
Learning-Based Pricing and Matching for Two-Sided Queues
Abstract
We consider a dynamic system with multiple types of customers and servers. Each type of waiting customer or server joins a separate queue, forming a bipartite graph with customer-side queues and server-side queues. The platform can match the servers and customers and then the matched pairs leave the system. The platform will charge a customer a price according to their type when they arrive and will pay a server a price according to their type. The arrival rate of each queue is determined by the price according to some unknown demand or supply functions. Our goal is to design pricing and matching algorithms to maximize the profit of the platform with unknown demand and supply functions while keeping queue lengths of both customers and servers below a predetermined threshold. The difficulties of the problem include simultaneous learning and decision making and the tradeoff between maximizing profit and minimizing queue length. We use a longest-queue-first matching algorithm and propose a learning-based pricing algorithm, which combines gradient-free stochastic projected gradient ascent with bisection search. We prove that our proposed algorithm yields a sublinear regret and queue-length bound , where T is the time horizon. We further establish a tradeoff between the regret bound and the queue-length bound.
Funding: This research was supported in part by the National Science Foundation [Grants 2112471, 2207548, 2228974, and 2240981].
Supplemental Material: The online appendix is available at https://doi.org/10.1287/stsy.2024.0073.
1. Introduction
We study pricing and matching in two-sided queueing systems with multiple types of customers and servers. Take ride sharing (Uber, Lyft, etc.) as an example. A ride order (request) can be viewed as a customer, and an available driver can be viewed as a server. A ride order can have multiple types. For example, we can view different numbers of passengers in the order as different customer types. We can also view different pick-up locations of the order as different customer types. A driver can also have multiple types. For example, we can view different vehicle capacities as different server types. We can also view different locations of the drivers as different server types. Each type of waiting ride order or driver joins a separate queue, forming a bipartite graph with customer-side (passenger-side) queues and server-side (driver-side) queues. We consider a discrete-time system. At each time slot, the ride-sharing platform will determine a price for each customer or server type. If a passenger accepts the price, they will be charged and join the queue. Similarly, if a driver accepts the price, they will be paid and join the queue. Therefore, the arrival rate of each type of ride order (or driver) is governed by the corresponding price according to some unknown demand (or supply) function. After that, the platform will match the drivers and ride orders in the queues if their types are compatible. For example, if the customer type is the number of passengers in the ride order and the server type is the capacity of the vehicle, then their types are compatible if the capacity of the vehicle is no less than the number of passengers in the ride order. The matched pairs then leave the system. The same process repeats in the next time slot. The profit of the platform is equal to the income from ride orders minus the cost paid to drivers. Assuming the demand and supply functions are unknown, the goal is to design pricing and matching algorithms to maximize the total profit of the platform over a finite time horizon while keeping the queue lengths of both customers and servers below a predetermined threshold.
Similar pricing and matching problems in two-sided queues have been studied in the literature (Caldentey et al. 2009; Adan and Weiss 2012; Gurvich and Ward 2015; Nguyen and Stolyar 2018; Chen and Hu 2020; Varma et al. 2020, 2023; Hu and Zhou 2022; Vaze and Nair 2022; Aveklouris et al. 2023, 2024). Caldentey et al. (2009), Adan and Weiss (2012), Hu and Zhou (2022), and Aveklouris et al. (2023, 2024) study matching problems in two-sided queueing systems with multiple types of demand and multiple types of supply. Nguyen and Stolyar (2018) study a two-sided queueing system with on-demand servers with the goal of designing adaptive server invitation scheme to minimize waiting times. Gurvich and Ward (2015) study a matching problem for multisided queues. However, these works do not consider pricing. Varma et al. (2020) and Chen and Hu (2020) study pricing and matching problems in two-sided queues, but they consider scenarios with strategic demand side and/or supply side, which is different from our setting, where customers and servers are not strategic, and their arrival rates are based on demand and supply functions. Vaze and Nair (2022) consider a two-sided queueing system where servers arrive at a fixed rate, and the arrival rate of customers is controlled by the price. They consider one-sided pricing and single-type customers and servers, whereas we consider two-sided pricing and matching and multiple customer and server types. The most relevant work in the literature is Varma et al. (2023), whose model is similar to ours. The differences between Varma et al. (2023) and ours include the following:
The key difference is that they assume that the platform knows the demand and supply functions, whereas in our setting, the demand and supply functions are unknown.
The objective in Varma et al. (2023) is the asymptotic long run expected profit of the platform subtracting a penalty that is linear in the queue length, whereas our objective is to maximize the total profit of the platform over a finite time horizon while keeping the queue lengths below a predetermined threshold during the entire time horizon.
Varma et al. (2023) consider a large-scale regime in which they scale the arrival rates and study the profit loss in steady state. We focus on finite-time analysis without scaling the arrival rates.
There are some other related works about learning-based dynamic pricing and matching. Besbes and Zeevi (2015) study dynamic pricing with demand learning but they do not consider queueing. Chen and Shi (2024) study a dual-sourcing inventory system with demand learning, which is different from our two-sided queueing system. Tassiulas and Ephremides (1990) and Srikant and Ying (2014) study MaxWeight algorithms for scheduling in one-sided multiserver queueing systems. Our matching algorithm can also be seen as a MaxWeight algorithm but applied to a two-sided matching setting (Varma et al. 2023). Flaxman et al. (2004), Agarwal et al. (2010), Duchi et al. (2015), Shamir (2017), and Lattimore (2024) study zero-order gradient descent algorithms, some ideas from which are incorporated into parts of our pricing algorithm. There are other online learning algorithms in queueing systems (Chen et al. 2023, 2024; Yang et al. 2023), but they consider only one-sided queueing system.
