
Frontiers: The Demand for Counterfeits: A Descriptive Analysis
Abstract
We descriptively document a robust U-shaped relationship between income and counterfeit consumption using large-scale field data on U.S. consumers. Relative to the middle-income cohort ($50k–$75k), both low-income () and high-income () consumers are more active in counterfeit markets: they purchase more, buy more repeatedly, and disproportionately choose higher-priced and niche listings as well as brands’ classic product series. The tails differ in composition: relative to the middle-income cohort, low-income demand loads more on lower-tier brands, whereas high-income demand tilts toward ultraluxury and toward higher-priced listings within a series, consistent with greater willingness to pay for counterfeit quality. A cross-brand copurchase network corroborates these patterns, with pronounced clustering by product category and brand position. We discuss implications for theory and practice.
History: Puneet Manchanda served as the senior editor.
Conflict of Interest Statement: All authors certify that they have no affiliations with or involvement in any organization or entity with any financial interest or nonfinancial interest in the subject matter or materials discussed in this manuscript. The authors have no funding to report.
Supplemental Material: The online appendix and data files are available at https://doi.org/10.1287/mksc.2025.0565.
1. Introduction
Certain consumer demands are deemed illicit because they are judged socially harmful, yet these markets persist and increasingly operate online. Counterfeits are a leading case: estimates attribute more than 2% of global trade to counterfeit goods and associate them with welfare and growth losses (e.g., Fink et al. 2016, Federal Research Division, Library of Congress 2020, Organisation for Economic Co-operation and Development 2021a). The internet has reduced search and transaction costs, expanding markets for fakes—especially through cross-border commerce (e.g., U.S. Department of Homeland Security 2020, Organisation for Economic Co-operation and Development 2021b).
Counterfeit demand differs from demand for genuine products: social norms introduce nonprice motives into the choice to buy or abstain (Akerlof 1980, Benabou and Tirole 2026). In the United States, purchasing counterfeit goods for personal use is not a criminal offense,1 yet attitudes are strongly negative: in a 2021 survey of 1,000 U.S. adults, 61% disagreed that buying counterfeits is a “victimless crime.”2
Because counterfeit consumption is hard to observe, the basic empirical patterns remain underdocumented (e.g., U.S. Government Accountability Office 2010, Qian 2014, European Union Intellectual Property Office 2023b). We still lack evidence on which populations are more susceptible to illicit purchasing—knowledge essential for targeting policy and assessing the distributional effects of stricter enforcement. Existing evidence is dominated by self-reported surveys and laboratory experiments (e.g., Wilcox et al. 2009, Qian and Xie 2014).
This paper documents, in a descriptive sense, new evidence about counterfeit demand using large-scale field data from a cross-border e-commerce platform. During the sample period, U.S. consumers could purchase counterfeits from foreign sellers. The catalog covers major brands (e.g., Louis Vuitton (LV), Nike, Chanel, Hermès). We observe destination ZIP codes for millions of counterfeit orders spanning ZIP codes that contain about 94% of the U.S. population. Because sellers operate outside the United States and platform conditions are uniform, supply is reasonably fixed across ZIP codes; we therefore treat ZIP-level differences as primarily demand driven.
We begin by mapping the income–counterfeit gradient: how counterfeit consumption varies with household income. Income shapes budgets and preferences and proxies social position; because luxury goods serve as status signals, counterfeits can offer a shortcut to status (Grossman and Shapiro 1988). We do not observe individual buyers’ incomes. Instead, we combine transaction data with census data reporting ZIP-level shares in 10 income bins and estimate a transparent regression of ZIP counterfeit intensity on local income composition.
Signaling models often predict peak demand among middle-income consumers (Feltovich et al. 2002): those far below a status threshold may view mainstream status goods as out of reach or low return, whereas those far above may have less need to signal (or may benefit from not appearing to try). Instead, we document a robust U shape: ZIP codes with larger shares of high-income () or low-income () households purchase more counterfeits than ZIP codes dominated by the middle-income reference group. The pattern survives a battery of checks: it is not explained by cross-income-cohort spillovers, is not mechanically driven by contextual heterogeneity, and it holds on both the extensive margin (entry) and the intensive margin (repeat purchasing). A natural interpretation is “middle-class conformity”—if the social costs of norm violation peak near the middle of the status distribution, counterfeit buying can be lowest there (Phillips and Zuckerman 2001).
We then show that this U shape is both broad and structured. Reestimating the income gradient separately for 41 brands, the U shape appears consistently, with meaningful brand-level differences. Four illustrative cases make the structure clear: Nike (mass-market), Louis Vuitton (the most popular luxury brand), and the ultraluxury houses Chanel and Hermès. Relative to the middle-income cohort, low-income consumers display similar incremental demand for Nike, LV, and Chanel, and slightly weaker incremental demand for Hermès. At the top, high-income consumers tilt strongly toward ultraluxury (Hermès and Chanel), exhibit less incremental demand for LV, and show no incremental demand for Nike.
To suggest potential mechanisms, we study heterogeneity in two salient listing attributes: price and popularity. By price, the U shape is most pronounced among the most expensive listings: both tails are more likely than the middle-income cohort to buy very high-priced counterfeits, challenging a purely budget-driven account of low-income demand and pointing to substantial willingness to pay at both tails. By popularity, the U shape is stronger for niche listings and weaker for very popular ones, consistent with discovery-driven “treasure-hunt” motives being more salient at the tails.
