
Using Deep Learning to Overcome Privacy and Scalability Issues in Customer Data Transfer
Abstract
Customer privacy is increasingly important to marketers. High-profile breaches of databases containing sensitive customer information, and the growing need to build the infrastructure required to support analysis of big data present nontrivial obstacles to researchers seeking individual-level customer data from firms. In this paper, we show that recent developments in machine learning may enable firms to transfer a generative model instead of data, thus potentially obviating the process of anonymizing and sampling customer data for release for use in a variety of analytic use cases. We demonstrate the efficacy of a specific deep learning model, generative adversarial networks (GANs), in preserving desired characteristics of original data. We validate in real-world settings and find that GANs outperform benchmarks on the accuracy-privacy tradeoff. We also demonstrate that GANs can be used to solve marketing problems of price markups for optimal profits and customer targeting. Finally, we demonstrate that GANs have volume and velocity advantages, as the size of informational transfer grows according to model complexity, and it can readily handle real-time data streams.
History: K. Sudhir served as the senior editor for this article.
Supplemental Material: The data and online appendix are available at https://doi.org/10.1287/mksc.2022.1365.
1. Introduction
Firms’ sensitive customer data are highly sought after by researchers who use statistical and econometric models for causal and predictive analyses. The challenges to obtaining these data entail both privacy and scalability issues. Marketers, for example, who need to build pricing and targeting models for consumer-packaged goods, require access to sales data at either the household or store level, as well as the corresponding prices of given brands. Although prices are publicly observable in stores and through promotion and advertisements, customer privacy concerns, legal restrictions, or firms’ concerns regarding disclosure of valuable information to competitors are impediments to external sharing of sales data. Therefore, traditional methods of external data release, for example, through a third-party vendor such as The AC Nielsen Company, require a high transaction cost because of prohibitive nondisclosure agreements (NDAs) and restricted data usage agreements (DUAs).
Central to the NDAs and DUAs is the original data provider’s need to control the privacy and accuracy of the data released. The current paradigm widely used to facilitate this exchange process is transfer of samples of customer data, which are anonymized by transferring small samples that are either obfuscated or aggregated. On the one hand, the larger the amount of data firms release to researchers, the more accurate are the price elasticity and targeting estimates. Firms therefore have incentives to release more data that are as unobfuscated as possible. However, firms incur fewer privacy risks with a smaller data sample release and a higher degree of obfuscation. This tradeoff between accuracy and privacy in data disclosures has been extensively discussed in prior literature: Real-world situations drive the data provider to exert control along this tradeoff (Duncan and Stokes 2004).
Exacerbating the transaction cost of this process is the actual transfer of the data itself. In the age of big data and digital commerce, the four Vs of big data gain significance: volume, velocity, variety, and veracity (Chintagunta et al. 2016, Ansari and Li 2018). In this paper, we focus on the volume and velocity aspects of big data, as they can present nontrivial obstacles to the data transfer itself. Although researchers seeking to maximize the accuracy and generalizability of the data have the incentive to acquire as much data from providers as possible, transferring and housing large amounts of customer data can require nontrivial technical know-how and significant data storage costs. Furthermore, the velocity of data that refreshes into a data provider’s databases, often a matter of seconds, can vastly outpace the speed of a single data exchange. Therefore, the need arises for an approach to customer data transfer that can potentially address these issues.
Recent developments in deep learning offer the possibility of training a generative model that can mimic data generating distributions with an unprecedented degree of accuracy (Goodfellow et al. 2013). Generative adversarial networks (GANs) provide a flexible framework that can train two neural networks—a discriminator model (discriminator henceforth) and a generator model (generator henceforth)—simultaneously by pitting them against each other. GANs involve training a generative model that generates synthetic data and simultaneously training a discriminator model able to distinguish between the real and generated synthetic data, resulting in the generator mimicking the firm-side data generating distribution with a high degree of accuracy. This obviates the need to share private and sensitive data with the generator and allows for updating the generator as additional real-time data arrive. In contrast to estimation techniques that first estimate a model on the firm’s side and then subsequently transfer some form of “data” such as actual data or synthetic data to the researcher, the decoupled nature of this training algorithm has both privacy and scalability advantages.
We propose an approach for preserving customer privacy that involves transfer of a generator (from GANs) as opposed to the aforementioned traditional approaches. This also provides improved privacy protection: no private and sensitive customer data leaves the servers of the firm because only the discriminator, which is housed inside the firm’s firewalls, has access to the private data. Furthermore, we find that our proposed method has scalability advantages. The volume and velocity aspects of big data require any analysis to be sufficiently flexible to handle large volumes of newly arriving data; accordingly, this method’s data exchange cost, measured in computational and logistical time, does not grow proportionate to data size. Furthermore, marketers will be interested in our proposed approach to tackle marketing problems. We show two things along these lines. First, as a proof of concept, we show that two marketing problems: price markups for optimal profits and customer targeting can be effectively tackled using our proposed approach. Second, we also show that a firm need not train multiple GANs to tackle different problems. That is, a single GAN trained on the firm data can be used to solve two marketing problems of price markups for optimal profits and customer targeting. Thus, in this paper, we build on the privacy literature in marketing and additionally analyze data scalability and ability to tackle marketing problems. We therefore explore the following four research questions:
Accuracy: How well do GANs mimic the data-generating process (DGP)?
Privacy: How well do GANs preserve privacy in the event that the transferred generator is compromised?
Scalability: How do GANs accommodate the volume and velocity aspects of big data?
Applicability: How well do GANs perform on marketing problems of price markups for optimal profits and customer targeting and can one GAN perform both tasks? Can GANs accommodate different heterogeneity in data, data misspecifications, and different researchers’ inference methods?
We find that GANs perform exceptionally well against benchmark methods in terms of accuracy of replicating the original data, as evaluated via the standard accuracy-privacy framework from prior literature. GANs outperform benchmark methods in terms of mimicking the true data, both in density plots and as measured using the Kolmogorov-Smirnov (KS) test, Jensen-Shannon divergence (JSD), and Kullback-Leibler (KL) divergence.1 Furthermore, by modifying the training algorithm to incorporate customer heterogeneity, the firm can control the accuracy-privacy tradeoff. In both cases, we find that GANs have lower information loss and lower loss in privacy compared with benchmarks. We also validate our findings on the Nielsen household-level data and find that our accuracy-privacy results hold.
Next, GANs, leveraging the “online” nature of stochastic gradient descent (SGD), are designed to handle both volume and velocity. In terms of data volume, we find that the SGD framework scales well with respect to (w.r.t) the size of the data set because of its distributed nature allowing for out-of-the-box parallel CPU or GPU computing. The order of magnitude of the per iteration computation time does not grow according to the data size but grows instead according to factors under the researcher’s control, such as mini-batch size, number of training iterations, and GAN complexity. We find that training time per iteration only increases marginally as we increase data volume from one thousand rows of data to ten million rows of data and stays the same order of magnitude. In addition to training advantages with volume of data, we find that GANs outperform benchmarks on the accuracy-privacy tradeoff with larger data volumes.2 Furthermore, GANs tackle the velocity aspects as the decoupled estimation nature of GANs requires that only the gradients of the objective function as opposed to a costly transfer of an entire data set. We find that transferring a generator instead of data are cheaper because of lower file size, especially when the data volume grows large.3 This allows for a lightweight automated exchange method between the two parties, such as the use of an application program interface (API) to “stream” the latest gradients to the generator in the exchange process. We find that the information loss converges faster when we stream the gradients as opposed to redoing the entire training with the new data. This lightweight, automated exchange method also has logistical benefits. The traditional data transfer approach from the synthetic data literature requires the involvement of trained data scientists for each synthetic data set generated subsequent to the inflow of a substantial amount of new data. This process can be both error prone and costly to firms and researchers. The automated exchange process potentially alleviates this problem.4
Finally, we find that GANs perform well on the two tasks of optimal price markups and customer targeting compared with benchmarks. To test for robustness of GANs to different issues in the data and inference models, we evaluate GANs and other benchmarks in the presence of heterogeneity in the data, data generating process misspecification including correlated variables and omitted variables, and different researchers’ inference methods.5 Especially relevant for marketing managers, we find that a single GAN can handle both these tasks simultaneously; that is, a single GAN can tackle both these problems. Throughout these three contexts, GANs also outperform benchmarks on the accuracy-privacy tradeoff. These results extend from GANs ability to mimic the data generation process closely while providing higher privacy protection.
