Request Username
Can't sign in? Forgot your username?
Enter your email address below and we will send you your username

Published Online: January 20, 2026
While every discipline has its own terminology, jargon, mathematical models and commonly used inferential methods, Marketing’s focus on latent constructs (e.g., choice utility) as an underpinning of consumer behavior makes its “distance” to other fields, especially psychometrics (and its measurement of latent ability) very small. In this reflection/thought piece, I will discuss how as a Bayesian Statistician and Psychometrician I hope to methodologically and meaningfully contribute to Marketing Science and note (to scholars within and outside of marketing) how we are much less discipline specific than you might think.
One (of many) research paradigms within quantitative marketing science is to mathematically model manifest variables (i.e., observed dependent variables) as a function of latent constructs. In fact, the equivalence between latent variable random utility models and choice models (i.e., choice utility, McFadden 1974) as an economically rational utility maximizing framework underpins much of the empirical and theoretical work in our field. In parallel, in the field of mathematical psychology, item response theory (IRT, Lord et al. 1968) models dominate the purported relationship between educational manifest variables (e.g., test item scores) and latent (test-taking) ability. The premise of this article is that whether you call it “latent choice utility” or “latent test ability”, underlying consumer propensity to buy or underlying examinee strength, product characteristics or test item features, cross-person choice heterogeneity or heterogenous abilities, within-person latent states (e.g., modeled via an HMM, Netzer et al. 2008) or time-varying ability (Bradlow et al. 1998), these models of behavior are remarkably similar. In addition, and what I hope to expand on here, is that the open research questions are remarkably similar and these two fields can and should borrow from each other conceptually, methodologically and in practice because the “distance” between them is quite small.
Marketing “utilized” random utility models (MRUMs, typically) propose a structure where the utility assigned to person
where
We compare and contrast this marketing/economics random utility model with a commonly used psychometrics-IRT model,
where the ability of test-taker
We discuss next another important conceptual similarity between Marketing and Psychometrics-based utility models, the distance they imply between the consumer’s utility and a corresponding threshold.
While the mathematics of (binary) DV random utility models is straightforward, subjects purchase (get an item correct) when
Figure 1. A Graphical Depiction of a Random Utility Model with Threshold
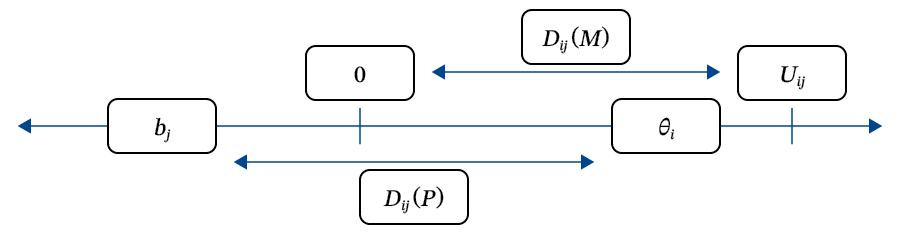
Notes. Things that drive
From Figure 1, we can see the following:
What this suggests, as per the dual-meaning title of this research thought piece, distance matters. In fact, many probabilistic models (race models of behavior in psychology (Merkle and Van Zandt 2006); random utility models in marketing; IRT models in educational testing) are purely distance models where the latent locations are what need to be estimated.
The similarities between these two disciplines go far beyond just recognizing the isomorphism between their mathematical forms. As I discuss next, the extensions and challenges that each discipline has tackled, and the future challenges, appear (to me) to be almost identical. Two that I describe below are heterogeneity and functional form (different decision rules used across respondents).
A common challenge in MRUMs is how to handle cross-person heterogeneity which can come in many forms. The most widely addressed is for parameters (Rossi et al. 1996) reflecting that individuals put different weights on various aspects of
Other forms of “well-studied” heterogeneity include within-person implying the propensities change over time for a given individual that could reflect state switching (HMMs), non-stationarity (reflecting both exogenous changes over time and those that are more structural and “caused” by firm action), and reference/context effects that include topics like state-dependence (which are commonly believed to exist in choice models, Dubé et al. 2010), but attempted to be designed away or modeled (Bradlow et al. 1999) in educational tests where items are meant to be conditionally independent.
