
Asymptotic Welfare Performance of Boston Assignment Algorithms
Abstract
We make a detailed analysis in a special case of the Boston algorithm, which is widely used around the world to assign students to schools. We compute the limiting distribution in large random markets of both the utilitarian welfare and the order bias, a recently introduced average-case fairness measure. Our results show that the differences in utilitarian welfare between the Boston algorithms and the serial dictatorship (SD) algorithm are small and positive, whereas the differences in terms of order bias are large and positive. The naive implementation of the Boston algorithm beats its adaptive implementation on both utilitarian welfare and order bias, and both apparently beat SD on both criteria. In order to establish our results, we derive several basic results on the time evolution of the assignments made by the algorithms, which we expect to be useful for other applications. For example, we compute limiting distributions as a function of of the exit time and preference rank obtained for an arbitrary agent whose initial relative position in the tiebreak order is θ.
1. Introduction
The school choice problem, involving matching students to places in schools, is of great theoretical and practical interest. The Boston mechanism is widely used in practice for school choice, despite criticism that it gives strategic incentives for agents (students and parents) to misrepresent their preferences. Its main rival is the (student-proposing) deferred acceptance (DA) mechanism, which is strategyproof; there is no incentive for students to misrepresent their preferences. However, it has been long known that DA pays a price in overall welfare for this. This important trade-off has been heavily studied.
Analysis of such mechanisms is not easy in full generality, and various simplifying assumptions are often made. As do many authors, we consider here the very special case in which each school has a single seat, schools have strict priorities given by a common tiebreak order over the students, and students have complete strict preferences over schools. This leads us to the house allocation (Hylland and Zeckhauser 1979) or one-sided matching problem, another classic problem in the area of allocation of indivisible goods. Note that this is different from the closely related housing market problem of Shapley and Scarf (1974) because in our case, agents do not start with an item and trade it but are simply matched to an item.
In the housing allocation framework, perhaps the most commonly seen mechanism in theory and practice is serial dictatorship (SD), which is strategyproof. The Boston algorithms are believed to generally outperform SD in overall welfare, but analytic results are currently lacking. The present paper derives precise asymptotic results to help fill this gap.
1.1. The Algorithms
In this paper, we consider three prominent algorithms: serial dictatorship and the naive and adaptive variants of the Boston mechanism. Each can be described (and may be implemented in practice) via a centralized procedure that takes an entire preference profile and outputs a matching of agents to items, but each is more easily and commonly interpreted as a dynamic process. This interpretation does not change the results because we care only about which agent ultimately obtains which item, not the process that delivers such an allocation. Each algorithm assumes an exogenous total order on agents, allowing them to take turns choosing or bidding for items.
SD is perhaps the most famous algorithm for housing allocation; each agent, in turn, chooses and is matched to the item he most prefers among those still available.
Naive Boston (NB) proceeds in rounds. In each round, some of the agents and items will be permanently matched, and the rest will be relegated to the following round. At round r (), each remaining unmatched agent, in turn, bids for his rth choice among all the items and will be matched to that item if it is still available.
Adaptive Boston (AB) is similar but differs in the bidding. At each round of this algorithm, each remaining agent, in turn, bids for his most-preferred item among those still available at the start of the round. The adaptive Boston mechanism takes fewer rounds to finish than the naive version because agents do not waste time bidding for items that have already been assigned to someone else in a previous round. Naive and adaptive Boston are identical in the first round but different thereafter; in round r, each remaining agent bids for his sth preference, where and s depends on the agent (and the history of the process so far).
1.2. Performance Measures
Comparisons between mechanisms require a performance measure (sometimes called a figure of merit) to assess the value of the matchings achieved. If such a measure is to be derived from the agents’ satisfaction with the items they are assigned, then in the absence of other information, it can only be based on their ordinal preference ranks for those items. One commonly used way to quantify this is to devise a positional scoring rule giving the utility derived by any agent from receiving his sth choice of item. In this paper, we consider two performance measures and two scoring rules. The normalized Borda score (also known as linear utility) for the sth preference among n items is . For many purposes, any decreasing linear function of s would be equivalent. The other scoring rule is k-approval, which has for and for s > k.
Utilitarian welfare judges the value of a matching to be the total utility derived by all agents from the items they are assigned. Order bias (Freeman et al. 2021), a more recently introduced measure, is the maximum difference in expected utility obtained by any two agents. This is an average-case measure; the use of expected utilities implies averaging over a probability distribution on profiles and their resulting outcomes, a point we discuss. Usually but not always, the two agents whose expected utilities are maximally different will be the first and last agents in the exogenous choosing order.
1.3. Random Markets
A baseline probability model for preferences is that each agent has a preference order chosen at random, independently of other agents, with all possible permutations of the items being equally likely. This is often called the random market model or (sometimes in the social choice literature) impartial culture. Although far from realistic, this model has the advantage of mathematical tractability; it is often possible to obtain explicit distributional results for the outcomes of social-choice mechanisms in the random-market case.
1.4. Assumptions on Agent Behavior
We make the further assumption that agents are sincere; they do not misrepresent their preferences in an attempt to obtain a better outcome for themselves. Both Boston mechanisms are susceptible to this kind of manipulation, which can lead to worse outcomes for less adept players.
As a justification for this assumption, we offer two arguments. First, the random market model provides a partial defense against manipulation. If each agent knows only the (uniform) distribution of preferences of the other agents (which seems realistic in many applications), then there is no incentive to deviate from sincerity; in other words, the sincere profile is a Bayesian Nash equilibrium for the game induced by the mechanism. Second, understanding the social choice rule underlying a given mechanism is a first important step when comparing mechanisms, and the approach is often used in the literature.
In any case, from now on we shall ignore any issues of strategic behavior by agents.
1.5. Description of Our Results
This paper reports results on the asymptotic performance for the housing allocation problem of the Boston mechanisms in large random markets, where the number n of agents (and of items) tends to .
A key general observation regarding this setting is that agents’ preferences are rather diverse, so much so that with high probability, it is possible to match most of the agents to one of their first few preferences—and both Boston algorithms will successfully do so. More precisely, a given agent’s preference rank R for the item he is assigned has a probability distribution that converges to a limit as . This means, in particular, that the value of R an agent is likely to obtain does not increase with n but has much the same distribution for any sufficiently large n. For the Boston mechanisms (but not for serial dictatorship), this is even true of the very last agent in the choosing order. This paper’s main results describe explicitly the limiting distributions for the preference rank obtained by an agent in a given position in the choosing order, as a function of θ. We then obtain consequent results for the order bias and utilitarian welfare. To our knowledge, these are the first detailed analytic results on the rank distribution of allocations given by the Boston algorithms.
Our results suggest that serial dictatorship is (slightly) inferior to the Boston algorithms in utilitarian welfare and (very much) inferior in order bias.