2. Existing Literature
Existing work in the privacy literature in marketing and economics focuses on protection of data under the paradigm of transfer of true data between parties. Security is afforded by masking true data via a predetermined mechanism and accepting the tradeoff between privacy and usefulness, as for targetability (Goldfarb and Tucker 2011). Past work in marketing and statistics literature on synthetic data protection has discussed, for example, such data masking mechanisms as (i) aggregation (Link 1995, Christen et al. 1997, Steenburgh et al. 2003, Tenn 2006), (ii) swapping (Reiter 2010), (iii) truncation/rounding (Schneider et al. 2018), and (iv) random noise addition (Reiter 2005). These varied benchmark methods and associated performance metrics are used by Schneider et al. (2018) to evaluate their proposed data protection schemes for point-of-sale data. Following the tradition of synthetic data transfer (Abowd et al. 2012, Hu et al. 2014, Schneider and Abowd 2015), in which the provider generates synthetic data for transfer to the user, Schneider et al. (2018) proposes a Bayesian generalized linear model (GLM) for generating protected synthetic data ex post data creation. Recent work has proposed coresets as a better alternative to uniform sampling for regressions problems when sharing data (Huang et al. 2020). Our work differs from extant literature in that GANs can generate synthetic data for purposes of predictive modeling and inference via the “lightweight” transfer of a generator instead of data in the transfer process. Contributions of this paper entail the examination of the desirable properties of this paradigm shift, which are data volume scalability, transfer-file compression, and data streaming capabilities.
A growing stream of literature on using machine learning in marketing has developed in response to the call for integrating methods from computer science and statistics to address the Vs of big data: volume, velocity, variety, and veracity (Chintagunta et al. 2016, Ansari and Li 2018). For example, Liu et al. (2016) leverage a combination of cloud computing, text mining, and machine learning to handle massive volumes of online social platform data to forecast sales, and Timoshenko and Hauser (2019) use a convolutional neural network to identify customer needs from user-generated content. The latter neural network, estimated using SGD, scales well on volume of data and computing requirements. Without being restricted to large computer cloud clusters, model training can, with the proper settings, be performed on a laptop. Rafieian and Yoganarasimhan (2021) use the extreme gradient boosting method that enables scalability in the prediction of click-through rates for mobile advertisements. Puranam et al. (2017) use a scalable Bayesian topic model to estimate the impact of New York City calorie posting regulation on discussions of health-related topic in restaurant reviews. A fully automated system designed by Culotta and Cutler (2016) to estimate brand ratings from near real-time keyword Twitter data addresses the velocity of big data. We build on this stream of literature by demonstrating that, when GANs are implemented on the backbone of SGD-type training, the latter’s scalability properties carry over to considerations of volume and velocity associated with implementing algorithms for privacy protection.
Last, this paper builds on the small but growing literature in marketing that uses GANs. Burnap et al. (2019) use an ensemble of deep learning methods to predict aesthetic appeal of automotive designs as a means of augmenting aesthetic design process. They use GANs to generate product esthetic proposals. Malik and Singh (2019) discuss different deep learning methods in computer vision and note that GANs have enabled realistic image generation. Our work differs from that reported in this literature in that we demonstrate that GANs can provide scalable and privacy preserving approach that can be used to solve multiple marketing problems.
3. Methodology: Extant Approach and Benchmarks
We first compare the difference between the extant data transfer paradigm and our proposed data transfer paradigm. We then evaluate our methodology using benchmark methods.
3.1. Extant vs. Proposed Data Transfer Paradigm
In this section, we first examine the extant data transfer paradigm and its associated obstacles. We then demonstrate how our proposed data transfer approach may alleviate these obstacles.
Current approaches involving data transfer from a firm to researchers often require the researchers to sign legally binding contracts such as NDAs and DUAs to access the data. Once the researchers sign these contracts, the firm then sets up mechanisms to transfer the data to the researchers. There are three broad decisions that the data provider makes. First, whether to provide the full data for all its customers or for a subsampled set of its customers. The second decision that the data provider makes is whether to provide data from the true data, that is, its actual data, or to provide “synthetic” data, such as data generated using synthetic data generation method (Schneider et al. 2018). The third decision is the level of obfuscation or aggregation done to the data to protect privacy. These include doing top coding, that is, truncating at a certain percentile; rounding, that is, rounding the data to a certain digit; and swapping, that is, randomly swapping sales data in a certain set of observations. The data provider can also choose to aggregate data at a certain level, for example, at product lines level or markets level. Inherent to the third decision is the firm’s attempt to tradeoff accuracy of data shared with researchers and its need to protect privacy of the data shared. These data are then transferred to the researchers, who apply research methods such as reduced form analysis, structural econometrics, or machine learning methods, for results comprising a combination of inference, prediction, and counterfactuals.
There are three major concerns with this approach. First, data privacy is a concern: Once the data leave the confines of the firm, the firm has very little control over the data protection. The data are vulnerable to hacking, which would create a significant privacy breach for the firm. Second, there is the generalizability issue because the transferred data are often much smaller compared with the firm’s entire customer base. Third, the data transfer process is slow and time consuming, and this increases the firm’s transaction costs each time the research methods are trained on new data.
Our approach eliminates the need for any real customer data or synthetic data to leave the firm. Instead, we propose transferring a generator to the researcher. The generator is trained in an adversarial framework, and the discriminator sits inside the firm’s walls.6 The generator, which sits with the researchers, never accesses the private data. Only the discriminator can access the private data, and the generator is trained using the gradients of the discriminator’s loss function. Thus, the generator can generate data up to the size of the full population of a given firm’s customers and can be retrained using a semiautomated interface (API) such that little or no manual intervention is needed. This allows us to tackle the three primary concerns of traditional data transfer approaches. First, our approach offers higher privacy protection because no customer data leaves the control of the firm. We empirically demonstrate that, should the generator on the researcher’s side be hacked, our approach’s privacy protection remains superior to that of the benchmark methods. Second, the generalizability concern is potentially alleviated because the generator can generate data up to the size of the firm’s customer population. Third, with new streaming customer data, the use of a semiautomated API significantly reduces the transaction costs for the firm, as well as reducing the time needed to update the generator controlled by the researchers.
Of the existing approaches, an important one is that of Schneider et al. (2018). Although the approach of Schneider et al. (2018) has been demonstrated on stores point of sales data, it can conceptually be extended to consumer level data. However, a key difference from our approach is that Schneider et al. (2018) requires prior knowledge of data generating process that is embedded in the synthetic data generation process itself. We argue that our approach is data generating process agnostic (the GAN model is not explicitly trained using a specific inference model), and its only objective is to “mimic” the data generation process of the true data.7 Furthermore, our proposed approach has scalability advantages.
An important point to note is that the firm can choose when and how the researcher gets the generator. There are two possible approaches of training the generator in our paradigm, both of which will lead to the same results. In the first approach, the firm trains both the generator and the discriminator on its end, and hands over the generator to the researcher once the generator is trained. In this situation, the researcher starts with a pretrained generator and can update it as and when new data arrives with the firm. In the second approach, the researcher starts with an uninitialized generator at its end and trains the generator from scratch by making API calls to the discriminator residing inside the firm’s walls. In this situation, the researcher makes API calls for each of the training iteration as it updates the generator parameters. The generator obtained after training in either of the approaches would be the same, and the firm can chose whether it wishes to pass on a trained generator to the researcher or ask the researcher to train a generator from scratch.8
3.2. Benchmark Methodology
In this section, we describe our methodology for evaluating our proposed GANs and benchmarks. We do so along the following seven dimensions:
Data characteristics: To what extend do the probability distribution statistics (e.g., probability density function, KL divergence) and other distributional characteristics differ?
Information loss: To what extent do results differ from model-based analyses, such as price elasticity coefficient estimates from regressions?
Privacy: How well does the proposed model protect customer privacy compared with benchmark methods.
Volume: How well does the proposed model’s training speed and information transfer size scale with the volume of data.
Velocity: How does continual estimation compare with restart estimation of the model with the arrival of new customer data?
Generalizability to marketing problems:
• Optimal price markups: How high are the optimal profits as compared with those obtained from true data?
• Customer targeting: How accurate are the targeting models as compared with those trained on the true data?
• Tackling multiple marketing problems with one GAN: Can a single GAN trained on the full firm data be used generate synthetic data that can solve multiple marketing problems?
