
Learning in Temporally Complex Problems: The Role of External Knowledge
Abstract
We explore how decision makers utilize external and internal knowledge in problems characterized by temporal complexity where there is a separation between action and outcome. Many strategic and organizational decisions have longer-term consequences, yet behavioral models of learning have underexplored this class of problems. Consequently, we do not know much about the role of external knowledge in tackling temporally complex problems, let alone how it interacts with internal knowledge from experiential learning processes. Our computational analyses show that, although having a greater level of external knowledge is generally advantageous, its positive impact diminishes notably or can even become negative when external knowledge is limited. Surprisingly, decision makers operating with limited external knowledge can perform worse than those without any external guidance at all. In a temporally complex problem, knowing what to do at any given point is not sufficient as one still needs to undertake a long sequence of actions before reaching the goal. In other words, external knowledge does not guarantee that optimal actions will be chosen in subsequent decision-making situations. This dynamic may lead the decision makers to overvalue actions that serve as stepping stones to the available external knowledge and undervalue alternative actions that may provide more desirable paths toward the goal.
Funding: This research was supported by the Yonsei University Research Fund of 2021 [2021-22-0098].
Supplemental Material: The online appendix is available at https://doi.org/10.1287/orsc.2022.16469.
1. Introduction
Many organizational decisions and activities do not yield immediate payoff consequences (March and Simon 1958, Cyert and March 1963, Allison 1971, Nelson and Winter 1982, Levitt and March 1988, Gersick and Hackman 1990). Instead, an action taken today may set the stage for future actions (Cohen and Bacdayan 1994), and a sequence of actions must be carried out to observe a payoff outcome (Denrell et al. 2004, Dunne and Dougherty 2016). Consider the game of chess, in which outcome feedback is delayed until a long sequence of moves has been played, and the game is either won or lost. After each move, it is not clear whether the move is good and whether it contributes to the eventual losing or winning of the game. As argued by Levinthal (2021), this kind of separation between action and feedback results in temporal complexity, which constitutes a fundamental aspect that makes strategy problems “hard” or “complex.”1 Decision makers face the so-called credit assignment challenge (Minsky 1961): how to assign credit from the overall sequence of actions to its antecedent actions? Despite significant conceptual work on this important problem (Thompson 1967, Ghemawat 1991, Levinthal and March 1993, Kogut and Kulatilaka 2001), the formal modeling of temporal complexity has received limited attention in the organizational learning literature (Rahmandad and Gary 2023).
Chess captures the essence of strategic decisions with long-term consequences that are hard to foresee or measure. Similarly, consider the drug development process, which typically takes on average 10 years from conception to market. Initially, a target molecule is identified for development. Subsequent preclinical tests assess potential compounds both in vitro and in vivo to mimic human conditions closely. This is followed by clinical trials to determine drug safety and efficacy before market launch. This lengthy process presents challenges in learning the value of actions without immediate feedback, particularly as early decisions are made without clear indications of long-term success (Pisano 2006). Through repeated experience, drug companies learn to refine these processes and navigate the sequence of actions to improve their odds of success.
Despite the prevalence of temporal complexity, most behavioral models of learning have examined situations where immediate performance feedback follows organizational actions (Cyert and March 1963, Lave and James 1975, Levinthal and March 1981, Herriott et al. 1985, Levitt and March 1988, Lant and Mezias 1992, Roth and Erev 1995, Levinthal 1997, McKelvey 1999, Gavetti and Levinthal 2000, Rivkin 2000). Nevertheless, there is a growing literature on how organizations can address temporal complexity and improve their performance over time (Brehmer 1992, Diehl and Sterman 1995, Denrell et al. 2004, Rahmandad 2008, Rahmandad and Gary 2023). These studies have shown that organizations recognize the long-term consequences of their actions by leveraging experiential learning and gradually assigning credit to choices that lead to other actions perceived as stepping stones toward the goal (Denrell et al. 2004, Fang 2012).
However, experiential learning is not the only source of knowledge that decision makers rely on when addressing complex problems. In addition to knowledge acquired through experiential learning on a particular problem, referred to here as “internal knowledge,” organizations can utilize and access information before engaging with and getting experience with that problem. This includes rules, templates, standard operating procedures, and initial mental representations related to the focal problem (Orr 1996, Gavetti and Levinthal 2000, Gavetti 2005, Winter et al. 2007, Oldroyd et al. 2019). In contrast to internal knowledge, we refer to this type as external knowledge. This knowledge enables organizations to anticipate or simulate future outcomes even before taking any actions and thus is external to a particular problem solving journey. For example, Xerox provided workers with strict repair guides for copiers (Orr 1996), and Alessi relies on detailed procedures for new product development (Salvato 2009). In a similar vein, strategy frameworks simplify complex business phenomena into manageable problems, enabling decision makers to focus on key variables influencing organizational outcomes (Csaszar et al. 2024).
Despite the widespread use of external knowledge in practice, most earlier work has focused on problems where outcome feedback is immediately available. Thus, we still know relatively little about the relationship among external knowledge, internal knowledge, and organizational performance in the class of underexplored problems characterized by temporal complexity. In such contexts, external knowledge may serve as an alternative basis of actions in the absence of immediate outcome feedback. For instance, workers can access generic organizational rules and routines before embarking on a new organizational task. Such external knowledge serves as subgoals guiding early choices and helping organizations effectively navigate toward beneficial outcomes. However, because outcome feedback is only available after a long sequence of actions, knowing what the right action at specific points in time does not guarantee that subsequent decisions will also align with the desired outcome, unless external knowledge is extensive. Furthermore, organizations might place excessive value on choices that lead them toward subgoals created by external knowledge, even at the expense of diverging from the eventual goal. For instance, workers may pursue actions that are deemed important in the rulebooks rather than engaging with a fuller spectrum of choices that may lead to the goal more expeditiously. External knowledge may constrain and narrow the scope and direction of experiential learning and subsequently the accumulation of their internal knowledge. Thus, temporal complexity creates a possible tension in using external knowledge for organizational search. As Leiblein et al. (2018) point out, an opportunity to contribute to research regarding temporal interdependence lies in “clarifying the role of learning, mental representation, and theory in supporting particular forms of temporal interdependence” (p. 566).
We advance this discourse by building a behavioral model of learning to explore the dynamic interplay between external and internal knowledge in the context of temporal complexity (Levinthal and March 1993). We devise a labyrinth-like task structure where the “treasure” is revealed only after the problem-solving agent executes a sequence of actions (Denrell et al. 2004, Fang 2012). To navigate toward the treasure, the agent must identify or attribute credit to key “stepping stones” guiding them toward the goal. External knowledge is represented as a set of interim choices (or clues) available to the agents, whereas internal knowledge is represented by a gradual accumulation of understanding via trial-and-error learning. We then investigate how performance may vary with different degrees of the external knowledge (i.e., how many clues are available).
We find that, although having a greater level of external knowledge is generally advantageous, its positive impact diminishes notably or can even become negative when external knowledge is limited. Surprisingly, decision makers operating with limited external knowledge can perform worse than those without any external guidance at all. In contrast to the fable of Weick (1995) where a group of lost soldiers in the Alps survived by using the maps of the Pyrenees, we find that having a limited map can be worse than having no map at all. Without any external knowledge (or map), decision makers are free to search broadly and perform potentially better. This highlights a potential upside of having no clues at all in complex problems. Starting with a clean slate may be surprisingly effective. Our behavioral model documents how two types of knowledge may interact in complex and nonobvious ways and explores the conditions under which external knowledge can be leveraged in temporally complex problems.
Our work contributes to the organizational learning literature by shedding light on the challenges associated with learning in a relatively underexplored class of problems, where action and feedback are separated across time (Levinthal 2021). Modeling both external and internal knowledge as different bases of action, we show that the interaction between them can introduce counterintuitive results in organizational search. We articulate a mechanism behind the surprising penalty associated with limited external knowledge and highlight several implications. For instance, organizations may be cautious of relying on upstream knowledge that depends on a long sequence of downstream decisions to be useful. In addition, the experiential learning process may also lead to the overvaluation of actions that serve as stepping stones to external knowledge yet are in fact detours from the goal. To avoid the negative penalty, organizations can postpone the use of external knowledge until decision makers have acquired sufficient internal knowledge through trial-and-error learning on their own. Our work also suggests systematic interventions to potentially tackle temporal complexity even when external knowledge is limited.
2. Theoretical Motivation
To clarify the research gaps in the existing literature, we summarize in Table 1 prior work along two dimensions: (1) the presence or absence of temporal complexity and (2) the presence or absence of external knowledge. Most prior studies have mainly focused on the first three quadrants: (I) scenarios without temporal complexity and external knowledge; (II) those with external knowledge but no temporal complexity; and (III) those with temporal complexity but no external knowledge. In contrast, there is a relative paucity in research on Quadrant IV, where both temporal complexity and external knowledge are present. Our work therefore seeks to address this gap in the literature.
|

Table 1. Review of Prior Models
| Temporal complexity (i.e., delayed feedback) | |||
|---|---|---|---|
| No | Yes | ||
| External knowledge | No | I. Experiential learning with immediate feedback | III. Experiential learning with delayed feedback |
| Levinthal (1997), Denrell and March (2001), Rivkin and Siggelkow (2002), Posen and Levinthal (2012) | Denrell et al. (2004), Rahmandad (2008), Fang and Levinthal (2009), Fang (2012), Rahmandad and Gary (2023) | ||
| Yes | II. Use of external knowledge without temporal complexity | IV. Use of external knowledge with temporal complexity | |
| Gavetti and Levinthal (2000), Gavetti (2005), Winter et al. (2007), Levinthal and Marino (2015), Martignoni et al. (2016) | Our study | ||
2.1. Temporal Complexity and the Credit Assignment Problem
Learning from experience typically results in improvement over time (Argote 1999), and existing learning models have identified several challenges associated with organizational learning (Levitt and March 1988, Puranam et al. 2015). Levinthal and March (1993), in particular, argue that “learning processes seek to simplify experience, to minimize interactions and restrict effects to the spatial and temporal neighborhood of actions” (p. 97), known as “spatial” and “temporal” myopia (p. 110). On the one hand, strategy is about “part-whole” relationships in intertwined systems of activities at any given point in time (Levinthal 2021). In such settings, learning tends to favor effects that occur near the learner (Levinthal and March 1993). On the other hand, intertemporal linkages can also make strategy problems computationally hard (Leiblein et al. 2018, Levinthal 2021). For instance, Newell and Simon (1972) used chess as the setting for their early work on human problem solving, because a given move in chess influences future positions and opportunities for victory (Levinthal 2021). Learning in this setting tends to sacrifice the long run to the short run, known as temporal myopia (Levinthal and March 1993).