1.6. Literature Review
We give a brief summary of some key references, with no claim to be complete. The housing allocation problem was formally introduced by Hylland and Zeckhauser (1979), the school choice problem was introduced by Abdulkadiroğlu and Sönmez (2003), and the Boston mechanism was introduced by Abdulkadiroğlu et al. (2005). The adaptive Boston mechanism was formalized by Mennle and Seuken (2021).
A persistent theme of the research literature is the inevitable trade-off between strategy proofness and agent welfare, and there is still much to be learned about these issues. SD is strategyproof, whereas neither Boston mechanism is; AB gives less incentive to strategize than NB (Mennle and Seuken 2021). A comparison of Boston and other school choice mechanisms shows that welfare is generally higher under Boston (Calsamiglia et al. 2020). The Boston mechanism has been studied axiomatically (Kojima and Ünver 2014, Dur et al. 2018). Several arguments in favor of the Boston mechanism have been made, mainly on the basis of improved efficiency/welfare (Miralles 2009, Abdulkadiroğlu et al. 2011), and several against (Ergin and Sönmez 2006, Pathak and Sönmez 2008), mainly on the basis of unfairness to agents who strategize poorly.
Several authors have studied the behavior of prominent algorithms for house allocation in the large random market model (Knuth 1996, Nikzad 2022, Ortega and Klein 2022) (we say more about their results in Section 8.2). More general analysis of entire classes of algorithms was performed by Che and Tercieux (2018), showing that under rather general conditions on the utility functions of agents and even allowing for some correlation in preferences, all Pareto efficient mechanisms (a class that includes Boston and SD) asymptotically achieve the maximum possible utilitarian welfare. Pycia (2019) showed that, for a more general class of problems that includes house allocation, most common measures of performance are asymptotically the same for all Pareto efficient and strategyproof mechanisms.
1.7. Outline of the Remainder of the Paper
Each section deals first with average-case results for an arbitrary initial segment of agents in the choosing order and then, with the fate of an individual agent at an arbitrary position.
The core technical results for naive Boston are Theorem 7 (number of agents remaining at a given round) and Theorem 9 (exit time of a given agent). For adaptive Boston, we have Theorem 10 (number of agents remaining at a given round), Theorem 12 (bids and exits at a given round), and Theorem 13 (fate of a given agent). The results involve recursively defined quantities .
The results for serial dictatorship are straightforwardly derived, but the Boston algorithms require nontrivial analysis. Of those, naive Boston is much easier because the exit time of an agent equals the preference rank of the item obtained by the agent. However, in adaptive Boston, this is no longer true, which necessitates substantial extra technical work.
We apply the basic results to compute utilitarian welfare in Section 3.1, the key result being Theorem 2 and its corollaries, and order bias in Section 3.2, the main results being Theorems 4–6. Sections 4–6 present and prove the technical results needed to establish the results. We give all remaining proofs of the main results in Section 7. In Section 8, we discuss the limitations and implications of our results and point out opportunities for future work.
2. Preliminaries
In this section, we list more formally the basic assumptions that delineate our study in this paper.
2.1. The Model
We assume throughout that n is a positive integer. An instance of the housing allocation problem of size n is defined by a set An of n agents and a set In of n items. Each agent has a complete strict preference ordering (linear order) of items, and together, these form a preference profile. We assume sincere behavior by all agents throughout—their submitted preference orders are identical to their sincere orders.
In addition, there is an exogenous linear order ρ on An. All of the algorithms we consider will rely on this order when agents are required to take turns choosing or bidding. We shall consider the fortunes of agents as functions of their position in the order ρ.
Define the relative position of an agent a in the order ρ to be the fraction of all the agents whose position in ρ is no worse than that of a (this includes a itself). Thus, the first agent in ρ has relative position , and the last has relative position 1. For , let denote the set of agents whose relative position is at most θ, and let be the last agent in .
For completeness, when we let be the first agent in ρ. This exceptional definition will cause no trouble, as for it applies to only finitely many n and so, does not affect asymptotic results, whereas for θ = 0, it allows us to say something about the first agent in ρ.
We shall assume throughout that we deal with a random market. This means that each agent’s preference order is sampled independently from the uniform distribution on all such orders of In. The order ρ on agents is not random but fixed. Our results deal exclusively with large random markets: that is, asymptotically as .
2.2. Evolution of Assignments by the Algorithms
Each matching algorithm could be described and implemented as a two-step process. First, the agents generate their preference orders; then, a centralized procedure processes the preference profile and outputs a matching of agents to items. However, it is often more convenient to imagine the agents developing their preference orders as the algorithm proceeds rather than in advance. This interpretation does not change the result, only the process that delivers the final matching. The evolution of the assignments for the Boston algorithms can then be described by the following stochastic processes.
In the first round, the naive and adaptive Boston processes proceed identically; each agent randomly chooses one of the n items, independently of other agents and with uniform probabilities , as his most preferred item for which to bid. Each item that is so chosen is assigned to the first (in the sense of the agent order ρ) agent who bids for it; items not chosen by any agent are relegated, along with the unsuccessful agents, to the next round.
In the rth round (), the naive algorithm causes each remaining agent to randomly choose his rth most-preferred item, independently of other agents and of his own previous choices, uniformly from the items for which he has not previously bid. (Note that included among these are all the items still available in the current round.) Each item so chosen is assigned to the first agent who chose it; other items and unsuccessful agents are relegated to the next round.
In the rth round of the adaptive Boston algorithm, each agent repeatedly chooses his next most-preferred item by random sampling, without replacement, from the set of items he has not previously chosen until the item chosen is among those still available at this round. This item becomes his bid for the round. Bids are then resolved as in the naive mechanism. Each chosen item is assigned to the first agent who chose it; other items and unsuccessful agents are relegated to the next round.
Consider a situation with n = 4, agents and objects , and an exogenous order on the agents. Suppose that agents 1, 3, 4 have a as their first choice, and agent 2 ranks b first. Under SD, agent 1 takes object a, and agent 2 takes b. We then proceed to agent 3, who must take his second choice—unless that is b, in which case he must be content with his third choice. Finally, agent 4 takes the last remaining object.
If the same four agents instead use NB, then in the first round, agent 1 takes a and agent 2 takes b. In the second round, agents 3 and 4 each bid for their second choice. Suppose these bids are b for agent 3 and c for agent 4; then, agent 4 takes c and agent 3 is relegated to the third round, in which he is the only participant. It is now inevitable that agent 3 will be matched to d, the only remaining item, but if we suppose that his third choice is c, he must first make a useless bid for that item before receiving d in the fourth round.
Should the same agents instead use AB, the first round is the same as for NB, but in the second round, agents 3 and 4 both bid for c, which is given to agent 3. The process terminates after the third round, in which agent 4 bids for and receives d.
Thus, if the partial profile looks like , then under SD, we obtain the assignment ; under NB, ; and under AB, . For each algorithm, every 1 of the 72 profiles consistent with this partial profile outputs the same assignment.
2.3. Performance Measures
To compare the performance of the algorithms, we impute utility to agents. This requires a means of converting ordinal preferences to numerical utility values.
