
Who’s Cheating? Mining Patterns of Collusion from Text and Events in Online Exams
Abstract
As the COVID-19 pandemic motivated a shift to virtual teaching, exams have increasingly moved online too. Detecting cheating through collusion is not easy when tech-savvy students take online exams at home and on their own devices. Such online at-home exams may tempt students to collude and share materials and answers. However, online exams’ digital output also enables computer-aided detection of collusion patterns. This paper presents two simple data-driven techniques to analyze exam event logs and essay-form answers. Based on examples from exams in social sciences, we show that such analyses can reveal patterns of student collusion. We suggest using these patterns to quantify the degree of collusion. Finally, we summarize a set of lessons learned about designing and analyzing online exams.
Note: This article was the winner of the INFORMS Transactions on Education journal’s 2024 Best Paper Award.
1. Introduction
Although the COVID-19 pandemic caused disruptions in all areas of life, academic teaching in particular encountered novel challenges. Relatively little insight is currently available on the implications of online-exclusive assessments for students’ academic integrity (Manoharan and Ye 2020). In many cases, students can take exams at home using their own device by logging into a learning platform and, for example, identifying through their confidential log-in information. As it is difficult to monitor students in their own homes, we follow Myyry and Joutsenvirta (2015) in arguing that such online exams tend to be, by nature, open book: Students can access notes, texts, or resource materials while taking an exam. This is not necessarily bad as open-book exams might then focus on questions that assess transfer knowledge, that is, the students’ ability to apply what they learned rather than relying on rote learning (Myyry and Joutsenvirta 2015, Bengtsson 2019). Nevertheless, even exam questions that reliably assess students’ performance in the open-book setting do not prevent cheating through collusion. Students may collude in various ways: discuss and exchange answers in person, by email, phone calls, or any kind of instant messaging tool, like Whatsapp or Telegram. As Cluskey Jr. et al. (2011, p. 3) state, “Cheating […] seems limited only by one’s imagination.” Lately, the topic has also been discussed in various newspaper reports (Appiah 2020, Lau et al. 2020, Smith 2021).
To monitor online exams, several existing reviews introduce and compare a wide range of proctoring options (Atoum et al. 2017, Alessio and Maurer 2018, Hussein et al. 2020). However, as pointed out by Cluskey Jr. et al. (2011), proctoring is costly. Additionally, Goldberg (2021) thoroughly criticizes the idea of successful proctoring, voicing concerns toward its efficacy and even pointing out the increased potential technical difficulties. We concur with these authors, as—when taking an exam at home—students can overcome any browser restriction by additional software, devices, and even human helpers. In contrast, video monitoring is not just fallible, too, but also doubtful in terms of students’ personal rights. Additionally, browser restrictions and video monitoring posit additional strains on students with limited technical equipment and bandwidth.
The low expectation of success in preventing students from seeking forbidden help in online exams motivates Miltenburg (2019) to advise against this form of final assessment. However, during the COVID-19 pandemic, epidemiological concern has prohibited many universities from asking the students to take exams within university rooms, electronically or not. Alternatives like switching to online oral exams are often too time consuming, especially in courses with a large number of participants. Therefore, many teachers have to assess courses via at-home online exams as the last step of distance learning.
At the same time, online exams offer new opportunities for learning analytics when exam platforms digitally record students’ answers and automatically log events related to students’ interaction with an online exam. As examiners are in charge of guaranteeing an equal, fair, and objective assessment of all participants of an exam, we suggest using these opportunities for detecting collusion.
From reviewing existing research, we found little on using automated analytics for identifying patterns of collusion in online exams. Therefore, we aim to contribute and demonstrate data-driven tools to that end. We first show that simple text mining functionality as available, for example, in R or Python, can highlight similarities in student answers even for large and diverse sets of exams. Second, we illustrate how mining the event-logs of exams can add a temporal dimension and reveal parallel-work-patterns or leader-follower-patterns. All presented techniques still require manual validation to check whether detected similarities are more than just a spurious incidence. As a precondition to the analyses proposed in this paper, students have to agree that submitted results and meta-data on their work on the exam are stored and analyzed. We empirically use data from exams of two German universities and two different study programs (bachelor in political sciences and master in business administration) to illustrate the application of the proposed tools. Finally, we summarize lessons learned from this analysis and from posing online exams over two virtual-teaching terms. We hope that the resulting description of tools, illustrative examples, and lessons learned contributes to enabling fair online assessments even beyond the pandemic circumstances.
Specifically, we rely on analyzing data collected by the online platform during the exam to detect patterns that indicate that students jointly worked on the exam or relied on a common collaborator. Note that the analysis proposed here cannot reveal whether students collaborated only with each other or were supported by a third party who did not participate in the exam themselves. Additionally, it does not detect or prevent other sources of fraud, such as faked technical difficulties. In fact, in all exams we analyzed, students had the option to redo the exam without negative consequences should they encounter and announce any technical difficulties, like an interrupted network connection, during the exam. Notably, very few students used this opportunity.
