
Cautious Exploitation: Learning and Search in Problems of Evaluation and Discovery
Abstract
Underlying the macrophenomenon of organizational search lie two central mechanisms: belief updating and explicit strategies of exploration/exploitation. We find that slow learning with respect to belief updating, in conjunction with a strategy of exploration/exploitation heavily tilted toward exploitation, leads to an effective process of organizational adaptation in a wide variety of settings. This joint search strategy can be thought of as “cautious exploitation.” Belief updating proves to be a more effective catalyst to search, facilitating both the process of discovery of alternatives and persistence in favorable alternatives, than an explicit strategy of exploration. However, it is important to consider the boundary conditions around this finding. Problems of search differ in important respects: from settings that are primarily problems of discovery where the critical challenge is identifying a promising alternative, but its promise is self-evident once identified, to problems of evaluation where assessing the merit of alternatives that are identified is itself a challenge. We find that our conventional wisdom about the role of explicit strategies of exploration holds in settings that are primarily problems of discovery. However, when the evaluation of alternatives is problematic and assessed through experience with a given alternative, we find that the macrophenomenon of effective organizational search is best realized with slow rates of belief updating in conjunction with an explicit strategy of exploration/exploitation that is tilted to be highly exploitative.
Supplemental Material: The online appendix is available at https://doi.org/10.1287/orsc.2023.17538.
1. Introduction
Underlying the macrophenomenon of organizational search lie two central mechanisms: belief updating and explicit strategies of exploration. While discussions of search tend to focus on these mechanisms in isolation, organizational search is a consequence of both these processes operating jointly. In this regard, it is important to recognize that organizations can usefully be viewed as complex adaptive systems (Simon 1962, Holland 1975, Axelrod and Cohen 1999). One of the hallmarks of such systems is that their behavior is emergent; it is a consequence of various underlying microprocesses. As a result, understanding such systems challenges our efforts as social scientists or managers at reductionism: efforts to identify specific causal mechanisms and, in turn, managerial levers of control. This desire for reductionism in the face of complexity is an ongoing challenge in our consideration of processes of organizational learning where, as a convenient shorthand, the literature often speaks of organizations as searching, exploring, or exploiting, while often under-attending to the various micromechanisms that jointly influence these macrobehaviors.
In this vein, it is useful to deconstruct the process of search at the organizational level and what constitutes the underlying mechanisms. Empirically, exploration and exploitation are generally treated in a behavioral manner; for instance, are organizations drawing on a familiar stock of patents or novel ones (Katila and Ahuja 2002), are organizations engaging in novel sorts of alliances or more familiar ones (Lavie and Rosenkopf 2006, Lavie et al. 2011)? In more theoretical treatments, exploration and exploitation are often interpreted as a strategy: to what degree does the organization privilege alternatives that it views more favorably than those it views less favorably? However, organizational search, whether new arenas of technology, partnerships, or markets, is a macrophenomenon driven by both a process of belief updating regarding what actions the organization views as desirable, as well as an explicit strategy with respect to exploration/exploitation.
These two mechanisms, belief updating and a strategy of exploration/exploitation, are generally not given equal attention as work tends to focus on one facet or the other, such as the emphasis on actors’ cognitive model in work that highlights the updating of beliefs (Denrell and March 2001) or the organization’s search strategy (Lee and Puranam 2016, Stieglitz et al. 2016). A largely unexamined question is the relative importance and possible interactions between these two learning mechanisms.
Further, per Simon’s (1990) observation regarding the two blades of the scissors and the need to examine both properties of the decision maker and the context in which they operate, it is important to consider how these micromechanisms of belief updating and explicit strategies of exploration/exploitation operate in different problem environments. In particular, problem contexts of search differ in important respects: from settings that are largely problems of discovery—identifying a favorable action in a large space of possibilities (Levinthal 1997)—to problems of evaluation, where assessing the merit of an identified alternative is itself a challenge (Denrell and March 2001). The nature of the search challenge and the relative efficacy and importance of belief updating and explicit strategies of exploration are likely to vary across these contexts.
A key factor that impacts the relative importance of the challenge of discovery and the challenge of evaluation is the degree to which there is noise or ambiguity in the feedback process. When Edison was searching for a filament that had the desired properties to illuminate a lightbulb, he was searching through a large combinatoric space of possibilities. However, there was little issue with respect to the evaluation of a given alternative; the filament either achieved or failed to achieve a given level of illumination. In this spirit, Fleming (2001) and Fleming and Sorenson (2001, 2004) highlight the challenges and opportunities of searching through a space of technological possibilities. In contrast, when evaluating the merit of alternative organizational processes, for instance how to organize product development efforts, the outcome of any given initiative that stems from the process may be a success or not, but even very effective processes may at times yield disappointing outcomes.
Many management practices as well as products and services offered in particular contexts to particular customers or market niches at particular moments can pose challenges of evaluation as to what the observed outcome means for the underlying, systematic value of the initiative. Given the mixed or noisy feedback that stems from many initiatives in management and strategy contexts, effective adaptation requires not just the discovery of promising alternatives via search, but also necessitates the capacity to persist with alternatives that are indeed favorable (Rivkin and Siggelkow 2003, Knudsen and Levinthal 2007). Does an unfavorable product development effort imply that a formerly successful approach to product development is no longer valid, or was the most recent effort an aberration? Similarly, is a disappointing quarterly sales result indicative of flaws in the business model or merely the vagaries of temporary market conditions?
Even the context of technological innovation, such as drug discovery and development, often entails both the challenge of discovery and evaluation. The space of the human genome is vast, and the question of how to link this set of possibilities to particular clinical applications is challenging (Tranchero 2023). However, even with the identification of a promising candidate drug, the evaluation of that promise is challenging: what do the laboratory results mean for possible clinical applications, what do initial animal trials mean for human application, what do mixed results in human trials mean for the success of possible variants or alternative clinical applications?
Challenges of evaluation, in turn, pose two distinct challenges regarding persistence with a given alternative. These can be understood as corresponding to a form of type I and type II errors (Csaszar 2013). The literature on learning and, in particular, discussions of competency traps (Levinthal and March 1981, Levitt and March 1988) largely focuses on the type I error of commission: persisting with an alternative that is, in fact, inferior to other possibilities and, as a result, a failure to discover superior alternatives. However, the challenge of evaluation also poses the possibility of type II errors of omission: failing to persist with what is, in fact, a favorable alternative given mixed feedback over time as to its merit (Denrell and March 2001). In problems of pure discovery, where the challenge is one of identifying a superior approach and the merit of the approach once identified is not problematic, organizations do not face the possibility of these type II errors—failure to persist with a superior alternative in the face of mixed feedback—and the learning challenge becomes one of reducing the risk of type I errors of commission.
We examine these issues in a computational model of organizational learning. This modeling exercise allows us to partial out the conceptually distinct mechanisms of learning as driven by the updating of beliefs and strategies of exploration/exploitation. To do so, we specify a modeling environment that problematizes both discovery and persistence. We use the N-armed bandit as our basic structure, a structure that is regarded as a canonical representation of the exploration/exploitation trade-off (Holland 1975, March 2003, Posen and Levinthal 2012), but we examine this structure in a much larger problem context, as characterized by the number of latent alternatives, than the small problem contexts used in prior work (e.g., Denrell and March 2001, Posen and Levinthal 2012, Lee and Puranam 2016, Keil et al. 2023).