A positional scoring rule is given by a sequence of real numbers with for .
Each positional scoring rule defines an induced rank utility function, common to all agents; an agent matched to his sth preference derives utility therefrom. Commonly used scoring rules include k-approval defined by , where the number of ones is fixed at k independent of n; when k = 1, this is the usual plurality rule. Note that k-approval is coherent; for all n, the utility of a fixed rank object depends only on the rank and not on n. Another well-known rule is Borda defined by ; Borda is not coherent. Borda utility is often used in the literature, sometimes under the name linear utilities.
The (utilitarian) welfare performance measure is defined as follows. Suppose that an assignment mechanism for n agents matches of the agents with relative position at most θ to their sth preferences, for each . According to the utility function induced by the scoring rule , the welfare (total utility) of the agents with relative position at most θ is thus
Note that the k-approval welfare is just the fraction of agents who obtain one of their top k choices. Also, the average rank of the item received by a random agent, another well used measure, equals , where u is the expected Borda utility. Thus, as if and only if the expected rank is o(n).
We also consider the order bias, an average-case performance measure recently introduced in Freeman et al. (2021). The relevant definitions are recalled here for an arbitrary discrete assignment algorithm that fixes an order on agents (such as the order ρ assumed in the present paper).
The expected rank distribution under is the mapping on whose value at (r, j) is the probability, under the random-market assumption, that assigns the rth agent his jth most-preferred item.
We usually represent this mapping as a matrix where the rows represent agents and the columns represent items.
Let u be a common rank utility function for all agents; u(j) is the utility derived by an agent who obtains his jth preference. Define the order bias of by
It is often desirable that βn be as small as possible, out of fairness to each position in the order in the absence of any knowledge of the profile. In any case, knowledge of the order bias is important. For example, we may wish to apply “affirmative action,” as is done for example in many sports draft procedures.
In all three mechanisms in this paper (naive and adaptive Boston and serial dictatorship), the two agents whose expected utilities are maximally different are the first and last agents in ρ. The first agent in ρ always obtains his first-choice item, and so has the best possible expected utility. The last agent in ρ has the smallest expected utility; this is a consequence of the following result.
(Earlier Positions Do Better on Average). Let a be an agent in an instance of the house allocation problem with random-market preferences. Let the random variable S be the preference rank of the item obtained by a. The naive and adaptive Boston mechanisms and serial dictatorship all have the property that for all is monotone increasing in the relative position of a (i.e., greater for later agents in ρ).
See Section 7. □
Thus, the probability distribution of the preference rank of the item received by an agent stochastically dominates that for any later agent. For each common rank utility function u, the expected utility of agent a is , so Theorem 1 implies that the expected utility is monotone decreasing in the relative position of a. In particular, the first agent has the highest and the last agent the lowest expected utility.
3. Main Results on Agent Satisfaction
In this section, we state the main results of this paper. Proofs are deferred to Section 7.
3.1. Welfare
In this section, we state results on the utilitarian welfare achieved by the three mechanisms.
For each , we denote by the number of agents with relative position at most θ who are matched to their sth preferences.
(Asymptotic Welfare of the Mechanisms). Assume an assignment mechanism with
Then, the welfare given by (1) satisfies
The average k-approval welfare over all agents satisfies
The sequence ωk is defined by and the recursion for . The bivariate sequence urs is defined by the recursion for s > 1, urs = 0 for s < r, and
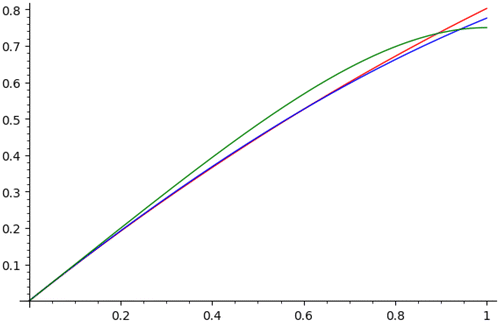
The limiting values of k-approval welfare are given in some special cases in Table 1. Figure 1 shows the limiting values for the three-approval scoring rule. It shows that naive Boston outperforms the adaptive version, with much of the difference attributable to the last 20% of agents. Also, serial dictatorship is more favorable for agents in the middle of the order but much worse for those toward the end.
|

Table 1. Limiting Values as of k-Approval Welfare
| Algorithm | k = 1 | k = 2 | k = 3 |
|---|---|---|---|
| Naive Boston | |||
| Adaptive Boston | |||
| Serial dictatorship |
Let σ be a positional scoring rule such that for all but finitely many s, for all n. Then, the asymptotic utilitarian welfare with respect to σ is strictly greater under naive Boston than under serial dictatorship.
This last result is intuitively reasonable because naive Boston maximizes the number of agents receiving their first choice, then subject to that the number receiving their second choice, etc. Note that this is not a proof because it may be that NB makes choices that may prevent it beating SD in some lower ranks. Adaptive Boston apparently scores better than serial dictatorship for each k and worse than naive Boston, although we do not yet have a formal proof. Figure 2 illustrates this for . Already for k = 3, the algorithms give similar welfare results, and they each asymptotically approach one as .
Note. (Top line) Naive Boston. (Middle line) Adaptive Boston. (Bottom line) Serial dictatorship.
In contrast to the results for k-approval, the Borda welfare does not distinguish asymptotically between the three algorithms.
For an assignment mechanism as in Theorem 2, the Borda welfare satisfies
For each of naive Boston, adaptive Boston, and serial dictatorship, the average normalized Borda welfare over all agents is asymptotically equal to one, and hence, the average rank obtained by an agent is o(n).
Note that the Borda utility of a fixed preference rank s has the limit , meaning that, in the asymptotic limit as , agents value the sth preference (of n) just as highly as the first preference. Consequently, mechanisms such as serial dictatorship or the Boston algorithms, which in a random market, are able to give most agents one of their first few preferences, achieve the same asymptotic Borda welfare as if every agent was matched to his first preference. This behavior is really a consequence of the normalization of the Borda utilities to the interval ; the first few preferences all have utility close to one.
A striking feature of our welfare results is that although the Boston algorithms have a utilitarian welfare advantage over serial dictatorship, the advantage is rather small. Asymptotically, both achieve maximum possible welfare under the Borda scoring rule. Under k-approval for fixed k, there is an advantage to Boston that of course decreases with k. These results are consistent with those of Che and Tercieux (2018), which state that under rather weak conditions, Pareto efficient mechanisms all asymptotically attain the maximum possible utilitarian welfare (normalized to one in our results). This is because the k-approval utility function does not satisfy the hypotheses of the results in Che and Tercieux (2018), and although neither does Borda, that case is similar to the special case with ; the utilities are chosen independently and uniformly distributed on , so that the utility of the kth preference will be approximately if n is large.
3.2. Order Bias
In this section, we state results on the order bias achieved by the three mechanisms. Proofs are mostly deferred to Section 7.