We use methods commonly used in existing literature for data protection as benchmarks against which to compare our proposed approach (Table 1), ranging from aggregation (i.e., at market level) to obfuscation (e.g., adding random noise). Schneider et al. (2018) find data protection schemes to generally entail a tradeoff between accuracy and privacy; the goal of the seven benchmark methods, which include using true data, is to track juxtaposition of the respective metrics along these two dimensions. We modify these benchmark methods, which Schneider et al. (2018) apply to store-level point-of-sales data, to use household level sales and pricing data while preserving the panel structure of the data set. Similar to Schneider et al. (2018), we protect only the sales variables of the individual households, with brand prices being public and observable in stores.
|

Table 1. Description of Benchmark Methods
| Benchmark method | Description | |
|---|---|---|
| 1 | “True” or unprotected data | Original household-level sales data without any protection. |
| 2 | Random noise | Observations are binned into deciles based on sales, and random noise is added to the sales in each decile. |
| 3 | Rounding | Sales are rounded to the nearest hundredth place. |
| 4 | Top coding | Sales greater than the 95th percentile are truncated. |
| 5 | 20% swapping | 20% of observations are divided into two groups and their sales data exchanged. |
| 6 | 50% swapping | 50% of observations are divided into two groups and their sales data exchanged. |
| 7 | Market level | For each week, sales are summed and prices averaged across households to the market level. |
3.3. Performance Metrics
3.3.1. Comparison of Data Characteristics.
We use three measures commonly used in the statistics and marketing literature: KL divergence, JSD, and the KS statistic. We do so to measure the distance between the real data and the synthetic data generated from GANs and benchmarks.
The KL and JSD divergences provide, respectively, asymmetric and symmetric distance measures of the distribution of the true data relative to the synthetic data generated by a protection method. We also calculate the KS statistic as a quantitative estimate of the maximum difference in two cumulative distribution functions. The KS statistic has an additional advantage that it exists regardless of the support of the two distributions (Toubia and Netzer 2016).
The KL divergence (Kullback and Leibler 1951) is a measure of relative entropy between two probability distributions: P and Q. For discrete probability distributions, we have
The KL divergence for distributions P and Q measures how much extra information is needed to arrive at Q as the posterior, when P is the prior distribution. The closer the KL divergence to zero, the more “similar” the distributions P and Q.9 To see its ties to maximum log-likelihood estimation, we can write , where is the log-likelihood of observing the data from P given the parameters of the distribution Q (Eguchi and Copas 2006). Thus, minimizing the KL divergence is equivalent to obtaining the maximum likelihood estimates for the distribution Q.
The JSD (Lin 1991), a symmetric measure of the information difference between two distributions, can be formulated in terms of the KL divergence. In the information sciences literature, it has been used to measure distances between distributions and provide the upper and lower bounds for the Bayes probability of error.10 The JSD for discrete distributions P and Q, with average distribution A = 0.5(P + Q), is given by
Finally, we use the KS test as a quantitative estimate of the maximum difference in cumulative distribution functions and corresponding significance levels. The KS test for two samples, P and Q, is given by
3.3.2. Information Loss.
To calculate information loss, we first define a commonly used inference framework to estimate coefficients (β) from the true data. We then estimate the same coefficients using our proposed approach and benchmarks, denoted .
We estimate the following multiple regression framework with continuous independent variables of prices P and dependent variables of sales S, and we propose the following log-log regression in a standard panel data setting with entity i, brand j, and time period t:
With the previous inference model, we measure mean absolute percentage difference (MAPD; Christen et al. 1997) as a measure of information loss. MAPD provides an estimate of how good the coefficient estimates are from our proposed approach and benchmarks compared with those obtained from the true data, because it quantifies the difference between the regression estimates. More formally, MAPD for J number of coefficients of interest is given by
3.3.3. Loss of Privacy.
In the manner of Schneider et al. (2018), we use maximum loss of privacy (MLP) as the metric for data protection. To compute MLP for the data, we first define the loss in privacy (LP) metric. Schneider et al. (2018) define the LP metric as the “intruder’s” confidence in the data to identify an entity. Thus, we use the LP measure for a customer i (from n customers and across T time periods) as follows:
Here, is the probability of identifying an observation Yit as belonging to a customer given the observed sales Sit and prices Pit, normalized by the probability for customer 1: ). Thus, is the mean probability (mean across all time periods) of identifying a customer i in the data. We compute as follows12:
Equations (6) and (7), for loss in privacy, can be extended to include further unprotected variables such as marketing variables, customer visit counts, and other similar variables depending on the data context. Thus, with this metric, we then define the MLP metric. MLP can measure the maximum loss of privacy across all customers in the data set; it serves as the measure of the privacy for the least privacy protected customer in the data13:
3.3.4. Tradeoff Between Information Loss and Privacy Protection.
The risk-utility curve introduced by Duncan and Stokes (2004), describes the fundamental tradeoff between the risk of confidential data disclosure and the utility of a data set for analysis. From this stream of literature, we know that firms and regulators collect data with the underlying promise that the data will be kept confidential. To honor this confidentiality pledge, firms need to share data such that the risk of disclosure is minimized. De-identification, that is, removing identifiers such as names, addresses, phone numbers, and so on, from the data are not sufficient to reduce disclosure risks to acceptable levels, as “data snoopers,” that is, entities with authorized access to the data but goals of uncovering individuals in the data, can link the data to other data sets that have names and identifiers associated with them, and with such “linkage,” data can be reidentified. They argue that masking strategies, such as data coarsening, top coding, aggregating, and so on, allow for reduced disclosure risk as the data becomes less identifiable; however, the data utility, that is, quality of inference from this masked data, also reduces, because the perturbations, or noise, added to the data impact the inference that can be drawn from the data. This inherent tradeoff between disclosure risk and data utility is the essence of the stream of literature that looks at accuracy-privacy tradeoff.
Using this concept to quantify the tradeoffs between the two measures of accuracy and loss of privacy, we compare the performance of our generator against those of the benchmark methods. Similar to Schneider et al. (2018), we plot various methods’ information loss (utility of data) against the loss of privacy (risk of disclosure). We further explore how incorporating heterogeneity informs the privacy tradeoff.
3.3.5. Data Volume Scalability: Training Speed.
In this section, we examine scalability in terms of training time when protection is provided in terms of numbers of rows of data (N). One challenge in comparing speed of training using SGD is that the training algorithm can accommodate an arbitrary number of iterations. We therefore run the training algorithm well past the number of iterations at which the loss function becomes stationary from visual inspection. We then measure total run time and run time per iteration to examine how run time scales to volume of data.
3.3.6. Data Volume Scalability: Information Size.
An additional benefit of using a GAN is that the size of information passed between parties in big data settings is significantly less when only a generative model is being transferred and not actual data. By incorporating the data-generating process, the generator effectively serves as a data compression algorithm. Size measured by information transfer is a function of GAN complexity measured by number of neurons as opposed to the size of the data set.
3.3.7. Data Velocity Scalability.
We examine here how the online nature of SGD can be exploited to train the GAN as new data stream into the provider. First, we train a GAN to convergence, subsequently referred to as the baseline model. Then, we explore how the SGD responds to a single burst of new data by simulating a small new training data set from the data generating distribution. We then run two versions of the proposed model. In the first, the new data are “streamed” into the baseline model, and in the second, the training is “restarted” by retraining on the combination of new and old training data. We then compare the point at which both training methods regain the same level of information loss in the presence of new data.
3.3.8. Generalizability to Marketing Problems: Price Markups and Optimal Profits.
Marketing managers are interested in estimating price markups for their products to obtain optimal profits based on their customers behavior. We now discuss how we evaluate price markups and optimal profits from our proposed approach and compare with those obtained from benchmark methods, following the approach given in Schneider et al. (2018).
We use the Monte Carlo data and compute the price elasticities using Equation (4). Thus, we first estimate the price markups (as a proportion of cost) for the original data and data from benchmark methods as
3.3.9. Generalizability to Marketing Problems: Customer Targeting.
We now discuss an application of GANs to customer targeting models. Because real-world contexts for customer targeting often involve sensitive information such as demographics, we explore the case when we protect not one but two variables. That is, two variables are considered private and not shared with the researcher.