The bandit model derives its name from a metaphoric kinship with that of a slot machine. Imagine a casino with multiple slot machines that differ in their tendency to provide a payoff. A gambler may wish to sample a number of machines to see which one seems to be most “favorable,” but even favorable machines often give unfavorable results. This observation points to the important contrast between the merit of a given policy or strategy and the favorability of any individual outcome. Good organizational processes generate, on average, favorable outcomes, but not in all instances. Similarly, good strategies tend to generate more favorable results than alternative strategies, but still need not lead to favorable results at each moment of time.
Per these dual challenges of persistence in the face of mixed feedback and the possible value of discovering new alternatives, managers are often encouraged to stay the course but, at the same time, not to have a status quo bias and be overly locked into past practices and strategies. Navigating these dual imperatives of an appropriate level of persistence in the face of noisy feedback with an openness to the possible need to search for new approaches is a core management challenge. Further, this tension between persisting in the face of mixed feedback and search is related to, but distinct from, the classic exploration/exploitation trade-off (Holland 1975, March 1991). The exploration/exploitation trade-off poses the challenge, as March (1991, p. 71) frames it, of the “exploration of new possibilities and the exploitation of old certainties.” The tension stems from the opportunity cost of shifting from what is known and reasonably effective to less known and possibly superior—or inferior—alternative possibilities. However, when evaluation is problematic—when the merit of the current action is less certain—organizational search is not only a question of the possible benefits of discovering the new, but of the possible reevaluation of the old.
We find that slow learning with respect to belief updating, in conjunction with a strategy of exploration/exploitation heavily tilted toward exploitation, leads to an effective process of organizational adaptation in settings where the evaluation of alternatives is problematic. We refer to this joint approach as being one of “cautious exploitation.” In the face of noisy feedback, slow learning has the virtue of tending to aggregate experience across learning trials. Put another way, slow learning causes the organization to take on new information but in a measured, or cautious, fashion. Thus, while a single negative experience reduces the beliefs about the merit of the current action, it need not lead to a change in behavior. However, even with slow learning, belief updating can serve as a catalyst to search following more systematic negative signals. In contrast, an explicit strategy of exploration is a heavy hammer of adaptation that tends to be less responsive to the shifting needs of an effective search process in balancing the process of discovery and persistence with what has been discovered.
This joint strategy of cautious exploitation, a slow rate of belief updating in conjunction with a highly exploitative search strategy, has important resonance regarding an organization’s adaptive journey. Organizations may pivot in their behavior, but that pivot or change in behavior is, per the slow rate of belief updating, supported by an accumulation of evidence; further, the choice regarding the new behavior is not the outcome of some biased coin-flipping, as suggested by a balance of a strategy of exploration/exploitation (Posen and Levinthal 2012, Stieglitz et al. 2016), but rather a decisive choice of a new behavior contingent on the organization’s current beliefs.
That is not to say, however, that there is not some role for a contingent logic in varying the rate at which beliefs update or the value of an exploration/exploitation strategy as a function of the problem setting. A very stark boundary condition for the merit of a slow rate of belief updating in conjunction with a highly exploitive strategy, what we term cautious exploitation, is when the problem context privileges the challenge of discovery and minimizes issues of the evaluation of alternatives. Such a setting is, as we suggest, indicative of the challenge of scientific discovery (Fleming 2001; Fleming and Sorenson 2001, 2004) and how search on a fitness landscape is often considered (Levinthal 1997), with belief updating having a one-shot learning quality in the absence of a stochastic relationship between actions and outcomes.1 In such settings, belief updating can cause the organization to search, but once an alternative is viewed as satisfactory, subsequent search ceases in the absence of an explicit strategy of exploration. Thus, in these settings, an explicit strategy of exploration is important in order to reduce excess type I (false positive) errors of persisting with a less than ideal alternative. Further, when the evaluation challenge manifests in settings where the payoffs for a given alternative shift over time, the efficacy of slow learning is somewhat eroded, and the desired rate of belief updating shifts slightly upward. This slightly faster rate of belief updating effectively depreciates prior experience, and as a result, the organization is more responsive to this changing environment, though the preferred strategy of exploration/exploitation remains highly exploitive.
2. Unpacking the Bases of Search and Learning
Effective adaptation requires both identifying promising alternatives, a problem of discovery, and persisting in those alternatives that are indeed favorable (Rivkin and Siggelkow 2003, Knudsen and Levinthal 2007). The problem of persistence is generally treated as one of the organization mistakenly continuing to engage in an alternative action that is a second, third, or even inferior best and thereby settling prematurely on a less than ideal alternative. There are multiple distinct processes that might engender such settling. One is the phenomena of a competence trap (Levinthal and March 1981, Levitt and March 1988). Experience with an alternative not only provides evidence of its merit, it also may provide the organization with greater efficacy with its use. The joint process of belief revision and competency learning with respect to alternatives can result in the organization preferring its current action, with which it is skilled, to an alternative action that is latently preferable but for which it currently lacks competence (Levinthal and March 1981, Denrell and March 2001). A related but distinct trapping mechanism stems from local search on a multi-peak landscape (Levinthal 1997). Local search processes can lead to performance improvement; however, that journey of performance improvement leads the organization to a local peak that may or may not have favorable global properties.
The persistence problem suggested by this line of work is a form of false positive (a type I error of commission). The organization is receiving positive feedback from persisting with a less than ideal alternative. However, it is important to recognize a different sort of persistence problem which can be considered a false negative (a type II error or an error of omission), whereby a favorable alternative may generate occasional negative feedback. For instance, even talented creative artists typically do not reliably create one hit after another (Berg 2022, Denrell et al. 2023). As March (2010) notes, experience can often be a poor teacher. As a result, the process of organizational learning can revolve around a different problem of persistence: the challenge of persisting with a relatively favorable alternative in the face of mixed feedback. The degree to which the persistence challenge that an organization faces is one of false positives, persisting with an inferior alternative, or false negatives, failing to persist in a superior alternative because of the happenstance of a particular instance of negative feedback, is a function of the problem environment that the organization faces. Search in rugged fitness landscapes (Levinthal 1997) highlights the problem of discovery and, in the absence of any stochastic element in the feedback process, only permits the persistence problem of false positives: local peaks.
In contrast, a bandit process can present both a challenge of evaluation, a given alternative need not yield the same payoff across different trials, and a problem of discovery, the search process may converge prior to identifying the most favorable alternative. In bandit models of learning, this premature convergence on an alternative is a by-product of the process of belief revision (Denrell and March 2001, Piezunka et al. 2022). Early in the search process, organizations are likely to have diffuse beliefs as to what constitutes a favorable action. Through experience, those beliefs become sharper and more distinct. However, as Denrell and March (2001) point out, experience is not generated randomly. Rather, the organization is inclined to engage in alternatives that it views favorably, and as a result, the organization tends to cease updating its beliefs regarding those alternatives it views as less favorable. In other words, experience is endogenous with respect to beliefs (Denrell and March 2001). In a setting of multiple alternatives and some degree of noisy feedback, such a process tends to lead to convergence on a focal alternative that may or may not constitute the most favorable action.
However, the degree to which a bandit problem poses a problem of discovery is a function of the number of available alternatives relative to the time horizon under consideration. A modest number of alternatives minimizes the challenge of discovery—all alternatives are likely to be sampled—and highlights the challenge of evaluation and the potential pathology of false negatives: negative feedback with an alternative that is, in fact, on average, favorable. In this light, it is striking that analyses of bandit models tend to focus on small problem contexts of a modest number of alternatives with work focusing on two alternatives (Denrell and March 2001, Keil et al. 2023) or 10 alternatives (Posen and Levinthal 2012, Lee and Puranam 2016, Stieglitz et al. 2016). As a result, prior work using the bandit model highlights the challenge of evaluation, learning from alternatives with stochastic feedback, and minimizes the challenge of discovery, as all alternatives are likely to be sampled over the time horizon under consideration.