Finally, we cascade the composition result from macro to micro, tracing demand across four nested levels: (i) categories, (ii) brand segments within category, (iii) product series within brand, and (iv) listings within series. Bags are more expressive and status signaling than shoes; consistent with this, the right-tail uplift is stronger for bags, whereas the left-tail uplift is stronger for shoes. Demand also sorts sharply by bag tier: relative to the middle-income baseline, low-income cohorts load more on lower-tier brands (e.g., Coach) and high-income cohorts on higher-tier brands (e.g., Hermès), corroborated by buyer-level copurchase clustering. Within brands, the U shape loads most strongly on classic, widely recognized series, and within a series, high-income cohorts tilt toward higher-priced listings—especially for Hermès and Chanel—consistent with greater willingness to pay for higher-quality counterfeits.
1.1. Literature
We add to the literature on counterfeits. Grossman and Shapiro (1988) develop an analytical model to examine the welfare implications induced by intentional demand for foreign counterfeits. Qian (2008) leverage natural variations and field data to estimate the impacts of counterfeit entry on authentic prices, quality, and other market outcomes (see also Qian 2014, Fink et al. 2016).3 Wilcox et al. (2009) use surveys to study consumers’ incentives for intentionally purchasing counterfeit luxury brands (e.g., Wee et al. 1995, Tom et al. 1998, Nia and Zaichkowsky 2000, Eisend and Schuchert-Güler 2006, Rutter and Bryce 2008, Bian and Moutinho 2009). Han et al. (2010) find that consumers’ wealth and status needs influence their preference for authentic versus counterfeit luxury goods.
Our paper is new in that we use large-scale field data to uncover local socioeconomic profiles in counterfeit markets. Most relevant to our work, Qian and Xie (2014) highlight the challenges of limited data availability in understanding counterfeit demand and propose a data-fusion method that combines survey data on counterfeit demand with firm-internal data. Alternatively, Fisman and Wei (2009) empirically analyze the illicit trade in cultural property and antiques, taking advantage of different reporting incentives between source and destination countries.
2. Data
The growth of e-commerce has shifted counterfeit sales from street markets to online platforms, increasing concealment and global reach (Organisation for Economic Co-operation and Development 2021b).
Our data are drawn from an anonymized cross-border e-commerce platform, best thought of as an e-commerce hub for designer dupes. The platform has appeared in the U.S. Trade Representative’s Notorious Markets report for many years and is a frequent target of brand-owner lawsuits. It has served buyers in many jurisdictions and listed millions of products, many counterfeiting well-known brands.
Our analysis focuses on platform-classified counterfeit listings that are internally tagged with the authentic brand and product series they imitate (e.g., LV Speedy, Hermès Birkin).4 The sample contains millions of counterfeit orders, placed by U.S. buyers with foreign sellers, spanning major brands (e.g., LV, Chanel, Nike, Hermès). For each order, we observe the transaction price, product attributes (category and referenced authentic product series), and destination ZIP code. All entries are anonymized. Deidentified buyer identifiers allow us to compute counts of unique buyers in addition to orders.
We construct counterfeit gross merchandise value (GMV) as the sum of transaction prices and aggregate to the ZIP-code level. The sample includes 24,721 U.S. ZIP codes with at least one purchase, covering about 94% of the population. To proxy for resale, we exclude orders with more than five identical items; estimates are similar when these orders are retained. For confidentiality, we apply a constant multiplicative rescaling to ZIP-level consumption measures (e.g., GMV per household). Because the factor is uniform across observations, relative comparisons and regression coefficients (up to scale) are unaffected.5
Table 1 reports scaled GMV per household and household income shares across the 10 standard American Community Survey brackets (U.S. Census Bureau 2023). The tails—below 15,000 and above 150,000—vary substantially across ZIP codes, enabling inference on how local income structure relates to counterfeit demand.
|

Table 1. ZIP-Level Income Distribution and Counterfeit Demand
| Variable | N | Mean | Std. dev. | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|---|
| GMV per Household | 24,721 | 10 | 9.34 | 0 | 3.60 | 7.73 | 13.71 | 271.30 |
| Income_Less_10K | 24,721 | 4.827 | 3.862 | 0 | 2.3 | 4.0 | 6.3 | 76.0 |
| Income_10K_to_15K | 24,721 | 4.116 | 3.779 | 0 | 1.6 | 3.2 | 5.6 | 67.3 |
| Income_15K_to_25K | 24,721 | 7.813 | 4.994 | 0 | 4.3 | 7.0 | 10.4 | 61.0 |
| Income_25K_to_35K | 24,721 | 8.080 | 4.723 | 0 | 4.9 | 7.5 | 10.4 | 85.8 |
| Income_35K_to_50K | 24,721 | 11.569 | 5.495 | 0 | 8.0 | 11.3 | 14.4 | 90.2 |
| Income_50K_to_75K | 24,721 | 17.012 | 6.236 | 0 | 13.4 | 16.8 | 20.1 | 85.8 |
| Income_75K_to_100K | 24,721 | 13.197 | 5.148 | 0 | 10.2 | 12.9 | 15.7 | 77.2 |
| Income_100K_to_150K | 24,721 | 16.748 | 6.647 | 0 | 12.5 | 16.6 | 20.6 | 88.9 |
| Income_150K_to_200K | 24,721 | 7.756 | 5.085 | 0 | 4.0 | 6.9 | 10.9 | 56.9 |
| Income_More_Than_200K | 24,721 | 8.882 | 9.788 | 0 | 2.7 | 5.5 | 11.2 | 89.0 |
Notes. Table 1 reports descriptive statistics for all U.S. ZIP codes with at least one observed order. GMV per household is scaled to have a mean of 10. Income variables are the share of households in each cohort from the American Community Survey. Std. dev., Standard deviation.