Hence, a strategy problem is temporally complex when actions may not yield immediate payoff consequences but rather set the stage for subsequent actions (Denrell et al. 2004, Dunne and Dougherty 2016, Leiblein et al. 2018). To navigate such problems, organizations need to create means-ends chains by “(1) starting with the general goal to be achieved (2) discovering a set of means, very generally specified, for accomplishing this goal (3) taking each of these means, in turn, as a new subgoal and discovering a set of more detailed means for achieving it, etc.” (March and Simon 1958, p. 191).
Although most existing research conceptualizes learning as cycles of taking action and observing payoffs directly attributable to the latest action (Rahmandad 2008), temporal complexity disrupts this cycle such that the value of each action cannot be evaluated independent of the actions taken in the past and future periods. Temporal complexity poses the so-called “credit assignment problem,” wherein the outcome reflects the value of a series of actions rather than any individual action. The credit assignment problem has received attention from scholars in a number of related disciplines, ranging from cognitive neuroscience (Schultz et al. 1997, Pagnoni et al. 2002, Niv 2009, Amo et al. 2022), to system dynamics (Sterman 1994, 2006; Rahmandad et al. 2009), and to organization studies (Denrell et al. 2004, Rahmandad 2008, Fang and Levinthal 2009, Fang 2012). Prior work has shown empirically that decision makers often underestimate the delays in receiving feedback (Sterman 1994). Even minimal delays can have a significantly negative impact on the quality of decision making (Brehmer 1992, Sterman 2006). Furthermore, decision makers still struggle to improve their performance even with practice (Brehmer 1980), complete information about task structure (Diehl and Sterman 1995, Rahmandad et al. 2021), or high pay-for-performance incentives (Diehl and Sterman 1995). Their performance suffers with additional cognitive limitations imposed by workload or time pressure (Gonzalez 2004, 2005).
2.2. Role of External Knowledge
Prior studies on temporal complexity have primarily examined how problem solvers develop a gradual understanding of the long-term consequences of their current actions through experiential learning (Gonzalez et al. 2017). Relatively little attention has been paid to an alternative basis of intelligent actions: external knowledge. Although internal knowledge is defined as decision makers’ understanding of the particular problem that is acquired gradually through trial-and-error experiential learning, external knowledge can encompass any information decision makers can access prior to gaining experience with a particular problem (Gavetti and Levinthal 2000, Winter et al. 2007). Examples include templates, routines, and decision rules (Cyert and March 1963, Salvato 2009, Oldroyd et al. 2019).
Furthermore, prior work focusing on problems that do not involve temporal complexity suggests that the role of external knowledge might not be straightforward. On the one hand, external knowledge can guide organizational decision makers by providing an initial, advantageous starting point for problem solving. This is described as positioning the organization in a superior “basin of attraction,” which can help the agent navigate more efficiently toward successful outcomes. Furthermore, external knowledge simplifies complex problems, which in turn enhances organizational performance. Indeed, “greater fidelity between the mental model of action-outcome linkages presumably leads to more efficacious choices of action” (Gavetti and Levinthal 2000, p.113). Even limited knowledge can be highly useful in solving problems, as exemplified in the illustration of Simon (1962) of cracking a defective safe. On the other hand, other studies present a counterpoint to this view (Csaszar and Levinthal 2016, Martignoni et al. 2016, Puranam and Swamy 2016). For instance, Csaszar and Levinthal (2016) argue that incomplete understanding of a task environment reduces local search getting stuck in the “nooks and crannies of a more elaborate representation” (p. 2042) and can be preferable to complete ones (p. 2041).
Our distinction between internal and external knowledge maps onto but does not perfectly align with the distinction between internal and external representations in prior work such as Csaszar (2018) and Zhang and Norman (1994). According to them, although internal representations (e.g., propositions, productions, schemas, mental images, connectionist networks, or other forms) are in the mind, external representations are in the world, as physical symbols (e.g., written symbols, beads of abacuses, etc.) or as external rules, constraints, or relations embedded in physical configurations. Hence, the two forms of representations differ in the loci of knowledge, inside or outside of the decision maker. In contrast, our conception of external versus internal knowledge emphasizes a different (although related) dimension of knowledge: whether it is a product of experiential learning in solving a specific problem.
2.3. Existing Literature
As seen in Table 1, prior work on behavioral models has mostly focused on Quadrants I, II, and III. Quadrant I contains prior work studying how experiential learning and internal knowledge help learners tackle the challenge arising from immediate but potentially misleading feedback. For instance, studies have explored how different spatial interaction patterns across organizational choices may affect the efficacy of organizational search (Levinthal 1997, Rivkin and Siggelkow 2002, Siggelkow and Levinthal 2003, Csaszar and Siggelkow 2010). Because of these complex interactions (i.e., the rugged landscape) and bounded rationality, a firm does not observe or implement a globally optimal set of choices. In particular, internal knowledge is accumulated through a trial-and-error process: Firms learn by trying a novel alternative in the vicinity of the current strategic position and making a change only if the new alternative improves the situation. This tradition has yielded significant insights into how interactions among choices at any given time may influence organizational learning. For instance, decision makers often fail to explore and search locally (Levinthal 1997), resulting in suboptimal organizational choices that may appear reasonable in a local context but not in a global one (Rivkin and Siggelkow 2002).
Quadrant II consists of studies that examine the performance implications of various forms of external knowledge in settings devoid of temporal complexity (Gavetti and Levinthal 2000, Winter et al. 2007, Levinthal and Marino 2015, Csaszar and Ostler 2020). External knowledge has been modeled in various ways: a lower dimensional representation of the underlying NK landscape (Gavetti and Levinthal 2000, Levinthal and Marino 2015, Csaszar and Levinthal 2016), (mis)specification of interactions among organizational choices (Siggelkow 2002), a preferred direction of search (Winter et al. 2007), or a contingency matrix (Martignoni et al. 2016). Agents first search offline for the best alternatives (as prescribed by their external knowledge) before making actual investments or commitments. For instance, Gavetti and Levinthal (2000) examine how knowledge available to the problem solver even before engaging with experiential learning processes can help improve firm performance.
Quadrant III begins to pay attention to the underexplored problem context, where outcome feedback is often delayed, and longer-term consequences are not immediately apparent (Denrell et al. 2004, Rahmandad 2008, Fang and Levinthal 2009, Gary and Wood 2011, Luoma et al. 2017, Rahmandad et al. 2021).2 Using a different analytical approach based on the temporal differencing (TD) algorithms in computer science, these studies model how internal knowledge evolves as a function of experiential learning. The key to such experiential wisdom is the explicit acknowledgment and incorporation of rational decision rules, which recognize an action that may set the stage for, and serve as “stepping stones” to future (not immediate) rewards (Bellman 1957). This perceived value of “setting up and reaching for a future goal” can also serve as an alternative guide for action. In other words, the agent updates the belief about the current position by considering how the position helps to create a valuable future position. Building on this insight, this body of work has modeled experiential learning as a gradual process, where the values of actions are updated to reflect both their immediate impact on performance, as well as the future impact (Denrell et al. 2004, Fang and Levinthal 2009, Fang 2012, Rahmandad et al. 2021). Such reinforcement results in organizational rules or routines that can guide organizational choices without the calculation of long-term consequences (Nelson and Winter 1982).
This set of studies illustrates how decision makers can tackle a temporally complex problem by relying exclusively on experientially learned internal knowledge alone. Notably absent is the use of external knowledge, independent and orthogonal to experiential learning. Therefore, these papers abstract away from the dynamic interplay between external knowledge and internal knowledge.3
Quadrant IV is where there is relative paucity in research, with both external knowledge and temporal complexity. Our work is situated here. On the one hand, external knowledge can illuminate the future downstream consequences of current actions and enhance organizational performance. On the other hand, decision makers may assign excessive values to choices that serve as stepping stones to external knowledge, even when such choices may divert them from reaching the goal. Thus, the separation between action and outcomes over time introduces a possible tension between the two sources of knowledge. What would be the overall impact on search and performance, as we vary the level of external knowledge? How does the interaction between external and internal knowledge impact performance? To address these, we build a computational model where agents solve a temporally complex problem repeatedly, relying on both external knowledge (operationalized as explicit guidance on what to do in the next step) and internal knowledge (operationalized as learning based on an updating algorithm).
3. Model
3.1. Task Structure
We use a hypercube to represent a temporally complex problem, where the vertices represent distinct states and the edges the available actions. Notably, within the hypercube, only a single state, referred to as the goal, yields a positive reward, in line with previous studies (Denrell et al. 2004, Fang 2012). Decision makers have to undertake a sequence of actions, and they receive no immediate outcome feedback unless they find the goal. After choosing an edge within the hypercube, they transition to a neighboring state linked by that particular edge. Formally, we represent a vertex or state S within the hypercube as a string of N binary elements, where each element can take either a value of zero or one. Consequently, there are 2N distinct states in total. We set the goal state to have one for all N elements (i.e., 1 … 1).4 Consistent with prior work in this area (Denrell et al. 2004), we assume the labels (i.e., zeros and ones) are not meaningful coordinates. Search for the goal state becomes trivial if the agent recognizes their current state and the goal state and flips every zero in the current state. At each state, the agent can perform action A to transition to neighboring states by changing a single element in the string.5 Suppose the agent is in state 001. By flipping the first element from zero to one, the agent can move to the neighboring state 101. Similarly, the agent can choose to flip the second or third element to reach other neighboring states, such as 011 or 000. Hence, in each of the 2N states, there are N possible actions. The agent continues this process of selecting an action by flipping an element and moving to a neighboring state until the goal state is identified.
In this problem, the objective is to efficiently locate the goal, minimizing the search time or search cost involved. Because finding the goal requires taking many steps, we operationalize temporal complexity as feedback delays following prior work (Denrell et al. 2004, Rahmandad 2008, Fang and Levinthal 2009, Rahmandad et al. 2009, Fang 2012). In addition, we define performance as the number of steps taken by the agent to reach the goal state, which we call time to solution (TTS). An increase in TTS indicates a worsening of performance.