While we have framed these basic challenges of search in terms of these canonical models, one can also map this discussion onto some important strands of contemporary management discourse. Organizations are increasingly encouraged to take an experimental approach and test hypotheses regarding the relative merit of alternative products and organizational processes (Camuffo et al. 2020, Koning et al. 2022). Such efforts highlight the problem of evaluation. Discussions of A/B testing do not problematize what constitutes the alternative B, but rather its merit relative to a status quo option of A. In contrast, work on design thinking (Osborn 1953, Brown 2009) or the search for “blue oceans” (Kim and Mauborgne 2014) highlight the challenge of identifying creative and effective alternatives and the organizational processes that may facilitate that search, but tends to unproblematize the assessment of the novel alternatives once identified.
However, organizations must both identify potential novelty and assess the possible merit of that novelty (Knudsen and Levinthal 2007). Reflecting that dual agenda, two foundational mechanisms of organizational search are the processes of belief updating and the strategy of exploration/exploitation that translates these beliefs into behavior. Highlighting this dual role of belief updating and strategies of exploration/exploitation speaks to the issues raised by Holland et al. (1989) as to the importance of considering both the learning processes associated with actors’ model of the environment in which they are operating and the rules of action in those environments.
While March (1991) and work that builds directly on it, such as Fang et al. (2010), treat the manner by which beliefs update as a central mechanism in examining the exploration/exploitation trade-off, subsequent work, employing the bandit model, has simply postulated that beliefs equal the organization’s average experience (Posen and Levinthal 2012, Lee and Puranam 2016). While shifting beliefs play a central role in these models in influencing choice behavior (via the softmax choice rule; Luce 1959), postulating that beliefs are equal to average experience does not allow for a consideration as to how the rate at which beliefs update from experience influences the adaptive dynamics of the entity.
In contrast, work that models belief revision as a fractional adjustment process (Bush and Mosteller 1955, Levinthal and March 1981, Denrell and March 2001), whereby the revised beliefs are a mixture of the prior beliefs and whether recent experience is viewed favorably or not, forces an explicit consideration of the rate of learning with respect to beliefs. A partial adjustment process is also more consistent with experimental evidence that shows that more recent events, even in a static problem environment, are weighed more heavily than earlier events (Estes 1972, Hogarth and Einhorn 1992, Camerer and Ho 1999), in contrast to the assumption that beliefs correspond to average experience which weighs all experience equally. Thus, what is often treated as a fairly narrow technical modeling assumption either invites or foreclosures an explicit consideration of a basic mechanism of learning.
We show that equating beliefs to average experience with an alternative leads to an implicit learning rate with a sharp decline over time as each new experience has a diminished marginal impact on the organization’s beliefs. We show that the finding of prior work that moderate levels of exploration is a preferred strategy, such as Posen and Levinthal (2012) and Lee and Puranam (2016), stems from the need for a moderate level of exploration to counter the high level of inertia that stems from the property that beliefs are a simple average of prior experience.
Even from a normative point of view, the assumption of equating beliefs to average experience with an alternative is not unproblematic. While in a static setting, equating beliefs to average experience provides the best estimate of the value of an alternative, making this assumption in a dynamic setting where the value of alternatives change is clearly problematic. Prior realizations with a given alternative may not be indicative of future realizations in such settings. Even more striking, we show that setting beliefs to correspond to average experience in conjunction with the level of exploration that yields the best performance with that mode of belief updating actually leads to a slightly inferior organizational search process compared with a behavioral process of adaptive learning with respect to beliefs via a partial adjustment process and a highly exploitative strategy of exploration/exploitation. This finding further supports our earlier observation of the challenge of making inferences as to the efficacy of a component of an organizational learning process—in this case, how beliefs are updated—for the efficacy of the more macrophenomenon of organizational adaptation.
3. Model Structure
3.1. Task Environment
We consider an environment in which organizations face a sequential choice, N-alternative bandit problem (Posen and Levinthal 2012). In each period, t, an organization must choose one of N alternatives. The realized reward from the choice of a specific alternative i is a Bernoulli distribution whereby the outcome is either favorable, yielding a payoff of one, or unfavorable, yielding a payoff of zero, with respective probabilities of and . As such, the underlying state of the environment can be described as a set of probabilities (expected payoffs) to the alternatives with .
The underlying reward structure of alternatives is characterized by generating the payoff probabilities for each alternative from a beta distribution. We consider a bell-shaped beta distribution with a mean value of 0.5 that is characterized by the parameter setting α = 2 and β = 2.2 We treat the choice situation as being composed of a large number of potential options, consisting of 100 potential alternatives to be evaluated over 100 time periods. This setting of a large set of potential alternatives places a premium on the possibility of discovery. Given that there are as many alternatives as time periods, potentially the organization could sample a novel opportunity each period. More generally, the organization faces the choice of continuing with its current alternative, resampling an alternative with which it has had some prior experience, or trying a new alternative with which it has had no prior experience. To dock our analysis with prior work that has tended to focus on a modest number of alternatives (typically 10), we examine that setting as well, and to examine the robustness of our results, we also consider settings over much more extended time horizons (up to 10,000 time periods).
3.2. Choice
An alternative is selected based on the assessment of its merit relative to the full set of alternatives. The belief about alternative i at time t is denoted as . The beliefs across the set of N alternatives is with . Initial beliefs are assumed to be homogenous, and these initial beliefs regarding the merit of each alternative are set equal to the mean of the beta distribution characterizing the distribution of alternatives. As a result, the organization has no initial preferences among alternatives.
Consistent with prior work, the degree to which favorable beliefs are privileged in the choice process is characterized by the softmax function (Luce 1959). The critical parameter determining this mapping is τ, often called the temperature, which tunes the strength of the relationship between beliefs and choice behavior. Formally, the softmax choice rule specifies the probability of selecting alternative i, , as
In addition, in robustness analysis, we consider the implications of an epsilon-greedy choice rule whereby the organization chooses the alternative that it perceives as most favorable with probability (1 − ε) and with probability ε chooses one of the N alternatives at random. We examine this alternative decision rule as it allows us to disentangle the role of the variance in beliefs in driving the search process, as the variance plays a critical role in determining choice behavior under the softmax rule, from shifts in what the organization considers to be its more preferred alternative as beliefs are updated.
3.3. Belief Updating
The organization modifies its beliefs about the attractiveness of various alternatives over repeated trials. Making a choice in a given period both generates a payoff from that choice as well as provides information as to the merit of that choice. In this sense, the organization “earns as it learns.” The organization receives feedback from the environment in the form of a binary outcome, where a reward of one is seen as a success and zero is seen as a failure. We assume that beliefs update in accordance with the Bush–Mosteller fractional adjustment methodology (Bush and Mosteller 1955, Denrell and March 2001). As such, if alternative i is selected and yields a positive outcome, then the attractiveness of alternative i in period t + 1 increases such that
Furthermore, we assume that updating occurs only with respect to the alternative selected in each period. Hence, the beliefs regarding all other alternatives j at t + 1 remain fixed such that . Our analysis varies ϕ as well as τ to better understand the relationship between the learning rate with respect to beliefs (ϕ), an explicit strategy of exploration/exploitation (τ), performance, and the dual challenges of search and persistence underlying the process of organizational adaptation.
