
Asymptotically Optimal Inventory Control for Assemble-to-Order Systems
Abstract
We consider assemble-to-order (ATO) inventory systems with a general bill of materials and general deterministic lead times. Unsatisfied demands are always backlogged. We apply a four-step asymptotic framework to develop inventory policies for minimizing the long-run average expected total inventory cost. Our approach features a multistage stochastic program (SP) to establish a lower bound on the inventory cost and determine parameter values for inventory control. Our replenishment policy deviates from the conventional constant base stock policies to accommodate nonidentical lead times. Our component allocation policy differentiates demands based on backlog costs, bill of materials, and component availabilities. We prove that our policy is asymptotically optimal on the diffusion scale, that is, as the longest lead time grows, the percentage difference between the average cost under our policy and its lower bound converges to zero. In developing these results, we formulate a broad stochastic tracking model and prove general convergence results from which the asymptotic optimality of our policy follows as specialized corollaries.
Funding: This study is based on work supported by the National Science Foundation [Grant CMMI-1363314].
1. Introduction
Optimal control of assemble-to-order (ATO) inventory systems is a canonical problem in inventory theory. In an ATO system, product assembly is assumed to take a negligible amount of time, so there is no need to keep inventories of final products. Component supplies are not capacity constrained, but it is necessary to hold inventories for them to accommodate replenishment lead times (i.e., delays between ordering and receiving components). The goal of ATO inventory management is to minimize the total inventory cost, which consists of both holding and backlog costs, by controlling the timing and quantities of component orders and allocation of available components to different product demands.
Although optimal control of single-product ATO systems has long been settled (see Karlin and Scarf (1958) and Rosling (1989) for systems with single and multiple components, respectively), optimizing multiproduct ATO systems is an immensely more difficult problem that remains unsolved. The complexity arises from the need to allocate components that are used by multiple products. Optimal allocation depends on component availabilities, which are outcomes of replenishment decisions. Optimal replenishment needs to take into account how components will be allocated. A joint optimal solution of both decisions is contingent on not only the current inventory and backlog levels, but also the arrival times of all outstanding replenishment orders, giving rise to an enormous state space. The problem becomes even more complicated in systems where components do not have identical lead times, because the ordering of components often needs to be coordinated with the availabilities of other components with longer lead times.
There has been a large body of studies on managing multiproduct ATO systems. One may find a thorough review of the related literature in Song and Zipkin (2003), and a more recent one in Atan et al. (2017). Many previous studies focus on particular types of policies, such as base stock replenishment policies, FIFO, or no-hold-back allocation policies (see Lu and Song (2005), Lu et al. (2010), and Huang and de Kok (2015) for some samples), and for periodic-review systems, allocation policies that always satisfy demands from previous periods first (Zhang 1997, Hausman et al. 1998, Agrawal and Cohen 2001, Akçay and Xu 2004). Restricting the consideration to these types of policies makes the problem more tractable, but also sacrifices optimality, because both analytical and numerical studies (Doğru et al. 2010, 2017) have shown that there are often better alternatives in other types of policies.
Asymptotic analysis has recently emerged as a powerful tool for analyzing inventory systems. Although a weaker standard than being exactly optimal, asymptotic optimality provides vital guidance to formulating novel inventory policies and evaluating their performance when meeting the latter criterion is analytically intractable. Asymptotic optimality has been used to justify the use of base stock policies in lost sale inventory systems (in the regime of high penalty costs; Huh and Rusmevichienton 2009), ATO inventory systems with identical lead times (Reiman and Wang 2015) or when differences in lead times are small relative to the lead times themselves (Reiman et al. 2016), or systems with nonstationary demands and probabilistic service level constraints (Wei et al. 2021). It also supports the use of no-hold-back allocation policies in assemble-to-order N and W systems (Lu et al. 2015). Asymptotic analysis has led to several surprising discoveries. For instance, simple constant ordering policies can be highly effective in managing lost sale inventory systems with long lead times (Reiman 2004, Goldberg et al. 2016, Xin and Goldberg 2016, Bu et al. 2020), and randomness of lead times is a useful feature that can be exploited to reduce the inventory cost in backlog systems when orders can cross in time (Stolyar and Wang 2022). We refer readers to Goldberg (2021) for a comprehensive review of these developments.
In this paper, we study ATO inventory systems with nonidentical, deterministic lead times and a general bill of materials (BOM). We develop an inventory policy that includes both replenishment and allocation decisions. We prove that our policy is asymptotically optimal, that is, as the longest lead time increases, the percentage difference between the long-run average inventory cost under our policy and the optimal policy converges to zero.
Our analysis follows a general four-step asymptotic framework that has produced many ground-breaking results in the study of stochastic processing networks (Harrison 1988, 1996; Harrison and Wein 1990; Harrison and López 1999). It has also been adopted for optimizing pricing, capacity, and allocation decisions in ATO production-inventory systems (Plambeck and Ward 2006). In Reiman and Wang (2015), the framework is formally summarized where each step is explicitly described and specialized to the study of ATO inventory systems with identical lead times. As a continuation of the latter work, here we apply the framework to address ATO inventory systems with general deterministic lead times. A step-by-step discussion of previous results and our new contributions is provided.
Step 1: Relax some feasibility constraints of the original system to formulate a proxy model that is easier to solve and provides a lower bound on the cost achievable under any feasible policy.
In Reiman and Wang (2012), a multistage stochastic program (SP) is formulated as a static analog to dynamic ATO systems. The optimal objective value of the SP is proven to be a lower bound on the average inventory cost of the latter systems under any feasible policy. Unfortunately, this lower bound takes the form of an infimum that is often not attained at finite values of the decision variables.
As a contribution of this paper, we transform this SP into an equivalent form where the optimal objective value is the same, whereas the optimal decision variables are finite. This paves the way for using these optimal decision variables as parameters for ATO inventory control policies.
Step 2: Solve the proxy model.
There have been many studies on the model structure and computational efficiency of the aforementioned SP, mainly on special cases that have two stages and correspond to systems with particular BOMs (Doğru et al. 2010, Nadar et al. 2014, van Jaarsveld and Scheller-Wolf 2015, Zipkin 2016, DeValve et al. 2020). Developing efficient algorithms for multistage SPs is an active area of research. Although we solve the SP for some simple examples in Section 8, solving more general cases is well beyond the scope of this paper, and we focus on a different aspect of the problem that is critical for proving asymptotic optimality of our policy. To use optimal solutions of the SP as parameters of inventory control policies, we need to show that these values are stable; that is, they do not change drastically in response to small fluctuations of inputs. The analysis should be applicable to the SP with a general number of stages and general BOMs.
To this end, we show that with a negligible loss of the accuracy, the SP can be approximated by a finite-dimension linear program (LP), which has a unique optimal solution that is Lipschitz continuous in input parameters. By characterizing and making use of the structure of constraints of the approximating LPs, we prove that their optimal solutions are Lipschitz continuous in inputs that change with the state of the ATO system, and importantly, the Lipschitz constant is independent of the problem size.
Step 3: Use the optimal solution of the proxy model to formulate inventory control policies for the original systems.
In Reiman and Wang (2015), a two-stage SP is used to set asymptotically optimal inventory policies for systems with identical lead times. Replenishment decisions follow a base stock policy with the base stock levels specified by the first stage SP solution. Allocation decisions are controlled by an allocation principle, which uses the second-stage SP solution to set backlog targets to dynamically choose the amount of each demand to serve. However, it is well known that base stock policies are inefficient for general ATO systems considered in this paper, which allow significantly different lead times (Zipkin 2000).
To the best of our knowledge, except for single-product ATO systems (Rosling 1989), an asymptotically optimal replenishment policy remains to be developed for systems with general deterministic lead times and general BOMs. We fill the gap in this paper by formulating such a policy, which uses the optimal solutions of the aforementioned multistage SP to set dynamic targets for inventory positions that determine order quantities. The policy generalizes previous work: it specializes to the policy in Rosling (1989) in systems with a single product and the base stock policy in Reiman and Wang (2015) in systems with identical lead times. We adopt the same allocation principle in Reiman and Wang (2015) with minor twists to fit with the new replenishment policy.
Step 4: Show the performance benefit of the policy by proving that it is asymptotically optimal.
For the special case of identical lead times, an SP-based policy has been shown to be asymptotically optimal (Reiman and Wang 2015). However, the proof relies on the fact that the constant inventory positions prescribed by the two-stage SP can be exactly followed by a base stock policy. Also, the state of the system under this policy is completely determined by the history within the previous lead time. In contrast, for systems with nonidentical lead times, the ideal inventory positions prescribed by the multistage SP may not always be attainable. The state of system can be affected by the history in the unbounded past. Therefore, new techniques are needed to prove asymptotic optimality of our policy for general systems.
We introduce a broadly defined stochastic tracking model, which features a general target process and a general tracking process. We prove that the expected difference between these two processes converges to zero. We apply this model to compare the inventory position and backlog targets prescribed by the SP for reaching the cost lower bound with their actual levels under our policy. We show that these comparisons are special cases of the convergence results of this tracking model and use this to establish asymptotic optimality of our policy. We also perform simulations on several special ATO systems to illustrate that our policy performs well, even under “nonasymptotic” conditions.
The rest of the paper is organized as follows. We define the problem in Section 2. In Section 3, we formulate the SP, develop bounds on its optimal solutions (Theorem 1), and show that its optimal objective value is the same as that of the SP in Reiman and Wang (2012) and thus is a lower bound on the average inventory cost of the ATO system (Theorem 2). In Section 4, we present our inventory policy. In Section 5, we show that the policy is asymptotically optimal if the resulting inventory positions and backlog levels converge to their respective SP-based targets (Theorem 3). The latter convergence results are proven in Section 6 with the formulation and analysis of the aforementioned stochastic tracking model. There, Theorem 4 proves convergence for the general stochastic tracking model. Its corollaries show that inventory positions and backlog levels converge to their targets if the latter satisfy stability conditions that require them to be asymptotically Lipschitz continuous in changes of demands in some previous periods. In Section 7, we prove that the target stability conditions are indeed satisfied with the aforementioned development of finite-dimensional LP approximations. We support our analysis with numerical studies in Section 8 and conclude the paper in Section 9.
As for notation, and are, respectively, sets of l-dimensional real vectors and nonnegative real vectors (). Their superscripts are omitted when l = 1. We define to be an indicator function, which equals one if the statement inside the bracket is true and zero otherwise. The maximum and minimum of x1 and x2 are denoted by and , respectively, and is denoted by x+. Vector symbols are always in bold, and as two special vectors, is the unit vector with the jth element taking the value of unity, and is the vector of all 1s (dimensions of both vectors depend on the context). The norm on is defined by for and . For each pair of vectors and , the maximum and minimum, and , are taken componentwise. Between any pair of vectors, if every component of is greater (less) than or equal to its corresponding component in , and unless each component in equals the corresponding component in .
To improve the flow and avoid distracting from our main results, we leave proofs of all lemmas and some theorems in Appendix A. To highlight the major ideas of our work, we include proofs of key results, Theorems 3, 4, and 6, and related corollaries, in the main body of the paper.
2. Problem Formulation
We consider continuous-review ATO inventory systems. Inventories are nonperishable and unserved demands are always backlogged. Component lead times are deterministic but may differ from each other. Our policy and analysis apply to periodic-review systems but do not extend to cases with perishable inventories, lost sales, or stochastic lead times.
2.1. System
There are m products and n components. The BOM, given as an n × m nonnegative integer matrix, A, specifies the use of components by different products. Elements of A, aji, represents the amount of component j needed to assemble product i (). Thus, the jth row of A, , specifies the amounts of component j needed by all products (). Without loss of generality, we assume that there is at least one nonzero entry in every row and every column of A.
