On the existence of fixed points for approximate value iteration and temporal-difference learning. J. Optim. Theory Appl. 105(3):589–608.Google Scholar
- (2003) The linear programming approach to approximate dynamic programming. Oper. Res. 51(6):850–865.Link, Google Scholar
- (2004) On constraint sampling in the linear programming approach to approximate dynamic programming. Math. Oper. Res. 29:462–478.Link, Google Scholar
- (2012) Approximate dynamic programming via a smoothed linear program. Oper. Res. 60(3):655–674.Link, Google Scholar
- (2021) Examining average and discounted reward optimality criteria in reinforcement learning. Preprint, submitted July 3, https://arxiv.org/abs/2107.01348.Google Scholar
- (2002)
Batch Value Function Approximation via Support Vectors , Advances in Neural Information Processing Systems, vol. 14 (MIT Press, Cambridge, MA), 1491–1498.Google Scholar - (2003) Bayes meets Bellman: The Gaussian process approach to temporal difference learning. Proc. 20th Internat. Conf. Machine Learning (AAAI Press, Washington, DC), 154–161.Google Scholar
- (2005) Tree-based batch mode reinforcement learning. J. Machine Learning Res. 6:503–556.Google Scholar
- (2009a) Regularized policy iteration. Adv. Neural Inform. Processing Systems 21:441–448.Google Scholar
- (2009b) Regularized fitted Q-iteration for planning in continuous-space Markovian decision problems. 2009 Amer. Control Conf. ACC’09 (IEEE, Piscataway, NJ), 725–730.Google Scholar
- (1989) Scheduling network of queues: Heavy traffic analysis of a simple open network. Queueing Systems 5:265–280.Google Scholar
- (2016) Empirical dynamic programming. Math. Oper. Res. 41(2):402–429.Link, Google Scholar
- (2015) The dependence of effective planning horizon on model accuracy. Proc. 2015 Internat. Conf. Autonomous Agents Multiagent Systems (IFAAMAS, Richland, SC), 1181–1189.Google Scholar
- (1999) Advances in kernel methods: Support vector learning. Schölkopf B, Burges CJC, Smola AJ, eds. Making Large-Scale Support Vector Machine Learning Practical (MIT Press, Cambridge, MA), 169–184.Google Scholar
- (2009) Regularization and feature selection in least-squares temporal difference learning. ICML’09 Proc. 26th Annu. Internat. Conf. Machine Learning (Association for Computing Machinery, New York), 521–528.Google Scholar
- (1990) Dynamic instabilities and stabilization methods in distributed real-time scheduling of manufacturing systems. IEEE Trans. Automatic Control 35(3):289–298.Google Scholar
- (2004) A numerical method for solving singular stochastic control problems. Oper. Res. 52(4):563–582.Link, Google Scholar
- (1996) Heavy traffic analysis of a controlled multiclass queueing network via weak convergence methods. SIAM J. Control Optim. 34(5):1781–1797.Google Scholar
- (1997) Optimization by Vector Space Methods (John Wiley & Sons, Inc., New York).Google Scholar
- (1960) Linear programming and sequential decisions. Management Sci. 6(3):259–267.Link, Google Scholar
- (1996) Heavy traffic convergence of a controlled multiclass queueing network. SIAM J. Control Optim. 34(6):2133–2171.Google Scholar
- (2008) Approximate and data-driven dynamic programming for queueing networks. Working paper, Columbia University, New York.Google Scholar
- (2002) Kernel-based reinforcement learning in average cost problems. IEEE Trans. Automatic Control 47(10):1624–1636.Google Scholar
- (2002) Tree-based batch mode reinforcement learning. Machine Learning 49(2):161–178.Google Scholar
- (1997) An improved training algorithm for support vector machines. Neural Networks Signal Processing, Proc. 1997 IEEE Workshop (IEEE, Piscataway, NJ), 276–285.Google Scholar
- (2011) Non-parametric approximate linear programming for MDPs. Proc. Twenty-Fifth AAAI Conf. Artificial Intelligence (AAAI Press, Washington, DC), 459–464.Google Scholar
- (2010) Feature selection using regularization in approximate linear programs for Markov decision processes. ICML’10 Proc. 27th Annu. Internat. Conf. Machine Learning (Association for Computing Machinery, New York), 871–879.Google Scholar
- (2001) Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond (The MIT Press, Cambridge, MA).Google Scholar
- (1985) Generalized polynomial approximations in Markovian decision processes. J. Math. Anal. Appl. 110:568–582.Google Scholar
- (2004) Maxweight scheduling in a generalized switch: State space collapse and workload minimization in heavy traffic. Ann. Appl. Probab. 14:1–53.Google Scholar
- (1992) Stability properties of constrained queueing systems and scheduling policies for maximum throughput in multihop radio networks. IEEE Trans. Automatic Control 37(12):1936–1948.Google Scholar
- (2006) Performance loss bounds for approximate value iteration with state aggregation. Math. Oper. Res. 31(2):234–244.Link, Google Scholar
- (2007) Kernel-based least squares policy iteration for reinforcement learning. IEEE Trans. Neural Networks 18(4):973–992.Google Scholar