3.2. Internal Knowledge
To model how decision makers accumulate internal knowledge via a process of trial-and-error learning, we employ the SARSA algorithm, a TD algorithm commonly used in reinforcement learning (Sutton 1988, Fang and Levinthal 2009, Sutton and Barto 2018).6 The agent develops internal knowledge of how to solve the problem, represented by a Q(S, A) function. This function maps each state-action pair (S, A) to a real value ranging from zero to one, referred to as the Q-value, which represents the subjective value assigned to a specific action in a specific state. For example, if the agent finds themselves in state S = 101, there will be three Q-values associated with the N = 3 different actions: Q(101, flipping the first element), Q(101, flipping the second element), and Q(101, flipping the third element). A Q(S, A) function captures the values of each pair of 2N states and N actions.
This Q(S, A) function captures an agent’s assessment of the value of an action in a state and is iteratively adjusted based on the subsequent state and the immediate reward. From state S, suppose an agent takes a particular action A and arrives at a new state S′ following an action choice rule (specified in Section 3.4). There may or may not be an immediate reward associated with taking this action. In this new state S′, the agent selects an action A′. Intuitively, the state action pair (S, A) has enabled, or contributed to, a subsequent, future position in S′. Thus, part of the value of Q(S′, A′) can be attributed backward to the preceding state action pair (S, A). In other words, when the agent evaluates a state action pair (S, A), they take into account not only any instantaneous payoff but also the value of a future position Q(S′, A′) that the current action helps create.
The SARSA algorithm formalizes this intuition and has been extensively used in modeling reinforcement learning (Kaelbling et al. 1996, Fang and Levinthal 2009, Sutton and Barto 2018). An initial Q function represents an agent’s beliefs or priors and is set to zero for all states and actions. As agents interact with the environment over time, they update the Q(S, A) values based on the backward propagation principles in dynamic programming (Bellman 1957, Sutton and Barto 2018) as follows:
In this algorithm, two parameters, α and γ, control the learning process. The parameter α represents the learning rate, with a higher value resulting in quicker updates to the Q-values. The parameter γ is a discount factor that determines the weight (i.e., discount rate) assigned by the agent to the perceived value of the subsequent state-action pair. Hence, γ indicates the importance of future rewards. When γ is set to zero, the agent disregards any Q-values associated with future states or stepping stones, and learning is solely based on the immediate reward R, available only for the goal state. On the other hand, when γ is greater than zero, the agent takes into account the value of the next state-action pair when updating its beliefs about the value of the current state-action pair.
3.3. External Knowledge
We represent external knowledge as a set of “clues,” where each clue consists of a unique state paired with an action leading toward the goal. In other words, external knowledge is always accurate, in that it points the agents one step closer toward the goal. In other words, external knowledge indicates one of the actions that can get the agents closer to the goal, providing guidance to follow.7 For any state, given this definition, there can be multiple actions that qualify. If so, we choose a random action as the prescribed one. Also, external knowledge cannot be wrong, that is, take the agents away from the goal. External knowledge varies in their completeness: The parameter EK represents the degree of external knowledge, ranging from 0 to 2N − 1, essentially representing the number of available clues. When EK is zero, no guidance is provided for any states, whereas a value of 2N − 1 indicates that external knowledge contains guidance for all states (except the goal state). When EK is 2N − 1, the agent can simply follow external knowledge to identify the correct action for all states, readily identifying a path to the goal. We randomly select EK states from 2N − 1 possibilities (excluding the goal state) and pair each with an accurate action.
There are several additional assumptions regarding external knowledge. Firstly, we assign a constant value, denoted as V, to represent the valence (or perceived value) of the external knowledge. Some agents may undervalue external knowledge created by others, due to the not-invented-here syndrome (Katz and Allen 1982). Other agents likely put significant value in external knowledge, such as technology transferred from benchmarking firms or strategic guidance provided by field experts. In our baseline, we fix V = R = 1. The parameter V operates as follows: suppose an agent undertakes action A3 from state S, and transitions to state S′ where a clue is available. Recall that the agent takes into account both immediate feedback R, as well as future consequences Q(S′, A′) in evaluating current action A3. In this case, R is zero but Q(S′, A′) has a value of V. Therefore, Q(S, A3) is significantly reinforced based on V, because it helps create a future state S′ where external knowledge is accessible. As V declines, the recognition of A3’s value as a stepping stone decreases accordingly. Thus, V regulates the extent to which external knowledge establishes its own “basin of attraction.” In addition, we assume that V remains constant throughout the learning process and the decision-makers always adhere to the prescribed actions. In additional analyses, we explore how variations in these assumptions impact our results.
3.4. Choice of Actions
Action choice follows a Softmax choice rule, which attempts to balance the tradeoff between exploration and exploitation (Luce 1959). Given state S, the agent refers to its Q(S, A) table and selects an action that is likely to yield a highest payoff, whether it be an immediate reward R or future rewards. In other words, agents is likely to choose an action that has the highest Q-value, that is, be greedy and exploitative. However, this is not always the case. With some probability, they may explore and end up choosing an action that is currently associated with lower Q-values as specified below:
Here, τ is a parameter that tunes the degree of exploration. When τ approaches zero, the choice process becomes extremely exploitative, whereas increase in τ makes the choice process more explorative.
Our modeling of action choice departs significantly from the typical set up in the NK models (Levinthal 1997, Rivkin and Siggelkow 2002), which have commonly assumed that (1) there are clear linkages between a configuration of actions and payoff and (2) the organization does not assign values to a particular action. Prior work typically treats the entire configuration of choices as a unit of learning and analysis. Because the organization learns the value of configurations, rather than individual actions, action selection is blind: either a simple mutation (e.g., flipping a random binary element from zero to one or vice versa) or a crossover (e.g., copying several elements from a different configuration). In contrast, in models built on credit assignment principles, the unit of learning and analysis is the action. As in (1), an agent attempts to develop a value function that captures how a particular action contributes to the ultimate payoff (Sutton and Barto 2018). They then act intelligently by selecting an action that has a higher value in getting to the desirable goal state based on the value function.
3.5. Interaction Between External and Internal Knowledge
Note that we do not assume a priori any relationship between internal and external knowledge. In a state with external knowledge, there is a prescribed action that the agent can rely on. In states without any external knowledge, the agents evaluate the best action based on internal knowledge accumulated through experiential learning in their Q functions. At any given state, there is no interaction between external and internal knowledge; they are simply separate bases of action and agents do not compare between the prescribed actions and the alternative actions.
However, there are interactions between external and internal knowledge across different states: External knowledge guides agents’ experiential search and influences the accumulation of internal knowledge. In particular, the Q(S, A) value associated with the clued action (V) is used to update and inform any action that leads to the present state. According to the updating Equation (1), updating is based not only on the actual reward R but also on the perceived value of the future position that current action enables, that is, Q(S′, A′). In this new state, denoted as S′, if there is external knowledge that suggests taking action A′, the pair (S′, A′) is deemed valuable and is assigned a value of V. Because external knowledge is valuable, agents perceive that actions that lead to such knowledge are also valuable. They in turn learn to value choices that bring them closer to states with external knowledge. In this way, external knowledge shapes subsequent experiential learning and the accumulation of internal knowledge.
3.6. Flow of the Simulation
In the pseudo code below, we show how the simulation proceeds. Initially, the agents start with (1) a set of priors (i.e., initial Q-values), initialized as zeros for all states, and (2) external knowledge that encompasses a specified number (F) of states. Next, the agent undertakes the task of finding a path toward the goal. Each episode begins with the agent starting from a random state (or vertex) within the hypercube and progresses toward the goal, guided by the evolving Q(S, A) function. Once the goal is found, a new episode starts with the agent commencing from a random state. As agents accumulate experience and update their Q(S, A) function continuously, their search becomes less random over time. As in prior work (Fang and Levinthal 2009), we implement a learning phase for agents to explore, but make them exploit during the final episode where performance is measured. For any agent, their journey consists of a learning phase during the first 99 episodes, when they explore the problem under a high τ (degree of exploration) value. During the 100th episode (E = 100), they switch from exploration to exploitation, using a very small τ value. At the end of the 100th episode, we track their performance in terms of TTS. Key parameters are summarized in Table 2, and the reported results are based on averaging 1,000 independent runs.
Randomly select EK (degree of external knowledge) states and assign a clue for each of EK states. A clue in a particular state provides an accurate action that leads the agent toward the goal state.
Randomly select the initial state S0.
Set initial state S0 as the current state S.
If S contains a clue, select the clue-guided action as a current action A. Otherwise, apply the Softmax algorithm to select the current action A.
Repeat until the agent finds the goal state:
Get the next state S′ based on the current action A and current state S.
If S’ contains a clue, select the next action A′ using the clue. Otherwise, apply the Softmax algorithm to select the next action A′.
If the state-action pair (S, A) is a clue, refrain from updating Q(S, A) and maintain Q(S, A) equal to V. Alternatively, if it is not, employ the following algorithm to capture future implications of action A at state S:
If S′ is the goal state: Q(S, A) ← (1 − α) · Q(S, A) + α · R
If S′ is the clued state: Q(S, A) ← (1 − α) · Q(S, A) + α · γ · V
Otherwise: Q(S, A) ← (1 − α) · Q(S, A) + α · γ · Q(S′, A′) where α and γ are learning and discount rates, respectively.
Set S←S′ and A←A′ and repeat from 5a to 5c if S′ is not the goal state.
Repeat 2 − 5 for (E − 1) times while setting τ = 20.