The key challenge of our setting is that the demand and supply functions are unknown. Learning the demand and supply functions explicitly will not be adaptive if the demand or supply functions change over time. Therefore, we propose to learn and make pricing and matching decisions simultaneously. Although several candidate approaches exist, they are not suitable for our setting. One idea is to formulate the problem into a Markov decision process (MDP) and then use reinforcement learning (RL) to solve the MDP approximately. However, the state space of this MDP increases exponentially with the number of queues (i.e., customer and server types), so it is difficult to solve due to the curse of dimensionality. Another approach is to use bandit algorithms from Lipschitz bandits (Slivkins 2019). For example, one may discretize the price space and apply upper confidence bound (UCB)-based algorithms. However, such approaches fail to balance the matching rates and arrival rates on both sides, making it difficult to control the queue lengths. These algorithms also have a high computational complexity because the number of arms is large. Approaches from bandit convex optimization (Lattimore 2024) aim to solve convex optimization problems with bandit feedback. However, the control variables in our setting are prices and the profit function is not concave in terms of prices. The constraint set representing a set of balanced arrival rates is also not convex in terms of prices.
To deal with this challenge, we propose to use a longest-queue-first matching algorithm and a learning-based pricing algorithm, which combines gradient-free (zero-order) stochastic projected gradient ascent (Agarwal et al. 2010) with bisection search. We also borrow the idea of fluid pricing policy from Varma et al. (2023) to control the queue length by rejecting arrivals according to a predetermined queue-length threshold. In this paper, we prove that our proposed algorithm yields a sublinear regret when compared with a fluid-based baseline and guarantees an anytime queue-length bound , where T is the time horizon. Furthermore, we establish a tradeoff between the regret bound and the queue-length bound: For any , if we keep the queue lengths of both customers and servers below , then we have a regret upper bound . We prove a hardness result: The regret is at least to maintain the queue length below for a single-link system with demand and supply functions from a specific class, even when the functions are known.
2. Model
We consider a discrete-time system with two-sided queues: a customer side and a server side. There are multiple queues on each side, representing different types of customers and different types of servers. We can also view customers as demand and servers as supply. We model the system by a bipartite graph , where is the set of customer types and is the set of server types with and . is the set of all compatible links, which means that a type i customer can be served by a type j server if and only if . Figure 1 is an example with three types of customers and two types of servers (). At each time slot, there are arrivals of customers and servers. At time slot t, let and denote the number of arrivals of type i customers and type j servers, respectively. Assume that and follow independent Bernoulli distributions. Let and . At each time slot, after the arrival of customers and servers, the platform will match the customers and servers in the queues through compatible links. Once a customer is matched with a server, that is, the customer is served by the server, they will leave the system immediately. Let and denote the queue length of type i customers and that of type j servers, respectively, before arrivals and matching at time slot t. Assume the queues are all empty at .
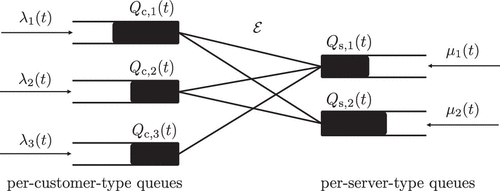
Note. An example with three types of customers and two types of servers.
There is also a price attached to each type of customer or server. Let denote the price of the type i customer and denote the price of the type j server at time slot t. At time slot t, when a customer of type i arrives, they will be charged units of money by the platform. When a server of type j arrives, they will be paid units of money by the platform. Note that the prices determine the arrival rates. Increasing the price of type i customers will reduce arrival rate ; increasing the price of type j servers will increase arrival rate . For a type i customer, the demand function is denoted by , where the input is an arrival rate , the output is the price corresponding to this arrival rate, and and are the minimum and maximum prices for type i customer, respectively. Similarly, for type j server, the supply function is denoted by , where the input is an arrival rate , the output is the price corresponding to this arrival rate, and and are the minimum and maximum prices for a type j server, respectively. Then we have and . We make the following assumption on the demand and supply functions and .
For any customer type i, is strictly decreasing, bijective, and -Lipschitz. Let denote the inverse function of . Assume that is -Lipschitz. For any server type j, is strictly increasing, bijective, and -Lipschitz. Let denote the inverse function of . Assume that is -Lipschitz.
From Assumption 1, we know for any customer type i and for any server type j.
The sequence of events occurring in each time slot is shown in Figure 2. At the beginning of time slot t, we first observe the lengths of all queues for all i, j. Then the platform runs a pricing algorithm to decide the prices . The arrival rates will be determined by these prices, and then the actual arrivals occur. Next, the platform runs a matching algorithm and then those matched customers and servers leave the system.