We build on the purchase model from Park and Park (2016) and briefly discuss the setup. Park and Park (2016) use click-stream data of an online retailer to predict purchase based on online visits and marketing efforts by modeling the visit behavior and purchase behavior in their proposed model. As a proof of concept, we adapt their purchase behavior model to include demographic variables of income, weight, and whether the person is a racial minority or not (variable: minority).14
Consistent with the previous data context, we construct purchase behavior for 30 customers over 365 days building on the purchase probability model from Park and Park (2016). More formally,
We consider the data constructed in this manner as the true data, with purchase variable (whether a customer purchased in a current week) and minority (whether the customer belongs to a racial minority or not) as the private, protected data. All other variables are considered public data. To measure information loss in targeting, we then compare the purchase data from the true data and compare the estimates from GANs and benchmarks. We use an F1 score as a composite measure of accuracy, given by
3.3.10. Generalizability to Marketing Problems: Tackling Multiple Marketing Problems with One GAN.
We now discuss a context to evaluate whether a single GANs can handle multiple marketing problems. As a proof concept, we construct Monte Carlo data for customer purchases when the firms set prices and chose combinations of other marketing instruments of product feature and product display.
In this setting, a customer in a given week observes publicly available prices and marketing variables for the five brands and subsequently makes purchases across the five brands. Consistent with our procedure before, we follow the log-log model as the data-generating process. The data-generating process specification is along the lines of Schneider et al. (2018), as they model purchase behavior of consumers based on observed prices and marketing mix variables along the lines of the market response model of SCAN*PRO. More formally,
Through this exercise, we measure the effectiveness of GANs in capturing both price elasticities and marketing variables of interest such as brand features and brand display. This also helps us evaluate whether a single GANs can solve multiple marketing problems.
4. Proposed Model
4.1. GANs
In this section, we describe the GAN method. The generator takes in as input the draws of random variable z and public data x and outputs generated data , where θg are generator’s parameters that are learned during the training process. The discriminator take in as input both the real, private data y, and generated data and attempts to distinguish between the real and the generated data in a binary classification task. The discriminators parameters are θd, which are learned during the training process. Following the design of Mirza and Osindero (2014), conditional GANs have the following objective function:
The objective function has theoretical links to both KL divergence and JSD (Goodfellow et al. 2014), and the underlying intuition is that the training procedure minimizes the distance between the distribution of the real and distribution of the generated data. Goodfellow et al. (2014) also provide theoretical guarantees that pg, that is, generated data distribution, converges to pd, that is, the true data distribution.16 As a proof of concept, we use only one hidden layer neural network for each of the generator and the discriminator in GANs.17
GANs have been traditionally used in the computer vision literature, where the generator learns the mapping θg from random noise to the space of real images, as the discriminator predicts images as being real or fake in this min-max game. GANs have been shown to be able to generate realistic images of faces (Radford et al. 2015, Chen et al. 2016) and several other categories of images such as home interiors, animals, and vehicles (Kim and Bengio 2016, Wang and Liu 2016). In Section 4.2, we discuss how we extend GANs to train on customer level data.
4.2. Picture-Data Analogy and Extension to Heterogeneity
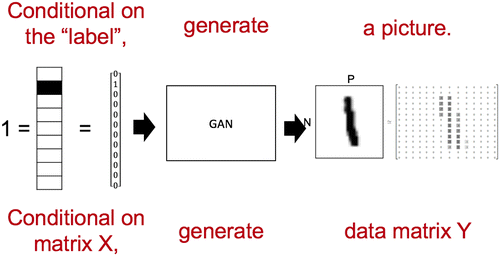
We now describe our extension of GANs to train on customer data. Conditional GANs were originally designed to mimic the data-generating process for pictures, when given a particular vector that conditions on labels. We see a direct parallel between the numerical matrices of which pictures are composed and the panel data format often used in marketing, economics, and statistics research.
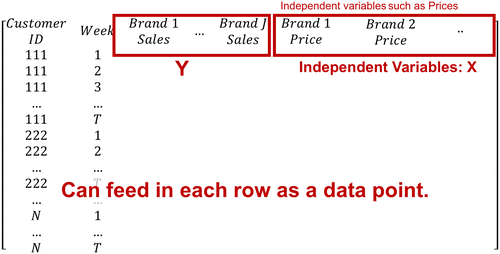
The connection between pictures and data are illustrated in Figure 1. Just as in the realm of computer vision, the conditional GAN “conditions” on a label and then generates a picture of a handwritten digit, the proposed GAN can condition on a matrix of unprotected data columns X and generate a data matrix Y. To carry this analogy further, we define what would constitute a picture in the panel data setting. Figure 2 presents an example of a Nielsen Scanner Panel household data set in which rows correspond to a household’s weekly observations and columns to weekly sales and advertising spend per brand. We protect the variable “sales,” that is, treat it as the private data, and share other variables, that is, treat them as public data. Effectively, we treat each observation as equivalent to a picture in the machine vision context, such that with a random noise matrix and conditional GAN specific X’s as the input, and generate a picture of the protected variable, sales (i.e., Y).
In the presence of considerable customer heterogeneity, such as K types of customers, this type of picture data analogy becomes less effective at capturing existing differences across customers. Heterogeneity implies that there exist unique segment averages in the X and Y variables, for each type of customer, that differentiate them from customers in the other segments. We operationalize this by treating block of customer data (of T rows) rather than each data row as a picture. We therefore define the two variants of our proposed models as (a) without heterogeneity (No Het.) and (b) with heterogeneity (Het.), depending on how we treat the picture equivalent in the data, that is, either each customer-week as a picture or each block of customer data across time periods as a picture.
Accuracy and privacy results are compared and discussed in the following section. Our analysis treats sales as the protected data and the rest of the data as public data. This approach is consistent with existing literature (Schneider et al. 2018). We also explore bivariate private data in Section 5.3.2.
4.3. Training
We now discuss the training process for the conditional GAN. For the purposes of illustration, we discuss the notation for GAN (Het.) case.18 We estimate the parameters for the generator θg and discriminator θd via SGD with momentum using the ADAM optimizer (Kingma and Ba 2014). Stochastic gradient descent updates the parameter θg (and similarly θd) based on the loss function for the generator ( for the discriminator) for a mini-batch of the data of size n customers using the following update procedure:
This approach provides several advantages. First, because the GAN training framework allows for the separation of generator and discriminator, the generator needs only the loss function and uses the gradient to update its parameters. The private, protected data of customer sales is available only to the discriminator via its objective function . Second, open-source software like Tensorflow allows for scalable parallel computing on graphics or tensor-processing units (Abadi et al. 2016). Third, the optimization is done in mini-batches to update parameters, which allows for the scalability advantages of online training. We explore in detail these scalability advantages provided by stochastic gradient descent in our results.
5. Empirical Context and Results
This section is organized in three parts. First, we demonstrate effectiveness of GANs on the accuracy and privacy protection metrics compared with benchmark methods using Monte Carlo data. Furthermore, we validate the accuracy-privacy tradeoff on real-world data. Second, by using Monte Carlo data, we explore scalability advantages of GANs: how GANs handle volume and velocity of data. Finally, as a proof of concept, we show generalizability of GANs. That is, we demonstrate that GANs can be used to tackle marketing problems of setting prices for optimal profits and customer targeting. Furthermore, we also demonstrate that a single GAN can handle both contexts combined.
5.1. Accuracy-Privacy Tradeoff
In this section, we estimate how well GANs perform on the accuracy and privacy metrics compared with benchmark methods using Monte Carlo data and subsequently validate on real-world Nielsen data.
5.1.1. Monte Carlo Experiment.
In this Monte Carlo experiment, we generate household-level customer data for five representative brands using the data-generating process specified in Section 3.3. The data context is thus similar to the real-world Nielsen data. We take as a starting point 200 customers over a span of 52 weeks for five brands’ sales and prices. Brand prices are public data (i.e., accessible by both researcher and the firm), whereas sales are private data (i.e., accessible only by the firm). Table A.1 reports summary statistics for the Monte Carlo data. We discuss further details of the Monte Carlo data in Online Appendix A.2.