4. Analysis
4.1. Persistence and Search
To highlight the effect of varying the parameters guiding organizational adaptation (ϕ and τ), organizations are analyzed as responding to the same set of environments, allowing for direct comparisons across organizations. Thus, a set of N alternatives are drawn from a given beta distribution. A population of organizations that vary in their learning rate (ϕ) and degree of exploration (τ) are analyzed facing this set of alternatives. A new draw from the same beta distribution is carried out, and similarly, a population of organizations varying in their ϕ and τ values are analyzed that face this environment. This process is carried out for 10,000 distinct draws of N alternatives from a given beta distribution characterizing the opportunity structure. Thus, for each pair of parameter values (ϕ and τ), we examine 10,000 unique environments where an environment is a sample of N draws from the beta distribution characterizing the task environment. In our baseline setting, the model is run for 100 periods and with the number of alternatives set at N = 100 though, as discussed below, we do examine longer timer horizons and smaller, N = 10, problem environments.
We consider organizations that vary in their rate of belief updating (tuned by the parameter ϕ) and their strategies of exploration/exploitation (tuned by the parameter τ). We examine ϕ values ranging from 0.1 to 1.0 with step sizes of 0.1 and τ values ranging from 0 (a strictly greedy choice rule) to 0.1 with step sizes of 0.02.3 Figure 1 plots the performance of organizations as a function of the level of ϕ and τ, where performance is operationalized as the cumulative percent loss relative to the optimal policy, often referred to as the regret in computational models, over the course of the 100 periods of the simulation. We present results as a percent cumulative loss as a means of normalizing performance relative to what is achievable in each setting and allowing for comparison across various manifestations of the environmental context. A loss of −25% implies that the organization is performing 25% below what would have been achieved had the organization selected the best alternative in each period of the simulation. Darker red colors reflect a higher level of performance (a less negative cumulative loss), whereas lighter red colors reflect lower levels of performance (a more negative cumulative loss).

We find that the best performing policy pair of ϕ and τ is the combination of being a slow learner with respect to beliefs (low value of ϕ) in conjunction with a greedy choice rule (τ = 0).4 This policy results in the loss function being approximately 21% below that which would be obtained by selecting the best alternative in each period. Conversely, the worst performing policy pair is to combine slow learning with respect to beliefs with a very exploratory strategy (ϕ = 0.1, τ = 0.1). This policy pair results in a percent loss of approximately 44%. Hence, we observe an important interaction between ϕ and τ. Slow learning with respect to beliefs, a low value of ϕ, and a high level of exploitation, a low value of τ, in and of themselves do not lead to a high level of performance but do so in conjunction. Finally, at high levels of the learning rate ϕ, performance becomes effectively invariant to the level of τ, the strategy of exploration/exploitation, resulting in a percent loss of approximately 32%.
While Figure 1 provides a sense of the overall performance, there remains the question as to how the rate of learning with respect to beliefs and the strategy of exploration/exploitation affect performance through the underlying processes of discovery (via search) and persistence. Specifically, is the advantage in performance experienced by slow belief updating and a greedy decision rule resulting primarily from discovery (search) or persistence? Turning first to discovery, Figure 2(a) plots the percentile of the best alternative the organization has sampled over the course of the 100 periods of the simulation. Dark red colors reflect a higher percentile associated with the best sampled alternative, which implies that the organization has conducted more search and, hence, performs better with regards to discovery. Conversely, light red colors suggest that organizations search less expansively and that the best identified alternative is less promising. As expected, organizations pursuing a slow rate of belief updating and a greedy strategy of exploration/exploitation are less able to discover superior alternatives because of less extensive search. Indeed, when ϕ = 0.1 and τ = 0, the organization identifies alternatives around the 90th percentile of performance and generally samples seven to eight out of the 100 alternatives; conversely, increases in τ lead to the discovery of better alternatives with organizations identifying alternatives close to the 99th percentile of the optimal alternative and leaving fewer unsampled alternatives. However, this relationship holds only for low levels of τ and ϕ. Once the rate of exploration (τ) or the rate of belief updating (ϕ) is set at a sufficiently high level, each mechanism alone (high levels of exploration or rapid rates of belief updating) is sufficient to generate a high level of discovery (for instance, with ϕ = 0.1 and τ = 0.1, the organization samples some 60% of the 100 alternatives, and with ϕ = 1.0 and τ = 0.1, nearly 40% are sampled).
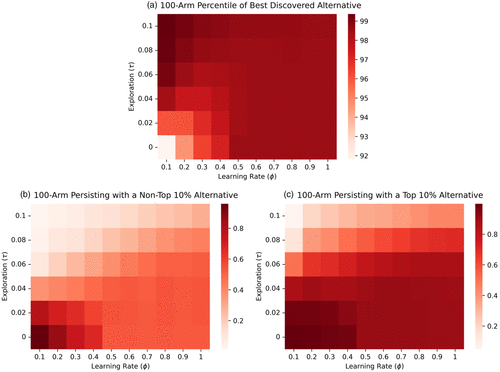
These results suggest that the superior performance of pursing a slow rate of belief updating and a greedy strategy of exploration/exploitation is not driven by greater levels of search or discovery. Hence, the performance differential likely stems from a superior ability to persist with a given favorable, if not ideal, alternative. However, whether persistence improves or inhibits superior performance is a function of whether the organization can avoid persistence and lock-in with inferior alternatives, and persist with favorable alternatives. Turning to this first, negative, form of persistence, Figure 2(b) plots the probability of an organization persisting with an alternative that is not in the top 10% of available alternatives. We examine the probability as to whether an organization that chooses in the penultimate period (period 99) an alternative that is outside the top 10% would continue to choose this same alternative in the final period (period 100). For instance, a probability of persisting of 0.8 means that 80% of the organizations that selected an inferior alternative (outside the top 10% alternatives available) in period 99 chose to persist with the same alternative in period 100. Darker red colors reflect a higher probability of persisting with light red colors reflecting a diminished likelihood of persisting. We observe that organizations that engage in slow learning with respect to beliefs and enact exploitative strategies have a higher probability of getting trapped on these inferior alternatives. This is consistent with the result of the previous figure (Figure 2(a)) where slow belief updating and an exploitive strategy of exploration/exploitation results in a reduced tendency to identify one of the very best alternatives.
If the superior performance of slow belief updating and an exploitive strategy of exploration/exploitation does not stem from superior search and the discovery of better alternatives and endures despite organizations with those sets of policies being more likely to get stuck on inferior alternatives, then the advantage of slow belief updating and an exploitive strategy must stem from a greater ability to persist with a good alternative once identified. Furthermore, this advantage must be sufficiently large to outweigh these liabilities of less effective discovery and the greater likelihood of getting trapped on inferior alternatives.
To test this intuition, we investigate the ability of the organization to persist with alternatives in the top 10% of the underlying performance distribution. These results are presented in Figure 2(c). The ability to persist with an alternative in the top 10% is operationalized as whether, given the organization chose in the penultimate period (period 99) a superior alternative, an alternative in the top 10%, would the organization continue to make this same choice in the final period (period 100). A probability of persisting of 0.8 means that 80% of the organizations that selected a superior alternative in period 99 selected the same alternative in period 100. Darker red colors imply a greater ability to persist, whereas lighter red colors imply a reduced ability to persist. We see that policies in the bottom left corner of the parameter space corresponding to slow learning of beliefs and exploitive choice rules are very effective in persisting. Indeed, a policy pair of ϕ = 0.1 and τ = 0 results in a rate of persistence of approximately 100%. Conversely, the lowest level of persistence corresponds to slow learning of beliefs combined with a rather exploratory policy (ϕ = 0.1, τ = 0.1), with such organizations being able to persist approximately 4.8% of the time.