3. The Demand for Counterfeits
3.1. Counterfeit Demand Across Income Spectrum
We study how counterfeit consumption varies across the income distribution. Our objective is descriptive (Reiss 2011): to document how ZIP-level counterfeit demand covaries with local income composition, not to estimate the causal effect of income shocks. This descriptive gradient is still policy and managerially relevant because income is a key targeting variable for both governments (e.g., tax and transfer thresholds) and firms (e.g., pricing and location decisions).
Our preferred specification is
The dark dots in Figure 1(a) display the estimated ’s from Equation (1), where coefficients are percentage differences relative to the omitted middle-income bracket. Counterfeit demand is U shaped: ZIP codes with larger shares of low- or high-income households purchase more counterfeits than ZIP codes dominated by the middle-income reference group.
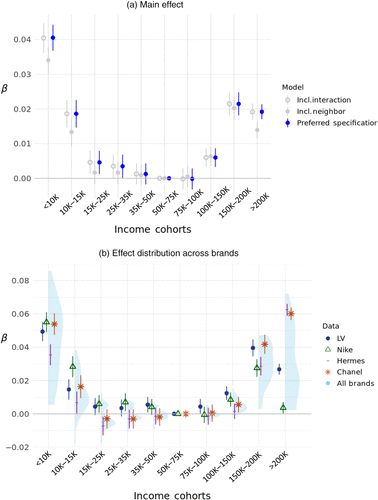
Notes. Figure 1 plots demand across income cohorts. In panel (a), the darker dots show the preferred specification (Equation (1)). Light hollow circles add an interaction between the highest and lowest cohorts, and light solid circles add neighboring ZIP-code cohorts. Panel (b) presents results for 41 brands. Light violin plots show the distribution of estimated coefficients. Point estimates with 95% confidence intervals for four highlighted brands—LV, Nike, Hermès, and Chanel—are shown. Middle-income households ($50,000–$75,000) form the reference level.
At first glance, this pattern is not obvious. Both budget pressure and status concerns could make middle-income consumers natural candidates for counterfeits (Han et al. 2010). Standard signaling models often predict peak demand among the middle-income group (Feltovich et al. 2002): for low-income consumers, elite signals may be too distant to generate meaningful marginal reputational gains; for high-income consumers, status may be more secure and additional conspicuous signaling can have lower (or even negative) returns. By contrast, middle-income consumers sit closer to the margin where signals can shift perceptions, so incentives to signal may be strongest.
A sociological lens offers a norm-based interpretation: middle-class conformity posits that adherence to social norms—and thus reluctance to violate authenticity norms—peaks in the middle of the status distribution and attenuates toward both tails (Phillips and Zuckerman 2001). If the primary deterrent to buying counterfeits is a nonmonetary penalty (e.g., stigma or shame) associated with norm violation (e.g., Bernheim 1994, Bénabou and Tirole 2004, Fehr and Schurtenberger 2018, Gneezy et al. 2018, Abeler et al. 2019), then observed purchases may reflect variation in the propensity to deviate from norms.
More broadly, we view counterfeit consumption as a cost–benefit trade-off. On the cost side, the nonmonetary penalty from violating authenticity norms may be highest for middle-income consumers, consistent with middle-class conformity. On the benefit side, counterfeits provide savings as well as signaling and consumption value. A U shape can arise if the norm cost peaks in the middle while the perceived benefits remain salient in the tails. Our data do not permit a clean decomposition of these channels. We therefore use the more granular tests in Section 3.2 to ask whether the U shape shifts in settings where these benefits plausibly change. Its broad stability across such shifts is consistent with the interpretation that norm-based mechanisms are likely at play.
We close this section by highlighting systematic heterogeneity across brands. Reestimating Equation (1) separately for the 41 brands in our sample, Figure 1(b) shows that the U shape is broadly preserved but with meaningful dispersion. Four cases illustrate the sorting: Nike (mass-market), Louis Vuitton (heritage luxury), and the ultraluxury maisons Chanel and Hermès. Relative to the middle-income cohort, low-income cohorts show similar incremental demand for Nike, Louis Vuitton, and Chanel (slightly weaker for Hermès). At the top, demand tilts toward ultraluxury: Hermès and Chanel load most strongly, Louis Vuitton less, and Nike least.
3.1.1. Interpretations and Robustness.
We conduct additional analyses to assess the robustness of our interpretation (see Online Appendix D for details).
3.1.1.1. Spillovers vs. Own-Cohort Effects.
Our interpretation of the U shape assumes that a cohort’s counterfeit demand is driven primarily by its own income share, rather than by cross-cohort spillovers (Charles et al. 2009). We assess this (i) by augmenting Equation (1) to allow each tail’s demand to vary with the presence of the other and (ii) by allowing the full income composition of the nearest ZIP code to affect local demand (see Online Appendix D.1). As in the light gray specifications in Figure 1(a), the U shape remains, suggesting that cross-income-cohort spillovers are not the primary driver.