After (E − 1) times, repeat 2 − 5 once while setting τ = 0.1.
|
Table 2. Key Parameters of the Model
| Parameters | Values | Description | Variations in robustness checks (see Online Appendix) |
|---|---|---|---|
| N | 6 | The size of the problem space: number of binary strings | 4, 8 |
| α | 0.8 | Learning parameter: speed of learning and updating | 0.2, 0.5 |
| γ | 0.9 | Learning parameter: discount factor, that is, the extent to which future consequences are considered | 0.2, 0.5 |
| λ | 1 | Learning parameter: number of preceding state-action pairs to which credit is assigned (Denrell et al. 2004) | 3, 5 |
| τ | 20 or 0.1 | Temperatures, for the first 99 episodes and the last episode. The higher the values of τ, the more explorative the agent is, that is, the more likely that a suboptimal action with low Q(S,A) value is chosen. | For the first 99 episodes: 0.1, 0.5, 1, 5 |
| E | 100 | Number of episodes of problem-solving: A search episode ends once the goal is identified. The agent repeats E rounds of search processes to find the goal. | 25, 1000 |
| R | 1 | Reward value at goal state | None |
| V | 1 | Fixed value assigned to prescribed actions (i.e., clues) | Constant: 0.75, 0.5, 0.25 Proportional: γHD-1, 1-HD/N |
| EK | 0, 1, …, 2N-1 | Degree of external knowledge: The number of states that contain a prescribed action (i.e., clues) | None |
| Prior | Zeros | Initial Q-values assigned to each state-action pair, except those associated with clues | Random number from [0,1) |
3.7. Canonical Example8
To illustrate our model setup, consider a first-time traveler in Paris who has just arrived and plans to visit the Eiffel Tower. Suppose further in their haste, they forget to take a map of Paris but had been advised to take the subway to the stop Bir-Hakeim. Not knowing how far it is or which direction to take, the traveler must decide whether to stay on the train or switch to another line or bus at each station along the journey. Finally they arrive at Bir-Hakeim. The next day the tourist decides to return to the Eiffel Tower. On this second trip, they might take the same route, and once they recognize the station one or several stops away from Bir-Hakeim, they’ll know they are close. After a few more visits, they start forming a mental “map” based on their experiences, recording the subjective value of subway stops along the journey: one might be two stops aways and another six stops away, and so on. Eventually, they learn directions from the hotel to the Eiffel Tower. This intuitive way of building up a mental map is a proxy for the formal solution approach we model here.
One could speed up the search considerably with directions from Google Maps, showing not only where the goal is but also how to get there from wherever they are. Google Maps would have provided complete and accurate external knowledge, reducing the complexity of the problem to a negligible level. However, because of WiFi shortages and language barriers, the Google Maps available to our traveler freezes from time to time and does not offer all-encompassing guidance.9
One might wonder—instead of gradually learning and building up a mental representation of Paris, why cannot the traveler simply hop to the goal after identifying it? Note that even though the tourist knows the exact coordinates and location of the Eiffel Tower, it is often not feasible to “jump to it” unless one hires a helicopter. In our model, agents, like the tourist in this example, can only move locally (i.e., between connected states). There are no long jumps or radical changes. Furthermore, as we mentioned before, one important assumption is that decision makers have limited rationality. In particular, they do not recognize that labels (i.e., zeros and ones) are meaningful coordinates, consistent with prior work in this area (Denrell et al. 2004). Search for the goal state becomes trivial if the agent recognizes their current state and the goal state and flips every zero in the current state.
More generally, our simple set up is a subset of a more general class of multistage, multiarmed bandit problems, which are often used to model how agents learn in the face of delayed performance feedback (Kaelbling et al. 1996, Sutton and Barto 2018). To jump to the identified solution, one would need to reverse engineer the relationship between each action and the corresponding multiarmed bandit game (that follows the action). However, identifying the goal state for the first time does not necessarily reveal how different bandit games are connected. A single trial does not provide enough information to identify the best choices at each step, so repeated exploration is necessary to uncover better strategies. This is even more challenging if the relationships between actions and bandit games are stochastic (Fu and Anderson 2008).
4. Results
4.1. Findings
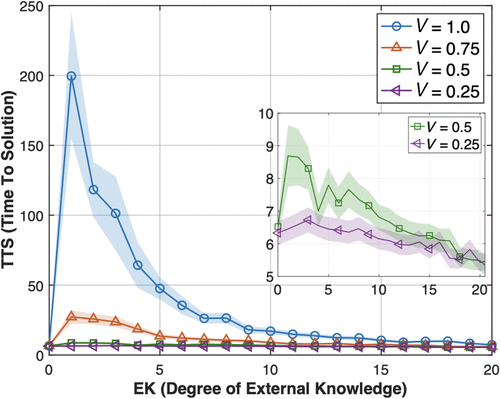
We investigate the impact of varying degrees of external knowledge on performance, measured by TTS.10 Figure 1 displays the relationship between TTS and the degree of external knowledge, represented by EK. EK ranges from 0 (no clues) to 63 (all states excluding the goal). Our main finding shows that external knowledge has a nonmonotonic relationship with performance. Without external knowledge (EK = 0), TTS is 6.56. However, when EK increases from zero to one (i.e., a single clue is available), TTS dramatically rises to 199.543. As external knowledge provides guidance for more states, that is, EK increases, TTS gradually decreases, reaching 3.019 when external knowledge covers all states (EK = 63). In addition, it is surprising that decision makers with limited external knowledge can perform worse than those without any external guidance at all. In the inset panel of the figure, we focus on small EK values ranging from 0 to 25. As seen, when external knowledge provides guidance for a limited number of states (0 < EK ≤ 23), the TTS curve exceeds the dotted line, representing TTS without external knowledge (EK = 0). This suggests that having no external knowledge (EK = 0) is actually more beneficial than possessing limited knowledge (0 < EK ≤ 23), even when external knowledge is accurate.
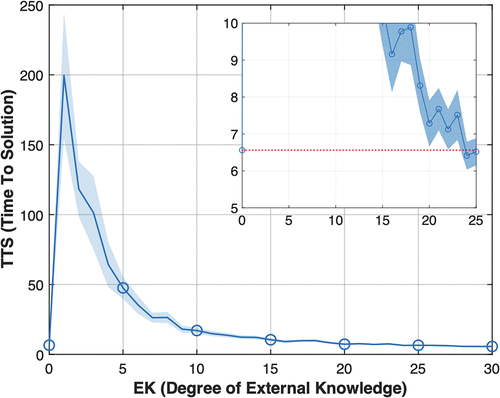
Notes. Performance is measured by TTS, that is, time to solution on the y axis. A lower TTS value corresponds to higher performance. EK (degree of external knowledge) is measured by the number of states with clues, shown on the x axis. EK ranges from 0 to 63 (i.e., 2N − 1, where N = 6). The inset plot highlights TTS for smaller EK values (0 < EK ≤ 25). The shades around each line in this and other figures represent 95% confidence intervals.
In other words, although having a greater level of external knowledge is generally advantageous, this positive association diminishes notably when external knowledge is limited. Why does performance suffer when agents use limited external knowledge? In particular, why does no external knowledge produce better performance than limited external knowledge? The answer is that, although external knowledge provides useful guidance for agents to speed up their search for the goal, agents may learn to overvalue actions that lead to external knowledge rather than those that lead more quickly to the goal. Consequently, they may assign high credit to actions serving as a stepping stone to external knowledge, even when such actions distract them away from the goal. For example, consider an agent that flips the third element in state 100000 and reaches state 101000 where external knowledge is available in the form of a prescribed action with a Q-value of V. The agent recognizes that flipping the third element at state 100000 is valuable because it leads to the desirable future state 101000. Over time, the agent recognizes the value of nearby states that lead to external knowledge. In doing so, the agent may consider some actions that distract the agent away from the goal, such as flipping the last element in state 100001 to be valuable. In essence, clues within external knowledge act as attractors that pull the agent’s search toward states with prescribed actions. As external knowledge attracts agents without serving as their final destination—because agents continue searching and eventually reach their goals—we introduce the term “interim attractor” to describe the attractors formed by these external knowledge.11
In contrast, when EK = 0, there are no competing interim attractors, as the goal state is the only state that provides a reward or reinforcement. Decision makers explore all actions and identify those that lead to the reward. They are not aided by any external knowledge that prescribes a direction, but neither are they distracted or constrained by it.
As an example related to our mechanism, consider BlackBerry Storm, the phone launched by Research in Motion (RIM) to combat Apple’s iPhone (McNish and Silcoff 2015). When the iPhone was first announced in 2007, AT&T (formerly Cingular) was the sole carrier of the product in the United States. Verizon pushed RIM to develop a touchscreen alternative that can outcompete iPhone, guaranteeing an estimated marketing budget of $100 million, as well as thousands of retail stores to promote the phone. Following the carriers’ request, RIM launched BlackBerry Storm, which combines a button and a touchscreen, within 9 months (while it usually took 18 months). However, Storm combined the worst aspects of physical keyboards and touchscreen typing, frustrating users who were accustomed to the reliable tactile feedback of traditional keyboards. This shift also disrupted BlackBerry’s established capabilities, resulting in increased manufacturing costs and defects. In this example, external knowledge contains accurate guidance—touchscreen devices became the standard. Yet RIM made choices that seemingly aligned with such guidance, which conflicted with its existing skills in physical keyboards.
Another good example is how big pharma groups missed the action in the race to develop an effective vaccine for COVID-19, largely because they preferred to prioritize existing methods. For instance, Merck had successfully developed vaccines for Ebola based on its proprietary recombinant vesicular stomatitis virus (rVSV) platform. Riding on the success of its Ebola vaccine, Merck pursued replicating viral vaccines using the same platform designed for Ebola for COVID-19. Former chief executive officer (CEO) Kenneth Frazier said “it helps to start with hardware you know.”12 Similarly, Sanofi and GSK had perfected their own technology already used for flu jab, which involves inactivating an virus so that it is not pathogenic yet still potent enough to induce an immune reaction. Both the rVSV platform (from Merck) and the virus inactivation approaches (from Sanofi and GSK) were learned during earlier vaccine efforts tackling different viruses, thus external to the focal vaccine journey (i.e., COVID-19). Unfortunately, the big pharma companies were led down paths that turned out to be dead ends, and all three subsequently abandoned their vaccine efforts.