Taken together, these results suggest that pursuing a slow rate of belief updating and an exploitive strategy of exploration/exploitation results in superior performance. Further, this performance improvement is driven by the often overlooked ability to persist with superior alternatives in the face of noisy feedback regarding their merit, despite these policies resulting in a comparatively reduced ability to discover superior alternatives via search and a greater propensity to fall into traps of persisting with inferior alternatives.
4.2. Hidden in Plain Sight: Belief Updating in Models of Exploration and Exploitation
Given the differences in results between our model and much of the existing work examining the efficacy of exploration using bandit models, we now seek to reconcile these seemingly contradictory results. One difference between our task environment and task environments commonly employed relates to the number of alternatives, which helps proxy for the extent to which the discovery problem is emphasized. Therefore, we examine the impact of reducing the number of alternatives to 10, thereby bringing the analysis in alignment with the number of alternatives employed in Posen and Levinthal (2012) and other studies (e.g., Lee and Puranam 2016, Stieglitz et al. 2016). As in our baseline environment, the underlying probabilities for each alternative are drawn from a bell-shaped beta distribution with α = 2 and β = 2.
The results of this analysis are reported in Figure 3, where darker red colors reflect a higher level of performance (a less negative cumulative loss), whereas lighter red colors reflect lower levels of performance (a more negative cumulative loss). As with Figure 1, we see that the best performing policy pair of ϕ and τ is the combination of being a slow learner with respect to beliefs coupled with a greedy choice rule (τ = 0).5 This policy results in a loss of approximately 11% relative to choosing the best alternative in each period. Furthermore, we continue to see that a combination of slow learning with respect to beliefs and an exploratory choice rule (ϕ = 0.1, τ = 0.1) results in poor performance with a cumulative percent loss of approximately 21%; however, the worst performing combination of ϕ and τ values corresponds to settings in which the learning rate (ϕ) equals 1.0—a setting of one-shot learning. Finally, it is important to note that, while changing the degree to which the problem is one of discovery (by shifting the number of alternatives) does not shift the location of the best performing ϕ–τ pair, it does have a demonstrable effect on the absolute level of performance achieved across the grid of ϕ–τ pairs. For example, the range of performance values in the 10-arm setting range from approximately −11% to −26% relative to approximately −21% to −44% in the 100-arm setting.
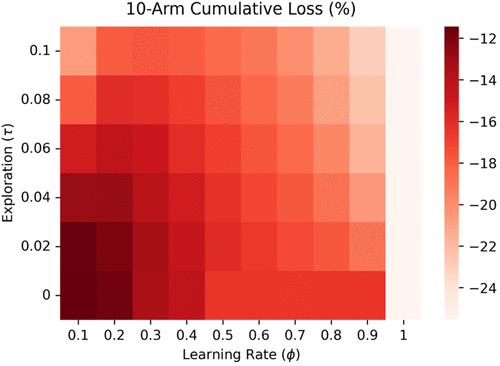
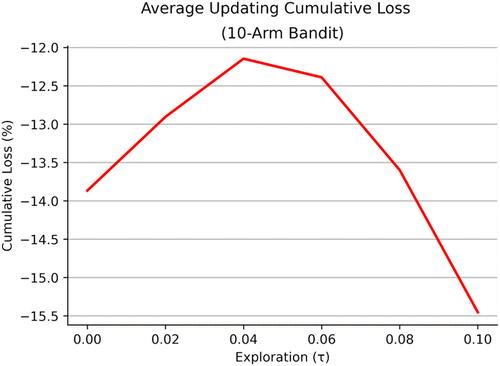
While the results reported for 10 arms are consistent with the findings of our baseline environment, the result with respect to exploration (τ) remains inconsistent with existing work that suggests a moderate degree of exploration improves performance relative to a purely greedy/exploitative choice rule. Hence, we conclude that the lack of evidence in favor of exploration in this setting stems not from the difference in the number of alternatives considered across models, but instead, stems from the different treatments of belief updating employed in conjunction with exploration. Specifically, Posen and Levinthal (2012) and subsequent treatments of exploration in bandit models (cf. Puranam et al. 2015) generally implement belief updating using the special case of average updating. To verify this intuition, we reran our analysis for 10 arms under the assumption of average updating where the learning rate is specified as , where is the number of times that alternative i has been selected at time t. The result of this analysis is presented in Figure 4, which plots the performance of organizations (operationalized as the cumulative loss relative to selecting the best alternative in each period) for a given value of τ. With beliefs specified as the average experience with an alternative, we observe the classic exploration–exploitation trade-off whereby a moderate degree of exploration, as characterized by the search strategy τ, results in the highest level of performance over the length of the simulation.6
That a moderate degree of exploration is desirable under an average updating mechanism but not when we examine an explicit treatment of the learning rate via a partial adjustment process suggests that whether a search strategy of exploration is necessary emerges as a function of how beliefs evolve over time. To understand the underlying mechanisms driving the results of exploration given average updating, we plot the effective learning rate (ELR) of organizations under an average updating process (Figure 5). The effective learning rate under the assumption of beliefs corresponding to the average of an organization’s experience with an alternative changes as a function of an organization’s experience with an alternative. An organization that updates its beliefs via an average updating rule experiences a rapid rate of belief updating in the first several periods, but then its beliefs quickly become relatively inert. Specifically, in the first period of the simulation, the effective learning rate is 0.5, a rather rapid rate of belief updating, because the organization is selecting an alternative for the first time . Over time, this effective learning rate declines precipitously until it is only slightly above 0 by period 100 as the organization has had multiple experiences with each alternative and many experiences with its most preferred alternative.
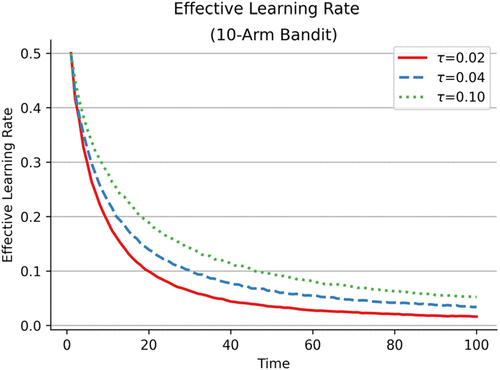
Exploration emerges as a desired strategy under the condition of average updating as such a strategy helps compensate for the rapid decline in the effective learning rate in this setting. In the absence of a moderate level of exploration, this decline in the ELR leads to excessive inertia. In settings where the effective learning rate is held constant (as in our main analysis), the shift in beliefs with experience can lead to search in the face of negative feedback even in later periods. Hence, search, sampling different alternatives, can occur even in the presence of a highly exploitive strategy with respect to τ with a more dynamic pattern of belief updating. When beliefs correspond to the average experience of the organization, an explicit strategy of exploration (a moderate value of τ) is necessary to sustain some level of search in later periods given the high level of inertia in beliefs.