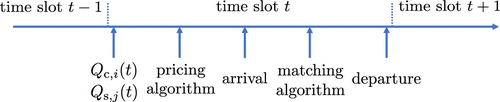
At time slot t, the platform makes a profit of
Our goal is to design an online pricing and matching algorithms to maximize the profit of the platform over T time slots without knowing the demand and supply functions while keeping queue lengths of both customers and servers below a predetermined threshold, that is, to maximize
For any customer type i, the revenue function is concave. For any server type j, the cost function is convex.
From Assumption 2, Objective (2) is concave. Note that the constraints are all affine. Hence, the baseline optimization problem (2)–(6) is concave, and there exists a solution that achieves the optimal value, denoted as .
Let and be the arrival rates at time t under any policy. Then from (1), the expected profit under the policy is
Let denote the optimal value of the fluid optimization problem (2)–(6). For the profit maximization, we consider the following expected regret with respect to the fluid baseline:
Let Assumption 1 and Assumption 2 hold. Then under any policy, we have
The proof of this lemma can be found in Appendix A. Lemma 1 means that the fluid baseline approximates the optimal profit, with an error at most proportional to the queue length at time T. This justifies the use of the regret definition (7). Specifically, let denote the expected regret with respect to the policy that maximizes the expected profit. Then Lemma 1 implies that
As long as the queue lengths and are orderwise smaller than , the regret defined in (7) approximates the “true” regret (with respect to the optimal expected profit). We consider policies that make the queue mean rate stable (Neely 2022); that is, under the policy, for all i, j,
Under any mean rate stable policy, using Lemma 1 and taking limit , we obtain
We make another assumption on the problem.
There exists a known positive number such that there exists an optimal solution to the fluid optimization problem that satisfies and for all i and j.
Assumption 3 means that we need the optimal arrival rates to be strictly greater than zero. This assumption is not restrictive, because any queue with an optimal arrival rate of zero, indicating it is redundant, can be easily identified in practice and removed from the problem formulation. Note that can be any lower bound on the optimal arrival rates.
Assume that the functions and are unknown. The platform cannot directly control the arrival rates, but they can control the prices of the customers and the servers and the matching algorithm. The platform can also observe the number of arrivals and the queue lengths of all the queues. At each time slot, the platform needs to design a price for each queue (customer or server) and to make a decision on how the customers and servers are matched. The objective is to minimize the regret while keeping the maximum queue length below a predetermined threshold. This anytime queue length constraint is necessary in certain practical scenarios—for instance, when the system has a finite buffer size for each queue. Moreover, customers’ experience is often affected by the anytime queue length because they typically expect a consistent level of service.
2.1. Notation
We use bold symbols to represent vectors in or or , such as . We use subscript i or j to indicate an element of a vector, for example, is the ith element of . Note that we view as a vector in rather than a matrix, and the order of elements in can be arbitrary as long as the order is fixed. We use subscript to indicate the customer side and for the server side. means that there exist positive constants C and such that for all ; means that there exist positive constants , and such that for all ; and means that there exist positive constants C and such that for all . We omit the base of logarithmic functions in , , and , for example, , because the base does not affect the order. We use to denote . We use , , and to suppress factors.
3. Summary of Our Main Results
In this section, we provide an overview of the main results in this paper. We use a longest-queue-first matching algorithm, which is a discrete-time version of the matching algorithm in Varma et al. (2023). We propose a learning-based pricing algorithm, which combines gradient-free (zero-order) stochastic projected gradient ascent (Agarwal et al. 2010) with bisection search, illustrated in Section 4 in detail. The proposed pricing algorithm learns from samples and make pricing decisions simultaneously. Under the proposed matching and pricing algorithms, we establish the following profit-regret bound and queue-length bound:
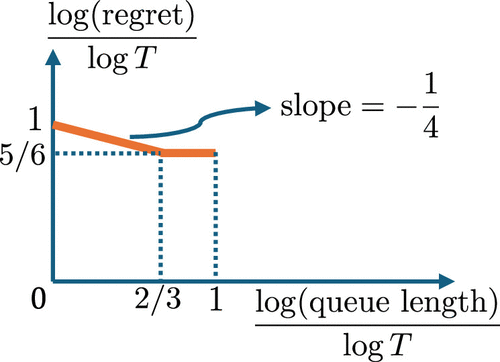
By changing the parameters of the proposed pricing algorithm, we can achieve the following tradeoff between regret and queue length: For any , there exists a set of parameters such that the algorithm can achieve:
The above results are shown in Figure 3. As the allowable queue length increases, the regret bound that we can achieve becomes better. However, if we allow the queue length to increase over , the regret bound cannot be further improved and remains .
3.1. Hardness Result
We show in the following lemma that in a single-link system, any policy that keeps the anytime queue length bounded by must incur a regret of at least .
Consider a single-link system with one customer queue and one server queue with demand function and supply function . Let and denote the customer-side queue length and server-side queue length, respectively. Consider the matching policy that matches all pairs whenever possible because there is no incentive to delay any match in a single-link system. There exists a class of problem instances that satisfies Assumption 1, Assumption 2, and Assumption 3, such that for any pricing policy satisfying the expected regret satisfies for any .
The definition of the class of problem instances and the proof of Lemma 2 can be found in Appendix B. Our upper bound results under the proposed algorithm also hold for this problem class. Note that when the queue length threshold is a constant (i.e., ), the regret under our algorithm becomes linear, which is unavoidable by Lemma 2.