For each fixed k, the k-approval order bias of naive Boston is asymptotically , where is as given in Definition 5.
For each fixed k, the k-approval order bias of adaptive Boston is asymptotically
is as given in (17).
The Borda order bias of each Boston mechanism is asymptotically zero.
The order bias of serial dictatorship is easy to analyze; we include the results here for comparison with the Boston mechanisms.
Fix and .
The k-approval order bias for serial dictatorship equals .
The Borda order bias for serial dictatorship equals .
For each fixed k, the k-approval order bias of SD is asymptotically equal to 1, and the Borda order bias is asymptotically equal to 1/2.
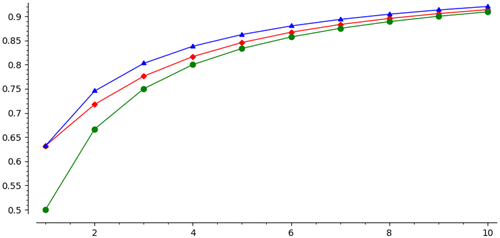
Figure 3 compares the asymptotic k-approval order bias for . Table 2 gives some numerical values.
Note. (Top line) Serial dictatorship. (Middle line) Adaptive Boston. (Bottom line) Naive Boston.
|
Table 2. Limiting Quantities for k-Approval Order Bias
| Algorithm | k = 1 | k = 2 | k = 3 |
|---|---|---|---|
| NB | |||
| AB | |||
| SD | 1 | 1 | 1 |
There is a large difference between mechanisms in their order bias. For k-approval, serial dictatorship is asymptotically as biased as it could be, whereas the Boston algorithms have much lower bias. The Boston algorithms are asymptotically unbiased with respect to our normalized Borda utilities, whereas SD has bias 1/2 for every n. In other words, when n is large then under SD, the last agent receives a random rank item, whereas under the Boston algorithms, this agent is quite likely to get one of his top few choices.
4. Technical Results and Proofs for Naive Boston
Theorem 2 involves a random quantity, which in the asymptotic limit as , approximates a constant (nonrandom) fraction of n. There are several more results of this kind in this section and the next one. A useful first move in approaching such results is to replace the random quantity with its expectation.
Let be a sequence of nonnegative random variables with and as , for some constant c. Then, as (convergence in probability).
The bounding of the variance of a random variable by its mean implies a distribution with relatively little variation about the mean when the mean is large. Lemma 1 makes use of this behavior to provide us with a stepping stone to establish results like Theorem 2 by performing an average-case analysis only. The same idea works if the averages are conditional expectations, as in the following lemma.
Let be a sequence of nonnegative random variables and a sequence of σ-fields, with and as . Then, as .
Lemma 1 is just the special case of Lemma 2, in which all the σ-fields are trivial. For a proof of Lemma 2, it suffices to show that . For any , we have by Chebyshev’s inequality (Durrett 2019)
Because , it follows that . As these conditional probabilities are a bounded (and thus, uniformly integrable) sequence, the convergence is also in (theorem 4.6.3 in Durrett 2019), and so,
In the present analysis, the random variables will mostly be numbers of agents who are successful (or not) at a given round of one of the Boston mechanisms. The next lemma provides the necessary variance bounds in such cases.
Suppose we have m items (), of which are blue. A sequence of agents (Agent 1, Agent 2, ) each randomly (independently and uniformly) chooses an item. Let be a subset of the agents, and let CA be the number of blue items first chosen by a member of A. Equivalently, CA is the number of members of A who choose a blue item that no previous agent has chosen: that is, the cardinality of the set
Lemma 3 describes a situation congruent to the way bids are resolved in a round of the naive Boston mechanism. The “blue” items correspond to those still available at the start of the round, and CA is the number of members of A who successfully obtain an item during the round. In the actual naive Boston algorithm, the set of unavailable items that an agent may still bid for will typically be different for different agents, but the number of them () is the same for all agents, which is all that matters for our purposes.
Lemma 3 is also applicable to the adaptive Boston mechanism. In this case, ; agents bid only for items still available at the start of the round.
Let Fi denote the agent who is first to choose item I and Xia the indicator of the event . That is, Xia = 1 if and only if Fi = a. We have ; agent a must choose i, whereas all previous agents choose items other than i. Let B be the set of blue items. Then, , so
For , these summands are identical for all (and zero for i = j); for a = b, they are identical for all i = j (and zero for ). Thus, (2) reduces to
The second term of (3) is again. For a < b and , we have
(Agents prior to a must choose neither i nor j, a must choose i, agents between a and b must choose items other than j, and b must choose j.) Because , this gives
As this last expression is symmetric in a and b, (4) also holds for a > b. Hence,
We have because . This gives
The limiting constants for the naive Boston algorithm will often involve terms of the following sequence.
The sequence is defined by and the recursion for .
Thus, for example, . The value of ωr approximates , a relationship made more precise in the following result.
For all ,
For , the inequalities can be verified by direct calculation. Beyond this, we rely on induction; assume the result for a given , and consider . Observe that the function is monotone increasing on ; this gives us
For , we have , and so, the result follows. □
4.1. Groups of Agents
In this subsection, we present results concerning the fortunes of those agents whose relative positions fall in an interval.
(Number of Agents Remaining). Consider the naive Boston algorithm. Fix and a relative position . Then, the number of members of present at round r satisfies
In particular, the total number of agents (and of items) present at round r satisfies
Induct on r. For r = 1, the result is immediate because . Now, fix , and assume the result for round r. Let be the σ-field generated by events prior to round r. Conditional on , we have the situation of Lemma 3; there are available items and agents of who will be the first to attempt to claim them, with the agents’ bids chosen independently and uniformly from a larger pool of items. Letting Sn denote the number of these agents whose bids are successful, Lemma 3 gives
Summing the geometric series,
It then follows by the inductive hypothesis that
By Lemma 2,
We have and so, obtain
The result follows. □
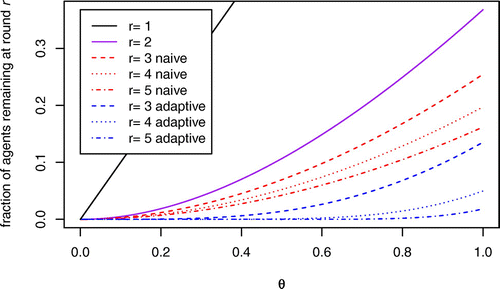
Some of the functions are illustrated in Figure 4. Note that agents with an earlier position in ρ are more likely to exit in the early rounds. A consequence is that the position of an unsuccessful agent relative to other unsuccessful agents tends to improve each time he fails to claim an item.
(Limiting Distribution of Exit Time/Preference Rank Obtained). The number of members of matched to their sth preference satisfies
In particular, the fraction of agents who exit at round s satisfies
An agent is matched to his sth preference if, and only if, he is present at round s but not at round s + 1. The result follows by Theorem 7. □
The limiting functions are illustrated in Figure 5 (note that the vertical scale is logarithmic).