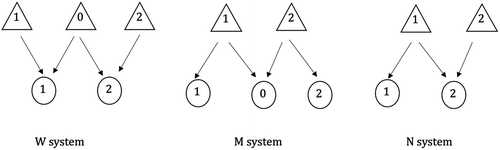
Figure 1 shows three ATO systems that are common in the literature. The W system has two products, and three components, one of which is used by both products. Each product is assembled from one unit of the common component and one unit of a product-specific component. With a slight deviation from the aforementioned notation, the common component is referred to as component 0. The M system uses two components to build three products. Products 1 and 2 use one unit of components 1 and 2, respectively. The third product, referred to as product 0 in a slight deviation from the aforementioned notation, uses one unit of both components. The N system is a special case of both the W and M systems. It has two products and two components. Product 0 uses one unit of both components 0 and 1 and Product 1 uses only one unit of component 0.
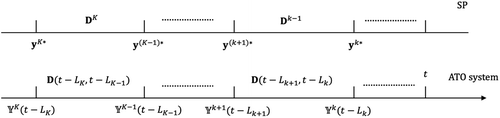
There are K distinct component lead times, . Define for notational convenience. Let nk be the number of components with lead time Lk (). Components are indexed according to an ascending order of their lead times. Let and (). Observe that . Thus, are the indexes of components with lead times Lk (). We associate each component j with an index kj () such that is the lead time of component j (). Without loss of generality, we arrange the rows of A in an order such that the submatrix Ak, composed of rows of A, specifies the use of components with lead time Lk ().
Without loss of generality and for simplicity, we let the system start at a time when there is no inventory on-hand, no order in transit, and no backlog, and define that time to be . Demand arrives according to an integer vector valued compound Poisson process
The covariance matrix of is denoted by , of which the diagonal elements, σii, are variances of demand i () over a unit of time. Because the demand process is stationary, and are also, respectively, the means and the covariance matrix of demands over ().
We assume that Si has a finite moment of order 6, that is,
As will be evident from the proof of Theorem 4, we assume a finite moment of order 6 for a similar reason as that in Huh et al. (2009), which is to use the moment to bound the difference between two stochastic processes. (Beyond that, both the time horizon and stochastic processes involved are completely different between the two studies.)
2.2. Inventory Control Problem
Inventory control includes both replenishment and allocation decisions. For components with lead time Lk, the replenishment starts from time and is defined by , an integer-valued vector process with nk components. Each component of , represents the amount of component j ordered over the period ). In this context, should be nonnegative and nondecreasing, which we assume in the paper. Orders are placed at distinct points of time. Hence, we assume the process is right-continuous.
The allocation decision is specified via an m-dimensional, integer-valued process . Each component of , represents the amount of demand for product i served over the period . We assume that is also nonnegative, nondecreasing, and right-continuous.
Both () and () must be adapted to the filtration generated by the initial states of the system, as well as (), (), and (), which means that policies under our consideration are nonanticipating.
For the inventory control to be feasible, at any point of time, the total amounts of demand served cannot exceed the amounts that have arrived. The amounts of components used cannot exceed the amounts that have been received. Because the replenishment of components with the lead time Lk starts at time , no unit is received and thus no demand can be served before time 0. In our model, these restrictions are formalized by the following assumptions:
Observe that by definition, are the amounts of components ordered at least one lead time before time t.
For , the inventory level of components with the lead time Lk is
By (1), both and are nonnegative. Also by (1) and our assumption about the replenishment starting times,
Let bi be the cost of backlogging one unit of demand of product i () per unit of time. Let hj be the cost of holding one unit of inventory of component j () per unit of time. We assume that hj () and bi () are strictly positive. Let
Then at each time t (), the system incurs the total inventory cost at the expected rate
The problem of inventory control is to develop integer-valued, nonnegative, nondecreasing, right-continuous, and nonanticipating vector processes () and (), subject to (1)–(3), to minimize the following long-run average expected total inventory cost:
2.3. Additional Variables, Processes, and Relationships
For the needs of our analysis, we introduce additional variables and processes and specify their relationships.
2.3.1. Variables and Processes.
The additional variables and processes, defined in terms of the more “primitive” processes introduced in Sections 2.1 and 2.2, are listed in Table 1 along with their definitions. For the convenience of the reader, Table 1 also includes the definitions of the inventory and backlog processes defined in Section 2.2. Further discussions of these quantities are as follows:
|

Table 1. Key Variables: Notation and Value
| Variables | Definitions | |
|---|---|---|
| Demand | ||
| Replenishment | ||
| Allocation | ||
| Inventory | ||
| Backlog | ||
| Inventory position | ||
| Inventory balance | , |
The first processes we introduce here denote increments of the processes , and over particular time intervals. Here denotes demand that arrives during the time interval ( are special cases of with and ), and
We also use as a shorthand of . (Recall that .) We also introduce some random vectors. Let and be random vectors that follow the same distributions of and , respectively. Let be a random vector that follows the same distribution of . We also define
Similarly, denotes the amounts of components ordered over the previous lead time, or for t < 0, since the beginning of the replenishment process. Each component of , represents the amount of component j that is in transit: ordered from the supplier but not yet arrived. The amounts of demand served over the interval is denoted by .
Next we introduce two additional processes: inventory position and component balance . For , entries of (), are the differences between the total amounts of components that have been ordered up to time t and the total amounts needed to serve all demands that have arrived by that time. Entries of (, are the differences between the amounts needed to serve demands and the total amounts that have been ordered and received.
Recall that the replenishment and allocation processes (which are the control processes) are assumed to be integer valued and right continuous. Thus, the controls are exercised at discrete time points. It is helpful to distinguish the values of certain processes immediately before these actions are taken. To this end, we let ) denote the inventory positions at time t before placing any order at that time, and let denote the backlog levels at time t ) before serving any demand at that time. In Table 1, , and are defined using the left limits ), and . These left limits exist because in (2) and (3), ), and are nondecreasing and right-continuous. One may also observe that by definition,
2.3.2. Relationships.
The key definitions (2) and (3), along with the definitions introduced in Section 2.3.1, allow us to obtain relationships that are useful in our analysis. Using (2) and (3), and the definitions of ) and in Table 1, changes of inventory and backlog levels over a lead time Lk can be determined by
Again using (2) and (3), along with definitions of and in the table,
The second line corresponds to another definition of the inventory position in the literature: the total amount of the component in the system, including both on-hand inventory and orders in-transit, minus the amount needed to clear all existing backlog at that time.
Yet again using (2) and (3), along with the definition of in the table, and then applying (6) and (7) to replace and ,
Observe that the negative of an entry of ,
2.3.3. Other Parameters.
Define
For convenience, we define additional variables to denote the smallest (nonzero) and largest components of A, , and in Table 2 below.
3. Stochastic Program
As we outlined in Section 1, the first step of our analysis is to develop a multistage SP that provides a lower bound on the average inventory cost and sets the stage for developing inventory control policies to drive the cost toward that bound. To this end, we first present a relevant SP from the literature and discuss the intuition that underlies its formulation in Section 3.1. In Section 3.2, we transform this SP into an alternative SP that we use for policy development in Section 4.
3.1. Previous Result
For ATO systems formulated in the last section, theorem 1 in Reiman and Wang (2012) proves that
We now take the rest of this section to provide some intuition as to why the SP (10)–(11) yields a lower bound on the cost in the ATO inventory control problem. The basic idea is that the SP (10)–(11) is a relaxation of the actual ATO inventory control problem. The SP corresponds to myopically focusing on a single point of time, with no concern for the effect that any replenishment or allocation decision might have on costs at other points of time. Thus, in the presence of random demand, all decisions are put off until the last possible moment, allowing as much information about actual demand as possible to be used for the decisions.
To explain the SP in more detail, using (6) and (9), with k = K when substituting for and
The cost at t depends only on states and processes over the period . Comparing (10)–(11) with this expression for the cost, corresponds to the initial backlog levels and corresponds to , the amounts of demand served in the period . For components with lead time Lk, includes the amounts in inventory at time , the amounts that will arrive between and t from the pipeline, and the amounts used in the period . Corresponding to the sum of these three quantities, represents the total amounts of these components that can be used to serve demands in period .
In (10)–(11), , and are chosen to minimize the inventory cost with no constraint other than the ones that must be satisfied by the aforementioned counterparts of these variables in the ATO system. By (1)–(3), and ) are nonnegative, so using (6):
Correspondingly, in (11),
The information constraint in the SP is less obvious, as the sequential/recursive nature of its formulation both encodes and potentially obscures the information available when certain decisions are made. Although it is not needed in the definition of the SP, the information available when decisions are made in the SP can be described via a discrete filtration
The filtration ) imitates the information available in the associated ATO system and is generated by both and , corresponding, respectively, to histories of demand arrivals in periods and decision making at times . In ATO systems, is the last moment of decision making that can affect the value of , so letting be adapted to allows its value to be chosen with the maximum amount of information. This adaptedness is not explicitly enforced in the SP but is implicit in the recursive structure of the SP. When (which corresponds to stage ) is solved to obtain , the prior decisions are all known, and is known as well. Similarly, t is the last moment of decision making that can affect , so the choice of is adapted to . It is not surprising that, with , and chosen under the minimum constraints and maximum information, (10) is a lower bound on the expected cost of the ATO system at any given time t and hence a lower bound on its average cost .
3.2. New Development
The SP in (11) is not directly applicable to our analysis. As one may observe from (10)–(11), and as is shown in the proof of Theorem 2, decreases in , and strictly so in many cases. Therefore, the lower bound is not directly computable by solving (11) with any fixed . To reach the infimum in (10), , and thus () and often have to approach infinity, so one cannot make use of the optimal values of these decision variables for policy development.
To address this issue, we transform (11) into an alternative SP by replacing in (11) with and with and, following (10), letting approach infinity. The transformation removes and the nonnegativity constraints in (11) and leads to
For any feasible solution , and in (11), and is a feasible solution to (13), so for all . Therefore, (13) can also be used to set a lower bound on the inventory cost of an ATO system, a result that we will formally present in Theorem 2. Here, we first prove that the optimal solution of (13) is bounded.
(See Appendix A for Proof). For any given values of , and , if is an optimal solution to the SP in (13) at stage k, that is,
|
Table 2. Smallest and Largest Components of Relevant Vectors and Matrix
| Symbol | |||||||
|---|---|---|---|---|---|---|---|
| Definition |
The formulation in (13) helps us to avoid the aforementioned issue with (10)–(11). By (14), the optimal solutions to the new SP are finite, so they can and will be used as parameters of our inventory policy. Moreover, instead of taking the infimum in (10), we can use the optimal objective value of (13), which is directly computable, to set the same lower bound on the cost objective.
(See Appendix A for Proof). Let be the lower bound defined in (10) and be the optimal objective value of the SP defined in (13). Then
For future analysis, we replace with in (13) to transform the last stage LP into
In represents the amounts of unserved demands and thus is analogous to (), backlog levels in the ATO system. Let be an optimal solution to be an optimal solution to (), be an optimal solution to , and . Then by Theorem 2:
Because both components and products are measured in discrete units, (11) and (13) should be discrete optimization problems that can be difficult to solve exactly. For the purpose of setting a lower bound, if suffices to solve (13) without the integrality constraint, which is a continuous relaxation of the discrete problem. However, as will be shown in the next section, we will also use the SP to formulate inventory control policies, and for that purpose, the solutions need to be integer valued and satisfy certain uniqueness and continuity conditions. These issues will be addressed in Section 7.
4. Inventory Policy
Here, we will first describe the general idea that motivates our approach in Section 4.1, followed by developments of our replenishment and allocation policies in Sections 4.2 and 4.3, respectively. We will then make a few important observations in Section 4.4. A simple example that illustrates the application of our inventory policy, involving the N system, is given in Appendix B.
4.1. General Idea
To drive the average cost of the ATO system toward its SP-based lower bound in (13), we formulate inventory policies that mimic the optimal solution of this SP. As is commonly known and easily verifiable from (6)–(7), in an ATO system, the net inventory levels satisfy
The second equality allows us to rewrite the expected cost rate as the following function of inventory positions and backlog levels:
Hence, the average inventory cost of an ATO system reaches its lower bound if (19)–(20) are both satisfied for all time. Based on this observation, we develop replenishment and allocation policies by using the SP solutions to set targets for inventory positions and backlog levels, keeping actual values “close” to these targets under feasibility constraints.