The paper is organized as follows. In Section 2, we review some related literature. Sections 3 and 4 describe the approaches for text-mining and event-mining collusion detection in the examples of real data from conducted online exams. Finally, Section 5 concludes the paper by presenting our lessons learned.
2. State of the Art
The existing research on online teaching is rich but somewhat fragmented across disciplines. This literature review does not aim to be exhaustive but to highlight clusters of research related to the contribution of this paper.
As noted with regard to “massive open online courses” (compare Lee et al. 2019), it is more difficult to hold students’ attention and involvement online than in the classroom. Miltenburg (2019) and Scherrer (2011) point out that about 15% of students are hard to reach by online teaching and, in consequence, achieve systematically lower grades. Specifically, Miltenburg (2019) describes his design of a large online course on business analytics in detail, offering valuable advice on designing lecture notes, podcasts, and assessments. Advice on the integration of video tutorials into blended learning can be found in Sharkey and Nurre (2016), whereas Mitra and Beenen (2019) particularly focus on motivational factors. As Miltenburg (2019) observes, it seems difficult to motivate students to seek an in-depth understanding of online course content.
Muzaffar et al. (2021) offer a systematic literature review of techniques and tools for online exams. Empirical research in Turkey presented in Ilgaz and Adanir (2020) find that students generally exhibit a high acceptance for online exams. Manoharan and Ye (2020) provide a differentiated analysis of the effect of online teaching on students’ academic integrity, particularly during COVID-19. As one example for assessing students’ work out of the classroom, Dicks et al. (2020) present a range of assessment approaches to organic chemistry courses. In particular, the authors highlight the importance of preparing students for taking a new style of exam through rehearsals and discussions with teaching assistants. Goldberg (2021) considers assessing student learning in online coding courses via take-home assignments or online exams. The authors differentiate issues with a lack of academic integrity as dependent on whether students can rely on “work for hire” regarding longer-term assignments or whether they have to take an exam-style assessment.
By considering opportunities for student cheating in online courses in general, McGee (2013) categorizes a range of types of dishonesty. Here, we focus on student collusion, where students share or jointly produce answers. Research on whether students are more likely to cheat when facing online exams is inconclusive (Harmon and Lambrinos 2008, Hollister and Berenson 2009, Fask et al. 2014). However, Harton et al. (2019) conclude that students find cheating easier in online exams. As also pointed out by Goldberg (2021), it is challenging to get students to admit to cheating even in an anonymous survey for fear of repercussions and social acceptability. From a wider standpoint, Gino et al. (2013) consider when people find it beneficial to cheat. In the paper at hand, we do not ask whether students are more likely to cheat in online settings. Instead, we attempt to take a pragmatic view of the matter by analyzing data generated within online exams for an ex post detection of collusion.
D’Souza and Siegfeldt (2017) present a conceptual framework to identify instances of student cheating through regression analysis of previous academic performance. As another example of checking for cheating through grade assessment, Dicks et al. (2020) conclude that the lack of significant improvement in grades indicates that students did not cheat, even when asked to consider the exam “closed book” despite a lack of proctoring. However, as Goldberg (2021, p. 7) emphasizes, the idea that online teaching outcomes potentially differ strongly from in-class outcomes may be a “lurking factor.” This factor can obscure findings from courses that were switched toward online teaching and assessment because of the COVID-19 crisis. Considering overall grade averages, in alignment with Dicks et al. (2020), we did not find an overall effect from online exams. Yet, considering subgroups of the exam, a positive effect triggered the search for plagiarism in the first case, which motivated our text-mining approach (compare Section 3). There was no notable grade difference on average in the second case, even though event mining shows clear collusion patterns (compare Section 4).
The task of identifying patterns of student collusion through text mining is linked to that of detecting plagiarism as reviewed in Fo`ynek et al. (2019). Lemantara et al. (2018) present a prototype to check for plagiarism in essay-style answers that students provide in an application for mobile learning. The necessity to check a large number of exams and the temporal component of students processing exams add additional dimensions to the problem. We hope that our paper helps educators on gaining more confidence for verifying potential cases of collusion through mining text and events.
3. Text-Mining Essay-Style Answers
When exam tasks predominantly require essay-style answers, we would expect that new, open-ended tasks result in highly individual answers. For such tasks, diverging answers can be equally correct, for example, when students provide different perspectives or application examples for a theoretical concept. In contrast, answers with a high text similarity constitute an initial suspicion for collusion.
3.1. Setting
The text-mining procedures described here were motivated by an at-home online exam posed for about 170 first-year undergraduate students in political science. Students participated in the exam by logging into the browser-based learning platform StudIP/Ilias (v. 5.4.17) from their own devices. Notably, this system provides only basic log files, excluding, for example, tasks’ begin and end times as are mined in Section 4 through another type of exam system. However, StudIP/Ilias does log students’ individual start and end times for the exam as a whole, which we use for the manual validation of our findings from the text-mining procedure described below. The exam was not proctored, but students had to assert their academic integrity in a preliminary task.