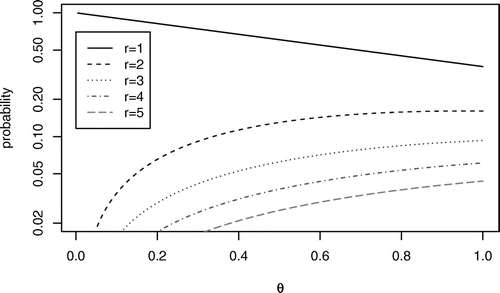
Note. Logarithmic scale on the vertical axis.
A better understanding of the functions is given by the following result.
The functions satisfy , where
In particular,
Differentiate (5) with respect to θ. Alternatively, integrate (6) by parts. □
The quantity can be interpreted (in a sense to be made precise later) as the conditional probability that an agent with relative position θ, if present at round r, is unmatched at that round. The quantity can then be interpreted as the probability that an agent with relative position θ is still unmatched at the beginning of round r. Other quantities for the first few rounds are shown in Table 3.
|
Table 3. Limiting Quantities as for the Early Rounds of the Naive Boston Algorithm
| Meaning at round r | Quantity | r = 1 | r = 2 | r = 3 |
|---|---|---|---|---|
| Fraction of all agents | ||||
| Present | ωr | 1 | ||
| In and present | θ | |||
| For an agent with relative position θ | ||||
| P(present) | 1 | |||
| P(unmatched—present) |
4.2. Individual Agents
Theorem 7 and Corollary 6 are concerned with the outcomes achieved by the agent population collectively and will yield the results in Section 3.1 on utilitarian welfare.
Suppose, however, that our interest lies with individual agents. It is tempting to informally “differentiate” the result of Theorem 7 with respect to θ and thereby, draw conclusions about the fate of a single agent. The following result puts those conclusions on a sound footing.
(Exit Time of Individual Agent). Consider the naive Boston algorithm. Fix and a relative position . Let denote the round number at which the agent (the last agent with relative position at most θ) is matched. Equivalently, is the preference rank of the item obtained by this agent. Then,
The result is trivial for r = 1. Assume the result for a given value of r, and let be the σ-field generated by events prior to round r. Conditional on , we can apply Lemma 3 to the single agent to obtain
Observe that from Theorem 7. Equation (10) gives
The second term converges to zero as by the inductive hypothesis. For the first term, note that the convergence is also convergence in by theorem 4.6.3 in Durrett (2019) and so, in also. □
The result of Theorem 9 could equivalently be stated as
Theorem 9 tells us that an agent with fixed relative position θ has a good chance of obtaining one of his first few preferences, even if n is large. This is even true of the very last agent (θ = 1). For example, the first agent is guaranteed his first choice, and an agent at relative position 1/2 has probability over 78%, whereas the last agent has corresponding probability just under 37%.
5. Technical Results and Proofs for Adaptive Boston
We again begin with results about initial segments of the queue of agents and follow up with results about individual agents. More work is required than in the naive case because the rank of the object obtained is not the same as the round in which it is obtained.
5.1. Groups of Agents
A simple stochastic model of bidding for the adaptive Boston mechanism can be similar to the naive case. At the beginning of the rth round, each remaining agent randomly chooses an item as his next preference for which to bid; the bid is successful and the agent is matched to that item if no other agent with an earlier position in the order ρ bids for the same item. However, whereas a naïve Boston participant chooses from the set of items for which he has not already bid, the adaptive Boston participant chooses from a smaller set: the items actually still available at the beginning of the round. This model allows a result analogous to Theorem 7.
(Number of Agents Remaining). Consider the adaptive Boston algorithm. Fix and a relative position . Then, the number of members of present at round r satisfies
In particular, the total number of agents (and of items) present at round r satisfies
Induct on r. For r = 1, we have ; the result follows immediately. Now, suppose the result for a given value of r, and consider r + 1. Let Tn be the number of agents of matched at round r. Conditioning on the σ-field generated by events prior to round r, we have the situation of Lemma 3 (with ); there are available items and agents of who will be the first to attempt to claim them, with each such agent bidding for one of the available items, chosen uniformly at random independently of other agents. Lemma 3 gives us and
By the inductive hypothesis,
This gives us
By Lemma 2, then
Because , it follows that and hence, the result. □
Some of the functions are illustrated in Figure 4. It is apparent that the adaptive Boston mechanism proceeds more quickly than naive Boston; decays much more quickly than ωr as . Also, the tendency of advantageously ranked agents to be matched in relatively early rounds is even greater for the adaptive version of the algorithm. In an adaptive Boston assignment of a large number of items to agents with random-market preferences, under 2% of the agents will be unmatched after four rounds (versus 16% for naive Boston), and most of these (about 2/3) will be among the last 10% of agents in the original agent order.
A better understanding of the functions is given by the following result, which is analogous to Theorem 8.
The functions satisfy , where
In particular,
Differentiate (11) with respect to θ. Alternatively, integrate (12) by parts. □
The quantity is analogous to in the naive case and can be interpreted (in a sense to be made precise later) as the conditional probability that an agent with relative position θ, if present at round r, is unmatched at that round. The quantity , analogous to in the naive case, can then be interpreted as the probability that an agent with relative position θ is still unmatched at the beginning of round r. Other quantities for the first two rounds are shown in Table 4.
|
Table 4. Limiting Quantities for the Early Rounds of the Adaptive Boston Algorithm
| Meaning at round r | Quantity | r = 1 | r = 2 |
|---|---|---|---|
| Fraction of all agents | |||
| Present | 1 | ||
| In and present | θ | ||
| For an agent with relative position θ | |||
| P(present) | 1 | ||
| P(unmatched—present) | |||
| P(bids for sth preference—present) | urs |
5.1.1. The Rank of the Item Received.
Theorem 10 is less satisfying than Theorem 7. The naive Boston mechanism has a key simplifying feature; the rank of an item within its assigned agent’s preference order is equal to the round number in which it was matched. This means that Theorem 7 already enables some conclusions about agents’ satisfaction with the outcome of the process (see Corollary 6). However, in the adaptive case, we know only that an item matched at round r > 1 will be no better (and could be worse) than its assigned agent’s rth preference.
To do better, we need a more detailed stochastic bidding model. An agent a still present at the beginning of the rth round will have thus far determined an initial subsequence of his preference order comprising some number of most-preferred items and failed to obtain any of them. He thus has a pool of previously unconsidered items from which to choose, of which the items actually still available are a subset. In accordance with the random market model, let us imagine that he now generates further preferences by repeated random sampling without replacement from the previously unconsidered items, until one of the available items is sampled; this item becomes his bid in the current round. Denote by Gar the number of items sampled to construct this bid; thus, and . If the bid is successful, the agent will be matched to his Farth preference.