This result suggests the importance of recognizing that organizational adaptation and search processes are a macrobehavior driven by the interplay of distinct micromechanisms and that it is problematic to examine these micromechanisms in isolation. As a stark finding in support of this argument, we find that the policy of updating beliefs to correspond to the organization’s average experience, which leads to the best estimate of the true value of alternatives, in conjunction with the best strategy of exploration/exploitation (τ value) for that setting actually leads to slightly inferior performance in comparison with a behavioral process of partial adjustment learning with a slow learning rate in conjunction with a strategy of exploitation. In particular, we find that a slow learning (ϕ = 0.1) fractional adjustment process coupled with a fully exploitative (greedy) choice rule (τ = 0) results in a cumulative percent loss of approximately −11% relative to the roughly −12% loss of average updating when combined with a τ value equal 0.04 (the best performing τ value conditional on average updating in that setting). Thus, the best mechanism of belief updating leads to the best estimate of beliefs but not, as driven by the joint processes of belief updating and a strategy of exploration/exploitation, to the most effective learning organization.
Clearly, the normative claim for beliefs to correspond to average experience becomes even more problematic in a setting where the environment itself is changing and the values of alternatives may change over time. In turbulent environments, evaluation is further complicated by the fact that not only is experience noisy, but past experiences become less representative of future experiences. Following the approach used in Posen and Levinthal (2012), we tune the degree of turbulence via the parameter η, which sets the probability of a shock occurring, where a shock corresponds to possible changes in the payoff associated with a given alternative. We vary η from 0 to 0.32, the maximal value used in Posen and Levinthal (2012), which implies that a shock occurs, on average, 32% of the time. Given an environmental shock at time t, the payoff to each alternative is, with probability 0.5, redrawn from the initial beta distribution.
We first investigate the impact of a changing environment on the degree of exploration. This is presented in Figure 6(a), which plots performance across the range of turbulence (η) and exploration (τ) values for the best performing ϕ–τ pair.7 First, we note that performance is eroded as turbulence increases. This result is consistent with Posen and Levinthal (2012). However, the more pertinent result for the discussion here is that, for a given value of η, the highest performing value of τ remains tightly clustered around zero, thereby demonstrating the robustness of exploitation (a greedy choice rule) to a variety of environments that vary in the degree of turbulence.
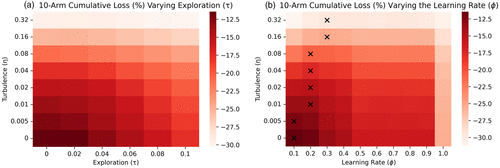
It is important to note that this result runs counter to the results presented in Posen and Levinthal (2012) in terms of both the level of exploration (as discussed above) and the dynamics of exploration across the range of turbulence values. Specifically, Posen and Levinthal (2012) note that the optimal rate of exploration (τ) initially increases in settings of low-to-moderate turbulence (η) before subsequently receding. As with the results reported in the static 10-arm setting, we see that, once an explicit consideration of the rate of adaptive learning of beliefs is introduced, as opposed to postulating that beliefs correspond to average experience, the role of an explicit strategy of exploration diminishes. Search can be driven by the dynamics of beliefs, and those beliefs will change as the payoffs associated with different alternatives change; again, we see that belief updating serves as a more nuanced catalyst to search than a strategy of exploration.
However, the relationship between organizational performance and the rate at which beliefs update does change with the rate of environmental change. Given the results of Figure 6(a), we hold τ constant at zero (greedy) and plot the cumulative loss across the range of learning rates (ϕ), where darker red colors correspond to higher performance (a less negative percent loss) and lighter red colors correspond to low performance. Further, we mark the best performing ϕ value for each value of η with a black X. We observe that as turbulence (η) increases, the best performing learning rate also increases. This pattern stems from the obsolescence effect of prior experiences. As the likelihood of the performance of an alternative being reset increases, prior experiences become less indicative of current payoffs, and hence, beliefs ought to be updated more quickly to depreciate prior information and place more weight on more recent observations. While the preferred rate of belief updating (ϕ) increases as a function of turbulence (η), the difference in performance that stems from this increase in the learning rate is rather modest. For example, at extraordinarily high levels of turbulence (η = 0.32), the difference in performance between ϕ = 0.1 and ϕ = 0.3 is quite small with the highest performing learning rate (ϕ = 0.3) corresponding to a cumulative loss of approximately 30% relative to a cumulative loss of approximately 31% for slow learning (ϕ = 0.1).
4.3. Problems of Discovery
In addition to tuning the degree to which evaluation is rendered more difficult, it is also important to consider environments where the primary problem is one of discovery, independent of concerns regarding evaluation. Specifically, we now consider the efficacy of alternative rates of belief updating and strategies of exploration/exploitation in settings of pure discovery where there are a large number of alternatives (N = 100) and the reward received by the organization in each period represents the true underlying merit of that alternative. We do so by treating the value of the alternative not as a probability value, but as a deterministic payoff. For example, if alternative i was associated with a probability p = 0.7 of generating a positive reward (one), choosing this alternative is, in this analysis, treated as generating a payoff of 0.7 with certainty. Hence, there is no noise and, therefore, no problem of evaluating the merits of a given opportunity as a single observation yields its true value (there is no sampling variation). As with the prior analysis, we evaluate a range of ϕ values between 0.1 and 1.0 with a step size of 0.1 and τ values from 0 to 0.1 with step sizes of 0.02.
In Figure 7(a), we plot the general relationship of τ and ϕ on the performance of organizations. Even though evaluation is not problematic, the degree to which beliefs change with this unambiguous feedback, which is a function of ϕ, impacts the level of search that occurs for a given value of τ. These results are presented as a heat map where darker red colors correspond to higher performance and lighter red colors correspond to lower performance. Turning first to greedy (τ = 0) strategies of exploration/exploitation, we observe that performance is largely invariant to the belief-updating process under such a search strategy. In a world of pure discovery, a greedy choice rule operates in a manner akin to a stopping rule. The organization samples alternatives until the first alternative is found that generates a reward that exceeds the belief about the merits of the unsampled population.8
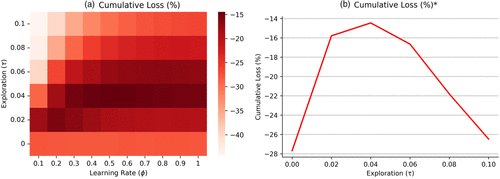
Note. Figure 7(b) plots the cumulative loss condition on the best performing ϕ value (ϕ*) for each value of τ.
Turning to high values of τ (0.08 and 0.1), we observe that performance begins to decline as a result of excessive search. Further, we note an important contingency between τ and ϕ. Specifically, as τ increases, rapid belief updating outperforms slow learning by a greater degree. This result stems from the fact that a greater shift in the beliefs as to the merit of an alternative can serve to attenuate the possibility of excessive search with a high level of exploration. In contrast, we see excessive search with modest rates of belief updating (ϕ = 0.1) and high levels of exploration (τ = 0.1). Finally, moving to moderate values of τ, we observe that the performance peaks when a moderate τ value is combined with a fast learning rate with respect to beliefs.
Given the interest in the extant literature on the preferred exploration strategy τ, we highlight how performance shifts as the strategy of exploration varies. To do so, we plot the performance of the highest performing ϕ–τ pair for each value of τ considered. That is, for each value of τ, we identify the value of the learning rate ϕ that yields the highest performance ϕ * (τ). The results of this analysis are presented in Figure 7(b), where the vertical axis is the cumulative percent loss at the end of the simulation and the horizontal axis is the value of τ. We observe an inverse-u pattern whereby a moderate degree of exploration is most efficacious for organizational performance: a result that mirrors much of the discussion in the literature regarding the need to balance exploration/exploitation and the merit of a moderate degree of exploration.