We randomly assigned students to one of two exam groups and had to notify participants of the group they belong to 12 hours in advance of the exam for technical reasons. The entire exam consisted of 44 tasks to be answered over the course of 70 minutes. Task types ranged from multiple-choice questions to simple calculations to short essay-style questions, where students had to explain a definition or a phenomenon or make an empirical evaluation based on their theoretical knowledge.1 The students were given a generous time interval to start working on the exam: they could start from 8:00 a.m. (earliest) to 12:30 p.m. (latest).
3.2. Automated Text Mining
To detect collusion between students answering essay-style tasks, we apply a four-stage approach to examine the results: (1) collect the full text of the essay-style answers as plain text files; (2) create a text corpus and compute the text similarity of every possible answer-pair;2 (3) evaluate the similarity pattern; (4) manually validate the results. In this, we follow the standard procedure of computational text analysis proposed in several studies (e.g., Grimmer and Stewart 2013, Welbers et al. 2017). Additionally, we rely on text analysis methods that are found suitable and are widely used in computational social science (e.g., Welbers et al. 2016; Meyer 2020, 2021).
We compute the text similarity of the essay-style answers based on the Jaccard similarity index. According to Leskovec et al. (2019), Jaccard similarity is suitable to detect similar documents. Like other measures (e.g., cosine similarity) as used in Lemantara et al. (2018), the Jaccard index focuses on character pattern. Accordingly, it is effective in detecting plagiarism by finding duplicates and near duplicates.
Jaccard similarity measures how close or similar two observations are to each other based on the number of common words. Basically, Jaccard similarity is defined as the size of the intersection of two sets divided by these two sets’ union size. For text documents, the Jaccard index measures the number of common words within two documents over the text documents’ total word count. The mathematical representation of the Jaccard similarity for text documents is
This results in a score that ranges from zero to one. For identical documents, Jaccard similarity is one; if there are no common words between two documents, it is zero.
We measure Jaccard similarity for every possible exam-answer pair for each task. On average, this yields a Jaccard similarity of 0.02. However, there also emerged a cluster of highly similar answers. Figure 1 illustrates two heat maps based on the Jaccard similarity score for the pairs of exam answers for two tasks (referred to as task no. 1 and task no. 2). The two dimensions in Figure 1 capture all students who answered the task. Each answer pair constitutes a box of the heat map.
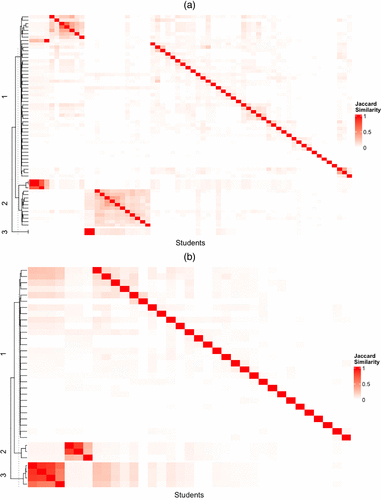
Notes. (a) Heatmap of Jaccard similarity for essay-style answers to task no. 1; (b) heatmap of Jaccard similarity for essay-style answers to task no. 2. On the two dimensions of these figures, students are pair-wise presented. Each box in the heatmap represents a single student pair. Dark red boxes arranged in stair structures represent the pairing of a student with herself or himself. Single lighter red boxes and rectangle structures consisting of several boxes in medium to dark red indicate pairs respectively clusters of students with slightly similar to very similar answers.
If the responses were perfectly independent (Jaccard similarity = 0), there should be a white map with a perfect dark staircase (where students are paired with themselves). Instead, both figures show clearly identifiable clusters of students with similar answers, which are indicated on the left and are observable by “broken” staircases. The clusters were identified with Euclidean distances. These results illustrate that most answer-pairs are not similar (light fields) or just slightly similar (medium fields). However, three student clusters in Figure 1(a) and two student clusters in Figure 1(b) exhibit very high Jaccard values (dark fields). Similar patterns were found for all task subsets of the exam.
3.3. Manual Validation
The heat maps of the Jaccard index deliver a strong indication where to look for collusion. But the purely automated approach has three weaknesses: identical short answers, reformulation, and the taint of circumstantial evidence.
3.3.1. Identical Short Answers
Because the essay-style answers observed in this exam are rather short texts of 4 to a maximum of 221 words, it stands to reason that the answer similarity might be mainly driven by specialized terminology, which was queried in the stated exam tasks. As an example, a group of students provided a single absolutely identical answer (Jaccard value of 1.0) for one task, which was, however, short and used many technical terms. Analyzing further answers of this group showed low similarity scores, and manual inspection indicated that systematic collusion was very unlikely. Considering Jaccard values without further validation may thus yield false positives, which need to be filtered by manual inspection to avoid faulty accusations.