4.2. Replenishment Policy
4.2.1 Overview.
The RHS of (19) is determined in (13). For k = K, is constant, and for , are determined recursively (going backward in k) on each sample path of as values of that minimize
Our replenishment policy is built on processes , with their distributions at each point of time mimicking those of . Figure 2 shows a match of these two quantities in any period (). Let , and determine recursively on each sample path of to minimize (21) with . Because and have the same distribution,
Motivated by (19), our policy uses and to set inventory position targets and make ordering decision to move actual inventory positions toward these targets.
Except for components with the longest lead time LK, inventory position targets typically change over time. When a target rises above the actual inventory position, it is feasible to bring the latter position to its target immediately by ordering an appropriate amount of the component. When a target falls below the actual position, it is not feasible to close the gap immediately before the target is reduced and/or new demand arrives. Recognizing the latter restriction, our replenishment policy orders a component when and only when its inventory position is below the target, in the exact amount needed to eliminate the deficit.
4.2.2. Specific Policy Procedure.
For components with the longest lead time LK, the inventory position target process starts from time and is determined by
For components with lead time Lk , the target process starts from and that its values are given by
Starting from time , the actual inventory position of a component with lead time Lk is compared with its target. New replenishment is ordered to keep the actual inventory position at
Although and are both continuous-time processes, their values change only at discrete points of time, corresponding to new demand arriving at t, or a demand arrival at one of a particular set of previous times, as follows. For components with lead time LK, as seen in (23), the procedure reduces to a constant base stock policy with as base stock levels. For components with lead time needs to be updated only when there is a demand arrival at time or t, which changes the value of , so (26) needs to be re-solved to update ). Similarly, by induction on k in (26), for can change only when there is a demand arrival at time (i) t, which changes , or (ii) () which might change , or (iii) , which changes both and (). Moreover, (27) implies that only at these times can change: because can only change at these times, and as Table 1 shows, can differ from only when there is a demand arrival at time t ).
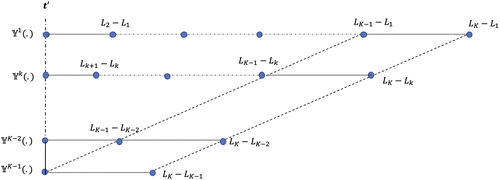
Although it may seem that an exact implementation of the previous idea would require looking back in time at every moment t, to see if there is any demand arrival at times , to decide whether to update and place orders to reach new ), there is an equivalent simpler and more intuitive implementation, which allows demand arrivals to drive future updates. Specifically, when there is a demand arrival at time t, schedule updates of inventory position targets and corresponding ordering decisions at times .
Figure 3 illustrates the process. The vertical line represents a particular time when there is a demand arrival. Each horizontal line corresponds to a lead time. On the line corresponding to Lk, circles mark points of time when (26) needs to be re-solved to update and ). The expression next to a circle shows the distance in time from time to the circle. Updates of take place at times and as demand arrival at time changes in (26) when or . Moreover, as shown by two parallel dashed lines, updates of at times and change values of in (26) when and , so needs to be updated at the latter two times ). In general updates of at times and trigger updates of at times and , respectively ).
The complete replenishment procedure is presented in Algorithm 1. The collection of times at which and possibly change is denoted by . The ceiling function on in step 2(c) ensures that both and are integer-valued (). In Steps 2(a) and 2(b), inventory position targets ) are updated repeatedly over time except for k = K, in which case are constants that are set once at time . It is easy to verify that prescribed in Algorithm 1 satisfy the feasibility requirements defined in Section 2: integer-valued, nonnegative, nondecreasing, right-continuous, and nonanticipating.
It is worth pointing out that in ATO systems with a single product, this replenishment policy specializes to the one prescribed by Rosling (1989). In this special case, the latter policy is exactly optimal because all components are used according to fixed proportions, so one can always keep inventory positions at their targets (after some initial lapse for these positions to reach “coordinated levels”). In systems with identical lead times, our policy specializes to the one formulated in Reiman and Wang (2015), which uses base stock policies for replenishment and is asymptotically optimal in the large lead time regime.
(Replenishment Policy Procedure)
Initialization: for , let
For :
4.3. Allocation Policy
4.3.1. Overview.
On the RHS of (20), is the optimal solution of the LP
As a result, (20) holds for , that is,
Although gives the desired backlog levels for the inventory cost to reach its lower bound, it is determined by (see (25) and (29))
Comparing with in Table 1, differs from actual component balances by having inventory position targets in place of actual positions . Because our replenishment policy in general does not keep inventory positions at their targets, does not always capture the exact state of component availability in the system. Recognizing this discrepancy, we set the backlog target at , which, like , is determined by minimizing (28), but using instead of to replace . Although (20) may not hold for at equality, our analysis shows that the difference is asymptotically negligible.
Actual backlog levels may exceed or fall below their targets. It is generally infeasible to keep all backlog levels at their targets: a below-target backlog level cannot be raised immediately to the target if there is no new demand arrival, and an above-target backlog level cannot be reduced if a required component is not available. Naturally, we prescribe an allocation policy that uses all available components to reduce backlogs that are above their targets and never serves a demand when its backlog level is at or below the target.
(Allocation Policy Procedure)
Initialization: let
For ,
if t = 0 or for some , then
1 .let be the value of that minimizes:
(31)2. let
(32)where must be integer-valued and its choice satisfies:(a) for all ,
(33)and(34)where(35)and by definition (8),(b) for all ,
(36)End of Algorithm 2
4.3.2. Specific Policy Procedures.
Algorithm 2 prescribes the specific policy procedure that implements the previous idea on component allocation.
To explain, the allocation decision starts at time 0 when the first batches of replenishment orders arrive. Before that time, backlogs simply accumulate as new demands arrive. After that time, new allocations are triggered by changes of (, the balance of some components. (This occurs as demands and replenishments arrive.) As Table 1 shows, is the difference between the accumulated demand and supply, . The former is a compound Poisson process and the latter is a pure jump process under the replenishment policy executed by Algorithm 1. Thus, allocation actions are taken at discrete points of time, which include using (31) to set backlog targets and serving demand under conditions (32)–(36). Of the latter conditions, (32) and (35) simply repeat definitions of and in Table 1. Distinct features of the policy are characterized by (33), (34), and (36).
In (33), is specified as an integer, is real number, and the floor function is applied to eliminate the rounding error in their difference. The equation defines the key feature of the policy: a backlog level can exceed its target (within the rounding error) only when the system runs out of a needed component to serve the demand, that is, when
The left inequality of (34) requires that the backlog level of a demand () should be kept at its existing level ( if the latter level does not exceed its target ().
The right inequality of (34) encodes that serving a demand can only reduces its backlog level.
Referring to (8), (36) is equivalent to
that is, demands cannot be served with a nonexisting component.
In prescribing this procedure, we have omitted specific processes for determining to satisfy (33), (34), and (36) because there can be many different ones. For instance, one can select all backlogs that exceed their targets and use available components to reduce them one at a time according to a particular order. Each backlog is reduced to the point where (33) applies, that is, either the backlog reaches the target or there are not enough components to bring it down further. This process obviously also satisfies (34) and (36). We can formulate many other processes by, for instance, changing the order by which backlogs are processed or not following a fixed order at all. Therefore, Algorithm 2 defines not a single policy but a family of eligible policies. Such policies always exist, for example, the one that follows the process we just described.
To show that this family of eligible policies satisfy requirements for feasible policies defined in Section 2: Once is determined, the original allocation process is fully specified by (32). By (32) and (35), we can write
From the first expression of in (8) and the constraints in the LP (31),
Therefore, for any given product i ,
Apply the inequality to (33) leads to the following important property of our allocation policy:
For any , if , then
See Table 2 for definitions of and .
By this property, our policy does not allow backlog of any product i to exceed its target by more than a rounding error when no backlog is below its target (i.e., for all ). A similar observation was made in Reiman and Wang (2015) for developing asymptotically optimal policies to manage ATO systems with identical lead times. Likewise, we will use this fact in Section 6.2.2.
4.4. Further Comments
Algorithms 1 and 2 show that our policies can be fully implemented by controlling inventory positions via (27) and choosing backlog levels that satisfy (33), (34), and (36). For brevity, from now on, we will only use the latter variables to characterize our policies, instead of invoking the original replenishment process and allocation process .
The procedures in these tables implicitly assume that there is no ambiguity about and , which is true if the related SPs for choosing these values all have unique optimal solutions. In Section 7, we will discuss how to perturb these SPs to satisfy the uniqueness condition without compromising asymptotic optimality.
5. Asymptotic Optimality
The rest of the paper will focus on performance evaluation, especially asymptotic optimality, of our policy, and this section provides a critical lead into this analysis. We first set up the asymptotic regime in Section 5.1. We then define the asymptotic optimality criteria in Section 5.2, followed by the development of a key theorem in Section 5.3 (Theorem 3) that specifies sufficient conditions for meeting these criteria.
5.1. Large Lead Time Asymptotic Regime
We introduce a family of systems indexed by L. In the Lth system, is the lead time of components (). The longest lead time . We define the large lead time asymptotic regime by letting the longest lead time .
For convenience, define . Let
We impose no assumptions on other lead times except that for all L,
5.1.1. Demand Process.
The Lth system is empty at time –L when the demand process () starts. This process is the same as in Section 2 except for the starting time. Similar to definitions of and in Table 1, let be the increment of over , with and denoting the mean and covariance matrix of , and be the instantaneous change of at t . Define
Let be a random vector with the same distribution as . Then
5.1.2. Replenishment and Inventory.
In the Lth system, replenishments of components with lead time start at time (). Following the policy description in Section 4.2, the inventory position targets are
Let be the actual inventory position in the Lth system. Under the aforementioned replenishment policy, for :
For , let
5.1.3. Allocation and Backlog.
Referring to our allocation policy in Algorithm 2, denote backlog targets in the Lth system by (). Denote backlog levels and by and (), respectively. Hence, is the optimal solution that minimizes
Corresponding to prescribed by (28)–(29), let be the optimal solution to (43) with replaced by .
Define
Obviously, and are optimal solutions to (43) with replaced by and , respectively.
5.1.4. Inventory Cost.
In the Lth system, the long-run average expected inventory cost is
Using (18), the expected inventory cost rate can be written as
Define
Then
5.1.5. Summary of Definitions.
For future reference, we summarize the definitions made in this subsection for asymptotic analysis. Some vectors of random processes are centered and scaled componentwise by
Some other processes and variables are scaled componentwise (without any centering) by
5.2. Asymptotic Optimality Criterion
Applying Theorem 2 to the Lth system, the average inventory cost has a lower bound , determined by the SP (13), using as inputs . Define
Let denote the infimum of the average inventory cost over all feasible policies. Because these values are bounded below by , this infimum exists. We show that our policy is asymptotically optimal in the traditional sense that
Because , we have
Hence, we can prove (47) by showing that
and,
To show (48) is true, apply the SP (13) to the Lth system with following changes: let be a product with , where component n has the longest lead time L. Keep hn and intact while resetting hj = 0 ) and bi = 0 (). The problem then becomes
Let be the optimal objective value of the above minimization problem. Obviously, , where is the objective value of (13) specialized to the Lth system. Apply and the new costs to (15) and compare the resulting value (denoted by ) with the lower bound and the minimum cost:
Furthermore, simple transformations of shows that
Hence, to show (47) is satisfied, we only need to prove (49); that is, our policy is asymptotically optimal on the diffusion scale.
5.3. Sufficient Conditions for Asymptotic Optimality
The following theorem shows that (49) holds if inventory positions and backlog levels converge to their respective targets. Recall that these targets were set at levels at which the average inventory cost can attain its SP-based lower bound (see (19) and (20)). Although meeting these targets exactly is not possible in general, the theorem shows that meeting them on the diffusion scale, which we will prove to be feasible in the next section, is sufficient to guarantee asymptotic optimality.