4.2. Mechanism
In short, when limited external knowledge is introduced, they create interim attractors, causing agents to pursue actions that may deviate from the goal.13 Agents can get trapped under the influence of such attractors, taking time to overcome the attractors’ pull and identify the goal. To illustrate the underlying mechanism behind the observed negative impact of a low degree of external knowledge (when EK is small), we carry out two additional analyses. First, to visualize agents’ understanding of what actions to take on a hypercube, we reduce the number of vertices from 64 to 8. As depicted in Figure 2(a), each edge represents an action that enables transition between states. The goal state is represented by 111, and the agent is restricted to visiting neighboring states only. External knowledge contains a single clue located at 000. A choice to visit 000 is an unnecessary step to reach the goal from any of its neighboring states. Figure 2(b) presents one possible visualization of the underlying interim attractors, illustrating how clues can pull agents and divert them away from their goal, resulting in a lengthier detour. For any given vertex (i.e., state), we only include an arrow (i.e., action) if it is associated with the highest Q(S, A), which is the action most likely chosen by the agent. As seen in Figure 2(b), for several states, the agent is more likely to move toward state 000 (where external knowledge exists) rather than state 111 (the goal). The absence of immediate feedback makes it challenging for the agent to recognize that moving toward the clue is actually costly to the search process. For instance, agents at state 110 would reach the goal in five steps, likely going through states 010, 000, 001, 011, and finally 111. However, state 110 is only one step away from the goal. Agents could have directly reached the goal in one step, had they not been hampered by the presence of the single clue at 000. In this sense, even if external knowledge consists of accurate clues, it impacts the agents’ experiential learning and may lead to worse performance outcomes compared with scenarios where no external knowledge is present.
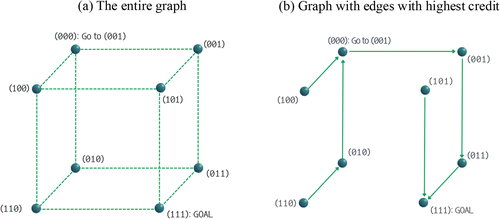
Notes. (a) The entire graph. (b) Graph with edges with highest credit.
Second, to understand why performance can deteriorate with the introduction of a single clue (EK = 1), we report in Figure 3 the frequency of the agent’s visits to states at specific Hamming distance14 (HD) away from the goal. The more visits a state attracts, the stronger its influence as an attractor. When EK = 0, the only state that can pull agents’ search is the goal state. Therefore, as agents repeatedly solve the problem, they learn to gradually recognize the value of states that are closer to the goal. Hence, they increasingly visit states closer to the goal more than those that are further away. In contrast, when EK = 1, one clue is introduced, there are now two states (one has external knowledge and the other being the goal) that attract agents’ search toward their directions. Even if this external knowledge is accurate (in that it points the agents in the right direction that reduces the HD between the current state and the goal), it may create a competing interim attractor. To demonstrate this, we fix EK at one but vary the location of this clue at varying HDs away from the goal.
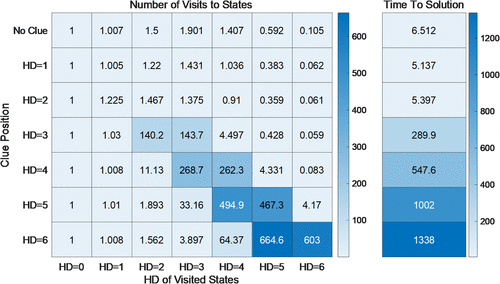
As seen in Figure 3, even with just one clue (i.e., EK = 1), agents dramatically increase the number of times they visit states around the clued state, resulting in a much longer TTS. In particular, relying on a single clue becomes more problematic as the HD between the clue and the goal state increases. When the clue is located in a state that is one or two HDs away from the goal, visiting the clued state puts one in close range of the goal. As such, the overall pattern of visits does not deviate much from the baseline case of EK = 0. In contrast, when the clue is located further away from the goal, it creates a separate and competing basin of attraction (vis-a-vis the goal).
In other words, visiting the clued state becomes a distraction, taking the agents away from their goal. For instance, when the clue is located at HDs of three away from the goal, the agents visit states that are close to the goal (HD = 1) on average 1.03 times, but the number of visits to states neighboring to the clued state (HD = 2 or 3) increases significantly, resulting in much higher TTS at 289 steps. In the extreme case when the clue is located at HD = 6, maximum distance away from the state, agents visit the states around the clue more than 600 times, even if these states are in reality far away from the goal. Instead of taking a direct path to the goal, they end up wandering around the single clue state with external knowledge. In short, even with one clue (EK = 1; low degree of external knowledge), it can disrupt the search and learning process, creating an interim attractor that pulls the agent’s away from the goal and worsening performance. This is analogous to introducing local peaks in an otherwise single-peaked performance landscape, therefore making the (perceived) landscape more rugged for the agents. Thus, limited external knowledge increases the likelihood of getting trapped in local optima compared with the case where external knowledge is absent.
To summarize, the core mechanism underlying our findings is related to the unique challenge in a temporally complex problem. When feedback is temporally distant from organizational actions, the decision maker’s task is like navigating a labyrinth (Denrell et al. 2004). Decision makers need to learn a means-end chain, linking preceding actions or “stepping stones,” with the goal. Knowing what to do at any given point is not sufficient as they still need to undertake a long sequence of actions before reaching the goal. Although external knowledge prescribes the direction the agent should move, they do not guarantee that an optimal action will be chosen in subsequent decision-making situations (Denrell et al. 2004). Thus, external knowledge, even if accurate, may not be useful in a problem characterized by temporal complexity. Unless external knowledge is extensive and specifies a complete sequence toward the goal, subsequent choices can deviate from the goal. In addition, this dynamic may lead the decision makers to overvalue actions that serve as stepping stones to the available external knowledge and undervalue alternative actions that may constitute more desirable paths toward the goal. As a result, relying on a low degree of external knowledge may hurt performance.
4.3. Implications
This mechanism suggests two important implications. First, the position of the clue within the problem structure matters: When external knowledge is provided in states closer to the goal, its potentially negative impact is reduced compared with when it is further away. Following “downstream” clues (i.e., closer to the goal) speeds up the search process because the agents’ gravitation toward external knowledge brings the agent closer to the goal. In contrast, following “upstream” clues (i.e., further away from the goal) can result in longer detours for the agent, because the resulting interim attractor sets up competing targets, diverting agents from the goal. Second, the valence of external knowledge also matters. The stronger the valence, the stronger the attraction toward these clues, and consequently, the bigger the potential penalty associated with limited external knowledge. To further explore these implications, below we report two additional analyses.
First, to explore the impact of the position of external knowledge, we compare two scenarios: one where external knowledge is concentrated in states that are at least four steps away from the goal (referred to as “far”), and another where clues are concentrated in states that are at most three steps away from the goal (referred to as “close”).15 Figure 4 shows two notable effects of the proximity of external knowledge on performance (i.e., TTS). First, consistent with our baseline results, limited external knowledge and few clues continue to be associated with a performance penalty. Second, the more upstream the clues, the lower the performance in general and the higher the penalty associated with limited external knowledge, across all levels of F. Consistent with our mechanism, when the limited external knowledge is far from the goal, it leads to a more circuitous search by diverting agents from the eventual goal. Conversely, when the limited external knowledge is located close to the goal, a low degree of external knowledge substantially decreases TTS. The negative effect of limited external knowledge is mitigated because the clues are already in proximity to the goal. By serving as a guidepost that reduces uncertainty and randomness in the search process, external knowledge speeds up the agents’ search for the goal. In this scenario, agents have a higher chance of stumbling upon the goal state just a few steps away.16 The penalty of limited external knowledge is stronger for upstream, rather than downstream, knowledge.
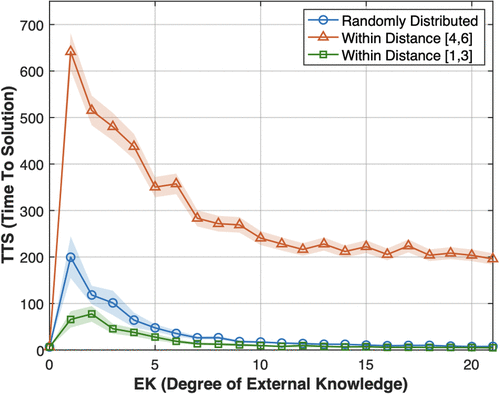
This finding has interesting implications on how to manage the limited external knowledge in temporally complex problems. Upstream guidance may lead to a decline in performance as it depends on a long sequence of downstream decisions to be useful. In temporally complex problems, the value of a correct action is not realized when followed by subsequent decisions that deviate from the goal. As a result, relying on upstream knowledge is likely to result in inferior outcomes than depending on downstream knowledge. For instance, in the drug development context, basic research around drug discovery may point to many possible downstream paths, yet considerable uncertainties about subsequent decision making persist. In contrast, downstream knowledge (such as about marketing) is much less problematic; because of its proximity to the goal, identifying the correct subsequent choices is less challenging. This is perhaps one of the many reasons why the pharmaceutical industry has been investing much more heavily on advertising recently (Drenik 2023).
Second, we investigate the impact of the clue’s valence, that is, the perceived value of the clue. In our baseline analysis, this parameter, denoted as V, is set to be one, which is equivalent to the value of the immediate reward R associated with reaching the goal. We now vary V from zero to one in increments of 0.2 while keeping the value of R fixed. If clues shape actions by creating competing basins of attraction, we would expect the negative effect of clues to be less pronounced when these clues carry less valence (i.e., smaller V). Figure 5 illustrates the performance implications of varying V. As shown in the figure, as V decreases from one to zero, the negative impact of having a small degree of external knowledge becomes less noticeable. The spike remains for much lower V values (e.g., V = 0.5). In other words, when we make the agents perceive external knowledge to be only half “valuable” than the rewards, the inverted U pattern remains. Only when the V is much less subjectively valuable than R (e.g., V = 0.25 or 0) does the spike disappear entirely. Again, this finding aligns with our proposed mechanism. When the value assigned to clues is reduced, the potential of these clues to divert agents from the goal is mitigated. In addition, the higher the valence V, the lower the overall performance across all values of F. This is because having a positive valence makes the states with external knowledge valuable: Actions that lead to clued states will be reinforced, whereas actions that do not lead to the clued states are not. In this way, external knowledge becomes potentially competing subgoals and causes detours and diversions.17
More generally, this finding raises interesting questions on how to best leverage external knowledge. In our model, external knowledge provides clues but such clues are just intermediate subgoals and not valuable end goals in and of themselves. Thus, assigning the credit to external knowledge (by having a large positive V) is performance decreasing. In particular, it is the relative magnitude of V in relation to R that matters. Recall that V represents the reinforcement assigned to external knowledge as intermediate steps to the goal. Hence, its value should be small compared with the actual reward R. If not, agents learn to excessively value actions leading to external knowledge, even when such actions distract them away from the goal. In other words, although organizations should leverage external knowledge, they should ensure that the prescribed actions are not overemphasized in comparison with the goal.