3.3.2. Obscuring by Reformulation
False negatives result when students reformulate answers from another exam sentence-by-sentence and only structurally plagiarize the original answer. This leads to medium-level Jaccard values. If students exchange answers, it is very likely that they modify the response to obscure collusion. This behavior might be revealed by systems that log the formation of a response text in the course of time, as considered in Section 4. To detect this, a text similarity check should not only address the final answers provided to a task but also earlier versions where modification of a copied response has not yet begun. A very basic form of “obscuring by reformulation” is altering the order of bullet points if students are asked for a list of examples or arguments. We observed a case where one student first entered argument A and then appended argument B into the text field. Another student first entered argument A but then inserted argument B before A into the list. The text similarity of both bullet point lists was detected automatically. The subsequent analysis of the sequence of response events revealed the unnatural text-entering behavior of the second student, which may be interpreted as an attempt of obscuring the collusion.
3.3.3. Circumstantial Evidence
Additionally, a very high Jaccard index for one task might be an indicator but is no proof. There need to be similar answers across multiple tasks to make the case for systematic collusion. To avoid false positives and false negatives, we validate answer-pairs with medium to high text similarity manually across several tasks. In this respect, we follow the classical steps of automatic text analyses, which have no explanatory power without manual validation (Grimmer and Stewart 2013).
The pair-wise or cluster-wise answers can be compared, for example, (1) by using an R-package that provides such functionality, (2) by using Microsoft Word text comparison, or (3) simply by putting the respective answers in tables next to each other. The latter is the quickest way to see patterns for short answers; the first two strategies may be more efficient for larger numbers of students, provide harder evidence, and can be supplemented with qualitative analysis.
Table 1 shows the collaboration of two pairs of students with Jaccard pair values of 0.9 and 0.7. It highlights text similarities in yellow. The first answer pair A and B is not a perfect match but provides strong circumstantial evidence. A closer inspection of the text also reveals that while changes were made, the answers exhibit two idiosyncrasies that are underlined in the table: the incorrect term “semipresident systems” does not exist in the literature and was also not used by other students. As a more substantial error, a directly elected president is, of course, not responsible to the parliament. These two idiosyncrasies in the pair A and B underline the suspicion of collusion beyond the high Jaccard index.
|

Table 1. Two Answer Pair Examples with Different Degrees of Text Similarity
| Answer pair A, B with a Jaccard similarity of 0.9, task no. 1 | |
| Answer A | Answer B |
| Answer pair X, Y with a Jaccard similarity of 0.7, task no. 2 | |
| Answer X | Answer Y |
Notes. The answers were translated from German language into English language by the authors. Differences between answers in the form of typos and wording were translated appropriately. Yellow indicates identical parts, white nonidentical.
As this example shows, identical faulty answers can offer revealing evidence. We consider it to be even more substantial evidence for collusion when two responses not only exhibit a high text similarity but are also factually wrong. In a computational task from the exam described in the next section, two answers were similar in the text (which can quickly occur for responses with a large share of mathematical terms) but applied the identical, yet erroneous, computation approach. For essay-style tasks, the corresponding case arises if two textually similar answers rely on the same erroneous argument or misused term.
The texts of the answer pair X and Y in Table 1 are also fairly similar. However, answer Y possesses several typos and an abrupt ending, as a result of which the Jaccard value drops to 0.7. Despite the Jaccard value dropping by 0.2 points, the answers still seem clearly related. As visible from these examples, Jaccard similarity values that exceed 0.5 should plausibly receive attention when answers are of similar length as in the example analyzed here. The high similarity pattern for the answer pairs A, B and X, Y is only exemplary here. The patterns could be confirmed across several tasks for groups of students in the analyzed exam.
Although for the exam considered here, the learning platform did not provide full log files, the system noted start and end time of the exam. The student cluster with the highest Jaccard values started and ended the exam as pairs of two at the same minute within the 4.5-hour interval being available, which is a further indication of collusion. The next section provides further insight into analyzing temporal patterns among exams.
4. Event-Mining Log Data from Online Exams
Checking for text similarity can be misleading and may produce false positives when an exam requires relatively short answers or if answers are expected in the form of numbers, code, or multiple-choice selections. Anyways, if exams consist of a substantial number of tasks and if the used exam system produces quite detailed logs of the task processing, event mining can be a useful tool for detecting collusion, as is shown in this section.
4.1. Setting
The event-mining procedures described here were motivated by an at-home online exam posed for 17 graduate students in business administration. Students participated in the exam by logging into the browser-based learning platform OpenOlat system (Frentix GmbH 2020), version 15.3.7, from their own devices. The exam was not proctored, but students had to confirm that they were participating in the exam on their own and without external help. The exam was officially declared “open book,” meaning that students could use all available course materials like lecture notes, videos of recorded lectures, or tutorials that were provided throughout the term.
The exam consisted of 14 tasks to be answered over the course of one hour. The tasks were a mix of questions where students had to explain concepts, list examples of phenomena, or provide numerical results from computations. For each task, OpenOlat provided a text field where students had to enter their answers. Participants had free access to all tasks, meaning that they could decide in which order to answer the tasks. They could also return to already-answered tasks at a later point in time to check and revise their answers.