Thus, in settings where the challenge is purely one of discovery, our conventional wisdom about the merits of exploration and the desirability of some moderate balance in the strategy of exploration and exploitation holds. In this light, it is worth noting that March (1991), which introduces the exploration–exploitation trade-off to the organization’s literature, is a model of pure belief updating through a social influence process.9 The model illustrates the challenge of the search for and diffusion of superior beliefs, but in a setting that unproblematizes evaluation. Thus, our intuition about the merit of exploration is grounded in some rather specific settings: either settings where evaluation is not problematic or, per Posen and Levinthal (2012) and Lee and Puranam (2016), settings where belief updating has been fixed in a particular manner. Expanding our consideration of the updating process and problem environments challenges that intuition.
5. Discussion
Organizational learning entails both discovery and the evaluation of what has been discovered. In some lines of work, such as the consideration of search on a fitness landscape (Levinthal 1997), the challenge of discovery is highlighted. How, out of a large combinatoric space, can more or less favorable alternatives be identified? In other lines of work, the problem of evaluation is highlighted. Experience may be ambiguous and subject to interpretation (March 2010). Feedback-based learning is challenging both as a result of the possible nonrepresentativeness of any finite sample of experience with a given alternative and the fact that the sampling process itself is endogenous with respect to experience (Denrell and March 2001).
The literature tends to point to the potential pathologies that stem from a lack of sufficient search and, in turn, a failure of discovery. This insufficient search stems from positive feedback with respect to current actions that curtail the search for other possibilities. This is clearly an important insight from the literature on organizational learning. But, in highlighting these failures of discovery, the literature tends to underplay the challenge of evaluating and, in particular, persisting with what has been discovered. Effective learning requires not only identifying favorable actions, but in persisting with those favorable actions.
What constitutes an effective search process is not a universal best, but rather a search process that addresses the basic challenge the organization faces. Many search challenges are primarily ones of discovery: there is a wide variety of possible practices and technologies that the organization may use, but the merit of them, once identified, is clear. In other contexts, the evaluation of alternatives may itself be problematic. Exploration plays an important role in the former settings, while the challenge of persistence is more salient in the latter. Consider, by way of illustration, two different kinds of search and discovery challenges that Google faces. In fine-tuning its search algorithm, Google’s software engineers are exploring a large combinatoric space of possibilities. However, through back-testing and online experiments, Google is able to garner very rich and rapid feedback as to the merit of a given search algorithm. Exploratory search is both valuable, given the large set of possibilities, and efficient, given the speed and clarity of feedback. In contrast, in its GoogleX division, Google is making a few bets on uncertain new initiatives, and the feedback it receives as to the merit of those initiatives is fairly noisy. For instance, what do initial experiments with lidar vision technology for driverless vehicles mean for the ultimate value of this technological approach, and more broadly, what do early indications of success and failure mean for the viability of the driverless vehicle initiative as a whole? In this setting, the challenge of persistence is central. How should the firm aggregate the history of feedback it has received on the initiative, and how should that feedback be mapped on to decisions to persist or shift from the current initiative? In such a setting, our analysis points to a search strategy of cautious exploitation. The caution regarding updating allows the organization to filter the noise in the feedback it receives, while the exploitive search strategy aids in the need to persist with favorable opportunities in the face of noisy feedback with respect to their merit and, at the same time, provides an impetus to a definitive switch in policy should sufficient negative evidence accumulate.
In addition, while we observe behaviors such as search, it is important to examine the underlying mechanisms of organizational learning. The process of revising beliefs is one part of the learning process, as are explicit strategies of exploration/exploitation. While the joint processes of belief revision and strategies of exploration/exploitation are featured in a number of studies, one mechanism tends to be in the foreground with the other relegated to a background role. However, models of learning need to consider both the adaptive dynamics of belief structures or, more broadly, mental models and the decision rules based on those beliefs (Holland et al. 1989).
We find a rich interplay between the process of belief revision and what constitutes more or less effective decision rules with regard to exploration/exploitation. Slow learning with respect to beliefs, in conjunction with an exploitive decision rule, or cautious exploitation, turns out to be a powerful driver of the adaptive dynamics, generating efforts at search and discovery in early periods while also facilitating persistence with favorable alternatives. However, slow rates of belief revision or an exploitive strategy of exploration/exploitation in and of themselves are not necessarily effective processes. In addition, the contexts in which these processes take place impact the relative import of problems of discovery and persistence. In problems of discovery, our standard intuition regarding the exploration/exploitation trade-off holds. In settings where evaluation is problematic, slow learning can be a helpful filter on that experience. At the same time, even with slow rates of learning, beliefs do shift, and those shifting beliefs can animate search even in the context of a highly exploitative strategy.
Thus, we need not only be mindful of Simon’s (1990) two blades of actor and task environment, but we also need to unpack how we model and conceptualize organizational decision making and learning. Organizations think, plan, strategize, and act. Organizations also learn from and interpret feedback. We find an important interplay between strategizing with respect to a search strategy and the process of learning from feedback. Slow learning with respect to experience tends to filter out noise, but allows strong and systematic signals to impact beliefs. Shifts in beliefs can, in turn, shift behavior even for organizations that are highly exploitive. We are not only faced with two blades, but neither blade is a monolith as we find considerable insight from the joint consideration of search strategies and learning processes.
This joint search strategy of slow rates of belief updating in conjunction with a highly exploitative strategy results in the organization both having a fair degree of inertia with respect to search, as beliefs regarding what is the most preferred alternative may be slow to change, and also being quite decisive in the decision to search. If an alternative is believed to be superior to the current one, the organization shifts with certainty. Further, this shift to a new alternative is not the result of some sort of lottery over possibilities as exploration is generally modeled, but rather a very guided and directed shift to what is perceived as the new preferred alternative. There is plasticity in the organization’s behavior, but it is not the result of a stochastic draw from a distribution of possible actions, but rather from the dynamicity of beliefs. While it is true that beliefs are subject to stochastic forces, a slow rate of belief updating mitigates those effects, and for a given set of beliefs, the organization is quite directed in its actions.
Organizations as complex adaptive systems need to be understood with respect to how various components of the adaptive system interact with one another. Whether an organization searches and whether those search efforts are ultimately adaptive are a joint consequence of the process of belief updating and the organization’s strategy with respect to exploration and exploitation. Looking at these processes in isolation can be misleading. Experience, in the face of noisy feedback from the world, provides a central stochastic element in the organizational learning process. Slow rates of belief updating help filter that noise and aggregate experience. But a slow rate of learning is not a statement of inertia. Plasticity of beliefs can lead to plasticity of organizational behavior even in the context of a choice process that is tilted heavily toward exploitation. Our conversation around exploration/exploitation would benefit from shifting from a highly reduced form representation of this process to one that engages more fully the various components of the organization’s adaptive mechanisms. Our conceptualization and modeling of the dual role of learning from experience and strategies of search is, admittedly stylized, but even this stylized representation points to the importance and value of such efforts.
The authors thank the senior editor, Peter Madsen, and three anonymous reviewers for helpful feedback on a prior draft.
1 In this regard, it is important to note that stochastic feedback can be incorporated into a fitness landscape. Indeed, Levinthal (1997) includes a robustness analysis with stochastic feedback, and Knudsen and Levinthal (2007) examine how imperfect screening of alternatives impacts the search process on a fitness landscape.
2 In addition, we have run robustness analyses across a range of beta distributions ranging from settings with relatively unfavorable opportunity structures (α = 2, β = 10) to settings with relatively favorable opportunities (α = 10, β = 2). We find that the qualitative results are robust to these changes in specification.