4. Algorithm
In this section, we present the proposed matching and pricing algorithms in detail. The matching algorithm is to match the customers on the demand-side queues with the servers on the supply-side queues, and the pricing algorithm is to learn and design the prices without knowing the demand and supply functions.
4.1. Matching Algorithm
We use a longest-queue-first matching algorithm as shown in Algorithm 1 and Figure 4, where we present the matching algorithm for one time slot, and it is the same for all time slots. In the algorithm, for each time slot, we iterate over each queue on both the customer and server sides. For each queue, we check whether there is a new arrival in the queue. If there is a new arrival (a customer or a server), the algorithm will match the arrival with one server (or customer) in the longest compatible queue on the other side, as shown in Figure 4. After matching, we decrease the queue length by one for both matched queues. Then we move on to the next queue and repeat the process.

Notes. At each time slot, for each queue, if there is a new arrival, it will be matched with one server (or customer) in the longest compatible queue on the other side. Then the matched pairs leave the system and we move on to check the next queue and repeat the same process.
(
1 At each time slot t, without loss of generality, assume that the arrivals come in order .
2 Initialize: for all i and for all j.
3 for to I do
4 Observe and update ;
5 Let with ties broken arbitrarily;
6 if and then
7 Match the arrival with a server in queue ;
8 Then update and ;
9 for to J do
10 Observe and update ;
11 Let with ties broken arbitrarily;
12 if and then
13 Match the arrival with a customer in queue ;
14 Then update and ;
4.2. Pricing Algorithm
Because the functions are unknown and the arrival rates cannot be directly controlled, we cannot simply solve the optimization problem (2)–(6) and obtain the prices. In this section, we propose to combine the techniques of gradient-free (zero-order) stochastic projected gradient descent (Agarwal et al. 2010) and bisection search to solve the problem.
Before presenting the details of our pricing algorithm, we begin by providing a simple example to understand the idea of our algorithm. We consider two customer queues, which are connected to one server queue. Let denote the arrival rates of customer queue 1 and customer queue 2, respectively. Then the arrival rate of the server queue should be equal to due to the balance constraints (3) and (4). Let , where k denote the iteration. Suppose the demand and supply functions are known and the gradients are known; that is, we have first-order access to the profit function f. In this case, we can use the gradient ascent algorithm to solve the problem, as shown in Figure 5(a), where is the step size. Suppose the demand and supply functions are known but the gradients are unknown; that is, we only have zero-order access to the profit function f. Then we can use the two-point zero-order method (Agarwal et al. 2010) to solve the problem, as shown in Figure 5(b). In the two point method, in each iteration k, we first sample a uniformly random direction ( is a unit vector) and then calculate the profits using two points, and , where is small number. Then we can estimate the gradient and update using the formula in Figure 5(b). However, if the demand and supply functions and the gradients are all unknown, simply using the two-point method does not work because we even do not have zero-order access to the profit function f. As shown in Figure 5(c), for or , to estimate the profit , we need to estimate the prices of all queues because , where is the arrival rate of the server queue. Take as an example. Estimating is equivalent to finding the solution to the equation given . We propose using bisection search on prices to estimate p such that , as shown in Figure 5(c), where the horizontal axis is price p, the vertical axis is arrival rate x of the queue, and the green dashed curve is the inverse demand function . We first have the initial knowledge that the price will be between some lower bound and some upper bound, which forms our first search interval. Then we set the price of the queue to be the midpoint of the search interval and run the system for multiple time slots to calculate average number of arrivals per time slot. This is how we get an estimated value of for a chosen p. Then we determine the next search interval by comparing it with , as shown in Figure 5(c). The bisection search stops when the accuracy is good enough. Note that during the process of running the system, we reject arrivals if the queue length is larger than or equal to a predetermined threshold, to control the queue length. After the bisection search, we obtain estimates of the profits and . Then we can substitute these estimates into the two-point method in Figure 5(b) to get an estimate of the gradient and then update the arrival rate .
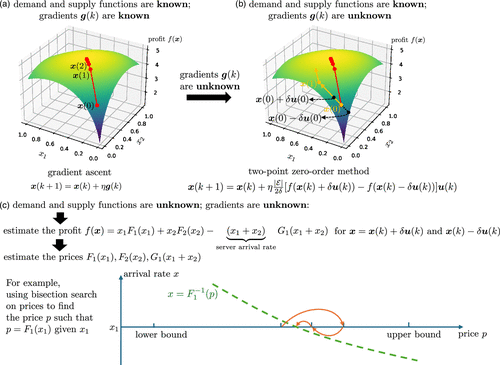
Notes. This is an example with two customer queues connected to one server queue. Let and denote the arrival rates of the two customer queues, respectively. The arrival rate of the server queue should be because of the balance constraint. Let , where k denotes the iteration.
Now we present the details of the pricing algorithm in the general case. The structure of our pricing algorithm is shown in Figure 6. Before presenting the algorithm, we first define some notations and a shrunk feasible set. Let and denote the sets of all queues that are connected to customer queue i and server queue j, respectively. By substituting and by Assumption 3, the optimization problem (2)–(6) can be equivalently rewritten as
Note that we view as a vector in . Note that the problem (8)–(11) is also concave. Let denote the feasible set of the problem (8)–(11), that is,
Let denote the maximum cardinality of the sets and . Define a shrunk set of with a parameter as follows:
Assume that for all i and for all j.