3.1.1.2. Contextual Heterogeneity.
Our interpretation assumes that preference profiles, , do not vary systematically across places in a way that could mechanically generate the observed pattern. If they did, ZIP-level estimates might fail to reflect individual-level associations. We gauge sensitivity by reestimating Equation (1) in split samples by median income, income dispersion (Gini), median age, and the sex ratio. Figure A.9 shows that the U shape is stable across all splits (see Online Appendix D.2).
3.1.1.3. Buyer Types.
We ask whether the U shape is driven by entry or repeat purchasing. We classify buyers as one-time (one order) or repeat (two or more; see Online Appendix D.3) and compute, by ZIP code, the number of unique buyers of each type per household. Figure A.10a shows that the U shape holds for both buyer types, so the income–demand relationship is not driven solely by one-off purchases or by heavier purchasing conditional on entry.
3.1.2. Listing Price and Popularity as Moderators.
We examine heterogeneity along two salient listing attributes—price and popularity—to inform competing theories of counterfeit consumption.
3.1.2.1. Listing Price.
Although both low- and high-income cohorts purchase more counterfeits than the middle-income cohort, their motives may differ. If low-income demand were mainly price driven, it should concentrate in the cheapest listings. We partition transactions into four price bins using the 10th, 50th, and 90th percentiles of the listing-price distribution (see Figure 2(b)) and reestimate Equation (1) within each bin. The U shape persists in all bins and is most pronounced for the highest-price bin (Figure 2(a)): both tails are more likely than the middle-income cohort to purchase the most expensive counterfeits. This pattern is difficult to reconcile with a purely “budget-driven” account of low-income demand and indicates substantial willingness to pay for counterfeits at both tails.
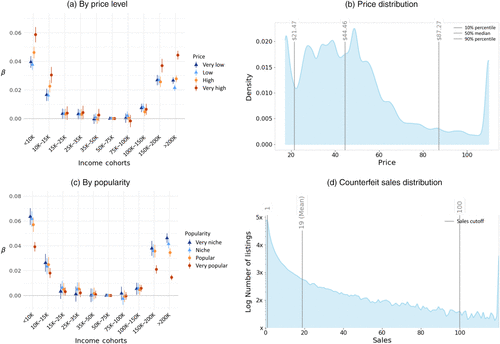
Notes. Figure 2 plots counterfeit demand across income cohorts by price tiers and popularity, using Equation (1). In panel (a), listings are classified into four price tiers based on the 10%, median, and 90% price percentiles: very low priced (), low priced ($21.47–$44.46), high priced ($44.46–$87.27), and very high priced (). Panel (b) displays the density of transaction prices. Three gray lines mark the price-tier cutoffs. Panel (c) partitions listings by sales into four tiers: very niche (1 order), niche (2–19 orders), popular (20–100 orders), and very popular (>100 orders). Panel (d) shows listing-level sales with a logarithmic y-axis normalized for confidentiality. Vertical gray lines denote the popularity-tier cutoffs. Markers indicate demand intensity, with whiskers denoting 95% confidence intervals. Middle-income households ($50,000–$75,000) form the reference group.
3.1.2.2. Listing Popularity.
Prior research emphasizes hedonic treasure-hunt motives—enjoyment of search, secrecy, and discovery. We therefore group listings into four popularity tiers based on total sales per listing (see Figure 2(d)) and reestimate Equation (1) within each tier. The U shape persists, is stronger for niche listings, and is substantially weaker for very popular listings—consistent with discovery-driven incentives being more salient at the tails.7
3.2. Composition Cascade: From Macro to Micro Heterogeneity
Section 3.1 documents a U-shaped relationship between income cohorts and counterfeit consumption. We now trace this composition pattern from macro to micro, examining demand at four nested levels: (i) across categories; (ii) across brand segments within a category; (iii) across product series within a brand; and (iv) across listings within a product series. At each level, we exploit additional within-group variation to infer the motives underlying counterfeit consumption.
3.2.1. Product Categories.
An important first dimension of product choice is category—for example, bags versus shoes. We focus on these two categories because they account for the largest demand in our data and provide a sharp contrast in motives: shoes are relatively functional, whereas bags are more expressive and status signaling.
Figure 3 reports category-specific estimates from Equation (1). Points and vertical bars show coefficient estimates and 95% confidence intervals from category-level regressions. The shaded densities summarize the distribution of estimates from separate brand-by-category regressions.
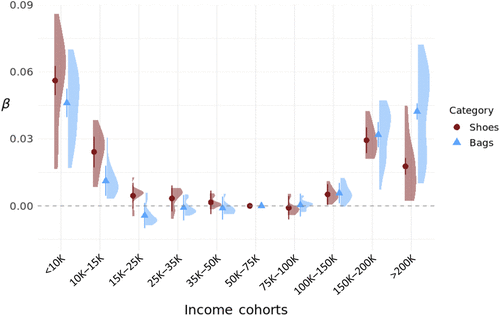
Notes. Figure 3 plots counterfeit demand across income cohorts by two product categories—shoes and bags—which together account for over 85% of orders. Shaded violin plots show the distribution of brand-level estimates within each category. Markers denote estimated demand intensity, with whiskers indicating 95% confidence intervals. Middle-income households ($50,000–$75,000) form the reference level.