5.1.1.1. Distributional Accuracy.
We examine the proposed GAN’s generated synthetic data distributional accuracy relative to that of the true data.20 In Table 2, we examine the corresponding distribution metrics, namely, JSD, KL divergence, and KS statistic. Examining the JSD metric, we observe the lowest value for the GAN (Het.) of 0.0213. Rounding benchmark follows second with a JSD of 0.0288, closely followed by GAN (No Het.) of 0.0307. This finding indicates that the probability distributions for GANs and true data are the close. When we consider the KL divergence metric, we find that GAN (Het.) also has the lowest value of 0.0231. Thus, GAN (Het.) probability distribution is closest to the true data distribution. This conclusion is also the case for the KS statistic, with GAN (Het.) registering the lowest score on the KS test of 0.0077, which gives the upper bound on the difference in cumulative density functions for two distributions. GANs (No Het.) also beats the best performing benchmark on the KS test, with a value of 0.0322 as opposed to 0.05 for top coding. Thus, through these three different metrics, we find that the GAN (Het.) distribution is closest to the true data across all measures of statistical differences in distributions. This provides confirmatory empirical evidence that the GANs best mimics the true data.
|
Table 2. Distribution Metrics (Lower Is Better)
| Model | JSD | KL | KS |
|---|---|---|---|
| Random noise | 2.147 | 3.8847 | 0.1173 |
| Rounding | 0.0288 | 0.0274 | 0.1036 |
| Top coding | 0.4718 | 0.8474 | 0.0500 |
| GAN (No Het.) | 0.0307 | 0.0419 | 0.0332 |
| GAN (Het.) | 0.0213 | 0.0231 | 0.0077 |
5.1.1.2. Balance Between Accuracy and Privacy.
We use the information loss metrics to examine accuracy and MLP for the benchmarks. Although the separability of the GAN provides a first layer of protection, the MLP metric gives us quantitative estimates of the loss in privacy in the situation that the transferred generator was hacked. Using the case of a compromised generator, we investigate the likelihood that the generated data can be traced back to the original IDs of customers.
We find evidence consistent with those in the Nielsen data. Figure 3 shows the results. Benchmark methods for random noise, rounding, and top coding have lower loss of information, MAPD, but higher loss in privacy protection compared with other benchmark methods. The 20% swap has a much lower information loss compared with the 50% swap, which by construction has information loss, MAPD, of approximately 50. A fifty-percent swap, however, has much better privacy protection than other individual customer level benchmark methods. The market-level benchmark method offers the best privacy protection, MLP of zero, by construction, but comes with a high information loss of 56.
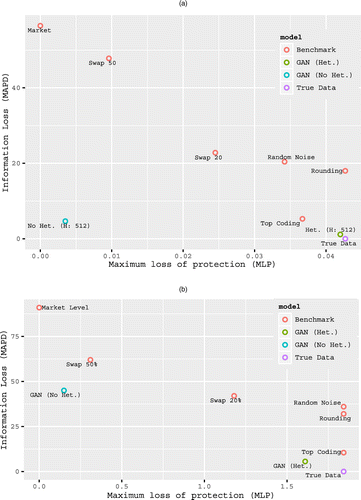
Notes. (a) On Monte Carlo data. This figure reports the loss in information (MAPD) and loss in privacy (MLP) estimated for GANs and benchmarks for the data generated using Equation (4). (b) On Nielsen data. This figure reports the loss in information (MAPD) and loss in privacy (MLP) estimated for GANs and benchmarks for the Nielsen data.
Ideally, we want to be at the bottom left of the MAPD-MLP plot, with low information loss and low loss of privacy. We find that our proposed generators show consistently lower information loss and superior privacy protection than all the benchmark methods. We find lower information loss in terms of MAPD for GAN (Het.) than for GAN (No Het.). Specifically for this Monte Carlo data setting, we find that GAN (Het.) with 512 neurons has an MAPD of 1.2, which is 4.6 times improvement in accuracy compared with the best benchmark method, which is top coding, with an MAPD of 5.3. This finding is consistent with JSD and KS statistic measures obtained in the previous section. We find, however, with lower information loss comes a tradeoff regarding privacy protection. GAN (No Het.) has significantly superior privacy protection than GAN (Het.) but with higher loss in information. Interestingly, we find that GANs (No Het.) have an MLP of 0.0035, which is closest to the market-level data compared with each of the other methods: The loss of information varies between 4.6 and 10, which is significantly superior to the information loss for 50% swap. At the cost of potential privacy loss, GAN (Het.) has much lower information loss than all other methods. Furthermore, despite this tradeoff, we find that our proposed generators occupy the bottom left of the MAPD-MLP plot, thus indicating that, relative to the benchmark methods, they offer a superior overall balance between accuracy and privacy.21
5.1.2. Real Data Validation: Nielsen Data.
We apply the proposed and benchmark methods for protecting a data set in a real-world setting using the 2006 Nielsen Household Panel and Retail Scanner data sets. Both have been studied extensively in the marketing literature and are used by marketing practitioners. Although our method should be applicable to any data transfer setting in downstream applications using any class of inference models, these canonical data inform a natural proof of concept examining real-world performance related to information and privacy loss.
To demonstrate the applicability of our proposed method on a reasonably large data set in a real-world setting, our initial analysis uses the Nielsen data set to construct a sample with at least 10,000 rows composed of data for 200 households across 50 weeks for the year 2006. We define variables similar to those used by Hendel and Nevo (2006) and Schneider et al. (2018).
Following Hendel and Nevo (2006), we examine consumer purchases in the liquid detergent category aggregated at brand level for the leading brands: Tide, Cheer, All, and Wisk, the remainder combined as Others. The unit of observation is household-week, and we observe purchases ($amount) of each brand by each household, and the prices ($amount) observed during that week for each of the brands. We consider prices as the publicly available data and treat sales as the private data that only the data provider has access to. We thus create a data set of 200 randomly sampled households that made at least 10 purchases in the year 2006. We then estimate the private data, that is, sales from benchmark methods and from the data generated by our proposed GANs. To estimate accuracy, we compute coefficients from the true data and benchmarks for Equation (4), estimate the MAPD metric using Equation (5), and estimate the loss of privacy metric MLP using Equation (8). Figure 3 illustrates our examination of information and privacy loss with the proposed and benchmark methods.22
We find in the context of this Nielsen data that GAN (Het.) has an MAPD of 5.6% compared with the best benchmark method, that is, top coding, with an MAPD of 11%.23 GAN (No Het.), despite a higher MAPD of 45% compared with 5.6% for GAN (Het.), has the lowest loss in privacy among the nonaggregate benchmarks, with an MLP of 0.15 compared with 0.31 for 50% swap. Overall, we find that our proposed generators consistently outperform the benchmark data protection methods.
5.2. Scalability
In this section, we examine the scalability aspect of volume and velocity for GANs, that is, how well do GANs scale with the volume of data in terms of model estimation time and transferred information size and how well do GANs handle newly arriving data, that is, streaming data. For the purposes of this section, we use the Monte Carlo data described earlier and summarized in Table A.1.
5.2.1. Estimation Time.
In this section, we discuss the relationship between volume of data and estimation time for GANs. We vary the size of data from ∼1,000 rows of data (N), that is, 10 customers (Nc) and 102 weeks (T) per customer, to ∼10 million rows of data, that is, 100,000 customers and 102 weeks per customer.24 We find that training time per iteration increases only marginally with data volume, from 6.33 milliseconds per iteration with 1,000 rows of data to 7.55 milliseconds per iteration with 10 million rows of data. We find that the training time across different data volumes stays the same substantially despite considerable increase in volume of data. This observation can be attributed to the SGD algorithm used to train the GAN, as its parameters are trained in each iteration using a sample of the data, because of which the proposed generator scales well with respect to volume of data. However, the training time may increase because of other factors, such as SGD mini-batch sample size and GAN complexity, both of which are controlled by the researcher and can be adjusted according to available computing equipment.
5.2.2. Transferred Information Size.
We next examine the relationship between data volume and transferred file size. As expected, the original file size that will otherwise need to be transferred (using comparable benchmark methods) grows with the rows of data. In the context in which we transfer the generator, however, the size of the file grows only in proportion to GAN complexity. We find that the data file grows linearly with number of rows, with a file size of 180 KB for data with 1,000 rows to a file size of 1.7 GB for data with 10 million rows. The size of the GAN model, however, is consistently at 7.79 MB.25 These findings assure us that our proposed generator scales well for transferred information size with respect to data volume and GAN complexity.
5.2.3. Data Velocity Scalability.
We examine information loss when the algorithm is trained on in-flowing data. Figure 4 presents the results of comparing the traditional “restart,” in which the GAN is trained from scratch with each new inflow of data, and the “streaming” method, in which the GAN is trained continuously from previously known estimates. We find that in the case of streaming rather than restart, information loss stabilizes sooner, and in the first 50,000 iterations, the MAPD is lower. We observe less information loss in the streaming than in the restart case, in which the GAN parameters are learned from scratch. This finding results from using stochastic gradient descent as the training method for streaming, whereby training of the GAN parameters is continuous yet with more data. More generally, the “online” nature of SGD can be exploited as a learning method in GANs with continuous streaming data to train GAN parameters as soon as new data presents.