As long as is small enough, Assumption 4 holds. Because and , we have
(
1 Initialize: Choose an exploration parameter . Choose a step size . Choose an accuracy parameter . Choose a queue length threshold . Choose as the initial point. Define and according to (C.1) and (C.2). Define and , where is a constant.
2 Time step counter ;
3 Outer iteration counter ;
4 repeat
// Step 1. generate a random direction and two points
5 Choose a unit vector uniformly at random, that is, ;
6 Let and ;
7 Let , , , ;
8 Let be a vector of . Define similarly , , and .
// Step 2. bisection search to approximate .
9 if then
10 For all i, let , ;
11 For all j, let , ;
12 Let ; // We do not reject arrivals for .
13 else
14 For all i, let , ;
15 For all j, let , ;
16 Let ;
17 Let be a vector of . Define similarly , , .
18 t, , Bisection ;
19 Do Line 9–18 for . Denote the counterparts of the prices by , , , , , .
// Step 3. gradient calculation
20 Let ;
// Step 4. gradient ascent update
21 Projected Gradient Ascent: ;
22 ;
23 until ;
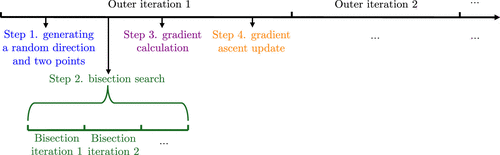
The details of the proposed pricing algorithm are shown in Algorithm 2 and Algorithm 3. In the notation in Algorithms 2 and 3, denotes the kth outer iteration; denotes the mth bisection iteration in the kth outer iteration. As shown in Algorithm 2, we first choose , and ; is an exploration parameter for estimating the gradient, and it is used to construct the set . We choose as the initial point of the algorithm; is the step size for the gradient ascent step; and is the accuracy for the bisection algorithm. The threshold is used to control queue length. We also define and , which can be later proved to be the upper bounds of the change of the prices in one outer iteration. Note that the parameters can be a function of total number of time steps T and can be optimized later to obtain a sublinear regret. In each outer iteration k, we have four steps.
Step 1: We first generate a random direction, that is, a unit vector that is uniformly sampled from the unit sphere, and then change in the direction of and also in the opposite direction of , generating and , as shown in Line 6 of Algorithm 2. We can then calculate the arrival rates and as shown in Line 7 of Algorithm 2.
Step 2: Next, we find the prices that approximate , and using the bisection search shown in Algorithm 3, which will be illustrated in detail later in this section. Here, we specify the initial search intervals for the bisection search. If , we start with search intervals and , as shown in Lines 10 and 11 of Algorithm 2. Note that we do not reject arrivals in the first iteration because we want to quickly learn the price that can keep the queues balanced. If , we use , , and to construct the lower and upper bounds for the bisection algorithm, as shown in Lines 14 and 15 of Algorithm 2, where and , and the exact expressions can be found in Appendix C.
Step 3: The bisection algorithm will output approximated prices , , , and that correspond to , respectively, as shown in Lines 18 and 19 of Algorithm 2. Then we can use these arrival rates and prices to calculate an estimate of the gradient of the objective function in (8), as shown in Line 20 of Algorithm 2.
Step 4: With this gradient estimate, we do a projected gradient ascent as shown in Line 21 of Algorithm 2. The algorithm stops until the number of time steps .
(
1 for to M do
2 Let for all i;
3 Let for all j;
4 Let for all i and for all j;
5 repeat
6 for to I do
7 if then set price for queue i;
8 else set price for queue i and ;
9 for to J do
10 if then set price for queue j;
11 else set price for queue j and ;
12 Use the above set of prices to run one step of the system;
13 ;
14 Terminate the algorithm when ;
15 until for all queues i, , that is, the price is run for at least N times and for all queues j, , that is, the price is run for at least N times;
16 Let denote the time slot when the price is run for the nth time for the customer-side queue i; let denote the time slot when the price is run for the time for the server-side queue j;
17 for to I do
18 Let ; // sample average
19 if then ;
20 else ;
21 for to J do
22 Let ; // sample average
23 if then ;
24 else ;
25 Let be a vector of and define similarly .
26 return t, ,
The proposed bisection algorithm is shown in Algorithm 3, which is to find the prices such that and for some given target arrival rates with initial intervals and for all i, j. In each bisection iteration m, we first calculate the midpoints of the intervals, and for all i, j just like the standard bisection search, as shown in Lines 2 and 3 of Algorithm 3. For each queue, if the queue length is less than , we will set the price with or that was just calculated; otherwise, we will temporarily reject new arrivals into the queue to control the queue length by using the prices or . We will use this set of prices to run the system for a number of time slots such that every price has at least N i.i.d. samples, as shown in Lines 4–15 of Algorithm 3. Next, with the samples we obtained, we can calculate an estimate of the arrival rate corresponding to the price we set for each queue, or , as shown in Lines 18 and 22 of Algorithm 3. Then we can update the lower and upper bounds of the searching intervals by comparing , with , , as shown in Lines 19 and 20 and Lines 23 and 24 of Algorithm 3. We conduct bisection iterations to obtain sufficiently high accuracy.