A practical strategy may be to postpone the use of external knowledge until decision makers have acquired sufficient internal knowledge through trial-and-error learning on their own. During an initial learning phase, agents should freely explore the problem space without any external guidance. Recall that in our model, actions and feedback are separated across time. Decision makers need to learn a means-end chain, linking preceding actions or “stepping stones,” with the goal. They acquire internal knowledge via experiential learning, which tells them what to do at different state action pairs. In contrast, external knowledge only prescribes what to do in any single and standalone state. As such, knowing what to do at any given point does not guarantee that actions taken afterward will be optimal. This is much less of an issue when external knowledge is extensive and covers many state-action pairs, providing accurate guidance over a connected sequence of actions. In the absence of well-formed chains of actions, decision makers who rely on limited external knowledge may end up taking a circuitous path, resulting in poor overall performance.
4.4. Extensions
Next, we extend the model to incorporate alternative assumptions around the nature of external knowledge.18 First, in our baseline, external knowledge always provides accurate guidance toward the goal state. However, external knowledge can sometimes be inaccurate. For instance, templates or practices adopted from a different franchisee might contain inaccurate elements, and errors can also occur during the transfer process. To incorporate the possibility that external knowledge can sometimes lead the agent away from the goal, we introduce a parameter A that captures the degree of accuracy (A ∈ [0,1]). With a probability of A, the clue provides an accurate action for the current state that reduces the distance from the goal state. But with a probability of (1−A), the clue leads the agent away from the goal state.
Figure 6(a) presents our findings. First, even at low levels of accuracy (A = 0.4), the penalty of having a limited degree of external knowledge persists. Second, the more inaccurate the external knowledge, the longer it takes to find the goal, and the worse is the organizational performance, across all levels of F. Third, with low accuracy, having many clues is no longer always helpful. For instance, at A = 0.6, having no clues consistently outperforms having 63 clues, with TTS values of 6.469 and 12.348, respectively. This suggests that inaccurate clues, when abundantly available (with high EK values), are constantly diverting the agents away from the goal. Thus, as EK increases, agents’ performance decreases, reflecting the excessive amount of noise in the clues.
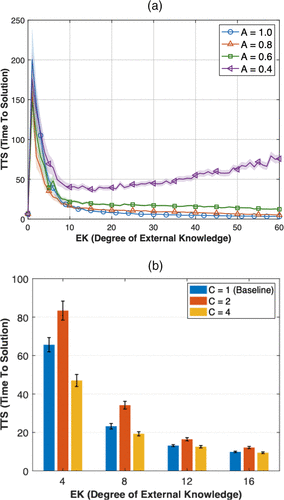
Notes. (a) Varying degrees of accuracy of external knowledge (A). (b) Varying degrees of clustering of external knowledge (C).
This raises interesting questions beyond the scope of our current work. For instance, how to manage the tradeoff between accuracy and completeness in external knowledge? When the underlying external knowledge varies along these two dimensions, what differential implications it may have on performance outcomes? Is it better to invest in complete versus accurate external knowledge? Although our paper cannot do justice to these intriguing questions, our analysis shows that organizations should distrust much of the limited external knowledge and at the very least apply it judiciously.
Next, our baseline model also assumes that external knowledge is randomly distributed in the problem space. Recall that external knowledge is generated by randomly selecting EK states from 2N − 1 possibilities (excluding the goal state) and pairing each with an accurate action. In reality, clues may not exist in isolation and instead cluster together: A clue in a particular state leads to the next state, for which a clue also exists. For instance, organizational templates usually consist of a sequence of steps to follow (Oldroyd et al. 2019). This connected cluster ensures that finding a clue in one state provides a series of guidance toward the goal. Consequently, clustered clues can be more effective, compared with unclustered clues, in solving credit assignment problems.
We analyze how performance varies with cluster size, by introducing a new parameter C to indicate the number of clues that are connected. We compare three scenarios: one with unconnected and randomly scattered clues (our baseline) and two others with two (C = 2) or four (C = 4) connected clues. For instance, when EK = 8, there can be four clusters of size two or two clusters of size four. Based on 10,000 independent simulation runs, Figure 6(b) indicates that moderately sized clusters can result in the worst TTS. Unless there are enough clues, clusters of size two lead to a longer time to reach a solution compared with alternative scenarios. The reason is that performance depends on two opposing effects: On the one hand, a large cluster enables the agents to get multiple steps closer to the goal. On the other hand, a large cluster also attracts agents from distant states, potentially distracting the agents from their pursuit of the goal. In contrast, when cluster size is small, there is limited guidance as neighboring states are not necessarily connected but the pull of any potentially competing interim attractors are also less far reaching. Therefore, agents are less likely to be distracted when clusters are smaller. A moderate cluster size therefore leads to the worst performance.
This raises several questions on how to acquire and rely on external knowledge of varying degrees of connectedness. For instance, is it worthwhile for organizations to invest in external knowledge that is more and more linked to each other? Under what conditions, are clusters of external knowledge better than randomly dispersed ones? Are moderately sized clusters always the worst? Although our results reported above may suggest some caution and preliminary answers, much more needs to be done in future work to adequately address these questions.
4.5. Robustness Checks
To explore the generalizability and boundary conditions of our key findings across different parameters and specifications, we summarize in Figure 7 the robustness checks. Results are either qualitatively the same or vary predictably with these changes. Generally, the performance in our task depends on (1) how challenging the task environment is and (2) how efficiently agents can learn from their experience. The task environment is characterized by several parameters: (1) the number of decision variables N; (2) the starting points of each problem solving episode, random or fixed at a certain distance away from the solution; and (3) the length of learning phase E. External knowledge can be more or less complete (varying EK) and may also vary in their valence V in relation to the final reward R. Internal knowledge on the other hand, is acquired via decision makers’ own experiential learning, tuned by a host of parameters following prior work in the reinforcement learning tradition: The agents may update existing internal knowledge more slowly (lower α), assign more weight to future positions (higher γ), recognize preceding positions more extensively (higher λ), and explore more (higher τ). The default values of these learning parameters are chosen in accordance with prior work utilizing the same learning algorithm (Denrell et al. 2004, Fang and Levinthal 2009).
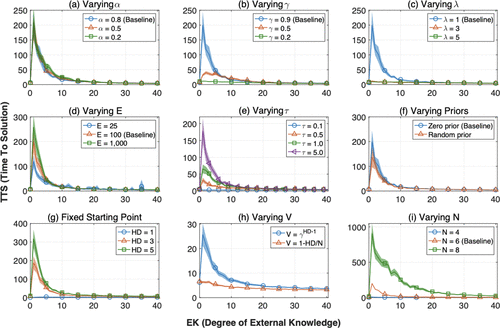
Intuitively, a low degree of external knowledge is more problematic whenever it becomes a stronger interim attractor. This is likely to result from (1) more efficacious experiential learning (γ, λ); (2) higher valence assigned to external knowledge (i.e., V) compared with the goal (i.e., R); and (3) more exploration and learning (higher τ, higher E). The spike is also likely to be more pronounced when the problem is more complex (e.g., high N, starting points distant from the goal).19
More importantly, these robustness checks reveal several organizational interventions that can be used to mitigate the negative penalty associated with limited external knowledge. First, all else equal, our results indicate the negative penalty decreases as (1) the parameter γ is reduced or (2) the parameter λ increases. Although experiential learning is integral to the successful navigation in a temporally complex problem, decision makers may need to tune the credit assignment process carefully. By reducing the weights assigned to future position values (γ), the agent prevents the establishment of a strong interim attractor surrounding external knowledge. Additionally, when decision makers assign credit to more preceding actions based on feedback (increasing λ), the basins of attractions from the goal state and other external knowledge overlap more with each other. Even the actions distant from the goal are assigned high credits, guiding the agents toward the goal. This overlap attenuates the agents’ gravitation toward external knowledge. Hence, more extensive backward propagation of credits to past actions can prove beneficial in problem solving based on external knowledge.
As we point out earlier, recognizing the value of intermediate actions, which serve as a stepping stone to the goal, is key to intelligent action in a temporally complex problem where feedback and action are separated. Yet the same credit assignment process that recognizes the value of intermediary steps to the goal also recognizes the value of steps to external knowledge, leading to possible performance penalty. Here lies an interesting dilemma facing the decision makers: A strong credit assignment that makes tackling temporal complexity possible may also lead to the misguided recognition of subgoals that are in fact detours. How to manage this tradeoff varies depending on the empirical contexts; nonetheless, the same principle holds: Decision makers need to carefully structure external knowledge in such a way that provides guidance without producing a broad competing basin of attraction.
Second, our results indicate that limiting explorative search helps attenuate the performance penalty resulting from the limited external knowledge. Organizations can reduce exploration by reducing either the learning phase (E) and/or the exploration parameter (τ). This is good news, because in real life settings, there are often constraints on problem solving time, for instance, in hyper-turbulent high-velocity markets (Bourgeois and Eisenhardt 1988). Our results show that organizations with limited opportunity to learn can nonetheless leverage external knowledge to supplement their lack of direct experience. Within the setup of our model, more experience and exploration in fact can aggravate the potential penalty associated with a limited degree of external knowledge.
5. Discussion, Limitations, and Conclusion
We set out to explore how decision makers may utilize external and internal knowledge in problems characterized by temporal complexity (Levinthal and March 1993, Levinthal 2021). Many organizational decisions have long-term consequences, yet behavioral models of learning have underexplored this class of problems. We build a computational model of learning based on two sources of knowledge: internal knowledge from decision makers’ own experiential learning process and external knowledge that they can access before engaging in trial-and-error learning. We show that the interaction between them can lead to counterintuitive complications in organizational search and performance. Our analyses reveal that although a higher level of external knowledge is typically beneficial, its positive effects notably decline or can even turn negative when external knowledge is limited. Surprisingly, decision makers with limited external knowledge may perform worse than those with no external guidance at all. This pattern of results is robust to a variety of changes in parameters and specifications.
Our findings have several interesting implications. For instance, organizations need to be more judicious in their leveraging of external knowledge. An upstream knowledge in particular is potentially problematic as it depends on a long sequence of downstream decisions to be useful. In addition, to mitigate the negative penalty, organizations may postpone the use of external knowledge until decision makers have acquired sufficient internal knowledge through trial-and-error learning on their own. More generally, our work provides systematic ways to tackle temporal complexity even when external knowledge is limited and raises interesting questions beyond the scope of our current work.