Substantial heterogeneity across brands remains even within category, which we examine next. At the category level, however, the U shape is evident for both bags and shoes. The difference lies in where it is most pronounced: the right-tail uplift is significantly stronger for bags, whereas the left-tail uplift is somewhat stronger for shoes (most notably for the $10K–$15K cohort). This asymmetry is consistent with, relative to the middle-income baseline, high-income cohorts’ excess demand being more tied to the expressive/status content of bags, whereas low-income cohorts’ excess demand is more concentrated in the more utilitarian shoe category.
3.2.2. Brand Segmentation.
An informative question is how the income–demand relationship varies across brand tiers. We classify brands using their brand-level average authentic retail price (details in Online Appendix F) and analyze bags and shoes separately, given the category differences in Figure 3. For bags, we distinguish accessible luxury (average retail $700–$1,500; e.g., Coach, Tory Burch), premium luxury ($2,000–$4,000; e.g., Gucci, Prada), and ultraluxury ($6,000+; e.g., Chanel, Hermès). For shoes, we separate mass-market shoes (retail ; e.g., Nike, New Balance) and luxury shoes ($300–$2,500; e.g., Golden Goose, Gucci).
Counterfeits sell at a small fraction of authentic prices. In Figure 4(c), the average transaction-to-official price ratio is for ultraluxury bags, for premium luxury, and for accessible luxury. For shoes (Figure 4(d)), the ratios are for luxury and for mass-market. These gaps arise because authentic prices vary far more across tiers than counterfeit prices. Higher-tier counterfeits offer larger monetary gains—the gap between authentic and counterfeit prices.
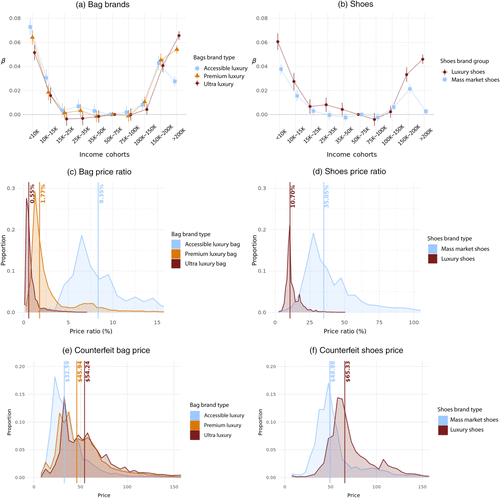
Notes. Figure 4 reports estimates from Equation (1) of counterfeit demand by income cohort and brand tier for bags (panel (a)) and shoes (panel (b)). Markers indicate demand intensity; whiskers are 95% confidence intervals. The $50,000–$75,000 cohort is the reference group. Panels (c) and (d) plot the distributions of counterfeit-to-authentic price ratios by brand tier for bags and shoes, respectively. Panels (e) and (f) plot the distributions of counterfeit prices by brand tier for bags and shoes, respectively.
Yet counterfeit prices themselves are only modestly different across tiers. Figure 4, (e) and (f), shows that an ultraluxury bag averages about $54 versus $32 for an accessible luxury bag, and counterfeit Nike versus Gucci shoes differ by less than $20 on average. These differences are small relative to authentic prices and unlikely to shift the aggregate pattern (consistent with Figure 2(a)). Ex ante, modest cross-tier differences in counterfeit prices make an affordability-based explanation unlikely.
Nevertheless, demand sorts strongly by tier. Figure 4(a) shows U-shaped demand in each bag segment, but the composition differs across tails. Relative to the middle-income baseline, excess demand among low-income cohorts is larger for lower-tier brands (a negative gradient across tiers), whereas excess demand among high-income cohorts is larger for higher-tier brands (a positive gradient across tiers). This tier sorting indicates that the two tails disproportionately purchase different types of counterfeit bags.
Shoes provide a useful boundary case. In Figure 4(b), the right tail is muted for mass-market shoes: the top-income cohort (>$200k) does not purchase more mass-market shoe counterfeits than the middle-income reference group. Consistent with intuition, when the authentic product is already relatively affordable (e.g., Nike), high-income consumers show little incremental demand for counterfeits.
3.2.2.1. Copurchase Pattern.
We use buyer-level copurchase behavior as a complementary, model-free check on our brand-tier segmentation. If tiers capture meaningful preference segments in counterfeit demand, brands that occupy similar positions should share buyers more frequently.
Using anonymized buyer IDs, we construct a weighted brand network where edge weights reflect buyer overlap (share of buyers purchasing both brands). Figure 5 visualizes this network, and communities are identified using the Infomap algorithm (see Online Appendix G for technical details).
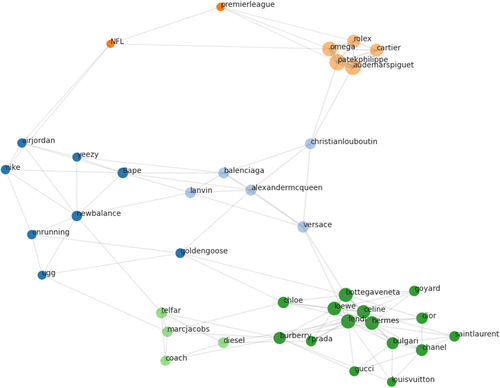
Notes. Figure 5 shows the copurchase network using Infomap community detection. Node size indicates brand centrality, edge thickness reflects copurchase strength, and shading denotes brand community. The sample includes 39 brands. Two with coverage are excluded.