5.3. Generalizability to Marketing Problems
In this section, we demonstrate as a proof of concept how GANs can generalize to marketing contexts of setting prices for optimal profits, customer targeting, and demonstrate that a single GAN tackle multiple problems. We do so using a series of Monte Carlo data sets. For this analysis, we focus on GAN (Het.) because we find from our prior results that GAN (Het.) achieves higher accuracy than GAN (No Het.). Furthermore, GAN (Het.) performs better than benchmarks on the accuracy-privacy tradeoff.
5.3.1. Price Markups for Optimal Profits.
We now discuss how GANs compare relative to benchmarks on setting price markups for optimal profits. We use the Monte Carlo data set from before and as described in Online Appendix Table A.1. Table 3 shows the price markups for each of the five brands. These markups are obtained using Equation (9), which uses the price elasticities as computed from benchmark data protection methods and the price elasticities in the true data. We find that for each of the brands, the price markups (as a percentage of costs) estimated from GAN (Het.) is closest to the true markups. Among the benchmark methods, we find that swap 50 and random noise lead to nonmeaningful price markups for some of the brands, that is, price that is lower than cost. This is similar to Schneider et al. (2018), who find that swap 50 leads to some nonmeaningful price markups.
|
Table 3. Price Markups from Equation (9) for True Data and Benchmarks
| Method | Brand 1 | Brand 2 | Brand 3 | Brand 4 | Brand 5 |
|---|---|---|---|---|---|
| True markups | 200.00% | 142.86% | 99.01% | 102.04% | 111.11% |
| GAN (Het.) | 241.98% | 234.36% | 99.34% | 165.22% | 113.09% |
| Random noise | 205.46% | NM | NM | 79.02% | NM |
| Rounding | 140.34% | 163.86% | 118.49% | 190.83% | 819.11% |
| Swap 20 | 84.45% | 543.69% | 64.36% | 97.25% | 923.39% |
| Swap 50 | NM | NM | 104.31% | NM | NM |
| Top coding | 122.76% | 147.22% | 95.99% | 120.00% | 396.21% |
Notes. This table shows the price markups (as a percentage of costs) for optimal profits obtained from Equation (9) for the true price elasticities, GANs, and other benchmarks. We obtain price markups for each of the five brands. NM, not meaningful.
We next estimate optimal profit ratios using Equation (10). Table 4 shows the ratio of the optimal profits obtained from benchmark methods, w.r.t. the optimal profits obtained from using the true data. We find here that the optimal profits obtained from GAN (Het.) are consistently higher than 94.48% of those obtained if the true price elasticities were known for each of the five brands, and it also consistently outperforms other benchmark methods. Among the other benchmark methods, the closest is top coding, whose optimal profits vary from 70.30% for brand 5 to 99.98% for brand 3. For the benchmark methods where we got nonmeaningful price markups in Table 3, we do not report profits ratios.
|
Table 4. Optimal Profit Ratio from Equation (10) for Benchmark Methods w.r.t. True Data
| Method | Brand 1 | Brand 2 | Brand 3 | Brand 4 | Brand 5 |
|---|---|---|---|---|---|
| GAN (Het.) | 99.41% | 95.26% | 99.99% | 94.48% | 99.99% |
| Random noise | 99.98% | NA | NA | 98.40% | NA |
| Rounding | 97.86% | 99.62% | 99.20% | 90.92% | 45.06% |
| Swap 20 | 87.60% | 72.57% | 95.48% | 99.94% | 41.41% |
| Swap 50 | NA | NA | 99.93% | NA | NA |
| Top coding | 95.93% | 99.98% | 99.98% | 99.36% | 70.30% |
Notes. This table shows the optimal profit ratios (as a % of profits obtained by using the true price elasticities) using Equation (10) for GANs and other benchmarks. We obtain optimal profit ratios for each of the five brands. NA, not available.
This finding suggests that managers can use GANs to make pricing decisions that lead to higher profits compared with benchmark approaches. Furthermore, GANs fare better on the accuracy-privacy tradeoff for this Monte Carlo data (Figure 3). Thus, GANs can provide a suitable alternative to the true data as marketing managers using customer sales data will be interested in computing price markups and optimizing profits.
5.3.2. Customer Targeting.
To estimate customer targeting accuracy for GANs and traditional benchmarks, we generate a Monte Carlo data set using the process described in Section 3.3. The data comprise 30 customers and 365 days for a total of 10,950 observations. For each customer-day, we observe whether the customer was marketed to or not (dummy variable: Marketing), whether the customer made a purchase in the previous week (dummy variable: Previous Purchase),26 and how many times the customer has visited the store thus far (log(Visits So Far)). Importantly, different from previous contexts, the private data consist of two variables: the outcome variable of interest (whether the customer makes a purchase or not in the current week (dummy variable: Purchase) and whether the customer is a racial minority or not (dummy variable: Minority). Therefore, GANs now generate two variables: purchase and minority.
With these data, we estimate loss in customer targeting accuracy, that is, 1 − F1 from true data and benchmarks. With the outcome variable of whether a customer purchased (or not), the benchmarks methods of random noise, rounding, and top coding do not apply because they are applicable only on continuous outcome variables. Thus, we generate the protected (private) data from GANs and benchmarks of swap 20 and swap 50 methods and compare these generated data with the real data to estimate the loss in accuracy for customer purchase behavior: purchase variable.27
We find that for these Monte Carlo data, GANs have the lowest loss in accuracy compared with benchmarks of 13% (1 − F1 score) in accurately predicting whether a customer makes a purchase or not. Benchmarks of swap 20 and swap 50 have loss in accuracy corresponding to 16% and 37%, respectively. Furthermore, GANs can achieve higher privacy protection compared with benchmarks, with an MLP of 2.50 compared with 0.35 for swap 20 and 3.27 for swap 50. This finding suggests that marketing managers, who need to build customer targeting models often with sensitive demographic information, will obtain substantially higher accuracy at customer targeting with GANs. Furthermore, GANs offer better privacy protection, thus alleviating privacy concerns of data providers who are sharing data. We explore GANs effectiveness in the presence of heterogeneity in the data, correlations in the independent variables, misspecification with omitted variables, variance in the error term, and nonlinear terms in the data generating process in Online Appendix A.3. We find reassuring evidence that GANs outperform benchmarks across these data contexts.
Thus, GANs can provide a suitable alternative to the true data and benchmarks to marketing managers interested in building customer targeting models with multiple protected data.
5.3.3. Tackling Multiple Marketing Problems with One GAN.
Because the purpose of a GAN is to generate privacy protected synthetic data, we test whether data generated from GANs can be used to run a variety of inferences similar to those that are possible on the true data. We test as a proof of concept whether a single GAN can handle combined marketing problems pricing and targeting. We generate a Monte Carlo data set using the process described in Section 3.3. These data comprise 200 customers and 52 weeks across five brands for a total of 10,400 observations.
For each customer-week, we observe the following across the five brands the public data: whether the brand was featured to the customer or not (dummy variable: Feature), whether the brand was displayed to the customer or not (dummy variable: Display), and the price (log(Price)). The private data and the outcome variable of interest are how much the customer purchases a certain brand during a week: log(Sales). Online Appendix Table A.9 shows the summary statistics for the Monte Carlo data.
We report the MAPD and MLP results from Equation (13) in Figure 5.28 We find that in this Monte Carlo data, GANs outperform benchmark methods; GANs have an MAPD of 0.0139, that is, a 1.39% difference in the price elasticities and coefficients for feature and display and their interaction term. The only benchmark that comes close is rounding, with an MAPD of 0.0207, whereas other benchmarks have an MAPD an entire order of magnitude higher at about 0.2 or higher. Furthermore, we find that GANs provide higher privacy protection compared with benchmarks. Thus, our empirical evidence suggests that GANs can indeed incorporate multiple marketing problems with a single model and that this outperforms other benchmarks in terms of accuracy-privacy tradeoff.