5. Main Result
The main result of the paper is shown in Theorem 1.
Let Assumptions 1–4 hold. Under Algorithm 1, Algorithm 2, and Algorithm 3, if , , and , we have
Based on Theorem 1, we optimize the regret bound by setting the parameters to be a function of T. Assume that and are large enough. Then we can first focus on minimizing the order of the following term:
If we ignore logarithmic order, the optimal solution is , , and the optimal order of (17) is . By setting and , we obtain . We summarize the above result as the following corollary.
Let Assumptions 1–4 hold. Under Algorithm 1, Algorithm 2, and Algorithm 3, with parameters , , , , for sufficiently large T such that , , , and , we can achieve a sublinear regret as
From (15) and (16) in Theorem 1, we can see that there is a tradeoff between minimizing the regret and minimizing the queue length. Firstly, we should not set to be greater than the order of because it will not benefit the regret bound orderwisely because is large enough to achieve the optimal order of (17). However, we can reduce so that the queue-length bound can be improved, although we may suffer a larger regret. Suppose we want the queue-length bound to be the order of , where . Then we need to set and by (16). From (15), we need to set the parameters to optimize the regret bound. Assume is large enough. Then optimizing the regret bound is equivalent to minimizing the order of the following term (ignoring logarithmic terms):
The optimal solution is , , and the optimal order of (18) is . By setting , we obtain . We summarize the above tradeoff as the following corollary.
Let Assumptions 1–4 hold. For any , under Algorithm 1, Algorithm 2, and Algorithm 3, with parameters , , , , for sufficiently large T such that , , , and , we can achieve a sublinear regret as
From Corollary 1 and Corollary 2, when the allowable queue length increases (up to ), the regret bound that we can achieve becomes better. However, even if we allow the queue length to increase over , the regret bound cannot be improved and remains .
6. Proof Roadmap
In this section, we present a proof roadmap for Theorem 1. The complete proof of Theorem 1 can be found in the Online Appendix. In the proof roadmap, we will consider the choice of parameters as in Corollary 1 to make the proof idea clear, that is, , , , .
For the first outer iteration, we have no control of the queue length, so the queue length will possibly increase up to . Also, because the queue length is controlled by the threshold after the first outer iteration, the queue-length bound is .
For the regret bound, the proof roadmap is shown in Figure 7. We first define an event , which means that the estimations of all the arrival rates are -accurate. Then the regret can be divided into the regret when the event occurs and the regret when the event does not occur. We show in Lemma 5 in the Online Appendix that the complement of the event, , happens with low probability. Intuitively, because for each estimation we use samples, we can obtain accuracy with high probability by Hoeffding’s inequality. Note that Lemma 5 cannot be proved by simply applying Hoeffding’s inequality, and we will discuss the challenge in Section 7.

Therefore, the regret when the event does not happen can be bounded. For the regret when the event happens, that is, the estimations are -accurate, we further divide it into two parts. One part is the regret when the lengths of all the queues are less than the threshold so that there is no queue that is rejecting arrivals, and the other part is the regret induced by rejecting arrivals when there exists a queue whose length is greater than or equal to the threshold . For the latter part, we can bound it by the expected number of time slots when a queue is rejecting arrivals. We show in Lemma 6 in the Online Appendix that this can be bounded by . The proof is using Lyapunov drift analysis with a Lyapunov function for the customer side and for the server side. The challenge of the proof will be discussed in Section 7.
For the part of regret when there is no queue that is rejecting arrivals, regret is induced by zero-order optimization process. We show in the Online Appendix that this part of regret can be bounded by . The intuition is as follows. If there is only one run of the system in each outer iteration, then from the literature of two-point method of zero-order optimization (Agarwal et al. 2010), the regret will be bounded by , where K is the number of outer iterations. In our algorithm, there are runs of the systems in each outer iterations, and there are outer iterations. Hence, the regret will be bounded by . However, the proof needs additional steps because, even in the same outer iteration, the prices and arrival rates are changing. In fact, we need to connect the actual prices to the prices corresponding to . Moreover, there can be dependence between the arrival rate estimation and the randomness of the optimization algorithm, which we will discuss in Section 7.
7. Challenges in the Proof
In this section, we discuss the challenges in the proof of Theorem 1 and the methods we use to overcome them.
The first challenge is to prove that the event occurs with low probability (Lemma 5 in the Online Appendix). The event is defined as
The second challenge is to prove the upper bound on the expected number of time slots when the length of one of the queues is greater than or equal to the threshold (Lemma 6 in the Online Appendix). As mentioned in the proof roadmap in the previous section, we use Lyapunov drift analysis with quadratic Lyapunov functions. The challenge is how we make sure that the actual arrival rates are balanced or almost balanced. We know that , so the corresponding arrival rates are balanced. Because and are -close to , their corresponding arrival rates are almost balanced. We want to prove that the actual arrival rates are close enough to the almost balanced arrival rates corresponding to or . To show this, we use an important property that the true price corresponding to or is within the search interval of the bisection algorithm with high probability and an important fact that the width of the search interval is small enough for . Therefore, the actual arrival rates are also almost balanced for .