Note that although the simple bidding model used in Theorem 10 provides enough information to determine the matching of items to agents (along with the round numbers at which the items are matched), it does not completely determine the agents’ preference orders. In particular, it does not determine the agents’ preference ranks for the items they are assigned. The random variables Gar provide additional information sufficient to determine this interesting feature of the outcome.
It is convenient to think of the Gar and Far as being determined by an auxiliary process that runs after the simple bidding model has been run and the matching of agents to items determined. This auxiliary process can be described in the following way. Fix integers .
Place n1 balls, numbered from one to n1, in an urn.
For ,
deem the ni lowest-numbered balls remaining in the urn “good,” and
draw balls at random from the urn, without replacement, until a good ball is drawn.
Let be the probability distribution of the total number of balls drawn and , where .
Denote by the σ-field generated by the simple bidding model, including the items on which each agent bids and the resulting matching. Conditional on , the random variable Far for an agent a still present at round r has the distribution. That is,
Also, the are conditionally independent given .
, for s > 1, and for s < r or . The distribution’s other probabilities are given by the recurrence
Let N be the number of balls drawn in the first r – 1 iterations of the process and M the number drawn in the final iteration. Then, , and we have
(The final iteration must first sample consecutive nongood balls; the probabilities of achieving this are for the first, for the second, for the last. At last, a good ball must be drawn; the probability of this is .) The result follows. □
Our interest in the distribution mostly concerns its asymptotic limits as the numbers of balls become large, and the “without replacement” stipulation becomes unimportant. To this end, fix , and let , where are independent random variables with geometric distributions: for .
, for s < r, and
Consider the adaptive Boston mechanism, and fix s. We have
Use the convergence of given by Theorem 10. □
Corollary 7 and (16) give us an asymptotic limit for the distribution, conditional on , of Far, the preference rank of the bid made at round r by an agent still present at that round. To condense notation, we will denote the limit by urs. That is,
Note that the limit urs does not depend on the position of the agent a in the choosing order. It is fairly clear why this should be so; all remaining agents must enter their bids at the beginning of the round, before any other agent has bid, and so, the bidding process, at least, treats them symmetrically. The advantage arising from a favorable position lies in a higher probability of obtaining the item bid for, not in constructing the bid itself.
We make use of the following simplified recurrence.
and for s < r; other values are given by the recurrence
In particular, for s > 1, urs = 0 for s < r, and
The recurrence in (17) has a unique solution, as does the one in Lemma 6. It is easy to check that either solution also satisfies the other recurrence. □
It follows directly from (17) that the bivariate generating function satisfies the defining equation . It follows directly (from substituting y = 1) that , consistent with its role as a probability distribution. We have not found a nicer explicit formula for urs.
We can now state a more detailed version of Theorem 10.
(The Bidding Process at a Given Round). Consider the adaptive Boston algorithm. Fix and a relative position . Let be as in Theorem 10 and urs be as in Lemma 8.
The number of members of making a bid for their sth preference at round r satisfies
The number of members of making an unsuccessful bid for their sth preference at round r satisfies
The number of members of making a successful bid for their sth preference at round r satisfies
Conditional on the σ-field , each agent a participating in round r enters a bid for his Farth preference; the Far for this group of agents is conditionally independent given . Thus, the conditional distribution of given is the binomial distribution with trials and success probability given by (16). The variance of a binomial distribution never exceeds its mean (Feller 1970), so Lemma 2 applies. We will thus obtain part (i) of the theorem if we can merely show that ; that is,
Theorem 10 gives , and Corollary 7 gives . Part (i) follows.
The proof of part (ii) is very similar; the conditional distribution of given is the binomial distribution with trials and success probability given by (16). Part (iii) follows from parts (i) and (ii). □
We now have the analog for adaptive Boston of Corollary 6.
(Limiting Distribution of Preference Rank Obtained). The number of members of matched to their sth preference satisfies
In particular,
This is an immediate consequence of part (iii) of Theorem 12, with Theorem 11 providing the integral form of the limit. □
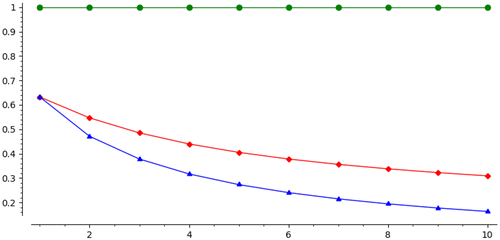
The functions are illustrated in Figure 6. Figure 7 shows for the last agent (θ = 1) the distribution of the rank of the item bid for and the item obtained at the second round.
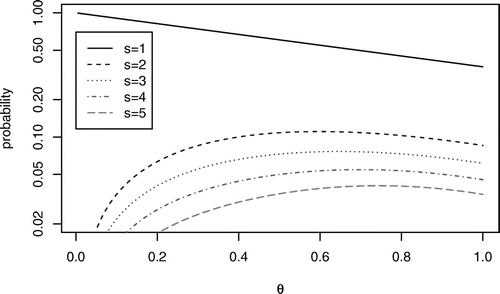
Note. Logarithmic scale on the vertical axis.
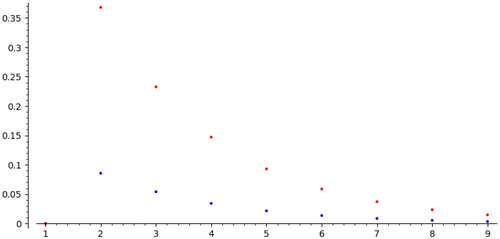
It is clear from the definition (and Remark 11) that . This is consistent with the implied role of as a probability distribution: the limiting probability that an agent in position θ obtains his sth preference. See also Theorem 13, part (iv).
5.2. Individual Agents
If we wish to follow the fate of a single agent in the adaptive Boston mechanism, we need limits analogous to that of Theorem 9. These are provided by the following result.
(Exit Time and Rank Obtained for Individual Agent). Consider the adaptive Boston algorithm. Fix and a relative position . Let denote the preference rank of the item for which the agent (the last agent with relative position at most θ) bids at round r. (For completeness, set whenever is not present at round r.) Let denote the round number at which is matched.
(Agent present at round r.)
(Agent bids for sth preference at round r.)
(Agent matched to sth preference at round r.)
(Agent matched to sth preference.)
The limiting quantities , urs, and are as defined in Theorem 11, Lemma 8, and Corollary 8.
Part (i) is proved in a similar way to Theorem 9. The result is trivial for r = 1. Assume the result for a given value of r, and let be the σ-field generated by events prior to round r. Then,
Observe that by Theorem 10. Equation (19) gives
The second term converges to zero as by the inductive hypothesis. For the first term, note that the convergence is also convergence in by theorem 4.6.3 in Durrett (2019) and so, in also. Part (i) follows.
For part (ii), we have
Hence,
Both terms converge in probability to zero. For the second term, the convergence is given by part (i). For the first term, it is a consequence of Corollary 7: , which is also convergence in by theorem 4.6.3 in Durrett (2019). Part (ii) follows.