The network is sharply segmented, with clusters that align closely with familiar category–tier groupings in authentic markets. A watch cluster centers on Rolex and Patek Philippe, whereas a small licensed-sports cluster links the NFL and the Premier League. Footwear splits into mass/casual (Nike, New Balance) and designer (Balenciaga, Christian Louboutin) communities. Handbags similarly divide into premium/ultraluxury (Hermès, Chanel) and accessible luxury (Coach, Telfar). Overall, clustering is strongest within category and within tier, consistent with standard segmentation in the authentic market, and the remaining cross-community links tend to run through boundary brands (e.g., designer footwear adjacent to the luxury handbag cluster).
3.2.3. Within-Brand Product Series.
Next we ask whether, conditional on brand, the income–counterfeit gradient varies across product series. This speaks to luxury product-line management by indicating how potential leakage or dilution pattern may differ across series with different positioning.
We focus on the four representative brands highlighted in Figure 1(b). Within each brand, we classify product series into three groups based on symbolic prominence. Classic series are long-running signature designs central to the brand’s identity. Fashion series are newer or trend-driven lines whose prominence is shaped by seasonal appeal or collaborations. Past-season series include legacy designs or short-lived models that no longer occupy a core position in the current lineup (details in Online Appendix F).
Figure 6, (a)–(d) reports the results. For Hermès and Chanel, the U shape is strongest for classic icons (Birkin, Classic Flap), weaker for fashion lines (Lindy, Boy), and smallest for past-season models (Herbag, Gabrielle). For Louis Vuitton, the U shape is pronounced for both classic and fashion series (Speedy, Dauphine), with limited separation between them. For Nike, the pattern is clearest for classic heritage (Air Force 1) and attenuates for fashion collaborations and past-season models (VaporWaffle, Blazer).
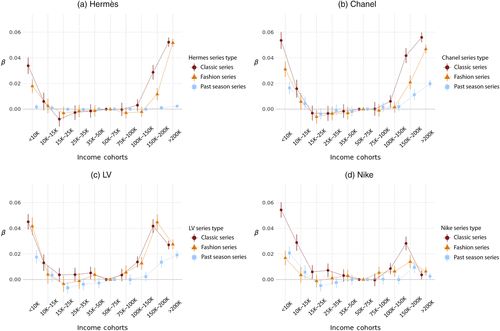
Notes. Figure 6 reports estimates from Equation (1) of counterfeit demand by income cohort, disaggregated by product series within four representative brands. Series types are defined in Online Appendix F. Points denote demand intensity; whiskers are 95% confidence intervals. The $50,000–$75,000 cohort is the reference group.
Overall, within brand, the U shape loads most strongly on series with salient, widely recognizable symbolic content. If demand were mainly novelty driven, fashion series should dominate. Instead, the steepest gradients arise for long-standing classic icons, consistent with a signaling motive: classic lines offer durable, broadly legible status cues. The weaker classic–fashion contrast for LV is consistent with a complementary mechanism—strong branding cues across many LV lines (e.g., distinctive monograms or signature leathers) may reduce the incremental signaling value of “classic” relative to “fashion.”
3.2.4. Within-Series Price.
The final choice a buyer makes is which listing to purchase after selecting a specific counterfeit series (e.g., Birkin). A natural driver of this within-series choice is quality, which we proxy with price. For each series, we split transactions into low, mid, and high price tiers using that series’ own price distribution. At this granularity, residual price differences plausibly capture quality variation (or willingness to pay for quality).8
Figure 7 reports estimates for four representative brands. Coefficients have a percentage interpretation and are measured relative to the middle-income reference group within each price tier. Comparing tiers therefore asks whether, within a series, high-income (or low-income) cohorts’ demand deviates more from the middle-income cohort when listings are higher priced.
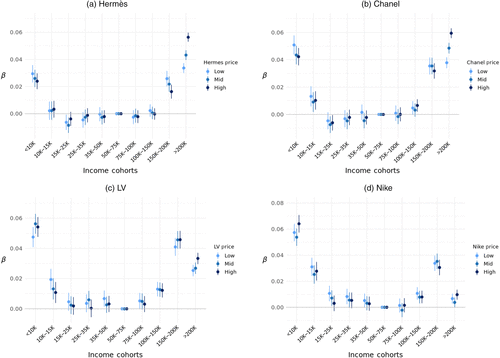
Notes. Figure 7 reports results by within-series price terciles for four brands, with cutoffs at the 33rd and 67th percentiles of each series’ listing-price distribution. Within each brand, shading intensity encodes relative price: darker shades denote higher-priced listings, and lighter shades denote lower-priced listings. Markers show demand intensity; whiskers denote 95% confidence intervals. Middle-income households ($50,000–$75,000) form the reference group.
Two patterns stand out. For Hermès and Chanel (Figure 7, (a) and (b)), the right tail tilts toward higher-priced listings: relative to the middle-income baseline, the highest-income cohort’s demand is more elevated in the high-price tier. At the left tail, the within-series price gradient is weaker and sometimes reverses, consistent with a lower marginal willingness to pay for incremental counterfeit quality.