Our mechanism is different from several well-known ones documented in earlier work. First, concepts like “Einstellung effect” and “functional fixedness” describe the negative impact of partial knowledge when transferred to a new situation, where this knowledge does not provide accurate guidance (Bilalić et al. 2008, p. 652). In our setting, external knowledge is accurate, although it may not be exhaustive or complete. The environment is also stable, and the decision maker solves the same problem repeatedly. We show that the negative impacts of partial knowledge can still occur even when such knowledge provides accurate guidance and the environment is stable. In addition, we provide a process model outlining how external knowledge may interact with the experiential learning process. Our analysis reveals that this external knowledge creates an interim attractor, causing agents to favor actions that lead to such knowledge, rather than those leading to the goal. Second, our model shares surface level similarities with the phenomenon of overfitting, which arises from training with samples that are either too small or too noisy. There is no sampling in our model. We show that even accurate external knowledge can pose a danger. In addition, in overfitting, there is a moderate level of fitting that will provide adequate explanation of the overall data set. Our finding is almost the exact reverse: External knowledge at either high or zero level is fine but very unreliable at small levels.
There are several important limitations of our work. First, our setting is that decision makers solve a temporally complex task repeatedly, where each problem-solving episode is the same as before (except varying starting points). This implies that the task environment remains relatively fixed. States and actions are also assumed to be well defined. Although these features, repeated journeys, stable environments, and well-defined states and milestones, are likely to be canonical of many strategic and organizational contexts, they may be less representative of other problems such as infrequent disruptions. Second, with our existing model and analysis, our claims are along the lines of an existence statement: That in the presence of temporal complexity, there exists a possibility that some external knowledge actually hurts performance. Our point is not that temporal complexity is a sufficient condition for such a finding. Rather, complexity in general widens the gaps between reality and the decision makers’ body of knowledge (whether internal or external) and renders their actions less efficacious.
In future work, it will be interesting to explore several related issues. First, how do humans rely on both sources of knowledge to solve the credit assignment challenge in a temporally complex task? For instance, we assumed that agents in our world do what they are told and follow the external knowledge given to them. This assumption may not hold in the real world, which may have important implications on the generality of our findings. A first step may be to examine this in controlled laboratory settings, where deviations from prescribed clues can be tracked and analyzed. Second, it may be interesting to derive analytical solutions in a simplified setup. For instance, with four states each with two actions (i.e., a rectangle), we can show that TTS with EK = 1 is higher than EK = 0, depending on learning parameters such as γ and α. It may be possible to compute expected performance for higher-dimensional hypercubes. In addition, it will be interesting to examine questions related to various levers to tackle or mitigate the performance penalty we document here. Issues surrounding accuracy, clustering and connectedness of external knowledge are particularly intriguing.
To conclude, a key aspect of what makes a decision strategic is intertemporal interdependence (Leiblein et al. 2018). Our behavioral model and analyses offer a preliminary exploration of the role of external knowledge in temporally complex problems. Our findings demonstrate a novel tradeoff: When external knowledge is limited, it can narrow the scope and direction of the acquisition of internal knowledge through experiential learning. Future research can benefit from integrating different methodologies to further clarify how decision makers utilize these two sources of knowledge when tackling temporally complex problems. We hope our evidence on the interplay between external and internal knowledge marks a valuable initial step in this direction.
The authors thank Felipe Csaszar and three anonymous reviewers for constructive critiques and thoughtful comments and Jen Brown, Jaeho Choi, Matt Higgins, Bo Kyung Kim, Houk Lee, Mooweon Rhee, Bill Schulze, Todd Zenger, and the seminar participants at the Academy of Management (2018), Wisconsin Organizational Modeling Meeting (2018), Theoretical Organizational Models (2021), the University of California Irvine, the University of Texas at Austin, and Yonsei University for comments that improved the paper. Authorship is alphabetical, and all authors contributed equally to the entirety of the manuscript. All errors remain our own.
1 We use the term “temporal complexity” differently from computer science literature, where temporal complexity (also known as time complexity) refers to the amount of computer time to run an algorithm.
2 Because feedback is delayed temporally, conventional models of learning that have been built under the assumption of immediate availability of feedback would not work. Consider a typical NK problem where an agent takes actions based on immediate feedback observed. If the immediate feedback improves current performance, the agent adopts it and moves to a different strategic position. If not, the agent stays in the current position. Therefore, conventional models (Levinthal 1997, Gavetti and Levinthal 2000) are not able to model adaptation without immediate feedback (Denrell et al. 2004).
3 Quadrant III represents our baseline expectations (without jointly examining temporal complexity and external knowledge). Decision makers have to solve the temporally challenging problem without any external knowledge. Thus, they can only rely on their own internal knowledge derived from experiential learning.
4 Because locations in this hypercube do not have any inherent meaning, the choice of a particular goal state does not impact the generality of our results.
5 Only a single action is allowed in any given period. Consider an agent who is currently in the state 00 where N is 2. Then, the agent can move to either 01 or 10 by a single action but not to 11. In other words, agents move locally. There is no long jump or radical change in our setup.
6 Temporal differencing (TD) algorithms have been widely used to address the credit assignment problem (Niv 2009, Sutton and Barto 2018, Amo et al. 2022) in practical applications such as playing a game of backgammon or dispatching a group of elevators (Tesauro 1994, Crites and Barto 1998). Neuroscientists have also demonstrated the utility of TD algorithms in modeling biological systems. For instance, dopamine signals the error between expected and actual outcomes (Starkweather and Uchida 2021, Amo et al. 2022), essentially the degree of surprise caused by unexpected rewards—and interacts with cortical and basal ganglia circuits to reinforce favorable decisions (Niv 2009, Walsh and Anderson 2014, Amo et al. 2022). Moreover, temporal differencing has also allowed machine learning agents to surpass human workers in performance (Tesauro 1994, Barto 2019).
7 Note that accurate external knowledge here does not describe the optimal sequence among all possible paths in the hypercube.
8 We thank the editor for suggesting this intuitive example to facilitate a better understanding of our model.
9 Google Map, although realistic in the example, may not be always available in real-life problems that are multidimensional and complex. Consider the drug discovery process whose goal is to identify a best-selling drug for a particular condition. Even though the goal is clear, the directions on how to get there represent the “holy grail” of pharma and biotech companies.
10 The organization’s task is to identify a path from its starting position in the landscape to the solution state. Organizations with more accurate understanding can find the solution faster, in a smaller number of steps, whereas those with less accurate understanding take longer. TTS can also be alternatively conceived as a proxy for search cost. Each action implicitly incurs a cost, and the agent’s goal is to obtain the reward with the minimum cost, thus minimum TTS. We assume that the cost of implementing an action is identical for all actions.
11 Kauffman (1993) refers to the set of locations in the landscape for which local search results in a common local optimum as the “basin of attraction” (Levinthal 1997). Our interim attractors create essentially temporary basins of attractions, which is temporary because agents eventually leave such basins of attractions to reach the goal.
12 See https://www.ft.com/content/657b123a-78ba-4fba-b18e-23c07e313331.
13 These interim attractors can be thought of as “artificial” local peaks, in an otherwise smooth, one-peaked objective landscape. Just like local peaks that can trap decision makers, these interim attractors may cause agents to deviate from the ultimate goal.
14 Hamming distance is a metric to compare the distance between two binary strings. It is the number of different bit positions across two strings. For instance, the Hamming distance between states 1111 and 0011 is two, as the first two bits are different.
15 Clues are also randomly chosen after the proximity criterion is satisfied.
16 There are many more actions that take the agents one step closer to the goal, for nodes further away. In this sense, it is inherently easier to select a correct action from states that are further away: The number of possible paths towards the goal is exponentially more than that for states closer. Note, however, that in any given state S, we choose only one of the possible actions from S randomly.
17 An alternative way to change the valence of V is to allow V to be updated according to our updating Equation (1). In our baseline model, V is constant. Updating V implies that the value of a clue gets discounted, because the updated value of a clue will reflect the perceived value of a subsequent state-action pair Q(S′, A′), which is usually smaller than V. This has the same effect of setting V to a small value (compared with R). In additional analysis not reported here, the negative penalty associated with limited external knowledge also becomes much less pronounced. We thank an anonymous reviewer for suggesting this analysis.