In a family of systems indexed by their longest lead time L, if
Following (17), in the Lth system,
Specializing (22) and (30) in our policy formulation to the Lth system:
Moreover, has the same distribution as by definition. Thus,
By the definition of and applying the second equality of the above equation:
Comparing this with (46):
The theorem follows immediately by applying (50) and (51) to (52). □
6. Proof of Sufficient Conditions
Continuing from Theorem 3, we prove in this section that (50)–(51) are satisfied under target stability conditions to be defined later. To put results obtained in this section in perspective, it was shown in Reiman and Wang (2015) that for systems with identical lead times only (51) was needed because asymptotic optimality can be achieved under a base-stock policy that keeps the inventory positions constant. The convergence (51) was shown in theorem 4 in Reiman and Wang (2015), whereas here it is shown in Corollary 2. The proof of (51) in Reiman and Wang (2015) does not carry over to this setting because it assumes the use of a base stock policy for replenishment.
Target Stability Conditions. Under our inventory policy, , obtained by solving (26), (), obtained by solving (28)–(29), and , obtained by solving (31), have the following properties: there exists some constant κ, depending only on , and A, such that on each sample path of these processes,
for all ,
(53)for all ,
(54)and for all ,(55)
We will develop an SP solution procedure in Section 7 to satisfy (53)–(55). Here in this section, we assume these conditions hold to prove (50) and (51).
Let us first give an informal explanation of the intuition of our proof. Under our replenishment policy, an inventory position can differ from its target only by exceeding it. When this happens, our policy will stop ordering the component, so its inventory position drops at the same rate as its demand arrival rate. The target may also change as new demand arrives. However, Condition (53) ensures that the latter change in the target is “slow” in comparison with demand arrivals, so the excess of inventory position over its target can be eliminated fast enough to satisfy (50). We then use a similar argument to show that under Conditions (54)–(55), (51) cannot be violated by having a backlog level falling below its target. To show that (51) can also not be violated by having a backlog level exceeding its target, we make use of the property of our allocation policy given in (37); that is, no backlog level will exceed its target when no other backlog level is below its target.
To reduce redundancy and improve generality, in Section 6.1, we define a general problem, referred to as the stochastic tracking model, based on common features of (50) and (51). We develop Theorem 4, which applies to the general model and contains (50) and (51) as special cases.
6.1. Stochastic Tracking Model
Consider a family of systems indexed by L > 0, where the Lth system is associated with the following parameters and processes:
The process ( is the same compound Poisson demand process defined in Section 5.1.1 for the Lth system, with the arrival rate and order sizes apply to all systems. For the results of this section, it is important to recall that components of , Si , are assumed to have a finite moment of order 6. As in Section 5.1.1, the increment of over interval is denoted by and the jump of at time t is denoted by .
The vector is an m-dimensional vector of nonnegative integers. The value of the vector is the same for all systems and at least one of its elements is strictly positive.
Each system is associated with a set of constants (). Values of differ between systems, but the index set , which is finite, remains the same for all systems. In the Lth system,
The process , which we refer to as the target process, is a pure jump process that starts at time , where in the Lth system,
The process , which we refer to as the tracking process, is another pure jump process that also starts at time from an initial level . The process is defined by
(57)
For convenience, we denote the initial difference between the target and tracking processes by
Observe that the tracking process can instantly catch the target that rises higher than its level. When the target is lower, the gap can be closed after a sufficient amount of demand has arrived.
Let and be defined the same as in (39). Let
Following the conditions imposed on and in their definitions,
Let
Finally, the definition of the model also requires the following asymptotic Lipschitz continuity condition on the target processes in this family of systems:
Asymptotic Lipschitz Condition. There exists some constant κ that applies to all systems, such that for all ,
Then
The main conclusion we draw from this model is in Theorem 4, which shows that as L increases, the tracking process converges to the target process on the diffusion scale.
Assume that Si has a finite moment of order 6. If
Before proving the theorem, we provide some context and intuition for the result. The convergence in (62) is, in essence, an example of “state-space collapse,” a phenomenon that plays a critical role in the heavy traffic analysis of queueing systems and stochastic processing networks (Reiman 1984, Harrison and van Miegham 1997, Bramson 1998, Bell and Williams 2001, Atar et al. 2019). As noted previously, the tracking process is able to instantly match the upward jumps of the target process but not the downward jumps. Under the scaling that we introduced, the family of processes satisfies a functional central limit theorem (FCLT). This implies that has “almost continuous” paths for large L. The assumed asymptotic Lipschitz continuity of implies that it has almost continuous paths as well. When , it is following total demand downward. This is uncentered demand, so that is decreasing at a “rate” that is when . Thus, never gets “far away” from , and the two-dimensional processes “collapse” into a one-dimensional process with in the limit. The proof of Theorem 4 makes this intuitive description rigorous.
As noted previously, satisfies an FCLT. Interestingly, we never actually invoke this fact in our proofs. A key reason is that it would not be enough to obtain the result that we need. FCLTs involve convergence over a finite time interval. To prove asymptotic optimality under the long run average cost criterion that we use, we need uniform convergence over an infinite time interval, which does not follow from the FCLT.
The proof of Theorem 4 is built on the following four lemmas. The first two are restatements of two lemmas in Reiman and Wang (2015), and the next two are new. In all lemmas, order sizes Si are assumed to have a finite moment of order (), except for Lemma 3, which requires a stronger condition of having a finite moment of order 6.
(Lemma 2 in Reiman and Wang 2015). For all ,
(Lemma 3 in Reiman and Wang 2015). For all ,
This is where σii is the variance of .
Let g be any strictly positive constant. Then for all ,
(See Appendix A for Proof). Assume that Si has a finite moment of order 6 . Let ν be any strictly positive constant. Then for all ,
(See Appendix A for Proof). Let ν be any strictly positive constant. Then for all ,
The theorem is proved here by showing that there is uniform upper bound on the expected value at the left-hand side (LHS) on (62) and the bound converges to zero as L increases.
We prove (62) in the theorem by bounding and prove the bound converges uniformly to zero for all . By definition,
Observe that
To prove (69), when for all , so by (57),
By applying the previous expression and Condition (59), for any time t ,
Therefore, under Condition (61), (69) holds if
Let
Then
Because () is a stationary process,
Because , for all ,
To prove (70), by the definition of , in cases where ,
Because for all , by (57),
For the last two items in (75), by (59),
Let
By applying (76), (77), (78), and (79) to bound each item in the last expression of (75) and replacing with , we can prove that (70) holds under Condition (61) by showing that for all and ,
For each given i and l ,
(Recall that , so in the previous expression). Therefore, (80) and (81) follow from a similar argument that proves (74): by the use of Lemma 3,
To prove (82), because and the demand process is stationary,
6.2. Convergence to Targets
We again consider a family of ATO systems indexed by L, with as the demand process in the Lth system. For each component and for each product, we specify other parameters in (56) to define an instance of the stochastic tracking model and prove (50) and (51) as corollaries of Theorem 4. In fact, the theorem shows convergence of over an infinite time horizon, which is a stronger result than what is needed, which is the convergence of .
The proofs use the following lemma.
(See Appendix A for Proof). Let be defined in (42) with and ν be any strictly positive constant. Then
6.2.1. Proof of Condition (50).
For each component j , define
To verify this is an instance of the stochastic tracking model, by our replenishment policy in Algorithm 1, () is a pure jump process. Apply (25) to the Lth system,
Thus, under (53), the asymptotic Lipschitz condition (59)–(60) is satisfied with .
By the definition of in Table 1 and referral to (27), in the Lth system,
For all ,
The first equality follows from definitions in (42) because the fractional value of can be ignored when . Theorem 4 shows that the second equality holds if
Applying (25) to the Lth system,
Therefore, by Lemma 5 with ,
6.2.2. Proof of Condition (51).
It is helpful to first review the processes that will be involved in the analysis. In the Lth system and for product i ), is the backlog target and is the ideal backlog level for reaching our SP-based lower bound. Both are determined by the LP in (43), using actual inventory positions and inventory position targets as their respective inputs. The backlog level under our allocation policy is . To help with the analysis, we will define below an auxiliary process , which mimics , except that it is not allowed to rise above the target .
For each product i , we construct an instance of the stochastic tracking model by letting
Here, we will show that is a target process, which, following the previous definition, also implies that is a tracking process.
When defining our allocation policy in Section 4.3.2, we have shown that () is a pure jump process. To show that is asymptotically Lipschitz continuous, let
Then
By applying (29) to (55), there exists some constant κ such that
where under (53), there also exists some constant κ such that
By (54), there exists some constant κ such that
Thus, (60) follows directly from Corollary 1.
Having shown that is an instance of the target and tracking processes, we now can prove (51) as the following corollary to Theorem 4.
For , let
Then,
To prove this initial condition, observe that
Because minimizes (31) with , there exists some constant κ, which depends only on matrix A, such that
Because under our replenishment policy (see (27)),
Let . By its definition, . Therefore,
Because ) is stationary, Lemmas 3 and 5 imply (90), which proves (89).
To show that (89) implies (51),
By (88), the last term is simply that satisfies (60); thus, we only need to prove
As is shown in (34), under our allocation policy,
Moreover, because Property (37) applies when , in all cases,
Combine the above two inequalities,
7. Stability of SP Optimal Solution
In this section, we finalize our analysis by showing that with proper treatments of the SP (13), Conditions (53), (54), and (55) can be satisfied. To this end, we need to address two issues: uniqueness of the optimal solutions and values of Lipschitz constants.
Recall that and ) are optimal solutions to the same LP (28) with different RHS coefficients in constraints. Hence, by Hoffman’s lemma, for each t (), there exist and that satisfy (54), and for each t1 and t2 ), there exist and that satisfy (55). Nevertheless, the lemma does not exclude the possibility that if the optimal solution of (28) is not unique, then to satisfy (55) at the same t1, we may need different for different t2. In this case, a well-defined process that satisfies (55) for all t1 and t2 () is not guaranteed. To avoid this situation, we use perturbation to keep the optimal solution of (28) unique. As a result, both and are uniquely defined processes that satisfy (54) and (55).
It takes significantly more effort to address (53). Because the supports of are unbounded, in (13) are infinite-dimensional problems, so their optimal solutions may not satisfy the continuity condition specified by (53). We develop finite-dimensional LPs to approximate the latter problem and prove that we can always keep the approximation error negligible by keeping the dimension of the LP sufficiently high. We also use perturbation to maintain uniqueness of the optimal solution. Both the approximation and perturbation (which also addresses uniqueness of the optimal solution to (28)) are developed in Section 7.1.
In the asymptotic analysis, when lead times increase, probabilities of having larger sample values of increase, so the dimension of the approximating LP needs to increase to keep the approximation sufficiently accurate. To sustain (53), we need to rule out the possibility that the Lipschitz constant κ has to grow unboundedly with the problem dimension. In Section 7.2, we show that κ can be kept at a finite value regardless how large the dimension of the LP becomes.
7.1. Approximation and Perturbation
We develop finite-dimensional approximations to SP (13) by taking following steps: let be a m-dimensional vector with all entries equal to an integer M > 0. Denote by (). Replace in (13) with in () to define
Because are integers, for given M, have a finite support (). Hence, for each k (), is a finite-dimension problem, which can be equivalently formulated as an LP. The LP formulation is thoroughly elaborated on in section 3.1.3 of Shapiro et al. (2009). Appendix C describes the detailed steps of specializing this standard process to (92), which leads to
Here is the set of strings that encode sample paths . For each sample path ,
The probability attached to sample path is denoted by . For and (), we write if the sample path encoded by is on the same sample path encoded by .
We perturb coefficients in the objective function (93) to keep the optimal solution of the LP unique. The approach is standard, so we leave the details to Appendix C. As a general description, because Ak and are integer-valued, the optimal solution must be rational numbers when k = K, and by induction, so are the optimal solutions when . By adding tiny different irrational values, we replace , and in (93) with their perturbed values, which are denoted, respectively, by (), and (). The use of the perturbed coefficients removes the possibility that two different rational solutions can yield the same objective value, and thus guarantees the uniqueness of the optimal solution.