The OpenOlat system produces a log file covering the entire exam time for each participant. The plain-text log file lists various events as they occur over time. We specifically consider the events NEXT_ITEM, RESPONSE, and ATTEMPT_VALID. NEXT_ITEM indicates that a student started working on a task, whereas ATTEMPT_VALID indicates that a student left that task to work on some other task. RESPONSE events are generated once per minute while a student is working on a task. Each event is logged with the ID of the current task, a time stamp, and a string that stores the current response.
4.2. Automated Event Mining
We implement a Python script to parse the log files, clean the event list, and analyze the relevant information. Parsing and cleaning handle a number of issues. For example, the process adds an extra NEXT_ITEM event for the first task of the exam, as OpenOlat does not create a corresponding event when students first start the exam. We also remove events with a blank response, as these indicate that students read the task without immediately responding to it. Further, we remove events where students did not change their previously given response but only proofread their work. The resulting event list represents a subset of all events and constitutes a time series describing how a participant worked through the exam and what responses this student gave over time.
Figure 2(a) illustrates an example of such a time series. An upward pointing triangle indicates that a student entered the task (NEXT_ITEM), whereas a downward pointing triangle indicates that the task was left (ATTEMPT_VALID). The horizontal line indicates the first logged RESPONSE event. In the example of Figure 2(a), the student worked through tasks 1–11 in the given sequence, skipped task 12, worked on task 13, returned to task 12, and finished by responding to task 14. The plot depicts the first set of NEXT_ITEM, RESPONSE, and ATTEMPT_VALID events per task, that is, the first time span where the student actually worked on that question. It does not display later returns to a task that involved revisions or extensions of previous responses. We neglect such returns in our analysis, as they were rare in the data set considered.
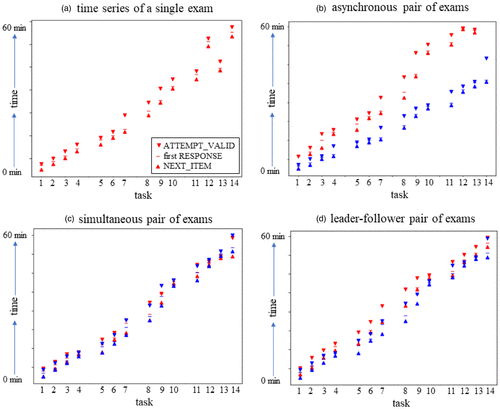
Based on the logged event series per student, we conduct pair-wise comparisons. Figure 2(b)–(d) illustrate selected pairs of event series. Figure 2(b) illustrates a case where both students answered the 14 tasks in the given sequence but with diverging timing. The student represented by the blue series worked through the exam somewhat faster compared with the red student. Except when starting on the first task, the pair did not work simultaneously on any of the other tasks. In contrast, Figure 2(c) shows a case where two students processed their exams with extremely similar timing.
To quantify the similarity of time series, we computed for each pair of exams e1 and e2 a simple distance measure. This measure is the Average Absolute Deviation (ADD) of NEXT_ITEM and ATTEMPT_VALID events over all n tasks to which both participants provided an answer (here, n is up to 14) and the corresponding events (here, up to 28), as computed by
For the event series in Figure 2(c), AAD is 70 seconds; for the series in Figure 2(b), it is 1,062 seconds. These examples show that the temporal similarity of the exams is effectively captured by the distance measure.
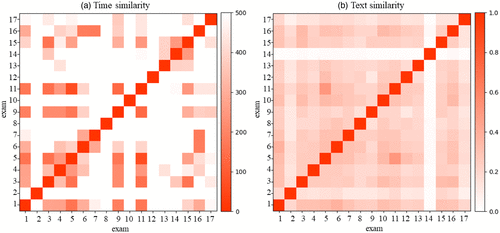
Figure 3(a) illustrates the pair-wise comparison of all exams by means of AAD, where dark colors indicate a low value of AAD, that is, high temporal similarity of the pair of exams. White color indicates pairs of exams where AAD is 500 seconds or even higher. Pair (5,11) is the one that was already illustrated in Figure 2(c). It shows the lowest AAD value among all pairs. Note that there are many further pairs with low AAD values. An explanation for this is that many students work through the set of tasks one by one from task 1 to task 14 at similar speed, which naturally causes similar time patterns. This illustrates that such a quantitative analysis might reveal suspicious cases, but it does not immediately constitute proof for cheating. Further analysis is required for these cases as is described below.
Note that there might be further suspicious patterns that are not detected well through AAD. Figure 2(d) provides an example: The blue and red series progress through the tasks in a very similar time fashion but with a quite constant temporal shift such that red is somewhat later than blue for almost all tasks. The AAD is relatively high with 248 seconds, but the low variance of the interexam distance per task and event might be used for detecting this pattern. In other words, quantifying other types of patterns in these time series might require alternative distance measures, which, however, we do not further consider here.
4.3. Manual Validation
The above discussion shows that a quantitative analysis of time similarity and text similarity can help in identifying suspicious cases of collusion among students. Clearly, the examiner has to collect sufficient evidence before accusing students of cheating. Observing just a single indicator is surely insufficient and can easily lead to false accusations. One example of this is the sole existence of time similarity (low values of AAD), which can simply occur if students work on their own but answer the tasks in a same order and at a similar speed. As with text similarity analysis described in Section 3, collecting more than one piece of evidence when analyzing a particular pair of exams substantiates accusations. With regard to event mining, we identified several aspects that may indicate collusion.