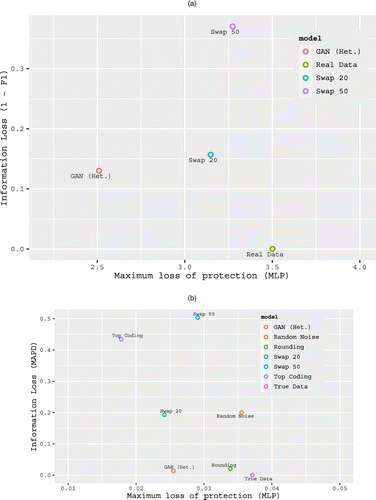
Notes. (a) Customer targeting. This figure shows the loss in customer targeting (1-F1) for GANs and benchmarks with loss in privacy (MLP). (b) Combined: Pricing and targeting. This figure shows the loss in information (MAPD) for models that combine pricing (price elasticities) and targeting (based on feature and display variables) for GANs and benchmarks with loss in privacy (MLP).
The finding that GANs can tackle multiple marketing problems will be of much interest to data providers and researchers. Data providers need to train only one GAN model on their entire data set, which can subsequently be used by researchers to draw multiple inferences such as pricing and customer targeting.
6. Discussion
In this paper, we address the concerns of researchers who need access to firms’ sensitive customer data and present a novel approach that differs from traditional data transfer approaches. We address the three concerns firms and researchers have regarding data transfer: (i) our approach is effective in preserving the privacy of sensitive customer data with higher accuracy; (ii) our proposed generative model scales to big data; and (iii) our proposed approach can be used to tackle multiple marketing problems.
The decoupled nature of GANs, consisting of two competing neural networks, a discriminator network and a generator network, lends both privacy and scalability advantages. Privacy advantages derive from only the discriminator accessing the real data on the firm’s side, thereby ensuring that no real data leaves the walls of the firm. The scalability advantages derive from only the gradients of the loss function’s being passed from the discriminator to the generator. The researcher, with the generator neural network, can generate data mimicking the true data to a high degree of accuracy.
We test these generative models on four data sets, a household scanner panel data from AC Nielsen and three Monte Carlo customer data sets, and validate the accuracy of our proposed generative model in comparison with benchmarks. We find that data generated from GANs have probability distributions closest to the true data and outperform benchmarks on the accuracy-privacy tradeoff. We also evaluated GANs on marketing problems of optimal price markups for profit maximization, customer targeting with protected demographic variables, and the ability to tackle multiple marketing problems with the use of a single GAN. We find that GANs outperform benchmarks on tackling marketing problems and alleviate data providers’ logistical and computational overhead as the data providers need to only train one GAN model that can tackle several marketing problems.
We also address the scalability concerns that are typical for big data. First, we find that our generator scales effectively with respect to data volume and velocity. We find that the training time per iteration is of the same order of magnitude for different data volumes. Second, we find that the transferred information size outshines true data transfer when the data volume is of the order of hundreds of thousands rows or more. Finally, we also demonstrate that the SGD allows us to handle streaming data; that is, because the generator training can be resumed without much loss in informational value, it scales effectively regarding new data.
An important limitation of our GAN model is that we currently do not model consumer dynamics. This concern can be addressed by modifying the GANs to incorporate attention, which can enable us to capture a possible source of heterogeneity. Additionally, there are two extensions that can be studied in further research. First, given that this study considers a limited number of variables: how can GANs handle data contexts with much larger variable space can be studied in future research. Second, given that this study uses Monte Carlo data and validation on real-world data: how do GANs generalize across several real-world data sets.
In conclusion, we present a novel scalable approach as a proof of concept for data transfer, which demonstrates improved privacy protection compared with benchmark methods and can be used to solve several marketing problems. In light of recent regulatory concerns over data privacy, our findings have significant implications for firms, consumers, and regulators, as privacy protection becomes increasingly important for marketers.
Both authors contributed equally and are listed in alphabetical order. This paper is part of P. Anand’s thesis work. The authors thank Vithala Rao, Olivier Toubia, Glen Urban, K. Sudhir, and the participants in the 2018 Marketing Science and Frontiers of Empirical Marketing conferences for helpful comments. All errors are the authors’ own. Researchers’ own analyses calculated (or derived) based in part on data from Nielsen Consumer LLC and marketing databases provided through the NielsenIQ Datasets at the Kilts Center for Marketing Data Center at The University of Chicago Booth School of Business. The conclusions drawn from the NielsenIQ data are those of the researchers and do not reflect the views of NielsenIQ. NielsenIQ is not responsible for, had no role in, and was not involved in analyzing and preparing the results reported herein.
1 We report the density plots in Online Appendix A.2. We discuss in Online Appendix A.7 that increasing the GAN complexity (number of neurons) reduces information loss. However, the improvements in information loss have a point of diminishing returns after an optimum value of number of neurons.
2 We show that GANs outperform benchmarks on the accuracy-privacy tradeoff when the data are 100 times the baseline volume of our Monte-Carlo data in Online Appendix A.3.
3 The data provider can also train a generator on its own end and transfer the trained generator to the researcher. Our proposed approach is indifferent to either approach that the data provider chooses.
4 Quantifying the nature of API calls (volume, network bandwidth, server requirements, among others) is not the primary focus of our paper, and we argue that GANs can be trained using API calls with “sufficient” network bandwidth.
5 We do so in Online Appendix A.3.
6 The term “adversarial” comes from the name of the deep learning model: generative adversarial networks. The “adversaries” in this context are the generator and discriminator that compete with each other; that is, the generator creates data in an attempt to fool the discriminator into classifying it as real data, and the discriminator has to classify the true data as different from the fake data.
7 See Section 3.3 for discussion of how we measure effectiveness in approximating the data-generating process of the true data.
8 An alternate to the entire data or model transfer could be that the data providing firm directly shares coefficients of the inference model to researchers. In this situation, the researchers are limited to the inference models of the data provider, and the data provider will have to re-estimate the models and reshare with the researchers every time there is a requirement for a new inference approach nor with new data. GANs alleviates these concerns as they are inference approach agnostic and mimic the real data.
9 The KL divergence is not symmetric, as the amount of information needed to go from distribution P to Q need not be the same as the amount of information needed to go from distribution Q to P, whereas the Jensen-Shannon divergence is a symmetric measure.
10 See discussion in Lin (1991) on the derivation of the upper and lower bounds for the Bayes probability of error using the Jensen-Shannon divergence.
11 We use the brands’ own price elasticities as the coefficients of interest in the subsequent sections when MAPD is reported. We discuss the inference model and MAPD in detail in Online Appendix A.1.
12 The parameters and are estimated from a multinomial logit model that predicts the probability of a customer based on their observed sales using leave-one-out approach. This is the approach proposed by Schneider et al. (2018). We then use the fitted values for each customer during a time period to obtain their loss in privacy: LP.
13 To account for out-of-sample fit, we calculate the previous metrics using a leave-one-out cross-validation procedure, as specified by Schneider et al. (2018). Furthermore, we use the MLP of the true data as the upper bound on the MLPs for all other methods.
14 We model these variables for customers as draws from a random uniform distribution with thresholds to approximate the general U.S. population based on data for age from US Census—median age (https://www.census.gov/data/tables/time-series/demo/popest/2010s-national-detail.html), income from US Census (https://www.census.gov/quickfacts/fact/table/US/SEX255219), weight from Gallup (https://news.gallup.com/poll/328241/americans-average-weight-holds-steady-2020.aspx), and minority from 2020 US Census (https://data.census.gov/cedsci/table?q=United%20States&tid=ACSDP1Y2019.DP05). Furthermore, we give additional details on the data generating process in Online Appendix A.3.
15 We also report additional robustness with heterogeneity in effects, correlations in independent variables, missing variables, and with random forest as an additional inference approach in Online Appendix A.3.
16 Goodfellow et al. (2014) derive theoretical guarantees for convergence in Sections 4.1 and 4.2 of their paper and argue that the generated data distribution converges to the true data distribution when the discriminator is allowed to reach its optimum at each iteration. We rely on this theoretical guarantee for convergence, and, in our experiments, we set the number of iterations to 100,000 as we found that the objective function stopped improving sufficiently prior to this number of iterations.
17 We discuss further details of the GANs architecture in Online Appendix A.8.
18 We consider k = 52 weeks as the duration; thus, each customer has 52 weeks of purchase data that constitutes a picture data for the training purposes. For the No Het. case, we randomly sample 52 customer-weeks across the entire data as rows to construct a picture equivalent. The training process is identical for both types: Het. and No Het.
19 ADAM uses adaptive learning rate such that ηg, ηd hyperparameters are optimized during training. We refer the readers to Kingma and Ba (2014) for a detailed description of the ADAM optimizer. We also discuss in Online Appendix A.6 the training process for our GAN with gradients flow used to update the parameters.