The third challenge is bounding the regret induced by zero-order optimization conditioned on -accurate arrival rate estimations (Lemma 7 in the Online Appendix). As mentioned in the proof roadmap in the previous section, the challenge is that there could be dependence between the estimation of arrival rates and the randomness () in the optimization algorithm. By defining the event such that the -accuracy is required for all arrival rates in [0, 1], we can show that the event is independent of . Note that if we change the definition of such that only the estimations of the actual arrival rates are -accurate, this independence does not hold. This independence between and is essential so that, conditioned on the event , we can use the proof idea of two-point method of zero-order optimization to bound the regret.
8. Numerical Results
In this section, we present numerical results of the proposed algorithm and compare its performance with that of the UCB algorithm with uniform discretization designed for Lipschitz bandits (Slivkins 2019).
We consider a system with three types of customers () and three types of servers (). The compatibility graph is given by The demand and supply functions are given by for all and for all . We compare the following algorithms.
Proposed algorithm: The parameters are set to , , , , , and .
Discretization-UCB: We first discretize the price space uniformly and then apply UCB algorithm as in Slivkins (2019). We gradually refine the discretization so that the discretization error decreases at the rate of , which theoretically achieves the optimal regret order for Lipschitz bandits according to Slivkins (2019).
Discretization-UCB with : As mentioned in the introduction, the discretization-UCB algorithm fails to balance the matching rates and arrival rates, making it difficult to control the queue length. Therefore, we modify this algorithm by adding a penalty/bonus term such that the reward of pulling an arm at time t becomes
For all the algorithms, we set a queue length threshold of for fair comparison, which can be viewed as the buffer size of each queue. All the algorithms use the longest-queue-first matching policy.
Figure 8 presents the results of the profit regret and the maximum queue lengths. Note that both the x axis and y axis of the figures are in log scale. We can see that the proposed algorithm significantly outperforms the discretization-UCB algorithm () in terms of both profit regret and maximum queue length. The maximum queue length under the discretization-UCB algorithm grows at the same rate as the threshold , meaning that the queue lengths consistently hit the buffer size. This indicates that the discretization-UCB algorithm fails to control the queue lengths. The regret under the discretization-UCB algorithm grows almost linearly with t, because rejecting arrivals whenever the queue length hits the buffer size (threshold) incurs a constant regret, and the queue lengths hit the threshold frequently. The modified discretization-UCB algorithms with and achieve a better maximum queue length performance. However, their profit regret remains significantly worse than that of the proposed algorithm. The reason could be that the additional penalty/bonus affects the exploration of the arms (prices).
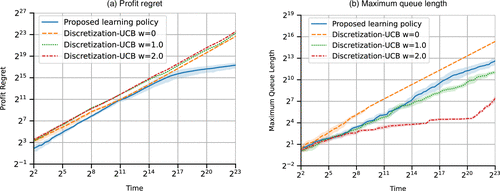
Note. The shaded areas represent 95% confidence intervals, calculated from 10 runs.
Sensitivity analysis of the proposed algorithm to its parameters, along with additional numerical results, can be found in the Online Appendix.
9. Conclusions
We studied the pricing and matching problem for two-sided queueing systems with unknown demand and supply functions. We proposed a novel learning-based pricing algorithm that combines zero-order stochastic projected gradient ascent with bisection search. We proved that the proposed algorithm yields a sublinear regret and guarantees an anytime queue-length bound and established a tradeoff between the regret bound and the queue-length bound: versus for In addition to ride-sharing platforms, the proposed algorithm also has potential applications in online marketplaces and healthcare systems.
Appendix A. Proof of Lemma 1
Fix any policy. By the concavity in Assumption 2, we have
By Jensen’s inequality, we have
Combining (A.1) and (A.2), we have
Note that the dynamics of the queue length of type i customers is
Taking time average on both sides, we have
Similar argument holds for the server side and hence
From (A.5) and (A.6), we know that the tuple
By the Lipschitz property in Assumption 1, we know that the function is Lipschitz in , and the function is Lipschitz in . This can be shown as below:
Similarly,
Hence, we have
Combining (A.3), (A.7), and (A.8), we have
Lemma 1 is proved.
Appendix B. Proof of Lemma 2
For the single-link system, we will omit the subscripts i, j in the notations because there is only one customer queue and one server queue. The fluid optimization problem (2)–(6) reduces to
Let . Consider a class of problem instances (i.e., a class of functions F, G) satisfying Assumptions 1–3 for which there exists an optimal solution to Problem (B.1) satisfying the following properties:
(A) .
(B) There exist constants , , and such that for any ,
We will first show that this class of problem instances is not empty. Consider the following functions F and G:
We can show that this problem instance (B.2) satisfies the requirement. First note that both F and G are strictly decreasing, bijective, and Lipschitz in [0, 1]. Also, the inverse functions of F and G are also Lipschitz because the derivatives/subderivatives of F and G are strictly greater than zero. Hence, Assumption 1 holds. By definition, we obtain
By definition, we can show that r is concave and c is convex. Hence, Assumption 2 holds. The subdifferentials of r and c are as follows:
Also, we have
Because , is an optimal solution to Problem (B.1). Hence, Assumption 3 and Property (A) hold. Next, we will prove Property (B). Let , , and . Note that . Consider two cases, and .
: For r, we have
Then
Hence, . For c, we have
Then
Hence, .
: For r, we have
Then
Hence, . For c, we have
Then
Hence, .