Lastly, both MRUMs and PRUMs want to understand both descriptors of heterogeneity and actions (firm in the MRUM case and test design/educator in the PRUM case) that can optimize some objective function (sales, test-scores, learning, etc.). This is commonly accomplished in MRUMs via hierarchical models where:
with
Another area of research that is common in both cases, and one that is less researched than parameter heterogeneity, is allowing for alternative decision models that aren’t linear and compensatory that "
Lastly, there is a need for future research on a significant number of topics related to RUMs. These include a growing need for RUMs that can jointly model data of multi-modalities (e.g., surveys and transactions, multiple-choice items and essays, responses and response times) simultaneously which given cookie tracking and other technologies is becoming more prevalent, models where coefficients are non-stationary and dependent on firm action (e.g., the firm drops price and the consumer becomes more price-sensitive; i.e., their “state” changes), and models that consider context-dependent utilities where the context may be very high dimensional (e.g., based on a consumer’s very rich test responses, response times or analogously a consumer’s clickstream history in a given session).
While the goal of this research note was to try and draw similarities between two disparate literatures, another reason for writing it was a reflection on my own career and a path, of sorts, for others. As methodologists, we should all be looking for problems where the methods, models, open challenges, solutions, etc. stay the same but the jargon is simply different. For me, whether it’s building latent variable IRT models or latent variable models to understand marketing outcomes of interest, the distance between these two fields is small. Hopefully, this will lead PhD students today to study more math psychology and psychometrics as investing in these measurement tools will lead to broad training in random utility modeling in marketing.
Eric T. Bradlow ([email protected]) is the K.P. Chao Professor, Professor of Marketing, Statistics and Data Science, Economics and Education, Chairperson Wharton Marketing Department and Vice Dean of AI and Analytics at the Wharton School of the University of Pennsylvania. He served as Editor-in-Chief of Marketing Science from 2008-2010.
Kim M, Bradlow ET, Iyengar R (2022) Selecting data granularity and model specification using the scaled power likelihood with multiple weights. Marketing Sci. 41(4):848-866.
Stourm L, Iyengar R, Bradlow ET (2020) A flexible demand model for complements using household production theory. Marketing Sci. 39(4):763-787.
Schwartz EM, Bradlow ET, Fader PS (2017) Customer acquisition via display advertising using multi-armed bandit experiments. Marketing Sci. 36(4):500-522.
Gopalakrishnan A, Bradlow ET, Fader PS (2017) A cross-cohort changepoint model for customer-base analysis. Marketing Sci. 36(2):195-213.
Zhang Y, Bradlow ET, Small DS (2015) Predicting customer value using clumpiness: From RFM to RFMC. Marketing Sci. 34(2):195-208.
Schwartz EM, Bradlow ET, Fader PS (2014) Model selection using database characteristics: Developing a classification tree for longitudinal incidence data. Marketing Sci. 33(2):188-205.
Gordon BR, Thomadsen R, Bradlow ET, Dubé JP, Staelin R (2011) Foreword—Revisiting the Workshop on Quantitative Marketing and Structural Econometrics. Marketing Sci. 30(6):945-949.
Bradlow ET (2010) Editorial—It's never good-bye to marketing science. Marketing Sci. 29(6):963.
Bradlow ET (2009) Editorial—Does everything not being resolved equal nothing gained? Bringing in the wisdom of the academic crowd. Marketing Sci. 28(5):809.
Hui SK, Fader PS, Bradlow ET (2009) Research Note—The traveling salesman goes shopping: The systematic deviations of grocery paths from TSP optimality. Marketing Sci. 28(3):566-572.
Bradlow ET, Coughlan AT (2009) Editorial—Analytical transparency. Marketing Sci. 28(3):403.
Hui SK, Fader PS, Bradlow ET (2009) Path data in marketing: An integrative framework and prospectus for model building. Marketing Sci. 28(2):320-335.