In our following discussion, we will refer to as if they correspond to the stage k problem of (92), or equivalently, (93)–(97), with perturbed coefficient values. At each stage, the perturbation does not change with inputs ) and . In other words, the same perturbed coefficients apply to all instances, including cases when the problem is solved repeatedly over time with different inputs to execute our inventory policies.
For this truncated and perturbed SP to be an effective proxy of the SP in (13), its optimal objective value, , must stay close to that of the original problem. To this end, we define Δ as the range of perturbation, that is,
The following theorem shows the convergence of the two optimal objective values under proper choices of M and Δ.
(See Appendix A for Proof). For any constant ϵ, there exists such that
There also exists , such that for all (), and () in the range defined by (98),
In Appendix C, we show that for any , it is easy to find perturbed coefficients that guarantee the uniqueness of the optimal solution while also fitting into the range defined in (98). Hence, the theorem indicates that the lower bound on the average inventory cost,
For inventory control, we incorporate the previous approximation into our inventory policy to specify a unique trajectory of targets on each sample path. In the replenishment policy defined in Algorithm 1, instead of (26), we set inventory position targets at Step 2(a) by solving the stage k problem of (92) (or equivalently, the LP in (93)–(97)),
Observe a subtle difference from (92): here only demands of future scenarios are truncated to , which keeps the dimension of the problem finite. Demands that have already arrived by time t, , enter the SP as inputs without truncation, allowing their amounts to be fully accounted for in the determination of desirable inventory positions.
In the allocation policy implemented by Algorithm 2, (31) is equivalent to in (92) for all M, and we solve the LP with substituted by its perturbed values of . Similarly, as the input we use
To evaluate the performance of the targets set by the above process, we consider how their values and resulting inventory costs can be represented by solutions and objective values of the approximating SPs. Let denote the optimal solution to stage k ) and denote the optimal solution to the stage 0 problem of (92) with perturbed coefficient values. Inputs to the stage k problem are (),
It is important to observe that the values of and may differ even though they both are based on the same problem formulation in (92). The latter is the optimal objective value when the problem is solved in its entirety, with perturbed coefficients and truncated demand input,
(See Appendix A for Proof). Under any truncation parameter M and perturbed coefficient values,
Hence, given the same ϵ, M0, and Δ in Theorem 5, for all ,
The corollary shows that we can use a perturbed finite-dimensional version of the SP (13) in our policy without compromising asymptotic optimality: fix a constant , and for each system L, choose a proper constant M and range Δ to keep
This difference is asymptotically negligible on the diffusion scale.
The remaining question is whether the previous development can provide us with the targets we need. For backlogs, the answer is immediate. Because in (92) is the same LP as (31) for all M, we only need to replace with and keep the latter value the same in all cases. Hoffman’s lemma immediately leads to the following.
Let be the (unique) optimal solution of (31) and be the (unique) optimal solution of the same LP with replaced by ). Then and satisfy (54) and satisfies (55).
For inventory position targets, the analysis is much more involved and given in Section 7.2.
7.2. Values of Lipschitz Constants
The approximation and perturbation scheme in Section 7.1 is developed to set inventory position targets that satisfy (53) and backlog targets that satisfy (54)–(55). In the asymptotic analysis, the LP (31) stays the same when L changes, so (54)–(55) are satisfied as long as the optimal solution is kept unique by the aforementioned perturbation. On the other hand, as L increases, larger M is needed in (93)–(97) for an accurate approximation of the demand distribution. For (53) to hold, the value of κ needs to be independent of the change of M. Theorem 6 and its corollary show that such a value always exists.
For , let and be (unique) optimal solutions to (93)–(97) under inputs and , respectively. Then
Before proving the theorem, we first show its implication by deriving a corollary: as is specified in Section 7.1, we solve (93)–(97) to obtain values of () for implementing our replenishment policy. For this purpose, needs to satisfy (53), which is clearly satisfied when k = K, in which case these values are kept constant. Theorem 6 allows us to use induction to extend (53) to k < K, which is stated as the following corollary.
For , let be the (unique) optimal solution of defined in (93)–(97), with inputs given by (101). Then (53) holds for a constant κ that depends only on and Ak .
For given k, suppose that (53) holds for all l > k (which is the case for ). This means that there exists some κ, depending only on and Ak , such that for all ,
Because () is obtained by solving (93)–(97) using (101) for inputs () and , by Theorem 6,
The remainder of this section is dedicated to proving Theorem 6. We start from the following theorem 2.4 in Mangasarian and Shiau (1987) (for convenience, we denote and in their theorem by and , respectively, here):
Let and (so that is the dual norm of ). Let the linear program
To apply the theorem to defined in (93)–(97), let be the LHS constraint matrix of the latter LP. Because there is no equality constraint, we can ignore and C. Let , and thus . Then and in the theorem specialize to
The following lemma builds a critical connection between the formulation of the previous quantities and the conclusion of Theorem 6.
(See Appendix A for Proof). For , let be a maximal nonsingular submatrix of . Let be a vector that has the same number of components as the number of rows in . Then there exists a constant κ, depending only on and the values of the components of Ak , such that
Proving this lemma is quite involved because we need to exploit the particular structure of to show that the result, which does not apply to an arbitrary matrix, is true here. As may be seen from the proof of this lemma in Appendix A, it takes some effort to define this structure, especially for cases where k > 1. To help with the understanding of this result, we explain the intuition behind the lemma’s conclusion, after we first use the lemma to give the following proof of Theorem 6.
Let be any vector such that and rows of corresponding to nonzero elements of are linearly independent. Let be a maximal nonsingular submatrix of that contains all these independent rows. Let be a subvector of that is composed of components corresponding to rows in in , and thus includes all nonzero elements of .
By Lemma 7, there exists a constant κ, depending only on and component values of , such that
By theorem 2.4 in Mangasarian and Shiau (1987), satisfies (104), so does κ. □
To explain the insights on proving Lemma 7, we start from the identity
Thus, we can let κ in (107) be the largest over all (nonsingular submatrices of ). What needs to be explained then is why this value of κ can stay bounded as M increases, which leads to more elements in and () and thus a larger .
Our explanation focuses on k = 1, in which case (95) is irrelevant and
Any nonsingular submatrix of can be written as
As a thought experiment, suppose that for every aforementioned nonsingular matrix , we can find a matrix to make the following linear transformation
Here is a nonsingular matrix in the form of
Suppose further that for all , (a) entries of the corresponding matrix are values in a finite set and (b) the number of nonzero entries on each row of is bounded by an integer function of m and n1. Then the previous expression implies that regardless how large M is, the maximum absolute value of entries of stays bounded, and the number of nonzero entries on each row of remains finite. Thus and thus the value of the aforementioned κ is bounded by some constant that is independent of M.
The actual proof of Lemma 7 is based on a similar idea to earlier, although we do not need to specify and carry out the aforementioned transformation explicitly. Roughly speaking, we observe that in (109), all s have finite dimensions and has a finite number of columns () with zero or one as their entries. This structure allows all nonzero entries of , which recovers from (in the sense of (108)), to be obtained by inverting submatrices of . These submatrices have finite dimensions and values of their entries do not depend on M. Consequently, in , both the number of nonzero entries on each row and their values are finite, so can remain bounded as M increases.
Similar insights are used to prove Lemma 7 for cases with k > 1, but the procedure gets considerably more complicated. For instance, when k = 2, the LHS matrix of (94)–(97) is
8. Numerical Results
We evaluate the performance of our policy by simulating its application to the examples of ATO systems shown in Figure 1. Each system features two distinct lead times. We vary cost parameters and lead times to generate various cases. For all cases the demand for products consists of independent Poisson processes, with the arrival rate of demand for product i denoted by λi. In each case, is the SP lower bound, Cs is the average inventory cost determined by the simulation, and the following optimality gap
For each case, we carry out 30 simulation runs. Depending on the lead times, the length of each run ranges from 150,000 to 600,000 time units, ensuring that it is at least 1,250 times of the longer lead time. The first one-tenth of the simulation time is for warm-up. Values presented are summaries of outputs from the remaining periods, averaged over the 30 simulation runs.
We first consider the W system, using 27 parameter sets given in Doğru et al. (2010, section 4.1). The inventory holding cost of the common component, h0, is normalized to unity and demand arrival rates are kept at . Values of h1, h2, b1, and b2, which are shown in the tables, are chosen to cover a wide range of cost relationships. Components 1 and 2 have the same lead time, which differs from that of component 0.
Table 5 shows optimality gaps when component 0 has the shorter lead time. Entries marked by * correspond to cases where the SP solution is within the 95% confidence interval (CI) of the average cost estimated by 30 simulation runs. In these cases, the difference between the inventory cost under our policy and its lower bound is not statistically significant. In all other cases, the optimality gap decreases as the lead times increase, consistent with the trend predicted by Theorem 3. The optimality gaps fall to a level that is close to or below 1% in many cases when , and in a majority of cases when . We stop running simulations for these cases with longer lead times (as indicated by “-” in the table). In a few cases, the optimality gap stays significantly above 1% in all simulations, but nevertheless, still follows a clear pattern of converging to 0. These cases (e.g., 15, 21, 27) are normally associated with a high ratio. Discussions in section 4.2 in Doğru et al. (2010) explain why the gap tends to be larger under these parameter values for systems with identical lead times. The same intuition applies here for systems with nonidentical lead times.
|
Table 3. Centered and Scaled Processes and Vectors
| Process/vector | |||||
|---|---|---|---|---|---|
| Centering | |||||
| Centered and scaled |
In Table 6, we use the same parameter set but let the common component have the longer lead time and the other two components have the same shorter lead time. Like results in Table 5, it is evident that in each case, the optimality gap converges to zero as the lead times increase. Nevertheless, these gaps are generally larger here. For instance, when , the gap is close to 2% in cases 21 and 27. We have additional runs for these two cases with and found the gap drops to 1.03% and 1.26%, respectively.
|
Table 4. Scaled Processes and Variables
| Process/variable | ||||||||
|---|---|---|---|---|---|---|---|---|
| Scaled |
It is interesting to focus on the first four cases where c1 = c2. In Table 5, the SP lower bound is within the 95% CI except for case 4 when . A further calculation shows that this bound is within the (wider) 99.9% CI. In Table 6, the SP lower bound is outside the 95% CI in cases 1, 3, and 4 when . Further calculations show that in cases 3 and 4, the SP lower bound is also outside the 99.9% CI. Comparing the sample mean of the average cost obtained from the simulation with the lower bound, the t value is 4.69 for case 3 and 6.48 for case 4. Given that the sample size is 30, these values suggest that the inventory cost in both cases is significantly higher than the lower bound (with ).
The observation is consistent with theorem 4 in Reiman and Wang (2012), which concludes that in W systems with c1 = c2, the SP lower bound is reachable when the common component has the shorter lead time. However, the conclusion does not extend to W systems in which the common component has the longer lead time. Here, we use a special case of the W system, the N system shown in Figure 1, to explain this subtlety.
When c1 = c2, serving a unit of either product 1 or 2 removes the same amount of inventory cost from the system. Thus, the optimal allocation outcome prescribed by the SP solution is trivially attainable. However, when the common component has the longer lead time, it may not be possible to meet the SP-based inventory position target of the other component for all time. To see this point, consider a time t when a large batch of demand for product 1 has just arrived, exhausting all inventory of component 0, both on hand and in transit at the moment.
When component 0 has the longer lead time, any new order of it will not arrive until , which means that its net inventory level at is nonpositive. Correspondingly at time t, the inventory position target of component 1, constrained by the availability of component 0 at , will be set at a nonpositive level. The system may not be able to meet this target because the actual inventory position is affected by previous ordering decisions, and therefore can be positive at t even without ordering any new unit. Reducing it to a nonpositive level requires removing existing units, which is not feasible.
This situation does not happen when component 0 has the shorter lead time. In this case, the SP sets a constant inventory position target for component 1, which is always met (excluding the initial period) under a constant base stock policy. Any usage of component 1 is accompanied by the usage of component 0 by the same amount. Therefore, when the inventory position target of component 0 needs to be reduced because of the lack of component 1 within the next (shorter) lead time, its actual inventory position is also at a lowered level, which allows the target to be met without removing any unit from the system.