The proof of part (iii) is very similar to that of part (ii); just replace by and by .
Part (iv) is obtained from part (iii) by summation over r. □
6. Technical Results and Proofs for Serial Dictatorship
Unlike the Boston algorithms, SD is strategyproof, but it is known to behave worse in welfare and fairness. However, we are not aware of detailed quantitative comparisons in the literature. The analysis for SD is very much simpler than for the Boston algorithms. In particular, the exit time is not interesting.
6.1. Groups of Agents
Analysis in this case is much simpler than for the Boston algorithms. Results analogous to those in Sections 4 and 5 are obtainable from the following explicit formula.
The probability that the kth agent obtains his sth preference is for and zero for other values of s.
By the time agent k gets an item, a random subset T of k – 1 of the n items is already taken. This agent’s sth preference will be the best one left if and only if T includes his first s – 1 preferences but not the sth preference. Of the equally probable subsets T, the number satisfying this condition is ; the remaining k – s items in T must be chosen from n – s possibilities. □
In particular, the nth and last agent is equally likely to get each possible item.
(Preference Rank Obtained). Consider the serial dictatorship algorithm. Fix and a relative position . The number of members of matched to their sth preference satisfies
Let . Let Xkn be the indicator of the event that the kth agent (of n) is matched to his sth preference; thus, and . The impartial culture model requires agents to choose their preferences independently; thus, the random variables are independent. We have
Note that
Hence,
As pointwise; because we also have , the dominated convergence theorem (Durrett 2019) ensures that . □
6.2. Individual Agents
For individual agents, we have the following analogous result.
(Preference Rank Obtained). Consider the serial dictatorship algorithm. Fix and a relative position . The probability that agent (the last with relative position at most θ) is matched to his sth preference converges to as .
From Theorem 14, this probability is
The result follows immediately. □
Figure 8 compares the limiting values of for our three algorithms. There is an interesting relationship between the curves. For small θ, AB is most likely to get its third choice, followed by NB and then SD. For most of the range, SD is the most likely, and NB overtakes AB only around . Near θ = 1, SD drops dramatically, consistent with what we already know about how badly the last 10%–20% of agents are treated under SD.
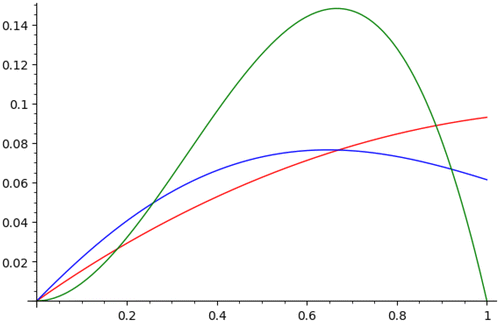
7. Remaining Proofs of Theorems
In this section, we provide proofs of results not provided earlier in the paper.
Let a1 and a2 be consecutive agents, with a2 immediately after a1 in ρ. Let S1 and S2 be the preference ranks of the items obtained by a1 and a2. It will suffice to show that . To this end, consider an alternative instance of the problem in which a1 and a2 exchange preference orders before the allocation mechanism is applied. We will refer to this instance and the original one as the “exchanged” and “nonexchanged” processes, respectively. Denote by and the preference ranks of the items obtained by a1 and a2 in the exchanged process. Because the exchanged process is also a random market, S1 and have the same probability distribution and similarly, S2 and .
We now show that all three of our allocation mechanisms have the property that . From this, the result will follow because .
For serial dictatorship, the exchanged and nonexchanged processes evolve identically for agents preceding a1 and a2. In the nonexchanged process, agent a1 then finds that his first preferences are already taken; in the exchanged process, these same items are the first preferences of a2. Hence, .
For the Boston mechanisms, let R be the number of unsuccessful bids made by a1 in the nonexchanged process. Then, the exchanged and nonexchanged processes evolve identically for the first R rounds, except that the bids of a1 and a2 are made in reversed order; this reversal has no effect on the availability of items to other agents. After these R rounds, a1 (in the nonexchanged process) and a2 (in the exchanged process) have reached the same point in their common preference order; in the next round, both will bid for the S1th preference in this order. Hence, . □
For convenience, define when n < s; this allows us to write . For any fixed , the finite sum defined by
We can now establish the required convergence in probability. Let , and choose so that . Then, (21) gives
Combine Theorem 2 with Corollary 6 (naive Boston), Corollary 8 (adaptive Boston), and Corollary 9 (serial dictatorship). □
Each such σ can be written as a finite nonnegative linear combination of k-approval rules. For each k-approval rule, Corollary 1 and Lemma 4 show that NB strictly beats SD. □
Combine Theorem 2 with Corollary 6 (naive Boston), Corollary 8 (adaptive Boston), and Corollary 9 (serial dictatorship). □
This follows directly from Corollary 3 and Remark 2. □
By Theorem 9, the asymptotic probability that the last agent obtains one of his first k choices is
The corresponding probability for the first agent is one. For other agents, this probability falls between the values for the first and last agents (Theorem 1). Hence, the asymptotic order bias is , which according to Theorem 8, can also be written . □
The probability that the last agent in ρ is matched to one of his first k preferences is . According to Theorem 13, part (iv), the asymptotic limit of this quantity is , where
The asymptotic order bias is thus
As noted in Remark 10, we have . The result follows. □
Let denote the expected Borda utility of the last agent in ρ: that is,
Then, for any s0,
From Theorem 14, we see that the first agent always gets his first choice, whereas the last agent gets each rank with probability (this special case is obvious and does not require Theorem 14). Hence, the expected utility under k-approval for the last agent is k/n, and the expected utility under Borda for that agent is
The result follows immediately by subtraction. □
This follows immediately from Theorem 6 because k is fixed and . □
8. Conclusion
We conclude this paper with discussion of possible extensions to the work herein.
8.1. Robustness to the Model Assumptions
If we relax the strict random-market assumption on preferences, we should expect different results, although the relative performance of the three algorithms will likely not vary. For example, simulations (Freeman et al. 2021) with preferences drawn from the Mallows distribution show that for small values of the Mallows dispersion parameter, it is much harder to satisfy all agents or keep order bias or average rank low, but nevertheless, NB beats AB, which beats SD, over the entire range of parameters. It is also clear that the Boston mechanisms beat SD in egalitarian welfare; the last agent in particular fares considerably better.
We have studied only sincere behavior by agents. Strategic behavior under the Boston mechanisms does occur in practice and does cause welfare loss, but the social welfare cost of adopting a strategyproof alternative such as (random) serial dictatorship is often substantial, as shown, for example, in analysis of Harvard course matching (Budish and Cantillon 2012). Note that for symmetric heterogeneous preferences such as those provided by our random markets assumption, there is no incentive for agents to report their preferences untruthfully. Even if strategic behavior is a serious consideration in some situations, it is still important to analyze and compare the underlying algorithms thoroughly.