18 We thank three anonymous reviewers and our editor for suggesting these extensions.
19 For a detailed discussion of these results, please refer to the Online Appendix.
References
- (1971) Essence of Decision (Little, Brown and Company, Boston).Google Scholar
- (2022) A gradual temporal shift of dopamine responses mirrors the progression of temporal difference error in machine learning. Nature Neurosci. 25(8):1082–1092.Crossref, Google Scholar
- (1999) Organizational Learning: Creating, Retaining and Transferring Knowledge (Norwell, Kluwer, MA).Google Scholar
- (2019) Reinforcement learning: Connections, surprises, and challenges. AI Magazine 40(1):3–15.Crossref, Google Scholar
- (1957) Dynamic Programming (Princeton University Press, Princeton, NJ).Google Scholar
- (2008) Why good thoughts block better ones: The mechanism of the pernicious Einstellung (set) effect. Cognition 108(3):652–661.Crossref, Google Scholar
- (1988) Strategic decision processes in high velocity environments: Four cases in the microcomputer industry. Management Sci. 34(7):816–835.Link, Google Scholar
- (1980) In one word: Not from experience. Acta Psych. 45(1–3):223–241.Crossref, Google Scholar
- (1992) Dynamic decision making: Human control of complex systems. Acta Psych. (Amsterdam) 81(3):211–241.Crossref, Google Scholar
- (1994) Organizational routines are stored as procedural memory: Evidence from a laboratory study. Organ. Sci. 5(4):554–568.Link, Google Scholar
- (1998) Elevator group control using multiple reinforcement learning agents. Machine Learn. 33:235–262.Crossref, Google Scholar
- (2018) What makes a decision strategic? Strategic representations. Strategy Sci. 3(4):606–619.Link, Google Scholar
- (2016) Mental representation and the discovery of new strategies. Strategic Management J. 37:2031–2049.Crossref, Google Scholar
- (2020) A contingency theory of representational complexity in organizations. Organ. Sci. 31(5):1198–1219.Link, Google Scholar
- (2010) How much to copy? Determinants of effective imitation breadth. Organ. Sci. 21(3):661–676.Link, Google Scholar
- (2024) External representations in strategic decision‐making: Understanding strategy’s reliance on visuals. Strategic Management J. 45(11):2191–2226.Crossref, Google Scholar
- (1963) A Behavioral Theory of the Firm (Prentice-Hall, Englewood Cliffs, NJ).Google Scholar
- (2001) Adaptation as information restriction: The hot stove effect. Organ. Sci. 12(5):523–538.Link, Google Scholar
- (2004) From T-mazes to labyrinths: Learning from model-based feedback. Management Sci. 50(10):1366–1378.Link, Google Scholar
- (1995) Effects of feedback complexity on dynamic decision making. Organ. Behav. Human Decision Processes 62(2):198–215.Crossref, Google Scholar
- (2023) How real-world data is shaping the future of pharmaceutical marketing. Forbes (November 14), https://www.forbes.com/sites/garydrenik/2023/11/14/how-real-world-data-is-shaping-the-future-of-pharmaceutical-marketing/.Google Scholar
- (2016) Abductive reasoning: How innovators navigate in the labyrinth of complex product innovation. Organ. Stud. 37(2):131–159.Crossref, Google Scholar
- (2012) Organizational learning as credit assignment: A model and two experiments. Organ. Sci. 23(6):1717–1732.Link, Google Scholar
- (2009) Near-term liability of exploitation: Exploration and exploitation in multistage problems. Organ. Sci. 20(3):538–551.Link, Google Scholar
- (2008) Solving the credit assignment problem: Explicit and implicit learning of action sequences with probabilistic outcomes. Psych. Res. 72(3):321–330.Crossref, Google Scholar
- (2011) Mental models, decision rules, and performance heterogeneity. Strategic Management J. 32(6):569–594.Crossref, Google Scholar
- (2005) Cognition and hierarchy: Rethinking the microfoundations of capabilities’ development. Organ. Sci. 16(6):599–617.Link, Google Scholar
- (2000) Looking forward and looking backward: Cognitive and experiential search. Admin. Sci. Quart. 45(1):113–137.Crossref, Google Scholar
- (1990) Habitual routines in task-performing groups. Organ. Behav. Human Decision Processes 47(1):65–97.Crossref, Google Scholar
- (1991) Commitment (Simon and Schuster, New York).Google Scholar
- (2004) Learning to make decisions in dynamic environments: Effects of time constraints and cognitive abilities. Human Factors 46(3):449–460.Crossref, Google Scholar
- (2005) Decision support for real-time, dynamic decision-making tasks. Organ. Behav. Human Decision Processes 96(2):142–154.Crossref, Google Scholar
- (2017) Dynamic decision making: Learning processes and new research directions. Human Factors 59(5):713–721.Crossref, Google Scholar
- (1985) Learning from experience in organizations. Amer. Econom. Rev. 75(2):298–302.Google Scholar
- (1996) Reinforcement learning: A survey. J. Artificial Intelligence Res. 4:237–285.Crossref, Google Scholar
- (1982) Investigating the not invented here (NIH) syndrome: A look at the performance, tenure, and communication patterns of 50 R&D Project Groups. R&D Management 12(1):7–20.Crossref, Google Scholar
- (1993) The Origins of Order: Self-Organization and Selection in Evolution (Oxford University Press, Oxford, UK).Crossref, Google Scholar
- (2001) Capabilities as real options. Organ. Sci. 12(6):744–758.Link, Google Scholar
- (1992) An organizational learning model of convergence and reorientation. Organ. Sci. 3(1):47–71.Link, Google Scholar
- (1975) An Introduction to Models in the Social Sciences (Harper & Row, New York).Google Scholar
- (2018) What makes a decision strategic? Strategy Sci. 3(4):558–573.Link, Google Scholar
- (1997) Adaptation on rugged landscapes. Management Sci. 43(7):934–950.Link, Google Scholar
- (2021) Evolutionary Processes and Organizational Adaptation: A Mendelian Perspective on Strategic Management (Oxford University Press, Oxford, UK).Crossref, Google Scholar
- (1981) A model of adaptive organizational learning. J. Econom. Behav. Organ. 2(4):307–333.Crossref, Google Scholar
- (1993) The myopia of learning. Strategic Management J. 14:95–112.Crossref, Google Scholar
- (2015) Three facets of organizational adaptation: Selection, variety, and plasticity. Organ. Sci. 26(3):743–755.Link, Google Scholar
- (1988) Organizational learning. Annu. Rev. Sociol. 14(1):319–338.Crossref, Google Scholar
- (1959) Individual Choice Behavior (John Wiley and Sons, New York).Google Scholar
- (2017) Time delays, competitive interdependence, and firm performance. Strategic Management J. 38(3):506–525.Crossref, Google Scholar
- (1958) Organizations (John Wiley and Sons, New York).Google Scholar
- (2016) Consequences of misspecified mental models: Contrasting effects and the role of cognitive fit. Strategic Management J. 37:2545–2568.Crossref, Google Scholar
- (1999) Avoiding Complexity catastrophe in coevolutionary pockets: Strategies for rugged landscapes. Organ. Sci. 10(3):294–321.Link, Google Scholar
- (2015) Losing the Signal: The Untold Story behind the Extraordinary Rise and Spectacular Fall of BlackBerry (Macmillan).Google Scholar
- (1961) Steps toward artificial intelligence. Proc. IRE 49(1):8–30.Crossref, Google Scholar
- (1982) An Evolutionary Theory of Economic Change (Harvard University Press, Cambridge, MA).Google Scholar
- (1972) Human Problem Solving (Prentice Hall, Upper Saddle River, NJ).Google Scholar
- (2009) Reinforcement learning in the brain. J. Math. Psych. 53(3):139–154.Crossref, Google Scholar
- (2019) Principles or templates? The antecedents and performance effects of cross-border knowledge transfer. Strategic Management J. 40(13):2191–2213.Crossref, Google Scholar
- (1996) Talking About Machines: An Ethnography of a Modern Job (Cornell University Press, Ithaca, NY).Google Scholar
- (2002) Activity in human ventral striatum locked to errors of reward prediction. Nature Neurosci. 5(2):97–98.Crossref, Google Scholar
- (2006) Can science be a business. Harvard Bus. Rev. 10:1–12.Google Scholar
- (2012) Chasing a moving target: Exploitation and exploration in dynamic environments. Management Sci. 58(3):587–601.Link, Google Scholar
- (2015) Modelling bounded rationality in organizations: Progress and prospects. Acad. Management Ann. 9(1):337–392.Crossref, Google Scholar
- (2008) Effect of delays on complexity of organizational learning. Management Sci. 54(7):1297–1312.Link, Google Scholar
- (2023) Delays impair learning and can drive convergence to inefficient strategies. Organ. Sci. 34(6):2392–2414.Link, Google Scholar
- (2021) What makes dynamic strategic problems difficult? Evidence from an experimental study. Strategic Management J. 42(5):865–897.Crossref, Google Scholar
- (2009) Effects of feedback delay on learning. System Dynamics Rev. 25(4):309–338.Crossref, Google Scholar
- (2000) Imitation of complex strategies. Management Sci. 46(6):824–844.Link, Google Scholar
- (2002) Organizational sticking points on NK landscapes. Complexity 7(5):31–43.Crossref, Google Scholar
- (1995) Learning in extensive-form games: Experimental data and simple dynamic models in the intermediate term. Games Econom. Behav. 8(1):164–212.Crossref, Google Scholar
- (2009) Capabilities unveiled: The role of ordinary activities in the evolution of product development processes. Organ. Sci. 20(2):384–409.Link, Google Scholar
- (1997) A neural substrate of prediction and reward. Science 275(5306):1593–1599.Crossref, Google Scholar
- (2002) Misperceiving interactions among complements and substitutes: Organizational consequences. Management Sci. 48(7):900–916.Link, Google Scholar
- (2003) Temporarily divide to conquer: Centralized, decentralized, and reintegrated organizational approaches to exploration and adaptation. Organ. Sci. 14(6):650–669.Link, Google Scholar
- (1962) The architecture of complexity. Proc. Amer. Philosophical Soc. 106(6):467–482.Google Scholar
- (2021) Dopamine signals as temporal difference errors: Recent advances. Current Opinion Neurobiology 67:95–105.Crossref, Google Scholar
- (1994) Learning in and about complex systems. System Dynamics Rev. 10(2–3):291–330.Crossref, Google Scholar
- (2006)
Operational and behavioral causes of supply chain instability . The Bullwhip Effect in Supply Chains: A Review of Methods, Components and Cases, 17–56.Google Scholar - (1988) Learning to predict by the methods of temporal differences. Machine Learn. 3(1):9–44.Crossref, Google Scholar
- (2018) Reinforcement Learning: An Introduction, 2nd ed. (MIT Press, Cambridge, MA).Google Scholar
- (1994) TD-Gammon, a self-teaching backgammon program, achieves master-level play. Neural Comput. 6(2):215–219.Crossref, Google Scholar
- (1967) Organizations in Action (McGraw-Hill, New York).Google Scholar
- (2014) Navigating complex decision spaces: Problems and paradigms in sequential choice. Psych. Bull. 140(2):466–486.Google Scholar
- (1995) Sensemaking in Organizations (Sage Publications, Thousand Oaks, CA).Google Scholar
- (2007) The value of moderate obsession: Insights from a new model of organizational search. Organ. Sci. 18(3):403–419.Link, Google Scholar
- (1994) Representations in distributed cognitive tasks. Cognitive Sci. 18(1):87–122.Crossref, Google Scholar
Christina Fang is a professor of management at the Stern School of Business, New York University. She received her PhD from the Wharton School at the University of Pennsylvania. Her research interests include organizational learning, strategy and behavioral decision making, and technological innovation.
Ji-hyun (Jason) Kim is a professor of management at Yonsei University. He earned his PhD from New York University’s Stern School of Business, an MA in economics from University of California-Los Angeles, and a BBA from Yonsei University. His research delves into complexity, organizational learning, and firm performance, integrating computational approaches.
Hisan Yang is a postdoctoral researcher at the Hong Kong Polytechnic University and an assistant professor of strategy at the E. J. Ourso College of Business, Louisiana State University (as of August 2025). He received his PhD from the David Eccles School of Business at the University of Utah. His research interests lie in various tradeoffs organizations face in managing complex problems.