The impact of this difference on the optimality gap is shown by a few examples in Table 7. The first three columns give cost parameters. For each example, we compare the SP lower bound with the average cost from 100 simulation runs. Results in columns 4, 5, and 6 are from examples in which component 0 has the longer lead time. In each example, the SP lower bound is strictly below the lower end of the 99.9% CI of the average cost. Comparing the sample mean of the latter cost with the lower bound, the t values are 25.08, 16.81, and 33.30, respectively, in these three cases, so the optimality gap is strictly positive at exceedingly high significance levels. Results in columns 7, 8, 9 are from examples in which component 0 has the shorter lead time. In all examples, the SP lower bound is inside the 95% CI and thus certainly inside the (wider) 99.9% CI. The t values are 1.28, 0.97, and 1.34, respectively, none of them is significant at .
|
Table 5. Optimality Gaps: W System, Component 0 Has the Shorter Lead Time,
| Case no. | h1 | h2 | b1 | b2 | Optimality gap (L1: component 0, L2: components 1 and 2) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 4 | 4 | 0.03% * | 0.14% * | 0.04% * | — | — | — | — |
| 2 | 0.2 | 0.2 | 2.4 | 2.4 | 0.01% * | 0.04% * | 0.08% * | — | — | — | — |
| 3 | 1 | 5 | 10 | 6 | 0.10% * | 0.07% * | 0.19% * | — | — | — | — |
| 4 | 5 | 5 | 12 | 12 | 0.05% | 0.01% * | 0.00% * | — | — | — | — |
| 5 | 0.2 | 1 | 6 | 4 | 0.56% | 0.12% * | 0.24% * | — | — | — | — |
| 6 | 0.2 | 0.2 | 2.4 | 1.2 | 3.51% | 1.92% | 1.34% | 0.83% | — | — | — |
| 7 | 1 | 1 | 4 | 2 | 1.04% | 0.68% | 0.49% | — | — | — | — |
| 8 | 5 | 5 | 12 | 6 | 0.13% | 0.08% | 0.04% * | — | — | — | — |
| 9 | 1 | 0.2 | 4 | 2.4 | 2.20% | 1.03% | 0.79% | — | — | — | — |
| 10 | 0.2 | 0.2 | 6 | 2 | 3.41% | 1.63% | 1.22% | 0.87% | — | — | — |
| 11 | 1 | 1 | 10 | 4 | 2.07% | 1.24% | 0.76% | — | — | — | — |
| 12 | 5 | 5 | 30 | 12 | 0.40% | 0.12% * | 0.04% * | — | — | — | — |
| 13 | 0.2 | 0.2 | 6 | 2.4 | 5.47% | 2.89% | 2.03% | 1.56% | 1.03% | — | — |
| 14 | 1 | 0.2 | 4 | 1.2 | 5.85% | 2.98% | 2.07% | 1.45% | 0.98% | — | — |
| 15 | 0.2 | 0.2 | 6 | 1.2 | 14.36% | 7.17% | 5.34% | 3.75% | 2.48% | 1.92% | 1.37% |
| 16 | 1 | 1 | 10 | 2 | 5.20% | 2.55% | 2.12% | 1.45% | 0.86% | — | — |
| 17 | 5 | 1 | 12 | 4 | 1.45% | 1.09% | 0.72% | — | — | — | — |
| 18 | 5 | 5 | 30 | 6 | 0.84% | 0.32% | 0.23% | — | — | — | — |
| 19 | 1 | 0.2 | 10 | 2.4 | 7.10% | 3.73% | 2.79% | 2.04% | 1.52% | 1.01% | — |
| 20 | 5 | 1 | 12 | 2 | 3.12% | 1.63% | 1.15% | 0.78% | — | — | — |
| 21 | 1 | 0.2 | 10 | 1.2 | 14.85% | 7.98% | 5.47% | 4.08% | 2.88% | 2.17% | 1.36% |
| 22 | 5 | 0.2 | 12 | 2.4 | 4.65% | 2.45% | 1.83% | 1.35% | 0.87% | — | — |
| 23 | 5 | 1 | 30 | 4 | 4.21% | 2.21% | 1.47% | 1.30% | 0.75% | — | — |
| 24 | 5 | 0.2 | 12 | 1.2 | 9.03% | 4.48% | 3.53% | 2.51% | 1.78% | 1.26% | — |
| 25 | 5 | 1 | 30 | 2 | 7.79% | 3.81% | 3.08% | 2.06% | 1.59% | 1.05% | — |
| 26 | 5 | 0.2 | 30 | 2.4 | 9.65% | 5.24% | 3.91% | 2.76% | 1.89% | 1.38% | — |
| 27 | 5 | 0.2 | 30 | 1.2 | 17.01% | 8.65% | 6.47% | 4.53% | 2.92% | 2.30% | 1.55% |
Note. See the text for an explanation of entries with * or —.
We also conducted simulations on the M system shown in Figure 1. We use the same cost parameters as these in Dogru et al. (2017). The inventory holding costs of both components, h1 and h2, are set to unity. Backlog costs, b0, b1, and b2, are varied (see the second row in Tables 8 and 9) to generate four regions of different cost relationships: (1) (region A); (2) (region B); (3) (region C); and (4) (region D). As discussed in Doğru et al. (2017), our allocation policy specializes to allocation rules that are qualitatively different between the regions. Tables 8 and 9 show optimality gaps for cases when component 1 has the shorter and longer lead times, respectively. In both cases, the gaps are above zero when and significantly so in regions A and D. Nevertheless, in each case, there is also a clear trend that the gap converges toward zero as the lead times increase, as is predicted by Theorem 3.
|
Table 6. Optimality Gaps: W System, Component 0 Has the Longer Lead Time,
| Case no. | h1 | h2 | b1 | b2 | Optimality gap (L1: components 1 and 2, L2: component 0) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 4 | 4 | 0.16% | 0.08% * | 0.08% * | — | — | — | — |
| 2 | 0.2 | 0.2 | 2.4 | 2.4 | 0.11% * | 0.05% * | 0.11% * | — | — | — | — |
| 3 | 1 | 5 | 10 | 6 | 0.30% | 0.10% * | 0.15% * | — | — | — | — |
| 4 | 5 | 5 | 12 | 12 | 0.34% | 0.11% * | 0.14% | — | — | — | — |
| 5 | 0.2 | 1 | 6 | 4 | 0.78% | 0.31% | 0.20% | — | — | — | — |
| 6 | 0.2 | 0.2 | 2.4 | 1.2 | 3.46% | 2.04% | 1.28% | 0.94% | — | — | — |
| 7 | 1 | 1 | 4 | 2 | 1.65% | 0.72% | 0.43% | — | — | — | — |
| 8 | 5 | 5 | 12 | 6 | 0.94% | 0.42% | 0.13% | — | — | — | — |
| 9 | 1 | 0.2 | 4 | 2.4 | 2.72% | 1.25% | 0.95% | — | — | — | — |
| 10 | 0.2 | 0.2 | 6 | 2 | 3.97% | 1.88% | 1.39% | 0.92% | — | — | — |
| 11 | 1 | 1 | 10 | 4 | 2.63% | 1.38% | 0.97% | — | — | — | — |
| 12 | 5 | 5 | 30 | 12 | 0.96% | 0.37% | 0.33% | — | — | — | — |
| 13 | 0.2 | 0.2 | 6 | 2.4 | 5.76% | 2.77% | 1.97% | 1.52% | 1.00% | 0.53% | — |
| 14 | 1 | 0.2 | 4 | 1.2 | 7.74% | 3.61% | 2.74% | 2.04% | 1.33% | 0.97% | — |
| 15 | 0.2 | 0.2 | 6 | 1.2 | 14.47% | 7.29% | 5.07% | 3.67% | 2.67% | 2.04% | 1.50% |
| 16 | 1 | 1 | 10 | 2 | 6.56% | 3.19% | 2.55% | 1.81% | 1.41% | 0.95% | — |
| 17 | 5 | 1 | 12 | 4 | 2.79% | 1.55% | 1.17% | 0.86% | — | — | — |
| 18 | 5 | 5 | 30 | 6 | 2.23% | 1.11% | 0.69% | — | — | — | — |
| 19 | 1 | 0.2 | 10 | 2.4 | 8.78% | 4.54% | 3.33% | 2.46% | 1.60% | 1.10% | 0.77% |
| 20 | 5 | 1 | 12 | 2 | 5.73% | 3.19% | 2.32% | 1.58% | 1.15% | 0.83% | — |
| 21 | 1 | 0.2 | 10 | 1.2 | 17.04% | 8.88% | 6.77% | 4.87% | 3.35% | 2.79% | 1.95% |
| 22 | 5 | 0.2 | 12 | 2.4 | 7.43% | 3.71% | 2.72% | 1.97% | 1.33% | 0.87% | — |
| 23 | 5 | 1 | 30 | 4 | 6.32% | 3.49% | 2.44% | 1.57% | 1.19% | 0.77% | — |
| 24 | 5 | 0.2 | 12 | 1.2 | 13.02% | 6.64% | 4.99% | 3.60% | 2.62% | 1.75% | 1.31% |
| 25 | 5 | 1 | 30 | 2 | 10.83% | 5.87% | 4.17% | 2.98% | 2.21% | 1.64% | 0.86% |
| 26 | 5 | 0.2 | 30 | 2.4 | 13.29% | 6.75% | 5.02% | 3.67% | 2.59% | 1.97% | 1.03% |
| 27 | 5 | 0.2 | 30 | 1.2 | 24.68% | 12.13% | 8.52% | 6.00% | 4.39% | 3.09% | 1.98% |
Note. See the text for an explanation of entries with * or —.
|
Table 7. Optimality Gaps: N-System with Symmetric Costs ()
| h1 | b1 | b2 | L1: component 1 | L1: component 0 | ||||
|---|---|---|---|---|---|---|---|---|
| L2: component 0 | L2: component 1 | |||||||
| Lower bound | Average | 99.9% CI | Lower bound | Average | 95% CI | |||
| 0.1 | 0.4 | 0.5 | 21.38 | 21.56 | [21.54,21.59] | 18.95 | 18.95 | [18.94,18.97] |
| 0.1 | 0.7 | 0. 8 | 28.82 | 29.00 | [28.96,29.04] | 25.26 | 25.27 | [25.25,25.29] |
| 1 | 1 | 2 | 51.38 | 51.98 | [51.91,52.04] | 49.24 | 49.25 | [49.23,49.28] |
|
Table 8. Optimality Gaps: M System, Component 1 Has the Shorter Lead Time,
| Lead time L1: component 1 L2: component 2 | A | B | C | D | |
|---|---|---|---|---|---|
| 10.03% | 4.60% | 5.72% | 23.20% | ||
| 4.82% | 2.30% | 2.87% | 11.27% | ||
| 3.29% | 1.72% | 2.07% | 8.18% | ||
| 2.32% | 1.17% | 1.44% | 6.13% | ||
| 1.75% | — | 1.00% | 4.45% | ||
| 1.37% | — | — | 3.20% |
|
Table 9. Optimality Gaps: M System, Component 2 Has the Shorter Lead Time,
| Lead time L1: component 2 L2: component 1 | A | B | C | D | |
|---|---|---|---|---|---|
| 9.07% | 4.20% | 5.20% | 22.48% | ||
| 4.42% | 2.25% | 2.67% | 11.16% | ||
| 3.17% | 1.40% | 1.87% | 8.12% | ||
| 2.25% | 0.99% | 1.29% | 5.74% | ||
| 1.46% | — | 0.88% | 3.99% | ||
| 0.94% | — | — | 2.69% |
9. Conclusion
Optimal inventory control of ATO systems with multiple products is a long-standing problem in the literature. In principle, this paper has settled the issue of developing an asymptotically optimal control policy for systems with general BOMs and deterministic lead times. We have “collapsed” the design of a dynamic control policy for minimizing the average cost over an infinite time horizon to the solution of certain multistage stochastic programs. The approach leads to drastically simplified analyses and feasible inventory policies with provable optimality properties.