For Louis Vuitton and Nike (Figure 7, (c) and (d)), tier patterns are less stable. A plausible interpretation is that these are thicker, more competitive markets, where posted prices could reflect both quality and sellers’ pricing strategies, making within-series price a noisier proxy for quality.
4. Conclusion
This paper documents a robust U-shaped relationship between counterfeit demand and household income: demand is elevated in ZIP codes with larger shares of low- and high-income households. Using large-scale field data and a transparent empirical design, we show that this pattern is stable across specifications and not readily explained by spillovers, contextual confounds, or mechanical differences between entry and repeat purchasing. These descriptive facts are policy and managerially relevant. For intellectual property (IP) enforcement and consumer education, they imply that demand is not concentrated in a single “middle” segment; efforts aimed only at the median consumer may miss substantial activity at both tails. For brand owners, the presence of meaningful affluent demand suggests that effective anticounterfeiting might recover revenue from consumers with high willingness to pay, whereas elevated demand at the lower tail raises distinct concerns about brand dilution and the management of brand meaning.
We use layered heterogeneity to discipline interpretation. The U shape is not driven by simple price sensitivity: both tails disproportionately buy expensive counterfeits, and high-income cohorts tilt toward higher-priced listings within a series, consistent with greater willingness to pay for quality. Popularity patterns point to discovery motives: the U shape is stronger for niche listings and weaker for very popular ones, consistent with treasure-hunt incentives amplified by online search and long-tail assortments. The gradient also varies systematically with brand position and product design: demand sorts by tier (low-income cohorts load more on lower-tier brands, high-income cohorts on higher-tier brands) and is steepest for classic, widely recognizable series with durable status cues.
More broadly, cross-border e-commerce has made counterfeiting more pervasive than most existing evidence can speak to (e.g., U.S. Government Accountability Office 2010, Fink et al. 2016, European Union Intellectual Property Office 2023b). We view our results as a baseline map of where demand concentrates and how it covaries with product design. This evidence can help target enforcement and brand responses and provides a foundation for future work that separates mechanisms and evaluates interventions.
The authors thank Liran Einav, Masakazu Ishihara, Ganesh Iyer, Ginger Jin, Tesary Lin, Stephan Seiler, Greg Taylor, Hans-Joachim Voth, and Zemin Zhong for helpful comments. The authors are grateful to editor Puneet Manchanda, the anonymous associate editor, and two reviewers for constructive feedback. The authors thank Lee Hao Rong Javier for excellent research assistance. Any remaining errors are the authors’.
1 See the U.S. Department of Justice’s Criminal Resource Manual, Section 1709 (U.S. Department of Justice).
2 See the 2021 Anaqua Consumer Survey (Anaqua 2021). The European Union Intellectual Property Office reports similarly negative perceptions in Europe in the IP Perception Study 2023 (European Union Intellectual Property Office 2023a).
3 A broader review appears in Online Appendix A.
4 In our sample period, platform-classified counterfeit listings account for roughly 90% of transaction volume; among these, over 30% receive a specific product-series label indicating the item being copied. Results are robust when we expand to the full 90% sample. Online Appendix B draws only on publicly available information to provide additional context about the platform.
5 We adopt a common rescaling convention: within each regression set, we multiply the ZIP-level GMV per household by a constant so that its sample mean equals 10. As Bellemare and Wichman (2020) note, when outcomes are very small, the IHS transform is less log like and “percent-effect” interpretations become less accurate. We follow this guidance and verify robustness to larger scaling constants.
6 Because ZIP-code-level income profiles are measured with error, coefficient magnitudes may be attenuated. To benchmark scale, Online Appendix C plots ZIP-code credit scores using the same procedure. As credit scores are tightly linked to income, this provides a familiar yardstick; our estimated income–counterfeit gradient is substantially steeper.
7 Online Appendix E shows that this conclusion is robust when popularity is measured using product-series-level sales.
8 Figure 2(a) shows that the U shape strengthens with price in the pooled data; that pattern may partly reflect composition across brands or series. The within-series splits here isolate price differences within a series.