Combining the above two cases, we have proved Property (B). Hence, this problem instance (B.2) belongs to the defined class of problem instances. Therefore, the defined class of problem instances is not empty.
Next, we will show that, for this class of problem instances, any policy that keeps the anytime maximum queue length bounded by must incur a regret of at least . Fix any . Fix any policy such that . From the regret definition (7), we have
From (B.3) and Property (B), we can obtain the following lower bound:
From the queue dynamics, we have
Taking expectation on both sides, we have
Hence, we have
Define . Then, we have
Summing both sides from to and noting that , we obtain
From (B.4) and (B.5), we obtain
By Lemma 3 in the Online Appendix, we know that either or . Hence, under the policy. Hence, (B.6) can be further bounded by
By the triangle inequality, the term in (B.7) can be bounded by
Next, we will bound the term in (B.8) using the Lyapunov drift method. Consider the drift . By the queue dynamics, we can obtain
For the variance term in (B.9), we have
Adding and subtracting and , we further obtain
Hence, from (B.9) and (B.10), we have
Rearranging terms and noting that , we obtain
Because by Property (A), we have . Hence, . Hence, we have
From (B.7) and (B.12), we have
Appendix C. Exact Expressions of and in Algorithm 2
References
- (2012) Exact FCFS matching rates for two infinite multitype sequences. Oper. Res. 60(2):475–489.Link, Google Scholar
- (2010) Optimal algorithms for online convex optimization with multi-point bandit feedback. Kalai AT, Mohri M, eds. Proc. 23rd Annual Conf. Learn. Theory (ACM, New York), 28–40.Google Scholar
- (2023) A fluid approximation for a matching model with general reneging distributions. Queueing Systems 106:199–238.Google Scholar
- (2024) Matching impatient and heterogeneous demand and supply. Oper. Res. 73(3):1637–1658.Link, Google Scholar
- (2015) On the (surprising) sufficiency of linear models for dynamic pricing with demand learning. Management Sci. 61(4):723–739.Link, Google Scholar
- (2009) FCFS infinite bipartite matching of servers and customers. Adv. Appl. Probability 41(3):695–730.Google Scholar
- (2020) Pricing and matching with forward-looking buyers and sellers. Manufacturing Service Oper. Management 22(4):717–734.Link, Google Scholar
- (2024) Tailored base-surge policies in dual-sourcing inventory systems with demand learning. Oper. Res. 73(4):1723–1743.Google Scholar
- (2023) Online learning and optimization for queues with unknown demand curve and service distribution. Preprint, submitted March 6, https://arxiv.org/abs/2303.03399.Google Scholar
- (2024) An online learning approach to dynamic pricing and capacity sizing in service systems. Oper. Res. 72(6):2677–2697.Link, Google Scholar
- (2015) Optimal rates for zero-order convex optimization: The power of two function evaluations. IEEE Trans. Inform. Theory 61(5):2788–2806.Google Scholar
- (2004) Online convex optimization in the bandit setting: Gradient descent without a gradient. Preprint, submitted August 2, https://arxiv.org/abs/cs/0408007.Google Scholar
- (2015) On the dynamic control of matching queues. Stochastic Systems 4(2):479–523.Link, Google Scholar
- (2022) Dynamic type matching. Manufacturing Service Oper. Management 24(1):125–142.Link, Google Scholar
- (2024) Bandit convex optimisation. Preprint, submitted February 9, https://arxiv.org/abs/2402.06535.Google Scholar
- (2020) Bandit Algorithms (Cambridge University Press, Cambridge, UK).Google Scholar
- (2022) Stochastic Network Optimization with Application to Communication and Queueing Systems (Springer, Cham, Switzerland).Google Scholar
- (2018) A queueing system with on-demand servers: Local stability of fluid limits. Queueing Systems 89:243–268.Google Scholar
- (2017) An optimal algorithm for bandit and zero-order convex optimization with two-point feedback. J. Machine Learn. Res. 18(52):1–11.Google Scholar
- (2019) Introduction to multi-armed bandits. Foundations Trends Machine Learn. 12(1–2):1–286.Google Scholar
- (2014) Communication Networks: An Optimization, Control and Stochastic Networks Perspective (Cambridge University Press, Cambridge, UK).Google Scholar
- (1990) Stability properties of constrained queueing systems and scheduling policies for maximum throughput in multihop radio networks. Proc. 29th IEEE Conf. Decision Control (IEEE, Piscataway, NJ), 2130–2132.Google Scholar
- (2020) Near optimal control in ride hailing platforms with strategic servers. Preprint, submitted August 9, https://arxiv.org/abs/2008.03762.Google Scholar
- (2023) Dynamic pricing and matching for two-sided queues. Oper. Res. 71(1):83–100.Link, Google Scholar
- (2022) Non-asymptotic near optimal algorithms for two sided matchings. Proc. 20th Internat. Sympos. Modeling Optim. Mobile Ad Hoc Wireless Networks (IEEE, Piscataway, NJ), 17–24.Google Scholar
- (2023) Learning while scheduling in multi-server systems with unknown statistics: Maxweight with discounted UCB. Ruiz F, Dy J, van de Meent J-W, eds. Proc. Internat. Conf. Artificial Intelligence Statist. (PMLR, New York), 4275–4312.Google Scholar