4.3.1. Simultaneous Work
As shown at the example of Figure 2(c), a systematic temporal overlap of event series is one indicator of students jointly working through an exam. The used AAD measure can be applied for quickly identifying suspected cases of such a form of collaboration. It still detects time similarity if the order in which the two students worked on the tasks differs from the natural order 1, 2, 3, …. AAD can become an even stronger indicator of collaboration, if the ordering of tasks was randomized for each student. Simultaneous work then requires that the order in which tasks are answered is (actively) aligned by the students. For example, if two students get presented their tasks in order “3, 1, 2” and “2, 1, 3,” respectively, but both students answer them in the order “2, 1, 3,” it is likely that the first student has aligned his or her answering to the second student. This can be detected through low values of AAD or through measuring the similarity of the ordering of tasks versus the ordering of answers for each pair of students.
4.3.2. Leader Follower
A leader-follower pattern like in Figure 2(d) may justify the assumption that one student answered the tasks one by one and the other systematically transferred the finished answers into his or her own exam. Such a pattern might be detected by advanced similarity measures that capture the variance of the temporal distances among the event time series of two exams.
4.3.3. Crosswise Answering
A further pattern that we observed is that students may distribute the work among each other such that one student first answers one task while the other answers another task. Afterward, they share their answers. As a result, the two students enter the answers for these two tasks in differing order and at different times, which is not well detected through AAD. Anyways, the event logs can be used for detecting such crosswise work patterns. A further check of the text similarity of the final responses (see next paragraph) might then help with dissolving or confirming the suspicion for collusion.
4.3.4. Combining Event and Text Analysis
To complement our findings on temporal similarity, we also conduct a quantitative text-similarity analysis of responses, as described in Section 3.2. For this, we use Python’s Natural Language Toolkit (see NLTK.org 2020 and Bird et al. 2009) to compute a distance measure for any pair of responses given in two exams for a particular task. Figure 3(b) illustrates this similarity as an average over all responses available in both exams. Here, red indicates similar responses. We see that exam pair (5,11) has a text similarity score of about 0.5, which is the highest score among all exam pairs. In combination with the temporal similarity identified for this exam pair, this underlines the suspicion of collaborative work for these students. As a note, the light row/column 14 refers to a student who answered all tasks in English, whereas others answered in German, which shows that a text similarity check runs into its boundaries if various languages are allowed for responding to the questions.
4.3.5. Revision of Incorrect Answers
As the OpenOlat system logs the response text given to a task once per minute, it provides insight into how a response evolves in the course of time. From this, we observed two final answers with a high text similarity score where a response contained an obvious mistake in its first version that was entered into the system. Later, at the time when the second student entered the correct answer into the system, the faulty answer was corrected by the first student within a second.
5. Conclusion and Lessons Learned
When aiming to detect cheating in general and collusion in particular, examiners have to collect substantial evidence to avoid false accusations. The increasing role of online, at-home exams calls for appropriate methods to that end. This paper contributed two techniques to detect suspicious patterns of student collusion in hindsight: pair-wise text analysis of exam questions and pair-wise temporal analysis of log files. As noted in the introduction, to apply the tools proposed here, both technical and legal preconditions apply with regard to the storage and analysis of student data. Furthermore, these techniques only detect patterns of collusion but cannot indicate the precise cause for these patterns, be it joint work, reliance on common prepared answers, or support from a third party.
The analysis presented in this paper relied exclusively on temporal data on students’ timing in answering exam tasks and on the answer texts themselves. Notably, further data, which were not available in the cases considered here, could be used in complement. For example, when the system stores students’ IP addresses, two students that use the same IP address—hence, work from the same network location—and have a similar timing in their answers are particularly suspect of collusion. However, the mere fact of shared IP addresses should not be used as an argument for collusion alone, because many students live communally, especially in student residence halls.
We emphasize that we observed the presented indicators for cheating through collusion only in a very small share of analyzed exams. We do not doubt that the large majority of students conduct their exams with great academic integrity. However, particularly in light of this and to ensure a fair and equal treatment of all students, we regard it as the educator’s duty to detect and avoid fraud. To apply the instruments presented here carefully and deliberately, we therefore offer some additional advice:
Do analyze multiple tasks to check for the validity of a suspicion.
Do account for the fact that any patterns identified may be regarded just as circumstantial evidence but no proof from a judicial perspective.
Do consider applying a spell check before looking for text similarities, but note that this might delete “smoking guns” in terms of joint typos.
Don’t be fooled by rephrasing: If students are smart enough to rephrase well, evidence from event mining is weakened and evidence from text mining largely disappears. This advice is in line with Leskovec et al. (2019, p. 83), who emphasize that “no simple process of comparing document character by character will detect a sophisticated plagiarism.”