This paper is a continuation of a stream of past work on ATO inventory systems. The multistage SP in Section 3 generalizes the two-stage SP in (34), which applies only to systems with identical lead times. In comparison with the formulation in (33), the SP here is a better alternative as it directly sets the same lower bound on the average cost, eliminating the need to take the infimum of the objective values and yields optimal solutions that have finite values and hence can be used as parameters of inventory control policies. Although the allocation policy follows the same principle as that in (34), we break new ground in developing a replenishment policy. The conventional base stock policy is justified by asymptotic analysis for use in systems with identical or near identical lead times (Reiman and Wang 2012, Reiman et al. 2016), whereas a different policy has been shown to be optimal for one-product systems with nonidentical lead times (Rosling 1989). Subsuming both as special cases, our policy is supported by the proof of asymptotic optimality and numerical results for its use in systems with general BOMs and lead times.
As a result of the new policy development, the asymptotic analysis is more involved than for systems with identical lead times in (34). Instead of setting constant targets for inventory positions, the new policy updates them repeatedly over time based on changes of relevant system states, giving rise to the question about the stability of these targets. In general, it is not possible to keep actual inventory positions at their targets for all times, and in theory, the influence of the discrepancies can last into the indefinite future. We address these issues with new approaches, such as the formulation and analysis of the “stochastic tracking model” and the characterization and exploitation of the matrix structures of SP constraints. We develop these technical machineries for general settings, making it possible to apply them to models other than ATO systems, for example, to prove convergence of other stochastic processes or address Lipschitz continuity of certain types of infinite LPs.
This paper is, in a sense, the culmination of the stream of previously mentioned work. On the other hand, this is not the end of the story. In particular, making our policy implementable in practical ATO systems requires new approaches to overcome the computational complexity of multistage SPs. In this paper, we consider the use of finite-dimensional LPs to approximate the original problems to generate stable targets for inventory positions and backlog levels. For the approximation to be sufficiently accurate, the dimensions of these LPs may need to be exceedingly high, especially when the system has many different and very long lead times. Moreover, the SPs need to be reoptimized repeatedly over time to update policy parameters, which makes the computation even more expensive.
Recent studies on two-stage SPs show that exploring structural properties of ATO problems implied by their BOMs can facilitate solution procedures (Zipkin 2016, Doğru et al. 2017, DeValve et al. 2020). How to extend this strategy to multistage SPs is an issue yet to be explored. It has also been shown that when the percentage difference between the longest and shortest lead times becomes insignificant, it can be asymptotically optimal to follow a base stock policy (32), reducing the SP to a two-stage problem and eliminating the need to update inventory position targets. Similarly, it also seems possible to preserve asymptotic optimality while reducing computational efforts by applying simple replenishment rules without resorting to SP solutions on components whose lead times are insignificant fractions of the longest lead time. In general, there can be opportunities to systematically explore exploiting small lead time differences to reduce the number of stages of the SPs. Furthermore, one may also find ways to reduce the computational burden by resolving multistage SPs less frequently. Although interesting and important, these topics are certainly beyond the scope of one paper, and we leave them for future research.
As a broader message, our work highlights the power of asymptotic analysis to tackle difficult inventory models that defy exact analysis. There is no shortage of such problems in the inventory theory literature, giving rise to ample opportunities for innovative research. On this subject, we refer to a recent survey Goldberg et al. (2021) for detailed discussions.
The authors are grateful to the associate editor and anonymous referees for constructive comments.
Appendix A. Proof of Theorems
The proof will use the following primal-dual transformation of the last stage LP in (13):
Given that all components of A are nonnegative, it is always optimal to set for any j such that . Thus, without the loss of generality, we replace with in (A.1), in which case
In (A.2), for any feasible solution of ,
Let be a deviation from the optimal objective value , obtained by changing to while keeping all other values at the optimal levels. Then
For the latter condition to hold, it is necessary that
When , apply Markov’s Inequality to the above inequality,
This upper bound obviously applies when .
To prove the lower bound, fix a component j of (i.e., kj = k) and consider the following feasible solution to (A.2)
Apply the inequality to (A.3) (notice that in corresponds to in in (A.3)),
Let be an optimal solution of . Then is a feasible solution of and yields the following objective value:
Therefore,
Using (A.5) and (A.6), and applying that :
Therefore,
By substituting with () and with in (11):
Using (10), we prove (15) by showing that
Let M be a positive integer and be a m-dimensional vector with all components equal to M. Let be the optimal objective value of the SP defined in (13) with inputs replaced by
Likewise, let be the optimal objective value of the SP defined in (A.7) with the replacement of by . Following Theorem 5, as converges to and converges to uniformly over all (see (A.20) and the later discussion in the proof of Theorem 5). Although the latter theorem and its proof appear later in the paper, they do not rely on the conclusion that we are proving here. Thus, to prove (A.8), we only need to show that for any given M, there exists some , such that
Let be an optimal solution of . By Theorem 1, is finite. For , because every entry of in , which is
Obviously, for any and
Otherwise, one can improve the objective value by increasing zi without violating any constraint. Because () and are bounded, is also bounded by some constant . When , any optimal solution to is a feasible solution to , so (A.11) holds in reverse. This completes the proof of the theorem. □
Observe that
Notice that is a stationary process and () is a sub-martingale:
To bound the sum in the above, observe that
By eliminating terms that contain and thus equal zero in the expansion,
Applying the above and bounds in (64) and (65) of Lemma 2 to (A.13) proves (66). □
For each ,
It is easy to verify from the expressions in (13) that because minimize (40)–(40′), minimize the same functions with the same linear transformation of inputs as follows: at each stage k , let replace take the value of instead of , and replace .
For each , applying (14), there exists a constant such that
For any constant , let
Because () is a stationary process and ,
Applying Lemma 3 to the last expression in the above inequality concludes the proof. □
To prove (99), we use induction to show that for and any and , there exists a η, depending only on and , such that
Because in (13) and in (92) are the same LP, (A.16) holds when k = 0. Furthermore, for any and such that ,
The induction starts from the assumption that when k = l , there exists constant η, depending only on and Ak , such that
We have proved both conditions for the case with k = 0. We now prove that they are also true when .
Let be an optimal solution of . Then
Let be an optimal solution to . Then
To prove (A.19) holds for , for any and , where ,
We have thus proved (99). As a slight extension, in proving Theorem 2, we refer to this theorem to show that
To prove (100), note that and are optimal objective values of (92) under the original and perturbed coefficient values, respectively. Because the perturbation only applies to coefficients of the objective function, the feasible set remains the same between the two problems (so one problem’s optimal solution is also a feasible solution of the other). Therefore, we only need to show that under a chosen M, the optimal solution in either problem is bounded by some quantities that are independent of perturbed coefficient values as long as they satisfy (98). Thus, by reducing Δ in (98), the difference of the two optimal objective values can be kept arbitrary small.
Theorem 1 shows that, with or without coefficient perturbation, in (92) satisfies for some finite constant γ1. With truncated to (), in (14), for some finite constant γ2, and ) are finite even without truncation. Although the allowed ranges of and do depend on and , the definitions of these two quantities also imply that there are non-empty ranges of perturbed coefficients to which some fixed values of and apply.
To show that is also bounded, first note that the constraint in of (92), along with the upper bound on shown in the last paragraph imply that . To bound the optimal value of zi, when this value is negative, it must be in at least one of the constraints at equality (otherwise, the objective value can be improved by increasing zi). Combining the above bounds yields . □
The formulation of the LP (93)–(97) implies that for any given , if , then
Let
Then, for all ,
Apply this inequality repeatedly from k = K to k = 1,
The proof requires a substantial amount of articulation. To facilitate understanding, we will first prove the special case with k = 1 before proving the general case in which k can vary from 1 to K.
Special Case (). Consider , in which (94)–(97) specialize to
The coefficient matrix on the LHS of constraints can be expressed as
All components of submatrix are zero except for those in block matrices on the diagonal (here and below we will deviate slightly from the standard definition by referring to a submatrix on the diagonal as a block even if it is not a square one). The number of blocks, N, is the number of elements in . Each block Hi is composed of coefficients associated with of a particular , and thus has rows and m columns. In particular,
The matrix is composed of coefficients of . It has n1 columns (the number of components in ) and its components are either 0 or –1. Because every Hi has an identity submatrix, has a negative identity submatrix, and these submatrices are on different rows, in (A.22) has full column rank.
In general, we define a matrix as a finite coupling block matrix (FCBM) with characterization numbers if:
With necessary permutations of rows and columns, can fit into the pattern defined by (A.22);
The matrix is of full column rank;
The submatrix has a finite number of blocks (denoted by N); all blocks, Hi , have the same finite number of columns (denoted by m), but can have different number of rows;
The submatrix has a finite number of columns (denoted by n1), and its components are either 0 or –1.
Let be a maximal nonsingular submatrix of a FCBM . Because is of full column rank, has the same number of columns as . Referring to (A.22), because each block Hi in is of full column rank (or otherwise will not be so), must contain at least m rows from each block. To be a square matrix, must draw more rows than columns from some blocks, and the total number of these extra rows is exactly n1 (the number of columns of ). This means that the number of blocks with more than m rows in is somewhere between one and n1. Correspondingly we can divide Hi into two groups: group 1 are those with exactly m rows in , each forms a m-dimensional nonsingular submatrix. Group 2 are those with more than m rows in . Hence, by permuting rows and columns, we can write as
Under these specifications, Lemma 7 holds when k = 1 if the following statement is true:
For any FCBM with characterization numbers , where m and n1 can be any positive integer, let be a maximal nonsingular submatrix of . Let be the set of values of elements of . Let be any vector with the same number of components as the number of rows in . Then there exists a constant κ, depending only on and , such that
To prove this statement, let be the set of indexes of nonsingular blocks in . We partition into and such that when multiplying with , components of are multiplied with and components of are multiplied with . Similarly, we partition into () where components of are multiplied with block Hi in . For each , Hi is nonsingular, thus
Here Hi are m-dimensional nonsingular matrices, with their components taking values from the finite set , and κ1 is the maximum component value of all possible ).
Define . Because both and are nonsingular matrices, is also nonsingular. Each block in has m columns. For to be a square matrix, has n1 more rows than columns, so the dimension of is between if has one block with rows and if has n1 blocks, each with m + 1 rows. Let κ2 be the maximum component of all possible formation of , where is a nonsingular matrix with dimension between and and component values drawn from the finite set . Then
It follows that
General Case (). We can extend the proof of (107) to cases with by induction. To do that, we first generalize the definition of FCBM with the following recursive characterizations:
A matrix is stage 0 FCBM with characterization number m if it is a finite-dimensional matrix with m columns and full column rank;
A matrix is a stage k FCBM with characterization numbers if it is of full column rank, and with necessary permutations of rows and columns, can be written as
(A.30)whereThe matrix has nonzero entries only in diagonal blocks, the number of which, denoted by Nk, can take any finite value. Specifically,
(A.31)where each block ) is a stage- FCBM with characterization numbers ; blocks might not be identical, but they all have the same number of columns;The matrix has a finite number of columns (denoted by nk) and its components are either 0 or −1.
For , the LHS constraint matrix of is a FCBM. To show this, when k = 2, (94)–(97) specialize to
With necessary permutations of rows and columns, its LHS constraint matrix can be written as
Here is composed of coefficients of and N2 is the number of elements in . Each corresponds to a particular , and
For general k , the same can be shown by induction. Referring to (94)–(97). Let Nk be the number of elements in . Then we can make the induction assumption that coefficients of and are given by a number of Nk stage- FCBMs with characterization numbers , which we denote by . Coefficients of , which are either −1 or 0, are given by matrix , which has nk columns. Thus, with necessary permutations of rows and columns, the LHS constraint matrix of can be written as
Because every column in Constraints (94), (95), and (96) are covered by an identity or negative identity matrix and rows of these matrices do not overlap, by definition is a FCBM with characterization numbers .