Bradlow ET (2009) Editorial—Marketing science and the financial crisis. Marketing Sci. 28(2):201.
Schweidel DA, Fader PS, Bradlow ET (2008) A bivariate timing model of customer acquisition and retention. Marketing Sci. 27(5):829-843.
Bradlow ET (2008) Editorial—Maximizing impact via database submissions. Marketing Sci. 27(4):541.
Bradlow ET (2008) Editorial—The scientific process at its best. Marketing Sci. 27(3):323.
Bradlow ET (2008) Editorial—Enticing and publishing the home run paper. Marketing Sci. 27(1):4-6.
Shugan SM, Bradlow ET (2008) Editorial—Database submissions. Marketing Sci. 27(1):7-8.
Bradlow ET, Park YH (2007) Bayesian estimation of bid sequences in internet auctions using a generalized record-breaking model. Marketing Sci. 26(2):218-229.
Hoch SJ, Bradlow ET, Wansink B (2002) Rejoinder to “The variety of an assortment: An extension to the attribute-based approach”. Marketing Sci. 21(3):342-346.
Bradlow ET, Schmittlein DC (2000) The little engines that could: Modeling the performance of World Wide Web search engines. Marketing Sci. 19(1):43-62.
Hoch SJ, Bradlow ET, Wansink B (1999) The variety of an assortment. Marketing Sci. 18(4):527-546.
Montgomery AL, Bradlow ET (1999) Why analyst overconfidence about the functional form of demand models can lead to overpricing. Marketing Sci. 18(4):569-583.
Birnbaum A (1968) Some latent trait models and their use in inferring an examinee’s ability. Lord FM, Novick MR, eds. Statistical Theories of Mental Test Scores (Addison-Wesley, Reading, MA), 397-479.
Bradlow ET, Weiss RL, Cho M (1998) Bayesian identification of outliers in computerized adaptive tests. J. Amer. Statist. Assoc. 93(443):910-919.
Bradlow ET, Wainer H, Wang X (1999) A Bayesian random effects model for testlets. Psychometrika 64(2):153–168.
Dubé JP, Hitsch G, Rossi PE (2010) State dependence and alternative explanations for consumer inertia. RAND J. Econom. 41(3):417–445.
Ferguson T (1973) A Bayesian analysis of some nonparametric problems. Ann. Statist. 1(2):209-230.
Gilbride TJ, Allenby GM (2004) A choice model with conjunctive, disjunctive, and compensatory screening rules. Marketing Sci. 23(3):391–406.
Hauser J, Toubia O, Evgeniou T, Befurt R, Dyzabura D (2010) Disjunctions of conjunctions, cognitive simplicity, and consideration sets. J. Marketing Res. 47(3):485-496.
Kamakura WA, Russell GJ (1989) A probabilistic choice model for market segmentation and elasticity structure. J. Marketing Res. 26(4):379-390.
Komboz B, Strobl C, Zeileis A (2016) Tree-based global model tests for polytomous Rasch models. Educ. Psychol. Meas. 78(1):128-166.
Lord FM, Novick MR, Birnbaum A (1968) Statistical Theories of Mental Test Scores (Addison-Wesley, Reading, MA).
McFadden D (1974) The measurement of urban travel demand. J. Public Econ. 3(4):303-328.
Merkle EC, Van Zandt T (2006) An application of the Poisson race model to confidence calibration. J. Exp. Psychol. Gen. 135(3):391-408.
Netzer O, Lattin JM, Srinivasan V (2008) A hidden Markov model of customer relationship dynamics. Marketing Sci. 27(2):185-204.
Rasch G (1960) Probabilistic Model for Some Intelligence and Achievement Tests. (Danish Institute for Educational Research, Copenhagen).
Rossi PE, McCulloch RE, Allenby GM (1996) The value of purchase history data in target marketing. Marketing Sci. 15(4):321-340.
Bradlow, Eric T. (2026) “From Psychometrics to Marketing Science: The ‘Distance' is Not as Far as You Think!” ISMS Fellows Forum (January 20), https://