Finally, we suggest to carefully consider whether to confront students with the techniques and analyses presented here before posing another exam. In writing this paper, we have frequently considered whether it would be beneficial to present its contents to students ahead of the exam, aiming to deter them from cheating by limiting the expectation of success. However, as Goldberg (2021, p. 49) states, in doing so, one may wonder, “had I just taught my class to cheat more covertly”?
A key to avoiding fraud in the first place is a suitable design of online exams. Without doubt, the exams analyzed in this paper could have benefited from improved designs too. Following the related literature, such as Khare and Lam (2008), Manoharan (2019), Dicks et al. (2020), and Goldberg (2021), we use the opportunity to highlight concepts of how to design online exams to prevent cheating by collusion:
Don’t ask questions where answers can be copied or easily adapted from the lecture notes or other sources.
Don’t ask the same question to everyone if that question requires only a very short answer. Text-mining patterns are then not a reliable indicator of collaboration. However, asking individualized short-answer questions to students is okay because similar answers are then unlikely and, if detected, they are a strong indicator of collaboration.
Do find strength in numbers: Drawing individualized exams from a large pool of questions makes it difficult for students to find partners for collusion. However, this requires much effort in creating the question pool and in grading the resulting individualized exams, as also noted in the literature. Additional challenges result when aiming to keep the level of difficulty equitable across individual exams. Notably, Manoharan (2019) offers some advice to that end.
Do introduce randomness: If possible, let the learning platform scramble the sequence of questions that students are confronted with, so that it becomes more difficult for them to work in teams through the exam from start to finish.
Do limit the time frame, both for students to take the exam and for students to know assigned groups, to avoid opportunities for organised and leader-follower collusion.
Do find glory in prevention: When successfully designing an exam in a way that prevents collusion, applying the instruments presented in this paper should not reveal any patterns in terms of text or time.
None of the exams considered in our analysis followed a “cannot go back” approach to exam design as suggested by Miltenburg (2019). This would force students to face questions in strict sequence and prohibits returning to already answered questions to make collusion more difficult. However, for complex questions and empowered students, we regard the ability to prioritize questions and revise answers as crucial.
As a limitation, our analyses are founded on a pair-wise comparison of exams. The tools presented here do not necessarily work if multiple students collaborate where answers are sourced from and shared among different parties. Such an approach, however, might circumvent attempts to prohibit collusion through randomization and scrambling. It might be a subject for future research to conduct corresponding network analyses and derive suitable methods for this, for example, based on identifying similar typos or phrases.
Our paper shows two ways of identifying potential student collusion in open-book exams by using time-stamped data from logs as well as text mining data. However, after identifying potential fraud, there is still a legal question to be answered. Plagiarism in essays and theses as well as classic ways of cheating in written exams, like looking into the neighbor’s sheet or depositing files in secret places, are well established as exam fraud. With regard to open-book exams, we are in largely uncharted territory judicially. The proof is based on circumstantial evidence and may be less clear even in cases where the same typos occur across answers. Therefore, if formal actions are taken against colluding students by an examiner, the outcome might be strongly dependent on the considerations of the members of the examination board deciding on the case and the risk aversion of the legal officer of a university. Extending existing rules for offline exams toward novel forms of online examination seems, thus, advisable.
1 Some of the 44 tasks had already been used in previous exams or as illustrative tasks in the lecture material. A set of eight tasks per exam group was completely new and never used before. These tasks were short, essay style and thus suited for automated text analysis. We chose the eight entirely new essay-style tasks for analysis to avoid false positives. Well-prepared students might have revised the previously used tasks and worked together on a “master” solution in advance of the exam, which then would have produced a high similarity.
2 Text corpus, answer-pair assembly, and text similarity computation are realized with R package textreuse of Mullen (2016).