3 Formally, the softmax function is not defined for a τ value of zero. For that setting of τ, we simply chose the alternative associated with the highest belief and, if there is more than one alternative with this highest belief, randomize among them.
4 We find essentially the same result when we examine an epsilon-greedy choice rule (see results in the Online Technical Appendix). Under an epsilon-greedy choice rule, the only relevant consideration with respect to beliefs is which alternative is viewed as most favorable in a given period. We find that, under this decision structure, a slow learning rate (ϕ = 0.1) in conjunction with a maximally greedy strategy of ε = 0 leads to the highest performance. We also examine longer time horizons (up to 10,000 periods) and find that the best performing learning rate (ϕ) increases slightly from 0.1 to 0.2, whereas the best performing strategy of exploration/exploitation (for this value of ϕ) remains greedy (τ = 0).
5 In addition, we have run robustness across a range of different numbers of alternatives from N = 5 to N = 100. We find that qualitative results are robust to these changes in specification.
6 Posen and Levinthal’s (2012) optimal τ value is in the range of 0.05 to 0.06, whereas our τ value is closer to 0.04. This difference stems from the difference in the number of periods considered in our analysis and theirs (100 versus 500, respectively). Running our analysis for 500 periods provides results that correspond to theirs with respect to the desired value of τ under the assumption that beliefs equal average experience.
7 This is, for each value of τ we identify the value of ϕ that yields the highest performance.
8 Given the assumption that priors equal the average arm value, this is the first alternative that is greater than 0.5. A higher cutoff would result in search being stopped later.
9 In March (1991), organizational performance is measured as the accuracy of beliefs—there is no action taken, let alone a stochastic link between actions and payoffs—and those individuals whose beliefs are superior to the organizational code are identified and grouped with certainty.
References
- (1999) Harnessing Complexity (Free Press, New York).Google Scholar
- (2022) One-hit wonders vs. hit makers: Sustaining success in creative industries. Admin. Sci. Quart. 67(3):630–673.Crossref, Google Scholar
- (2009) Change by Design: How Design Thinking Transforms Organizations and Inspires Innovation (HarperBusiness, New York).Google Scholar
- (1955) Stochastic Models for Learning (John Wiley & Sons, Inc., Oxford, UK).Crossref, Google Scholar
- (1999) Experience-weighted attraction learning in normal form games. Econometrica 67(4):827–874.Crossref, Google Scholar
- (2020) A scientific approach to entrepreneurial decision making: Evidence from a randomized control trial. Management Sci. 66(2):564–586.Link, Google Scholar
- (2013) An efficient frontier in organizational design: Organizational structure as a determinant of exploration/exploitation. Organ. Sci. 24(4):1083–1101.Link, Google Scholar
- (2001) Adaptation as information restriction: The hot stove effect. Organ. Sci. 12(5):523–538.Link, Google Scholar
- (2023) Underdogs and one-hit wonders: When is overcoming adversity impressive? Management Sci. 69(9):5461–5481.Link, Google Scholar
- (1972) Research and theory on the learning of probabilities. J. Amer. Statist. Assoc. 67(337):81–102.Crossref, Google Scholar
- (2010) Balancing exploration and exploitation through structural design: The isolation of subgroups and organizational learning. Organ. Sci. 21(3):625–642.Link, Google Scholar
- (2001) Recombinant uncertainty in technological search. Management Sci. 47(1):117–132.Link, Google Scholar
- (2001) Technology as a complex adaptive system: Evidence from patent data. Res. Policy 30(7):1019–1039.Crossref, Google Scholar
- (2004) Science as a map in technological search. Strategic Management J. 25(8–9):909–928.Crossref, Google Scholar
- (1992) Order effects in belief updating: The belief-adjustment model. Cognitive Psych. 24(1):1–55.Crossref, Google Scholar
- (1975) Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence (University of Michigan Press, Oxford, UK).Google Scholar
- (1989) Induction: Processes of Inference, Learning, and Discovery (MIT Press, Cambridge, MA).Crossref, Google Scholar
- (2002) Something old, something new: A longitudinal study of search behavior and new product introduction. Acad. Management J. 45(6):1183–1194.Crossref, Google Scholar
- Keil T, Posen H, Workiewicz M (2023) Aspirations, beliefs and a new idea: Building on March’s other model of performance feedback. Academy Management Rev. 48(4):749–771.Google Scholar
- (2014) Blue Ocean Strategy: How to Create Uncontested Market Space and Make the Competition Irrelevant (Harvard Business Review Press, Boston).Google Scholar
- (2007) Two faces of search: Alternative generation and alternative evaluation. Organ. Sci. 18(1):39–54.Link, Google Scholar
- (2022) Experimentation and start-up performance: Evidence from a/b testing. Management Sci. 68(9):6434–6453.Link, Google Scholar
- (2006) Balancing exploration and exploitation in alliance formation. Acad. Management J. 49(4):797–818.Crossref, Google Scholar
- (2011) Balance within and across domains: The performance implications of exploration and exploitation in alliances. Organ. Sci. 22(6):1517–1538.Link, Google Scholar
- (2016) The implementation imperative: Why one should implement even imperfect strategies perfectly. Strategic Management J. 37(8):1529–1546.Crossref, Google Scholar
- (1997) Adaptation on rugged landscapes. Management Sci. 43(7):934–950.Link, Google Scholar
- (1981) A model of adaptive organizational search. J. Econom. Behav. Organ. 2(4):307–333.Crossref, Google Scholar
- (1988) Organizational learning. Annual Rev. Sociol. 14:319–340.Crossref, Google Scholar
- (1959) On the possible psychophysical laws. Psych. Rev. 66(2):81–95.Crossref, Google Scholar
- (1991) Exploration and exploitation in organizational learning. Organ. Sci. 2(1):71–87.Link, Google Scholar
- (2003) Understanding organizational adaptation. Soc. Econom. 25(1):1–10.Crossref, Google Scholar
- (2010) The Ambiguities of Experience (Cornell University Press, Ithaca, NY).Crossref, Google Scholar
- (1953) Applied Imagination (Scribner’s, Oxford, UK).Google Scholar
- (2022) The aggregation–learning trade-off. Organ. Sci. 33(3):1094–1115.Link, Google Scholar
- (2012) Chasing a moving target: Exploitation and exploration in dynamic environments. Management Sci. 58(3):587–601.Link, Google Scholar
- (2015) Modelling bounded rationality in organizations: Progress and prospects. Acad. Management Ann. 9(1):337–392.Crossref, Google Scholar
- (2003) Balancing search and stability: Interdependencies among elements of organizational design. Management Sci. 49(3):290–311.Link, Google Scholar
- (1962) The architecture of complexity. Proc. Amer. Philos. Soc. 106(6):467–482.Google Scholar
- (1990) Invariants of human behavior. Annual Rev. Psych. 41(1):1–20.Crossref, Google Scholar
- (2016) Adaptation and inertia in dynamic environments. Strategic Management J. 37(9):1854–1864.Crossref, Google Scholar
- (2023) Finding diamonds in the rough: Data-driven opportunities and pharmaceutical innovation. Working paper, Haas School of Business, University of California, Berkeley.Google Scholar
Daniel A. Levinthal is the Reginald H. Jones professor of corporate strategy at the Wharton School, University of Pennsylvania. Levinthal works on issues of organizational adaptation and industry evolution, particularly in the context of technological change.
Daniel Schliesmann is a doctoral candidate in the management department at the Wharton School, University of Pennsylvania. His research focuses on organizational learning and adaptation with a particular emphasis on entrepreneurship.