Let be a maximal nonsingular submatrix of . Then following the same reasoning that leads to (A.24), and must have the same number of columns because has full column rank. By (A.30) and (A.31), for contains either a maximal nonsingular submatrix of (the rank of the submatrix equals the column rank of ) or a submatrix that includes every column of and has more rows than columns. The total number of extra rows is nk for to be nonsingular. Hence can be written as
Under the previous specifications, the lemma holds for all k if the following statement is true:
For , let be a stage-k FCBM with characterization numbers , where can be any positive integers. Let be a maximal nonsingular submatrix of . Let be the set of component values in . Let be any vector with the same number of components as the number of rows in . Then there exists a constant κ, depending only on and , such that
We have already shown in (A.29) that the previous statement is true for k = 1, and thus can use induction to prove the same for k > 1:
Assume that (A.37) holds for any maximal nonsingular submatrix of a stage- FCBM (k > 1) with any finite and positive characterization numbers. Let be a stage-k FCBM with characterization numbers . Recall that by permuting rows and columns, a maximal nonsingular matrix of can be written as
We partition the vector into and such that in the product of and , components of and are multiplied with rows in and , respectively. We also partition into such that components of are multiplied with rows in ().
Because () is a nonsingular stage- FCBM, its maximal nonsingular submatrix is the matrix itself. Therefore, by the induction assumption, there exists a constant κ1, depending only on and , such that
To bound , recall that is a diagonal block matrix that contains no more than nk (non-square) blocks. Suppose that the actual number is . As noted previously, each block is a stage- FCBM with full column rank. Let be the index set of these blocks and denote them by (). Following the definition in (A.30) and (A.31),
For the ease of presentation, we let indexes in take integer values . Thus, the lower right submatrix in (A.38) can be written as
Applying (A.30) and (A.31) recursively, every is a diagonal block matrix, where each block is a stage- FCBM with characterization numbers . Let M(i) be the number of blocks in . Denote a block in by . Then with necessary permutations of rows and columns, can be written in a more expanded form as
The submatrix to the left of is a diagonal block matrix, where each block is a stage FCBM. The submatrix on the right has either 0 and –1 as its component value. Since has nk columns, each has columns, and the number of components of is , the latter submatrix has a finite number of columns. Also by (A.38), has full rank. Hence, fits the definition as a nonsingular stage FCBM with characterizations numbers of .
By the induction assumption, there exists a constant κ2, which depends only on and (and thus ) because ), such that
The proof can then be completed by observing that
Appendix B. Illustration of the Inventory Policy
We use a very simple example, the N system, to illustrate our inventory policy developed in Section 4. Figure 1 in Section 2 shows that the system has two products and two components. One unit of component 1 is used by both products, and one unit of component 2 is used by product 2 only. Components have different lead times and . Thus, K = 2. We also assume that .
The formulation of the SP (13) for this system specializes to
To maximize ,
Correspondingly, with y2 and given, is chosen to minimize
It follows that the replenishment policy prescribed in Algorithm 1 specializes to the following actions:
Let be the (constant) inventory position target for component 2 and follow a base stock policy to keep the actual inventory position at that level.
At time t, where t is either or any time afterward when there is a demand arrival:
choose to minimize (B.1) with , set component 1’s inventory position target to
and order units of that component;schedule a future update of the inventory position target and a possible new replenishment at time . Repeat Step 2(a) when the system reaches .
For the allocation policy, the procedure prescribed in Algorithm 2 specializes to the following actions:
At each time t, where t is either zero or any time afterward when there is a demand arrival or some previously ordered component is received:
Set backlog targets at
which correspond to the optimal solution tousingUse component 1 to serve demand 1 until either the component runs out or . In the latter case, use the remaining amount of component 1 and the available amount of component 2 to serve as much demand 2 as possible.
In this process, the backlog target does not depend on system state and is the higher shortage level of the two components. Thus, the previous procedure can be simplified to a priority policy, that is, use available components to serve as much demand as possible, and when there is not sufficient component 1 to serve both demands, use the component for product 1 first.
Appendix C. Formulation and Perturbation of LP (93)–(97)
The SP in (92) has K + 1 stages. Correspondingly, we develop a scenario tree with K + 1 levels to encode information available at each stage. The top level (k = K) has a single node, which is the root of the tree. A node at lower levels is the root node of a subtree that starts from that level. On that subtree, the path from the root node to a descendant node at level () is encoded by a string
For any two strings ω1 and ω2, write if ω1 is a prefix substring of string ω2. On any subtree that starts from level k (), let () encode a path between its root node and a descendant node at level (). Let () encode a path between the root node and a descendant node at a lower level (). Then the former path is a segment of the latter one if and only if .
A tree starting from level k (), as specified previously, and associated with data (), allows us to formulate as the following LP (recall that for as the set that contains a single element):
This is the same formulation as (93)–(97) given in Section 7.1. When k = K, (C.2)–(C.6) is the same problem defined in (92). When k < K, it defines subproblems of (92) at stage k (), with given by decisions already taken at stages (), and representing the amounts of existing demands.
We perturb coefficients in (C.2) to keep the optimal solution of the LP unique. Let be perturbed values of be perturbed value of , and referring to (C.1), let be the perturbed values of . Consequently,
In each system, we assign same values to (), , and . Hence, the same perturbed coefficients are used in , independent of data (). These coefficients are chosen to satisfy the following conditions.
First, there are no two nonzero rational vectors and such that
To meet this condition, we can, for instance, add distinct irrational values to , and (). These irrational values are chosen to keep the ratio of any two perturbed coefficients irrational, so that their weighted sum cannot be zero if weights are rational numbers. The condition guarantees that the optimal solution of (C.2)–(C.6) is unique, because if not, then the LP would have two extreme-point solutions, which must be rational-valued because Ak and () in (C.3)–(C.6) are integers. Thus, by induction from k = K downward, on the RHS of (C.6) are rational vectors. Because the two solutions yield the same objective value, (C.7) is satisfied if we let be the difference in and be the difference in , which is a contradiction.
Second, these values can be kept sufficiently small; that is, they can satisfy (98) for any choice of . This is easily achievable by dividing the aforementioned irrational values by a sufficiently large integer before adding them to the original coefficients.
References
- (2001) Optimal material control in an assembly system with component commonality. Naval Res. Logist. 48:409–429.Google Scholar
- (2004) Joint inventory replenishment and component allocation optimization in an assemble-to-order system. Management Sci. 50:99–116.Link, Google Scholar
- (2017) Assemble-to-order systems: A review. Eur. J. Oper. Res. 261:866–879.Google Scholar
- (2019) Replicate to the shortest queues. Queueing Systems 92(1):1–23.Google Scholar
- (2001) Dynamic scheduling of a system with two parallel servers in heavy traffic with resource pooling: Asymptotic optimality of a threshold policy. Ann. Appl. Probability 11:608–649.Google Scholar
- (1998) State space collapse with application to heavy traffic limits for multiclass queueing networks. Queueing Systems 30:89–140.Google Scholar
- (2020) Constant-order policies for lost-sales inventory models with random supply functions: Asymptotics and heuristic. Oper. Res. 68:1063–1073.Link, Google Scholar
- (2020) A primal-dual approach to analyzing ATO systems. Management Sci. 66:5389–5407.Link, Google Scholar
- (2010) A stochastic programming based inventory policy for assemble-to-order systems with application to the W model. Oper. Res. 58:849–864.Link, Google Scholar
- (2017) Assemble-to-order inventory management via stochastic programming: Chained BOMs and the M-system. Production Oper. Management 26:446–468.Google Scholar
- , Reiman MI, Wang Q (2021) A survey of recent progress in the asymptotic analysis of inventory systems. Prod. Oper. Manag. 30:1718–1750.Google Scholar
- (2016) Asymptotic optimality of constant-order policies for lost sales inventory models with large lead times. Math. Oper. Res. 41:898–913.Link, Google Scholar
- (1988) Brownian models of queueing networks with heterogeneous customer populations. Inst. Math. Its Appl. 10:147.Google Scholar
- (1996) The bigstep approach to flow management in stochastic processing networks. Stochastic Networks Theory Appl. 4:147–186.Google Scholar
- (1999) Heavy traffic resource pooling in parallel-server systems. Queueing Systems 33:339–368.Google Scholar
- (1990) Scheduling networks of queues: Heavy traffic analysis of a two-station closed network. Oper. Res. 38:1052–1064.Link, Google Scholar
- (1997) Dynamic control of Brownian networks: State space collapse and equivalent workload formulations. Ann. Appl. Probability 7:747–771.Google Scholar
- (1998) Order response time reliability in a multi-item inventory system. Eur. J. Oper. Res. 109:646–659.Google Scholar
- (2015) Optimal FCFS allocation rules for periodic-review assemble-to-order systems. Naval Res. Logist. 62:158–169.Google Scholar
- (2009) A nonparametric asymptotic analysis of inventory planning with censored demand. Math. Oper. Res. 34:103–123.Link, Google Scholar
- (2009) Asymptotic optimality of order-up-to policies in lost sales inventory systems. Management Sci. 55:404–420.Link, Google Scholar
- (1958) Inventory models of the Arrow-Harris-Marschak type with time lag. Stud. Math. Theory Inventory Production 1:155.Google Scholar
- (2005) Order-based cost optimization in assemble-to-order systems. Oper. Res. 53:151–169.Link, Google Scholar
- (2015) Optimal and asymptotically optimal policies for assemble-to-order N- and W-systems. Naval Res. Logist. 62:617–645.Google Scholar
- (2010) No-holdback allocation rules for continuous-time assemble-to-order systems. Oper. Res. 58:691–705.Link, Google Scholar
- (1987) Lipschitz continuity of solutions of linear inequalities, programs, and complementarity problems. SIAM J. Control Optim. 25:583–595.Google Scholar
- (2000) Matrix Analysis and Applied Linear Algebra, vol. 71 (SIAM, Philadelphia).Google Scholar
- (2014) Optimal structural results for assemble-to-order generalized M-systems. Oper. Res. 62:571–579.Link, Google Scholar
- (2006) Optimal control of a high-volume assemble-to-order system. Math. Oper. Res. 31:453–477.Link, Google Scholar
- (1984)
Some diffusion approximations with state space collapse . Modelling and Performance Evaluation Methodology (Springer, Berlin), 207–240.Google Scholar - (2004) A new and simple policy for a continuous review lost-sales inventory model. Unpublished manuscript.Google Scholar
- (2012) A stochastic program based lower bound for assemble-to-order inventory systems. Oper. Res. Lett. 40:89–95.Google Scholar
- (2015) Asymptotically optimal inventory control for assemble-to-order systems with identical lead times. Oper. Res. 63:716–732.Link, Google Scholar
- (2016) On the use of independent base-stock policies in assemble-to-order inventory systems with nonidentical lead times. Oper. Res. Lett. 44:436–442.Google Scholar
- (1989) Optimal inventory policies for assembly systems under random demands. Oper. Res. 37:565–579.Link, Google Scholar
- (1986) Theory of Linear and Integer Programming (John Wiley & Sons, Hoboken, NJ).Google Scholar
- (2009) Lectures on Stochastic Programming: Modeling and Theory (SIAM, Philadelphia).Google Scholar
- (2003) Supply chain operations: Assemble-to-order systems. Handbook Oper. Res. Management Sci. 11:561–596.Google Scholar
- (2022) Exploiting random lead times for significant inventory cost savings. Oper Res. 70(4):2496–2516.Google Scholar
- (2015) Optimization of industrial-scale assemble-to-order systems. INFORMS J. Comput. 27:544–560.Link, Google Scholar
- (2021) On a deterministic approximation of inventory systems with sequential service-level constraints. Oper. Res. 69:1057–1076.Link, Google Scholar
- (2016) Optimality gap of constant-order policies decays exponentially in the lead time for lost sales models. Oper. Res. 64:1556–1565.Link, Google Scholar
- (1997) Demand fulfillment rates in an assembleto-order system with multiple products and dependent demands. Production Oper. Management 6:309–324.Google Scholar
- (2000) Foundations of Inventory Management (McGraw-Hill, New York).Google Scholar
- (2016) Some specially structured assemble-to-order systems. Oper. Res. Lett. 44:136–142.Google Scholar