References
- (2018) The impact of video proctoring in online courses. J. Excellence College Teaching 29(3-4):183–192.Google Scholar
- (2020) If my classmates are going to cheat on an online exam, why can’t I? Accessed March 23, 2021, https://www.nytimes.com/2020/04/07/magazine/if-my-classmates-are-going-to-cheat-on-an-online-exam-why-cant-i.html.Google Scholar
- (2017) Automated online exam proctoring. IEEE Trans. Multimedia 19(7):1609–1624.Crossref, Google Scholar
- (2019) Take-home exams in higher education: A systematic review. Ed. Sci. (Basel) 9(4):267.Google Scholar
- (2009) Natural Language Processing with Python (O’Reilly Media Inc., Sebastopol, CA).Google Scholar
- (2011) Thwarting online exam cheating without proctor supervision. J. Acad. Bus. Ethics 4(1):1–7.Google Scholar
- (2020) Lessons learned from the COVID-19 crisis: Adjusting assessment approaches within introductory organic courses. J. Chemical Ed. 97(9):3406–3412.Crossref, Google Scholar
- (2017) A conceptual framework for detecting cheating in online and take-home exams. Decision Sci. J. Innovative Ed. 15(4):370–391.Crossref, Google Scholar
- (2014) Do online exams facilitate cheating? An experiment designed to separate possible cheating from the effect of the online test taking environment. J. Acad. Ethics 12(2):101–112.Crossref, Google Scholar
- (2019) Academic plagiarism detection: A systematic literature review. ACM Comput. Surveys 52(6):1–42.Crossref, Google Scholar
- (2020) OpenOlat. Accessed March 23, 2021, https://www.openolat.com.Google Scholar
- (2013) License to cheat: Voluntary regulation and ethical behavior. Management Sci. 59(10):2187–2203.Link, Google Scholar
- (2021) Programming in a pandemic: Attaining academic integrity in online coding courses. Comm. Assoc. Inform. Systems 48(1):47–54.Google Scholar
- (2013) Text as data: The promise and pitfalls of automatic content analysis methods for political texts. Political Anal. 21(3):267–297.Crossref, Google Scholar
- (2008) Are online exams an invitation to cheat? J. Econom. Ed. 39(2):116–125.Crossref, Google Scholar
- (2019) Faculty and student perceptions of cheating in online vs. traditional classes. Online J. Distance Learn. Admin. 22(4):n4.Google Scholar
- (2009) Proctored vs. unproctored online exams: Studying the impact of exam environment on student performance. Decision Sci. J. Innovative Ed. 7(1):271–294.Crossref, Google Scholar
- (2020) An evaluation of online proctoring tools. Open Praxis 12(4):509–525.Crossref, Google Scholar
- (2020) Providing online exams for online learners: Does it really matter for them? Ed. Inform. Tech. 25(2):1255–1269.Google Scholar
- (2008) Assessing student achievement and progress with online examinations: Some pedagogical and technical issues. Internat. J. E-Learn. 7(3):383–402.Google Scholar
- (2020) Cheating allegations prompt South Korean online exam rethink. Accessed March 23, 2021, https://www.timeshighereducation.com/news/cheating-allegations-prompt-south-korean-online-exam-rethink.Google Scholar
- (2019) Systematic literature review on self-regulated learning in massive open online courses. Australasian J. Ed. Tech. 35(1):28–41.Google Scholar
- (2018) Prototype of online examination on MoLearn applications using text similarity to detect plagiarism. 2018 5th Internat. Conf. Inform. Tech. Comput. Electr. Engrg. (ICITACEE) (IEEE, Piscataway, NJ), 131–136.Google Scholar
- (2019) Mining of massive datasets. Accessed March 23, 2021, http://infolab.stanford.edu/ullman/mmds/book0n.pdf.Google Scholar
- (2019) Cheat-resistant multiple-choice examinations using personalization. Comput. Ed. 130:139–151.Crossref, Google Scholar
- (2020) On upholding academic integrity in online examinations. 2020 IEEE Conf. e-Learn., e-Management e-Services (IC3e) (IEEE, Piscataway, NJ), 33–37.Google Scholar
- (2013) Supporting academic honesty in online courses. J. Educators Online 10(1):1–31.Crossref, Google Scholar
- (2020) Explaining media coverage on Constitutional Court decisions in Germany: The role of case characteristics. Political Comm. 38(4):426–446.Crossref, Google Scholar
- (2021) Promoted media coverage of court decisions: Media gatekeeping of court press releases and the role of news values. Journalism Stud. 22(6):723–740.Crossref, Google Scholar
- (2019) Online teaching in a large, required, undergraduate management science course. INFORMS Trans. Ed. 19(2):89–104.Link, Google Scholar
- (2019) A comparative study of learning styles and motivational factors in traditional and online sections of a business course. INFORMS Trans. Ed. 20(1):1–15.Link, Google Scholar
- (2016) textreuse: Detect text reuse and document similarity. Accessed March 23, 2021, https://cran.r-project.org/package=textreuse.Google Scholar
- (2021) A systematic review of online exams solutions in e-learning: Techniques, tools, and global adoption. IEEE Access 9:32689–32712.Crossref, Google Scholar
- (2015) Open-book, open-web online examinations: Developing examination practices to support university students’ learning and self-efficacy. Active Learn. Higher Ed. 16(2):119–132.Crossref, Google Scholar
NLTK.org (2020) Natural language toolkit. Version 3.5. Accessed March 23, 2021, https://www.nltk.org/.Google Scholar- (2011) Comparison of an introductory level undergraduate statistics course taught with traditional, hybrid, and online delivery methods. INFORMS Trans. Ed. 11(3):106–110.Link, Google Scholar
- (2016) Video tutorials within an undergraduate operations research course: Student perception on their integration and creating a blended learning environment. INFORMS Trans. Ed. 17(1):1–12.Link, Google Scholar
- (2021) Online cheating is the next hurdle for students and schools. Accessed March 23, 2021, https://www.independent.co.uk/news/education/online-cheating-learning-students-schools-b1787289.html.Google Scholar
- (2017) Text analysis in R. Comm. Methods Measures 11(4):245–265.Crossref, Google Scholar
- (2016) A gatekeeper among gatekeepers. Journalism Stud. 19(3):315–333.Crossref, Google Scholar