The k-approval utilities we have used here are widely used in assignment applications. For example, statistics, such as the fraction of school choice students obtaining one of their top three choices or their one favorite course, are commonly discussed. This makes sense in many practical situations because eliciting complete agent preferences over n items for large n is infeasible, and many agents will have only a few items they consider acceptable. Furthermore, we have seen that in a random market, a large fraction of agents obtains one of their first few choices. We have also seen that Borda utilities yield different results from the k-approval case, as would any utility function satisfying the conditions of Che and Tercieux (2018). However, we do not expect that the relative order of the algorithms with respect to utilitarian welfare (naive Boston beats adaptive Boston, which beats serial dictatorship) will change.
8.2. Ideas for Future Work
An obvious question that we did not answer here is what the expected rank of the item gained by a random agent is. For SD, the asymptotic answer was derived by Frieze and Pittel (1995), and this was refined to an exact formula by Knuth (1996). For the Boston mechanisms, Corollary 4 shows that the rank is o(n), but we suspect that it is much smaller. It is known (Nikzad 2022, Ortega and Klein 2022) that for the rank-maximizing mechanism RM (Featherstone 2020), which maximizes the number of agents receiving their first choice, then subject to that the number of agents receiving their second choice, etc., the expected average rank in a random market is asymptotically constant. Although similar to RM at first sight, naive Boston is not as strict because it makes a choice based on tiebreaking at the first round and hence, may diverge from RM even at the second round. Based on numerical simulation, we conjecture that the expected average ranks for naive Boston and adaptive Boston are each in fact but smaller by a constant factor than that for SD.
Another important question concerns the expectation of the largest rank obtained by some agent (the egalitarian welfare). This coincides for NB with the number of rounds of the algorithm. The techniques of this paper do not allow us to answer this question. We conjecture based on the size of ωr that for NB, the expected egalitarian welfare is . Note that the analogous quantities for SD and RM are at least and about , respectively (Ortega and Klein 2022).
A simple idea that will reduce order bias is to reverse the order in which agents choose at each round (or just at the second round). Quantifying the improvement via an analysis analogous to that in this paper is not easy because it is no longer clear that the worse-off agent will be the last one in the initial choosing order; indeed, preliminary analysis shows it is not. We leave further exploration of this variant for future work.
The Boston algorithms discussed here are specializations of algorithms used for school choice to the case where each school has a single seat and schools have a common preference order over applicants. Further analysis of school choice mechanisms in the general case, from the viewpoint of welfare and order bias, would be very desirable. It would also be interesting to study welfare and order bias in the multiunit assignment model used by Budish and Cantillon (2012).
The basic results on distribution of exit time and rank of the item received by an agent may be useful in other contexts. As noted by Knuth (1996), there is direct connection between the analysis here of SD and that of uniform hashing. Naive Boston corresponds to a form of hashing where if a slot is full, the item must go to the back of the queue and wait its turn to be rehashed.
The order bias of the Boston algorithms, although smaller than that of SD, is still rather large. Thus, if this fairness criterion is important, it makes sense to use a mechanism like top trading cycles, which is strategyproof and has zero order bias in this situation with respect to every scoring rule (Freeman et al. 2021). Note that because the top trading cycles mechanism (TTC) (with a randomly chosen endowment) is equivalent to the randomized version of SD, RSD (Abdulkadiroğlu and Sönmez 1998), and SD does not give up much in utilitarian welfare to NB, TTC may be a good choice if preferences of agents are well described by IC.
The authors acknowledge useful feedback by Nick Arnosti and Rupert Freeman.
References
- (1998) Random serial dictatorship and the core from random endowments in house allocation problems. Econometrica 66(3):689–701.Google Scholar
- (2003) School choice: A mechanism design approach. Amer. Econom. Rev. 93(3):729–747.Google Scholar
- (2011) Resolving conflicting preferences in school choice: The “Boston mechanism” reconsidered. Amer. Econom. Rev. 101(1):399–410.Google Scholar
- (2005) The Boston public school match. Amer. Econom. Rev. 95(2):368–371.Google Scholar
- (2012) The multi-unit assignment problem: Theory and evidence from course allocation at Harvard. Amer. Econom. Rev. 102(5):2237–2271.Google Scholar
- (2020) Structural estimation of a model of school choices: The Boston mechanism vs. its alternatives. J. Polital Econom. 128(2):642–680.Google Scholar
- (2018) Payoff equivalence of efficient mechanisms in large matching markets. Theoret. Econom. 13(1):239–271.Google Scholar
- (2018) First-choice maximal and first-choice stable school choice mechanisms. Tardos E, Elkind E, Vohra R, eds. Proc. 2018 ACM Conf. Econom. Comput. (ACM, New York), 251–268.Google Scholar
- (2019) Probability: Theory and Examples, Cambridge Series in Statistical and Probabilistic Mathematics, 5th ed. (Cambridge University Press, Cambridge, UK).Google Scholar
- (2006) Games of school choice under the Boston mechanism. J. Public Econom. 90(1–2):215–237.Google Scholar
- (2020) Rank efficiency: Modeling a common policymaker objective. Working paper, Baylor University, Waco, TX., https://clayton-featherstone.github.io/.Google Scholar
- (1970) An Introduction to Probability Theory and Its Applications, vol. 1, 3rd ed. (Wiley, New York).Google Scholar
- (2021) Order symmetry: A new fairness criterion for assignment mechanisms. Preprint, submitted July 20, https://doi.org/10.31235/osf.io/xt37c.Google Scholar
- (1995) Probabilistic analysis of an algorithm in the theory of markets in indivisible goods. Ann. Appl. Probab. 5(3):768–808.Google Scholar
- (1979) The efficient allocation of individuals to positions. J. Political Econom. 87(2):293–314.Google Scholar
- (1996) An exact analysis of stable allocation. J. Algorithms 20(2):431–442.Google Scholar
- (2014) The “Boston” school-choice mechanism: An axiomatic approach. Econom. Theory 55(3):515–544.Google Scholar
- (2021) Partial strategyproofness: Relaxing strategyproofness for the random assignment problem. J. Econom. Theory 191(2021):105144.Google Scholar
- (2009) School choice: The case for the Boston mechanism. Internat. Conf. Auctions Market Mechanisms Their Appl. (Springer, Berlin), 58–60.Google Scholar
- (2022) Rank-optimal assignments in uniform markets. Theoret. Econom. 17(1):25–55.Google Scholar
- (2022) A more efficient and egalitarian mechanism for school choice. Preprint, submitted July 15, https://arxiv.org/abs/2204.07255.Google Scholar
- (2008) Leveling the playing field: Sincere and sophisticated players in the Boston mechanism. Amer. Econom. Rev. 98(4):1636–1652.Google Scholar
- (2019) Evaluating with statistics: Which outcome measures differentiate among matching mechanisms? Working paper, University of Zurich, Zurich.Google Scholar
- (1974) On cores and indivisibility. J. Math. Econom. 1(1):23–37.Google Scholar