References
- (2019) Preferences for truth-telling. Econometrica 87(4):1115–1153.Crossref, Google Scholar
- (1980) A theory of social custom, of which unemployment may be one consequence. Quart. J. Econom. 94(4):749–775.Crossref, Google Scholar
- Anaqua (2021) Anaqua consumer survey: The state of counterfeit goods. Accessed April 13, 2026, https://www.anaqua.com/resource/anaqua-consumer-survey-the-state-of-counterfeit-goods-blog/.Google Scholar
- (2022) Why do people stay poor? Quart. J. Econom. 137(2):785–844.Crossref, Google Scholar
- (2020) Elasticities and the inverse hyperbolic sine transformation. Oxford Bull. Econom. Statist. 82(1):50–61.Crossref, Google Scholar
- (2004) Willpower and personal rules. J. Political Econom. 112(4):848–886.Crossref, Google Scholar
- (2026) Laws and norms. J. Political Econom. 134(2):731–772..Google Scholar
- (1994) A theory of conformity. J. Political Econom. 102(5):841–877.Crossref, Google Scholar
- (2009) An investigation of determinants of counterfeit purchase consideration. J. Bus. Res. 62(3):368–378.Crossref, Google Scholar
- (2009) Conspicuous consumption and race. Quart. J. Econom. 124(2):425–467.Crossref, Google Scholar
- (2006) Explaining counterfeit purchases: A review and preview. Acad. Marketing Sci. Rev. 12:1–25.Google Scholar
- European Union Intellectual Property Office (2023a) European citizens and intellectual property: Perception, awareness and behaviour (IP Perception Study 2023). Accessed April 13, 2026, https://www.euipo.europa.eu/en/publications/ip-perception-study-2023.Google Scholar
European Union Intellectual Property Office (2023b) Choice experiment for the demand for counterfeits workstream: Final report. Technical report, European Union Intellectual Property Office, Alicante, Spain.Google Scholar- Federal Research Division, Library of Congress (2020) U.S. Intellectual Property and Counterfeit Goods—Landscape Review of Existing/Emerging Research. Technical report, Library of Congress, Washington, DC. Prepared under an interagency agreement with the U.S. Patent and Trademark Office. https://www.uspto.gov/sites/default/files/documents/USPTO-Counterfeit.pdf.Google Scholar
- (2018) Normative foundations of human cooperation. Nature Hum. Behav. 2(7):458–468.Crossref, Google Scholar
- (2002) Too cool for school? Signalling and countersignalling. RAND J. Econom. 33(4):630–649. Crossref, Google Scholar
- (2016) The economic effects of counterfeiting and piracy: A review and implications for developing countries. World Bank Res. Observer 31(1):1–28.Google Scholar
- (2009) The smuggling of art, and the art of smuggling: Uncovering the illicit trade in cultural property and antiques. Amer. Econom. J. Appl. Econom. 1(3):82–96.Crossref, Google Scholar
- (2018) Lying aversion and the size of the lie. Amer. Econom. Rev. 108(2):419–453.Crossref, Google Scholar
- (1988) Foreign counterfeiting of status goods. Quart. J. Econom. 103(1):79–100.Crossref, Google Scholar
- (2010) Signaling status with luxury goods: The role of brand prominence. J. Marketing 74(4):15–30.Crossref, Google Scholar
- (2000) Do counterfeits devalue the ownership of luxury brands? J. Product Brand Management 9(7):485–497. Crossref, Google Scholar
Organisation for Economic Co-operation and Development (2021a) Global trade in fakes: A worrying threat. Report, Organisation for Economic Co-operation and Development Publishing, Paris.Google ScholarOrganisation for Economic Co-operation and Development (2021b) Misuse of e-commerce for trade in counterfeits. Report, Organisation for Economic Co-operation and Development, Paris.Google Scholar- (2001) Middle-status conformity: Theoretical restatement and empirical demonstration in two markets. Amer. J. Sociol. 107(2):379–429.Crossref, Google Scholar
- (2008) Impacts of entry by counterfeiters. Quart. J. Econom. 123(4):1577–1609.Crossref, Google Scholar
- (2014) Counterfeiters: Foes or friends? How counterfeits affect sales by product quality tier. Management Sci. 60(10):2381–2400.Link, Google Scholar
- (2014) Which brand purchasers are lost to counterfeiters? An application of new data fusion approaches. Marketing Sci. 33(3):437–448.Link, Google Scholar
- (2011) Structural workshop paper—Descriptive, structural, and experimental empirical methods in marketing research. Marketing Sci. 30(6):950–964.Link, Google Scholar
- (2008) The consumption of counterfeit goods: ‘Here be pirates?’ Sociology 42(6):1146–1164.Crossref, Google Scholar
- (1998) Consumer demand for counterfeit goods. Psych. Marketing 15(5):405–421.Crossref, Google Scholar
U.S. Census Bureau (2023) American Community Survey (ACS). Accessed April 13, 2026, https://www.census.gov/programs-surveys/acs.Google ScholarU.S. Department of Homeland Security (2020) Combating trafficking in counterfeit and pirated goods. Technical report, Office of Strategy, Policy & Plans, U.S. Department of Homeland Security, Washington, DC.Google Scholar- U.S. Department of Justice (n.d.) 1709. Joint Statement—Parts C and D. Definitions—“Trafficking”—“Counterfeit Marks”. Criminal resource manual. Accessed April 13, 2026, https://www.justice.gov/archives/jm/criminal-resource-manual-1709-joint-statement-parts-c-and-d-definitions-trafficking-counterfeit.Google Scholar
U.S. Government Accountability Office (2010) Observations on efforts to quantify the economic effects of counterfeit and pirated goods. Technical report, U.S. Government Accountability Office, Washington, DC.Google Scholar- (1995) Non-price determinants of intention to purchase counterfeit goods: An exploratory study. Internat. Marketing Rev. 12(6):19–46.Crossref, Google Scholar
- (2009) Why do consumers buy counterfeit luxury brands? J. Marketing Res. 46(2):247–259.Crossref, Google Scholar
Nan Chen is an assistant professor of information systems and analytics at the National University of Singapore. His research focuses on the economics of technology, quantitative marketing, and industrial organization.
Mengqi Xiang is a PhD candidate in information systems and analytics at the National University of Singapore. Her research interests include consumer behavior, the economics of online markets, and human–artificial intelligence interaction.