20 We report the distribution plots in Online Appendix A.2.
21 We explore the relationship between model parameters, number of neurons and the accuracy of GANs, in Online Appendix A.7. We also explore the robustness of model’s architecture such as activation functions, batch normalization, and the noise distribution used to generate data in Online Appendix A.8.
22 We modify top coding (99.9 percentile instead of 95) and random noise (centiles instead of deciles) to increase the difficulty of the benchmark comparison, as the 95% and deciles have higher information loss, and we did not want the real-data benchmark to be easier than the Monte Carlo data setting. Rounding is modified to the nearest dollar instead of nearest cent (100th place) or nearest 10th cent (10th place), because in the true data the sales are often ending in 9 cents (e.g., $3.89 is rounded to $4.00).
23 Both GAN (Het.) and GAN (No Het.) have 512 neurons each. We discuss how number of neurons affects accuracy in Online Appendix A.7.
24 We run the GANs with 512 neurons and mini-batch size of 128 customers in Tensorflow 1.4 on a computer with the following configuration: Intel Core i9-9000X 10 Core 3.3 GHz, 64 GB RAM, and Titan Xp GPU (Pascal), for 100,000 iterations. We use this as a training stopping point because the RMSE between the real data and the synthetically generated samples stabilizes prior to this point, implying GAN convergence.
25 The data size reported is the size of the checkpoint data that Tensorflow saves for the generator parameters. The generator uses 512 number of neurons.
26 Our results are similar when we exclude previous purchase variable. The argument for including this variable, previous purchase, follows from Park and Park (2016). They note that this variable is needed to account for dependence in the outcome variable (purchase) for the current time period on the previous time periods. Furthermore, this parameter is important in their parameter estimates (the 95% posterior interval does not include zero). Finally, the setting that previous purchase are public data, but current period purchase are private data and are not an artificial setting. In contexts such as financial data, executive and senior managers previous inside trades are publicly disclosed, but their current period trades are kept private and required only to be disclosed within two business days. See, for example, https://undervaluedequity.com/sec-forms-3,-4,-5/. Also, other settings with streaming data and dependence on previous period outcomes will have this context.
27 We also explore random forests as a targeting model built on top of the protected data in Online Appendix A.3. We find consistent results that GANs outperform benchmarks on the accuracy-privacy tradeoff.
28 We do not consider market aggregated benchmark because the feature and display for a brand is at customer-week level; thus, aggregating it across multiple customers is a weak benchmark.
References
- (2016) Tensorflow: A system for large-scale machine learning. Proc. 12th USENIX Sympos. on Operating Systems Design and Implementation (USENIX Association), 265–283.Google Scholar
- (2012) Dynamically consistent noise infusion and partially synthetic data as confidentiality protection measures for related time series. Preprint, submitted July 1, http://dx.doi.org/10.2139/ssrn.2159800.Google Scholar
- (2018) Big Data Analytics. Handbook of Marketing Analytics (Edward Elgar Publishing, Cheltenham, UK).Google Scholar
- (2019) Design and evaluation of product aesthetics: A human-machine hybrid approach. Preprint, submitted July 19, https://dx.doi.org/10.2139/ssrn.3421771.Google Scholar
- (2016) Infogan: Interpretable representation learning by information maximizing generative adversarial nets. Lee D, Sugiyama M, Luxburg U, Guyon I, Garnett R, eds. Adv. Neural Inform. Processing Systems (Curran Associates, Inc., Red Hook, NJ), 29:2172–2180.Google Scholar
- (2016) Editorial: Marketing science and big data. Marketing Sci. 35(3):341–342.Link, Google Scholar
- (1997) Using market-level data to understand promotion effects in a nonlinear model. J. Marketing Res. (SAGE Publications, Los Angeles, CA), 34(3):322–334.Crossref, Google Scholar
- (2016) Mining brand perceptions from Twitter social networks. Marketing Sci. 35(3):343–362.Link, Google Scholar
- (2004) Disclosure risk vs. data utility: The RU confidentiality map as applied to topcoding. Chance 17(3):16–20.Crossref, Google Scholar
- (2006) Interpreting Kullback–Leibler divergence with the Neyman–Pearson lemma. J. Multivariate Anal. 97(9):2034–2040.Crossref, Google Scholar
- (2011) Online display advertising: Targeting and obtrusiveness. Marketing Sci. 30(3):389–404.Link, Google Scholar
- (2014) Generative adversarial nets. Ghahramani Z, Welling M, Cortes C, Lawrence N, Weinberger KQ, eds. Adv. Neural Inform. Processing Systems 27:2672–2680.Google Scholar
- (2013) An empirical investigation of catastrophic forgetting in gradient-based neural networks. Preprint, submitted December 21, https://arxiv.org/abs/1312.6211.Google Scholar
- (2006) Sales and consumer inventory. RAND J. Econom. 37(3):543–561.Crossref, Google Scholar
- (2014) Disclosure risk evaluation for fully synthetic categorical data. Proc. Internat. Conf. on Privacy in Statist. Databases (Springer, Berlin), 185–199.Google Scholar
- (2020) Coresets for regressions with panel data. Preprint, submitted November 2, https://arxiv.org/abs/2011.00981.Google Scholar
- (2016) Deep directed generative models with energy-based probability estimation. Preprint, submitted June 10, https://arxiv.org/abs/1606.03439.Google Scholar
- (2014) Adam: A method for stochastic optimization. Preprint, submitted XX, https://arxiv.org/abs/1412.6980.Google Scholar
- (1951) On information and sufficiency. Ann. Math. Statist. 22(1):79–86.Crossref, Google Scholar
- (2000) Building models for marketing decisions: Past, present and future. Internat. J. Res. Marketing 17(2–3):105–126.Crossref, Google Scholar
- (1991) Divergence measures based on the Shannon entropy. IEEE Trans. Inform. Theory 37(1):145–151.Crossref, Google Scholar
- (1995) Are aggregate scanner data models biased? J. Advertising Res. 35(5):RC8–RC8.Google Scholar
- (2016) A structured analysis of unstructured big data by leveraging cloud computing. Marketing Sci. 35(3):363–388.Link, Google Scholar
- (2019) Deep learning in computer vision: Methods, interpretation, causation and fairness. INFORMS TutORials Oper. Res. 73–100.Google Scholar
- (2014) Conditional generative adversarial nets. Preprint, submitted November 6, https://arxiv.org/abs/1411.1784.Google Scholar
- (2016) Investigating purchase conversion by uncovering online visit patterns. Marketing Sci. 35(6):894–914.Link, Google Scholar
- (2017) The effect of calorie posting regulation on consumer opinion: A flexible latent dirichlet allocation model with informative priors. Marketing Sci. 36(5):726–746.Link, Google Scholar
- (2015) Unsupervised representation learning with deep convolutional generative adversarial networks. Preprint, submitted November 19, https://arxiv.org/abs/1511.06434.Google Scholar
- (2021) Targeting and privacy in mobile advertising. Marketing Sci. (INFORMS), 40(2):193–218.Google Scholar
- (2005) Estimating risks of identification disclosure in microdata. J. Amer. Statist. Assoc. 100(472):1103–1112.Crossref, Google Scholar
- (2010) Multiple imputation for disclosure limitation: Future research challenges. J. Privacy Confidentiality 1(2):223–233.Crossref, Google Scholar
- (2015) A new method for protecting interrelated time series with Bayesian prior distributions and synthetic data. J. Roy. Statist. Soc. Ser. A 178(4):963–975.Crossref, Google Scholar
- (2018) A flexible method for protecting marketing data: An application to point-of-sale data. Marketing Sci. 37(1):153–171.Link, Google Scholar
- (2003) Massively categorical variables: Revealing the information in zip codes. Marketing Sci. 22(1):40–57.Link, Google Scholar
- (2006) Avoiding aggregation bias in demand estimation: A multivariate promotional disaggregation approach. Quant. Marketing Econom. 4(4):383–405.Crossref, Google Scholar
- (2019) Identifying customer needs from user-generated content. Marketing Sci. 38(1):1–20.Link, Google Scholar
- (2016) Idea generation, creativity, and prototypicality. Marketing Sci. 36(1):1–20.Link, Google Scholar
- (2016) Learning to draw samples: With application to amortized MLE for generative adversarial learning. Preprint, submitted November 6, https://arxiv.org/abs/1611.01722.Google Scholar

